Adversarial Robust and Explainable Network Intrusion Detection Systems Based on Deep Learning


Abstract
:1. Introduction
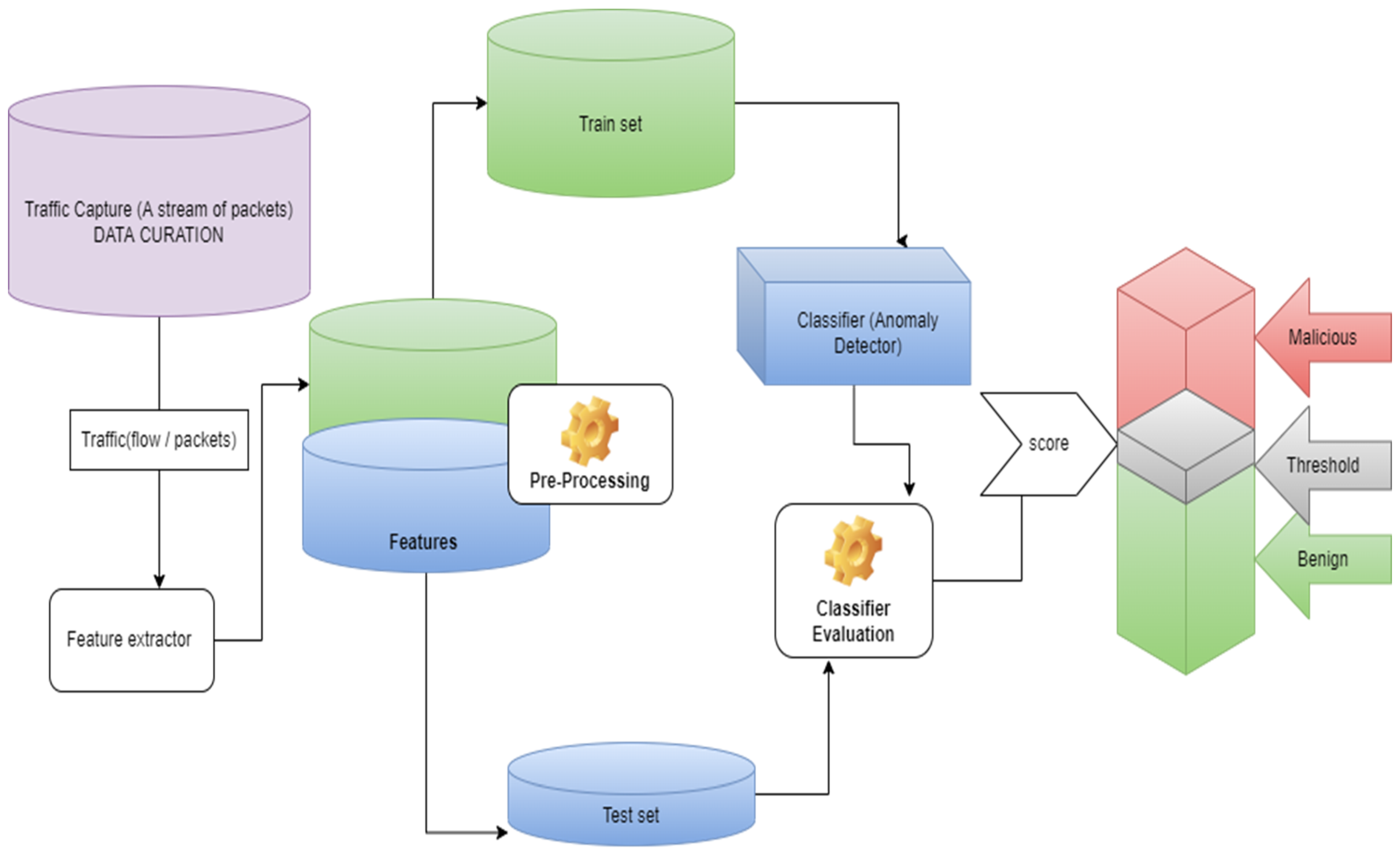
1.1. Anomaly-Based NIDS
1.2. Explainable Deep Learning-Based NIDS
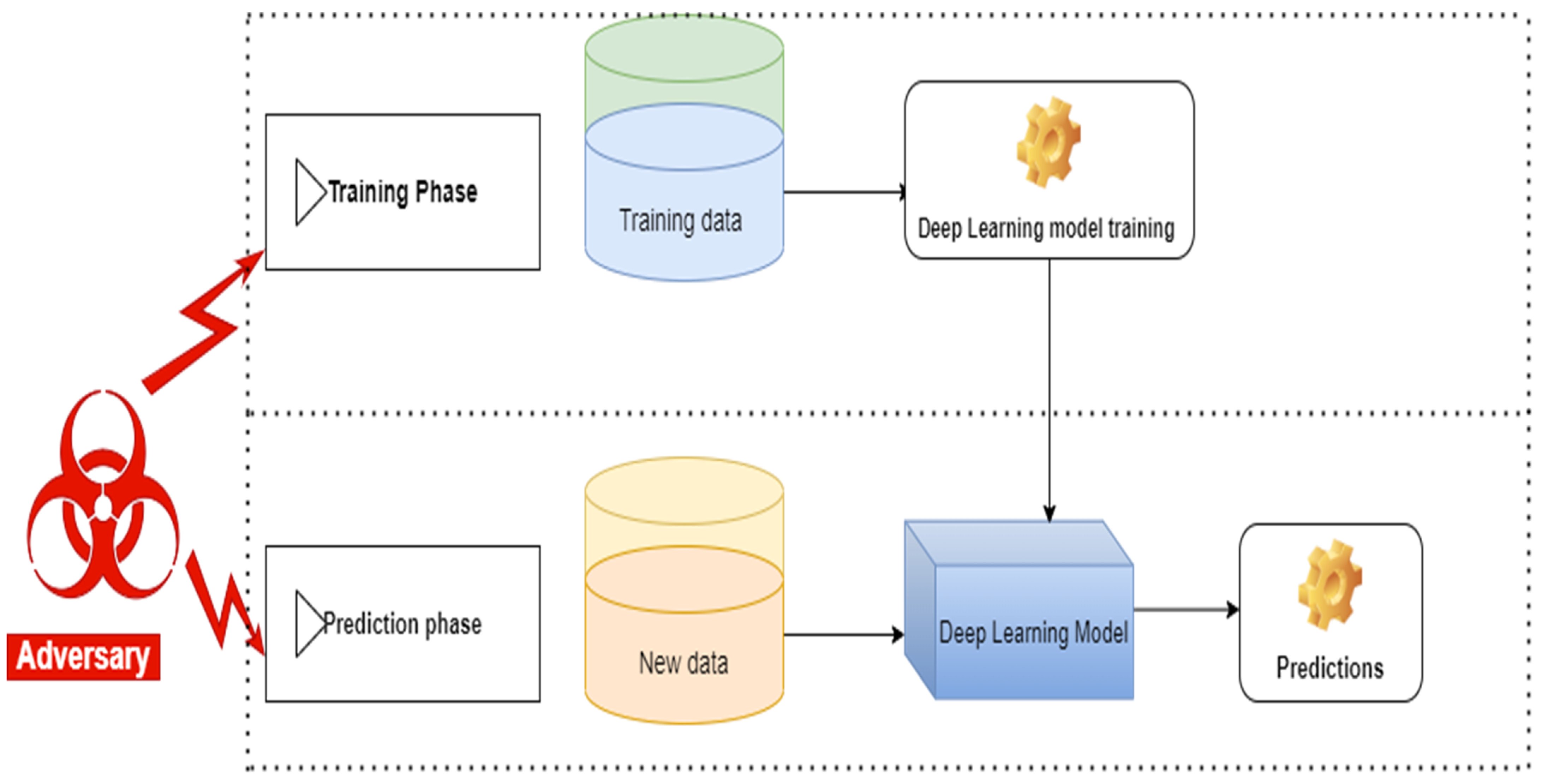
1.3. Adversarial Machine Learning
1.3.1. Fast Gradient Sign Method (FGSM)
1.3.2. Projected Gradient Descent (PGD)
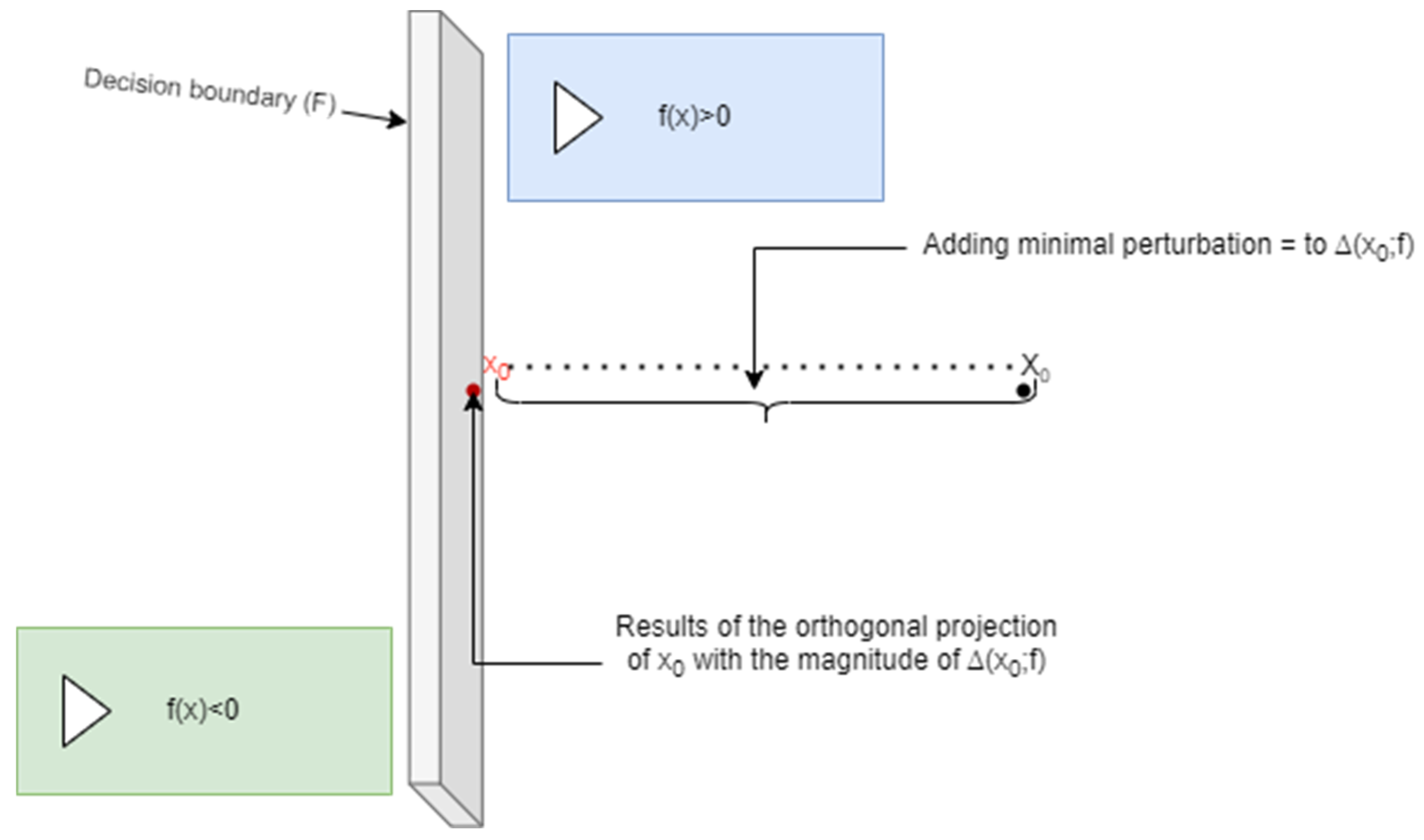
1.3.3. DeepFool
1.3.4. Carlini and Wagner Attack (C&W)
1.3.5. Jacobian-Based Saliency Map Approach (JSMA)
1.4. Adversarial Robustness
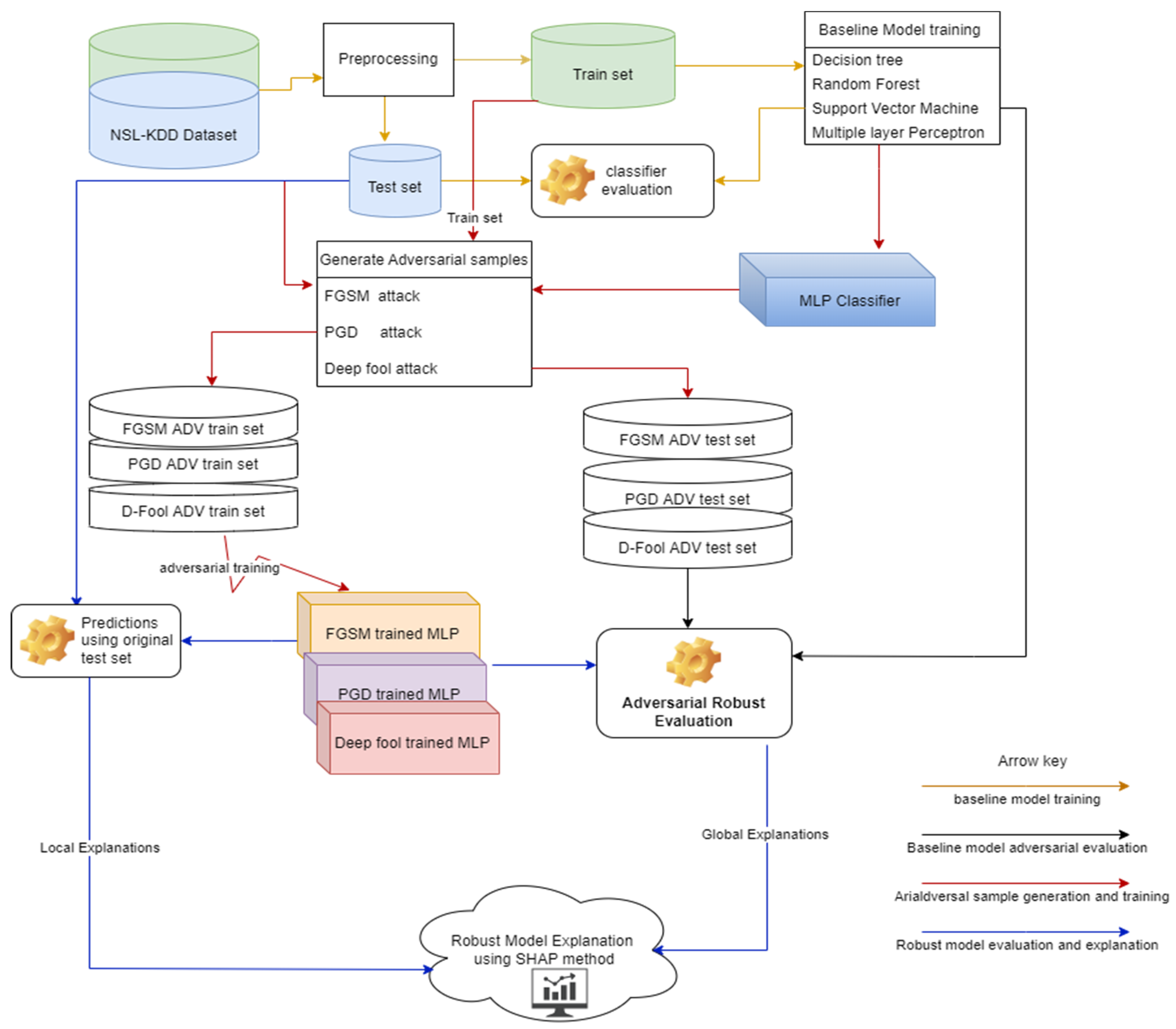
2. Materials and Methods
Proposed Method
3. Experiments and Results
3.1. IDS Datasets Selection
3.2. Data Preprocessing
3.3. Classical Machine Learning Multi-Class Classifiers
3.4. Deep Learning-Based NID
3.5. Evaluation Metrics
3.5.1. Precision
3.5.2. Recall
3.5.3. F1 Score
3.5.4. ROC Curve
3.5.5. ROC-AUC: Area under the ROC Curve
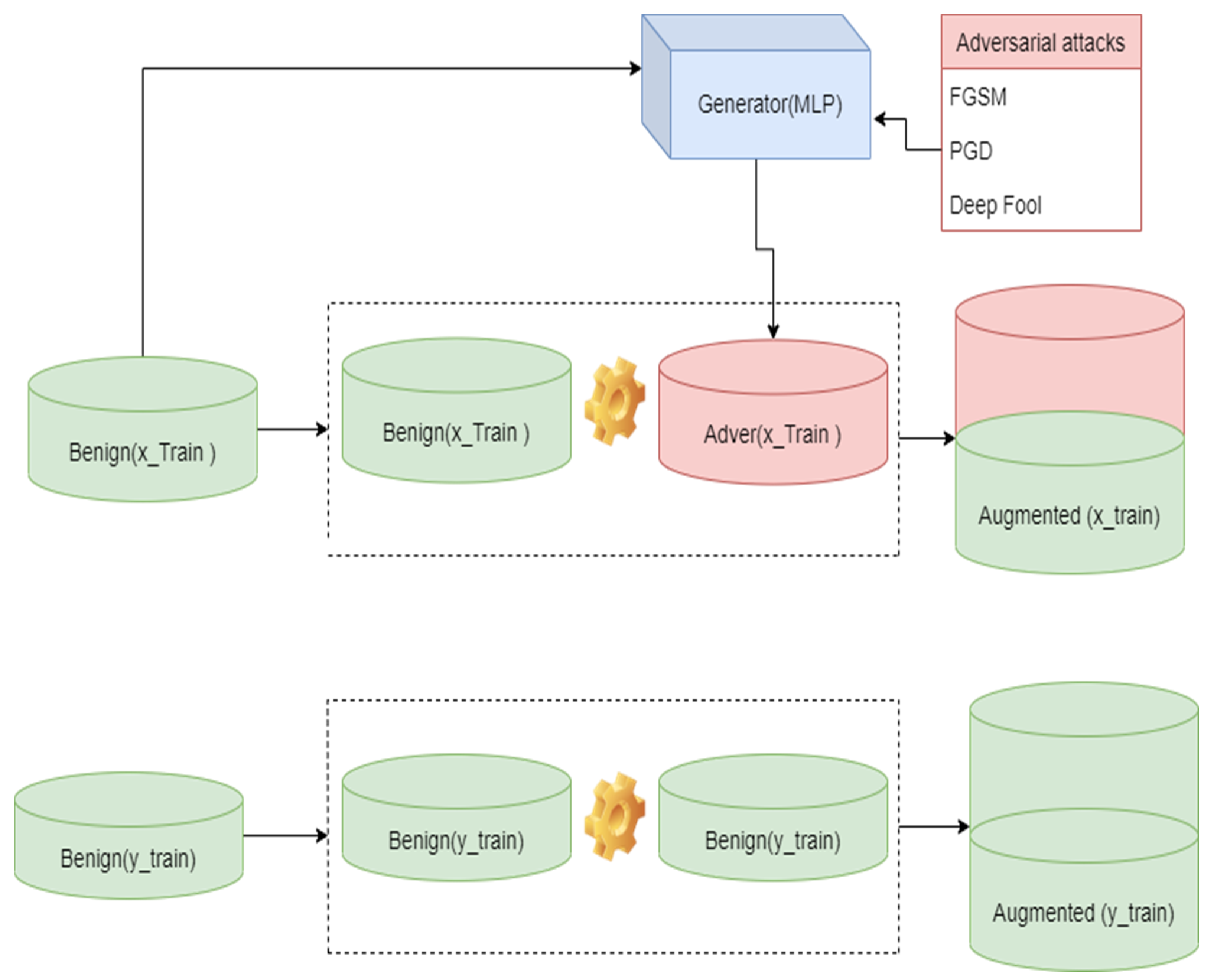
3.6. Generating Adversarial Samples
Adversarial Robustness
3.7. Baseline Models Performance Evaluation
3.8. Adversarial Sample Generation
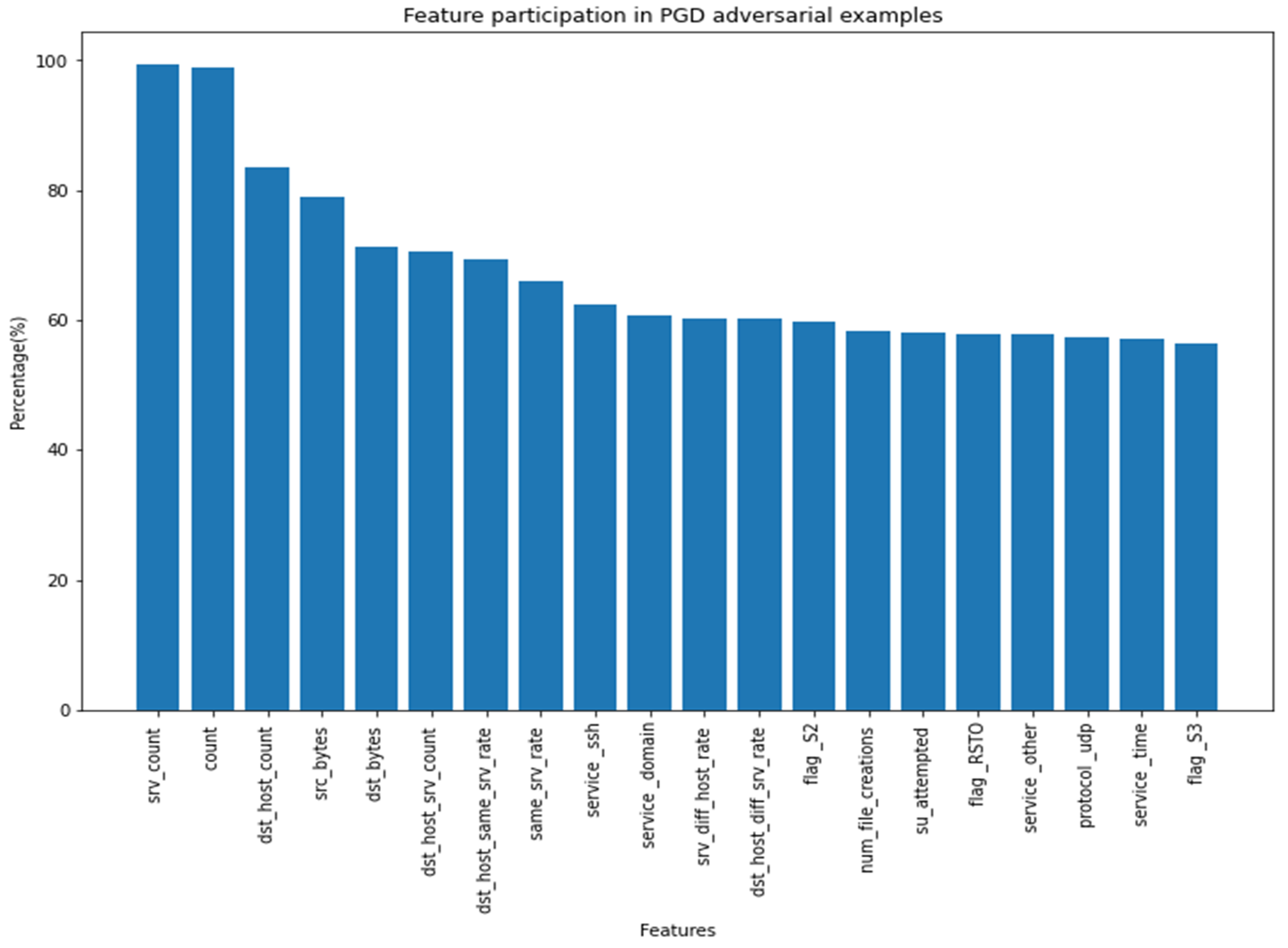
Feature Participation in Adversarial Sample Generation
3.9. Baseline Model Adversarial Resistant Evaluation
3.9.1. Adversarial Robustness Evaluation
3.9.2. Robust Model Local and Global Explanation Results
3.9.3. Robust Model Global Explanation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
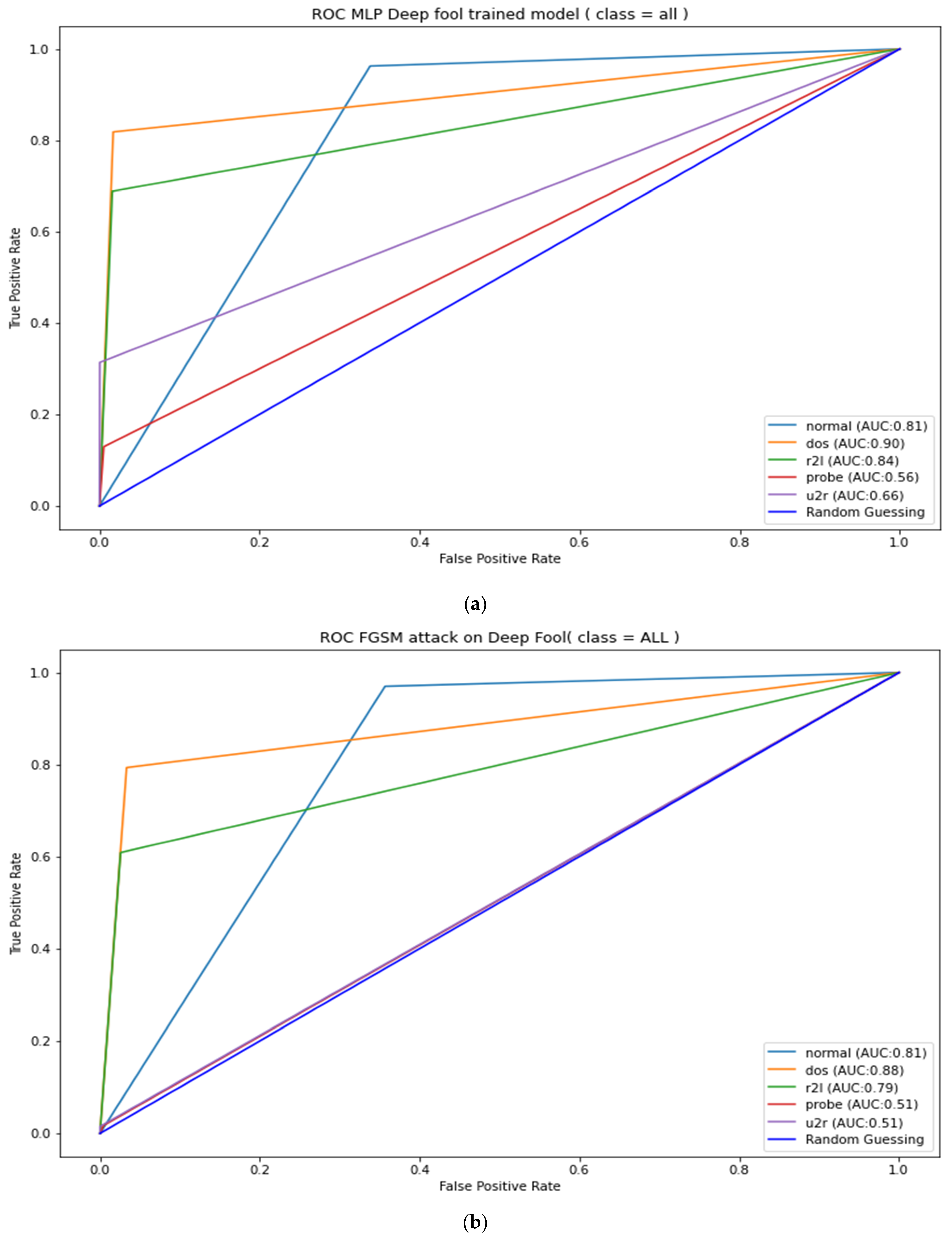
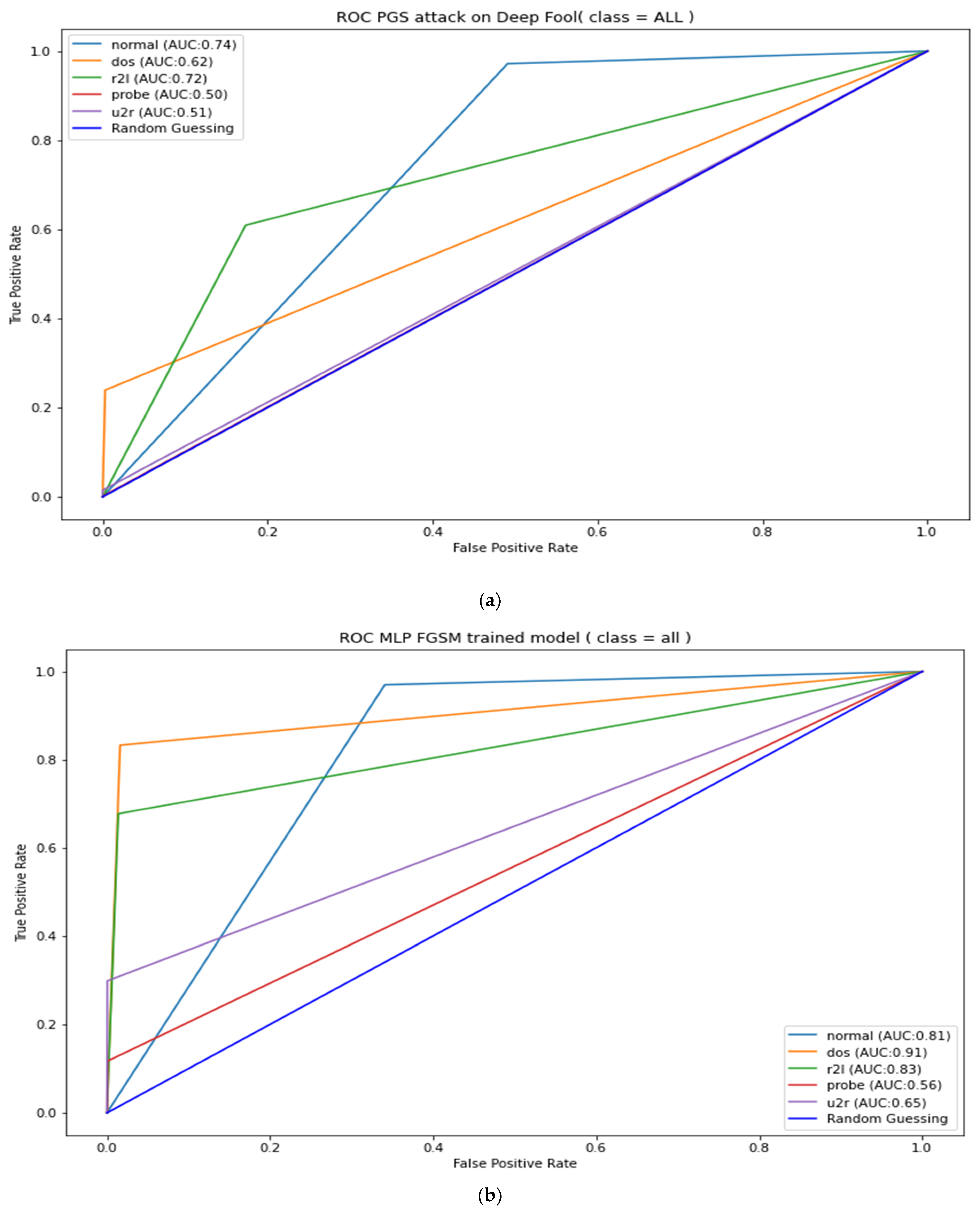
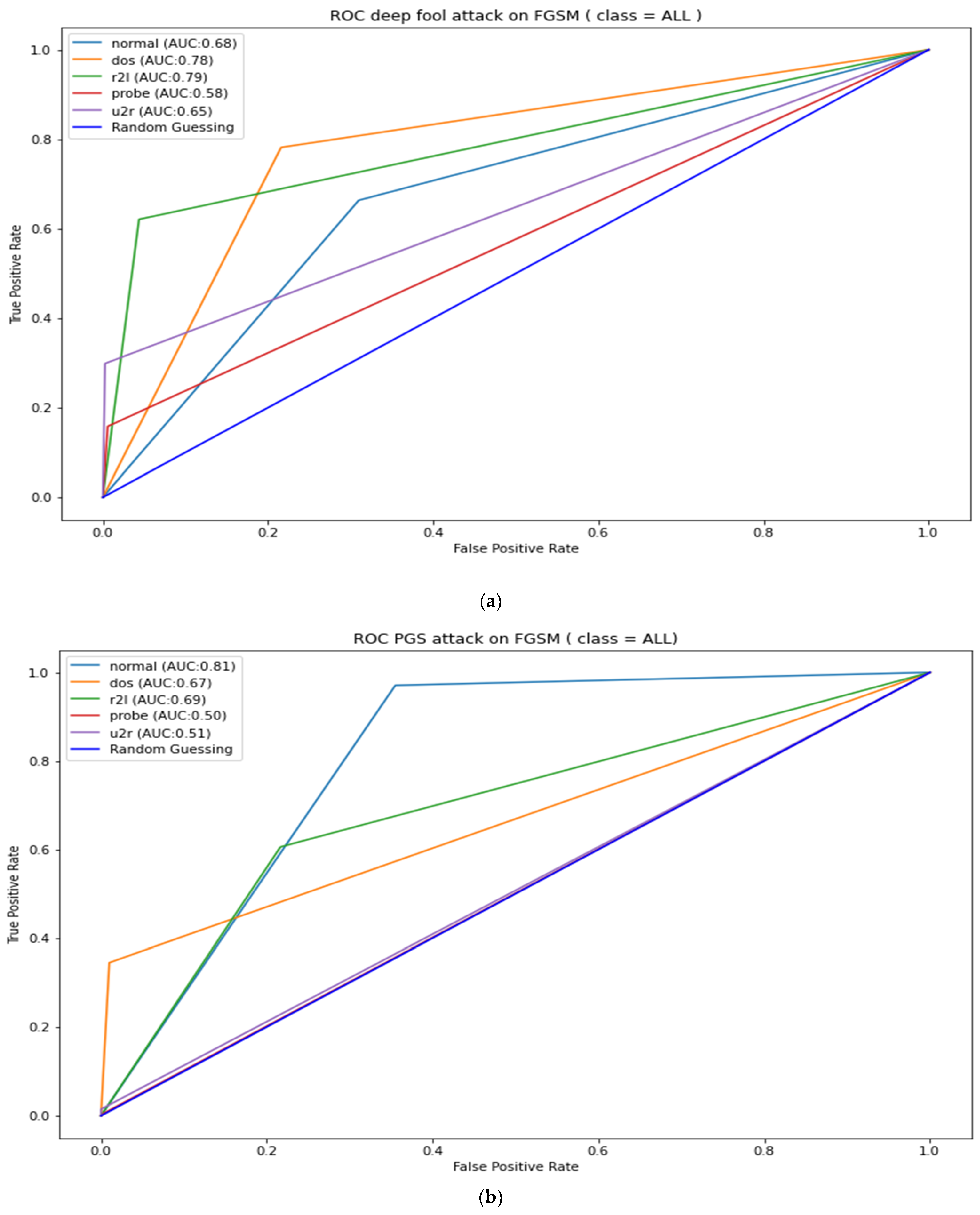
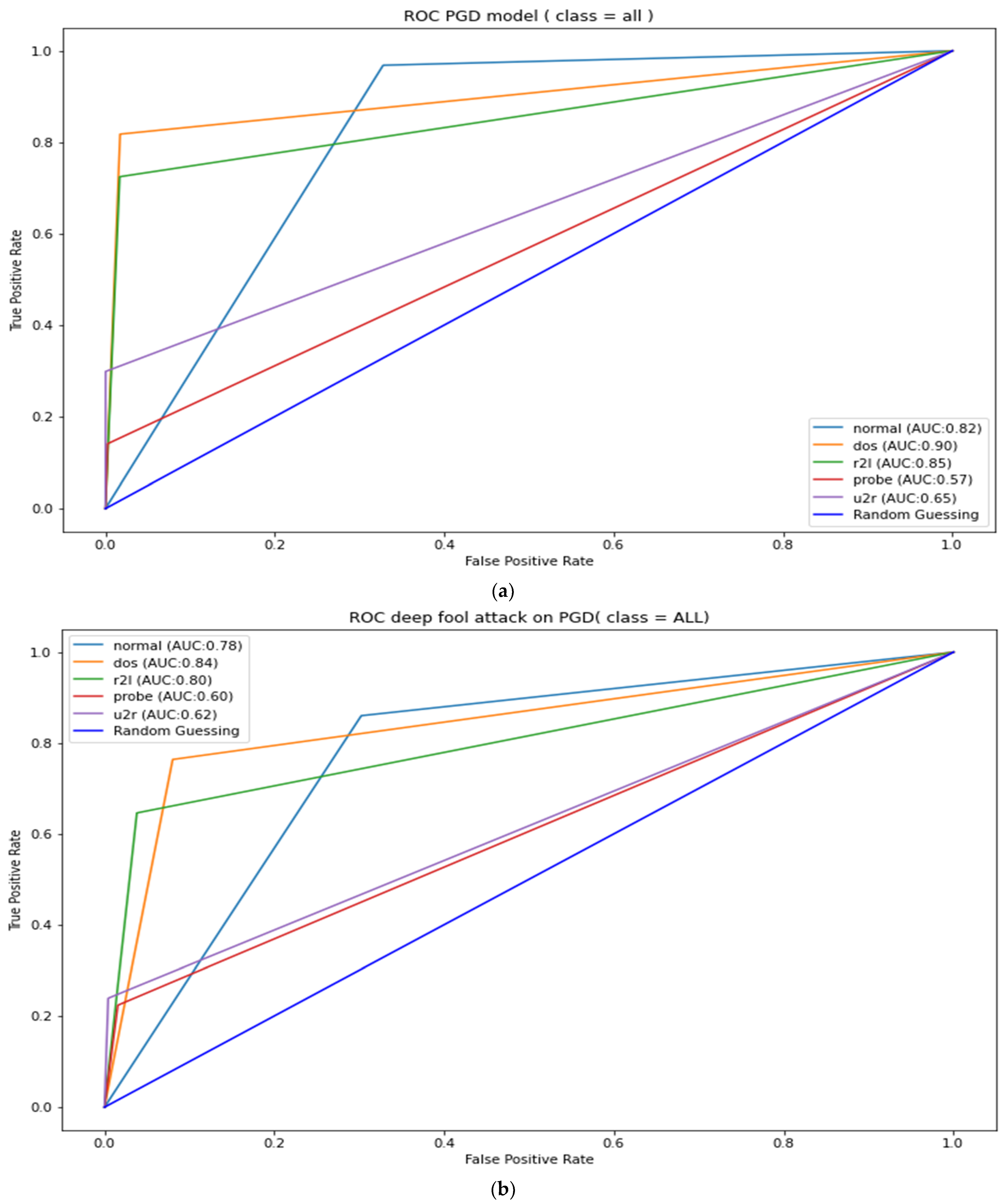
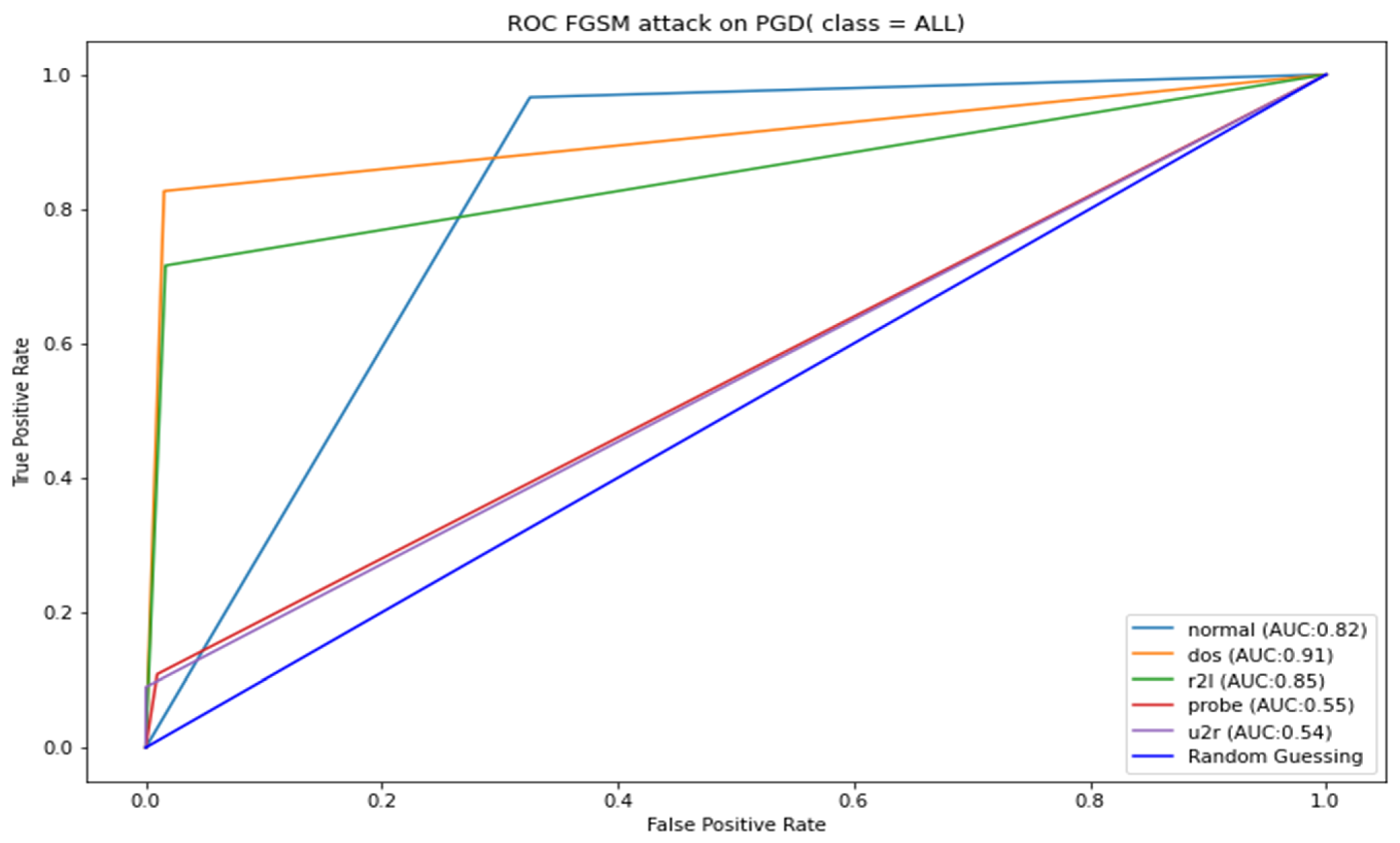
Appendix B
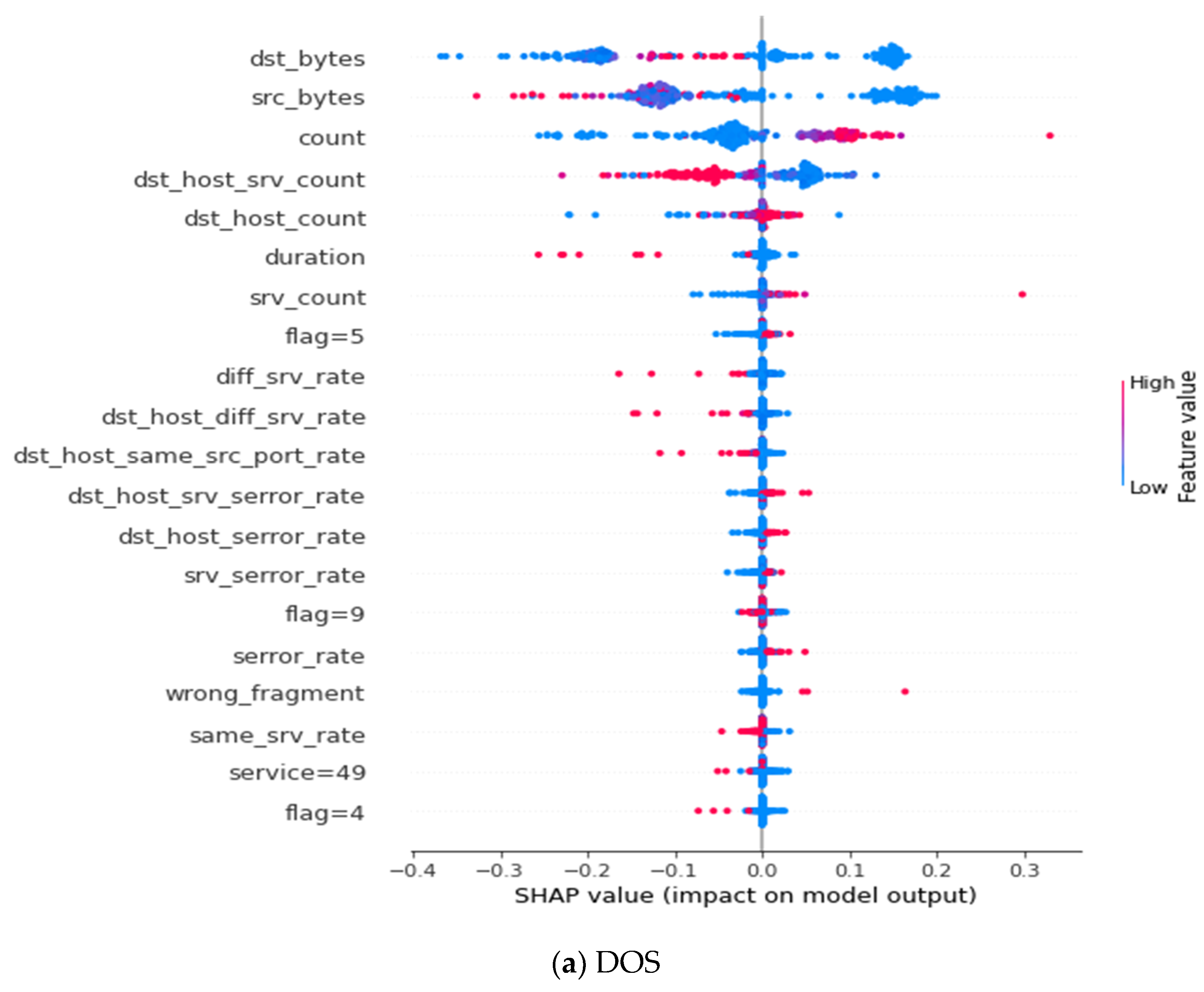

Appendix C
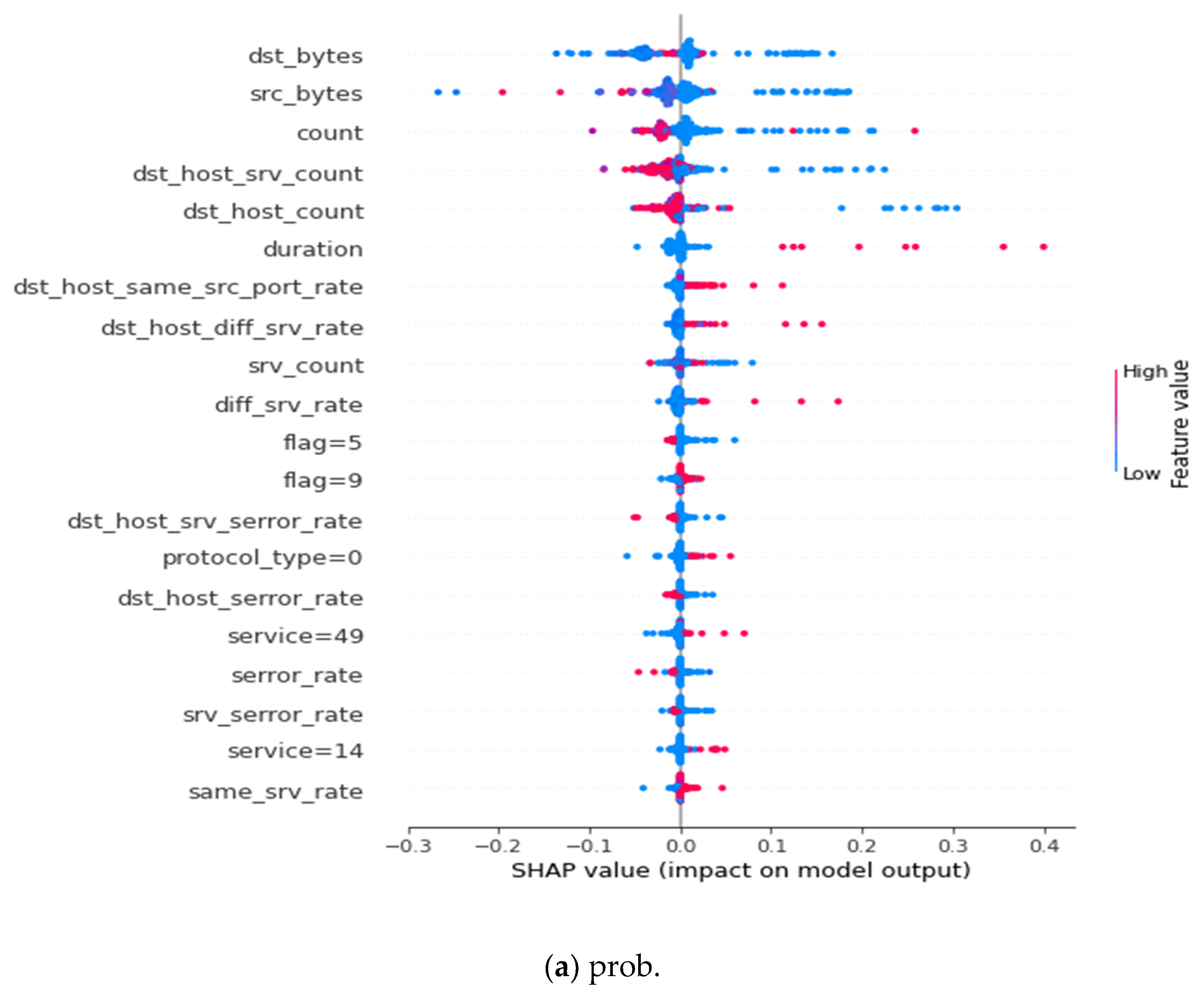
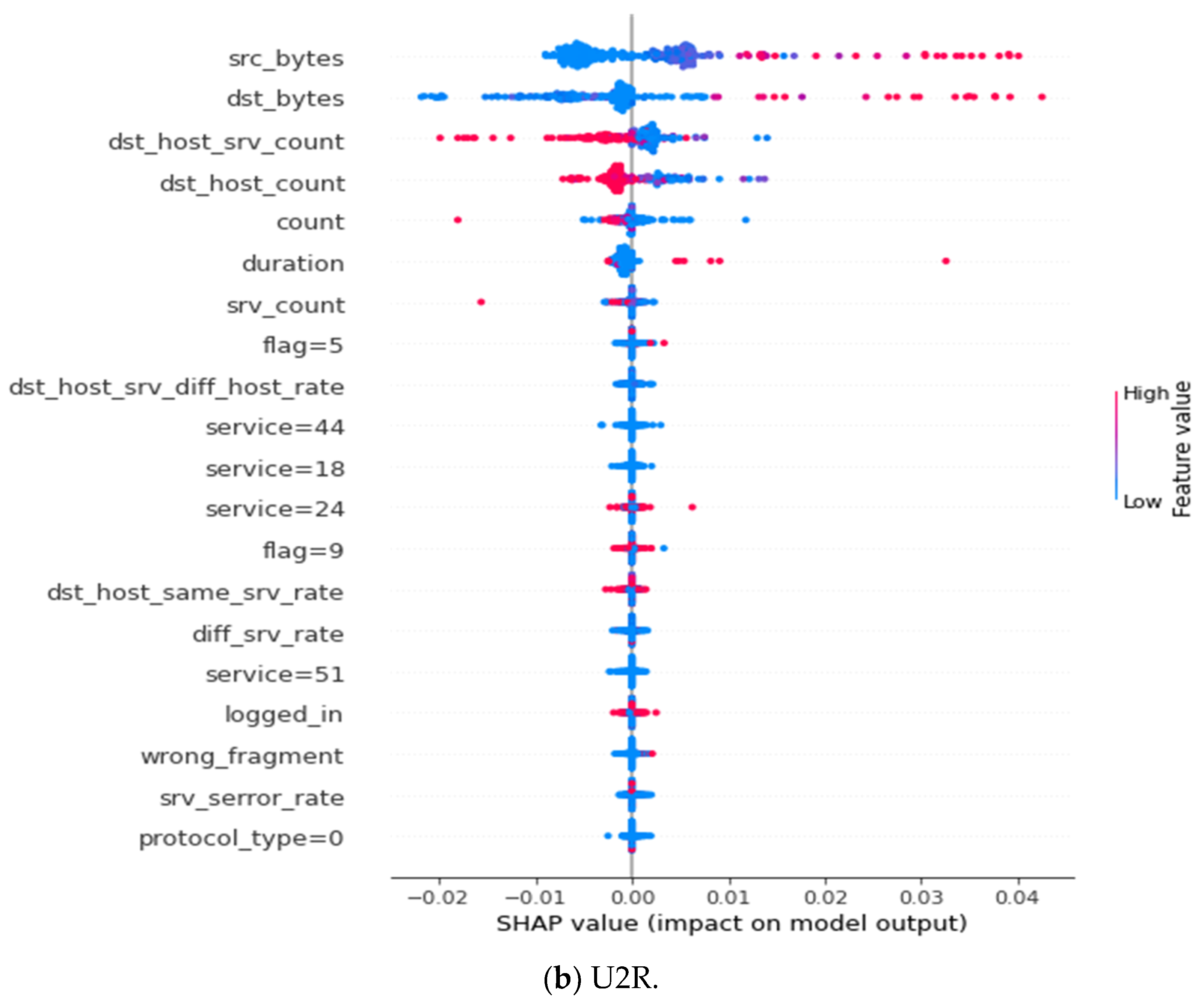
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2018, arXiv:1706.06083. [Google Scholar]
- Papernot, N.; McDaniel, P.D.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P’16), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. arXiv 2015, arXiv:1511.04599. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef] [Green Version]
- Han, D.; Wang, Z.; Zhong, Y.; Chen, W.; Yang, J.; Lu, S.; Shi, X.; Yin, X. Evaluating and Improving Adversarial Robustness of Machine Learning-Based Network Intrusion Detectors. IEEE J. Sel. Areas Commun. 2021, 39, 2632–2647. [Google Scholar] [CrossRef]
- Rigaki, M. Adversarial Deep Learning against Intrusion Detection Classifiers. Master’s Thesis, Lulea University of Technology, Luleå, Sweden, 2017. [Google Scholar]
- Wang, Z. Deep Learning-Based Intrusion Detection with Adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Hashemi, M.; Keller, E. Enhancing Robustness against Adversarial Examples in Network Intrusion Detection Systems. In Proceedings of the 2020 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Leganes, Spain, 10–12 November 2020; pp. 37–43. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Portmann, M. An Explainable Machine Learning-based Network Intrusion Detection System for Enabling Generalisability in Securing IoT Networks. arXiv 2021, arXiv:2104.07183. [Google Scholar]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. arXiv 2018, arXiv:1808.00033. [Google Scholar] [CrossRef] [Green Version]
- Rigaki, M. Adversarial deep learning against intrusion detection classifiers. In Proceedings of the NATO IST-152 Workshop on Intelligent Autonomous Agents for Cyber Defence and Resilience, IST-152 2017, Prague, Czech Republic, 18–20 October 2017. [Google Scholar]
- Xu, H.; Ma, Y.; Liu, H.; Deb, D.; Liu, H.S.; Tang, J.; Jain, A.K. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. Int. J. Autom. Comput. 2020, 17, 151–178. [Google Scholar] [CrossRef] [Green Version]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dhillon, G.S.; Azizzadenesheli, K.; Lipton, Z.C.; Bernstein, J.; Kossaifi, J.; Khanna, A.; Anandkumar, A. Stochastic Activation Pruning for Robust Adversarial Defense. arXiv 2018, arXiv:1803.01442. [Google Scholar]
- Debicha, I.; Debatty, T.; Dricot, J.; Mees, W. Adversarial Training for Deep Learning-based Intrusion Detection Systems. arXiv 2021, arXiv:2104.09852. [Google Scholar]
- Aiken, J.; Scott-Hayward, S. Investigating Adversarial Attacks against Network Intrusion Detection Systems in SDNs. In Proceedings of the 2019 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Dallas, TX, USA, 12–14 November 2019; pp. 1–7. [Google Scholar]
- Nicolae, M.; Sinn, M.; Tran, M.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.0.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Thakkar, A.; Lohiya, R. A Review of the Advancement in Intrusion Detection Datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Canadian Institute for Cybersecurity. (n.d.-b). NSL-KDD. UNB. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 13 September 2021).
- Hettich, S.; Bay, S.D. The UCI KDD Archive; University of California, Department of Information and Computer Science: Irvine, CA, USA, 1999; Available online: http://kdd.ics.uci.edu (accessed on 28 April 2022).
- Khamis, R.A.; Matrawy, A. Evaluation of Adversarial Training on Different Types of Neural Networks in Deep Learning-based IDSs. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar]
- Fenanir, S.; Semchedine, F.; Harous, S.; Baadache, A. A semi-supervised deep auto-encoder based intrusion detection for IoT. Ingénierie Systèmes D’Information 2020, 25, 569–577. [Google Scholar] [CrossRef]
- Mane, S.; Rao, D. Explaining Network Intrusion Detection System Using Explainable AI Framework. arXiv 2021, arXiv:2103.07110. [Google Scholar]
- Yang, K.; Liu, J.; Zhang, C.; Fang, Y. Adversarial Examples against the Deep Learning Based Network Intrusion Detection Systems. In Proceedings of the MILCOM 2018—2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 559–564. [Google Scholar] [CrossRef]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An Explainable Machine Learning Framework for Intrusion Detection Systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Classification: ROC Curve and AUC|Machine Learning Crash Course|. 10 February 2020. Google Developers. Available online: https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc#:%7E:text=An%20ROC%20curve%20(receiver%20operating,False%20Positive%20Rate (accessed on 15 January 2022).
- Brzezinski, D.; Stefanowski, J. Prequential AUC: Properties of the area under the ROC curve for data streams with concept drift. Knowl. Inf. Syst. 2017, 52, 531–562. [Google Scholar] [CrossRef] [Green Version]
- Reddy, S.K. AUC ROC Score and Curve in Multi-Class Classification Problems: InBlog. Ineuron. 1 November 2020. Available online: https://blog.ineuron.ai/AUC-ROC-score-and-curve-in-multiclass-classification-problems-2ja4jOHb2X (accessed on 24 March 2022).
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Ratner, A.J.; Ehrenberg, H.R.; Hussain, Z.; Dunnmon, J.A.; Ré, C. Learning to Compose Domain-Specific Transformations for Data Augmentation. Adv. Neural Inf. Process. Syst. 2017, 30, 3239–3249. [Google Scholar] [PubMed]
- Nisioti, A.; Mylonas, A.; Yoo, P.D.; Katos, V. From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods. IEEE Commun. Surv. Tutor. 2018, 20, 3369–3388. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Machine Learning at Scale. arXiv 2017, arXiv:1611.01236. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D.A. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. arXiv 2018, arXiv:1802.00420. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Number | Feature | Type | Description |
|---|---|---|---|
| 1 | Duration | Numeric | Duration of the connection |
| 2 | Protocol_type | Nominal | Type of the protocol |
| 3 | Service | Nominal | Network service on the destination |
| 4 | Flag | Nominal | Normal or error status of the connection |
| 5 | Src_bytes | Numeric | Number of bytes transferred from source to destination |
| 6 | Dst_bytes | Numeric | number of bytes transferred from destination to source |
| 7 | Land | Binary | 1 if the connection is from/to the same host/port; 0 otherwise |
| 8 | Wrong_fragment | Numeric | number of “wrong” fragments |
| 9 | Urgent | Numeric | number of urgent packets (with the urgent bit set) |
| 10 | Hot | Numeric | number of “hot” indicators |
| 11 | Num_failed_logins | Numeric | number of failed login attempts |
| 12 | Logged_in | Binary | 1 if successfully logged in; 0 otherwise |
| 13 | Num_compromissed | Numeric | number of “compromised” conditions |
| 14 | Root_shell | Binary | 1 if root shell is obtained; 0 otherwise |
| 15 | Su_attempted | Binary | 1 if “su root” command attempted; 0 otherwise |
| 16 | Num_root | Numeric | number of “root” accesses |
| 17 | Num file cre ations | Numeric | number of file creation operations |
| 18 | Num_shells | Binary | number of shell prompts |
| 19 | Num_access_files | Numeric | number of operations on access control files |
| 20 | Num_outbound_cmds | Numeric | number of outbound commands in an ftp session |
| 21 | Is_hot_login | Binary | 1 if the login belongs to the “hot” list: 0 otherwise |
| 22 | Is_guest_login | Binary | 1 if the login is a “guest” login; 0 otherwise |
| 23 | Count | Numeric | number of connections to the same host as the current connection (Note) |
| 24 | Serror_rate | Numeric | number of connections that have “SYN” errors |
| 25 | Rerror_rate | Numeric | % of connections that have “REJ” errors |
| 26 | Same_srv_rate | Numeric | % of connections to the same service |
| 27 | Diff_srv_rate | Numeric | % of connections to different services |
| 28 | Srv_count | Numeric | % of connections to the same service as the current connection in |
| 29 | Srv_serror_rate | Numeric | % of connections that have “SYN” errors |
| 30 | Srv_rerror_rate | Numeric | % of connections that have “REJ” errors |
| 31 | Srv_diff_host_rate | Numeric | % of connections to different hosts |
| 32 | Dst host_count | Numeric | number of connections having the same destination host |
| 33 | Dst_host_srv_count | Numeric | number of connections using the same service |
| 34 | Dst_host_same_srv_ | Numeric | % of connections using the same service |
| 35 | Dst_host_srv_diff_ | Numeric | % of different services on the current host |
| 36 | Dst_host_same_src_ | Numeric | % of connections to the current host having the same src port |
| 37 | Dst_host_srv_diff_ | Numeric | % of connections to the same service coming from different hosts |
| 38 | Dst_host_serror_rate | Numeric | % of connections to the current host that have a so error |
| 39 | Dst_host_srv_serror_rate | Numeric | % of connections to the current host and specified service that |
| 40 | Dst_host_rerror_rate | Numeric | % of connections to the current host that have an RST error |
| 41 | Dst_host_srv_rerror_rate | Numeric | % of connections to the current host and specified service that |
| Attack Label | Attack Type |
|---|---|
| Denial of service (DOS) | Back, Land, Naptune, Pod, Smurf, Teardrop, Apache2, Udpstorm, Processable, Worm Mailbomb |
| Prob | ipsweep, saint, mscan, satan, nmap, portsweep |
| Remote to local (R2L) | Guess_Password, Ftp_write, Imap, Phf, Multihop, Warezmaster, Xlock, Xsnoop, Snmpguess, Snmpgetattack, Httptunnel, Sendmail, Named |
| User To Root (U2R) | Buffer_overflow, Rootkit, Perl, Sqlattack, Xterm, Ps, loadmodule |
| Attack Label | Attack Type |
|---|---|
| Denial of service (DOS) | Back, Land, Naptune, Pod, Smurf, Teardrop, |
| Prob | Buffer_overflow, ipsweep, portsweep, nmap, satan |
| Remote to local (R2L) | Guess_Password, Ftp_write, Imap, Phf, Multihop, Warezmaster, Warezclient, Spy, |
| User To Root (U2R) | Loadmodule, Rootkit, Perl, |
| Method | Accuracy | F1 Score | AUC (Class = Normal) |
|---|---|---|---|
| Decision Tree Classifier | 0.71 | 0.74 | 0.79 |
| Random Forest Classifier | 0.71 | 0.72 | 0.78 |
| Linear SVM Classifier | 0.68 | 0.72 | 0.78 |
| Baseline MLP model | 0.79 | - | 0.87 |
| Method | Number of Unique Features Changed | Number of Average Features Changed per Datapoint | Average Perturbations/Sample (KDDTest+) |
|---|---|---|---|
| DeepFool | 122 | 51.73 | 0.10 |
| FGSM | 122 | 56.81 | 0.15 |
| PGD | 122 | 80.58 | 0.21 |
| Method | Features |
|---|---|
| DeepFool | ‘srv_count’, ‘count’, ‘dst_host_srv_count’, ‘is_guest_login’, ‘dst_host_same_src_port_rate’, ‘root_shell’, ‘dst_host_diff_srv_rate’, ‘diff_srv_rate’, ‘dst_host_same_srv_rate’, ‘service_eco_i’ |
| FGSM | ‘land’, ‘dst_host_same_srv_rate’, ‘dst_host_count_srv_rerror_rate’, ‘root_shell’, ‘dst_host_same_src_port_rate’, ‘protocol_icmp’, ‘dst_host_srv_serror_rate’, ‘service_ecr_i’, ‘num_outbound_cmds’ |
| PGD | ‘srv_count’, ‘count’, ‘dst_host_count’, ‘src_bytes’, ‘dst_bytes’, ‘dst_host_srv_count’, ‘dst_host_same_srv_rate’, ‘same_srv_rate’, ‘service_ssh’, ‘service_domain’ |
| Method | ROC-AUC | |||
|---|---|---|---|---|
| Normal | DeepFool | PGD | FGSM | |
| Decision Tree | 0.79 | 0.65 | 0.27 | 0.30 |
| Random Forest | 0.78 | 0.53 | 0.23 | 0.26 |
| Linear SVM | 0.78 | 0.51 | 0.23 | 0.26 |
| Base MLP | 0.87 | 0.62 | 0.61 | 0.60 |
| Method | ROC-AUC | Adversarial Robust Evaluation | ||||||
|---|---|---|---|---|---|---|---|---|
| Normal | DeepFool | FGSM | PGD | Normal | DeepFool_A | FGSM_A | PGD_A | |
| DeepFool_M | 0.86 | 0.86 | 0.84 | 0.73 | 0 | −0.20% | −2.33% | −15.12% |
| FGSM_M | 0.86 | 0.77 | 0.86 | 0.75 | 0 | −10.47% | 0.01% | −12.79% |
| PGD_M | 0.87 | 0.79 | 0.87 | 0.76 | 0 | −9.20% | 0 | −13.65% |
| Baseline MPL | 0.87 | 0.62 | 0.60 | 0.61 | 0 | −28.74% | −31.03% | −29.89% |
| Attack Label | Important Features Extracted by the Adversarial Robust NIDS |
|---|---|
| Denial of service (DOS) | dst-bytes, src_byte, count, dst_hiost_srv_count, dst_host_count, duration, srv_count, flag = 5, diff_srv_rate, dst_host_diff_srv_rate, dst_host_same_src_port_rate, dst_host_src_serror_rate, dst_host_serror_rate, srv_serror_rate, flag = 9, serror_rate, wrong_fragment, same_srv_rate, service = 49, flag = 9 |
| Prob | dst_bytes, src_bytes, count, dst_host_srv_count, dst_host_count, duration, dst_host_same_src_port_rate, dst_host_diff_srv_rate, srv_count, diff_srv_rate, flag = 5, flag = 9, dst_host_srv_seror_rate, protocol_type = 0, dst_host_serror_rate, service = 49, serror_rate, srv_serro_rate, service = 14, same_srv_rate |
| Remote to local (R2L) | src_bytes, dst_bytes, dst_host_srv_count., dst_host_count, duration, count, srv_count, flag = 5, num_compromised, dst_host_srv_diff_host_rate, service = 66, dst_host_same_rv_rate, service = 44, flag = 1, service = 20, service = 24, service- = 65, service- = 51, dst_host_rerror_rate |
| User To Root (U2R) | src_bytes, dst_bytes, dst_host_srv_count, dst_host_count, count, duration, srv_count, flag = 5, dst_host_srv_diff_host_rate, service = 44, service = 18, service = 24, flag = 9, dst_host_same_srv_rate, diff_srv_rate, service = 51, logged_in, wrong_fragment, srv_serror_rate, protocol_type = 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sauka, K.; Shin, G.-Y.; Kim, D.-W.; Han, M.-M. Adversarial Robust and Explainable Network Intrusion Detection Systems Based on Deep Learning. Appl. Sci. 2022, 12, 6451. https://doi.org/10.3390/app12136451
Sauka K, Shin G-Y, Kim D-W, Han M-M. Adversarial Robust and Explainable Network Intrusion Detection Systems Based on Deep Learning. Applied Sciences. 2022; 12(13):6451. https://doi.org/10.3390/app12136451
Chicago/Turabian StyleSauka, Kudzai, Gun-Yoo Shin, Dong-Wook Kim, and Myung-Mook Han. 2022. "Adversarial Robust and Explainable Network Intrusion Detection Systems Based on Deep Learning" Applied Sciences 12, no. 13: 6451. https://doi.org/10.3390/app12136451
APA StyleSauka, K., Shin, G.-Y., Kim, D.-W., & Han, M.-M. (2022). Adversarial Robust and Explainable Network Intrusion Detection Systems Based on Deep Learning. Applied Sciences, 12(13), 6451. https://doi.org/10.3390/app12136451