
A Clustering Algorithm for Evolving Data Streams Using Temporal Spatial Hyper Cube


 , ,
, ,  ,
,  and
and
Abstract
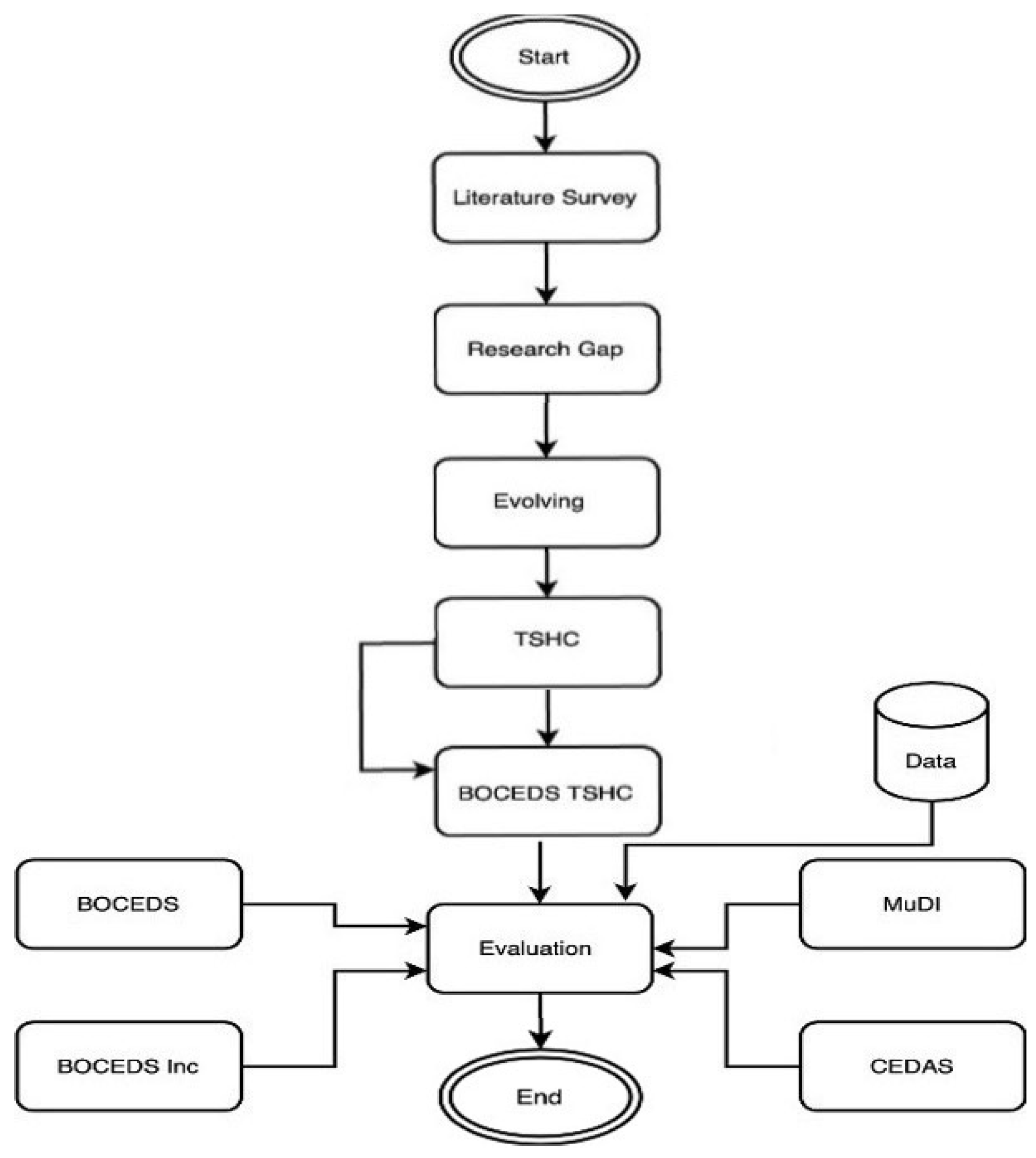
:1. Introduction
- i.
- The proposed BOCEDS TSHC uses a tempo-spatial hyper cube to add more dimensions to the data summarization for more degree of freedom.The hyper-cube is a quantization level that will map various values to one value in each coordinate to reduce the resolution of data storing and eliminate the effect of slight changes that do not influence the meaning of the data (type of filtering). The hyper-cube features heterogeneity to handle heterogeneous data and dynamicity to handle the evolving data according to the values of its features or coordinates.
- ii.
- The TSHC algorithm is built using the recursive and dynamic update for adaptive quantization of arrived data when they are projected to the clustering space.
- iii.
- The developed TSHC algorithm is an add-on to a single-phase clustering algorithm that assists in generating clusters from evolving data streams in a fully online manner. It can work independently or jointly with an existing clustering algorithm such as BOCEDS.
2. Literature Review
3. Methodology
3.1. Definitions of Algorithm Parameters
- Inc Step for Quantization: The step that is used for increasing the quantization at any dimension to fulfill the condition given in the inequality of Equation (1).
- Initial quantization level (q0): The value that is given as the initial quantization level when starting the algorithm.
- Decay: Decay is the number of data points that arrive per unit time from the data stream. It is the data transfer rate. A decay of 50 indicates that 50 data points are extracted consecutively from the data stream on average per unit time (second, minute). It is utilized to keep the energy of micro-clusters up to date. This value is determined based on the application’s expert knowledge.
- Maximum (Rmax) and Minimum (Rmin): The maximum and minimum radii of micro-clusters are determined using professional knowledge of the application. The maximum radius demonstrates the separation and smoothness of micro-clusters, whilst the minimum radius demonstrates the development of micro-clusters with enough data points.
- CM Threshold: The density threshold that is used to convert the data arrived at a certain grid to a core micro-cluster.
- Cell Threshold: The threshold used to determine when the Tempo Spatial Hyper Cube has converged, and no additional quantization level increments are required in any dimension.
- Outlier Threshold: The density threshold that is used to convert a CM to an outlier for removing it.
3.2. Parameters Setting
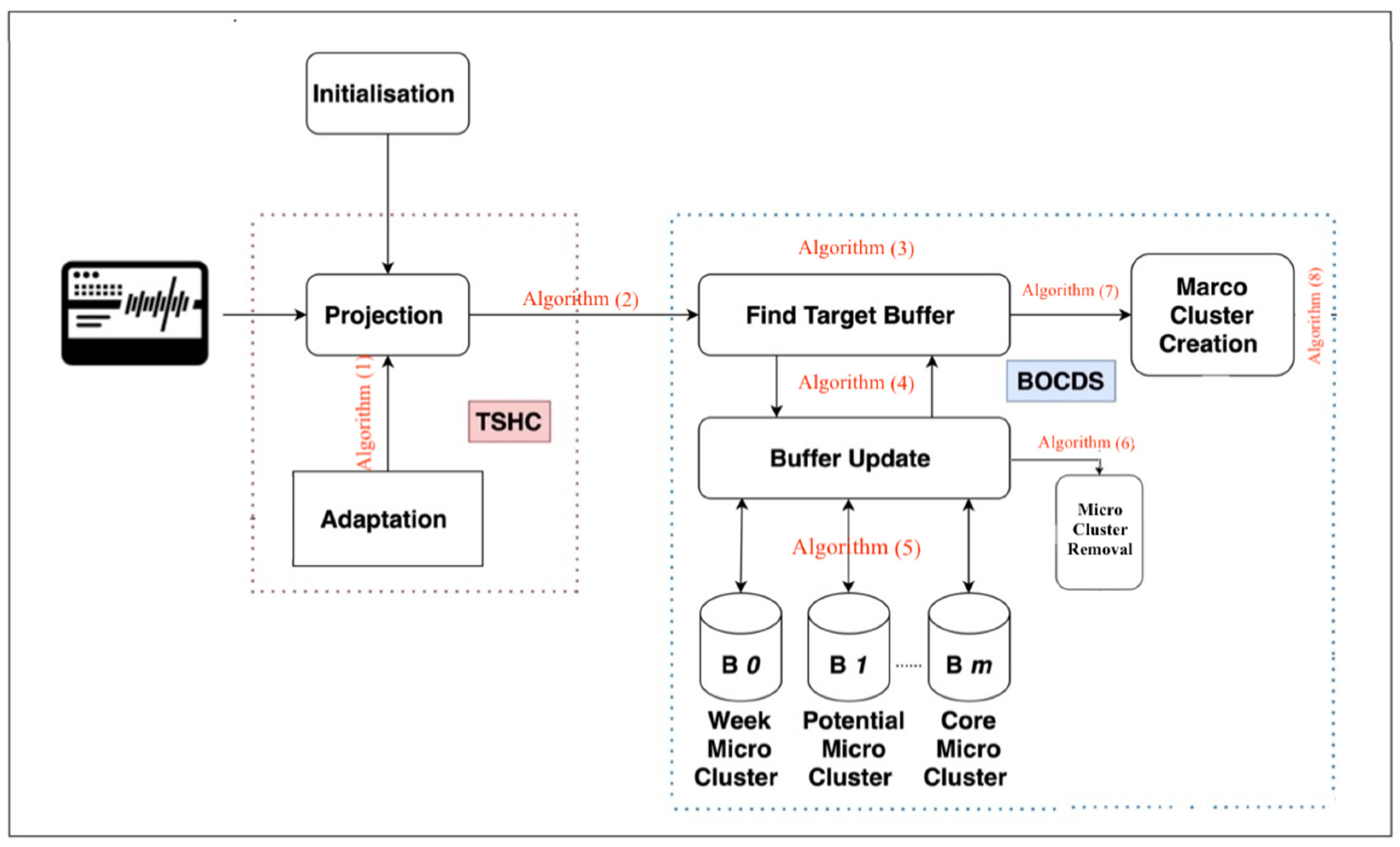
3.3. Algorithm Operation
3.4. Developed Algorithms
3.4.1. Temporal Spatial Hyper Cube (TSHC)
| Algorithm 1: Tempo Spatial Hyper Cube |
| Input: (1) B: Data Buffer. (2) q0: Initial quantization level. (3) Delta: step size. (4) outliersThreshold. (5) cellThreshold. Output: Q = [q1, q2, …qm]: the quantization levels where m is the number of dimensions. 1- start algorithm 2- initialization: notConverged ← true Q ← q0. openDimensions ← 1:m. NumPoints ← []. 3- while notConverged do 4- use Q to build set of hyper-cubes that contains all data points in B. 5- for each hyper cube do 6- calculate the number of points inside it and add it to NumPoints array. 7- end for 8- remove outlierscells which its NumPoints < outliersThreshold. 9- if min(NumPoints) > cellThreshold then 10- converged = 1 break 11- end if 12- chose random dimension i from openDimensions 13- if q(i) + delta * max(B(:, i)) <= max(B(:, i)/2 then 14- q(i) = q(i) + delta * max(B(::i)). 15- else 16- remove i from openDimensions. 17- end if 18- end while 19- 1 return Q 20- end algorithm |
3.4.2. BOCEDS-TSHC
| Algorithm 2: TSHC BOCEDS |
| Input: (1) Data: data stream. (2) q0: Initial quantization level. (3) Delta: step size. (4) outliersThreshold. (5) cellThreshold. (6) RmaxRatio: the ratio to calculate from Q. (7) RminRatio: the ratio to calculate Rmin from Rmax (8) B: buffer Output: Clusters: the clustering result for each data point in B. Detected Anomaly: the Anomaly data detected in the stream 1- start algorithm 2- initialization: endOfStream ← false Q ← TSHC(B, q0, Delta, outliersThreshold, cellThreshold). Rmax ← RmaxRatio ∗ norm(Q) Rmin ← RminRatio ∗ Rmax iniate: CMCs, PMCs, WMCs “types of micro clusters” Tc ← 1 G ← graph() Clusters ← [] 3- while ¬ endOfStream do 4- B ← data(T c) 5- for each data piont Xi in B do 6- T ← searchForTargetMC (Xi, Rmin, Rmax, CMCs, PMCs, WMCs) Algorithm 3 7- if T == [] then 8- create a new PMC 9- else 10- update the micro-clusters using Algorithm 4 11- end if 12- update Energy of CMC using Algorithm 5 13- end if 14- Clusters ← assignToMacroClusters (G, CMC, Clusters) 15- Tc ← Tc + 1 16- if Tc ≥ size(data) then 17- endOfStream←true 18- end if 19- end while 20- end algorithm |
3.4.3. BOCEDS Micro-Cluster Searching
| Algorithm 3: BOCEDS Micro-Cluster Searching |
| Input: (1) Xi: Data point (2) CMCs: core micro-cluster set (3) PMCs: potential micro-cluster set (4) WMCs: weak micro-cluster set Output: T: the Micro-cluster that contains Xi. 1- start algorithm 2- initalization: T ← [] 3- Find a weak micro-cluster Q that satisfied Equation (2). 4- if Q not empty then 5- T ← Q Go to Ret 6- end if 7- Find a potential micro-cluster Q that satisfied Equation (2). 8- if Q not empty then 9- T ← Q Go to Ret 10- end if 11- Find a core micro-cluster Q that satisfied Equation (2). 12- if Q not empty then 13- T ← Q Go to Ret 14- end if 15- Ret:Return T 16- end algorithm |
3.4.4. BOCEDS Micro-Cluster Update
| Algorithm 4: BOCEDS Micro-Cluster Update |
| Input: (1) Xi: Data point (2) CMCs: core micro-cluster set (3) PMCs: potential micro-cluster set (4) WMCs: weak micro-cluster set (5) T: the Micro-cluster that contains Xi Output: (1) CMCs:core micro-cluster set (2) PMCs:potential micro-cluster set (3) WMCs:weak micro-cluster set 1- start algorithm 2- Update the local density (Nt) of T using Equation (3). 3- if [(T ∈ PMCs) ∧ (Nt+1 = Thdensity)] ∨ (T ∈ WMCs) then 4- CMCs=CMCs U T 5- Update the radius (Rt+1) of the micro-cluster (T) using Equation (4). 6- Et+1 ← 1 7- else if T ∈ MC core then 8- Update the radius (Rt+1) of the micro-cluster (T) using Equation (4). 9- Update the energy (Et+1) of the micro-cluster (T) using Equation (5). 10- end if 11- d ← distance (Xi, T.Center) 12- If < d ≤ Rt+1, then 13- Update the number of data points in the shell region (Nt+1) of the micro-cluster (T) using Equation (10). 14- Update the center (Ct+1) of the micro-cluster (T) using Equation (7). 15- Update Cluster Graph using Algorithm 5 16- end if 17- end algorithm |
3.4.5. BOCEDS Moving Weak Micro-Clusters to a Buffer
| Algorithm 5: BOCEDS Moving Weak Micro-Clusters to A Buffer |
| Input: (1) CMCs: core micro-cluster set (2) WMCs: weak micro-cluster set (3) Decay: the decaying period Output: (1) CMCs: core micro-cluster set (2) WMCs: weak micro-cluster set 1- start algorithm 2- Reduce an energy of from all CMCs 3- for each T in CMCs do 4- if T.Energy ≤ 0 then 5- T.Edges ← [] 6- remove T from all CMCs edges T.M ← 0 7- Remove T from CMCs T.Energy ← 0.5 8- WMCs = WMCs U T 9- end if 10- end for 11- end algorithm |
3.4.6. BOCEDS Micro-Cluster Removal
| Algorithm 6: BOCEDS Micro-Clusters Removal |
| Input: (1) PMCs: potential micro-cluster set (2) WMCs: weak micro-cluster set (3) Decay: the decaying period Output: (1) PMCs: potential micro-cluster set (2) WMCs: weak micro-cluster set 1- start algorithm 2- Reduce an energy of from all WMCs 3- for each W in WMCs do 4- if T.Energy ≤ 0 then 5- Remove W from WMCs 6- end if 7- end for 8- Reduce an energy of from all PMCs 9- for each P in PMCs do 10- if T.Energy ≤ 0 then 11- Remove P from PMCs 12- end if 13- end for 14- end algorithm |
3.4.7. BOCEDS Update Cluster Graph
| Algorithm 7: BOCEDS Update Cluster Graph |
| Input: (1) CMCs: core micro-cluster set (2) T: A core micro cluster that has been generated or modified (3) G: clustering graph Output: (1) CMCs: core micro-cluster set (2) G: clustering graph 1- start algorithm 2- for each C in CMCs do 3- d ← Euclideandistance(T.c, C.c) 4- d′ ← intersectingdistance(T, C) from Equation (8) 5- if d ≤ d′ then 6- T.EL = T.EL ∪ Edge (T, C) 7- C.EL = C.EL ∪ Edge (T, C) 8- end if 9- end for 10- if any micro-cluster edge list has changed then 11- Set a new number of macro-clusters throughout the graph. 12- end if 13- end algorithm |
4. Results and Discussions
4.1. Quality Evaluation
4.1.1. Anomaly Detection Ratio (ADR)
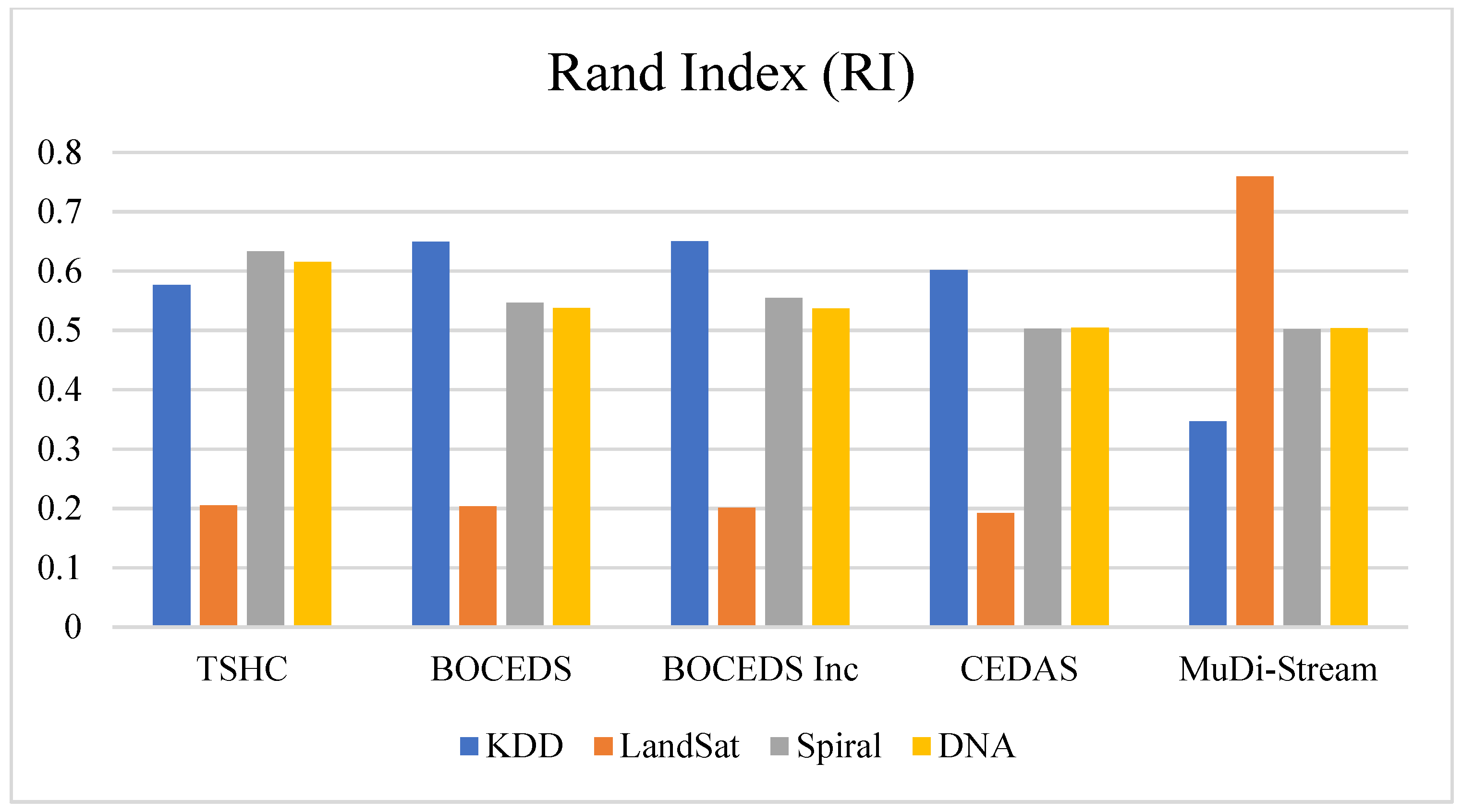
4.1.2. Rand Index (RI)
4.1.3. Adjusted Rand Index (ARI)
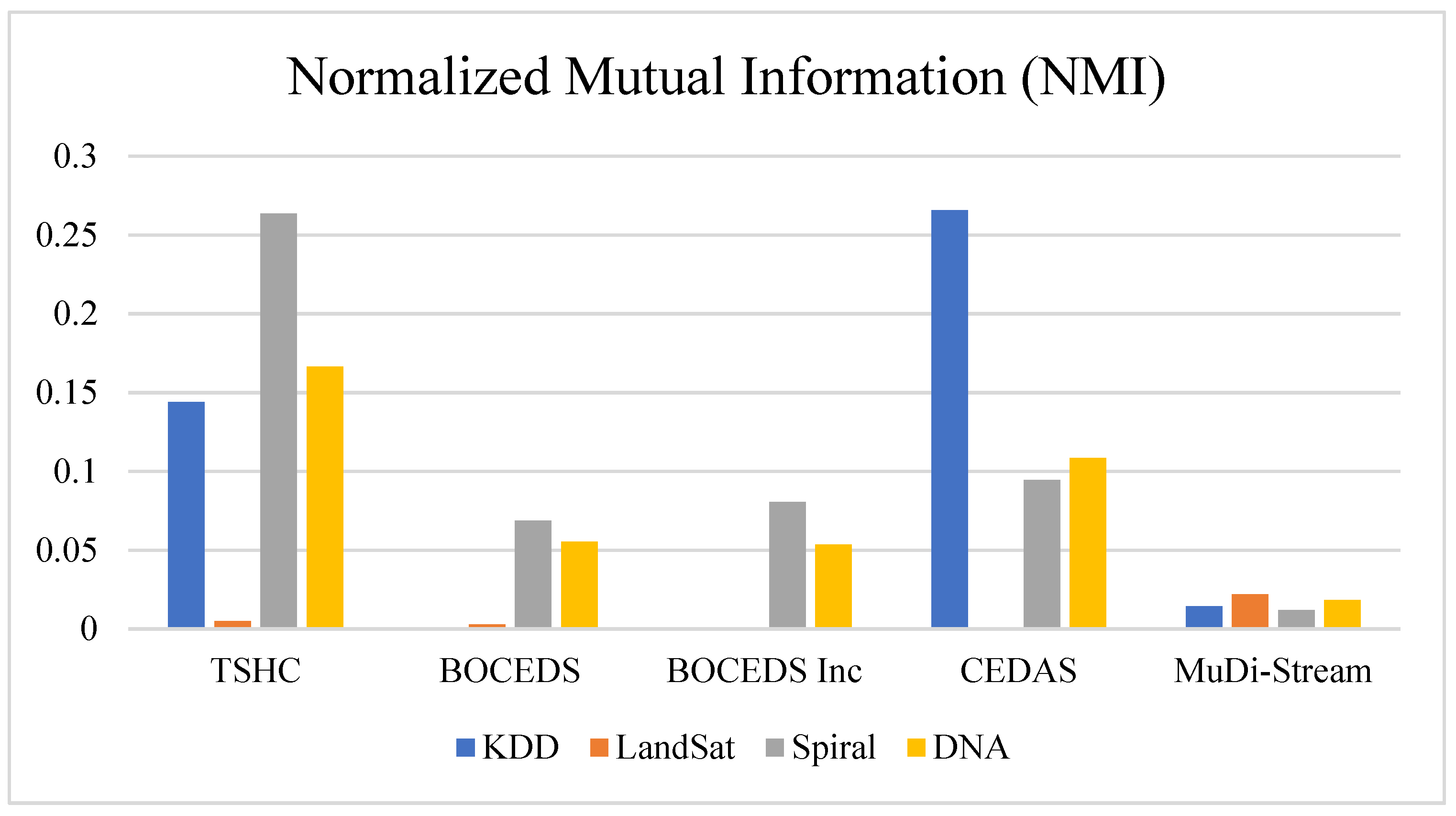
4.1.4. Normalized Mutual Information (NMI)
4.2. Efficiency Evaluation
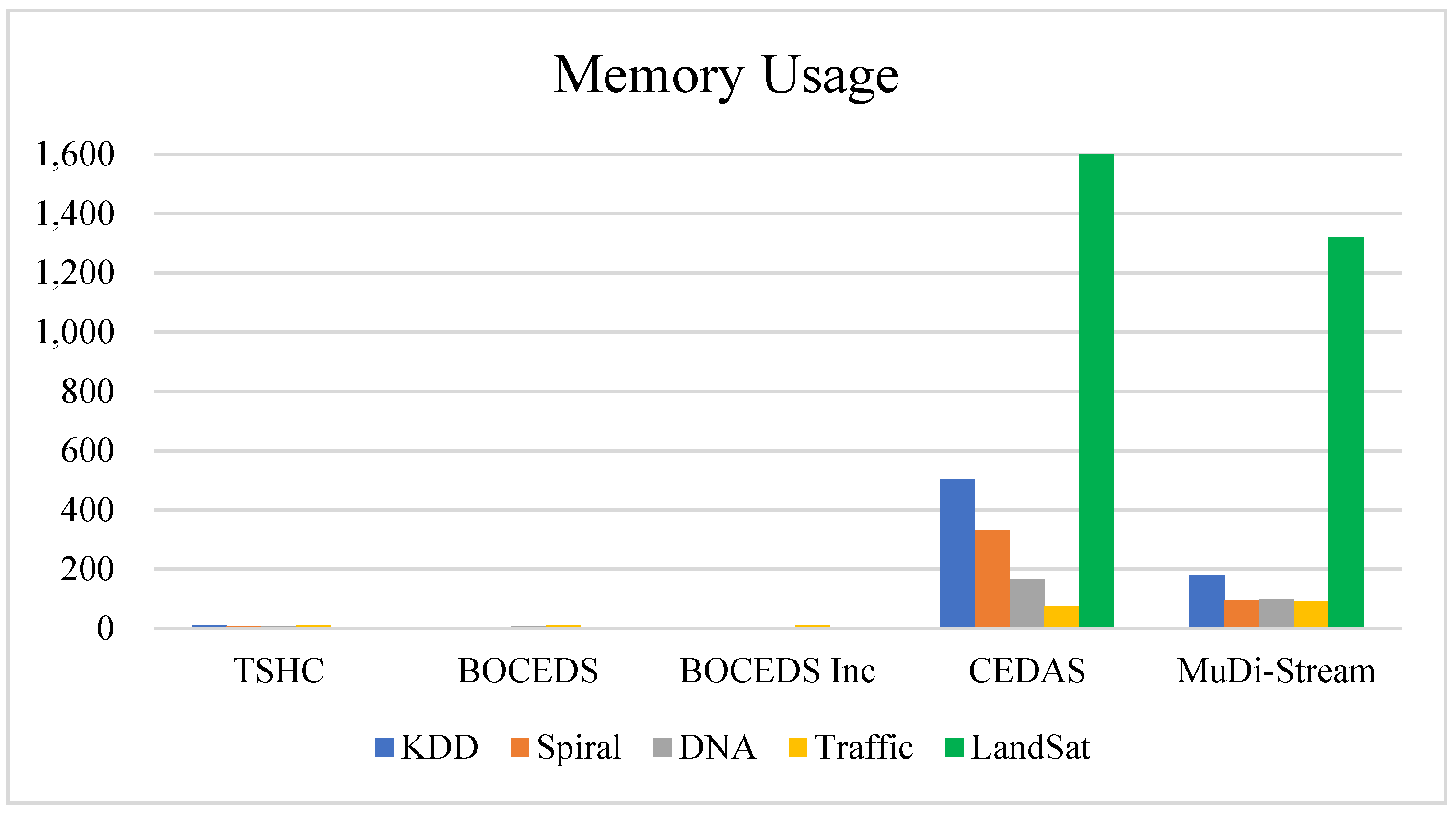
4.2.1. Memory Usage
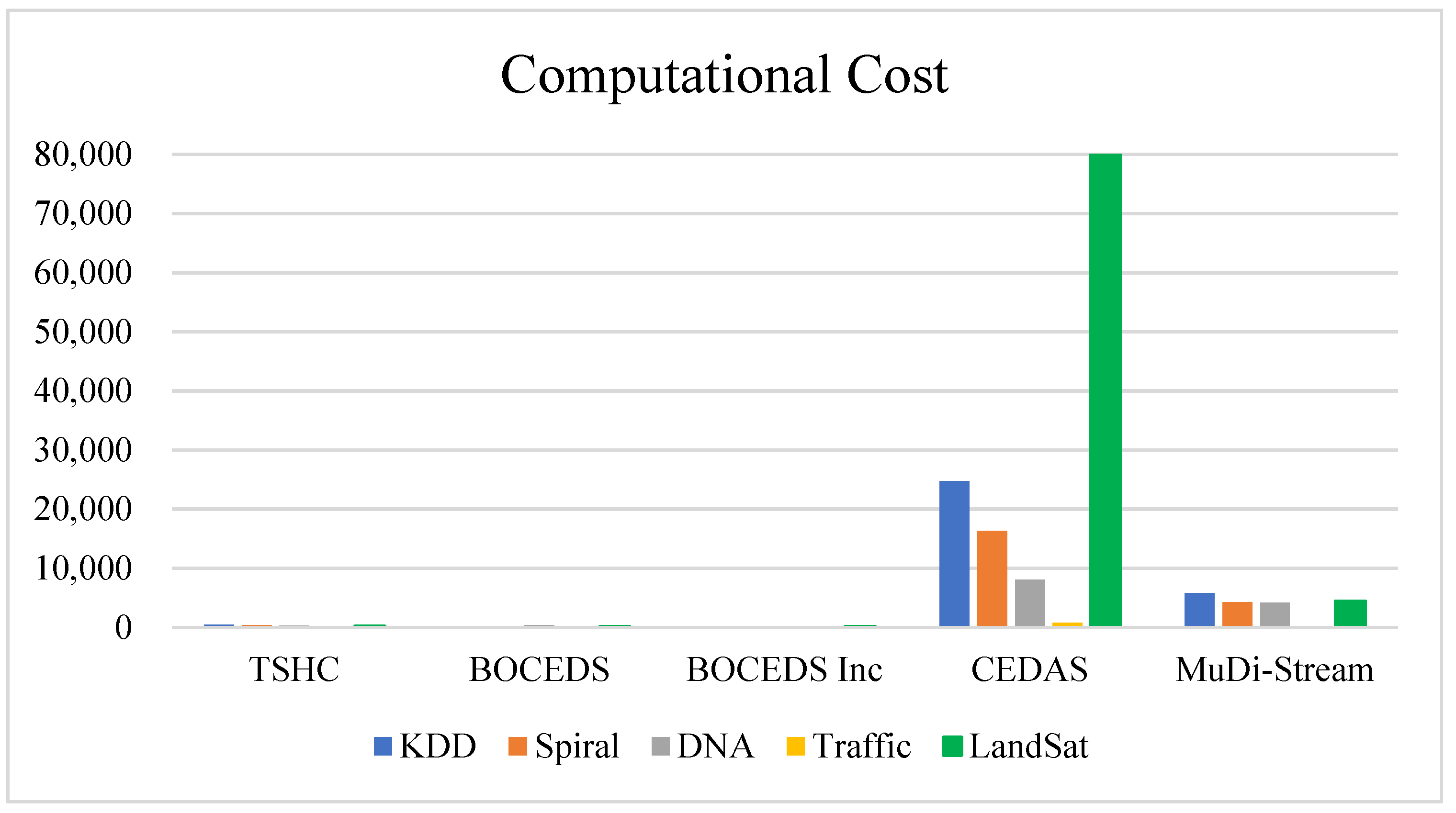
4.2.2. Computational Cost
5. Finding and Summary
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviation
| B | Data Buffer |
| q0 | Initial quantization level |
| Delta | Step size |
| RmaxRatio | The ratio to calculate from Q |
| RminRatio | The ratio to calculate Rmin from Rmax |
| Xi | Data point |
| CMCs | Core micro-cluster set |
| PMCs | Potential micro-cluster set |
| WMCs | Weak micro-cluster set |
| T | The Micro-cluster that contains Xi |
| Decay | The decaying period |
| G | Clustering graph |
References
- Yu, K.; Shi, W.; Santoro, N. Designing a streaming algorithm for outlier detection in data mining—An incrementa approach. Sensors 2020, 20, 1261. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Degirmenci, A.; Karal, O. Efficient Density and Cluster Based Incremental Outlier Detection in Data Streams. Inf. Sci. 2022, 607, 901–920. [Google Scholar] [CrossRef]
- Al-Amri, R.; Murugesan, R.K.; Alshari, E.M.; Alhadawi, H.S. Toward a Full Exploitation of IoT in Smart Cities: A Review of IoT Anomaly Detection Techniques. In International Conference on Emerging Technologies and Intelligent Systems; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; Volume 322, pp. 193–214. [Google Scholar] [CrossRef]
- Märzinger, T.; Kotík, J.; Pfeifer, C. Application of hierarchical agglomerative clustering (Hac) for systemic classification of pop-up housing (puh) environments. Appl. Sci. 2021, 11, 11122. [Google Scholar] [CrossRef]
- Zubaroğlu, A.; Atalay, V. Data Stream Clustering: A Review; Springer: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Al-amri, R.; Murugesan, R.K.; Man, M.; Abdulateef, A.F. A Review of Machine Learning and Deep Learning Techniques for Anomaly Detection in IoT Data. Appl. Sci. 2021, 11, 5320. [Google Scholar] [CrossRef]
- Habeeb, R.A.A.; Nasaruddin, F.; Gani, A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Real-time big data processing for anomaly detection: A Survey. Int. J. Inf. Manag. 2019, 45, 289–307. [Google Scholar] [CrossRef] [Green Version]
- Carnein, M.; Trautmann, H. Optimizing Data Stream Representation: An Extensive Survey on Stream Clustering Algorithms. Bus. Inf. Syst. Eng. 2019, 61, 277–297. [Google Scholar] [CrossRef] [Green Version]
- Maia, J.; Junior, C.A.S.; Guimarães, F.G.; de Castro, C.L.; Lemos, A.P.; Galindo, J.C.F.; Cohen, M.W. Evolving clustering algorithm based on mixture of typicalities for stream data mining. Future Gener. Comput. Syst. 2020, 106, 672–684. [Google Scholar] [CrossRef]
- Manzoor, E.; Lamba, H.; Akoglu, L. xStream: Outlier Detection in Feature-Evolving Data Streams. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 19–23 August 2018. [Google Scholar] [CrossRef]
- Anandharaj, A.; Sivakumar, P.B. Anomaly Detection in Time Series data using Hierarchical Temporal Memory Model. In Proceedings of the 2019 3rd International conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 12–14 June 2019; pp. 1287–1292. [Google Scholar] [CrossRef]
- Gottwalt, F.; Chang, E.; Dillon, T. CorrCorr: A feature selection method for multivariate correlation network anomaly detection techniques. Comput. Secur. 2019, 83, 234–245. [Google Scholar] [CrossRef]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series. IEEE Access 2019, 7, 1991–2005. [Google Scholar] [CrossRef]
- Hyde, R.; Angelov, P.; MacKenzie, A.R. Fully online clustering of evolving data streams into arbitrarily shaped clusters. Inf. Sci. 2017, 382–383, 96–114. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.K.; Ahmed, M.M.; Zamli, K.Z. A buffer-based online clustering for evolving data stream. Inf. Sci. 2019, 489, 113–135. [Google Scholar] [CrossRef]
- Amini, A.; Saboohi, H.; Herawan, T.; Wah, T.Y. MuDi-Stream: A multi density clustering algorithm for evolving data stream. J. Netw. Comput. Appl. 2016, 59, 370–385. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Zavadskas, E.K.; Turskis, Z.; Antucheviciene, J. A new combinative distance-based assessment (CODAS) method for multi-criteria decision-making. Econ. Comput. Econ. Cybern. Stud. Res. 2016, 50, 25–44. [Google Scholar]
- Škrjanc, I.; Ozawa, S.; Ban, T.; Dovžan, D. Large-scale cyber attacks monitoring using Evolving Cauchy Possibilistic Clustering. Appl. Soft Comput. J. 2018, 62, 592–601. [Google Scholar] [CrossRef]
- Chenaghlou, M.; Moshtaghi, M.; Leckie, C.; Salehi, M. Online Clustering for Evolving Data Streams with Online Anomaly Detection; Springer International Publishing: Cham, Switzerland, 2018; Volume 10938. [Google Scholar]
- Islam, M.K.; Ahmed, M.M.; Zamli, K.Z. I-CODAS: An improved online data stream clustering in arbitrary shaped clusters. Eng. Lett. 2019, 27, 752–776. [Google Scholar]
- Salort Sanchez, C.; Tudoran, R.; Al Hajj Hassan, M.; Bortoli Stefano Brasche, G.; Baumbach, J.; Axenie, C. An Online Incremental Clustering Framework for Real-Time Stream Analytics. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1480–1485. [Google Scholar] [CrossRef]
- Roa, N.B.; Travé-Massuyès, L.; Grisales-Palacio, V.H. DyClee: Dynamic clustering for tracking evolving environments. Pattern Recognit. 2019, 94, 162–186. [Google Scholar] [CrossRef] [Green Version]
- Tareq, M.; Sundararajan, E.A.; Mohd, M.; Sani, N.S. Online Clustering of Evolving Data Streams Using a Density Grid-Based Method. IEEE Access 2020, 8, 166472–166490. [Google Scholar] [CrossRef]
- Islam, M.K.; Sarker, B. An Online Clustering Approach for Evolving Data-Stream Based on Data Point Density. In Proceedings of the International Conference on Emerging Technologies and Intelligent Systems, Al Buraimi, Oman, 25–26 June 2021; pp. 105–115. [Google Scholar]
- Xia, Y.; Fang, J.; Chao, P.; Pan, Z.; Shang, J.S. Cost-effective and adaptive clustering algorithm for stream processing on cloud system. Geoinformatica 2021, 1–21. [Google Scholar] [CrossRef]
- Tareq, M.; Sundararajan, E.A.; Harwood, A.; Bakar, A.A. A Systematic Review of Density Grid-Based Clustering for Data Streams. IEEE Access 2022, 10, 579–596. [Google Scholar] [CrossRef]
- Albertini, M.K.; de Mello, R.F. Estimating data stream tendencies to adapt clustering parameters. Int. J. High Perform. Comput. Netw. 2018, 11, 34–44. [Google Scholar] [CrossRef]
- Zheng, J.; Qu, H.; Li, Z.; Li, L.; Tang, X. An irrelevant attributes resistant approach to anomaly detection in high-dimensional space using a deep hypersphere structure. Appl. Soft Comput. 2022, 116, 108301. [Google Scholar] [CrossRef]
- Carnein, M.; Trautmann, H. evoStream—Evolutionary Stream Clustering Utilizing Idle Times. Big Data Res. 2018, 14, 101–111. [Google Scholar] [CrossRef]
- Yeh, C.C.; Yang, M.S. Evaluation measures for cluster ensembles based on a fuzzy generalized Rand index. Appl. Soft Comput. 2017, 57, 225–234. [Google Scholar] [CrossRef]
- Xu, L.; Ye, X.; Kang, K.; Guo, T.; Dou, W.; Wang, W.; Wei, J. DistStream: An Order-Aware Distributed Framework for Online-Offline Stream Clustering Algorithms. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 842–852. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | BOCEDS-TSHC | BOCEDS | BOCEDS Inc. | CEDAS | MuDi-Stream |
|---|---|---|---|---|---|
| cellThresh | 5 | - | - | - | - |
| outlierThresh | 2 | - | - | - | - |
| incStep for quantization | 0.02 | - | - | - | - |
| q0 | 0.01 | - | - | - | - |
| Decay | 50 | 50 | 50 | 50 | - |
| RmaxRatio | 2 | - | - | - | - |
| RminRatio | 0.25 | - | - | - | - |
| CMThresh | 10 | 10 | 10 | - | - |
| Rmax | - | 0.1 | 0.1 | - | - |
| Rmin | - | 0.05 | 0.05 | - | - |
| Radius | - | - | - | 0.01 | - |
| minThreshold | - | - | - | 3 | - |
| Stream speed | - | - | - | - | 50 |
| Cm | - | - | - | - | 1 |
| Cl | - | - | - | - | 0.5 |
| Lamda | - | - | - | - | 0.998 |
| gridGranularity | - | - | - | - | 10 |
| MinPts | - | - | - | - | 3 |
| Horizon | - | - | - | - | 2 |
| Dataset Name | Number of Records | Number of Classes | Number of Features | Type | Range | |
|---|---|---|---|---|---|---|
| DNA.mat | 6006 | 2 | 1 | double | [0.1, 1] | |
| 2 | double | [0, 1] | ||||
| Spiral.mat | 6012 | 2 | 1 | double | [−0.4, 1] | |
| 2 | double | [−0.4, 0.6] | ||||
| LandSat | Number | Meaning | Number of records | Type | Range | |
| 1 | red soil | 1072 | Integer | [0, 255] | ||
| 2 | cotton crop | 479 | ||||
| 3 | grey soil | 961 | ||||
| 4 | damp grey soil | 415 | ||||
| 5 | soil with vegetation stubble | 470 | ||||
| 6 | very damp grey soil | 1038 | ||||
| KDD Cup’99 | Number of records | Attributes | Type of Attacks | |||
| 495020 | 42 | 21 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-amri, R.; Murugesan, R.K.; Almutairi, M.; Munir, K.; Alkawsi, G.; Baashar, Y. A Clustering Algorithm for Evolving Data Streams Using Temporal Spatial Hyper Cube. Appl. Sci. 2022, 12, 6523. https://doi.org/10.3390/app12136523
Al-amri R, Murugesan RK, Almutairi M, Munir K, Alkawsi G, Baashar Y. A Clustering Algorithm for Evolving Data Streams Using Temporal Spatial Hyper Cube. Applied Sciences. 2022; 12(13):6523. https://doi.org/10.3390/app12136523
Chicago/Turabian StyleAl-amri, Redhwan, Raja Kumar Murugesan, Mubarak Almutairi, Kashif Munir, Gamal Alkawsi, and Yahia Baashar. 2022. "A Clustering Algorithm for Evolving Data Streams Using Temporal Spatial Hyper Cube" Applied Sciences 12, no. 13: 6523. https://doi.org/10.3390/app12136523
APA StyleAl-amri, R., Murugesan, R. K., Almutairi, M., Munir, K., Alkawsi, G., & Baashar, Y. (2022). A Clustering Algorithm for Evolving Data Streams Using Temporal Spatial Hyper Cube. Applied Sciences, 12(13), 6523. https://doi.org/10.3390/app12136523