
Time-Multiplexed Spiking Convolutional Neural Network Based on VCSELs for Unsupervised Image Classification

 ,
, 

Abstract
1. Introduction
2. Neural Network Architecture
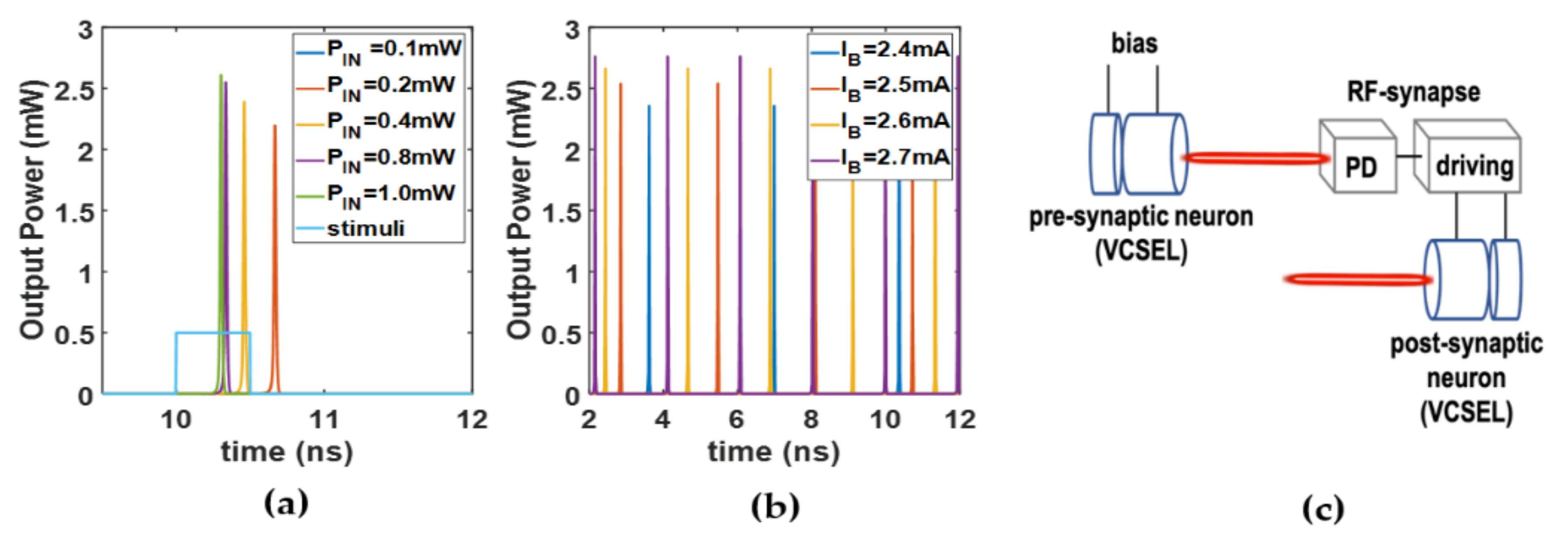
2.1. VCSEL-Neuron Modeling and Dynamic Regimes
2.2. Building Blocks of the Network
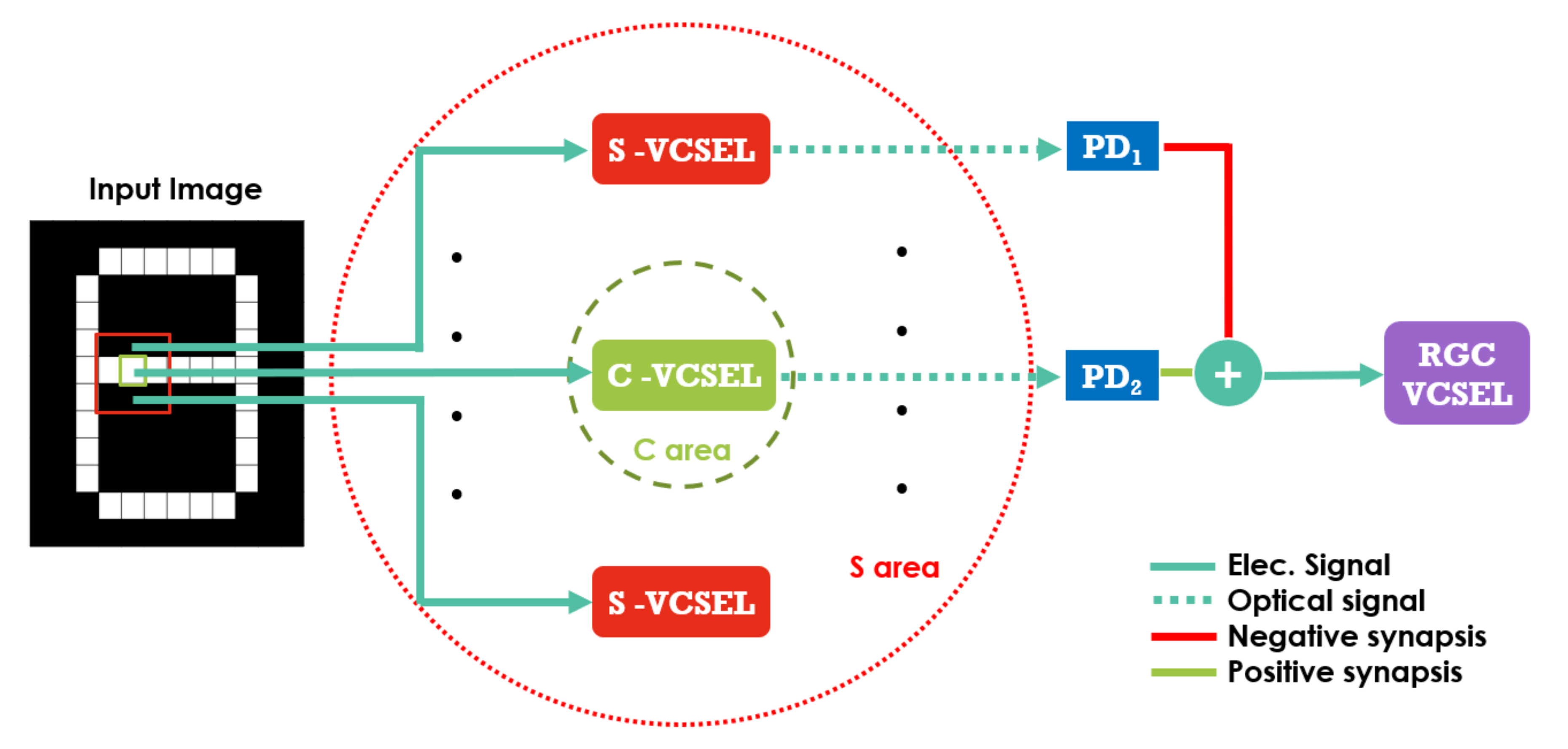
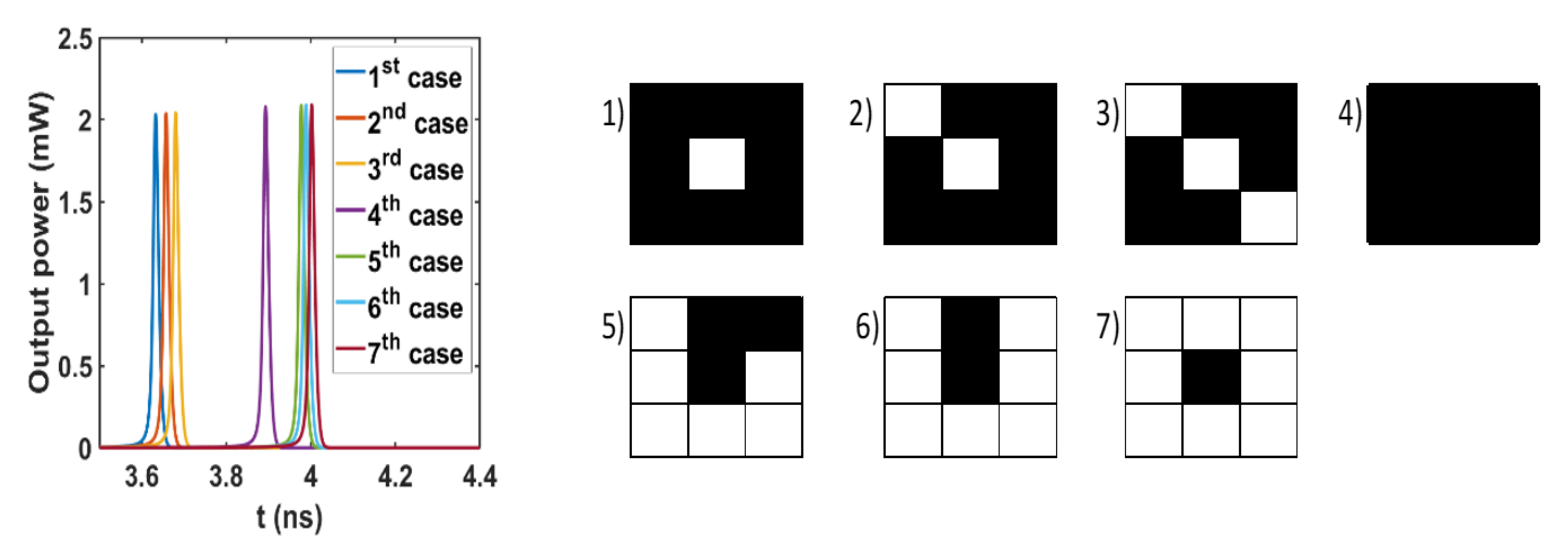
2.2.1. Contrast Detection Layer (CDL)
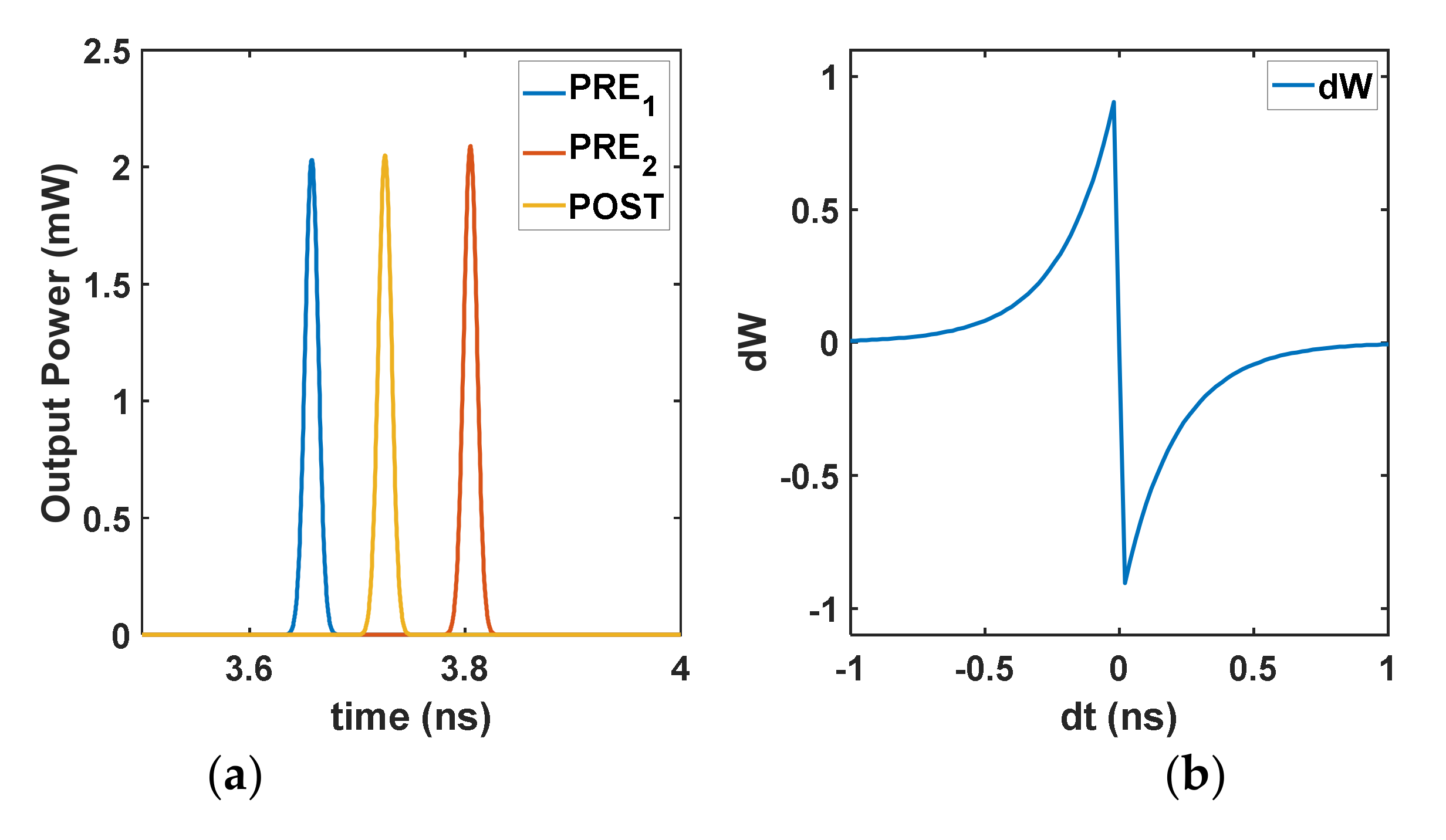
2.2.2. Synchronizing Layer
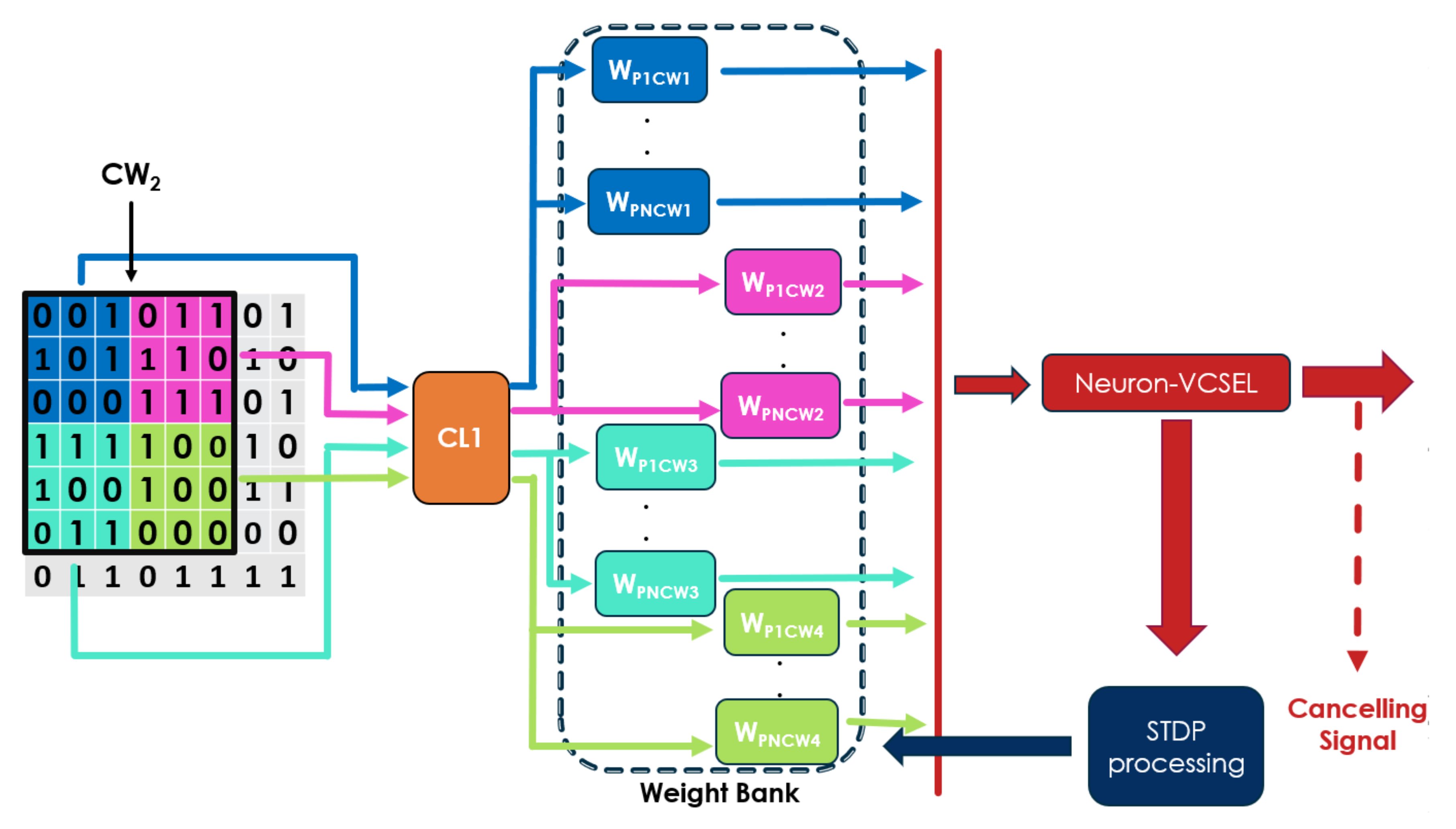
2.2.3. First Convolutional Layer (CL1)
2.2.4. Second Convolutional Layer (CL2)
2.2.5. Third Convolutional Layer (CL3)
2.2.6. Classification Layer
3. Results
3.1. Training and Interference
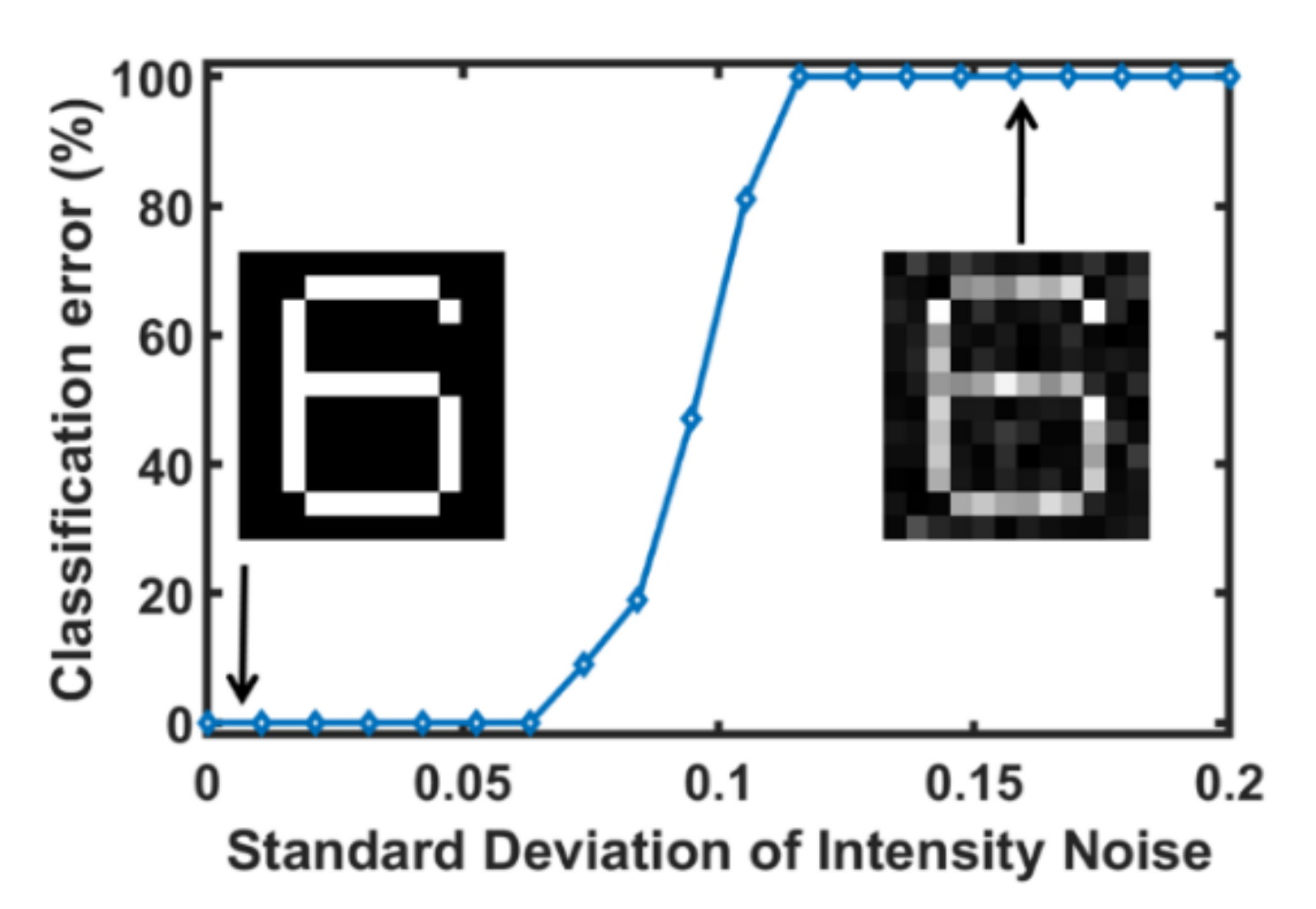
3.2. Noise Analysis
3.3. Bandwidth Limitations
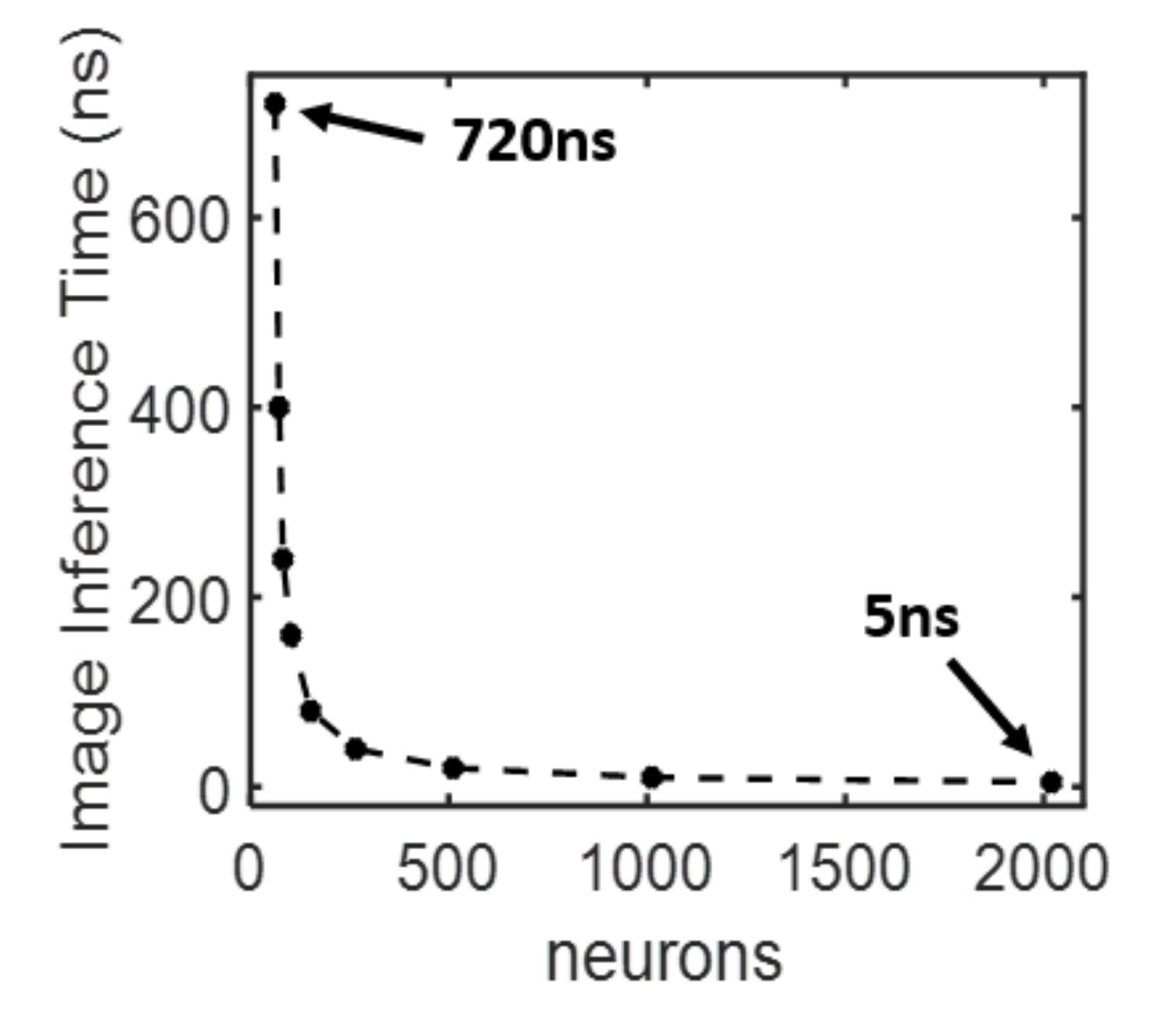
3.4. Processing Time versus Neuron Count
3.5. Comparative Study with Previous VCSEL-Based Neural Networks
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abu-Mostafa, Y.S.; Psaltis, D. Optical neural computers. Sci. Am. 1987, 256, 88–95. [Google Scholar] [CrossRef]
- Mahapatra, N.R.; Venkatrao, B. The processor-memory bottleneck: Problems and solutions. Crossroads 2008, 5, 2. [Google Scholar] [CrossRef]
- Miller, D.A.B. Device Requirements for Optical Interconnects to Silicon Chips. Proc. IEEE 2009, 97, 1166–1185. [Google Scholar] [CrossRef]
- Indiveri, G.; Liu, S.-C. Memory and information processing in neuromorphic systems. Proc. IEEE 2015, 103, 1379–1397. [Google Scholar] [CrossRef]
- Roy, K.; Jaiswal, K.; Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef]
- Mainen, Z.; Sejnowski, T. Reliability of spike timing in neocortical neurons. Science 1995, 268, 1503–1506. [Google Scholar] [CrossRef]
- Hopfield, J.J. Pattern recognition computation using action potential timing for stimulus representation. Nature 1995, 376, 33–36. [Google Scholar] [CrossRef]
- Gautrais, J.; Thorpe, S. Rate coding versus temporal order coding: A theoretical approach. Biosystems 1998, 48, 57–65. [Google Scholar] [CrossRef]
- Prucnal, P.R.; Shastri, B.J.; Ferreira, T.; Nahmias, M.A.; Tait, A.N. Recent progress in semiconductor excitable lasers for photonic spike processing. Adv. Opt. Photonics 2016, 8, 228–299. [Google Scholar] [CrossRef]
- Burd, T.D.; Brodersen, R.W. Energy efficient CMOS microprocessor design. In Proceedings of the 28th Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, 3–6 January 1995. [Google Scholar]
- Prucnal, P.R.; Shastri, B.J. Neuromorphic Photonics; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Caulfield, H.J.; Dolev, S. Why future supercomputing requires optics. Nat. Photonics 2010, 4, 261–263. [Google Scholar] [CrossRef]
- Shastri, B.J.; Nahmias, M.A.; Tait, A.N.; Rodriguez, A.W.; Wu, B.; Prucnal, P.R. Spike processing with a graphene excitable laser. Sci. Rep. 2016, 6, 19126–19138. [Google Scholar] [CrossRef] [PubMed]
- Coomans, W.; Gelens, L.; Beri, S.; Danckaert, J.; Sande, G.V. Solitary and coupled semiconductor ring lasers as optical spiking neurons. Phys. Rev. 2011, 84, 36209. [Google Scholar] [CrossRef] [PubMed]
- Van Vaerenbergh, T.; Fiers, M.; Mechet, P.; Spuesens, T.; Kumar, R.; Morthier, G.; Schrauwen, B.; Dambre, J.; Bienstman, P. Cascadable excitability in microrings. Opt. Express 2012, 20, 20292–20308. [Google Scholar] [CrossRef] [PubMed]
- Koen, A.; van Vaerenbergh, T.; Fiers, M.; Mechet, P.; Dambre, J.; Bienstman, P. Excitability in optically injected microdisk lasers with phase controlled excitatory and inhibitory response. Opt. Express 2013, 21, 26182–26191. [Google Scholar] [CrossRef]
- Sarantoglou, G.; Skontranis, M.; Mesaritakis, C. All Optical Integrate and Fire Neuromorphic Node Based on Single Section Quantum Dot Laser. IEEE J. Sel. Top. Quantum Electron. 2019, 26, 1900310. [Google Scholar] [CrossRef]
- Goulding, D.; Hegarty, S.P.; Rasskazov, O.; Melnik, S. Excitability in a quantum dot semiconductor laser with optical injection. Phys. Rev. 2007, 98, 4–7. [Google Scholar] [CrossRef] [PubMed]
- Yacomotti, A.M.; Monnier, P.; Raineri, F.; Bakir, B.B.; Seassal, C.; Raj, R.; Levenson, J.A. Fast thermo-optical excitability in a two-dimensional photonic crystal. Phys. Rev. 2006, 97, 143904. [Google Scholar] [CrossRef]
- Brunstein, M.; Yacomotti, A.M.; Sagnes, I.; Raineri, F.; Bigot, L.; Levenson, A. Excitability and self-pulsing in a photonic crystal nanocavity. Phys. Rev. 2012, 85, 31803. [Google Scholar] [CrossRef]
- Garbin, B.; Goulding, D.; Hegarty, S.P.; Huyet, G.; Kelleher, B.; Barland, S. Incoherent optical triggering of excitable pulses in an injection-locked semiconductor laser. Opt. Lett. 2014, 39, 1254–1257. [Google Scholar] [CrossRef]
- Garbin, B.; Javaloyes, J.; Tissoni, G.; Barland, S. Topological solitons as addressable phase bits in a driven laser. Nat. Commun. 2015, 6, 5915. [Google Scholar] [CrossRef]
- Aragoneses, A.; Perrone, S.; Sorrentino, T.; Torrent, M.C.; Masoller, C. Unveiling the complex organization of recurrent patterns in spiking dynamical systems. Sci. Rep. 2014, 4, 4696–4712. [Google Scholar] [CrossRef] [PubMed]
- Giudici, M.; Green, C.; Giacomelli, G.; Nespolo, U.; Tredicce, J.R. Andronov bifurcation and excitability in semiconductor lasers with optical feedback. Phys. Rev. 1997, 55, 6414–6418. [Google Scholar] [CrossRef]
- Hurtado, A.; Javaloyes, J. Controllable spiking patterns in long-wavelength vertical cavity surface emitting lasers for neuromorphic photonics systems. Appl. Phys. 2015, 107, 241103. [Google Scholar] [CrossRef]
- Hurtado, A.; Schires, K.; Henning, I.D.; Adams, M.J. Investigation of vertical cavity surface emitting laser dynamics for neuromorphic photonic systems. Appl. Phys. Lett. 2012, 100, 103703. [Google Scholar] [CrossRef]
- Nahmias, M.A.; Shastri, B.J.; Tait, A.N.; Prucnal, P.R. A leaky integrate-and-fire laser neuron for ultrafast cognitive computing. IEEE J. Sel. Top.Quantum Electron. 2013, 19, 1800212. [Google Scholar] [CrossRef]
- Hurtado, A.; Henning, I.D.; Adams, M.J. Optical neuron using polarization switching in a 1550 nm-VCSEL. Opt. Express 2010, 18, 25170–25176. [Google Scholar] [CrossRef] [PubMed]
- Robertson, J.; Wade, E.; Kopp, Y.; Bueno, J.; Hurtado, A. Towards Neuromorphic Photonic Networks of Ultrafast Spiking Laser Neurons. IEEE J. Sel. Top. Quantum Electron. 2019, 26, 1. [Google Scholar] [CrossRef]
- Robertson, J.; Zhang, Y.; Hejda, M.; Adair, A.; Bueno, J.; Xiang, S.; Hurtado, A. Convolutional Image Edge Detection Using Ultrafast Photonic Spiking VCSEL-Neurons. arXiv 2020, arXiv:2007.10309. [Google Scholar]
- Xiang, S.; Ren, Z.; Zhang, Y.; Song, Z.; Guo, X.; Han, G.; Hao, Y. Training a Multi-Layer Photonic Spiking Neural Network with Modified Supervised Learning Algorithm Based on Photonic STDP. IEEE J. Sel. Top. Quantum Electron. 2021, 27, 7500109. [Google Scholar] [CrossRef]
- Xiang, S.; Ren, Z.; Song, Z.; Zhang, Y.; Guo, X.; Han, G.; Hao, Y. Computing Primitive of Fully VCSEL-Based All-Optical Spiking Neural Network for Supervised Learning and Pattern Classification. IEEE J. Sel. Top. Quantum Electron. 2020, 1–12. [Google Scholar] [CrossRef]
- Robertson, J.; Hejda, M.; Bueno, J.; Hurtado, A. Ultrafast optical integration and pattern classification for neuromorphic photonics based on spiking VCSEL neurons. Sci. Rep. 2020, 10, 6098. [Google Scholar] [CrossRef] [PubMed]
- Feldmann, J.; Youngblood, N.; Wright, C.D.; Bhaskaran, H.; Pernice, W.H.P. All-optical spiking neurosynaptic networks with self-learning capabilities. Nature 2019, 569, 208–214. [Google Scholar] [CrossRef] [PubMed]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Masquelier, T.; Guyonneau, R.; Thorpe, S.J. Competitive STDP based spike pattern learning. Neural Comput. 2009, 21, 1259–1276. [Google Scholar] [CrossRef] [PubMed]
- Xiang, S.; Zhang, Y.; Gong, J.; Guo, X.; Lin, L.; Hao, Y. STDP-Based Unsupervised Spike Pattern Learning in a Photonic Spiking Neural Network with VCSELs and VCSOAs. IEEE J. Sel. Top. Quantum Electron. 2019, 25, 1700109. [Google Scholar] [CrossRef]
- Liquon, L. Principles of Neurobiology, 2nd ed.; Taylor & Francis Group, LLC: New York, NY, USA, 2016; pp. 121–164. [Google Scholar]
- Thorpe, S.J.; Delorme, A.; Van Rullen, R. Spike-based strategies for rapid processing. Neural Netw. 2001, 14, 715–726. [Google Scholar] [CrossRef]
- Mesaritakis, C.; Skontranis, M.; Sarantoglou, G.; Bogris, A. Micro-Ring-Resonator Based Passive Photonic Spike-Time-Dependent-Plasticity Scheme for Unsupervised Learning in Optical Neural Networks. In Proceedings of the 2020 Optical Fiber Communications Conference and Exhibition (OFC), San Diego, CA, USA, 8–12 March 2020; pp. 1–3. [Google Scholar]
- Nvidia. Available online: www.nvidia.com/en-eu/geforce/graphics-cards/rtx-2080-ti/ (accessed on 18 December 2020).
- Barbay, S.; Kuszelewicz, R.; Yacomotti, A.M. Excitability in a semiconductor laser with saturable absorber. Opt. Lett. 2011, 36, 4476–4478. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Gain Section | Absorber Section |
|---|---|---|
| Cavity Volume Vg,a | 2.4 ∙ 10−18 m3 | 2.4 ∙ 10−18 m3 |
| Confinement factor Γg,a | 0.06 | 0.05 |
| Carrier Lifetime τg,a | 1 ns | 100 ps |
| Differential gain/loss gg,a | 2.9 ∙ 10−12 m3 s−1 | 14.5 ∙ 10−12 m3 s−1 |
| Carriers at transparency n0g,a | 1.1 ∙ 1024 m−3 | 0.89 ∙ 1024 m−3 |
| White Pixels (Pixel Value = ‘1’) | Wfinal |
|---|---|
| 3 | 0.43 |
| 4 | 0.3 |
| 5 | 0.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skontranis, M.; Sarantoglou, G.; Deligiannidis, S.; Bogris, A.; Mesaritakis, C. Time-Multiplexed Spiking Convolutional Neural Network Based on VCSELs for Unsupervised Image Classification. Appl. Sci. 2021, 11, 1383. https://doi.org/10.3390/app11041383
Skontranis M, Sarantoglou G, Deligiannidis S, Bogris A, Mesaritakis C. Time-Multiplexed Spiking Convolutional Neural Network Based on VCSELs for Unsupervised Image Classification. Applied Sciences. 2021; 11(4):1383. https://doi.org/10.3390/app11041383
Chicago/Turabian StyleSkontranis, Menelaos, George Sarantoglou, Stavros Deligiannidis, Adonis Bogris, and Charis Mesaritakis. 2021. "Time-Multiplexed Spiking Convolutional Neural Network Based on VCSELs for Unsupervised Image Classification" Applied Sciences 11, no. 4: 1383. https://doi.org/10.3390/app11041383
APA StyleSkontranis, M., Sarantoglou, G., Deligiannidis, S., Bogris, A., & Mesaritakis, C. (2021). Time-Multiplexed Spiking Convolutional Neural Network Based on VCSELs for Unsupervised Image Classification. Applied Sciences, 11(4), 1383. https://doi.org/10.3390/app11041383