
Named Entity Recognition Using Conditional Random Fields

 , , and
, , and
Abstract
:1. Introduction
- The provision of a named entity annotated dataset consisting of 2161 news sentences with 5283 entities. The news articles were obtained from the BBC Urdu website (https://www.bbc.com/urdu (accessed on 15 February 2022)), which is a valuable resource of Urdu text in digital format. The newly developed Urdu NER dataset was named the UNER-I dataset.
- We proposed a condition random field (CRF)-based approach for NER in Urdu. We also proposed the notation of a feature template and a novel set of features and feature functions. It includes dependent and independent features, such as the context-of-words and part-of-speech tags, to address the NER problem in Urdu.
- Experimentation using the UNER-I dataset and its counterpart to demonstrate the usefulness of the UNER-I dataset, as well as the effectiveness of the proposed approach.
2. Related Work
3. Characteristics of Urdu Language
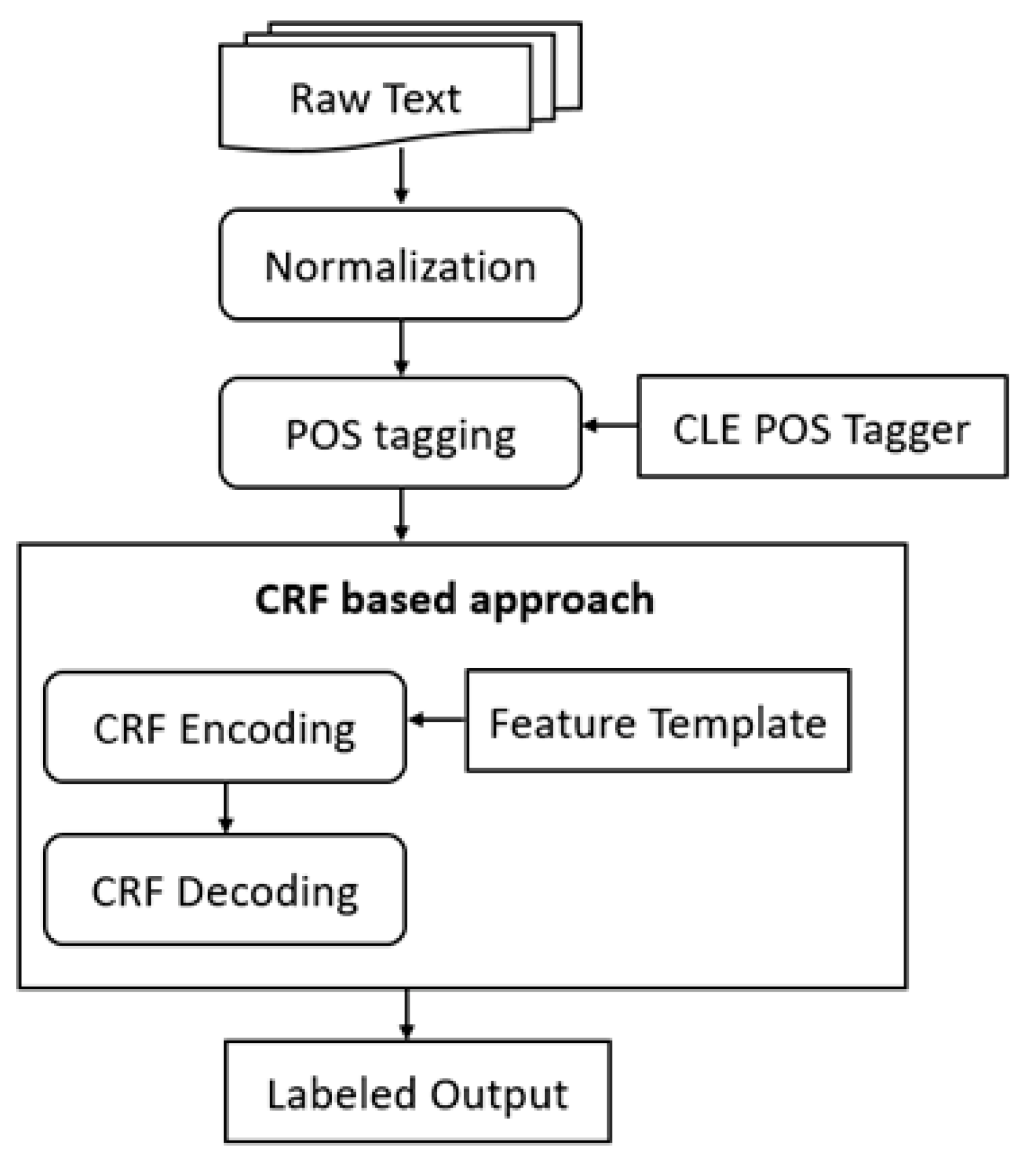
4. Urdu NER Using Condition Random Fields
4.1. Conditional Random Field
4.2. Feature Templates
4.3. Feature Functions
4.4. Encoding
| Algorithm 1: Encoding of the CRF model. |
| 1. CRF_NER_Encode (string [Feature File, Trining Data, Mode = Train] Argument) 2. For (L = 0; L < Argument. Length; L++) 3. End For 4. If mode = train 5. Load Training Data 6. While (Training_data. End == false) 7. Fetch line by line record of Train Data 8. For (J = 0; J < Featuer File; J++) 9. Read feature file from {0} 10. Extract feature set 11. Remove feature with frequency below threshold {0} 12. Store feature in Model file to be used in Decoding phase 13. End for 14. End while |
4.5. Decoding
| Algorithm 2: Decoding of the CRF model. |
| 1. CRF_NER_Decode (string [Testing Data, Enocde_Model_file, Mode = Test, Results] Arguments) 2. For (J = 0;J < args. Length; J++) 3. Read Arguments 4. End for 5. If mode = Test 6. Read model data file 7. While (test data file.End == false) 8. Fetch line by line record of Test Data 9. While (model data file.End == false) 10. Make a decoder tagging object 11. Initialize the outcome 12. To forecast the tags of a given string, use the CRFSharp wrapper. 13. Output raw result with probability 14. Save the result in the result file 15. End while 16. End while Set all of the input parameters to their default values. |
5. Urdu UNER Datasets
5.1. The Baseline Dataset
5.2. The UNER-I Dataset
6. Evaluation
6.1. Datasets
6.2. Evaluation Measures
6.3. Experimental Setup
7. Results and Discussion
7.1. Results of News Genres
7.2. Results of NE Types
7.3. Error Analysis
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Espla-Gomis, M.; Sánchez-Martínez, F.; Forcada, M.L. Using machine translation to provide target-language edit hints in computer aided translation based on translation memories. J. Artif. Intell. Res. 2015, 53, 169–222. [Google Scholar] [CrossRef] [Green Version]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Sundheim, B.M. Overview of Results of the MUC-6 Evaluation. In Proceedings of the Sixth Message Understanding Conference, Vienna, VA, USA, 6–8 May 1996; pp. 423–442. [Google Scholar]
- Khattak, A.; Asghar, M.Z.; Saeed, A.; Hameed, I.A.; Hassan, S.A.; Ahmad, S. A survey on sentiment analysis in Urdu: A resource-poor language. Egypt. Inform. J. 2021, 22, 53–74. [Google Scholar] [CrossRef]
- Khan, I.U.; Khan, A.; Khan, W.; Su’ud, M.M.; Alam, M.M.; Subhan, F.; Asghar, M.Z. A review of Urdu sentiment analysis with multilingual perspective: A case of Urdu and roman Urdu language. Computers 2022, 11, 3. [Google Scholar] [CrossRef]
- Riaz, K. Rule-Based Named Entity Recognition in Urdu. In Proceedings of the 2010 Named Entities Workshop, Uppsala, Sweden, 16 July 2010; Association for Computational Linguistics: Minneapolis, MN, USA, 2010; pp. 126–135. [Google Scholar]
- Malik, M.K.; Sarwar, S.M. urdu named entity recognition and classification system using conditional random field. Sci. Int. 2015, 5, 4473–4477. [Google Scholar]
- Saha, S.K.; Chatterji, S.; Dandapat, S.; Sarkar, S.; Mitra, P. A hybrid named entity recognition system for south and south east asian languages. In Proceedings of the IJCNLP-08 Workshop on Named Entity Recognition for South and South East Asian Languages; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2008; pp. 83–88. [Google Scholar]
- Roberts, A.; Gaizauskas, R.J.; Hepple, M.; Guo, Y. Combining Terminology Resources and Statistical Methods for Entity Recognition: An Evaluation. In Proceedings of the the Conference on Language Resources and Evaluation (LRE’08), Marrakech, Morocco, 26 May–1 July 2008; pp. 2974–2980. [Google Scholar]
- Tjong Kim Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Stroudsburg, PA, USA, 31 May 2003; Volume 4, pp. 142–147. [Google Scholar]
- Shaalan, K.; Raza, H. NERA: Named entity recognition for Arabic. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1652–1663. [Google Scholar] [CrossRef]
- Singh, U.; Goyal, V.; Lehal, G.S. Named Entity Recognition System for Urdu. In Proceedings of the COLING, Mumbai, India, 8–15 December 2012; pp. 2507–2518. [Google Scholar]
- Ekbal, A.; Haque, R.; Bandyopadhyay, S. Named Entity Recognition in Bengali: A Conditional Random Field Approach. In Proceedings of the the International Joint Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan, 27 November–1 December 2008; pp. 589–594. [Google Scholar]
- Mukund, S.; Srihari, R.; Peterson, E. An Information-Extraction System for Urdu—A Resource-Poor Language. ACM Trans. Asian Lang. Inf. Processing (TALIP) 2010, 9, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Kazama, J.I.; Torisawa, K. Exploiting Wikipedia as External Knowledge for Named Entity Recognition. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; pp. 698–707. [Google Scholar]
- Chiong, R.; Wei, W. Named Entity Recognition Using Hybrid Machine Learning Approach. In Proceedings of the 5th IEEE International Conference on Cognitive Informatics, Beijing, China, 17–19 June 2006; pp. 578–583. [Google Scholar]
- Shaalan, K. A survey of arabic named entity recognition and classification. Comput. Linguist. 2014, 40, 469–510. [Google Scholar] [CrossRef]
- Collins, M.; Singer, Y. Unsupervised Models for Named Entity Classification. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999; pp. 100–110. [Google Scholar]
- Capstick, J.; Diagne, A.K.; Erbach, G.; Uszkoreit, H.; Leisenberg, A.; Leisenberg, M. A system for supporting cross-lingual information retrieval. Inf. Processing Manag. 2000, 36, 275–289. [Google Scholar] [CrossRef]
- Daud, A.; Khan, W.; Che, D. Urdu language processing: A survey. Artif. Intell. Rev. 2016, 47, 279–331. [Google Scholar] [CrossRef]
- Villa, S.; Stella, F. Learning Continuous Time Bayesian Networks in Non-stationary Domains. J. Artif. Intell. Res.(JAIR) 2016, 57, 1–37. [Google Scholar] [CrossRef]
- Khan, W.; Daud, A.; Nasir, J.A.; Amjad, T. A survey on the state-of-the-art machine learning models in the context of NLP. Kuwait J. Sci. 2016, 43, 66–84. [Google Scholar]
- Oudah, M.; Shaalan, K. NERA 2.0: Improving coverage and performance of rule-based named entity recognition for Arabic. Nat. Lang. Eng. 2016, 23, 441–472. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Haq, R.; Zhang, X.; Khan, W.; Feng, Z. Urdu Named Entity Recognition System Using Deep Learning Approaches. Comput. J. 2022. [Google Scholar] [CrossRef]
- Thenmalar, S.; Balaji, J.; Geetha, T. Semi-supervised Bootstrapping approach for Named Entity Recognition. arXiv 2015, arXiv:1511.06833. [Google Scholar]
- Dubba, K.S.; Cohn, A.G.; Hogg, D.C.; Bhatt, M.; Dylla, F. Learning relational event models from video. J. Artif. Intell. Res. 2015, 53, 41–90. [Google Scholar] [CrossRef]
- Oudah, M.; Shaalan, K.F. A Pipeline Arabic Named Entity Recognition Using a Hybrid Approach. In Proceedings of the COLING, Mumbai, India, December 2012; pp. 2159–2176. [Google Scholar]
- Hardie, A. Developing a Tagset for Automated Part-of-Speech Tagging in Urdu. In Corpus Linguistics; UCREL Technical Papers; Department of Linguistics, Lancaster University: Lancaster, UK, 2003. [Google Scholar]
- Anwar, W.; Wang, X.; Wang, X.-l. A Survey of Automatic Urdu Language Processing. In Proceedings of the International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 4489–4494. [Google Scholar]
- Akram, Q.-u.-A.; Naseer, A.; Hussain, S. Assas-Band, an Affix-Exception-List Based Urdu Stemmer. In Proceedings of the 7th Workshop on Asian Language Resources, Suntec, Singapore, 6–7 August 2009; pp. 40–46. [Google Scholar]
- Ahmed, T.; Hautli, A. A first approach towards an Urdu WordNet. Linguist. Lit. Rev. 2011, 1, 1–14. [Google Scholar] [CrossRef]
- Adeeba, F.; Hussain, S. Experiences in Building the Urdu WordNet. In Proceedings of the 9th Workshop on Asian Language Resources Collocated with IJCNLP, Chiang Mai, Thailand, 12–13 November 2011; pp. 31–35. [Google Scholar]
- Anwar, W.; Wang, X.; Li, L.; Wang, X.-L. A Statistical Based Part of Speech Tagger for Urdu Language. In Proceedings of the International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; pp. 3418–3424. [Google Scholar]
- Khan, W.; Daud, A.; Alotaibi, F.; Aljohani, N.; Arafat, S. Deep recurrent neural networks with word embeddings for Urdu named entity recognition. ETRI J. 2020, 42, 90–100. [Google Scholar] [CrossRef] [Green Version]
- Rasheed, I.; Banka, H.; Khan, H.M.; Daud, A. Building a text collection for Urdu information retrieval. ETRI J. 2021, 43, 856–868. [Google Scholar] [CrossRef]
- Hussain, S. Resources for Urdu Language Processing. In Proceedings of the IJCNLP, Hyderabad, India, 7–12 January 2008; pp. 99–100. [Google Scholar]
- Jakobsson, U.; Westergren, A. Statistical methods for assessing agreement for ordinal data. Scand. J. Caring Sci. 2005, 19, 427–431. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
| Language | Example Sentence | Flow |
|---|---|---|
| English | Today’s newspaper | Left to right (→) |
| French | Le journal d’aujourd’hui | Left to right (→) |
| German | Die heutige Zeitung | Left to right (→) |
| Urdu | آج کا اخبار | Right to left (←) |
| Example: Riyadh Is the Capital | ||
|---|---|---|
 | ||
 |  |  |
| [x, y] | Description |
|---|---|
| [0, 0] | Position of the current word |
| [−1, 0] | Position of the preceding word |
| [1, 0] | Represents the position of the next lexical word |
| [−1, 1] | Represents the position of the POS tag of the preceding word |
| [0, 1] | Represents the position of the POS tag of the current word |
| [1, 1] | Represents the position of the POS tag of the next lexical word |
| Feature Templates | Values of Elements | Description | |||
|---|---|---|---|---|---|
| PR | ID | PS | TG | ||
| <U1:%x[−1, 0]> | U | 1 | [−1, 0] | - | Prior vocabulary term |
| <U2:%x[0, 0]> | U | 2 | [0, 0] | - | Present vocabulary term |
| <U3:%x[1, 0]> | U | 3 | [1, 0] | - | Succeeding vocabulary term |
| <U4:%x[0, 1]> | U | 4 | [0, 1] | - | Syntactic tag of the current word |
| <U5:%x[−1, 1]> | U | 5 | [−1, 1] | - | Syntactic tag of the preceding lexical word |
| <U6:%x[1, 1]> | U | 6 | [1, 1] | - | Syntactic tag of the succeeding lexical word |
| <U7:%x[0, 0]% [0, 1]%> | U | 7 | [0, 0] | [0, 1] | Current word/current syntactic tag |
| <U8:%x[0, 0]%x[1, 1]> | U | 8 | [0, 0] | [1, 1] | Current word/next syntactic tag |
| <U9:%x[0, 0]%x[−1, 1]> | U | 9 | [0, 0] | [−1, 1] | Current word/previous syntactic tag |
| <B10:%x[0, 1]> | B | 10 | - | [0, 1] | Bigram of the current syntactic tag |
| <B11:%x[0, 0]> | B | 11 | - | [0, 0] | Bigram of the current word |
| Token | POS Tag | Class Label |
|---|---|---|
| ریحام | PNN | S_PERSON |
| پی | PNN | B_ORGANIZATION |
| ٹی | PNN | M_ORGANIZATION |
| آئی | PNN | E_ORGANIZATION |
| کے | PSP | NOR |
| ٹکٹ | NN | NOR |
| پر | PSP | NOR |
| انتحابات | NN | NOR |
| بھی | PRT | NOR |
| نہیں | NEG | NOR |
| لڑیں | OOV | NOR |
| گی | AUXT | NOR |
| Total No. of Words | 40,408 |
| Total No. of Sentences | 1097 |
| Total No. of Named Entities | 1115 |
| NE Type | Count |
|---|---|
| Person | 277 |
| Location | 490 |
| Organization | 48 |
| Designation | 69 |
| Date | 123 |
| Number | 123 |
| Total | 1115 |
| Cumulative Amount of Words | 58,633 |
| Overall Number of Sentences | 2161 |
| Total Count of Identified Entities | 5283 |
| Domain/Entity | Person | Location | Organization | Date | Time | Number | Designation | Total |
|---|---|---|---|---|---|---|---|---|
| Sports | 605 | 455 | 53 | 48 | 10 | 589 | 42 | 1802 |
| National | 401 | 390 | 400 | 81 | 40 | 270 | 167 | 1749 |
| International | 201 | 360 | 210 | 74 | 23 | 132 | 70 | 1070 |
| Arts | 355 | 120 | 41 | 42 | 33 | 56 | 15 | 662 |
| Total | 1562 | 1325 | 704 | 245 | 106 | 1047 | 294 | 5283 |
| Approach | IJCNLP-Urdu Dataset | UNER-I Dataset | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Precision | Recall | F-Measure | |
| Baseline | 50.46 | 67.21 | 53.49 | 76.5875 | 74.2225 | 73.1925 |
| Proposed | 49.93 | 67.76 | 54.02 | 78.205 | 75.7875 | 74.8125 |
| Genres | Baseline Approach | Proposed Approach | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Precision | Recall | F-Measure | |
| National | 87.14 | 81.01 | 82.32 | 88.21 | 84.05 | 84.68 |
| Sports | 75.48 | 73.39 | 73.23 | 77.44 | 75.02 | 74.92 |
| International | 73.45 | 71.66 | 69.65 | 75.84 | 72.62 | 71.56 |
| Art | 70.28 | 70.83 | 67.57 | 71.33 | 71.46 | 68.09 |
| NE Type | Baseline Approach | Proposed Approach | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| Person | 65.7 | 76.64 | 69.79 | 64.46 | 80.24 | 70.09 |
| Location | 75.23 | 95.41 | 83.41 | 75.16 | 95.31 | 83.47 |
| Organization | 40.47 | 51.81 | 38.32 | 38.89 | 51.18 | 38.78 |
| Date | 39.45 | 58.26 | 42.77 | 40.67 | 59.12 | 45.05 |
| Designation | 45.54 | 62.19 | 47.42 | 50.3 | 67.01 | 53.24 |
| Number | 36.38 | 58.93 | 39.22 | 35.24 | 59.77 | 39.01 |
| NE Type | Baseline Approach | Proposed Approach | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| Person | 81.94 | 94.82 | 87.16 | 82.84 | 95.14 | 87.94 |
| Location | 84.76 | 86.40 | 85.17 | 84.49 | 86.32 | 84.84 |
| Organization | 73.17 | 70.15 | 70.31 | 75.68 | 70.60 | 71.54 |
| Date | 79.66 | 63.71 | 68.38 | 82.00 | 66.77 | 70.77 |
| Designation | 83.18 | 80.28 | 80.403 | 86.163 | 80.12 | 81.50 |
| Number | 72.99 | 77.46 | 72.66 | 76.16 | 81.10 | 76.33 |
| Time | 55.64 | 46.59 | 46.42 | 55.35 | 50.08 | 48.72 |
| Genre | NE Type | Baseline Approach | Proposed Approach | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | ||
| National | Person | 83.38 | 91.96 | 87.08 | 83.64 | 92.79 | 87.66 |
| Location | 85.86 | 88.36 | 86.86 | 89.44 | 89.87 | 89.4 | |
| Organization | 89.4 | 89 | 88.9 | 91.83 | 89.52 | 90.47 | |
| Date | 92.09 | 74.52 | 80.02 | 93.21 | 78.72 | 82.23 | |
| Designation | 78.98 | 73 | 75.29 | 78.78 | 73.74 | 75.61 | |
| Number | 85.19 | 83.41 | 83.56 | 87.34 | 87.12 | 86.73 | |
| Time | 95.04 | 66.79 | 74.53 | 93.25 | 76.57 | 80.67 | |
| Sports | Person | 94.22 | 98.9 | 96.37 | 94.04 | 98.82 | 96.23 |
| Location | 95.46 | 97.05 | 96.17 | 95.7 | 96.7 | 96.1 | |
| Organization | 44.48 | 36.13 | 38.76 | 58.09 | 48.68 | 51.52 | |
| Date | 68.47 | 60.15 | 60.55 | 76.51 | 64.46 | 66.09 | |
| Designation | 96.94 | 95.74 | 95.64 | 96.67 | 92.34 | 93.29 | |
| Number | 88.76 | 96.2 | 92.21 | 87.53 | 94.57 | 90.77 | |
| Time | 40 | 29.54 | 32.92 | 33.57 | 29.54 | 30.42 | |
| International | Person | 69.09 | 90.28 | 76.67 | 71.38 | 90.81 | 78.65 |
| Location | 82.23 | 86.3 | 83.84 | 80.22 | 86.54 | 82.75 | |
| Organization | 81.63 | 84.61 | 82.12 | 80.08 | 81.55 | 79.99 | |
| Date | 82.26 | 63.88 | 70.4 | 76.95 | 63.66 | 68.31 | |
| Designation | 73.62 | 72.12 | 70.28 | 83.04 | 74.29 | 75.62 | |
| Number | 76.19 | 75.33 | 73.43 | 82.15 | 78.7 | 78.38 | |
| Time | 49.15 | 29.11 | 30.83 | 57.06 | 32.82 | 37.23 | |
| Art | Person | 81.09 | 98.17 | 88.52 | 82.33 | 98.17 | 89.25 |
| Location | 75.51 | 73.89 | 73.81 | 72.61 | 72.19 | 71.11 | |
| Organization | 77.17 | 70.86 | 71.49 | 72.74 | 62.66 | 64.19 | |
| Date | 75.83 | 56.32 | 62.56 | 81.34 | 60.27 | 66.47 | |
| Number | 41.82 | 54.9 | 41.44 | 47.64 | 64.02 | 49.44 | |
| Time | 38.38 | 60.93 | 47.40 | 37.55 | 61.39 | 46.59 | |
| Sentence 1 | Sentence 2 | ||||
|---|---|---|---|---|---|
| Token | Actual Tag | Predicted Tag | Token | Actual Tag | Predicted Tag |
| یہ | NOR | NOR | ڈیرہغازیخان | <LOCATION> | <NUMBER> |
| ہولناک | NOR | NOR | کمسن | NOR | NOR |
| کھیل | NOR | NOR | سواروں | NOR | NOR |
| ہر | NOR | NOR | کی | NOR | NOR |
| سال | NOR | NOR | فراہمی | NOR | NOR |
| وسط | NOR | NOR | کے | NOR | NOR |
| اکتوبر | <DATE> | <LOCATION> | لئے | NOR | NOR |
| اور | NOR | NOR | بڑی | NOR | NOR |
| فروری | <DATE> | <LOCATION> | کی | NOR | NOR |
| میں | NOR | NOR | شکل | NOR | NOR |
| جنوبیپنجاب | <LOCATION> | <LOCATION> | اختیار | NOR | NOR |
| منعقد | NOR | NOR | کر | NOR | NOR |
| ہوتا | NOR | NOR | گیا | NOR | NOR |
| ہے | NOR | NOR | ہے | NOR | NOR |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, W.; Daud, A.; Shahzad, K.; Amjad, T.; Banjar, A.; Fasihuddin, H. Named Entity Recognition Using Conditional Random Fields. Appl. Sci. 2022, 12, 6391. https://doi.org/10.3390/app12136391
Khan W, Daud A, Shahzad K, Amjad T, Banjar A, Fasihuddin H. Named Entity Recognition Using Conditional Random Fields. Applied Sciences. 2022; 12(13):6391. https://doi.org/10.3390/app12136391
Chicago/Turabian StyleKhan, Wahab, Ali Daud, Khurram Shahzad, Tehmina Amjad, Ameen Banjar, and Heba Fasihuddin. 2022. "Named Entity Recognition Using Conditional Random Fields" Applied Sciences 12, no. 13: 6391. https://doi.org/10.3390/app12136391
APA StyleKhan, W., Daud, A., Shahzad, K., Amjad, T., Banjar, A., & Fasihuddin, H. (2022). Named Entity Recognition Using Conditional Random Fields. Applied Sciences, 12(13), 6391. https://doi.org/10.3390/app12136391