
Scene Adaptive Segmentation for Crowd Counting in Population Heterogeneous Distribution


Abstract
:1. Introduction
- (1)
- A novel scene adaptive segmentation network is proposed that can adaptively divide the input image into distant-view regions and close-up view regions with different densities.
- (2)
- We exploit simultaneously distant view and close-up view crowd counting modules, which can extract features of different scales from the two views according to different receptive fields of image.
- (3)
- A dilated convolution is employed to lower greatly the number of parameters.
2. Related Work
2.1. Traditional Methods
2.2. Deep-Learning-Based Methods
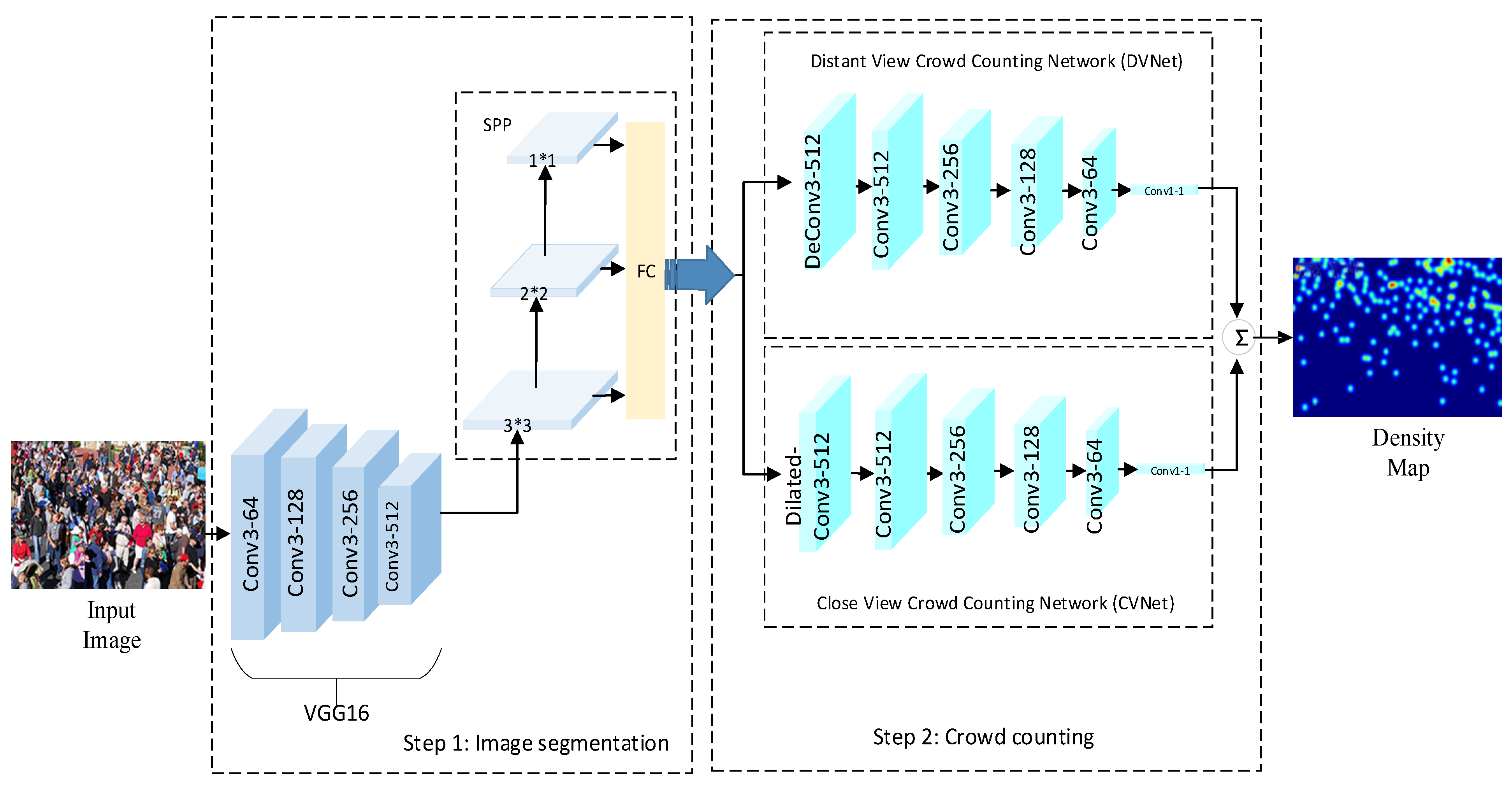
3. Methodology
3.1. Scene Adaptive Segmentation
3.2. Crowd Counting Module
3.2.1. Distant View Crowd Counting
3.2.2. Close-Up View Crowd Counting
3.3. Density Estimation Map
3.4. Loss Function
4. Experiments
4.1. Implementation
4.2. Evaluation Criteria
4.3. Datasets
4.3.1. ShanghaiTech
4.3.2. UCF_CC_50
4.3.3. UCF_QNRF
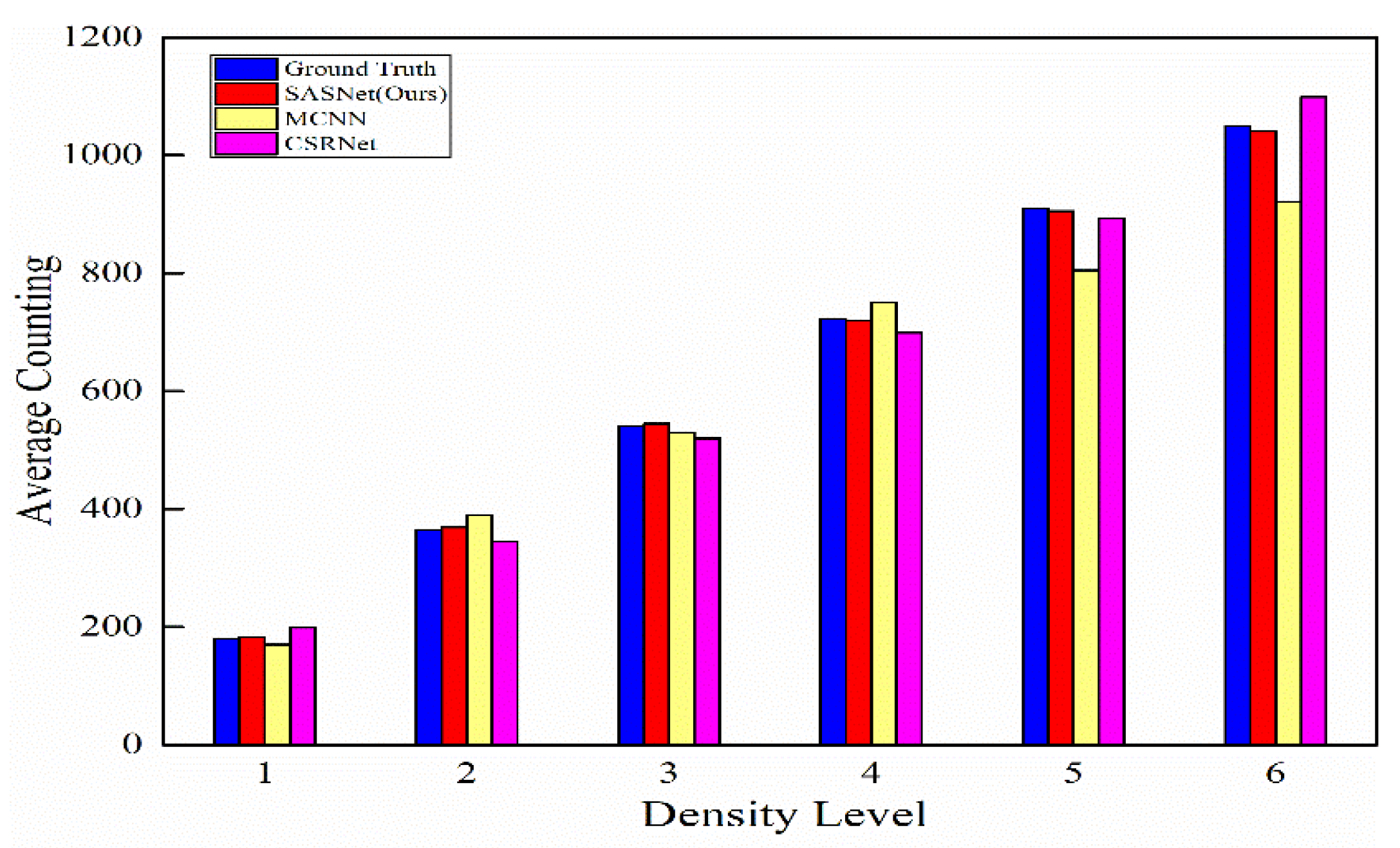
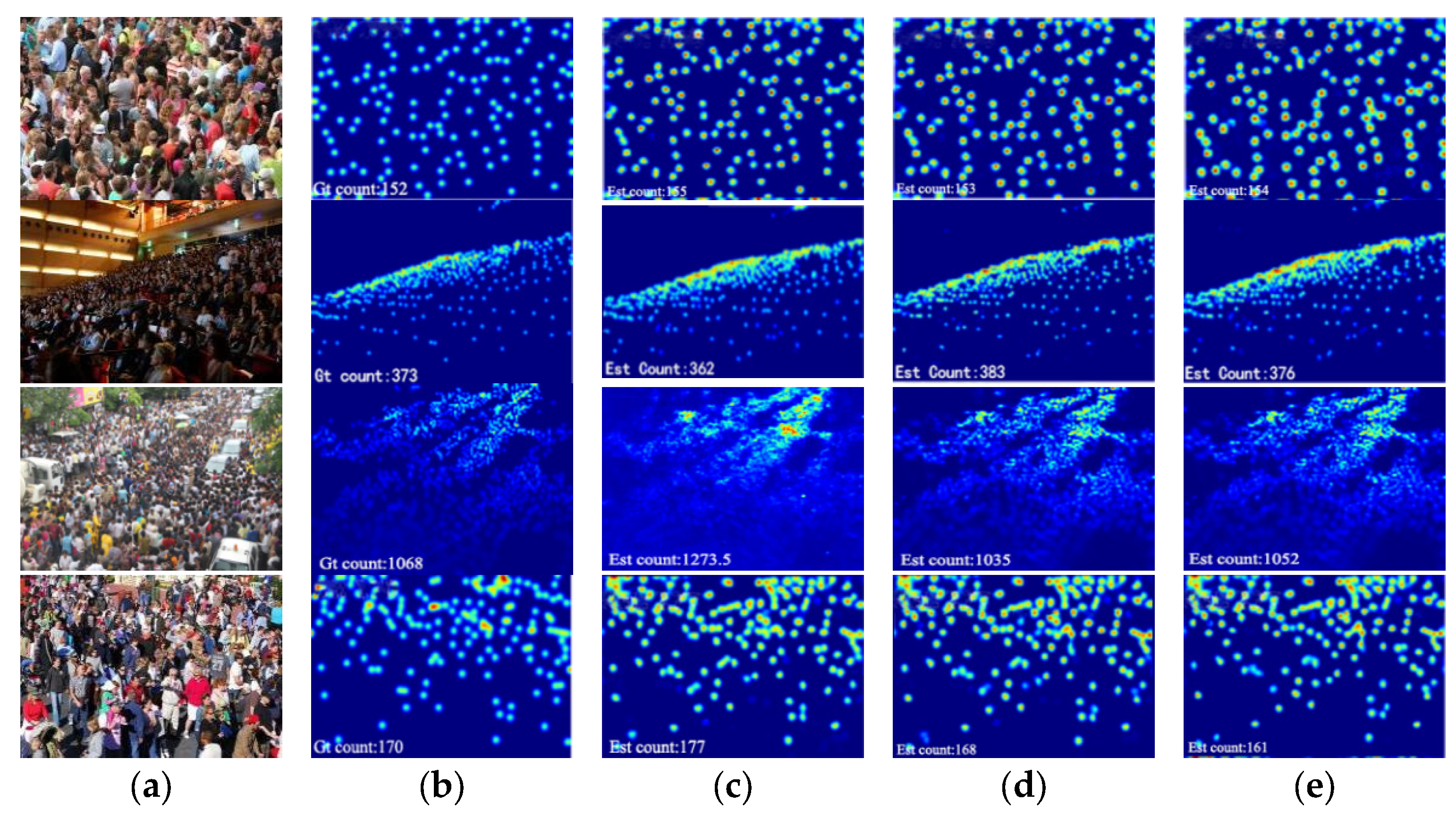
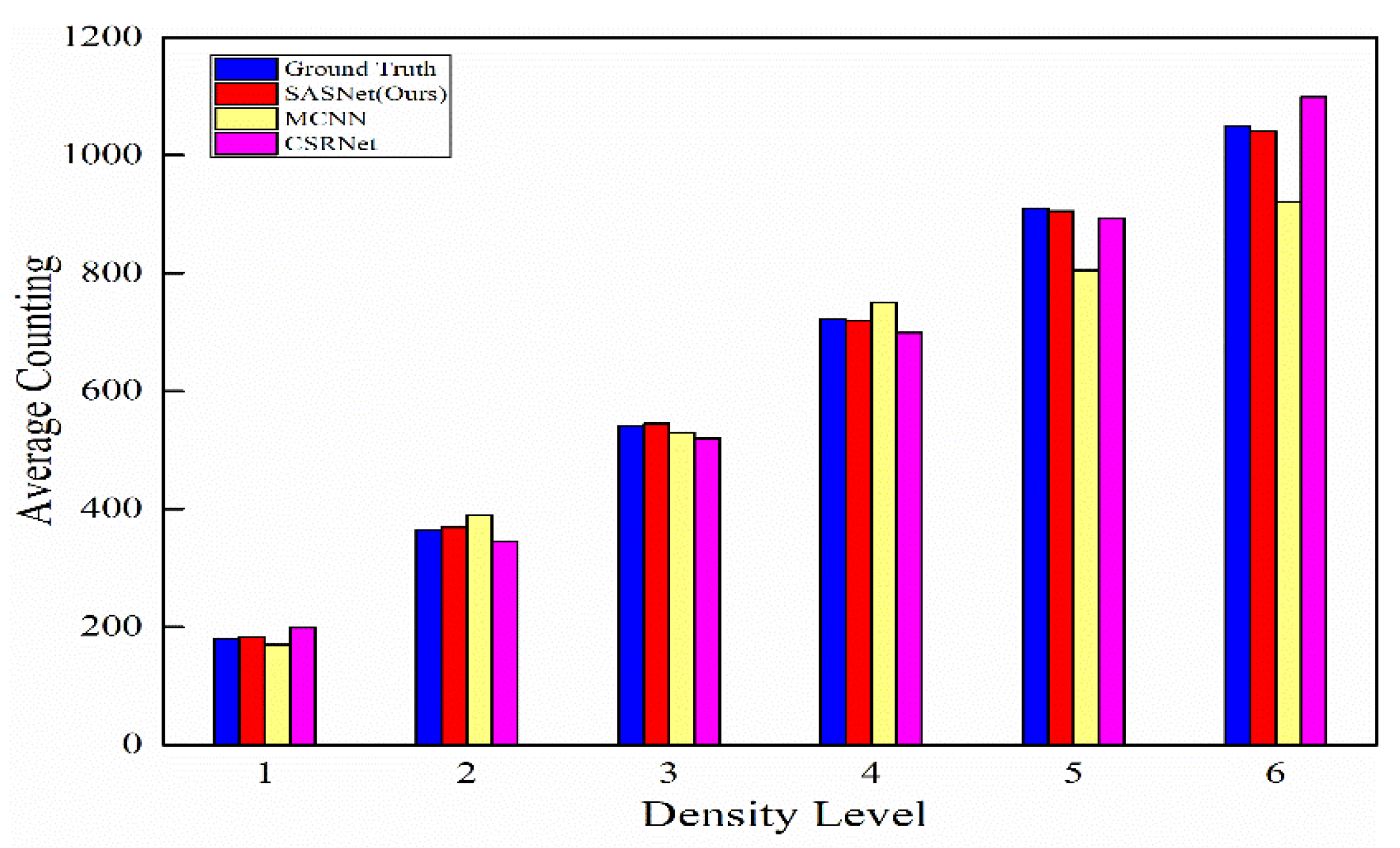
4.4. Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, B.; Huang, H.; Zhang, A.; Liu, P.-C. Approaches on crowd counting and density estimation: A review. Pattern Anal. Appl. 2021, 24, 853–874. [Google Scholar] [CrossRef]
- Gavrila, D.M.; Philomin, V. Real-time object detection for “smart” vehicles. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 1, pp. 8–93. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Chen, S.; Fern, A.; Todorovic, S. Person count localization in videos from noisy foreground and detections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1364–1372. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-Scale Counting in Extremely Dense Crowd Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Lempitsky, V.S.; Zisserman, A. Learning to Count Objects in Images. Adv. Neural Inf. Process. Syst. 2010, 23, 1324–1332. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Loy, C.C. Cumulative Attribute Space for Age and Crowd Density Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2467–2474. [Google Scholar]
- Shang, C.; Ai, H.; Bai, B. End-to-end crowd counting via joint learning local and global count. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1215–1219. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.S.; Babu, R.V. CrowdNet: A Deep Convolutional Network for Dense Crowd Counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. Fully Convolutional Crowd Counting on Highly Congested Scenes. arXiv 2017, arXiv:1612.00220. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating High-Quality Crowd Density Maps Using Contextual Pyramid CNNs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1879–1888. [Google Scholar]
- Oñoro-Rubio, D.; López-Sastre, R.J. Towards Perspective-Free Object Counting with Deep Learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 615–629. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. CNN-Based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Zhang, A.; Shen, J.; Xiao, Z.; Zhu, F.; Shao, L. Relational Attention Network for Crowd Counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6787–6796. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhao, S.; Jia, Z.; Chen, H.; Li, L. PDANet: Polarity-Consistent Deep Attention Network for Fine-Grained Visual Emotion Regression. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 192–201. [Google Scholar]
- Basalamah, S.M.; Khan, S.D.; Ullah, H. Scale Driven Convolutional Neural Network Model for People Counting and Localization in Crowd Scenes. IEEE Access 2019, 7, 71576–71584. [Google Scholar] [CrossRef]
- Wang, M.; Cai, H.; Zhou, J.; Gong, M. Interlayer and Intralayer Scale Aggregation for Scale-Invariant Crowd Counting. Neurocomputing 2021, 441, 128–137. [Google Scholar] [CrossRef]
- Tutsoy, O.; Çolak, Ş. Adaptive estimator design for unstable output error systems: A test problem and traditional system identification based analysis. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2015, 229, 902–916. [Google Scholar] [CrossRef]
- Tutsoy, O. Design and Comparison Base Analysis of Adaptive Estimator for Completely Unknown Linear Systems in the Presence of OE Noise and Constant Input Time Delay. Asian J. Control 2016, 18, 1020–1029. [Google Scholar] [CrossRef]
- Yu, Y.; Zhu, H.; Wang, L.; Pedrycz, W. Dense crowd counting based on adaptive scene division. Int. J. Mach. Learn. Cybern. 2021, 12, 931–942. [Google Scholar] [CrossRef]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar]
- Gao, J.; Wang, Q.; Li, X. PCC Net: Perspective Crowd Counting via Spatial Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3486–3498. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.S.; Shao, L. Crowd Counting and Density Estimation by Trellis Encoder-Decoder Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6126–6135. [Google Scholar]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd Counting with Deep Structured Scale Integration Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1774–1783. [Google Scholar]
- Dong, L.; Zhang, H.; Ji, Y.; Ding, Y. Crowd counting by using multi-level density-based spatial information: A Multi-scale CNN framework. Inf. Sci. 2020, 528, 79–91. [Google Scholar] [CrossRef]
- Luo, A.; Yang, F.; Li, X.; Nie, D.; Jiao, Z.; Zhou, S.; Cheng, H. Hybrid Graph Neural Networks for Crowd Counting. arXiv 2020, arXiv:2002.00092. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, N.; Zhao, Z.; Abraham, A.; Liu, H. Crowd counting based on attention-guided multi-scale fusion networks. Neurocomputing 2021, 451, 12–24. [Google Scholar] [CrossRef]
- Zhou, F.; Zhao, H.; Zhang, Y.; Zhang, Q.; Liang, L.; Li, Y.; Duan, Z. COMAL: Compositional multi-scale feature enhanced learning for crowd counting. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | No. of Samples | Max | Min | Avg | Sum | |
|---|---|---|---|---|---|---|---|
| ShanghaiTech | Part_A | different | 482 | 3193 | 33 | 501.4 | 241,677 |
| Part_B | 768 × 1024 | 716 | 578 | 9 | 123.6 | 88,488 | |
| UCF_CC_50 | different | 50 | 4543 | 94 | 1279.5 | 63,974 | |
| UCF_QNRF | 2013 × 2902 | 1535 | 12,865 | 49 | 815 | 1,251,642 | |
| Method | ShanghaiTech Part_A | UCF_CC_50 | UCF_QNRF | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| MCNN [5] | 110.2 | 173.2 | 377.6 | 509.1 | 243.5 | 364.7 |
| Switching CNN [28] | 90.4 | 135 | 318.1 | 439.2 | 228 | 445 |
| CMTL [18] | 101.3 | 152.4 | 322.8 | 397.9 | 252 | 514 |
| CSRNet [19] | 68.2 | 115 | 266.1 | 397.5 | 120.3 | 208.5 |
| PCCNet [29] | 73.5 | 124 | 240 | 315.5 | 149 | 247 |
| TEDnet [30] | 64.2 | 109.1 | 249.4 | 354.5 | 113 | 188 |
| DSSINet [31] | 60.6 | 96 | 216.9 | 302.4 | 99.1 | 159.2 |
| MMNet [32] | 60.8 | 99 | 209.7 | 309.7 | 104 | 178 |
| HyGnn [33] | 60.2 | 94.5 | 184.4 | 270.1 | 100.8 | 185.3 |
| AMS-Net [34] | 63.8 | 108.5 | 236.5 | 319.2 | 86.5 | 167.2 |
| COMAL [35] | 59.6 | 97.1 | 231.9 | 333.7 | 102.1 | 178.3 |
| SASNet (Ours) | 60.5 | 101.3 | 184.3 | 258.1 | 91.1 | 169.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, H.; Deng, M.; Zhao, W.; Zhang, D. Scene Adaptive Segmentation for Crowd Counting in Population Heterogeneous Distribution. Appl. Sci. 2022, 12, 5183. https://doi.org/10.3390/app12105183
Gao H, Deng M, Zhao W, Zhang D. Scene Adaptive Segmentation for Crowd Counting in Population Heterogeneous Distribution. Applied Sciences. 2022; 12(10):5183. https://doi.org/10.3390/app12105183
Chicago/Turabian StyleGao, Hui, Miaolei Deng, Wenjun Zhao, and Dexian Zhang. 2022. "Scene Adaptive Segmentation for Crowd Counting in Population Heterogeneous Distribution" Applied Sciences 12, no. 10: 5183. https://doi.org/10.3390/app12105183
APA StyleGao, H., Deng, M., Zhao, W., & Zhang, D. (2022). Scene Adaptive Segmentation for Crowd Counting in Population Heterogeneous Distribution. Applied Sciences, 12(10), 5183. https://doi.org/10.3390/app12105183