
DATLMedQA: A Data Augmentation and Transfer Learning Based Solution for Medical Question Answering

Abstract
:1. Introduction and Background
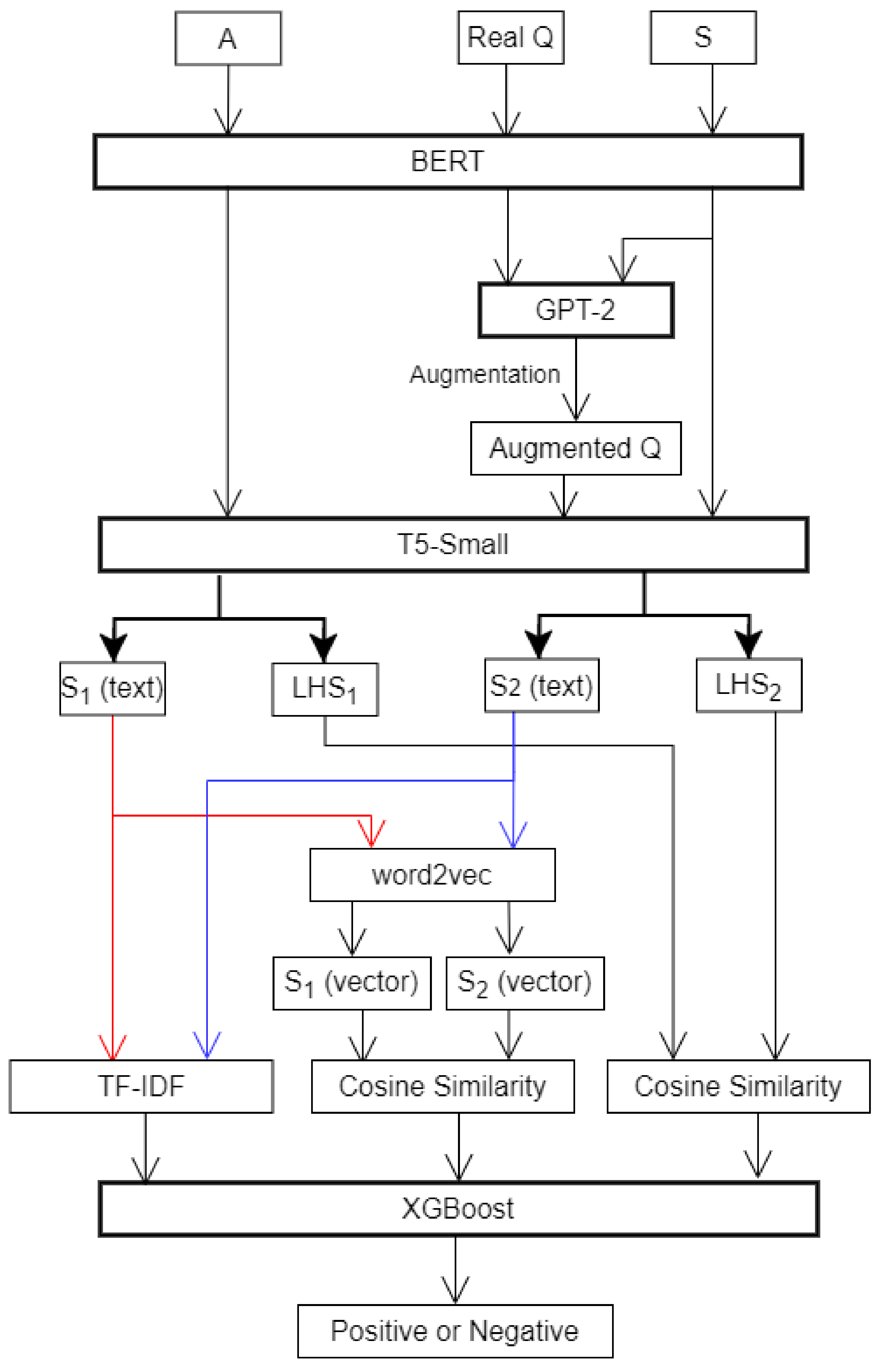
- We use GPT-2 to augment the question (Q) samples and use S (meaning) and A (answer) as keywords to generate complete sentences as data augmentation for a problem;
- We use T5-Small, a transfer learning model, to perform the extraction on answer (A) and the extraction on question (Q), which is based on a larger corpus. We put more biomedical corpus into our proposed augmentation model for learning, which improves the prediction accuracy of the model in medical question answering tasks.
2. Related Work
2.1. Medical Question Answering and Data Augmentation
2.2. GPT-2 and Question Answering System
2.3. T5 and Question Answering
3. Materials and Method
3.1. Dataset
3.2. System Architecture
3.2.1. Fine-Tuning GPT-2
3.2.2. Extraction of and Using T5-Small
3.2.3. , and XGBoost Prediction
4. Experiments and Results
4.1. Model and Experiment Design
4.2. Evaluation Metrics
4.3. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Cheng, S.; Yu, X.; Xu, H. Chinese Public’s Attention to the COVID-19 Epidemic on Social Media: Observational Descriptive Study. J. Med. Internet. Res. 2020, 22, e18825. [Google Scholar] [CrossRef] [PubMed]
- Kataoka, Y.; Oide, S.; Arlie, T.; Tsujimoto, Y.; Furukawa, T. COVID-19 randomized controlled trials in medRxiv and PubMed. Eur. J. Int. Med. 2020, 81, 97–99. [Google Scholar] [CrossRef] [PubMed]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.W.; Lu, X. PubMedQA: A Dataset for Biomedical Research Question Answering. arXiv 2019, arXiv:1909.06146v1. [Google Scholar]
- Ong, E.; Wong, M.U.; Huffman, A.; He, Y. COVID-19 coronavirus vaccine design using reverse vaccinology and machine learning. bioRxiv 2020. [Google Scholar] [CrossRef]
- Mahase, E. COVID-19: WHO declares pandemic because of “alarming levels” of spread, severity, and inaction. BMJ 2020, 368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Surita, G.; Nogueira, R.; Lotufo, R. Can questions summarize a corpus? Using question generation for characterizing COVID-19 research. arXiv 2020, arXiv:2009.092900. [Google Scholar]
- Yadav, S.; Gupta, D.; Abacha, A.; Demner-Fushman, D. Question-aware Transformer Models for Consumer Health Question Summarization. arXiv 2021, arXiv:2106.00219. [Google Scholar]
- He, Y.; Yu, H.; Ong, E.; Wang, Y.; Liu, Y.; Huffman, A.; Huang, H.H.; Beverley, J.; Hur, J.; Yang, X.; et al. CIDO, a community-based ontology for coronavirus disease knowledge and data integration, sharing, and analysis. Sci. Data 2020, 7, 181. [Google Scholar] [CrossRef]
- Li, X.; Liu, Q. Social Media Use, eHealth Literacy, Disease Knowledge, and Preventive Behaviors in the COVID-19 Pandemic: Cross-Sectional Study on Chinese Netizens. J. Med. Internet Res. 2020, 22, e19684. [Google Scholar] [CrossRef]
- Yang, H.; Wang, H.; Du, L.; Wang, Y.; Wang, X.; Zhang, R. Disease knowledge and self-management behavior of COPD patients in China. Medicine 2019, 98, e14460. [Google Scholar] [CrossRef]
- Romanov, A.; Shivade, C.P. Lessons from Natural Language Inference in the Clinical Domain. arXiv 2018, arXiv:1808.06752. [Google Scholar]
- Doğan, R.I.; Leaman, R.; Lu, Z. NCBI disease corpus: A resource for disease name recognition and concept normalization. J. Biomed. Inform. 2014, 47, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Du, X.; Shao, J.; Cardie, C. Learning to ask: Neural question generation for reading comprehension. arXiv 2017, arXiv:1705.00106. [Google Scholar]
- Tang, D.; Duan, N.; Qin, T.; Yan, Z.; Zhou, M. Question answering and question generation as dual tasks. arXiv 2017, arXiv:1706.02027. [Google Scholar]
- Kim, Y.; Lee, H.; Shin, J.; Jung, K. Improving neural question generation using answer separation. In Proceedings of the AAAI Conference on Artificial Intelligence. arXiv 2019, arXiv:1809.02393. [Google Scholar]
- Song, L.; Wang, Z.; Hamza, W.Z.; Zhang, Y.; Gildea, D. Leveraging context information for natural question generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Volume 2. Available online: https://aclanthology.org/N18-2090 (accessed on 22 November 2021).
- Lewis, P.; Denoyer, L.; Riedel, S. Unsupervised question answering by cloze translation. arXiv 2019, arXiv:1906.04980. [Google Scholar]
- Chen, Y.; Wu, L.; Zaki, M.J. Reinforcement learning based graph-to-sequence model for natural question generation. arXiv 2019, arXiv:1908.04942. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; AI-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gonez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in neural information processing systems. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Jin, Q.; Yuan, Z.; Xiong, G.; Yu, Q. Biomedical question answering: A comprehensive review. arXiv 2021, arXiv:2102.05281. [Google Scholar]
- Xu, G.; Rong, W.; Wang, Y.; Ouyang, Y.; Xiong, Z. External features enriched model for biomedical question answering. BMC Bioinform. 2021, 22, 1–19. [Google Scholar] [CrossRef]
- Akdemir, A.; Shibuya, T. Transfer Learning for Biomedical Question Answering. In CLEF (Working Notes); 2020; Available online: http://ceur-ws.org/Vol-2696/paper_66.pdf (accessed on 22 November 2021).
- Jeong, M.; Sung, M.; Kim, G.; Kim, D.; Yoon, W.; Yoo, J.; Kang, J. Transferability of natural language inference to biomedical question answering. arXiv 2020, arXiv:2007.00217. [Google Scholar]
- Sarrouti, M.; Gupta, D.; Abacha, A.B.; Demner-Fushman, D. NLM at BioASQ Synergy 2021: Deep Learning-Based Methods for Biomedical Semantic Question Answering about COVID-19. CLEF 2021—Conference and Labs of the Evaluation Forum. Available online: http://ceur-ws.org/Vol-2936/paper-25.pdf (accessed on 22 November 2021).
- Sarrouti, M.; El Alaoui, S.O. SemBioNLQA: A semantic biomedical question answering system for retrieving exact and ideal answers to natural language questions. Artif. Intell. Med. 2020, 102, 101767. [Google Scholar] [CrossRef]
- Gouthaman, K.V.; Mittal, A. Reducing language biases in visual question answering with visually-grounded question encoder. Proceedings of Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Part XIII 16.s. [Google Scholar]
- Peng, K.; Yin, C.; Rong, W.; Lin, C.; Zhou, D.; Xiong, Z. Named Entity Aware Transfer Learning for Biomedical Factoid Question Answering. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021. [Google Scholar] [CrossRef]
- Pergola, G.; Kochkina, E.; Gui, L.; Liakata, M.; He, Y. Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies. arXiv 2021, arXiv:2102.08366. [Google Scholar]
- Yadav, S.; Sarrouti, M.; Gupta, D. NLM at MEDIQA 2021: Transfer Learning-based Approaches for Consumer Question and Multi-Answer Summarization. In Proceedings of the 20th Workshop on Biomedical Language Processing (BIONLP 2021); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 291–301. [Google Scholar]
- Yue, X.; Zhang, X.; Yao, Z.; Lin, S.; Sun, H. CliniQG4QA: Generating Diverse Questions for Domain Adaptation of Clinical Question Answering. arXiv 2020, arXiv:2010.16021. [Google Scholar]
- Suwarningsih, W. e-Health Education Using Automatic Question Generation-Based Natural Language (Case Study: Respiratory Tract Infection). In Emerging Technologies in Biomedical Engineering and Sustainable TeleMedicine; Springer: Berlin/Heidelberg, Germany, 2021; pp. 69–79. [Google Scholar]
- Esteva, A.; Kale, A.; Paulu, S.R.; Hashimoto, K.; Yin, W.; Radev, D.; Socher, R. Co-search: COVID-19 information retrieval with semantic search, question answering, and abstractive summarization. arXiv 2020, arXiv:2006.09595. [Google Scholar]
- Papanikolaou, Y.; Pierleoni, A. DARE: Data Augmented Relation Extraction with GPT-2. arXiv 2020, arXiv:2004.13845. [Google Scholar]
- Oniani, D.; Wang, Y. A Qualitative Evaluation of Language Models on Automatic Question-Answering for COVID-19. In Proceedings of the 11th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics. Association for Computing Machinery, Virtual Event, 21–24 September 2020; p. 33. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Roberts, A.; Raffel, C.; Shazeer, N. How much knowledge can you pack into the parameters of a language model? arXiv 2020, arXiv:2002.08910. [Google Scholar]
- Ngai, H.; Park, Y.; Chen, J.; Parsa, M. Transfermer-Based Models for Question Answering on COVID19. arXiv 2021, arXiv:2101.11432v1. [Google Scholar]
- He, Y.; Zhu, Z.; Zhang, Y.; Chen, Q.; Caverlee, J. Infusing Disease Knowledge into BERT for Health Question Answering, Medical Inference and Disease Name Recognition. arXiv 2020, arXiv:2010.03746. [Google Scholar]
- Abacha, A.B.; Shivade, C.; Demner-Fushman, D. Overview of the mediqa 2019 shared task on textual inference, question entailment and question answering. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019; pp. 370–5039. Available online: https://aclanthology.org/W19-5039.pdf (accessed on 22 November 2021).
- Abacha, A.B.; Agichtein, E.; Pinter, Y.; Demner-Fushman, D. Overview of the Medical Question Answering Task at TREC 2017 LiveQA. In TREC; 2018. Available online: https://trec.nist.gov/pubs/trec26/papers/Overview-QA.pdf (accessed on 22 November 2021).
- Lee, J.-S.; Hsiang, J. Patent claim generation by fine-tuning OpenAI GPT-2. arXiv 2020, arXiv:1907.02052. [Google Scholar] [CrossRef]
- Prismana, I.; Prehanto, D.R.; Dermawan, D.A.; Herlingga, A.C.; Wibawa, S.C. Nazief & Adriani Stemming Algorithm With Cosine Similarity Method For Integrated Telegram Chatbots With Service. In IOP Conference Series: Materials Science and Engineering; Workshop on Environmental Science, Society, and Technology (WESTECH 2020); IOP: Makassar, Indonesia, 2021; Volume 1125. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Céspedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]

{kind=link}
| S | Q | A |
|---|---|---|
| Hemorrhagic septicemia: diagnosis | What are the diagnosis of hemorrhagic septicemia? | Diagnosis on bases of blood smear and clinical findings. |
| Hemorrhagic septicemia: treatments | What are the treatments of hemorrhagic septicemia? | Sulphadimadine 100 mL orally and injection of oxytetracycline 40 mL for 3 days continuously. |
| Microsporidiosis: diagnosis | What are the diagnosis of microsporidiosis? | The best option for diagnosis is using pcr. |
| Microsporidiosis: treatments | What are the treatments of microsporidiosis? | The best option for diagnosis is using pcr. |
| Hemorrhagic septicemia: treatments | What are the treatments of hemorrhagic septicemia? | Fumagillin has been used in the treatment. another agent used is albendazole. |
| ...... | ...... | ...... |
| Ego: general | What is ego? | Ego or ego may refer to: |
| Borderline leprosy: general | What is borderline leprosy? | Borderline leprosy is a cutaneous skin condition with numerous skin lesions that are red irregularly shaped plaques. |
| Synovial chondromatosis: general | what is synovial chondromatosis? | Synovial chondromatosis is a disease affecting the synovium, a thin flexible membrane around a joint. |
| Priapism: physiology | What are the physiology of priapism? | The mechanisms are poorly understood but involve complex neurological and vascular factors. |
| Acute myeloid leukemia: symptoms | What are the symptoms of acute myeloid leukemia? | Image:amlcase-66.jpg|thumb|upright. |
| Datasets | Train | Dev | Test |
|---|---|---|---|
| MEDIQA-2019 | 208 (1701) | 25 (234) | 150 (1107) |
| TRECQA-2017 | 254 (1969) | 25 (234) | 104 (839) |
| ID (Label) | Type | Question |
|---|---|---|
| Pair #1 (True) | Premise | I have a list of questions about Tay sachs disease and clubfoot 1. what is TSD/Clubfoot, and how does it effect a baby 2. what causes both? can it be prevented, treated, or cured 3. How common is TSD? how common is Clubfoot 4. How can your agency help a women/couple who are concerned about this congenital condition, and is there a cost? If you can answer these few questions I would be thankful, please get back as soon as you can. |
| Hypothesis | How does congenital talipes equinovarus affect a child? | |
| Pair #2 (True) | Premise | When and how do you know when you have congenital night blindness? |
| Hypothesis | What are the symptoms of X-linked congenital stationary night blindness ? | |
| Pair #3 (True) | Premise | Polycystic ovarian syndrome Is it possible for parents to pass this on in the genes to their children - is there any other way this can be acquired? |
| Hypothesis | Can polycystic ovary syndrome be inherited ? | |
| Pair #4 (False) | Premise | spina bifida; vertbral fusion; syrinx tethered cord. can u help for treatment of these problem |
| Hypothesis | Does Spina Bifida cause vertebral fusion? | |
| Pair #5 (False) | Premise | aricella shingles How can I determine whether or not I have had chicken pox. If there is a test for it, what are the results of the tests I need to know that will tell me whether or not I have had chicken pox? I want to know this to determine if I should have shingles vaccine (Zostavax) Thank you. |
| Hypothesis | Who can catch shingles? |
| CHQ 1 | Subject: ClinicalTrials.gov - Compliment. Message: Hi I have retinitis pigmentosa for 3years. Im suffering from this disease. Please intoduce me any way to treat mg eyes such as stem cell …I am 25 years old and I have only central vision. Please help me. Thank you |
| CHQ 2: | Subject: abetalipoproteimemia Message: hi, I would like to know if there is any support for those suffering with abetalipoproteinemia? I am not diagnosed but have had many test that indicate I am suffering with this, keen to learn how to get it diagnosed and how to manage, many thanks |
| CHQ 3: | Subject: ingredients in Kapvay Message: Is there any sufites sulfates sulfa in Kapvay? I am allergic. |
| Models | MEDIQA-2019 | TRCEQA-2017 | ||||
|---|---|---|---|---|---|---|
| Acc | MRR | Precision | Acc | MRR | Precision | |
| T5-Small + XGBoost + disease * | 79.11 | 91.04 | 82.41 | 79.75 | 57.63 | 62.87 |
| GPT-2 + T5-Small + XGBoost + disease * | 80.23 | 92.17 | 84.31 | 80.5 | 58.49 | 63.71 |
| ALBERT + disease * (SOTA) | 79.49 | 90 | 84.02 | 80.1 | 57.21 | 62.4 |
| Epoch | Training Loss | Validation Loss | Rouge-1 | Rouge-2 | Rouge-L | Rougelsum | Gen Len |
|---|---|---|---|---|---|---|---|
| 1 | 1.465100 | 0.778861 | 10.915500 | 9.591100 | 10.847200 | 10.841800 | 1.336200 |
| 2 | 0.136700 | 0.088763 | 94.831500 | 93.273400 | 95.031000 | 95.016300 | 9.840600 |
| 3 | 0.099000 | 0.063339 | 95.130600 | 93.521000 | 95.134200 | 95.125400 | 9.860800 |
| Epoch | Training Loss | Validation Loss | Rouge-1 | Rouge-2 | Rouge-L | Rougelsum | Gen Len |
|---|---|---|---|---|---|---|---|
| 1 | 1.540800 | 0.703044 | 7.854000 | 6.959400 | 7.797700 | 7.801300 | 0.987300 |
| 2 | 0.087000 | 0.057968 | 98.035900 | 96.298300 | 98.036500 | 98.016100 | 9.844000 |
| 3 | 0.076400 | 0.041612 | 98.125900 | 96.552000 | 98.133500 | 98.118200 | 9.864200 |
| Epoch | Training Loss | Validation Loss | Rouge-1 | Rouge-2 | Rouge-L | Rougelsum | Gen Len |
|---|---|---|---|---|---|---|---|
| 1 | 1.5477 | 0.701432 | 8.1709 | 7.1679 | 8.1113 | 8.1318 | 1.0161 |
| 2 | 0.0871 | 0.057756 | 97.9991 | 96.2342 | 98.0032 | 97.9846 | 9.8444 |
| 3 | 0.0755 | 0.041416 | 98.1493 | 96.5391 | 98.152 | 98.1347 | 9.8673 |
| Epoch | Training Loss | Validation Loss | Rouge-1 | Rouge-2 | Rouge-L | Rougelsum | Gen Len |
|---|---|---|---|---|---|---|---|
| 1 | 0.0895 | 0.070495 | 97.8938 | 95.9368 | 97.8686 | 97.8596 | 9.8269 |
| 2 | 0.0702 | 0.040085 | 98.1784 | 96.6557 | 98.1859 | 98.1808 | 9.8611 |
| 3 | 0.0276 | 0.036042 | 98.2122 | 96.7045 | 98.217 | 98.2109 | 9.8683 |
| Q2S-Prediction | A2S-Prediction | cos_sim |
|---|---|---|
| ingrown nail: prevention. click here for mor… | sss: physiology: symptoms: causes. hepatit… | 0.671224 |
| schistosoma japonicum: prevention. | post kala-azar dermal leishmaniasis: japonicum… | 0.753213 |
| central diabetes insipidus is a disease charac… | traumatic shaking of a baby: physiology: cau… | 0.692533 |
| Real_Target | Q2S-Prediction | A2S-Prediction | Cosine |
|---|---|---|---|
| ingrown nail: prevention | ingrown nail: prevention. click here for mor… | ingrown toe nails: physiology. diagnosis: c… | 0.752199 |
| hives: symptoms | hives symptoms: symptoms of a coma. | cutaneous condition|welts from hives. causes … | 0.666359 |
| central diabetes insipidus: treatments | central diabetes insipidus is a disease charac… | desmopressin: treatments physiology: treatme… | 0.743902 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Zhang, Y. DATLMedQA: A Data Augmentation and Transfer Learning Based Solution for Medical Question Answering. Appl. Sci. 2021, 11, 11251. https://doi.org/10.3390/app112311251
Zhou S, Zhang Y. DATLMedQA: A Data Augmentation and Transfer Learning Based Solution for Medical Question Answering. Applied Sciences. 2021; 11(23):11251. https://doi.org/10.3390/app112311251
Chicago/Turabian StyleZhou, Shuohua, and Yanping Zhang. 2021. "DATLMedQA: A Data Augmentation and Transfer Learning Based Solution for Medical Question Answering" Applied Sciences 11, no. 23: 11251. https://doi.org/10.3390/app112311251
APA StyleZhou, S., & Zhang, Y. (2021). DATLMedQA: A Data Augmentation and Transfer Learning Based Solution for Medical Question Answering. Applied Sciences, 11(23), 11251. https://doi.org/10.3390/app112311251