
Grouping Bilinear Pooling for Fine-Grained Image Classification


Abstract
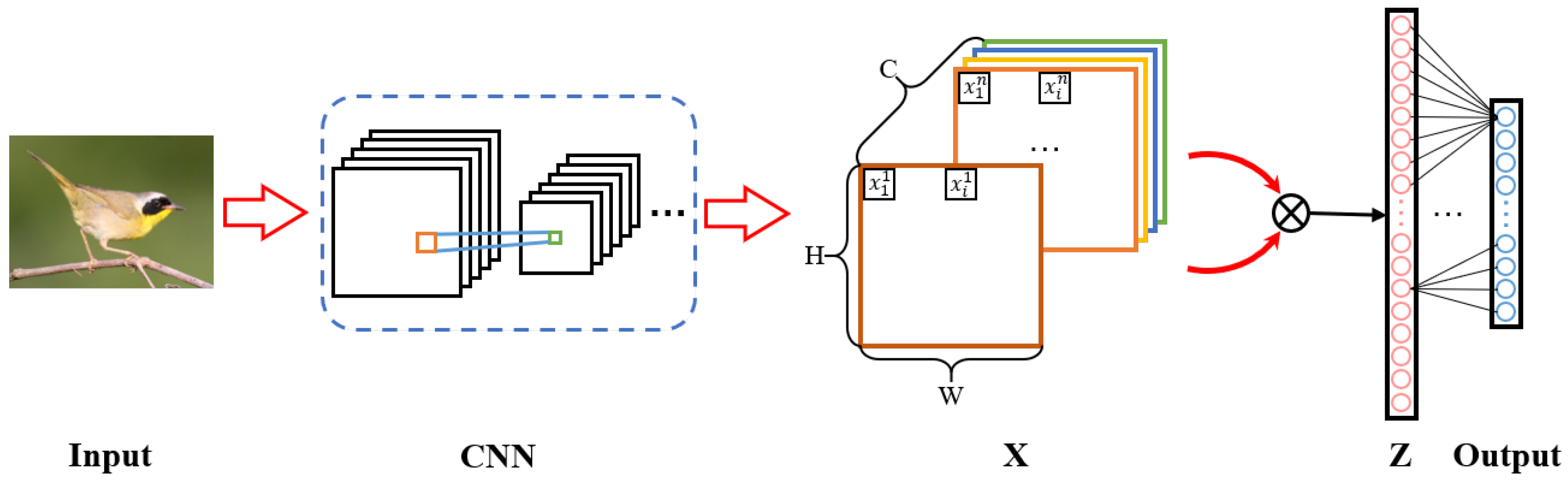
:1. Introduction
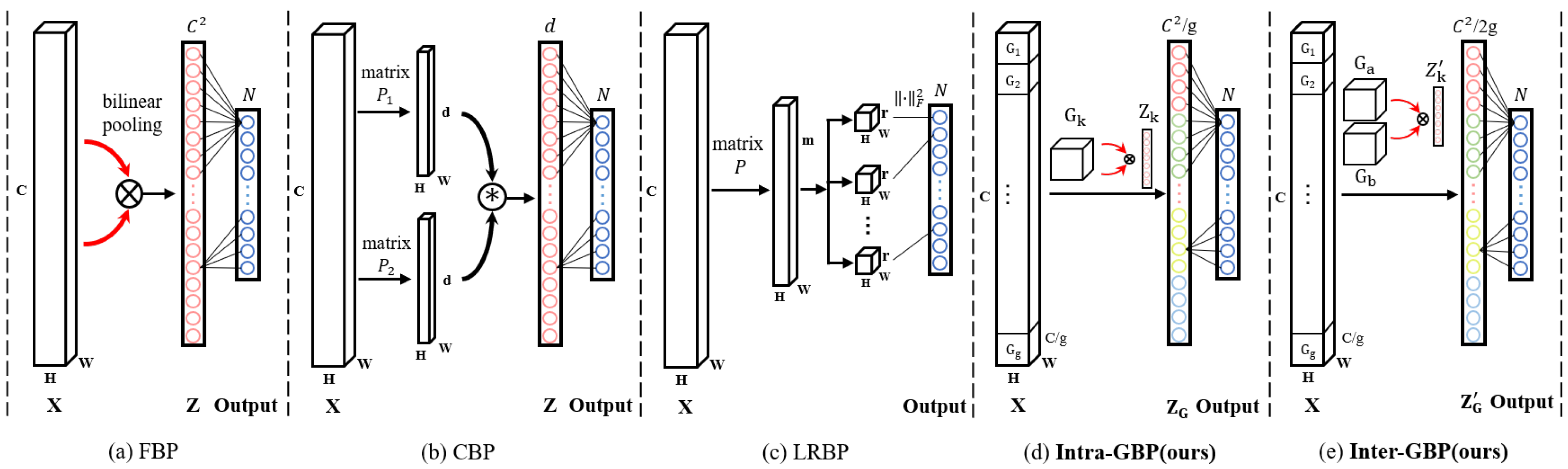
2. Analysis of Bilinear Pooling
3. Grouping Bilinear Pooling
3.1. Intra-Group Bilinear Pooling
3.2. Inter-Group Bilinear Pooling
4. Experiment
4.1. Datasets, Backbone and Experiment Configurations
4.1.1. Datasets
4.1.2. Backbone
4.1.3. Experimental Configurations
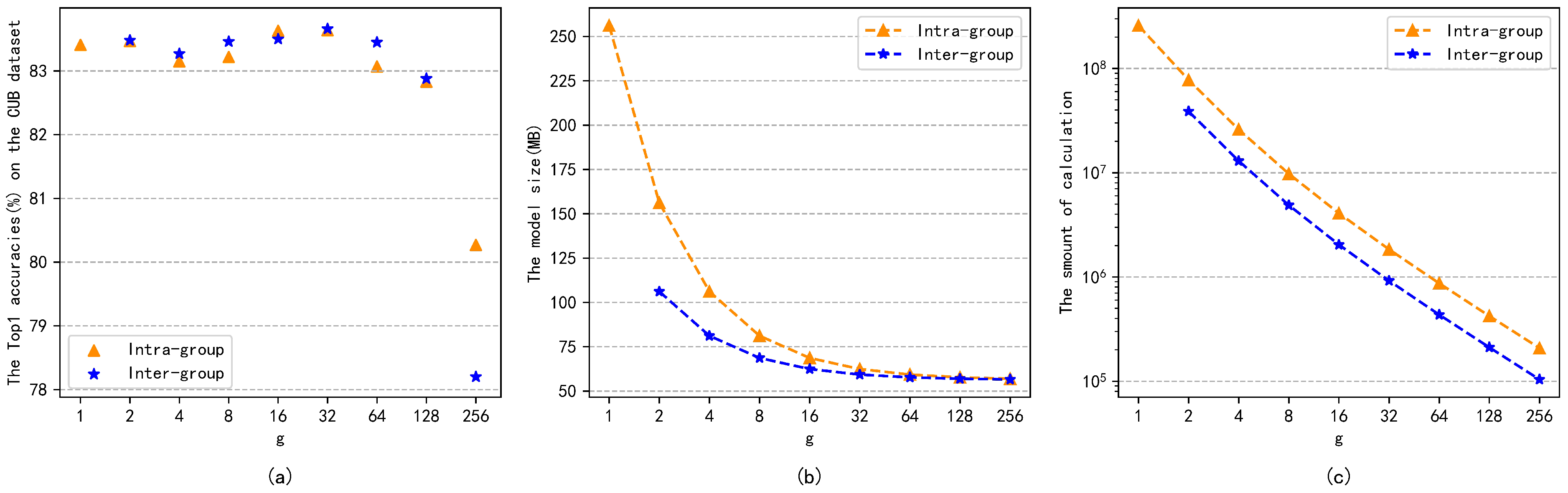
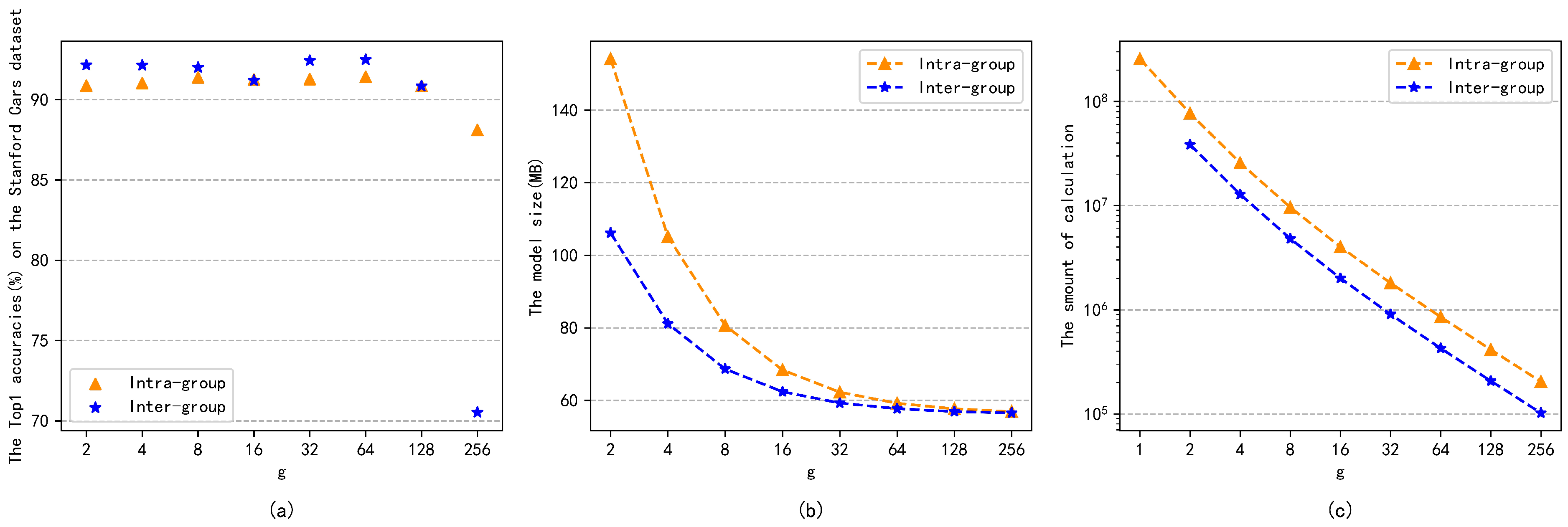
4.2. Evaluation
4.3. Comparing with Other Compact Bilinear Pooling
4.4. Comparison with the State-of-the-Art
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Computation & Neural Systems Technical Report, 2010-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar] [CrossRef]
- Sohaib, M.; Kim, J.M. Data Driven Leakage Detection and Classification of a Boiler Tube. Appl. Sci. 2019, 9, 2450. [Google Scholar] [CrossRef] [Green Version]
- Wang, E.; Jiang, Y.; Li, Y.; Yang, J.; Zhang, Q. MFCSNet: Multi-Scale Deep Features Fusion and Cost-Sensitive Loss Function Based Segmentation Network for Remote Sensing Images. Appl. Sci. 2019, 9, 4043. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeiler, M.; Fergus, R. Stochastic Pooling for Regularization of Deep Convolutional Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Yu, D.; Wang, H.; Chen, P.; Wei, Z. Mixed Pooling for Convolutional Neural Networks. In International Conference On Rough Sets and Knowledge Technology; Springer: Cham, Switzerland, 2014; pp. 364–375. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, M.; Yuan, Y.; Zhou, F.; Ding, E. Multi-Attention Multi-Class Constraint for Fine-grained Image Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Daniilidis, K.; Maragos, P.; Paragios, N. Improving the Fisher Kernel for Large-Scale Image Classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher Kernels on Visual Vocabularies for Image Categorization. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar] [CrossRef] [Green Version]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-Grained Visual Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar] [CrossRef]
- Yu, C.; Zhao, X.; Zheng, Q.; Zhang, P.; You, X. Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 595–610. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact Bilinear Pooling. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 317–326. [Google Scholar] [CrossRef] [Green Version]
- Ni, Z.L.; Bian, G.B.; Wang, G.; Zhou, X.H.; Hou, Z.G.; Xie, X.L.; Chen, H.B.; Li, Z. Pyramid Attention Aggregation Network for Semantic Segmentation of Surgical Instruments. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar] [CrossRef]
- Kong, S.; Fowlkes, C. Low-Rank Bilinear Pooling for Fine-Grained Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Fu, J.; Zha, Z.J.; Luo, J. Learning Deep Bilinear Transformation for Fine-grained Image Representation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Kar, P.; Karnick, H. Random feature maps for dot product kernels. J. Mach. Learn. Res. 2012, 22, 583–591. [Google Scholar]
- Pham, N.; Pagh, R. Fast and scalable polynomial kernels via explicit feature maps. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 239–247. [Google Scholar] [CrossRef] [Green Version]
- Fukui, A.; Park, D.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-view harmonized bilinear network for 3d object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Pan, J.; Lai, J.; Zhang, J. Deep bilinear learning for rgb-d action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Lin, T.Y.; Maji, S. Improved Bilinear Pooling with CNNs. arXiv 2017, arXiv:1707.06772. [Google Scholar]
- Gou, M.; Xiong, F.; Camps, O.; Sznaier, M. MoNet: Moments Embedding Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3175–3183. [Google Scholar]
- Gao, Z.; Wu, Y.; Zhang, X.; Dai, J.; Jia, Y.; Harandi, M. Revisiting Bilinear Pooling: A Coding Perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3954–3961. [Google Scholar]
- Liao, Q.; Wang, D.; Holewa, H.; Xu, M. Squeezed Bilinear Pooling for Fine-Grained Visual Categorization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 728–732. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, H.; Li, T.; Shen, C. Deep CNNs with Spatially Weighted Pooling for Fine-Grained Car Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3147–3156. [Google Scholar] [CrossRef]
- Tan, M.; Wang, G.; Zhou, J.; Peng, Z.; Zheng, M. Fine-Grained Classification via Hierarchical Bilinear Pooling with Aggregated Slack Mask. IEEE Access 2019, 7, 117944–117953. [Google Scholar] [CrossRef]
- Luo, W.; Zhang, H.; Li, J.; Wei, X.S. Learning Semantically Enhanced Feature for Fine-Grained Image Classification. IEEE Signal Process. Lett. 2020, 27, 1545–1549. [Google Scholar] [CrossRef]
- Chang, D.; Ding, Y.; Xie, J.; Bhunia, A.K.; Li, X.; Ma, Z.; Wu, M.; Guo, J.; Song, Y.Z. The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification. IEEE Trans. Image Process. 2020, 29, 4683–4695. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Testing | Category |
|---|---|---|---|
| CUB [1] | 5994 | 5794 | 200 |
| Stanford Cars [2] | 8144 | 8041 | 196 |
| The Groups | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|---|---|---|---|
| CUB (%) | 83.79 | 84.19 | 85.13 | 85.28 | 85.23 | 85.11 | 85.07 | 85.21 | 85.32 | 85.54 |
| Model size (MB) | 987.81 | 497.81 | 297.81 | 197.81 | 147.81 | 122.81 | 110.31 | 104.06 | 100.94 | 99.37 |
| Stanford Cars (%) | 92.11 | 92.34 | 92.35 | 92.29 | 92.33 | 92.49 | 92.61 | 92.75 | 92.74 | 92.86 |
| Model size (MB) | 971.81 | 489.81 | 293.81 | 195.81 | 146.81 | 122.31 | 110.06 | 103.94 | 100.87 | 99.34 |
| Backbone | Method | Dimension | Computing | Parameters | ||||
|---|---|---|---|---|---|---|---|---|
| Pooling | Classifying | Total | Projection | Classifier | Total | |||
| VGG-16 | FBP [15] | [262 K] | 257,949,696 | 0 | 200 MB | |||
| iFBP [32] | [262 K] | 257,949,696 | 0 | 200 MB | ||||
| CBP-TS [17] | d [10 K] | 85,532,672 | 8 MB | |||||
| CBP-RM [17] | d [10 K] | 3,289,972,736 | 48 MB | |||||
| LRBP-I [19] | [78 K] | 165,580,800 | MB | |||||
| LRBP-II [19] | [10 K] | 63,980,800 | MB | |||||
| Intra-GBP (ours) | [2 K] | 422,144 | 0 | MB | ||||
| Inter-GBP | [1 K] | 211,072 | 0 | MB | ||||
| ResNet-50 | FBP [15] | [4194 K] | 1,660,944,384 | 0 | 3200 MB | |||
| Intra-GBP | [4 K] | 819,984 | 0 | MB | ||||
| Inter-GBP | [2 K] | 409,992 | 0 | MB | ||||
| Method | FBP [15] | iFBP [32] | CBP-TS [17] | CBP-RM [17] | LRBP [19] | Intra-GBP | Inter-GBP |
|---|---|---|---|---|---|---|---|
| CUB (%) | 84.01 | 85.80 | 84.00 | 83.86 | 84.21 | 83.64 | 83.66 |
| Cars (%) | 91.18 | 92.10 | 90.19 | 89.54 | 90.92 | 91.42 | 92.49 |
| Method | Backbone | Dimension | Parameters | CUB (%) | Stanford Cars (%) |
|---|---|---|---|---|---|
| VGG-16 [27] | - | 25 K | 20 MB | 74.59 | 85.05 |
| ResNet-50 [28] | - | 2 K | 1.6 MB | 82.15 | 92.19 |
| ResNet-101 [28] | - | 2 K | 1.6 MB | 82.58 | 92.56 |
| ResNet-152 [28] | - | 2 K | 1.6 MB | 82.74 | 92.64 |
| FBP [15] | VGG-16 | 260 K | 200 MB | 84.01 | 91.18 |
| iFBP [32] | 85.80 | 92.10 | |||
| MoNet-FBP [33] | 86.40 | 91.80 | |||
| CBP [17] | VGG-16 | 10 K | 8 MB | 84.00 | 90.19 |
| LRBP [19] | 10 K | 0.8 MB | 84.21 | 90.90 | |
| MoNet-TS [33] | 10 K | 8 MB | 85.70 | 90.80 | |
| FBC [34] | 8 K | 6.4 MB | 84.30 | - | |
| SBP-EN [35] | 10 K | 8 MB | 84.50 | 90.90 | |
| SWP [36] | VGG-16 | - | - | - | 90.70 |
| ResNet-50 | - | - | - | 92.30 | |
| ResNet-101 | - | - | - | 93.10 | |
| HBPASM [37] | ResNet-34 | - | - | 86.80 | 92.80 |
| HBP [16] | VGG-16 | 24 K | 19 MB | 87.01 | 93.70 |
| SEF [38] | VGG-16 | - | - | 81.10 | 88.30 |
| ResNet-50 | - | - | 87.30 | 94.00 | |
| MC-loss [39] | ResNet-50 | - | - | 87.30 | 93.70 |
| Inter-GBP | VGG-16 | 1 K | 0.8 MB | 83.66 | 92.49 |
| ResNet-50 | 2 K | 1.6 MB | 85.54 | 92.86 | |
| ResNet-101 | 2 K | 1.6 MB | 86.10 | 93.76 | |
| ResNet-152 | 2K | 1.6 MB | 86.31 | 94.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, R.; He, J. Grouping Bilinear Pooling for Fine-Grained Image Classification. Appl. Sci. 2022, 12, 5063. https://doi.org/10.3390/app12105063
Zeng R, He J. Grouping Bilinear Pooling for Fine-Grained Image Classification. Applied Sciences. 2022; 12(10):5063. https://doi.org/10.3390/app12105063
Chicago/Turabian StyleZeng, Rui, and Jingsong He. 2022. "Grouping Bilinear Pooling for Fine-Grained Image Classification" Applied Sciences 12, no. 10: 5063. https://doi.org/10.3390/app12105063
APA StyleZeng, R., & He, J. (2022). Grouping Bilinear Pooling for Fine-Grained Image Classification. Applied Sciences, 12(10), 5063. https://doi.org/10.3390/app12105063