
Neural Graph Similarity Computation with Contrastive Learning


Abstract
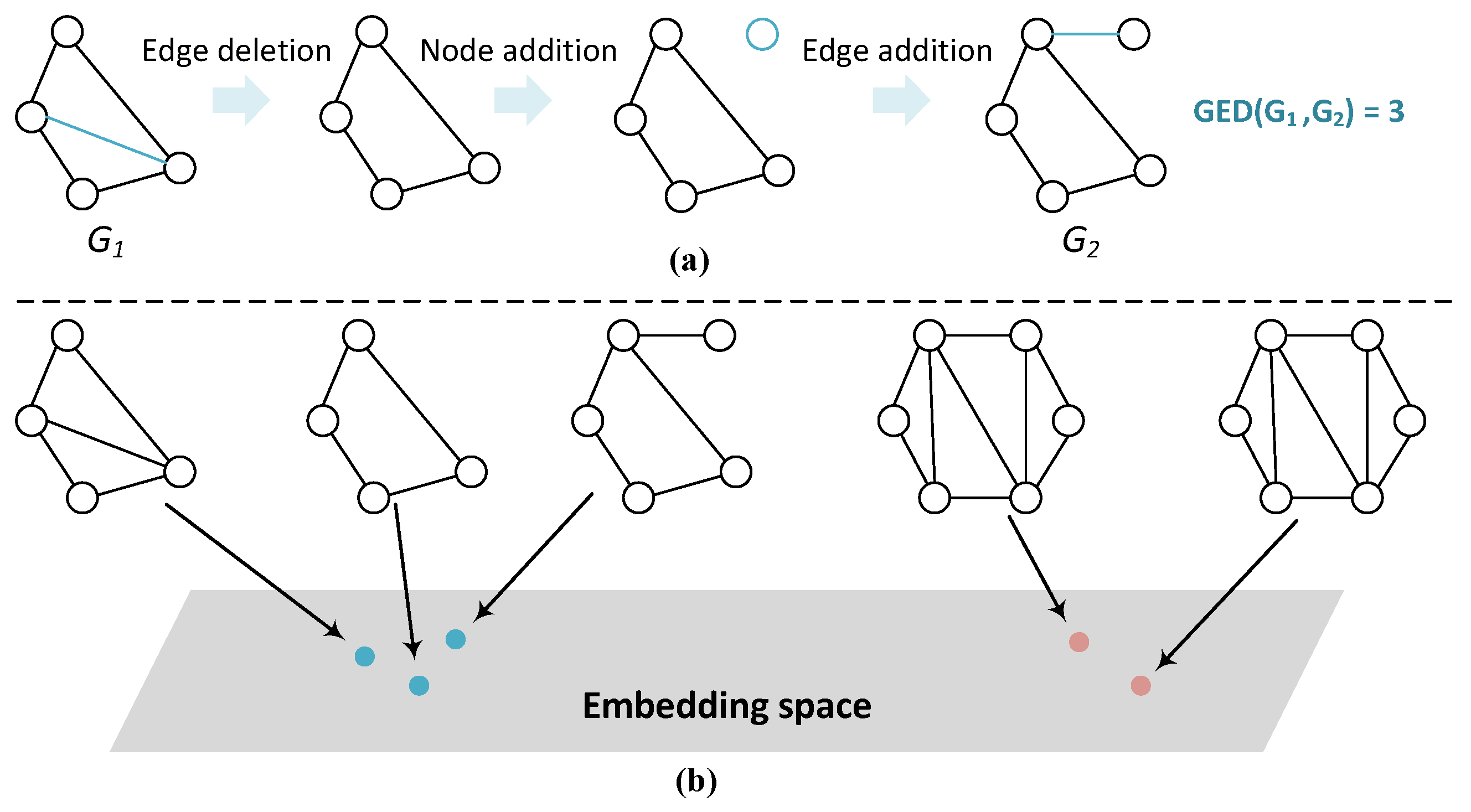
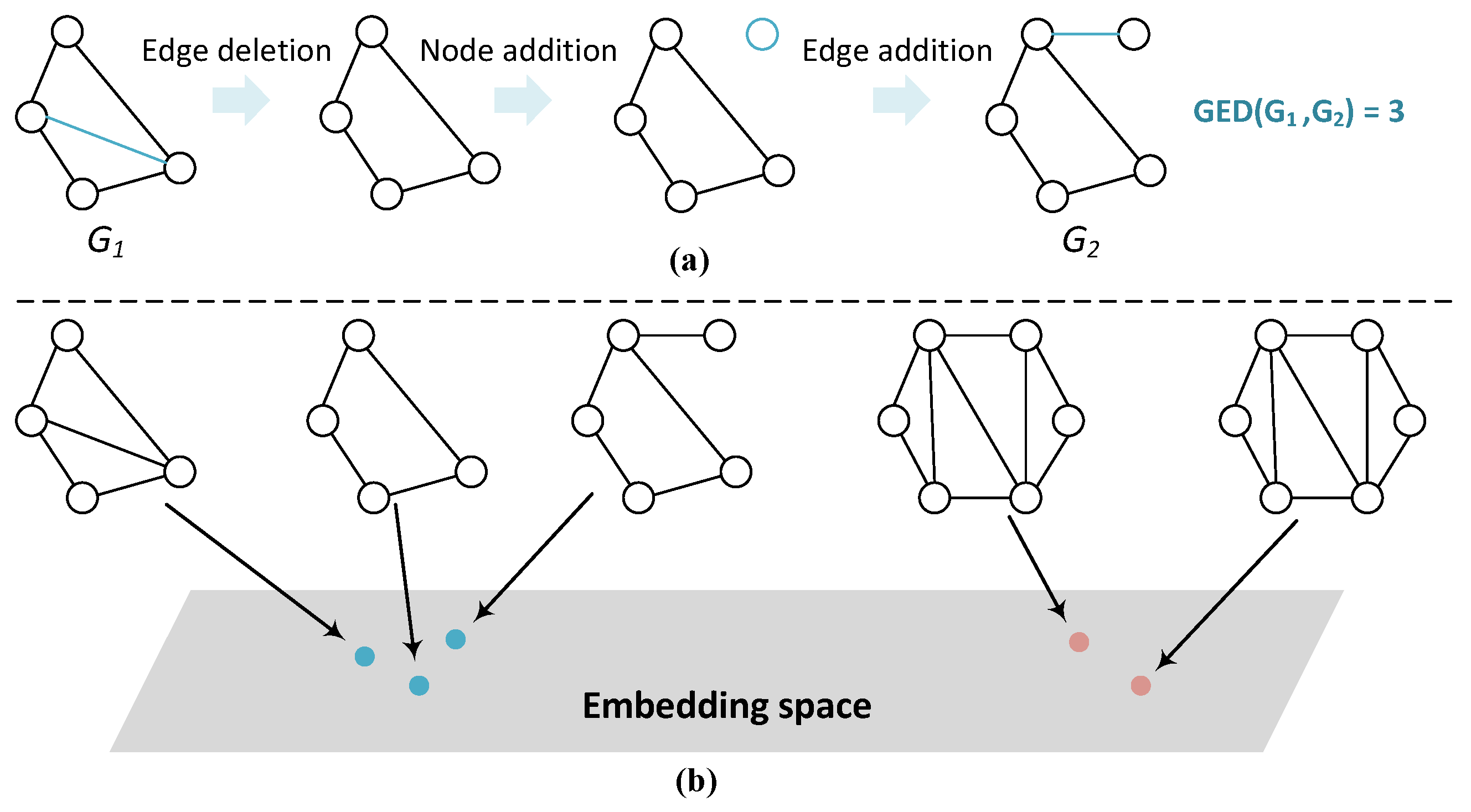
:1. Introduction
- Existing neural methods still require excessive running time and memory space due to the intricate neural network structure design, which might fail to work in real-life settings;
- They heavily rely on the labeled data for training an effective model and neglect the information hidden in the vast unlabeled data. Practically, the labeled data are difficult to obtain.
- To the best of our knowledge, we are among the first attempts to utilize contrastive learning to facilitate the neural graph similarity computation process.
- We propose to simplify the graph similarity prediction network, and the resultant model attains higher efficiency and maintains competitive performance.
- We compare our proposed model, Conga, against state-of-the-art methods on existing benchmarks, and the results demonstrate that our proposed model attains superior performance.
2. Related Works
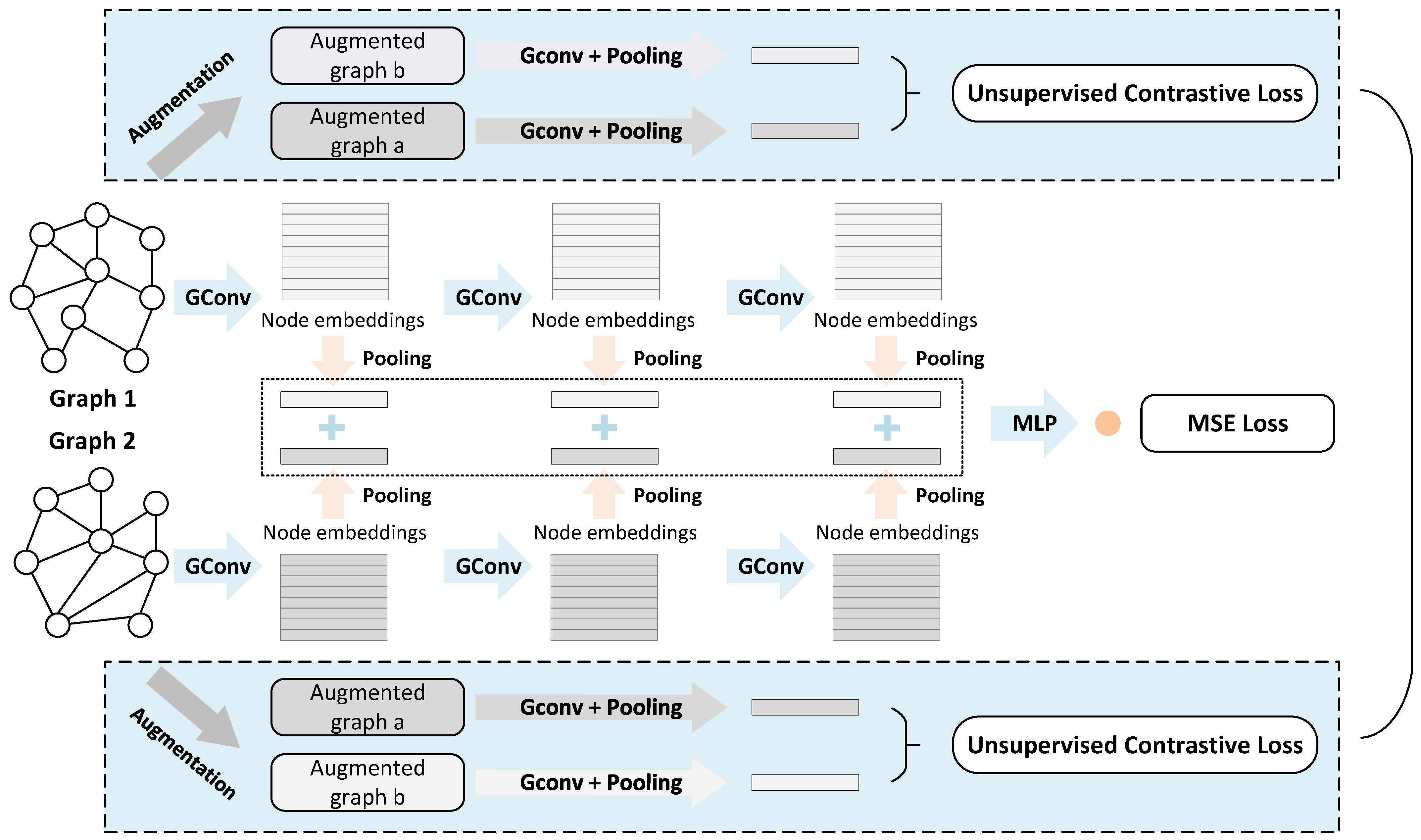
3. Methodology
3.1. Model Overview
3.2. Graph Similarity Prediction Network
3.2.1. Graph Convolutional Layer
3.2.2. Attention-Based Graph Pooling
3.2.3. Graph–Graph Interaction and Similarity Prediction
3.2.4. Loss Function
3.3. Contrastive Learning
3.3.1. Graph Augmentations
3.3.2. Unsupervised Contrastive Loss
3.4. Training
3.5. Algorithmic Descriptions
| Algorithm 1: Graph similarity prediction network. |
| Input : Two input graphs: and |
| Output: Similarity score: s |
| 1 Generate the node embeddings via graph convolutional layer, i.e., Equation (1) |
| 2 Generate the graph embeddings via attention-based pooling, i.e., Equation (2) |
| 3 Calculate the graph–graph similarity score s, i.e., Equation (3) |
| 4 return s; |
| Algorithm 2: Algorithmic description of Conga |
 |
4. Experiments and Results
4.1. Experimental Settings
4.1.1. Datasets
- AIDS [49], a dataset consisting of molecular compounds from the antiviral screen database of active compounds. The molecular compounds are converted to graphs, where atoms are represented as nodes and covalent bonds are regarded as edges. It comprises 42,687 chemical compound structures, where 700 graphs were selected and used for evaluating graph similarity search;
- LINUX [50], a dataset consisting of program dependence graphs in the Linux kernel. Each graph represents a function, where statements are represented as nodes and the dependence between two statements are represented as edges. A total of 1000 graphs were selected and used for evaluation;
- IMDB [51], a dataset consisting of ego-networks of film stars, where nodes are people and edges represent that two people appear in the same movie. It consists of 1500 networks.
4.1.2. Evaluation Metrics
4.1.3. Parameter Settings
4.1.4. Baseline Models
- SimGNN [7], which uses a histogram function to model the node–node interactions and supplement with the graph-level interactions for predicting the graph similarity;
- GMN [26], which computes the similarity score through a cross-graph attention mechanism to associate nodes across graphs;
- GraphSim [13], which estimates the graph similarity by applying a convolutional neural network (CNN) on the node–node similarity matrix of the two graphs;
- GOTSim [20], which formulates graph similarity as the minimal transformation from one graph to another in the node embedding space, where an efficient differentiable model training strategy is designed;
- MGMN [14], which models global-level graph–graph interactions, local-level node–node interactions, and cross-level interactions, constituting a multilevel graph matching network for computing graph similarity. It has two variants, i.e., SGNN, a siamese graph neural network to learn global-level interactions and NGMN, a node–graph matching network for effectively learning cross-level interactions;
- [27], which learns the graph representations from the perspective of hypergraphs, and thus captures rich substructure similarities across the graph. It has two variants, i.e., , which uses random walks to construct the hypergraphs and , which uses node neighborhood information to build the hypergraphs.
- GENN- [28], which uses dynamic node embeddings to improve the branching process of the traditional A* algorithm;
- Noah [29], which combines A* search algorithm and graph neural networks to compute approximate GED, where the estimated cost function and the elastic beam size are learned through the neural networks.
4.2. Experimental Results
4.2.1. Main Results
4.2.2. Ablation Results
4.2.3. Efficiency Comparison
4.3. Further Analysis
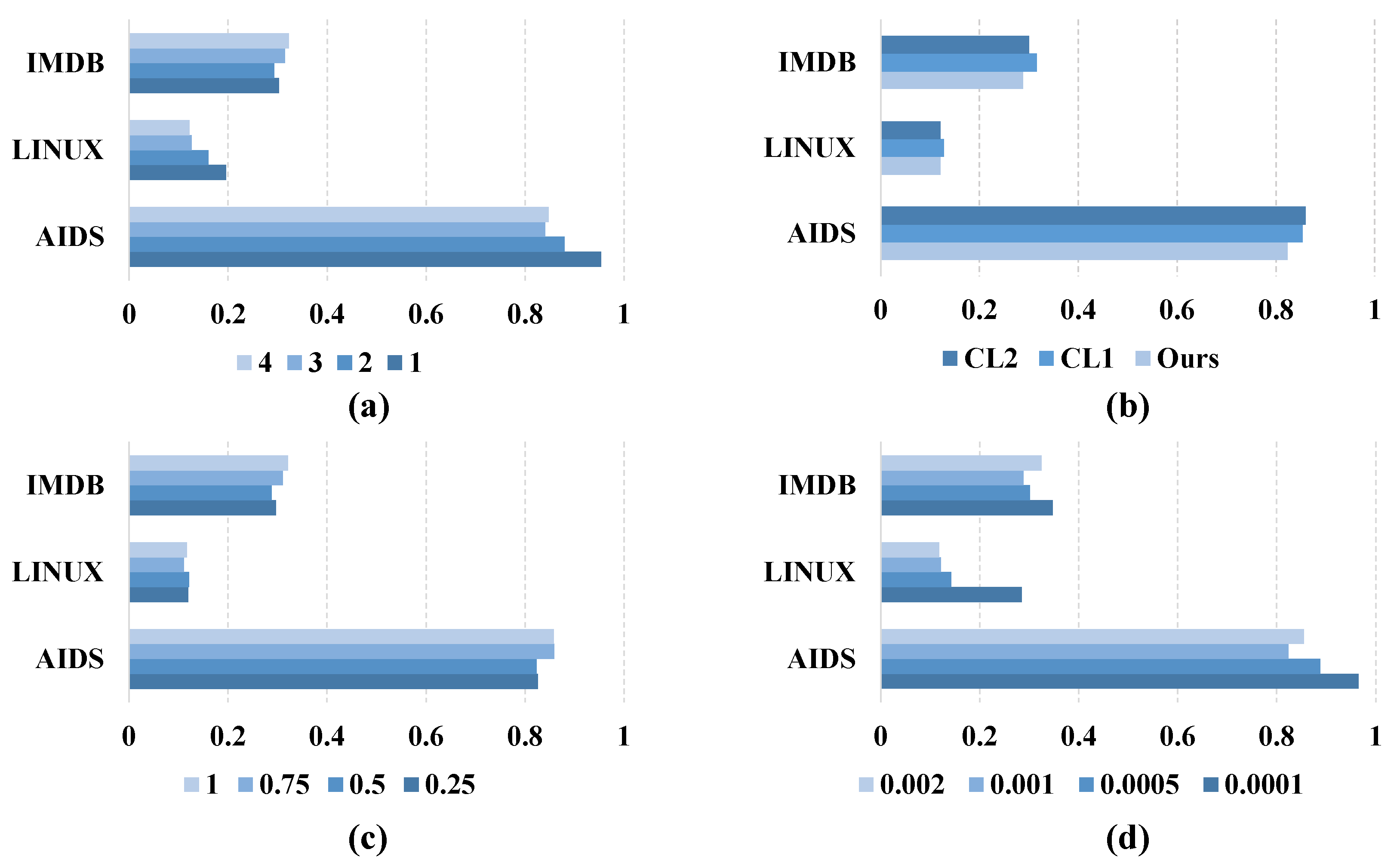
4.3.1. On GNN Layers
4.3.2. On Graph Augmentation in Contrastive Learning
4.3.3. On Loss Function
4.3.4. On Learning Rate
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kriegel, H.; Pfeifle, M.; Schönauer, S. Similarity Search in Biological and Engineering Databases. IEEE Data Eng. Bull. 2004, 27, 37–44. [Google Scholar]
- Wang, S.; Chen, Z.; Yu, X.; Li, D.; Ni, J.; Tang, L.; Gui, J.; Li, Z.; Chen, H.; Yu, P.S. Heterogeneous Graph Matching Networks for Unknown Malware Detection. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; pp. 3762–3770. [Google Scholar]
- Zeng, W.; Zhao, X.; Tang, J.; Lin, X.; Groth, P. Reinforcement Learning-based Collective Entity Alignment with Adaptive Features. ACM Trans. Inf. Syst. 2021, 39, 26:1–26:31. [Google Scholar] [CrossRef]
- Zeng, W.; Zhao, X.; Tang, J.; Li, X.; Luo, M.; Zheng, Q. Towards Entity Alignment in the Open World: An Unsupervised Approach. In Proceedings of the Database Systems for Advanced Applications—26th International Conference, DASFAA 2021, Taipei, Taiwan, 11–14 April 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12681, pp. 272–289. [Google Scholar]
- Bunke, H. On a relation between graph edit distance and maximum common subgraph. Pattern Recognit. Lett. 1997, 18, 689–694. [Google Scholar] [CrossRef]
- Bunke, H.; Shearer, K. A graph distance metric based on the maximal common subgraph. Pattern Recognit. Lett. 1998, 19, 255–259. [Google Scholar] [CrossRef]
- Bai, Y.; Ding, H.; Bian, S.; Chen, T.; Sun, Y.; Wang, W. SimGNN: A Neural Network Approach to Fast Graph Similarity Computation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, Australia, 11–15 February 2019; pp. 384–392. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Zeng, Z.; Tung, A.K.H.; Wang, J.; Feng, J.; Zhou, L. Comparing Stars: On Approximating Graph Edit Distance. Proc. VLDB Endow. 2009, 2, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Fischer, A.; Suen, C.Y.; Frinken, V.; Riesen, K.; Bunke, H. Approximation of graph edit distance based on Hausdorff matching. Pattern Recognit. 2015, 48, 331–343. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ying, Z.; You, J.; Morris, C.; Ren, X.; Hamilton, W.L.; Leskovec, J. Hierarchical Graph Representation Learning with Differentiable Pooling. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 4805–4815. [Google Scholar]
- Bai, Y.; Ding, H.; Gu, K.; Sun, Y.; Wang, W. Learning-Based Efficient Graph Similarity Computation via Multi-Scale Convolutional Set Matching. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 3219–3226. [Google Scholar]
- Ling, X.; Wu, L.; Wang, S.; Ma, T.; Xu, F.; Liu, A.X.; Wu, C.; Ji, S. Multilevel Graph Matching Networks for Deep Graph Similarity Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Neuhaus, M.; Riesen, K.; Bunke, H. Fast Suboptimal Algorithms for the Computation of Graph Edit Distance; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4109, pp. 163–172. [Google Scholar]
- Zhao, X.; Xiao, C.; Lin, X.; Wang, W.; Ishikawa, Y. Efficient processing of graph similarity queries with edit distance constraints. VLDB J. 2013, 22, 727–752. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Lin, X.; Wang, Y.; Guo, D. Efficient Mining of Frequent Patterns on Uncertain Graphs. IEEE Trans. Knowl. Data Eng. 2019, 31, 287–300. [Google Scholar] [CrossRef]
- Zhao, X.; Xiao, C.; Lin, X.; Zhang, W.; Wang, Y. Efficient structure similarity searches: A partition-based approach. VLDB J. 2018, 27, 53–78. [Google Scholar] [CrossRef]
- Raymond, J.W.; Gardiner, E.J.; Willett, P. RASCAL: Calculation of Graph Similarity using Maximum Common Edge Subgraphs. Comput. J. 2002, 45, 631–644. [Google Scholar] [CrossRef]
- Doan, K.D.; Manchanda, S.; Mahapatra, S.; Reddy, C.K. Interpretable Graph Similarity Computation via Differentiable Optimal Alignment of Node Embeddings. In Proceedings of the SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 665–674. [Google Scholar]
- Riesen, K.; Bunke, H. Approximate graph edit distance computation by means of bipartite graph matching. Image Vis. Comput. 2009, 27, 950–959. [Google Scholar] [CrossRef]
- Fankhauser, S.; Riesen, K.; Bunke, H. Speeding Up Graph Edit Distance Computation through Fast Bipartite Matching; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6658, pp. 102–111. [Google Scholar]
- Ma, G.; Ahmed, N.K.; Willke, T.L.; Yu, P.S. Deep graph similarity learning: A survey. Data Min. Knowl. Discov. 2021, 35, 688–725. [Google Scholar] [CrossRef]
- Xu, H.; Duan, Z.; Wang, Y.; Feng, J.; Chen, R.; Zhang, Q.; Xu, Z. Graph partitioning and graph neural network based hierarchical graph matching for graph similarity computation. Neurocomputing 2021, 439, 348–362. [Google Scholar] [CrossRef]
- Bai, Y.; Ding, H.; Sun, Y.; Wang, W. Convolutional Set Matching for Graph Similarity. arXiv 2018, arXiv:1810.10866. [Google Scholar]
- Li, Y.; Gu, C.; Dullien, T.; Vinyals, O.; Kohli, P. Graph Matching Networks for Learning the Similarity of Graph Structured Objects. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3835–3845. [Google Scholar]
- Zhang, Z.; Bu, J.; Ester, M.; Li, Z.; Yao, C.; Yu, Z.; Wang, C. H2MN: Graph Similarity Learning with Hierarchical Hypergraph Matching Networks. In Proceedings of the KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 14–18 August 2021; pp. 2274–2284. [Google Scholar]
- Wang, R.; Zhang, T.; Yu, T.; Yan, J.; Yang, X. Combinatorial Learning of Graph Edit Distance via Dynamic Embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 5241–5250. [Google Scholar]
- Yang, L.; Zou, L. Noah: Neural-optimized A* Search Algorithm for Graph Edit Distance Computation. In Proceedings of the 37th IEEE International Conference on Data Engineering, ICDE 2021, Chania, Greece, 19–22 April 2021; pp. 576–587. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zeng, W.; Zhao, X.; Tang, J.; Fan, C. Reinforced Active Entity Alignment. In Proceedings of the CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, 1–5 November 2021; pp. 2477–2486. [Google Scholar]
- Jin, M.; Zheng, Y.; Li, Y.; Gong, C.; Zhou, C.; Pan, S. Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event, 19–27 August 2021; pp. 1477–1483. [Google Scholar]
- Hong, H.; Li, X.; Pan, Y.; Tsang, I.W. Domain-Adversarial Network Alignment. IEEE Trans. Knowl. Data Eng. 2022, 34, 3211–3224. [Google Scholar] [CrossRef]
- Du, X.; Yan, J.; Zhang, R.; Zha, H. Cross-Network Skip-Gram Embedding for Joint Network Alignment and Link Prediction. IEEE Trans. Knowl. Data Eng. 2022, 34, 1080–1095. [Google Scholar] [CrossRef]
- Zanfir, A.; Sminchisescu, C. Deep Learning of Graph Matching. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2684–2693. [Google Scholar]
- Zhang, Z.; Lee, W.S. Deep Graphical Feature Learning for the Feature Matching Problem. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October– 2 November 2019; pp. 5086–5095. [Google Scholar]
- Zhao, X.; Zeng, W.; Tang, J.; Wang, W.; Suchanek, F.M. An Experimental Study of State-of-the-Art Entity Alignment Approaches. IEEE Trans. Knowl. Data Eng. 2022, 34, 2610–2625. [Google Scholar] [CrossRef]
- Zeng, W.; Zhao, X.; Wang, W.; Tang, J.; Tan, Z. Degree-Aware Alignment for Entities in Tail. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2020, Virtual Event, 25–30 July 2020; pp. 811–820. [Google Scholar]
- Zeng, W.; Zhao, X.; Li, X.; Tang, J.; Wang, W. On entity alignment at scale. VLDB J. 2022. [Google Scholar] [CrossRef]
- Malviya, S.; Kumar, P.; Namasudra, S.; Tiwary, U.S. Experience Replay-Based Deep Reinforcement Learning for Dialogue Management Optimisation. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022. [Google Scholar] [CrossRef]
- Manjari, K.; Verma, M.; Singal, G.; Namasudra, S. QEST: Quantized and Efficient Scene Text Detector Using Deep Learning. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022. [Google Scholar] [CrossRef]
- Agrawal, D.; Minocha, S.; Namasudra, S.; Kumar, S. Ensemble Algorithm using Transfer Learning for Sheep Breed Classification. In Proceedings of the 15th IEEE International Symposium on Applied Computational Intelligence and Informatics, SACI 2021, Timisoara, Romania, 19–21 May 2021; pp. 199–204. [Google Scholar] [CrossRef]
- Devi, D.; Namasudra, S.; Kadry, S.N. A Boosting-Aided Adaptive Cluster-Based Undersampling Approach for Treatment of Class Imbalance Problem. Int. J. Data Warehous. Min. 2020, 16, 60–86. [Google Scholar] [CrossRef]
- Chakraborty, A.; Mondal, S.P.; Alam, S.; Mahata, A. Cylindrical neutrosophic single-valued number and its application in networking problem, multi-criterion group decision-making problem and graph theory. CAAI Trans. Intell. Technol. 2020, 5, 68–77. [Google Scholar] [CrossRef]
- Liu, R. Study on single-valued neutrosophic graph with application in shortest path problem. CAAI Trans. Intell. Technol. 2020, 5, 308–313. [Google Scholar] [CrossRef]
- Chen, L.; Qiao, S.; Han, N.; Yuan, C.; Song, X.; Huang, P.; Xiao, Y. Friendship prediction model based on factor graphs integrating geographical location. CAAI Trans. Intell. Technol. 2020, 5, 193–199. [Google Scholar] [CrossRef]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph Contrastive Learning with Augmentations. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Trivedi, P.; Lubana, E.S.; Yan, Y.; Yang, Y.; Koutra, D. Augmentations in Graph Contrastive Learning: Current Methodological Flaws & Towards Better Practices. In Proceedings of the WWW ’22: The ACM Web Conference 2022, Virtual Event, 25–29 April 2022; pp. 1538–1549. [Google Scholar]
- Liang, Y.; Zhao, P. Similarity Search in Graph Databases: A Multi-Layered Indexing Approach. In Proceedings of the 33rd IEEE International Conference on Data Engineering, ICDE 2017, San Diego, CA, USA, 19–22 April 2017; pp. 783–794. [Google Scholar]
- Wang, X.; Ding, X.; Tung, A.K.H.; Ying, S.; Jin, H. An Efficient Graph Indexing Method. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 210–221. [Google Scholar]
- Yanardag, P.; Vishwanathan, S.V.N. Deep Graph Kernels. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1365–1374. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Methods | Type | Year | Ref. | Methods | Type | Year | Ref. |
|---|---|---|---|---|---|---|---|
| Classical | 1968 | [8] | SimGNN | Neural | 2019 | [7] | |
| Beam | Classical | 2006 | [15] | GMN | Neural | 2019 | [26] |
| Hungarian | Classical | 2009 | [21] | GraphSim | Neural | 2020 | [13] |
| VJ | Classical | 2011 | [22] | MGMN | Neural | 2021 | [14] |
| HED | Classical | 2015 | [10] | Neural | 2021 | [27] | |
| Noah | Hybrid | 2021 | [29] | GOTSim | Neural | 2021 | [20] |
| GENN- | Hybrid | 2021 | [28] |
| Dataset | Contents | #Graphs | #Pairs | #A. N. | # A. E. | Label |
|---|---|---|---|---|---|---|
| AIDS | Molecular Compounds | 700 | 490 K | 8.9 | 8.8 | Yes |
| LINUX | Program Dependence Graph | 1000 | 1 M | 7.53 | 6.94 | No |
| IMDB | Film Star Ego-Networks | 1500 | 2.25 M | 13 | 65.94 | No |
| Datasets | AIDS | LINUX | IMDB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metrics | mse(↓) | (↑) | p@10(↑) | mse(↓) | (↑) | p@10(↑) | mse(↓) | (↑) | p@10(↑) |
| 0.000 | 1.000 | 1.000 | 0.000 | 1.000 | 1.000 | / | / | / | |
| Beam | 12.090 | 0.609 | 0.481 | 9.268 | 0.827 | 0.973 | 2.413 | 0.905 | 0.813 |
| Hungarian | 25.296 | 0.510 | 0.360 | 29.805 | 0.638 | 0.913 | 1.845 | 0.932 | 0.825 |
| VJ | 29.157 | 0.517 | 0.310 | 63.863 | 0.581 | 0.287 | 1.831 | 0.934 | 0.815 |
| HED | 28.925 | 0.621 | 0.386 | 19.553 | 0.897 | 0.982 | 19.400 | 0.751 | 0.801 |
| SimGNN | 1.376 | 0.824 | 0.400 | 2.479 | 0.912 | 0.635 | 1.264 | 0.878 | 0.759 |
| GMN | 4.610 | 0.672 | 0.200 | 2.571 | 0.906 | 0.888 | 4.422 | 0.725 | 0.604 |
| GraphSim | 1.919 | 0.849 | 0.446 | 0.471 | 0.976 | 0.956 | 0.743 | 0.926 | 0.828 |
| GOTSim | 1.180 | 0.860 | 0.870 | 2.125 | 0.920 | 0.860 | 2.960 | 0.850 | 0.730 |
| SGNN | 2.822 | 0.765 | 0.289 | 11.830 | 0.566 | 0.226 | 1.430 | 0.870 | 0.748 |
| NGMN | 1.191 | 0.904 | 0.465 | 1.561 | 0.945 | 0.743 | 1.331 | 0.889 | 0.805 |
| MGMN | 1.169 | 0.905 | 0.456 | 0.439 | 0.985 | 0.955 | 0.335 | 0.919 | 0.837 |
| 0.957 | 0.877 | 0.517 | 0.227 | 0.984 | 0.953 | 0.308 | 0.912 | 0.861 | |
| 0.913 | 0.881 | 0.521 | 0.105 | 0.990 | 0.975 | 0.589 | 0.913 | 0.889 | |
| Noah | 1.545 | 0.734 | 0.809 | / | / | / | 27.818 | 0.810 | 0.354 |
| GENN- | 0.839 | 0.953 | 0.866 | 0.324 | 0.991 | 0.962 | / | / | / |
| Conga | 0.823 | 0.892 | 0.550 | 0.121 | 0.992 | 0.987 | 0.288 | 0.948 | 0.871 |
| w/o CL | 0.840 | 0.890 | 0.544 | 0.126 | 0.992 | 0.994 | 0.315 | 0.947 | 0.866 |
| Methods | AIDS | LINUX | IMDB | Methods | AIDS | LINUX | IMDB |
|---|---|---|---|---|---|---|---|
| SimGNN | 5.3 | 5 | 6.6 | 1324.7 | 896.3 | / | |
| GMN | 7 | 7.1 | 9.1 | Beam | 13.2 | 9.5 | 119.4 |
| GraphSim | 7.5 | 7.5 | 8.1 | Hungarian | 8.2 | 6.8 | 105.6 |
| MGMN | 5.2 | 5.6 | 7.1 | VJ | 9 | 7.4 | 109.1 |
| 0.9 | 0.8 | 1.2 | Noah | >10.0 | / | >100.0 | |
| Conga | 0.3 | 0.3 | 0.3 | GENN- | >10.0 | >10.0 | / |
| w/o CL | 0.2 | 0.2 | 0.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, S.; Zeng, W.; Zhang, P.; Tang, J. Neural Graph Similarity Computation with Contrastive Learning. Appl. Sci. 2022, 12, 7668. https://doi.org/10.3390/app12157668
Hu S, Zeng W, Zhang P, Tang J. Neural Graph Similarity Computation with Contrastive Learning. Applied Sciences. 2022; 12(15):7668. https://doi.org/10.3390/app12157668
Chicago/Turabian StyleHu, Shengze, Weixin Zeng, Pengfei Zhang, and Jiuyang Tang. 2022. "Neural Graph Similarity Computation with Contrastive Learning" Applied Sciences 12, no. 15: 7668. https://doi.org/10.3390/app12157668
APA StyleHu, S., Zeng, W., Zhang, P., & Tang, J. (2022). Neural Graph Similarity Computation with Contrastive Learning. Applied Sciences, 12(15), 7668. https://doi.org/10.3390/app12157668