
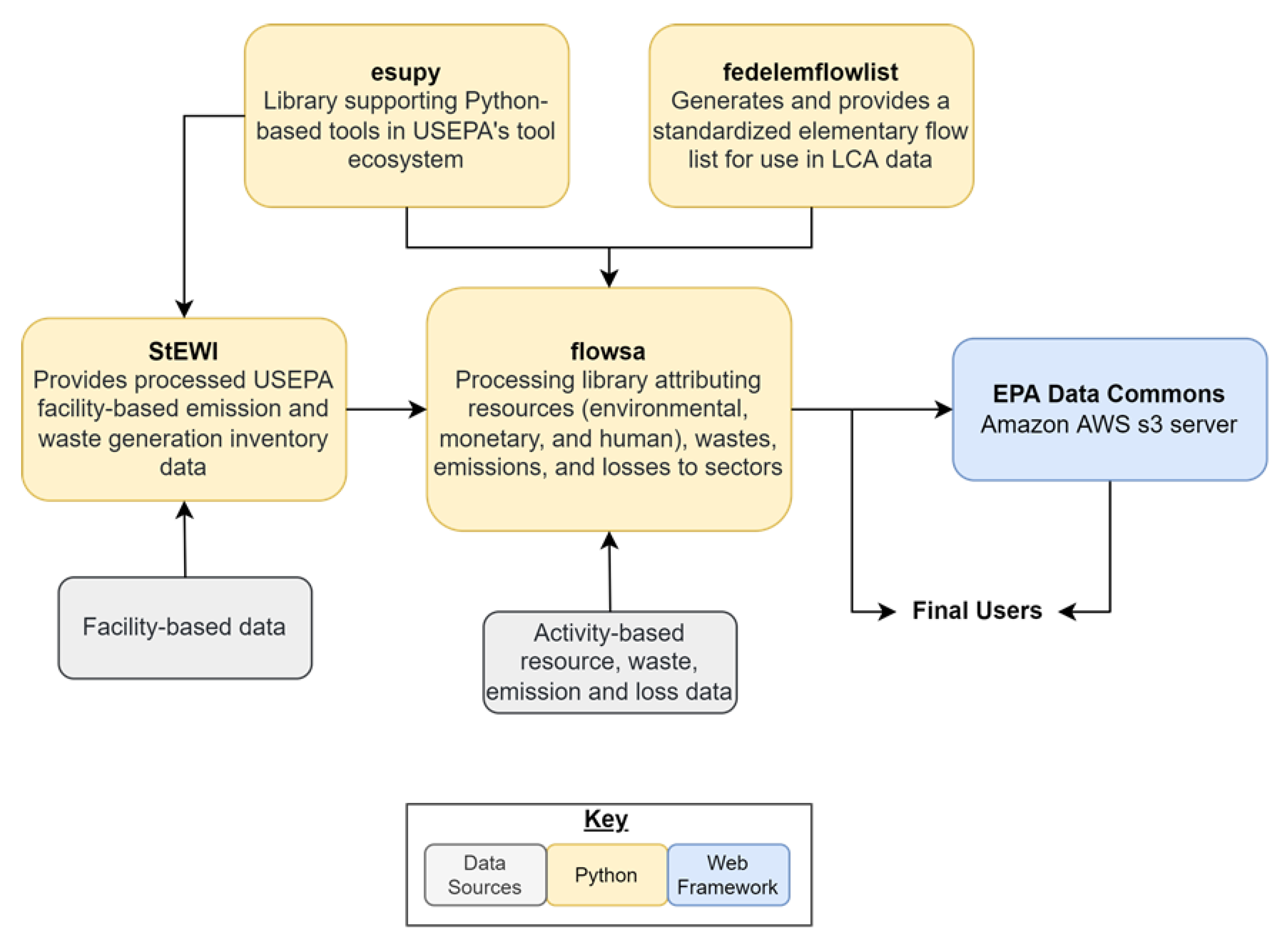
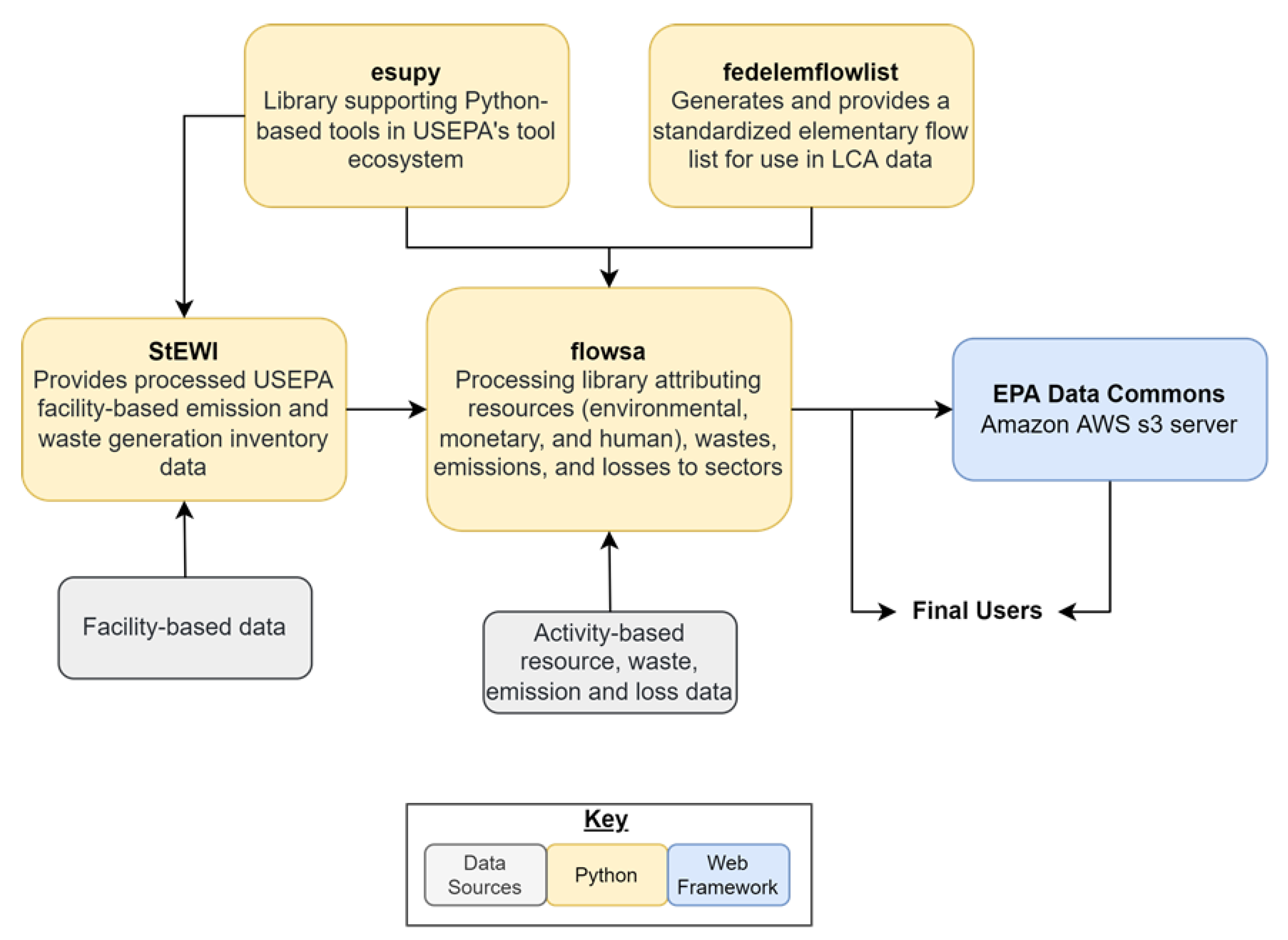
FLOWSA: A Python Package Attributing Resource Use, Waste, Emissions, and Other Flows to Industries

 , , ,
, , , 
Abstract
:1. Introduction
2. Materials and Methods
- Retrieves and formats publicly available environmental and economic data into Flow-By-Activity (FBA) tables;
- Maps unique source activity names to sectors, generally NAICS codes, and classifies each sector as an industry or commodity;
- Attributes source activities in FBA datasets to all related sectors using specified allocation methods, formatted into Flow-by-Sector (FBS) tables;
- Enables model result exploration and comparison with data visualization functions.
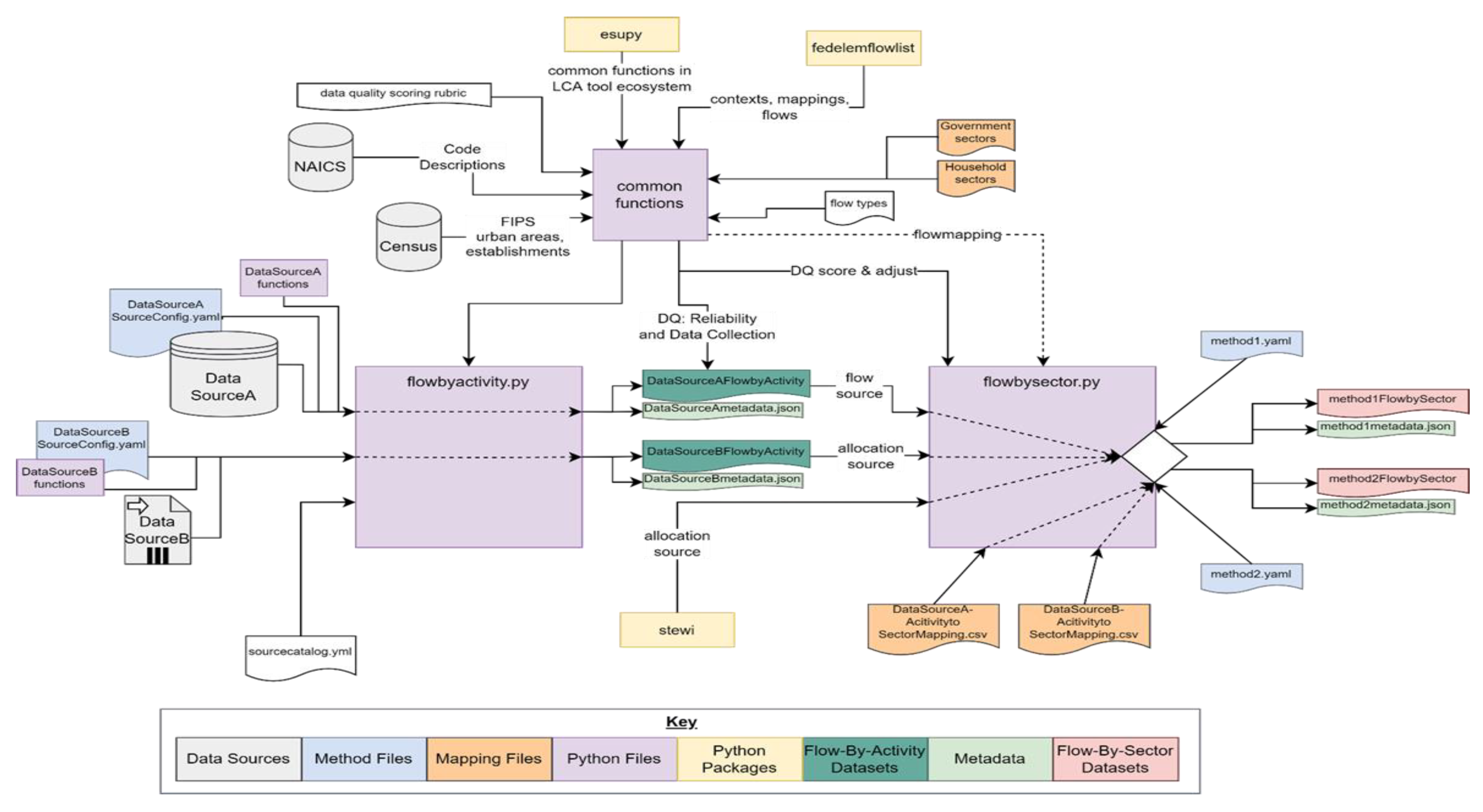
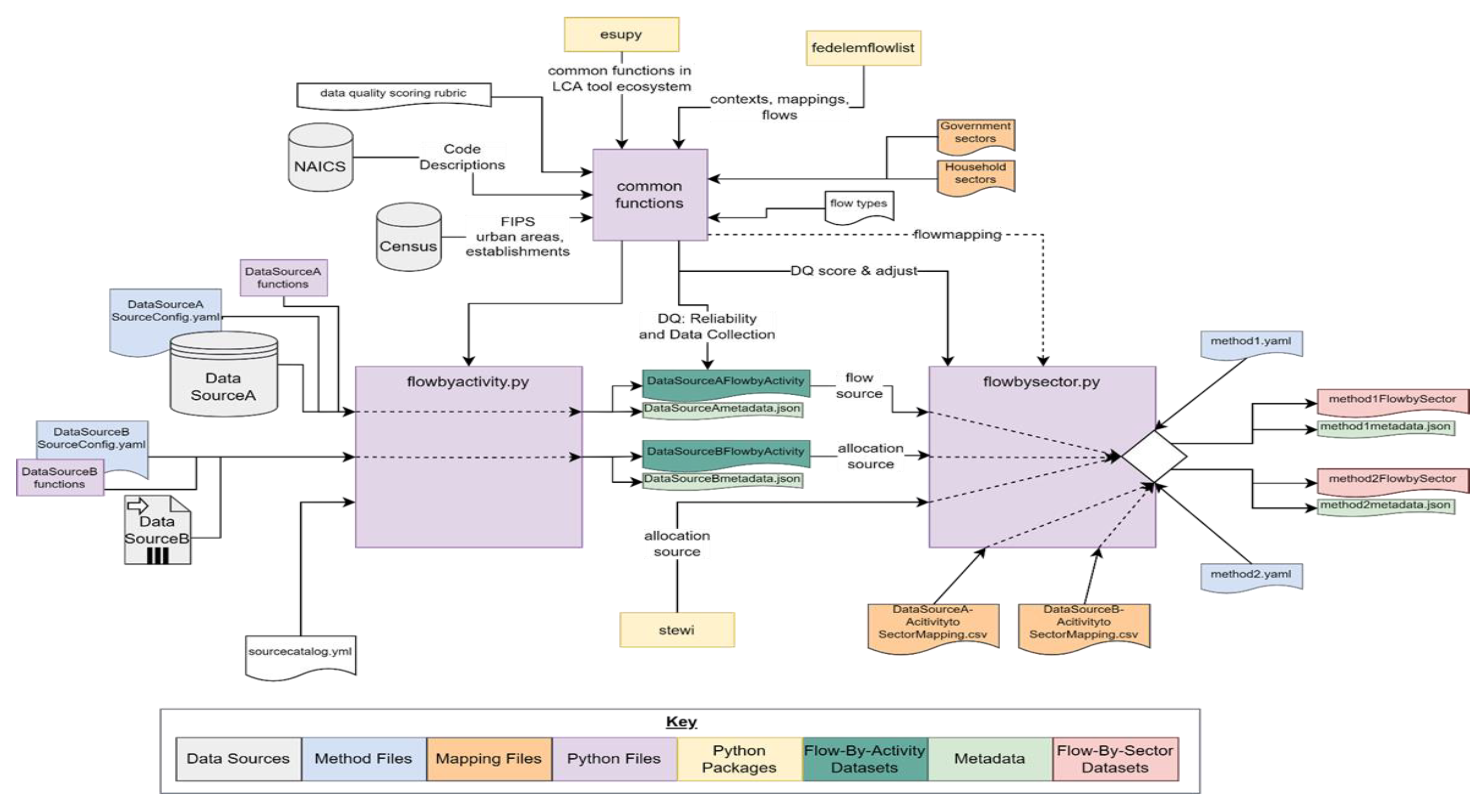
2.1. Flow-by-Activity (FBA) Datasets
Flow-by-Activity Generation
2.2. Mapping Flow-by-Activity Datasets to Sectors
2.3. Flow-by-Sector Datasets
Flow-by-Sector Generation
2.4. Data Visualization Functions
3. Results
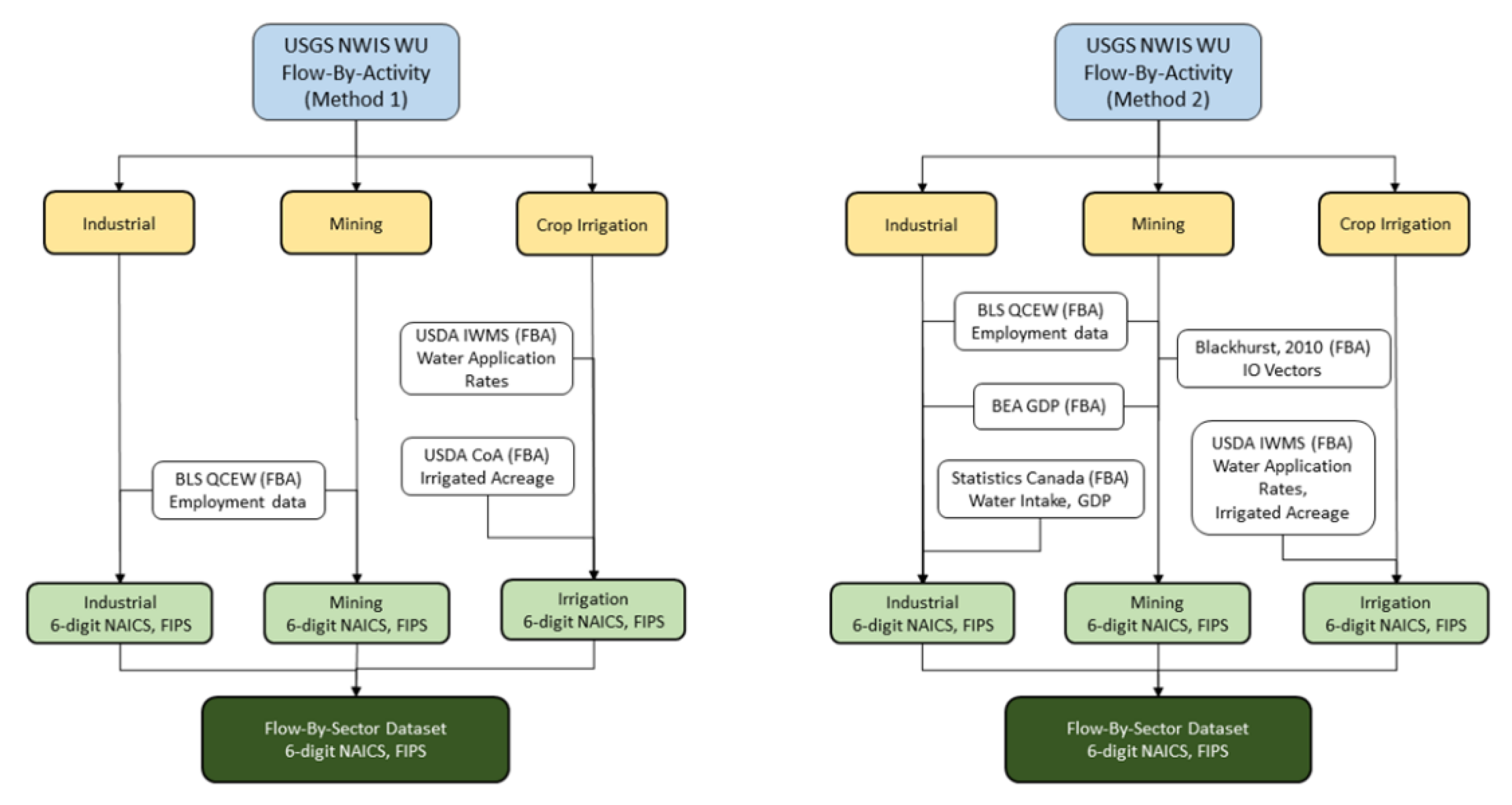
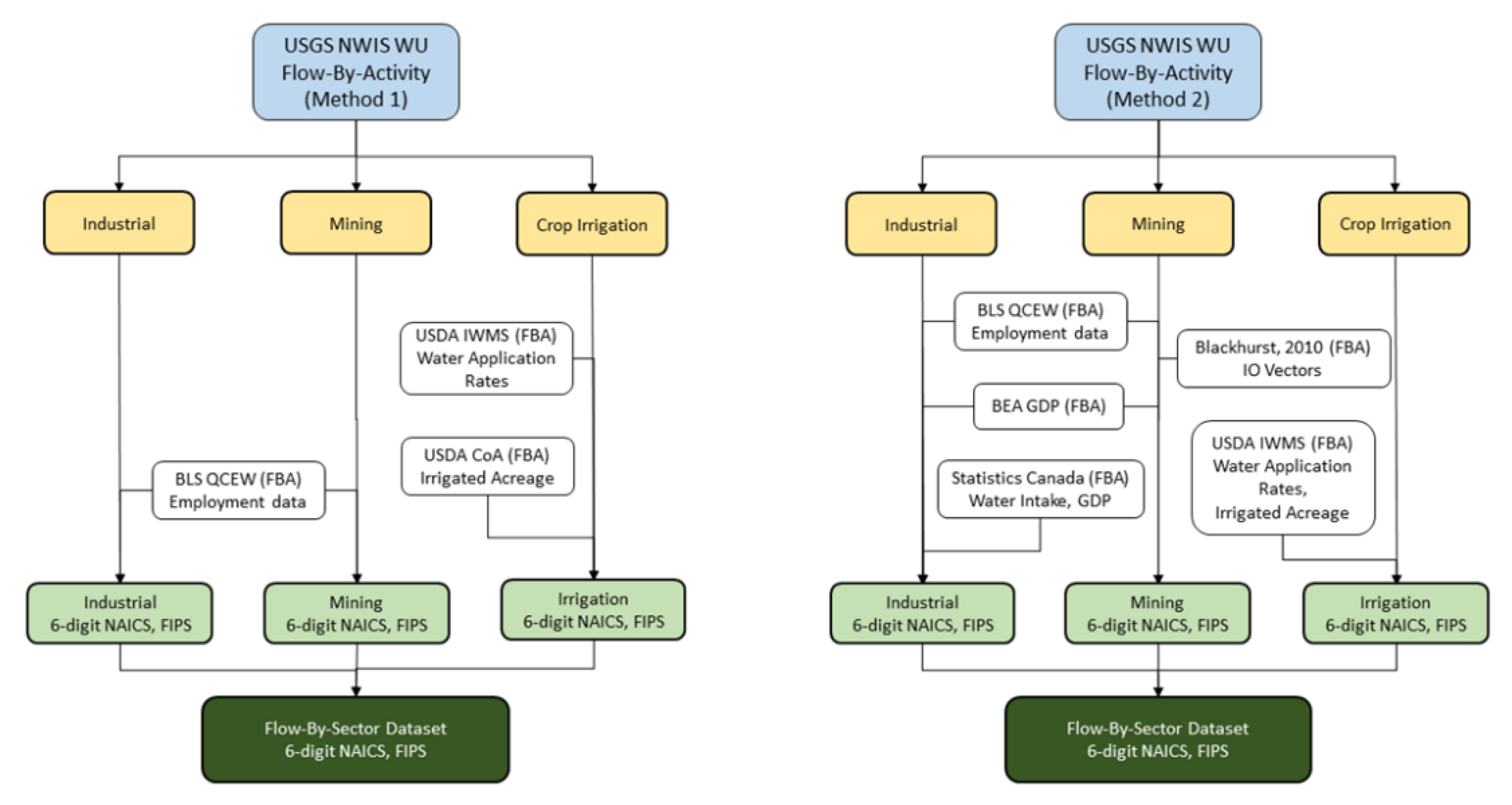
3.1. Conceptual Water Withdrawal Flow-by-Sector Methodology Example
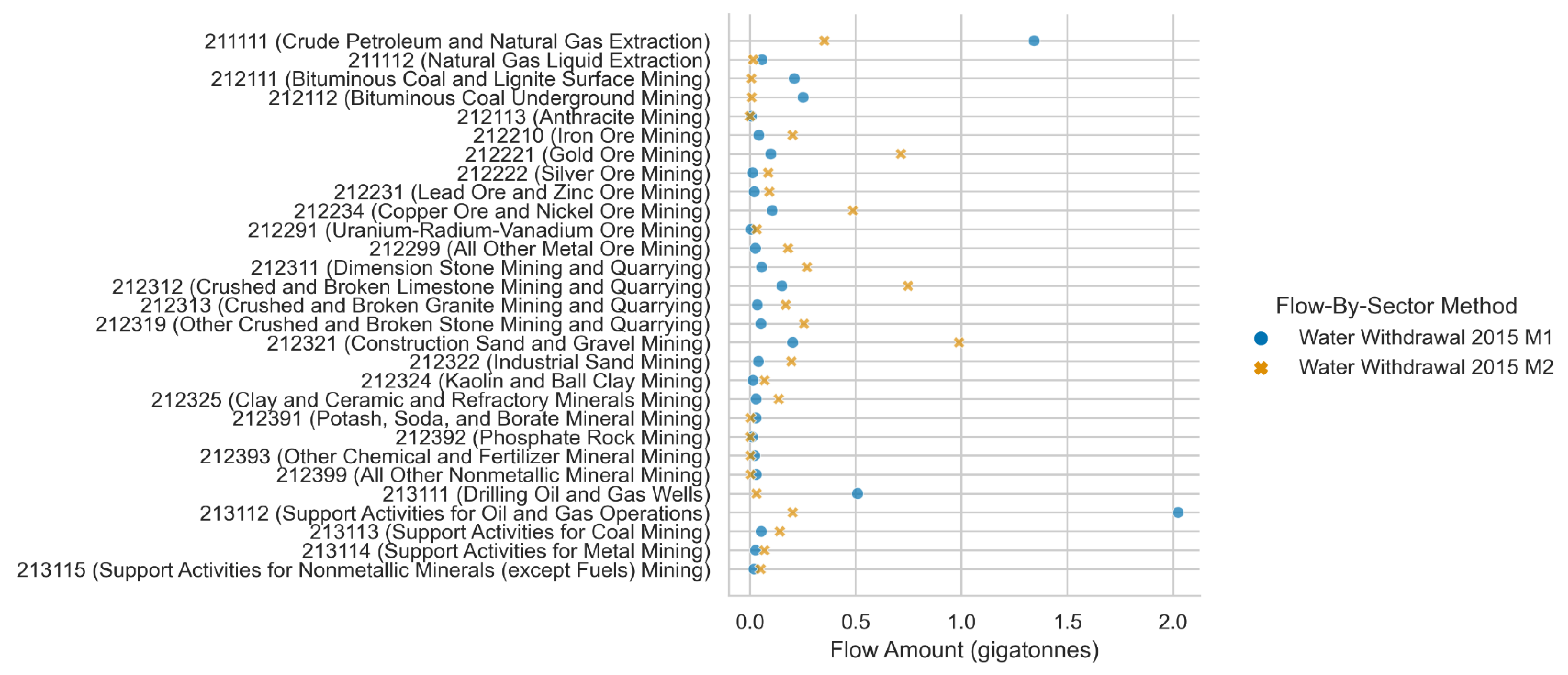
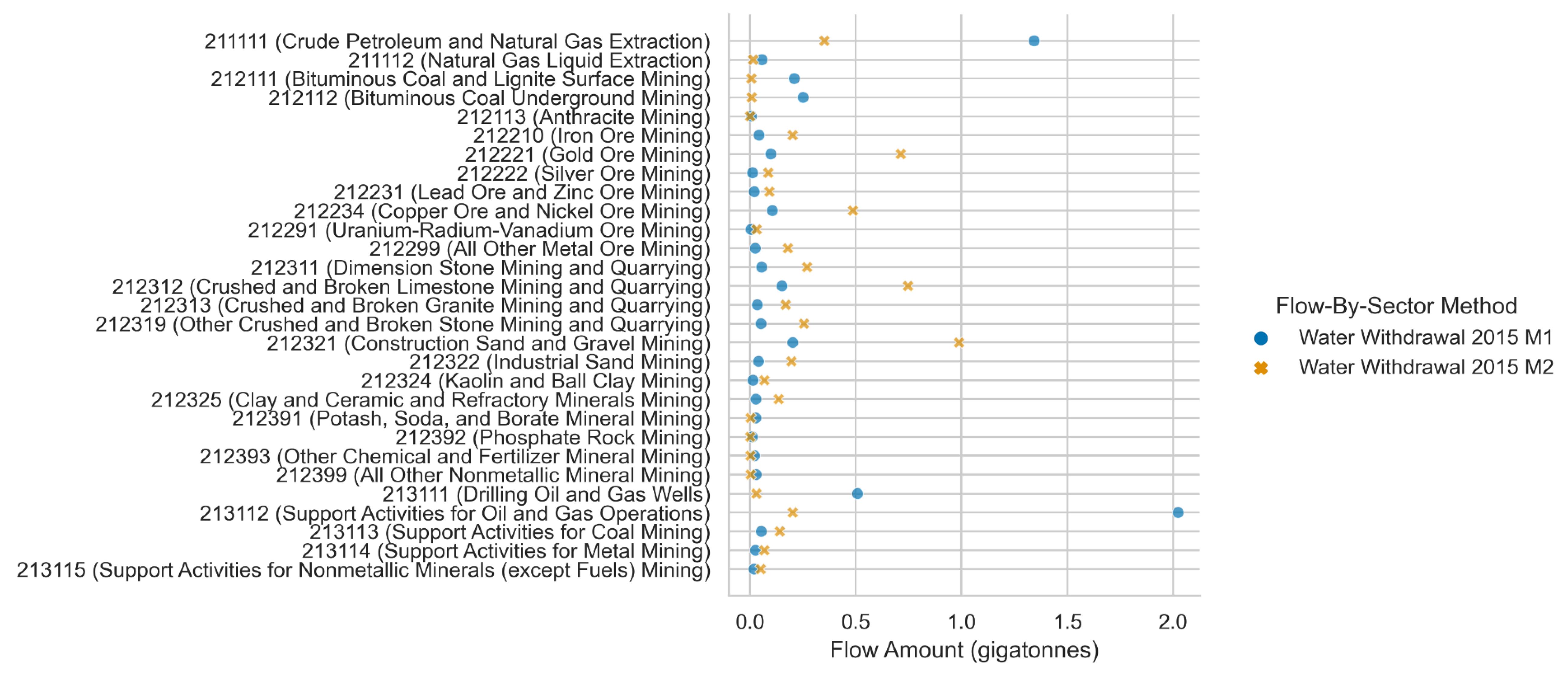
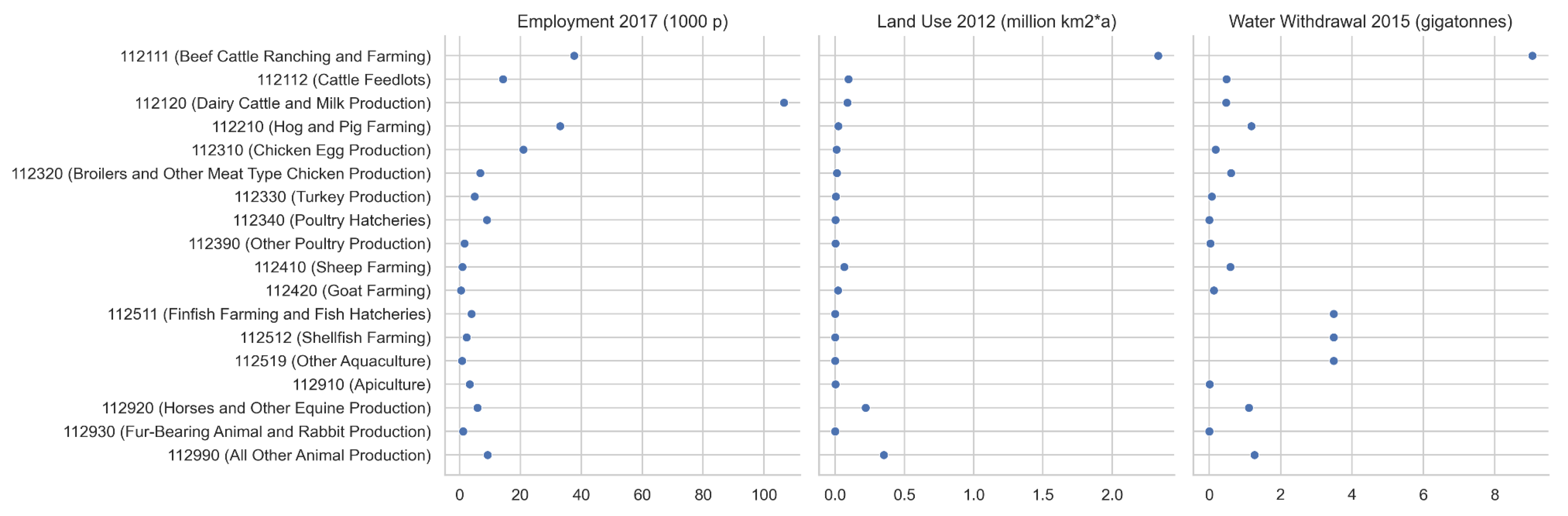
3.2. Select Flow-by-Sector Model Results
4. Discussion
4.1. Sector Attribution Challenges
4.2. FLOWSA Integration with Life Cycle Assessment Modeling
4.3. Potential Applications of FLOWSA
4.4. Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Edelen, A.; Hottle, T.; Cashman, S.; Ingwersen, W. The Federal LCA Commons Elementary Flow List: Background, Approach, Description and Recommendations for Use; U.S. Environmental Protection Agency: Washington, DC, USA, 2019. Available online: https://cfpub.epa.gov/si/si_public_record_report.cfm?dirEntryId=347251 (accessed on 2 May 2022).
- Yang, Y.; Ingwersen, W.W.; Hawkins, T.R.; Srocka, M.; Meyer, D.E. USEEIO: A New and Transparent United States Environmentally-Extended Input-Output Model. J. Clean. Prod. 2017, 158, 308–318. [Google Scholar] [CrossRef] [PubMed]
- Canning, P.; Rehkamp, S.; Waters, A.; Etemadnia, H. The Role of Fossil Fuels in the US Food System and the American Diet; United States Department of Agriculture Economic Research Service: Washington, DC, USA, 2017. Available online: https://www.ers.usda.gov/publications/pub-details/?pubid=82193 (accessed on 2 May 2022).
- Blackhurst, M.; Hendrickson, C.; Vidal, J.S.I. Direct and Indirect Water Withdrawals for U.S. Industrial Sectors. Environ. Sci. Technol. 2010, 44, 2126–2130. [Google Scholar] [CrossRef]
- Birney, C.; Young, B.; Conner, M.; Specht, J.; Li, M.; Ingwersen, W. FLOWSA; v1.0.1; Zenodo: Genève, Switzerland, 2021. Available online: https://zenodo.org/record/6370115 (accessed on 2 May 2022).
- Li, M.; Ingwersen, W.W.; Young, B.; Vendries, J.; Birney, C. useeior: An Open-Source R Package for Building and Using US Environmentally-Extended Input-Output Models. Appl. Sci. 2022, 12, 4469. [Google Scholar] [CrossRef]
- Ingwersen, W. Open Source Tool Ecosystem for Automating LCA Model Creation and Linkage; U.S. Environmental Protection Agency: Washington, DC, USA, 2020. Available online: https://cfpub.epa.gov/si/si_public_record_report.cfm?dirEntryId=350369 (accessed on 2 May 2022).
- Young, B.; Ingwersen, W.W.; Bergmann, M.; Hernandez-Betancur, J.D.; Ghosh, T.; Bell, E.; Cashman, S. A System for Standardizing and Combining U.S. Environmental Protection Agency Emissions and Waste Inventory Data. Appl. Sci. 2022, 12, 3447. [Google Scholar] [CrossRef]
- Ingwersen, W.; Edelen, A.; Hottle, T.; Young, B.; Cashman, S.; Srocka, M. Fedelemflowlist; Zenodo: Genève, Switzerland, 2021; Available online: https://zenodo.org/record/6370618 (accessed on 2 May 2022).
- Edelen, A.; Ingwersen, W. The Creation, Management, and Use of Data Quality Information for Life Cycle Assessment. Int. J. Life Cycle Assess 2018, 23, 759–772. [Google Scholar] [CrossRef] [PubMed]
- McKinney, W.; Van Der Walt, S.; Millman, J. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef] [Green Version]
- North American Industry Classification System; U.S. Census Bureau: Washington, DC, USA, 2022. Available online: https://www.census.gov/naics/ (accessed on 2 May 2022).
- Census of Agriculture 2017; U.S. Department of Agriculture, National Agricultural Statistics Service: Washington, DC, USA, 2021. Available online: https://quickstats.nass.usda.gov/ (accessed on 12 March 2021).
- Water Data for the Nation 2015; U.S. Geological Survey: Washington, DC, USA, 2015. Available online: https://waterdata.usgs.gov/nwis (accessed on 16 March 2021).
- Ingwersen, W.W.; Young, B.; Birney, C.; Beck, A. Esupy, v0.1.7; Zenodo: Genève, Switzerland, 2021. Available online: https://github.com/USEPA/esupy/releases/tag/v0.1.7(accessed on 2 May 2022).
- Young, B.; Ingwersen, W.; Bergmann, M.; Hernandez-Betancur, J.; Ghosh, T.; Bell, E.; Beck, A.; Chambers, M. USEPA/standardizedinventories, v1.0.5; Zenodo: Genève, Switzerland, 2022. Available online: https://zenodo.org/record/6539511(accessed on 2 May 2022).
- Toxics Release Inventory 2017; U.S. Environmental Protection Agency: Washington, DC, USA, 2018. Available online: http://www2.epa.gov/toxics-release-inventory-tri-program/tri-data-and-tools (accessed on 2 May 2022).
- National Emissions Inventory 2017; U.S. Environmental Protection Agency: Washington, DC, USA, 2019. Available online: https://www.epa.gov/air-emissions-inventories/national-emissions-inventory-nei (accessed on 2 May 2022).
- Discharge Monitoring Report (DMR) Pollutant Loading Tool; U.S. Environmental Protection Agency: Washington, DC, USA, 2018. Available online: https://echo.epa.gov/trends/loading-tool/water-pollution-search (accessed on 2 May 2022).
- National Biennial Hazardous Waste Report 2017; U.S. Environmental Protection Agency: Washington, DC, USA, 2018. Available online: https://www.epa.gov/hwgenerators/biennial-hazardous-waste-report (accessed on 2 May 2022).
- Topinka, T. Statistic, Jetbrains. 2021. Available online: https://plugins.jetbrains.com/plugin/4509-statistic (accessed on 2 May 2022).
- U.S. Census Bureau: Washington, DC, USA. 2020. Available online: https://www.census.gov/naics/2012NAICS/2-digit_2012_Codes.xls (accessed on 2 May 2022).
- Lovelace, J.K. Method for Estimating Water Withdrawals for Livestock in the United States, 2005; U.S. Geological Survey: Liston, VA, USA, 2009.
- Quarterly Census of Employment and Wages 2015; U.S. Bureau of Labor Statistics: Washington, DC, USA, 2020. Available online: https://www.bls.gov/cew/downloadable-data-files.htm (accessed on 16 March 2021).
- Irrigation and Water Management Survey 2018; U.S. Department of Agriculture: Washington, DC, USA, 2019. Available online: https://www.nass.usda.gov/Publications/AgCensus/2017/Online_Resources/Farm_and_Ranch_Irrigation_Survey/fris.pdf (accessed on 2 May 2022).
- Input-Output Accounts Data; U.S. Bureau of Economic Analysis: Washington, DC, USA, 2021. Available online: https://www.bea.gov/industry/input-output-accounts-data (accessed on 28 January 2021).
- Water Use Parameters in Manufacturing Industries, by Industry; Statistics Canada: Ottawa, ON, Canada, 2020. Available online: https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=3810003701 (accessed on 25 May 2020).
- Natural Gas Gross Withdrawals and Production; U.S. Energy Information Administration: Washington, DC, USA, 2020. Available online: https://www.eia.gov/dnav/ng/ng_prod_sum_a_EPG0_FGW_mmcf_m.htm (accessed on 22 March 2021).
- Li, M.; Ingwersen, W.; Young, B.; Vendries, J.; Birney, C. Useeior; Zenodo: Genève, Switzerland, 2021. [Google Scholar]
- Ingwersen, W.; Li, M.; Young, B.; Vendries, J.; Birney, C. The US Environmentally-Extended Input-Output Model v2.0 (USEEIOv2.0). Sci. Data 2022, 9, 1–24. [Google Scholar] [CrossRef] [PubMed]
- System of Environmental Economic Accounting; United Nations: Geneva, Switzerland, 2021; Available online: https://seea.un.org/ (accessed on 25 May 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flow Class | Description | Flow Types |
|---|---|---|
| Chemicals | Emissions of chemicals and groups of chemicals | ELEMENTARY_FLOWS |
| Employment | Jobs | ELEMENTARY_FLOWS |
| Energy | Energy consumption, transfer as electricity or waste heat | All types |
| Geological | Mineral and metal use | All types |
| Land | Land area occupied | ELEMENTARY_FLOWS |
| Money | Purchases | TECHNOSPHERE_FLOWS |
| Water | Water use and release data, including wastewater | All types |
| Other | Misc flows used for supporting data | All types |
| Code | Dataset | Class | Geographic Scale | Description | Years |
|---|---|---|---|---|---|
| BEA_GDP_GrossOutput | Bureau of Economic Analysis Gross Output by Industry | Money | National | Gross output | 2007–2018 |
| BEA_Make_AR | Bureau of Economic Analysis Make Table After Redefinition | Money | National | Gross output, producer value, after redefinition | 2002 |
| BEA_Make_Detail_BeforeRedef | Bureau of Economic Analysis Make Before Redefinitions | Money | National | Gross output before redefinition, detail level | 2012 |
| BEA_Use_Detail_PRO_BeforeRedef | Bureau of Economic Analysis Use Before Redefinitions | Money | National | Gross output before redefinition, detail level, producer value | 2012 |
| BLM_PLS | Bureau of Land Management Public Land Statistics | Land | National | Land resources and information | 2007, 2011, 2012 |
| BLS_QCEW | Bureau of Labor Statistics Quarterly Census of Employment and Wages | Employment, Money, Other | National, State, County | Number of employees per industry, Annual payroll per industry, Number of establishments per industry | 2002, 2010–2018 |
| Blackhurst_IO | Input–Output Vector of 2002 Water Withdrawals for the United States | Water | National | Input–Output vectors of US water withdrawals | 2002 |
| CalRecycle_WasteCharacterization | CalRecycle | Other | California | Disposal-Facility-Based Characterization of Solid Waste in California | 2014 |
| Census_CBP | Census Bureau County Business Patterns | Employment, Money, Other | National, State, County | Number of employees per industry, Annual payroll per industry, Number of establishments per industry | 2010–2017 |
| Census_PEP_Population | Census Bureau Population Estimates | Other | National, State, County | Population | 2010, 2013–2017 |
| Census_VIP | Value of Construction Put in Place | Money | National | Construction Spending | 2009–2020 |
| EIA_CBECS_Land | Energy Information Administration Commercial Buildings Energy Consumption Survey | Land | National | Floorspace by building type | 2012 |
| EIA_CBECS_Water | Energy Information Administration Commercial Buildings Energy Consumption Survey | Water | Country | Water consumption in large buildings | 2012 |
| EIA_MECS_Energy | Energy Information Administration Manufacturing Energy Consumption Survey | Energy, Other | Region | Fuel and nonfuel consumption of energy flows by manufacturing industries | 2010, 2014, 2018 |
| EIA_MECS_Land | Energy Information Administration Manufacturing Energy Consumption Survey | Land | National, Regional | Floorspace by building type | 2010, 2014, 2018 |
| EIA_MER | Energy Information Administration Monthly Energy Review | Energy | National | Energy consumption and production | 2010–2020 |
| EPA_CDDPath | Construction and Demolition Debris | Other | National | Estimates of amount and disposition of Construction and Demolition materials | 2014 |
| EPA_EQUATES | Air QUAlity TimE Series Project | Chemicals | Chemical atmospheric concentrations and deposition | 2002–2017 | |
| EPA_GHGI | Inventory of U.S. Greenhouse Gas Emissions and Sinks | Chemicals, Energy, Other | National | US GHG emissions and sinks by source, economic sector, and greenhouse gas | 2010–2019 |
| EPA_NEI_Nonpoint | Environmental Protection Agency National Emissions Inventory Nonpoint sources | Chemicals | County | Air emissions of criteria pollutants, criteria precursors, and hazardous air pollutants | 2008, 2011, 2014, 2017 |
| EPA_NEI_Nonroad | Environmental Protection Agency National Emissions Inventory Nonroad sources | Chemicals | County | Air emissions of criteria pollutants, criteria precursors, and hazardous air pollutants | 2008, 2011, 2014, 2017 |
| EPA_NEI_Onroad | Environmental Protection Agency National Emissions Inventory Onroad sources | Chemicals | County | Air emissions of criteria pollutants, criteria precursors, and hazardous air pollutants | 2008, 2011, 2014, 2017 |
| EPA_NI | Nitrogen Inventories | Chemicals | HUC8 | Nitrogen inputs and fluxes | 2002, 2007, 2012 |
| EPA_PI | Phosphorus Inventories | Chemicals | HUC8 | Phosphorus inputs and fluxes | 2002, 2007, 2012 |
| NETL_EIA_PlantWater | Modified EIA Thermoelectric Plant Water Withdrawals | Water | National | Water discharge, consumption, withdrawal | 2015 |
| NOAA_FisheryLandings | National Oceanic and Atmospheric Administration Fisheries | Money | State | Fishery landings | 2012–2018 |
| StatCan_GDP | Statistics Canada Gross Domestic Product | Money | Canada | GDP for Canada | 2010–2015 |
| StatCan_IWS_MI | Statistics Canada Industrial Water Survey | Water | Country | Water use by NAICS | 2005, 2007, 2009, 2011, 2013, 2015 |
| StatCan_LFS | Statistics Canada Labour Force Study | Employment | Canada | Employment by industry | 2010–2019 |
| USDA_ACUP_Fertilizer | Chemical Use Survey | Chemicals | State | Fertilizer use by crop | 2012, 2015, 2017, 2018, 2020 |
| USDA_ACUP_Pesticide | Chemical Use Survey | Chemicals | State | Pesticide use by crop | 2012, 2015, 2017, 2018, 2020 |
| USDA_CoA_Cropland | USDA Census of Agriculture | Land, Other | County | Crop area by farm size and irrigation status by crop | 2012, 2017 |
| USDA_CoA_Cropland_NAICS | USDA Census of Agriculture | Land | State | Crop area by farm size and irrigation status by NAICS | 2012, 2017 |
| USDA_CoA_Livestock | USDA Census of Agriculture | Other | County | Livestock count by farm size | 2012, 2017 |
| USDA_ERS_FIWS | USDA Farm Income and Wealth Statistics | Money | National, State | Cash receipts value | 2010–2019 |
| USDA_ERS_MLU | USDA Major Land Uses | Land | National | Land use by category | 2007, 2012 |
| USDA_IWMS | USDA Irrigation and Water Management Survey | Water | State | Water application rate by state and crop | 2013, 2018 |
| USGS_MYB | USGS Mineral Yearbook | Geological | National | Imports, Exports, Production, Consumption | 2012–2018 |
| USGS_NWIS_WU | US Geological Survey Water Use in the US | Water | County | Annual national-level water use by various activities | 2010, 2015 |
| USGS_SPARROW | USGS SPARROW MAPPERS | Chemicals | HUC | Phosphorus and nitrogen in streams and coastal waters | 2012 |
| USGS_WU_Coef | USDA Water Use Coefficients | Water | National | Method for estimating water withdrawals for livestock | 2005 |
| Activity SourceName | Activity | SectorSourceName | Sector | SectorDescription | SectorType |
|---|---|---|---|---|---|
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 1133 | Logging | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 23 | Construction | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 31-33 | Manufacturing | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 48839 | Other Support Activities for Water Transportation | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 5111 | Newspaper, Periodical, Book, and Directory Publishers | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 51222 | Integrated Record Production/Distribution | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 51223 | Music Publishers | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 54171 | Research and Development in the Physical, Engineering, and Life Sciences | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 56291 | Remediation Services | I |
| USGS_NWIS_WU | Industrial | NAICS_2012_Code | 81149 | Other Personal and Household Goods Repair and Maintenance | I |
| Data | Method Name | Years | Geographic Scale | Available Methods |
|---|---|---|---|---|
| Commercial non-hazardous waste for construction | CNHWC_national_20XX | 2014 | National | 1 |
| Commercial non-hazardous waste | CNHW_CA_20XX | 2014 | California | 1 |
| Commercial non-hazardous waste | CNHW_national_20XX | 2014 | National | 1 |
| Commercial RCRA-defined hazardous waste | CRHW_national_20XX | 2017 | National | 1 |
| Commercial RCRA-defined hazardous waste | CRHW_state_20XX | 2017 | National | 1 |
| Criteria and hazardous air emissions | CAP_HAP_national_20XX | 2017 | National | 1 |
| Electricity generation emissions | Electricity_gen_emissions_national_20XX | 2016 | National | 1 |
| Employment | Employment_national_20XX | 2017 | National | 1 |
| Employment | Employment_state_20XX | 2012–2017 | State | 1 |
| Land use | Land_national_20XX | 2012 | National | 1 |
| Point source industrial releases to ground | GRDREL_national_20XX | 2017 | National | 1 |
| Point source industrial releases to ground | GRDREL_state_20XX | 2017 | State | 1 |
| Point source releases to water | TRI_DMR_national_20XX | 2017 | National | 1 |
| Point source releases to water | TRI_DMR_state_20XX | 2017 | State | 1 |
| Water withdrawal | Water_national_20XX | 2010, 2015 | National | 3 |
| Water withdrawal | Water_state_20XX | 2015 | State | 1 |
| Type | File Count | Lines Code |
|---|---|---|
| py | 109 | 24,730 |
| yaml | 136 | 5220 |
| csv | 78 | 79,163 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Birney, C.; Young, B.; Li, M.; Conner, M.; Specht, J.; Ingwersen, W.W. FLOWSA: A Python Package Attributing Resource Use, Waste, Emissions, and Other Flows to Industries. Appl. Sci. 2022, 12, 5742. https://doi.org/10.3390/app12115742
Birney C, Young B, Li M, Conner M, Specht J, Ingwersen WW. FLOWSA: A Python Package Attributing Resource Use, Waste, Emissions, and Other Flows to Industries. Applied Sciences. 2022; 12(11):5742. https://doi.org/10.3390/app12115742
Chicago/Turabian StyleBirney, Catherine, Ben Young, Mo Li, Melissa Conner, Jacob Specht, and Wesley W. Ingwersen. 2022. "FLOWSA: A Python Package Attributing Resource Use, Waste, Emissions, and Other Flows to Industries" Applied Sciences 12, no. 11: 5742. https://doi.org/10.3390/app12115742
APA StyleBirney, C., Young, B., Li, M., Conner, M., Specht, J., & Ingwersen, W. W. (2022). FLOWSA: A Python Package Attributing Resource Use, Waste, Emissions, and Other Flows to Industries. Applied Sciences, 12(11), 5742. https://doi.org/10.3390/app12115742