This section describes the main characteristics and properties of the selected dataset as well as the nature of the machine and deep learning techniques that were applied. Each model is briefly explained and all configurations and parameters are detailed. The employed evaluation metrics are also carefully explained so that the comparison between methods can be better understood. The objectives of our study can be described as follows:
3.1. Dataset Description
The Coburg Intrusion Detection Data Set (CIDDS-001), disclosed by Markus Ring et al. in [
8], contains about four weeks of network traffic from 5:43:57 p.m., 3 March 2017 up until 11:59:30 p.m., 18 April 2017, comprising a total of nearly 33 million flows captured from two different environments, an emulated small business environment (OpenStack) and an External Server that captured real and up-to-date traffic from the internet. The OpenStack environment includes several clients and typical servers like an E-Mail server or a Web server. The dataset contains labeled flow-based data that can be used to evaluate anomaly-based network intrusion detection systems considering normal activity as well as DoS, Brute Force, Ping Scans and Port Scan attacks. The python scripts used for traffic generation can be found in a github repository [
24].
The CIDDS-001 is a very reliable dataset for studying and evaluating network-based intrusion detection methods since it is considerably recent, comprises a considerable collection of network flows and regards several up-to-date attack types. The collection of data provided by the CIDDS-001 dataset is represented in a unidirectional Netflow format.
Table 1 provides an overview of the dataset attributes. All attributes from 1 to 12 are default Netflow features, whereas those from 13 to 16 result from the labelling process.
Regarding the
AttackType label, CIDDS-001 is a very unbalanced and realistic dataset. The majority class corresponds to benign traffic. Each of the other classes represents one of four distinct attack types that are not equally distributed over time.
Table 2 describes the attack type distribution over time.
For the OpenStack environment, only the first two weeks contain data related to attacks while the remaining weeks only contain benign behaviour. On the other hand, for the External Server, the first week does not contain any attack attempt and the remaing three weeks onyl contain instances of the DoS and Port Scan attack types.
3.2. Data Preprocessing and Sampling
In order to train the Machine Learning methods, the CIDDS-001 data first had to be preprocessed. The data were first analysed in order to detect errors, duplicated values and inconsistent data. Some abnormalities were found, such as the Flows column, with the same value for each dataset entry and the Bytes columns representation for its numerical values being 1K instead of 1000. Thereby, the Flows column was removed as well as three other columns that correspond to labels not considered in our study, Class, AttackID and AttackDescription. Only AttackType was considered because this research is focused on the evaluation of different machine- and deep-learning approaches for attack recognition and specification. Some additional transformations were also done to correct the Bytes column, such as replacing “K” for and “M” for and then converting the corresponding result to its correct numeric representation. The Date first seen feature was used to index the data in order to preserve the flow sequence.
After these operations seven categorical features and three numerical features remained. The resulting feature vector is composed of the following features: Src IP, Src Port, Dest IP, Dest Port, Proto, Flags, ToS, Duration, Bytes and Packets. Since the input value of the employed algorithms is expected to be a numerical matrix, all non-numerical features, such as
Src IP and
Dst IP, were encoded into a representative numerical form using the ordinal encoding method. Finally, every feature was normalized between 0 and 1 using min–max normalization to enhance the performance of the mentioned techniques. Min–max scales look at each feature individually according to the following equation
where
represents the scaled value of
x.
As previously stated, the dataset comprises a total of nearly 33 million flows. Due to this considerable number of flows, high hardware requirements are needed to conduct this study. In order to solve this problem and substantially decrease the required amount of memory, processing power and time, only a portion of the data were used.
Since one of the objectives of this research is to better understand the effect of temporal dependencies in intelligent attack detection and classification, a random and stratified split approach could not be used because it would not preserve the flow sequence. Hence, efforts were made to find a smaller flow interval that could be used a good representation of the dataset, with instances of every attack and similar class proportions. Thereby, only the first two weeks of OpenStack environment were considered since they contain instances of every attack type, and a sample of 2,535,456 flows between 2:18:05 p.m., 17 March 2017 and 5:42:17 p.m., 20 March 2017 was selected.
Table 3 establishes a comparison in terms of size and class proportion between the chosen sample, the first two weeks of OpenStack environment and the whole dataset.
3.3. Models
One machine learning model, Random Forest [
20], and two deep learning models, Multi-Layer Perceptron [
25] and Long-Short Term Memory [
14,
15] were employed. These state-of-the-art techniques for intrusion detection systems presented very promising results in previous research for multiple state-of-the-art datasets, namely for the CICIDS2017 [
10] and the UNSW-NB15 [
11]. In order to better understand the main differences in each technique, a brief description of their nature is provided as well as all the considered parameters and configurations.
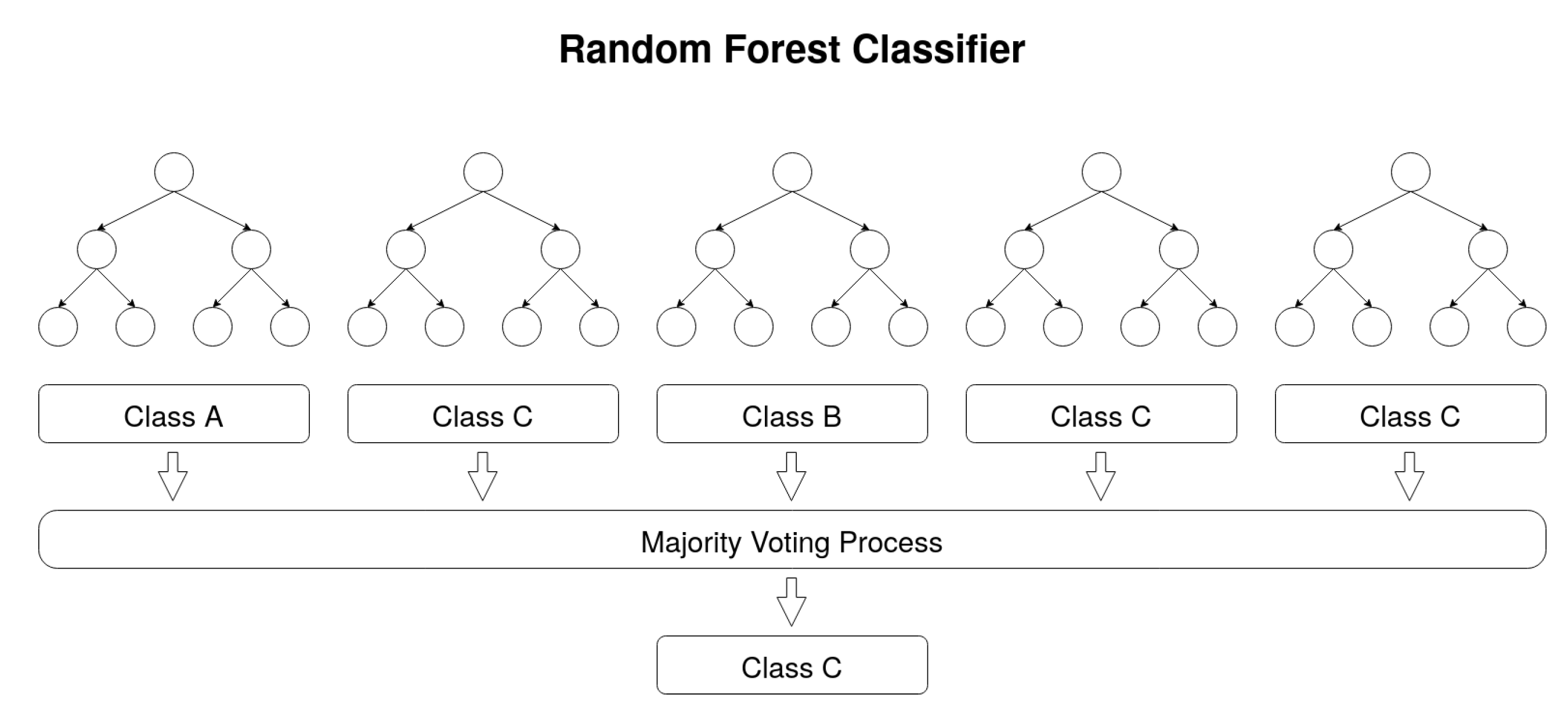
Random Forest Classifier [
26]. A Random Forest (RF) consists in a large number of Decision Trees that operate together as an ensemble. Each Decision Tree is a decision tool that works in a tree-like model of decisions and outcomes. For a given dataset entry, each tree of a Random Forest model predicts a given class and the most voted one is elected as the model’s output. The underlying theory behind Random Forests is the wisdom of crowds. In order to assure good performance, the algorithm must be trained with good representative data and the correlation between the predictions of each tree must be low [
27].
Figure 1 represents the behaviour of the classifier.
The Random Forest Classifier has multiple parameters that can be configured.
Table 4 summarizes some important parameters that were applied.
Max tree depth was set to 35 to prevent the occurrence of overfitting and to ensure generalization. Class weights were adjusted to be inversely proportional to class frequencies in the input data in order to avoid poor classification on the minority classes, since the CIDDS-001 dataset is highly unbalanced [
20]. This way, it was possible to tune the classifier to favor the minority classes over the majority classes by using weights obtained through the following equation
where
is the weight of class one,
is the number of occurrences of class one in the input data and
represents the total number of samples of the input.
The remaining values for the number of estimators, split criterion, min samples split, min samples leaf and max features were set to the default of Scikit-learn [
28] python library, since they are recognised as well established configurations for a vast majority of contexts.
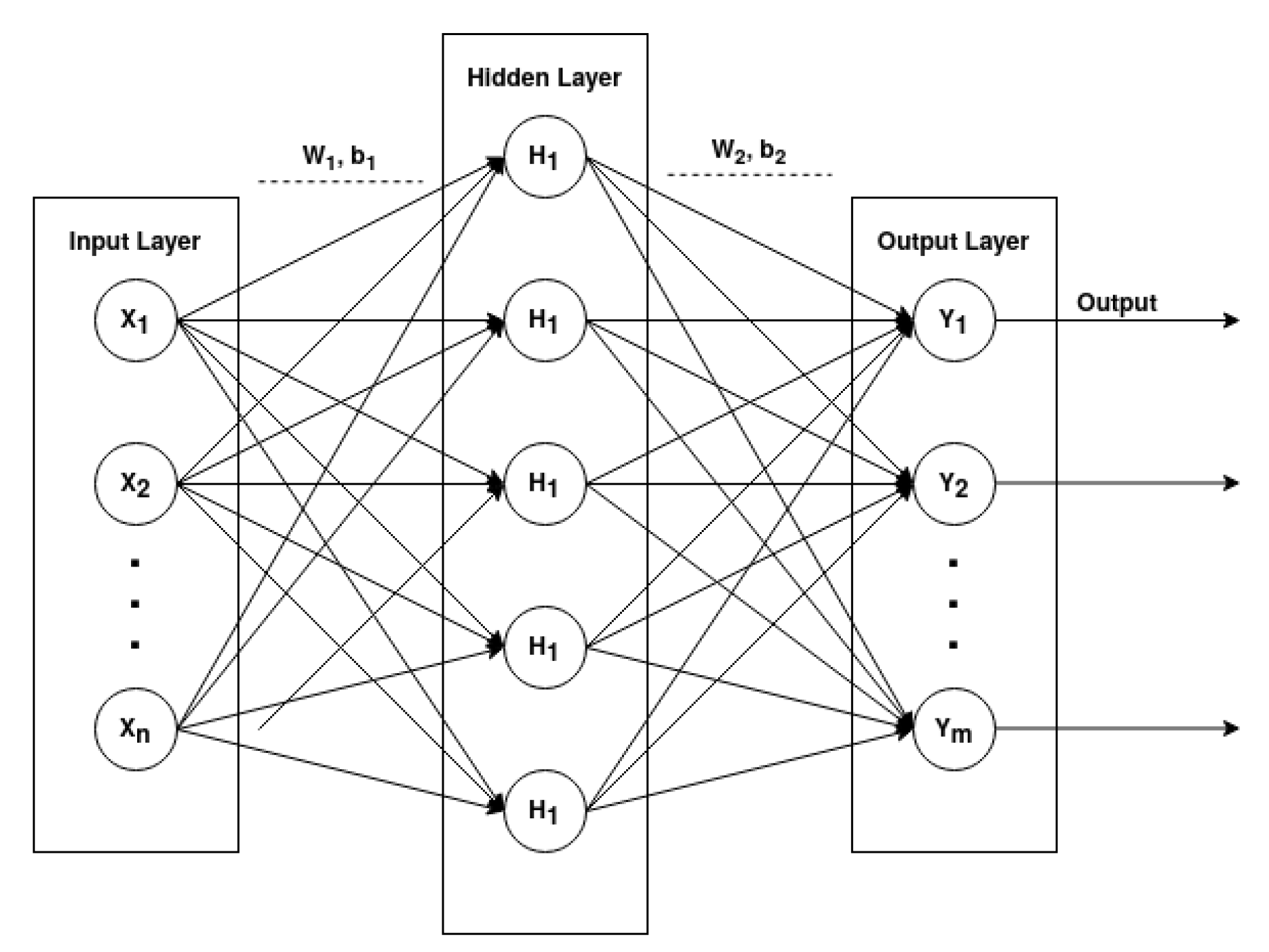
Multi-Layer Perceptron [
29]. A Multi-Layer Perceptron (MLP) is a type of Feed-Forward Network which can be represented as an acyclic graph with no feedback connections (the outputs of the model are not fed back into itself). An MLP comprises three or more layers, having one input layer, one or more hidden layers and an output layer, in which each layer has multiple neurons that can be represented in mathematical notation.
Each hidden layer
can be mathematically described by
where
is the input vector,
is the weights vector,
is the bias and
f is a non-linear activation function like
sigmoid,
hyperbolic tangent or
softmax (preferred for the output layer). These activation function are mathematically represented as
where
x defines a given input.
Figure 2 graphically represents a fully connected architecture of a MLP with one input layer, one hidden layer and one output layer.
The employed MLP consists of the four-layered architecture described in
Table 5. The input layer node number is the same as the number of considered features, 10 for single flow classification and 10 multiplied by the window size for multi-flow. The output layer node is 5, the same as the number of different categories for the
AttackType label. Two hidden layers of 100 neurons each were considered. For each layer, a Dropout probability of 0.2 was used. This method will remove some of the next layer inputs (20%) in order to reduce the probability of overfitting.
Rectified Linear Unit (
ReLU) was selected as the activation function of the hidden layers. This activation function has proven to be very computationally efficient and it was one of the main breakthroughs in the neural network history for reducing the vanishing and exploding gradient phenomenon [
30]. Its mathematical representation is
where
x defines the input.
Softmax was used for the output layer since it assigns decimal probabilities to the prediction of each class in a multi-classification problem. The sum of all probabilities adds up to one. Categorical Cross-Entropy was chosen as loss objective function and Adam was used as optimization function. The batch size was set to 1024, the epoch size to 50 and an early stopping method was employed in order to stop the training as soon as the loss value stabilized. The learning rate was set to 0.001 to avoid a quick convergence to a sub-optimal solution.
Table 6 summarizes the main configurations of the MLP model.
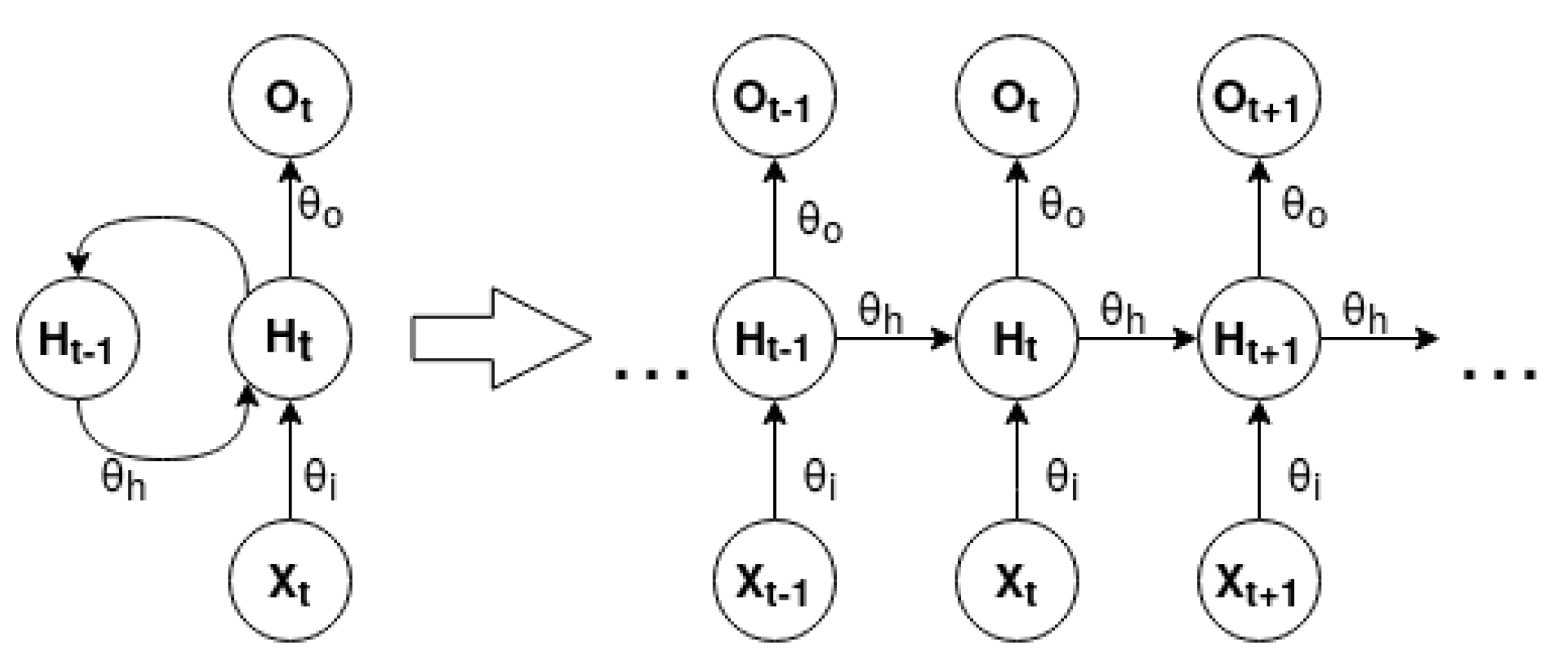
Long-Short Term Memory [
31,
32]. A Long-Short Term Memory (LSTM) is a type of Recurrent Neural Network (RNN). An RNN contains feedback connections that allow information to travel in a loop from layer to layer. These networks store information about past computations through a hidden state that represents the network memory. Therefore, the output,
, for a given input,
, at a given timestep,
t, is influenced by the inputs of its previous timesteps,
, where
n defines the total number of prior timesteps. This characteristic allows RNNs to be very suited to working with sequential data.
Figure 3 represents the unfold form of a standard
many to many RNN.
Unfold is a concept associated with RNN graphical representation. The network is expanded according to the size of its input and output sequence. RNN can be modeled for
one to one,
one to many,
many to one and
many to many problems. The difference between each of the presented problems is the distinct cardinality between the input and output of the network. An RNN can be mathematically expressed by the following equations [
33]
where
is the input,
is the output and
is the hidden state at a given timestep
t.
is the hidden state of previous timestep and
comprises the weights and biases of the network.
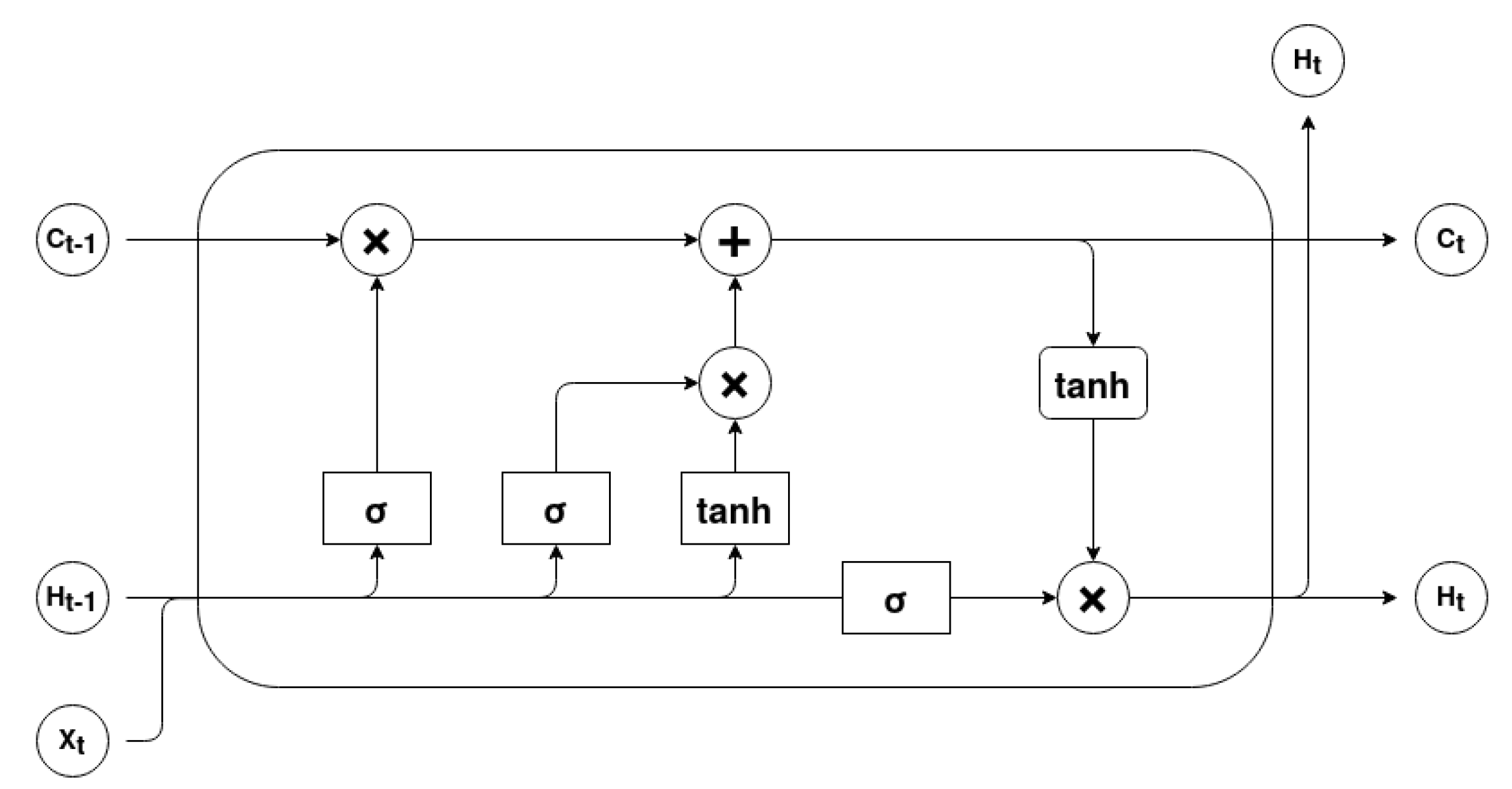
RNNs’ main issue is that they have difficulties in learning long-term relationships between the elements of the input sequence due to the vanishing and exploding gradient problem. LSTM cells were designed to overcome this problem through the use of cell memory and gating units. Therefore, an input
at a given timestep
t can change or even override the cell state. This process is carefully regulated by three gating units, the
input gate, the
forget gate and the
output gate [
34].
Figure 4 describes the basic architecture of an LSTM cell.
The
forget gate is a
sigmoid layer that outputs a result between 0 and 1 for each value of the cell state
. This results determines which information should be erased or kept. It can be mathematically represented as
The input gate determines which values should be updated and the
tanh layer creates a vector of candidate values
. The current cell state,
, results from the addition of the forget computation, obtained by the multiplication of
and
, with the scaled candidate values. This process can be represented by the following equations
The
output gate establishes the output information. The
sigmoid layer determines what cell status information will be output. The cell state
is processed by
hyperbolic tangent in order to scale its values between −1 and 1. Finally the multiplication between these outputs is the LSTM cell output value. The process can be mathematically defined as
The employed LSTM network model has one input layer of shape (1, 10), two hidden layers with 100 nodes each, and one output layer with five nodes, one for each class. Changes in the length of the flow window implies alterations in the input shape from (1, 10) to (Window Size, 10). Each hidden layer has Dropout set to 0.2 to prevent the network to overfit the training data.
Table 7 describes the employed LSTM network architecture.
The LSTM network configurations are the same as the ones configured for the MLP. Categorical Cross-Entropy remains as the loss objective function and an Adam optimizer with a default 0.001 learning rate was used. The number of epochs was set to 50 and batch size to 1024.
Table 8 summarizes the main configurations of the LSTM model.
3.4. Anomaly Detection
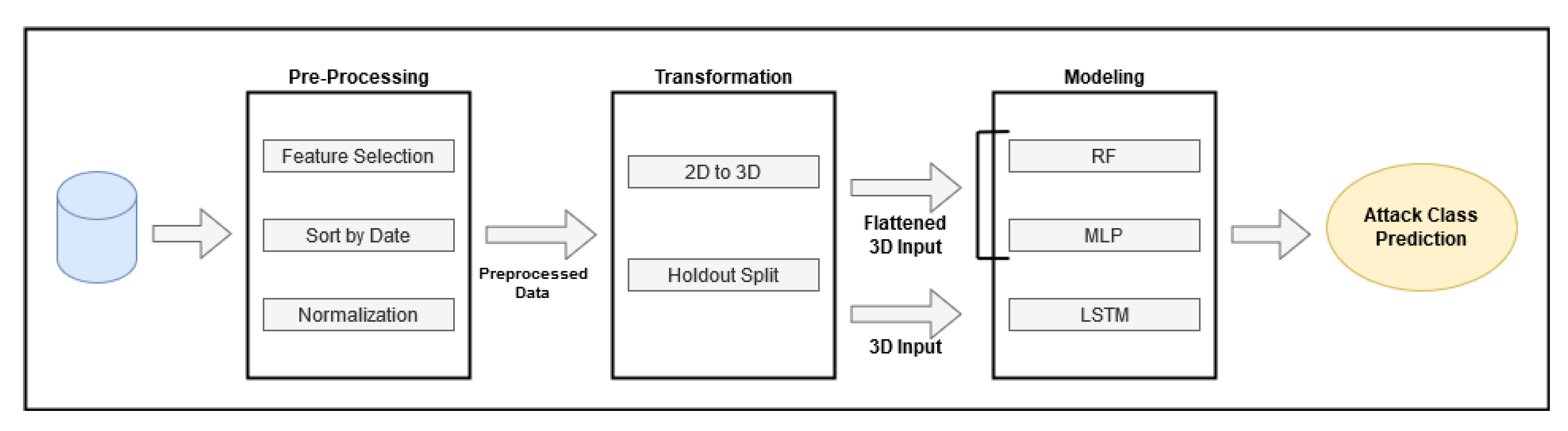
In our research, anomaly detection is addressed from two distinct viewpoints. The first viewpoint consists of finding patterns in single-flow features, while the second attempts to make a more informed analysis by considering an entire sequence of flows. For the single-flow viewpoint, each enumerated technique was trained with the preprocessed data of the CIDDS-001 dataset. RF and MLP expected a 2D matrix as input, while LSTM, which was specifically designed for sequential data, requires a 3D input.
Figure 5 exemplifies how the two dimensional CIDDS-001 preprocessed data and its corresponding 3D transformation can be visualized.
The multi-flow approach addresses the problem from a different point of view. Patterns acquired from single-flow features can be insufficient to correctly detect and differentiate anomalies. From a temporal and sequential analysis of a given window of flows, it is possible to combine individual patterns with short- to long-term relations between flows, which can potentially lead to better results. In order to conduct this analysis, data had to be reorganized and prepared to reflect the intended temporal properties. The original 2D data were reshaped to a 3D format by performing an one-to-one window overlap. For a selected window size
s, a dataset entry
can be defined as
, where
x is a given flow at a given timestep
t. Algorithm 1 describes how the introduced transformation was implemented.
| Algorithm 1 Pseudo-code for the data reshape algorithm |
- 1:
Input - 2:
D 2D matrix of original data, where } - 3:
s Window size - 4:
- 5:
Output - 6:
R 3D resulting matrix, where - 7:
- 8:
procedureTransformToSequential() ▹ Transforms D into a 3D matrix - 9:
- 10:
- 11:
for do - 12:
if i >= s then ▹ The first s rows should be removed - 13:
for do - 14:
- 15:
- 16:
end for - 17:
end if - 18:
end for - 19:
return R - 20:
end procedure
|
Suppose a given entry, , contains flows. In that case, the first s rows of the algorithm’s output matrix should be disregarded because they have invalid data due to the insufficient number of previous timesteps. For this study, the first 99 rows were removed to ensure that the algorithms are trained and tested with the same data, regardless of the selected window size (which is never higher than this value).
As previously explained, LSTM is a model designed to deal with three-dimensional data and already expects a 3D matrix as input, while RF and MLP require the conventional 2D input. To provide such an input, the sequential data were flattened into a two-dimensional space. This operation implies no distinction between the features of independent flows and that data, although containing information from previous timesteps, cannot be interpreted as a sequence. This process is represented in
Figure 6.
In conclusion, in our approach the network traffic data are first preprocessed, removing the least meaningful features, then the flows are ordered in chronological order and the resultant feature vector is transformed into a numerical representative form, as explained in
Section 3.2 Then, the preprocessed data are transformed to a three-dimensional format according to a given window size and split into train, validation and test sets. For the RF and MLP models, the 3D data are reshaped into a corresponding 2D format, and for the LSTM, the data are directly used in their 3D representation. Finally, each model produces predictions, which are evaluated by the metrics described in
Section 3.5.
Regarding the hold-out method, 70% of the total data were selected for training, while the remaining 30% were used for testing. From the training set, 10% of data were set aside for validation. The full scope of our approach is summarized in
Figure 7.
3.5. Evaluation Metrics
Several metrics, such as Accuracy, Recall, Precision and F1-Score, can be used to evaluate the performance of a given classifier [
35]. However, these metrics’ employment should not be made carelessly, particularly in intrusion detection systems, where high-class imbalance situations are relatively common. This section will briefly describe the metrics used in this research, their mathematical representation [
36], and how they can be interpreted to better understand the results obtained from applying the previously enumerated methods.
Accuracy is one of the most common metrics used in classification problems and usually gives a reliable measure of the model’s performance. It can be calculated through the following equation [
28]
where
is the number of samples of a given dataset,
is the vector of predicted values,
is the corresponding vector of true values and
I is the indicator function, which returns 1 if
matches
and 0 otherwise.
In this particular case, due to the fact that CIDDS-001 is a very unbalanced dataset, accuracy is not a good metric to use. In the selected sample, 82.53% of the flows are benign traffic. Even if the classifier fails to classify every other attack class and only predicts the benign flows correctly, it would still achieve an accuracy value of 82.53%. When working with unbalanced data, the accuracy is biased towards the majority class. To overcome this situation, other metrics were considered.
In terms of the number of true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN) reported by the confusion matrix, the macro-averaged precision can be expressed as follows
Precision measures the number of labels a model has incorrectly predicted to be positive that were actually negative. is the number of flows correctly classified as class and is the amount of flows whose true value corresponds to a given class , where that were incorrectly labeled as .
On the other hand, recall expresses the ability of a model to find relevant instances in a dataset. Macro-averaged recall can be defined as
where
stands for the number of flows of a class
that were incorrecly labeled as a class
.
F1-score is a metric that considers both precision and recall through the computation of their harmonic mean. The macro-averaged f1-score is well suited for unbalanced datasets such as CIDDS-001, and it can be mathematically described as
False Positive Rate (FPR), or Fall-Out, expresses the probability of false alarm and can be determined by the following mathematical statement
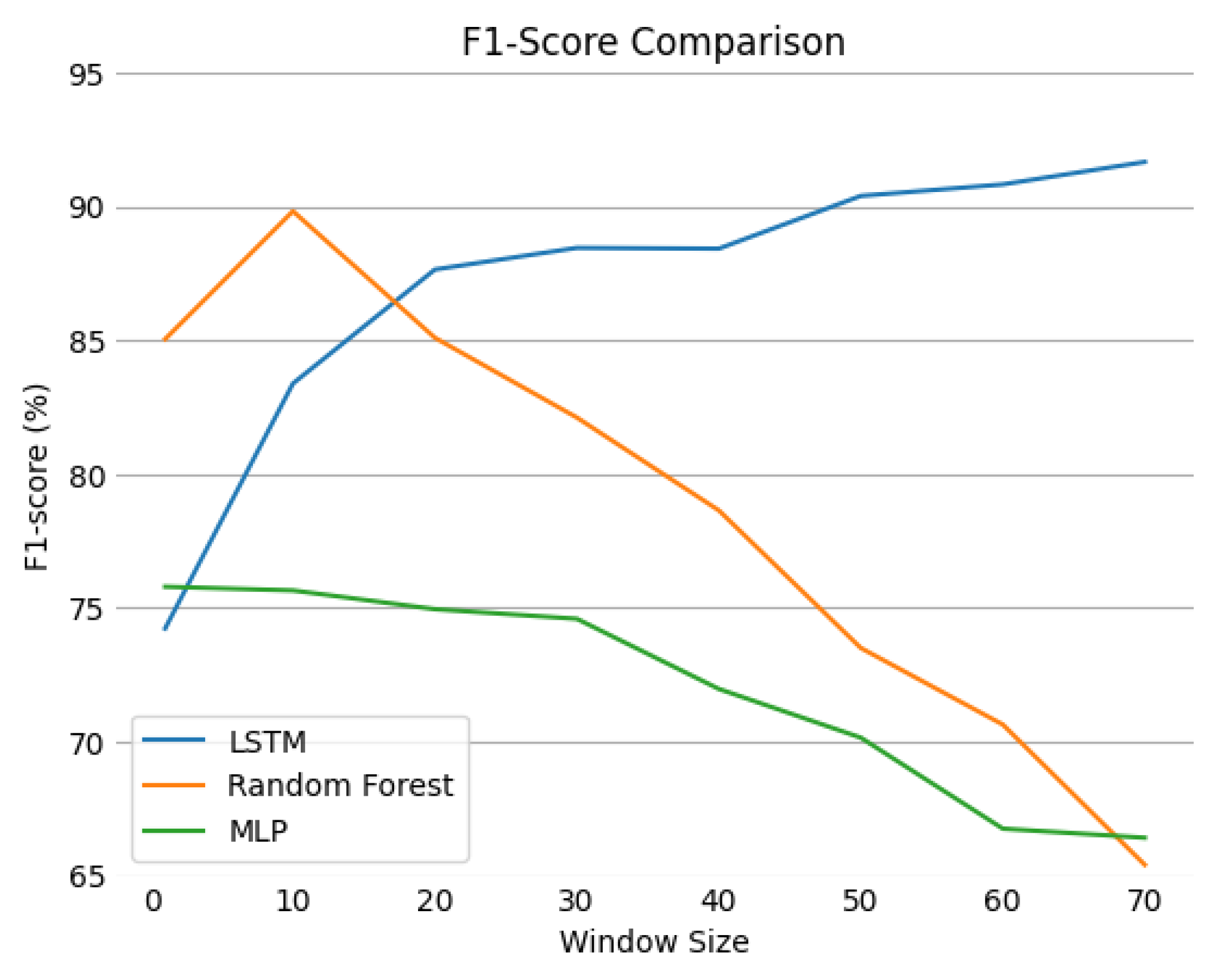
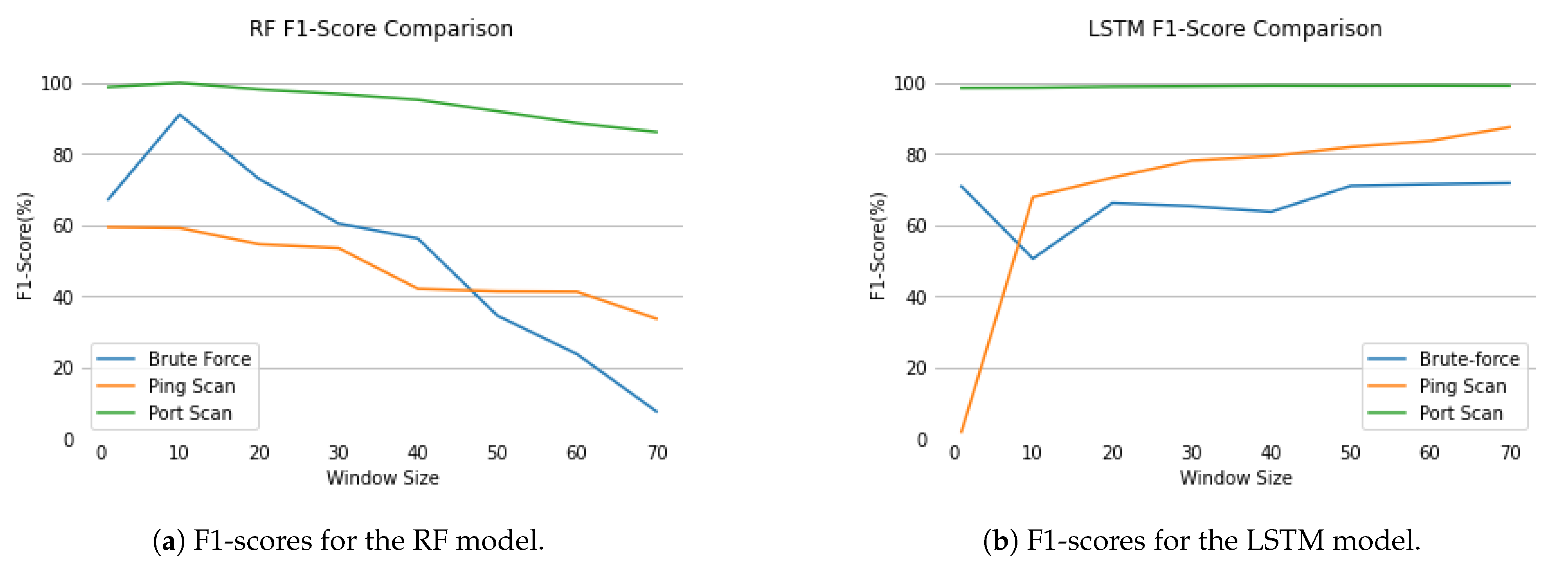
In this research, results are expressed through all the above measures. Understanding each evaluation metric and each employed model’s nature is crucial to making sense of the obtained results.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}