
An In-Depth Survey of Bypassing Buffer Overflow Mitigation Techniques

 , , , and
, , , and 
Abstract
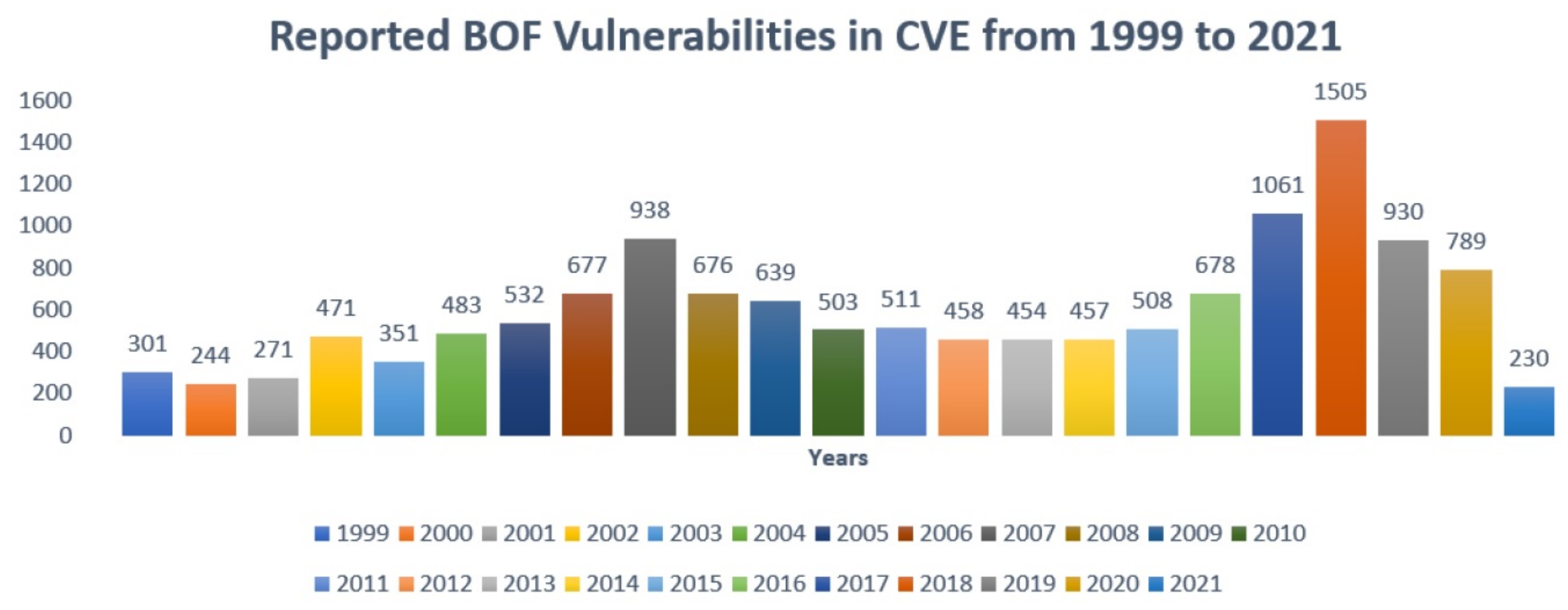
1. Introduction
1.1. Stack Based Buffer Overflow
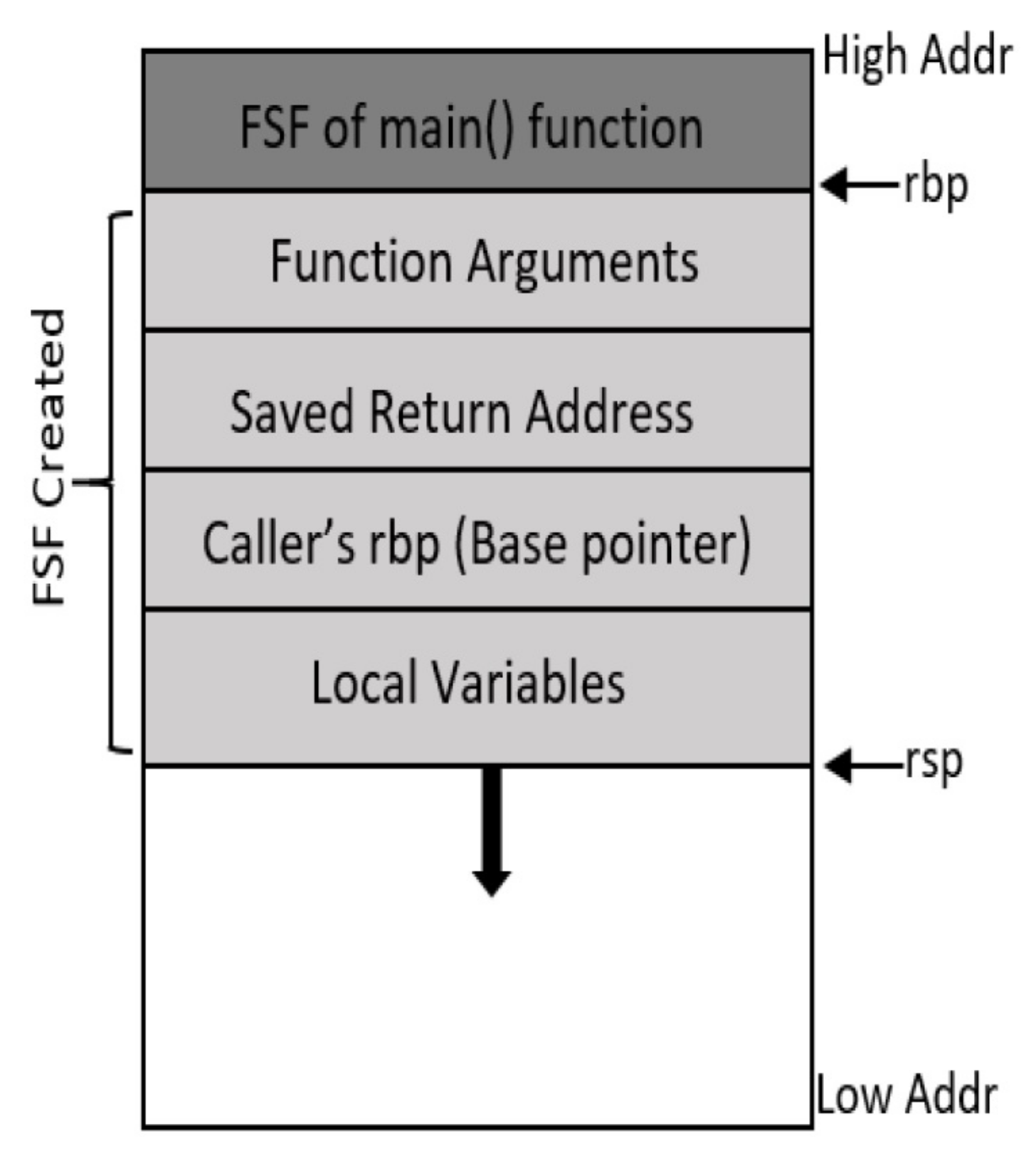
1.1.1. Process Stack
1.1.2. Stack Smashing
2. Threats to Validity
3. Hardware-Based Mitigation Techniques
3.1. NX Bit
3.2. Exploiting the NX Bit Mitigation Technique
- On x86 32-bit machines, arguments can be controlled because they are push on the stack. However, on 64-bit machines, since the function arguments are passed via registers, therefore, return-to-libc attacks would not work.
- Attacker can only use those functions present in the code segment or the library’s code, limiting the attack functionality.
- The arguments that are passed by the attacker might need to contain NULL bytes. However, If the cause of buffer overflow is a function like strcpy() that terminates when encounters NULL bytes. Then return-to-libc attack payload can’t carry NULL bytes in the middle of the payload.
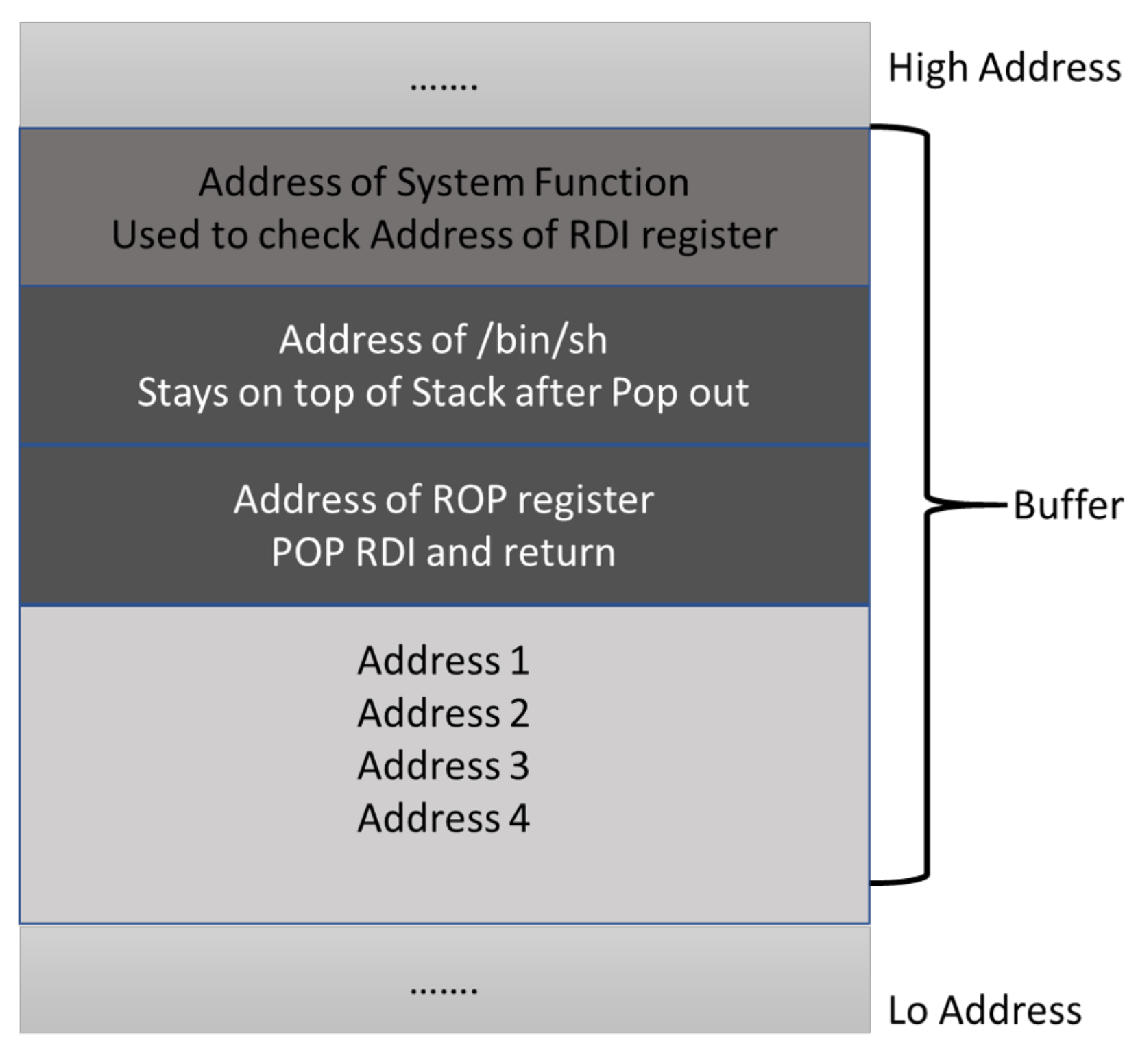
3.2.1. Return-Oriented Programming (ROP)
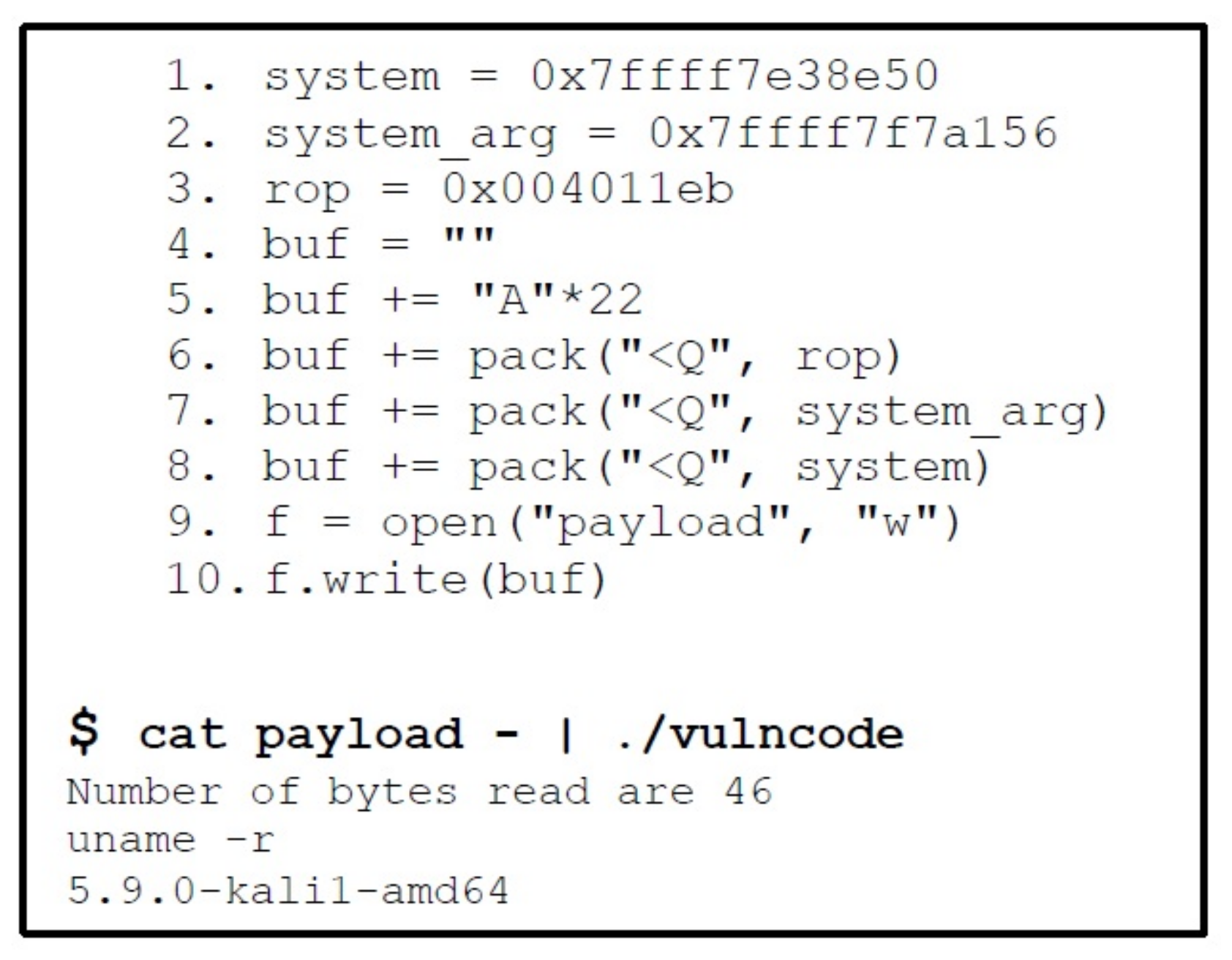
3.2.2. Step by Step Procedure of Bypassing NX Bit Mitigation
4. OS-Based Mitigation Techniques
4.1. Address Space Layout Randomization
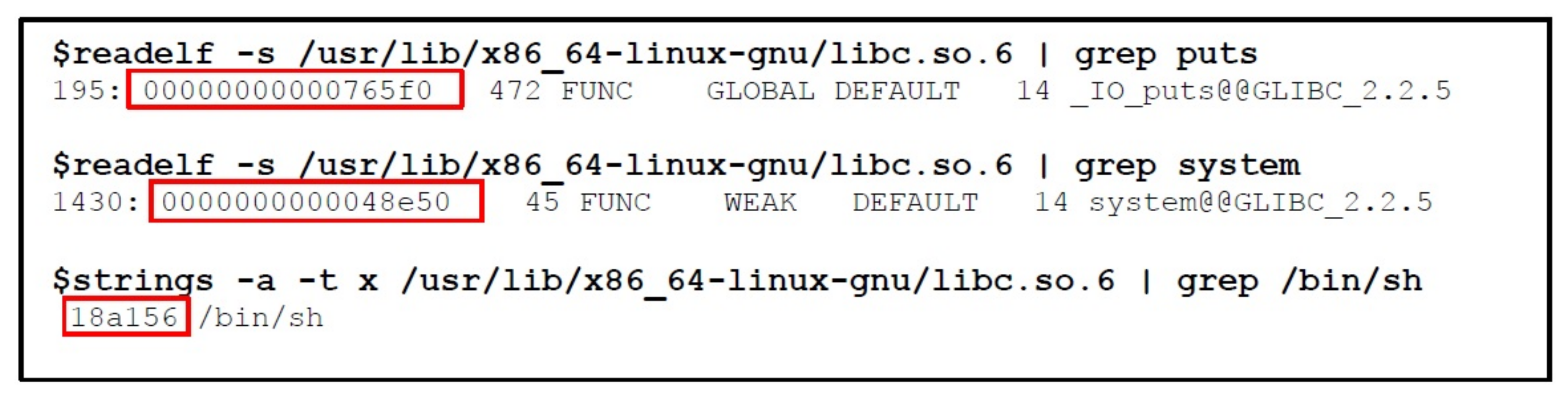
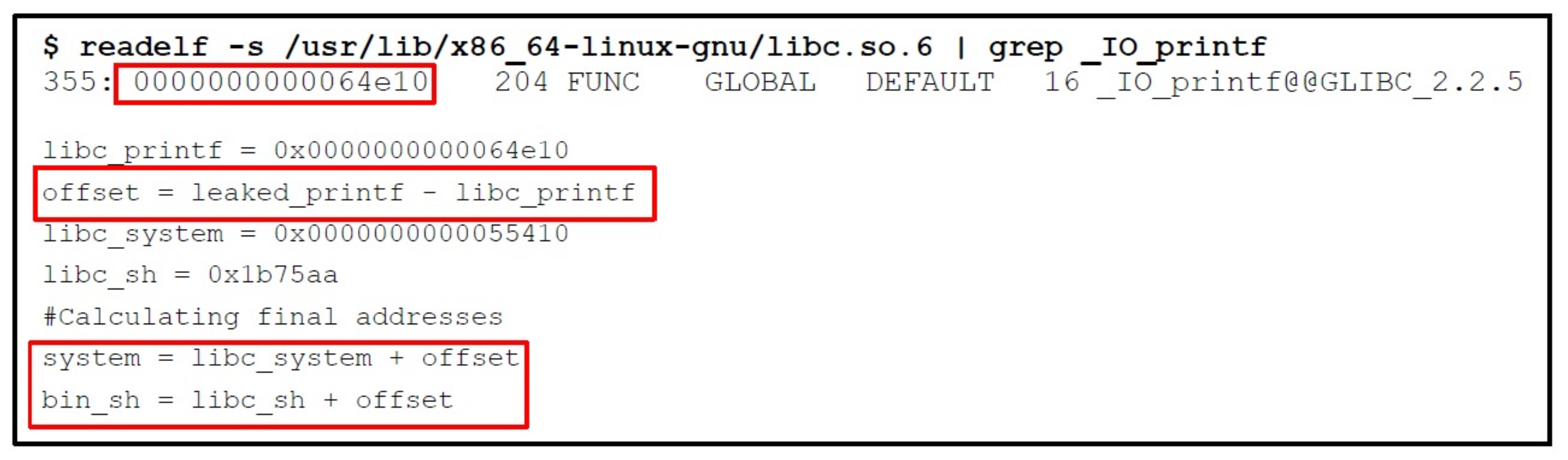
4.2. Exploiting the ASLR Mitigation Technique
Step by Step Procedure of Bypassing ASLR Mitigation
4.3. Protecting the ELF Binaries
4.3.1. Position Independent Executable (PIE)
4.3.2. Relocation Read-Only (RELRO)
4.3.3. Step by Step Procedure of Bypassing PIE and RELRO Mitigations
5. Compiler Based Mitigation Techniques
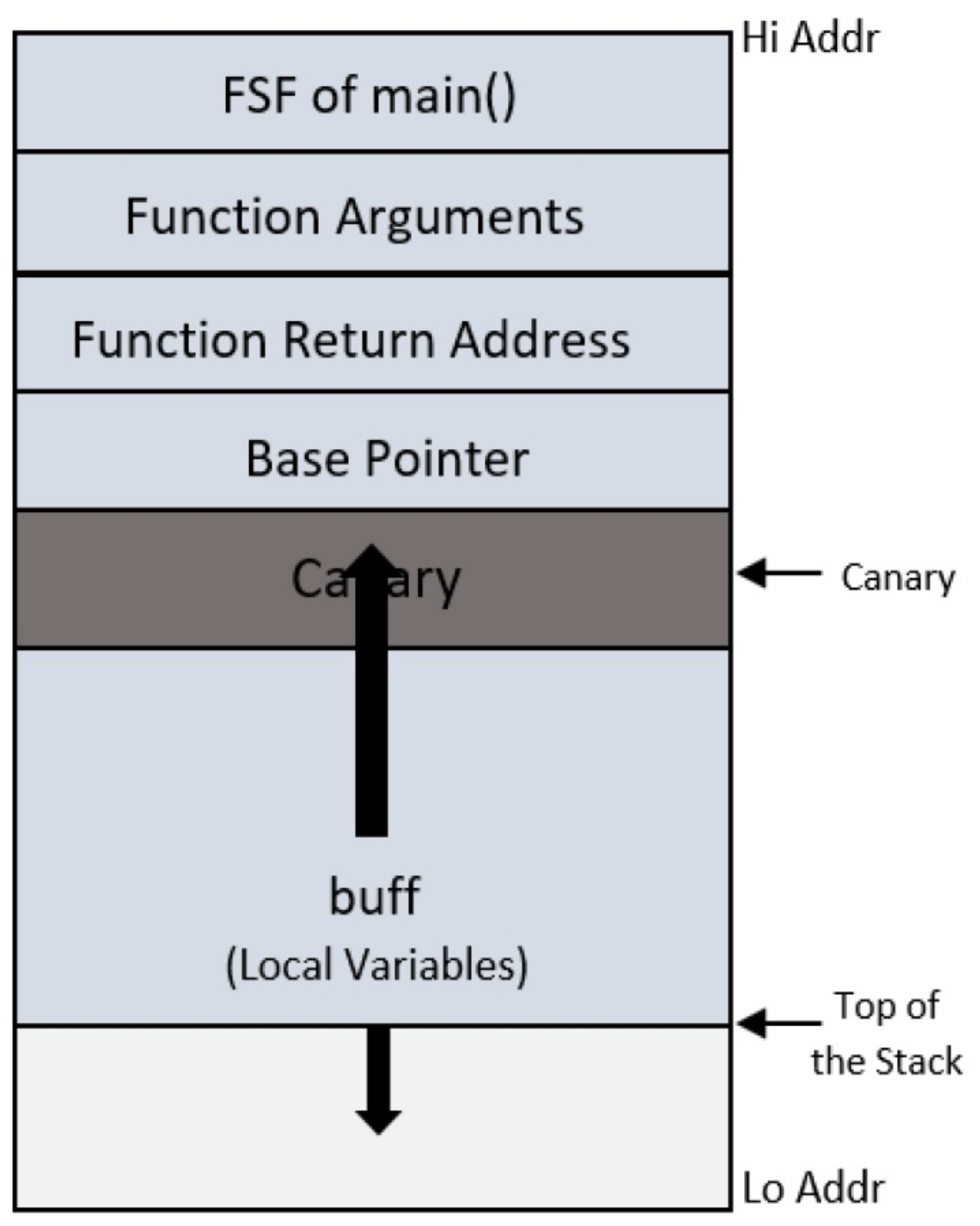
5.1. Stack Canary
5.2. Step by Step Procedure of Bypassing Canary, PIE, ASLR, and NX Mitigation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alenezi, M.; Javed, Y. Developer companion: A framework to produce secure web applications. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 12. [Google Scholar]
- Javed, Y.; Alenezi, M. Defectiveness evolution in open source software systems. Procedia Comput. Sci. 2016, 82, 107–114. [Google Scholar] [CrossRef][Green Version]
- Zeddini, B.; Maachaoui, M.; Inedjaren, Y. Security threats in intelligent transportation systems and their risk levels. Risks 2022, 10, 91. [Google Scholar] [CrossRef]
- Kim, M.h. North Korea’s Cyber Capabilities and Their Implications for International Security. Sustainability 2022, 14, 1744. [Google Scholar] [CrossRef]
- Dinger, M.; Wade, J.T. The Strategic Problem of Information Security and Data Breaches. Coast. Bus. J. 2022, 17, 1. [Google Scholar]
- Yao, D.D.; Rahaman, S.; Xiao, Y.; Afrose, S.; Frantz, M.; Tian, K.; Meng, N.; Cifuentes, C.; Zhao, Y.; Allen, N.; et al. Being the Developers’ Friend: Our Experience Developing a High-Precision Tool for Secure Coding. IEEE Secur. Priv. 2022, 1, 2–11. [Google Scholar] [CrossRef]
- Tobah, Y.; Kwong, A.; Kang, I.; Genkin, D.; Shin, K.G. SpecHammer: Combining Spectre and Rowhammer for New Speculative Attacks. In Proceedings of the IEEE Symposium on Security and Privacy (S&P), San Francisco, CA, USA, 22–26 May 2022. [Google Scholar]
- Nugroho, Y.S.; Gunawan, D.; Puspa Putri, D.A.; Islam, S.; Alhefdhi, A. A Study of Vulnerability Identifiers in Code Comments: Source, Purpose, and Severity. J. Commun. Softw. Syst. 2022, 18, 165–174. [Google Scholar] [CrossRef]
- Russo, B.; Camilli, M.; Mock, M. WeakSATD: Detecting Weak Self-admitted Technical Debt. arXiv 2022, arXiv:2205.02208. [Google Scholar]
- Watts, K.; Oman, P. Stack-based buffer overflows in Harvard class embedded systems. In Proceedings of the International Conference on Critical Infrastructure Protection, Hanover, NH, USA, 23–25 March 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 185–197. [Google Scholar]
- Gramoli, V. More than you ever wanted to know about synchronization: Synchrobench, measuring the impact of the synchronization on concurrent algorithms. In Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, San Francisco, CA, USA, 7–11 February 2015; pp. 1–10. [Google Scholar]
- Aljedaani, W.; Javed, Y. Empirical Study of Software Test Suite Evolution. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020; pp. 87–93. [Google Scholar]
- Kaur, M.; Raj, M.; Lee, H.N. Cross Channel Scripting and Code Injection Attacks on Web and Cloud-Based Applications: A Comprehensive Review. Sensors 2022, 22, 1959. [Google Scholar]
- Jin, X.; Hu, X.; Ying, K.; Du, W.; Yin, H.; Peri, G.N. Code injection attacks on html5-based mobile apps: Characterization, detection and mitigation. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 66–77. [Google Scholar]
- Ozdoganoglu, H.; Vijaykumar, T.; Brodley, C.E.; Kuperman, B.A.; Jalote, A. SmashGuard: A hardware solution to prevent security attacks on the function return address. IEEE Trans. Comput. 2006, 55, 1271–1285. [Google Scholar] [CrossRef]
- McGregor, J.P.; Karig, D.K.; Shi, Z.; Lee, R.B. A processor architecture defense against buffer overflow attacks. In Proceedings of the International Conference on Information Technology: Research and Education, Neward, NJ, USA, 11–13 August 2003; pp. 243–250. [Google Scholar]
- Xia, Y.; Liu, Y.; Chen, H. Architecture support for guest-transparent vm protection from untrusted hypervisor and physical attacks. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 246–257. [Google Scholar]
- Piromsopa, K.; Enbody, R.J. Survey of protections from buffer-overflow attacks. Eng. J. 2011, 15, 31–52. [Google Scholar] [CrossRef]
- Khan, A.S.; Javed, Y.; Abdullah, J.; Zen, K. Trust-based lightweight security protocol for device to device multihop cellular communication (TLwS). J. Ambient. Intell. Humaniz. Comput. 2021, 1, 1–18. [Google Scholar] [CrossRef]
- Shao, Z.; Xue, C.; Zhuge, Q.; Qiu, M.; Xiao, B.; Sha, E.M. Security protection and checking for embedded system integration against buffer overflow attacks via hardware/software. IEEE Trans. Comput. 2006, 55, 443–453. [Google Scholar] [CrossRef]
- Simpson, T.; Novak, J. Hands on Virtual Computing; Cengage Learning: Boston, MA, USA, 2017. [Google Scholar]
- Piessens, F.; Verbauwhede, I. Software security: Vulnerabilities and countermeasures for two attacker models. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 990–999. [Google Scholar]
- Xu, S.; Sandhu, R.; White, G.; Winsborough, W.; Korkmaz, T. Protecting Cryptographic Keys and Functions from Malware Attacks. 2010. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.298.8685&rep=rep1&type=pdf (accessed on 19 April 2022).
- Sulieman, S.M.A. Evaluation of Stack Based on Buffer Overflow as Memory Corruption Class. Ph.D. Thesis, University of Gezira, Wad Madani, Sudan, 2013. [Google Scholar]
- Cugliari, A.; Part, L.; Graziano, M.; Part, W. Smashing the Stack in 2010. Doctoral Dissertation, Politecnico di Torino, Turin, Italy, 2010. [Google Scholar]
- Ravindrababu, S.G.; Venugopal, V.; Alves-Foss, J. Analysis of Firmware Security Mechanisms. In Intelligent Sustainable Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 537–545. [Google Scholar]
- Nikolaev, R.; Nadeem, H.; Stone, C.; Ravindran, B. Adelie: Continuous Address Space Layout Re-randomization for Linux Drivers. arXiv 2022, arXiv:2201.08378. [Google Scholar]
- Skeppstedt, D. Identification and Exploitation of Vulnerabilities in a Large-Scale ITSystem. 2019. Available online: http://www.diva-portal.org/smash/record.jsf (accessed on 19 April 2022).
- Wang, Y.; Wu, J.; Yue, T.; Ning, Z.; Zhang, F. RetTag: Hardware-assisted return address integrity on RISC-V. In Proceedings of the 15th European Workshop on Systems Security, Rennes, France, 5–8 April 2022; pp. 50–56. [Google Scholar]
- Baratloo, A.; Singh, N.; Tsai, T. Transparent Run-Time Defense Against Stack-Smashing Attacks. In Proceedings of the 2000 USENIX Annual Technical Conference (USENIX ATC 00), San Diego, CA, USA, 18–23 June 2000. [Google Scholar]
- Xu, S.; Wang, Y. Defending against Return-Oriented Programming attacks based on return instruction using static analysis and binary patch techniques. Sci. Comput. Program. 2022, 217, 102768. [Google Scholar] [CrossRef]
- Roemer, R.; Buchanan, E.; Shacham, H.; Savage, S. Return-oriented programming: Systems, languages, and applications. ACM Trans. Inf. Syst. Secur. 2012, 15, 1–34. [Google Scholar] [CrossRef]
- Omotosho, A.; Welearegai, G.B.; Hammer, C. Detecting return-oriented programming on firmware-only embedded devices using hardware performance counters. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual, 25–29 April 2022; pp. 510–519. [Google Scholar]
- Kc, G.S.; Keromytis, A.D.; Prevelakis, V. Countering code-injection attacks with instruction-set randomization. In Proceedings of the 10th ACM conference on Computer and Communications Security, Washington, DC, USA, 27–30 October 2003; pp. 272–280. [Google Scholar]
- Necula, G.C.; Lee, P. Safe, untrusted agents using proof-carrying code. In Mobile Agents and Security; Springer: Berlin/Heidelberg, Germany, 1998; pp. 61–91. [Google Scholar]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control 2021, 68, 102726. [Google Scholar] [CrossRef]
- Kiriansky, V.; Bruening, D.; Amarasinghe, S. Secure execution via program shepherding. In Proceedings of the 11th USENIX Security Symposium (USENIX Security 02), San Francisco, CA, USA, 5–9 August 2002. [Google Scholar]
- Bhatkar, S.; DuVarney, D.C.; Sekar, R. Address obfuscation: An efficient approach to combat a broad range of memory error exploits. In Proceedings of the 12th USENIX Security Symposium (USENIX Security 03), Washington, DC, USA, 4–8 August 2003. [Google Scholar]
- Wartell, R.; Mohan, V.; Hamlen, K.W.; Lin, Z. Binary stirring: Self-randomizing instruction addresses of legacy x86 binary code. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 157–168. [Google Scholar]
- Gupta, A.; Habibi, J.; Kirkpatrick, M.S.; Bertino, E. Marlin: Mitigating code reuse attacks using code randomization. IEEE Trans. Dependable Secur. Comput. 2014, 12, 326–337. [Google Scholar] [CrossRef]
- Jang, D. Badaslr: Exceptional cases of ASLR aiding exploitation. Comput. Secur. 2022, 112, 102510. [Google Scholar] [CrossRef]
- Marco-Gisbert, H.; Ripoll Ripoll, I. Address space layout randomization next generation. Appl. Sci. 2019, 9, 2928. [Google Scholar] [CrossRef]
- Vano-Garcia, F.; Marco-Gisbert, H. KASLR-MT: Kernel address space layout randomization for multi-tenant cloud systems. J. Parallel Distrib. Comput. 2020, 137, 77–90. [Google Scholar] [CrossRef]
- Snow, K.Z.; Monrose, F.; Davi, L.; Dmitrienko, A.; Liebchen, C.; Sadeghi, A.R. Just-in-time code reuse: On the effectiveness of fine-grained address space layout randomization. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 574–588. [Google Scholar]
- Marco-Gisbert, H.; Ripoll, I. On the Effectiveness of Full-ASLR on 64-bit Linux. In Proceedings of the In-Depth Security Conference, Vienna, Austria, 18–21 November 2014. [Google Scholar]
- Marco-Gisbert, H.; Ripoll-Ripoll, I. Exploiting Linux and PaX ASLR’s weaknesses on 32-and 64-bit systems. Blackhat Asia 2016, 1, 1–19. [Google Scholar]
- Seo, J.; Lee, B.; Kim, S.M.; Shih, M.W.; Shin, I.; Han, D.; Kim, T. SGX-Shield: Enabling Address Space Layout Randomization for SGX Programs. In Proceedings of the NDSS, San Diego, CA, USA, 26 February–1 March 2017. [Google Scholar]
- Li, Y.; Chung, Y.C.; Bao, Y.; Lu, Y.; Guo, S.; Lin, G. KPointer: Keep the code pointers on the stack point to the right code. Comput. Secur. 2022, 102781. [Google Scholar] [CrossRef]
- Jeong, S.; Hwang, J.; Kwon, H.; Shin, D. A cfi countermeasure against got overwrite attacks. IEEE Access 2020, 8, 36267–36280. [Google Scholar] [CrossRef]
- Jurn, J.; Kim, T.; Kim, H. An automated vulnerability detection and remediation method for software security. Sustainability 2018, 10, 1652. [Google Scholar] [CrossRef]
- Shehab, D.A.H.; Batarfi, O.A. RCR for preventing stack smashing attacks bypass stack canaries. In Proceedings of the 2017 Computing Conference, London, UK, 18–20 July 2017; pp. 795–800. [Google Scholar]
- Lhee, K.S.; Chapin, S.J. Type-Assisted Dynamic Buffer Overflow Detection. In Proceedings of the 11th USENIX Security Symposium (USENIX Security 02), San Francisco, CA, USA, 5–9 August 2002. [Google Scholar]
- Ghorbani-Renani, N.; González, A.D.; Barker, K. A decomposition approach for solving tri-level defender-attacker-defender problems. Comput. Ind. Eng. 2021, 153, 107085. [Google Scholar] [CrossRef]
- Medicherla, R.K.; Nagalakshmi, M.; Sharma, T.; Komondoor, R. HDR-Fuzz: Detecting Buffer Overruns using AddressSanitizer Instrumentation and Fuzzing. arXiv 2021, arXiv:2104.10466. [Google Scholar]
- Alzahrani, S.M. Buffer Overflow Attack and Defense Techniques. Int. J. Comput. Sci. Netw. Secur. 2021, 21, 207–212. [Google Scholar]
- Wagle, P.; Cowan, C. Stackguard: Simple stack smash protection for gcc. In Proceedings of the GCC Developers Summit, Montréal, QC, Canada, May 25–27 2003; pp. 243–255. [Google Scholar]
- Cowan, C.; Pu, C.; Maier, D.; Walpole, J.; Bakke, P.; Beattie, S.; Grier, A.; Wagle, P.; Zhang, Q.; Hinton, H. Stackguard: Automatic adaptive detection and prevention of buffer-overflow attacks. In Proceedings of the USENIX Security Symposium, San Antonio, TX, USA, 26–29 January 1998; Volume 98, pp. 63–78. [Google Scholar]



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exploits | Vulnerable Software | Targeted OS | Year | Infected Hosts | Scan Rate |
|---|---|---|---|---|---|
| Morris Worm | Finger Service Exploited | BSD UNIX (VAX OS) | 1988 | 6000 | — |
| Code Red Worm | Microsoft IIS Server | Microsoft Windows (2000, XP server) | 2001 | 359,000 apprx | 2000 scans/60 s |
| Slammer Worm | Microsoft SQL server/Desktop engine | Microsoft Windows | 2003 | 75000 | 55 million scans/s |
| Blaster Worm | Remote procedure call (RPC) | Microsoft Windows (XP, 2000, NT) | 2003 | 100,000 | 500 scans/h |
| Sasser Worm | Local security authority subsystem service (LSASS) | Microsoft Windows (2000, XP) | 2004 | 500,000 | — |
| Conficker Worm | NetBIOS | Microsoft Windows | 2008 | 15 million | — |
| Stuxnet Worm | Siemens Step7 | Microsoft Windows | 2010 | 30,000 | — |
| Flame Worm | Windows Update Service | Microsoft Windows | 2012 | 1000 | — |
| Triton Malware | Triconex SIS controller | Microsoft Windows | 2017 | — | — |
| Software | Vulnerablity | Target | Year | Vulnerable Version | Patched Version |
|---|---|---|---|---|---|
| Acrobat and Adobe Reader | core application plug-in | Windows, Linux, Mac OS, Solaris | 2005 | 5.0–7.0.2, 5.1–7.0.2 | 7.0.5 |
| VLC Media Player | ASF Demuxer | Windows, Mac OS X | 2013 | 2.0.5 | 2.0.6 |
| OpenSSL | HeartBleed | Web Server, websites, email | 2014 | 1.0.1 | 1.0.1 g |
| Standard C library (glibc) | GHOST | Red Hat Linux | 2015 | glibc-2.2 | glibc-2.7, 2.8 |
| NVIDIA Shield TV | NVIDIA Tegra bootloader | — | 2019 | Prior v8.0.1 | 8.0.1 |
| Exim (Mail Transfer Agent) | String_vformat | Public Mail Servers | 2019 | 4.92–4.92.2 | 4.92.3 |
| Sudo | Baron Samedit | Linux / UNIX | 2021 | Sudo 1.7.7–1.7.10p9, 1.8.2–1.8.31p2, 1.9.0–1.9.5p1 | 1.8.32 & 1.9.5p2 |
| Sr. | Article | Journal | Year | Vulnerability | Mitigation Technique | Bypassing | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ANY | BOF | NX | ASLR | PIE | RELRO | Canary | Strategy | ||||
| 1 | Baron Samedit (SUDO) vulnerability | https://www.sudo.ws/alerts/unescape_overflow.html accessed on 2 February 2022 | 2021 | ✓ | ✓ | × | × | × | × | × | × |
| 2 | An automated approach to fix buffer overflows | International Journal of Electrical and Computer Engineering | 2020 | ✓ | ✓ | × | × | × | × | × | × |
| 3 | Cybersecurity hazards and financial system vulnerability: a synthesis of literature | Risk Management | 2020 | ✓ | × | × | × | × | × | × | × |
| 4 | Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation | Applied Sciences | 2020 | ✓ | ✓ | × | × | × | × | × | × |
| 5 | Security Bulletin: NVIDIA SHIELD TV | https://nvidia.custhelp.com/app/answers/detail/a_id/4875 accessed on 2 February 2022 | 2021 | ✓ | ✓ | × | × | × | × | × | × |
| 6 | CVE-2019-16928: Exim Vuln Exploit via EHLO Strings | https://www.trendmicro.com/en_us/research/19/j/cve-2019-16928-exploiting-an-exim-vulnerability-via-ehlo-strings.html accessed on 2 February 2022 | 2019 | ✓ | ✓ | × | × | × | × | × | × |
| 7 | Bypassing NX bit Using ROP | https://www.bordergate.co.uk/64-bit-nx-bypass accessed on 5 February 2022 | 2019 | ✓ | ✓ | ✓ | × | × | × | × | ✓ |
| 8 | Address space layout randomization next generation | Applied Sciences | 2019 | ✓ | ✓ | × | ✓ | ✓ | × | × | ✓ |
| 9 | Hardening elf binaries using relocation read-only (relro) | Red Hat | 2019 | ✓ | ✓ | ✓ | × | × | ✓ | × | ✓ |
| 10 | bypass NX, ASLR, PIE and Canary | https://ironhackers.es/en/tutoriales/pwn-rop-bypass-nx-aslr-pie-y-canary accessed on 2 February 2022 | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| 11 | Advancing Memory-corruption Attacks and Defenses | PHD Thesis | 2018 | ✓ | ✓ | × | × | × | × | × | ✓ |
| 12 | An overview of prevention/mitigation against memory corruption attack | Proceedings of the 2nd International Symposium on Computer Science and Intelligent Control | 2018 | ✓ | ✓ | ✓ | ✓ | × | × | ✓ | ✓ |
| 13 | 2.5 Million more people potentially exposed in Equifax breach (Web Page) | New York Times | 2017 | ✓ | × | × | × | × | × | × | × |
| 14 | Triton: hackers take out safety systems in’watershed’attack on energy plant | The Guardian | 2017 | ✓ | ✓ | × | × | × | × | × | × |
| 15 | How to Make ASLR Win the Clone Wars: Runtime Re-Randomization | NDSS | 2016 | ✓ | ✓ | × | ✓ | ✓ | × | × | ✓ |
| 16 | GHOST gethostbyname () heap overflow in glibc | https://access.redhat.com/security/vulnerabilities/ghost accessed on 2 February 2022 | 2015 | ✓ | ✓ | × | × | × | × | × | × |
| 16 | Marlin: Mitigating code reuse attacks using code randomization | IEEE Transactions on Dependable and Secure Computing | 2014 | ✓ | ✓ | × | ✓ | × | × | × | ✓ |
| 17 | On the Effectiveness of Full-ASLR on 64-bit Linux | Proceedings of the In-Depth Security Conference | 2014 | ✓ | ✓ | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| 18 | Home Depot: 56 million cards exposed in breach (Web Page) | CNNMoney | 2014 | ✓ | × | × | × | × | × | × | × |
| 19 | The matter of heartbleed | Proceedings of the 2014 conference on internet measurement conference | 2014 | ✓ | ✓ | × | × | × | × | × | × |
| 20 | Hacking blind | IEEE Symposium on Security and Privacy | 2014 | ✓ | ✓ | × | ✓ | ✓ | × | ✓ | ✓ |
| 21 | Mitre CVE | https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-1954 accessed on 2 February 2022 | 2013 | ✓ | ✓ | × | × | × | × | × | × |
| 22 | Return-oriented programming: Systems, languages, and applications | ACM Transactions on Information and System Security (TISSEC) | 2012 | ✓ | ✓ | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| 23 | Binary stirring: Self-randomizing instruction addresses of legacy x86 binary code | Proceedings of the 2012 ACM conference on Computer and communications security | 2012 | ✓ | ✓ | ✓ | ✓ | ✓ | × | × | ✓ |
| 24 | The cousins of stuxnet: Duqu, flame, and gauss | Future Internet | 2012 | ✓ | ✓ | × | × | × | × | × | × |
| 25 | A large-scale empirical study of conficker | IEEE Transactions on Information Forensics and Security | 2011 | ✓ | ✓ | × | × | × | × | × | × |
| 26 | Stuxnet: Dissecting a cyberwarfare weapon | IEEE Security & Privacy | 2011 | ✓ | ✓ | × | × | × | × | × | × |
| 27 | Ranking attacks based on vulnerability analysis | 43rd Hawaii International Conference on System Sciences (IEEE) | 2010 | ✓ | ✓ | × | × | × | × | × | × |
| 28 | Surgically returning to randomized lib (c) | Annual Computer Security Applications Conference (IEEE) | 2009 | ✓ | ✓ | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| 29 | The geometry of innocent flesh on the bone: Return-into-libc without function calls (on the x86) | Proceedings of the 14th ACM conference on Computer and communications security | 2007 | ✓ | ✓ | ✓ | ✓ | × | × | × | ✓ |
| 30 | Security Advisory: Acrobat and Adobe Reader plug-in buffer overflow | https://www.adobe.com/support/techdocs/321644.html accessed on 2 February 2022 | 2006 | ✓ | ✓ | × | × | × | × | × | × |
| 31 | Secure bit: Transparent, hardware buffer-overflow protection | IEEE Transactions on Dependable and Secure Computing | 2006 | ✓ | ✓ | × | × | × | × | ✓ | × |
| 32 | Security protection and checking for embedded system integration against buffer overflow attacks via hardware/software | IEEE Transactions on Computers | 2006 | ✓ | ✓ | × | × | × | × | × | × |
| 33 | The blaster worm: Then and now | IEEE Security & Privacy | 2005 | ✓ | ✓ | × | × | × | × | × | × |
| 34 | Computer worms: past, present, and future | East Carolina University | 2005 | ✓ | ✓ | × | × | × | × | × | × |
| 35 | Detection and prevention of stack buffer overflow attacks | Communications of the ACM | 2005 | ✓ | ✓ | × | × | × | × | ✓ | × |
| 36 | Defeating compiler-level buffer overflow protection | The USENIX Magazine | 2005 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 37 | On the effectiveness of address-space randomization | Proceedings of the 11th ACM conference on Computer and communications security | 2004 | ✓ | ✓ | ✓ | ✓ | × | × | ✓ | ✓ |
| 38 | Inside the slammer worm | IEEE Security & Privacy | 2003 | ✓ | ✓ | × | × | × | × | × | × |
| 39 | Exploring security vulnerabilities by exploiting buffer overflow using the MIPS ISA | ACM SIGCSE Bulletin | 2003 | ✓ | ✓ | × | × | × | × | × | ✓ |
| 40 | A processor architecture defense against buffer overflow attacks | Proceedings. ITRE2003 (IEEE) | 2003 | ✓ | ✓ | × | × | × | × | ✓ | × |
| 41 | Implementing an untrusted operating system on trusted hardware | Proceedings of the nineteenth ACM symposium on Operating systems principles | 2003 | ✓ | × | × | × | × | × | × | × |
| 42 | Address Obfuscation: An Efficient Approach to Combat a Broad Range of Memory Error Exploits | USENIX Security Symposium | 2003 | ✓ | ✓ | × | ✓ | ✓ | × | ✓ | × |
| 43 | Four different tricks to bypass stackshield and stackguard protection | World Wide Web | 2002 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 44 | Code-Red: a case study on the spread and victims of an Internet worm | Proceedings of the 2nd ACM SIGCOMM Workshop on Internet measurment | 2002 | ✓ | ✓ | × | × | × | × | × | × |
| 45 | Secure Execution via Program Shepherding | USENIX Security Symposium | 2002 | ✓ | ✓ | × | × | × | × | × | × |
| 46 | RAD: A compile-time solution to buffer overflow attacks | Proceedings 21st International Conference on Distributed Computing Systems (IEEE) | 2001 | ✓ | ✓ | × | × | × | × | ✓ | × |
| 47 | Buffer overflows: Attacks and defenses for the vulnerability of the decade | DISCEX’00 (IEEE) | 2000 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 48 | Smashguard: A hardware solution to prevent attacks on the function return address | Technical Report | 2000 | ✓ | ✓ | × | ✓ | ✓ | × | ✓ | ✓ |
| 49 | Transparent run-time defense against stack-smashing attacks | USENIX Annual Technical Conference, General Track | 2000 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 50 | GCC extension for protecting applications from stack-smashing attacks | http://www.trl.ibm.com/projects/security/ssp accessed on 2 February 2022 | 2000 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 51 | Mitre CVE Buffer Overflow (Web Page) | https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=Buffer+Overflow accessed on 2 February 2022 | 1999 | ✓ | ✓ | × | × | × | × | × | × |
| 52 | Protecting systems from stack smashing attacks with StackGuard | Linux Expo | 1999 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 53 | Stackguard: automatic adaptive detection and prevention of buffer-overflow attacks | USENIX Security Symposium | 1998 | ✓ | ✓ | × | × | × | × | ✓ | ✓ |
| 54 | Proof-carrying code | Proceedings of 24th ACM SIGPLAN-SIGACT symposium on Principles of programming languages | 1997 | ✓ | × | × | × | × | × | × | × |
| 55 | Smashing the stack for fun and profit | Phrack magazine | 1996 | ✓ | ✓ | × | × | × | × | × | ✓ |
| 56 | With Microscope and Tweezers: An Analysis of the Internet Virus of November 1988 | IEEE Symposium on Security and Privacy | 1989 | ✓ | ✓ | × | × | × | × | × | × |
| 57 | NX bit | http://index-of.es/EBooks/NX-bit.pdf accessed on 2 February 2022 | — | ✓ | ✓ | ✓ | × | × | × | × | ✓ |
| 58 | NX bit Wikipedia | https://en.wikipedia.org/wiki/NX_bit accessed on 2 February 2022 | — | ✓ | ✓ | ✓ | × | × | × | × | ✓ |
| Mitigation Technique | Architecture (First Implemented) | Strategy |
|---|---|---|
| Smashguard | Alpha | Return Address Protection |
| SRAS | Alpha 21264 | Return Address Protection |
| XOMOS | SimOS simulator | Encrypt Memory Values |
| Secure Bit | BOCHS emulator | Marked control data untrustworthy |
| HSDefender | StrongARM-110 | Secure call instructions |
| NX bit | AMD64 | Marked Memory Regions Non-executable |
| Mitigation Technique | Operating System (First Implemented) | Strategy |
|---|---|---|
| Libsafe | Linux | Execute safe version of vulnerable C library functions |
| Proof-Carrying Code DEC Alpha Processor | ||
| (no practical implementation) | Uses safety policy defined by Code Consumer | |
| Program Shepherding | Linux and Windows (IA-32) | Enforce Security Policy |
| Address Obfuscation | Linux | Randomization Strategy |
| Binary Stirring | Windows and Linux | Self randomizes instruction addresses |
| Marlin | Linux (customized bash shell) | Randomizes block addresses of binaries at load time |
| ASLR | Linux, Windows, macOS, iOS | Randomizes addresses of stack, heap, libraries and executables |
| Mitigation Technique | Compiler (First Implemented) | Strategy |
|---|---|---|
| SSP (Pro police) | GCC extension (3.x) | Reordering of local variables |
| StackShield | GCC extension | Return address protection using duplicate address |
| Return Address Defender (RAD) | GCC extension (2.95.2) | Return address protection using return address repository (RAR) |
| Address Sanitizer | Clang, GCC, Xcode, MSVC | Perform bounds checking |
| Automatic Fortification | GCC extension (4.0) | Perform bounds checking |
| Stackguard / Stack Canary | GCC extension (2.7.2.3) | Return address protection using Canary value |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Butt, M.A.; Ajmal, Z.; Khan, Z.I.; Idrees, M.; Javed, Y. An In-Depth Survey of Bypassing Buffer Overflow Mitigation Techniques. Appl. Sci. 2022, 12, 6702. https://doi.org/10.3390/app12136702
Butt MA, Ajmal Z, Khan ZI, Idrees M, Javed Y. An In-Depth Survey of Bypassing Buffer Overflow Mitigation Techniques. Applied Sciences. 2022; 12(13):6702. https://doi.org/10.3390/app12136702
Chicago/Turabian StyleButt, Muhammad Arif, Zarafshan Ajmal, Zafar Iqbal Khan, Muhammad Idrees, and Yasir Javed. 2022. "An In-Depth Survey of Bypassing Buffer Overflow Mitigation Techniques" Applied Sciences 12, no. 13: 6702. https://doi.org/10.3390/app12136702
APA StyleButt, M. A., Ajmal, Z., Khan, Z. I., Idrees, M., & Javed, Y. (2022). An In-Depth Survey of Bypassing Buffer Overflow Mitigation Techniques. Applied Sciences, 12(13), 6702. https://doi.org/10.3390/app12136702