
Novel Hate Speech Detection Using Word Cloud Visualization and Ensemble Learning Coupled with Count Vectorizer



Abstract
:1. Introduction
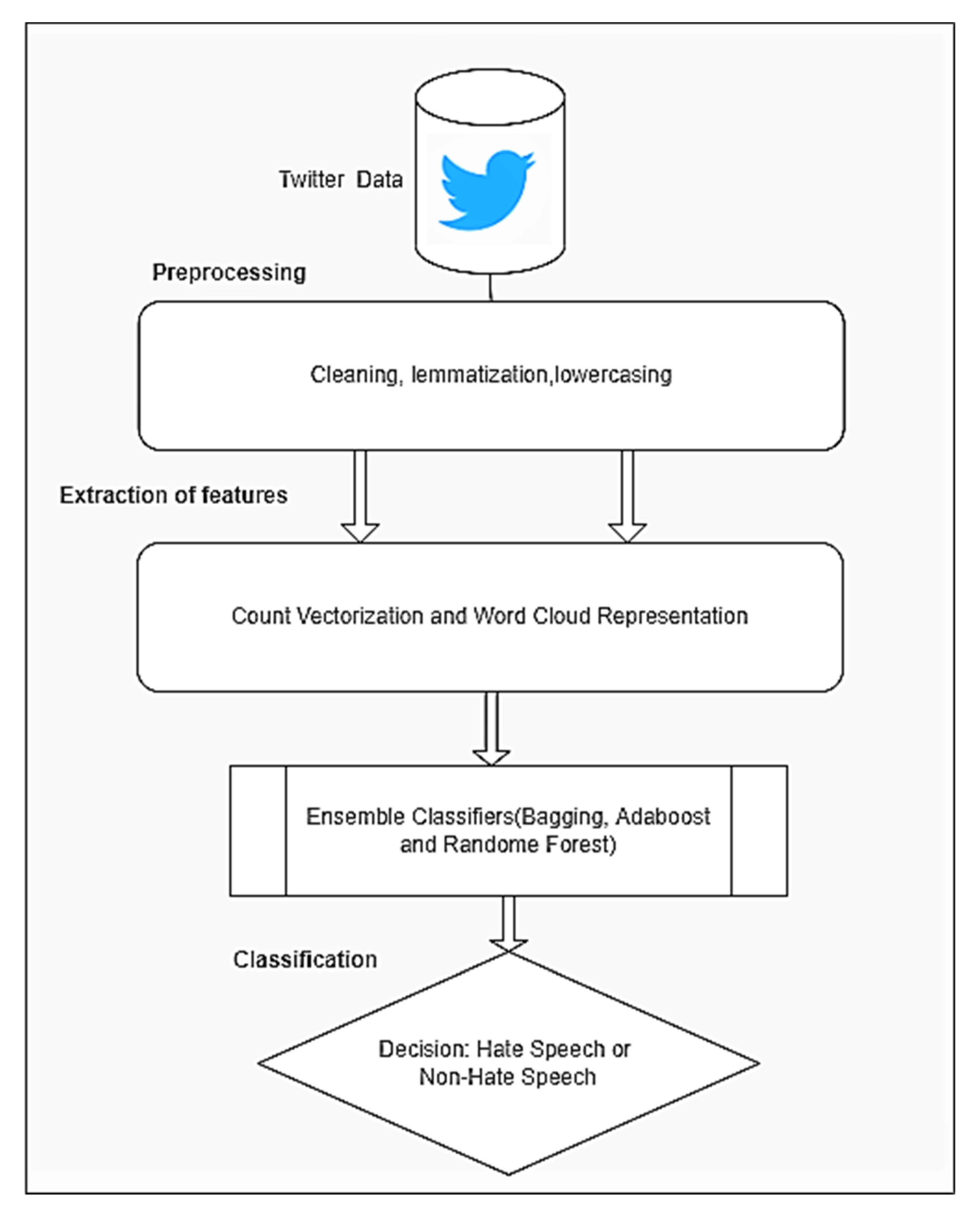
- Our proposed framework can determine the unique features that were extracted from Twitter. The incorporation of count vectorizer library has proven to be a good choice for the feature extraction.
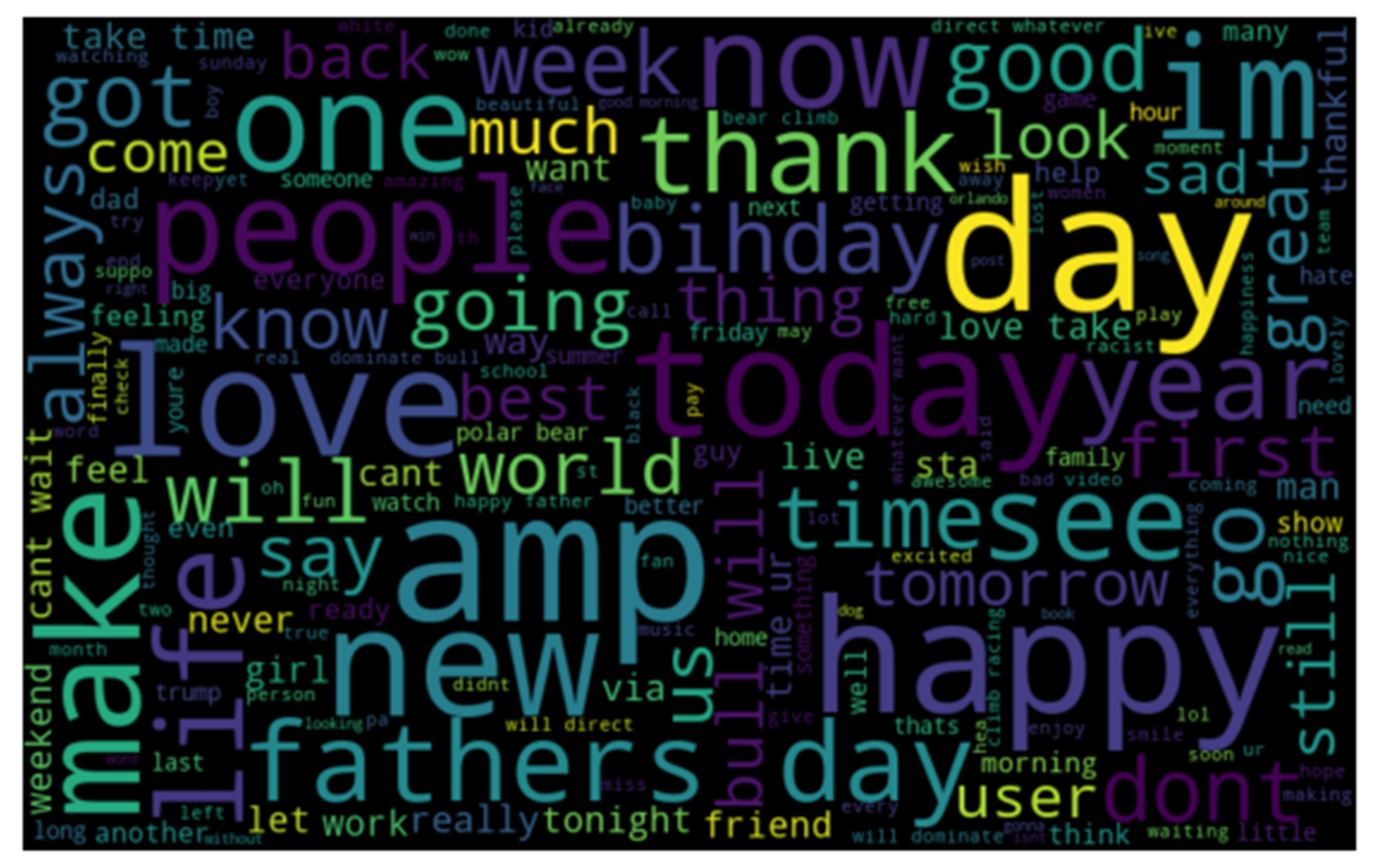
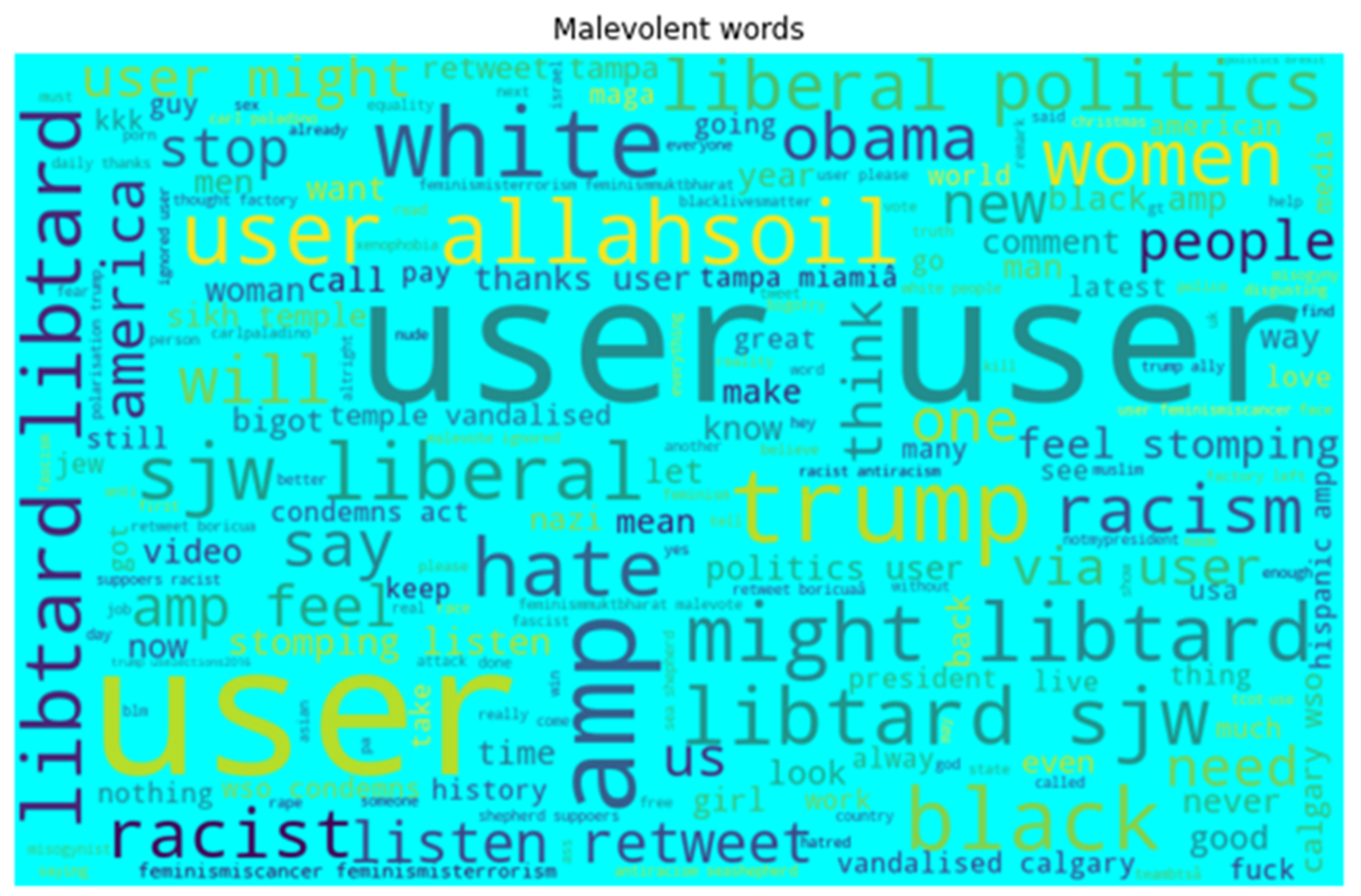
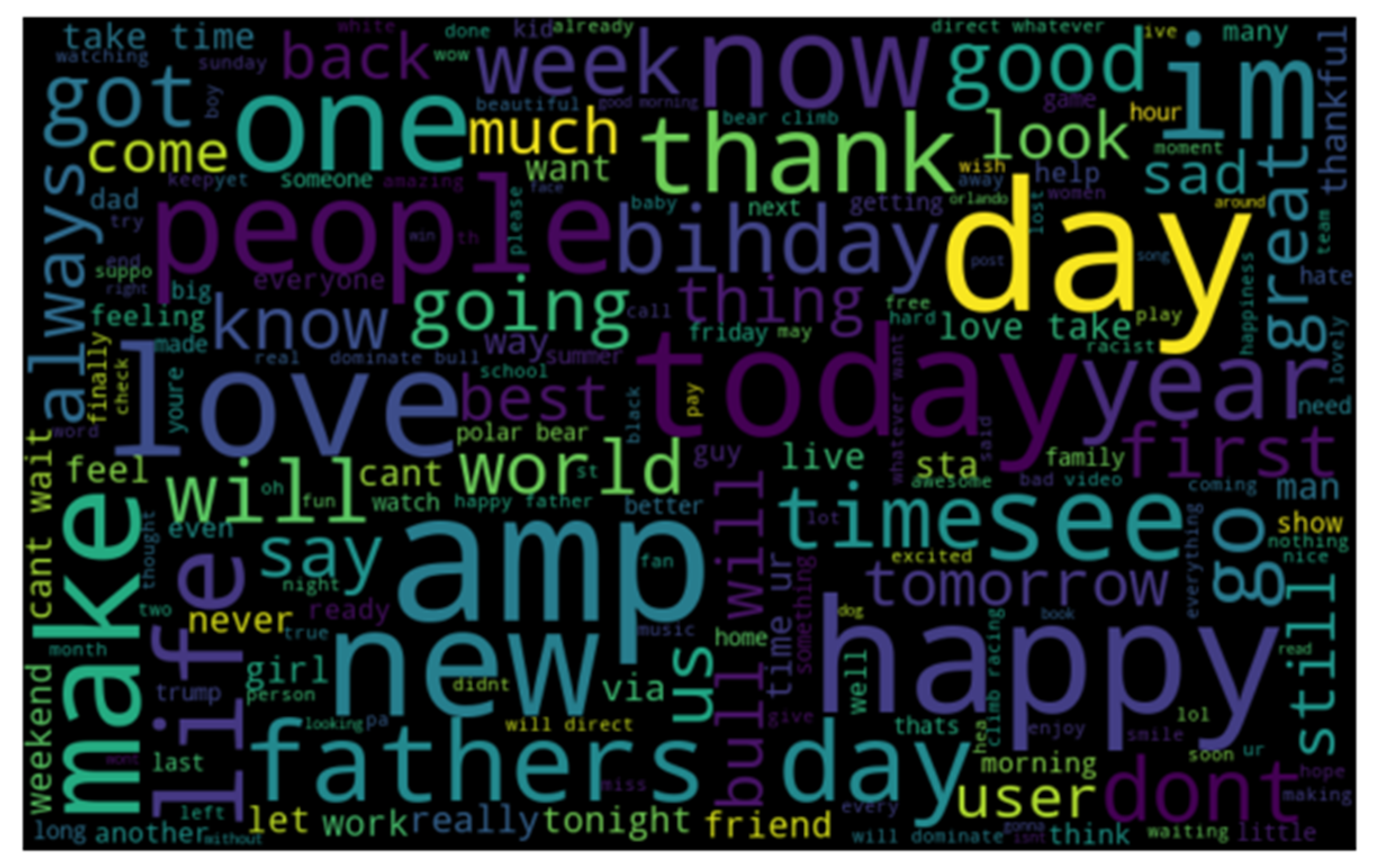
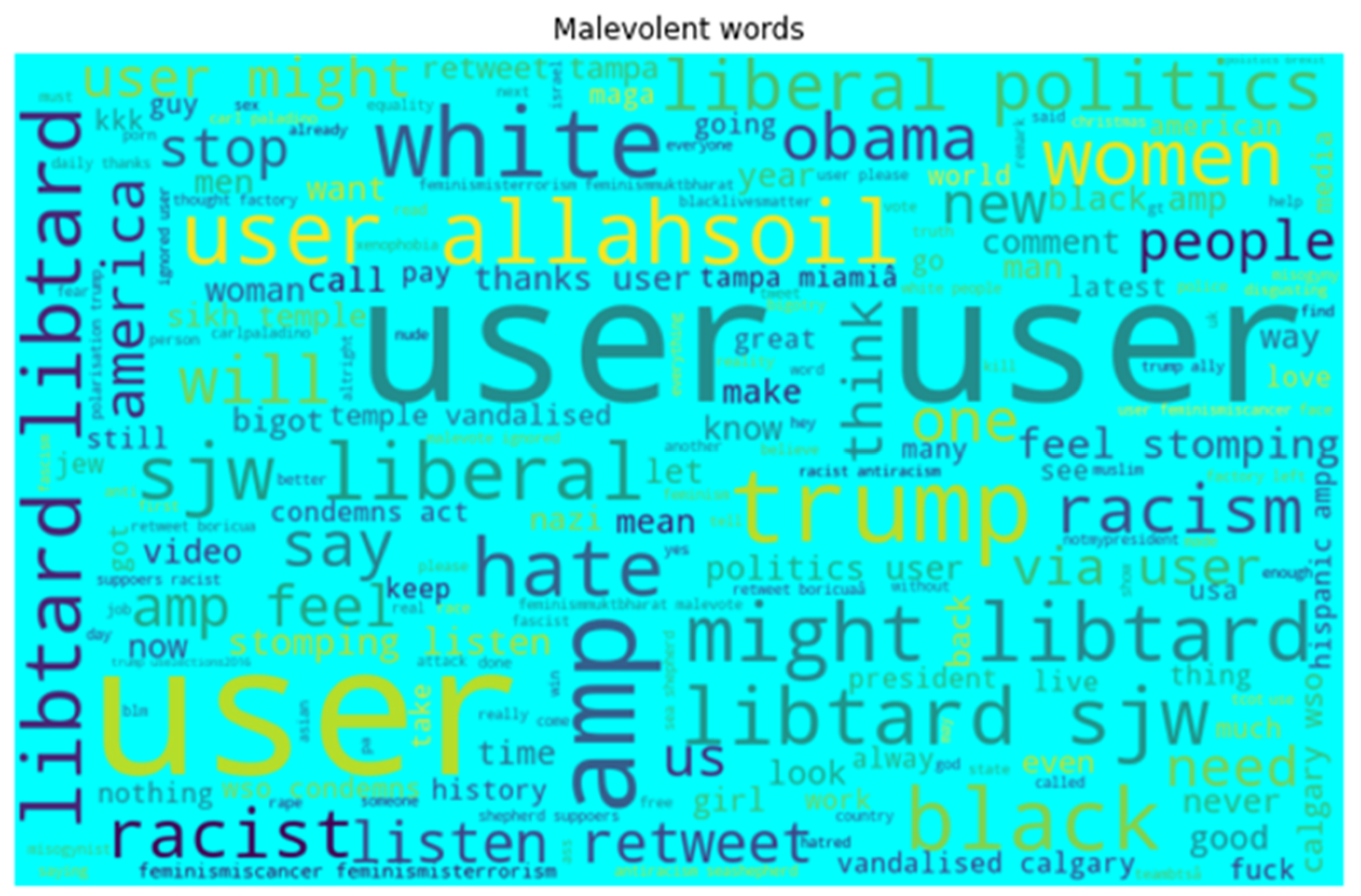
- We provide word-cloud representation to identify (1) important words and (2) hateful words. Then, we provide statistical information about the tweets in terms of frequency and distribution. Word cloud is very significant in terms of exploratory textual analysis as this can represent the frequently appearing words in the case of tweets. It helps to understand the most salient themes or words that make speech hateful.
- We construct a corpus of tweets, followed by pre-processing and cleaning of tweets. Then, we construct feature vectors via a text augmentation technique. Finally, the constructed feature vectors along with the labels are fed to ensemble methods for training and predicting hate speech of new tweets.
- We perform a comprehensive comparative study among the proposed ensemble methods and provide detailed detection report using several performance measures such as accuracy, precision, recall, AUC, and F1 scores.
2. Related Work
3. Materials and Methods
3.1. Dataset Preparation and Preprocessing
- Removal of stop words and punctuation: For analysing the sentiment of the tweet, unwanted and irrelevant words are to be deleted because this affects the accuracy of the model. Stop wards removal has helped us to prepare a quality of the input text. Afterwards, punctuation and numbers were also removed from the tweets.
- Lowercase: All tweets are converted to lowercase because it is necessary for the input, and normalization has been performed. This also helps us to produce a better prediction.
- Tokenization and hashtag extraction: All texts are tokenized in this step. Tokens are a small sentence or word or symbol. Moreover, we perform a hashtag extraction.
- Statistics: In Table 3, a comprehensive statistical description of the dataset has been given. In this table id-count, mean, standard deviation, minimum and maximum value have been shown.
- Feature Vectors Construction: We have used the count vectorization method to represent the tweets. The vectors are built based on the dimensionality of the size of the tweet vocabulary. The count increases every time one word is encountered, and dimensions are also increased by one. The main objective of a count vectorizer is to fit and learn each word given in the vocabulary. Based on this created vocabulary it creates a document term matrix. In document classification terminologies, count vectorizer is by nature a Boolean model representation, where documents are represented as a collection of terms. In our study, tweets are represented as a set of terms. All terms are either present or absent in the tweet. For a given ith tweet, the feature vector xi, is constructed after the binary encoding of each term as
3.2. Classification Methods
3.2.1. Bagging for Hate Speech Detection
| Algorithm 1 Bagging algorithm |
| 1: Bagging(S = {(x1,y1), …, (xn,yn)}) 2: for i = 1 to k do 3: Drawing of a bootstrap sample Di of size n form S 4: Weak learning algorithm takes as input Di to induce hi ▷Training Step 5: end for 6: ▷Testing Step {I(.) = 1 if the expression is true and 0 otherwise, y∈ {hate,none-hate}} |
3.2.2. Random Forest for Hate Speech Detection
| Algorithm 2 Random forest algorithm |
| 1: RandomForest(S = {(x1,y1), …, (xn,yn)}) 2: for i = 1 to k do 3: Drawing of a bootstrap sample Di of size n form S 4: Decision tree takes as input Di to induce hi ▷Training Step after incorporating the following: - features randomly - features by highest gain Δ using gini impurity measures as Δ counts examples of give note} -Make a split of two child nodes 5: end for 6: ▷Testing Step {I(.) = 1 if the expression is true and 0 otherwise, y∈ {hate,none-hate}} |
3.2.3. Adaboost for Hate Speech Detection
| Algorithm 3 AdaBoost algorithm |
| 1: AdaBoost (S = {(x1,y1), …, (xn,yn)}) 2: for i = 1 to n do 3: 4: end for 5: for j = 1 to k do 6: Create a training set Dj by sampling (with replacement) for S base on Wj 7: Weak learning algorithm takes as input Dj to induce hj ▷Training Step 8: 9: 10: for i = 1 to n do 11: 12: end for 13: end for 14: ▷Testing Step {I(.) = 1 if the expression is true and 0 otherwise, y∈ {hate,none-hate}} |
4. Experiments and Results
4.1. Evaluation Metrics
4.2. Results and Discussion
4.2.1. Word Cloud Method
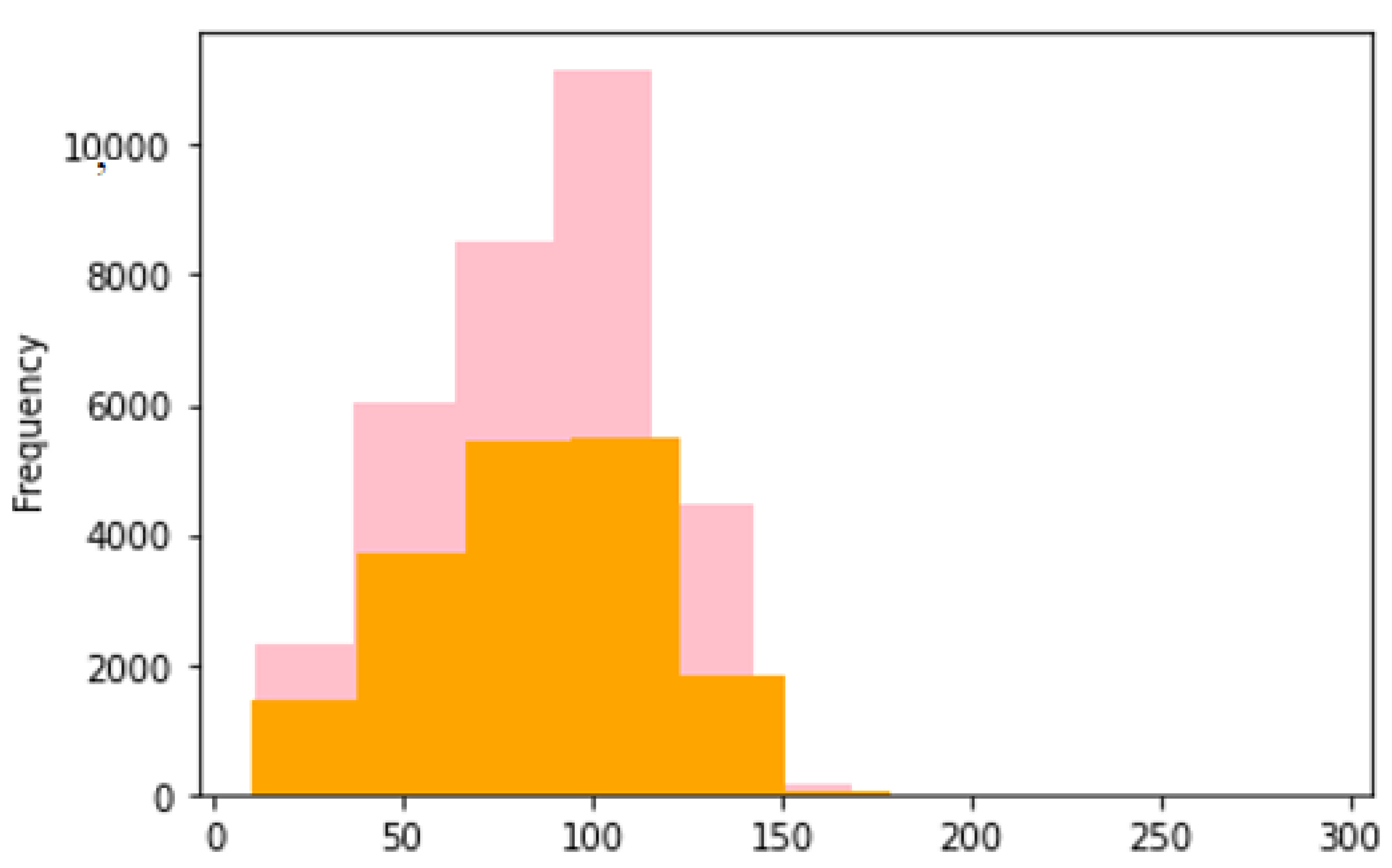
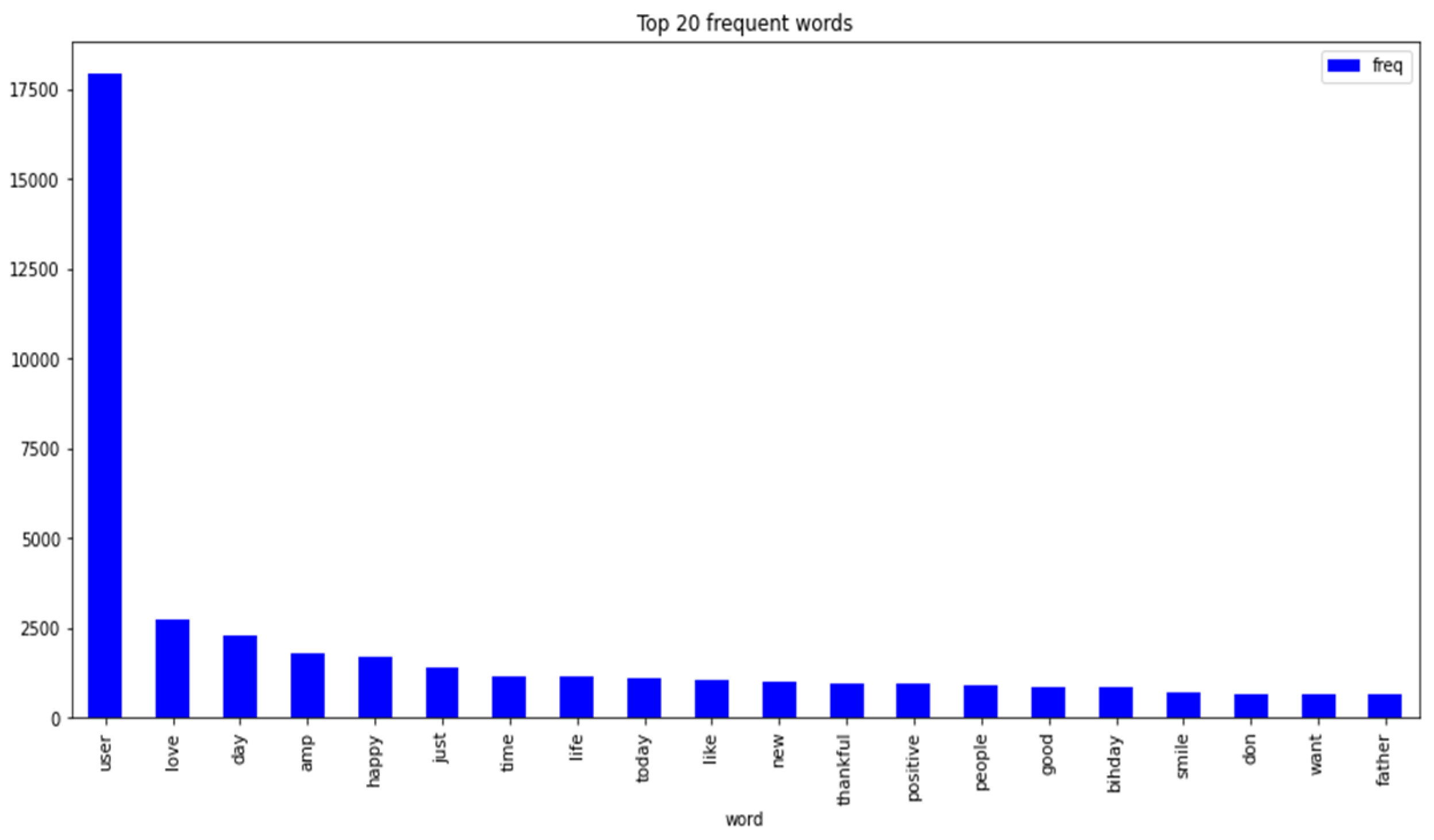
4.2.2. Distribution, Frequent Words and Training Examples of Tweets
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Araque, O.; Iglesias, C.A. An ensemble method for radicalization and hate speech detection online empowered by sentic computing. Cogn. Comput. 2021, 14, 48–61. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef] [PubMed]
- Hajibabaee, P.; Malekzadeh, M.; Ahmadi, M.; Heidari, M.; Esmaeilzadeh, A.; Abdolazimi, R.; James, H., Jr. Offensive language detection on social media based on text classification. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 92–98. [Google Scholar]
- Chia, Z.L.; Ptaszynski, M.; Masui, F.; Leliwa, G.; Wroczynski, M. Machine Learning and feature engineering-based study into sarcasm and irony classification with application to cyberbullying detection. Inf. Process. Manag. 2021, 58, 102600. [Google Scholar] [CrossRef]
- Van Hee, C.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Detection and fine-grained classification of cyberbullying events. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Online, 1–3 September 2015; pp. 672–680. [Google Scholar]
- Shekhar, S.; Garg, H.; Agrawal, R.; Shivani, S.; Sharma, B. Hatred and trolling detection transliteration framework using hierarchical LSTM in code-mixed social media text. Complex Intell. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Mihaylova, T.; Gencheva, P.; Boyanov, M.; Yovcheva, I.; Mihaylov, T.; Hardalov, M.; Kiprov, Y.; Balchev, D.; Koychev, I.; Nikolova, I.; et al. SUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering. arXiv 2021, arXiv:2109.15120. [Google Scholar]
- Alnazzawi, N. Using Twitter to Detect Hate Crimes and Their Motivations: The HateMotiv Corpus. Data 2022, 7, 69. [Google Scholar] [CrossRef]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 85–90. [Google Scholar]
- Schmidt, A.; Wiegand, M. A survey on hate speech detection using natural language processing. In Proceedings of the International Workshop on Natural Language Processing for Social Media, SocialNLP, ACL, Valencia, Spain, 3 April 2017; pp. 1–10. [Google Scholar]
- Greevy, E.; Smeaton, A.F. Classifying racist texts using a support vector machine. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, Sheffield, UK, 25–29 July 2004; pp. 468–469. [Google Scholar]
- Alkomah, F.; Ma, X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information 2022, 13, 273. [Google Scholar] [CrossRef]
- Abro, S.; Shaikh, Z.S.; Khan, S.; Mujtaba, G.; Khand, Z.H. Automatic Hate speech Detection using Machine Learning: A Comparative Study. Mach. Learn. 2020, 11, 484–491. [Google Scholar] [CrossRef]
- Diao, S.; Xu, R.; Su, H.; Jiang, Y.; Song, Y.; Zhang, T. Taming Pre-trained Language Models with N-gram Representations for Low-Resource Domain Adaptation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Long Papers; Volume 1, pp. 3336–3349. [Google Scholar]
- Agarwal, S.; Chowdary, C.R. Combating hate speech using an adaptive ensemble learning model with a case study on COVID-19. Expert Syst. Appl. 2021, 185, 115632. [Google Scholar] [CrossRef]
- Sadiq, S.; Mehmood, A.; Ullah, S.; Ahmad, M.; Choi, G.S.; On, B.W. Aggression detection through deep neural model on twitter. Future Gener. Comput. Syst. 2021, 114, 120–129. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Jahan, M.S.; Oussalah, M. Data expansion using back translation and paraphrasing for hate speech detection. Online Soc. Netw. Media 2021, 24, 100153. [Google Scholar] [CrossRef]
- Alammary, A.S. Arabic Questions Classification Using Modified TF-IDF. IEEE Access 2021, 9, 95109–95122. [Google Scholar] [CrossRef]
- Sharma, A.; Kabra, A.; Jain, M. Ceasing hate with MoH: Hate Speech Detection in Hindi–English code-switched language. Inf. Processing Manag. 2022, 59, 102760. [Google Scholar] [CrossRef]
- Roy, P.K.; Tripathy, A.K.; Das, T.K.; Gao, X.Z. A Framework for Hate speech Detection Using Deep Convolutional Neural Network. IEEE Access 2020, 8, 204951–204962. [Google Scholar] [CrossRef]
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Mohapatra, S.K.; Prasad, S.; Bebarta, D.K.; Das, T.K.; Srinivasan, K.; Hu, Y.C. Automatic Hate speech Detection in English-Odia Code Mixed Social Media Data Using Machine Learning Techniques. Appl. Sci. 2021, 11, 8575. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Zisad, S.N.; Hossain, M.S.; Andersson, K. Speech emotion recognition in neurological disorders using convolutional neural network. In Proceedings of the International Conference on Brain Informatics, Padua, Italy, 19 September 2020; Springer: Cham, Switzerland, 2020; pp. 287–296. [Google Scholar]
- Goel, K.; Rajani, N.; Vig, J.; Tan, S.; Wu, J.; Zheng, S.; Xiong, C.; Bansal, M.; Ré, C. Robustness gym: Unifying the nlp evaluation land-scape. arXiv 2021, arXiv:2101.04840. [Google Scholar]
- Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I. Augmented sbert: Data augmentation method for improv-ing bi-encoders for pairwise sentence scoring tasks. arXiv 2020, arXiv:2010.08240. [Google Scholar]
- Ciolino, M.; Noever, D.; Kalin, J. Multilingual Augmenter: The Model Chooses. arXiv 2021, arXiv:2102.09708. [Google Scholar]
- Hu, Z.; Jiang, Y.; Bach, N.; Wang, T.; Huang, Z.; Huang, F.; Tu, K. Multi-View Cross-Lingual Structured Prediction with Minimum Supervision. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Long Papers; Volume 1, pp. 2661–2674. [Google Scholar]
- Gao, Y.; Zhu, H.; Ng, P.; Santos CN, D.; Wang, Z.; Nan, F.; Zhang, D.; Nallapati, R.; Arnold, A.O.; Xiang, B. Answering ambiguous questions through generative evidence fusion and round-trip prediction. arXiv 2020, arXiv:2011.13137. [Google Scholar]
- William, P.; Gade, R.; esh Chaudhari, R.; Pawar, A.B.; Jawale, M.A. Machine Learning based Automatic Hate Speech Recognition System. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 315–318. [Google Scholar]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, J.; Plastino, A. On the evaluation and combination of state- of-the-art features in twitter sentiment analysis. Artif. Intell. Rev. 2021, 54, 1887–1936. [Google Scholar] [CrossRef]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. [Google Scholar] [CrossRef]
- Daghriri, T.; Proctor, M.; Matthews, S. Evolution of Select Epidemiological Modeling and the Rise of Population Sentiment Analysis: A Literature Review and COVID-19 Sentiment Illustration. Int. J. Environ. Res. Public Health 2022, 19, 3230. [Google Scholar] [CrossRef]
- Gorrell, G.; Kochkina, E.; Liakata, M.; Aker, A.; Zubiaga, A.; Bontcheva, K.; Derczynski, L. SemEval-2019 task 7: RumourEval, determining rumour veracity and support for rumours. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 845–854. [Google Scholar]
- Ayo, F.E.; Folorunso, O.; Ibharalu, F.T.; Osinuga, I.A.; Abayomi-Alli, A. A probabilistic clustering model for hate speech classification in twitter. Expert Syst. Appl. 2021, 173, 114762. [Google Scholar] [CrossRef]
- Vel, S.S. Pre-Processing techniques of Text Mining using Computational Linguistics and Python Libraries. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; IEEE: Manhattan, NY, USA, 2021; pp. 879–884. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recogni-tion, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Gholizadeh, S. Top Popular Python Libraries in Research; Authorea Preprints; ResearchGate: Berlin, Germany, 2022. [Google Scholar]
- Pajankar, A.; Joshi, A. Introduction to Pandas. In Hands-on Machine Learning with Python; Apress: Berkeley, CA, USA, 2022; pp. 45–61. [Google Scholar]
- Jokić, D.; Stanković, R.; Krstev, C.; Šandrih, B. A Twitter Corpus and lexicon for abusive speech detection in Serbian. In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Zaragoza, Spain, 1–4 September 2021; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2021. [Google Scholar]
- Corazza, M.; Menini, S.; Cabrio, E.; Tonelli, S.; Villata, S. A multilingual evaluation for online hate speech detection. ACM Trans. Internet Technol. TOIT 2020, 20, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Waseem, Z. Are you a racist or am I seeing things? Annotator influence on hate speech detection on twitter. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 5 November 2016; pp. 138–142. [Google Scholar]
- Khan, S.; Kamal, A.; Fazil, M.; Alshara, M.A.; Sejwal, V.K.; Alotaibi, R.M.; Baig, A.R.; Alqahtani, S. HCovBi-caps: Hate speech detection using convolutional and Bi-directional gated recurrent unit with Capsule network. IEEE Access 2022, 10, 7881–7894. [Google Scholar] [CrossRef]
- He, B.; Ziems, C.; Soni, S.; Ramakrishnan, N.; Yang, D.; Kumar, S. Racism is a virus: Anti-asian hate and counterspeech in social media during the COVID-19 crisis. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Virtual Event, The Netherlands, 8–11 November 2021; pp. 90–94. [Google Scholar]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Model/Models | Representation of Feature | Outcomes | Limitations or Gap | Dataset |
|---|---|---|---|---|---|
| Araque and Iglesias [1] | TF-IDF and SIMilarity-based sentiment projectiON (SIMON) | TFIDF | F1-scores | Could have tried combination method | Pro-Neu, Pro-Anti, Magazines, SemEval-2019, Davidson |
| Heidari et al. [3] | Feed Forward Neural Network (FFNN) and Logistic Regression (LR) | Word embedding | Accuracy, F1 score | No of evaluation metrics could have been more | Cresci 2017 |
| Chia et al. [4] | Various classifiers have been used | TFIDF | F score | Larger variety of preprocessing methods will be adopted by the authors | Dataset created by Semantic Evaluation 2018 Task 3: Irony Detection in English Tweets |
| Shekhar et al. [6] | LSTM | Context words, First & last words etc. | F score | Multiple languages could have been considered | WordNet |
| Agarwal and Chowdary [15] | ensemble learning-based adaptive model f | Word vector | F1, Precision and recall | Lack of fine-grained and free data set | COVID-19 and US elections |
| Sadiq et al. [16] | CNN-LSTM and CNN-BiLSTM | unigram and bigram encode with TF–IDF | F1, Accuracy, Precision, Recall | Not considered different features | Cyber-Trolls dataset was created |
| Alammary [18] | Modified TF-IDF model | TFPOS-IDF | Accuracy, Precision, Recall | Word embedding method not carried out | Made own data set based on Bloom’s Taxonomy |
| Sharma et al. [19] | MoH + M-Bert; MoH + MuRIL | Not mentioned | Precision, Recall and F1 | Error causing factors could be futher enhanced | TRAC-I; HOT and HS Data |
| Roy et al. [20] | DCNN, LSTM | tf-idf | precision, recall and F1-score | Insufficient data set | Kaggle.com |
| Al-Garadi et al. [21] | Naïve Bayes, Support vector machine (SVM), Random Forest, KNN | Feature engineering | F1, Precision, recall, AUC, ROC | Cyberbullying concept could have been explored | geo-tagged tweets |
| Mohapatra et al. [22] | Support vector machine (SVM), naïve Bayes (NB) and Random Forest (RF) | TF-IDF | F1, Precision, recall, accuracy | Different languages could have been considered | From various social media pages |
| Dataset | No. of Instances | No. of Classes | Source |
|---|---|---|---|
| Al-garadi et al. [21] | 2.5 million geo-tagged tweets | 2 | |
| SemEval-2019 [35] | 10,000 | 2 | |
| Waseem (2016) [43] | 16,000 | 2 | |
| Khan et al. (2022) [44] | DS1 = 80,000 tweets & DS2 = 31,962 tweets | 2 | |
| He et al. (2021) [45] | 2400 | 2 | |
| Our proposed model | 31,962 | 2 | Prepared |
| Label | Id-Count | Mean | SD | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| 0 | 29720 | 15,974.45 | 9223.78 | 1.0 | 7981.75 | 15,971.5 | 23,965.25 | 31,962.0 |
| 1 | 2242 | 16,074.90 | 9267.956 | 14.0 | 8075.25 | 16,095.0 | 24,022.00 | 31,961.0 |
| Id | Label | Tweet | Clean Tweet | Length | |
|---|---|---|---|---|---|
| 0 | 31434.0 | 0 | ode to depression|infusing reality with hope | ode to depression infusing reality with hope | 49 |
| 1 | 14785.0 | 0 | what an awful day on #Twitter. crazies on both... | what an awful day on crazies on both ends of... | 135 |
| 2 | 7561.0 | 0 | @user @user #wishing you a lovely mid week we... | you a lovely mid week wednesday day | 60 |
| 3 | 29558.0 | vine by | 76 | ||
| 4 | 903.0 | 0 | “a picture is woh a thousand words.” #sundayre... | a picture is woh a thousand words | 88 |
| 5 | 22216.0 | 0 | my thoughts and prayers and deepest condolence... | my thoughts and prayers and deepest condolence... | 113 |
| 6 | 10853.0 | 1 | @user #allahsoil not all muslims hate america.... | not all muslims hate america | 102 |
| 7 | 2761.0 | 0 | how to save thanksgiving #thanksgiving | how to save thanksgiving | 41 |
| 8 | 12039.0 | 0 | beautiful world | beautiful world ~ happy friday | 96 |
| 9 | 9170.0 | 0 | if you don’t think every day is a good day, ju... | if you don’t think every day is a good day just... | 103 |
| Accuracy | F1 Score | AUC | |
|---|---|---|---|
| Bagging | 0.94 | 0.60 | 0.76 |
| Random Forest | 0.95 | 0.95 | 0.78 |
| AdaBoost | 0.94 | 0.53 | 0.69 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 1 | 0.65 | 0.55 | 0.60 | 520 |
| 0 | 0.96 | 0.97 | 0.97 | 6013 |
| accuracy | 0.94 | 8166 | ||
| macro avg | 0.81 | 0.77 | 0.79 | 8166 |
| weighted avg | 0.94 | 0.94 | 0.94 | 8166 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 1 | 0.74 | 0.58 | 0.65 | 520 |
| 0 | 0.96 | 0.98 | 0.97 | 6013 |
| macro avg | 0.85 | 0.78 | 0.81 | 6533 |
| weighted avg | 0.95 | 0.95 | 0.95 | 6533 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 1 | 0.79 | 0.40 | 0.54 | 672 |
| 0 | 0.95 | 0.99 | 0.97 | 7494 |
| macro avg | 0.87 | 0.70 | 0.75 | 8166 |
| weighted avg | 0.94 | 0.94 | 0.93 | 8166 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Turki, T.; Roy, S.S. Novel Hate Speech Detection Using Word Cloud Visualization and Ensemble Learning Coupled with Count Vectorizer. Appl. Sci. 2022, 12, 6611. https://doi.org/10.3390/app12136611
Turki T, Roy SS. Novel Hate Speech Detection Using Word Cloud Visualization and Ensemble Learning Coupled with Count Vectorizer. Applied Sciences. 2022; 12(13):6611. https://doi.org/10.3390/app12136611
Chicago/Turabian StyleTurki, Turki, and Sanjiban Sekhar Roy. 2022. "Novel Hate Speech Detection Using Word Cloud Visualization and Ensemble Learning Coupled with Count Vectorizer" Applied Sciences 12, no. 13: 6611. https://doi.org/10.3390/app12136611
APA StyleTurki, T., & Roy, S. S. (2022). Novel Hate Speech Detection Using Word Cloud Visualization and Ensemble Learning Coupled with Count Vectorizer. Applied Sciences, 12(13), 6611. https://doi.org/10.3390/app12136611