
Smart Web Service of Ti-Based Alloy’s Quality Evaluation for Medical Implants Manufacturing

 ,
,  ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
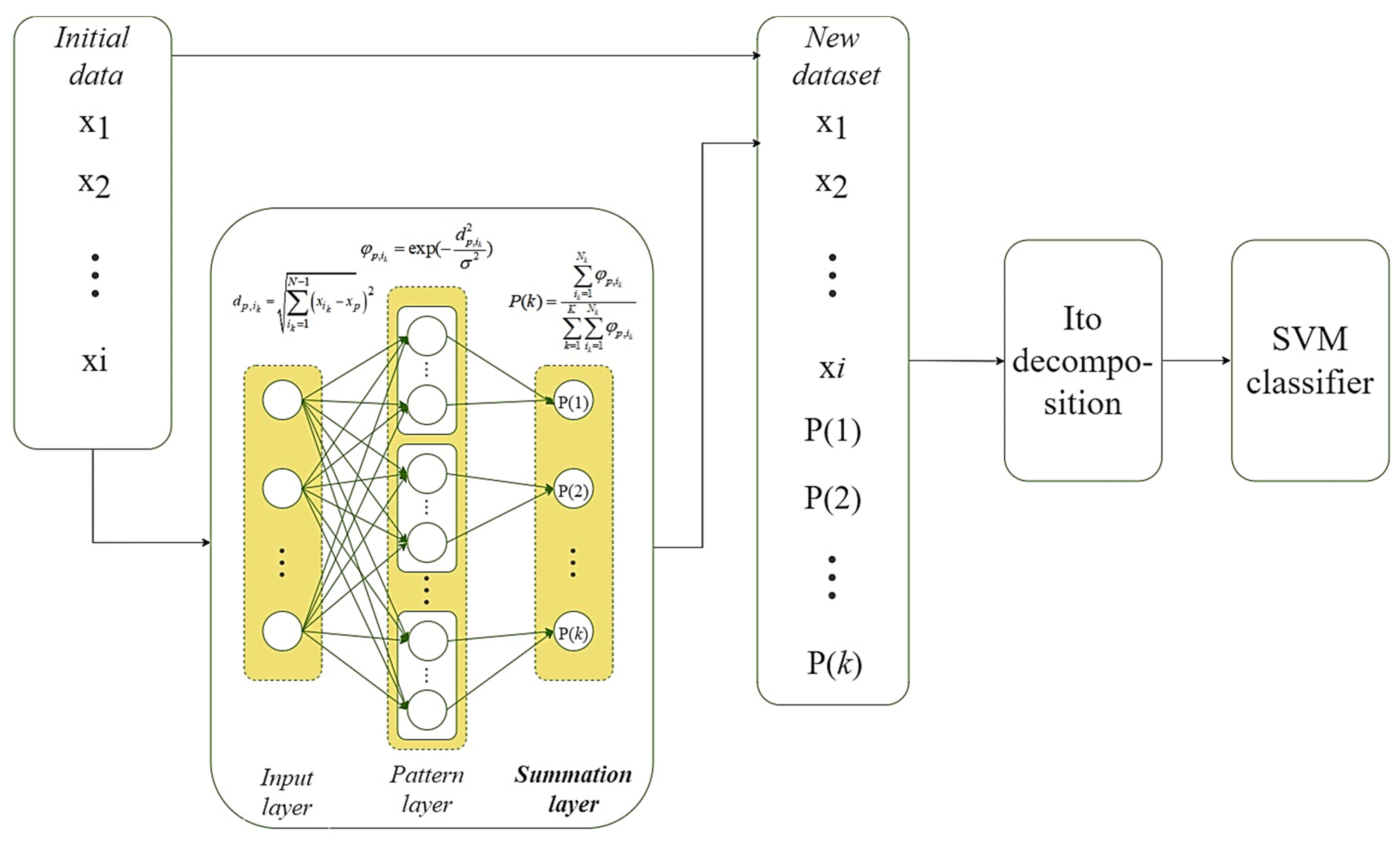
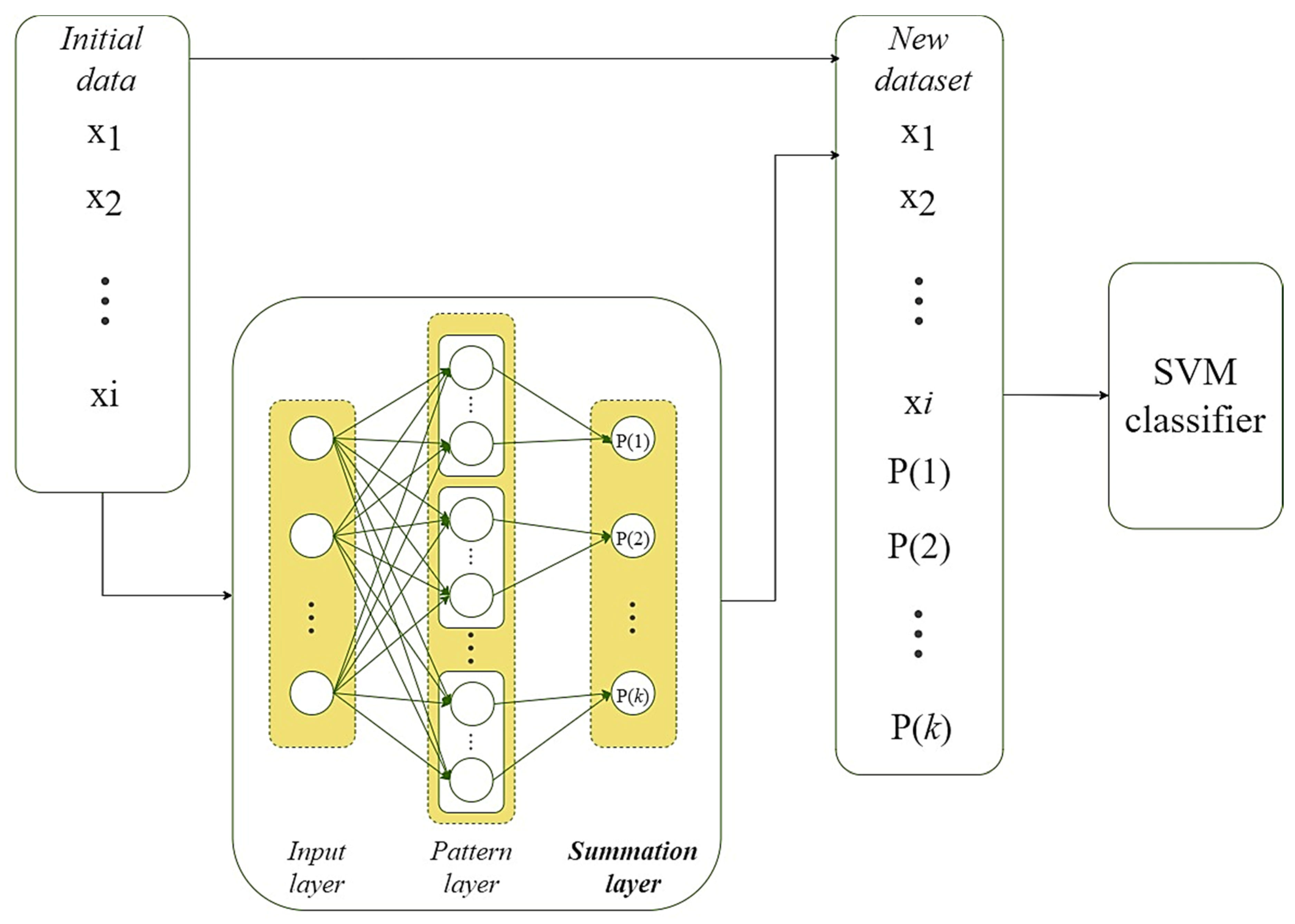
- we have generalized the approach to preprocessing small-sized and middle-sized datasets for further use by an arbitrary classifier. It is based on the different use of the output signals of the summation layer of the modified version of the Probabilistic Neural Network (PNN), the outputs of which form a complete system of events;
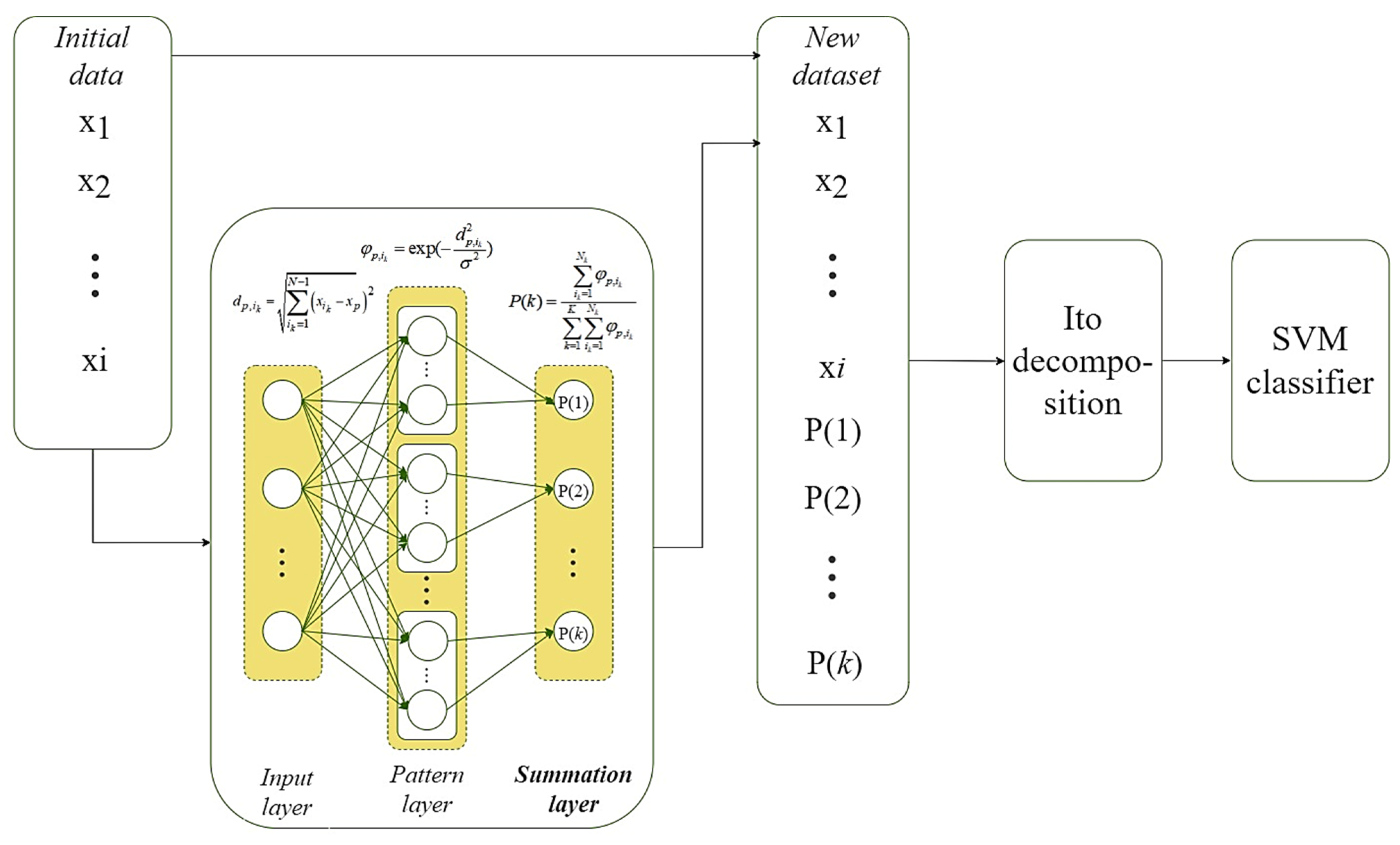
- we have improved the hybrid PNN-SVM system by additional modeling the relationships between all attributes of the extended dataset by PNN summation layer outputs based on the Ito decomposition;
- we have developed a smart web service for Ti-based alloy’s quality evaluation for medical implant manufacturing which is based on different options for preprocessing a given dataset using the outputs of a PNN’s summation layer with subsequent analysis of the obtained dataset by the SVM classifier.
- The modified variant of realization of a PNN provides an increase in classification accuracy compared to the basic variant of realization of this ANN. In addition, the use of the neural network’s summation layer outputs provides the possibility of further use of the obtained set of probabilities belonging to each class of the task to replace the initial inputs of the problem (reduce dimension) or expand the attributes of the initial dataset to build comprehensive diagnostic systems;
- advanced hybrid PNN-SVM system provides a significant increase in classification accuracy compared to both existing and single models, which form it when solving the task of predicting the properties of the material for the manufacture of biocompatible titanium implants for various applications;
- designed smart web-service of Ti-based alloy’s quality evaluation for medical implant manufacturing implements three different data mining options based on PNN-SVM classifier and provides flexibility, high accuracy, and high speed, which significantly reduces human, material, and time resources when solving the stated problem.
2. State-of-the-Arts
3. Materials and Methods
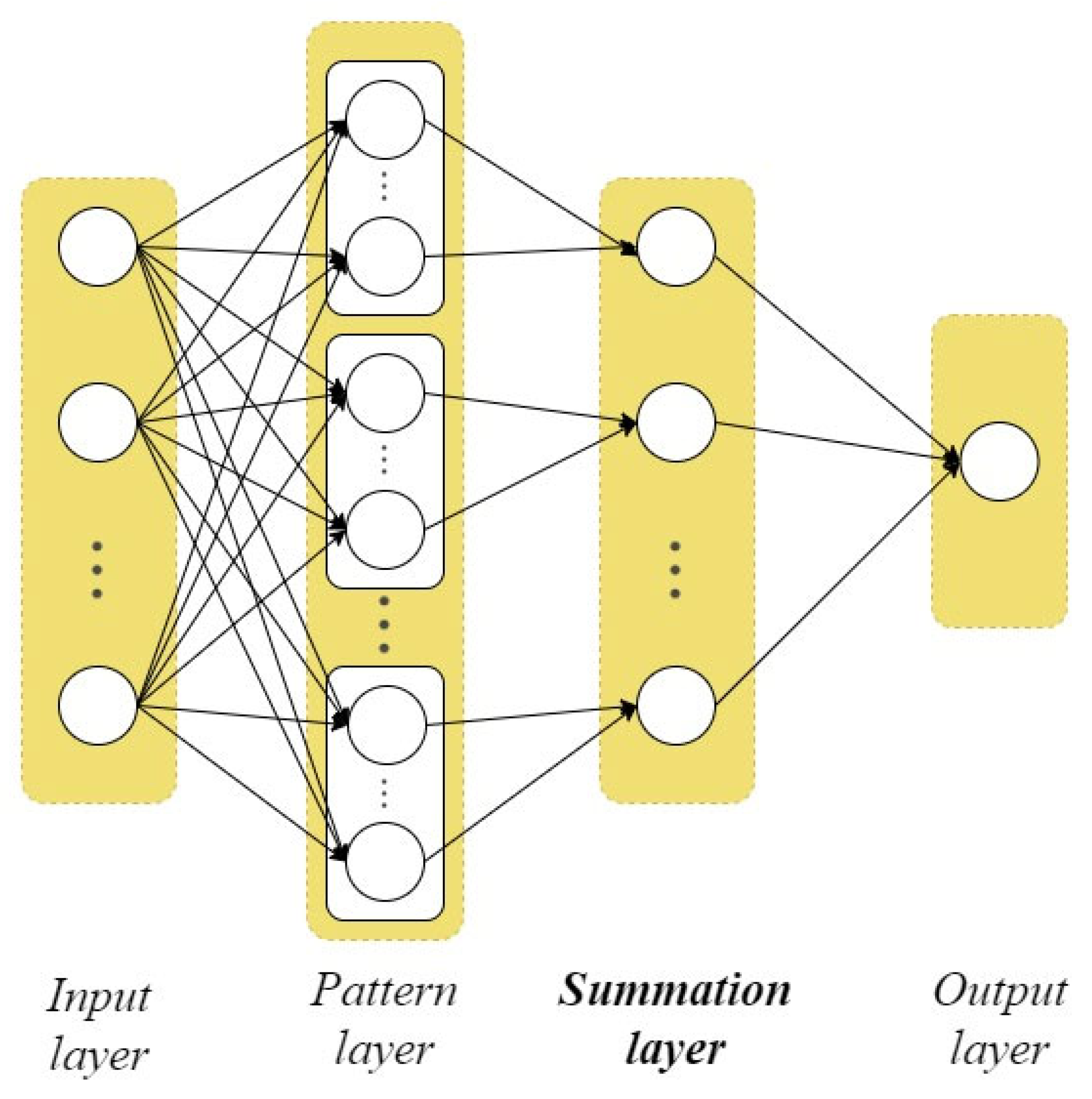
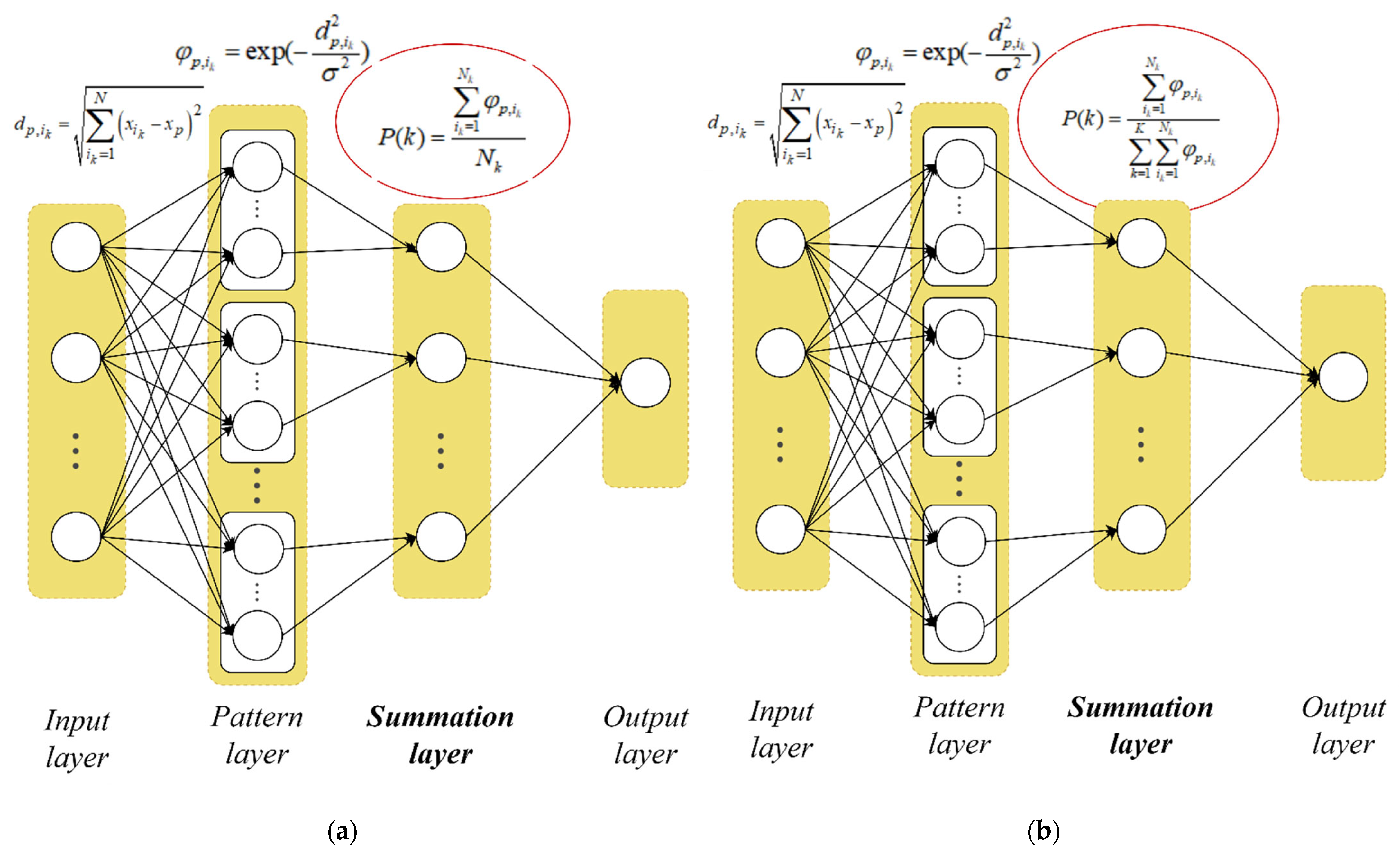
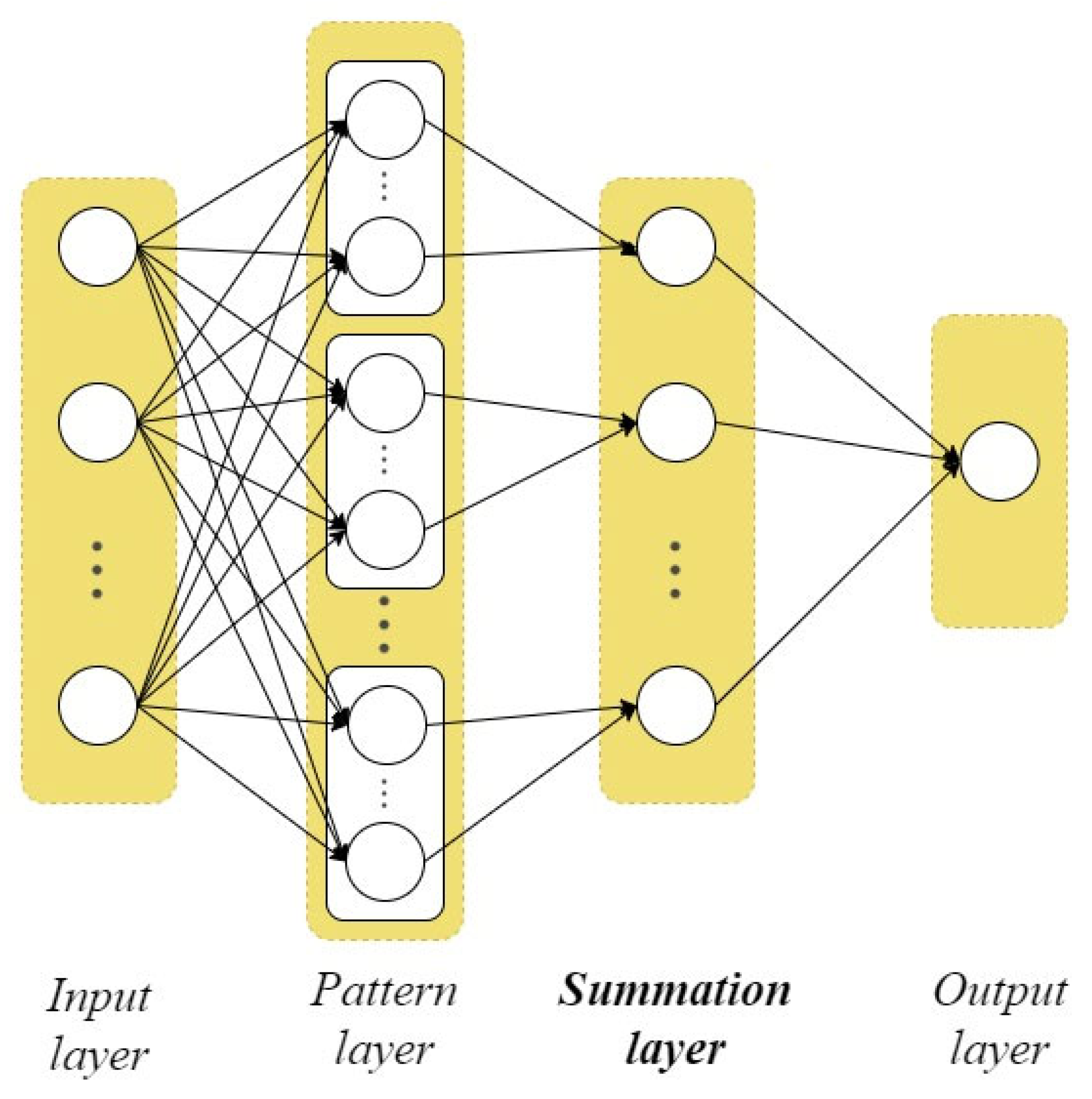
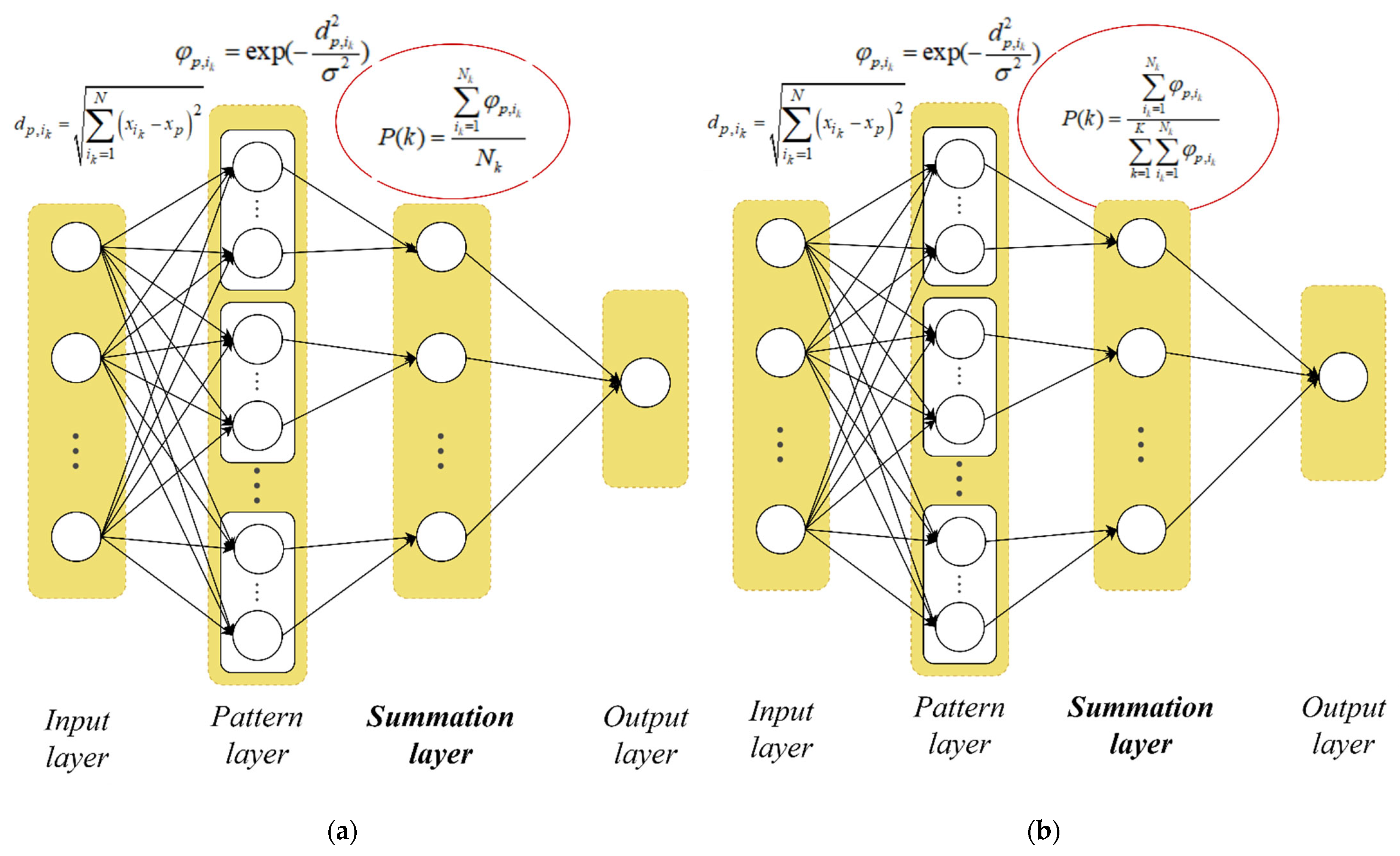
3.1. Modified PNN
- Calculate the Euclidean distances from the current vector to each vector of a given dataset , which belong to the corresponding -th class according to the formula:
- Calculate Gaussian functions from according to the formula:where is the scope parameter of the Gaussian function (smooth factor). It should be noted that this is the only PNN parameter to be configured for each specific task.
- Calculate the probabilities of belonging of the vector to each predefined classes based on (3) according to the expression:
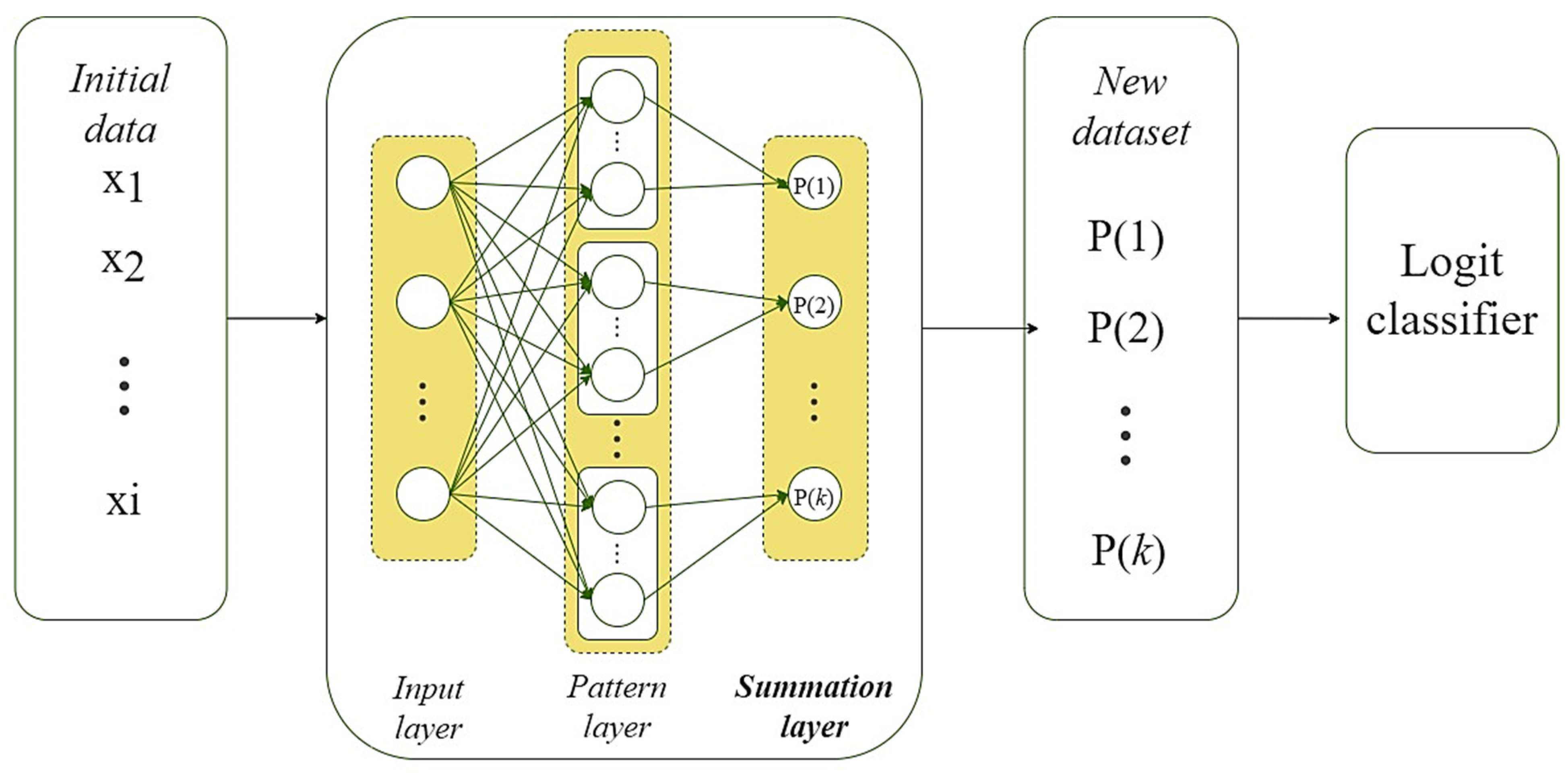
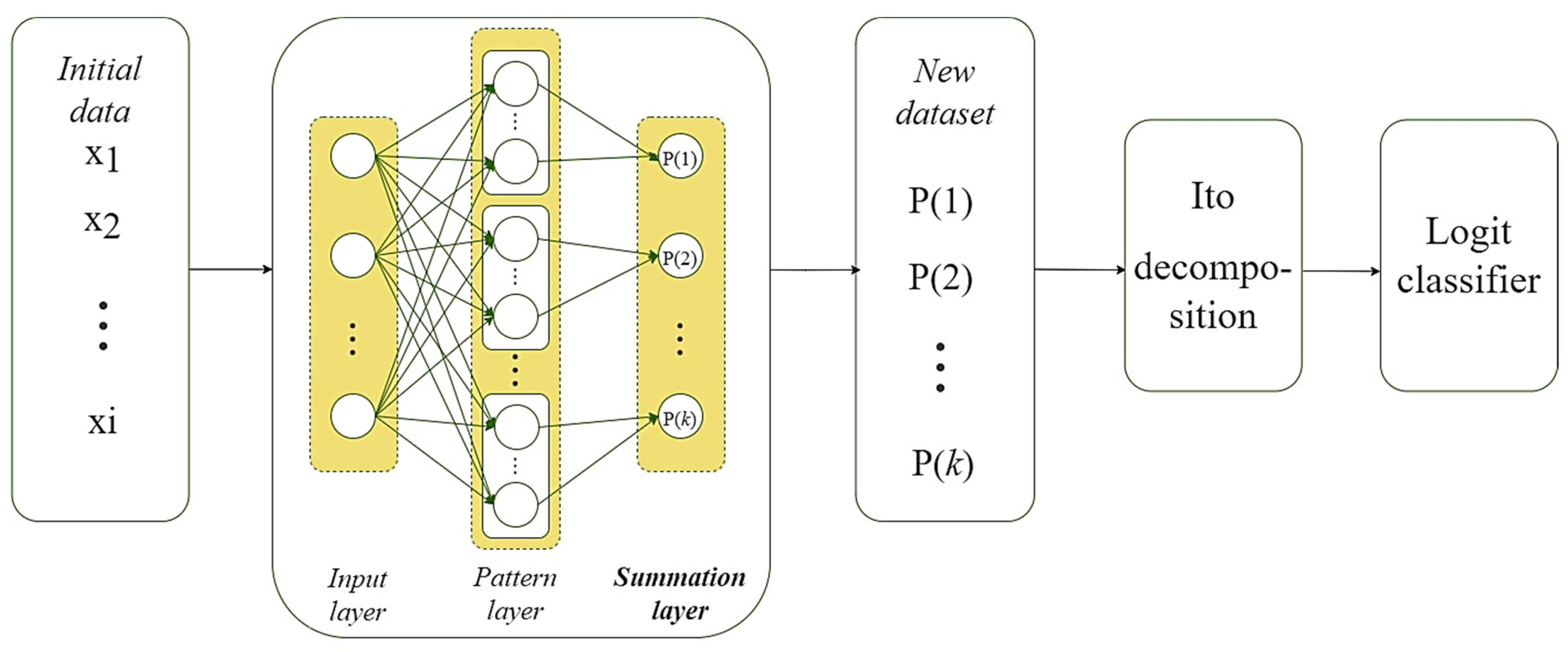
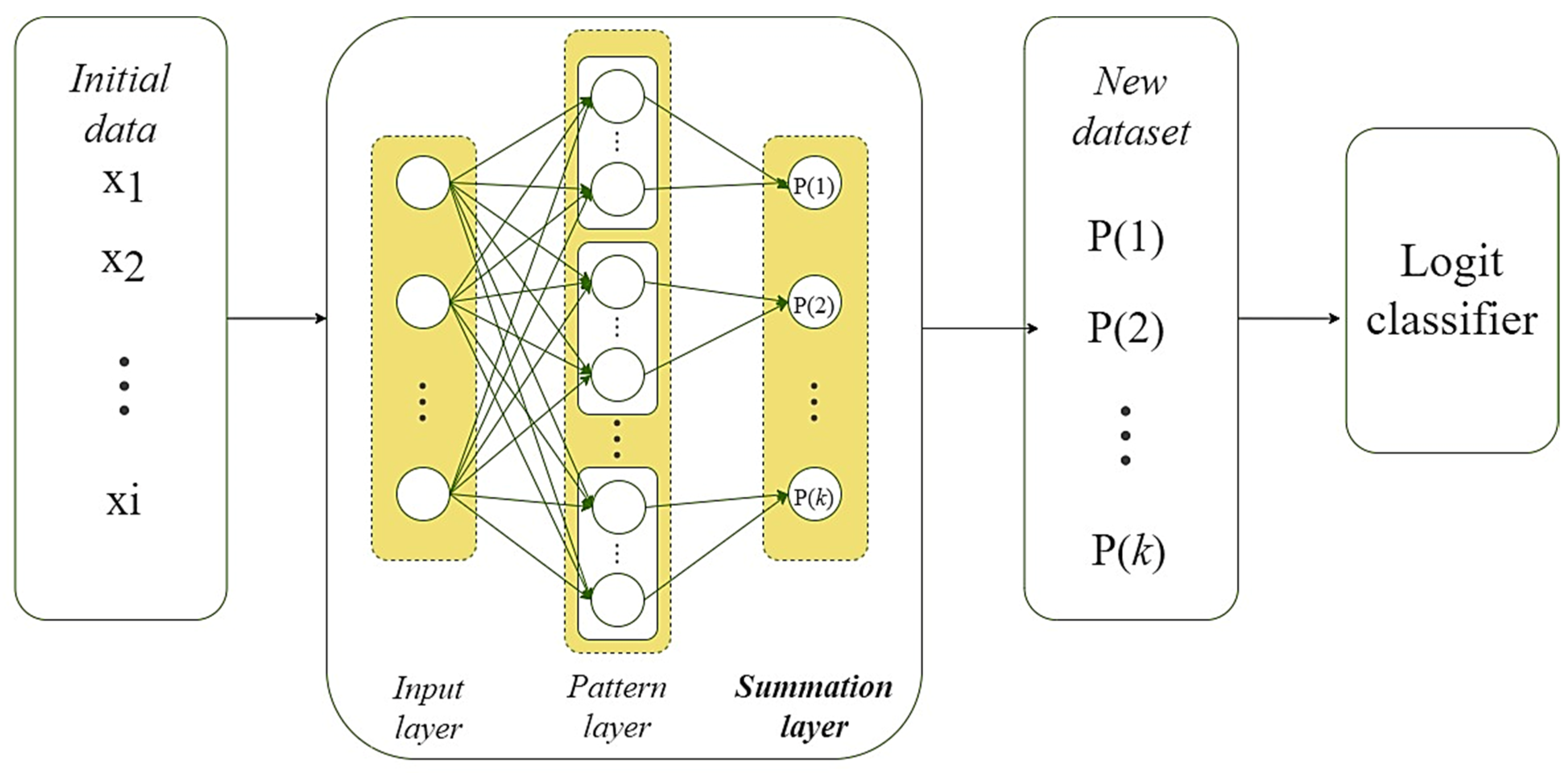
3.2. Improved PNN-SVM System
- prepare and apply a modified PNN to obtain a set of probabilities of belonging of each observation from the training set to each of the defined classes of the stated task;
- form a new set of training data by combining the initial dataset with the corresponding probability vectors obtained in the previous step;
- perform nonlinear expansion of a new dataset using the second-degree Ito decomposition according to (1);
- perform SVM-based linear classifier training using the extended training dataset in the previous step.
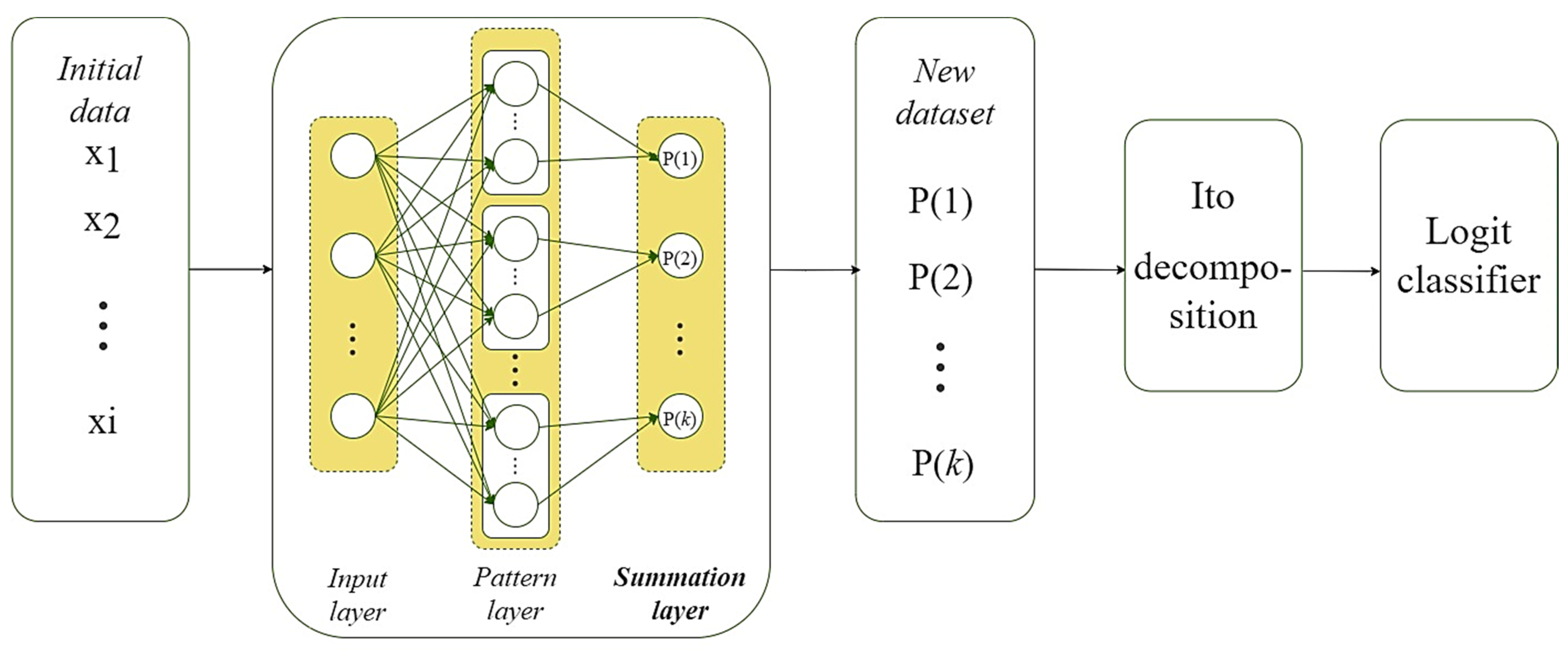
- apply the prepared PNN to the current vector to obtain the vector of probabilities of its belonging to each of the defined classes of the stated task;
- form a new vector by combining the current vector with the probability vector obtained in the previous step;
- perform the second-degree Ito decomposition on the extended vector to model the relationships between the input attributes of a given vector and the probabilities of its belonging to each of the defined classes of the stated task;
- perform classification using pre-trained SVM with the linear kernel;
- get the result of the system work.
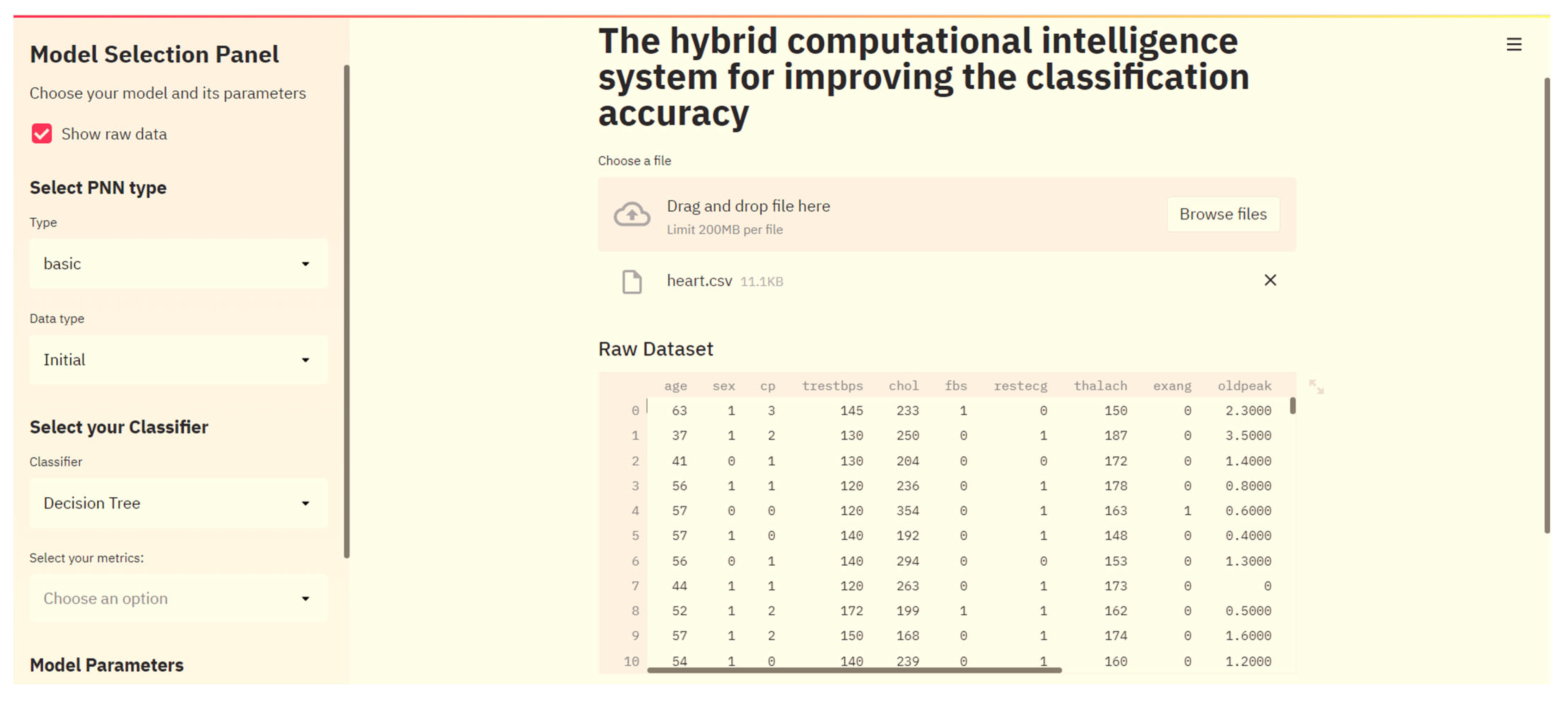
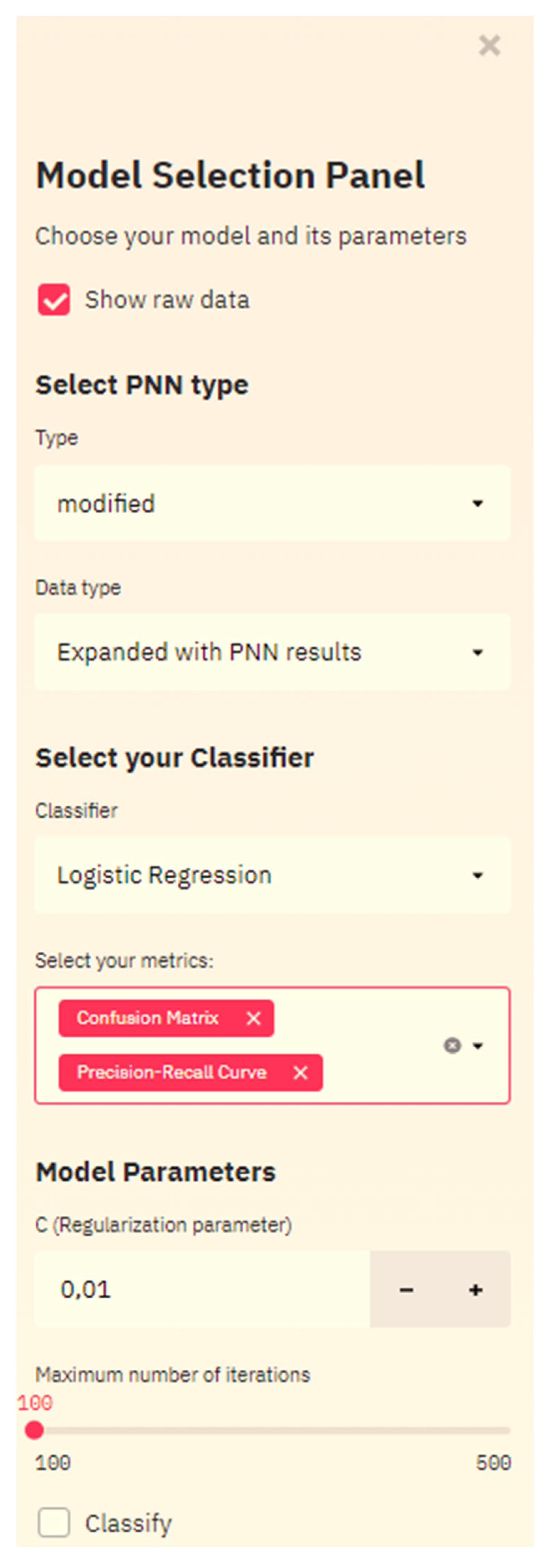
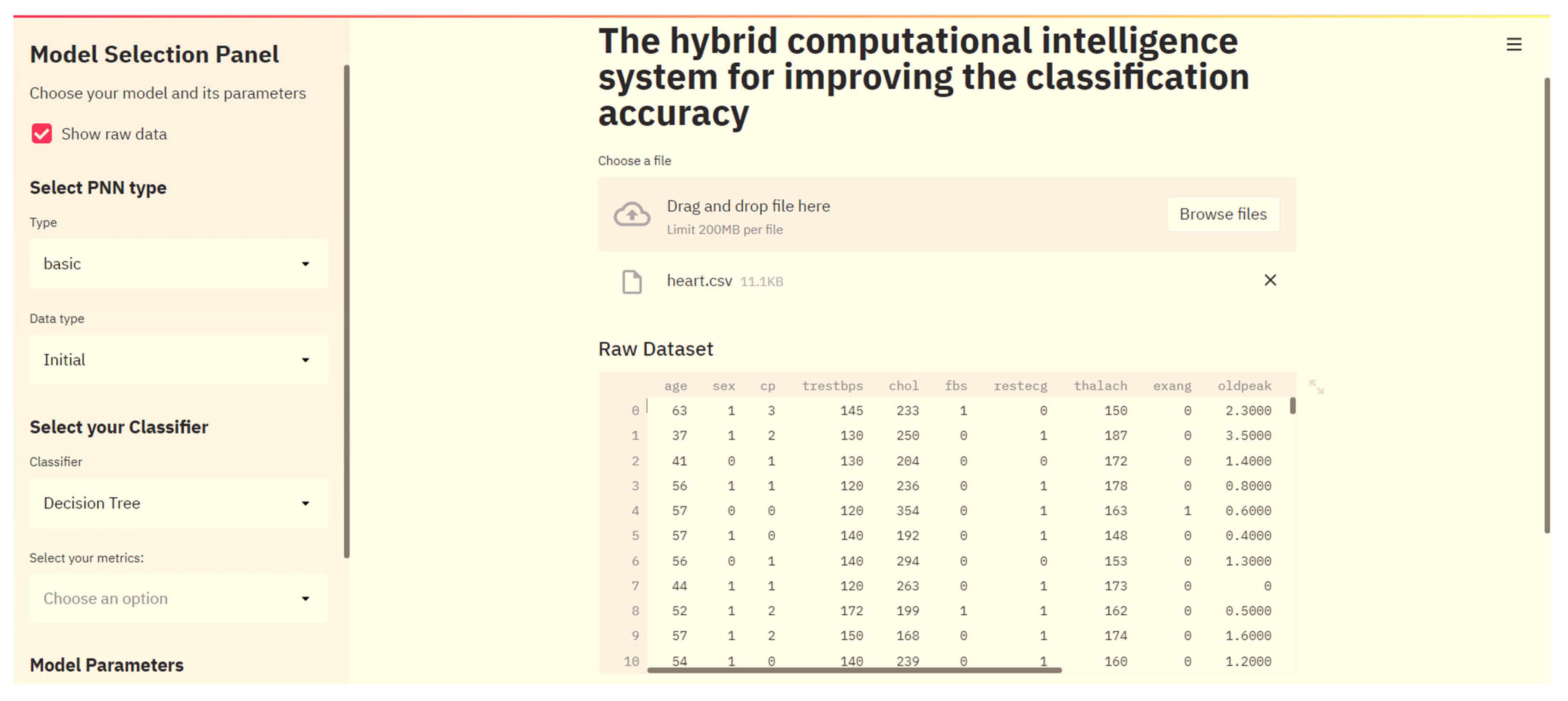
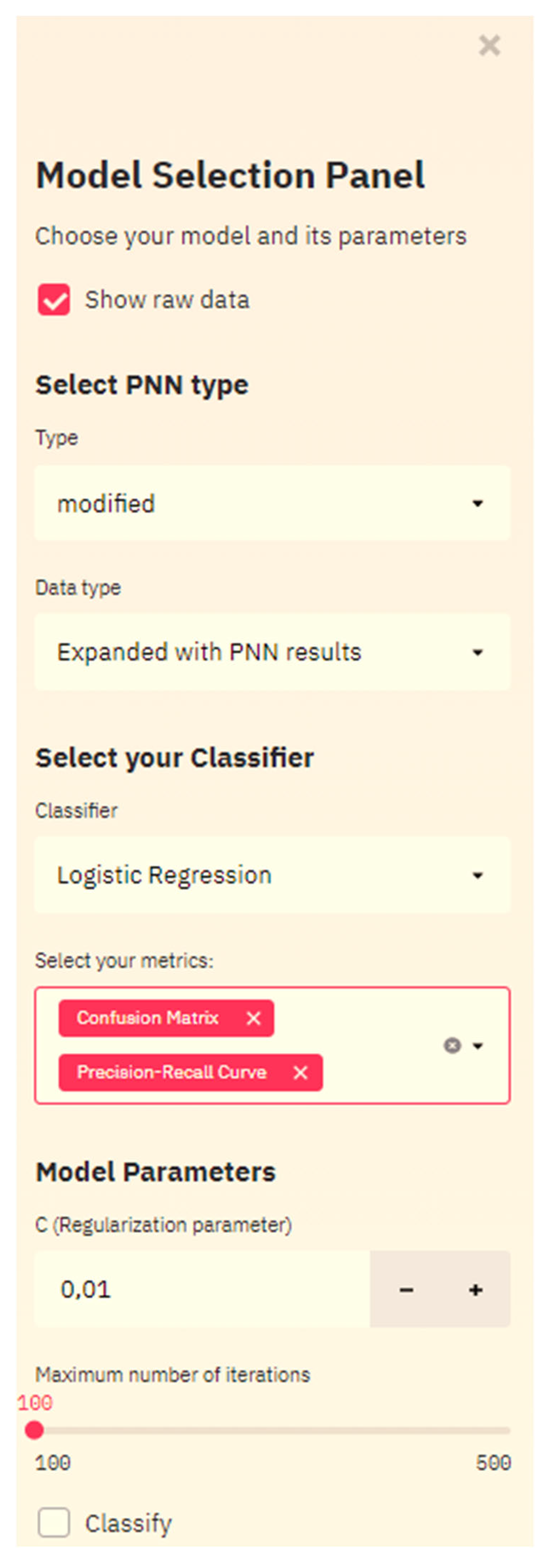
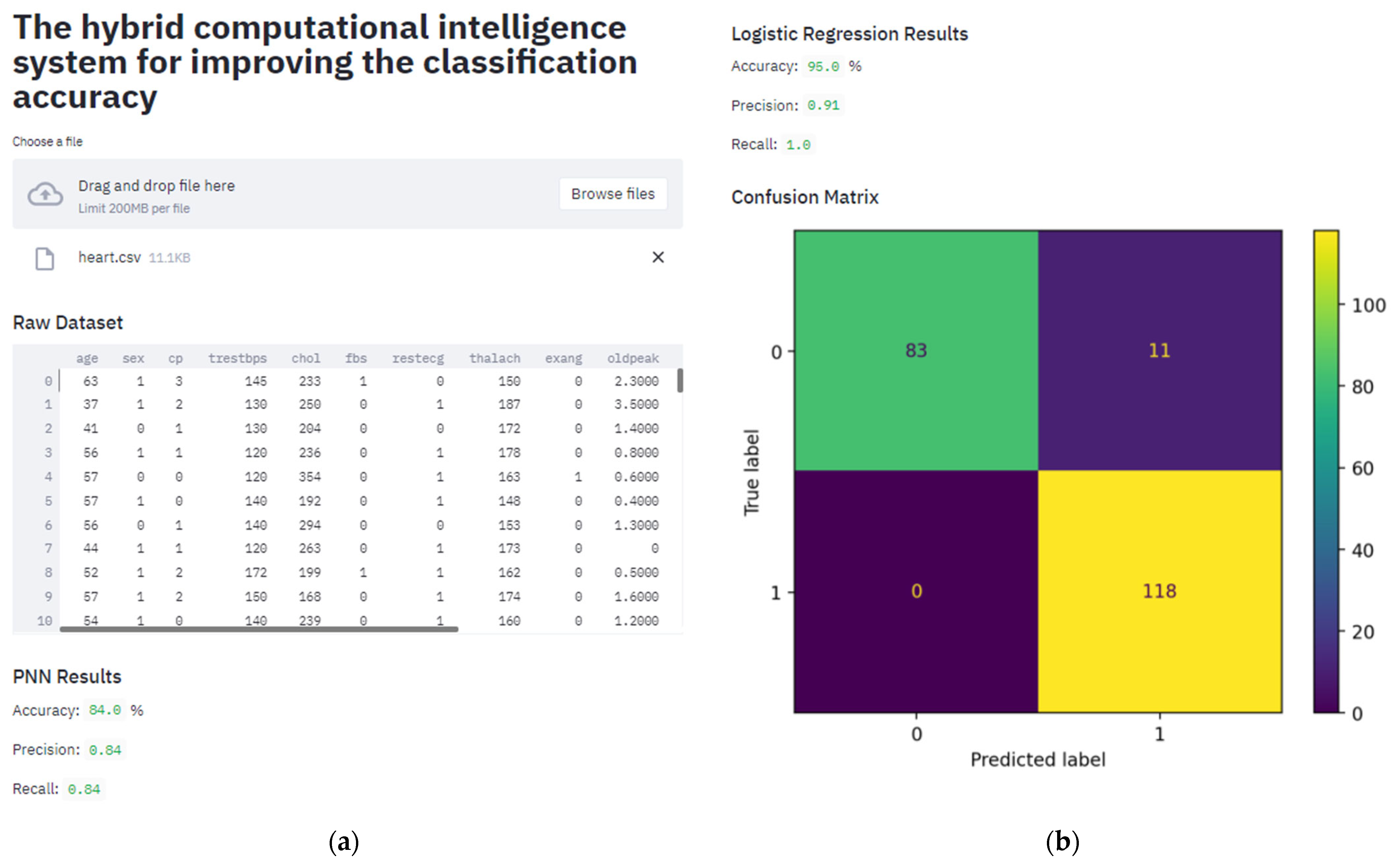
3.3. Smart Web-Service
4. Modeling and Results
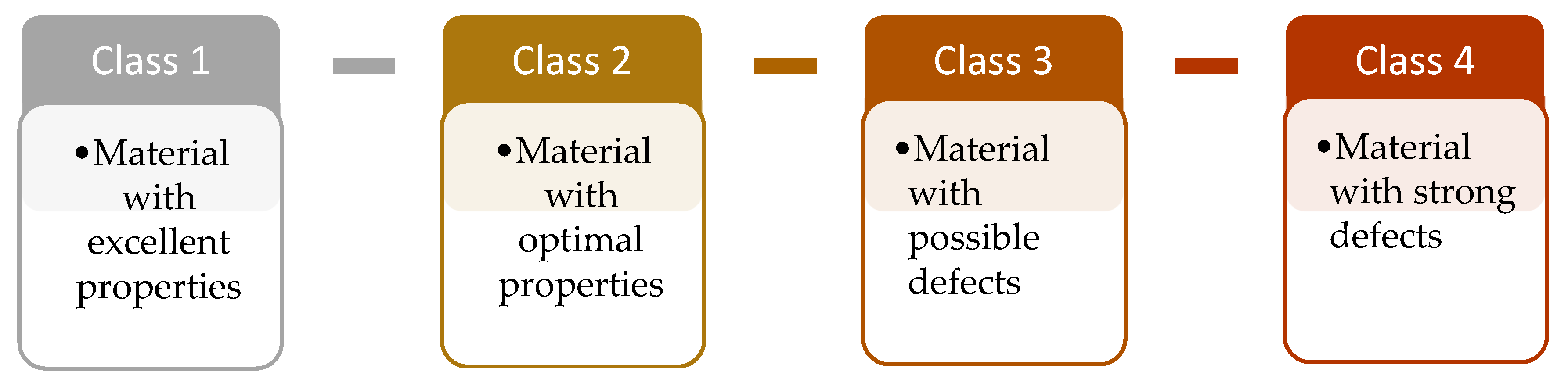
4.1. Dataset Description
4.2. Improved PNN-SVM System Results
4.3. Results of All Other Variants of the Investigated Smart System
- Classical PNN;
- Modified PNN;
- PNN-Logit system from [12] that used PNN-based dimensionality reduction;
- Modified PNN-Ito-Logit system proposed in [12] that used PNN-based dimensionality reduction;
- PNN-SVM system that used PNN-based dimensionality reduction;
- Modified PNN-Ito-SVM system that used PNN-based dimensionality reduction;
- PNN-SVM system proposed in [39].
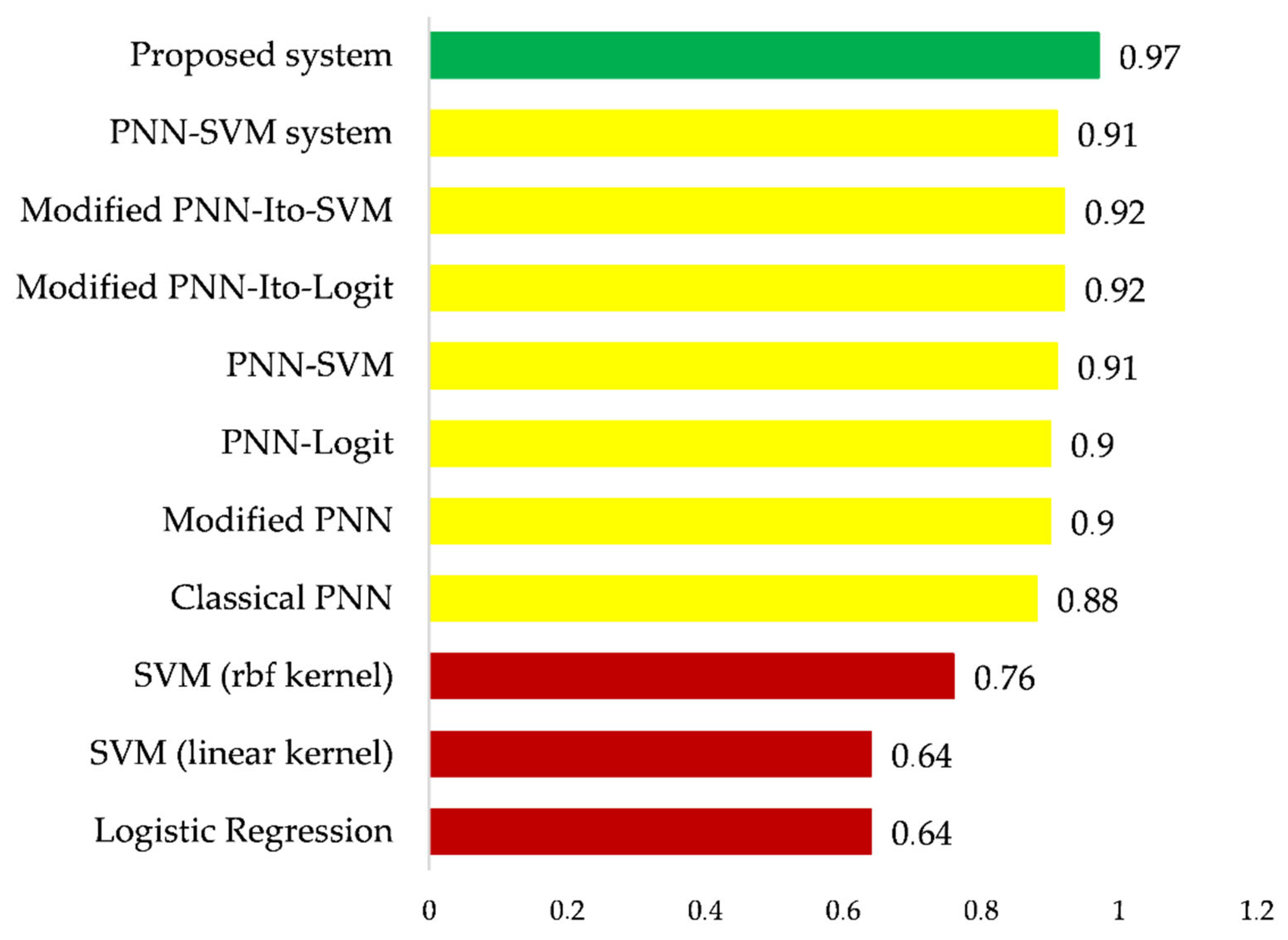
5. Comparison and Discussion
- Logistic Regression Classifier;
- SVM with linear kernel Classifier;
- SVM with rbf kernel Classifier.
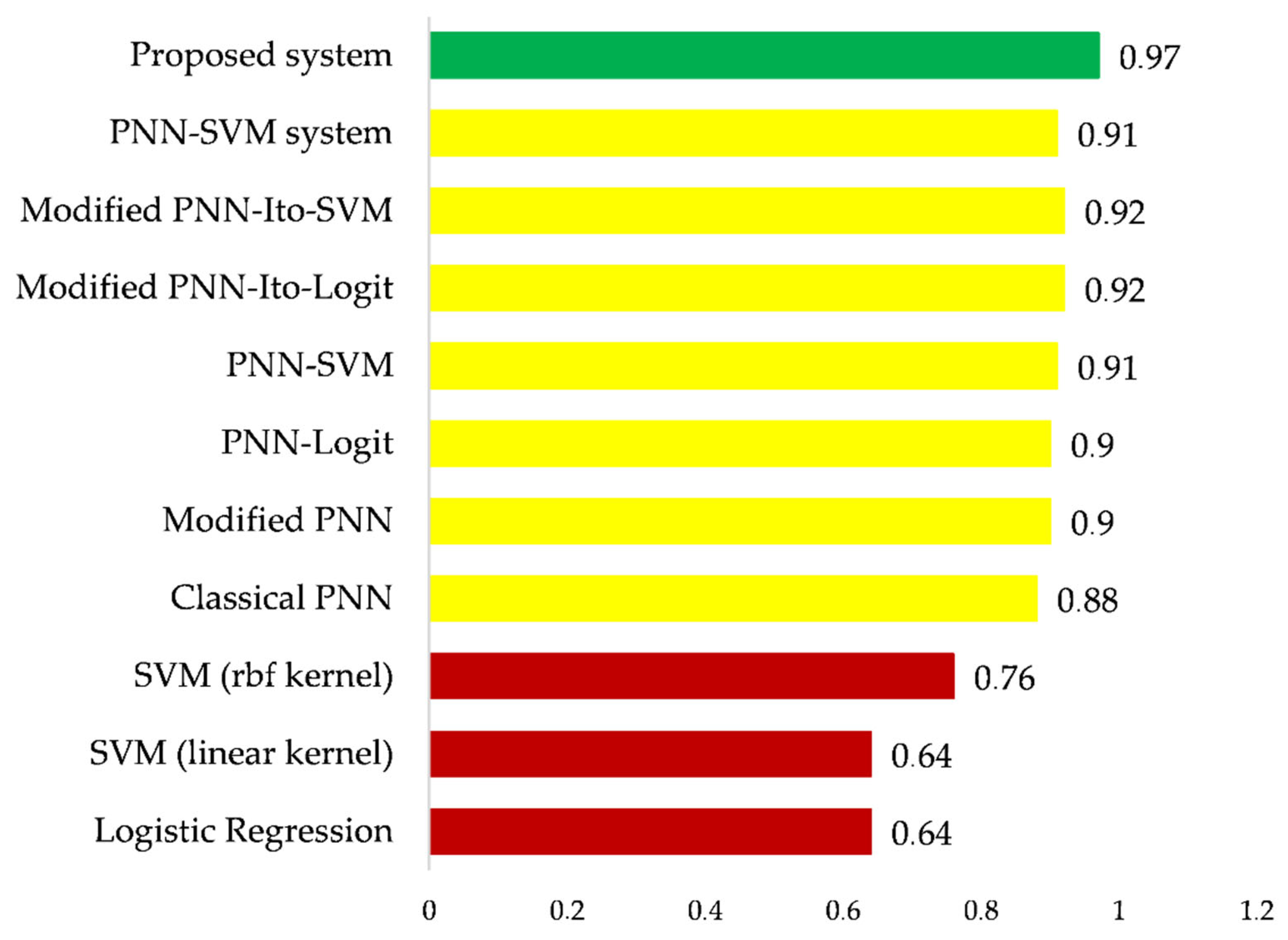
- Classical machine learning methods (red bars of the histogram), both linear and nonlinear, do not provide a satisfactory level of accuracy in solving the multiclass classification task;
- Probabilistic Neural Network without training, as well as its modification, provide satisfactory but insufficient accuracy for their practical use;
- All considered hybrid intelligent systems provide an increase of accuracy in comparison with the basic classifiers which form them;
- Systems where PNN is used to reduce the dimension of the input data space of the task provide a slight increase in accuracy, although significantly reduce the duration of training procedures for such systems;
- PNN-based systems for expanding the input data space of the task increased the accuracy of linear classifiers, which is fully justified by Cover’s theorem. However, high enough accuracy is not obtained here;
- The highest classification accuracy in solving the stated task is obtained using the improved system proposed in this paper. In particular, due to additional modeling of the attributes of the extended dataset based on the Ito Decomposition, it was possible to increase the system’s accuracy by more than 6% compared to the existing implementation of the system.
- a linear SVM is selected as the basic classifier, which is quite fast [57]. The processing of nonlinear extended inputs also provides significantly higher classification accuracy than other kernels of this method. In addition, the optimal implementations of this method, which are laid down in the Scikit-learn library and its was used in this paper, provide high performance of this machine learning method;
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hatami, S. Variation of Fatigue Strength of Parts Manufactured by Laser Powder Bed Fusion. Powder Metall. 2021, 1–6. [Google Scholar] [CrossRef]
- Laxminarayana, P.; Reddy, G.C.M.; Reddy, G.M.S. Process Parameters Influence on Impact Toughness and Microstructure of Pre-Heat Treated Friction Welded 15CDV6 Alloy Steel. Int. J. Eng. Manuf. 2016, 6, 38–47. [Google Scholar] [CrossRef] [Green Version]
- Bansiddhi, A.; Sargeant, T.D.; Stupp, S.I.; Dunand, D.C. Porous NiTi for Bone Implants: A Review. Acta Biomater. 2008, 4, 773–782. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.-H.; Chen, R.-B.; Qi, G.; Wang, Z.-T.; Deng, Z.-Y. Powder Sintering of Porous Ti–15Mo Alloy from TiH2 and Mo Powders. J. Alloys Compd. 2009, 485, 215–218. [Google Scholar] [CrossRef]
- Ryan, G.; Pandit, A.; Apatsidis, D.P. Fabrication Methods of Porous Metals for Use in Orthopaedic Applications. Biomaterials 2006, 27, 2651–2670. [Google Scholar] [CrossRef]
- Angelo, P.C.; Subramanian, R. Powder Metallurgy: Science, Technology and Applications, Eastern Economy ed.; 2. Print; PHI Learning: New Delhi, India, 2009; ISBN 978-81-203-3281-2. [Google Scholar]
- Kostyk, K.; Hatala, M.; Kostyk, V.; Ivanov, V.; Pavlenko, I.; Duplakova, D. Simulation of Diffusion Processes in Chemical and Thermal Processing of Machine Parts. Processes 2021, 9, 698. [Google Scholar] [CrossRef]
- Ivanov, V.; Pavlenko, I.; Kuric, I.; Kosov, M. Mathematical Modeling and Numerical Simulation of Fixtures for Fork-Type Parts Manufacturing. In Industry 4.0: Trends in Management of Intelligent Manufacturing Systems; Knapčíková, L., Balog, M., Eds.; EAI/Springer Innovations in Communication and Computing; Springer International Publishing: Cham, Switzerland, 2019; pp. 133–142. ISBN 978-3-030-14010-6. [Google Scholar]
- Taylor, N.; Dunand, D.; Mortensen, A. Initial Stage Hot Pressing of Monosized Ti and 90% Ti-10% TiC Powders. Acta Metall. Mater. 1993, 41, 955–965. [Google Scholar] [CrossRef]
- Duriagina, Z.A.; Filimonov, O.S.; Kulyk, V.V.; Lemishka, I.A.; Kuziola, R. Investigation of Structural-Geometric Parameters and Elemental Composition of Spherical VT20 Alloy Powders. J. Achiev. Mater. Manuf. Eng. 2019, 95, 49–56. [Google Scholar] [CrossRef]
- Duriagina, Z.; Lemishka, I.; Litvinchev, I.; Marmolejo, J.A.; Pankratov, A.; Romanova, T.; Yaskov, G. Optimized Filling of a Given Cuboid with Spherical Powders for Additive Manufacturing. J. Oper. Res. Soc. China 2020, 9, 853–868. [Google Scholar] [CrossRef]
- Izonin, I.; Tkachenko, R.; Gregus, M.; Ryvak, L.; Kulyk, V.; Chopyak, V. Hybrid Classifier via PNN-Based Dimensionality Reduction Approach for Biomedical Engineering Task. Procedia Comput. Sci. 2021, 191, 230–237. [Google Scholar] [CrossRef]
- Kumar, D.S.; Suman, K.N.S. Selection of Magnesium Alloy by MADM Methods for Automobile Wheels. Int. J. Eng. Manuf. 2014, 4, 31–41. [Google Scholar] [CrossRef] [Green Version]
- Tepla, T. Biocompatible Materials Selection via New Supervised Learning Methods; LAP LAMBERT Academic Publishing: Saarbrucken, Germany, 2019; ISBN 978-613-9-44384-0. [Google Scholar]
- Zhang, L.; Chen, L. A Review on Biomedical Titanium Alloys: Recent Progress and Prospect. Adv. Eng. Mater. 2019, 21, 1801215. [Google Scholar] [CrossRef] [Green Version]
- Nicholson, J.W. Titanium Alloys for Dental Implants: A Review. Prosthesis 2020, 2, 100–116. [Google Scholar] [CrossRef]
- Jeong, W.; Shin, S.-E.; Choi, H. Microstructure and Mechanical Properties of Titanium–Equine Bone Biocomposites. Metals 2020, 10, 581. [Google Scholar] [CrossRef]
- Jakubowicz, J. Ti-Based Biomaterials: Synthesis, Properties and Applications. Materials 2020, 13, 1696. [Google Scholar] [CrossRef] [Green Version]
- Slokar, L.; Matković, T.; Matković, P. Alloy Design and Property Evaluation of New Ti–Cr–Nb Alloys. Mater. Des. 2012, 33, 26–30. [Google Scholar] [CrossRef]
- de Viteri, V.S.; Fuentes, E. Titanium and Titanium Alloys as Biomaterials. In Tribology—Fundamentals and Advancements; Gegner, J., Ed.; InTech: Vienna, Austria, 2013; ISBN 978-953-51-1135-1. [Google Scholar]
- Baltatu, M.S.; Spataru, M.C.; Verestiuc, L.; Balan, V.; Solcan, C.; Sandu, A.V.; Geanta, V.; Voiculescu, I.; Vizureanu, P. Design, Synthesis, and Preliminary Evaluation for Ti-Mo-Zr-Ta-Si Alloys for Potential Implant Applications. Materials 2021, 14, 6806. [Google Scholar] [CrossRef]
- Peter, I. Investigations into Ti-Based Metallic Alloys for Biomedical Purposes. Metals 2021, 11, 1626. [Google Scholar] [CrossRef]
- Tshephe, T.S.; Akinwamide, S.O.; Olevsky, E.; Olubambi, P.A. Additive Manufacturing of Titanium-Based Alloys—A Review of Methods, Properties, Challenges, and Prospects. Heliyon 2022, 8, e09041. [Google Scholar] [CrossRef]
- Piletskiy, P.; Chumachenko, D.; Meniailov, I. Development and Analysis of Intelligent Recommendation System Using Machine Learning Approach. In Integrated Computer Technologies in Mechanical Engineering; Nechyporuk, M., Pavlikov, V., Kritskiy, D., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; Volume 1113, pp. 186–197. ISBN 978-3-030-37617-8. [Google Scholar]
- Smith, L. A Knowledge Based System for Powder Metallurgy Technology; Engineering Research Series; Wiley: New York, NY, USA, 2005; ISBN 978-0-470-02618-2. [Google Scholar]
- Cherian, R.P.; Smith, L.N.; Midha, P.S. A Neural Network Approach for Selection of Powder Metallurgy Materials and Process Parameters. Artif. Intell. Eng. 2000, 14, 39–44. [Google Scholar] [CrossRef]
- Tamura, R.; Osada, T.; Minagawa, K.; Kohata, T.; Hirosawa, M.; Tsuda, K.; Kawagishi, K. Machine Learning-Driven Optimization in Powder Manufacturing of Ni-Co Based Superalloy. Mater. Des. 2021, 198, 109290. [Google Scholar] [CrossRef]
- Naumov, O.; Voronenko, M.; Naumova, O.; Savina, N.; Vyshemyrska, S.; Korniychuk, V.; Lytvynenko, V. Using Bayesian Networks to Estimate the Effectiveness of Innovative Projects. In Lecture Notes in Computational Intelligence and Decision Making; Babichev, S., Lytvynenko, V., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer International Publishing: Cham, Switzerland, 2022; Volume 77, pp. 729–743. ISBN 978-3-030-82013-8. [Google Scholar]
- Duriagina, Z.A.; Tkachenko, R.O.; Trostianchyn, A.M.; Lemishka, I.A.; Kovalchuk, A.M.; Kulyk, V.V.; Kovbasyuk, T.M. Determination of the Best Microstructure and Titanium Alloy Powders Properties Using Neural Network. J. Achiev. Mater. Manuf. Eng. 2018, 87, 25–31. [Google Scholar] [CrossRef]
- Chaudhuri, A.K.; Ray, A.; Banerjee, D.K.; Das, A. A Multi-Stage Approach Combining Feature Selection with Machine Learning Techniques for Higher Prediction Reliability and Accuracy in Cervical Cancer Diagnosis. Int. J. Intell. Syst. Appl. 2021, 13, 46–63. [Google Scholar] [CrossRef]
- Kaminsky, R.; Mochurad, L.; Shakhovska, N.; Melnykova, N. Calculation of the Exact Value of the Fractal Dimension in the Time Series for the Box-Counting Method. In Proceedings of the 2019 9th International Conference on Advanced Computer Information Technologies (ACIT), Ceske Budejovice, Czech Republic, 5–7 June 2019; pp. 248–251. [Google Scholar]
- Guzman-Urbina, A.; Aoyama, A.; Choi, E. A Polynomial Neural Network Approach for Improving Risk Assessment and Industrial Safety. ICIC Express Lett. 2018, 12, 97–107. [Google Scholar] [CrossRef]
- Ghazanfari, N.; Gholami, S.; Emad, A.; Shekarchi, M. Evaluation of GMDH and MLP Networks for Prediction of Compressive Strength and Workability of Concrete. Bull. Soc. Roy. Sc. De Liège 2017, 86, 855–868. [Google Scholar] [CrossRef]
- Nikolaev, N.Y.; Iba, H. Polynomial Harmonic GMDH Learning Networks for Time Series Modeling. Neural Netw. 2003, 16, 1527–1540. [Google Scholar] [CrossRef]
- Tilve, M.V. GMDHreg: An R Package for GMDH Regression. 2021. Available online: https://cran.r-project.org/web/packages/GMDHreg/vignettes/GMDHreg.html (accessed on 17 May 2022).
- Kotsovsky, V.; Batyuk, A. On-Line Relaxation Versus Off-Line Spectral Algorithm in the Learning of Polynomial Neural Units. In Proceedings of the Data Stream Mining & Processing, Lviv, Ukraine, 21–25 August 2020; Babichev, S., Peleshko, D., Vynokurova, O., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 3–21. [Google Scholar]
- Kadhim, A.F.; Kamal, Z.A. Dynamic S-BOX Base on Primitive Polynomial and Chaos Theory. In Proceedings of the 2018 International Conference on Engineering Technology and their Applications (IICETA), Al-Najaf, Iraq, 8–9 May 2018; pp. 7–12. [Google Scholar]
- Zhang, Y.; Ling, C. A Strategy to Apply Machine Learning to Small Datasets in Materials Science. NPJ Comput. Mater. 2018, 4, 25. [Google Scholar] [CrossRef] [Green Version]
- Izonin, I.; Tkachenko, R.; Gregus, M.; Duriagina, Z.; Shakhovska, N. PNN-SVM Approach of Ti-Based Powder’s Properties Evaluation for Biomedical Implants Production. Comput. Mater. Contin. 2022, 71, 5933–5947. [Google Scholar] [CrossRef]
- Teslyuk, V.; Kazarian, A.; Kryvinska, N.; Tsmots, I. Optimal Artificial Neural Network Type Selection Method for Usage in Smart House Systems. Sensors 2021, 21, 47. [Google Scholar] [CrossRef]
- Lindon, J.C.; Nicholson, J.K.; Holmes, E. (Eds.) The Handbook of Metabonomics and Metabolomics, 1st ed.; Elsevier: Amsterdam, The Netherlands; Boston, MA, USA, 2007; ISBN 978-0-444-52841-4. [Google Scholar]
- Samuelson, F.; Brown, D.G. Application of Cover’s Theorem to the Evaluation of the Performance of CI Observers. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1020–1026. [Google Scholar]
- Hovorushchenko, T.; Pavlova, O.; Medzatyi, D. Ontology-Based Intelligent Agent for Determination of Sufficiency of Metric Information in the Software Requirements. In Lecture Notes in Computational Intelligence and Decision Making; Lytvynenko, V., Babichev, S., Wójcik, W., Vynokurova, O., Vyshemyrskaya, S., Radetskaya, S., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; Volume 1020, pp. 447–460. ISBN 978-3-030-26473-4. [Google Scholar]
- Hovorushchenko, T.; Pavlova, O. Method of Activity of Ontology-Based Intelligent Agent for Evaluating Initial Stages of the Software Lifecycle. In Recent Developments in Data Science and Intelligent Analysis of Information; Chertov, O., Mylovanov, T., Kondratenko, Y., Kacprzyk, J., Kreinovich, V., Stefanuk, V., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; Volume 836, pp. 169–178. ISBN 978-3-319-97884-0. [Google Scholar]
- Муляк, О.В.; Якoвина, В.С.; Вoлoчій, Б.Ю. Influence of Software Reliability Models on Reliability Measures of Software and Hardware Systems. East.-Eur. J. Enterp. Technol. 2015, 4, 53. [Google Scholar] [CrossRef]
- Shakhovska, N.; Yakovyna, V.; Kryvinska, N. An Improved Software Defect Prediction Algorithm Using Self-Organizing Maps Combined with Hierarchical Clustering and Data Preprocessing. In Proceedings of the Database and Expert Systems Applications, Bratislava, Slovakia, 14–17 September 2020; Hartmann, S., Küng, J., Kotsis, G., Tjoa, A.M., Khalil, I., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 414–424. [Google Scholar]
- Halyal, S.V. Running Google Colaboratory as a Server—Transferring Dynamic Data in and out of Colabs. Int. J. Educ. Manag. Eng. 2019, 9, 35–39. [Google Scholar] [CrossRef]
- Khan, K.; Sahai, A. A Glowworm Optimization Method for the Design of Web Services. Int. J. Intell. Syst. Appl. 2012, 4, 89–102. [Google Scholar] [CrossRef]
- Krak, I.; Barmak, O.; Manziuk, E. Using Visual Analytics to Develop Human and Machine-centric Models: A Review of Approaches and Proposed Information Technology. Comput. Intell. 2020; Online version of record. [Google Scholar] [CrossRef]
- Rawat, B.; Dwivedi, S.K. Selecting Appropriate Metrics for Evaluation of Recommender Systems. Int. J. Inf. Technol. Comput. Sci. 2019, 11, 14–23. [Google Scholar] [CrossRef]
- Lemishka, I.; Duriagina, Z.; Kulyk, V.; Izonin, I.; Tkachenko, R. Dataset of Titanium Layers Properties after Laser Sintering Depending on Chemical and Phase Composition, Size and Form of Parts, Polydispersity and Satellites Composition. 2018. Available online: https://www.researchgate.net/publication/355913560_Dataset_of_titanium_layers_properties_after_laser_sintering_depending_on_chemical_and_phase_composition_size_and_form_of_parts_polydispersity_and_satellites_composition (accessed on 17 May 2022).
- Pardede, J.; Sitohang, B.; Akbar, S.; Khodra, M.L. Implementation of Transfer Learning Using VGG16 on Fruit Ripeness Detection. Int. J. Intell. Syst. Appl. 2021, 13, 52–61. [Google Scholar] [CrossRef]
- Saad, M. Designing a Secure Environment for IoT Networks Using Lightweight AES Algorithm. Iraqi J. Sci. 2021, 62, 2759–2770. [Google Scholar] [CrossRef]
- Krak, Y.V. Dynamics of Manipulation Robots: Numerical-Analytical Method of Formation and Investigation of Computational Complexity. J. Autom. Inf. Sci. 1999, 31, 121–128. [Google Scholar] [CrossRef]
- Hu, Z.; Ivashchenko, M.; Lyushenko, L.; Klyushnyk, D. Artificial Neural Network Training Criterion Formulation Using Error Continuous Domain. Int. J. Mod. Educ. Comput. Sci. 2021, 13, 13–22. [Google Scholar] [CrossRef]
- Hu, Z.; Bodyanskiy, Y.V.; Kulishova, N.Y.; Tyshchenko, O.K. A Multidimensional Extended Neo-Fuzzy Neuron for Facial Expression Recognition. Int. J. Intell. Syst. Appl. 2017, 9, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Neela, A.G. Implementation of Support Vector Machine for Identification of Skin Cancer. Int. J. Eng. Manuf. 2019, 9, 42–52. [Google Scholar] [CrossRef]
- Himanen, L.; Geurts, A.; Foster, A.S.; Rinke, P. Data-Driven Materials Science: Status, Challenges, and Perspectives. Adv. Sci. 2019, 6, 1900808. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Indicator | Improved PNN-SVM Smart System | |
|---|---|---|
| Train Mode | Test Mode | |
| Total accuracy | 0.99 | 0.97 |
| Precision | 0.98 | 0.97 |
| Recall | 0.99 | 0.97 |
| F1-score | 0.99 | 0.97 |
| Investigated Smart System | Total Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Classical PNN (σ = 0.04) ** | 0.88 | 0.84 | 0.91 | 0.85 |
| Modified PNN (σ = 0.12) ** | 0.90 | 0.92 | 0.85 | 0.88 |
| PNN-Logit (where PNN used for dimensionality reduction) (σ = 0.12) ** | 0.90 | 0.90 | 0.90 | 0.90 |
| PNN-SVM (where PNN used for dimensionality reduction) * (σ = 0.12) ** | 0.91 | 0.91 | 0.91 | 0.90 |
| Modified PNN-Ito-Logit (where PNN used for dimensionality reduction) (σ = 0.12) ** | 0.92 | 0.92 | 0.92 | 0.91 |
| Modified PNN-Ito-SVM (where PNN used for dimensionality reduction) * (σ = 0.12) ** | 0.92 | 0.93 | 0.92 | 0.92 |
| PNN-SVM system (σ = 0.12) ** | 0.91 | 0.91 | 0.91 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Izonin, I.; Tkachenko, R.; Duriagina, Z.; Shakhovska, N.; Kovtun, V.; Lotoshynska, N. Smart Web Service of Ti-Based Alloy’s Quality Evaluation for Medical Implants Manufacturing. Appl. Sci. 2022, 12, 5238. https://doi.org/10.3390/app12105238
Izonin I, Tkachenko R, Duriagina Z, Shakhovska N, Kovtun V, Lotoshynska N. Smart Web Service of Ti-Based Alloy’s Quality Evaluation for Medical Implants Manufacturing. Applied Sciences. 2022; 12(10):5238. https://doi.org/10.3390/app12105238
Chicago/Turabian StyleIzonin, Ivan, Roman Tkachenko, Zoia Duriagina, Nataliya Shakhovska, Viacheslav Kovtun, and Natalia Lotoshynska. 2022. "Smart Web Service of Ti-Based Alloy’s Quality Evaluation for Medical Implants Manufacturing" Applied Sciences 12, no. 10: 5238. https://doi.org/10.3390/app12105238
APA StyleIzonin, I., Tkachenko, R., Duriagina, Z., Shakhovska, N., Kovtun, V., & Lotoshynska, N. (2022). Smart Web Service of Ti-Based Alloy’s Quality Evaluation for Medical Implants Manufacturing. Applied Sciences, 12(10), 5238. https://doi.org/10.3390/app12105238