
Arabic Automatic Speech Recognition: A Systematic Literature Review


Abstract
:1. Introduction
- Classical Arabic represents the most formal and standard form of Arabic as it is mainly used in the Holy Quran and the religious instructions of Islam [1];
- Modern Standard Arabic (MSA) represents the current formal linguistic standard of the Arabic language. It is generally used in written communication and media, and is taught in educational institutions [1];
- Dialectal Arabic (DA), also called colloquial Arabic, is a variation of the same language specific to countries or social groups used in everyday life. Various dialects of Arabic exist, and, sometimes, more than one DA can be used within a country [1].
- North Africa, which includes the Tunisian, Algerian, Moroccan, Mauritanian, and Libyan dialects;
- Gulf dialect, which includes Qatari, Kuwaiti, Saudi, Omani, Bahraini, and Emirati dialects;
- Nile Basin, including the Egyptian and Sudanese dialects;
- Yemeni dialect;
- Iraqi dialect;
- Levantine dialect is often used in Syria, Lebanon, Palestine, and western Jordan [9].
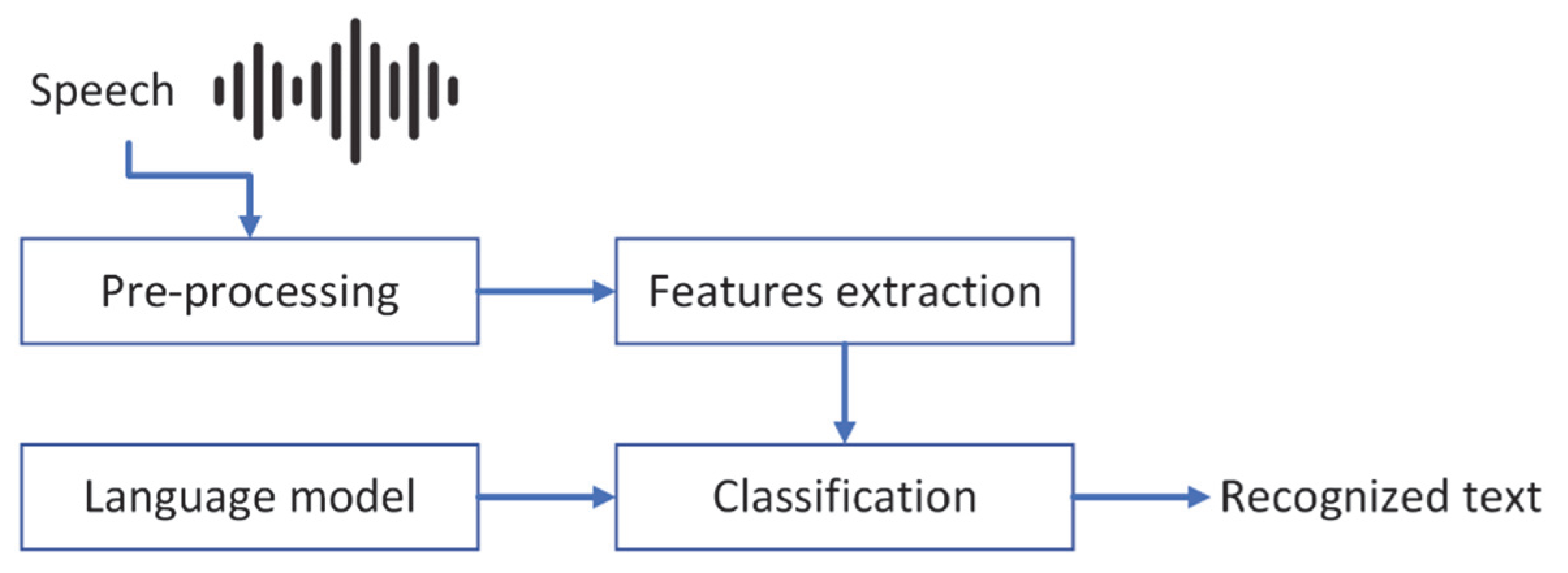
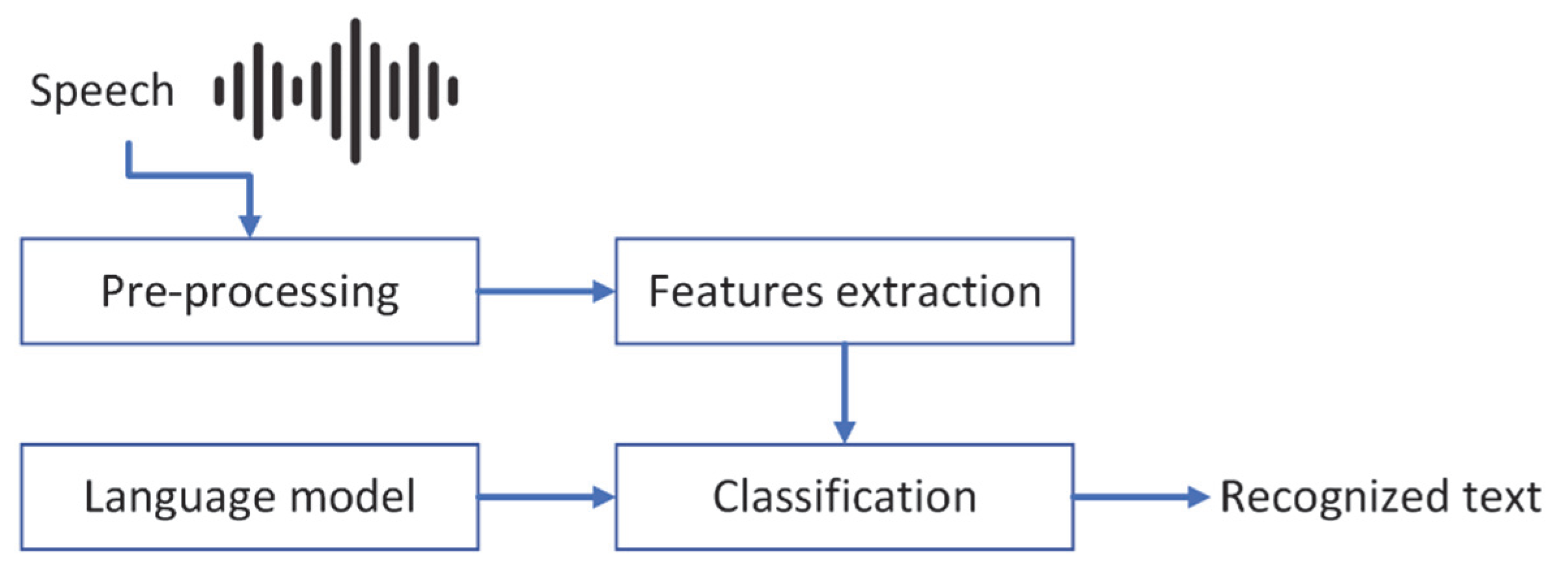
2. Background
- Isolated word recognition in which speakers pause momentarily between every spoken word;
- Continuous speech recognition allows speakers to speak almost naturally, with little or no breaks between words. The systems related to the second type are more complex than isolated word recognition and need large volumes of data to achieve excellent recognition rates;
- Connected words allow a minimal pause between the isolated utterances to be used together;
- Spontaneous speech remains normal-sounding and not conversational speech.
3. Method
3.1. Research Questions (RQ)
- RQ 1. What is the bibliographic information of the existing studies?
- SRQ 1.1. What are the most active countries?
- SRQ 1.2. How has the number of studies evolved across the years?
- SRQ 1.3. What are the types of venues (i.e., journals, conferences, or workshops) used by the authors of studies?
- RQ 2. What is the considered variant of Arabic in speech recognition studies?
- RQ 3. What are the toolkits most often used in the Arabic speech recognition field?
- RQ 4. Which datasets were most often used, and types of Arabic speech recognition were identified in these datasets?
- RQ 5. What are the used feature extraction and classification techniques for Arabic speech recognition studies?
- RQ 6. What are the current gaps and future research in the Arabic ASR field?
- RQ 7. What is the performance of Arabic recognition systems in terms of accuracy rate or WER?
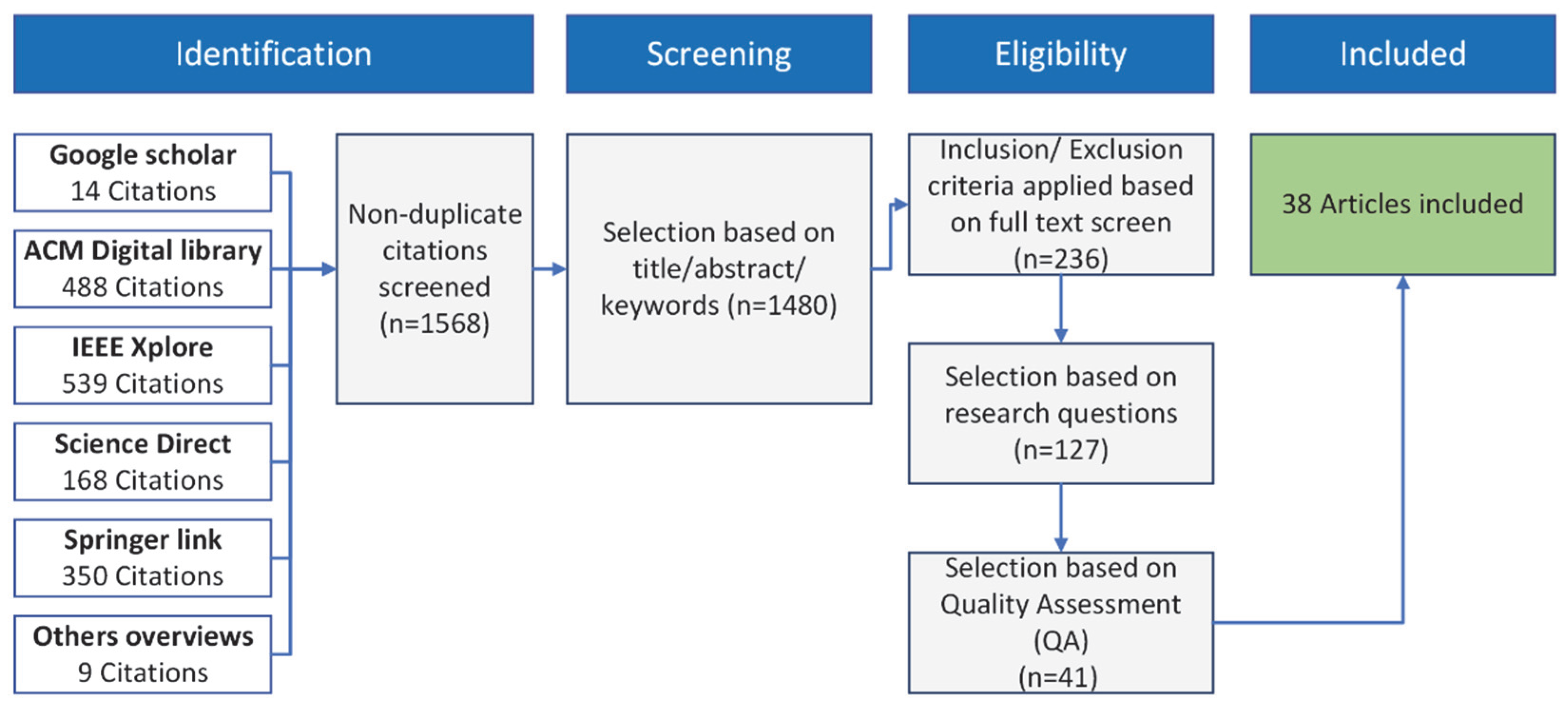
3.2. Search Strategy
3.2.1. Search Strings
- C1: “Arabic” OR “Arabic Language” OR “Multilingual”;
- C2: “Automat*” OR Computer”;
- C3: “Speech recogni*” OR “Speech trans*” OR “Speech to text” OR “Voice to text” OR “Voice recogni*” OR “SRT” OR “ASR” OR “STT”;
- C4: “System” OR “Tool” OR “Technology”
3.2.2. Electronic Databases
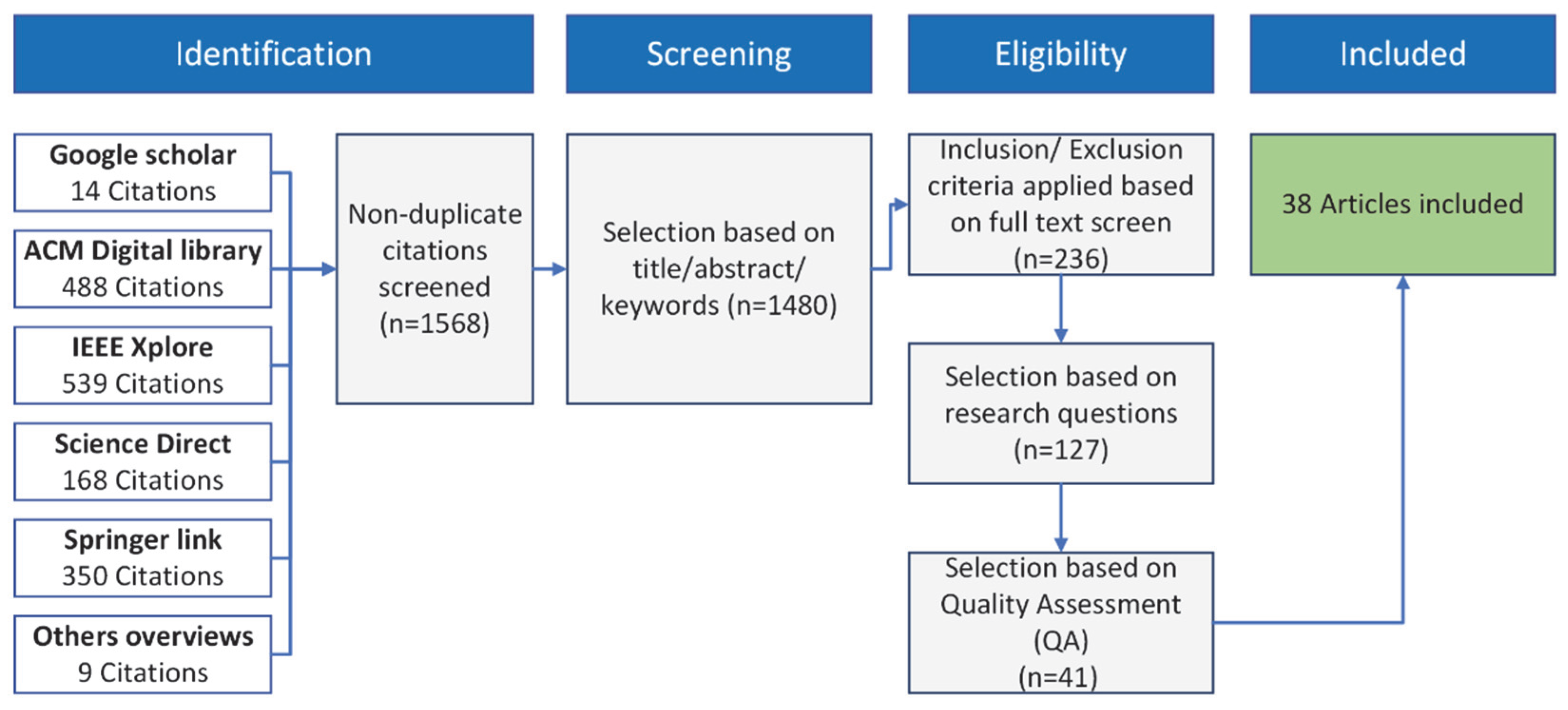
3.3. Study Selection
- The papers with two “include” votes or one “maybe” and one “include” vote were retained.
- The papers that received two “exclude” votes or one “maybe” and one “exclude” vote were eliminated from the dataset.
- The papers that received two “maybe” votes or one “include” and one “exclude” vote were resolved through discussion. In those cases, a deciding vote on including or excluding the paper are made by the third reviewer.
3.4. Quality Assessment
- QA 1. Are the research goals/aims clearly explained?
- QA 2. Does the technique/methodology in the research clearly describe?
- QA 3. Are all study questions answered?
- QA 4. Are the research findings reported?
- QA 5. Do the results of the study add to the speech recognition field?
- QA 6. Are the limitations of the current study adequately addressed?
4. Results and Discussion
- MLLT: Maximum Likelihood Linear Transform.
- PLP: Perceptual Linear Predictive.
- MLP: Multi-Layer Perceptron.
- GMM: Gaussian Mixture Model.
- PCA: Principal Component Analysis.
- RASTA-PLP: Relative Spectral-Perceptual Linear prediction.
- fMMLR: Feature Space Maximum Likelihood Linear Regression.
- bMMI: Boosted Maximum Mutual Information.
- SGMM: Subspace Gaussian Mixture Model.
- DNN: Deep Neural Networks.
- HSMM: Hidden Semi-Markov Model.
- MPE: Minimum Phone Error.
- TDNN: Time-Delay Neural Network.
- LSTM: Long Short-Term Memory.
- BLSTM: Bidirectional Long Short-Term Memory.
- FFBPNN: Feed-Forward Back Propagation Neural Network.
- SVM: Support Vector Machine.
- DBN: Dynamic Bayesian Networks.
- BDRNN: Bidirectional Recurrent Neural Network.
- CTC: Connectionist Temporal Classification.
- GLSTM: Guiding Long-Short Term Memory.
- CHMM: Coupled Hidden Markov Model.
- RNN: Recurrent Neural Network.
- LPC: Linear Predictive Coding.
- MFCC: Mel Frequency Cepstral Coefficient.
- PCA: Principal Component Analysis.
- ANN: Artificial Neural Network.
- SAT-GMM: Speaker Adaptive Training Gaussian Mixture Model-Gaussian Mixture Model.
- FFT: Fast Fourier Transform.
- MFSC: Log Frequency Spectral Coefficients.
- GFCC: Gammatone-Frequency Cepstral Coefficients.
- WLPCCS: Weighted Linear Prediction Cepstral Coefficients.
- MAP: Maximum a Posterior Adaptation.
- DTW: Dynamic Time Warping.
- GMMD: Gaussian Mixture Model Derived.
4.1. RQ1: What Is the Bibliographic Information of the Existing Studies?
4.1.1. SRQ1.1. What Are the Most Active Countries?
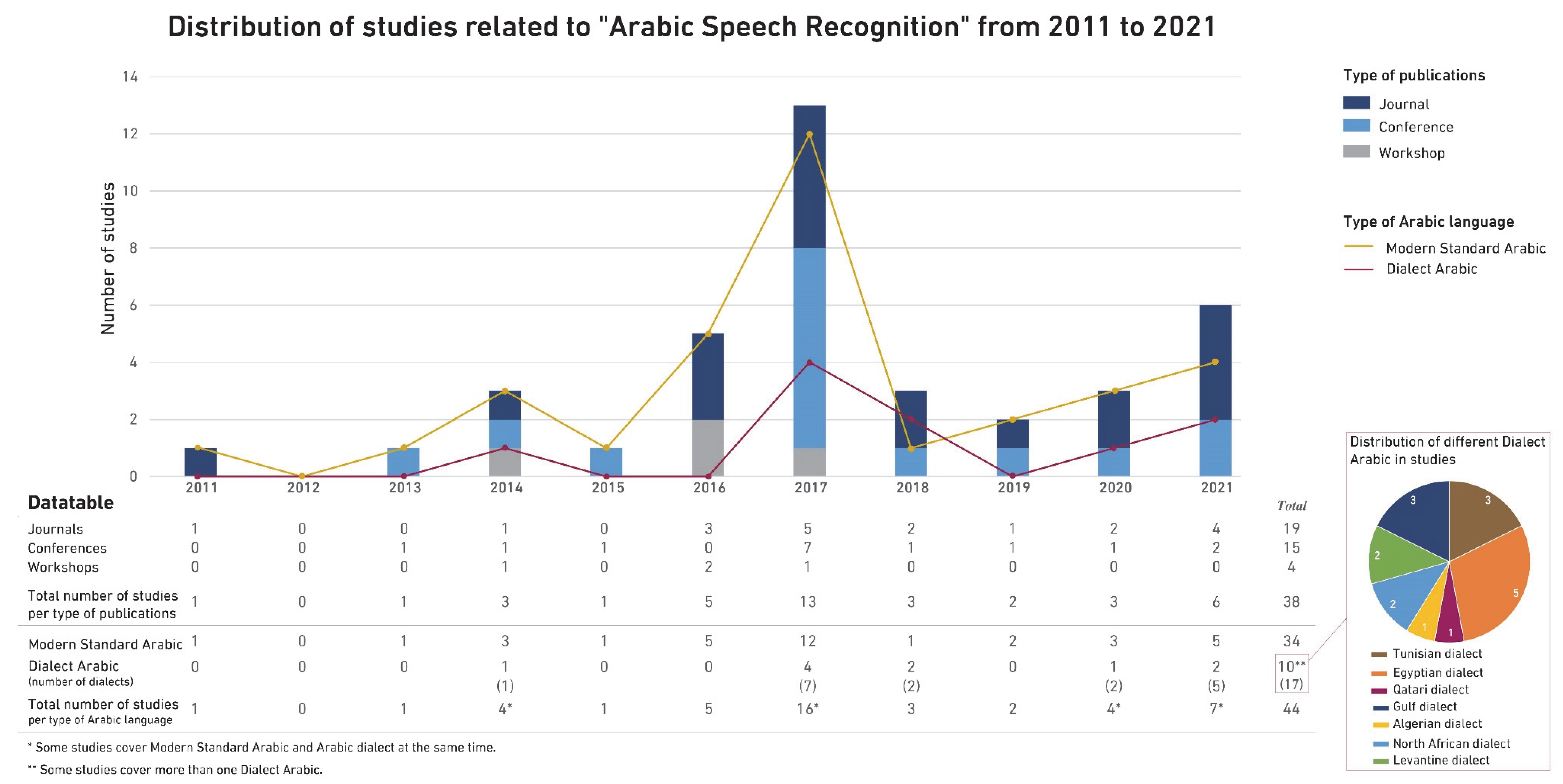
4.1.2. SRQ1.2. How Has the Number of Papers Evolved?
4.1.3. SRQ1.3. What Are the Types of Venues Used by the Authors of the Studies?
4.2. RQ2. What Is the Considered Variant of Arabic in Speech Recognition Studies?
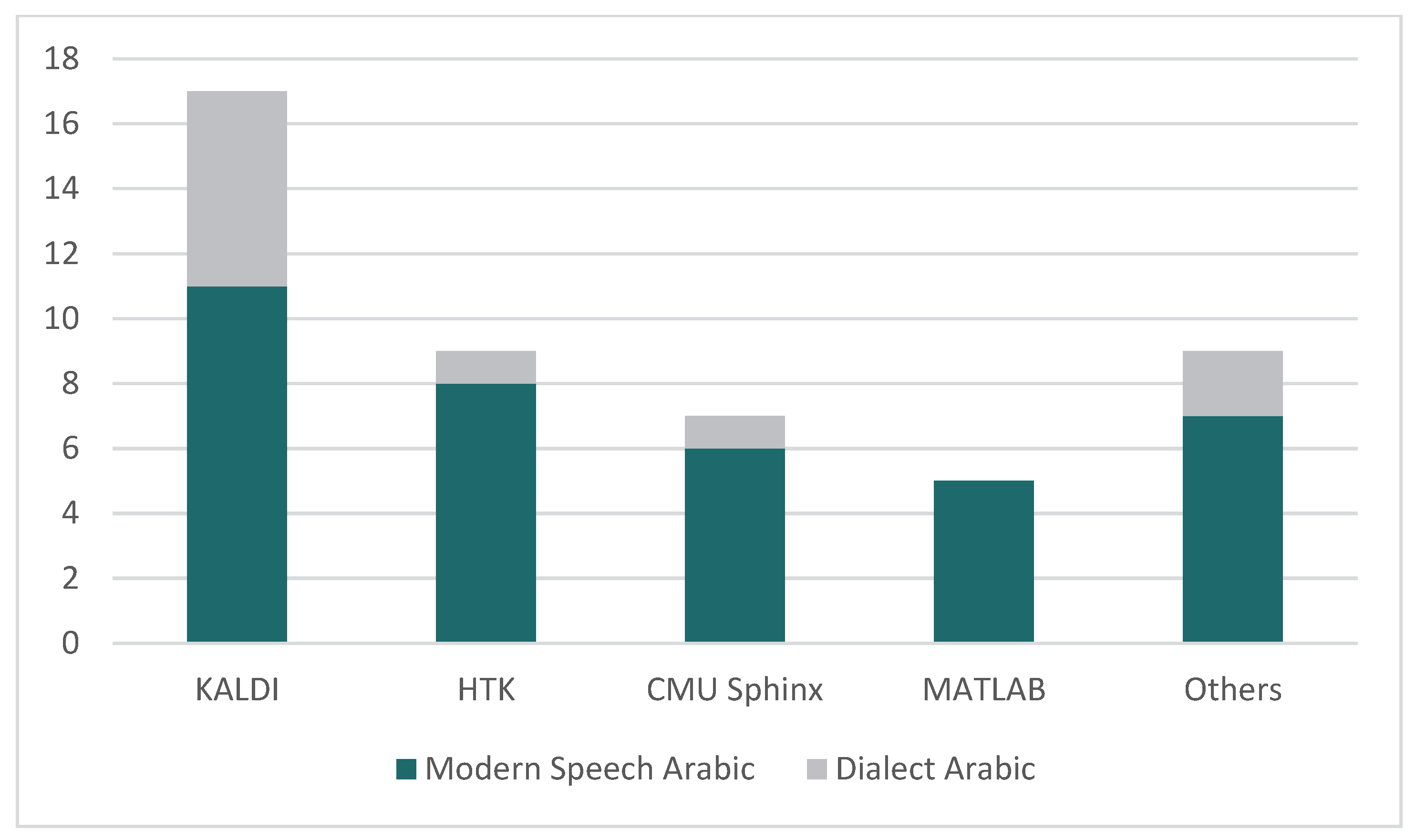
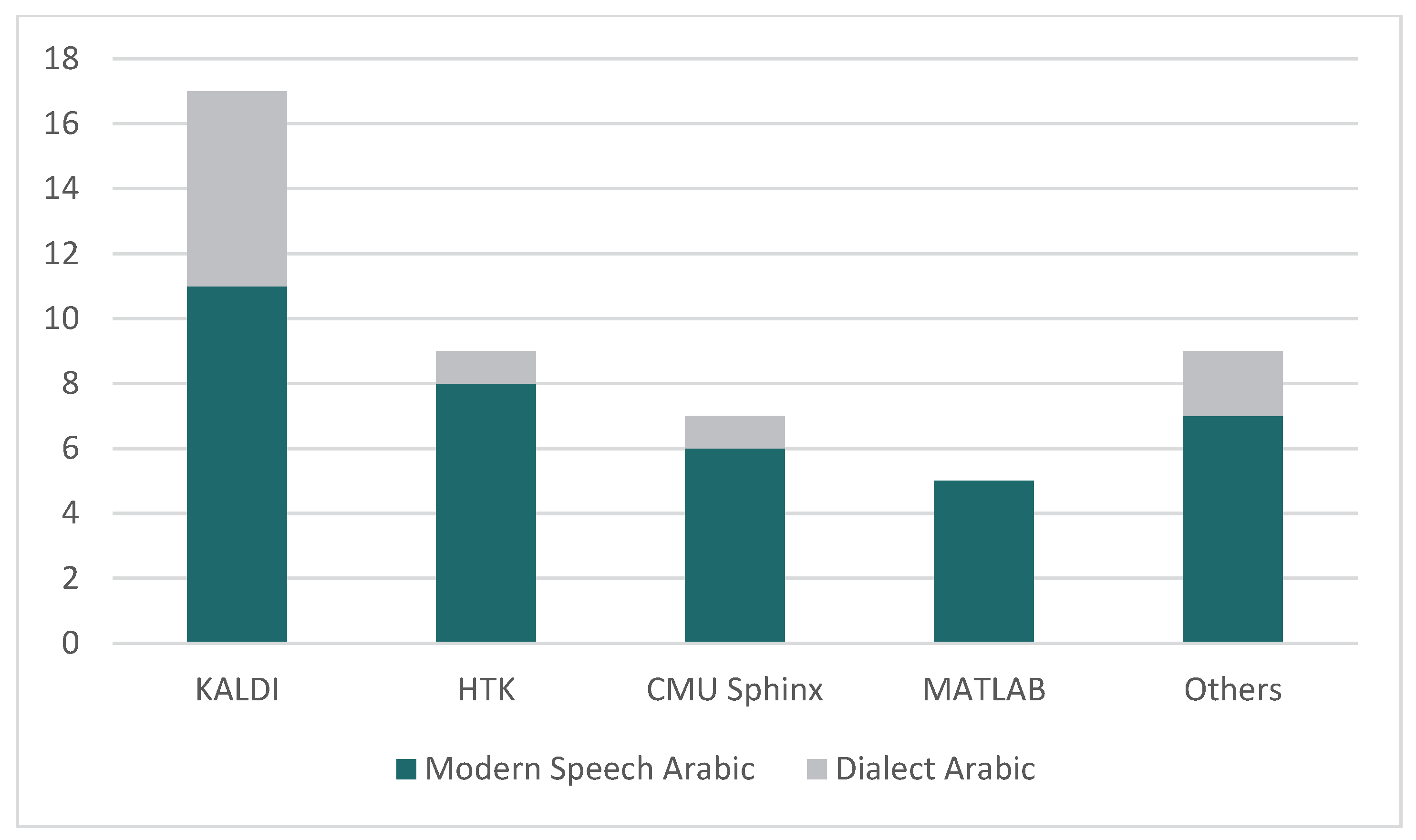
4.3. RQ 3. What Are the Toolkits Most Often Used in the Arabic Speech Recognition Field?
4.4. RQ 4. Which Datasets Were Most Often Used, and What Types of Arabic Speech Recognition Were Identified in These Datasets?
4.4.1. Isolated Words
4.4.2. Continuous Words
4.5. RQ 5. What Are the Used Feature Extraction and Classification Techniques for Arabic Speech Recognition Studies?
4.5.1. Feature Extraction Techniques
4.5.2. Feature Classification Techniques
4.6. RQ 6. What Are the Current Gaps and Future Research in the Arabic ASR Field?
4.7. RQ 7. What Is the Performance of Arabic Speech Recognition Systems?
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abushariah, M.A.M. TAMEEM V1.0: Speakers and Text Independent Arabic Automatic Continuous Speech Recognizer. Int. J. Speech Technol. 2017, 20, 261–280. [Google Scholar] [CrossRef]
- Sen, S.; Dutta, A.; Dey, N. Audio Processing and Speech Recognition: Concepts, Techniques and Research Overviews; SpringerBriefs in Applied Sciences and Technology; Springer: Singapore, 2019; ISBN 9789811360978. [Google Scholar]
- Jaber, H.Q.; Abdulbaqi, H.A. Real Time Arabic Speech Recognition Based on Convolution Neural Network. J. Inf. Optim. Sci. 2021, 42, 1657–1663. [Google Scholar] [CrossRef]
- Khelifa, M.O.M.; Elhadj, Y.M.; Abdellah, Y.; Belkasmi, M. Constructing Accurate and Robust HMM/GMM Models for an Arabic Speech Recognition System. Int. J. Speech Technol. 2017, 20, 937–949. [Google Scholar] [CrossRef]
- Al-Anzi, F.S.; AbuZeina, D. Synopsis on Arabic Speech Recognition. Ain Shams Eng. J. 2021, 13, 101534. [Google Scholar] [CrossRef]
- Elnagar, A.; Yagi, S.M.; Nassif, A.B.; Shahin, I.; Salloum, S.A. Systematic Literature Review of Dialectal Arabic: Identification and Detection. IEEE Access 2021, 9, 31010–31042. [Google Scholar] [CrossRef]
- Mubarak, H.; Darwish, K. Using Twitter to Collect a Multi-Dialectal Corpus of Arabic. In Proceedings of the EMNLP 2014 Workshop on Arabic Natural Language Processing (ANLP), Doha, Qatar, 25 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1–7. [Google Scholar]
- Abdelhamid, A.; Alsayadi, H.; Hegazy, I.; Fayed, Z. End-to-End Arabic Speech Recognition: A Review. In Proceedings of the 19th Conference of Language Engineering (ESOLEC’19), Alexandria, Egypt, 28 September 2020; pp. 26–30. [Google Scholar]
- Abuata, B.; Al-Omari, A. A Rule-Based Stemmer for Arabic Gulf Dialect. J. King Saud Univ. Comput. Inf. Sci. 2015, 27, 104–112. [Google Scholar] [CrossRef]
- Abushariah, M.; Ainon, R.; Zainuddin, R.; Elshafei, M.; Khalifa, O. Arabic Speaker-Independent Continuous Automatic Speech Recognition Based on a Phonetically Rich and Balanced Speech Corpus. Int. Arab. J. Inf. Technol. 2012, 9, 84–93. [Google Scholar]
- Ali, A.; Nakov, P.; Bell, P.; Renals, S. WERD: Using Social Text Spelling Variants for Evaluating Dialectal Speech Recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 141–148. [Google Scholar]
- Jurafsky, D. Speech & Language Processing; Pearson Education: Delhi, India, 2000. [Google Scholar]
- Al-Anzi, F.; AbuZeina, D. Literature Survey of Arabic Speech Recognition. In Proceedings of the 2018 International Conference on Computing Sciences and Engineering (ICCSE), Kuwait, Kuwait, 11–13 March 2018; pp. 1–6. [Google Scholar]
- Algihab, W.; Alawwad, N.; Aldawish, A.; AlHumoud, S. Arabic Speech Recognition with Deep Learning: A Review. In Social Computing and Social Media. Design, Human Behavior and Analytics, Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 26–31 July 2019; Meiselwitz, G., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 15–31. [Google Scholar]
- Shareef, S.R.; Irhayim, Y.F. A Review: Isolated Arabic Words Recognition Using Artificial Intelligent Techniques. J. Phys. Conf. Ser. 2021, 1897, 012026. [Google Scholar] [CrossRef]
- Sitaula, C.; He, J.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Neonatal Bowel Sound Detection Using Convolutional Neural Network and Laplace Hidden Semi-Markov Model. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1853–1864. [Google Scholar] [CrossRef]
- Subramanian, A.S.; Weng, C.; Watanabe, S.; Yu, M.; Yu, D. Deep Learning Based Multi-Source Localization with Source Splitting and Its Effectiveness in Multi-Talker Speech Recognition. Comput. Speech Lang. 2022, 75, 101360. [Google Scholar] [CrossRef]
- Labied, M.; Belangour, A.; Banane, M.; Erraissi, A. An Overview of Automatic Speech Recognition Preprocessing Techniques. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 804–809. [Google Scholar]
- Kourd, A.; Kourd, K. Arabic Isolated Word Speaker Dependent Recognition System. Br. J. Math. Comput. Sci. 2016, 14, 1–15. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Bhardwaj, V.; Ben Othman, M.T.; Kukreja, V.; Belkhier, Y.; Bajaj, M.; Goud, B.S.; Ur Rehman, A.; Shafiq, M.; Hamam, H. Automatic Speech Recognition (ASR) Systems for Children_ A Systematic Literature Review. Appl. Sci. 2022, 12, 4419. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; for the PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. BMJ 2009, 339, b2535. [Google Scholar] [CrossRef] [PubMed]
- Rayyan Systems Inc. Available online: https://www.rayyan.ai/ (accessed on 1 August 2022).
- Kitchenham, B.; Stuart, C. Guidelines for Performing Systematic Literature Reviews in Software Engineering, Version 2.3. EBSE Technical Report. EBSE-2007-01. Available online: http://www.elsevier.com/framework_products/promis_misc/525444systematicreviewsguide.pdf (accessed on 1 August 2022).
- Ali, A.; Zhang, Y.; Cardinal, P.; Dahak, N.; Vogel, S.; Glass, J. A Complete KALDI Recipe for Building Arabic Speech Recognition Systems. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 525–529. [Google Scholar]
- Ouisaadane, A.; Safi, S. A Comparative Study for Arabic Speech Recognition System in Noisy Environments. Int. J. Speech Technol. 2021, 24, 761–770. [Google Scholar] [CrossRef]
- Droua-Hamdani, G.; Sellouani, S.-A.; Boudraa, M. Effect of Characteristics of Speakers on MSA ASR Performance. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013. [Google Scholar]
- Khelifa, M.O.M.; Belkasmi, M.; Abdellah, Y.; ElHadj, Y.O.M. An Accurate HSMM-Based System for Arabic Phonemes Recognition. In Proceedings of the 2017 Ninth International Conference on Advanced Computational Intelligence (ICACI), Doha, Qatar, 4–6 February 2017; pp. 211–216. [Google Scholar]
- Nallasamy, U.; Metze, F.; Schultz, T. Active Learning for Accent Adaptation in Automatic Speech Recognition. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 360–365. [Google Scholar]
- Smit, P.; Gangireddy, S.R.; Enarvi, S.; Virpioja, S.; Kurimo, M. Aalto System for the 2017 Arabic Multi-Genre Broadcast Challenge. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 338–345. [Google Scholar]
- Helali, W.; Hajaiej, Z.; Cherif, A. Arabic Corpus Implementation: Application to Speech Recognition. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies (IC_ASET), Hammamet, Tunisia, 22–25 March 2018; pp. 50–53. [Google Scholar]
- Boussaid, L.; Hassine, M. Arabic Isolated Word Recognition System Using Hybrid Feature Extraction Techniques and Neural Network. Int. J. Speech Technol. 2018, 21, 29–37. [Google Scholar] [CrossRef]
- Elharati, H.A.; Alshaari, M.; Këpuska, V.Z. Arabic Speech Recognition System Based on MFCC and HMMs. J. Comput. Commun. 2020, 8, 28–34. [Google Scholar] [CrossRef]
- Masmoudi, A.; Bougares, F.; Ellouze, M.; Estève, Y.; Belguith, L. Automatic Speech Recognition System for Tunisian Dialect. Lang. Res. Eval. 2018, 52, 249–267. [Google Scholar] [CrossRef]
- Hussein, A.; Watanabe, S.; Ali, A. Arabic Speech Recognition by End-to-End, Modular Systems and Human. Comput. Speech Lang. 2021, 71, 101272. [Google Scholar] [CrossRef]
- Menacer, M.A.; Mella, O.; Fohr, D.; Jouvet, D.; Langlois, D.; Smaïli, K. Development of the Arabic Loria Automatic Speech Recognition System (ALASR) and Its Evaluation for Algerian Dialect. Procedia Comput. Sci. 2017, 117, 81–88. [Google Scholar] [CrossRef]
- AlHanai, T.; Hsu, W.-N.; Glass, J. Development of the MIT ASR System for the 2016 Arabic Multi-Genre Broadcast Challenge. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 299–304. [Google Scholar]
- Abed, S.; Alshayeji, M.; Sultan, S. Diacritics Effect on Arabic Speech Recognition. Arab. J. Sci. Eng. 2019, 44, 9043–9056. [Google Scholar] [CrossRef]
- Zarrouk, E.; Ben Ayed, Y.; Gargouri, F. Hybrid Continuous Speech Recognition Systems by HMM, MLP and SVM: A Comparative Study. Int. J. Speech Technol. 2014, 17, 223–233. [Google Scholar] [CrossRef]
- Zarrouk, E.; Benayed, Y.; Gargouri, F. Graphical Models for the Recognition of Arabic Continuous Speech Based Triphones Modeling. In Proceedings of the 2015 IEEE/ACIS 16th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Takamatsu, Japan, 1–3 June 2015. [Google Scholar]
- Hamdan, S.; Shaout, A. Hybrid Arabic Speech Recognition System Using FFT, Fuzzy Logic and Neural Network. IRACST Int. J. Comput. Sci. Inf. Technol. Secur. 2016, 6, 4–10. [Google Scholar]
- Alotaibi, Y.A.; Meftah, A.H.; Selouani, S.-A. Investigating the Impact of Phonetic Cross Language Modeling on Arabic and English Speech Recognition. In Proceedings of the 2014 9th International Symposium on Communication Systems, Networks Digital Sign (CSNDSP), Manchester, UK, 23–25 July 2014; pp. 585–590. [Google Scholar]
- Ahmed, A.; Hifny, Y.; Shaalan, K.; Toral, S. Lexicon Free Arabic Speech Recognition Recipe. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2016, Cairo, Egypt, 24–26 November 2016; Hassanien, A.E., Shaalan, K., Gaber, T., Azar, A.T., Tolba, M.F., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 147–159. [Google Scholar]
- Wahyuni, E.S. Arabic Speech Recognition Using MFCC Feature Extraction and ANN Classification. In Proceedings of the 2017 2nd International conferences on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 1–2 November 2017; pp. 22–25. [Google Scholar]
- Techini, E.; Sakka, Z.; Bouhlel, M. Robust Front-End Based on MVA and HEQ Post-Processing for Arabic Speech Recognition Using Hidden Markov Model Toolkit (HTK). In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 815–820. [Google Scholar]
- Soto, V.; Siohan, O.; Elfeky, M.; Moreno, P. Selection and Combination of Hypotheses for Dialectal Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5845–5849. [Google Scholar]
- Dendani, B.; Bahi, H.; Sari, T. Self-Supervised Speech Enhancement for Arabic Speech Recognition in Real-World Environments. Trait. Signal. 2021, 38, 349–358. [Google Scholar] [CrossRef]
- Ali, A.R. Multi-Dialect Arabic Speech Recognition. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Maouche, F.; Benmohammed, M. Dynamic Time Warping Inside a Genetic Algorithm for Automatic Speech Recognition. In Proceedings of the International Symposium on Modelling and Implementation of Complex Systems, Laghouat, Algeria, 16–18 December 2018; Chikhi, S., Amine, A., Chaoui, A., Saidouni, D.E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 180–192. [Google Scholar]
- Zaidi, B.F.; Boudraa, M.; Selouani, S.-A.; Sidi Yakoub, M.; Hamdani, G. Control Interface of an Automatic Continuous Speech Recognition System in Standard Arabic Language. In Proceedings of the 2020 SAI Intelligent Systems Conference, London, UK, 3–4 September 2020; Arai, K., Kapoor, S., Bhatia, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 295–303. [Google Scholar]
- Al-Anzi, F.S.; AbuZeina, D. The Effect of Diacritization on Arabic Speech Recogntion. In Proceedings of the 2017 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Aqaba, Jordan, 11–13 October 2017. [Google Scholar]
- AbuZeina, D.; Al-Khatib, W.; Elshafei, M.; Al-Muhtaseb, H. Toward Enhanced Arabic Speech Recognition Using Part of Speech Tagging. Int. J. Speech Technol. 2011, 14, 419–426. [Google Scholar] [CrossRef]
- Messaoudi, A.; Haddad, H.; Fourati, C.; Hmida, M.B.; Elhaj Mabrouk, A.B.; Graiet, M. Tunisian Dialectal End-to-End Speech Recognition Based on DeepSpeech. Procedia Comput. Sci. 2021, 189, 183–190. [Google Scholar] [CrossRef]
- Al-Anzi, F.S.; AbuZeina, D. The Impact of Phonological Rules on Arabic Speech Recognition. Int. J. Speech Technol. 2017, 20, 715–723. [Google Scholar] [CrossRef]
- Alsayadi, H.A.; Abdelhamid, A.A.; Hegazy, I.; Fayed, Z.T. Arabic Speech Recognition Using End-to-end Deep Learning. IFT Signal Process. 2021, 15, 521–534. [Google Scholar] [CrossRef]
- Abdelmaksoud, E.; Hassen, A.; Hassan, N.; Hesham, M. Convolutional Neural Network for Arabic Speech Recognition. Egypt. J. Lang. Eng. 2021, 8, 27–38. [Google Scholar] [CrossRef]
- Najafian, M.; Hsu, W.-N.; Ali, A.; Glass, J. Automatic Speech Recognition of Arabic Multi-Genre Broadcast Media. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 353–359. [Google Scholar]
- Zerari, N.; Abdelhamid, S.; Bouzgou, H.; Raymond, C. Bidirectional Deep Architecture for Arabic Speech Recognition. Open Comput. Sci. 2019, 9, 92–102. [Google Scholar] [CrossRef]
- Tomashenko, N.; Vythelingum, K.; Rousseau, A.; Estève, Y. LIUM ASR Systems for the 2016 Multi-Genre Broadcast Arabic Challenge. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 285–291. [Google Scholar]
- Al-Irhayim, D.Y.F.; Hussein, M.K. Speech Recognition of Isolated Arabic Words via Using Wavelet Transformation and Fuzzy Neural Network. Comput. Eng. Intel. Syst. 2016, 7, 21–31. [Google Scholar]
- Elmahdy, M.; Hasegawa-Johnson, M.; Mustafawi, E. Development of a TV Broadcasts Speech Recognition System for Qatari Arabic. LREC 2014, 14, 3057–3061. [Google Scholar]
- Alalshekmubarak, A.; Smith, L.S. On Improving the Classification Capability of Reservoir Computing for Arabic Speech Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Hamburg, Germany, 15–19 September 2014; Stefan, W., Cornelius, W., Włodzisław, D., Timo, H., Petia, K.-H., Sven, M., Günther, P., Alessandro, E.P.V., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 225–232. [Google Scholar]
- Droua-Hamdani, G.; Selouani, S.A.; Boudraa, M. Algerian Arabic Speech Database (ALGASD): Corpus Design and Automatic Speech Recognition Application. Arab. J. Sci. Eng. 2010, 35, 157–166. [Google Scholar]
- Ali, A.; Vogel, S.; Renals, S. Speech Recognition Challenge in the Wild: Arabic MGB-3. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 316–322. [Google Scholar]
- Ali, A.; Bell, P.; Glass, J.; Messaoui, Y.; Mubarak, H.; Renals, S.; Zhang, Y. The MGB-2 Challenge: Arabic Multi-Dialect Broadcast Media Recognition. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016. [Google Scholar]
- Ali, A.; Shon, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Glass, J.; Renals, S.; Choukri, K. The MGB-5 Challenge: Recognition and Dialect Identification of Dialectal Arabic Speech. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 1026–1033. [Google Scholar]
- Meftouh, K.; Harrat, S.; Jamoussi, S.; Abbas, M.; Smaili, K. Machine Translation Experiments on PADIC: A Parallel Arabic DIalect Corpus. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 26–34. [Google Scholar]
- Al-Diri, B.; Sharieh, A.; Hudaib, T. Database for Arabic Speech Recognition ARABIC_D; Paper or Report (Technical Report); University of Jordan: Amman, Jordan, 2002. [Google Scholar]
- Khurana, S.; Ali, A. QCRI Advanced Transcription System (QATS) for the Arabic Multi-Dialect Broadcast Media Recognition: MGB-2 Challenge. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 292–298. [Google Scholar]
- Almeman, K. The Building and Evaluation of a Mobile Parallel Multi-Dialect Speech Corpus for Arabic. Procedia Comput. Sci. 2018, 142, 166–173. [Google Scholar] [CrossRef]
- Kacur, J.; Rozinaj, G. Practical Issues of Building Robust HMM Models Using HTK and SPHINX Systems. In Speech Recognition; Mihelic, F., Zibert, J., Eds.; InTech: Rijeka, Croatia, 2008; pp. 171–192. ISBN 978-953-7619-29-9. [Google Scholar]
- Novak, J.R.; Dixon, P.R.; Furui, S. An Empirical Comparison of the T^3, Juicer, HDecode and Sphinx3 Decoders. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1890–1893. [Google Scholar]
- Zribi, I.; Ellouze, M.; Hadrich Belguith, L.; Blache, P. Spoken Tunisian Arabic Corpus “STAC”: Transcription and Annotation. Res. Comput. Sci. 2015, 90, 123–135. [Google Scholar] [CrossRef]
- Ahmed, B.H.A.; Ghabayen, A.S. Arabic Automatic Speech Recognition Enhancement. In Proceedings of the 2017 Palestinian International Conference on Information and Communication Technology (PICICT), Gaza, Palestine, 8–9 May 2017; pp. 98–102. [Google Scholar]
- Loots, L.; Niesler, T. Automatic Conversion between Pronunciations of Different English Accents. Speech Commun. 2011, 53, 75–84. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category 1 | Category 2 | Category 3 | Category 4 |
|---|---|---|---|
| Arabic | Automat 1 | Speech recogni 2 | System |
| Arabic language | Computer | Speech trans 3 | Technology |
| Multilingual | Speech to text | Tool | |
| Voice to text | |||
| Voice recogniti 2 | |||
| SRT 4 | |||
| ASR | |||
| STT |
| Database Source | Link |
|---|---|
| Google Scholar | https://scholar.google.com/ (accessed on 1 August 2022) |
| ACM Digital Library | https://dl.acm.org (accessed on 1 August 2022) |
| IEEE Xplore | https://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 1 August 2022) |
| Science Direct | https://www.sciencedirect.com (accessed on 1 August 2022) |
| Springer Link | https://link.springer.com/ (accessed on 1 August 2022) |
| Databases | Query String | Notes |
|---|---|---|
| Google Scholar | allintitle: (“Arabic” OR “Multilingual”) AND (“Speech recognition” OR “Speech recognizer” OR “Speech transformation” OR “Speech to text” OR “voice to text” OR “Voice recognition”) AND (“system” OR “technology”) | Custom range: 2011–2021 The number of characters per query is limited, so the shorter query was applied. |
| ACM Digital Library | (“Arabic” OR “Arabic Language” OR “Multilingual”) AND (“Automatic” OR “Automated” OR “Computer”) AND (“Speech recognition” OR “Speech recognizer” OR “Speech transformation” OR “Speech to text” OR “voice to text” OR “Voice recognition” OR “Voice recognizer” OR “SRT” OR “ASR” OR “STT”) AND (“system” OR “tool” OR “technology”) | Filter year: 2011–2021 Document Type: research articles (295) and journals (193). |
| IEEE Xplore | (“Arabic” OR “Arabic Language” OR “Multilingual”) AND (“Automat*” OR “Computer”) AND (“Speech recogni*” OR “Speech trans*” OR “Speech to text” OR “voice to text” OR “Voice recogni*” OR “SRT” OR “ASR” OR “STT”) AND (“system” OR “tool” OR “technology”) | Filter year: 2011–2021 Document type: Conferences (473) and Journals (66). IEEE Xplore recommends using short expressions. It does not work correctly with many disjunction terms. |
| Science Direct | (“Arabic” OR “Multilingual”) AND (“Speech recogni” OR “Speech trans” OR “Speech to text” OR “voice to text” OR “Voice recogni”) AND (“system” OR “technology”) | Filter by article types: “Research articles (168).” Filter by years: 2011–2021 The number of Boolean connectors is limited to 8 in the search. For this reason, we have used the shorter string The wildcard ‘*’ is not supported |
| Springer Link | (“Arabic” OR “Arabic Language” OR “Multilingual”) AND (“Automat” OR “Computer”) AND (“Speech recogni” OR “Speech trans” OR “Speech to text” OR “voice to text” OR “Voice recogni” OR “SRT” OR “ASR” OR “STT”) AND (“system” OR “tool” OR “technology”) | Two filters were applied to the result: Language is English Years: 2011–2021 Articles (189), conference papers (161) |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Papers undertaking Arabic speech recognition. | Papers venue is not journals, conferences, or workshops. |
| Papers focused only on spoken words in Arabic. | Papers undertaking spoken Arabic digit recognition. |
| Papers directly answer one or more of the RQ. | Papers not being available. |
| Published papers are between 2011 and 2021. | Studies in duplicity. |
| Papers are written in English | Theoretical papers. |
| Ref | Publication Title | Publication Year | Type of Venue | QA questions | Sum | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| QA1 | QA2 | QA3 | QA4 | QA5 | QA6 | |||||
| [25] | A complete KALDI Recipe for building Arabic speech recognition systems | 2014 | Workshop | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [26] | A comparative study of Arabic speech recognition system in noisy environments | 2021 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [27] | Effect of characteristics of speakers on MSA ASR performance | 2013 | Conference | 1 | 1 | 1 | 1 | 0.5 | 0.5 | 5 |
| [28] | An accurate HSMM-based system for Arabic phonemes recognition | 2017 | Conference | 0.5 | 0.5 | 0.5 | 1 | 0.5 | 0 | 3 |
| [29] | Active learning for accent adaptation in Automatic Speech Recognition | 2012 | Workshop | 1 | 0 | 0.5 | 0.5 | 0.5 | 0 | 2.5 |
| [30] | AALTO system for the 2017 Arabic multi-genre broadcast challenge | 2017 | Workshop | 0.5 | 0.5 | 1 | 0.5 | 0.5 | 0 | 3 |
| [31] | Arabic corpus Implementation: Application to Speech Recognition | 2018 | Conference | 1 | 1 | 0.5 | 0.5 | 1 | 0 | 4 |
| [32] | Arabic isolated word recognition system using hybrid feature extraction techniques and neural network | 2017 | Journal | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| [33] | Arabic Speech Recognition System Based on MFCC and HMMs | 2020 | Journal | 1 | 0.5 | 1 | 0.5 | 0.5 | 0 | 3.5 |
| [34] | Automatic speech recognition system for Tunisian dialect | 2018 | Journal | 1 | 1 | 1 | 0.5 | 1 | 1 | 5.5 |
| [35] | Arabic Speech Recognition by End-to-End, Modular Systems, and Human | 2021 | Journal | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| [4] | Constructing accurate and robust HMM/GMM models for an Arabic speech recognition system | 2017 | Journal | 1 | 1 | 1 | 1 | 1 | 1 | 6 |
| [36] | Development of the Arabic Loria Automatic Speech Recognition system (ALASR) and its evaluation of Algerian dialect | 2017 | Journal | 1 | 1 | 1 | 0.5 | 1 | 0.5 | 5 |
| [37] | Development of the MIT ASR system for the 2016 Arabic multi-genre broadcast challenge | 2016 | Workshop | 1 | 0.5 | 1 | 1 | 0.5 | 0 | 4 |
| [38] | Diacritics Effect on Arabic Speech Recognition | 2019 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [39] | Hybrid continuous speech recognition systems by HMM, MLP, and SVM: a comparative study | 2014 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [40] | Graphical Models for the Recognition of Arabic continuous speech based Triphones modeling | 2015 | Conference | 1 | 0.5 | 1 | 1 | 1 | 0 | 4.5 |
| [41] | Hybrid Arabic Speech Recognition System Using FFT, Fuzzy Logic, and Neural Network | 2016 | Journal | 1 | 0.5 | 1 | 0.5 | 1 | 1 | 5 |
| [42] | Investigating the impact of phonetic cross language modeling on Arabic and English speech recognition | 2014 | Conference | 0.5 | 0 | 1 | 0.5 | 0.5 | 0 | 2.5 |
| [43] | Lexicon Free Arabic Speech Recognition Recipe | 2016 | Conference | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [44] | Arabic Speech Recognition Using MFCC Feature Extraction and ANN Classification | 2017 | Conference | 1 | 0.5 | 1 | 0.5 | 0.5 | 0 | 3.5 |
| [45] | Robust Front-End based on MVA processing for Arabic Speech Recognition | 2017 | Conference | 0.5 | 0.5 | 1 | 0.5 | 0.5 | 0 | 3 |
| [46] | Selection and combination of hypotheses for dialectal speech recognition | 2016 | Conference | 1 | 0 | 0.5 | 0.5 | 0.5 | 0 | 2.5 |
| [47] | Self-Supervised Speech Enhancement for Arabic Speech Recognition in Real-World Environments | 2021 | Journal | 1 | 0 | 1 | 1 | 1 | 0 | 4 |
| [1] | TAMEEM V1.0: speakers and text independent Arabic automatic continuous speech recognizer | 2017 | Journal | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| [48] | Multi-Dialect Arabic Speech Recognition | 2020 | Conference | 1 | 0.5 | 1 | 0.5 | 1 | 0 | 4 |
| [49] | Dynamic Time Warping Inside a Genetic Algorithm for Automatic Speech Recognition | 2019 | Conference | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [50] | Control Interface of an Automatic Continuous Speech Recognition System in Standard Arabic Language | 2020 | Conference | 1 | 1 | 1 | 0 | 0.5 | 0 | 3.5 |
| [51] | The Effect of Diacritization on Arabic Speech Recognition | 2017 | Conference | 1 | 0.5 | 1 | 1 | 1 | 0 | 4.5 |
| [52] | Toward enhanced Arabic speech recognition using part of speech tagging | 2011 | Journal | 1 | 0.5 | 1 | 1 | 1 | 0.5 | 5 |
| [53] | Tunisian Dialectal End-to-end Speech Recognition based on Deep Speech | 2021 | Conference | 1 | 1 | 1 | 0.5 | 1 | 0 | 4.5 |
| [54] | The impact of phonological rules on Arabic speech recognition | 2017 | Journal | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| [55] | Arabic speech Recognition using end-to-end deep learning | 2021 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [56] | Convolutional Neural Network for Arabic Speech Recognition | 2021 | Journal | 1 | 1 | 1 | 0.5 | 1 | 0 | 4.5 |
| [57] | Automatic speech recognition of Arabic multi-genre broadcast media | 2017 | Conference | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| [58] | Bidirectional deep architecture for Arabic speech recognition | 2019 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [11] | WERD: using social text spelling variants for evaluating dialectal speech recognition | 2017 | Conference | 1 | 0.5 | 1 | 1 | 1 | 0.5 | 5 |
| [59] | LIUM ASR systems for the 2016 multi-genre Broadcast Arabic Challenge | 2016 | Workshop | 1 | 1 | 0.5 | 1 | 0.5 | 0 | 4 |
| [19] | Arabic Isolated Word Speaker Dependent Recognition System | 2016 | Journal | 1 | 1 | 1 | 1 | 1 | 0 | 5 |
| [60] | Speech Recognition of Isolated Arabic words via using Wavelet Transformation and Fuzzy Neural Network | 2016 | Journal | 1 | 0.5 | 1 | 0.5 | 0.5 | 0 | 3.5 |
| [61] | Development of a TV Broadcasts Speech Recognition System for Qatari Arabic | 2014 | Conference | 1 | 1 | 1 | 1 | 1 | 0.5 | 5.5 |
| Ref | Feature Techniques | Type of Arabic Language | Toolkits | Type of Speech Recognition | Datasets | ||
|---|---|---|---|---|---|---|---|
| Extraction Techniques | Classification Techniques | Mode | Speaker Dependency | ||||
| [25] | MFCC+LDA+MLLT | GMM, GMM-fMLLR, GMM-MPE, GMM-bMMI, SGMM-fMLLR, SGMM-bMMI, DNN, DNN-MPE | MSA | MADA, KALDI | Continuous speech | Speaker independent | A mix of 127 h of Broadcast Conversations (BC) and 76 h of Broadcast Report (BR). |
| [26] | MFCC | GMM-HMM, DNN-HMM | MSA | CMU Sphinx, KALDI | Isolated words | Speaker independent | A free Arabic Speech Corpus for Isolated Words dataset [62]. |
| [27] | MFCC | HMM | MSA | HTK | continuous speech | Speaker independent | The Algerian Arabic Speech Database (ALGASD) [63]. |
| [28] | MFCC | HSMM, GMM | MSA | HTK | Isolated words | N/A | Classical Arabic letters sound from Holy Quran. |
| [30] | LDA | TDNN, TDNN-LSTM, TDNN-BLSTM | MSA, Egyptian dialect | KALDI | Continuous words | Speaker independent | The 3rd Multi-Genre Broadcast challenge (MGB-3): an enormous audio corpus of primarily MSA speech and 5 h of Egyptian data [64]. |
| [31] | MFCC, PLP, LPC | HMM | Tunisian dialect | HTK | Continuous and connected words | N/A | 21 recordings of 5 words of vocabulary. |
| [32] | MFCC, PLP, PCA, RASTA-PLP | FFBPNN | MSA | N/A | Isolated words | Speaker dependent | 11 modern standard Arabic words. |
| [33] | MFCC | HMM | MSA | MATLAB | Isolated words | N/A | 24 Arabic words Consonant-Vowel [33]. |
| [34] | PLP, LDA, MLLT, fMLLR | GMM-HMM | Tunisian dialect | KALDI | Continuous words | Speaker independent | The Tunisian Arabic Railway Interaction Corpus (TARIC). It contains information requests in the Tunisian dialect about railway services. |
| [35] | MFCC | TDNN-LSTM | MSA, Egyptian, Gulf, Levantine, North African | KALDI | Continuous words | Speaker independent | Arabic Multi-Genre Broadcast corpus: MGB0F 1 [65], MGB3 [64], and MGB5 [66]. |
| [4] | MFCC | GMM-HMM | MSA | HTK, MATLAB | Isolated words | N/A | A speech database containing more than 8 h of speech recorded from the Holy Quran concerning Tajweed rules. |
| [36] | MFCC | DNN-HMM | MSA extended to the Algerian dialect | KALDI | Isolated words | Speaker independent | A corpus of Algerian dialect sentences extracted from the Parallel Arabic DIalect Corpus (PADIC) [67]. |
| [37] | LDA, MFCC, MLLT, fMLLR | GMM, DNN, CNN, TDNN, H-LSTM, GLSTM | MSA | KALDI, CNTK, SRILM | Continuous speech | N/A | A 1.200-h speech corpus was made available for the 2016 Arabic Multi-genre Broadcast (MGB) Challenge 2. |
| [38] | MFCC+LDA+MLLT | GMM-SI, GMM SAT, GMM MPE, GMM MMI, SGMM, SGMM-bMMI, DNN, DNN-MPE | MSA | KALDI, SRILM | Isolated words | Speaker independent | The total length of the corpus is 23 h of 4754 sentences with 193 speakers. |
| [39] | MFCC | HMM, MLP-HMM, SVM-HMM | MSA | HTK | Continuous speech | N/A | ARABIC_DB for large vocabulary continuous Speech recognition [68] |
| [40] | MFCC | HMM, Hybrid SVM-HMM DBN, Hybrid SVM-DBN | MSA | HTK | Isolated words | N/A | ARABIC_DB [68]. |
| [41] | FFT | Fuzzy logic, Neural network | MSA | MATLAB | Isolated words | N/A | 2 Arabic words. (شكراًً, مرحبا) |
| [43] | Filter bank, Neutral network | GMM-HMM, HMM-GMM-Tandem, BDRNN, CTC | MSA | HTK | Continuous speech | N/A | 8-h Aljazeera broadcast, which was collected and transcribed by Qatar Computing Research Institute (QCRI) using an advanced transcription system [69]. |
| [44] | MFCC | ANN | MSA | HTK | Isolated words | N/A | 3 Arabic letters of sa (س), tsa (ث), sya (ش). |
| [45] | MFCC, RASTA-PLP, PNCC | HMM | MSA | HTK | Isolated words | Speaker dependent | 4 isolated Arabic words. |
| [47] | DAE | HMM | MSA | CMU Sphinx | Isolated words | Speaker independent | A free Arabic mobile parallel multi-dialect speech corpus containing 15492 utterances from 12 speakers [70]. |
| [1] | MFCC | CHMM | MSA | CMU Sphinx | Continuous recognition | Speaker independent | The corpus contains recordings of 415 Arabic sentences. |
| [48] | MFCC | CNN, RNN | MSA, Egyptian, Gulf | CMU Sphinx | Isolated words | N/A | A corpus covering multiple dialects and different accents. |
| [49] | MFCC, FFT, Filter Bank | DTW, Genetic algorithm | MSA | MATLAB | Isolated words | Speaker independent | Corpus A is composed of 30 words. Corpus B is recorded in a natural environment containing 33 words. |
| [50] | N/A | HMM | MSA | HTK | Continuous speech | Speaker independent | The ALGerian Arabic Speech Database (ALGASD) [63]. |
| [51] | N/A | N/A | MSA | CMU Sphinx | Continuous speech | N/A | Broadcast news from As-Sabah TV. |
| [52] | N/A | N/A | MSA | CMU Sphinx | Continuous speech | N/A | A 5.4-h speech corpus of MSA. |
| [53] | MFCC | DNN, RNN | Dialectal Tunisian | KenLM | Continuous words | N/A | Tunisian dialect paired speech collection” TunSpeech” consisting of 11 h. |
| [54] | N/A | HMM | MSA | CMU Sphinx | Continuous speech | N/A | Broadcast news using MSA. |
| [55] | MFCC, FBANK | CNN-LSTM | MSA | KALDI | Isolated words | Speaker independent | 51 thousand words that required seven hours of recording via a single young male speaker |
| [56] | MFSC, GFCC | CNN | MSA | Librosa, Spafe, Keras, Tensorflow | Isolated Words | Speaker independent | 9992 utterances of 20 words spoken by 50 native male Arabic speakers. |
| [57] | MFCC, LDA, MLLT, fMLLR | DNN, TDNN, LSTM, BLSTM | MSA, Egyptian, Gulf, Levantine, North African | CNTK, KALDI, SRILM | Continuous speech | Speaker independent | An Egyptian broadcast data. |
| [58] | Mel Frequency, Filter Bank | LSTM, MLP | MSA | N/A | Isolated words | Speaker independent | Arabic TV commands and digits. |
| [11] | MFCC | TDNN, LSTMs, BiLSTMs | Egyptian dialect | KALDI | Continuous words | N/A | 2 h of Egyptian Arabic A broadcast news speech data. |
| [59] | (PLP, BN, GMMD) + (i-vectors, fMLLR, MAP) | DNN, SAT-GMM, TDNN | MSA | MADAMIRA, KALDI | Continuous speech | Speaker independent | 1128 h of Arabic broadcast speech. |
| [19] | MFCC, LPC | DTW, GMM | MSA | Praat, MATLAB | Isolated word | Speaker dependent | 40 Arabic words. |
| [60] | LPC, LPCS, WLPCCS | Neural Network, Neuro-Fuzzy Network | MSA | MATLAB | Isolated words | Speaker independent | 10 isolated Arabic words. |
| [61] | fMLLR, LDA, MLLT | GMM-HMM | MSA, Qatari dialect | KALDI | Continuous speech | Speaker independent | Different TV series and talk show programs. |
| Countries of the First Author | Studies Related to MSA | Studies Related to Dialect Arabic | Total Number of Studies |
|---|---|---|---|
| Morocco | 3 | 0 | 3 |
| Qatar | 4 | 3 (Qatari, Egyptian, Gulf/Levantine, /North African/Egyptian) | 4 |
| Finland | 1 | 1 (Egyptian) | 1 |
| Palestine | 1 | 0 | 1 |
| Tunisia | 4 | 3 (Tunisian) | 7 |
| Libya | 1 | 0 | 1 |
| Saudi Arabia | 1 | 0 | 1 |
| France | 2 | 1 (Algerian) | 2 |
| USA | 1 | 1 (Egyptian/Gulf, Levantine/North African) | 1 |
| Kuwait | 3 | 0 | 3 |
| Jordan | 2 | 0 | 2 |
| Spain | 1 | 0 | 1 |
| Indonesia | 1 | 0 | 1 |
| Algeria | 5 | 0 | 5 |
| UK | 1 | 1 (Egyptian/Gulf) | 1 |
| Yemen | 1 | 0 | 1 |
| Egypt | 1 | 0 | 1 |
| Iraq | 1 | 0 | 1 |
| Used Techniques | Percentage | References |
|---|---|---|
| fMLLR | 13% | [34,37,38,57,59,61] |
| MFCC | 63% | [1,4,11,19,25,26,27,28,31,32,33,35,36,37,38,39,40,44,45,48,49,53,55,57] |
| LDA | 18% | [25,30,34,37,38,57,61] |
| LPC | 8% | [19,31,60] |
| PLP | 10% | [31,32,34,59] |
| Used Techniques | Percentage | References |
|---|---|---|
| HMM | 21% | [27,31,33,45,47,50,54] |
| GMM-HMM | 13% | [4,26,34,43,61] |
| References | Performance |
|---|---|
| [25] | The obtained WER scored 15.81% on BR and 32.21% on a broadcast conversation. |
| [26] | The best WER for clean data was 96.2%. It was obtained with 256 mixtures per state. For the noisy data test, the best WER was 49.2% average for SNR levels under babble noise obtained with 256 mixtures. |
| [27] | The WER was 9%. |
| [28] | The overall system accuracy was 98%, and it was enhanced by around 1% by implementing HSMM instead of standard HMM to reach 99%. |
| [30] | The obtained WER was 13.2% on the MGB2 test. The obtained WER was 37.5% on MGB3. |
| [31] | The obtained average accuracy rate was 91.56% by using MFCC. The obtained average accuracy rate was 95.34% by using PLP. The obtained average accuracy rate was 86.15% by using LPC. |
| [32] | The WER reached 0.26% when using a combination of RASTA-PLP, PCA, and FFBPNN techniques. |
| [33] | The obtained accuracy was 92.92%. The obtained WER was 7.08%. |
| [34] | The obtained WER was 22.6% on the test set. |
| [35] | The ASR achieved 12.5% WER on MGB2. It achieved 27.5% WER on MGB3 and 33.8% WER on MGB5. |
| [4] | The recognition rate reached 95.5% for system 1. The recognition rate reached 94% for system 2. The recognition rate reached 97% for system 3. |
| [36] | The WER was 14.02% for MSA. The WER was 89% for the Algerian dialect. |
| [37] | The overall WER was 18.3%. |
| [38] | The WER scored 4.68%. Adding diacritics increased WER by 0.59. |
| [39] | The lowest average of WER was 11.42% for SVM/HMM, 11.92% for MLP/HMM, and 13.42% for HMM standards. |
| [40] | The use of HMM led to a recognition rate of 74.18%. The hybridization of MLP with HMM led to a recognition rate of 77.74%. The combination of SVM with HMM led to a recognition rate of 78.06%. The hybridization of SVM with DBN realized the best performance, which was 87.6%. |
| [41] | The achieved accuracy was 98%. |
| [43] | The obtained WER ranged between 3.9% and 55%. |
| [44] | The average accuracy is 92.42%, with recognition accuracy of each letter (sa (س), sya (ش), tsa (ث)) at 92.38%, 93.26%, and 91.63%, respectively. |
| [45] | The obtained accuracy ranged between 97.26% and 98.95%. |
| [47] | The WER ranged between 30.17% and 34.65%. |
| [1] | The average WER was 2.22% for speakers independent of the text-dependent data set. The achieved average WER was 7.82% for speakers independent with text-independent data set. |
| [48] | The system has achieved an overall WER of 14%. |
| [49] | The best recognition rate given by the system is 79% for multi-speaker recognition and 65% for independent speaker recognition. |
| [50] | The performance of the ACSRS setup gave the region of Algiers a recognition rate of 97.74% for words and 94.67% for sentences. |
| [51] | The WER scored 76.4% for the non-diacritized text system and 63.8% for the diacritized text-based system. |
| [52] | The obtained accuracy was 90.18%. |
| [53] | The best performance achieved was 24.4% of WER. |
| [54] | The experimental results show that the non-diacritized text system scored 81.2%, while the diacritized text-based system scored 69.1%. |
| [55] | The achieved result is 31.10% WER using the standard CTC-attention method. For CNN-LSTM with the attention method, the best result is obtained from this model: 28.48% as WER. |
| [56] | Accuracy when using GFCC with CNN was 99.77%. The maximum accuracy obtained when using GFCC with CNN was 99.77%. |
| [57] | The best WER obtained on MGB-3 using a 4-g re-scoring strategy is 42.25% for a BLSTM system, compared to 65.44% for a DNN system. |
| [58] | For TV commands, accuracy is over 95% for all models. |
| [11] | The WER is much higher on the dialectal Arabic dataset, ranging from 40% to 50%. The WER for the proposed ASR system using all five references achieved a score of 25.3%. |
| [59] | The final system was a combination of five systems where the result obtained succeeded the best single LIUM ASR system with a 9% of WER reduction and succeeded the baseline MGB system that the organizers provided with a 43% WER reduction. |
| [19] | The system accuracy reached 94.56%. |
| [60] | The recognition rate of trained data reached 97.8%. The recognition rate of non-trained data reached 81.1%. |
| [61] | The proposed ASR achieved a 28.9% relative reduction in WER. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhouib, A.; Othman, A.; El Ghoul, O.; Khribi, M.K.; Al Sinani, A. Arabic Automatic Speech Recognition: A Systematic Literature Review. Appl. Sci. 2022, 12, 8898. https://doi.org/10.3390/app12178898
Dhouib A, Othman A, El Ghoul O, Khribi MK, Al Sinani A. Arabic Automatic Speech Recognition: A Systematic Literature Review. Applied Sciences. 2022; 12(17):8898. https://doi.org/10.3390/app12178898
Chicago/Turabian StyleDhouib, Amira, Achraf Othman, Oussama El Ghoul, Mohamed Koutheair Khribi, and Aisha Al Sinani. 2022. "Arabic Automatic Speech Recognition: A Systematic Literature Review" Applied Sciences 12, no. 17: 8898. https://doi.org/10.3390/app12178898
APA StyleDhouib, A., Othman, A., El Ghoul, O., Khribi, M. K., & Al Sinani, A. (2022). Arabic Automatic Speech Recognition: A Systematic Literature Review. Applied Sciences, 12(17), 8898. https://doi.org/10.3390/app12178898