
A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network



Abstract
:1. Introduction
- Supervised learning methods are concerned with inferring a function from input–output pairs. The learning exhibited by these methods is achieved by optimizing a loss function computed from the output produced from the model and the expected output or ground truth.
- Unsupervised learning techniques attempt to learn the hidden structure present in training data without the use of an explicit error/reward signal. These techniques attempt to learn the structure naturally present in the training set and achieve this without an error or reward signal.
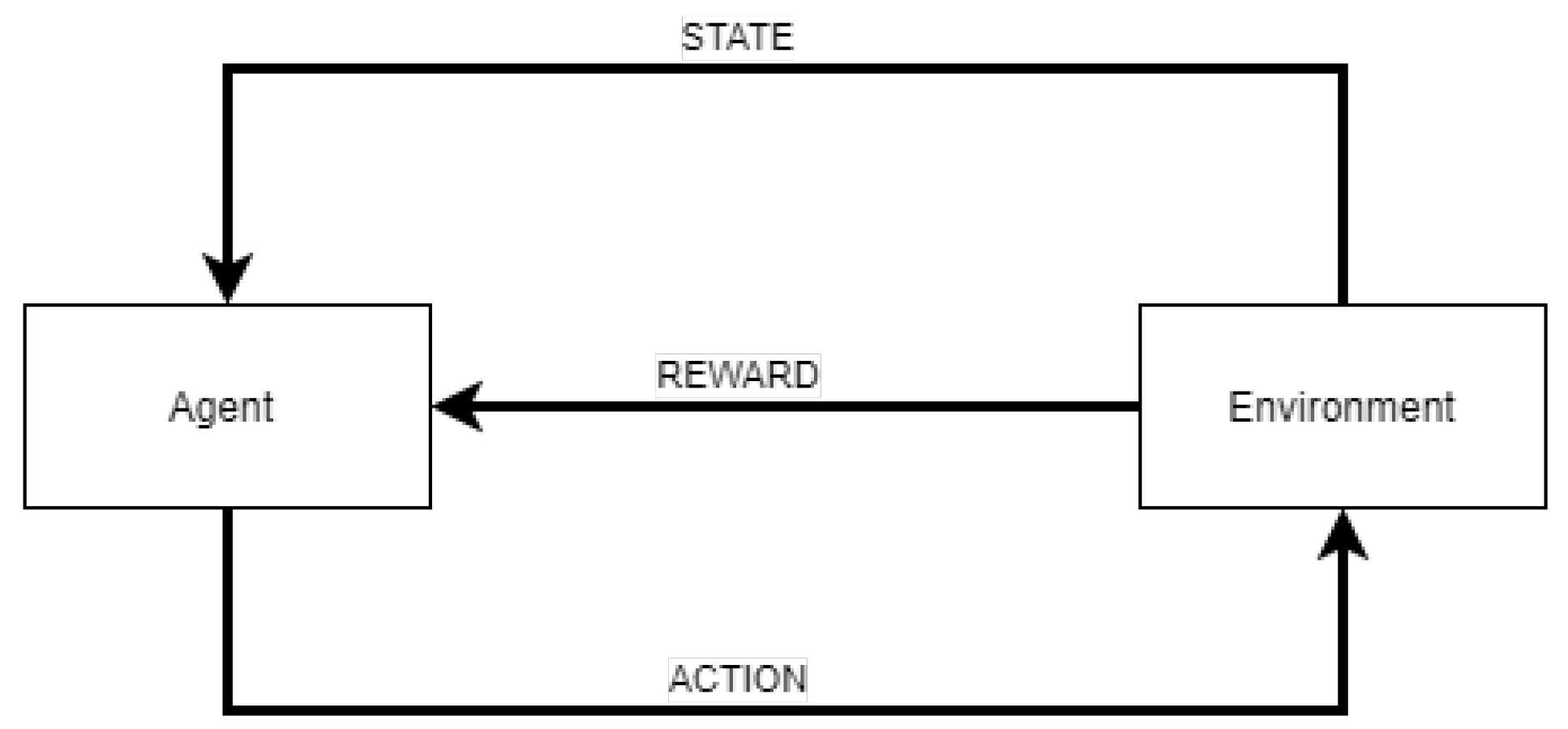
- Reinforcement learning (RL) attempts to learn a policy, that maps percepts to actions by interaction with the environment. The RL algorithms are inspired by behavioral psychology and attempt to answer the question of how an agent placed in an environment can learn to behave optimally.
- For an agent tasked with classifying images, the vector x consists of pixel intensities. The ground truth is a discrete value representing the class that the image belongs to.
- An agent classifying bank transactions as fraudulent or not, uses data related to transactions to form x. The ground truth y for each x is either a 1, meaning that the transaction data in x represents a fraudulent transaction or a 0, meaning that x represents a valid transaction.
- A robot navigating in an environment makes use of various sensor readings to form x. In the case of the robot navigating, defining a ground-truth becomes challenging.
- S denotes the set of states observable in the environment;
- A denotes the set of possible actions that can be performed;
- T is the set of time-steps in which decisions must be made. When a set of goal states exists the process terminates whenever these states are reached;
- p denotes the probability of transitioning from one state to another, and
- r denotes the reward function.
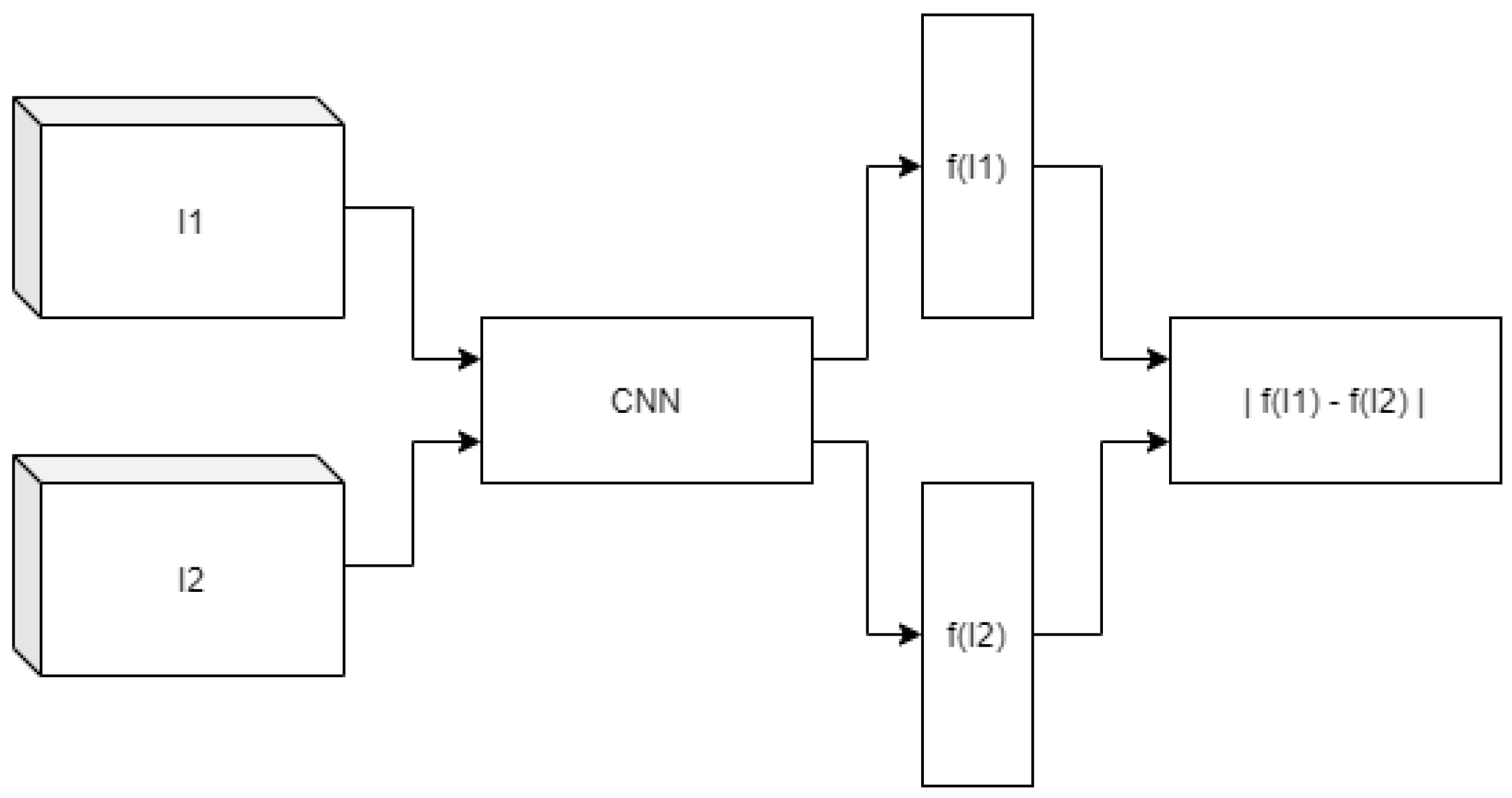
- represents the SCNN weights and biases;
- and represent the goal and state images, respectively;
- f denotes the convolutional feature encodings obtained from the SCNN.
- represents a policy; a function mapping states to actions;
- denotes the agents value estimate; how much reward can be expected from starting in state and following policy ;
- represents the Euclidean distance between the current state and the goal state.
- Identify a reformulation of an agent’s value function that takes into account the distance between the agent and its goal;
- Propose the use of a SCNN to estimate the distance between an agent and its goal;
- We demonstrate that the distance function can used to guide the agent towards its goal;
- We demonstrate that given a relatively small sample size for training, the Siamese convolutional neural network is able to outperform state-of-the-art convolutional neural networks pre-trained on large samples with complex architectures. In this study, we make use of ResNet18 and a KNN baseline model for comparison.
2. Related work
3. Materials and Methods
3.1. Data Collection
3.2. Proposed Solution Architecture
4. Results and Discussion
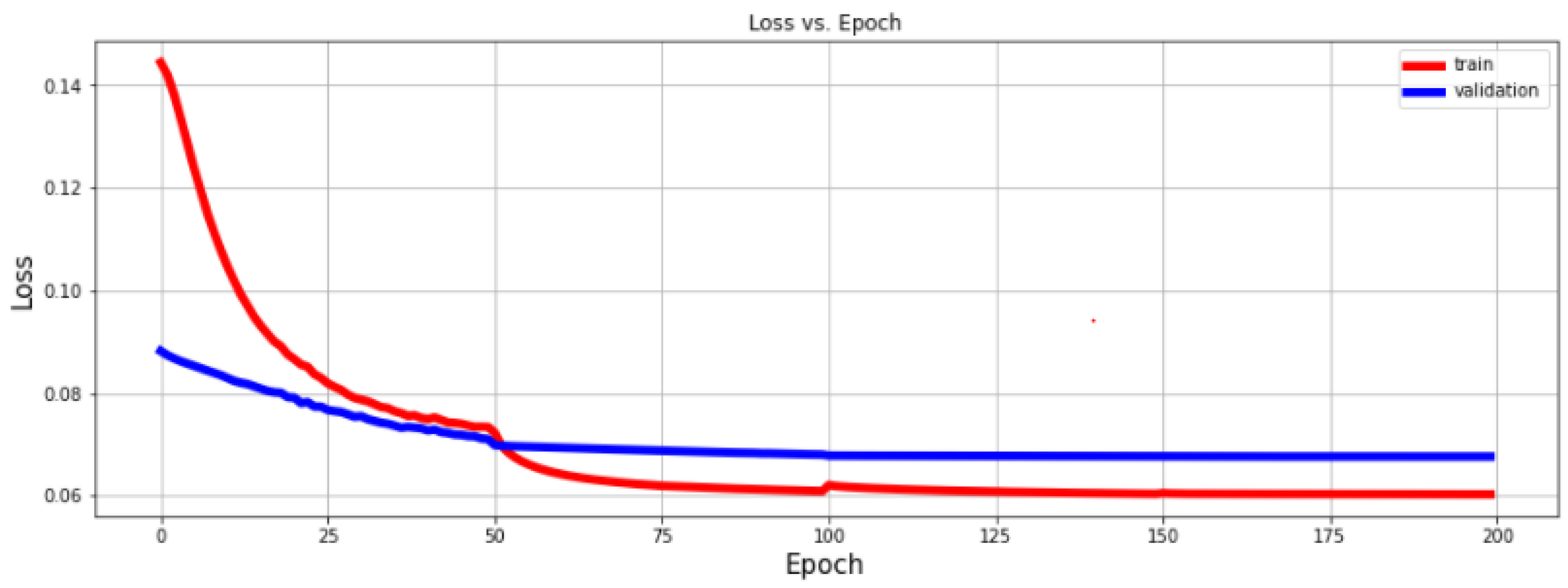

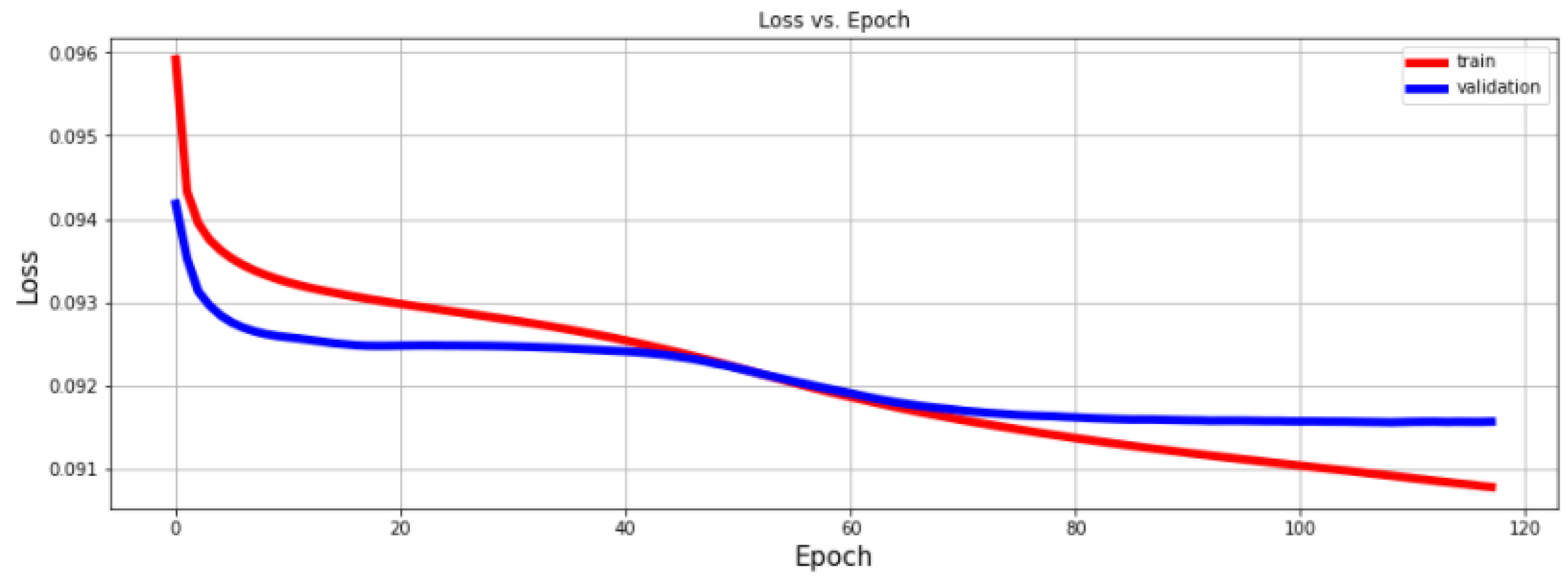
4.1. Discussion
4.2. Limitations of the Study
5. Conclusions and Future Work
- An agent tasked with locating a bomb may not know where the bomb is but may have some examples of what a bomb looks like;
- An agent tasked with helping an elderly person navigate their environment may not know where all the obstacles/items are located around it but it has a description given to it of what it needs to find;
- An agent tasked with guarding a premises from intruders may not know where the intruder is located but given examples of previous intrusions, it can locate and detain the intruder.
- LSTM layers in the DQN architecture would enable a sort of memory for an agent and would make more of the environment ‘visible’ to the agent at each t. The inclusion of LSTM layers would increase the complexity of the network and may increase time needed to learn the task.
- Using visual input as a state representation can be difficult when the goal is blocked by obstacles in the environment and is not visible to the agent. In future works we would like to incorporate more information into to overcome the problem of partial observable environments.
- In this article the two networks used are treated separately. In future work, the networks may be combined and their parameters updated as one. This would enable learning the task ‘on-the-fly’.
- In this work, we have made use of a pre-trained SCNN which may still require effort to collect a few samples of data for pre-training. We have taken a few-shot learning approach, in future works one-shot and zero-shot approaches can be explored to reduce the need for a dataset for pre-training.
- We make use of the Euclidean distance to calculate the distance between the embedding produced by the SCNN. In future we would like to explore the effects of various distance metrics on the navigation task.
- Imitation learning is a technique to learn models from a human teacher. In future works on mapless navigation we would like to explore a few-shot variant of imitation learning which is able to learn navigation policies from a single demonstration of navigation in an environment.
- The design of our agent was kept simple to demonstrate cost-effective mapless navigation in indoor environments. This may be enhanced to include outdoor environments with varying terrain and conditions by incorporating larger wheels with a track or tyre and stronger motors.
- The current study focused primarily on the DQN algorithm as a result of its relatively simple and intuitive nature. Since its inception, the DQN has been improved upon and as such we would like to test how our method performs when used with other algorithms from the RL literature.
- Multi-agent systems make use of multiple agents working together to achieve a goal. Multiple agents contributing towards the same goal may be useful in environments that are large or complex to navigate or where there are multiple goals to achieve. In future works we would like to incorporate mobile robots with drones. The mobile robot would observe the states obtainable from the ground and the drones obtained from the air. The drone would also allow for more of the state to be visible to the ground agent at the same time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RL | Reinforcement Learning |
| SCNN | Siamese Convolutional Neural Network |
| Conv2D | 2-D Convolution |
| MaxPool2D | 2-D Max Pooling |
| MSE | Mean Squared Error |
| DQN | Deep Q-Network |
| DNN | Deep Neural Network |
References
- Russel, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice-Hall: Hoboken, NJ, USA, 1995. [Google Scholar]
- Zhang, Q.; Zhu, M.; Zou, L.; Li, M.; Zhang, Y. Learning Reward Function with Matching Network for Mapless Navigation. Sensors 2020, 20, 3664. [Google Scholar] [CrossRef] [PubMed]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.L.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Ort, T.; Paull, L.; Rus, D. Autonomous vehicle navigation in rural environments without detailed prior maps. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2040–2047. [Google Scholar]
- Das, S.; Dey, A.; Pal, A.; Roy, N. Applications of Artificial Intelligence in Machine Learning: Review and Prospect. Int. J. Comput. Appl. 2015, 115, 31–41. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Dudek, G.; Jenkin, M. Computational Principles of Mobile Robotics; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Siguad, O.; Buffet, O. Markov Decision Processes in Artificial Intelligence; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Beakcheol, J. Q-Learning Algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar]
- Horita, L.; Wolf, D.; Junior, V. Effective Deep Reinforcement Learning Setups for Multiple Goals on Visual Navigation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Zeng, F.; Wang, C.; Ge, S. A Survey on Visual Navigation for Artificial Agents with Deep Reinforcement Learning. IEEE Access 2020, 8, 135426–135442. [Google Scholar] [CrossRef]
- Mitchell, T. Machine Learning. 1997. Available online: https://uvaml1.github.io/2020/slides/1.2_WhatIsMachineLearning.pdf (accessed on 21 October 2021).
- Qi, Y.; Song, Y.; Zhang, H.; Liu, J. Sketch-based Image Retrieval via Siamese Convolutional Neural Network. In Proceedings of the Sketch-based Image Retrieval via Siamese Convolutional Neural Network, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Thakare, Y.; Bagal, S. Performance Evaluation of K-means Clustering Algorithm with Various Distance Metrics. Int. J. Comput. Appl. 2015, 110, 12–16. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-shot Image Recognition. 2015. Available online: http://www.cs.toronto.edu/~gkoch/files/msc-thesis.pdf (accessed on 3 December 2021).
- Linhai, X. Towards Monocular vision-based Obstacle Detection through Deep Reinforcement Learning. arXiv 2017, arXiv:1706.09829. [Google Scholar]
- Citroni, R.; Di Paolo, F.; Livreri, P. A Novel Energy Harvester for Powering Small UAVs: Performance Analysis, Model Validation and Flight Results. Sensors 2019, 19, 1771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, D.K.; Chen, T. Deep Neural Network for real-time Autonomous Indoor Navigation. arXiv 2015, arXiv:1511.04668. [Google Scholar]
- Khriji, L.; Touati, F.; Benhmed, K.; Al-Yahmedi, A. Mobile Robot Navigation based on Q-Learning technique. Int. J. Adv. Robot. Syst. 2011, 8, 4. [Google Scholar] [CrossRef]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards Vision-based Deep Reinforcement Learning for Robotic Motion Control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep Reinforcement Learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar]
- Pengyu, Y.; Jing, X.; Liu, D.; Shan, M. Experimental Research on Deep Reinforcement Learning in Autonomous Navigation of Mobile Robot; IEEE: Piscataway, NJ, USA, 2019; pp. 1612–1616. [Google Scholar]
- Kulhanek, J.; Derner, E.; de Bruin, T.; Babuska, R. Vision-Based Navigation Using Deep Reinforcement Learning; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Thakare, Y.; Bagal, S. A Few Shot Adaptation of Visual Navigation Skills to New Observations using Meta-Learning. arXiv 2011, arXiv:2011.03609. [Google Scholar]
- Dobrevski, M.; Skocaj, D. Deep Reinfrocement Learning for Map-Less Goal-Driven Robot Navigation. Int. J. Adv. Robot. Syst. 2021, 18, 1729881421992621. [Google Scholar] [CrossRef]
- Grando, R.; de Jesus, J.; Kich, V.; Kolling, A.; Bortoluzzi, N.; Pinheiro, P.; Neto, A.; Drews, P. Deep Reinforcement Learning for Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Medium Transition. arXiv 2021, arXiv:2103.12883. [Google Scholar]
- Cimurs, R.; Lee, J.; Suh, I. Goal-Oriented Obstacle Avoidance with Deep Reinforcement Learning in Continuous Action Space. Electronics 2020, 9, 411. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| gamma | 0.999 |
| epsilon | 0.6 |
| alpha | 0.0001 |
| batch size | 4 |
| target network update | 10 |
| max steps per epoch | 200 |
| Layer | Input Channels | Output Channels | Window/Kernel Size | Padding |
|---|---|---|---|---|
| Conv2D | 3 | 16 | 3 | True |
| Conv2D | 16 | 32 | 3 | True |
| MaxPool2D | 32 | 32 | 2 | False |
| Conv2D | 32 | 16 | 3 | False |
| Conv2D | 16 | 8 | 3 | False |
| Layer | Input Channels | Output Channels | Window/Kernel Size | Padding |
|---|---|---|---|---|
| Conv2D | 3 | 16 | 5 | |
| Conv2D | 16 | 32 | 5 | |
| Linear | 32768 | 3 | n/a |
| Score Threshold | Classification Accuracy |
|---|---|
| 0.1 | 49.53 |
| 0.2 | 49.53 |
| 0.3 | 49.53 |
| 0.4 | 49.53 |
| 0.5 | 49.53 |
| 0.6 | 76 |
| 0.7 | 52.8 |
| 0.8 | 50.47 |
| 0.9 | 50.47 |
| 1.0 | 50.47 |
| Algorithm | Average Training Time (s) |
|---|---|
| SCNN with ResNet18 base (layers frozen) | 75.046 |
| SCNN with ResNet18 base | 371.412 |
| Custom SCNN architecture | 9.6437278 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kok, V.; Olusanya, M.; Ezugwu, A. A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network. Appl. Sci. 2022, 12, 5323. https://doi.org/10.3390/app12115323
Kok V, Olusanya M, Ezugwu A. A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network. Applied Sciences. 2022; 12(11):5323. https://doi.org/10.3390/app12115323
Chicago/Turabian StyleKok, Vernon, Micheal Olusanya, and Absalom Ezugwu. 2022. "A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network" Applied Sciences 12, no. 11: 5323. https://doi.org/10.3390/app12115323
APA StyleKok, V., Olusanya, M., & Ezugwu, A. (2022). A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network. Applied Sciences, 12(11), 5323. https://doi.org/10.3390/app12115323