
On the Track to Application Architectures in Public Transport Service Companies

Abstract
:1. Introduction
2. Current Frameworks and Maturity Models Which Could Be Used to Build Up an AI Landscape in Organizations
3. Compiling an AI Landscape for the Public Service Transportation Business Domain
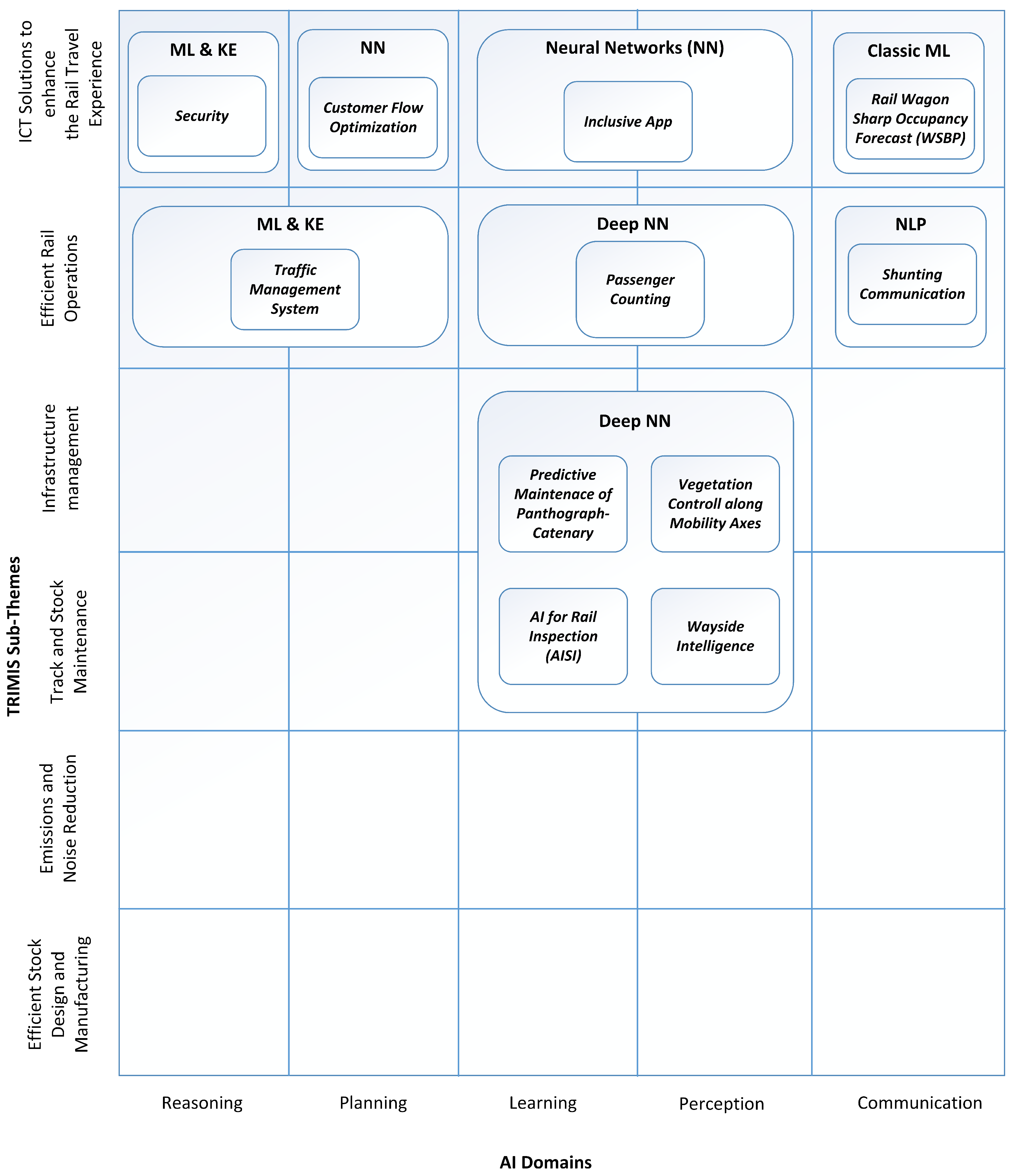
3.1. AIKM Landscape—The Domain-Specific Structural View
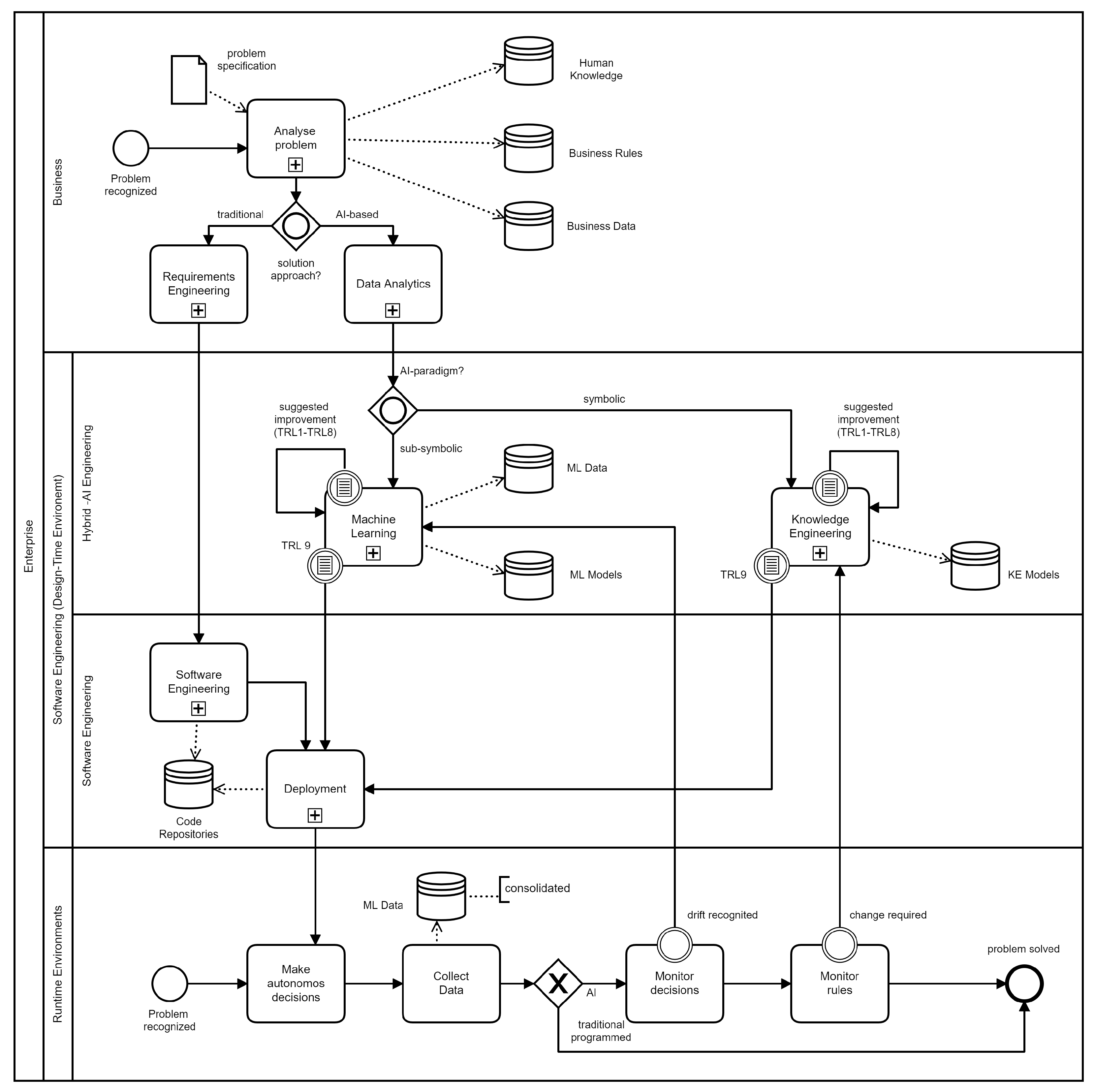
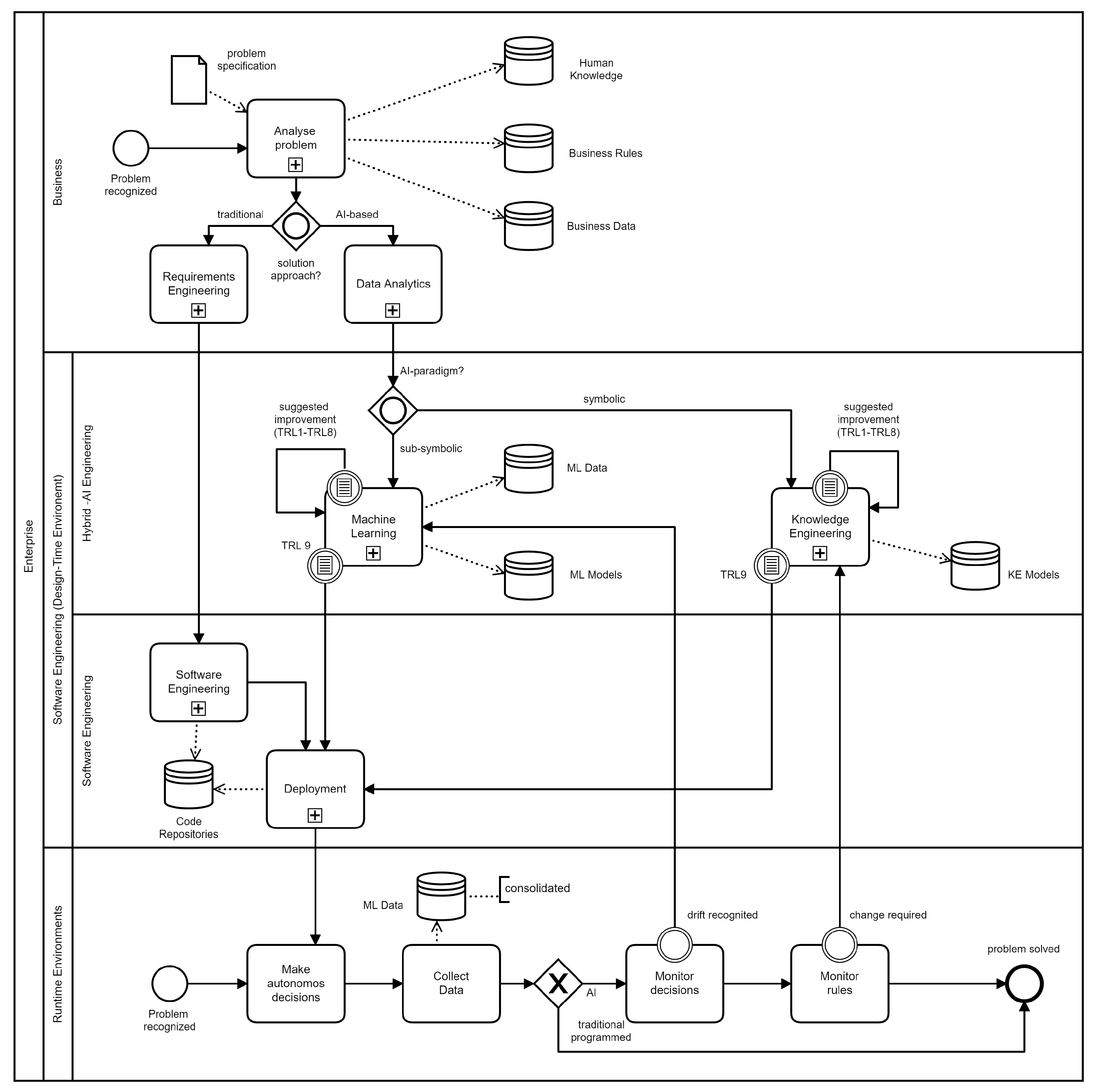
3.2. AI-Based Software Development Life-Cycle—Organizational Behavior View
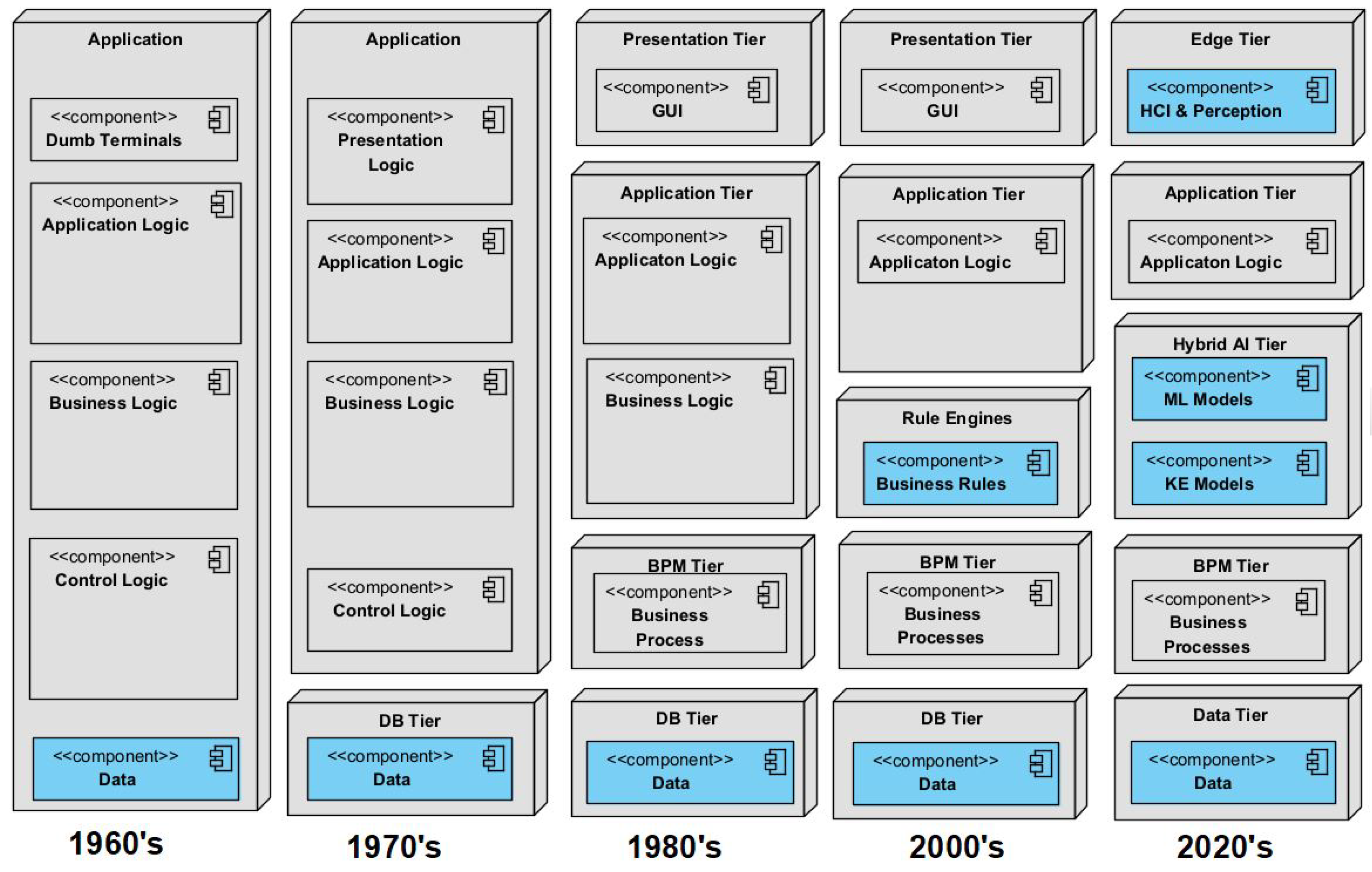
3.3. Towards an AI-Embedded Software Architecture
4. Current State of Use-Cases from Different Transportation Service Providers
4.1. Use Case—Passenger Counting at BVB
4.2. Predictive Maintenance of the Pantograph-Catenary System at RBS
4.3. AI in Rail-Inspect at SBB
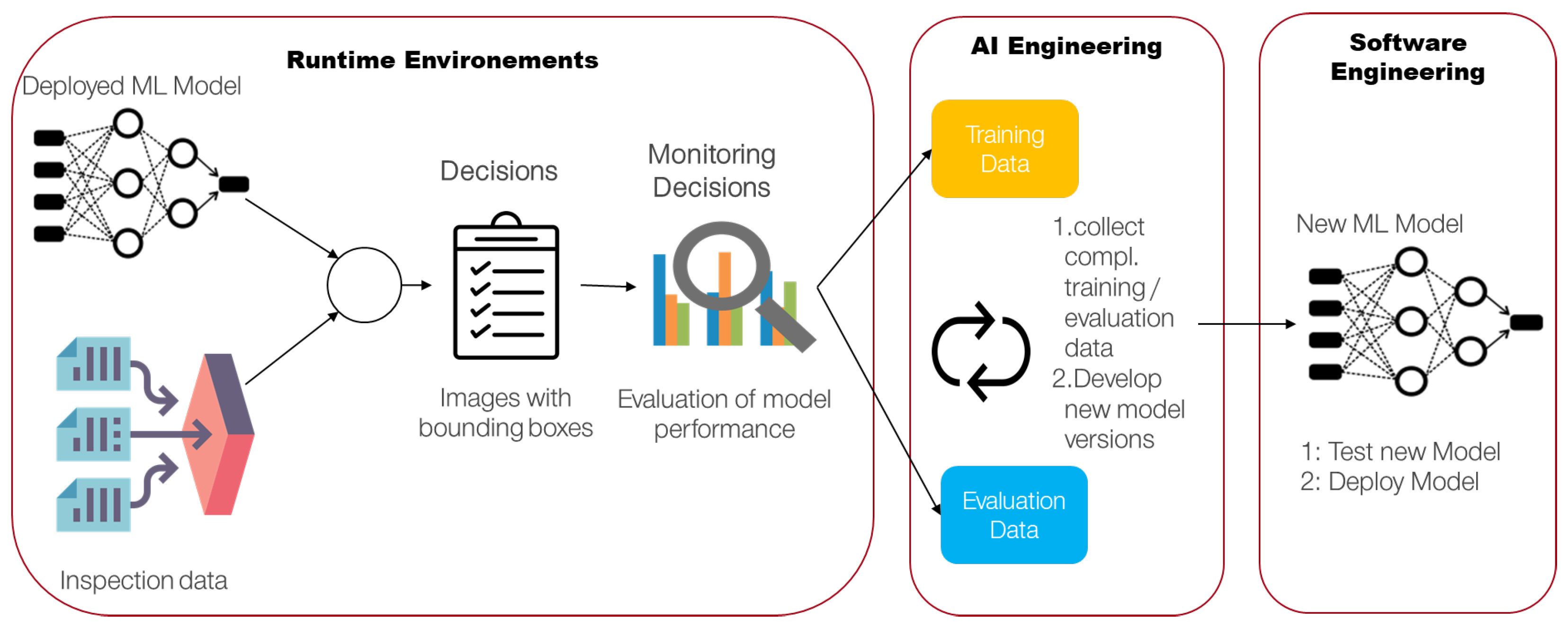
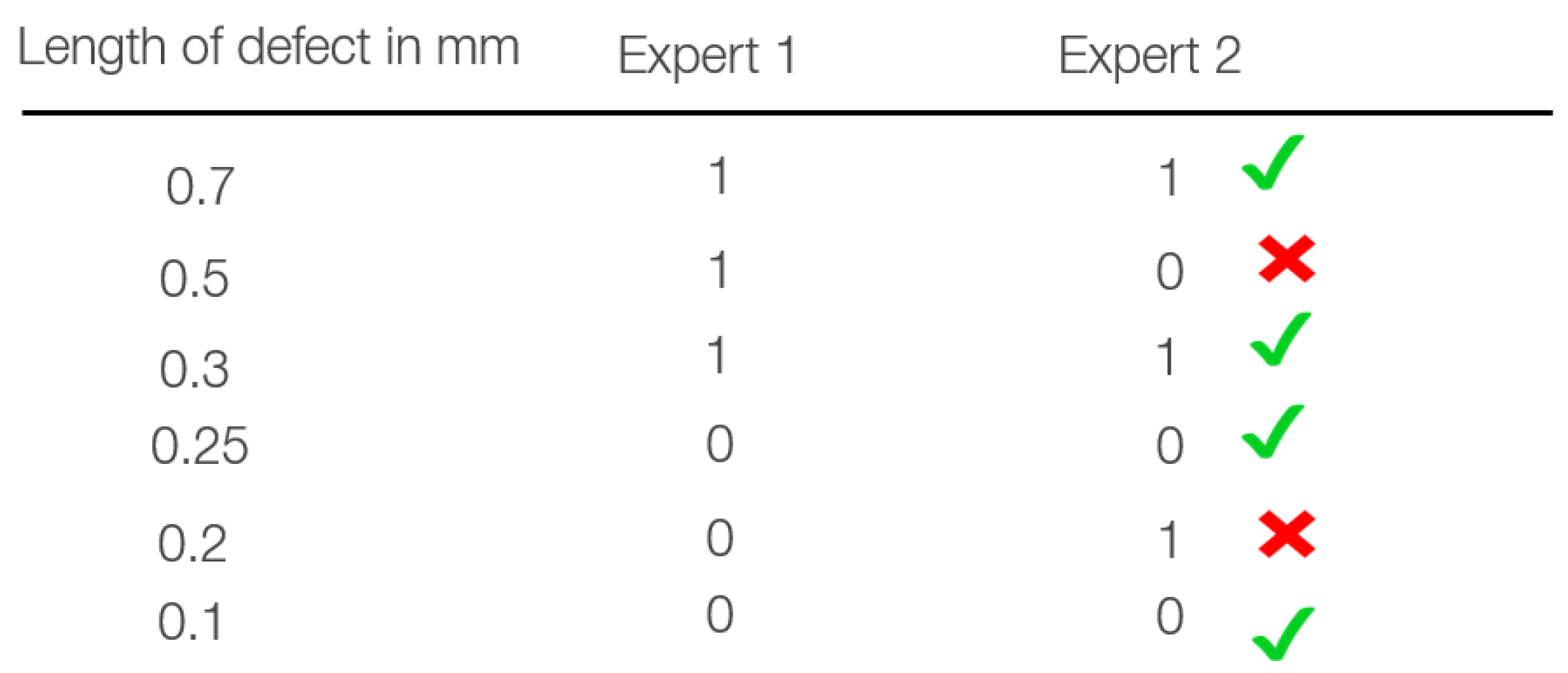
4.3.1. Data and Model Life-Cycle
4.3.2. Pipelines and Release-Management
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Webb, G.I.; Lee, L.K.; Goethals, B.; Petitjean, F. Analyzing concept drift and shift from sample data. Data Min. Knowl. Discov. 2018, 32, 1179–1199. [Google Scholar] [CrossRef]
- Object Management Group. Business Process Model and Notation; Object Management Group: Needham, MA, USA, 2021. [Google Scholar]
- Decision Model and Notation DMN v.1.3, 2021. Available online: https://www.omg.org/spec/DMN/1.3/About-DMN/ (accessed on 17 December 2021).
- Weber, C.V.; Curtis, B.; Chrissis, M.B. Capability Maturity Model, Version 1.1. IEEE Softw. 1993, 10, 18–27. [Google Scholar] [CrossRef]
- Lenarduzzi, V.; Lomio, F.; Moreschini, S.; Taibi, D.; Tamburri, D.A. Software Quality for AI: Where We Are Now? Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 404, pp. 43–53. [Google Scholar] [CrossRef]
- Gartner. The-Cios-Guide-to-Artificial-Intelligence. 2021. Available online: https://www.gartner.com (accessed on 17 December 2021).
- Little, C.; McCormick, J. Measure Your Digital Intelligence Maturity; Forrester Research: Cambridge, MA, USA, 2019; p. 11. [Google Scholar]
- Amershi, S.; Begel, A.; Bird, C.; DeLine, R.; Gall, H.; Kamar, E.; Nagappan, N.; Nushi, B.; Zimmermann, T. Software Engineering for Machine Learning: A Case Study. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP 2019), Montreal, QC, Canada, 25–31 May 2019; pp. 291–300. [Google Scholar] [CrossRef]
- Samoili, S.; López Cobo, M.; Gómez, E.; De Prato, G.; Martínez-Plumed, F.; Delipetrev, B. AI Watch—Defining Artificial Intelligence. Towards An Operational Definition and Taxonomy of Artificial Intelligence; EPrints: Southampton, UK, 2020; pp. 1–90. [Google Scholar] [CrossRef]
- Martínez-Plumed, F.; Gómez, E.; Hernández-Orallo, J. AI Watch: Assessing Technology Readiness Levels for Artificial Intelligence; Technical Report; Joint Research Centre: Ibaraki, Japan, 2020. [Google Scholar] [CrossRef]
- Jöhnk, J.; Weißert, M.; Wyrtki, K. Ready or Not, AI Comes—An Interview Study of Organizational AI Readiness Factors. Bus. Inf. Syst. Eng. 2021, 63, 5–20. [Google Scholar] [CrossRef]
- Franceso, C. AI knowledge Map: How to Classify AI Technologies, a Sketch of a New AI Technology Landscape; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Morley, J.; Machado, C.C.; Burr, C.; Cowls, J.; Joshi, I.; Taddeo, M.; Floridi, L. The Ethics of AI in Health Care: A Mapping Review. Philos. Stud. Ser. 2021, 144, 313–346. [Google Scholar] [CrossRef]
- Floridi, L. What the Near Future of Artificial Intelligence Could Be. Philos. Technol. 2019, 32, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Monitoring, I. Rail Transport Research and Innovation in Europe; Publications Office of the European Union: Luxembourg, 2021. [Google Scholar] [CrossRef]
- Schroeder, C. The Challenges of Industry 4.0 for Small and Medium-Sized Enterprises; Friedrich Ebert Foundation: Bonn, Germany, 2015; pp. 1–28. [Google Scholar]
- Hinkelmann, K.; Martin, A.; Fill, H.-G.; Gerber, A.; Lenat, D.; Stolle, R.F.v.H.E. Combining Machine Learning and Knowledge Engineering. In Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE 2021), Palo Alto, CA, USA, 22–24 March 2021. [Google Scholar]
- Peraic, M. Feasibility Study: Al-based Passenger Counting System for Public Transit. Bachelor’s Thesis, University of Applied Sciences and Arts Northwestern Switzerland, Basel, Switzerland, 2019. [Google Scholar]
- Jüngling, S.; Peraic, M.; Martin, A. Towards AI-based Solutions in the System Development Lifecycle. In Proceedings of the AAAI 2020 Spring Symposium on Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE 2020), Palo Alto, CA, USA, 23–25 March 2020; Volume I, p. 2600. [Google Scholar]
- Morandi, D.; Jüngling, S. Anomaly Detection in Railway Infrastructure. In Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge S Engineering in Practice (AAAI-MAKE 2021), Palo Alto, CA, USA, 22–24 March 2021. [Google Scholar]
- SBB. Flatland-Challenge. Available online: https://www.aicrowd.com (accessed on 17 December 2021).
- Miranda, L.J. Towards Data-Centric Machine Learning: A Short Review. Available online: https://ljvmiranda921.github.io (accessed on 17 December 2021).
- Tian, J.; Hsu, Y.C.; Shen, Y.; Jin, H.; Kira, Z. Exploring Covariate and Concept Shift for Detection and Calibration of Out-of-Distribution Data. arXiv 2021, arXiv:2110.15231. [Google Scholar]
- Wang, X.; Wang, Z.; Shao, W.; Jia, C.; Li, X. Explaining Concept Drift of Deep Learning Models. In Cyberspace Safety and Security; Series Title: Lecture Notes in Computer Science; Vaidya, J., Zhang, X., Li, J., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 11983, pp. 524–534. [Google Scholar] [CrossRef]
- Ng, A. A Chat with Andrew on MLOps: From Model-centric to Data-centric AI. Available online: https://www.deeplearning.ai/wp-content/uploads/2021/06/MLOps-From-Model-centric-to-Data-centric-AI.pdf (accessed on 17 December 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domains | Sub-Domains |
|---|---|
| CD—Reasoning | knowledge representation, automated reasoning, common sense reasoning |
| CD—Planning | planning and scheduling, searching, optimization |
| CD—Learning | machine learning |
| CD—Communication | natural language processing |
| CD—Perception | computer vision, audio processing |
| TD—Integration and Interaction | multi-agent systems, robotics and automation, connected and automated vehicles |
| TD—Services | AI Services |
| TD—Ethics and Philosophy | AI Ethics, Philosophy of AI |
| Categories | Technologies |
|---|---|
| Knowledge Representation & reasoning | Expert Systems |
| Learning | Recommender Systems, apprentices by demonstration |
| Communication | Machine Translation, Speech Recognition |
| Perception | Facial recognition, text recognition |
| Planning | Transport and scheduling systems |
| Physical Interaction (Robotics) | Self-Driving Cars, Home Cleaning Robots |
| Social & Collaborative Intelligence | Negotiation Agents |
| Integration Technology | Virtual Assistants |
| Technology Readiness Levels | Descriptions |
|---|---|
| TRL 1—Proof of concept | Basic principles observed |
| TRL 2—Proof of concept | Technology concept formulated |
| TRL 3—Proof of concept | Experimental proof of concept |
| TRL 4—Prototype | Technology validated in lab |
| TRL 5—Prototype | Technology validated in relevant environment |
| TRL 6—Prototype | Technology demonstrated in relevant environment |
| TRL 7—Prototype | System prototype demonstration in operational environment |
| TRL 8—Product or Service certified | System complete and qualified |
| TRL 9—Deployment | Actual System proven in operational environment |
| Categories | AI Readiness Factors |
|---|---|
| Strategic alignment | AI-business potentials, Customer AI readiness, Top management support, AI process fit, Data-driven decision making |
| Resources | Financial budget, Personnel, IT infrastructure |
| Knowledge | AI awareness, Upskilling, AI ethics |
| Culture | Innovativeness, Collaborative work, Change management |
| Data | Data availability, Data quality, Data accessibility, Data flow |
| Sub-Theme | Sub-Theme Focus |
|---|---|
| Efficient stock design and manufacturing: | Innovations in the area of rail stock (passenger trains, freight locomotives and wagons) in terms of both design and manufacturing. |
| Emissions and noise reduction: | Research projects investigating the reduction of railway noise and emissions; through reduced energy consumption and reduced railway vibrations causing noise (including track interventions to reduce noise) |
| Track and stock maintenance: | Technologies to predict maintenance needs of both rolling stock and the railway tracks, as well as techniques for monitoring the condition of each in real-time. |
| Efficient rail operations: | Improving the efficiency of the railway through traffic management systems, automation and control systems. |
| Infrastructure management: | Optimal management of railway infrastructure, which includes electrical infrastructure (overhead lines), level crossing safety and protection from potential threats. |
| Information and Communications Technologies (ICT) solutions to enhance the rail travel experience: | Services to improve the passenger experience, including smart-ticketing systems spanning multiple transport modes and considering passengers with restricted mobility. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jüngling, S.; Fetai, I.; Rogger, A.; Morandi, D.; Peraic, M. On the Track to Application Architectures in Public Transport Service Companies. Appl. Sci. 2022, 12, 6073. https://doi.org/10.3390/app12126073
Jüngling S, Fetai I, Rogger A, Morandi D, Peraic M. On the Track to Application Architectures in Public Transport Service Companies. Applied Sciences. 2022; 12(12):6073. https://doi.org/10.3390/app12126073
Chicago/Turabian StyleJüngling, Stephan, Ilir Fetai, André Rogger, David Morandi, and Martin Peraic. 2022. "On the Track to Application Architectures in Public Transport Service Companies" Applied Sciences 12, no. 12: 6073. https://doi.org/10.3390/app12126073
APA StyleJüngling, S., Fetai, I., Rogger, A., Morandi, D., & Peraic, M. (2022). On the Track to Application Architectures in Public Transport Service Companies. Applied Sciences, 12(12), 6073. https://doi.org/10.3390/app12126073