
High-Performance English–Chinese Machine Translation Based on GPU-Enabled Deep Neural Networks with Domain Corpus



Abstract
:1. Introduction
- We present a transformer-based machine translation system, which is built from scratch, based on a domain corpus.
- Our translation system is easy to use with a web interface, so that domain experts can extend the existing corpus and train the model in a fine-tuned manner.
- Our machine learning system is both portable and configurable and can be deployed on laptops, desktops, or servers with multiple GPUs.
- Our translation system trained based on a domain corpus can achieve competing performance with a production-level translation system.
2. Background and Related Work
2.1. Neural Machine Translation
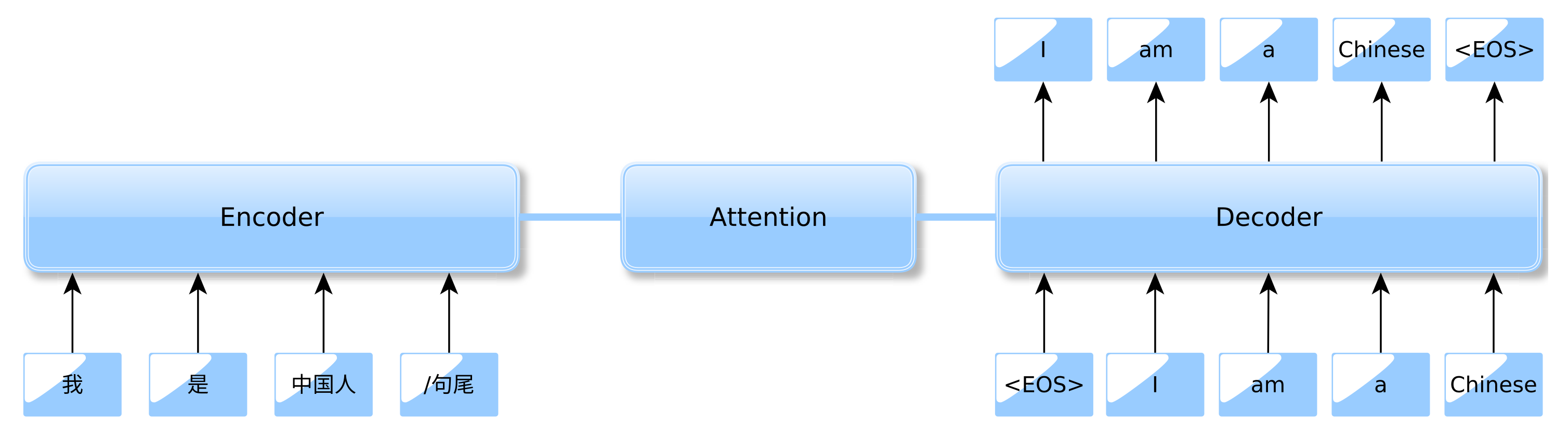
2.1.1. Formulating the NMT Task
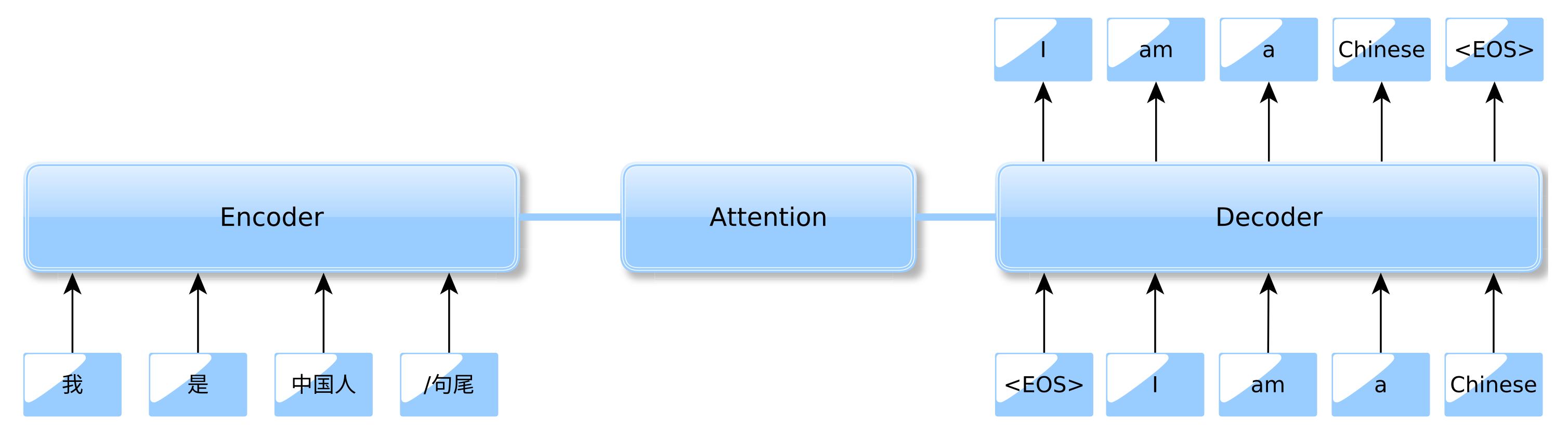
2.1.2. The NMT Structure
2.1.3. NMT with Attention Mechanism
2.1.4. NMT Model Training
2.1.5. Model Evaluation
2.2. English–Chinese Machine Translation
2.2.1. Designing New Learning Models
2.2.2. Leveraging Chinese Features
3. Our Methods
3.1. Word Segmentation
3.2. Data Preprocessing and Loading
3.3. Model Training
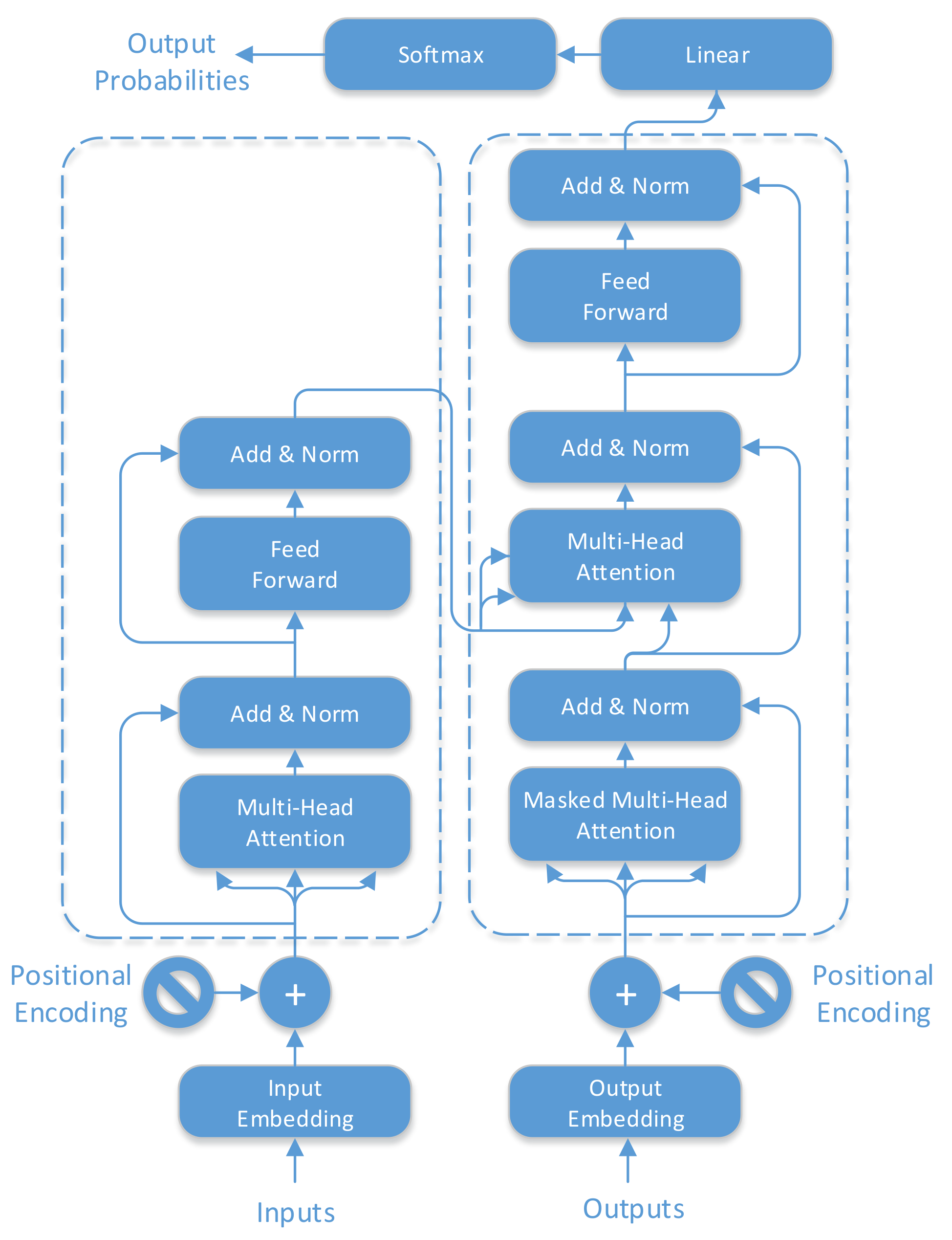
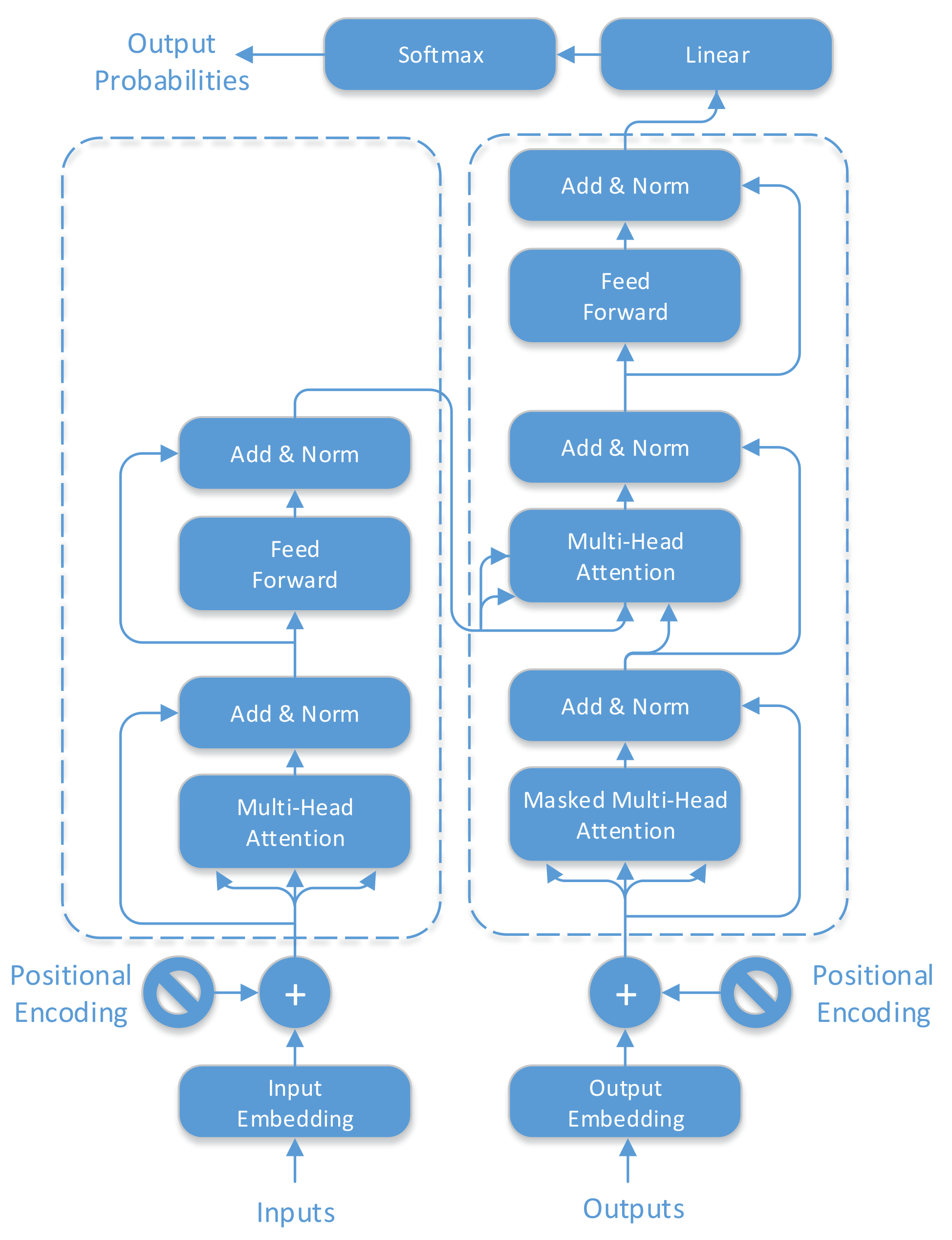
3.3.1. The Transformer Model
3.3.2. Training Optimizer
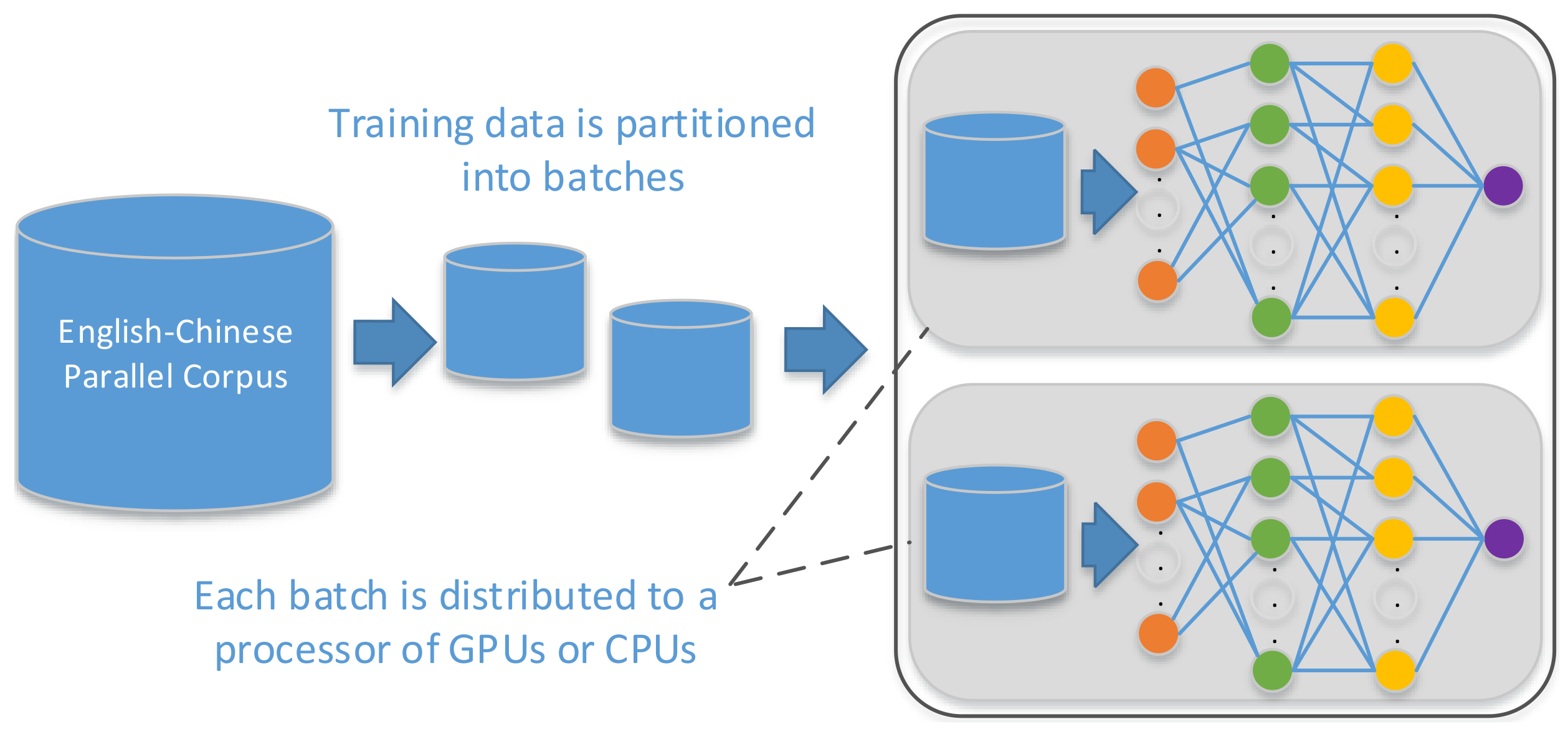
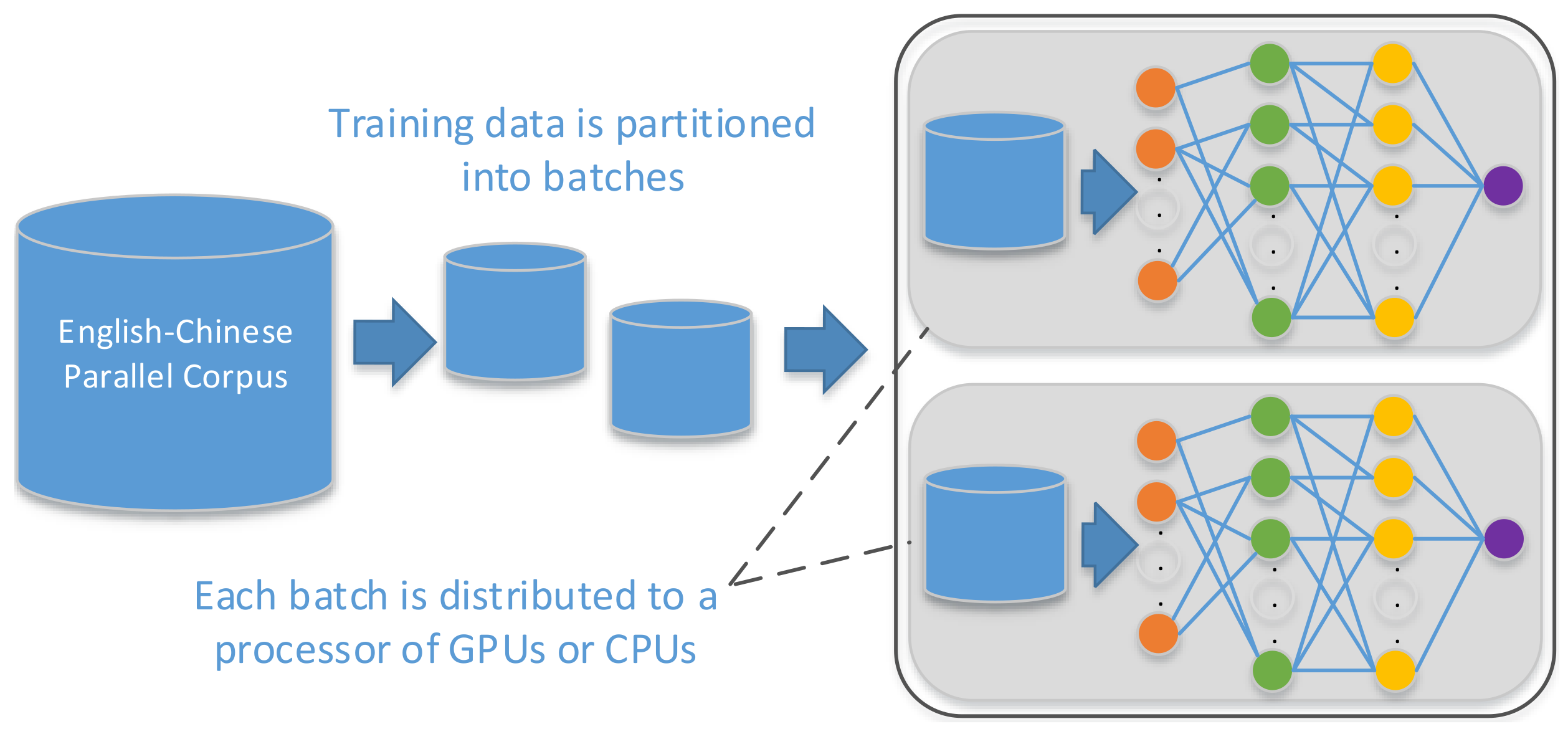
3.3.3. Parallel Training
3.4. Model Deployment
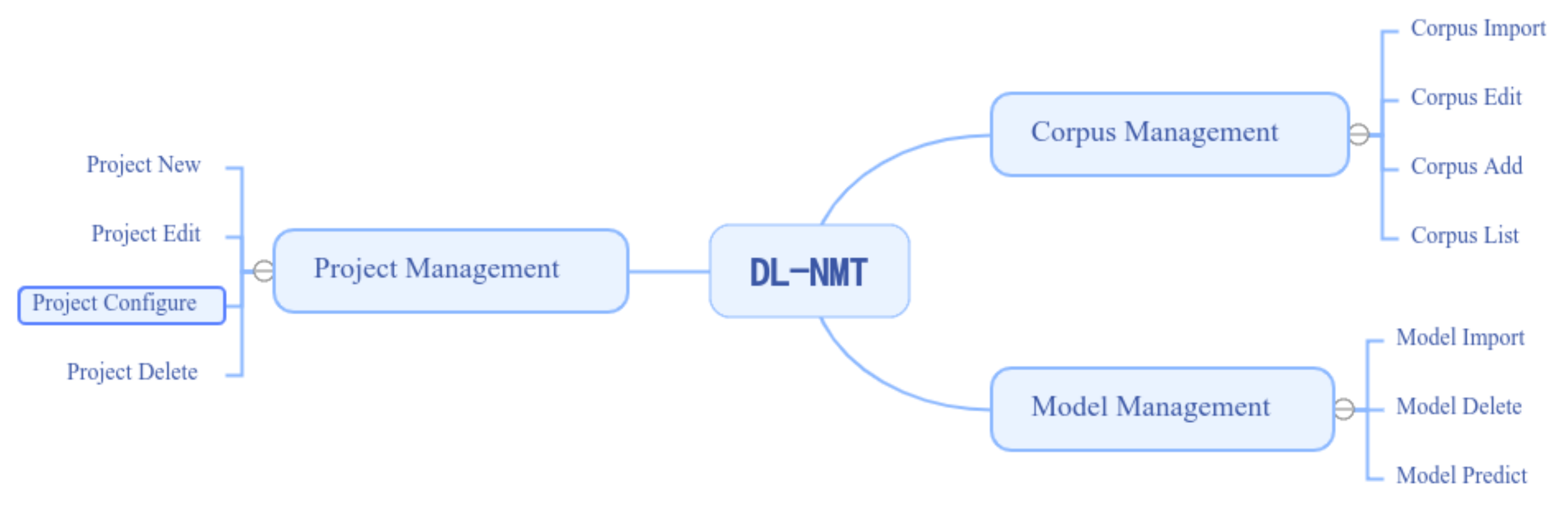
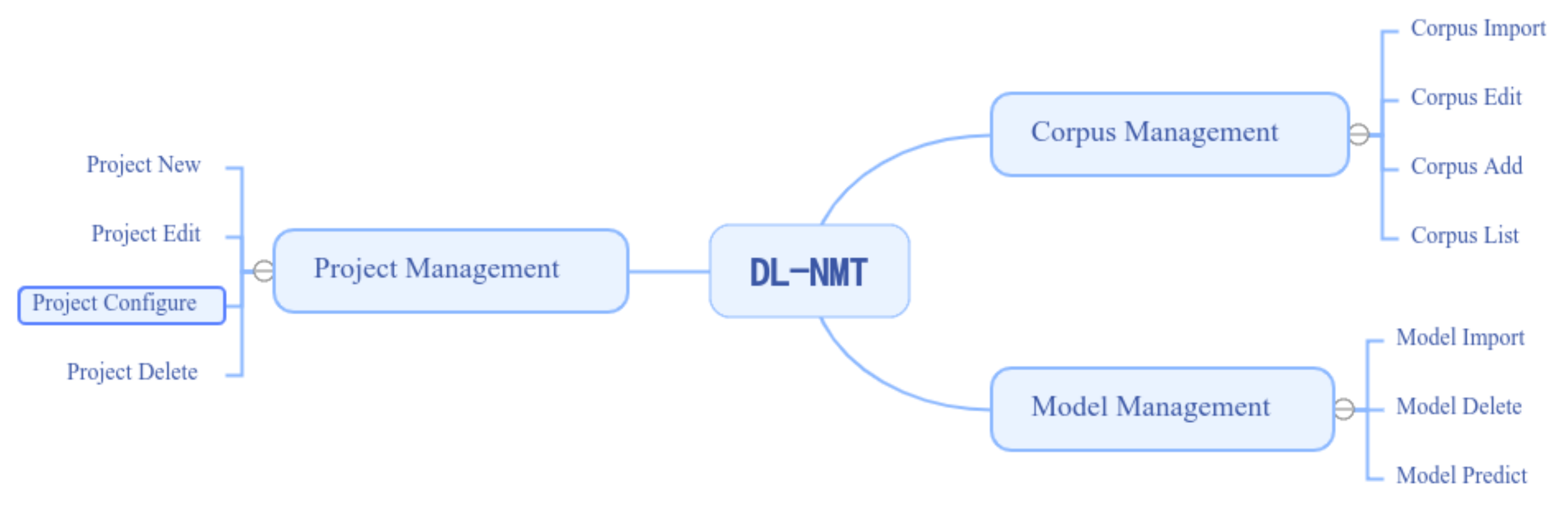
3.5. A DL-NMT Web Interface
3.5.1. Corpus Management
3.5.2. Project Management
3.5.3. Model Management
4. Results and Discussion
4.1. Experimental Setup
4.2. Performance Results
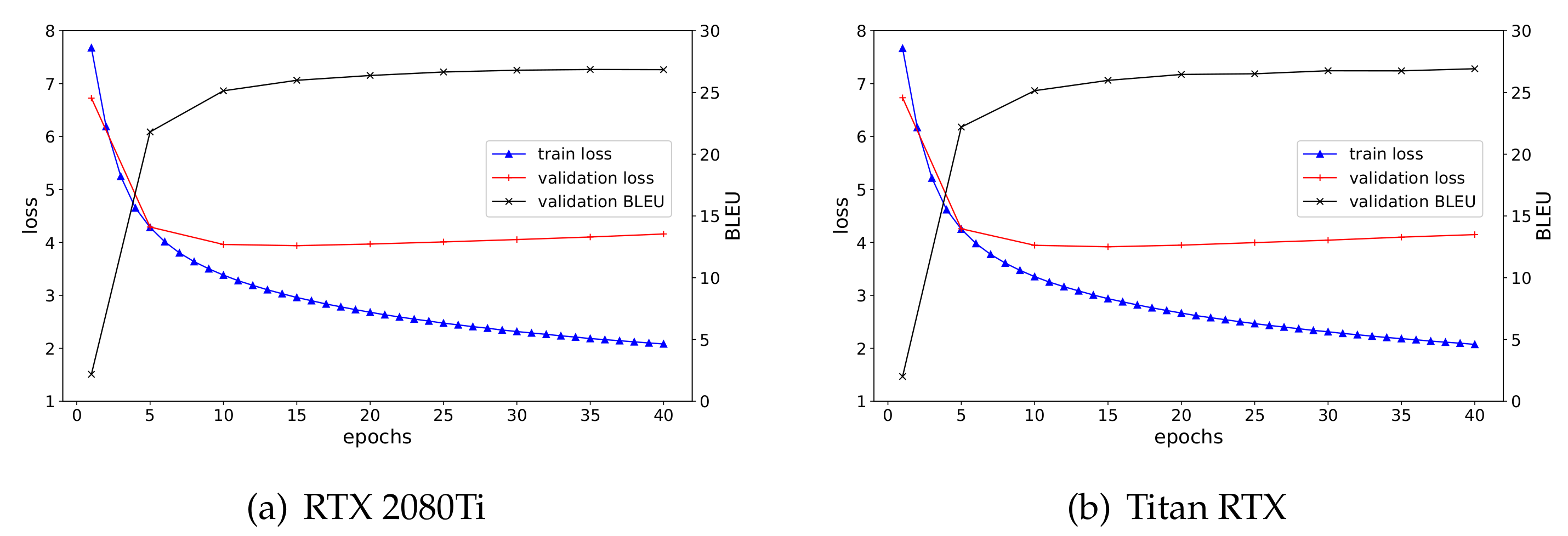
4.2.1. Training Accuracy
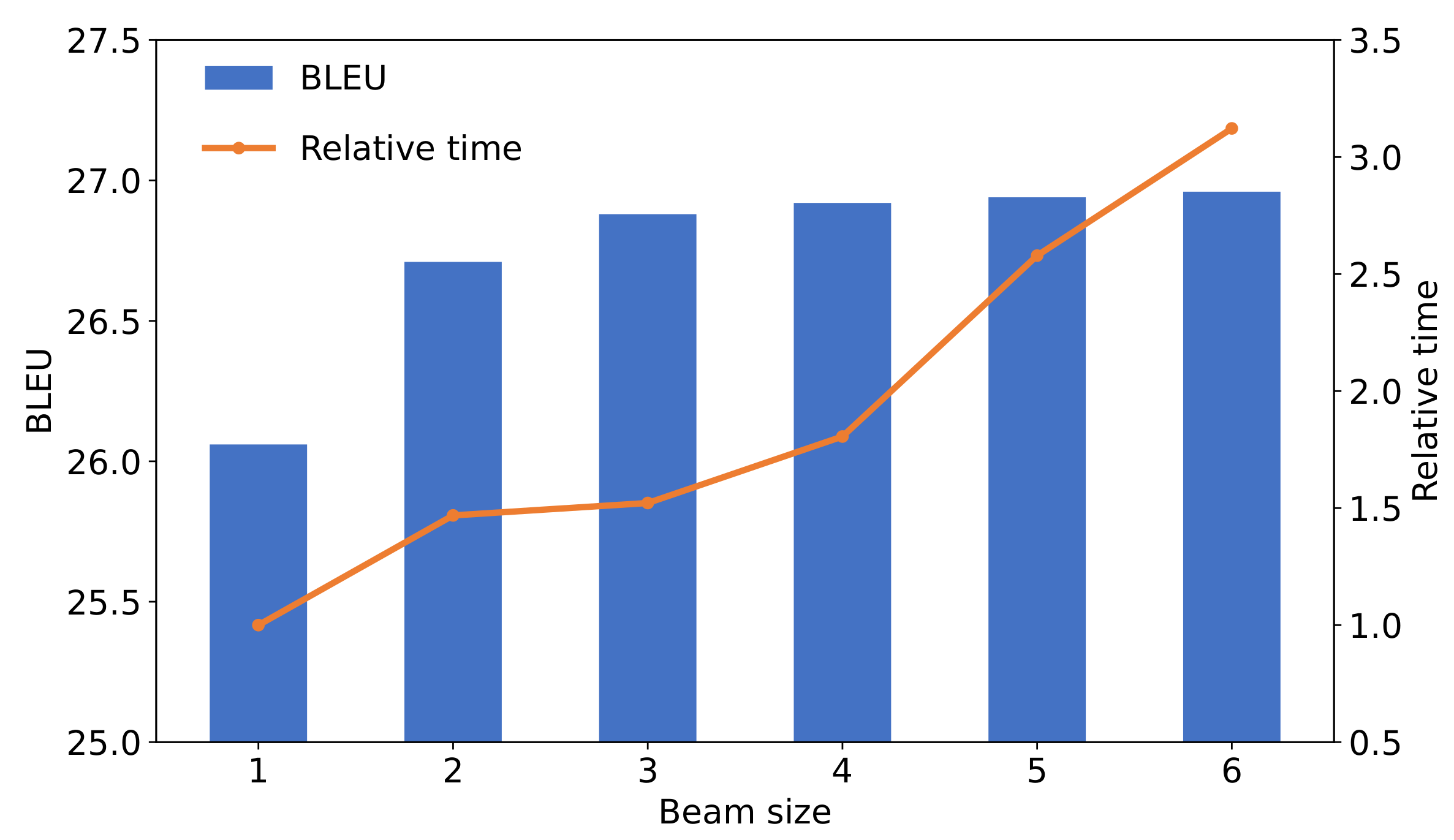
4.2.2. Decoding Stage
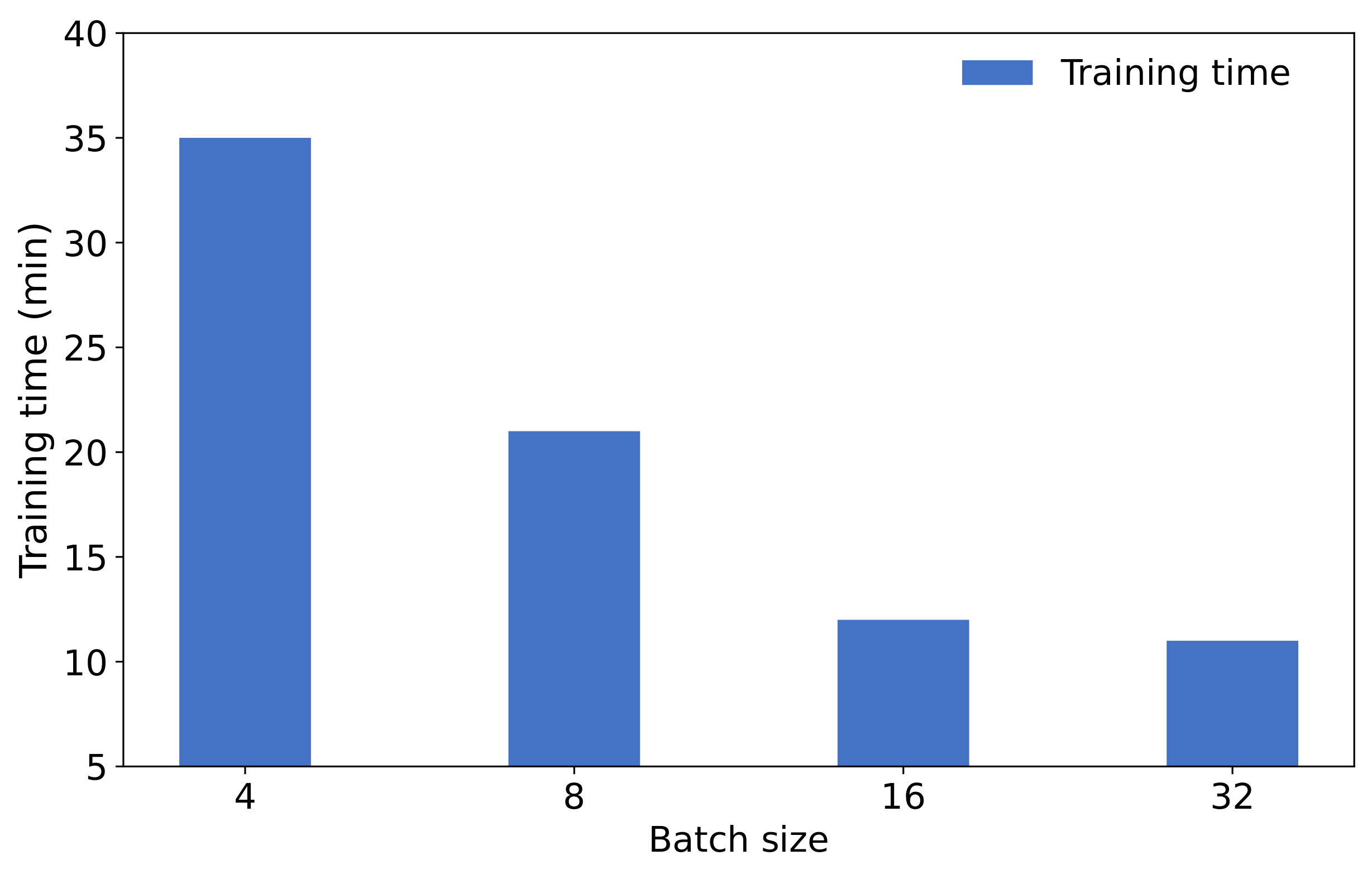
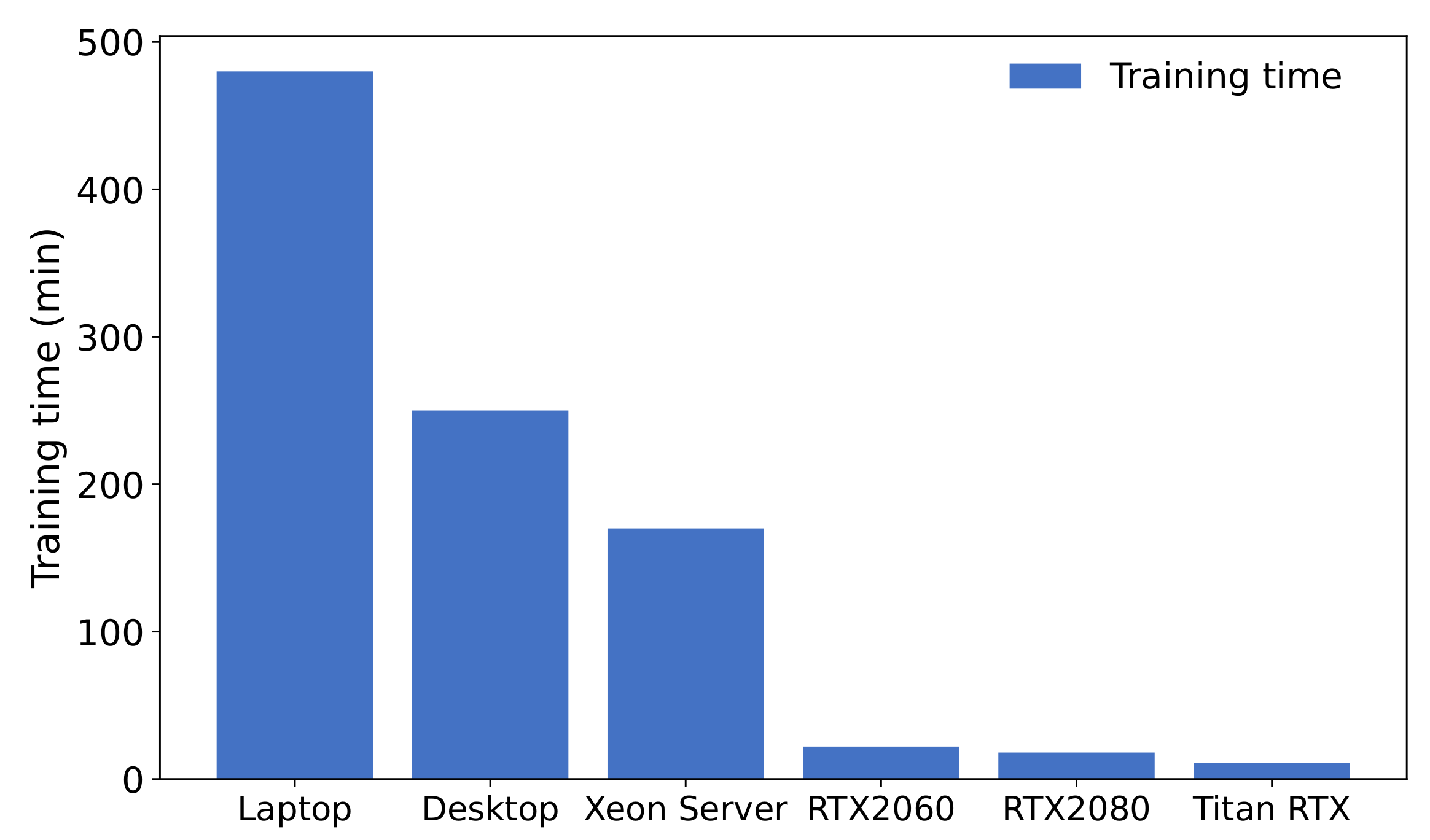
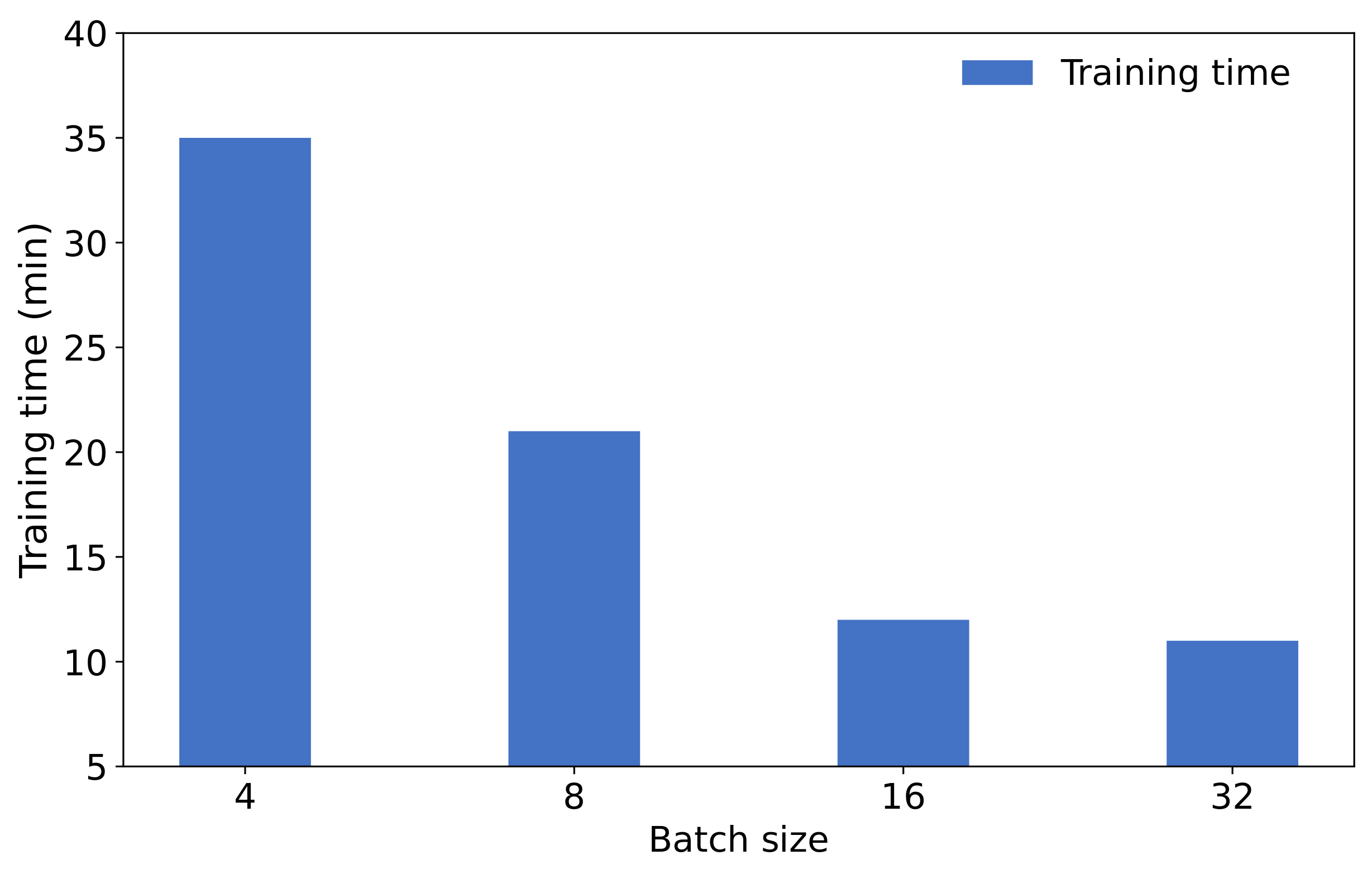
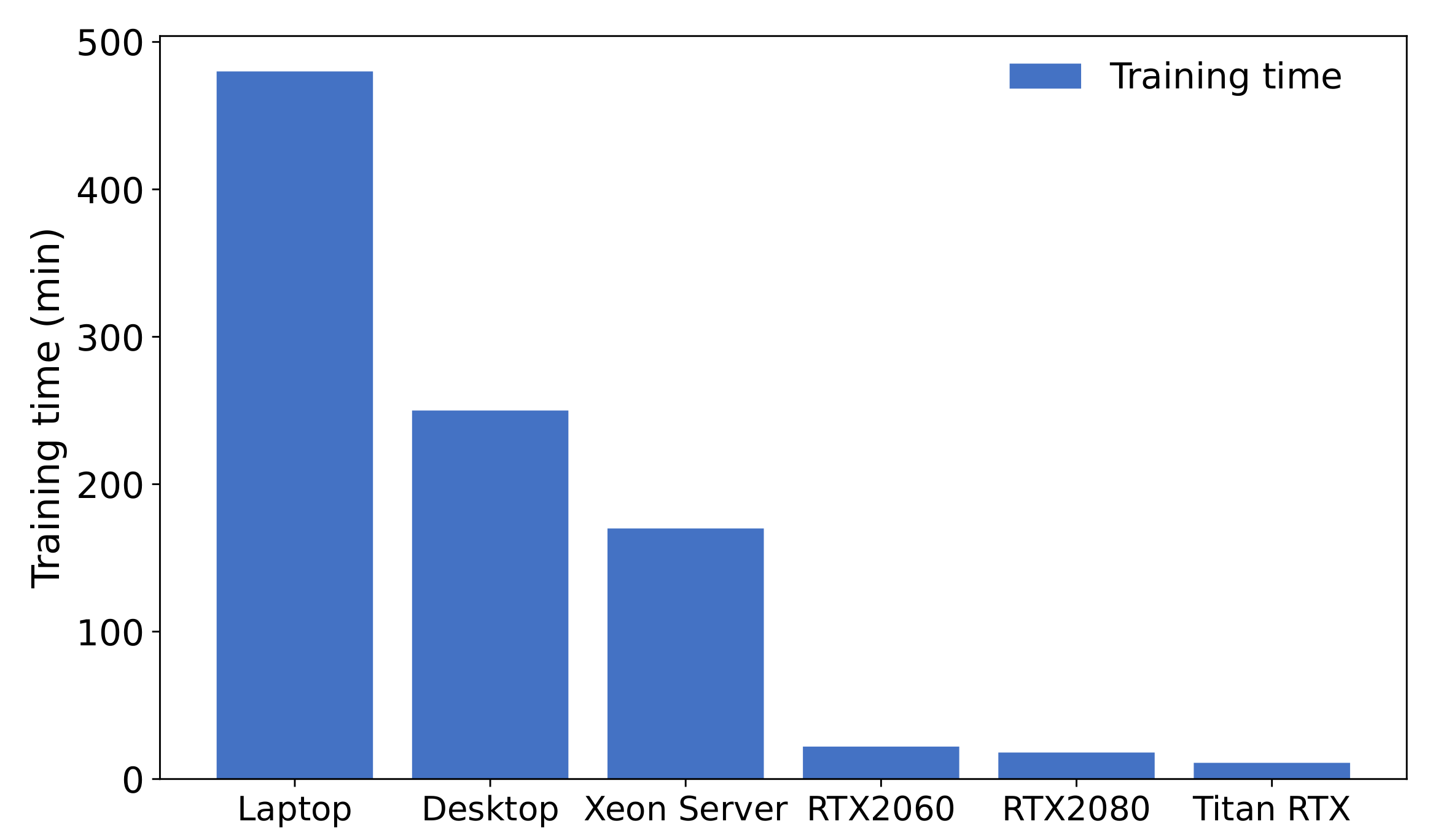
4.2.3. Training Speed
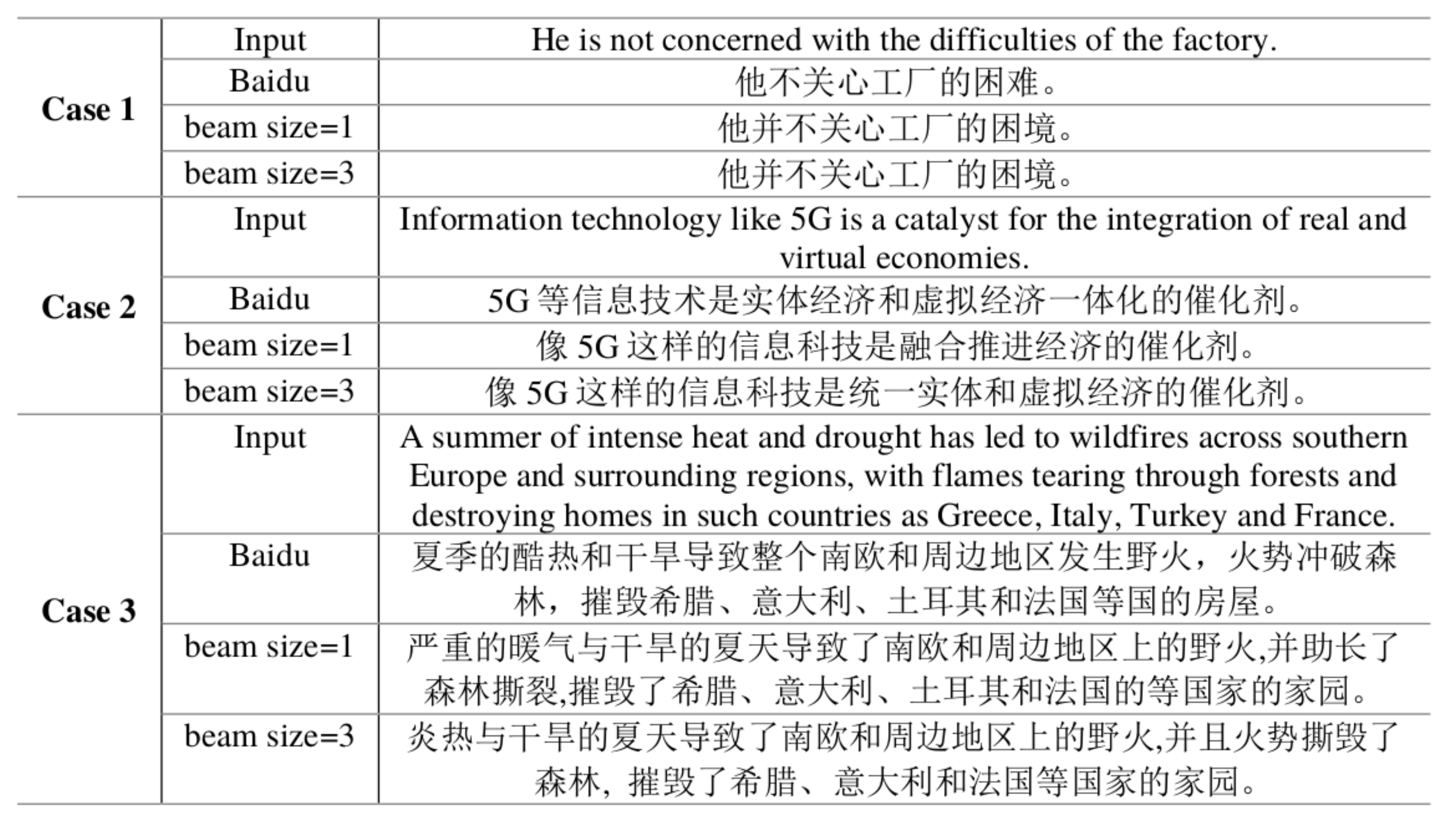
4.3. Case Study
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Trans. Speech Audio Process. 2012, 20, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Los Alamitos, CA, USA, 2012; pp. 3642–3649. [Google Scholar]
- Le, Q.V.; Ranzato, M.; Monga, R.; Devin, M.; Corrado, G.; Chen, K.; Dean, J.; Ng, A.Y. Building high-level features using large scale unsupervised learning. In Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, Scotland, UK, 26 June–1 July 2012. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual, Austria, 3–7 May 2021. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; (Long and Short Papers). Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems 33, Proceedings of the Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Forcada, M.L.; Ginestí-Rosell, M.; Nordfalk, J.; O’Regan, J.; Ortiz-Rojas, S.; Pérez-Ortiz, J.A.; Sánchez-Martínez, F.; Ramírez-Sánchez, G.; Tyers, F.M. Apertium: A free/open-source platform for rule-based machine translation. Mach. Transl. 2011, 25, 127–144. [Google Scholar] [CrossRef]
- Koehn, P.; Och, F.J.; Marcu, D. Statistical Phrase-Based Translation. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, HLT-NAACL 2003, Edmonton, AB, Canada, 27 May–1 June 2003; Hearst, M.A., Ostendorf, M., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2003. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the SSST@EMNLP 2014, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; Wu, D., Carpuat, M., Carreras, X., Vecchi, E.M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 103–111. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1243–1252. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://gregraiz.com/wp-content/uploads/2020/07/language_understanding_paper.pdf (accessed on 11 May 2021).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Rosset, C.; Xiong, C.; Phan, M.; Song, X.; Bennett, P.N.; Tiwary, S. Knowledge-Aware Language Model Pretraining. arXiv 2020, arXiv:2007.00655. [Google Scholar]
- Norrie, T.; Patil, N.; Yoon, D.H.; Kurian, G.; Li, S.; Laudon, J.; Young, C.; Jouppi, N.P.; Patterson, D.A. Google’s Training Chips Revealed: TPUv2 and TPUv3. In Proceedings of the IEEE Hot Chips 32 Symposium, HCS 2020, Palo Alto, CA, USA, 16–18 August 2020; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 1–70. [Google Scholar] [CrossRef]
- Ling, W.; Marujo, L.; Dyer, C.; Black, A.W.; Trancoso, I. Crowdsourcing High-Quality Parallel Data Extraction from Twitter. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 426–436. [Google Scholar] [CrossRef]
- Ling, W.; Marujo, L.; Dyer, C.; Black, A.W.; Trancoso, I. Mining Parallel Corpora from Sina Weibo and Twitter. Comput. Linguist. 2016, 42, 307–343. [Google Scholar] [CrossRef]
- Ling, W.; Xiang, G.; Dyer, C.; Black, A.W.; Trancoso, I. Microblogs as Parallel Corpora. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, ACL 2013, Sofia, Bulgaria, 4–9 August 2013; Long Papers. The Association for Computer Linguistics: Stroudsburg, PA, USA, 2013; Volume 1, pp. 176–186. [Google Scholar]
- Tian, L.; Wong, D.F.; Chao, L.S.; Quaresma, P.; Oliveira, F.; Yi, L. UM-Corpus: A Large English-Chinese Parallel Corpus for Statistical Machine Translation. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, 26–31 May 2014; Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; European Language Resources Association (ELRA): Luxemburg, 2014; pp. 1837–1842. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent Continuous Translation Models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, Grand Hyatt Seattle, Seattle, WA, USA, 18–21 October 2013; pp. 1700–1709. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1715–1725. [Google Scholar]
- Schuster, M.; Nakajima, K. Japanese and Korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2012, Kyoto, Japan, 25–30 March 2012; IEEE Computer Society: Los Alamitos, CA, USA, 2012; pp. 5149–5152. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; Blanco, E., Lu, W., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 66–71. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English News Translation. arXiv 2018, arXiv:1803.05567. [Google Scholar]
- Lin, X.; Liu, J.; Zhang, J.; Lim, S.J. A Novel Beam Search to Improve Neural Machine Translation for English-Chinese. Comput. Mater. Contin. 2020, 65, 387–404. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, J.; Kang, X.; Zong, C. Deep Neural Network-based Machine Translation System Combination. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2020, 19, 65:1–65:19. [Google Scholar] [CrossRef]
- Xiong, H.; He, Z.; Hu, X.; Wu, H. Multi-Channel Encoder for Neural Machine Translation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 4962–4969. [Google Scholar]
- Wang, Y.; Cheng, S.; Jiang, L.; Yang, J.; Chen, W.; Li, M.; Shi, L.; Wang, Y.; Yang, H. Sogou Neural Machine Translation Systems for WMT17. In Proceedings of the Second Conference on Machine Translation, WMT 2017, Copenhagen, Denmark, 7–8 September 2017; pp. 410–415. [Google Scholar]
- Wu, S.; Wang, X.; Wang, L.; Liu, F.; Xie, J.; Tu, Z.; Shi, S.; Li, M. Tencent Neural Machine Translation Systems for the WMT20 News Translation Task. In Proceedings of the Fifth Conference on Machine Translation, WMT@EMNLP 2020, Online, 19–20 November 2020; pp. 313–319. [Google Scholar]
- Yang, J.; Wu, S.; Zhang, D.; Li, Z.; Zhou, M. Improved Neural Machine Translation with Chinese Phonologic Features. In Natural Language Processing and Chinese Computing, Proceedings of the 7th CCF International Conference, NLPCC 2018, Hohhot, China, 26–30 August 2018; Zhang, M., Ng, V., Zhao, D., Li, S., Zan, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11108, pp. 303–315. [Google Scholar]
- Kuang, S.; Han, L. Apply Chinese Radicals Into Neural Machine Translation: Deeper Than Character Level. arXiv 2018, arXiv:1805.01565. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Notes | Defaults |
|---|---|---|
| src_vocab_size | English vocabulary size | 32,000 |
| tgt_vocab_size | Chinese vocabulary size | 32,000 |
| batch_size | Number of samples selected for one training | 32 |
| epoch_num | Number of epochs | 40 |
| d_model | Feature dimensions of the model | 512 |
| max_len | Max length of sentence | 60 |
| beam_size | Beam size for bleu | 3 |
| early_stop | Early stop for loss increase | 5 |
| optimizer | Use an optimizer for training | Adam |
| use_gpu | Whether or not to use a GPU | 0 |
| CPUs | Freq.|#Core | GPUs | Category | Linux Kernel | OpenMP |
|---|---|---|---|---|---|
| Intel Core i7-7500U | 2.7 GHz | 2 | N/A | Laptop | v4.15.0 | GCC v7.5.0 |
| Intel Core i7-7700K | 4.2 GHz | 4 | N/A | Desktop | v4.15.0 | GCC v7.5.0 |
| Intel Xeon Platinum 9242 | 2.3 GHz | 96 | N/A | Server | v3.10.0 | GCC v4.8.5 |
| Intel Xeon Silver 4210 | 2.2 GHz | 40 | NVIDIA Titian RTX | Server | v4.18.0 | GCC v8.4.1 |
| Intel Xeon Silver 4210 | 2.2 GHz | 40 | NVIDIA GeForce RTX 2080Ti | Server | v4.18.0 | GCC v8.4.1 |
| Intel Xeon Silver 4210 | 2.2 GHz | 40 | NVIDIA GeForce RTX 2060 SUPER | Server | v4.18.0 | GCC v8.3.1 |
| GPU | Best Dev BLEU | Test Loss | Test BLEU |
|---|---|---|---|
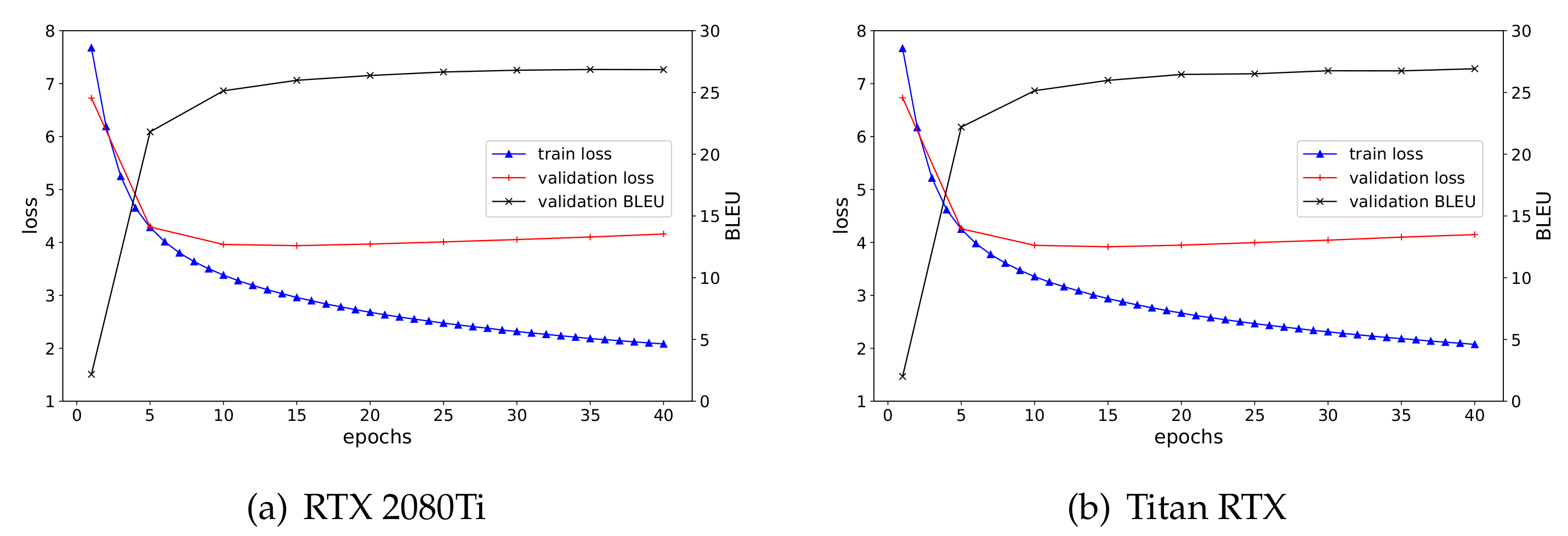
| RTX 2080Ti (bs = 8, step = 4) | 26.86 | 4.15 | 26.86 |
| Titan RTX (bs = 16, step = 2) | 26.92 | 4.16 | 26.88 |
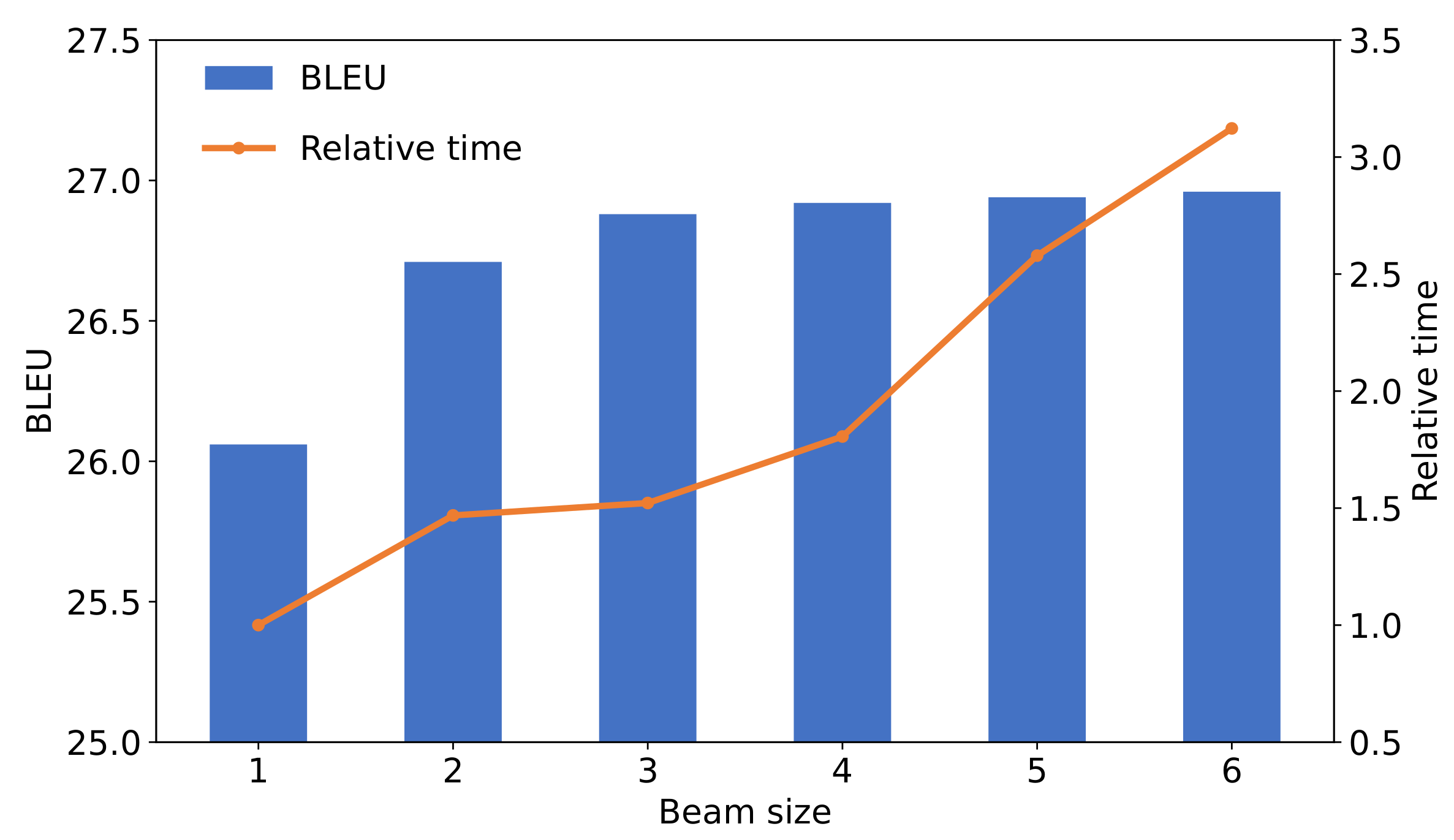
| Beam Size | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| BLEU | 26.06 | 26.71 | 26.88 | 26.92 | 26.94 | 26.96 |
| Time (s) | 1700 | 2497 | 2587 | 3070 | 4384 | 5308 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Gao, W.; Fang, J. High-Performance English–Chinese Machine Translation Based on GPU-Enabled Deep Neural Networks with Domain Corpus. Appl. Sci. 2021, 11, 10915. https://doi.org/10.3390/app112210915
Zhao L, Gao W, Fang J. High-Performance English–Chinese Machine Translation Based on GPU-Enabled Deep Neural Networks with Domain Corpus. Applied Sciences. 2021; 11(22):10915. https://doi.org/10.3390/app112210915
Chicago/Turabian StyleZhao, Lanxin, Wanrong Gao, and Jianbin Fang. 2021. "High-Performance English–Chinese Machine Translation Based on GPU-Enabled Deep Neural Networks with Domain Corpus" Applied Sciences 11, no. 22: 10915. https://doi.org/10.3390/app112210915
APA StyleZhao, L., Gao, W., & Fang, J. (2021). High-Performance English–Chinese Machine Translation Based on GPU-Enabled Deep Neural Networks with Domain Corpus. Applied Sciences, 11(22), 10915. https://doi.org/10.3390/app112210915