
Focus on Point: Parallel Multiscale Feature Aggregation for Lane Key Points Detection


Abstract
:1. Introduction
- Through abstracting the lane lines as a series of discrete key points, we propose a novel lane detection method based on key points, FPLane. Different from previous detection methods, the proposed method can accurately predict key points of lanes directly from input images or videos, which not only eliminates the need for an object detection box and complicated post-processing, but also reduces the influence of background pixels, thus simplifying the output of the model. Therefore, it is suitable for processing road scenes that include arbitrary numbers or any structures of lanes.
- We propose the parallel Multi-scale Feature Aggregation network to take full advantage of the prior information of adjacent lanes. MFANet can not only extract more discernible representations in complex scenarios with a weak appearance (e.g., vehicle occlusion, road degradation or weak light, etc.), but can also alleviate the information loss in the feature sampling to a certain extent.
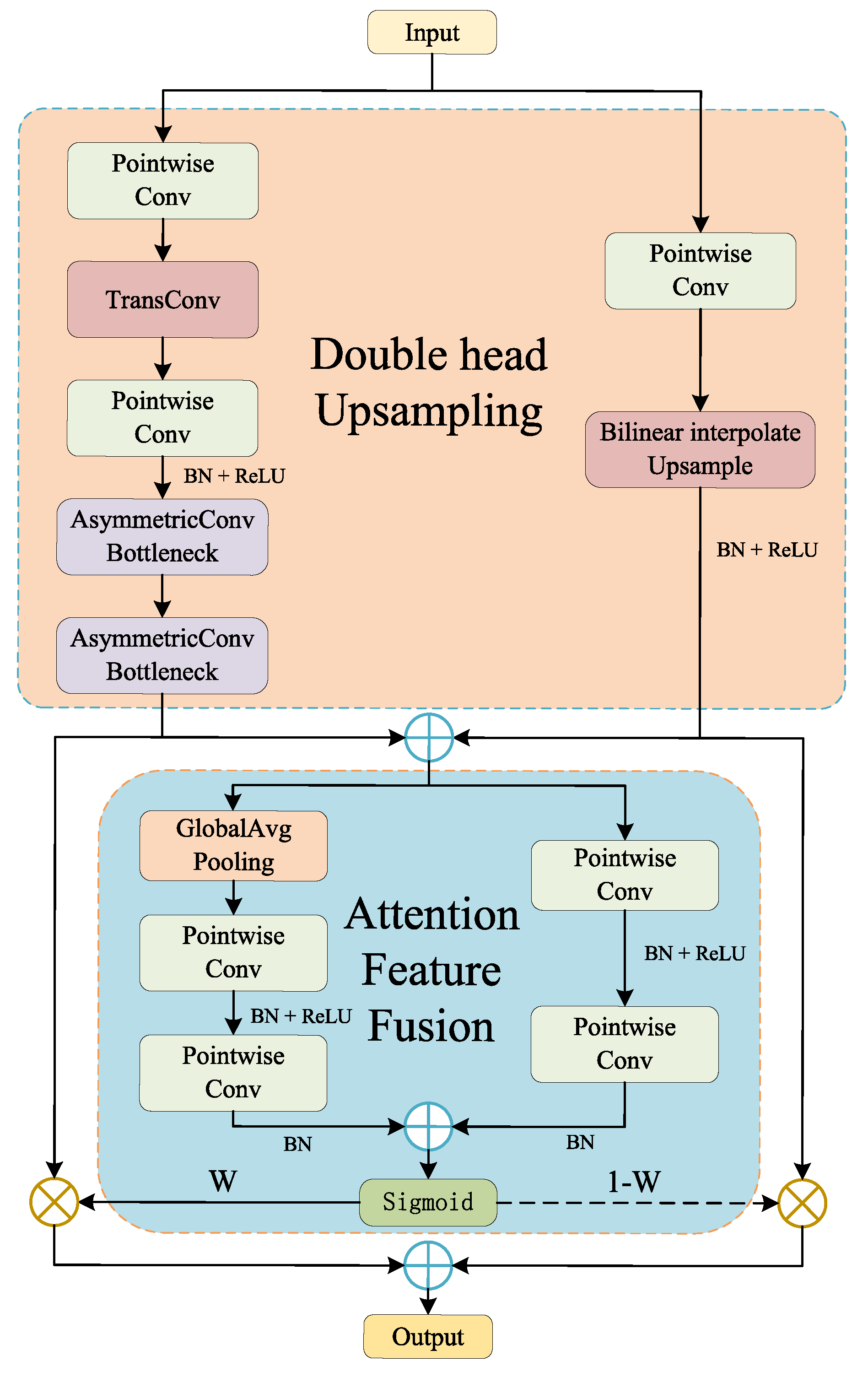
- We propose the Double-headed Attention Feature Fusion Up-sampling module and integrate it into MFANet. This module can precisely cast the sampled feature mapping to the higher resolution representation, and can effectively integrate the spatial information of depth features.
2. Related Work
2.1. Lane Detection
2.2. Network Architecture for Key Points Detection
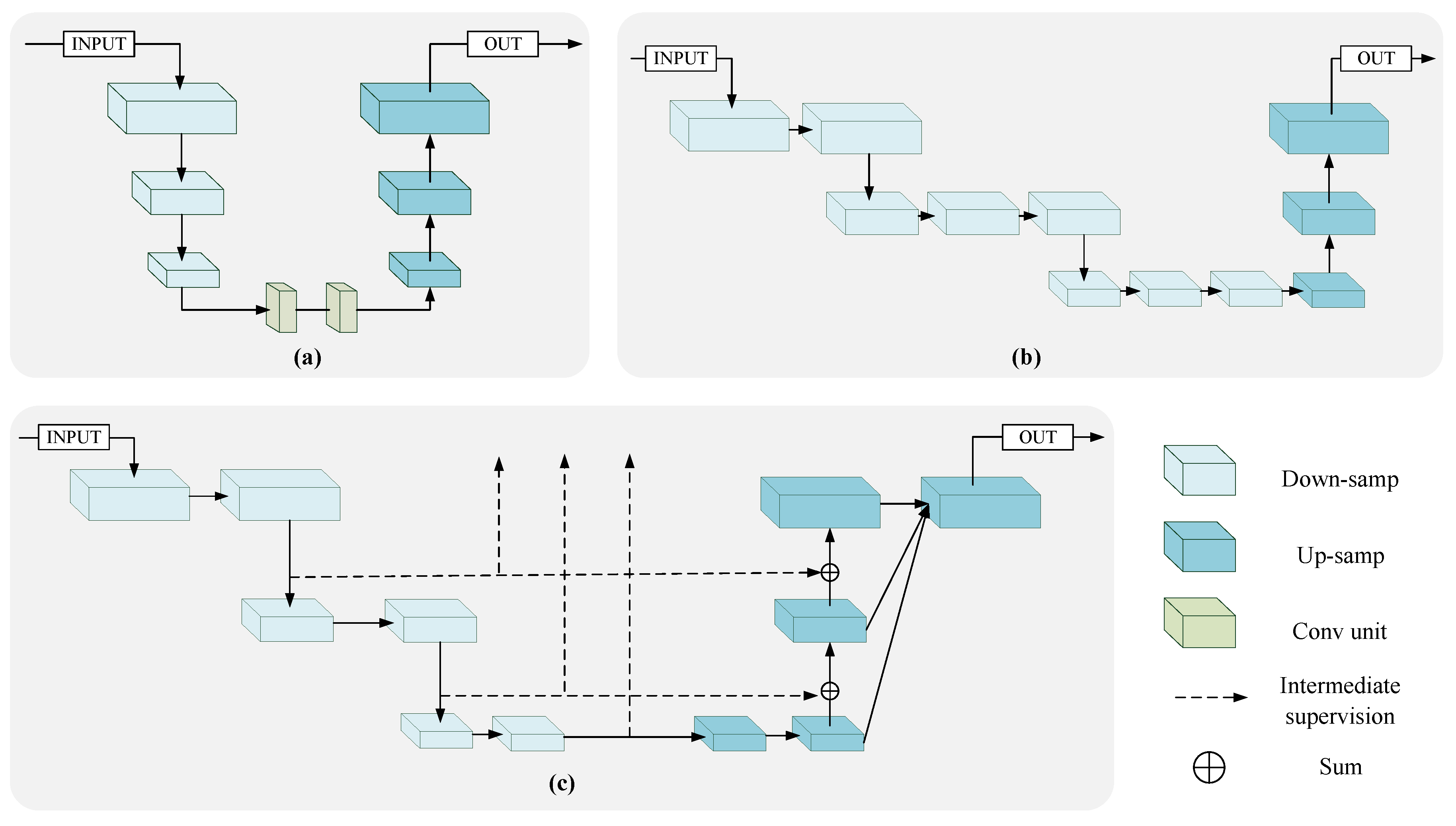
3. Methodology
3.1. Parallel Multi-Scale Feature Aggregation Network
3.1.1. Encoder
3.1.2. Decoder
3.1.3. Analysis of Architecture
3.2. Global Key Points Detection
3.3. Grouping Key Points with Association Embedding
- Setting the embedding distance threshold (where ), which is used to determine whether the embeddings belong to the same lane.
- Selecting a random embedding from all key point embeddings, and assigning a lane label l for it. The value of this embedding is the initial cluster center of the lane l.
- Selecting another embedding from remaining embeddings to calculate the feature distance between (L2 distance). If the feature distance is less than or equal to , is assigned to the same label l and the average value of and is taken as the new cluster center of the lane l. Otherwise, proceed to screen the next embedding.
- Repeating step 3 to go through all remaining embeddings and find all embeddings of the lane l.
- A new round of iteration is performed for remaining key point embeddings without labels, and steps 2, 3 and 4 are repeated until all key point embeddings are assigned a lane label.
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Result
4.3.1. TuSimple
4.3.2. CULane
4.4. Ablation Study
4.4.1. The Effect of Balanced Factor
4.4.2. Effectiveness Analysis of DAFU
4.4.3. Parallel Connections in MFANet
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dun, L.; Guo, Y.; Zhang, S.; Mu, T.; Huang, X. Lane Detection: A Survey with New Results. J. Comput. Sci. Technol. 2020, 35, 493–505. [Google Scholar]
- López, A.; Serrat, J.; Canero, C.; Lumbreras, F.; Graf, T. Robust lane markings detection and road geometry computation. Int. J. Automot. Technol. 2010, 11, 395–407. [Google Scholar] [CrossRef]
- Loose, H.; Franke, U.; Stiller, C. Kalman Particle Filter for lane recognition on rural roads. In Proceedings of the IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 60–65. [Google Scholar]
- Chiu, K.Y.; Lin, S.F. Lane detection using color-based segmentation. In Proceedings of the Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 706–711. [Google Scholar]
- Borkar, A.; Hayes, M.; Smith, M.T. Polar randomized hough transform for lane detection using loose constraints of parallel lines. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1037–1040. [Google Scholar]
- Borkar, A.; Hayes, M.; Smith, M.T. Robust lane detection and tracking with ransac and Kalman filter. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3261–3264. [Google Scholar]
- Xu, S.; Ye, P.; Han, S.; Sun, H.; Jia, Q. Road lane modeling based on RANSAC algorithm and hyperbolic model. In Proceedings of the 3rd International Conference on Systems and Informatics, Shanghai, China, 19–21 November 2016; pp. 97–101. [Google Scholar]
- Jung, S.; Youn, J.; Sull, S. Efficient Lane Detection Based on Spatiotemporal Images. IEEE Trans. Intell. Transp. Syst. 2016, 17, 289–295. [Google Scholar] [CrossRef]
- Berriel, R.F.; de Aguiar, E.; de Souza Filho, V.V.; Oliveira-Santos, T. A Particle Filter-Based Lane Marker Tracking Approach Using a Cubic Spline Model. In Proceedings of the 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 149–156. [Google Scholar]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedrycz, W. Key Points Estimation and Point Instance Segmentation Approach for Lane Detection. IEEE Trans. Intell. Transp. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. arXiv 2020, arXiv:2008.13719. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning Lightweight Lane Detection CNNs by Self Attention Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the 32th AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Neven, D.; Brabandere, B.D.; Georgoulis, S.; Proesmans, M.; Gool, L.V. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 256–272. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra Fast Structure-Aware Deep Lane Detection. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 276–291. [Google Scholar]
- Yoo, S.; Lee, H.; Myeong, H.; Yun, S.; Park, H.; Cho, J.; Kim, D. End-to-End Lane Marker Detection via Row-wise Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 4335–4343. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixão, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 294–302. [Google Scholar]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-CNN: End-to-End Traffic Line Detection with Line Proposal Unit. IEEE Trans. Intell. Transp. Syst. 2020, 21, 248–258. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Q.; Lian, C. PointLaneNet: Efficient end-to-end CNNs for Accurate Real-Time Lane Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2563–2568. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixão, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. PolyLaneNet: Lane Estimation via Deep Polynomial Regression. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6150–6156. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end Lane Shape Prediction with Transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3694–3702. [Google Scholar]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhan, W. Focus on Local: Detecting Lane Marker from Bottom Up via Key Point. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14117–14125. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-person Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning Feature Pyramids for Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1290–1299. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Ke, L.; Chang, M.; Qi, H.; Lyu, S. Multi-Scale Structure-Aware Network for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 713–728. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on Multi-Stage Networks for Human Pose Estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3559–3568. [Google Scholar]
- Newell, A.; Deng, J. Pixels to Graphs by Associative Embedding. Adv. Neural Inf. Proc. Syst. 2017, 30, 2172–2181. [Google Scholar]
- TuSimple. Tusimple Benchmark. Available online: https://github.com/TuSimple/tusimple-benchmark.html (accessed on 6 October 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Test | Resolution | Road Type | # Lane |
|---|---|---|---|---|---|
| Tusimple | 3626 | 2782 | 1280 × 720 | highway | ≤5 |
| CULane | 88,880 | 34,680 | 1640 × 590 | urban, rural and highway | ≤4 |
| Hyperparameter | Setting |
|---|---|
| Image size | 256 × 512 |
| 0.70 | |
| 2 | |
| 1.5 | |
| 0.81 | |
| 0.15 |
| Algorithm | Accuracy (%) | FP | FN |
|---|---|---|---|
| SCNN [13] | 96.53 | 0.0617 | 0.0180 |
| LaneNet [14] | 96.40 | 0.0780 | 0.0244 |
| PointLaneNet [20] | 96.34 | 0.0467 | 0.0518 |
| LaneATT(ResNet-18) [18] | 96.71 | 0.0356 | 0.0301 |
| ENet-SAD [12] | 96.64 | 0.0602 | 0.0205 |
| ERFNet-E2E [17] | 96.02 | 0.0321 | 0.0428 |
| PINet [10] | 96.75 | 0.0310 | 0.0250 |
| FPLane (ours) | 96.82 | 0.0315 | 0.0243 |
| Category | Proportion (%) | SCNN [13] | ENet-SAD [12] | ERFNet-E2E [17] | UFNet [16] | PINet [10] | FPLane (Ours) |
|---|---|---|---|---|---|---|---|
| Normal | 27.7 | 90.6 | 90.1 | 91.0 | 90.7 | 90.3 | 90.6 |
| Crowded | 23.4 | 69.7 | 68.8 | 73.1 | 70.2 | 72.3 | 73.4 |
| Night | 20.3 | 66.1 | 66.0 | 67.9 | 66.7 | 67.7 | 69.5 |
| No line | 11.7 | 43.4 | 41.6 | 46.6 | 44.4 | 49.8 | 48.2 |
| Shadow | 2.7 | 66.9 | 65.9 | 74.1 | 69.3 | 68.4 | 74.4 |
| Arrow | 2.6 | 84.1 | 84.0 | 85.8 | 85.7 | 83.7 | 86.3 |
| Dazzle light | 1.4 | 58.5 | 60.2 | 64.5 | 59.5 | 66.3 | 68.4 |
| Curve | 1.2 | 64.4 | 65.7 | 71.9 | 69.5 | 65.6 | 67.2 |
| Crossroad | 9.0 | 1990 | 1998 | 2022 | 2037 | 1427 | 1578 |
| Total | - | 71.6 | 70.8 | 74.0 | 72.3 | 74.4 | 75.2 |
| Runtime(ms) | - | 116 | 51 | - | 5.7 | 40 | 28 |
| TuSimple | CULane | |
|---|---|---|
| Accuracy (%) | F1-Score (%) | |
| - | 96.68 | 73.8 |
| 0.60 | 96.73 | 74.4 |
| 0.65 | 96.77 | 74.8 |
| 0.70 | 96.82 | 75.2 |
| 0.75 | 96.78 | 75.1 |
| 0.8 | 96.73 | 74.9 |
| Upsampling | Fusion Method | F1-Score (%) |
|---|---|---|
| Bilinear interpolation | - | 72.6 |
| TransConv | - | 74.3 |
| DAFU | DAF | 74.8 |
| DAFU | AFF | 75.2 |
| Connection Method | F1-Score (%) | Runtime (ms) |
|---|---|---|
| Series connection | 72.3 | 25 |
| Parallel connection | 75.2 | 28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, C.; Zhang, Y. Focus on Point: Parallel Multiscale Feature Aggregation for Lane Key Points Detection. Appl. Sci. 2022, 12, 5975. https://doi.org/10.3390/app12125975
Zuo C, Zhang Y. Focus on Point: Parallel Multiscale Feature Aggregation for Lane Key Points Detection. Applied Sciences. 2022; 12(12):5975. https://doi.org/10.3390/app12125975
Chicago/Turabian StyleZuo, Chao, and Yanyan Zhang. 2022. "Focus on Point: Parallel Multiscale Feature Aggregation for Lane Key Points Detection" Applied Sciences 12, no. 12: 5975. https://doi.org/10.3390/app12125975
APA StyleZuo, C., & Zhang, Y. (2022). Focus on Point: Parallel Multiscale Feature Aggregation for Lane Key Points Detection. Applied Sciences, 12(12), 5975. https://doi.org/10.3390/app12125975