1. Introduction
Nowadays, there is growing controversy regarding the emergence of polarization in discussions on social networks, and the responsibility of companies in this problem. For example, Facebook researchers have studied the spread of divisive content on the platform [
1,
2]. One of their findings is that users with hyperactive engagement are far more partisan on average than normal users. Facebook has launched some initiatives to try to mitigate the factors that may be helping the spread of such content [
3]. For example, they re-calibrated the prioritization of content in users’ News Feeds to give more preference to posts of friends and family over news content, justified by the findings that suggest that people derive more “meaningful social interactions”, or MSI, when they engage with people they know, although it is not clear what exactly comprises a meaningful social interaction for Facebook. Other actions include improving the detection of fake accounts and removing recommendations of pages that violate Facebook Community Standards or are rated false by their fact checkers.
However, the findings of Facebook suggest that completely fixing the polarization problem may be difficult. As they commented in an internal company presentation [
4], Facebook algorithms exploit the human brain’s attraction to divisiveness and tend to feed users with more and more divisive content, which seems to ensure that users will spend more time on the platform. Publishers and political parties reorient their posts toward outrage and sensationalism since this produces high levels of comments and reactions. Some political parties in Europe event told Facebook that the algorithm made them shift their policy positions. However, because engagement is of course fundamental for the profit of the company, social network companies should be cautious to not react disproportionately when trying to mitigate polarization.
In spite of all these issues, it is worth noticing that it is not clear how much responsibility we can give to social networks on these problems. For example, there is some work that indicates that, at least for polarization in people’s views of political parties, the increased use of social networks and the internet may not be necessarily increasing polarization [
5]. Putting aside whether specific social network platforms are more or less responsible for polarization, it is clear that what companies, or policymakers, can do is to define more transparent ways to monitor such possible non-desirable behaviors so that we can decide to act only in situations where there is some objective measure that polarization is taking place and to a certain level of severity.
Previous work has studied the presence of polarization in different concrete examples, trying to analyze the relevant characteristics in these cases. For example, the works [
6,
7] studied the emergence of so-called echo chambers, where users are found to interact mainly only with the users that agree with them and to have very few interactions with other groups. However, online discussions in social networks can also show polarization where there are answers with negative sentiment between different groups, which can be considered the most worrying situation. For example, in [
8] they studied hyperpartisanship and polarization in Twitter during the 2018 Brazilian presidential election. Their findings showed that there was more interaction within each group (pro/anti Bolzonaro) but there was also an interaction between both groups. Actually, there are also cases where the interaction between groups can be more relevant than those within groups, like in the case studied in [
9] where the analysis of the 2016 U.S. elections on Reddit showed a significant number of interactions between pro-Trump and pro-Hillary supporters. It is worth noting that the existence of polarization in debates could be partially explained as a consequence of the spiral of silence theory [
10]. In this theory, the public opinion about emotionally and morally laden issues is considered to be driven toward one opinion that receives the strongest support from people and mass media. In contrast, people with contrary opinions suffer isolation pressure from the supporters of the majority opinion, which makes them hide their opinions (or not defend them strongly). Thus, the existence of polarization around a certain topic can be explained as the result of a spiral of silence, where two strongly defended, but opposed, opinions tend to attract the attention of all the people and the isolation pressure forces them to join one of the sides. So, we may consider that, in fact, two opposing spirals emerge as a result. However, it is clear that around certain topics, in certain societies, there may exist a clear majority opinion that can makes it difficult for the emergence of secondary publicly supported opinions. For example, in [
11], it was studied the effect of governmental internet surveillance around the controversial topic of U.S. airstrikes against ISIS terrorists.
Our main focus in this work is to give a more clear and quantitative model for measuring polarization in an online debate such that this behavior can be monitored for generating a warning signal when necessary, that is, to detect communication patterns where users seem to interact positively only with a fixed group of users and negatively with the rest. Among the many online debating platforms that exist, in this work, we consider Reddit. Reddit (available at
http://www.reddit.com/) is a social news aggregation, web content rating, and discussion website. Users submit content to the site, such as links, text posts, and images, which are then voted up or down by other members who, in turn, can comment on others’ posts to continue the conversation. This online debating platform is widely used to create long and deep debates with comments and answers to comments, where, thanks to the almost unlimited text length of Reddit comments (40,000 characters), users can express their opinions more accurately, compared to other online debating platforms, such as Twitter which restricts the number of characters to 280.
As previous works seem to indicate that in a debate we can have interactions in two ways (within groups and between groups), an important aspect of our model is that it allows us to quantify the relevance of the kinds of interactions present. Our model is inspired by the model used in [
12] to identify supporting or opposing opinions in online debates, based on finding a maximum cut in a graph that models the interactions between users. In our case, as we are interested in quantifying polarization, we define a model that is based on a weighted graph and with labeled edges, where node weights represent the side of the user in the debate and edge labels represent the overall sentiment between two users. Then, given a bipartition of this graph, in our model, the polarization degree of the bipartition is based on how homogeneous each partition is and how negative the interactions are between both partitions. Finally, our measure of debate polarization is based on the maximum polarization we have in all the possible bipartitions of the graph.
The structure of the rest of the paper is as follows. In
Section 2, we present our user-based model to represent Reddit debates, the User Debate Graph, where a node represents a user’s opinion as to its whole set of comments in the debate. In
Section 3, we define a measure to quantify the polarization in a debate that is based on a value defined over bipartitions of the user debate graph. In
Section 4, we introduce a greedy local search optimization algorithm for finding the polarization of a debate, based on searching a bipartition with the highest possible polarization value. Finally, in
Section 5, we perform an empirical evaluation of the polarization value obtained with our algorithm with different Reddit debates.
2. User-Based Model for Reddit
In this section, we present a computational model to represent a Reddit debate that allows us to study the polarization of the debates based on the interactions between the participants. In Reddit, debates are generated from a main (root) comment that contains a link to some news and a set of comments, where each comment, except for the root comment, answers exactly one previous comment, usually by another user or author. These answers between comments lead to positive, negative or neutral interactions, and their analysis will allow us to classify users into three groups: users that are in agreement with the root comment of the debate, users that are in disagreement with it, and undecided users.
In order to analyze the agreement and disagreement between user comments in Reddit debates, recently in [
13], we defined an analysis system that represents a Reddit debate as a two-sided debate graph. In this graph, comments are divided into two groups, the ones that agree with the root comment of the debate, and the ones that disagree with it. The edges of the graph represent disagreement between the comments of the two groups. So, in this work, we use the two-sided debate model as a starting point to build the user-based model to study the polarization of the debates based on the interactions between the participants.
Following [
13], we first formalize the notions of a comment and Reddit debate for a root comment.
Definition 1 (Reddit comment and debate). A Reddit comment is a pair , where m is the text of the comment and u is the user’s identifier of the comment.
Let and be two comments. We say that answers if is a reply to the comment .
Let be a comment such that contains a link to some news. A Reddit debate on r is a non-empty set Γ of Reddit comments such that and every comment , , c answers a previous comment in Γ. We refer to r as the root comment of Γ.
Given the structure of a Reddit debate on a root comment r, the next step is to extract the relationships between the comments in . We represent as a labeled tree, where each comment gives rise to a node, and edges denote answers between comments and are labeled with a value in the real interval . The label for an edge denotes the sentiment expressed in the text of the comment in response to the text of the comment so that the value denotes a total disagreement and the value 2 a total agreement. We use the sentiment value 0 to denote both answers expressing a neutral position with respect to the opinion expressed in , and answers expressing, at the same time, agreement with part of the opinion expressed in , and disagreement with another part of .
Definition 2 (Debate Tree). Let Γ be a Reddit debate on a root comment r. A Debate Tree (DebT) for Γ is a tuple such that the following is true:
For every comment in Γ, there is a node in C;
Node is the root node of ;
If answers , then there is a directed edge in E, and
W is a labeling function of edges , where the value assigned to an edge denotes the sentiment of the answer, from highly negative (−2) to highly positive (2).
Only the nodes and edges obtained by applying this process belong to C and E, respectively.
Given a Reddit debate, we make its corresponding DebT using the Python Reddit API Wrapper (PRAW, available at
https://github.com/praw-dev/praw) to download its set of comments, and then we evaluate the sentiment for an edge (
,
) in the DebT using the sentiment analysis software of [
14] using the text of the comment
, where the value assigned denotes the sentiment of the answer, from highly negative (−2) to highly positive (2).
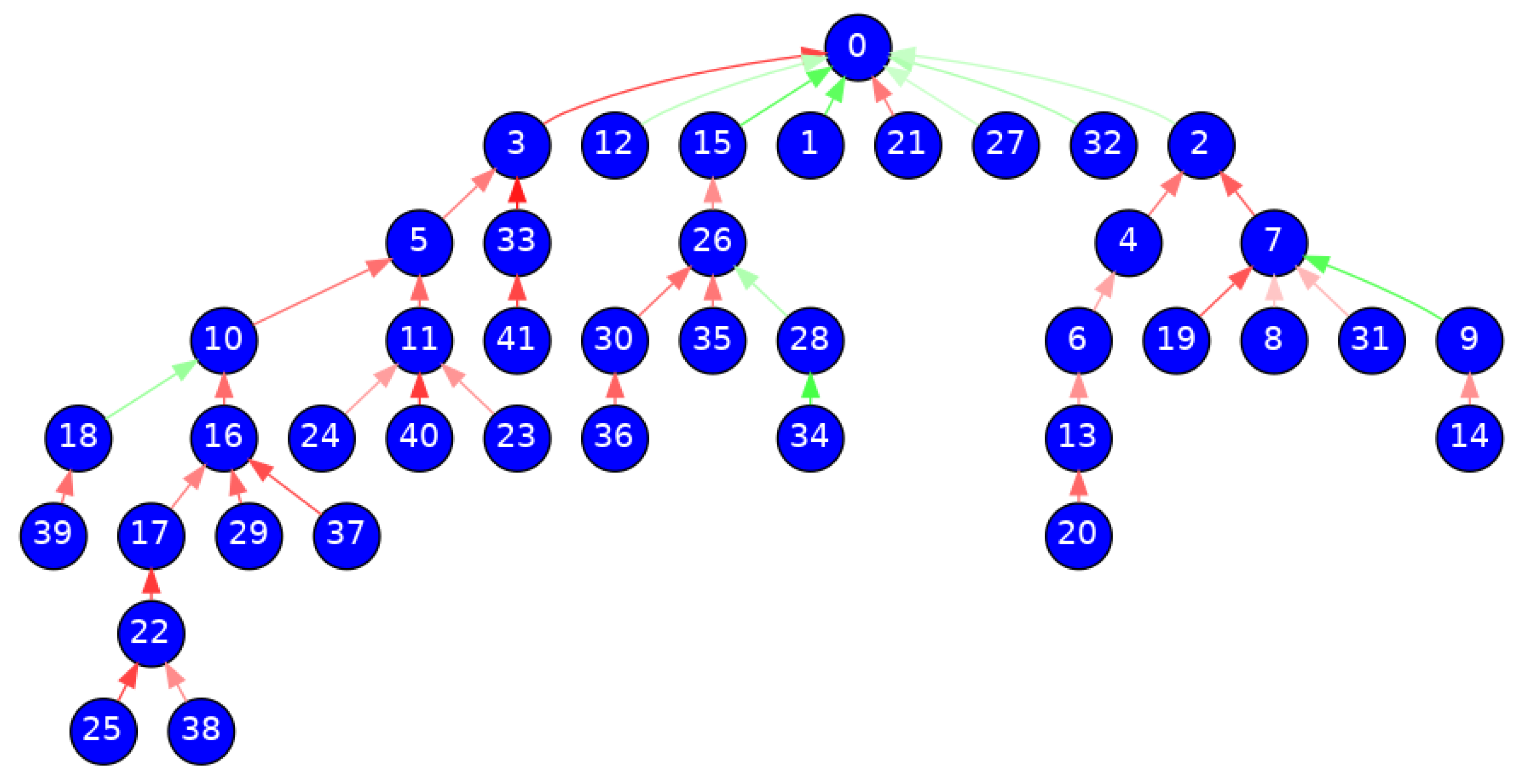
In
Figure 1, we show the DebT structure for a Reddit debate of the subreddit World News (r/worldnews) (
https://www.reddit.com/r/worldnews/comments/f62i35 accessed on 4 October 2020). Each comment is represented as a node, and each answer between comments is represented as an edge. The graph has 42 nodes and 41 edges since each comment responds exactly to one comment, except for the root comment. These 41 answers between comments are classified as agreement edges (painted in green color) and disagreement edges (painted in red color), and there is no neutral answer. The darkness of the color is directly proportional to the sentiment of the answer concerning the maximum value. The root comment of the discussion is labeled with 0, and the other comments are labeled with consecutive identifiers according to their generation order. Notice that the graph is acyclic since a comment only answers a previous comment in the discussion. Additionally, most of the answers are disagreement answers, and they seem to generate the longest discussion paths in the DebT. However, this model does not allow to infer directly neither the set of the most dominant users’ opinions between the different users in the debate, nor the position of every user concerning the root comment since the information of each user is represented by multiple nodes and edges in the DebT.
Analyzing the relationships between the DebT nodes, we classify the comments into two groups: comments that support the root comment and comments that disagree with it. With this objective, we extend the DebT structure with a labeling function of nodes denoting the side of each comment in the debate. We label the comments that support the root comment with 1 and the rest of the comments with . We refer to this tree extension as a two-sided debate tree.
Definition 3 (Two-sided debate tree). Let be a DebT for a Reddit debate Γ on a root comment r. A two-sided debate tree (SDebT) for is a tuple such that S is a labeling function of nodes defined as follows:
;
For all node in C, if for some node , and either and , or and ; otherwise, .
To evaluate the side of a comment
expressing a neutral position with respect the opinion expressed in
, i.e., with
, we consider a similar approach to the proposal of Murakami and Raymond [
12]. In their proposal, they consider neutral opinions to be (slightly) negative. The motivation for this is the realization of Agrawal et al. [
15] that, in newsgroups, people respond more frequently when they disagree. In Reddit, for example, when users agree with a comment, they can simply upvote without leaving any response. When users disagree, on the other hand, they can downvote, but it is more likely that they expose their reasons. Thus, from this perspective, a neutral response would be expressing more disagreement than agreement.
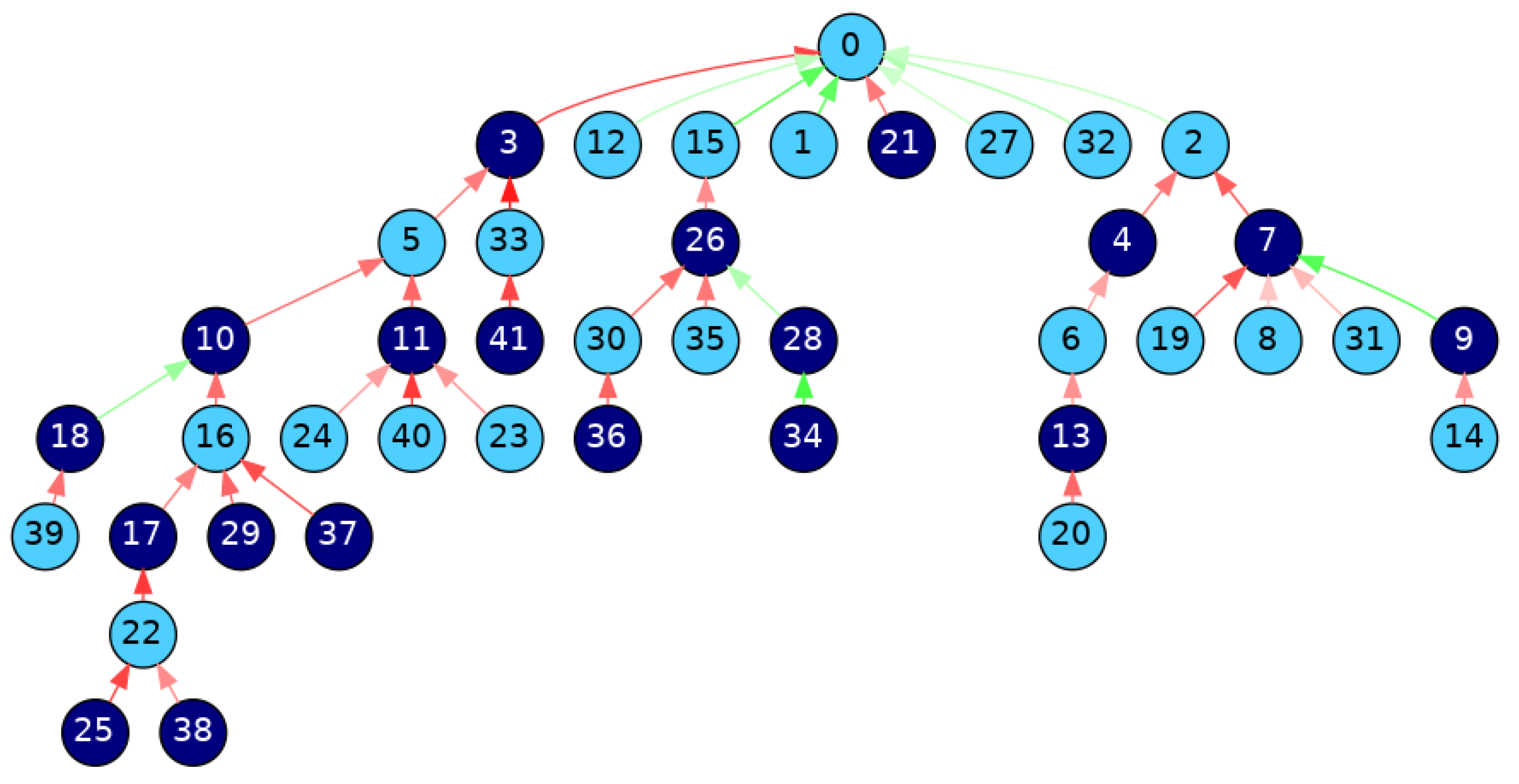
Figure 2 shows the SDebT structure we obtain for the Reddit debate of
Figure 1. The nodes (comments) that support the root comment are colored in cyan, while the rest are colored in navy blue.
At this point, we have classified the comments of a Reddit debate according to whether or not they offer support to the root comment and we have labeled the interactions between them according to the sentiment they express. So, to develop a quantitative model for measuring polarization in a Reddit debate, the next step is to introduce and investigate a suitable user-based model that allows us to represent the different interactions between the users to discover groups that either support or reject the root comment of the debate and how far these groups can be considered to be concerning each other.
To this end, once the comments are classified into two sides, in favor or against the root comment, we group comments by the user and we consider that the relationship between users’ opinions of two users is defined from the agreement and disagreement relationships between the individual comments of these two users. When we represent a debate grouping comments by users, interactions between different users can give rise to circular agreement and disagreement relationships, and the agreement or disagreement of a user concerning the opinion of another user in the debate should be defined by aggregating the set of single interactions that have occurred between them during the debate.
Given a debate on a root comment r with users’ identifiers , we define the opinion of the user , denoted , as the set of comments of in , except for the root comment r. We consider debates in which users are not self-referenced. That is, for all user and each pair of comments and , we assume does not respond to , nor to . Considering the particular case of root users (the users who post the root comment), we notice that when they do not participate in the debate, their opinion is empty, denoting that they have only posted the (root) news while staying passive throughout the debate. This is intentional since the root comment plays a special role in the debate, setting its topic. Thus, to be considered a “true participant” in the debate, the root user should contribute during the discussion. Notice that the Reddit platform itself distinguishes between root and non-root comments, as it provides two different global user metrics, Post Karma and Comment Karma, where the first one corresponds to the points achieved by posting interesting news (root comments) and the second one corresponds to the points achieved from non-root comments (debate generated on some root comment).
Next, we formalize the graph that we propose to represent user-based debates, called User Debate Graph, where the nodes are the users of the debate denoting their opinion concerning the root comment and the edges denote interactions between users mined from the prevailing sentiment among the aggregated comments of nodes. In addition, we define two weighting schemes: an opinion weighting scheme for nodes that associates every node of the graph with a side value representing the side of the user in the debate and an interaction weighting scheme for edges that associates every edge of the graph with a pair of values representing the overall sentiment of agreement or disagreement between users. For both schemes, we propose a skeptical approach based on stating that a user completely agrees or disagrees with a root comment or with another user if and only if one can be completely sure of it.
In a debate, a user can answer comments of different users, and thus, can agree or disagree with several users. This fact is represented in the User Debate Graph with a different edge for each user. However, if a user answers several comments of a same user , the interaction between them is represented with a single edge in the User Debate Graph, and with a single sentiment value which is meant to be defined from the set of the sentiment of the answers of the user to the user , i.e., from the set of weights . Moreover, a user can agree with part of a user’s opinion and disagree with the rest. To reflect the possible ambivalence between the users’ opinions, we also attach the edges of the User Debate Graph with a value that represents the ratio of interactions that agree with the users’ opinions.
Retaining this information is crucial for the analysis of the debate since, depending on how we aggregate the sentiments, a single highly negative comment could outweigh several moderately positive ones (or vice versa). By storing both values (aggregated sentiment and ratio of positive answers), we can differentiate between consistent interactions with moderate opinions and interactions whose aggregated sentiment seems moderate but is a combination of inconsistent (positive and negative) responses.
Definition 4 (User Debate Graph). Let Γ be a Reddit debate on a root comment r with users’ identifiers and let be a SDebT for Γ. A User Debate Graph (UDebG) for is a tuple , where:
is the set of nodes of defined as the set of users’ opinions ; i.e., with , for all users .
is the set of edges of defined as the set of interactions between different users in the debate, i.e., there is an edge , with and , if and only if for some we have that and .
is an opinion weighting scheme for that expresses the side of users in the debate based on the side of their comments. We define as the mapping that assigns to every node the valuein the real interval that expresses the side of the user with respect to the root comment, from strictly disagreement (−1) to strictly agreement (1), going through undecided opinions (0). is an interaction weighting scheme for that expresses both the ratio of positive interactions between the users’ opinions and the overall sentiment between users by combining the individual sentiment values assigned to the responses between their comments.
Let ⊕ be an aggregation operator of dimension n on the real interval , i.e., a bounded, monotonic, symmetric, and idempotent mapping . We define as the mapping that assigns to every edge the pair of values defined as follows:where p expresses the ratio of positive answers from the user to the user in the debate, and w expresses the overall sentiment of the user regarding the comments of the user , from highly negative (−2) to highly positive (2). Only the nodes and edges obtained by applying this process belong to and , respectively.
Notice that if a user only responds to the news of the debate (the root comment r), the user is mapped in the UDebG to a node in with zero output degree denoting that the user starts no discussion with other users. In addition, users whose comments do not generate answers from other users are represented with nodes whose input degree is zero. Therefore, isolated nodes may appear in the UDebG that correspond to users who have neither generated nor participated in the debate, that is, users that have only answered to the news and whose opinions can be considered to be accepted by all users since they have not been discussed yet.
In the UDebG, each node denotes a user’s opinion, and relationships between nodes are mined from the prevailing sentiment among the aggregated comments of those nodes. For instance, if we instantiate the aggregation operator ⊕ to the minimum function, we obtain a pessimistic interpretation of the degree of agreement and disagreement among users since it represents the fact that in a debate with multiple negative and positive responses from one user to another, a pessimistic analysis focuses on the most negative response and in the case of multiple positive responses, on the softest positive response. Similarly, the maximum operator corresponds to an optimistic interpretation and the mean operator to a more realistic interpretation based on an intermediate weight. Furthermore, the ratio of positive answers is either 1 or 0, only for strictly agreement or disagreement relationships, respectively, between users’ opinions; thus, the ratio of positive answers is a value in only for ambivalent relationships.
Finally, since the edges between nodes in the UDebG can reflect ambivalent relationships between users’ opinions, in our current user-based model, we do not consider indirect (transitive) relationships between users, and thus, the UDebG shows interactions between users only if there is enough evidence of such relationships through direct answers between authors’ comments. Moreover, the UDebG for a given SDebT may contain cycles, and these cycles provide fundamental information about the different relationships that are established from the interactions between different users.
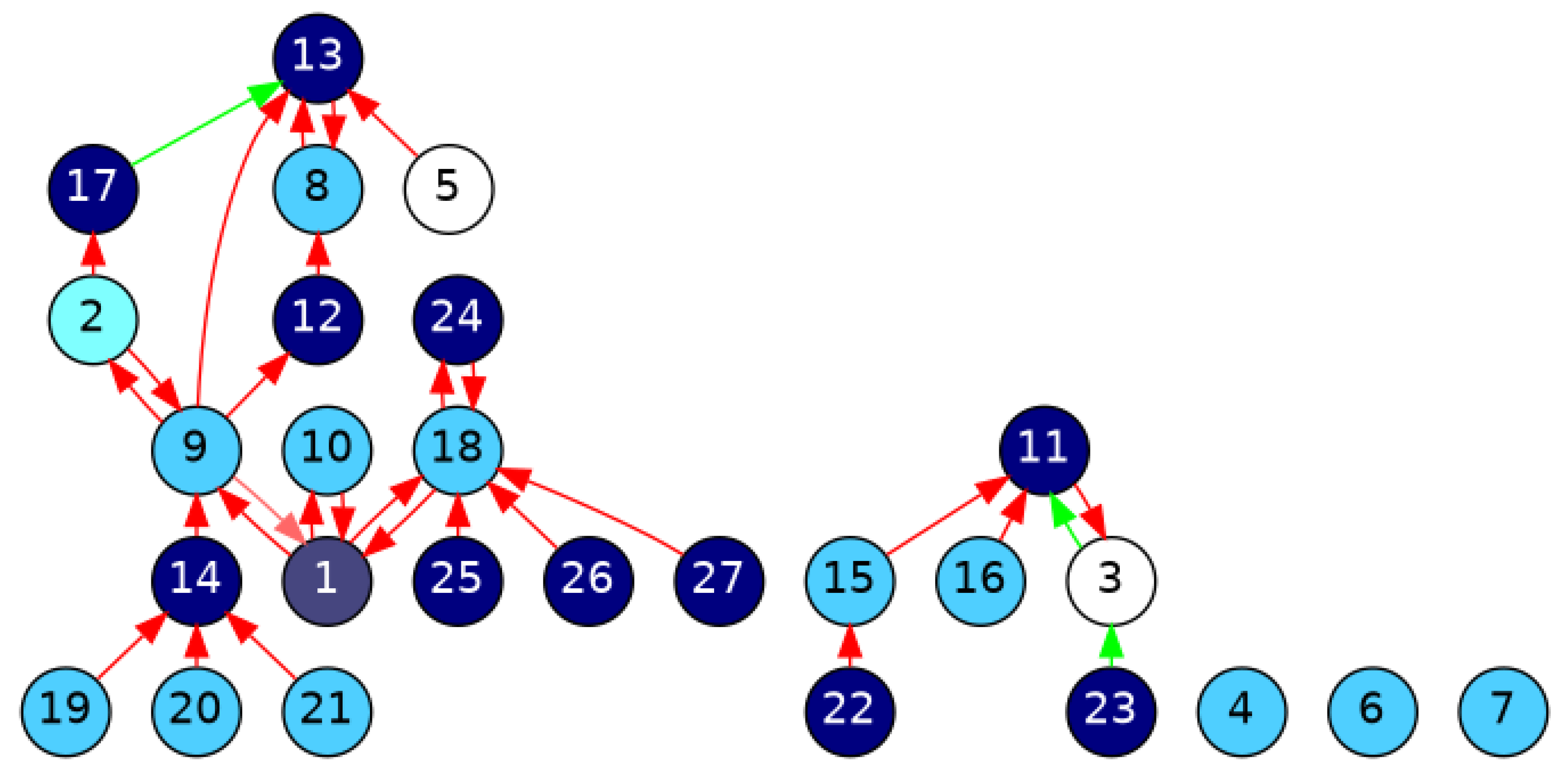
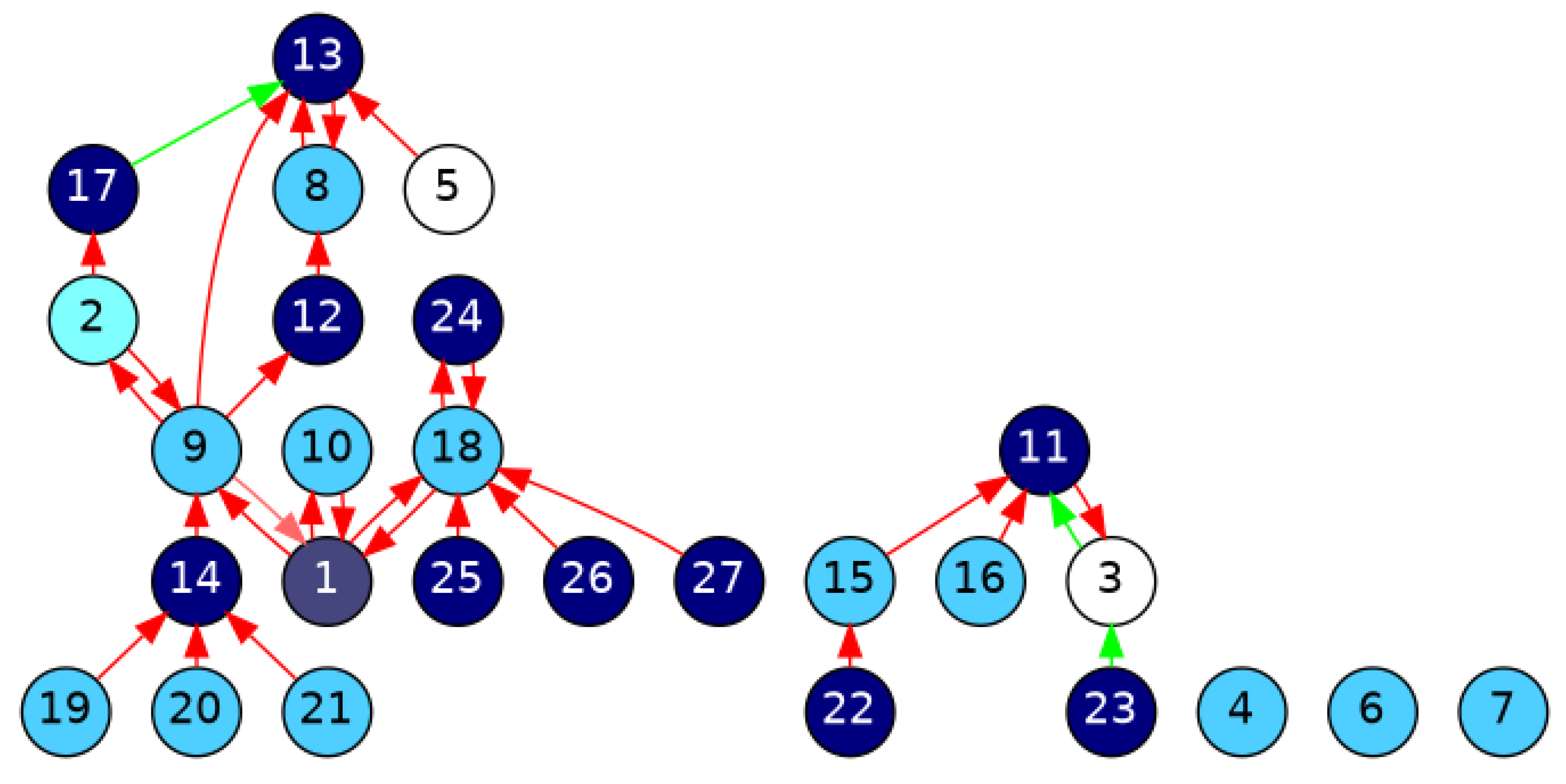
Figure 3 shows the UDebG structure we obtain for the two-sided debate tree of
Figure 2. Each user’s opinion is represented as a node, and each relationship between them is represented as an edge. The graph has 27 nodes and 31 edges; the overall sentiment for edges is evaluated using the mean operator, which leads to three agreement relationships, with the rest being disagreement. The edges are colored in green and red to denote agreement and disagreement relationships between users’ opinions, respectively, and the darkness of the color is directly proportional to the ratio of positive and negative answers among analyzed users. The nodes are colored with different colors to denote the side of users’ opinions in the debate based on the weighting scheme
. The nodes colored in cyan correspond with users whose opinion supports the root comment, i.e., nodes
with
, the nodes colored in navy blue denote disagreement opinions, i.e.,
, and white nodes denote undecided opinions, i.e.,
. In this case, the darkness of the color reflects the proportion of user comments for and against the root comment.
3. Debate Polarization
Given a User Debate Graph ,, we propose a model to measure the level of polarization in the debate between its users. We identify two characteristics that a polarization measure should capture. First, a polarized debate should contain a bipartition of into two sets such that the set L contains mainly users in disagreement, the set R contains mainly users in agreement, and both sets should be similar in size. The second ingredient is the sentiment between users of L and R. A polarized discussion should contain most of the negative interactions between users of L and users of R, whereas the positive interactions, if any, should be mainly within the users of L and within the users of R.
We believe that both factors are relevant, as the existence of only the first characteristic can indicate simply a set of two echo chambers, where within each group, everybody agrees with the rest of the group but nobody pays attention to the other group. So, negative interactions between users of the two sides are the second ingredient for the right measurement of the polarization, such that the more negative the interactions between users of L and R, the higher the polarization we interpret between both sides. In our measure, the echo chambers case is considered as a case with middle polarization.
To capture these two characteristics with a single value, we define two different measures and their combination in a final one referred to as
the bipartite polarization level. First, given a bipartition
of
, we define its level of consistency and how balanced the sizes of
L and
R are as follows:
where
evaluates the disagreement strength of the comments in
L (regarding the root comment) and
the agreement strength of the comments in
R. They are defined as follows:
The value of lies in the interval . The minimum value (0) is achieved when either there are no users in L with or no users in R with . The maximum value (0.25) is achieved when half of the users are users in disagreement with and are found in L, and the other half are users in agreement with and are found in R.
Secondly, the sentiment of the interactions between users of different sides is defined as follows:
with
, and where
and
denote the values of
p and
w, respectively, in
. It is worth noticing that the value of
lies in the interval
:
The minimum value (0) is achieved when all the interactions have (pure positive interactions with maximum sentiment value), and all of them are found between L and R.
The middle value (2) is achieved when the sum of negative values in the summatory of the numerator equals the sum of the positive ones. So, this represents a situation where positive and negative interactions between both partitions compensate for each other. As a special case, observe that if there are no interactions of any type between them (an echo chamber situation), then we also achieve this middle value.
The maximum value (4) is achieved when all the interactions have (pure negative interactions with minimum sentiment value), and all of them are found between L and R.
Finally, we combine the
and the
measures to define
the bipartite polarization level of a given bipartition
as follows:
So, given the range of values for the previous measures, the value of lies in the interval :
The minimum value (0) is achieved when either or . If this happens with and then in L, we have only neutral and positive users, at least one user in R, and some interactions between L and R that are not extremely positive (such that can be positive). So, we consider that not having users in disagreement in L with gives the lowest polarization level in the debate. We can also have and if both L and R contain nodes of both types (with and with ), and all the edges are found between L and R and have . This implies that the more edges we have in , the more different pairs of vertices we will have with the same sign in and , but in different sides of the partition. So, in this second case, a big quantity of edges implies an small value for , when .
The middle value (1/2) can of course be achieved for many combinations of these two factors, but there are two canonical cases that reflect well the intended meaning of this middle case. They are the cases where one of the two factors has its maximum value and the other has its middle value. This can happen in two cases. First, this happens when and . That is, when users in disagreement and users in agreement are perfectly balanced between L and R, as we discussed before when talking about the behavior of , and either there are no interactions between L and R (echo chambers situation), or positive interactions between them are canceled by the negative ones (so we can say that, overall, the interactions are neutral between them). Second, this also happens when and . These values can be obtained when in L, the sum of negative values represents 0.25 of the total number of comments, and analogously for R with the positive values, (so the partitions are maximally heterogeneous), and all the interactions have and are found only between L and R. That is, both partitions have a balanced representation of users in agreement and disagreement, and we have pure negative interactions between users in agreement of one partition and the users in disagreement of the other one.
The maximum value (1) is achieved when both factors have its maximum value. That is, perfect balance between users in disagreement in L and users in agreement in R () and all the interactions have and are found only between L and R. So, this extreme case represents a situation where there are two perfect homogeneous sides in the debate (agreement and disagreement sides) with sentiments that are maximally opposed (+1 and −1) and the only talking between them is to criticize the other side with maximum strength, so there are no positive answers between the two sides. This can be considered a very extreme situation because even in the most tense debates in a social network, one usually can find some positive answers, although these positive answers may be concentrated within each side, or not all the negative answers will have the extreme value (−2).
5. Empirical Evaluation
In this section, we present an empirical evaluation to detect if our optimization algorithm can find distinctive polarization in debates obtained from six representative subreddits with different topics: Halloween, travel, movies, Bitcoin, politics, and worldnews. Intuitively, we expect to have debates with low polarization in the Halloween and travel topics, those with higher polarization in the movies and Bitcoin topics, and those with the highest polarization in the politics and worldnews topics. From each subreddit, we downloaded debates from the last month, excluding the most recent debates that probably are still active, with comments per debate ranging from 50 to 500, and with a limit of 100 debates per subreddit.
Table 1 shows the average results for the polarization value (
BipPol) obtained with our algorithm for each of the six sets of debates using the algorithm with the two initialization methods, so we have two rows per subreddit.
In any case, the maximum number of iterations is fixed to the number of users in the debate graph. To analyze the reasons behind the BipPol values obtained, we also show the corresponding average values for the factors , (that make the value), and SWeight. The table also shows the total number of debates in each set, and the average values for the number of users and number of edges in their corresponding user debate graphs. The average results for the different subreddits show some differences in the BipPol values such that we can divide the six subreddits into three groups: subreddits with the lowest BipPol, the middle one, and the highest one.
In the first group (Halloween and travel), we observe average BipPol values around . However, looking into the value of the different factors, we can explain why there is an slightly higher BipPol value for the travel subreddit. For the Halloween subreddit, we observe that the agreement users group is more relevant ( value around in contrast to a value around ) and a SWeight value around (close to the neutral value for the global sentiment between users in agreement and disagreement). By contrast, for the travel subreddit, the value is higher than the value, but they are more balanced ( versus ), and the SWeight value is around . So now, negative interactions between both groups are more significant. These differences make sense if one looks into the nature of the discussions in both these subreddits. In the Halloween case, discussions are mainly friendly, discussing ideas about costumes and Halloween decorations. However, in the travel case, we find some controversies in many discussions about certain touristic destinations. Regarding the differences between using either the g0 or g1 initialization method in the algorithm, we observe no significant differences in the final value obtained; the only difference we observe is that when using the uniform random method (g0), the number of iterations needed by the algorithm can be about ten times higher, but in all the debates we have solved, the algorithm has never reached its maximum number of allowed iterations. So, even if the method (g0) makes the algorithm make more iterations, it seems that the quality of the solution obtained is similar to the one with g1.
In the second group (movies and Bitcoin), we observe average BipPol values around . The increase with respect to the first group can be explained due to slightly more balanced values for and (close to the value), although in the more hot topic of Bitcoin, the disagreement group value () is more significant, and also due to increased values for SWeight, but again, this is more significant in the Bitcoin sudreddit. It is worth noticing that a higher value for SWeight seems to be correlated with a higher size of the debate (in the values of and ). This is consistent with what we commented earlier about the tendency to respond more frequently when people disagree.
In the last group (politics and worldnews), we observe the highest BipPol average values, around . Here the values of and show a balance similar to the one of the second group (politics is similar to Bitcoin, and worldnews is similar to movies). However, the difference lies in the increase in the SWeight values, that again seems to be correlated with an increase in the size of the debates. The existence of the highest values for the SWeight in this last group of subreddits is somehow natural, as many of the topics discussed are highly controversial.
To further investigate the characteristics of the debates of these different subreddits, we also looked into the results obtained for the debates of each group with the minimum, median, and maximum
BipPol values within the group.
Table 2 shows these results, with three rows per subreddit, showing the results for the minimum, median, and maximum cases.
Looking at the results for the minimum, we observe that clearly the lowest
BipPol values are obtained in the Halloween and travel subreddits (
and
, respectively), in contrast to the minimum
BipPol value for the other subreddits, which is at least
. The median values show differences similar to the ones we observed for the average value in
Table 1, from the median value of
for Halloween to the median value of
for worldnews, so the differences in the minimum value are more significant. The maximum values are at least
(the maximum for Halloween), but the other maximum values are similar, around
. Curiously, the highest maximum value is observed in a debate from the travel subreddit (
). So, these results indicate that one can find polarized debates on many topics, but when looking at the average values of the previous table, we can conclude that the average polarization tends to be higher for certain topics.




{kind=link}
{kind=link}
{kind=link}
{kind=link}