
On Simulating the Propagation and Countermeasures of Hate Speech in Social Networks


Abstract
:1. Introduction
2. Related Work
2.1. Characterising Hateful Users in Social Networks
2.2. Models of Opinion Diffusion
2.3. Multi-Agent Simulations in the Context of Hatred and Polarisation
3. Terminology
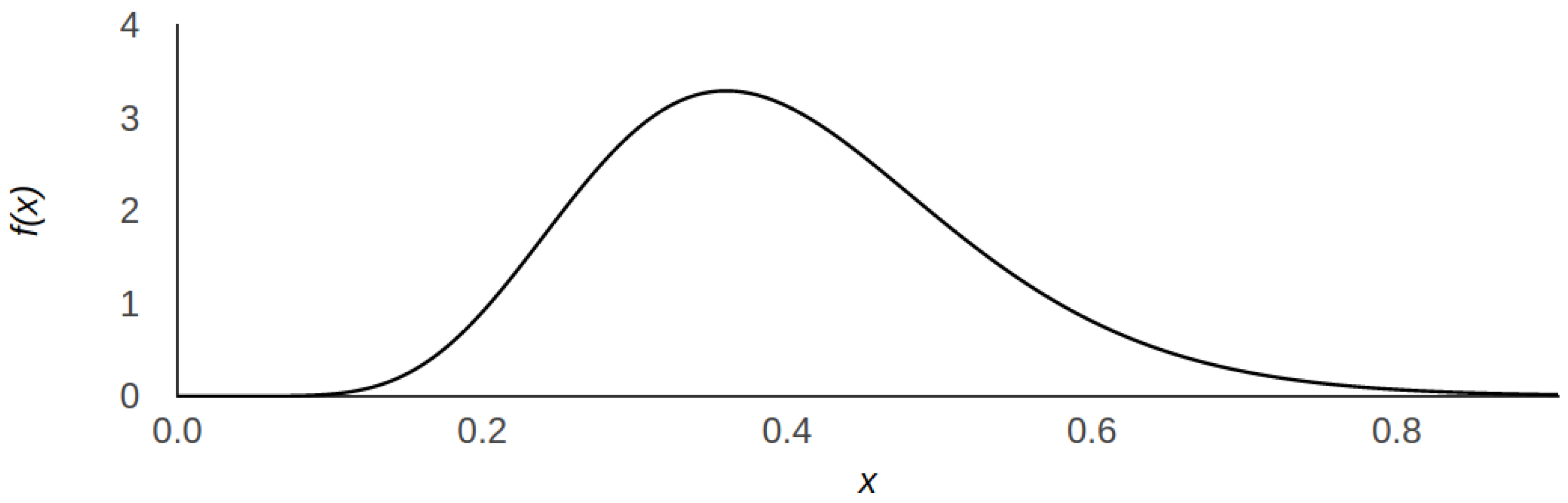
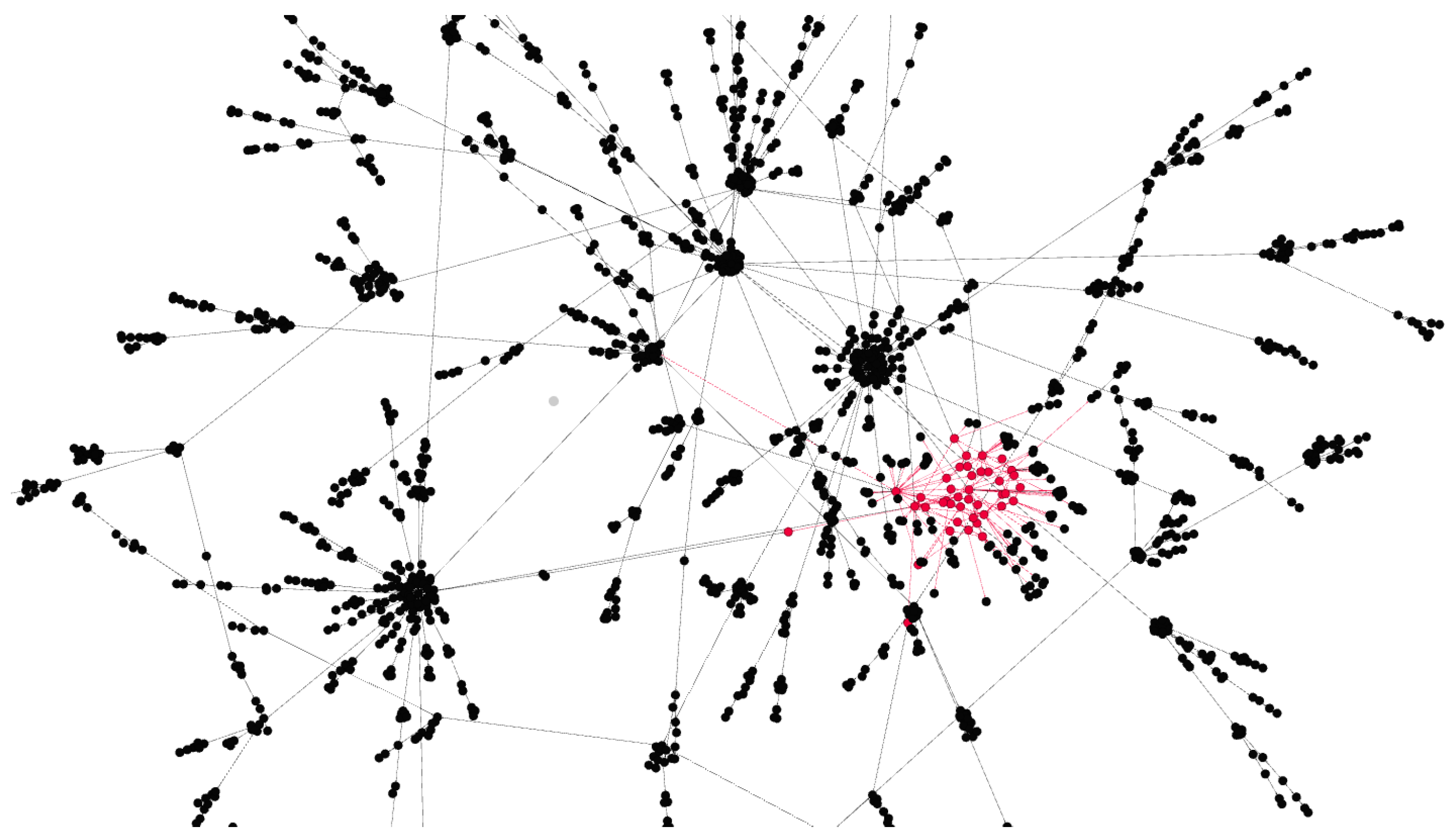
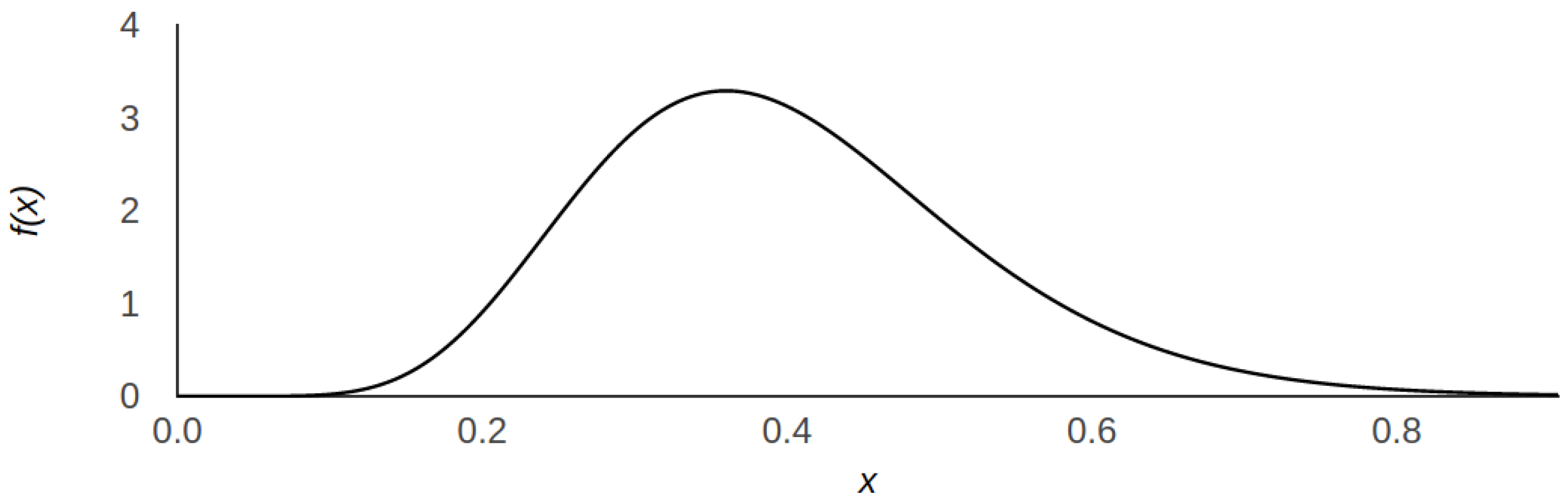
- Hate score is the central metric in our work and represents the users’ attitude and opinion about some polarised topic, which is discussed within a social network. For instance, immigration laws or equal rights of men and women. It is a real number in , where both extremes correspond to a very non-hateful and hateful opinions, respectively. We use the hate score as a user opinion value in our diffusion models but also as a threshold to characterise users. The same concept was also employed by Mathew et al. [6] who showed that hate score distribution on Gab is positively biased towards a non-hateful stance. Similarly, we define a user as hateful when and signal it as a red dot in the network graphical representation (see Figure 1). Otherwise, (i.e., when ) we assume the user to be normal and represent it as a black dot. We take this threshold in accordance to—and for better comparability with—previous work. As stated before, the amount of haters is known to be a minority of ca. 1%. Therefore, we model the hate score using the Gamma distribution as depicted in Figure 2, so that the area under curve for is ca. 0.01. For those rare cases when the Gamma distribution naturally exceeds the value of 1 we artificially set users’ hate score to the extreme stance of 1.
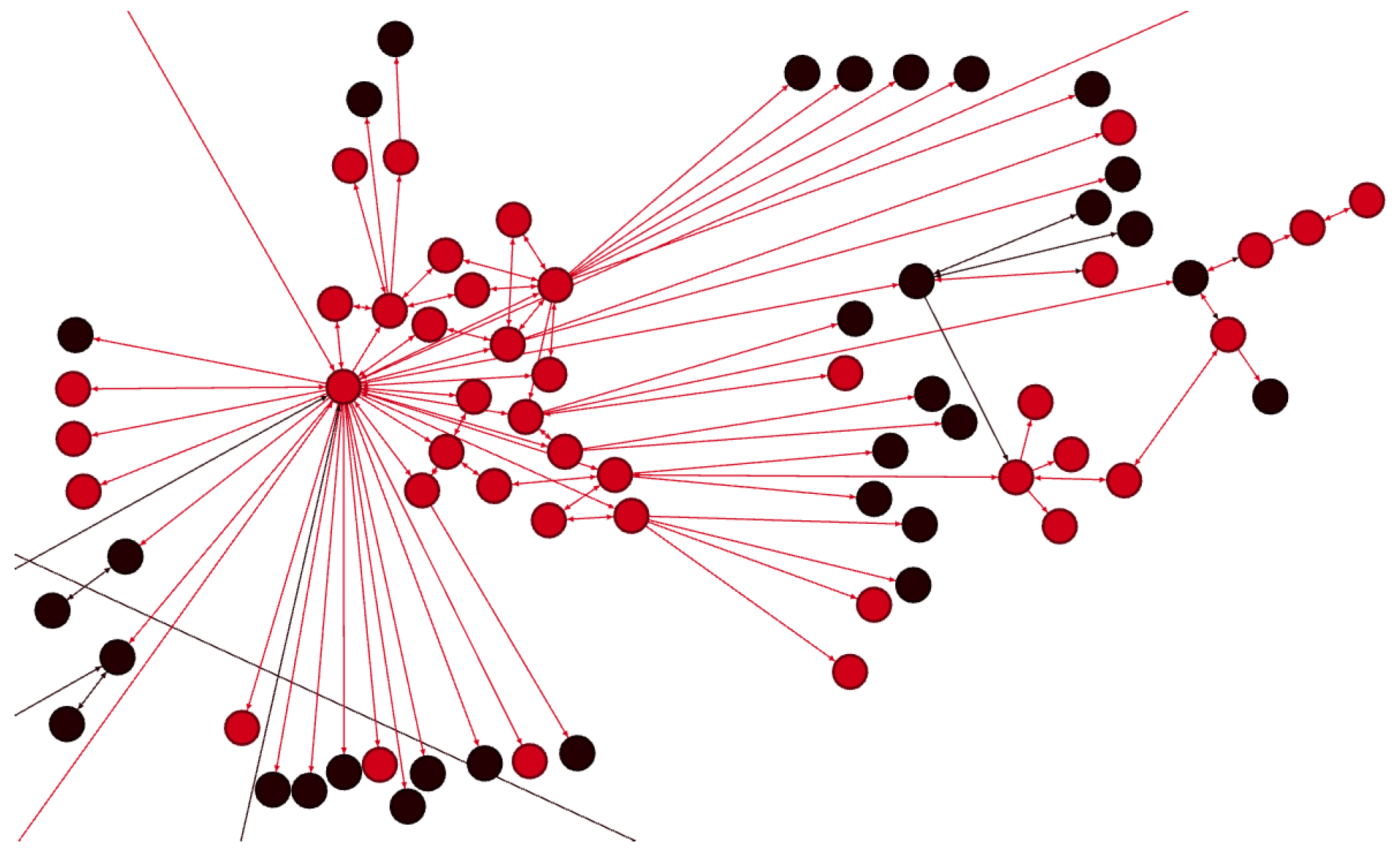
- Hate core is a network component consisting of densely connected hateful users. Figure 1 depicts how most hateful users (in red) are clustered together. Such components emerge from the high cohesiveness among hateful users as well as from their higher activity. It is also worth noticing that, although single users within a hate core do not exhibit the same influence as some famous mainstream users, as a compound, the hate core can achieve similar effects on the network and attract other users.
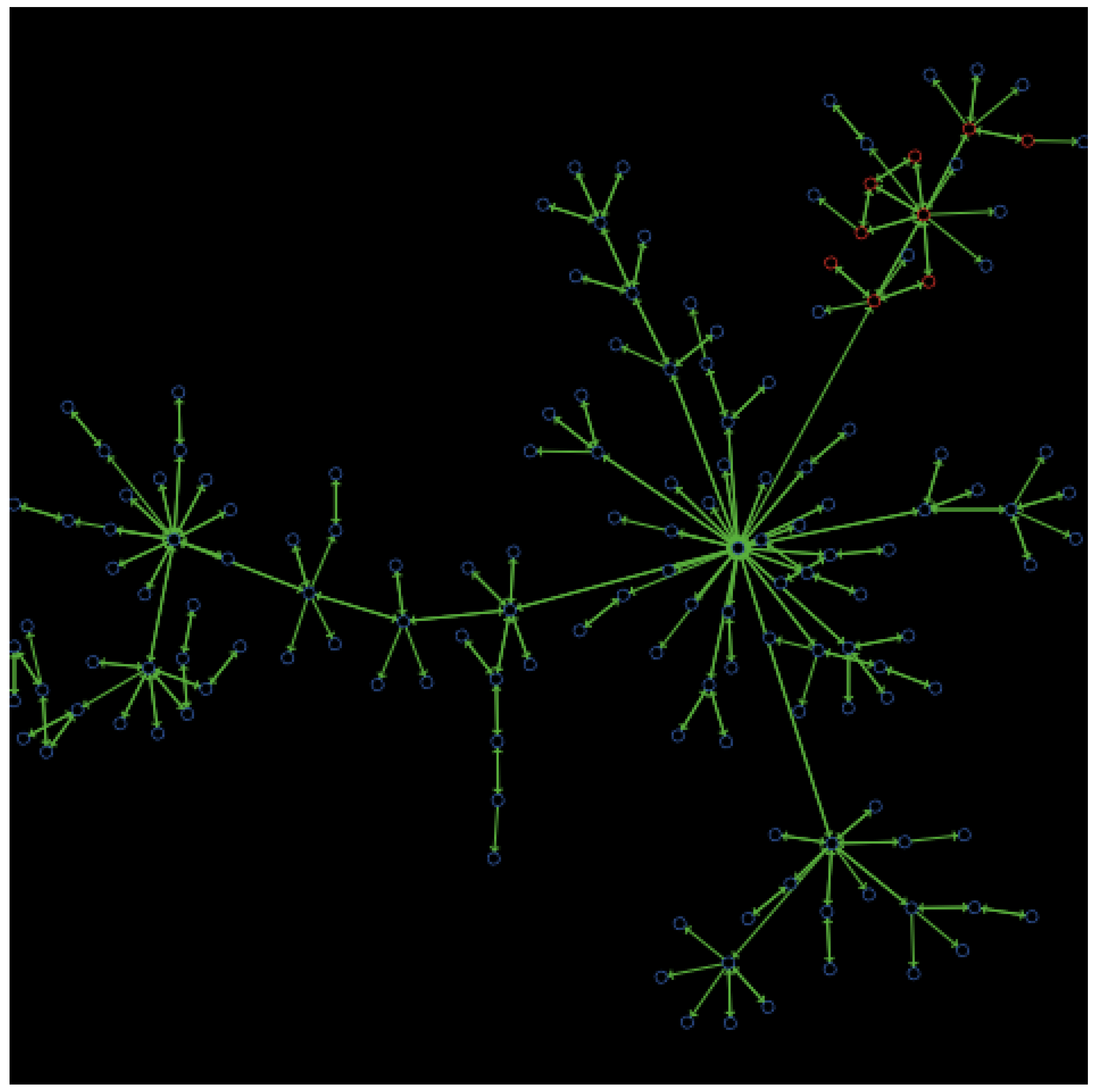
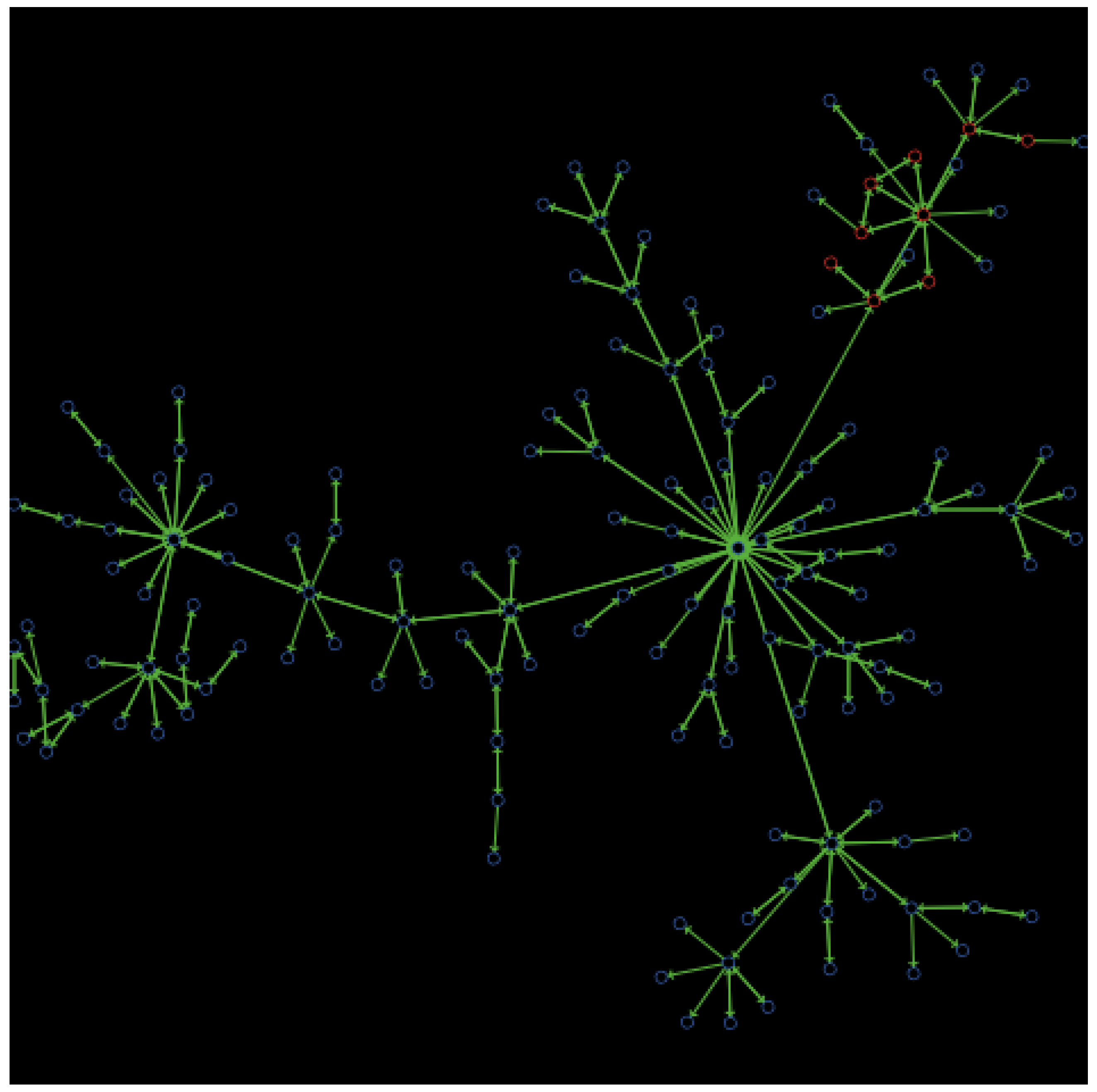
- Hate strains are extensions of hate cores. As illustrated by Figure 3, hate strains consist of connected hateful users, but exhibit less network density among them than the hate core that originated them. Most often, hate strains emerge from a hate core as the result of opinion diffusion under the negative influence of the hateful users in the core.
- Swap to a hateful society (by society we mean all the users in the social network). We identify such network transformation when hateful content floods the network and leads to a swap in the opinion of a significant number of users. In particular, we consider a society to be very hateful when the amount of hateful users exceeds 30% of all users in the social network. In fact, experiments have shown that after having trespassed this 30% limit, it becomes extremely difficult to return to a non-hateful society within the time scope of our simulation. Thus, although there may be some exceptions (as hate spread could still be stopped if strategical nodes with high influence within a hateful group were convinced to become non-hateful), we consider swap to a hateful society as the outcome of an irreversible process, which destabilises the society in a very severe way.
4. Our Multi-Agent Social Network: The Baseline Model
4.1. Network Construction
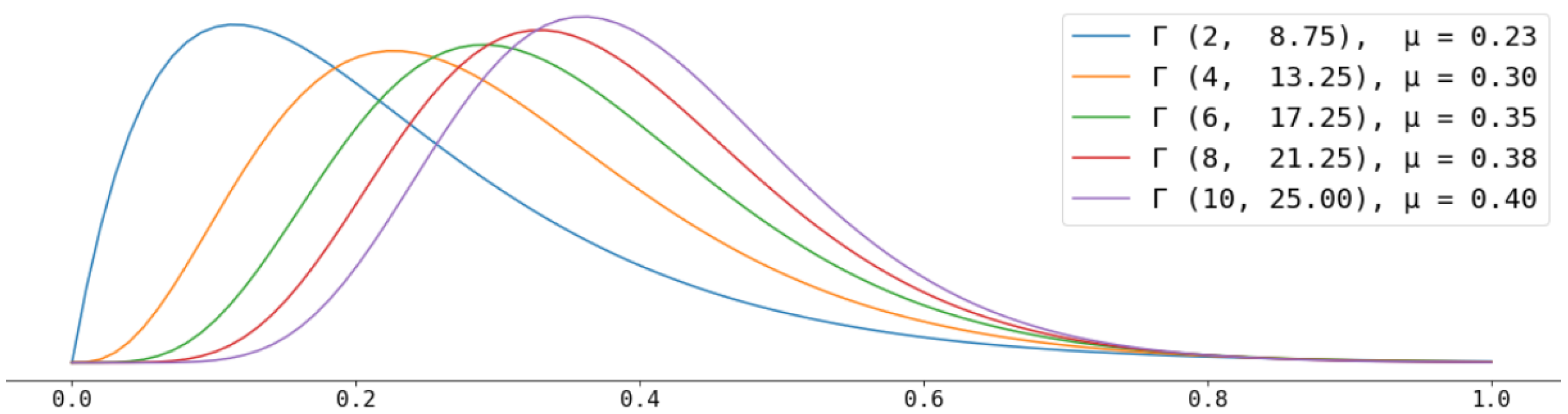
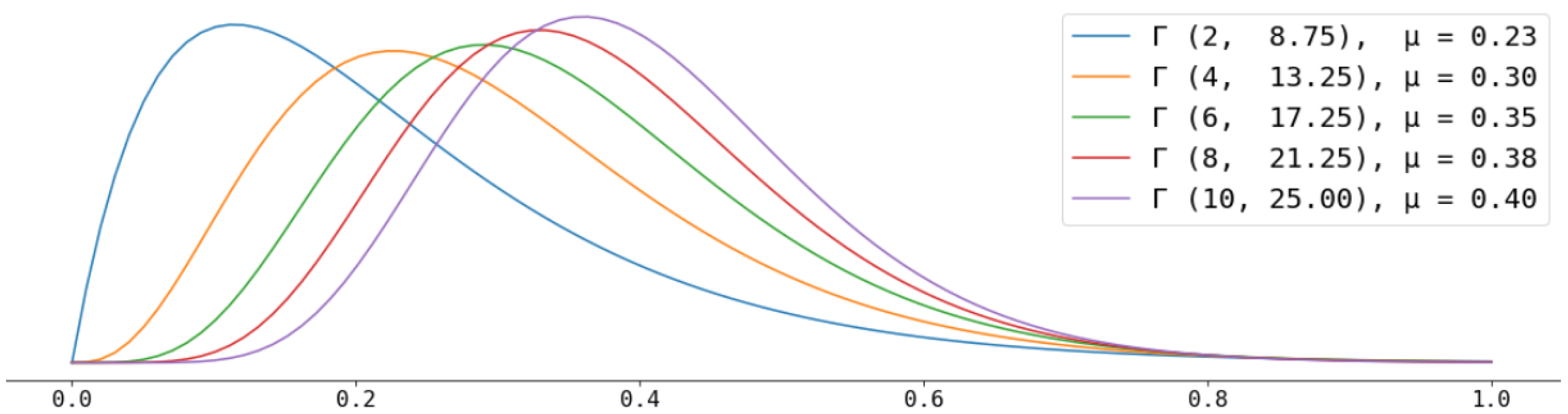
- Firstly, we create, for every simulation round (tick), a new user node and assign it with a hate score that is sampled from the Gamma distribution , the lavender (right-most) distribution depicted in Figure 5 (recall, from Section 3, that we do so to produce a proportion of about 1% of hateful users in the network). As a consequence of this hate score assignment, the new node becomes a normal user or a hater.
- Secondly, for each tick, we also connect the newly created user node with some other users so to mimic their behaviour on Gab and Twitter as described in Section 2.1. Specifically, we proceed by defining several variables that help us tailor the network connections as follows:
- When joining the network, a new hateful user creates twice new connections than a normal user. In our simulations, a hater sets connections, whereas a normal user only establishes connection (in the code, these limits are set with variables n_following_conn_hater and n_following_conn_normal, respectively). We adhere to Twitter’s terminology and refer to the new created node as the follower and the node it connects to—i.e., the one being followed—as the followee.
- A normal user connects to an existing user within the network according to the preferential attachment method, without considering its hate score. Conversely, a hateful user will prefer to attach to haters. In particular, a newly created hateful user opts in to connect to another hateful user with a probability (the arrow → in the notation indicates connection and, as for the code, this probability appears as p_hater_follows_hater), and thus, it can still connect to a normal user with a probability of . Preferential attachment is then used to choose the specific hater to connect to. As a response, the hateful followee spawns a following connection with the same probability (the arrow ← in the notation indicates following back and, as for the code, this probability appears as p_hater_back_follows_hater).
- Hateful users receive less followers from normal users per time interval. Hence, following back by normal users is modelled with a probability and . Lastly, haters will be less likely to follow back normal users with (in the code, these probabilities appear as p_normal_back_follows_normal, p_normal_back_follows_hater, and p_hater_back_follows_normal, respectively).
4.2. Opinion Diffusion by Content
- Hateful users are very active and post at every round (i.e., with a publication probability ), whereas normal users only post with probability (in the code, these probabilities appear as and , respectively).
- A post cannot be reposted twice by the same user. However, it can be reposted with some low probability even if the opinion does not correspond to reposter’s own opinion. We align here with the retweet statistics provided by Ribeiro et al. [21] and set reposting probabilities between normal (n) and hateful (h) users to , , and (here, the arrow → indicates content flow and, in the code, these probabilities appear as , , , and , respectively). In this manner, a hater will repost a normal post with the lowest probability.
- In order to model different users’ activity profiles, we limit the amount of reposts that a user can perform per round by setting variables to max_reposts_by_normals = 2 and max_reposts_by_haters = 6.
5. Modelling Countermeasures
5.1. Educational Bias
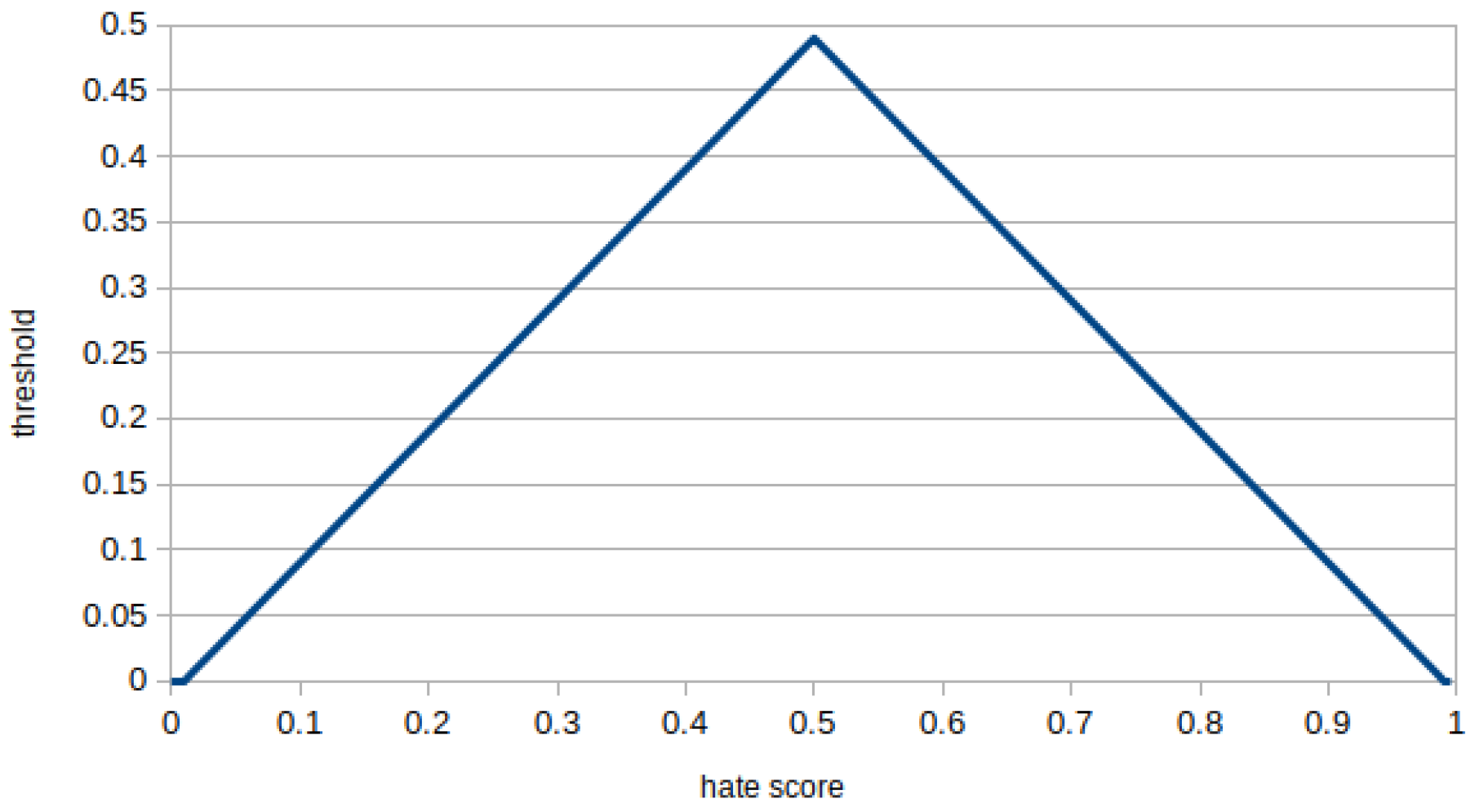
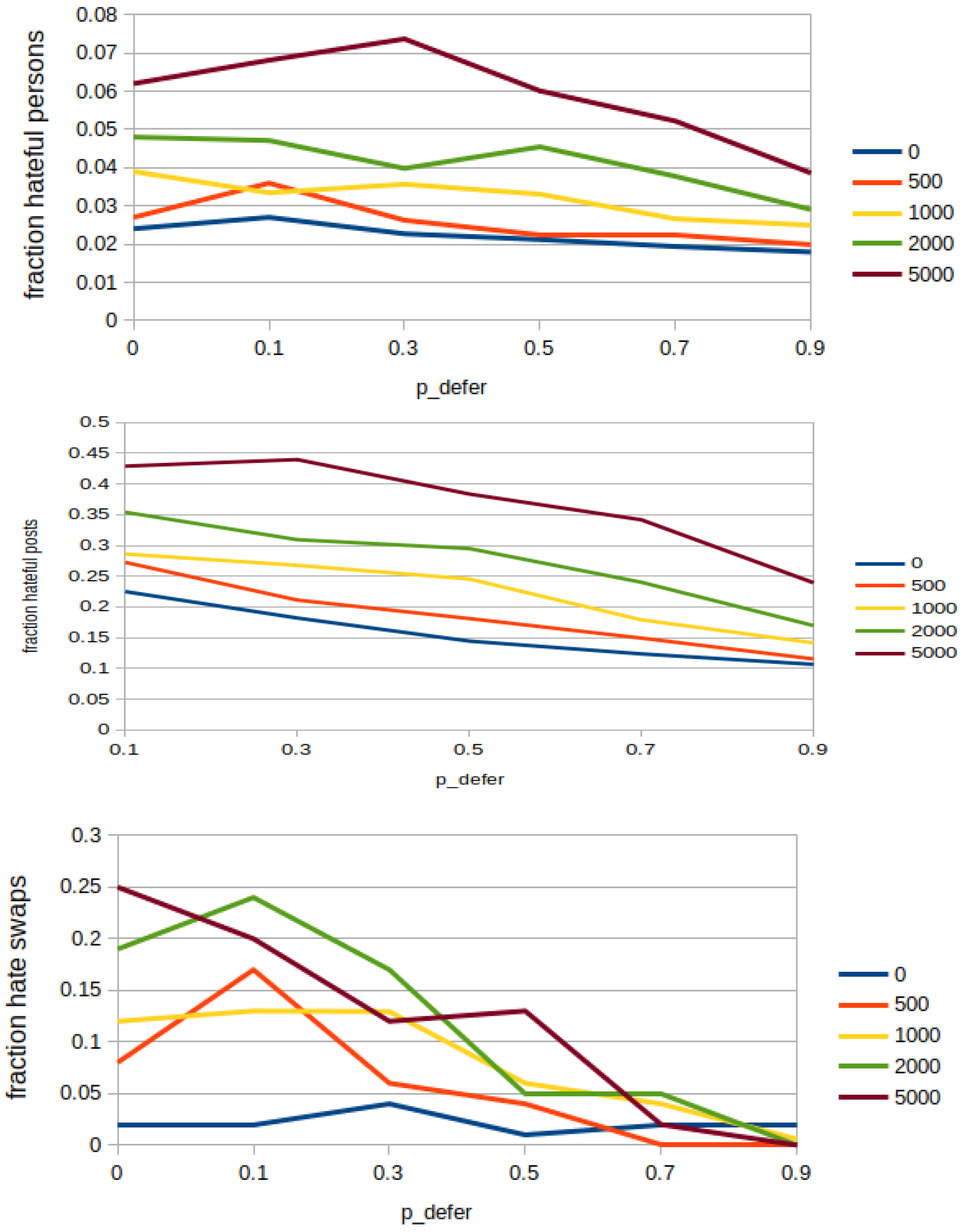
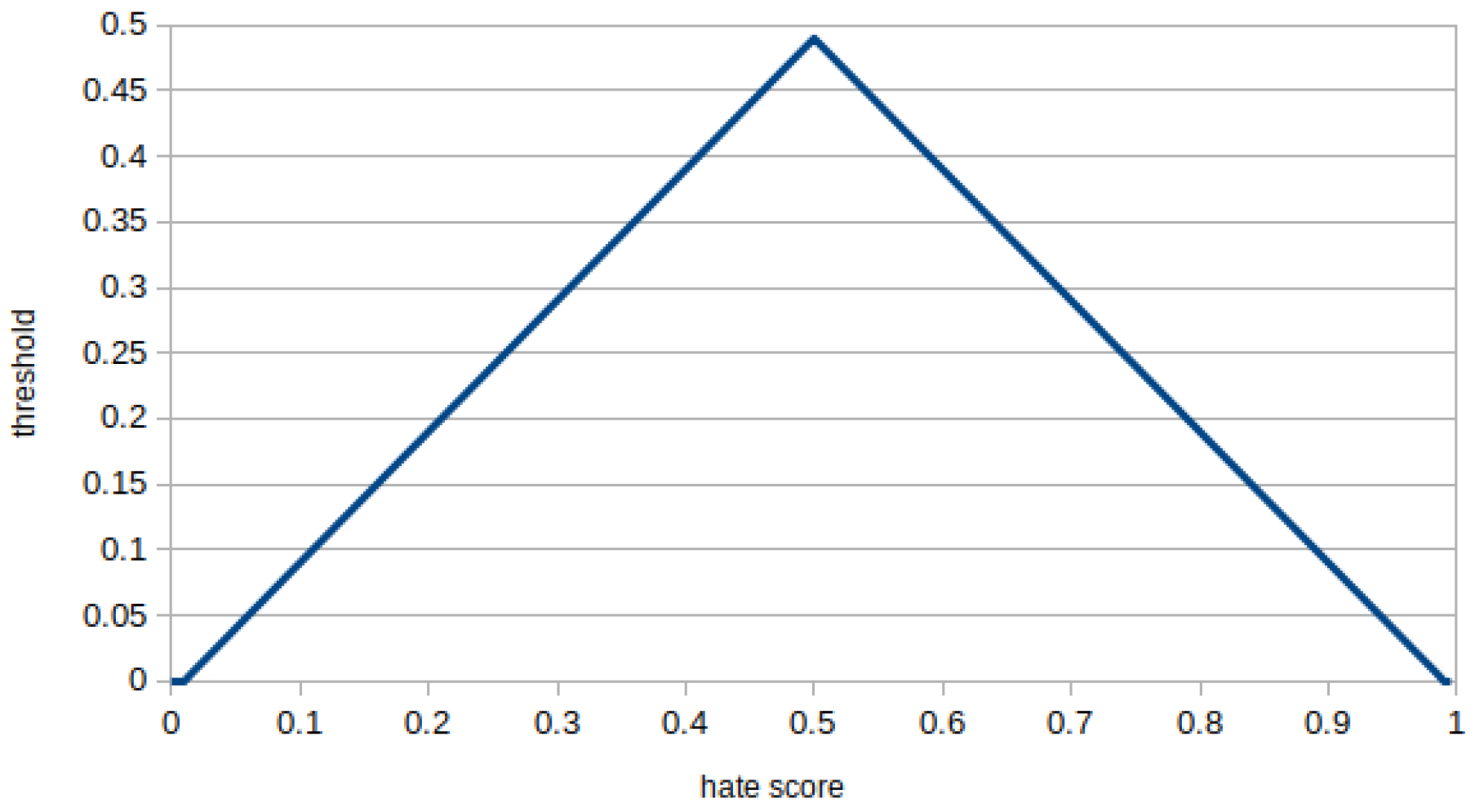
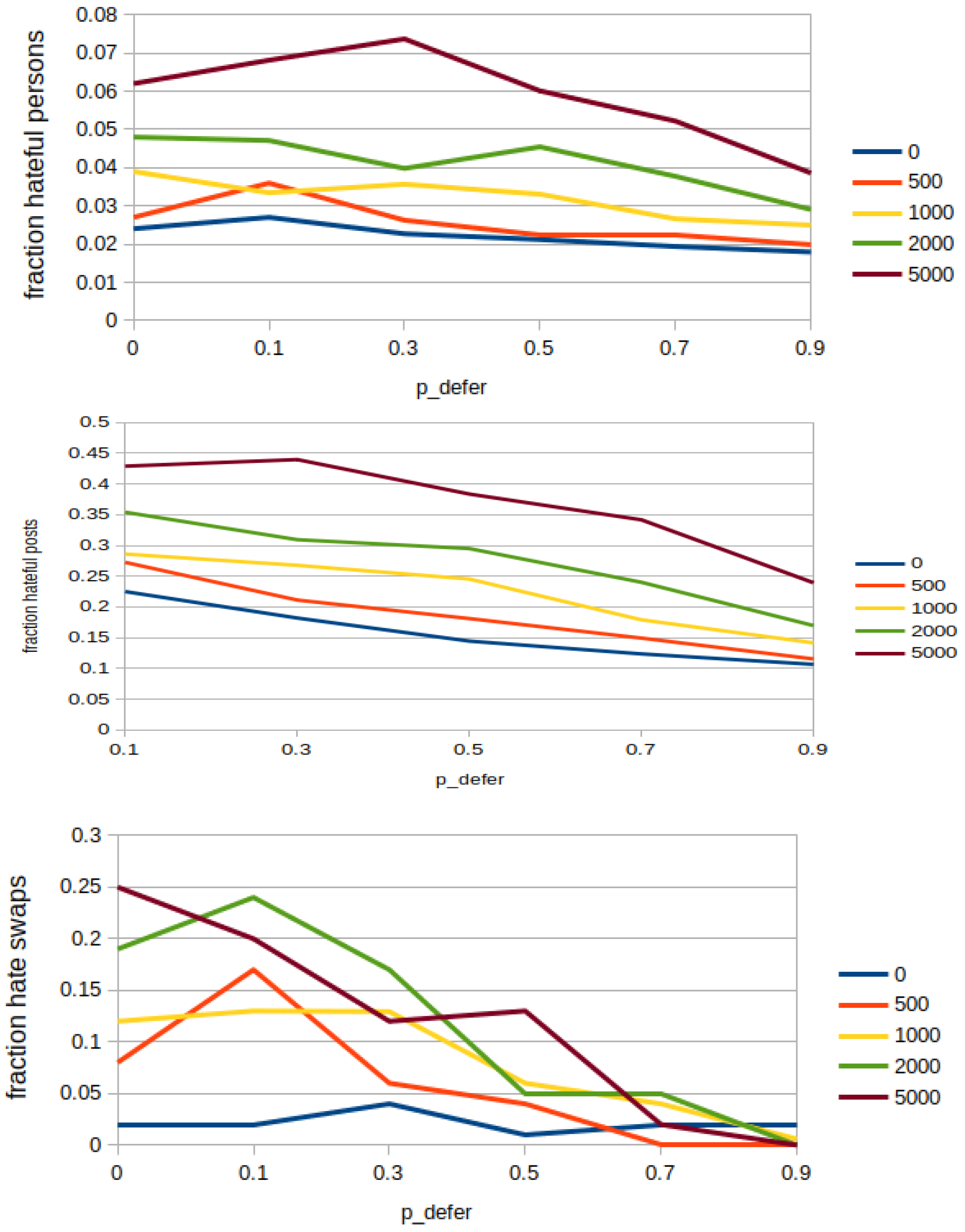
5.2. Deferring Hateful Content
- We employ a variable that stands for the probability of deferring a hateful post at each round (in the code, probability appears as ). Any hateful post can be deferred again, if it is reposted in further rounds.
- In addition to parameters in Section 4.2, a cumulative factor is used to decrease the probability of being reposted. This means that the probability of being reposted would diminish by a factor of 0.5 for posts deferred for one round, 0.25 for 2 rounds, 0.125 for 3 rounds and so on.
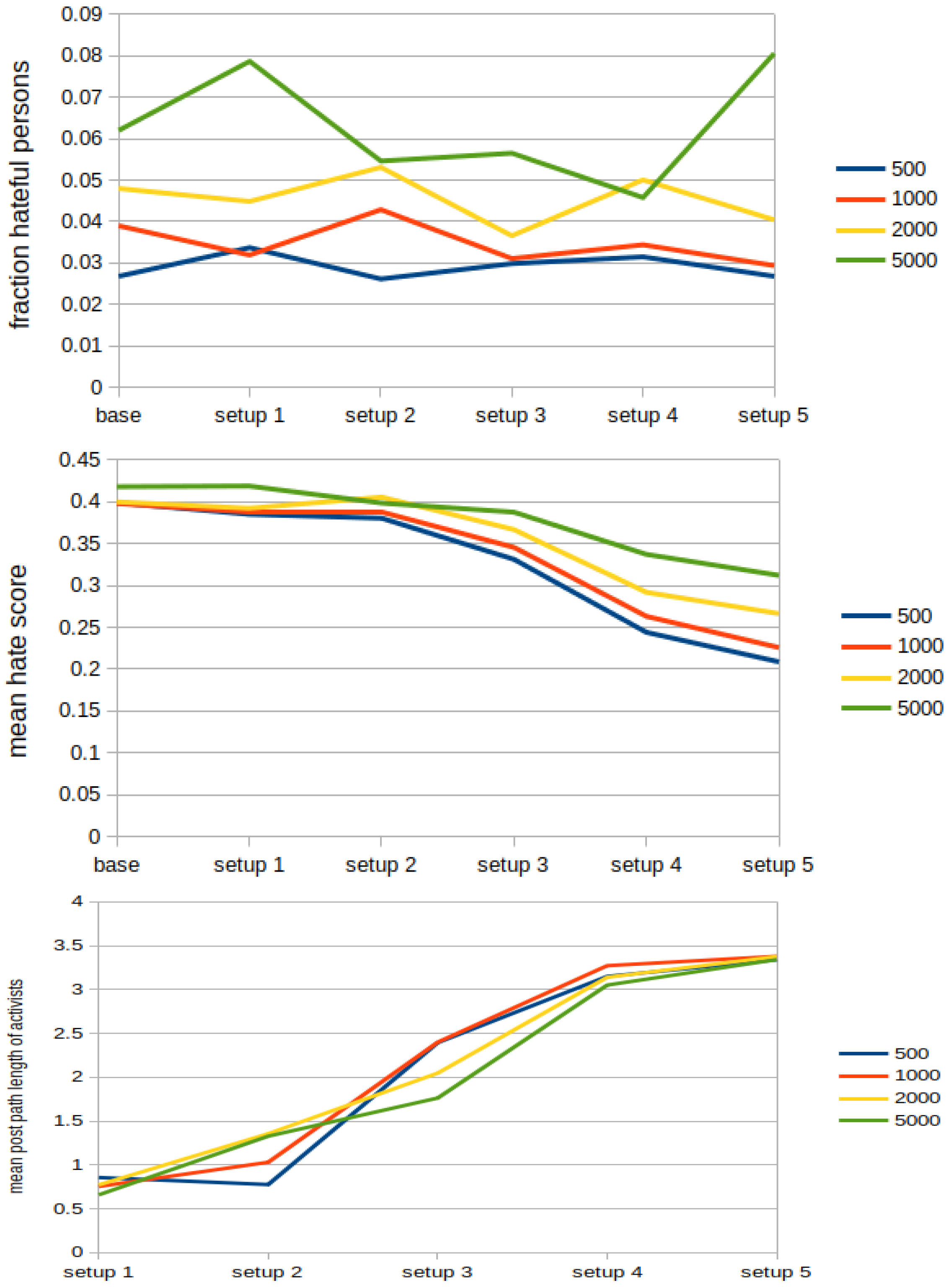
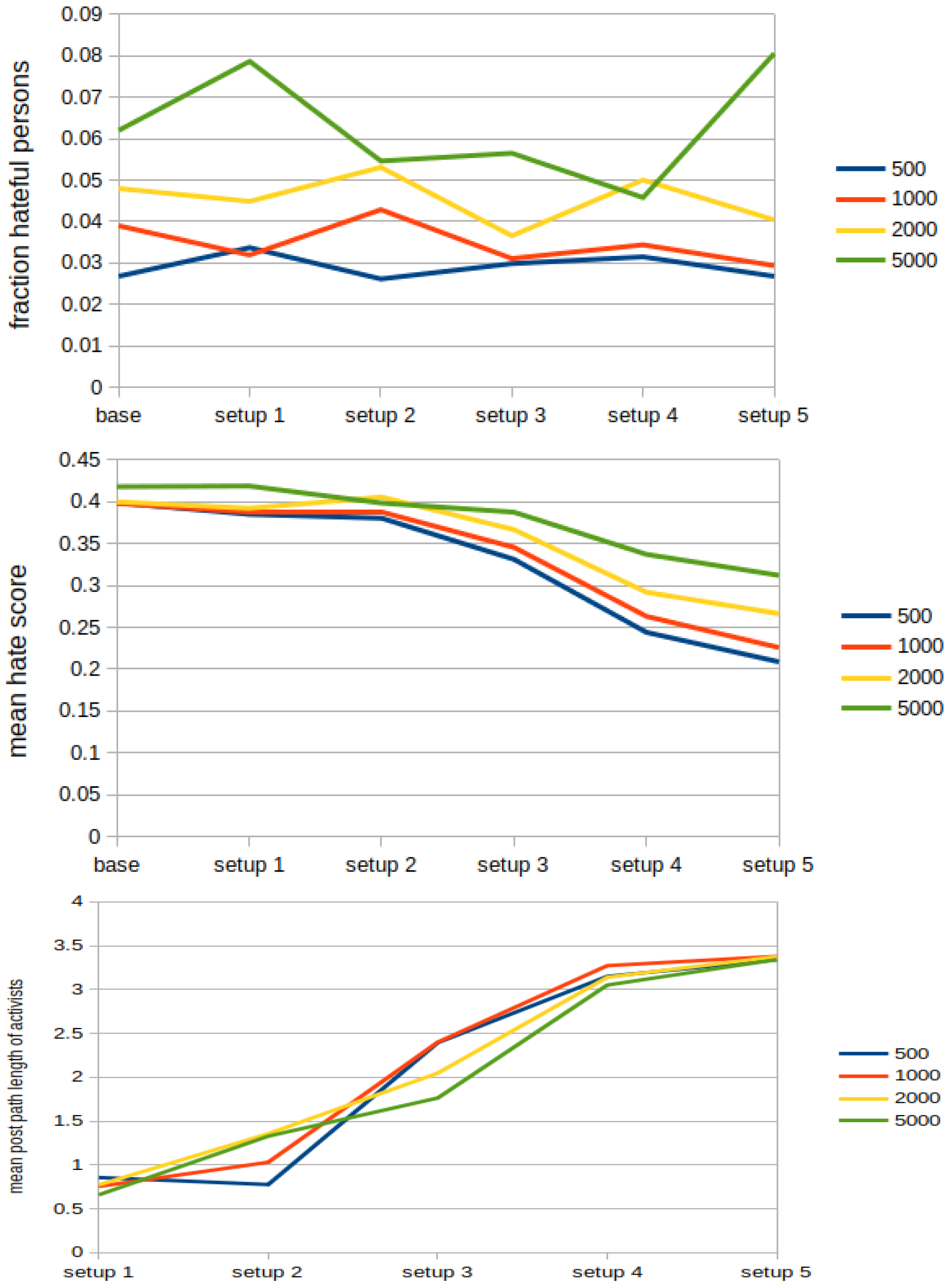
5.3. Counter Activism
- On becoming activist (denoted as a), a person spawns additional following connections to the group of all activists (in the code, this limit is set with the variable ), which are answered with the probability (in the code, probability appears as ).
- Activists are as active as hateful users and, thus, they publish posts with the probability at every round (in the code, probability appears as ).
- The maximal amount of reposts that an activist can perform per round is set to so that they promote non-hateful content frequently (in the code, appears as ). However, they never repost any content of haters (and vice versa) and the reposting probabilities are , and (in the code, these probabilities appear as p_activist_reposts_activist and , respectively).
6. Simulation Results
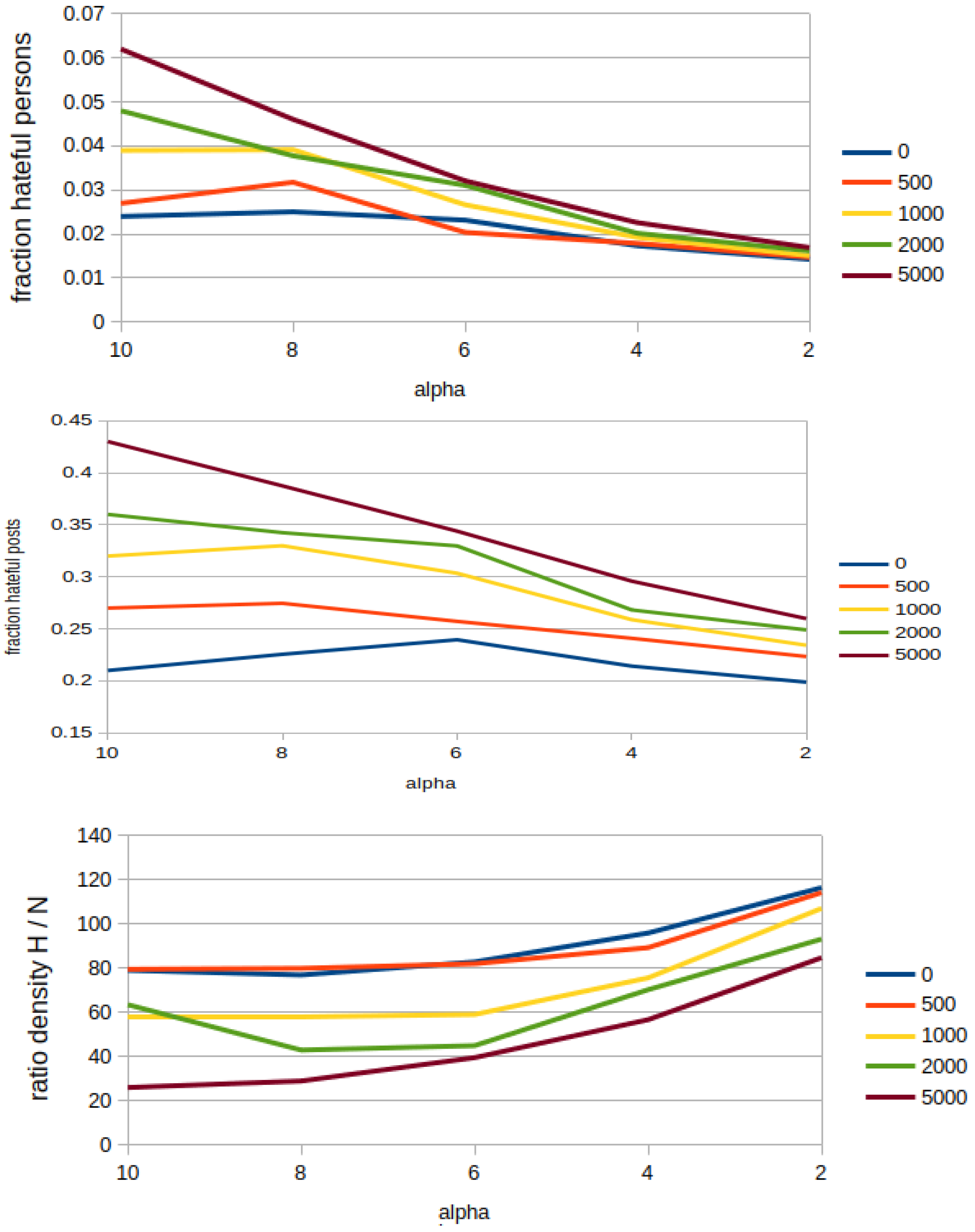
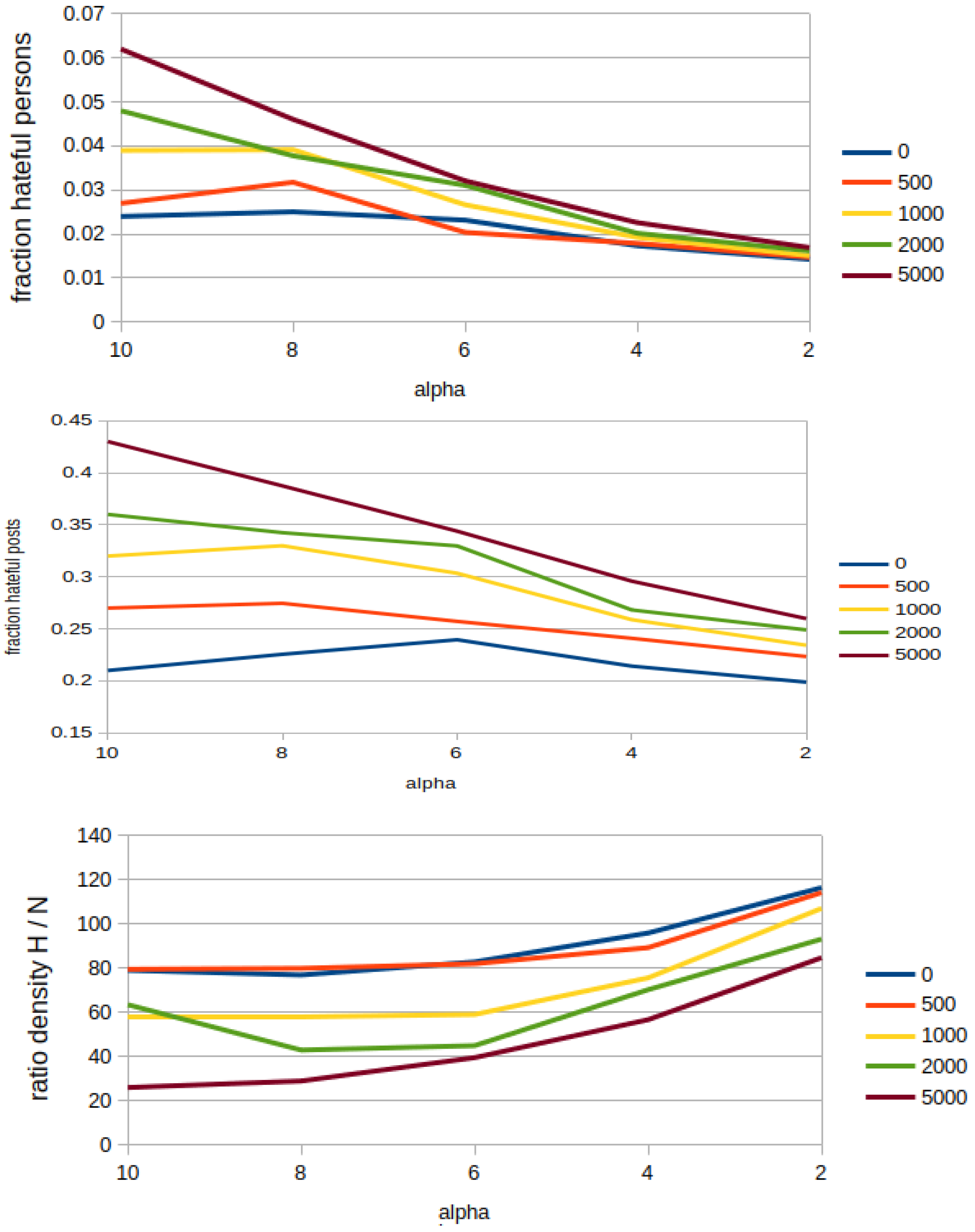
- Fractions of normal and hateful persons, which correspond, respectively, to the proportion of the normal and hateful persons over the whole network population.
- Fractions of normal and hateful posts: the proportion of posts authored by hateful and normal users over the whole amount of posts that exist at the current round. Notice that the amount of posts per round can be much higher than the amount of existing persons, because of the possibility to repost multiple posts from the own neighbours.
- Mean and standard deviation of hate score distribution within the society.
- Ratio of network densities of hateful over normal users, which shows how much the group of hateful users is more cohesive than the group of normal users. Network density for each group is computed as the division of actual_connections/potential_, where and n is the network population. The overall ratio is then computed as the division of both network densities: densities_ratio = network_density_haters/network_density_normals.
- Reciprocity of following within normal or hateful users. When two users follow each other (i.e., a followee back-follows its follower) we count these two links as one reciprocal connection. Then, we compute the number of reciprocal connections divided by all connections within a specific group—be it the haters or the group of normal users.
- Mean followers and mean followees, e.g., mean followers corresponds to the average amount of out-going influence connections over a group of (hateful or normal) persons.
- Mean ratio follower/followee: the average of out-going/in-coming influence connections. This metric shows the connectivity profile in terms of following relations and is of interest because haters are known to have less followers than the following connections their create.
- Mean path length of reposts through the network: the average over all post path lengths through the network. It is computed considering that each post generates multiple paths if reposted by different followers.
- Fraction of swaps to a hateful society: proportion of runs which end with a swap (i.e., having more than 30% of hateful users, see Section 3). Those are not taken into account for none of the above metrics due to the instability they introduce. Instead, they are tracked separately through this specific metric.
6.1. Validating the Baseline Model
6.2. Countermeasures Simulation Results
6.2.1. Educational Bias
6.2.2. Deferring Hateful Content
6.2.3. Counter Activism
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABM | Agent-Based Modelling |
| ACG | Average Consensus Gossiping |
| a.k.a | also kwnon as |
| ca. | circa (about) |
| e.g. | exempli gratia (for example) |
| et al. | et alia (and others) |
| DW | Deffuant–Weisbuch |
| HK | Hegselmann–Krause |
| i.e. | id est (this is) |
References
- Bilewicz, M.; Soral, W. Hate speech epidemic. The dynamic effects of derogatory language on intergroup relations and political radicalization. Political Psychol. 2020, 41, 3–33. [Google Scholar] [CrossRef]
- Cohen-Almagor, R. Fighting hate and bigotry on the Internet. Policy Internet 2011, 3, 1–26. [Google Scholar] [CrossRef]
- Jane, E.A. ‘Back to the kitchen, cunt’: Speaking the unspeakable about online misogyny. Continuum 2014, 28, 558–570. [Google Scholar] [CrossRef]
- Li, Q. Cyberbullying in schools: A research of gender differences. Sch. Psychol. Int. 2006, 27, 157–170. [Google Scholar] [CrossRef]
- Kümpel, A.S.; Rieger, D. Wandel der Sprach-und Debattenkultur in sozialen Online-Medien: Ein Literaturüberblick zu Ursachen und Wirkungen von Inziviler Kommunikation; Konrad-Adenauer-Stiftung e. V.: Berlin, Germany, 2019. [Google Scholar]
- Mathew, B.; Illendula, A.; Saha, P.; Sarkar, S.; Goyal, P.; Mukherjee, A. Hate begets hate: A temporal study of hate speech. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–24. [Google Scholar] [CrossRef]
- Garland, J.; Ghazi-Zahedi, K.; Young, J.G.; Hébert-Dufresne, L.; Galesic, M. Countering hate on social media: Large scale classification of hate and counter speech. arXiv 2020, arXiv:2006.01974. [Google Scholar]
- O’Callaghan, D.; Greene, D.; Conway, M.; Carthy, J.; Cunningham, P. Down the (white) rabbit hole: The extreme right and online recommender systems. Soc. Sci. Comput. Rev. 2015, 33, 459–478. [Google Scholar] [CrossRef]
- Keen, E.; Georgescu, M. Bookmarks: Manual for Combating Hate Speech through Human Rights Education. Council of Europe. 2016. Available online: https://www.coe.int/en/web/no-hate-campaign/compendium/-/asset_publisher/PyHuON7WYezs/content/-bookmarks-a-manual-for-combating-hate-speech-online-through-human-rights-education-?inheritRedirect=false (accessed on 8 November 2012).
- Isasi, A.C.; Juanatey, A.G. Hate Speech in Social Media: A State-of-the-Art Review. Available online: https://ajuntament.barcelona.cat/bcnvsodi/wp-content/uploads/2017/01/Informe_discurso-del-odio_ENG.pdf (accessed on 8 November 2012).
- Gagliardone, I.; Gal, D.; Alves, T.; Martinez, G. Countering Online Hate Speech; Unesco Publishing: Paris, France, 2015. [Google Scholar]
- Johnson, N.; Leahy, R.; Restrepo, N.J.; Velasquez, N.; Zheng, M.; Manrique, P.; Devkota, P.; Wuchty, S. Hidden resilience and adaptive dynamics of the global online hate ecology. Nature 2019, 573, 261–265. [Google Scholar] [CrossRef]
- Chandrasekharan, E.; Pavalanathan, U.; Srinivasan, A.; Glynn, A.; Eisenstein, J.; Gilbert, E. You cannot stay here: The efficacy of reddit’s 2015 ban examined through hate speech. Proc. ACM Hum.-Comput. Interact. 2017, 1, 1–22. [Google Scholar] [CrossRef]
- Van Dam, K.H.; Nikolic, I.; Lukszo, Z. Agent-Based Modelling of Socio-Technical Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 9. [Google Scholar]
- Müller, A.; Lopez-Sanchez, M. Countering Negative Effects of Hate Speech in a Multi-Agent Society. Front. Artif. Intell. Appl. Artif. Intell. Res. Dev. 2021, 339, 103–112. [Google Scholar]
- Sulis, E.; Terna, P. An Agent-based Decision Support for a Vaccination Campaign. J. Med. Syst. 2021, 45, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Le Page, C.; Bazile, D.; Becu, N.; Bommel, P.; Bousquet, F.; Etienne, M.; Mathevet, R.; Souchere, V.; Trébuil, G.; Weber, J. Agent-based modelling and simulation applied to environmental management. In Simulating Social Complexity; Springer: Berlin/Heidelberg, Germany, 2013; pp. 499–540. [Google Scholar]
- Ahrweiler, P.; Schilperoord, M.; Pyka, A.; Gilbert, N. Modelling research policy: Ex-ante evaluation of complex policy instruments. J. Artif. Soc. Soc. Simul. 2015, 18, 5. [Google Scholar] [CrossRef] [Green Version]
- Mathew, B.; Kumar, N.; Goyal, P.; Mukherjee, A. Interaction dynamics between hate and counter users on Twitter. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, Hyderabad, India, 5–7 January 2020; pp. 116–124. [Google Scholar]
- Frischlich, L.; Schatto-Eckrodt, T.; Boberg, S.; Wintterlin, F. Roots of incivility: How personality, media use, and online experiences shape uncivil participation. Media Commun. 2021, 9, 195–208. [Google Scholar] [CrossRef]
- Ribeiro, M.; Calais, P.; Santos, Y.; Almeida, V.; Meira, W., Jr. Characterizing and detecting hateful users on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]
- Mathew, B.; Dutt, R.; Goyal, P.; Mukherjee, A. Spread of hate speech in online social media. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 173–182. [Google Scholar]
- Ling, C.; AbuHilal, I.; Blackburn, J.; De Cristofaro, E.; Zannettou, S.; Stringhini, G. Dissecting the Meme Magic: Understanding Indicators of Virality in Image Memes. arXiv 2021, arXiv:2101.06535. [Google Scholar] [CrossRef]
- Soral, W.; Bilewicz, M.; Winiewski, M. Exposure to hate speech increases prejudice through desensitization. Aggress. Behav. 2018, 44, 136–146. [Google Scholar] [CrossRef]
- Calvert, C. Hate speech and its harms: A communication theory perspective. J. Commun. 1997, 47, 4–19. [Google Scholar] [CrossRef]
- Dimakis, A.G.; Kar, S.; Moura, J.M.; Rabbat, M.G.; Scaglione, A. Gossip algorithms for distributed signal processing. Proc. IEEE 2010, 98, 1847–1864. [Google Scholar] [CrossRef] [Green Version]
- DeGroot, M.H. Reaching a consensus. J. Am. Stat. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Friedkin, N.E.; Johnsen, E.C. Social influence and opinions. J. Math. Sociol. 1990, 15, 193–206. [Google Scholar] [CrossRef]
- Hegselmann, R.; Krause, U. Opinion dynamics and bounded confidence models, analysis, and simulation. J. Artif. Soc. Soc. Simul. 2002, 5, 1–33. [Google Scholar]
- Weisbuch, G. Bounded confidence and social networks. Eur. Phys. J. B 2004, 38, 339–343. [Google Scholar] [CrossRef] [Green Version]
- Terizi, C.; Chatzakou, D.; Pitoura, E.; Tsaparas, P.; Kourtellis, N. Angry Birds Flock Together: Aggression Propagation on Social Media. arXiv 2020, arXiv:2002.10131. [Google Scholar]
- Jager, W.; Amblard, F. Uniformity, bipolarization and pluriformity captured as generic stylized behavior with an agent-based simulation model of attitude change. Comput. Math. Organ. Theory 2005, 10, 295–303. [Google Scholar] [CrossRef] [Green Version]
- Sherif, M.; Hovland, C.I. Social Judgment: Assimilation and Contrast Effects in Communication and Attitude Change; Yale University Press: London, UK, 1961. [Google Scholar]
- Stefanelli, A.; Seidl, R. Opinions on contested energy infrastructures: An empirically based simulation approach. J. Environ. Psychol. 2017, 52, 204–217. [Google Scholar] [CrossRef]
- Schieb, C.; Preuss, M. Considering the Elaboration Likelihood Model for simulating hate and counter speech on Facebook. SCM Stud. Commun. Media 2018, 7, 580–606. [Google Scholar] [CrossRef]
- Petty, R.E.; Cacioppo, J.T. The elaboration likelihood model of persuasion. In Communication and Persuasion; Springer: Berlin/Heidelberg, Germany, 1986; pp. 1–24. [Google Scholar]
- Janssen, M.A. Agent-based modelling. Model. Ecol. Econ. 2005, 155, 172–181. [Google Scholar]
- Moon, J.W.; Moser, L. On cliques in graphs. Isr. J. Math. 1965, 3, 23–28. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Llansó, E.J. No amount of “AI” in content moderation will solve filtering’s prior-restraint problem. Big Data Soc. 2020, 7, 2053951720920686. [Google Scholar] [CrossRef] [Green Version]
- Howard, J.W. Free speech and hate speech. Annu. Rev. Political Sci. 2019, 22, 93–109. [Google Scholar] [CrossRef]
- Leets, L. Experiencing hate speech: Perceptions and responses to anti-semitism and antigay speech. J. Soc. Issues 2002, 58, 341–361. [Google Scholar] [CrossRef]
- Dharmapala, D.; McAdams, R.H. Words that kill? An economic model of the influence of speech on behavior (with particular reference to hate speech). J. Leg. Stud. 2005, 34, 93–136. [Google Scholar] [CrossRef]
- Liu, P.; Guberman, J.; Hemphill, L.; Culotta, A. Forecasting the presence and intensity of hostility on Instagram using linguistic and social features. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]
- Hrdina, M. Identity, activism and hatred: Hate speech against migrants on Facebook in the Czech Republic in 2015. Nase Spol. 2016, 1. [Google Scholar] [CrossRef]
- Wright, L.; Ruths, D.; Dillon, K.P.; Saleem, H.M.; Benesch, S. Vectors for counterspeech on twitter. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 57–62. [Google Scholar]
- Miškolci, J.; Kováčová, L.; Rigová, E. Countering hate speech on Facebook: The case of the Roma minority in Slovakia. Soc. Sci. Comput. Rev. 2020, 38, 128–146. [Google Scholar] [CrossRef]
- Schieb, C.; Preuss, M. Governing hate speech by means of counterspeech on Facebook. In Proceedings of the 66th Ica Annual Conference, Fukuoka, Japan, 9–13 June 2016; pp. 1–23. [Google Scholar]
- De Franco, M. #DecidimFest 2019: Strategies and Alliances to Curb Hate and Fear in a Polarized World. 2020. Available online: https://meta.decidim.org/conferences/decidimfest2020/f/1390/meetings/1453 (accessed on 19 November 2020).
- Fruchterman, T.M.; Reingold, E.M. Graph drawing by force-directed placement. Softw. Pract. Exp. 1991, 21, 1129–1164. [Google Scholar] [CrossRef]
- Aluru, S.S.; Mathew, B.; Saha, P.; Mukherjee, A. Deep Learning Models for Multilingual Hate Speech Detection. arXiv 2020, arXiv:2004.06465. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Opinion Diffusion Starts after t Ticks | ||||
|---|---|---|---|---|---|
| 0 | 500 | 1000 | 2000 | 5000 | |
| Fraction of H users | 0.024 | 0.027 | 0.039 | 0.048 | 0.062 |
| Fraction of posts by H | 0.210 | 0.256 | 0.320 | 0.361 | 0.429 |
| Ratio network density H/N | 79.130 | 79.605 | 58.116 | 63.550 | 26.061 |
| Reciprocity between N | 0.888 | 0.886 | 0.888 | 0.887 | 0.889 |
| Reciprocity between H | 0.725 | 0.751 | 0.736 | 0.758 | 0.761 |
| Mean followers of N | 1.783 | 1.774 | 1.772 | 1.770 | 1.765 |
| Mean followers of H | 2.312 | 2.626 | 2.382 | 2.450 | 2.263 |
| Mean followees of N | 1.788 | 1.784 | 1.784 | 1.784 | 1.780 |
| Mean followees of H | 2.311 | 2.383 | 2.155 | 2.144 | 2.025 |
| Mean follower/followee of N | 0.884 | 0.880 | 0.883 | 0.878 | 0.878 |
| Mean follower/followee of H | 0.763 | 0.826 | 0.880 | 0.815 | 0.784 |
| Mean path length N posts | 0.699 | 0.693 | 0.706 | 0.704 | 0.705 |
| Mean path length H posts | 1.738 | 2.148 | 2.274 | 2.357 | 2.627 |
| Experiment Setup | |||||
|---|---|---|---|---|---|
| # 1 | # 2 | # 3 | # 4 | # 5 | |
| Convincing probability | 0.01 | 0.01 | 0.04 | 0.01 | 0.01 |
| Additional connections to other activists | 1 | 2 | 1 | 2 | 2 |
| Fixed opinion (stubbornness) | false | false | false | true | true |
| Select activists by their influence | false | false | false | false | true |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez-Sanchez, M.; Müller, A. On Simulating the Propagation and Countermeasures of Hate Speech in Social Networks. Appl. Sci. 2021, 11, 12003. https://doi.org/10.3390/app112412003
Lopez-Sanchez M, Müller A. On Simulating the Propagation and Countermeasures of Hate Speech in Social Networks. Applied Sciences. 2021; 11(24):12003. https://doi.org/10.3390/app112412003
Chicago/Turabian StyleLopez-Sanchez, Maite, and Arthur Müller. 2021. "On Simulating the Propagation and Countermeasures of Hate Speech in Social Networks" Applied Sciences 11, no. 24: 12003. https://doi.org/10.3390/app112412003
APA StyleLopez-Sanchez, M., & Müller, A. (2021). On Simulating the Propagation and Countermeasures of Hate Speech in Social Networks. Applied Sciences, 11(24), 12003. https://doi.org/10.3390/app112412003