
A Short-Term Wind Speed Forecasting Model Based on EMD/CEEMD and ARIMA-SVM Algorithms



Abstract
:1. Introduction
2. Methodology
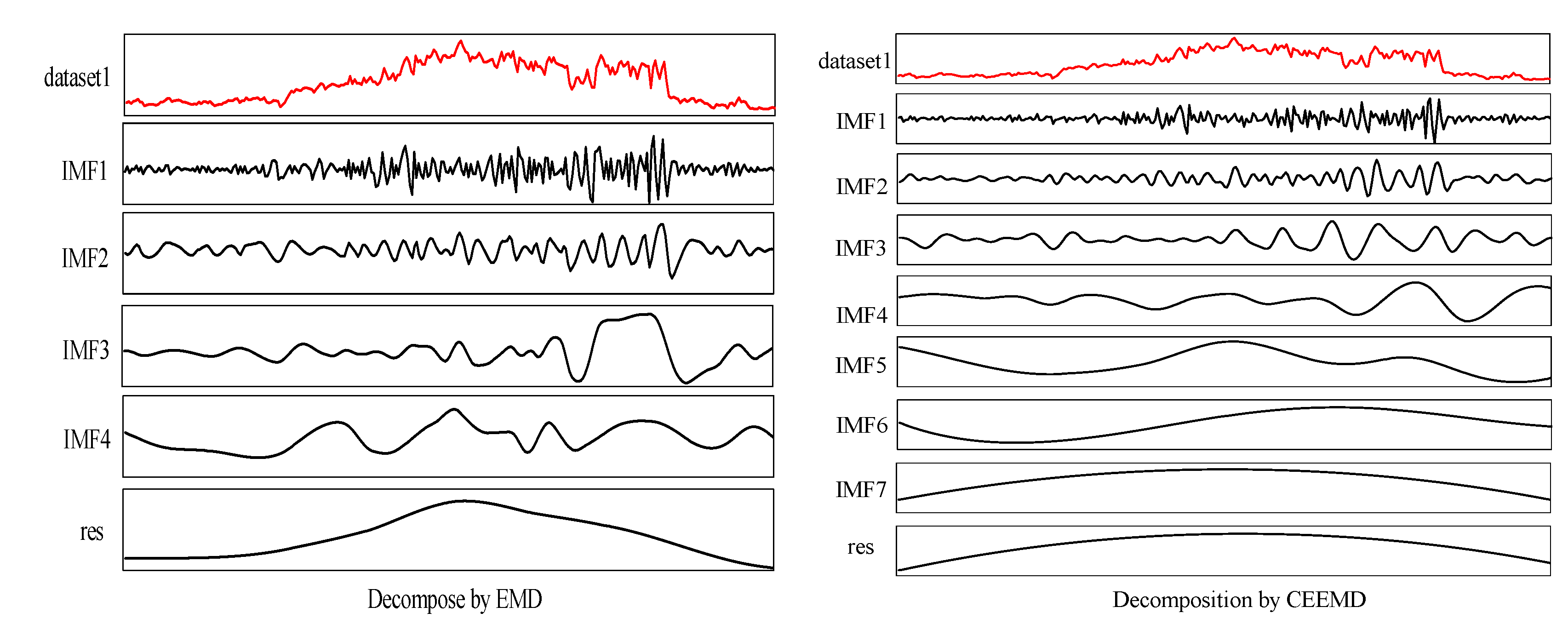
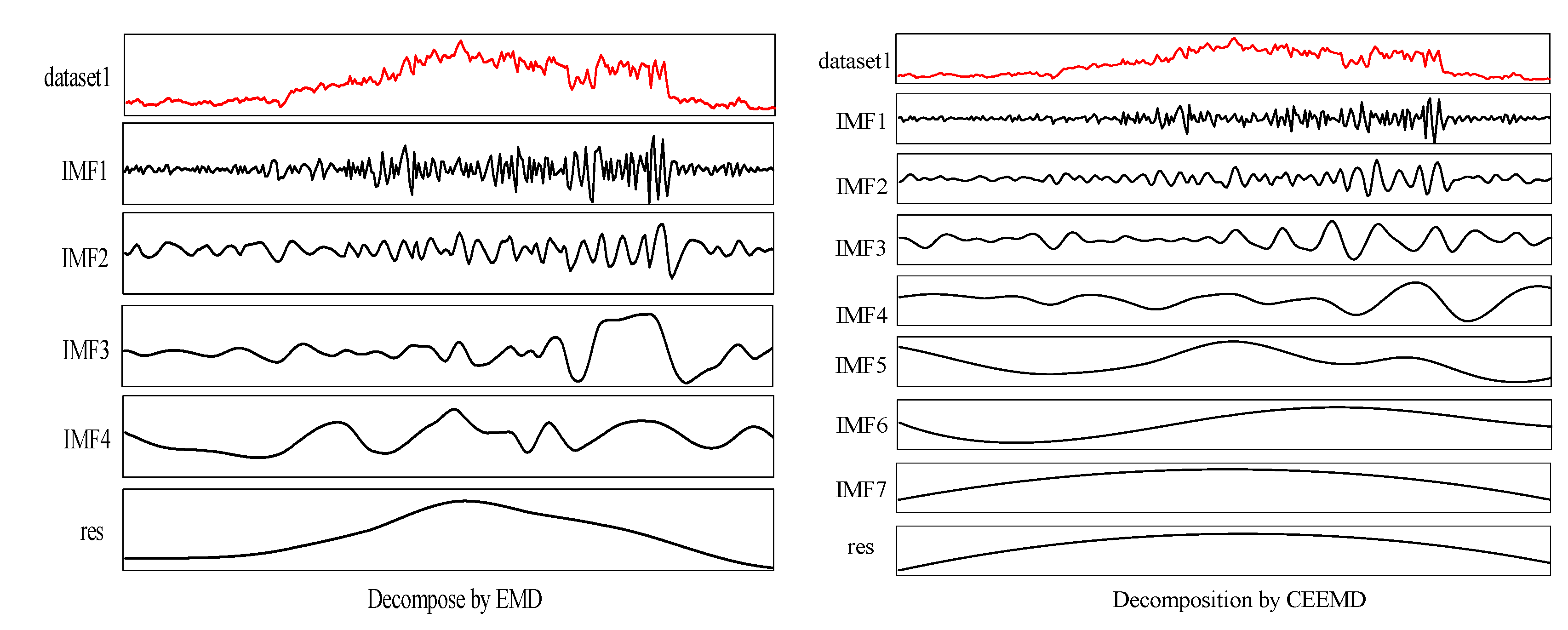
2.1. Modal Decomposition Technique
- The original signal is added with a pair of Gaussian white noises to form a new set of signals , namely
- The EMD is applied to the reconstructed signal of Equation (2) to obtain m IMF components:where, indicates the jth IMF of the EMD decomposition after the adding of the ith white noise; represents the trend term of the EMD decomposition.
- Different white noises (i = 1, 2, …, n), are added, repeating steps 1 and 2, getting n sets of IMFs and trend terms.
- The mean of all IMFs are calculated to obtain the final IMF :
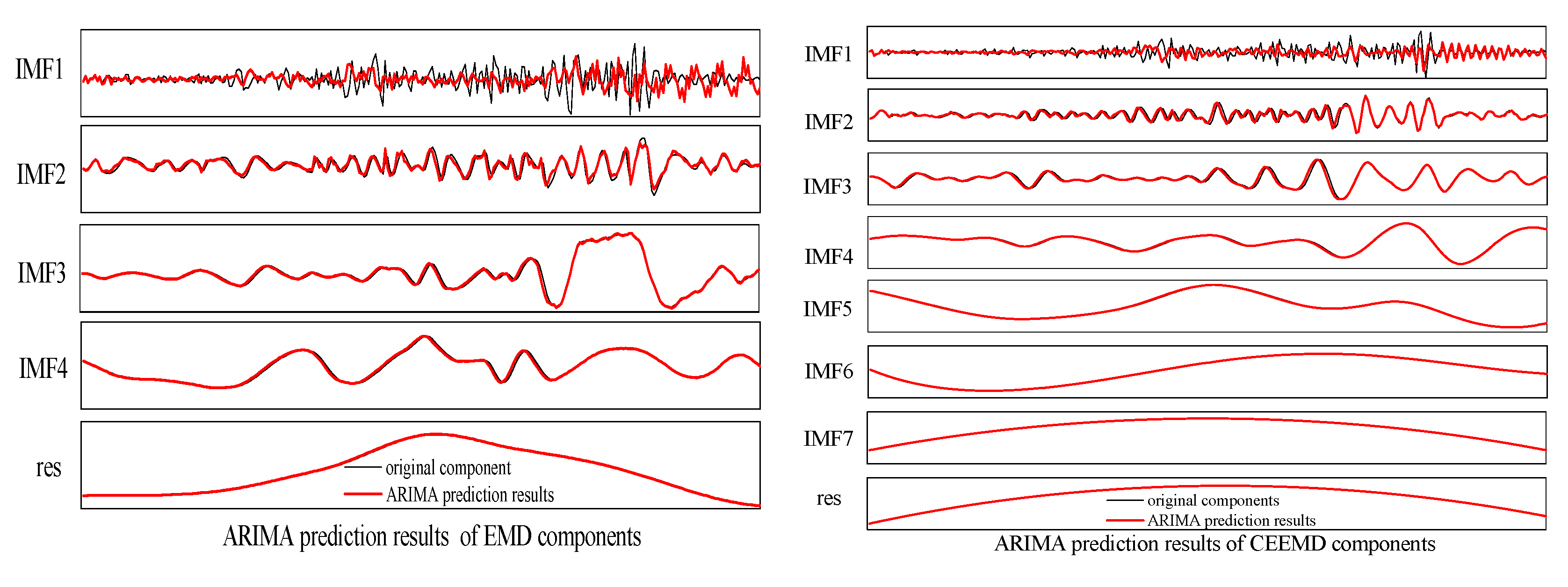
2.2. The Auto-Regressive Integrated Moving Average Models
- Model order identification. The stationarity detection of the time series is carried out. The time series should be converted to a stationary time series using differential operation if a non-stationary series is detected. Then, the differential order d can be determined. After that, the model orders p and q can be determined according to the AIC criteria by calculation of the Auto-Correlation function (ACF) and the Partial ACF (PACF).
- Estimation of the model parameters. The maximum likelihood method is usually adopted to estimate the model parameters.
- Diagnostic checking and prediction. Whether the model is suitable for the series is determined, and the future wind speeds are predicted by the constructed ARIMA model.
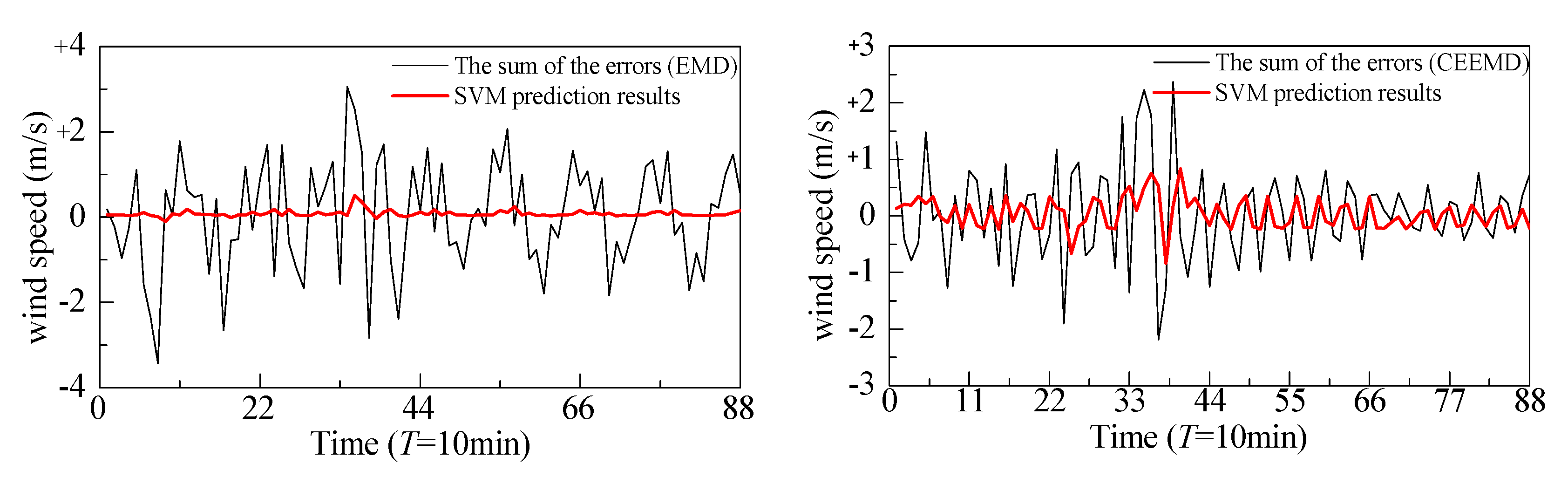
2.3. The Support Vector Machine (SVM)
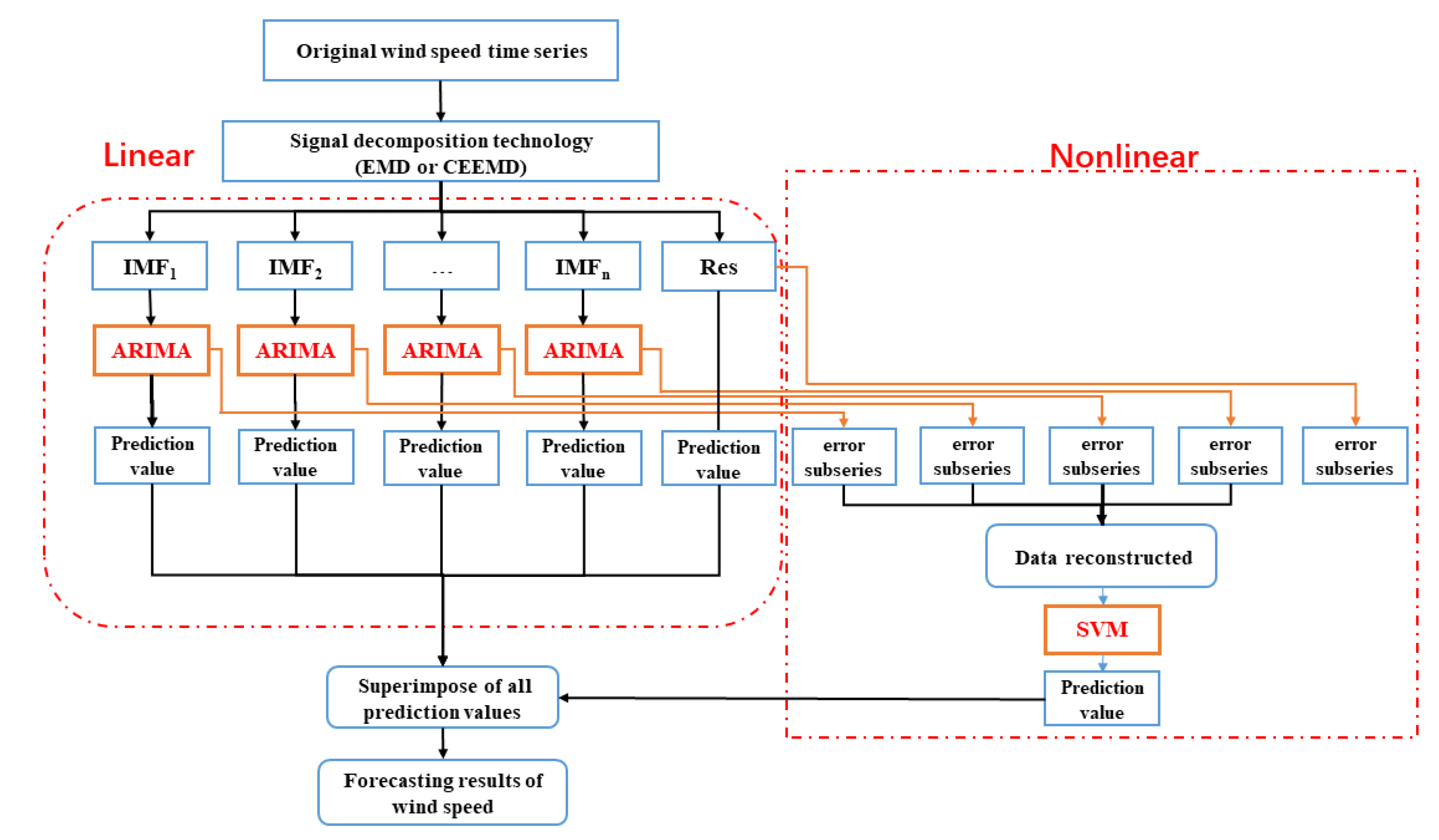
3. Framework of the Proposed Hybrid Wind Speed Prediction Model
4. Experiments and Results Analysis
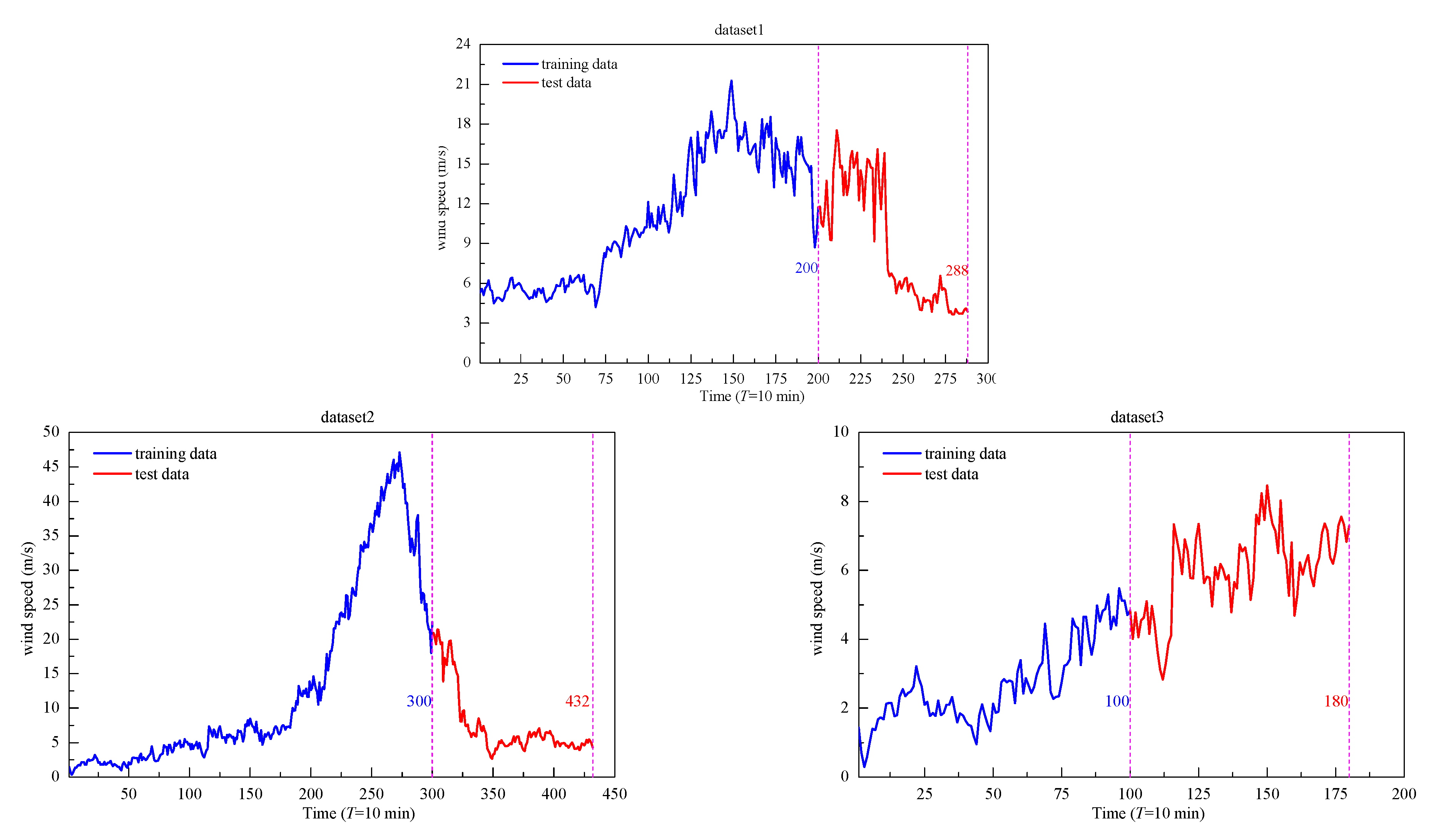
4.1. Description of Wind Speed Data
4.2. Evaluation Indexes
- Mean absolute error
- Mean absolute percentage error
- Root mean squared errorwhere is the measured wind speed at a certain moment in time; is the predicted wind speed; and N is the forecasted wind speed. The smaller the value of the three evaluation indexes, the higher the prediction accuracy of the forecasting model.
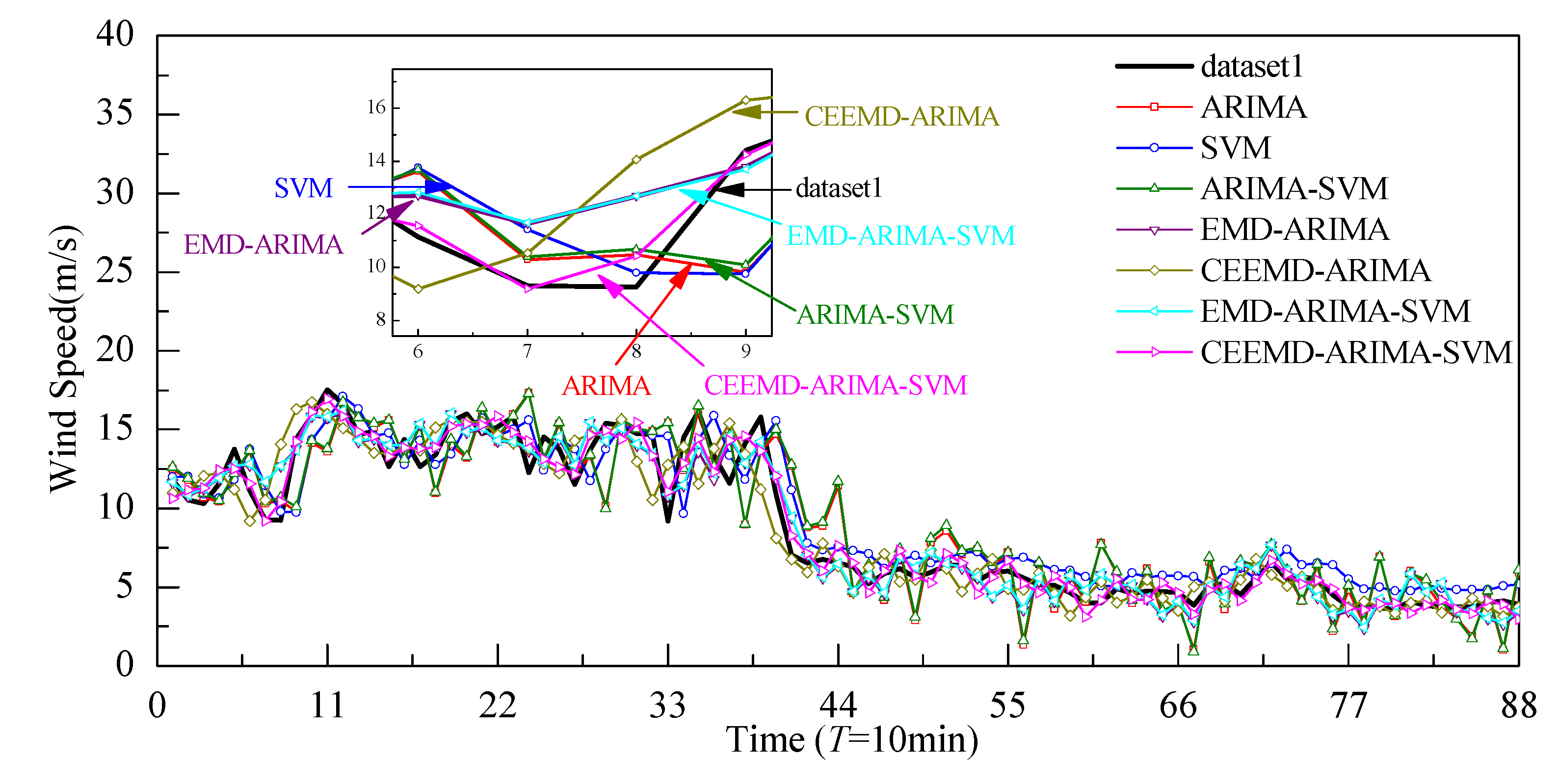
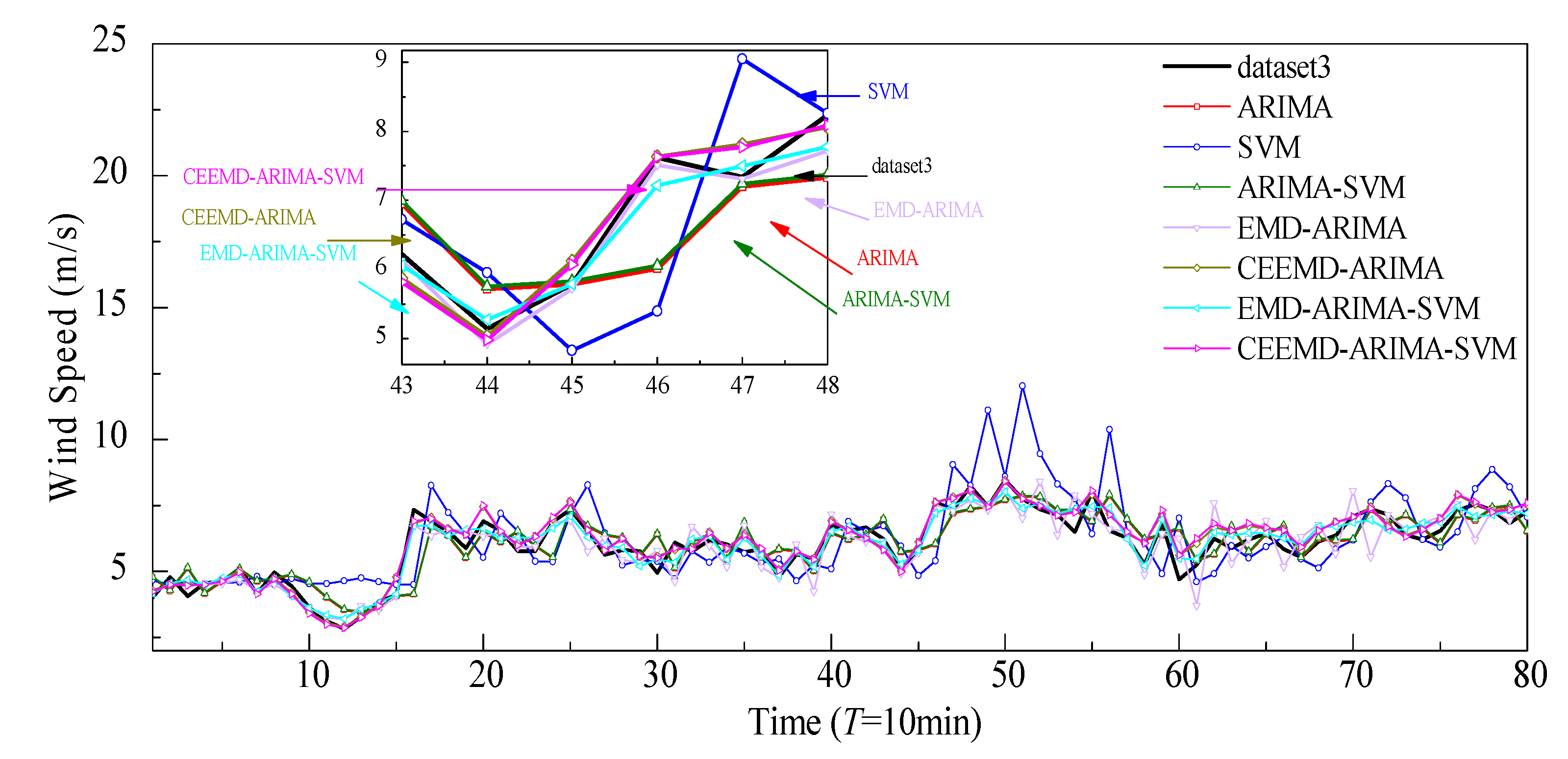
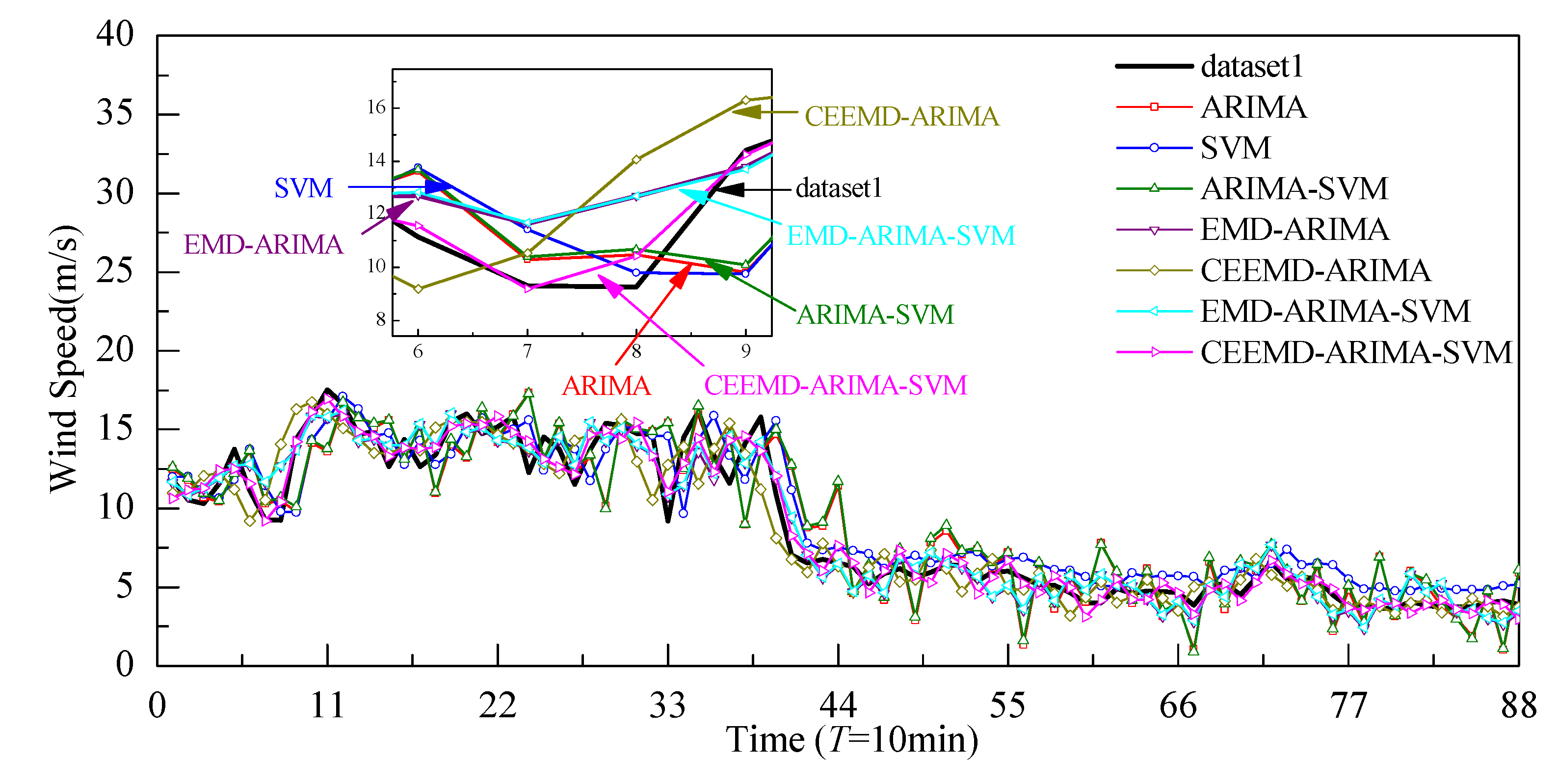
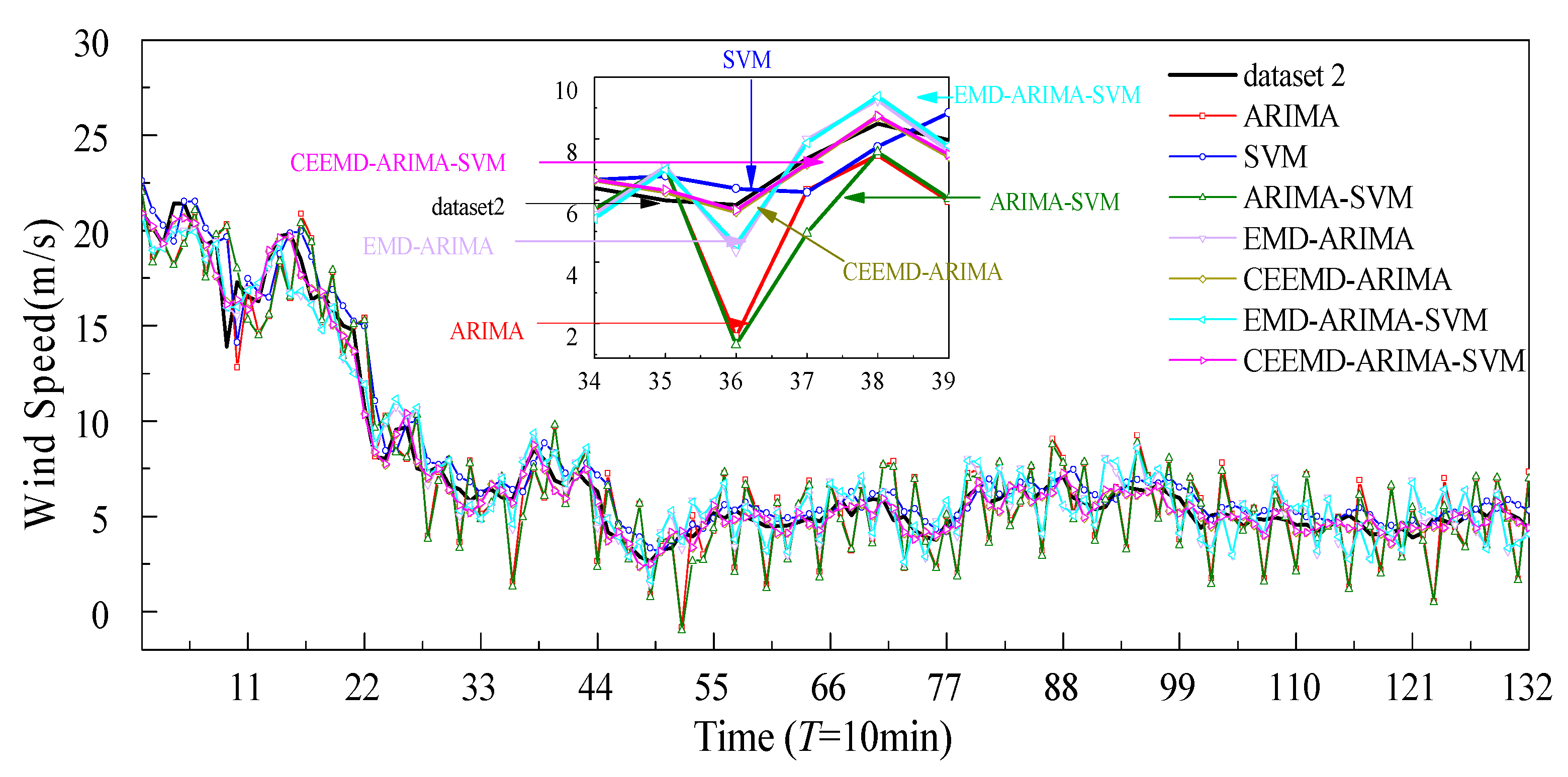
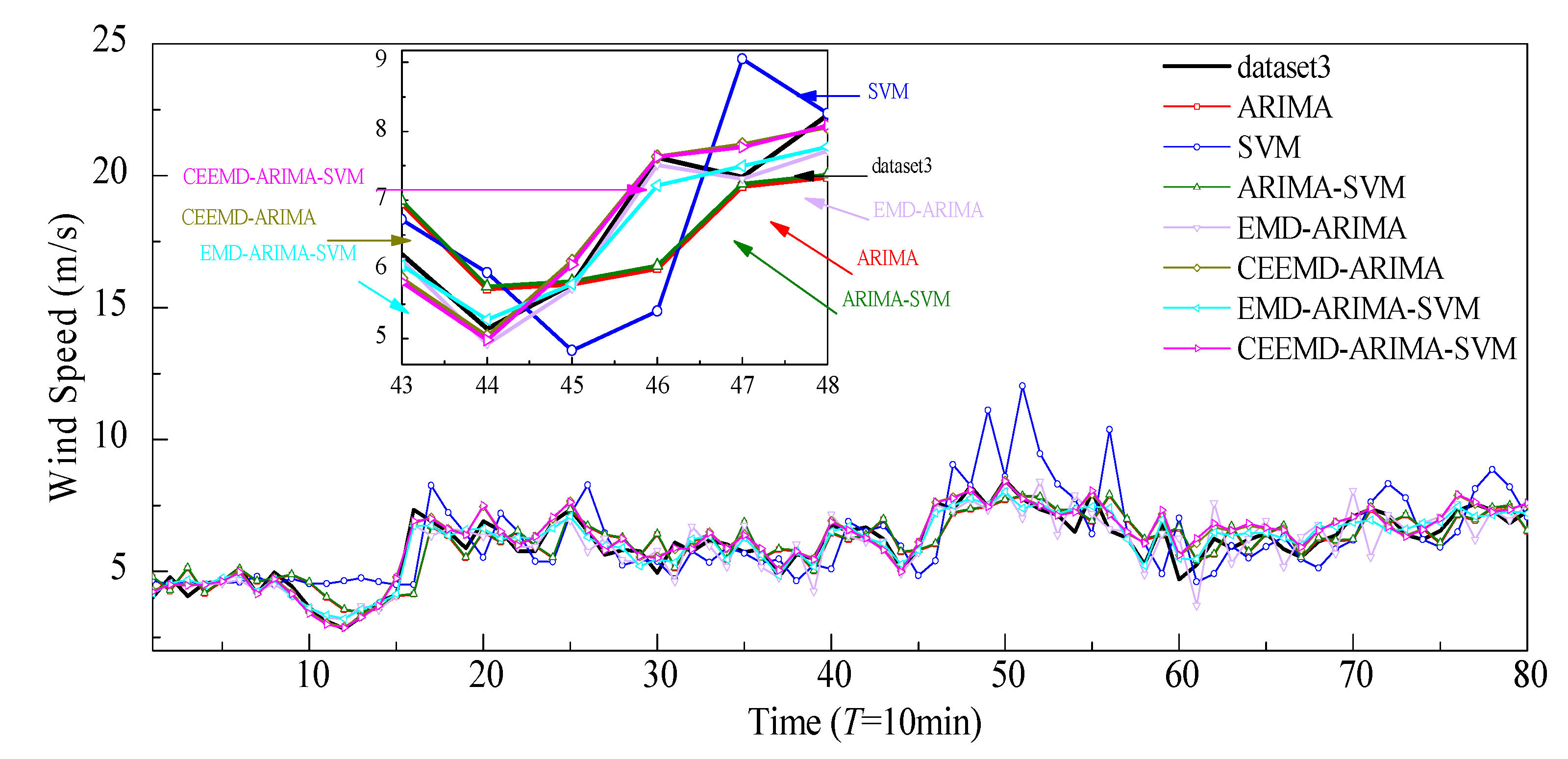
4.3. Analysis of Comparative Results
5. Conclusions
- The hybrid model shows higher prediction accuracy than the single model. The hybrid model is more suitable for higher volatility of wind speeds, exhibiting the ability to capture the fluctuating characteristics of wind speeds, while the single ARIMA model is more suitable for less volatile data.
- The EMD and CEEMD can reduced the nonstationarity and nonlinearity of the original wind speed. It decomposes the raw wind speeds into a series of subsequences, greatly reducing wind speed volatility. The prediction accuracy of the hybrid models has been obviously improved with the aid of the decomposition technologies, such as EMD and CEEMD, since CEEMD has removed the disadvantage of the appearance of modal mixing for EMD. Overall, the prediction performance of the CEEMD-ARIMA-SVM is better than that of the EMD-ARIMA-SVM model.
- Taking the three wind speed datasets as experiment examples, the prediction performance of the proposed EMD/CEEMD-ARIMA-SVM wind prediction model achieved optimum results according to the minimal evaluation indexes of MAE, MAPE, and RMSE.
- It seems that the prediction performance of the hybrid model mainly relies on the combination of CEEMD with ARIMA. The SVM method has only slight effects on the prediction performances of the hybrid model, as the error subseries prediction results using the SVM method show few improvement effects on the overall prediction results.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiang, H.; Li, Y.; Chen, S.; Hou, G. Wind loads of moving vehicle on bridge with solid wind barrier. Eng. Struct. 2018, 156, 188–196. [Google Scholar] [CrossRef]
- Kobayashi, N.; Shimamura, M. Study of a strong wind warning system. In JR East Technical Review; East Japan Railway Culture Foundation: Tokyo, Japan, 2003. [Google Scholar]
- Hoppmann, U.; Koenig, S.; Tielkes, T.; Matschke, G. A short-term strong wind prediction model for railway application: Design and verification. J. Wind Eng. Ind. Aerod. 2002, 90, 1127–1134. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Jahangir, H.; Golkar, M.A.; Alhameli, F.; Mazouz, A.; Ahmadian, A.; Elkamel, A. Short-term wind speed forecasting framework based on stacked denoising auto-encoders with rough ANN. Sustain. Energy Technol. Assess. 2020, 38, 100601. [Google Scholar] [CrossRef]
- Chen, G.; Tang, B.; Zeng, X.; Zhou, P.; Kang, P.; Long, H. Short-term wind speed forecasting based on long short-term memory and improved BP neural network. Int. J. Electr. Power Energy Syst. 2022, 134, 107365. [Google Scholar] [CrossRef]
- Zuluaga, C.D.; Álvarez, M.A.; Giraldo, E. Short-term wind speed prediction based on robust Kalman filtering: An experimental comparison. Appl. Energy 2015, 156, 321–330. [Google Scholar] [CrossRef]
- Liu, M.; Cao, Z.; Zhang, J.; Wang, L.; Huang, C.; Luo, X. Short-term wind speed forecasting based on the Jaya-SVM model. Int. J. Electr. Power Energy Syst. 2020, 121, 106056. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Jiang, P. The study and application of a novel hybrid forecasting model—A case study of wind speed forecasting in China. Appl. Energy 2015, 143, 472–488. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Liang, X.; Li, Y. New wind speed forecasting approaches using fast ensemble empirical model decomposition, genetic algorithm, Mind Evolutionary Algorithm and Artificial Neural Networks. Renew. Energy 2015, 83, 1066–1075. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Zhao, J.; Liu, T.; Zhu, T.; Zhang, K. Short-term wind speed forecasting using empirical mode decomposition and feature selection. Renew. Energy 2016, 96, 727–737. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Ma, K.; Zhang, Y. A self-adaptive hybrid approach for wind speed forecasting. Renew. Energy 2015, 78, 374–385. [Google Scholar] [CrossRef]
- Nair, K.R.; Vanitha, V.; Jisma, M. Forecasting of wind speed using ANN, ARIMA and Hybrid models. In Proceedings of the 2017 International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT), Kannur, India, 6–7 July 2017; pp. 170–175. [Google Scholar]
- Santhosh, M.; Venkaiah, C.; Vinod Kumar, D.M. Ensemble empirical mode decomposition based adaptive wavelet neural network method for wind speed prediction. Energy Convers. Manag. 2018, 168, 482–493. [Google Scholar] [CrossRef]
- Li, Y.; Shi, H.; Han, F.; Duan, Z.; Liu, H. Smart wind speed forecasting approach using various boosting algorithms, big multi-step forecasting strategy. Renew. Energy 2019, 135, 540–553. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, X.; Pan, K.; Liu, Y. A novel wind speed forecasting based on hybrid decomposition and online sequential outlier robust extreme learning machine. Energy Convers. Manag. 2019, 180, 338–357. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, G.; Yao, T. An EMD-SVM model with error compensation for short-term wind speed forecasting. Int. J. Inf. Technol. Manag. 2019, 18, 171. [Google Scholar]
- Tao, T.; Shi, P.; Wang, H.; Yuan, L.; Wang, S. Performance Evaluation of Linear and Nonlinear Models for Short-Term Forecasting of Tropical-Storm Winds. Appl. Sci. 2021, 11, 9441. [Google Scholar] [CrossRef]
- Liu, M.; Ding, L.; Bai, Y. Application of hybrid model based on empirical mode decomposition, novel recurrent neural networks and the ARIMA to wind speed prediction. Energy Convers. Manag. 2021, 233, 113917. [Google Scholar] [CrossRef]
- Li, Z.; Luo, X.; Liu, M.; Cao, X.; Du, S.; Sun, H. Wind power prediction based on EEMD-Tent-SSA-LS-SVM. Energy Rep. 2022, 8, 3234–3243. [Google Scholar] [CrossRef]
- Hu, H.; Li, Y.; Zhang, X.; Fang, M. A Novel Hybrid Model for Short-term Prediction of Wind Speed. Pattern Recogn. 2022, 127, 108623. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. A study of the characteristics of white noise using the empirical mode decomposition method. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 2004, 460, 1597–1611. [Google Scholar] [CrossRef]
- Yeh, J.; Shieh, J.; Huang, N.E. Complementary ensemble empirical mode decomposition: A novel noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Shukur, O.B.; Lee, M.H. Daily wind speed forecasting through hybrid KF-ANN model based on ARIMA. Renew. Energy 2015, 76, 637–647. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J. A robust combination approach for short-term wind speed forecasting and analysis–Combination of the ARIMA (Autoregressive Integrated Moving Average), ELM (Extreme Learning Machine), SVM (Support Vector Machine) and LSSVM (Least Square SVM) forecasts using a GPR (Gaussian Process Regression) model. Energy 2015, 93, 41–56. [Google Scholar]
- Vapnik, V.N. The Natural of Statistical Learnig Theory, 2nd ed.; Springer: New York, NY, USA, 1999. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Liu, S.; Heng, J.; Gao, Y. A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm. Appl. Sci. 2018, 8, 1754. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, S.; Kong, D.; Liu, S. Methane Detection Based on Improved Chicken Algorithm Optimization Support Vector Machine. Appl. Sci. 2019, 9, 1761. [Google Scholar] [CrossRef] [Green Version]
- Pai, P.; Lin, C. A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 2005, 33, 497–505. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, F.; Marti-Puig, P.; Caiafa, C.F.; Solé-Casals, J. Serial-EMD: Fast Empirical Mode Decomposition Method for Multi-dimensional Signals Based on Serialization. Inform. Sci. 2021, 581, 215–232. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typhoon | Sample Data | Number of Data | Training Set | Test Set | Mean Wind Speed (m/s) | Range of Wind Speed (m/s) | Volatility Level |
|---|---|---|---|---|---|---|---|
| Wutip | Dataset 1 | 288 | 200 | 88 | 10.23 | 3.64~21.69 | moderate |
| Ramason | Dataset 2 | 432 | 300 | 142 | 11.44 | 0.29~47.12 | high |
| Dataset 3 | 180 | 100 | 80 | 4.18 | 0.3~8.47 m/s | low |
| Dataset 1 | Dataset 2 | Dataset 3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE (m/s) | MAPE (%) | RMSE (m/s) | MAE (m/s) | MAPE (%) | RMSE (m/s) | MAE (m/s) | MAPE (%) | RMSE (m/s) | |
| ARIMA | 1.787 | 25.122 | 2.269 | 1.747 | 29.222 | 2.116 | 0.557 | 9.768 | 0.751 |
| SVM | 1.391 | 18.777 | 1.748 | 0.746 | 11.226 | 1.091 | 0.940 | 15.959 | 1.267 |
| ARIMA-SVM | 1.821 | 25.851 | 2.283 | 1.767 | 29.627 | 2.116 | 0.556 | 9.829 | 0.753 |
| EMD-ARIMA | 1.037 | 14.178 | 1.271 | 1.036 | 17.708 | 1.264 | 0.498 | 8.381 | 0.655 |
| CEEMD-ARIMA | 0.669 | 8.046 | 0.849 | 0.417 | 6.710 | 0.537 | 0.289 | 5.026 | 0.375 |
| EMD-ARIMA-SVM | 1.027 | 14.075 | 1.260 | 1.032 | 17.548 | 1.245 | 0.477 | 8.103 | 0.628 |
| CEEMD-ARIMA-SVM | 0.664 | 8.098 | 0.839 | 0.412 | 6.672 | 0.529 | 0.288 | 5.010 | 0.377 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, N.; Sun, H.; Zhang, Q.; Li, S. A Short-Term Wind Speed Forecasting Model Based on EMD/CEEMD and ARIMA-SVM Algorithms. Appl. Sci. 2022, 12, 6085. https://doi.org/10.3390/app12126085
Chen N, Sun H, Zhang Q, Li S. A Short-Term Wind Speed Forecasting Model Based on EMD/CEEMD and ARIMA-SVM Algorithms. Applied Sciences. 2022; 12(12):6085. https://doi.org/10.3390/app12126085
Chicago/Turabian StyleChen, Ning, Hongxin Sun, Qi Zhang, and Shouke Li. 2022. "A Short-Term Wind Speed Forecasting Model Based on EMD/CEEMD and ARIMA-SVM Algorithms" Applied Sciences 12, no. 12: 6085. https://doi.org/10.3390/app12126085
APA StyleChen, N., Sun, H., Zhang, Q., & Li, S. (2022). A Short-Term Wind Speed Forecasting Model Based on EMD/CEEMD and ARIMA-SVM Algorithms. Applied Sciences, 12(12), 6085. https://doi.org/10.3390/app12126085