
Distantly Supervised Named Entity Recognition with Self-Adaptive Label Correction


Abstract
:1. Introduction
- A self-adaptive learning framework termed SALO is proposed to improve the learning of NER models by dynamically incorporating adaptive label correction into training. An iterative training algorithm continuously optimizes the model while correcting noisy labels.
- A denoising classifier and a noisy label detector are introduced to identify noisy labels. The denoising classifier filters unreliable labeled tokens while the noisy label detector detects the wrongly hard supervision signals to be corrected.
- The built model is evaluated on four benchmark datasets, and the results demonstrate that SALO performs better than other baselines in all noisy datasets.
2. Related Works
2.1. Fully Supervised Named Entity Recognition
2.2. Distantly Supervised Named Entity Recognition
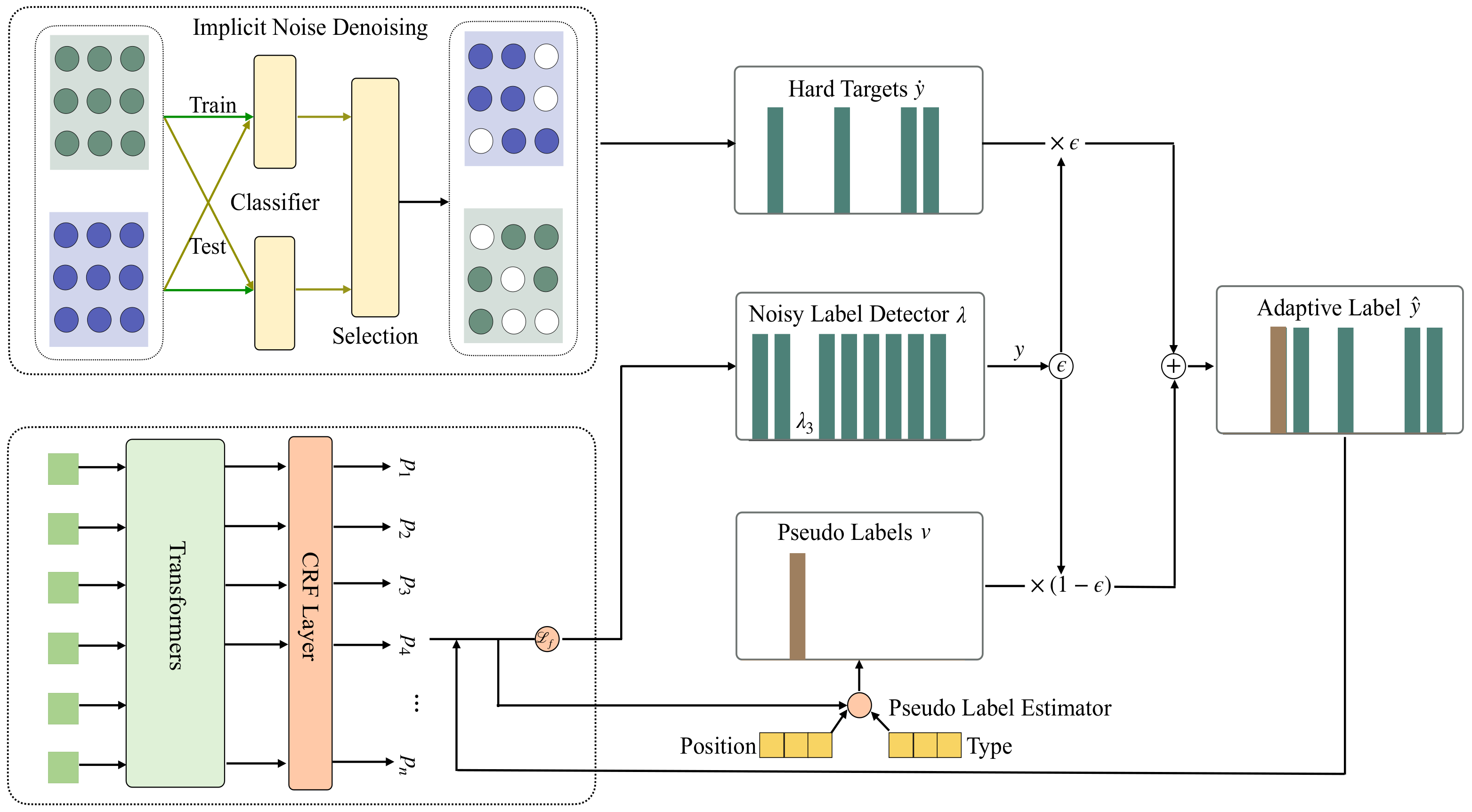
3. Methodology
3.1. Method Overview
3.2. Adaptive Label Correction
3.2.1. Implicit Noise Denoising
3.2.2. Noisy Example Detector
3.2.3. Pseudolabel Estimator
3.3. Iterative Training
| Algorithm 1 Self-Adaptive Label cOrrection algorithm |
|
4. Experiment
4.1. Datasets
4.2. Implementation Details
4.3. Comparison with State of the Arts
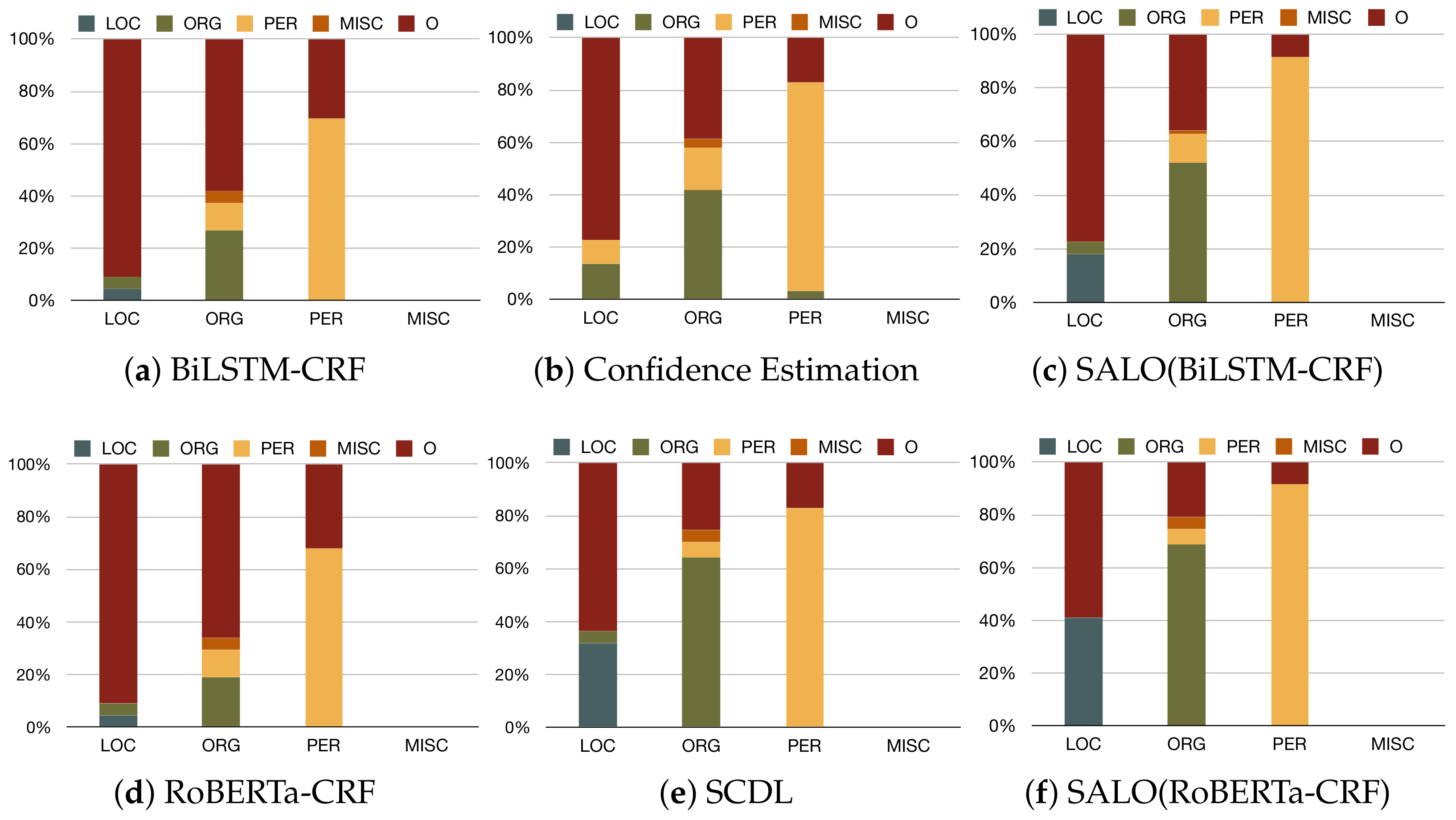
- The proposed SALO outperforms existing distantly supervised approaches on all datasets, which demonstrates the superiority of the built model in noisy NER label learning. An in-depth data analysis reveals that SALO is able to detect accurate boundaries of various few-shot entity mentions such as Lucy Vanderwende and Carolyn Rose in the Webpage dataset compared with BiLSTM-CRF.
- Models directly trained on noisy labels only obtain 41.88% and 58.98% average scores using BiLSTM-CRF and RoBERTa-base architectures, respectively. This reveals that noisy label learning is in demand for distantly supervised NER.
- Models trained in a fully supervised manner achieve upper bound performance, with 62.66% and 75.28% average scores using BiLSTM-CRF and RoBERTa-base architectures, respectively. The proposed SALO narrows the gap between fully supervised and distantly supervised NER methods, obtaining 58.91% and 68.20%, respectively. There still exists 3.75% and 7.08% gaps between fully supervised and distantly supervised models.
- Self-Training and Confidence Estimation are two strong baselines with the BiLSTM-CRF base model under the distantly supervised setting. The proposed SALO with BiLSTM-CRF architecture obtains 3.66% and 1.71% improvements on average scores over Self-Training and Confidence Estimation, respectively. This improvement could be attributed to the adaptive label correction, which can successfully avoid the overconfidence issue of deep neural networks for noisy data and does not require to know/model the ratio of noise data in the training data like Confidence Estimation.
- Bond and SCDL which are two advanced baselines with the RoBERTa base model under the distantly supervised setting. The proposed SALO counterpart achieves 4.37% and 1.35% improvements on average scores compared with Bond and SCDL, respectively.
- The models that explicitly handle the overconfidence issue (i.e., SALO and Confidence-Estimation) generally perform better than other distantly supervised baselines.
4.4. Ablation Study
4.4.1. Effectiveness of Implicit Denoising
4.4.2. Effectiveness of Noisy Example Detector
4.4.3. Effectiveness of Pseudolabel Estimator
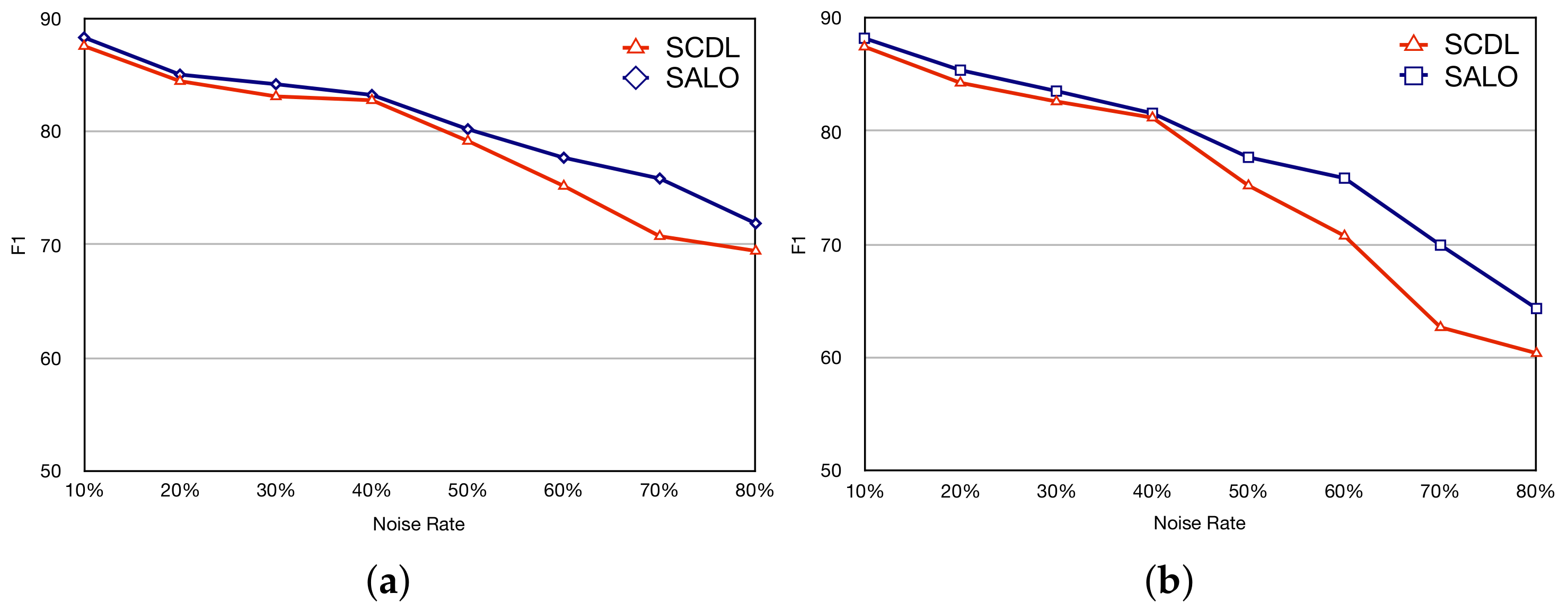
4.4.4. Robustness to Different Noise Ratio
4.5. Case Study
4.6. Results on Label Extensions
4.7. Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Chen, H.; Lin, Z.; Ding, G.; Lou, J.; Zhang, Y.; Karlsson, B. GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition. In Proceedings of the National Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6236–6243. [Google Scholar]
- Liu, Y.; Meng, F.; Zhang, J.; Xu, J.; Chen, Y.; Zhou, J. GCDT: A Global Context Enhanced Deep Transition Architecture for Sequence Labeling. In Proceedings of the Association for Computational Linguistics, Florence, Italy, 4–13 October 2019; pp. 2431–2441. [Google Scholar]
- Chen, M.; Lan, G.; Du, F.; Lobanov, V.S. Joint Learning with Pre-trained Transformer on Named Entity Recognition and Relation Extraction Tasks for Clinical Analytics. In Proceedings of the Empirical Methods in Natural Language Processing, Virtual, 16–20 November 2020; pp. 234–242. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Tanon, T.P.; Weikum, G.; Suchanek, F.M. YAGO 4: A Reason-able Knowledge Base. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2020; Volume 12123, pp. 583–596. [Google Scholar]
- Liang, C.; Yu, Y.; Jiang, H.; Er, S.; Wang, R.; Zhao, T.; Zhang, C. BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision. In Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining, Virtual, 6–10 July 2020; pp. 1054–1064. [Google Scholar]
- Arpit, D.; Jastrzebski, S.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.C.; Bengio, Y.; et al. A Closer Look at Memorization in Deep Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 233–242. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Krogh, A.; Hertz, J.A. A single weight decay can imrpove generalization. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; pp. 950–957. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Bellare, K.; McCallum, A. Learning extractors from unlabeled text using relevant databases. In Proceedings of the International Workshop on Information Integration on the Web, Linz, Austria, 29 November–1 December 2007. [Google Scholar]
- Mayhew, S.; Chaturvedi, S.; Tsai, C.; Roth, D. Named Entity Recognition with Partially Annotated Training Data. In Proceedings of the Conference on Natural Language Learning, Hong Kong, China, 3–4 November 2019; pp. 645–655. [Google Scholar]
- Shang, J.; Liu, L.; Gu, X.; Ren, X.; Ren, T.; Han, J. Learning Named Entity Tagger using Domain-Specific Dictionary. In Proceedings of the Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2054–2064. [Google Scholar]
- Zheng, S.; Wu, P.; Goswami, A.; Goswami, M.; Metaxas, D.N.; Chen, C. Error-Bounded Correction of Noisy Labels. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 11447–11457. [Google Scholar]
- Rau, L.F. Extracting company names from text. In Proceedings of the ICAISA, Miami Beach, FL, USA, 24–28 February 1991; pp. 29–32. [Google Scholar]
- Zhou, G.; Su, J. Named Entity Recognition using an HMM-based Chunk Tagger. In Proceedings of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 473–480. [Google Scholar]
- Malouf, R. Markov Models for Language-independent Named Entity Recognition. In Proceedings of the Conference on Natural Language Learning, Taipei, Taiwan, 24 August–1 September 2002. [Google Scholar]
- Li, Y.; Bontcheva, K.; Cunningham, H. SVM Based Learning System for Information Extraction. In Proceedings of the Deterministic and Statistical Methods in Machine Learning, First International Workshop, Sheffield, UK, 7–10 September 2004; Volume 3635, pp. 319–339. [Google Scholar]
- Ratinov, L.; Roth, D. Design Challenges and Misconceptions in Named Entity Recognition. In Proceedings of the Conference on Natural Language Learning, Boulder, CO, USA, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Jie, Z.; Xie, P.; Lu, W.; Ding, R.; Li, L. Better Modeling of Incomplete Annotations for Named Entity Recognition. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 729–734. [Google Scholar]
- Cao, Y.; Hu, Z.; Chua, T.; Liu, Z.; Ji, H. Low-Resource Name Tagging Learned with Weakly Labeled Data. In Proceedings of the Empirical Methods in Natural Language Processing-International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 261–270. [Google Scholar]
- Yang, Y.; Chen, W.; Li, Z.; He, Z.; Zhang, M. Distantly Supervised NER with Partial Annotation Learning and Reinforcement Learning. In Proceedings of the International Conference on Computational Liguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2159–2169. [Google Scholar]
- Peng, M.; Xing, X.; Zhang, Q.; Fu, J.; Huang, X. Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning. In Proceedings of the Association for Computational Linguistics, Florence, Italy, 4–13 October 2019; pp. 2409–2419. [Google Scholar]
- Zhang, H.; Long, D.; Xu, G.; Zhu, M.; Xie, P.; Huang, F.; Wang, J. Learning with Noise: Improving Distantly-Supervised Fine-grained Entity Typing via Automatic Relabeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2020; pp. 3808–3815. [Google Scholar]
- Liu, K.; Fu, Y.; Tan, C.; Chen, M.; Zhang, N.; Huang, S.; Gao, S. Noisy-Labeled NER with Confidence Estimation. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Virtual, 6–11 June 2021; pp. 3437–3445. [Google Scholar]
- Zhang, X.; Yu, B.; Liu, T.; Zhang, Z.; Sheng, J.; Xue, M.; Xu, H. Improving Distantly-Supervised Named Entity Recognition with Self-Collaborative Denoising Learning. In Proceedings of the Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Huang, J.; Qu, L.; Jia, R.; Zhao, B. O2u-net: A simple noisy label detection approach for deep neural networks. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3325–3333. [Google Scholar]
- Sang, E.F.T.K.; Meulder, F.D. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Mexico City, Mexico, 16 February 2003; pp. 142–147. [Google Scholar]
- Godin, F.; Vandersmissen, B.; Neve, W.D.; de Walle, R.V. Multimedia Lab @ ACL WNUT NER Shared Task: Named Entity Recognition for Twitter Microposts using Distributed Word Representations. In Proceedings of the Workshop on the Association for Computational Linguistics, Beijing, China, 30–31 July 2015; pp. 146–153. [Google Scholar]
- Balasuriya, D.; Ringland, N.; Nothman, J.; Murphy, T.; Curran, J.R. Named Entity Recognition in Wikipedia. In Proceedings of the Workshop on The People’s Web Meets, Singapore, 7 August 2009; pp. 10–18. [Google Scholar]
- Peters, M.E.; Neumann, M.; Logan, R.L.; Schwartz, R.; Joshi, V.; Singh, S.; Smith, N.A. Knowledge Enhanced Contextual Word Representations. In Proceedings of the Empirical Methods in Natural Language Processing-International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 43–54. [Google Scholar]
- Cao, N.D.; Izacard, G.; Riedel, S.; Petroni, F. Autoregressive Entity Retrieval. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Ma, X.; Hovy, E.H. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CoNLL03 | Webpage | Wikigold | |
|---|---|---|---|---|
| Fully Supervised | ||||
| BiLSTM-CRF (UB) | 91.21 (91.35/91.06) | 52.18 (60.01/46.16) | 52.34 (50.07/64.76) | 54.90 (55.40/54.30) |
| RoBERTa-base (UB) | 90.11 (89.14/91.10) | 52.19 (51.76/52.63) | 72.39 (66.29/79.73) | 86.43 (85.33/87.56) |
| Distantly Supervised | ||||
| BiLSTM-CRF (LB) | 59.50 (75.50/49.10) | 21.77 (46.91/14.18) | 43.34 (58.05/34.59) | 42.92 (47.55/39.11) |
| RoBERTa-base (LB) | 75.93 (82.29/70.47) | 46.45 (50.97/42.66) | 60.98 (59.24/62.84) | 52.57 (47.67/58.59) |
| AutoNER | 67.00 (75.21/60.40) | 26.10 (43.26/18.69) | 51.39 (48.82/54.23) | 47.54 (43.54/52.35) |
| LRNT | 69.74 (79.91/61.87) | 23.84 (46.94/15.98) | 47.74 (46.70/48.83) | 46.21 (45.60/46.84) |
| Self-training | 77.8 (-/-) | 42.3 (-/-) | 49.6 (-/-) | 51.3 (-/-) |
| Confidence-Estimation | 79.4 (-/-) | 43.6 (-/-) | 51.8 (-/-) | 54.0 (-/-) |
| Bond | 81.48 (82.05/80.92) | 48.01 (53.16/44.76) | 65.74 (67.37/64.19) | 60.07 (53.44/68.58) |
| SCDL | 83.69 (87.96/79.82) | 51.09 (59.87/44.57) | 68.47 (68.71/68.24) | 64.13 (62.25/66.12) |
| SALO (BiLSTM-CRF) | 80.08 (85.59/75.24) | 44.96 (54.02/38.50) | 54.90 (74.07/40.54) | 55.71 (53.31/58.33) |
| SALO (RoBERTa) | 84.90 (86.20/83.64) | 52.50 (68.48/42.57) | 69.66 (78.15/62.84) | 65.72 (63.31/68.33) |
| Method | Precision | Recall | |
|---|---|---|---|
| w/o denoising | 61.54 | 27.03 | 37.56 |
| hard denoising | 64.15 | 45.95 | 53.54 |
| SALO | 65.42 | 47.30 | 54.90 |
| Method | Precision | Recall | |
|---|---|---|---|
| Negative Detector | 61.54 | 27.03 | 37.56 |
| Positive Detector | 64.15 | 45.95 | 53.54 |
| Random Detector (, ) | 68.97 | 40.54 | 51.06 |
| Random Detector (, ) | 67.02 | 42.57 | 52.07 |
| SALO | 65.42 | 47.30 | 54.90 |
| Method | Precision | Recall | |
|---|---|---|---|
| Hard Label | 64.42 | 45.27 | 53.17 |
| Reweighting (Confidence) | 66.33 | 43.92 | 52.85 |
| SALO | 65.42 | 47.30 | 54.90 |
| Method | BiLSTM-CRF (Baseline) | BiLSTM-CRF (SALO) | ||||
|---|---|---|---|---|---|---|
| Dataset | Score | Precision | Recall | Score | Precision | Recall |
| CoNLL03 | 59.50 | 75.50 | 49.10 | 80.08 | 85.59 | 75.24 |
| CoNLL03-e | 61.22 | 85.67 | 47.63 | 81.95 | 88.83 | 77.41 |
| 21.77 | 46.91 | 14.18 | 44.96 | 54.02 | 38.50 | |
| Twitter-e | 22.90 | 55.16 | 14.45 | 45.11 | 60.92 | 35.81 |
| Webpage | 43.34 | 58.05 | 34.59 | 54.90 | 74.07 | 40.54 |
| Webpage-e | 45.97 | 57.00 | 38.51 | 56.07 | 73.63 | 45.27 |
| Wikigold | 42.92 | 47.55 | 39.11 | 55.71 | 53.31 | 58.33 |
| Wikigold-e | 44.54 | 51.84 | 39.04 | 56.13 | 67.96 | 47.97 |
| Method | RoBERTa (Baseline) | RoBERTa (SALO) | ||||
|---|---|---|---|---|---|---|
| Dataset | Score | Precision | Recall | Score | Precision | Recall |
| CoNLL03 | 75.93 | 82.29 | 70.47 | 84.90 | 86.20 | 83.64 |
| CoNLL03-e | 76.39 | 86.82 | 68.20 | 84.51 | 87.81 | 81.45 |
| 46.45 | 50.97 | 42.66 | 52.50 | 68.48 | 42.57 | |
| Twitter-e | 48.56 | 53.51 | 44.45 | 53.79 | 46.14 | 64.47 |
| Webpage | 60.98 | 59.24 | 62.84 | 69.66 | 78.15 | 62.84 |
| Webpage-e | 61.33 | 58.31 | 64.69 | 70.01 | 71.17 | 69.05 |
| Wikigold | 52.57 | 47.67 | 58.59 | 65.72 | 63.31 | 68.33 |
| Wikigold-e | 53.79 | 46.14 | 64.47 | 66.98 | 65.11 | 68.97 |
| Clean Label | Noisy Label | Implicit Denoising | SALO | Noise Rate | |
|---|---|---|---|---|---|
| √ | 91.21 | 0.00 | |||
| √ | 59.50 | 67.21 | |||
| √ | √ | 66.67 | 63.33 | ||
| √ | √ | 80.08 | 48.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, B.; Li, C. Distantly Supervised Named Entity Recognition with Self-Adaptive Label Correction. Appl. Sci. 2022, 12, 7659. https://doi.org/10.3390/app12157659
Nie B, Li C. Distantly Supervised Named Entity Recognition with Self-Adaptive Label Correction. Applied Sciences. 2022; 12(15):7659. https://doi.org/10.3390/app12157659
Chicago/Turabian StyleNie, Binling, and Chenyang Li. 2022. "Distantly Supervised Named Entity Recognition with Self-Adaptive Label Correction" Applied Sciences 12, no. 15: 7659. https://doi.org/10.3390/app12157659
APA StyleNie, B., & Li, C. (2022). Distantly Supervised Named Entity Recognition with Self-Adaptive Label Correction. Applied Sciences, 12(15), 7659. https://doi.org/10.3390/app12157659