
Group Assignments for Project-Based Learning Using Natural Language Processing—A Feasibility Study


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Group Learning in Project-Based Courses
1.2. Contributions of the Study
- What are the differences between the encodings using the two NLP algorithms?
- What are the differences between the NLP algorithms and humans in comparing text proposals?
- Which NLP algorithm is more effective in clustering text proposals?
2. Materials and Methods
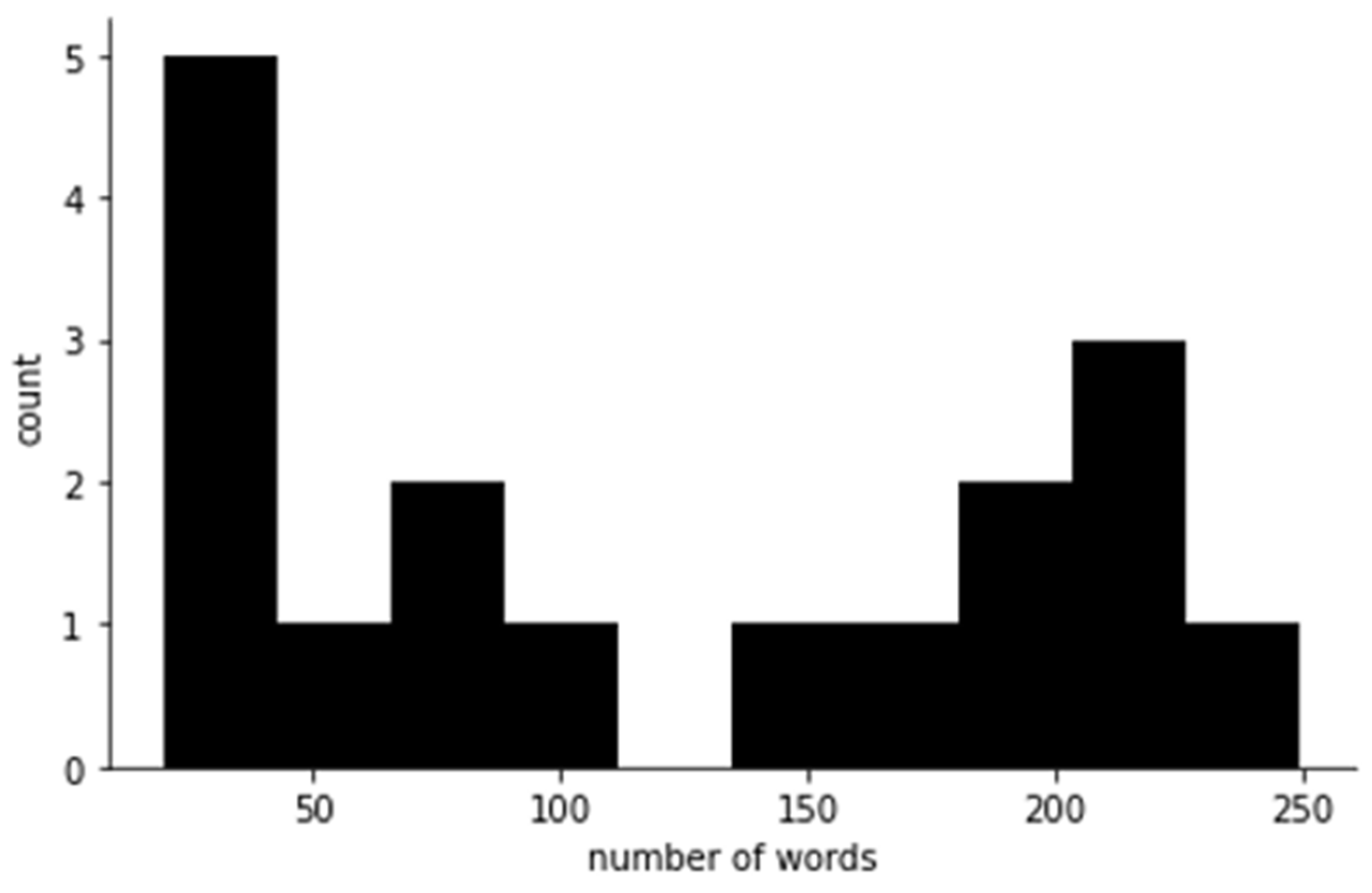
2.1. Data Collection
2.2. NLP-Based Team Assignment
2.3. Human Evaluation
3. Results
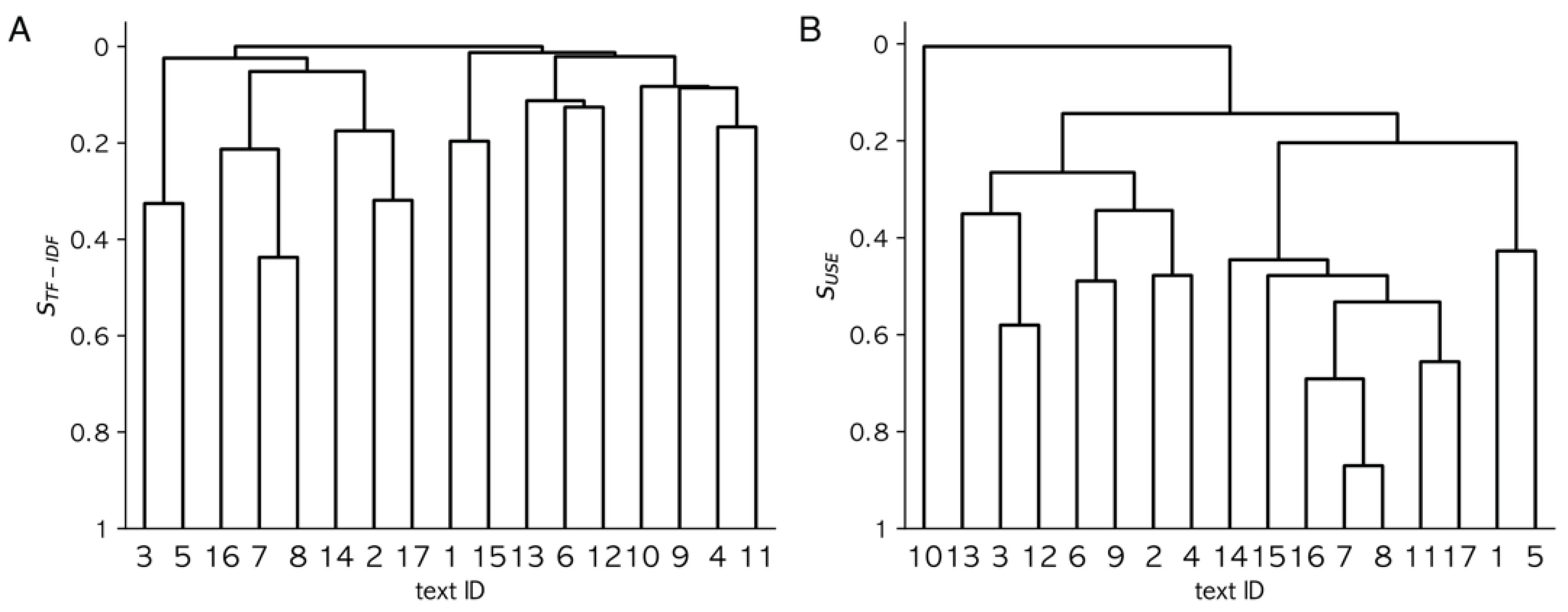
3.1. Similarity Measures Obtained Using TF-IDF vs. USE
3.2. NLP vs. Human Evaluation
3.3. Clustering Results
4. Discussion
5. Limitations of the Study
6. Conclusions and Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Newell, C.; Bain, A. Team-Based Collaboration in Higher Education Learning and Teaching: A Review of the Literature; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Michaelsen, L.K.; Watson, W.E.; Craigin, J.; Fink, D. Team learning: A potential solution to the problem of large classes. Organ. Behav. Teach. J. 1982, 7, 21–33. [Google Scholar] [CrossRef] [Green Version]
- Capelli, P.; Rogovsky, N. New work systems and skill requirements. Int. Labour Rev. 1994, 133, 205–220. [Google Scholar]
- Fiechtner, S.B.; Davis, E.A. Why some groups fail: A survey of students’ experiences with learning groups. J. Manag. Educ. 1984, 9, 58–73. [Google Scholar] [CrossRef] [Green Version]
- Baer, J. Grouping and achievement in cooperative learning. Coll. Teach. 2003, 51, 169–175. [Google Scholar] [CrossRef]
- Monson, R. Groups that work: Student achievement in group research projects and effects on individual learning. Teach. Sociol. 2017, 45, 240–251. [Google Scholar] [CrossRef]
- Schneider, R.M.; Krajcik, J.; Marx, R.W.; Soloway, E. Performance of students in project-based science classrooms on a national measure of science achievement. J. Res. Sci. Teach. Off. J. Natl. Assoc. Res. Sci. Teach. 2002, 39, 410–422. [Google Scholar] [CrossRef]
- Krajcik, J.S.; Czerniak, C.M. Teaching Science in Elementary and Middle School: A Project-Based Learning Approach; Routledge: London, UK, 2018. [Google Scholar]
- Dutson, A.J.; Todd, R.H.; Magleby, S.P.; Sorensen, C.D. A review of literature on teaching engineering design through project-oriented capstone courses. J. Eng. Educ. 1997, 86, 17–28. [Google Scholar] [CrossRef]
- Howe, S.; Rosenbauer, L.; Poulos, S. The 2015 Capstone Design Survey Results: Current Practices and Changes over Time. Int. J. Eng. Educ. 2017, 33, 1393. [Google Scholar]
- Pembridge, J.J.; Paretti, M.C. Characterizing capstone design teaching: A functional taxonomy. J. Eng. Educ. 2019, 108, 197–219. [Google Scholar] [CrossRef] [Green Version]
- Paretti, M.C. Teaching communication in capstone design: The role of the instructor in situated learning. J. Eng. Educ. 2008, 97, 491–503. [Google Scholar] [CrossRef]
- Ford, J.D.; Teare, S.W. The right answer is communication when capstone engineering courses drive the questions. J. STEM Educ. 2006, 7, 5–12. [Google Scholar]
- Marin, J.A.; Armstrong, J.E., Jr.; Kays, J.L. Elements of an optimal capstone design experience. J. Eng. Educ. 1999, 88, 19–22. [Google Scholar] [CrossRef]
- Meyer, D.G. Capstone design outcome assessment: Instruments for quantitative evaluation. In Proceedings of the Frontiers in Education 35th Annual Conference, Indianopolis, IN, USA, 19–22 October 2005; pp. F4D7–F4D11. [Google Scholar]
- Hotaling, N.; Fasse, B.B.; Bost, L.F.; Hermann, C.D.; Forest, C.R. A quantitative analysis of the effects of a multidisciplinary engineering capstone design course. J. Eng. Educ. 2012, 101, 630–656. [Google Scholar] [CrossRef]
- Hayes, J.; Flower, L. Identifying the organization of writing processes. In Cognitive Processes in Writing; Gregg, L., Steinberg, E., Eds.; Erlbaum: Hillsdale, NJ, USA, 1980; pp. 3–30. [Google Scholar]
- Hayes, J. A new framework for understanding cognition and affect in writing. In The Science of Writing: Theories, Methods, Individual Differences, and Applications; Levy, M., Ransdell, S., Eds.; Erlbaum: Mahwah, NJ, USA, 1996; pp. 1–27. [Google Scholar]
- Berninger, V.W.; Winn, W.D. Implications of advancements in brain research and technology for writing development, writing instruction, and educational evolution. In Handbook of Writing Research; MacArthur, C., Graham, S., Fitzgerald, J., Eds.; Guilford Press: New York, NY, USA, 2006; pp. 96–114. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Processing Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar]
- Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Abrego, G.H.; Yuan, S.; Tar, C.; Sung, Y.; et al. Multilingual Universal Sentence Encoder for Semantic Retrieval. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5 July 2000; pp. 87–94. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Open-Source Korean Text Processor. Available online: https://github.com/open-korean-text/open-korean-text (accessed on 12 May 2022).
- Choi, M.; Hur, J.; Jang, M.-G. Constructing Korean lexical concept network for encyclopedia question-answering system. In Proceedings of the 30th Annual Conference of IEEE Industrial Electronics Society, Busan, Korea, 2–6 November 2004; Volume 3, pp. 3115–3119. [Google Scholar]
- Yun, H.; Sim, G.; Seok, J. Stock Prices Prediction using the Title of Newspaper Articles with Korean Natural Language Processing. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication, Okinawa, Japan, 11–12 February 2019; pp. 19–21. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; pp. 66–71. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 1–11. [Google Scholar]
- TensorFlow Hub. Available online: https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3 (accessed on 19 April 2022).
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar]
- Stanovich, K.E.; West, R.F. Mechanisms of sentence context effects in reading: Automatic activation and conscious attention. Mem. Cogn. 1979, 7, 77–85. [Google Scholar] [CrossRef] [Green Version]
- Michael, H.; Frank, K. Modeling Human Reading with Neural Attention. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 85–95. [Google Scholar]
- Zheng, Y.; Mao, J.; Liu, Y.; Ye, Z.; Zhang, M.; Ma, S. Human behavior inspired machine reading comprehension. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 425–434. [Google Scholar]
- Kreutzer, J.; Caswell, I.; Wang, L.; Wahab, A.; van Esch, D.; Ulzii-Orshikh, N.; Tapo, A.; Subramani, N.; Sokolov, A.; Sikasote, C.; et al. Quality at a glance: An audit of web-crawled multilingual datasets. Trans. Assoc. Comput. Linguist. 2022, 10, 50–72. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Marie, B.; Fujita, A.; Rubino, R. Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Volume 1, pp. 7297–7306. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, W.; Yoo, Y. Group Assignments for Project-Based Learning Using Natural Language Processing—A Feasibility Study. Appl. Sci. 2022, 12, 6321. https://doi.org/10.3390/app12136321
Kim W, Yoo Y. Group Assignments for Project-Based Learning Using Natural Language Processing—A Feasibility Study. Applied Sciences. 2022; 12(13):6321. https://doi.org/10.3390/app12136321
Chicago/Turabian StyleKim, Woori, and Yongseok Yoo. 2022. "Group Assignments for Project-Based Learning Using Natural Language Processing—A Feasibility Study" Applied Sciences 12, no. 13: 6321. https://doi.org/10.3390/app12136321
APA StyleKim, W., & Yoo, Y. (2022). Group Assignments for Project-Based Learning Using Natural Language Processing—A Feasibility Study. Applied Sciences, 12(13), 6321. https://doi.org/10.3390/app12136321