1. Introduction
With the application of deep neural network (DNN) models, many computer vision problems have achieved tremendous performance in tasks such as object classification [
1], object segmentation [
2], object detection [
3], and object localization [
4]. However, the success of DNN models may depend on the quality and distribution of the labels in the dataset. As shown in [
5,
6,
7,
8,
9], a DNN model (and machine learning techniques) trained on an imbalanced dataset may show poor performance on minority labels. Cao et al. [
10] mentioned that large-scale datasets might have long-tailed label distributions, meaning that dataset imbalances could become problematic when samples are collected in a large-scale domain. Common approaches to addressing this problem, such as those reviewed by Chawla in [
11], include randomly oversampling minority or undersampling majority labels in data space or feature space. However, as the authors of [
12,
13] point out, these techniques may neglect potentially valuable data, sample unnecessary data, and risk losing relevant information. The authors of [
13,
14,
15] solve the imbalance problem by assigning weights to classes. Others chose to combine multiple sampling strategies, such as [
13,
14,
16]. In recent years, many methods have been proposed to deal with imbalanced datasets, such as those using machine learning techniques [
17,
18], DNNs [
19,
20], generative adversarial networks (GANs) [
21], or reinforcement learning (RL) [
22].
Many approaches using conventional training of DNN models to solve the weeds classification problem using imbalanced weeds datasets, such as those of Trong et al. [
23], who aggregated multiple DNN models and used the CNU Weeds dataset. The authors of [
24,
25,
26,
27,
28,
29,
30,
31,
32] developed and proposed novel models and techniques and applied them to the PlantSeedlings and PlantVillage datasets. In reality, weeds image datasets may have non-uniform distributions due to the relative prevalence of various species, some of which are common and diverse, while others are rare and identical. Hence, training a DNN model by selecting a batch of random samples from an entire training set makes the model robust to majority species, but sensitive to minority species, as Johnson and Khoshgoftaar pointed out in their survey [
33].
To reduce this bias, we proposed the yielding multi-fold training (YMufT) strategy, which trains the DNN model by arbitrarily dividing the training data into multiple folds and then trains the model on each of these folds consecutively. Furthermore, samples of minority species are trained more often than those of majority species so that the model pays more attention to minority species. The MCMB procedure assures this specification to determine the number of samples of each species selected and passed on each consecutive fold. In addition, we propose a formula to determine the number of training loops and training periods in YMufT. This formula aims to ensure that the number of loading training images in the YMufT strategy is approximately the same as, or less than, that in conventional training methods.
We explore our strategy on four weeds datasets, containing two large datasets (CNU and large PlantVillage) and two small datasets (PlantSeedlings and small PlantVillage). Both types of datasets have plain and in-the-wild weeds datasets. Experiments are done using three DNN models (Mobilenet, Resnet, and NASNet mobile) and the results are compared to those of the conventional training methods. We find that YMufT runs faster during the training period and is quicker to converge when training on the validation set, even though both approaches have the same training configurations and approximate training steps. The evaluation shows that training the DNN model using the YMufT strategy results in comparable performance to conventional training strategies on large datasets and higher performance on small datasets. Specifically, YMufT increases the F1 score in the NASNet model to 0.9708 on the CNU dataset and 0.9928 by using Mobilenet model training on large PlantVillage dataset. On the small PlantVillage dataset, Mobilenet achieves the highest performance of 0.9981 in accuracy and 0.9970 in F1 score. On the PlantSeedlings dataset, Resnet shows the highest accuracy (0.9718) and F1 score (0.9689). Grad-CAM visualization shows that YMufT guides the model to capture essential features of the leaf surface and correctly localize weeds targets. Conventional training methods mainly concentrate on high-level features and may capture insignificant features.
In summary, our main contributions are:
We propose a YMufT strategy to train the DNN model on imbalanced datasets. Using this strategy, the model is more generalized, performs better, and is less time-consuming during the training steps than conventional training methods.
We propose the MCMB procedure to select samples of each species to form a fold used to train the model. This fold has a uniform distribution, or at least much less imbalance than the distribution of species across the training set. This procedure also shows that the model pays more attention to minority species, reducing bias towards majority species.
Experiments show that YMufT improves performance on minority species while maintaining performance on majority species. In particular, YMufT outperforms conventional training methods on small datasets in terms of overall performance.
Grad-CAM visualization reveals that a model trained by the YMufT strategy tends to focus on microscopic features on the leaf surfaces, while the conventional trained model tends to concentrate on high-level features of the leaf.
2. Related Works
Kang et al. [
17] and Lin et al. [
22] noted that dealing with the imbalance problem by undersampling may increase computational complexity and decrease performance. Several approaches aimed to combine multiple sampling techniques, such as that of Gonzalez et al. [
13], who proposed a set of new sampling techniques and applied inside monotonic chains to preserve the monotonicity of the datasets and to improve performance on minority classes. Liu et al. [
14] simultaneously combined ensemble learning, evolutionary undersampling, and multiobjective feature selection. This combination resulted in an imbalanced classification method called Genetic Under-sampling and Multiobjectie Ant Colony Optimization based Feature selection, which efficiently solved the imbalanced classification problem. Nejatian et al. [
16] proposed modified-bagging by combining multiple poor classifiers similar to the decision tree method. This algorithm is suitable for an imbalanced dataset in which the samples of the minority classes are much less frequent than those of the majority class.
Another approach aimed at weight classes depends on the classes’ contribution to the total population. Zhang et al. [
12] assigned different misclassification costs for different classes based on the training data. Without prior domain knowledge, these costs were optimized using the adaptive differential evolution algorithm, which was then applied to the deep belief network. Khan et al. [
34] proposed a cost-sensitive DNN to learn robust feature representation for all classes. They incorporated class-dependent costs during model training. They automatically set these costs using statistics. Shu et al. [
15] proposed a one-hidden layer multi-layer perceptron (MLP) to learn weights directly from the data. During the training, they used a small, unbiased validation set to choose the optimal training parameters.
Besides applying sampling techniques, the use of the area under the receiver operating characteristic (ROC) is also a prominent approach to classification in the presence of imbalanced class distribution. The effectiveness of a ROC strategy depends on the classification threshold. Zou et al. [
35] proposed a sampling-based threshold auto-tuning method to identify the optimal classification threshold. Their approach improved classification performance over other commonly employed methods.
Using support vector machine (SVM) is a common method for classification problems in conventional machine learning, but an SVM loses its effectiveness on large-scale imbalanced datasets. Kang et al. [
17] proposed a weighted undersampling scheme to improve SVM performance. This scheme assigns weights to majority classes based on their Euclidean distance to the hyperplane. By grouping samples based on their weights, this scheme reduces the number of majority classes. Lemnaru and Potolea [
18] studied possible solutions to the class imbalance problem. They analyzed many standard classification algorithms, such as decision trees, Bayesian methods, and SVM. They found that none of these algorithms help all datasets, but MLP was the most robust to the imbalance problem, and SVM performed well on artificial data.
With the development of deep learning, many methods applied this technique to solve imbalance problems. Jia et al. [
19] applied a deep normalized convolutional neural network (CNN) to imbalanced fault classification of machinery. Using a neuron activation maximization algorithm to analyze kernels in the convolutional layers, they found that these kernels behave like filters—the deeper the layer, the more complex these kernels. Dong et al. [
20] formulated a class imbalanced deep learning model to train a model on an imbalanced dataset. They designed the model to minimize the dominance of majority classes using batch-wise mining of complex samples. They also proposed a class rectification loss regularization algorithm for minority class incremental rectification. Mullick et al. [
21] argued that oversampling techniques such as synthetic minority over sampling technique or deep oversampling framework could not be applied to an end-to-end deep learning system. Thus, they re-approached oversampling techniques by proposing an end-to-end feature-extraction-classification framework consisting of a convex generator, a multi-class classifier network, and a real/fake discriminator to generate new samples from minority classes.
An RL approach was proposed by Lin et al. [
22]. They argued that conventional classification algorithms fail when the data distribution is imbalanced. Using deep Q-learning, they formulated this problem as a sequential decision-making process. The agent performs a classification action. The environment evaluates this action and returns a reward to the agent such that the more minor the class, the larger the reward. This results in a model that pays more attention to the minority classes.
4. Methodology
Given a training set and a DNN model, the conventional training methods first train the whole training model with several epochs. In each epoch, the samples are randomly divided into an equal number of batches and each batch is fed to the model. No sample appears in two different batches. After the model is trained on every epoch, it is validated on the validation set. With this strategy, the model tends to encounter majority species more often than minority species, making the model robust to majority species since it can capture the whole variety of features in the majority samples. Otherwise, the lack of samples of minority species would make the model less focused and cause difficulties learning about the general characteristics of these species.
Our proposed strategy (YMufT) solves this problem by dividing the samples in the training set into multiple folds. Minority species are presented to the model more often than majority species. The smaller the number of samples, the more times the related species will be learned. This division strategy reduces the bias of the DNN model towards the majority species. We define the balance error (BE) to measure the imbalance of the dataset (Definition 1).
Definition 1 (Balance Error). A dataset has species, and each species has samples. and are the largest and smallest number of samples in a species, respectively. We calculate the Balance Error of using Formula (1) below. The lower the value of , the greater the balance of .
Consider the number of samples in a species as a discrete random variable. By this definition,
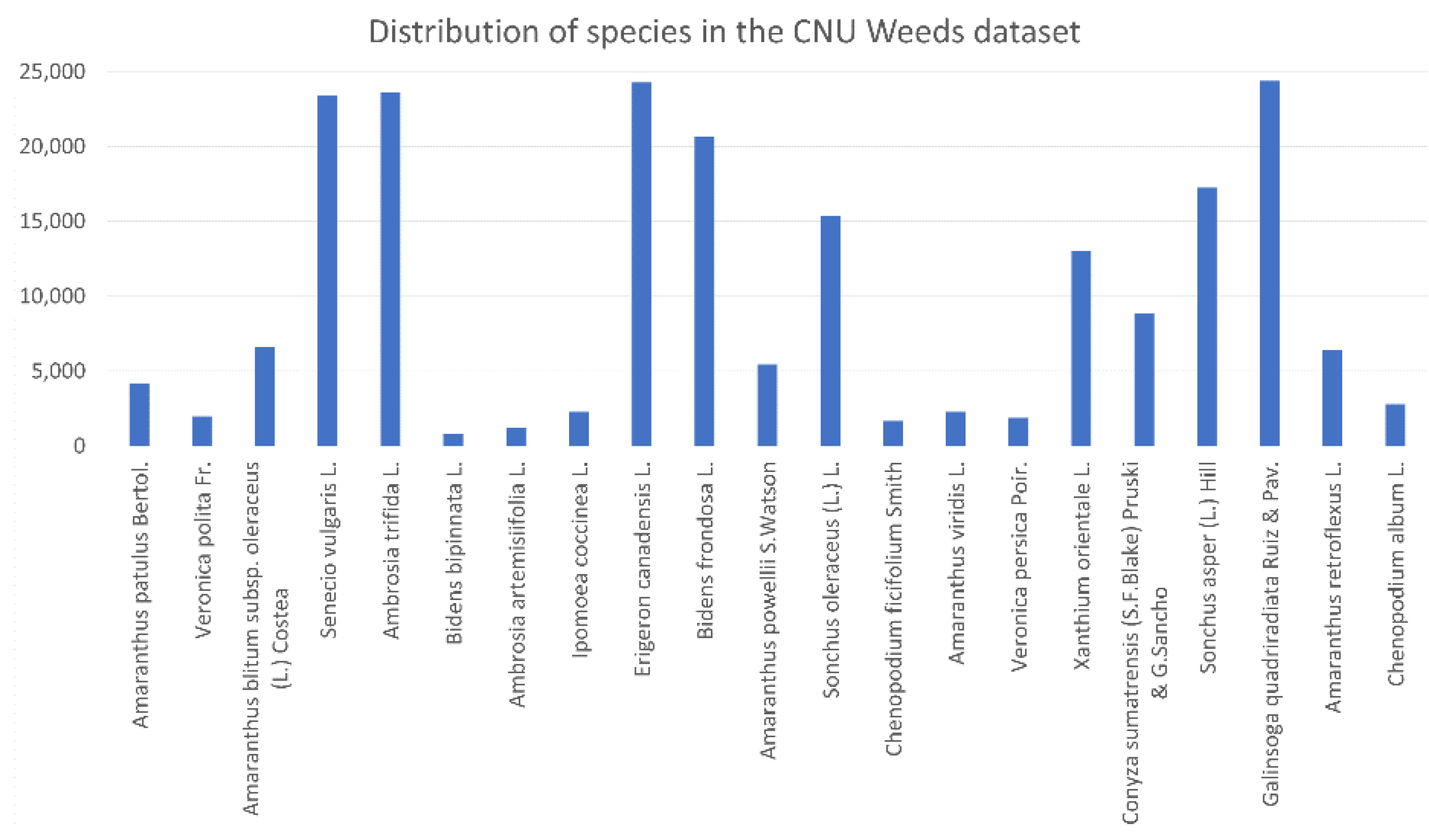
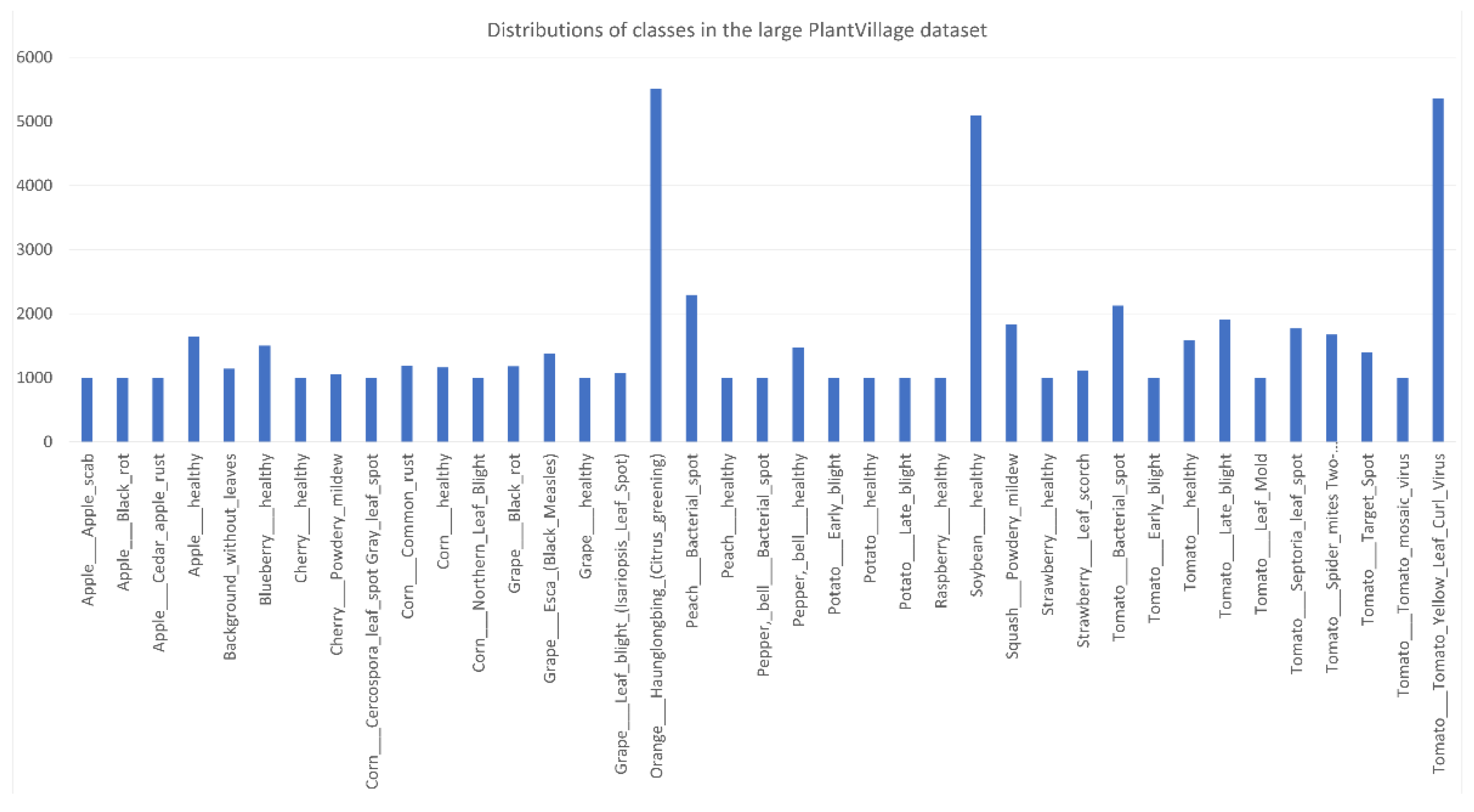
of the CNU Weeds dataset is 0.11316. Only five species have more than the median number of samples (18,974), and the standard deviation around this median is 12,557.854. In the large PlantVillage dataset,
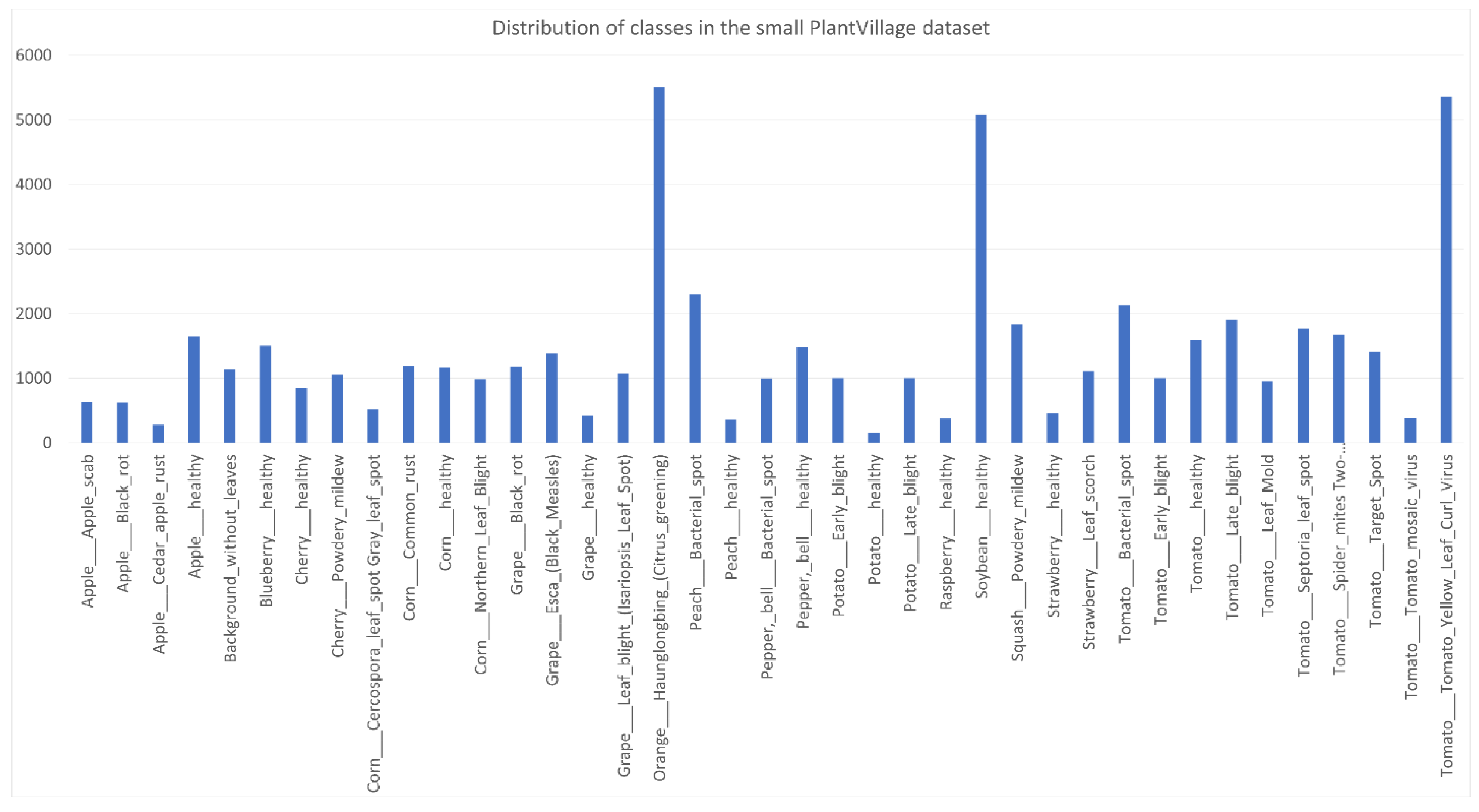
, and 11 classes have more samples than the median (1546.5). The standard deviation is 1135.824. In the small PlantVillage dataset, while
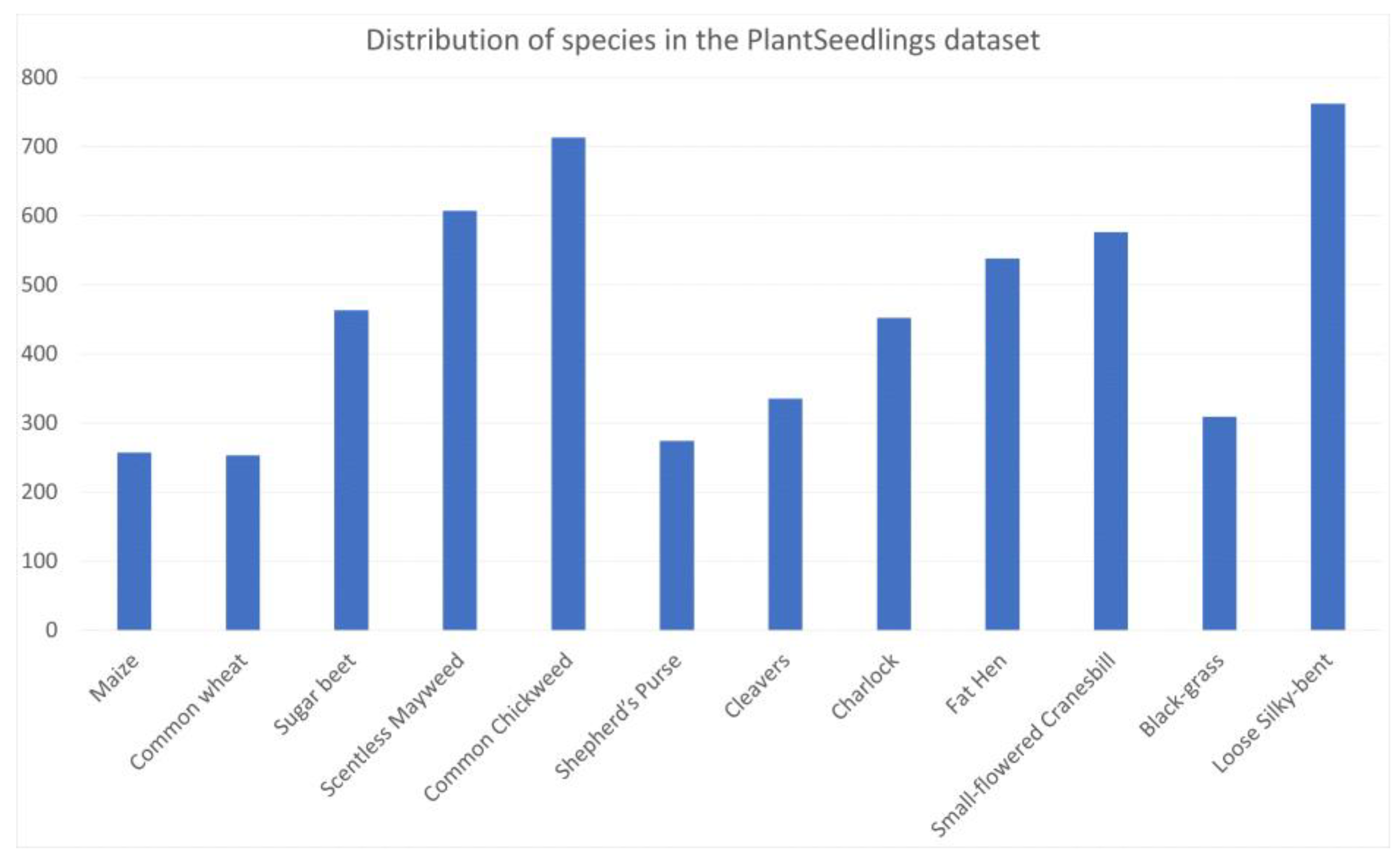
, only 10 classes have more than the median number of samples (1618). The standard deviation around this median is 1254.96. In the PlantSeedlings dataset,
, and five species have more than the median number of samples (500.5). The standard deviation is 97.62. Considering the uniform distribution as the standard distribution for a balanced dataset, we can measure the relative entropy from the distribution of a dataset to the uniform distribution. Equation (2) is the formula used to calculate the relative entropy from
to
, where
and
are two discrete probability distributions and
is a set of species in a dataset.
Assume that
is the probability distribution of a dataset with
species, and
is a uniform distribution. We can rewrite (2) to (3).
Using (3) to calculate the relative entropy of the distribution of a dataset to the uniform distribution, we obtain , and corresponding to the CNU Weeds, large PlantVillage, small PlantVillage, and PlantSeedlings datasets, respectively. This shows that the distribution of the PlantSeedlings dataset is close to uniform, while the CNU Weeds dataset is quite imbalanced.
We define a set consisting of the number of samples of each species. This set has elements, in which the element is . The notation of the maximum and minimum value in is .
Instead of training the DNN model directly on , we create a fold and train the model on this fold. Folds are established by randomly collecting samples of each species and placing them in . However, if the difference between the minimum and nth minimum value in is small, then we collect samples of each species and place them into , except we take all samples from a species containing a number of samples between and .
These perceptions lead us to come up with the MCMB procedure to divide samples into folds. First, we determine Min-Class in , which is . Then, we form a set containing elements in that are close to MC and determine Max-Bound of , which is . For all species, we take samples of species in and place them in . In practice, is determined by an excess ratio to , which is . This ratio aims to guarantee that the number of samples in the “Max-Bound” species cannot be more than 2 times greater than to avoid high imbalance distribution on .
Algorithm 1 shows the algorithm of the YMufT strategy. The folds division process proceeds until all samples are being divided. In this process, is a list containing non-divided samples, and consists of the number of samples in . The MCMB procedure is only applied on . After establishing the 1st fold, dividable samples are removed from . Additionally, all samples in species are being divided, so . In the subsequent division, we select samples for each species , except species , for which we select samples from , where is a list containing all samples in and is a set containing the number of samples in species in the original training dataset.
Generally, given the
fold division process, assume the MCMB procedure returns
We randomly select
if species
has non-divided samples or
if all samples in species
have already been divided.
Figure 8 illustrates the YMufT strategy with five species. With
, YMufT divides this data into four folds.
By applying the MCMB procedure, all samples of minority species are divided into the first few folds. We randomly re-select these samples at the next folds while choosing non-divided samples of the majority species and appending them to those folds. This action means that samples of minority species are selected more frequently, and the model may focus on learning the feature characteristics of those species, hence reducing the degree of bias toward majority species.
| Algorithm 1. Algorithm of the yielding multi-fold training (YMufT) strategy. |
| YMufT |
| input | A dataset has samples with corresponding species . : Number of species in . : An excess ratio, . |
| output | List of folds |
| Step 1 | Initialize has rows,
Initialize , .
Initialize an empty list . |
| Step 2 | Whiledo:
Initialize an empty fold
//Select the species has the smallest positive value in .
//Determine the maximum possible boundary.
//List of species that lay in the boundary.
//Select the maximum value.
For to do:
If
//Randomly select samples from .
//Delete these samples in .
Else:
//Randomly select samples from .
|
| Step 3 | Return . |
Assume a list contains folds. We have the following two definitions:
Definition 2. A training period is when the model trains all folds consecutively from the first fold to the last fold .
Definition 3. A training loop is a process in which the model trains a fold on a finite loop.
In the YMufT training strategy, we argue that training a model with
loops on
periods is not beneficial because the number of samples in each fold is much smaller than
, leading to overfitting if
is set too high. After capturing the characteristics of the samples, the model may converge quickly in later periods, leading to poor generalizability. To deal with this problem, we reduce
in later periods. We assign a finite sequence
, indicating the number of training loops
in the
training period, and ensure that
. After the completion of
training periods, the total number of times the loading samples are calculated is given by Formula (4)
where
is the number of batches and
indicates the number of samples in fold
. In the conventional training method, if we train the model on
for
epochs and the number of batches is
, the total number of times the loading samples are calculated is given by Formula (7).
To ensure that the YMufT training strategy results in faster training than conventional training methods, we solve inequality (8).
Since we can determine
and the number of epochs
used in conventional training, we only need to define the sequence
that satisfies inequality (8). If we choose this sequence as consecutive natural numbers beginning with
, inequality (8) becomes
Based on Vieta’s formulas, the left-hand side in inequality (12) has one positive solution. We select the natural number
to satisfy (8), in which
To assure the maximum possible value of
is at least 1, we need to solve inequality (14):
which means that the number of epochs in a conventional training method must be greater than or equal to the ratio between the total number of samples in
folds and the total number of samples in the training set.
5. Experiments
5.1. Performance Metrics
We applied the metrics described in [
23] to evaluate the performance of the conventional and YMufT strategies for training of a DNN model on an imbalanced dataset. Suppose the evaluation dataset
contains
images of
species. Assume
is the set of images classified as species
, then
True Positive (): The number of images in that are classified correctly.
False Positive (): The number of images in that are classified incorrectly.
False Negative (): The number of images of species that are incorrectly classified as not being .
We define the overall performance using four metrics: Accuracy, Precision, Recall, and F1 score.
In addition, we measured precision and recall on every species to estimate the behavior of minority and majority species.
5.2. Training of DNN Models
We trained the DNN models using the Keras library on an Ubuntu 16.04.5 LTS Linux server, Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz, 125 GB RAM. The graphics processing unit is a 12 GB NVIDIA TITAN V with CUDA 10.1. We selected 3 DNN models for the experiment. These models have different architectures, and capture species characteristics in different ways.
Mobilenet [
38]. This model architecture uses depthwise and pointwise convolution to learn an object’s features. There are fewer parameters in the model than in traditional convolution operators. Mobilenet is the lightest of the 3 DNN models. We used Mobilenet version 1, which has nearly 3.5 million trainable parameters.
Resnet [
39]. This is a deep residual learning model in which a shortcut connection is added between two blocks of convolutional layers, allowing information from one layer to flow directly to another layer. We used the 50-layer Resnet model that has over 24 million trainable parameters.
NASNet [
40]. This model architecture is generated by using Neural Architecture Search to build a network from the ImageNet dataset. We used the mobile version of NASNet, which has over 4.5 million trainable parameters.
We applied transfer learning, and used parameters trained on the ImageNet dataset as the initial parameters to train the model. We fine-tuned all three models by adding a fully connected layer of length 256, batch normalization, ReLU, and a Softmax layer. The input RGB image for the three models was
, normalized to the range
. Stochastic Gradient Descent was used as the optimization method with a learning rate of 0.001. We applied these model configurations on both strategies to enable a fair comparison between the conventional and YMufT strategies, except that the batch size varied depending on the model and dataset.
Table 1 show the batch sizes for each model and dataset, which were applied for both training approaches.
We evaluated model performance on two small datasets (small PlantVillage and PlantSeedlings) by applying 5-fold cross-validation and 2 data augmentation techniques, random rotation, and random zoom. We used the YMufT strategy and divided the training set into folds. Due to the small number of samples in each fold, we duplicated the images in each fold four times in PlantSeedlings and three times in the small PlantVillage dataset to avoided overfitting when training the model using those folds. On two large datasets (CNU Weeds and large PlantVillage), we randomly selected 60% of each species’ images for training, 20% for validation, and 20% for testing. We used no data augmentation techniques in the training set.
We applied a sequence of consecutive numbers
as the training loop on
periods, which required us to select a value of
that satisfied inequality (16).
Table 2 shows the total number of samples in the folds (2nd column) and the training set (3rd column) with
. The ratio in the 4th column indicates that use of
when training the model in the conventional training method guarantees that
. We trained the DNN models using the conventional training method on 50 epochs in CNU Weeds and PlantVillage, and 100 epochs on the PlantSeedlings dataset. We chose the maximum possible natural number
that satisfies inequality (16), as shown in
Table 3.
In the conventional training method, we validated the model on every epoch. In YMufT, we made every training loop through all periods. The number of times the model is validated in YMufT is calculated using expression (21).
Table 4 shows the number of validations in the conventional and YMufT strategies. As shown in this table, the YMufT strategy required more time to validate the model than the conventional training strategy, except on the PlantSeedlings dataset.
5.3. Computational Complexity
Two factors affect the processing time of both approaches: The training and validation time of the model. Assume that the model finishes training, without validation, at time
, and the time it takes to validate the model is
. We estimated the total time
for training and validation of the model using Formula (22)
where
is the number of times the model was validated. In the conventional training method,
equals the number of epochs, while in YMufT,
was calculated using Formula (21).
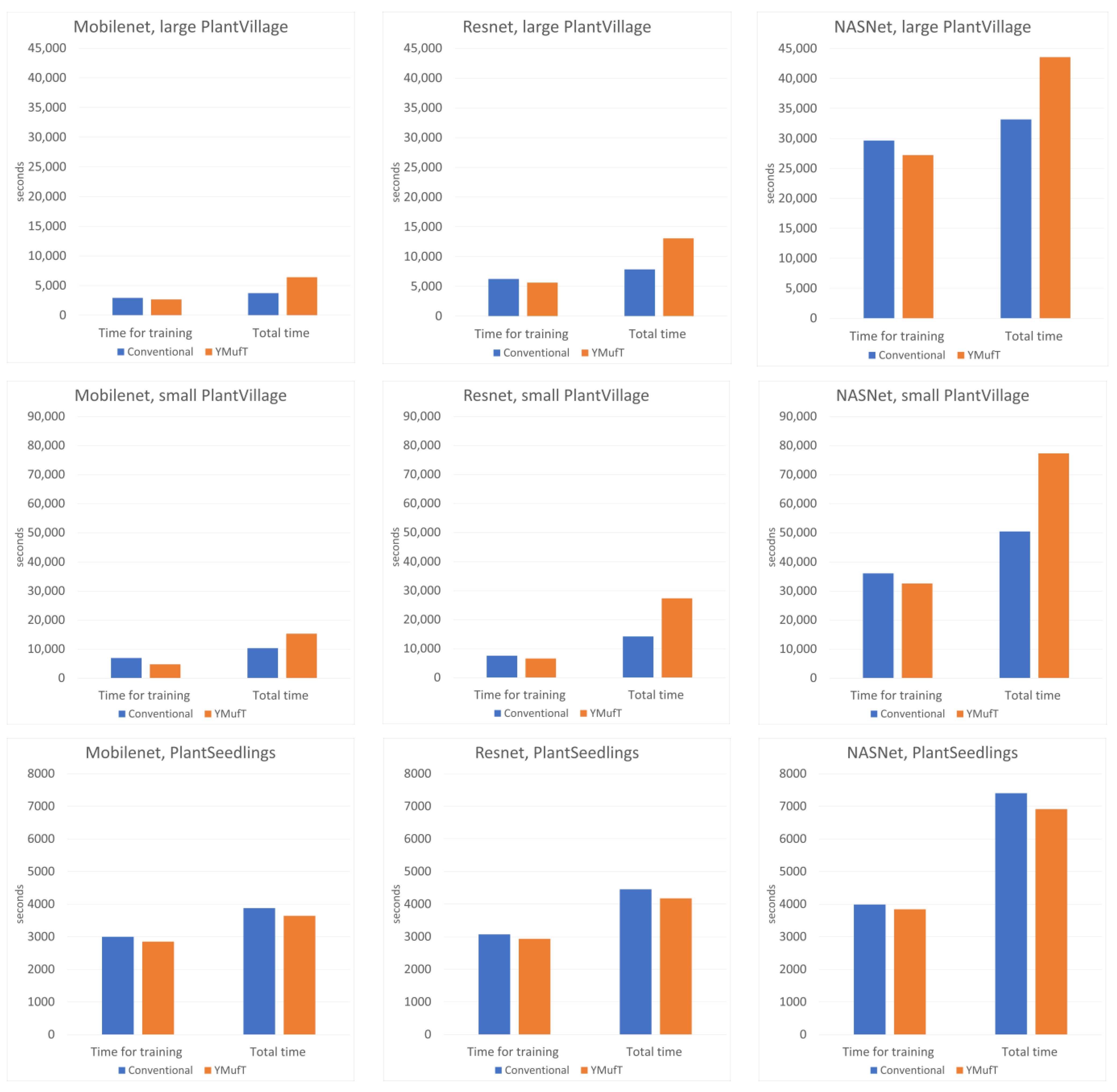
Figure 9 shows the number of times,
, the model was validated. Only Resnet on the CNU Weeds dataset ran faster than Mobilenet. On the other datasets, Mobilenet was the fastest at validating a model, followed by Resnet and NASNet.
Figure 10 compares
and
when training a model using the conventional method and YMufT strategy. In every case, YMufT required slightly less time to train a model than the conventional method. However, the increase in the number of validations meant that the YMufT strategy took more time to complete the training process, except on the PlantSeedlings dataset.
5.4. Results
5.4.1. CNU Weeds Dataset
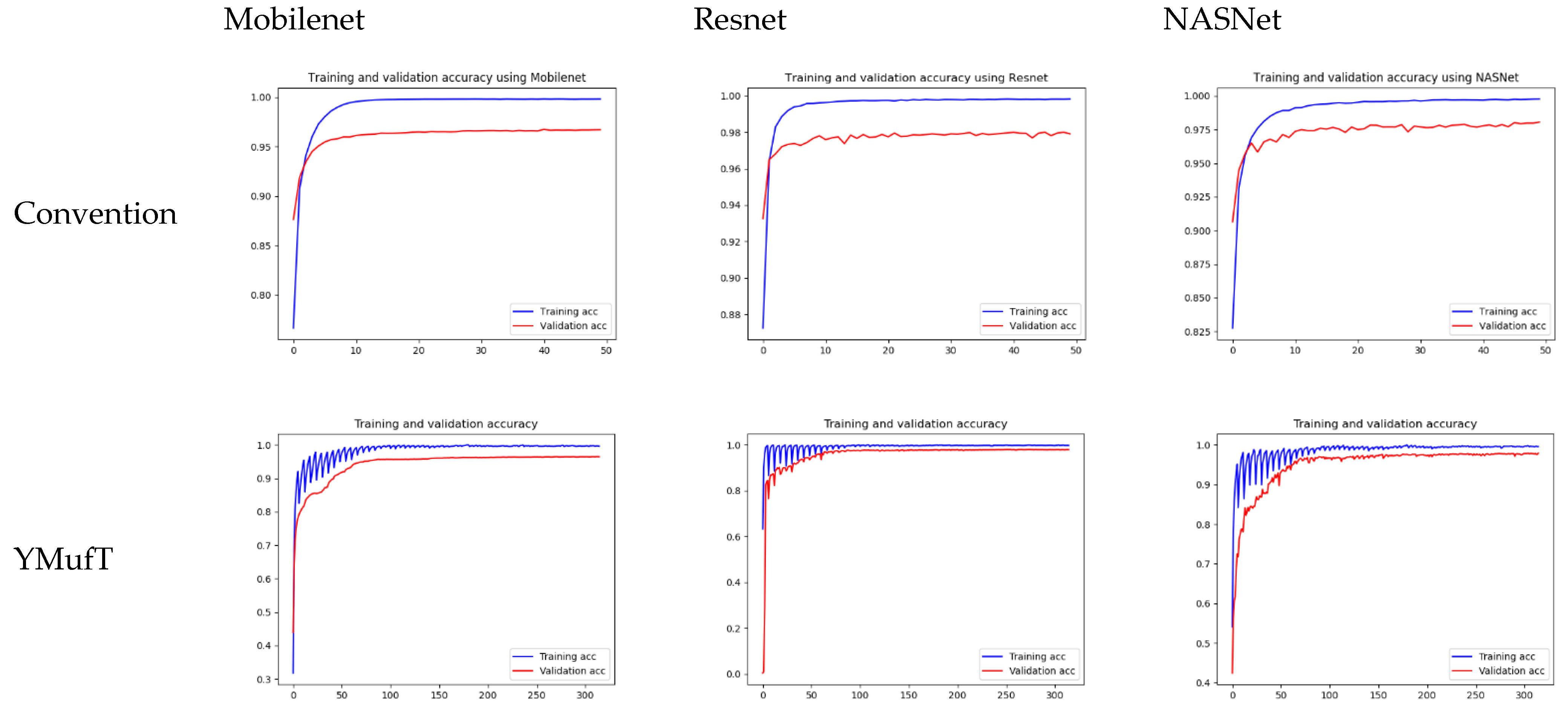
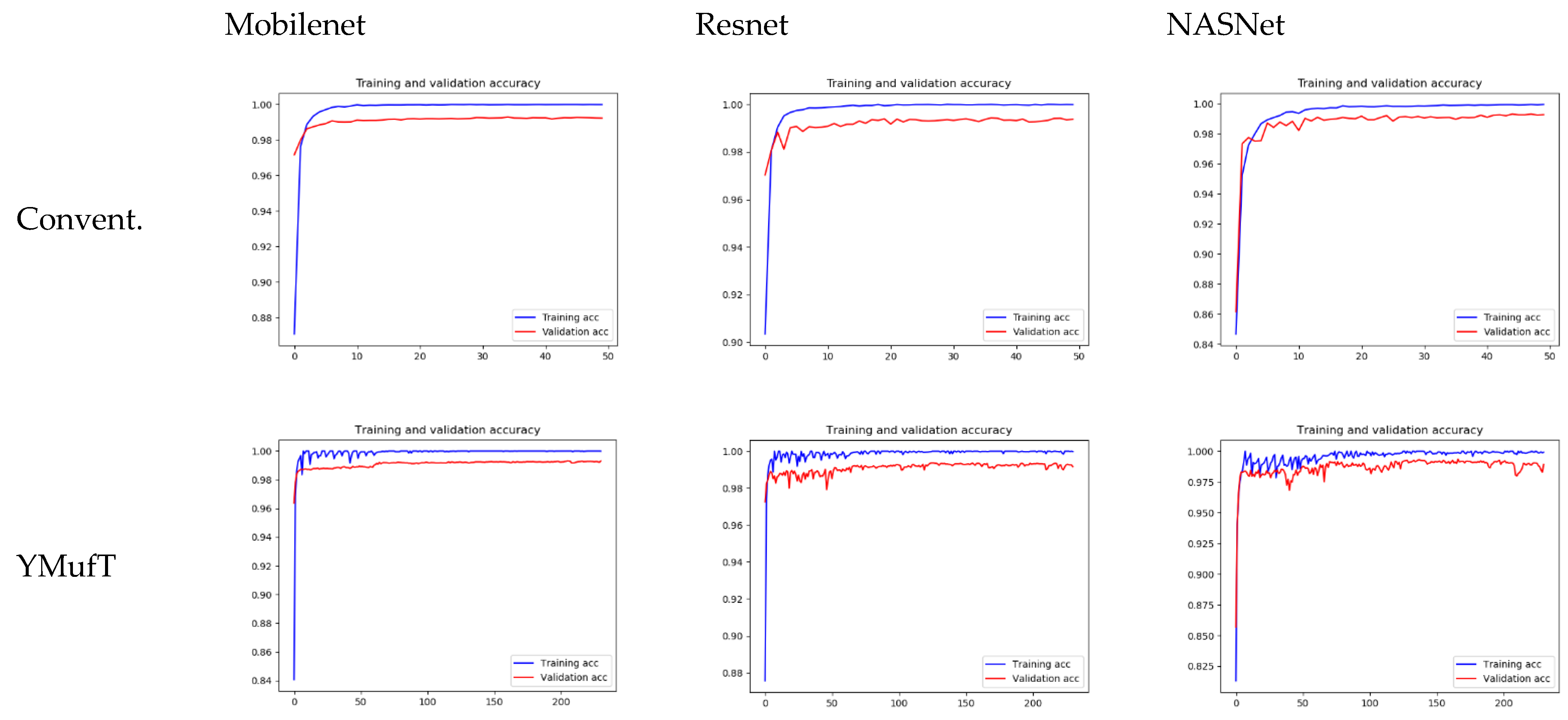
Figure 11 shows the learning curves of the 3 models trained by the conventional and YMufT strategies. In contrast to the smooth training curve of the conventional method, the training curve of YMufT had a sawtooth appearance, which reflected the transitions between folds. When the model began to converge, sawtooth marks appeared when it learned features from samples in one fold on a few training loops but then changed to a new fold with new samples. In this case, the model first showed a drop in performance but then began generalizing on the next training loop. Notice that later folds contained many species that already appeared on previous folds, which helped the model not decrease in performance to the same extent and made it easier to converge. After a few periods, the amplitude of each sawtooth was reduced and the model started to converge throughout many folds.
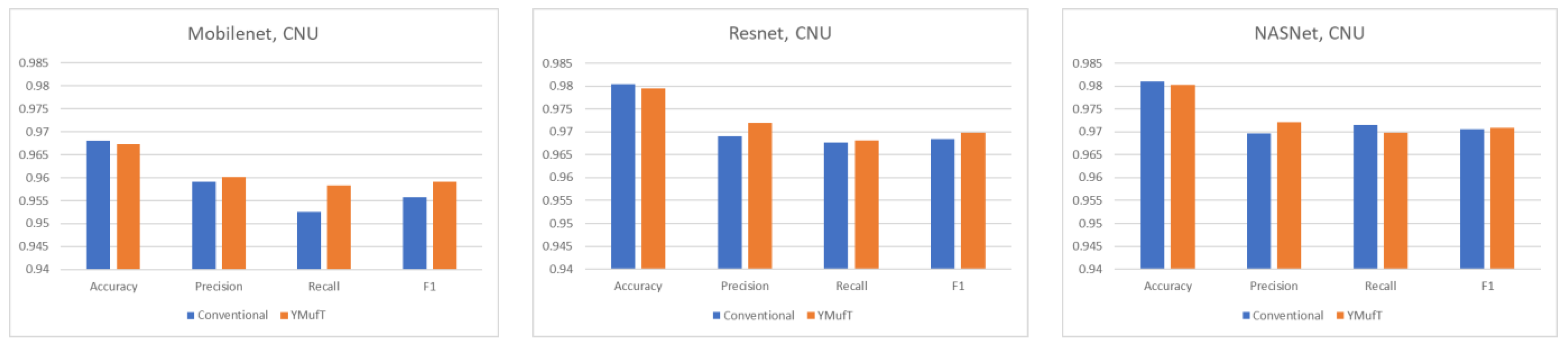
The model converged at the 10th validation in the conventional strategy; this was faster than in the YMufT strategy, which required 60 validations to converge. However, as illustrated by the overall performance scores in
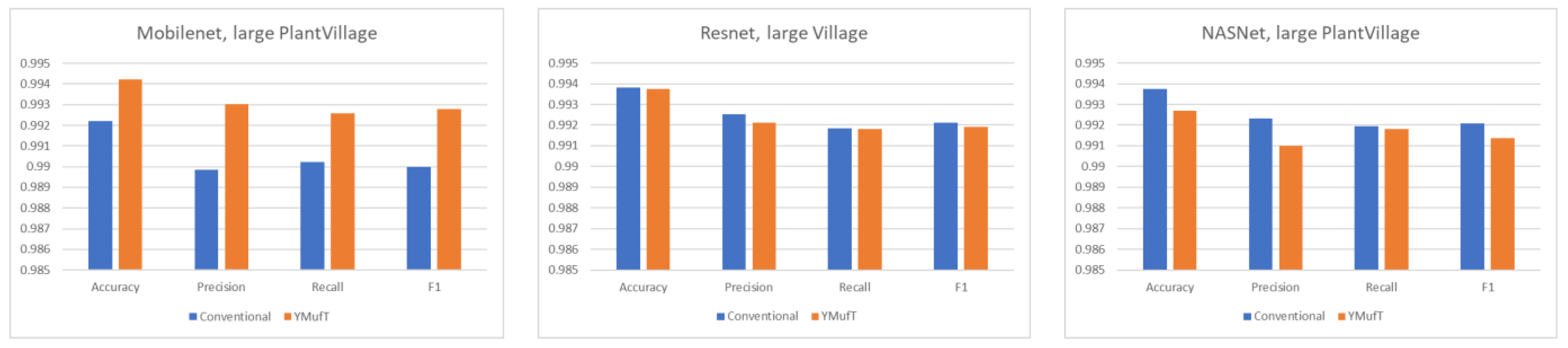
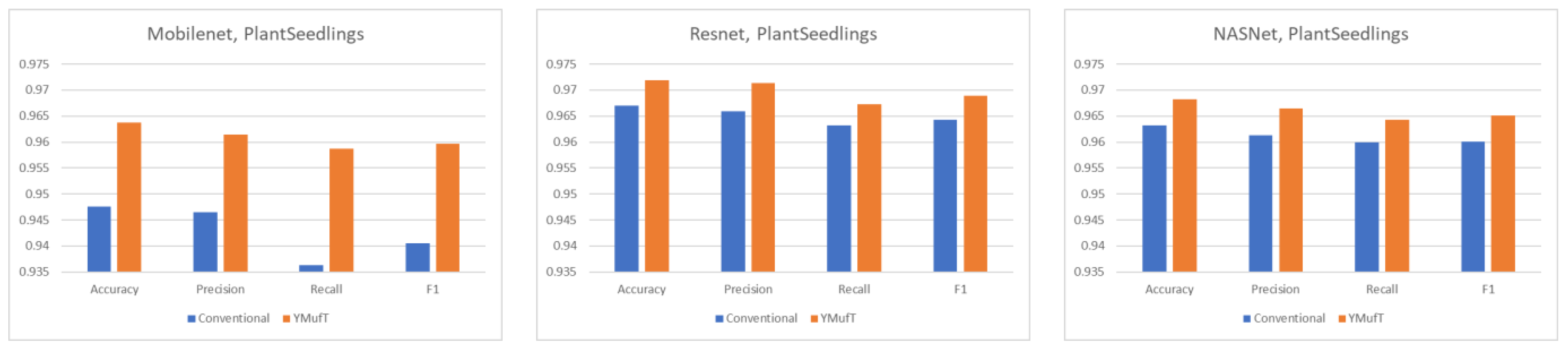
Figure 12, use of YMufT led to a higher F1 score, while the accuracy was approximately the same as that seen with conventional training.
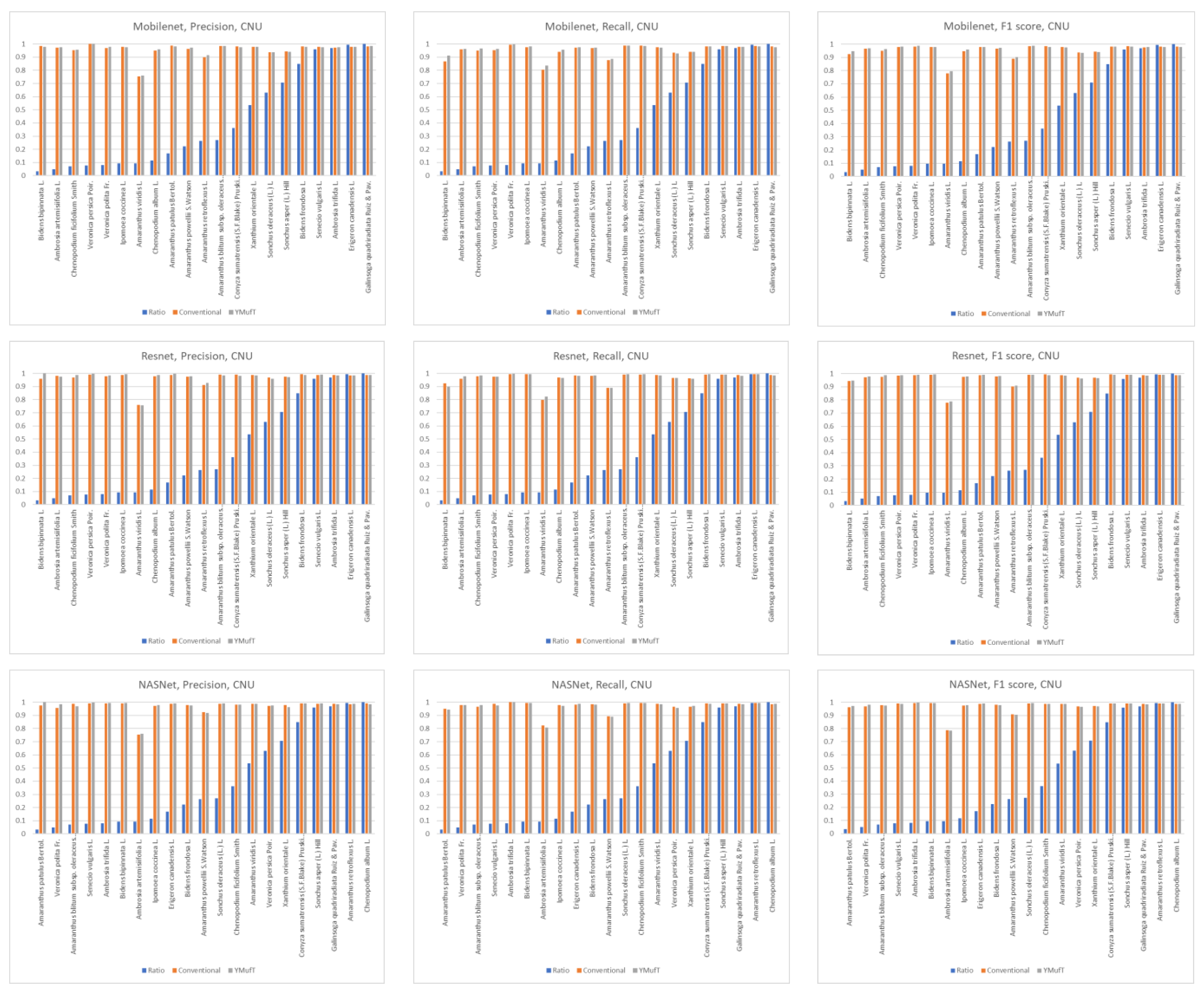
Figure 13 shows a comparison of the precision, recall, and F1 scores by species between the YMufT and conventional training strategies. In this figure, the species are arranged in ascending order, based on the ratio of the number of samples in a species to the maximum number of samples.
On Mobilenet, although YMufT did not have a clear advantage in terms of precision, it showed improved recall on minority species over the conventional training strategy while maintaining recall on majority species. Thus, the F1 score slightly increased on minority species. In Resnet, YMufT showed an advantage in terms of precision over the conventional training strategy on minority species but remained imprecise in terms of recall. Still, the F1 score of minority species was slightly better than that of the conventional training method. In NASNet, although the overall F1 score using YMufT was marginally higher than that of the conventional strategy, recall on minority species did not improve. Only precision showed a clear advantage of YMufT on minority species, which resulted in a slight improvement in F1 score on minority species.
5.4.2. Large PlantVillage
The learning curves in
Figure 14 show a shorter sawtooth than the CNU Weeds dataset because of the lack of variety in samples in the large PlantVillage dataset. In a given training fold, despite prior knowledge from the previous folds, the samples were not significantly different, which help the model converge quickly.
As with the CNU Weeds dataset, the model converged on the first few validations faster than YMufT, which needed 60 validations to converge.
Figure 15 shows the outstanding overall performance of YMufT in Mobilenet. Training Mobilenet in this dataset using the YMufT strategy resulted in an overall performance that was superior to those of Resnet and NASNet. The learning curves of the two latter models show more oscillation, illustrating the difficulty in generalizing sample characteristics in this dataset.
In
Figure 16, minority classes showed a slight improvement in precision and recall using Mobilenet trained by the YMufT strategy. This improvement led to an increase in F1 score in those classes. In contrast, YMufT showed inappreciable improvement on minority classes in terms of precision and recall, making the F1 score lower than that of the conventional training method.
5.4.3. Small PlantVillage
Figure 17 shows the learning curves of the 3 models trained on the small PlantVillage dataset. Unlike the large dataset, the validation curves of Resnet and NASNet trained using the conventional training method showed a large degree of oscillation. Specifically, Resnet was unable to converge. In contrast, the training and validation curves of the models trained using the YMufT strategy converged quickly after 20 validation times, which was faster than those of the models trained using the conventional method. The amplitudes of the sawtooth markings were also smaller than those on the large dataset.
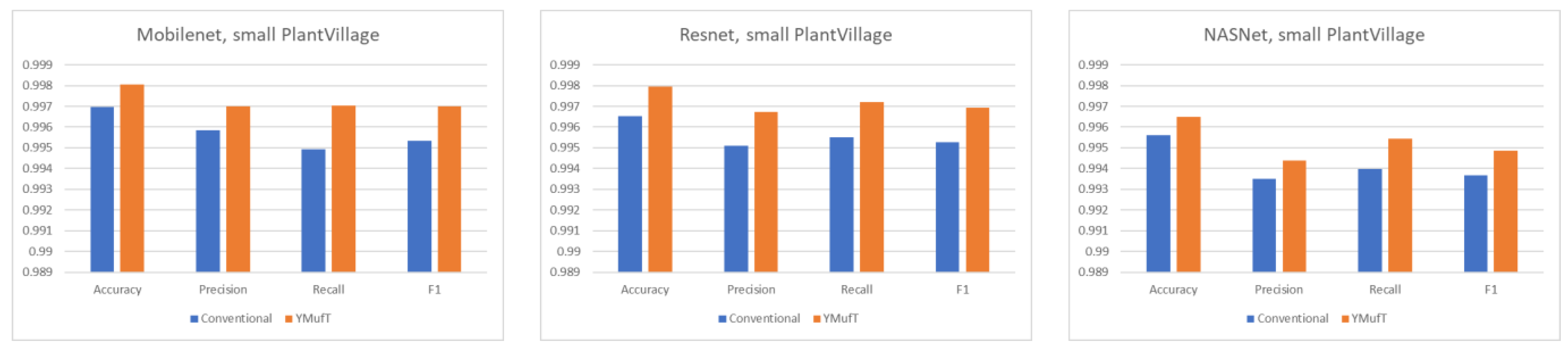
Figure 18 shows the average overall performance on 5-fold cross-validation. The performance of the model trained using YMufT was far superior to that of the model trained using the conventional training strategy. In general, Mobilenet and Resnet showed good performance on this dataset. As shown in
Figure 19, all three models showed high precision, recall, and F1 scores in most minority classes when the models were trained those models using the YMufT strategy.
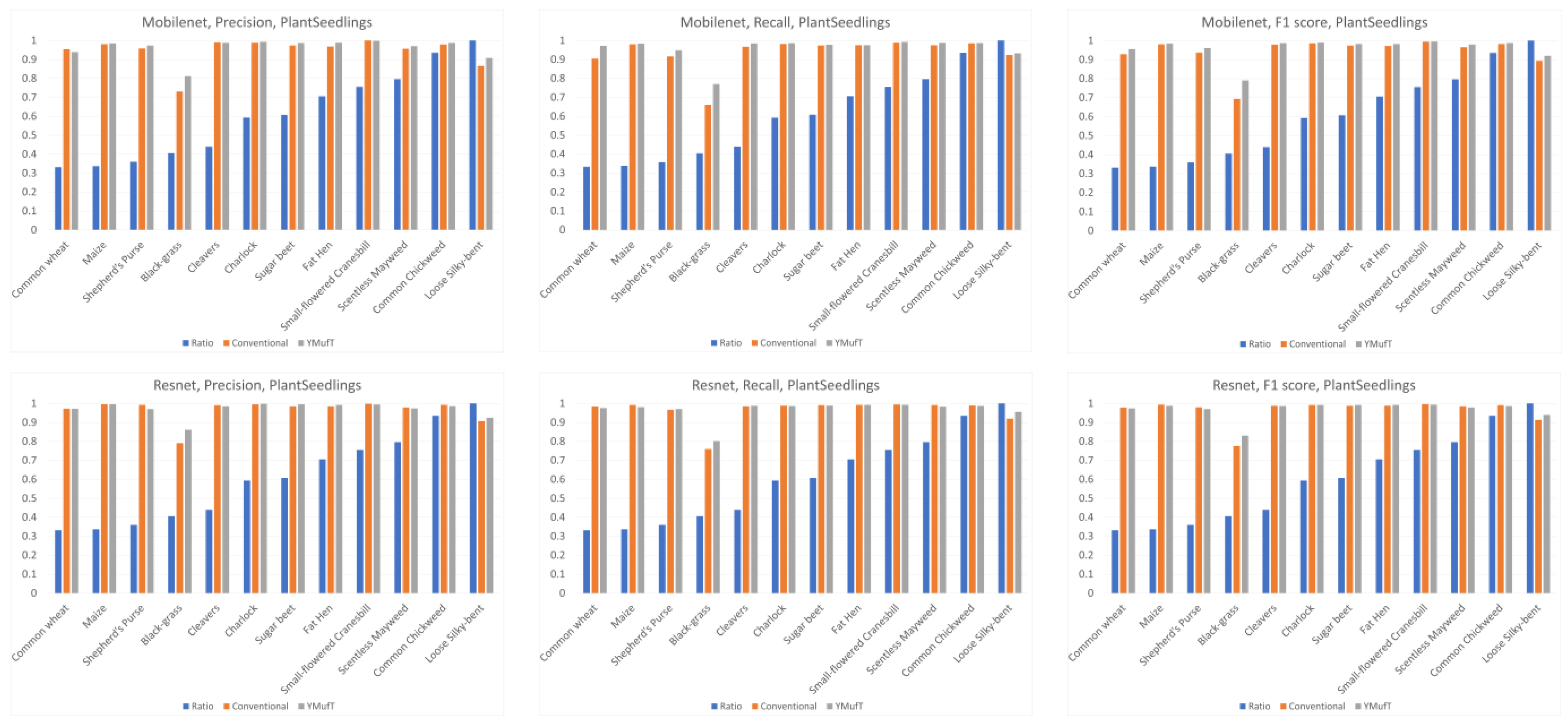
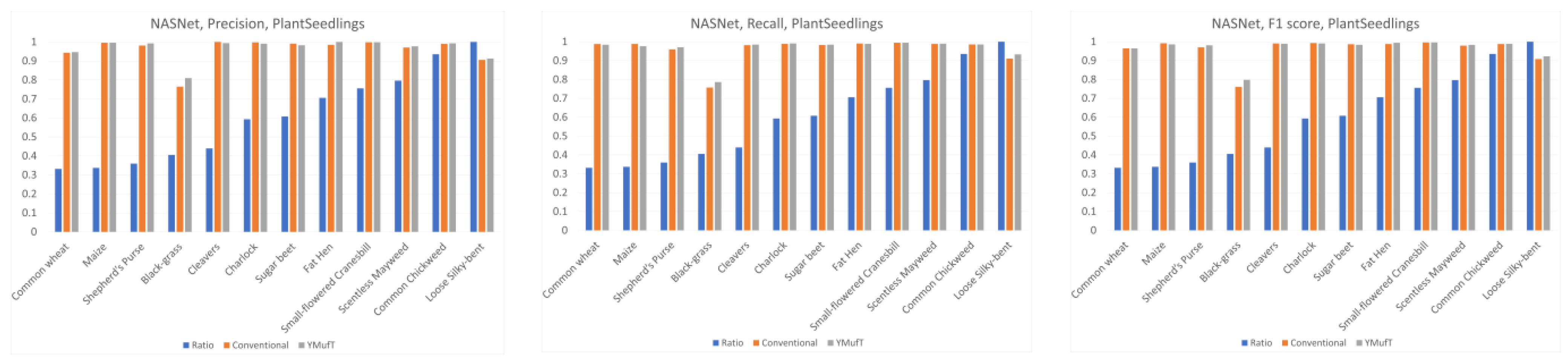
5.4.4. PlantSeedlings Dataset
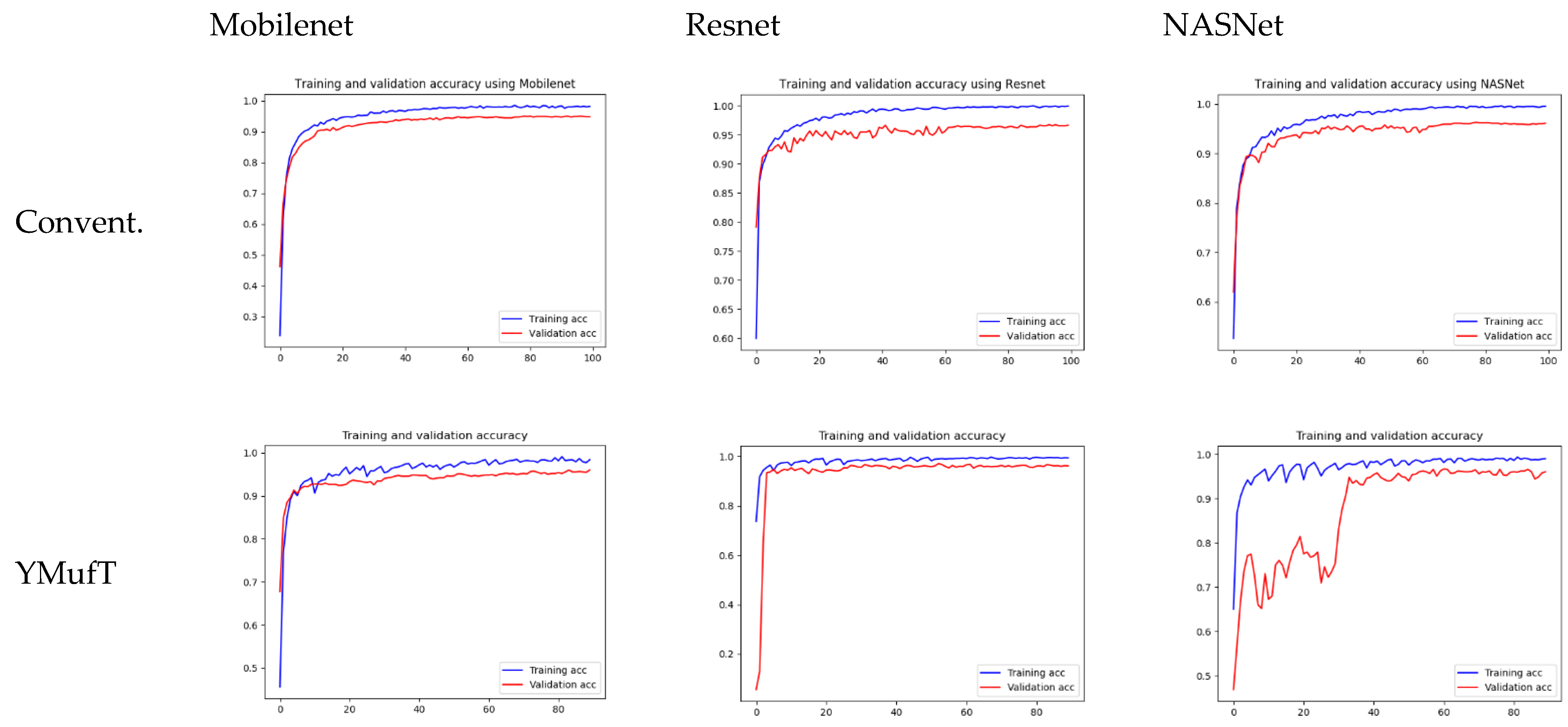
The learning curves in
Figure 20 show that both the YMufT and conventional training strategies helped the models converge quickly. In contrast, the validation curves of models trained using YMufT converged at the first few validation times, except that NASNet suffered from overfitting before the 30th validation, then quickly converged later. Like on the small PlantVillage dataset, in
Figure 21, YMufT was better than the conventional training method in terms of accuracy, precision, recall, and F1 score. In
Figure 22, in most cases, use of YMufT served to increase precision, recall, and F1 score in both minority and majority species.
5.5. Analysis
Generally, on large datasets (CNU Weeds and large PlantVillage), training a model using the YMufT strategy rather than the conventional training method made the validation slower to converge. Still, the overall F1 score and the score on minor species improved, while the F1 score was maintained on major species. Of the three models, NASNet achieved the best performance on the CNU Weeds dataset, while Mobilenet was the optimal solution on the large PlantVillage dataset.
On small datasets (small PlantVillage and PlantSeedlings), the models trained using the YMufT strategy were faster to converge on validation than those trained using the conventional training method. Furthermore, using the YMufT strategy, the overall performance of the models and the performance on minor species were significantly improved in comparison to the performance of the models trained using the conventional training method. Mobilenet and Resnet were the optimal models on the small PlantVillage dataset, and Resnet achieved the highest performance on the PlantSeedlings dataset.
Table 5 compares the YMufT strategy to other methods. On the CNU Weeds dataset, the NASNet model trained using the YMufT strategy showed slightly lower performance than the other 2 DNN models. On the large PlantVillage dataset, Mobilenet trained using YMufT was the optimal solution. On the two small datasets, DNN models trained using YMufT were superior to other methods. The optimal models on the small PlantVillage dataset were Mobilenet and Resnet. Resnet was also the optimal model on the PlantSeedlings dataset.
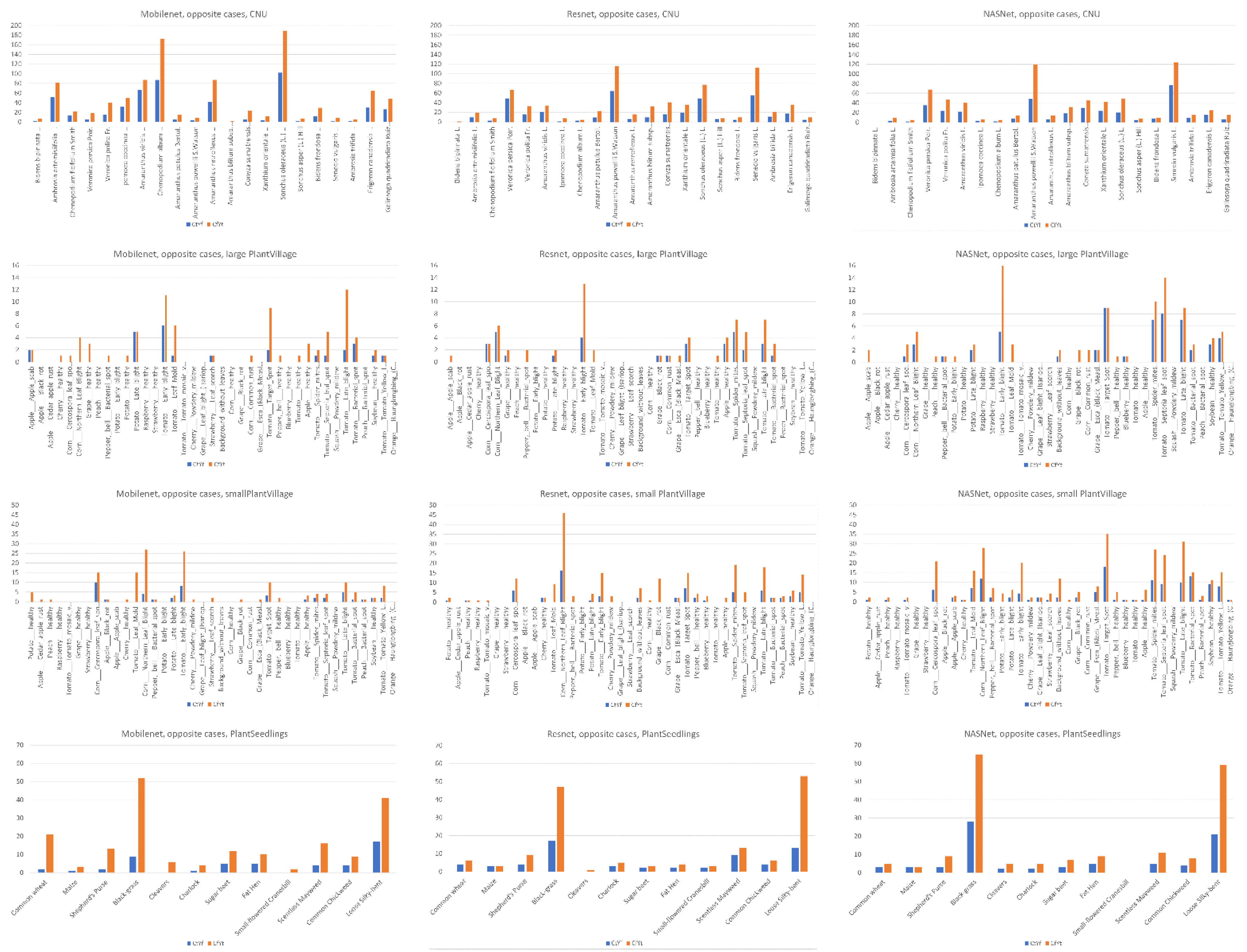
Figure 23 compares the number of images that were correctly classified using the conventional training method but incorrectly classified using YMufT (CtYf) and vice versa (CfYt). In all cases, use of YMufT effectively enhanced the models’ ability to classify images in both minor and major species.
To further explore the effectiveness of YMufT, we applied Grad-CAM [
41] to visualize the behavior of the models trained by the conventional method and YMufT strategy.
Figure 24 shows examples of images that were incorrectly predicted by the models trained with the conventional method but correctly classified by those trained using YMufT. On the CNU Weeds dataset, YMufT helped the models focus on the leaf surface, while conventional training was more focused on high-level features. Specifically, for the species
Veronica persica Poir. and
Amaranthus powellii S.Watson, conventional training focused on the lower curve position, while YMufT concentrated on leaf veins and leaf blades. A similar phenomenon also occurred on
Ambrosia artemisiifolia L.,
Ipomoea coccinea L., and
Chenopodium album L. species. The only image from
Chenopodium ficifolium Smith contains overlapping leaves, so the YMufT strategy guided the model to localized areas around leaf centroids, while the conventional training method focused on a lower region. Similar things happened on the large PlantVillage dataset, such as for images of Cherry___healthy, Tomato___Late_blight, Tomato___Bacterial_spot, Apple___Apple_scab, and Potato___Early_blight. For one image of Pepper,_bell___Bacterial_spot, both methods focused on the leaf surface, but the YMufT strategy mainly concentrated on the petiole region. Generally, on large datasets, YMufT helped the model focus on the leaf surface to capture essential low-level features. In contrast, the conventional training method focused on high-level features such as leaf curves, which may not be significant in terms of species characteristics.
In contrast, both the conventional training and YMufT strategies concentrated on the surfaces in images in the small PlantVillage dataset. Still, the heatmap color shown in Potato___healthy, Apple___Cedar_apple_rust, and Tomato___Leaf_Mold indicated that YMufT made the model pay more attention to the local area in the surface and reduced its attention to patterns in the background. Other images show that the two methods displayed different feature localization behavior. The conventional training method focused on the wide region in the middle of the leaf in Corn___ Cercospora_leaf_spot Gray_leaf_spot, but the YMufT strategy looked at micro-characteristics towards the top. In Corn___Northern_Leaf_Blight, the small region near the middle was not sufficient to classify this image, so YMufT extended the region towards both sides to collect additional essential features. Consider Potato___Late_blight image: although both methods focused on the left half of the image, the conventional method mainly focused on the upper and lower curve, while YMufT considered the inner region to capture essential features. In the PlantSeedlings dataset, low-quality images, as well as the small shapes of parts of the weeds, meant that the model trained by the conventional method suffered from difficulty in localizing the target weeds. This was true for images of maize, black-grass, charlock, and sugar beet. However, the YMufT strategy guided the model so that it localized the target properly, which increased the model’s performance. Examples include images of common wheat and cleavers.
6. Conclusions
In this work, we presented YMufT, a strategy for training DNN models on imbalanced datasets. Given an imbalanced dataset, YMufT divides the training set into multiple folds, and the model trains these folds consecutively. We proposed an MCMB procedure to divide samples from the training set into folds such that the model is trained on minority species more often than majority species, thus reducing the bias toward majority species. We developed a formula to determine the numbers of training loops and training periods. The number of times training samples are loaded in the YMufT strategy is smaller or approximately the same as that for the conventional training method. We used a sequence of decreasing consecutive natural numbers, starting with the number of the training period, as the number of training loops.
We experimented with our strategy on two large datasets (CNU and large PlantVillage) and two small datasets (small PlantVillage and PlantSeedlings). Without considering validation times that can be changed on purpose, on all types of weeds datasets, training of the model using the YMufT strategy was faster than training using the conventional training method. Despite a slight reduction in accuracy, YMufT produced an increase in the overall F1 score and the F1 score on minor species on the in-the-wild CNU weeds dataset (a large dataset). The F1 score was 0.9708 using the NASNet model. Similar results were obtained on the plain large PlantVillage weeds dataset, for which Mobilenet showed the best performance in terms of both accuracy (0.9942) and F1 score (0.9928). Use of YMufT to train DNN models on small datasets results in better model performance than use of conventional training methods. Mobilenet and Resnet were the optimal solutions for the plain small PlantVillage weeds dataset, with an accuracy of 0.9981 and F1 score of 0.9970 for Mobilenet, and an accuracy of 0.9979 and F1 score of 0.9970 for Resnet. Resnet was also the best-performing model on the in-the-wild PlantSeedlings dataset, with an accuracy of 0.9718 and an F1 score of 0.9689.
We used Grad-CAM to visualize and analyze the models’ behavior on large datasets. YMufT guided the model to focus on learning essential features on the leaf surfaces, while conventional training method led the model to pay attention to high-level features such as leaf curves or leaf centroids, which might be insufficient to describe species characteristics. On the small PlantVillage weeds dataset, both approaches concentrated on the leaf surface. Still, YMufT made the model pay more attention to the local area on the surface and reduced capture of patterns in the background. On the PlantSeedlings dataset, YMufT guided the model to properly localize the weeds targets.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}