
AMANDA: A Middleware for Automatic Migration between Different Database Paradigms

 , , , , , , and
, , , , , , and 
Abstract
:1. Introduction
- How to provide automatic migration between different database paradigms, ensuring data reliability with good computational performance?
- A flexible middleware to support different database paradigms migrations, considering specific definitions (i.e., tables and attributes), does not require the migrating of all of the databases, as in the previous works. In addition, the middleware is independent and extensible to other databases.
- Users can choose what to migrate, since the migration is based on what tables and attributes users choose to migrate. With the values informed by the user, the tool runs SQL queries to obtain the data.
- Evaluation performance experiments with real and public databases show a 100% of data migration success that is 26 times faster than previous tools and approaches.
2. Related Works
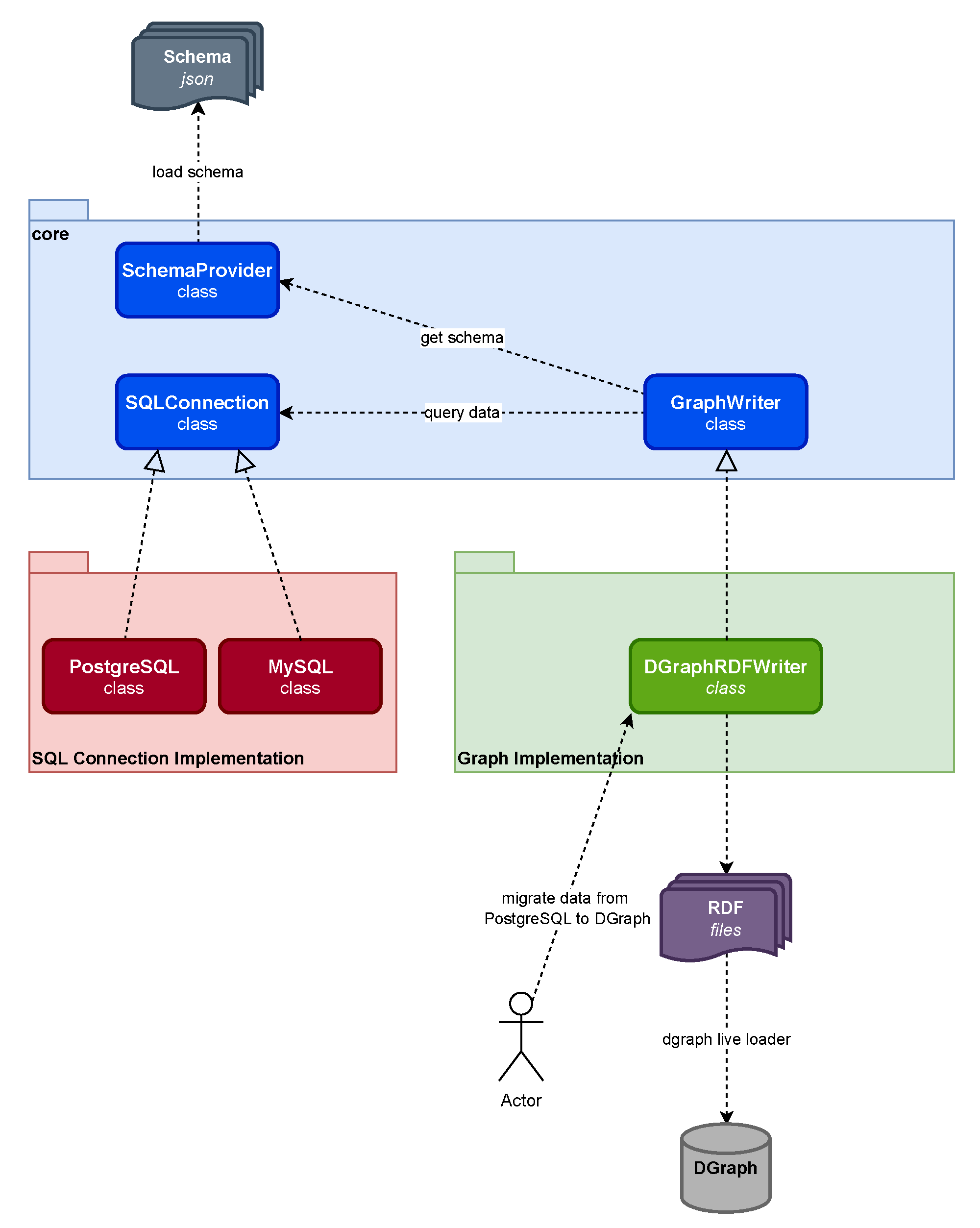
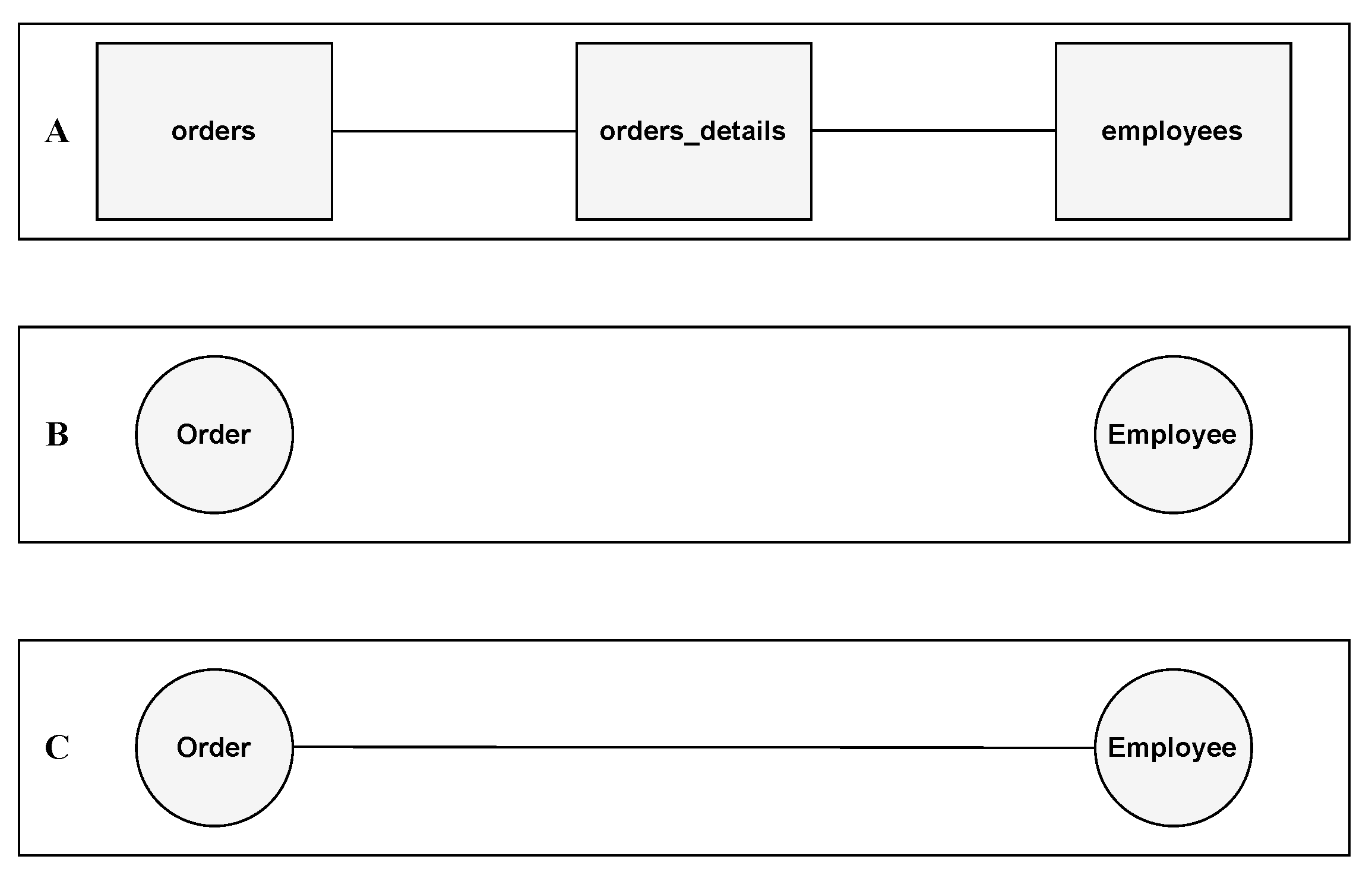
3. The Middleware
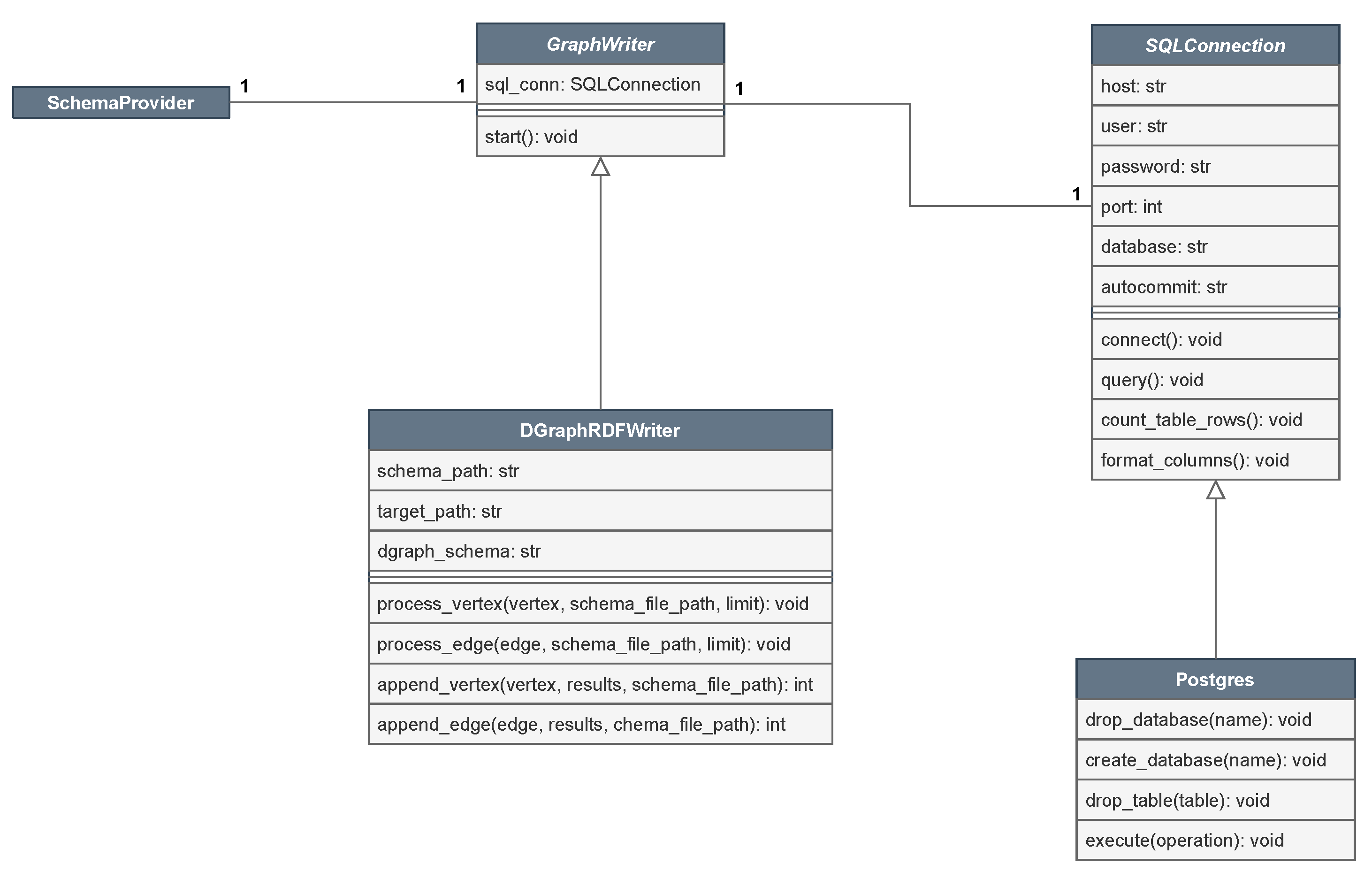
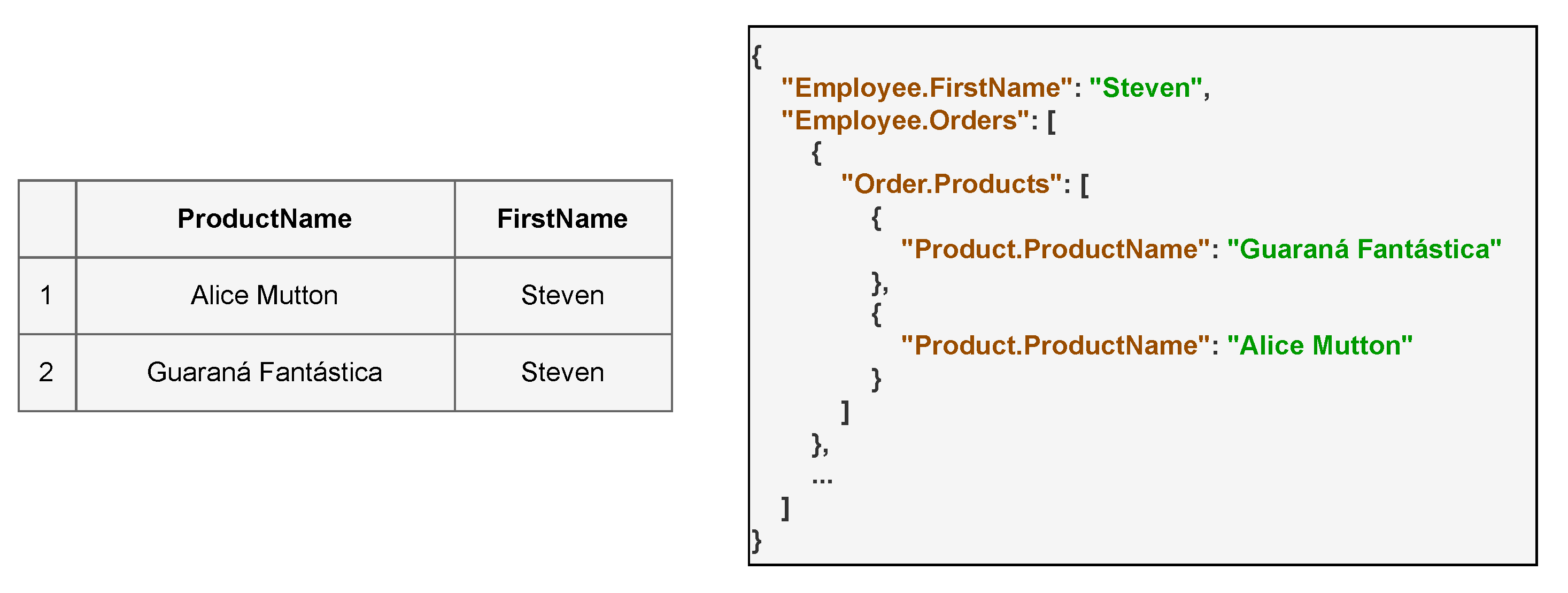
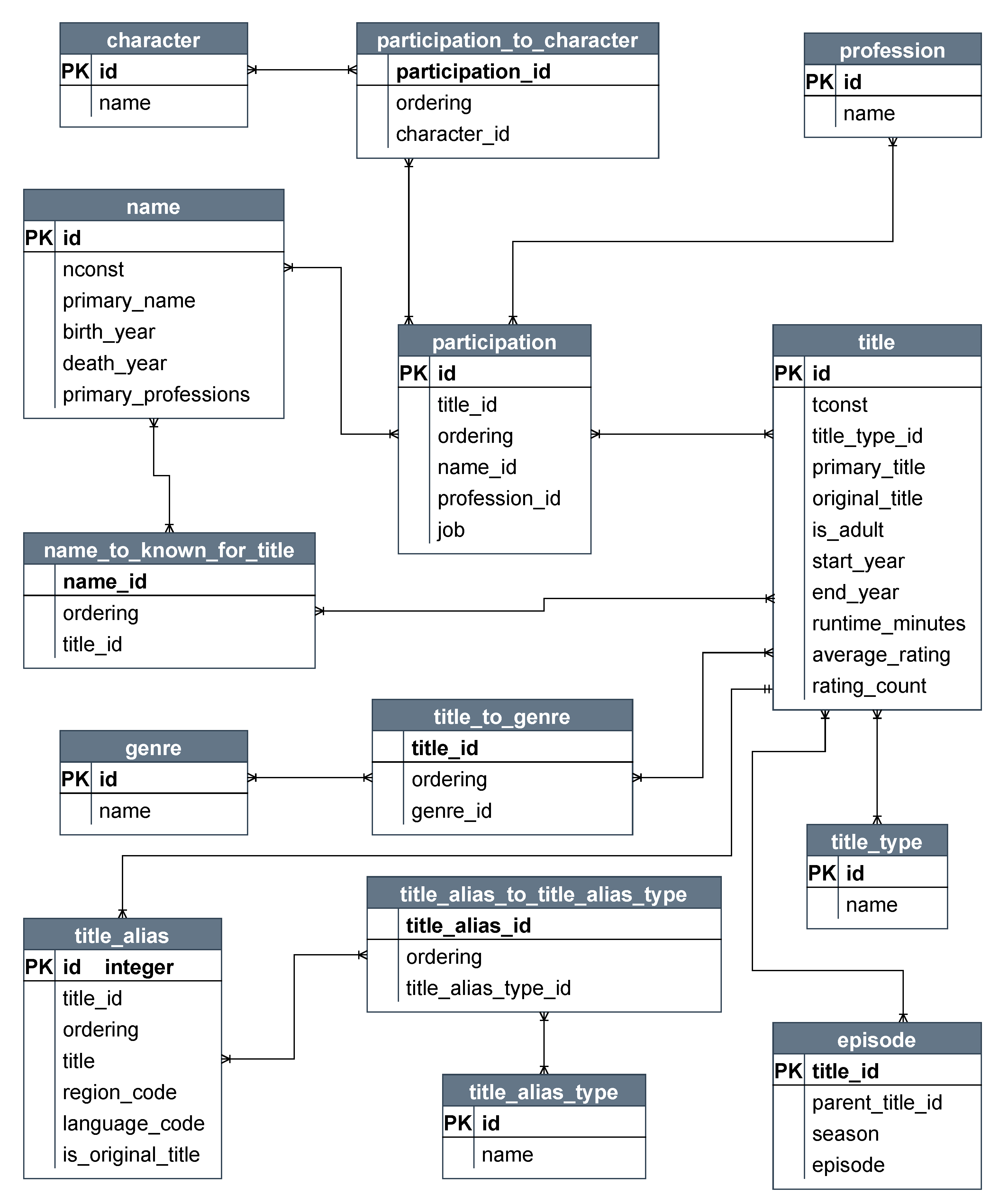
- Schema Provider: Obtains the tables and their properties from the file schema.json, which are then used during the querying process in the Relational Database Management System (RDBMS) to extract the data to be migrated. More details about schema.json are provided later in Listings 1 and 2.
- SQL Connection: Provides the required methods used for querying and connecting to a source RDBMS.
- GraphWriter: An abstraction of the Schema Provider and SQL Connection used to provide support for the target Graph Database, where the data will be migrated to.
| Listing 1. Example of Vertex. |
 |
 |
| Listing 2. Example of Edge. |
 |
| Listing 3. Example of Data migrated to a graph with RDF Syntax. |
 |
| Listing 4. SQL Queries. |
 |
- Create a schema.json file describing data that are expected to be migrated;
- Create a class containing the necessary methods for connecting and querying the source database;
- Create a class to handle incoming data from the source database and then generate a graph to the target database.
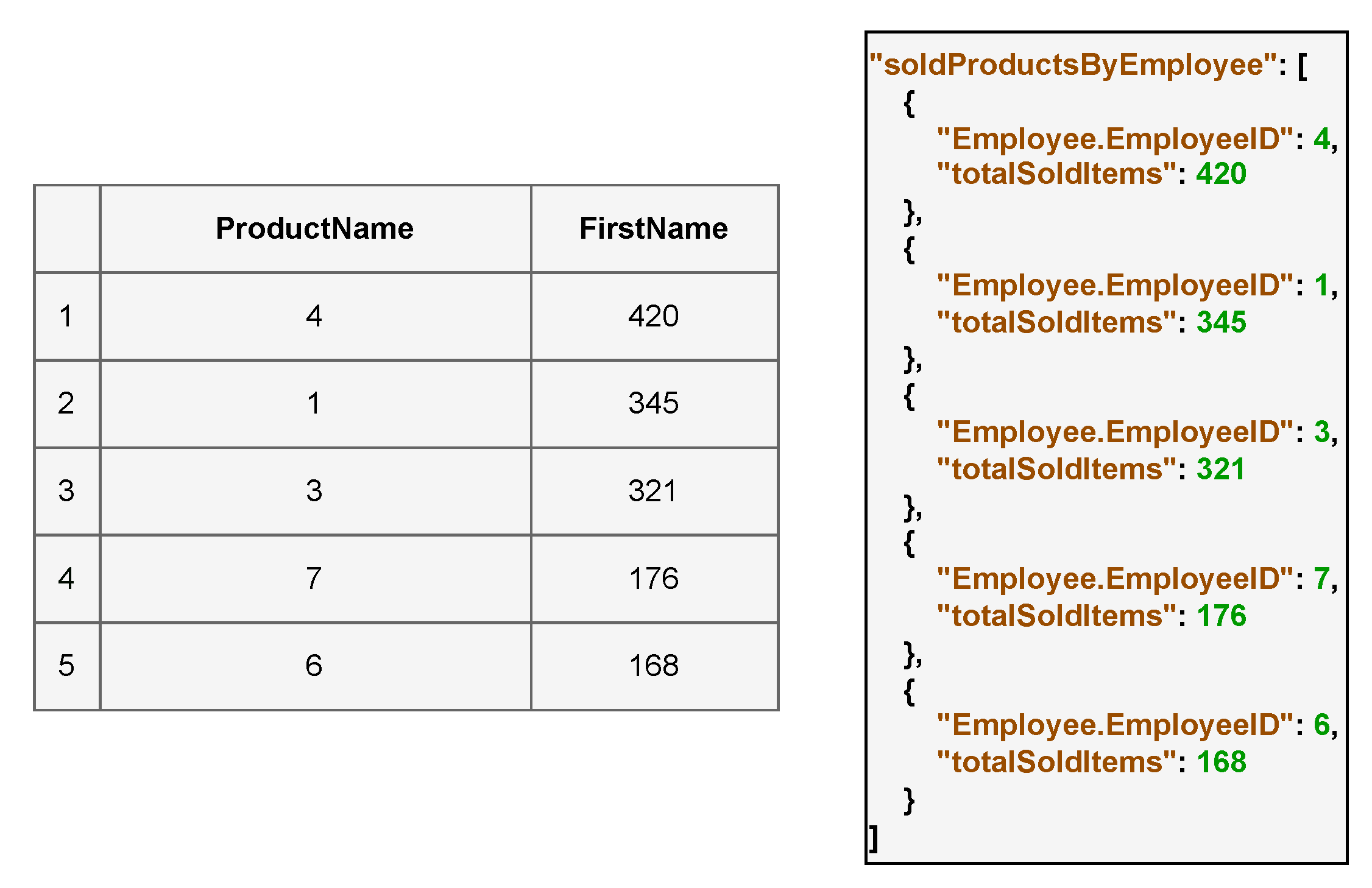
4. Evaluation
- Migration Correctness: Queries on each entity (e.g., Suppliers, Products) were conducted on Dgraph in order to ensure that all table rows have been successfully migrated into the target database;
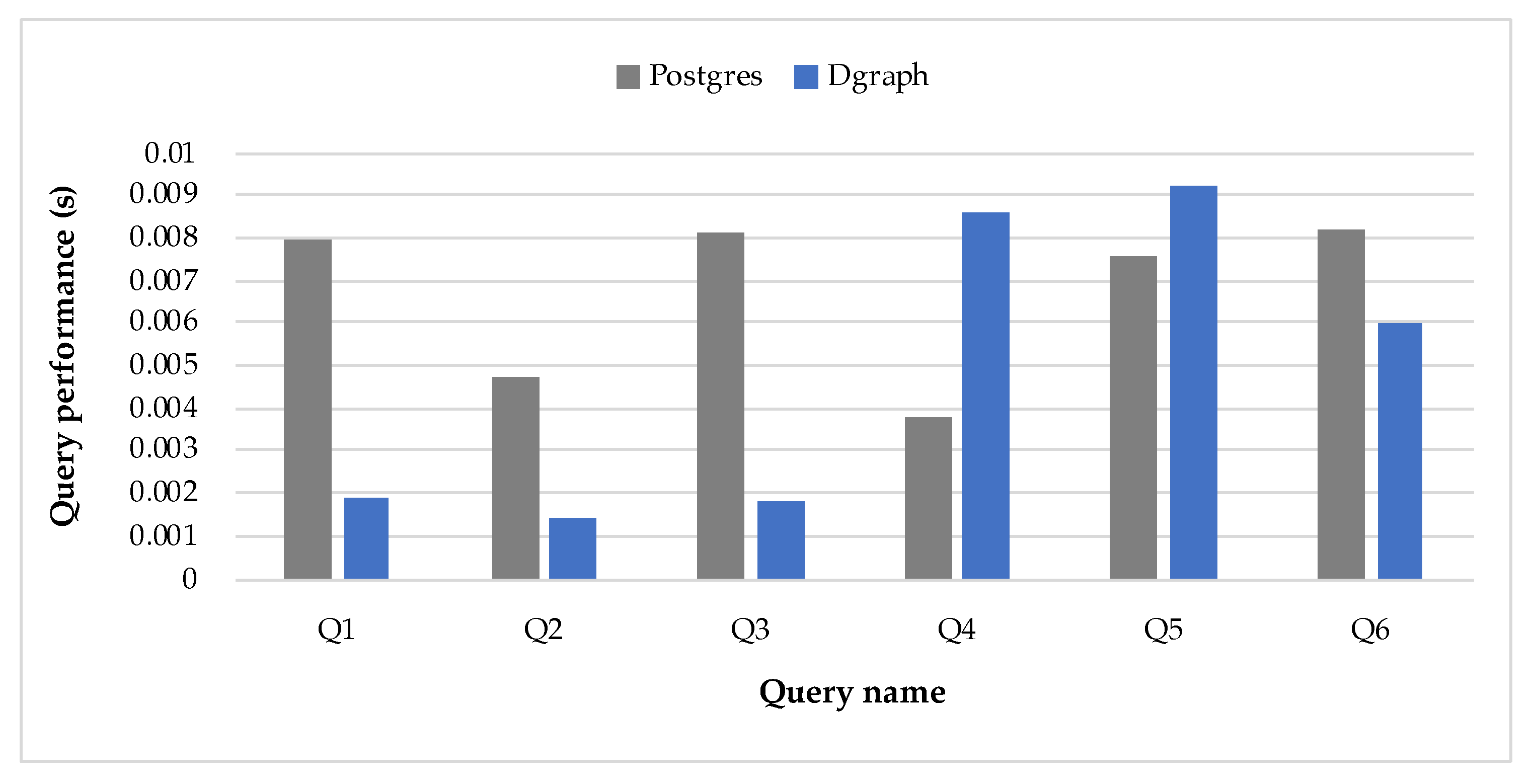
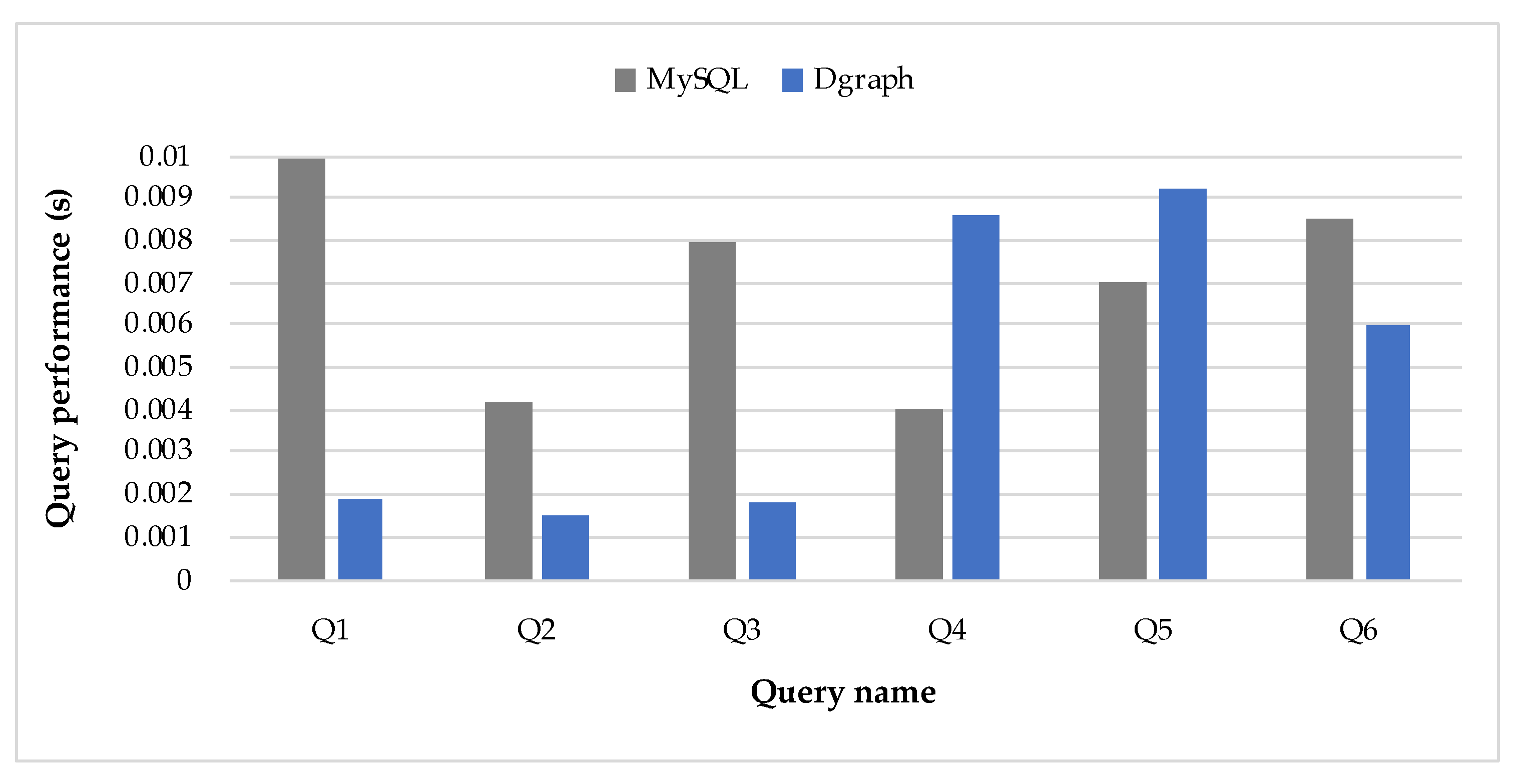
- Query Execution: Six queries were performed in Postgres, MySQL, and Dgraph in order to ensure that the same queries in the source databases can be executed in the target one. In this context, Postgres and MySQL are both source databases, whereas Dgraph is the target database.
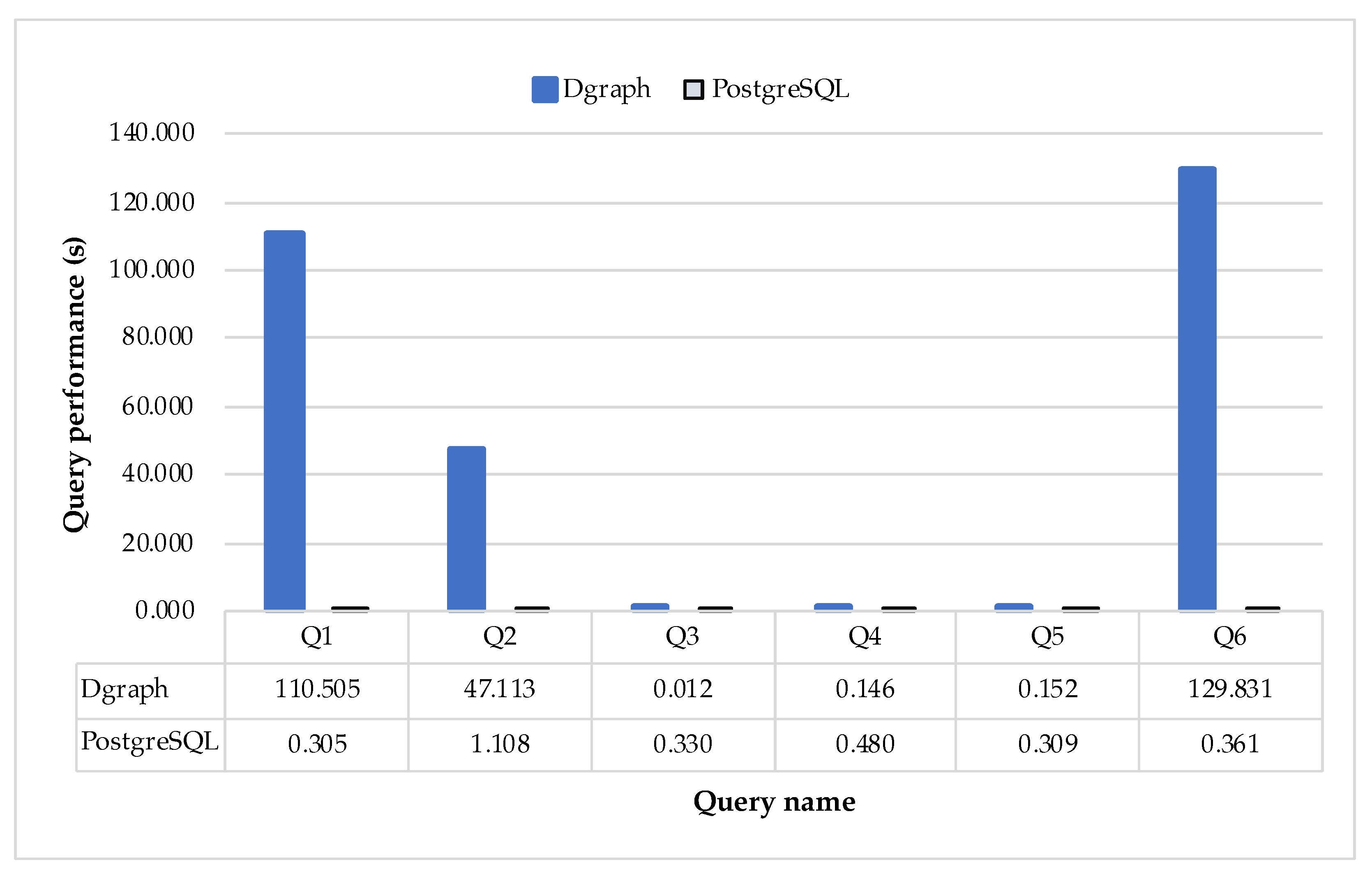
- Query Performance: Time execution assessment of six queries in Postgres, MySQL, and Dgraph. This comparison intends to verify whether the migration between databases is worth being executed. Each query (Q1–Q6) ran 100 times for each database (Postgres, MySQL, and Dgraph), and we calculated the average execution. The queries are presented later in this section.
- Migration Speed: The time required to produce a graph database starting from a Relational Database Management System (RDBMS). We executed and registered the execution time of the migration script in two scenarios: MySQL ⇒ Dgraph and Postgres ⇒ Dgraph.
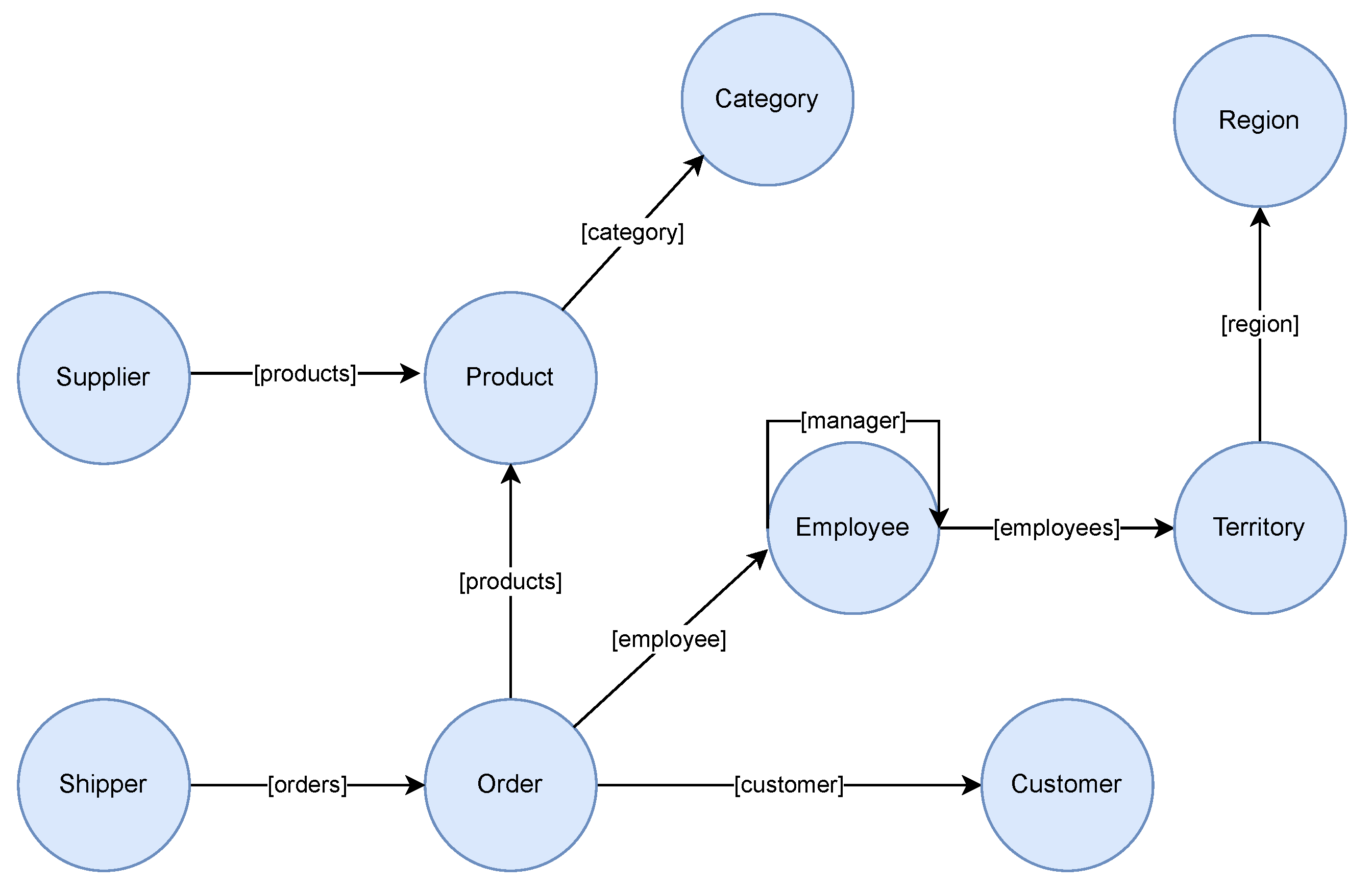
4.1. Case Study with the Northwind Dataset
- (Q1)
- Find a sample of employees who sold orders together with the products contained in those orders.
- (Q2)
- Find the supplier and category for a specific product.
- (Q3)
- Which employee had the highest cross-selling count of ’chocolate’ AND some other product?
- (Q4)
- How are the employees organized in terms of hierarchy and accountability? who reports to whom?
- (Q5)
- How many orders were made by each part of the hierarchy?
- (Q6)
- Which employees indirectly report to one another?
4.2. Case Study with IMDB Dataset Reviews
- (Q1)
- What are the actors/actresses of movie “Carmencita”?
- (Q2)
- What are the movies of genre “Action” and ended in 1960 or earlier?
- (Q3)
- Which movies is Henner Hofmann known for?
- (Q4)
- How many episodes has “The Bold and the Beautiful”?
- (Q5)
- What are the other names of “The Unchanging Sea”?
- (Q6)
- What title are “tvMiniSeries” and have the average rating 10?
5. Take Outs
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jaakkola, H.; Thalheim, B. Sixty years–and more–of data modelling. Inf. Model. Knowl. Bases 2021, 32, 56. [Google Scholar]
- Kellou-Menouer, K.; Kardoulakis, N.; Troullinou, G.; Kedad, Z.; Plexousakis, D.; Kondylakis, H. A survey on semantic schema discovery. VLDB J. 2021, 1–36. [Google Scholar] [CrossRef]
- Hamouda, S.; Zainol, Z. Document-Oriented Data Schema for Relational Database Migration to NoSQL. In Proceedings of the 2017 International Conference on Big Data Innovations and Applications (Innovate-Data), Prague, Czech Republic, 21–23 August 2017; pp. 43–50. [Google Scholar] [CrossRef]
- Giuntini, F.T.; de Moraes, K.L.; Cazzolato, M.T.; de Fátima Kirchner, L.; Dos Reis, M.d.J.D.; Traina, A.J.M.; Campbell, A.T.; Ueyama, J. Modeling and Assessing the Temporal Behavior of Emotional and Depressive User Interactions on Social Networks. IEEE Access 2021, 9, 93182–93194. [Google Scholar] [CrossRef]
- Lee, C.H.; Zheng, Y.L. SQL-to-NoSQL schema denormalization and migration: A study on content management systems. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2022–2026. [Google Scholar]
- Fonseca, S.C.; Lucena, M.C.; Reis, T.M.; Cabral, P.F.; Silva, W.A.; de Santos, S.F.; Giuntini, F.T.; Sales, J. Automatically Deciding on the Integration of Commits Based on Their Descriptions. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; pp. 1131–1135. [Google Scholar] [CrossRef]
- Machado, R.d.S.; Pires, F.d.S.; Caldeira, G.R.; Giuntini, F.T.; Santos, F.d.S.; Fonseca, P.R. Towards Energy Efficiency in Data Centers: An Industrial Experience Based on Reuse and Layout Changes. Appl. Sci. 2021, 11, 4719. [Google Scholar] [CrossRef]
- Freitas, H.; Faiçal, B.S.; Cardoso e Silva, A.V.; Ueyama, J. Use of UAVs for an efficient capsule distribution and smart path planning for biological pest control. Comput. Electron. Agric. 2020, 173, 105387. [Google Scholar] [CrossRef]
- Meneguette, R.; De Grande, R.; Ueyama, J.; Filho, G.P.R.; Madeira, E. Vehicular Edge Computing: Architecture, Resource Management, Security, and Challenges. ACM Comput. Surv. 2021, 55, 1–46. [Google Scholar] [CrossRef]
- Schulte, J.P.; Giuntini, F.T.; Nobre, R.A.; Nascimento, K.C.d.; Meneguette, R.I.; Li, W.; Gonçalves, V.P.; Rocha Filho, G.P. ELINAC: Autoencoder Approach for Electronic Invoices Data Clustering. Appl. Sci. 2022, 12, 3008. [Google Scholar] [CrossRef]
- El Hayat, S.A.; Bahaj, M. Modeling and Transformation from Temporal Object Relational Database into Mongodb: Rules. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 618–625. Available online: https://astesj.com/v05/i04/p73/ (accessed on 4 February 2022). [CrossRef]
- Giuntini, F.T.; Ueyama, J. Explorando a Teoria de Grafos e Redes Complexas na Análise de Estruturas de Redes Sociais: Um Estudo de Caso Com a Comunidade Online Reddit. 2017. Available online: https://www.researchgate.net/publication/317137094_Explorando_a_teoria_de_grafos_e_redes_complexas_na_analise_de_estruturas_de_redes_sociais_Um_estudo_de_caso_com_a_comunidade_online_Reddit (accessed on 3 January 2022).
- Cazzolato, M.T.; Giuntini, F.T.; Ruiz, L.P.; de Kirchner, F.L.; Passarelli, D.A.; de Jesus Dutra dos Reis, M.; Traina, C., Jr.; Ueyama, J.; Traina, A.J.M. Beyond Tears and Smiles with ReactSet: Records of Users’ Emotions in Facebook Posts. In Proceedings of the XXXIV Simpósio Brasileiro de Banco de Dados—Dataset Showcase Workshop (SBBD-DSW), Fortaleza, Brazil, 7–10 October 2019; pp. 1–12. [Google Scholar]
- Namdeo, B.; Suman, U. Schema design advisor model for RDBMS to NoSQL database migration. Int. J. Inf. Technol. 2021, 13, 277–286. [Google Scholar] [CrossRef]
- Giuntini, F.T.; de Moraes, K.L.P.; Cazzolato, M.T.; Kirchner, L.d.F.; Dos Reis, M.d.J.D.; Traina, A.J.M.; Campbell, A.T.; Ueyama, J. Tracing the Emotional Roadmap of Depressive Users on Social Media Through Sequential Pattern Mining. IEEE Access 2021, 9, 97621–97635. [Google Scholar] [CrossRef]
- Oracle. What is Big Data? Big Data Defined. 2022. Available online: www.oracle.com/big-data/what-is-big-data/ (accessed on 4 October 2021).
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: Survey, opportunities, and challenges. J. Big Data 2019, 6, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Unal, Y.; Oguztuzun, H. Migration of data from relational database to graph database. In Proceedings of the 8th International Conference on Information Systems and Technologies, Amman, Jordan, 11–12 July 2018; pp. 1–5. [Google Scholar]
- Rybiński, H. On First-Order-Logic Databases. ACM Trans. Database Syst. 1987, 12, 325–349. [Google Scholar] [CrossRef]
- Freitas, A.; Sales, J.E.; Handschuh, S.; Curry, E. How hard is this query? Measuring the Semantic Complexity of Schema-agnostic Queries. In Proceedings of the 11th International Conference on Computational Semantics, London, UK, 14–17 April 2015; Association for Computational Linguistics: London, UK, 2015; pp. 294–304. [Google Scholar]
- Namdeo, B.; Suman, U. A Model for Relational to NoSQL database Migration: Snapshot-Live Stream Db Migration Model. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 199–204. [Google Scholar] [CrossRef]
- PostgreSQL Global Development Group PostgreSQL—The World’s Most Advanced Open Source Relational Database. Available online: https://www.postgresql.org/ (accessed on 9 May 2022).
- MySQL, MySQL—The World’s Most Popular Open Source Database. Available online: https://dev.mysql.com/doc/ (accessed on 9 May 2022).
- Oracle Database. Available online: https://www.oracle.com/database/ (accessed on 9 May 2022).
- Chamberlin, D.D.; Boyce, R.F. SEQUEL: A Structured English Query Language. In Proceedings of the 1974 ACM SIGFIDET (Now SIGMOD) Workshop on Data Description, Access and Control, Ann Arbor, MI, USA, 1–3 May 1974; Association for Computing Machinery: New York, NY, USA, 1974; pp. 249–264. [Google Scholar] [CrossRef]
- Dormando. A Distributed Memory Object Caching System. Available online: http://memcached.org/ (accessed on 5 May 2022).
- The Application Data Platform. 2022. Available online: https://www.mongodb.com/ (accessed on 5 May 2022).
- Stax, D. Apache Cassandra: About Transactions and Concurrency Control. Available online: https://docs.datastax.com/en/cassandra-oss/2.1/cassandra/dml/dl_about_transactions_c.html (accessed on 21 March 2022).
- Neo4j. Concepts: Nosql to Graph—Developer Guides. Available online: https://neo4j.com/developer/graph-db-vs-nosql/ (accessed on 9 May 2022).
- Khasawneh, T.N.; AL-Sahlee, M.H.; Safia, A.A. SQL, NewSQL, and NOSQL Databases: A Comparative Survey. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 13–21. [Google Scholar] [CrossRef]
- Li, Y.; Manoharan, S. A performance comparison of SQL and NoSQL databases. In Proceedings of the 2013 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 27–29 August 2013; pp. 15–19. [Google Scholar] [CrossRef]
- Martins, P.; Abbasi, M.; Sá, F. A study over NoSQL performance. In Proceedings of the World Conference on Information Systems and Technologies, Galicia, Spain, 16–19 April 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 603–611. [Google Scholar]
- Falcão, T.A.; Furtado, P.M.; Queiroz, J.S.; Matos, P.J.; Antunes, T.F.; Carvalho, F.S.; Fonseca, P.C.; Giuntini, F.T. Comparative Analysis of Graph Databases for Git Data. J. Phys. Conf. Ser. 2021, 1944, 012004. [Google Scholar] [CrossRef]
- Orel, O.; Zakošek, S.; Baranovič, M. Property oriented relational-to-graph database conversion. Automatika 2016, 57, 836–845. [Google Scholar] [CrossRef] [Green Version]
- Sayeb, Y.; Ayari, R.; Naceur, S.; Ghézala, H.B. From Relational Database to Big Data: Converting Relational to Graph Database, MOOC Database as Example. J. Ubiquitous Syst. Pervasive Netw. 2017, 8, 15–20. [Google Scholar] [CrossRef]
- Vyawahare, H.R.; Karde, P.P.; Thakare, V.M. An efficient graph database model. Int. J. Innov. Technol. Explor. Eng. 2019, 88, 1292–1295. [Google Scholar]
- Nan, Z.; Bai, X. The study on data migration from relational database to graph database. J. Phys. Conf. Ser. 2019, 1345, 022061. [Google Scholar] [CrossRef]
- Kim, H.J.; Ko, E.J.; Jeon, Y.H.; Lee, K.H. Techniques and guidelines for effective migration from RDBMS to NoSQL. J. Supercomput. 2020, 76, 7936–7950. [Google Scholar] [CrossRef]
- De Virgilio, R.; Maccioni, A.; Torlone, R. Converting relational to graph databases. In Proceedings of the First International Workshop on Graph Data Management Experiences and Systems, New York, NY, USA, 23–24 June 2013; pp. 1–6. [Google Scholar]
- Palod, S. Transformation of Relational DATABASE domain into Graph-Based Domain for Graph-Based Data Mining; The University of Texas at Arlington: Arlington, TX, USA, 2004. [Google Scholar]
- De Virgilio, R.; Maccioni, A.; Torlone, R. R2G: A Tool for Migrating Relations to Graphs. EDBT 2014, 2014, 640–643. [Google Scholar]
- Megid, Y.A.; El-Tazi, N.; Fahmy, A. Using functional dependencies in conversion of relational databases to graph databases. In Proceedings of the International Conference on Database and Expert Systems Applications, Regensburg, Germany, 3–6 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 350–357. [Google Scholar]
- Sokolova, M.V.; Gómez, F.J.; Borisoglebskaya, L.N. Migration from an SQL to a hybrid SQL/NoSQL data model. J. Manag. Anal. 2020, 7, 1–11. [Google Scholar] [CrossRef]
- Yugabyte. About the Northwind Sample Database. Available online: https://docs.yugabyte.com/latest/sample-data/northwind/#about-the-northwind-sample-database (accessed on 21 March 2022).
- IMDB. IMDb Datasets. Information Courtesy of IMDb (https://www.imdb.com). Used with Permission. Available online: https://www.imdb.com/interfaces/ (accessed on 15 May 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | SQL DB | NonSQL SB | Dataset | Approach |
| Orel et al. | IBM Informix | Neo4J | A small set of data from dba.stackexchange.com, accessed on 9 May 2022 | Read database metadata to obtain tables information |
| Sayeb et al. | MySQL | Neo4J | Database from MOOC | Read database metadata to obtain tables information |
| Unal et al. | MySQL | Neo4J | Legal Document System | SchemaCrawler and Java SQL Library |
| Megid et al. | SQL Server | Neo4j | Northwind, Wikipedia-2008 subset, IMDB subset | Functional dependencies |
| Nan et al. | SQL Server | Neo4J | Northwind and IMDB | Entity Relation (ER) diagram |
| Vyawahare et al. | MySQL | Neo4J | Northwind | Read database metadata to obtain tables information |
| Hayat et al. | OracleDB | MongoDB | N/A | Formal rules and source’s DB ER diagram |
| Sokolova et al. | MySQL | MySQL + Apache Jena Fuseki | Retail business company | Ontology and combination of SQL and NoSQL DB |
| Kim et al. | MySQL | HBase + Phoenix | TPC-H | Query translation and denormalization |
| Namdeo et al. | MySQL | MongoDB | Database of an academic department | Database snapshot and streaming of changed data |
| Our Solution | Postgres | Dgraph | Northwind and IMDB | Direct query the database to migrate data specified in schema.json |
| Databases | ||
|---|---|---|
| Entity | Postgres | Dgraph |
| categories | 8 | 8 |
| customers | 91 | 91 |
| employees | 9 | 9 |
| orders | 830 | 830 |
| products | 77 | 77 |
| region | 4 | 4 |
| shippers | 6 | 6 |
| suppliers | 29 | 29 |
| territories | 53 | 53 |
| Databases | ||
|---|---|---|
| Entity | MySQL | Dgraph |
| categories | 8 | 8 |
| customers | 93 | 93 |
| employees | 9 | 9 |
| orders | 830 | 830 |
| products | 77 | 77 |
| region | 4 | 4 |
| shippers | 3 | 3 |
| suppliers | 29 | 29 |
| territories | 53 | 53 |
| Source DB | Target DB | Execution Time (s) | Memory (MB) | CPU Time (s) |
|---|---|---|---|---|
| Postgres | DGraph | 1 | 19.47 | 0.54 |
| MySQL | DGraph | 1 | 19.47 | 0.57 |
| Source DB | Target DB | Execution Time (h) | Memory (MB) | CPU Time (m) |
|---|---|---|---|---|
| Postgres | DGraph | 168 | 19.47 | 26.65 |
| Northwind | IMDB | |||||
|---|---|---|---|---|---|---|
| Work | Time | RAM | CPU | Time | RAM | CPU |
| AMANDA | 1 (s) | 19.47 | 0.54 | 168 (h) | 19.47 | 26.65 |
| Megid et al. | 26.10 (s) | NP | NP | 992 (h) | NP | NP |
| Nan et al. | NP | NP | NP | NP | NP | NP |
| Vyawahare et al. | NP | NP | NP | N/A | N/A | N/A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Queiroz, J.S.; Falcão , T.A.; Furtado, P.M.; Soares, F.L.; Souza, T.B.F.; Cleis, P.V.V.P.; Santos, F.S.; Giuntini, F.T. AMANDA: A Middleware for Automatic Migration between Different Database Paradigms. Appl. Sci. 2022, 12, 6106. https://doi.org/10.3390/app12126106
Queiroz JS, Falcão TA, Furtado PM, Soares FL, Souza TBF, Cleis PVVP, Santos FS, Giuntini FT. AMANDA: A Middleware for Automatic Migration between Different Database Paradigms. Applied Sciences. 2022; 12(12):6106. https://doi.org/10.3390/app12126106
Chicago/Turabian StyleQueiroz, Jordan S., Thiago A. Falcão , Phillip M. Furtado, Fabrício L. Soares, Tafarel Brayan F. Souza, Pedro Vitor V. P. Cleis, Flavia S. Santos, and Felipe T. Giuntini. 2022. "AMANDA: A Middleware for Automatic Migration between Different Database Paradigms" Applied Sciences 12, no. 12: 6106. https://doi.org/10.3390/app12126106
APA StyleQueiroz, J. S., Falcão , T. A., Furtado, P. M., Soares, F. L., Souza, T. B. F., Cleis, P. V. V. P., Santos, F. S., & Giuntini, F. T. (2022). AMANDA: A Middleware for Automatic Migration between Different Database Paradigms. Applied Sciences, 12(12), 6106. https://doi.org/10.3390/app12126106