1. Introduction
The performance of the speech recognition process has been enhanced using deep neural networks (DNNs). DNNs, as a subfield of machine learning (ML), comprise a hierarchical computation framework, where multiple layers of efficient learning algorithms are grouped to execute specific tasks. DNNs approximate the process using various non-linear activation functions to obtain the conceptual view. They also serve the learning process using generated feature sets from original data (speech signals). Due to the significant progress made in DNNs in the last decade, this approach has been used in diverse applications ranging from online data, filtering, dictation, web searches, speech recognition, speaker identification, image processing, and many machine intelligence-related problems. The most crucial phase of DNN was discovered in the 1980s, namely back propagation algorithm (BPA). This algorithm incorporated the gradient descent method to accelerate the training process at a rapid rate [
1]. Convolutional neural networks (CNNs) are successful variants of DNNs and valuable models for working with speech recognition systems. CNNs are moderately successful models for developing the speech recognition system, but this efficient architecture design is quite complicated. Their design requires prior and expert knowledge for performing the recognition process [
2]. The natural visual perception paradigm of living creatures inspired this learning architecture [
3]. The name was derived from linear mathematical operations between matrixes known as convolutions. Many studies have validated that CNNs provide better results for classification tasks. However, the standard CNN model may be impractical due to its high computational cost and slow learning procedure for large datasets.
This paper presents a CNN-based novel approach for uncommon speech signal recognition. While exploring the literature, it was observed that work related to Punjabi language speech recognition was performed using the Kaldi toolkit. The results were extended to the uncommon speech signals of Gurbani recitation, along with background music, which also reveals this study’s novelty and additional contribution to the field of speech recognition [
4,
5,
6,
7]. The main objective of the work was achieved by adopting and implementing the CNN framework. Mainly, two properties of the CNN, including the local frequency region, support achieving optimal performance, making the CNN more robust. In addition, the sparse local connections of the convolutional layer that need very few parameters to extract lower-level features of the input speech signal avoid overfitting [
8,
9,
10]. Input speech signals were examined with spectro-temporal filters, and the CNN learned about the lower-level features. No inbuilt data were used for this work; a database with different input speech signals was designed to achieve the main aim of the work. A CNN can work better than a DNN as far as noisy channels are concerned, and higher tolerance is expected with a CNN. In addition, a CNN is better for distorted speech signals as there is a difference between the speaker’s lips and the microphone as well as additive noise in speech signals [
8].
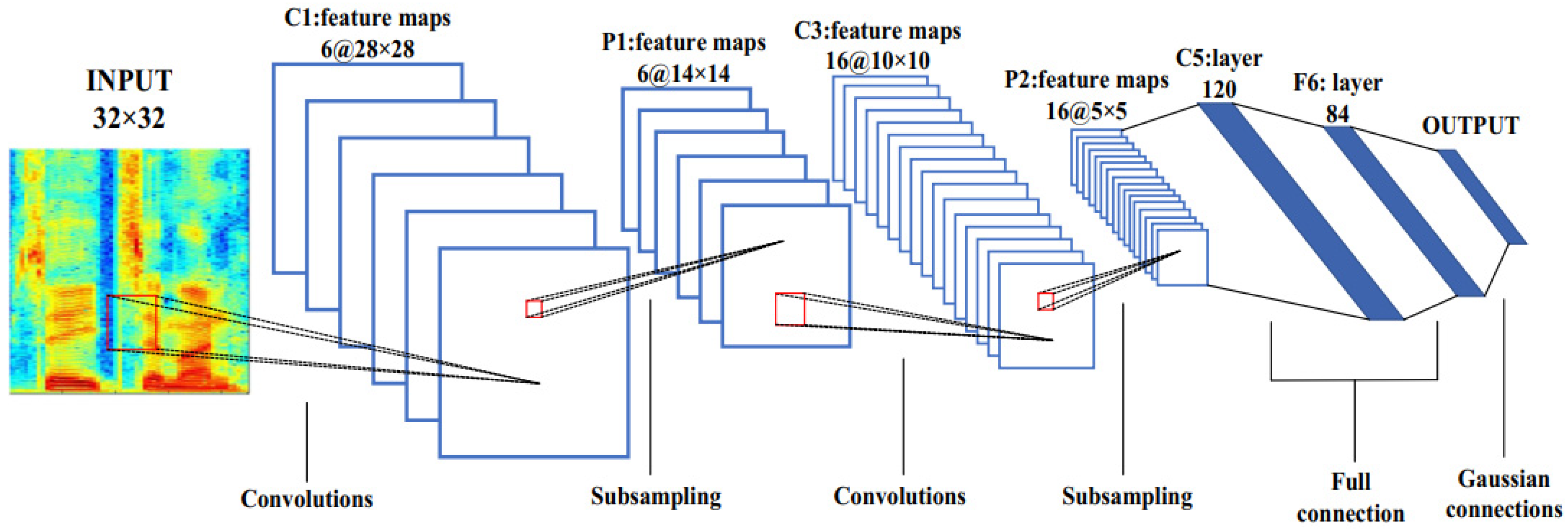
Figure 1 demonstrates the novel architecture of a CNN with its three layers—convolutional layer, pooling layer, and fully connected layer. Various convolution kernels obtain the feature map from the previous layers for each convolutional layer. To obtain the feature map, the input signal is combined with its trained kernel [
11,
12,
13].
For many years, various technologies and modeling approaches have been employed for training and recognizing common and uncommon speech signals, yet systems do not work well for tonal speech sentences. Finally, recent advancements in machine learning (ML) have motivated us to train the present speech recognition system with extensive data and tonal speech sentences.
Over the last few years, advancements in machine learning techniques have led to efficient training methods containing multiple layers of hidden units and output units. The objectives of this research paper are as follows:
- (a)
To study the various ML techniques and working processes utilized in the literature;
- (b)
To design the database for the proposed speech recognition system;
- (c)
To reveal the performance of ML and a CNN in a designed speech recognition database;
- (d)
To develop a speech-to-text recognition system for tonal speech signals and to compare the performance of the proposed work with existing systems.
Statement of Novelty
The current research was carried out to work with uncommon speech signals of the Punjabi language, i.e., speech signals in the form of tonal and emotional cues. In this work, we designed a new dataset consisting of some additional background noises (instrumental music and other noises) considered while recording 11 different input signals from 11 speakers of different ages, accents, and environments. Each recording/input speech signal was continuously spoken by the speakers and consisted of 38 additional stanzas.
In contrast to the existing systems for common speech signals and other languages. The existing systems attains a low WER and high accuracy. Therefore, we implemented the ML-CNN method with a new dataset of input speech signals and parameters. In addition, we observed the outcome of the work and found that although CNNs are being selected by many authors for our new dataset, CNNs outperform the existing datasets and techniques. The work concludes that CNNs can work well with prominent, minor, and tone-oriented datasets.
The paper is categorized into the following sections.
Section 2 describes essential studies related to speech recognition.
Section 3 describes the prevailing algorithms of DNN and also discusses the significance of speech type considered in the present work.
Section 4 describes the framework for the current system and the experimental study and result analysis.
Section 5 describes the results analysis of proposed system with existing works.
Section 6 concludes the entire paper with its outcome and findings.
2. Related Work
CNNs have been considered relatively successful models for designing large vocabulary and continuous speech recognition models, with excellent training speed [
2]. Since they have been proved to be an optimal approach for speech recognition, pattern recognition, and many other machine intelligence-related processes, many researchers have approached this newest network.
The utility and performance of this model can be measured from the research work carried out by various researchers. Multilayer perceptron (MLP), convolutional neural networks (CNNs), and recurrent neural networks (RNNs) are the essential algorithms of DNNs. Both CNNs and RNNs are considered suitable for implementing speech and natural language processing. Apart from these, speaker recognition, emotion recognition, speech enhancement, and voice activity detection are essential areas covered by CNNs and RNNs. DNNs use computational models, which are comprised of multiple processing layers. This feature tends to generate the ability to learn data representations with multi-level abstraction compared to single-processing layered models [
14]. DNNs have advanced computational power for training in computational models. They also tend to deal with highly complex learning tasks by integrating reinforcement learning [
15,
16].
Some authors developed a speech recognition system using the CNN approach by involving a limited-weight-sharing scheme under CNN architecture. The experimental results showed that the CNN reduced the word error rate by 6–10% compared to the method developed by the conventional technique [
11,
17]. In another work, the speech command recognition system used the CNN modeling approach to detect predefined keywords [
12]. This system used speech commands from Google’s TensorFlow and AIY teams containing 65,000 wave files. The authors used the Vanilla Single-Layer Softmax model, a deep neural network, and a convolutional neural network model. The system with the CNN yielded a 95.1% accuracy level.
Other authors worked with a CNN using end-to-end acoustic modeling [
13]. In their work, different databases were used to carry out the recognition process—TIMIT, WSJ, MP-DE, and MP-F. Their approach resulted in a 1.9%-word error rate, which was relatively lower than the other existing techniques. The overall analysis and contribution of existing works is illustrated in
Table 1.
From the above literature review, it can be concluded that most of the Punjabi language research work has been carried out using ordinary speech signals and HMM, GMM, and ANN modeling techniques. So, there are two aspects to the novelty of the current work: Different input speech signals were considered—the present speech recognition system can also recognize uncommon speech signals. Secondly, the literature survey reveals that CNNs are the most powerful tool and modeling paradigm when applied to speech recognition systems with large datasets [
26]. So, the inclusion of a CNN and MFCC was considered for the present system.
3. Conceptual View of the Present Speech Recognition System
In the current system framework, CNNs, MFCCs, and LibROSA were incorporated to reveal the best system performance for recognizing uncommon input speech signals. In contrast, the existing speech recognition system for the Punjabi language can only recognize commonly spoken sentences without additional background noises [
23,
24,
27]. LibROSA worked well for analyzing other noise (background music along with input speech signals) [
28]. The present speech recognition system is a significant contribution to speech recognition with an efficient framework and hyperparameters.
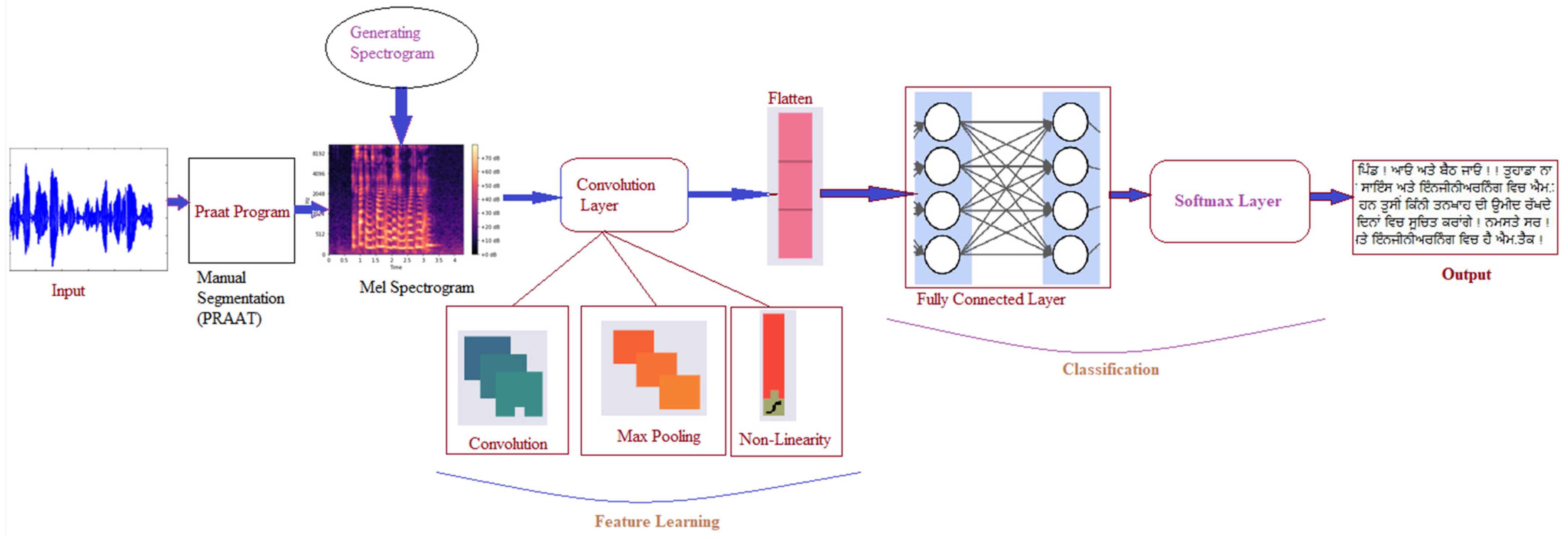
In
Figure 2, the framework that was adopted to model the present speech recognition system is depicted. Tonal speech signals are input and manually segmented with Praat software version 6.1.49. The Mel spectrogram is generated to analyze the audio input with low and high pitch. Later, a CNN with six layers of 2D convolution was applied, along with MaxPooling and 256 dense layer units [
25].
3.1. Algorithm for CNN Implementation
This work used a CNN model with six-layer convolution to implement the speech recognition system. Initially, we provided the speech as input to the design, and then, using the PRAAT technique, a Mel spectrogram was generated. We used six-layer 2D convolutional and two fully connected layers to extract and learn from the features. In addition, flattened layers were added between the 2D convolutional layers and the dense layers for better efficacy. Then, the Softmax activation function was used to activate the neurons and classify the adequate text from the speech input. Finally, the output was obtained in the output layer. The overall CNN implementation for the speech recognition system is illustrated in Algorithm 1.
| Algorithm 1. CNN implementation for the speech recognition system. |
| Parameters: Alpha–0.333, bias = 0.1 & axis = −1 |
| Input: sample audio .wav is provided |
| Step 1: Spectrogram and waveform is generated using PRAAT program |
| Step 2: Using LIBROSA python library, MFCC is extracted |
| Step 3: Feature learning using CNN, 6-2D Conv. And 2 FC layers |
| Step 4: Flatten layer is included between Conv2D and Dense Layer (256 Units) |
| Step 5: Activation by Softmax Activation Function |
| Step 6: Loss calculation by ‘Categorical Cross Entropy’ |
| Step 7: Comparing input (li1) with Ground Truth (gt)-li2 by diff (li1, li2) |
| Output: Recognized words and Accuracy Measurement |
3.2. Database Design
The performance of the speech recognition system depends on the quality of the labeled data for the training process. Still, there are various languages that are lacking sufficient resources. A lack of the required speech corpus is one of the main obstacles of the speech recognition process. The recognition task becomes relatively smooth when the required database is present for the operation of pre-processing and training. Small-scale vocabulary databases are readily available these days to carry out the needed research. However, we developed a new corpus of Gurbani hymns for the proposed system, as a necessary dataset of tonal speech sentences was not currently available.
The developed Gurbani hymn dataset is a collection of long recordings of 11 speakers reciting (the Gurbani hymns) in a continuous mode of speech. The speech comprises different tones and added background music.
Table 2 depicts all of the dataset-related parameters. The sounds are balanced according to the age distribution (18–30), (30–50), (50–65), and gender. Each recording comprises 38 different stanzas, and a total of 418 (38 × 11) sentences were considered. The recordings were obtained at a 44.1 kHz sampling rate. The audio files were recorded in .wav format. The speech files were transcribed and labeled using Praat software. Manual segmentation was carried out to generate small segments of long speech sounds.
3.3. Speech Segmentation
Praat segmented long speech sentences into smaller segments to make the CNN process easier. The Praat program is considered a versatile speech analysis program and has been proved to be a standard tool in the field of speech and language processing. Audio quality is a significant factor in speech segmentation. Speech segmentation analyzes different frequencies and amplitude characteristics of recorded speech to locate speech particles. Praat also offers various audio tools to improve audio quality, such as a noise gate, de-noising, and a normalizer tool [
29].
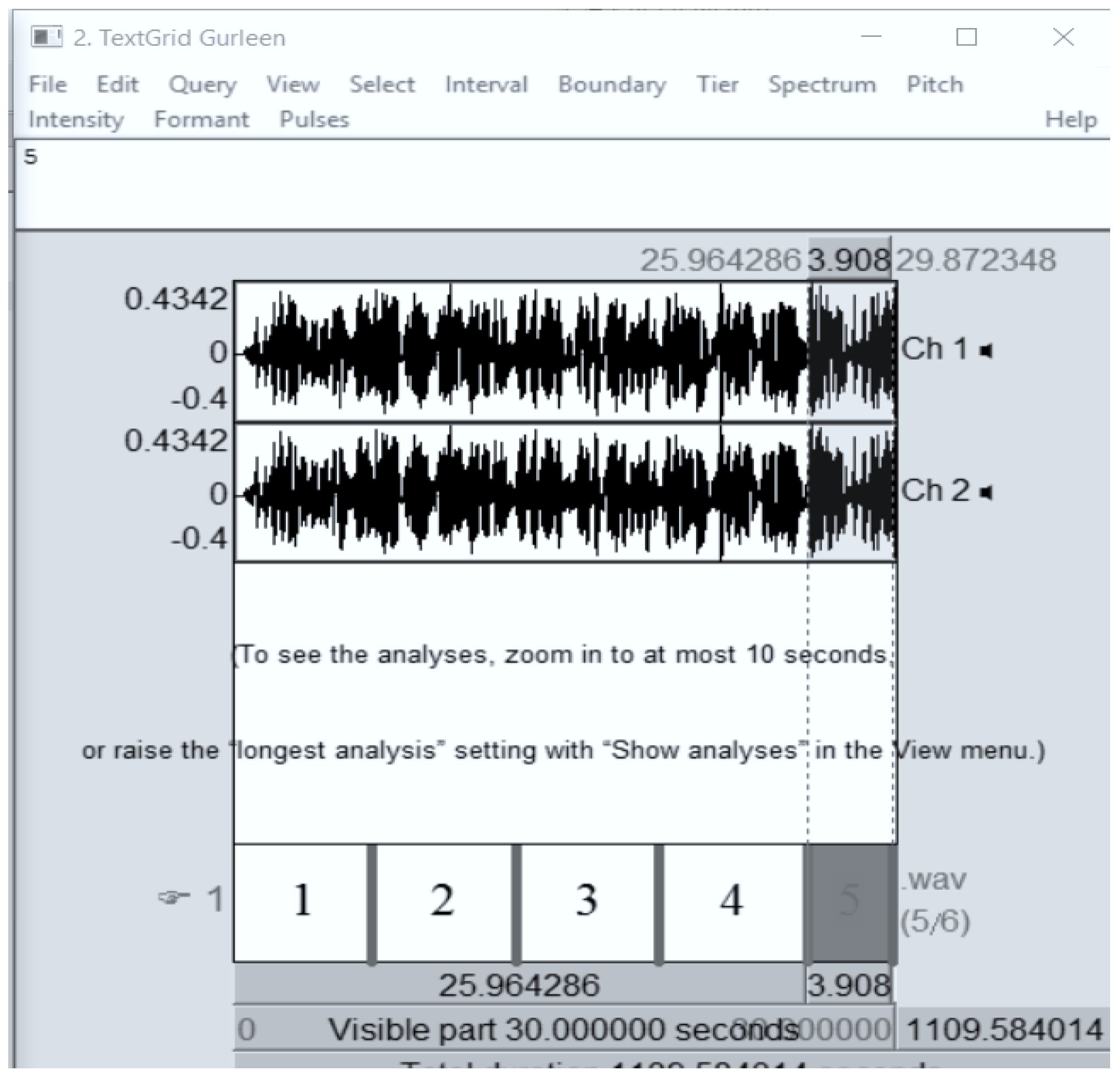
The Praat software tool was used to create manual segments of long-input speech audio.
Figure 3 shows how the segments were designed for the given audio file. Though automatic segmentation is an easy task, manual segmentation was adopted due to the detailed visualization and identification of the start and end of sentences in the input speech. Careful practice is needed when creating small segments.
Table 2 and
Table 3 demonstrate the system parameters for segmentation, including the programming language, the backend tool, GUI, the segmentation tool, and the development environment.
Figure 4 shows the segmentation procedure in the current ASR system. Here, five segments were created using Praat.
Figure 5 shows all the elements created for the input speech files, and text grids are shown on the left panel of the Praat window. These segments of lengthy audio files are valid for feature extraction and CNNs, as long sentences are too cumbersome. The proposed model was devised on a DELL machine with a VG card. The programming was implemented on Python, Tensor Flow was used as the backend, supported by Keras, and the Kaldi toolkit was used along with Python.
3.4. Feature Extraction Process
In this research work, the first convolutional layer had 64 feature maps, and each forward layer had a value twice the size of the last one. While generating the features, Fourier transformation-based log-Mel filter bank features were used to produce the feature vectors. For the feature extraction process, a Hamming window with a size of 25 ms was used. The CNN works by taking the feature vectors generated by the MFCC and LibROSA (Python Library). LibROSA extracts and generates audio features, audio spectrograms, MFCCs, and chromagrams at a sampling rate of 22,050 Hz.
Table 4 shows how the audio is loaded and how the MFCC is calculated with a 44.1 kHz sampling rate (sr).
3.5. Training of CNN
The training in this research work was conducted using Google’s Cloud Services and Keras Sequential API. For training, TensorFlow was imported as
. A database of required continuous speech of input speech signals was designed by taking recordings of 11 speakers. Recordings of Sikh prayers and Gurbani hymns were used as tonal input speech signals. In totality, 418 sentences were recorded by 11 speakers, of which 8 were female and 3 were male speakers. The average number of words was 24,255 [
28]. The speech sound sampling rate was 44.1 kHz, and the average recording time was 5.5 h. The convolutional base was created by adding six 2D convolutional layers and MaxPooling2D (2, 2). A dense layer with 256 units was added. The construction and training of the model was performed by adding the SGD optimizer.
3.6. Experimental Setup of the CNN
A CNN, along with the back propagation algorithm, was used in this work. A 2D CNN was involved in this research. In 2D CNNs, the kernel is generated, a small matrix for all weights. The kernel slides the 2D input data, performs element-wise multiplication with the current part of the input, and then performs the sum of the results. This process is repeated for every location it slides, converting the 2D matrix of the generated features into another 2D feature matrix. Here, the output features are the weighted sums of all the input features in the exact output pixel location. Of the two Keras models, the sequential model is approached, which allows for building the sequential layers from input to output in a straightforward manner. Then, the 2D convolutional layer is added using 64 convolution filters of 3 × 3 of each. The MaxPooling layer with a pool size of 3, 3 is added with a stride size of 2, 2, and the LeakyReLU is set to 0.1.
4. Result Analysis
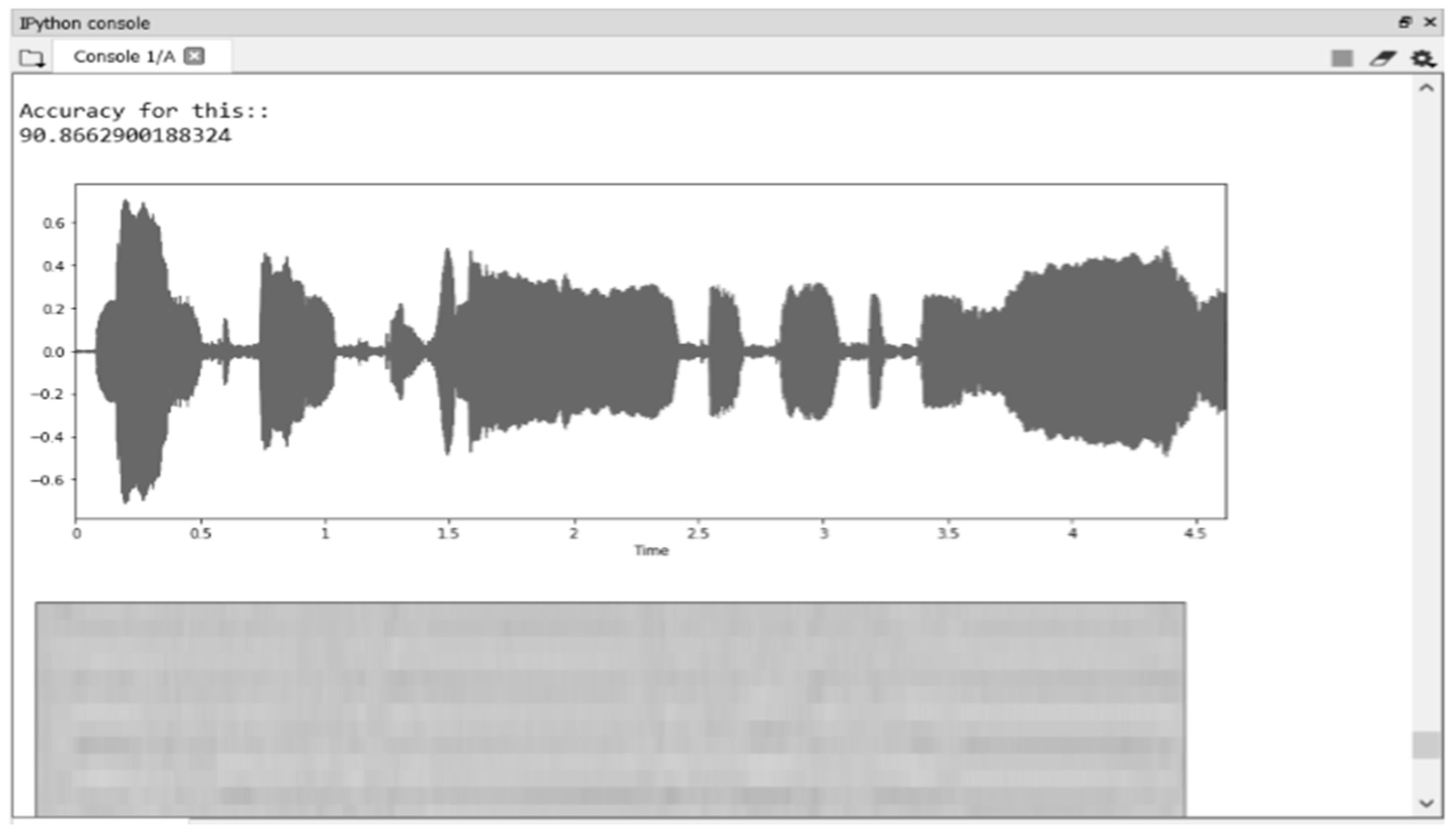
Here, a speaker-independent speech recognition system was designed and developed by 11 different speakers reciting (speaking) the same speech (Gurbani hymns, 38 stanzas). Eight female and three male speakers were involved in the experimental process. Since the methods of utterance, speech style, tonal speech, and timing vary from speaker to speaker, the system was expected to yield an optimal accuracy rate. In
Figure 6, the accuracy generated by the proposed model using CNN modeling was generated for Speaker 1 (sp1—90.866%), as shown in
Table 5.
Table 5 demonstrates the recognition rates of different speakers in the current ASR system.
Table 6 deliberates the recognition rates of different speakers in current ASR system. As for the recognition of tonal and emotional speech, our model yielded significant results. The accuracy (recognition rate) was calculated using Equation (1) [
5,
6], as follows:
4.1. Performance Evaluation
In the present ASR, the system’s performance was evaluated using WER. The WER of each speaker was calculated with a formula, as written in Equation (2).
where
S represents the number of substitutions;
D is the number of deletions;
I means the number of insertions. The overall WER was observed as 19.45%.
4.2. Comparative Analysis of Existing Systems with Present System Based on Accuracy Level and Word Error Rate (WER)
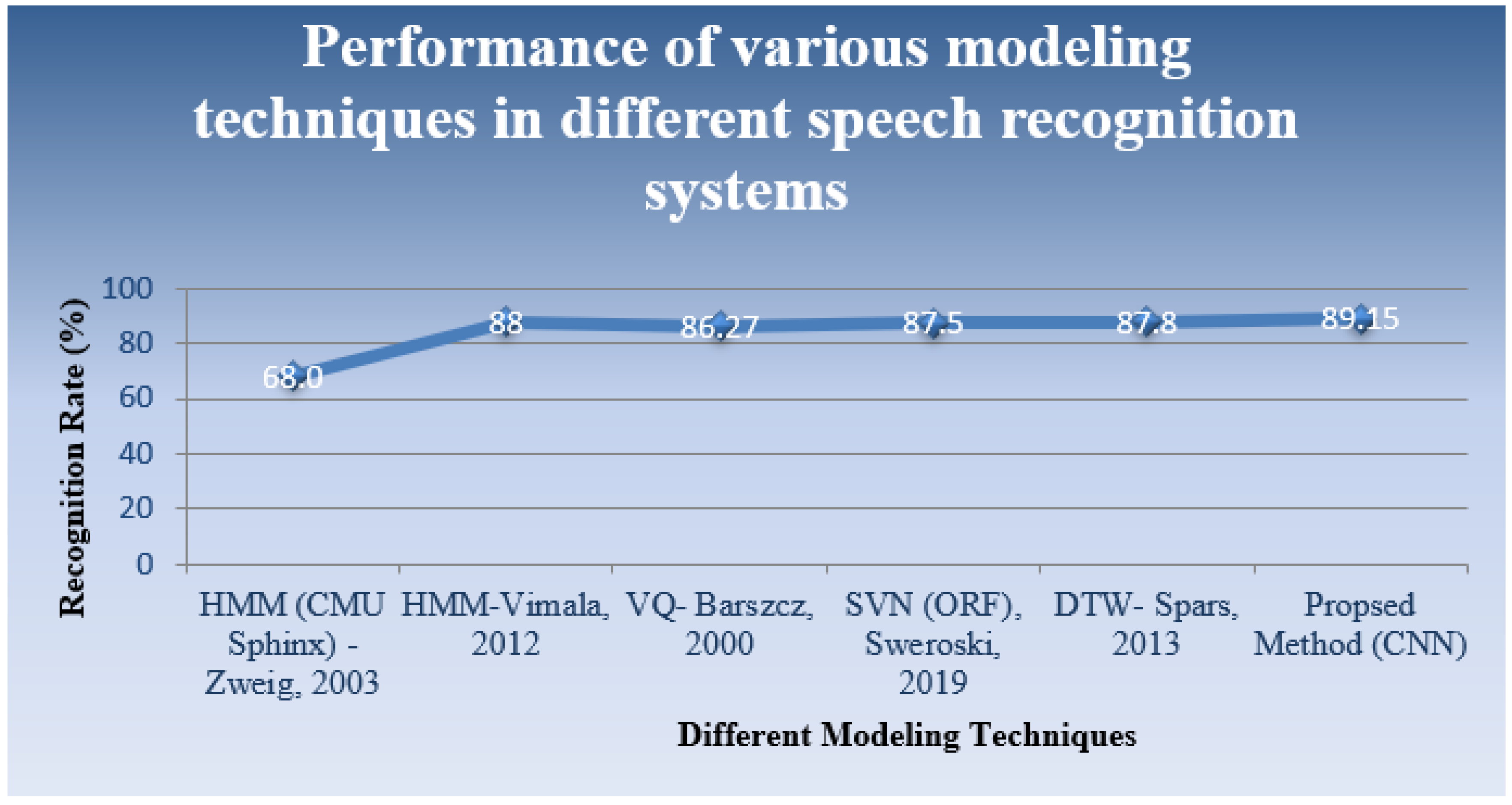
As per the results generated, the overall accuracy of the proposed system remained at 89.15% using 2D convolutional and 64-3 × 3 filters. When comparing the performance of the proposed system with similar parameters, the system yielded optimal results.
Table 7 compares different techniques with the proposed design using a CNN.
Figure 7 depicts the proposed approach’s graphical analysis of various existing methods.
5. Discussion
Motivated by recent advancements in DNNs and CNNs, the present work was initiated using a CNN modeling paradigm for tonal-based speech sentences. The results section demonstrates that better and optimal results can be achieved by embedding a convolutional neural network to train and handle large speech data. The results also reveal that using a CNN over the tonal speech signals acquired significant recognition. A study on recognizing Hindi sentences using the Kaldi toolkit revealed a WER of 11.63% [
32]. In contrast, the current speech recognition system designed for tonal and uncommon speech signals showed a WER of 10.56%, which is an improved word error rate compared to those of approaches developed with other techniques. This is because all training was performed using a CNN, and various new features of CNN methodology were applied throughout the training and modeling phases.
The current technique was implemented with different layers of CNN. In addition, to that we used cloud service during training phase. The literature review revealed using the MFCC is the best feature extraction technique. So, feature extraction was carried out using MFCCs and LibROSA (library of Python). Initially, the method was applied to input speech files from 11 speakers. The second layer of the CNN used 64-3 × 3 filters to generate the feature set forwarded to the CNN for learning. Segmentation was a necessary step to carry out as the long input was not smooth enough to be used by the CNN. Due to the long speech signals and long sentences, manual segmentation was performed. Praat software was used to create small segments of speech and label them. As per the results generated, the overall accuracy of the present system was 89.15% using the second layer of the CNN and 64-3 × 3 filters, while the WER was found to be 10.56%. When comparing the performance of the proposed system with similar parameters, this technique yielded an improved recognition accuracy rate.
However, the most challenging part of this research work was dealing with tonal input speech signals alongside background music and other noises. In addition, some of the approaches are introduced for coping with Punjabi tone-oriented speech. Here, an ML-CNN had to deal with such noisy signals from 11 speakers. Still, with the chosen hyperparameters, the developed system yielded a lower WER and high accuracy in contrast to the existing approaches.
6. Conclusions
Moving beyond some of the conventional speech recognition techniques, in the present speech recognition system, an excellent modeling paradigm, i.e., a CNN, was applied. One of the challenges was to deal with noisy and tonal speech signals. With this modeling and the MFCC as the feature extraction, it was possible to deal with these challenges. The results suggest that the present method may be applied to other hymns and tonal speech signals, merging CNN with other prevailing models. In place of the MFCC, hybrid techniques can be approached in the hope of obtaining better results. As per the results generated, the overall accuracy of the present system was 89.15% using the second layer of the CNN and 64-3 × 3 filters, while the WER was found to be 10.56%.
The current speech-to-text recognition system was designed keeping in mind s places where Gurbani hymns are recited, such as inside the main hall, as well as disabilities that prevent people from sitting inside the main entrance. Sitting outside, they can listen to the hymns and announcements. The system can also recognize tonal speech signals, so converted text signals could be generated on a screen. The present system was implemented considering 11 speakers.
In the future, we will work with higher numbers of speakers with the scaled dataset. Moreover, in the future, the work can be extended to enhance the system’s performance by designing a hybrid model using multiple approaches of ML.
Author Contributions
Conceptualization, S.D.; methodology, S.D. and S.S.K.; validation, R.R. and M.R.; formal analysis, Y.A. and A.D.; writing—original draft preparation, S.D.; writing—review and editing, M.R., A.G. and A.S.A.; supervision, S.S.K., R.S. and S.S.A.; funding acquisition, Y.A. All authors have read and agreed to the published version of the manuscript.
Funding
Taif University Researchers Supporting Project number (TURSP-2020/161), Taif University, Taif, Saudi Arabia.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The data used in this article will be made available upon request to the corresponding author.
Acknowledgments
The authors would like to thank the Taif University Researchers Supporting Project number (TURSP-2020/161), Taif University, Taif, Saudi Arabia for supporting this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ogunfunmi, T.; Ramachandran, R.P.; Togneri, R.; Zhao, Y.; Xia, X. A Primer on Deep Learning Architectures and applications in Speech Processing. Circuits Syst. Signal Process. 2019, 38, 3406–3432. [Google Scholar] [CrossRef]
- Passricha, V.; Aggarwal, R.K. PSO-based optimized CNN for Hindi ASR. Int. J. Speech Technol. 2019, 22, 1123–1133. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2019, 22, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Dua, M.; Aggarwal, R.K.; Biswas, M. Optimizing Integrated Features for Hindi Automatic Speech Recognition System. J. Intell. Syst. 2019, 29, 959–976. [Google Scholar] [CrossRef]
- Aggarwal, R.K. Improving Hindi Speech Recognition Using Filter Bank Optimization and Acoustic Model Refinement. Ph.D. Thesis, National Institute of Technology, Kurukshetra, India, 2012. [Google Scholar]
- Aggarwal, R.K.; Dave, M. Using Gaussian Mixtures for Hindi Speech Recognition system. Int. J. Signal Process. Image Process. Pattern Recognit. 2011, 4, 157–169. [Google Scholar]
- Bhandare, A.; Bhide, M.; Gokhale, P.; Chandavarkar, R. Applications of Convolutional Neural Networks. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 2206–2215. [Google Scholar]
- Chen, X.; Cai, C. A chain VQ clustering algorithm for real-time speech recognition. Pattern Recognit. Lett. 1993, 14, 229–235. [Google Scholar] [CrossRef]
- Deng, L.; Li, X. Machine Learning Paradigms for Speech Recognition: An Overview. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1060–1089. [Google Scholar] [CrossRef]
- Dua, M.; Aggarwal, R.K.; Kadyan, V.; Dua, S. Punjabi Automatic Speech Recognition Using HTK. IJCSI Int. J. Comput. Sci. Issues 2012, 9, 264–279. [Google Scholar]
- Hamid, O.A.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yen, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhou, Z. Speech command recognition with convolutional neural network. In CS229 Stanford Education; 2017. Available online: http://cs229.stanford.edu/proj2017/final-reports/5244201.pdf (accessed on 23 May 2022).
- Palaz, D.; Doss, M.M.; Collobert, R. End-to-end acoustic modeling using convolutional neural networks for HMM-based automatic speech recognition. Speech Commun. 2019, 108, 15–32. [Google Scholar] [CrossRef] [Green Version]
- Dhingra, S.D.; Nijhawan, G.; Pandit, P. Isolated speech recognition using MFCC and DTW. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2013, 2, 4085–4092. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Barszcz, M.; Chen, W.; Boulianne, G.; Kenny, P. Tree-structured vector quantization for speech recognition. Comput. Speech Lang. 2000, 14, 227–239. [Google Scholar] [CrossRef]
- Wei, K.; Zhang, Y.; Sun, S.; Xie, L.; Ma, L. Conversational Speech Recognition by Learning Conversation-Leve; Characteristics, ICASSP; IEEE: Singapore, 2022; ISBN 978-1-6654-0540-9. [Google Scholar]
- Baevski, A.; Hsu, W.N.; Conneau, A.; Auli, M. Unsupervised Speech Recognition. In Proceedings of the 35th Conference on Neural InformaTION Processing Systems (NeurIPS2021), Online, 6–14 December 2021. [Google Scholar]
- Huang, J.T.; Li, J.; Gong, Y. An analysis of Convolutional Neural Network for Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4989–4993. [Google Scholar]
- Nagajyothi, D.; Siddaiah, P. Speech Recognition Using Convolutional Neural Networks. Int. J. Eng. Technol. 2018, 7, 133–137. [Google Scholar] [CrossRef] [Green Version]
- Poliyev, A.V.; Korsun, O.N. Speech Recognition Using Convolutional Neural Networks on Small Training Sets. Workshop on Materials and Engineering in Aeronautics. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Moscow, Russia, 2019; p. 714. [Google Scholar]
- Kumar, Y.; Singh, W. Automatic Spontaneous Speech Recognition for Punjabi Language Interview Speech Corpus. IJ Educ. Manag. Eng. 2016, 6, 64–73. [Google Scholar] [CrossRef] [Green Version]
- Hasija, T.; Kadyan, V.; Guleria, K. Out Domain Data Augmentation on Punjabi Children Speech Recognition using Tacotron. J. Phys. Conf. Ser. 2021, 1950, 012044. [Google Scholar] [CrossRef]
- Guglani, J.; Mishra, A.N. Continuous Punjabi speech recognition model based on Kaldi ASR toolkit. Int. J. Speech Technol. 2018, 21, 211–216. [Google Scholar] [CrossRef]
- Sweitojamski, P.; Ghoshal, A.; Renals, S. Convolutional Neural Networks for Distant Speech Recognition. IEEE Signal Process. Lett. 2014, 21, 1120–1124. [Google Scholar] [CrossRef] [Green Version]
- Qian, Y.; Bi, M.; Tan, T.; Yu, K. Very Deep Convolutional Neural Networks for Noise Robust Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2263–2276. [Google Scholar] [CrossRef]
- Ghai, W.; Singh, N. Continuous Speech Recognition for Punjabi Language. Int. J. Comput. Appl. 2013, 72, 23–28. [Google Scholar] [CrossRef]
- Zweig, G. Bayesian network structures and inference techniques for automatic speech recognition. Comput. Speech Lang. 2003, 17, 173–193. [Google Scholar] [CrossRef]
- Pleva, M.; Jahr, J.; Thiessen, A. Automatic Acoustic Speech Segmentation in Praat using Cloud Based ASR. In Proceedings of the 25th International Conference Radioelektronika, Pardubice, Czech Republic, 21–22 April 2015; pp. 172–175. [Google Scholar]
- Radha, V. Speaker independent isolated speech recognition system for Tamil language using HMM. Procedia Eng. 2012, 30, 1097–1102. [Google Scholar]
- Darabkh, K.A.; Khalifeh, A.F.; Bathech, B.A.; Sabah, S.W. Efficient DTW-Based Speech Recognition System for Isolated Words of Arabic Language. World Acad. Sci. Eng. Technol. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2013, 7, 586–593. [Google Scholar]
- Upadhyaya, P.; Mittal, S.K.; Farooq, O.; Varshney, Y.V.; Abidi, M.R. Continuous hindi speech recognition using kaldi asr based on deep neural network. In Machine Intelligence and Signal Analysis; Springer: Singapore, 2019; pp. 303–311. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}