
Attention-Based Transfer Learning for Efficient Pneumonia Detection in Chest X-ray Images



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Preprocessing
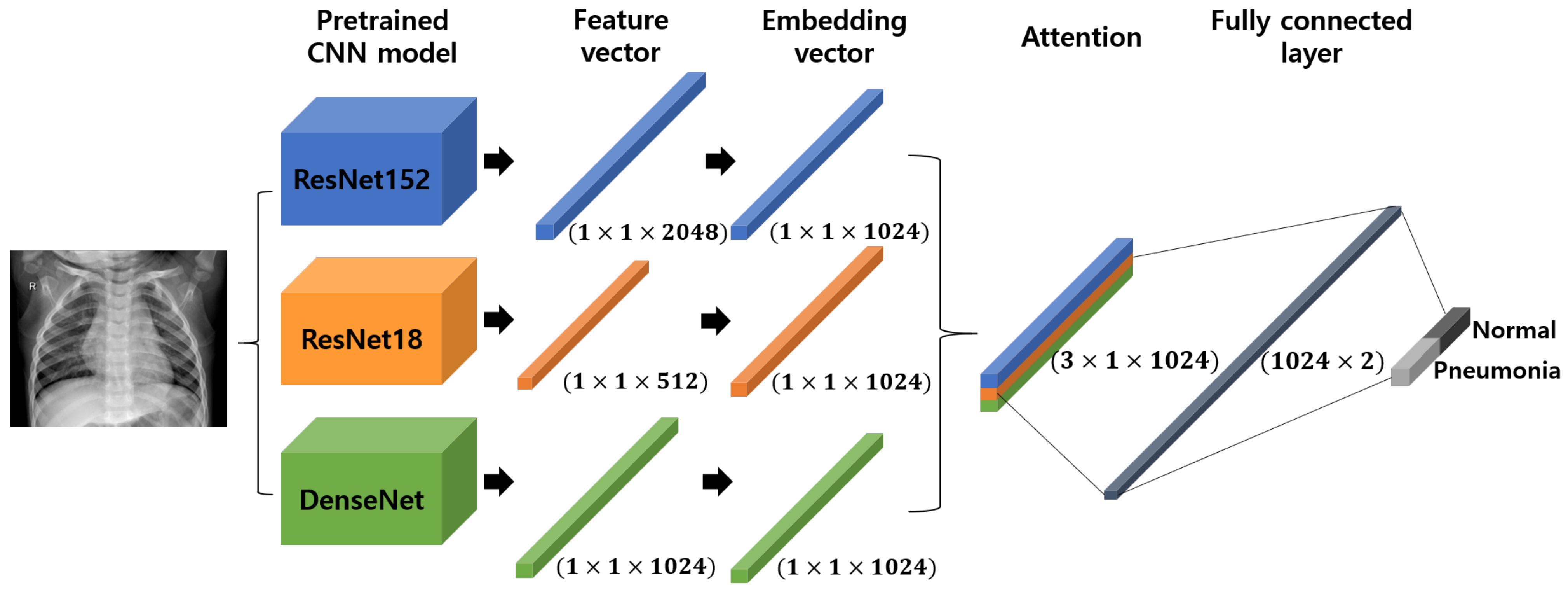
2.2. Pre-Trained CNN Models
2.2.1. ResNet
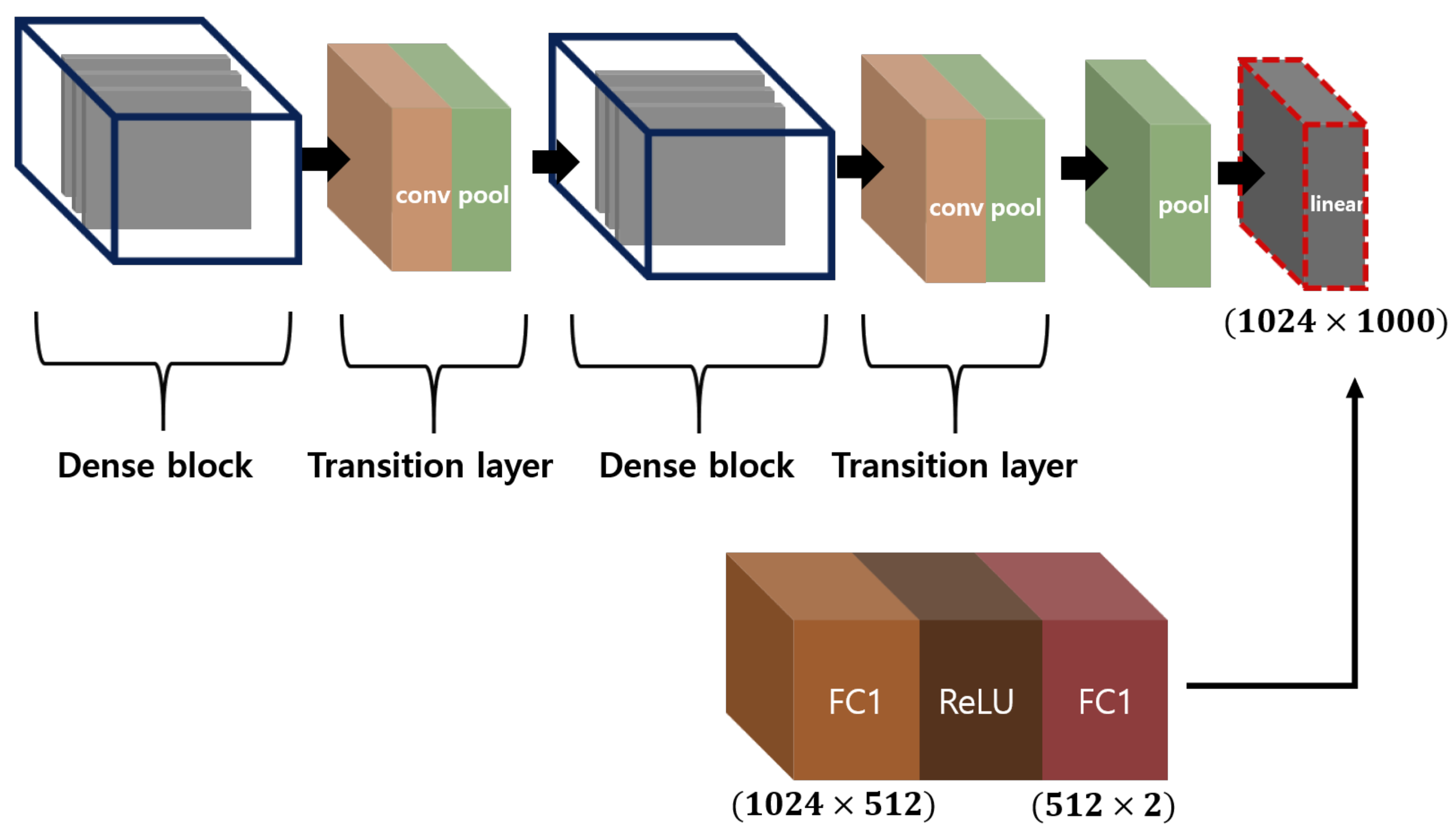
2.2.2. DenseNet
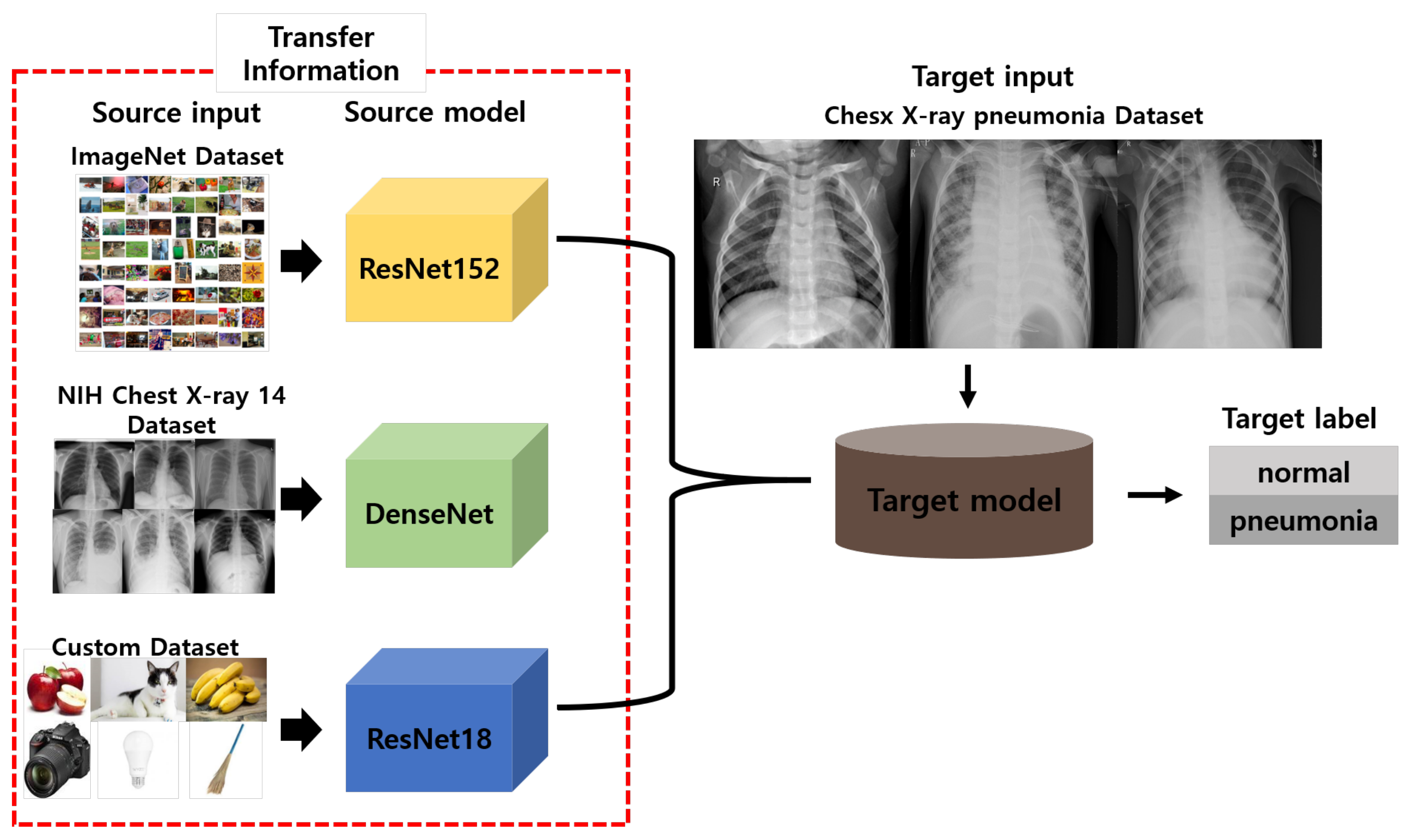
2.3. Transfer Learning
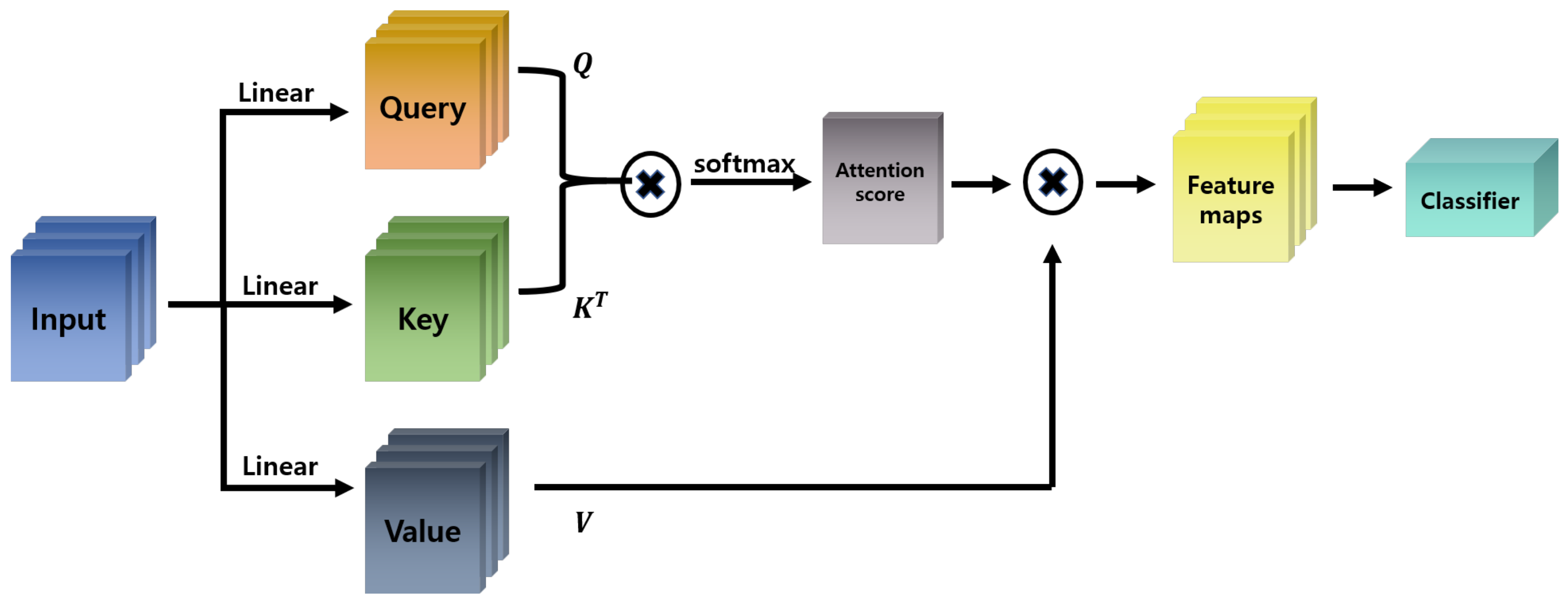
2.4. Attention Mechanism
2.4.1. Self-Attention
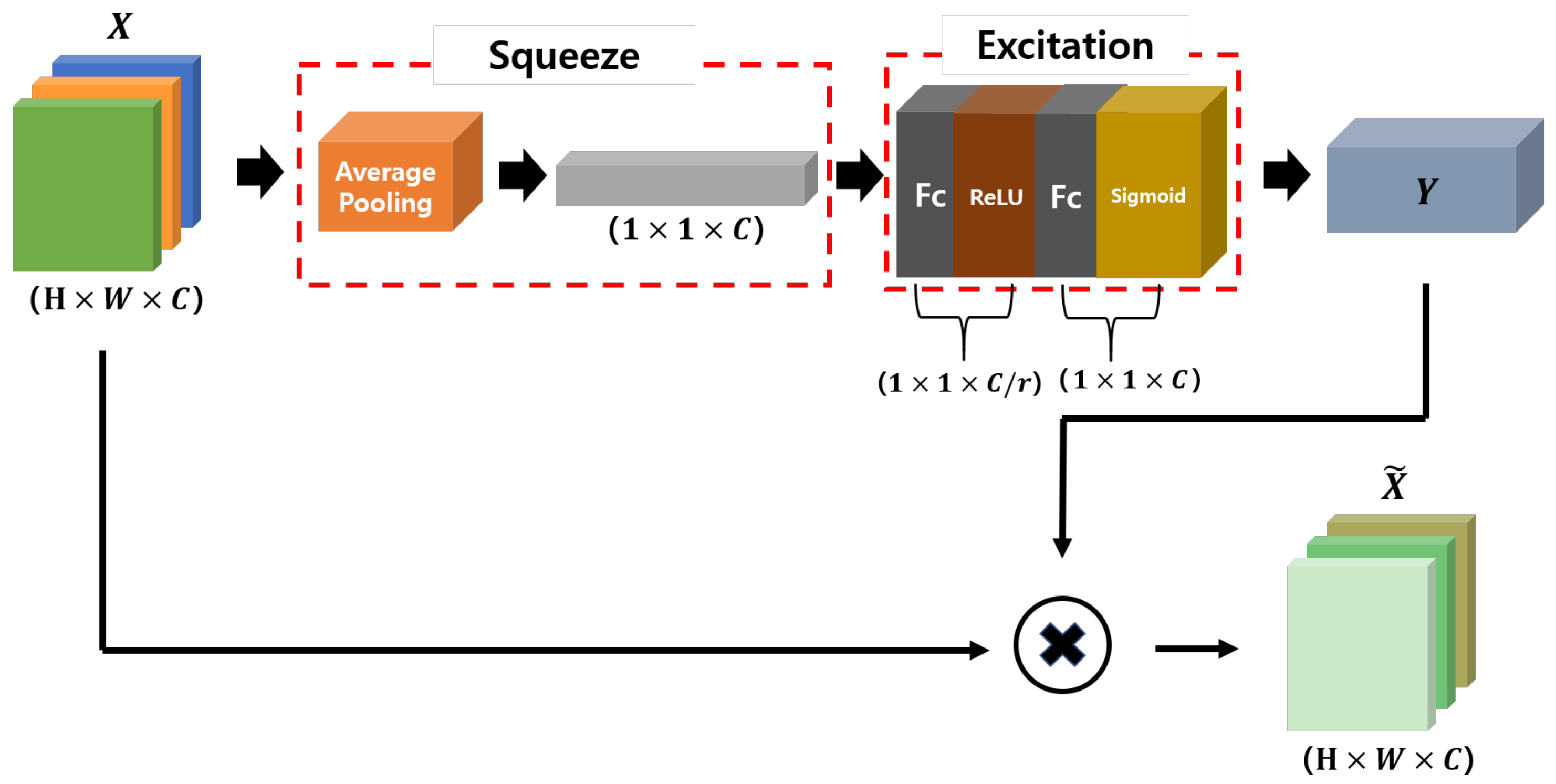
2.4.2. SENet
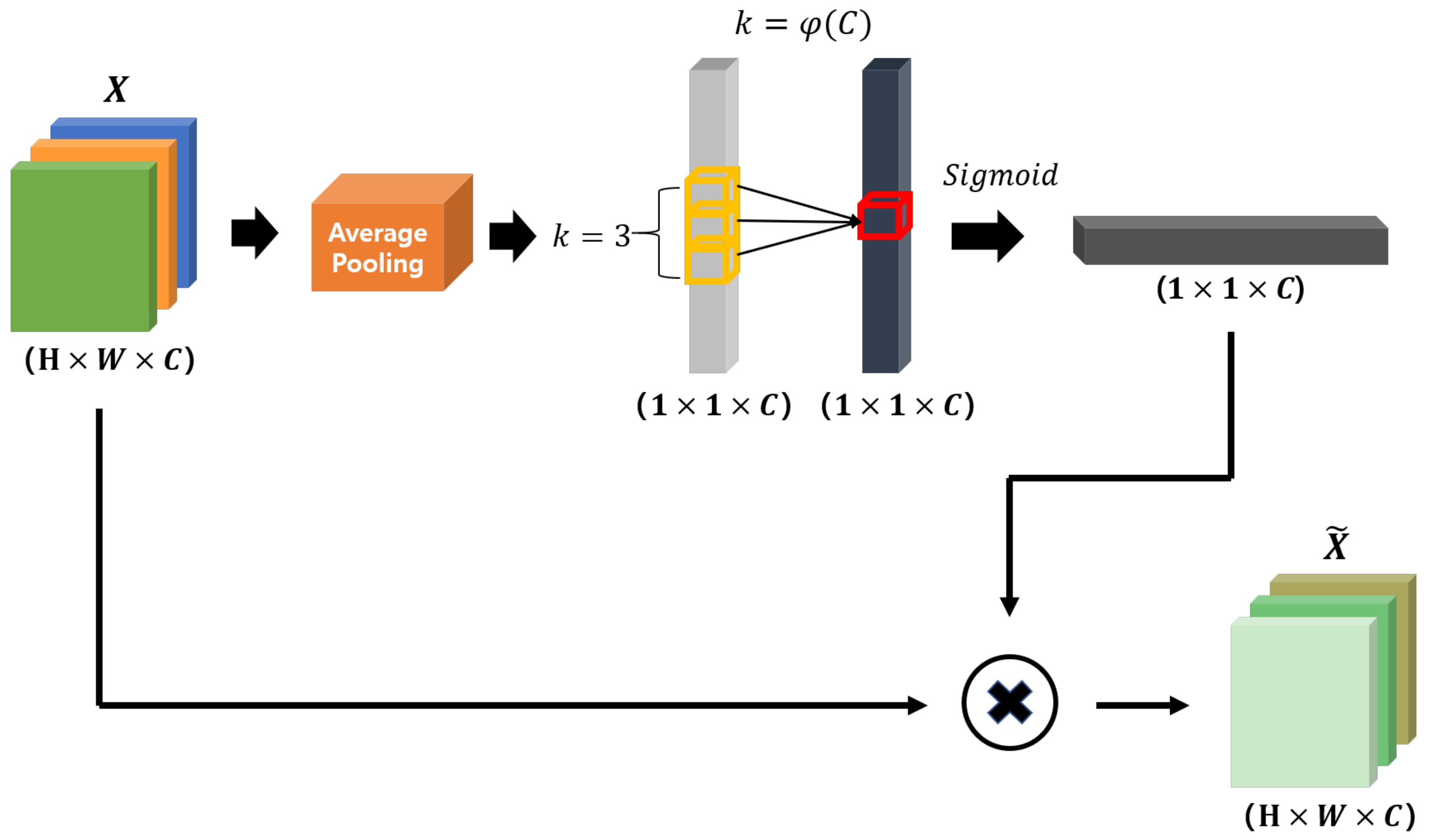
2.4.3. Efficient Channel Attention
2.5. Datasets
3. Results
3.1. Results
3.2. Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gilani, Z.; Kwong, Y.D.; Levine, O.S.; Deloria-Knoll, M.; Scott, J.A.G.; O’Brien, K.L.; Feikin, D.R. A literature review and survey of childhood pneumonia etiology studies: 2000–2010. Clin. Infect. Dis. 2012, 54, S102–S108. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. WHO Reveals Leading Causes of Death and Disability Worldwide: 2000–2019. Available online: https://www.who.int/news/item/09-12-2020-who-reveals-leading-causes-of-death-and-disability-worldwide-2000-2019 (accessed on 26 December 2020).
- Esayag, Y.; Nikitin, I.; Bar-Ziv, J.; Cytter, R.; Hadas-Halpern, I.; Zalut, T.; Yinnon, A.M. Diagnostic value of chest radiographs in bedridden patients suspected of having pneumonia. Am. J. Med. 2010, 123, 88.e1–88.e5. [Google Scholar] [CrossRef] [PubMed]
- ReliasMedia. Misdiagnosis of Flu Instead of Pneumonia Results in Death for 10-Year-Old Girl. Available online: https://www.reliasmedia.com/articles/17222-misdiagnosis-of-flu-instead-of-pneumonia-results-in-death-for-10-year-old-girl (accessed on 11 January 2021).
- Elemraid, M.A.; Muller, M.; Spencer, D.A.; Rushton, S.P.; Gorton, R.; Thomas, M.F.; Eastham, K.M.; Hampton, F.; Gennery, A.R.; Clark, J.E.; et al. Accuracy of the interpretation of chest radiographs for the diagnosis of paediatric pneumonia. PLoS ONE 2014, 9, e106051. [Google Scholar] [CrossRef] [PubMed]
- Kallianos, K.; Mongan, J.; Antani, S.; Henry, T.; Taylor, A.; Abuya, J.; Kohli, M. How far have we come? Artificial intelligence for chest radiograph interpretation. Clin. Radiol. 2019, 74, 338–345. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Varshni, D.; Thakral, K.; Agarwal, L.; Nijhawan, R.; Mittal, A. Pneumonia detection using CNN based feature extraction. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Liang, G.; Zheng, L. A transfer learning method with deep residual network for pediatric pneumonia diagnosis. Comput. Methods Programs Biomed. 2020, 187, 104964. [Google Scholar] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Washington, DC, USA, 2 July 2012; pp. 17–36. [Google Scholar]
- Pratt, L.Y.; Mostow, J.; Kamm, C.A.; Kamm, A.A. Direct Transfer of Learned Information Among Neural Networks; AAAI: Menlo Park, CA, USA, 1991; Volume 91, pp. 584–589. [Google Scholar]
- Cao, C.; Liu, X.; Yang, Y.; Yu, Y.; Wang, J.; Wang, Z.; Huang, Y.; Wang, L.; Huang, C.; Xu, W.; et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2956–2964. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Sahlol, A.T.; Abd Elaziz, M.; Tariq Jamal, A.; Damaševičius, R.; Farouk Hassan, O. A novel method for detection of tuberculosis in chest radiographs using artificial ecosystem-based optimisation of deep neural network features. Symmetry 2020, 12, 1146. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhao, W.; Wang, L.; Zhang, Z. Artificial ecosystem-based optimization: A novel nature-inspired meta-heuristic algorithm. Neural Comput. Appl. 2019, 1–43. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Yousri, D.; Ewees, A.A.; Al-Qaness, M.A.; Damasevicius, R.; Abd Elaziz, M. COVID-19 image classification using deep features and fractional-order marine predators algorithm. Sci. Rep. 2020, 10, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest X-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Anil Sathyan. Pytorch-Image-Classification. 2019. Available online: https://github.com/anilsathyan7/pytorch-image-classification (accessed on 20 December 2020).
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances In Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cohen, J.P.; Bertin, P.; Frappier, V. Chester: A Web Delivered Locally Computed Chest X-ray Disease Prediction System. arXiv 2019, arXiv:1901.11210. [Google Scholar]
- Rajaraman, S.; Candemir, S.; Kim, I.; Thoma, G.; Antani, S. Visualization and interpretation of convolutional neural network predictions in detecting pneumonia in pediatric chest radiographs. Appl. Sci. 2018, 8, 1715. [Google Scholar] [CrossRef] [PubMed]
- Saraiva, A.A.; Santos, D.; Costa, N.J.C.; Sousa, J.V.M.; Ferreira, N.M.F.; Valente, A.; Soares, S. Models of Learning to Classify X-ray Images for the Detection of Pneumonia using Neural Networks. In Proceedings of the 12th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2019), Prague, Czech Republic, 22–24 February 2019; pp. 76–83. [Google Scholar]
- Ayan, E.; Ünver, H.M. Diagnosis of Pneumonia from Chest X-ray Images Using Deep Learning. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Sharma, H.; Jain, J.S.; Bansal, P.; Gupta, S. Feature Extraction and Classification of Chest X-ray Images Using CNN to Detect Pneumonia. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 227–231. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Train | Validation | Test |
|---|---|---|---|
| Normal | 1341 | 8 | 234 |
| Pneumonia | 3875 | 8 | 390 |
| Total | 5216 | 16 | 624 |
| Model | Data | Epoch | Recall (%) | Precision (%) | AUC (%) | F-Score | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| ResNet152 | ImageNet dataset | 30 | 98.97 | 93.46 | 93.72 | 0.961 | 95.03 |
| DenseNet121 | NIH dataset | 30 | 98.72 | 94.13 | 94.23 | 0.964 | 95.35 |
| ResNet18 | Custom dataset | 30 | 98.97 | 93.24 | 93.50 | 0.960 | 94.87 |
| Self-attention | - | 30 | 98.72 | 96.46 | 93.72 | 0.976 | 95.03 |
| ECA | - | 30 | 98.21 | 95.99 | 95.68 | 0.971 | 96.31 |
| SE-Attention | - | 30 | 98.46 | 96.24 | 96.03 | 0.973 | 96.63 |
| Model | Recall (%) | Precision (%) | AUC (%) | F-Score | Accuracy (%) |
|---|---|---|---|---|---|
| Kermany et al. [32] | 93.2 | - | 96.8 | - | 92.8 |
| Cohen et al. [34] | - | - | 98.4 | - | - |
| Rajaraman et al. [35] | 96.2 | 97.7 | 99.3 | 0.970 | 96.2 |
| Sahlol et al. [24] | 87.22 | - | - | - | 94.18 |
| Saraiva et al. [36] | 94.85 | 95.72 | - | 0.953 | 95.07 |
| Ayan and Über [37] | 82 | - | - | - | 87 |
| Sharma H. et al. [38] | - | - | - | - | 90.68 |
| Our model(SE-Attention) | 98.46 | 96.24 | 96.03 | 0.973 | 96.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, S.-M.; Lee, S.-S.; Ko, B. Attention-Based Transfer Learning for Efficient Pneumonia Detection in Chest X-ray Images. Appl. Sci. 2021, 11, 1242. https://doi.org/10.3390/app11031242
Cha S-M, Lee S-S, Ko B. Attention-Based Transfer Learning for Efficient Pneumonia Detection in Chest X-ray Images. Applied Sciences. 2021; 11(3):1242. https://doi.org/10.3390/app11031242
Chicago/Turabian StyleCha, So-Mi, Seung-Seok Lee, and Bonggyun Ko. 2021. "Attention-Based Transfer Learning for Efficient Pneumonia Detection in Chest X-ray Images" Applied Sciences 11, no. 3: 1242. https://doi.org/10.3390/app11031242
APA StyleCha, S.-M., Lee, S.-S., & Ko, B. (2021). Attention-Based Transfer Learning for Efficient Pneumonia Detection in Chest X-ray Images. Applied Sciences, 11(3), 1242. https://doi.org/10.3390/app11031242