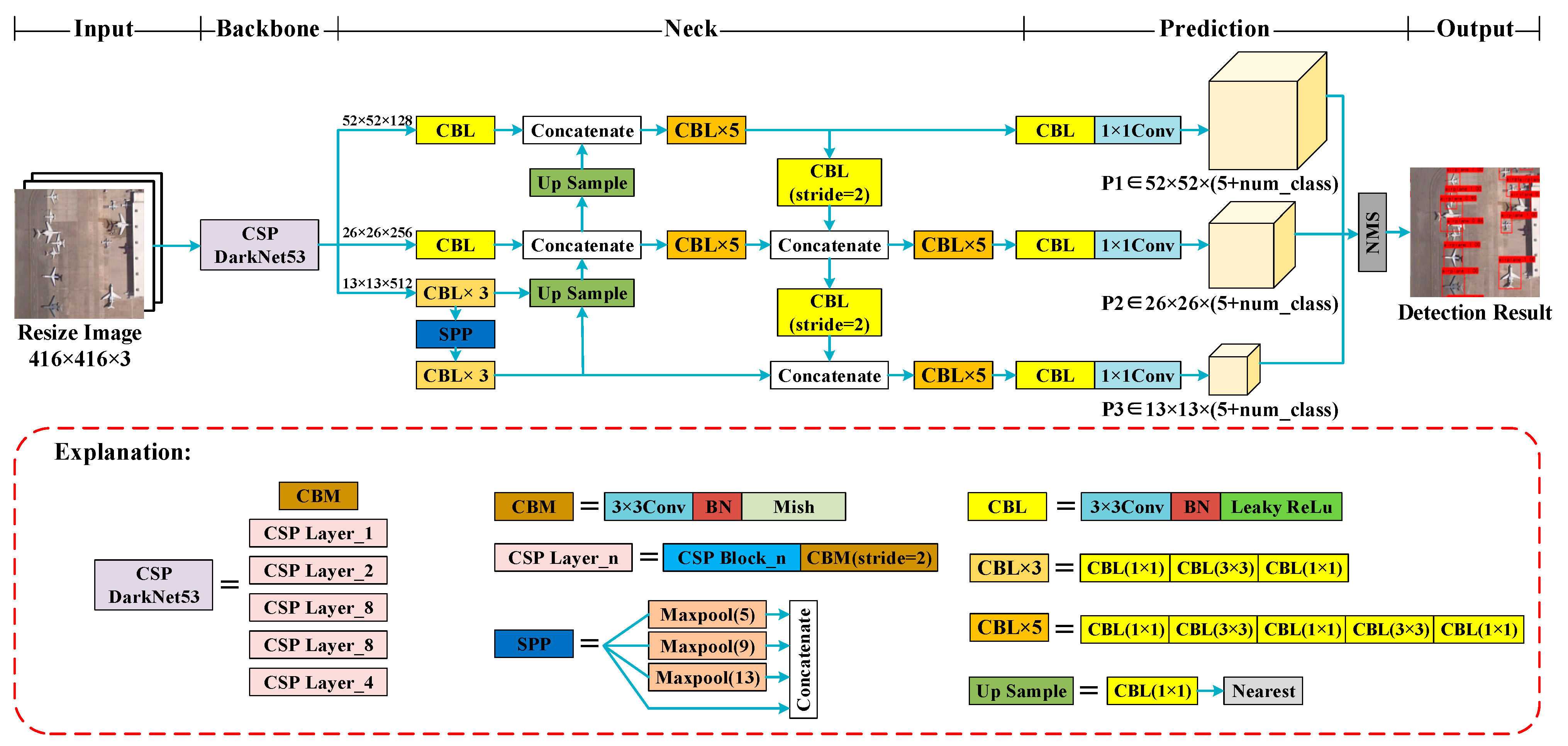
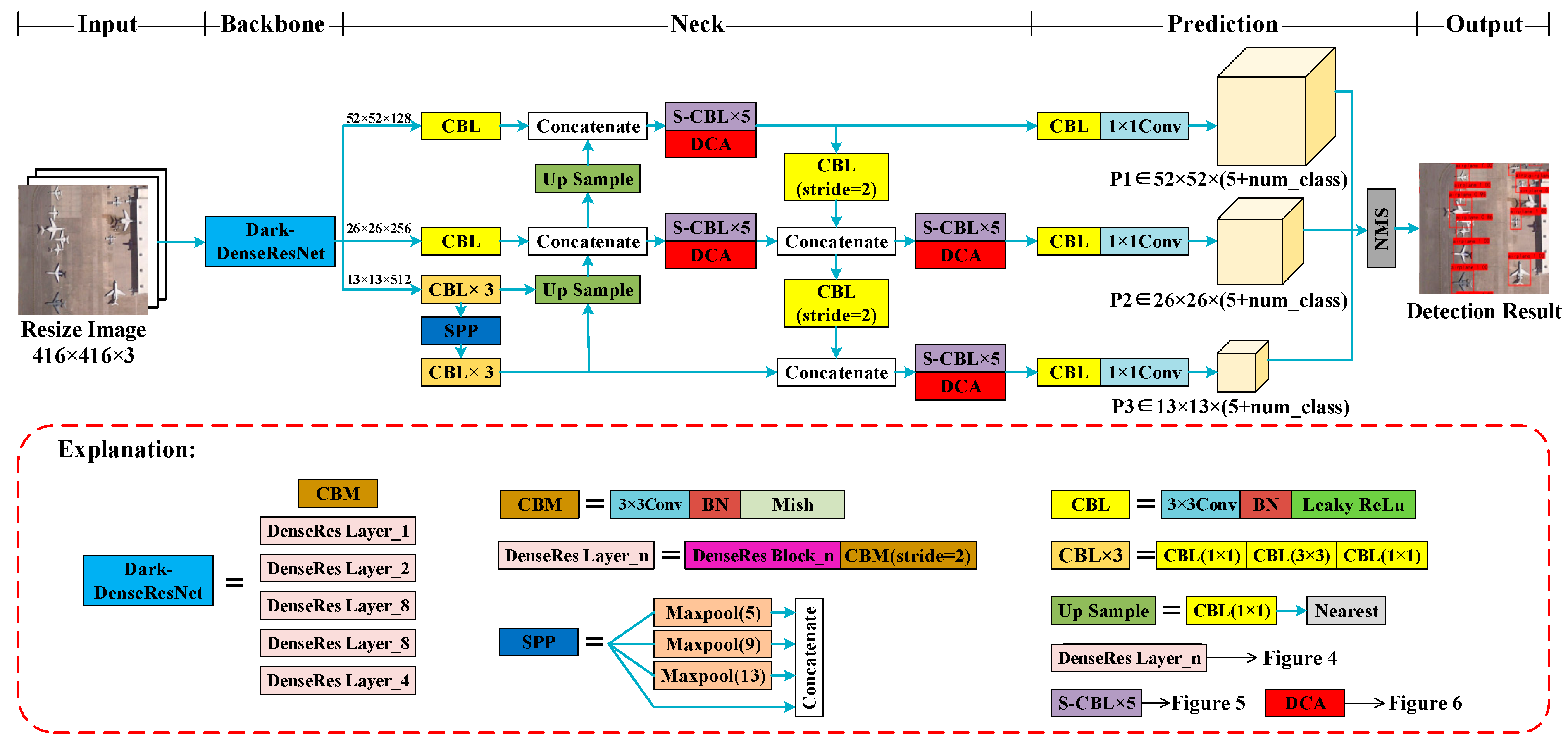
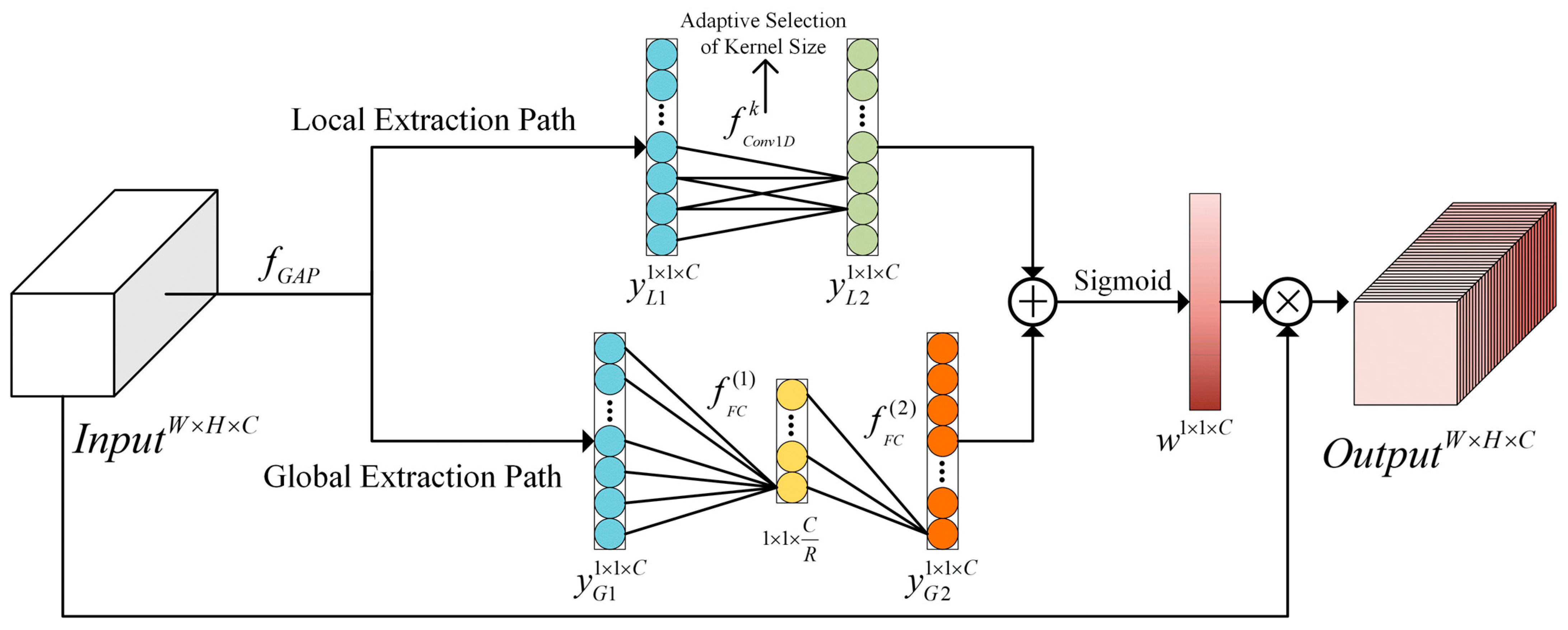
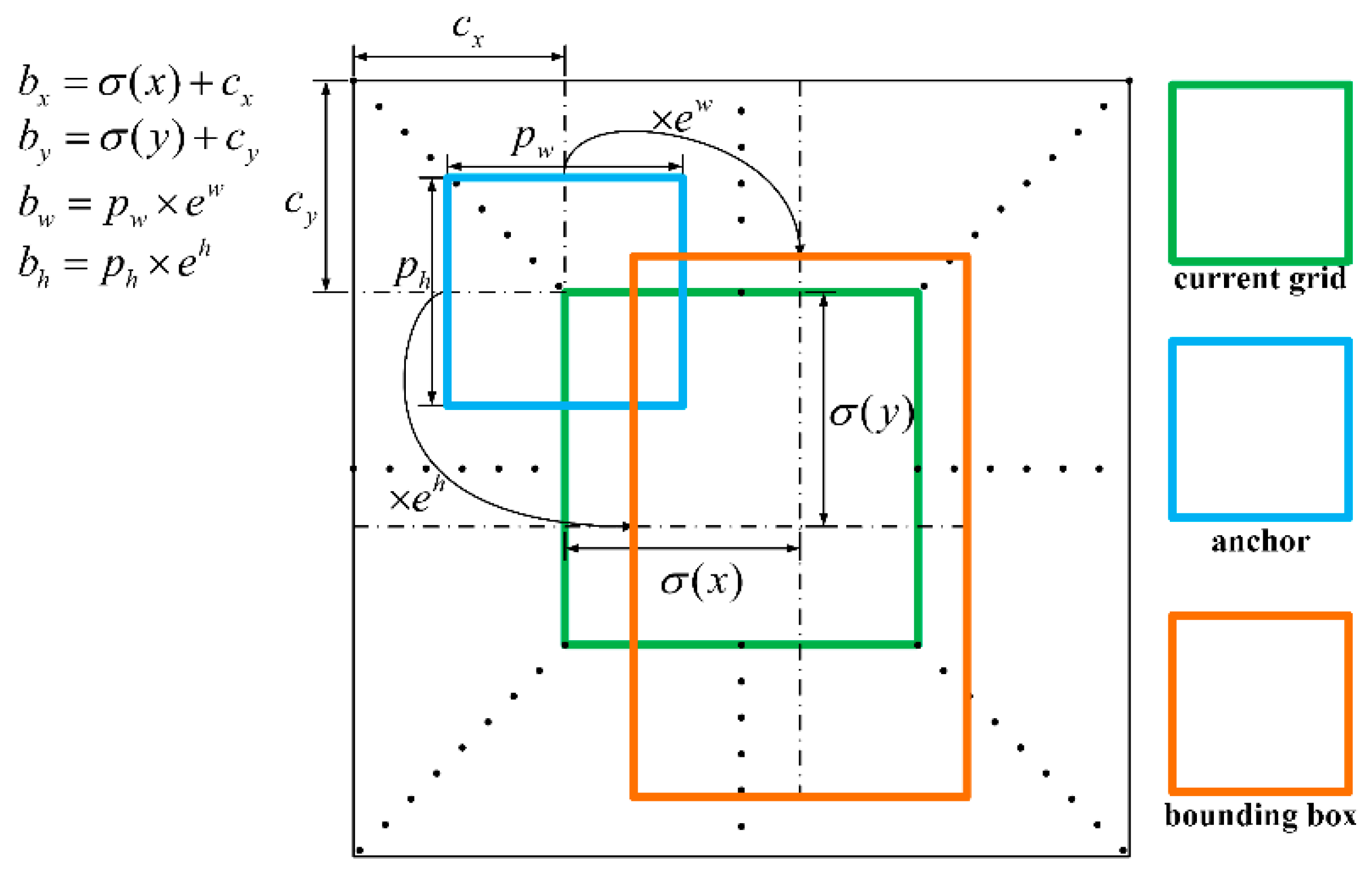
4.4.1. Ablation Experiment
Ablation experiments were conducted to verify the effectiveness of each improved module in YOLO-DSD, and the results are shown in
Table 2. The detector improved with the DenseRes Block reduces Params by 23.9% (
× 100%) and Flops by 29.7% (
× 100%), and increases FPS by 63.4% (
× 100%), while achieving a 0.2% higher mAP
0.5 and almost the same mAP
0.5:0.95 compared with YOLOv4 as the baseline. The detector improved by S-CBL×5 in the neck based on “+DenseRes Block” is beneficial for mAP
0.5 and mAP
0.5:0.95, which are brought about by the increase in mAP
M and mAP
L without affecting the deployability and inference speed. However, the mAP
S slightly decreased by 0.3% because the short-cut utilized in S-CBL×5 strengthened the transmitting of the feature, and thus introduced background features additionally, which attenuated the representation of the feature for small-sized objects. The detector further improved by the DCA Block achieved a significant increase in mAP due to the enhancement of feature expression, and made up for the loss of mAP
S caused by the short-cut with the same Params and Flops, while the FPS was only slightly reduced by 5.3 img/s.
In summary, YOLO-DSD outperforms YOLOv4 both in the detection accuracy, deployability and speed evaluation indicator. YOLO-DSD based on YOLOv4 increases the commonly used indicator mAP0.5 by 1.7% and the more rigorous indicator mAP0.5:0.95 by 0.9%. Specifically, YOLO-DSD has a greater advantage in mAPM and mAPL, while it achieves a similar and competitive mAPS compared with YOLOv4. In terms of deployability performance, the Params and Flops of YOLO-DSD decreased by 23.9% and 29.7% more than those of YOLOv4, respectively. YOLO-DSD also performs well in inference speed: it is 50.2% faster than YOLOv4 in FPS.
We further analyzed the performance of the DenseRes Block. The ablation results of the DenseRes Block are shown in
Table 3. The structure of the DenseRes Block in each detector is shown in
Figure 13. Model 1 is the detector improved by the DenseRes Block without the structure of the ‘Short-cut’ and ‘Combine’. ‘Short-cut’ and ‘Combine’ are introduced to the DenseRes Block in Model 2 and Model 3, respectively. Model 4 utilizes the complete DenseRes Block to improve the backbone of YOLOv4. From the comparison between Model 1 and Model 2, the ‘Short-cut’ introduced to DenseRes Block for the mitigation of feature loss can improve the mAP of objects in each size. After adding the ‘Combine’ to DenseRes Block, Model 3 performs better on the middle and large-sized object, while the mAP
S decreases slightly by 0.1%. The possible reason for this is that the feature of the middle and large-sized object is obvious enough to build high-level semantic relevance with the background feature, while the feature of the small object is not obvious enough and thus it is easy for it to be overwhelmed. Model 4 improved by the complete DenseRes Block achieves the highest mAP and a significant increase in mAP
S, mAP
M and mAP
L. It is probable that, on the basis of the ‘Short-cut’, the feature of each size object can be better retained when transmitting in the DenseRes Block, and can thus benefit the building of high-level semantic relevance with a background feature through ‘Combine’.
The experimental results of DCA module ablation are shown in
Table 4 and
Table 5.
Table 4 shows the influence of scaling factor R on the performance of the DCA Block. The results show that, when R = 32, DCA can achieve the best performance.
Table 5 exhibits the influence of three different fusion methods shown in
Figure 14 on the performance of the DCA Block. The results show that the DCA Block with a different fusion method can effectively improve the detection accuracy. Specifically, compared with DCA in series, DCA in parallel has a more obvious advantage in small and middle-sized objects, while the FPS is slightly reduced by 0.7 img/s. This may be due to the fact that, when employing the same number of operation layers in one building block, although the structure designed in parallel has a higher fragment, it can keep the integrity of the feature better compared with that in series. For the proposed DCA Block, which has a small structure complexity, utilizing the structure in parallel makes it perform better in the enhancement of feature expression without an obvious sacrifice of inference time.
4.4.2. Comparative Experiment
Four experiments were conducted in this study to verify the superiority of the proposed method. (1) ResNet50 [
34], VGG16 [
33] and the backbones that were established based on the CSP DarkNet framework with different feature extraction modules, including the Res Block [
34], ResNeXt Block [
35], Res2 Block [
36], Dense Block [
27], CSP Block [
37] and DenseRes Block, were compared. (2) A comparison of different neck structures, including FPN [
16], BFPN [
40], PANet [
41], S-PANet (PANet improved with the proposed S-CBL×5) and none (without feature pyramid structure), was conducted. (3) The performance of different attention mechanisms, including the SE Block [
42], ECA Block [
43], CA Block [
44], CBAM Block [
45] and DCA Block(R = 32), was compared and analyzed. (4) YOLO-DSD was compared with eight SOTA detectors, including Faster-RCNN, SSD, RetinaNet, YOLOv3, YOLOv4, YOLO-Lite (MobileNetV2 [
51]—YOLOv4), CenterNet [
7] and EfficientDet [
9], which have been widely applied in various natural scene visual detection tasks due to their acceptable tradeoff between accuracy, deployability and inference time.
Comparative experiment for different backbones: The performances of the CSP DarkNet, which is improved by the proposed DenseRes Block (DarkNet-DenseRes) and other backbones, are demonstrated in
Table 6. Based on the CSP DarkNet framework, the proposed DenseRes Block outperforms the ResNeXt Block and Dense Block in all indicators. Although the mAP
0.5 and mAP
0.5:0.95 of DarkNet-DenseRes are slightly lower than those of DarkNet-Res by 0.1% and 1.3%, the Params and Flops of DarkNet-DenseRes are only approximately 1/3 and 1/4 of DarkNet-Res, while the FPS of DarkNet-DenseRes is approximately 1/4 higher than that of DarkNet-Res. Similarly, the mAP
0.5 and mAP
0.5:0.95 of DarkNet-DenseRes are 0.9% and 1.1% lower than those of DarkNet-Res2; however, the Params and Flops of DarkNet-DenseRes are only approximately 1/3 and 1/2 of those of DarkNet-Res2, while the interference speed is 2.3 times that of DarkNet-Res2 according to FPS. The superiority of DarkNet-DenseRes compared with CSP DarkNet was analyzed and proved in ablation experiments. DarkNet-DenseRes also has obvious advantage in all indicators compared with ResNet50. Although DarkNet-DenseRes has a similar accuracy and speed to VGG16, VGG16 has seven times as much Flops than that of DarkNet-DenseRes. Therefore, DarkNet-DenseRes achieves the optimal balance of accuracy, deployability and speed.
Comparative experiment for different necks:
Table 7 shows the performance of each neck structure that was tested by applying a no-feature pyramid structure (None), FPN, BFPN, PANet (Baseline) and S-PANet to the modified YOLOv4, with the DenseRes Block in the backbone. ‘None’ has the lowest Params (18.83 M) and Flops (4.89 G) and the highest FPS (85.5 img/s), but it does not perform well in detection accuracy, and, in particular, its mAP
S is only 8.1%, whereas that of the other four necks ranges from 9.1% to 9.5%. Therefore, the feature pyramid structure is vital for detection accuracy and, in particular, for small size objects, which occupy more than 50% in DIOR. Although FPN and BFPN are slightly better than PANet in deployability and inference speed, they have more than a 2.6% inferiority in mAP of middle and large-sized objects, which, in total, account for approximately 50% of objects in DIOR. It was proven that the structure of PANet is important to the detection accuracy in YOLOv4 for ORSIs. PANet and S-PANet have almost the same Params, Flops and FPS, but our S-PANet performs better than PANet in mAP
0.5 and mAP
0.5:0.95. In conclusion, S-PANet is more suitable for optical remote sensing object detection than other necks.
Comparative experiments for different attention mechanisms: Taking modified YOLOv4 with the DenseRes Block in the backbone and S-PANet in the neck as the baseline (None), the indicator values of different attention mechanisms are exhibited and compared in
Table 8. The CA Block and CBAM Block containing the spatial attention mechanism fail to improve the detection accuracy, and the FPS decreases significantly due to those complex structures. Most channel attention mechanisms, including the SE Block, ECA Block and DCA Block, can improve the detection accuracy. The DCA Block improves the detection accuracy for small, medium and large sizes of objects, and achieves the highest mAP
0.5 = 73.0% and mAP
0.5:0.95 = 40.0%, with an increase of 1.1% and 0.8% compared with ‘None’, respectively, when R = 32, and the FPS only decreases by 5.3 img/s. In the case of the SE Block, mAP
0.5 and mAP
0.5:0.95 increases by 0.2% and 0.1%, and the FPS decreases by 3.4 img/s. The ECA Block improves both mAP
0.5 and mAP
0.5:0.95 by 0.1%, and decreases the FPS by 2.8 img/s. Therefore, the proposed DCA Block can achieve the best balance between accuracy and speed.
Comparative experiments for different detectors: The performances of the proposed YOLO-DSD and eight SOTA detectors are demonstrated in
Table 9. RetinaNet and EfficientDet have a better deployability than YOLO-DSD, but their detection accuracy, especially for small-sized objects and speed, are far behind that of YOLO-DSD, so this hinders the application of these detectors in optical remote sensing object detection. The large Flops of SSD and Faster-RCNN require a huge amount of computing resources, which greatly increases the difficulty in deploying them on edge devices. Although the Params and Flops of CenterNet are 67% and 69% that of YOLO-DSD, and the FPS is 46% faster, the detection accuracy of CenterNet is significantly lower than that of YOLO-DSD (mAP
0.5:0.95:35.8% vs. 40.0%), and the mAP
S is only 62.5% that of YOLO-DSD. YOLO-Lite has an obvious disadvantage in detection accuracy for small and large-sized objects, even though it has a better deployability compared with YOLO-DSD. The inference speed of YOLOv3 is nearly the same as that of YOLO-DSD, but the deployability and detection accuracy of YOLOv3 are obviously inferior to that of YOLO-DSD. The superiority of YOLO-DSD compared with YOLOv4 was analyzed and proved in ablation experiments. Therefore, YOLO-DSD outperforms other SOTA detectors in the balance of accuracy, deployability and speed.
Figure 15,
Figure 16 and
Figure 17 exhibit the detection performance of Faster-RCNN, CenterNet, YOLOv4 and YOLO-DSD on DIOR. The detection result of the small-sized instance in
Figure 15 indicates that both Faster-RCNN and CenterNet obviously miss detection. Although YOLOv4 could completely detect airplanes, it incorrectly detected a storage tank. Our YOLO-DSD can correctly detect all airplanes without any false detection.
Figure 16 presents the detection results of an instance in the complex urban background. We can see that Faster-RCNN only detects one ground track field, and that CenterNet misses two bridges and two ground track fields and misdetects an overpass. YOLOv4 misses one bridge and one ground track field, whereas YOLO-DSD detects all objects correctly. The detection results of instances in a complex suburban background are given in
Figure 17. It can be seen that Faster-RCNN detects only one Expressway-Service-Area, CenterNet has two false detections of an overpass and windmill, YOLOv4 detects two Expressway-Service-Areas as one, and YOLO-DSD correctly detects all objects. The above instances verify that YOLO-DSD can handle object detection under different complex backgrounds well.
The precision–recall curves and AP (IOU = 0.5) of YOLOv4 and YOLO-DSD in each category are given in
Figure 18 for a better illustration of the difference in detection accuracy. It can be seen that YOLO-DSD detects better than YOLOv4 in 11 categories, including airplane, airport, baseball field, chimney, dam, Expressway-Service-Area, golffield, groundtrackfield, stadium, storagetank and transtation. In particular, the AP of YOLO-DSD in airport, baseballfield, Expressway-Service-Area and groundtrackfield is over 2% higher than that of YOLOv4. The AP of YOLO-DSD in airplane, transtation and stadium significantly increase by 6.63%, 5.21% and 17.02%, respectively. For the other nine categories, YOLO-DSD only slightly decreases by 0.35~1.78% compared with YOLOv4 in AP, but still has a competitive accuracy. Therefore, YOLO-DSD has a better accuracy performance than YOLOv4 in the large-scale ORSIs dataset DIOR in total.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}