
EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring



Abstract
:1. Introduction
- 1
- We propose EssayGAN, which can automatically augment essays rated with a given score.
- 2
- We introduce a text-generation model that performs sentence-based prediction to generate long essays.
- 3
- We show that essay data augmentation can improve AES performance.
2. Related Studies
2.1. CS-GAN and SentiGAN
2.2. Automated Essay Scoring Based on Pre-Trained Models
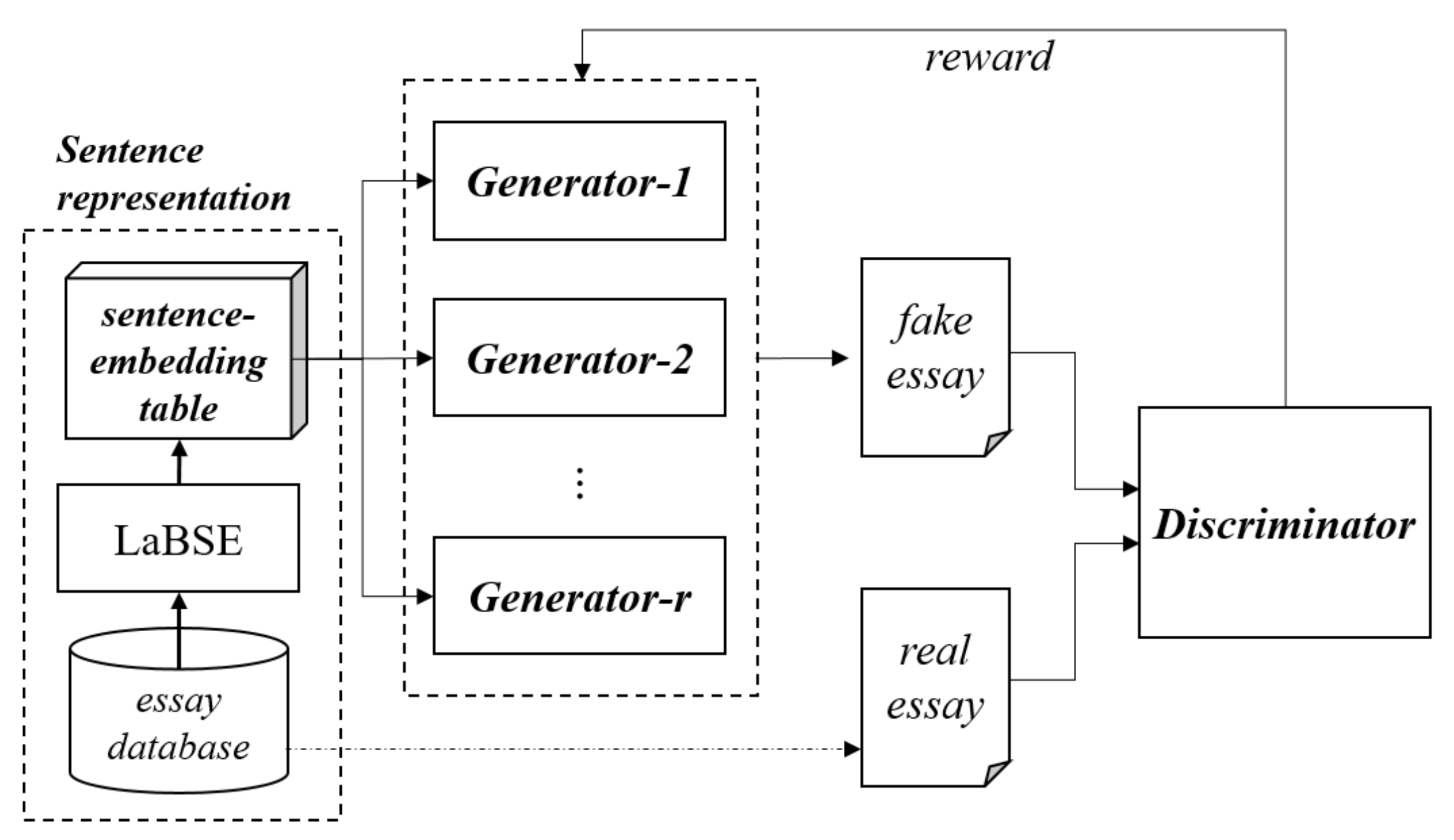
3. EssayGAN
3.1. Sentence Representation
3.2. Discriminator
3.3. Generator and Reinforcement Learning
4. Experimental Results
4.1. Training EssayGAN and Dataset
| Algorithm 1:Training EssayGAN for essay data augmentation |
Input: Generator , Policy models , Discriminator , Essay dataset assorted by r score ranges |
Output: well-trained Generators |
1: Initialize the parameters of , with random values |
2: Pre-train on using MLE |
3: Generate fake essays using to train |
4: pre-train on by minimizing the cross-entropy loss |
5: for eachi in 1:r |
6: repeat |
7: for t-steps do |
8: for i in do |
9: Train on using MLE |
10: end for |
11: end for |
12: for g-steps do |
13: for i in do |
14: Generate fake essays |
15: for tin do |
16: Compute by (5) |
17: end for |
18: Update the parameters via policy gradient |
19: end for |
20: end for |
21: for d-steps do |
22: Generate fake essays using |
23: Train on using the cross-entropy loss |
24: end for |
25: for eachi in 1:r |
26: until EssayGAN convergence |
4.2. Characteristics of Augmented Essays
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AES | Automated Essay Scoring |
| ASAP | Automated Student Assessment Prize |
| GANs | Generative Adversarial Networks |
| LSTM | Long Short-Term Memory |
| MLE | Maximum Likelihood Estimation |
| LaBSE | Language-agnostic BERT Sentence Embedding |
| MC | Monte Carlo |
| QWK | Quadratic Weighted Kappa |
Appendix A. Partition of Score Range
Appendix B. Examples of Automatically Generated Essays

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt 3 (Normalized Score = 3) | |
|---|---|
| (1) number of source essays = 2 | Being the early summer in souther California, the temperatures are going to be hot. He had gotten directions from a group of old men who hadent gone the places they told him about in a long time. Where they said there would be a town it was more like a ghost town. The day that the cyclist was riding was very hot and he was riding through the desert, @CAPS made it worse. Because of the heat he was drinking his water regularly to stay hydrated. This meant he was running out of it fast since the old men had given him directions through places that were no longer open he couldnt get more water. The cyclist also had to go over roads that were in bad condition @CAPS slowed him down even more. Those features at the setting affected the cyclist a lot on his trip. |
| (2) number of source essays = 3 | Author Joe Kurmaskie learns the dangers of a lifeless wilderness during his experience described in do not exceed posted speed limit. As a cyclist riding in one of the most undeveloped areas in California, the lack of water found in this setting proves crippling to his survival. The trails he was directed to had no towns or sources of fresh, drinkable water for days. Another quote that contributed to the cyclists journey was, that smoky blues tune Summer time rattled around in the dry honeycombs of my deteriorating brain. This expressed how dehydrated the summer heat way making him. This meant he was running out of it fast since the old men had given him directions through places that were no longer open he couldnt get more water. The cyclist also had to go over roads that were in bad condition @CAPS slowed him down even more. Those features at the setting affected the cyclist a lot on his trip. |
| (3) number of source essays = 3 | The features of the setting greatly effected the cyclist. He was riding along on a route he had little confidence would end up anywhere. That being the first time ever being on that rode and having only not of date knowledge about it made the cyclist rework. The temperature was very hot, where was little shade, the sun was beating down on him. Next, he came to a shed desperate for water only to find rusty pumps with tainted, unsafe water. Wide rings of dried sweat circled my shirt, and the growing realization that I could drop from heat stroke This states that he @CAPS the danger of not having enough water in his system. Features such as water and heat affected him/her throughout the story. Not having enough water could make him/her lose more sweat and the heat is making him lose even more sweat which can cause extreme heatstroke. |
| (4) number of source essays = 6 | The features of the setting affect the authors dispotion as well as his ability to complete the journey, thus creating an obstacle the author must overcome. At the end of the paragraph five the author writes that I was traveling through the high deserts of California. This setting is important because it adds a sense of urgency to his trip when he starts to run low on water. The terrain changing into short rolling hills didnt help the cyclist. For example, when the cyclist headed from the intense heat, he needed to find a town. Its June in California and the cyclist fears he @MONTH soon suffer from heat stroke if he doesnt find water yet. He said, I was going to die and the birds would pick me clean. Normally, this would not cause too much struggle, but since he was dehydrated and overheated, each hill seemed crippling, My thoughts are that if the setting had been a bit cooler and perhaps on the time period the old men had lived in, the cyclist would have had a much more enjoyable experience. |
References
- Hussein, M.A.; Hassan, H.; Nassef, M. Automated language essay scoring systems: A literature review. PeerJ Comput. Sci. 2019, 5, e208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27, Montréal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Proceedings of Machine Learning Research; PMLR: International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Wang, K.; Wan, X. SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 4446–4452. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Pan, Q.; Wang, S.; Yang, T.; Cambria, E. A generative model for category text generation. Inf. Sci. 2018, 450, 301–315. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Minneapolis, MI, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Rodriguez, P.U.; Jafari, A.; Ormerod, C.M. Language models and Automated Essay Scoring. arXiv 2019, arXiv:1909.09482. [Google Scholar]
- Yang, R.; Cao, J.; Wen, Z.; Wu, Y.; He, X. Enhancing Automated Essay Scoring Performance via Fine-tuning Pre-trained Language Models with Combination of Regression and Ranking. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1560–1569. [Google Scholar] [CrossRef]
- Ormerod, C.M.; Malhotra, A.; Jafari, A. Automated essay scoring using efficient transformer-based language models. arXiv 2021, arXiv:2102.13136,. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the 8th International Conference on Learning Representations (ICLR), Online, 27–30 April 2020. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: A Compact Task-Agnostic BERT for Resource-Limited Devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2158–2170. [Google Scholar] [CrossRef]
- Sethi, A.; Singh, K. Natural Language Processing based Automated Essay Scoring with Parameter-Efficient Transformer Approach. In Proceedings of the 2022 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; pp. 749–756. [Google Scholar] [CrossRef]
- Zügner, D.; Kirschstein, T.; Catasta, M.; Leskovec, J.; Günnemann, S. Language-Agnostic Representation Learning of Source Code from Structure and Context. arXiv 2021, arXiv:2103.11318. [Google Scholar]
- Chaslot, G.; Bakkes, S.; Szita, I.; Spronck, P. Monte-Carlo tree search: A new framework for game AI. In Proceedings of the Fourth Artificial Intelligence and Interactive Digital Entertainment Conference (AIIDE), Stanford, CA, USA, 22–24 October 2008; pp. 216–217. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Lapata, M.; Barzilay, R. Automatic Evaluation of Text Coherence: Models and Representations. In Proceedings of the IJCAI-05, Nineteenth International Joint Conference on Artificial Intelligence, Edinburgh, UK, 30 July–5 August 2005; pp. 1085–1090. [Google Scholar]
- Chen, H.; He, B. Automated Essay Scoring by Maximizing Human-Machine Agreement. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Association for Computational Linguistics: Seattle, WA, USA, 2013; pp. 1741–1752. [Google Scholar]
- Dong, F.; Zhang, Y.; Yang, J. Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring. In Proceedings of the SIGNLL Conference on Computational Natural Language Learning (CoNLL), Vancouver, BC, Canada, 3–4 August 2017; pp. 153–162. [Google Scholar]
- Tay, Y.; Phan, M.C.; Tuan, L.A.; Hui, S.C. SkipFlow: Incorporating Neural Coherence Features for End-to-End Automatic Text Scoring. In Proceedings of the Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5948–5955.
- Grzymala-Busse, J.W.; Hippe, Z.S.; Mroczek, T. Reduced Data Sets and Entropy-Based Discretization. Entropy 2019, 21, 51. [Google Scholar] [CrossRef] [Green Version]



| Generator | Discriminator | |
|---|---|---|
| embedding dimension | 768 (input) 1536 (hidden) | 768 (input) 1536 (hidden) |
| pre-training epoch(steps) | 150 | 3 (5) |
| batch size | 256 | 256 |
| learning rate | 0.01 (pretrain) 1 × 10 (adversarial) | 1 × 10 |
| Monte Carlo search rollout K | 16 | NA |
| dropout | NA | 0.2 |
| Prompt | Number of Essays | Average Length | Average Sentences per Essay | Score Range (Normalized) | Type of Essay | Number of Unique Sentences |
|---|---|---|---|---|---|---|
| 1 | 1783 | 350 | 22.76 | 2–12 (0–4) | ARG | 40,383 |
| 2 | 1800 | 350 | 20.33 | 1–6 (0–3) | ARG | 36,359 |
| 3 | 1726 | 150 | 6.27 | 0–3 (0–3) | RES | 10,551 |
| 4 | 1772 | 150 | 4.63 | 0–3 (0–3) | RES | 8134 |
| 5 | 1805 | 150 | 6.60 | 0–4 (0–4) | RES | 11,614 |
| 6 | 1800 | 150 | 7.78 | 0–4 (0–4) | RES | 13,457 |
| 7 | 1569 | 250 | 11.64 | 0–30 (0–4) | NAR | 17,927 |
| 8 | 723 | 650 | 34.76 | 0–60 (0–4) | NAR | 24,943 |
| Prompt | Number of Source Essays | ||||
|---|---|---|---|---|---|
| Random | RandomOrder | EssayGAN w/o t-Step | EssayGAN | Average Sentences perEssay | |
| 1 | 18.05 | 17.85 | 7.18 | 4.2 | 22.76 |
| 2 | 17.96 | 17.72 | 8.24 | 4.8 | 20.33 |
| 3 | 5.38 | 5.33 | 2.45 | 2.26 | 6.27 |
| 4 | 4.76 | 4.72 | 2.37 | 2.24 | 4.63 |
| 5 | 5.64 | 5.58 | 2.41 | 2.23 | 6.60 |
| 6 | 6.17 | 6.10 | 2.78 | 2.78 | 7.78 |
| 7 | 10.05 | 9.88 | 3.22 | 2.99 | 11.64 |
| 8 | 22.42 | 21.96 | 10.37 | 6.82 | 34.76 |
| AVG | 11.30 | 11.14 | 4.88 | 3.54 | 14.35 |
| Prompt | Number of Sentences in Reversed Order | |||
|---|---|---|---|---|
| Random | RandomOrder | EssayGAN w/o t-Step | EssayGAN | |
| 1 | 9.02 | 0.00 | 1.41 | 0.49 |
| 2 | 9.64 | 0.00 | 2.01 | 0.75 |
| 3 | 2.08 | 0.00 | 0.07 | 0.05 |
| 4 | 1.77 | 0.00 | 0.04 | 0.04 |
| 5 | 2.26 | 0.00 | 0.04 | 0.03 |
| 6 | 2.47 | 0.00 | 0.08 | 0.08 |
| 7 | 4.55 | 0.00 | 0.30 | 0.16 |
| 8 | 14.02 | 0.00 | 4.14 | 2.51 |
| AVG | 5.73 | 0.00 | 1.01 | 0.51 |
| Baseline | Data Augmentation (×1) | Comparison | |||||
|---|---|---|---|---|---|---|---|
| Prompt | Training Data | Random | RandomOrder | EssayGAN w/o t-Step | EssayGAN | Training Data + 1 Swapped | Training Data + 2 Swapped |
| 1 | 0.312 | 0.221 | 0.224 | 0.292 | 0.293 | 0.300 | 0.289 |
| (0.278) | (0.220) | (0.221) | (0.254) | (0.255) | (0.270) | (0.262) | |
| 2 | 0.320 | 0.215 | 0.220 | 0.294 | 0.297 | 0.303 | 0.290 |
| (0.287) | (0.214) | (0.219) | (0.255) | (0.259) | (0.273) | (0.264) | |
| 3 | 0.252 | 0.190 | 0.189 | 0.233 | 0.232 | 0.227 | 0.211 |
| (0.244) | (0.190) | (0.185) | (0.214) | (0.217) | (0.221) | (0.207) | |
| 4 | 0.300 | 0.226 | 0.220 | 0.266 | 0.258 | 0.254 | 0.235 |
| (0.297) | (0.224) | (0.221) | (0.256) | (0.250) | (0.254) | (0.236) | |
| 5 | 0.334 | 0.250 | 0.254 | 0.307 | 0.307 | 0.302 | 0.281 |
| (0.321) | (0.249) | (0.246) | (0.286) | (0.285) | (0.292) | (0.275) | |
| 6 | 0.292 | 0.256 | 0.258 | 0.282 | 0.278 | 0.278 | 0.269 |
| (0.288) | (0.256) | (0.255) | (0.271) | (0.268) | (0.276) | (0.268) | |
| 7 | 0.331 | 0.208 | 0.211 | 0.298 | 0.296 | 0.291 | 0.268 |
| (0.303) | (0.209) | (0.210) | (0.260) | (0.258) | (0.270) | (0.250) | |
| 8 | 0.332 | 0.214 | 0.219 | 0.293 | 0.293 | 0.321 | 0.310 |
| (0.284) | (0.214) | (0.215) | (0.246) | (0.246) | (0.276) | (0.269) | |
| AVG | 0.309 | 0.222 | 0.224 | 0.283 | 0.282 | 0.284 | 0.269 |
| (0.288) | (0.222) | (0.221) | (0.255) | (0.255) | (0.266) | (0.254) | |
| Baseline | Data Augmentation (×1) | |||||
|---|---|---|---|---|---|---|
| Prompt | Training Data | Random | RandomOrder | EssayGAN w/o t-Step | EssayGAN | CS-GAN |
| 1 | 0.7894 | 0.7601 | 0.7663 | 0.7656 | 0.818 | - |
| 2 | 0.6741 | 0.6587 | 0.6507 | 0.6918 | 0.696 | - |
| 3 | 0.6796 | 0.6525 | 0.6462 | 0.6776 | 0.686 | 0.665 |
| 4 | 0.8062 | 0.7695 | 0.7773 | 0.8128 | 0.828 | 0.788 |
| 5 | 0.8038 | 0.7614 | 0.7723 | 0.8054 | 0.824 | 0.790 |
| 6 | 0.8090 | 0.7767 | 0.7794 | 0.8166 | 0.829 | 0.799 |
| 7 | 0.8271 | 0.8056 | 0.8102 | 0.8286 | 0.865 | - |
| 8 | 0.6454 | 0.6989 | 0.7110 | 0.7195 | 0.761 | - |
| AVG | 0.7543 | 0.7354 | 0.7392 | 0.7647 | 0.788 | - |
| AES Systems | ||||||
|---|---|---|---|---|---|---|
| Prompt | BERT–CLS [8] | XLNet–CLS [8] | RBERT [9] | BERT –Ensemble [10] | BERT –Adapter [15] | BERT-CLS + Augmented Data of EssayGAN (Ours) |
| 1 | 0.792 | 0.776 | 0.817 | 0.831 | 0.743 | 0.818 |
| 2 | 0.679 | 0.680 | 0.719 | 0.679 | 0.674 | 0.696 |
| 3 | 0.715 | 0.692 | 0.698 | 0.690 | 0.718 | 0.686 |
| 4 | 0.800 | 0.806 | 0.845 | 0.825 | 0.884 | 0.828 |
| 5 | 0.805 | 0.783 | 0.841 | 0.817 | 0.834 | 0.824 |
| 6 | 0.805 | 0.793 | 0.847 | 0.822 | 0.842 | 0.829 |
| 7 | 0.785 | 0.786 | 0.839 | 0.841 | 0.819 | 0.865 |
| 8 | 0.595 | 0.628 | 0.744 | 0.748 | 0.744 | 0.761 |
| AVG | 0.748 | 0.743 | 0.794 | 0.782 | 0.785 | 0.788 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.-H.; Choi, Y.-S.; Park, C.-Y.; Lee, K.-J. EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring. Appl. Sci. 2022, 12, 5803. https://doi.org/10.3390/app12125803
Park Y-H, Choi Y-S, Park C-Y, Lee K-J. EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring. Applied Sciences. 2022; 12(12):5803. https://doi.org/10.3390/app12125803
Chicago/Turabian StylePark, Yo-Han, Yong-Seok Choi, Cheon-Young Park, and Kong-Joo Lee. 2022. "EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring" Applied Sciences 12, no. 12: 5803. https://doi.org/10.3390/app12125803
APA StylePark, Y.-H., Choi, Y.-S., Park, C.-Y., & Lee, K.-J. (2022). EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring. Applied Sciences, 12(12), 5803. https://doi.org/10.3390/app12125803