
Efficiently Supporting Online Privacy-Preserving Data Publishing in a Distributed Computing Environment

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Background and Problem Statement
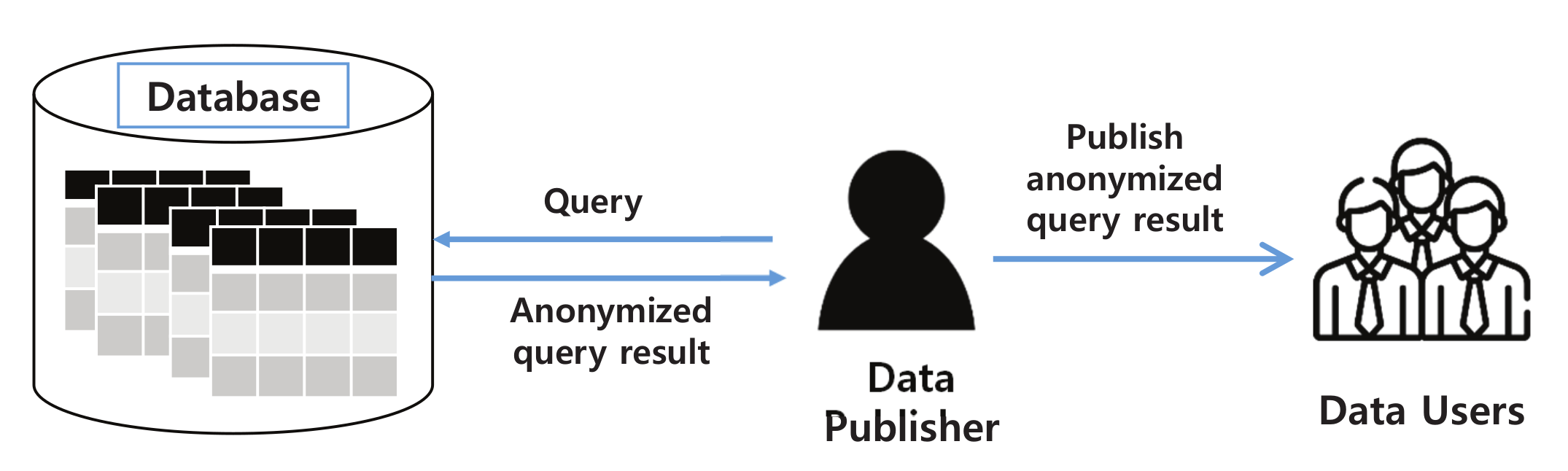
3.1. Background
3.2. Problem Statement
- SELECT
- FROM
- WHERE AND AND ⋯ AND .
- consists of attributes that are in either Q or S,
- the condition in the WHERE clause consists of l conjunctive selection conditions, , and
- each predicate can be either an equality condition or a range condition on an attribute not in .
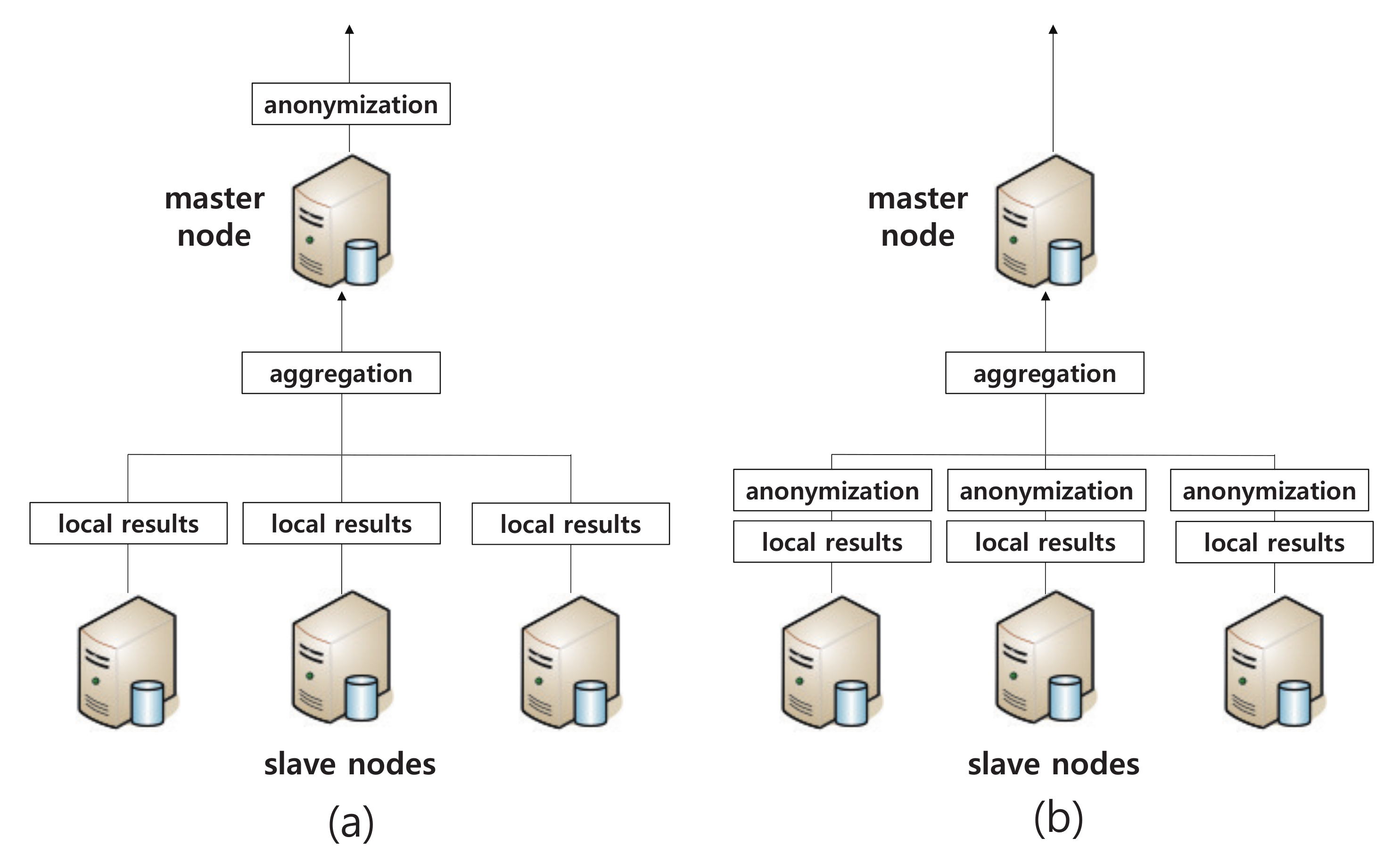
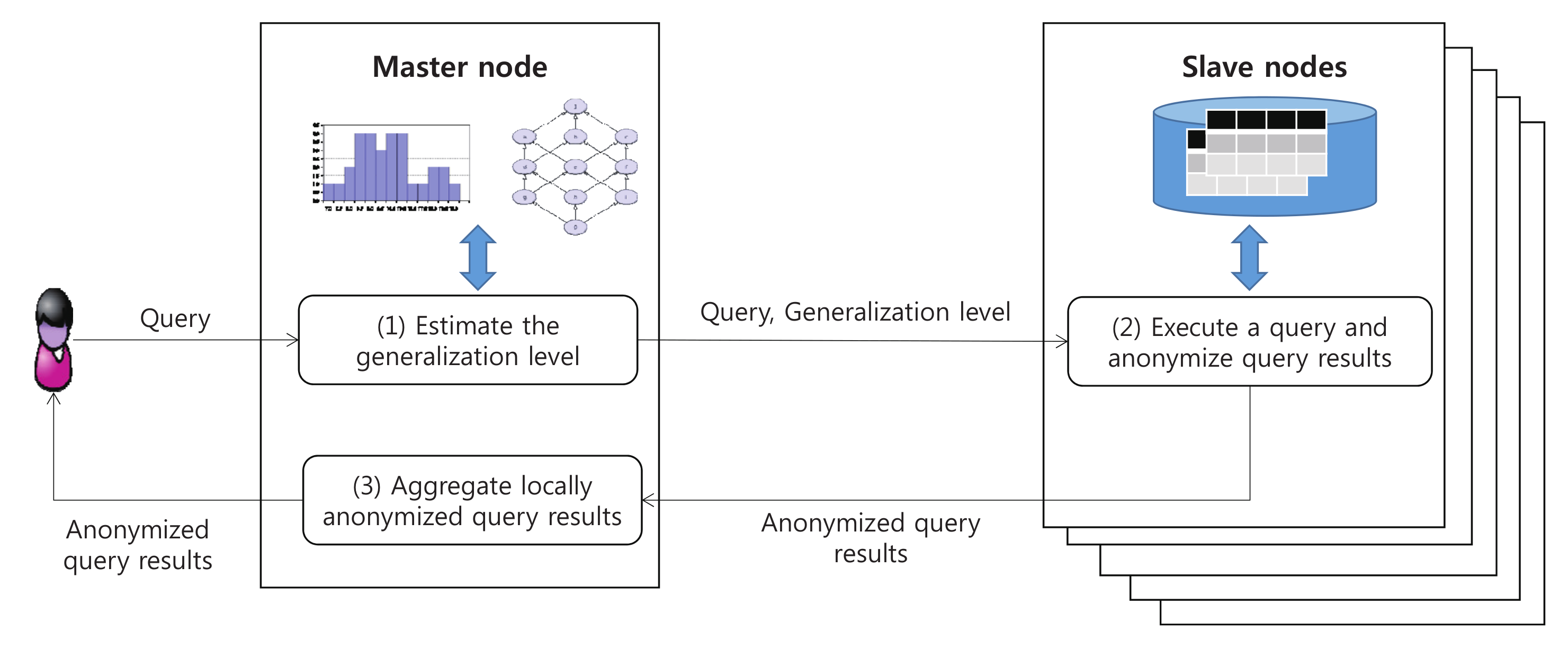
4. Efficient Support of Online Data Publishing
- First, given a query, the master node estimates the generalization level of each quasi-identifier attribute to satisfy the k-anonymity property over the query result datasets, and then send it to each slave node along with the user query (Section 4.1);
- Each slave node then executes the user query, anonymizes its own query results based on the generalization information received from the master node, and sends the anonymized query results to the master node (Section 4.2);
- Finally, the master node aggregates the anonymized query results from every slave node and returns the aggregated results to the user (Section 4.3).
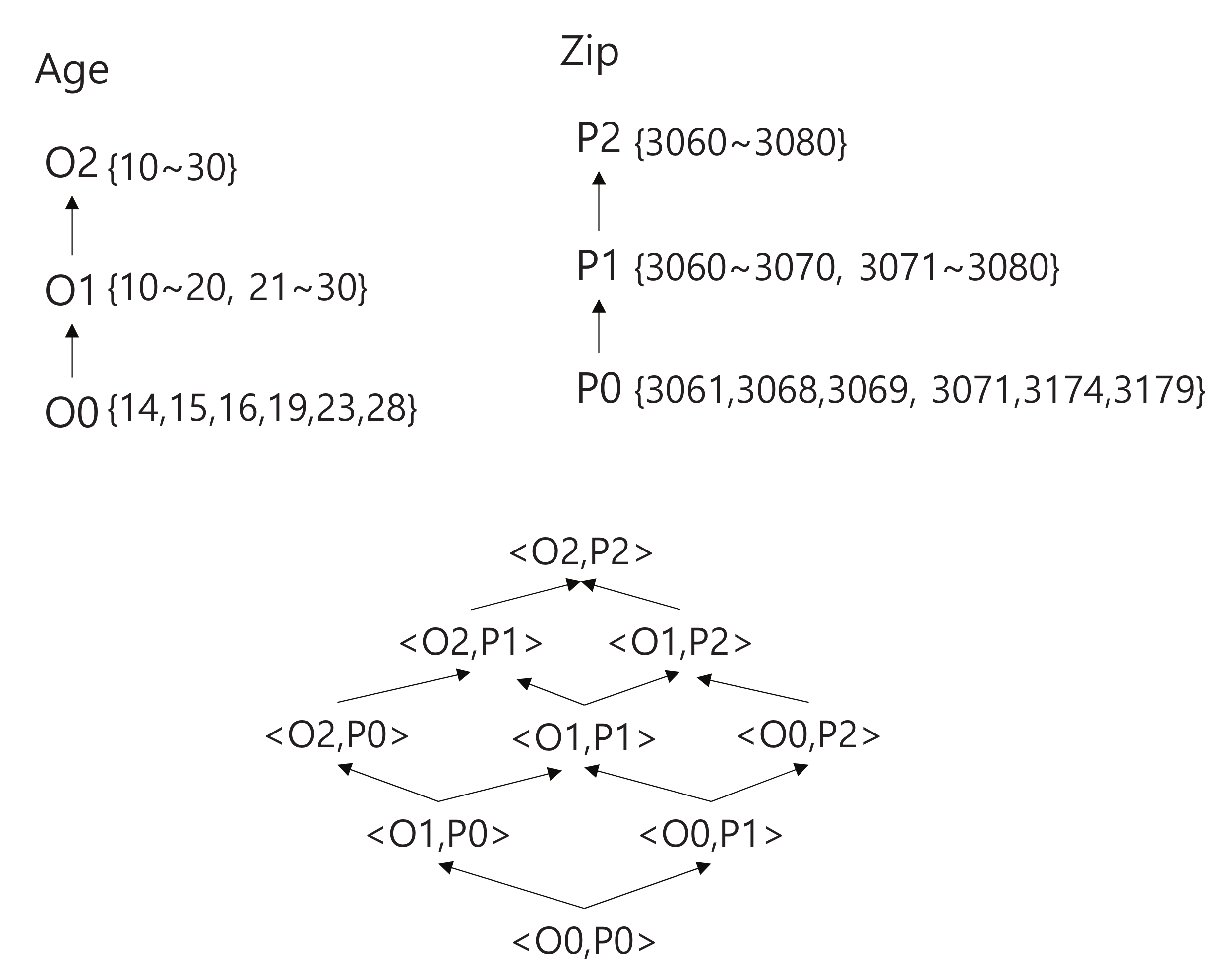
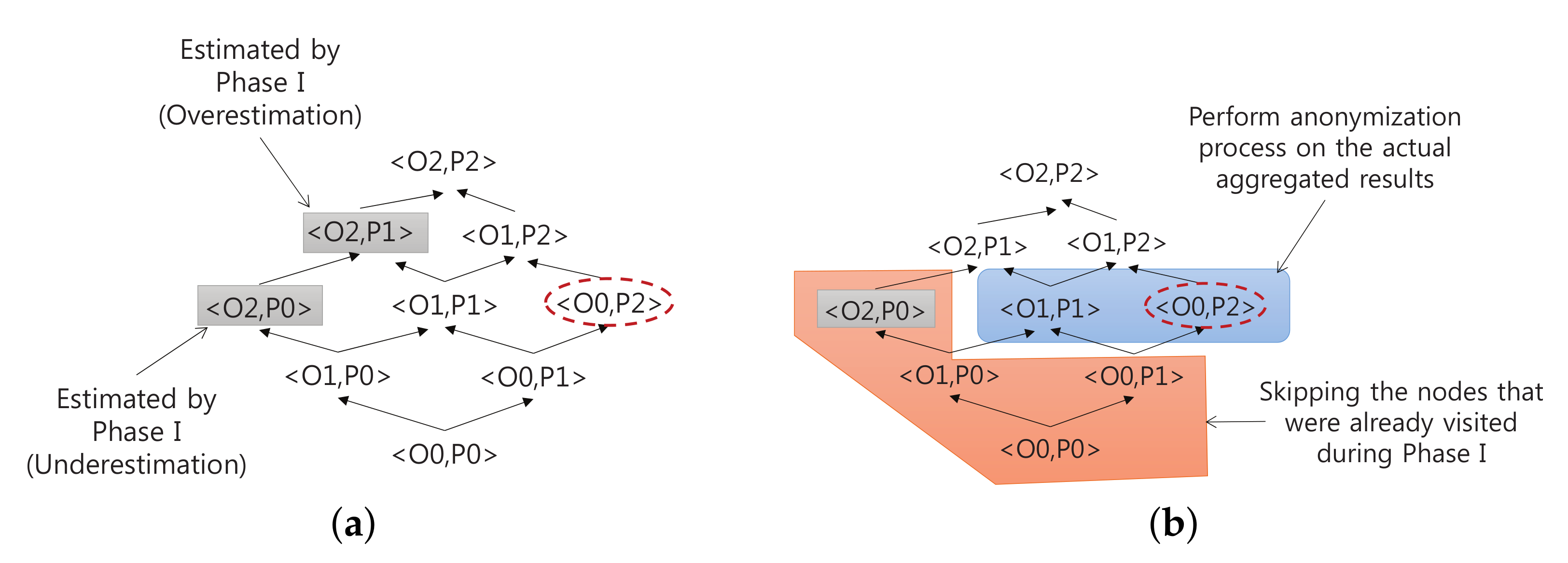
4.1. Phase I: Estimating the Generalization Level
4.2. Phase II: Executing a Query and Anonymizing Local Query Results
4.3. Phase III: Aggregating (and Further Anonymizing) Locally Anonymized Results
5. Experiment Evaluations
5.1. Experiment Setup
- SELECTAge, Sex, Length, Location, Surgery, Disease
- FROM
- WHEREHeight AND Height .
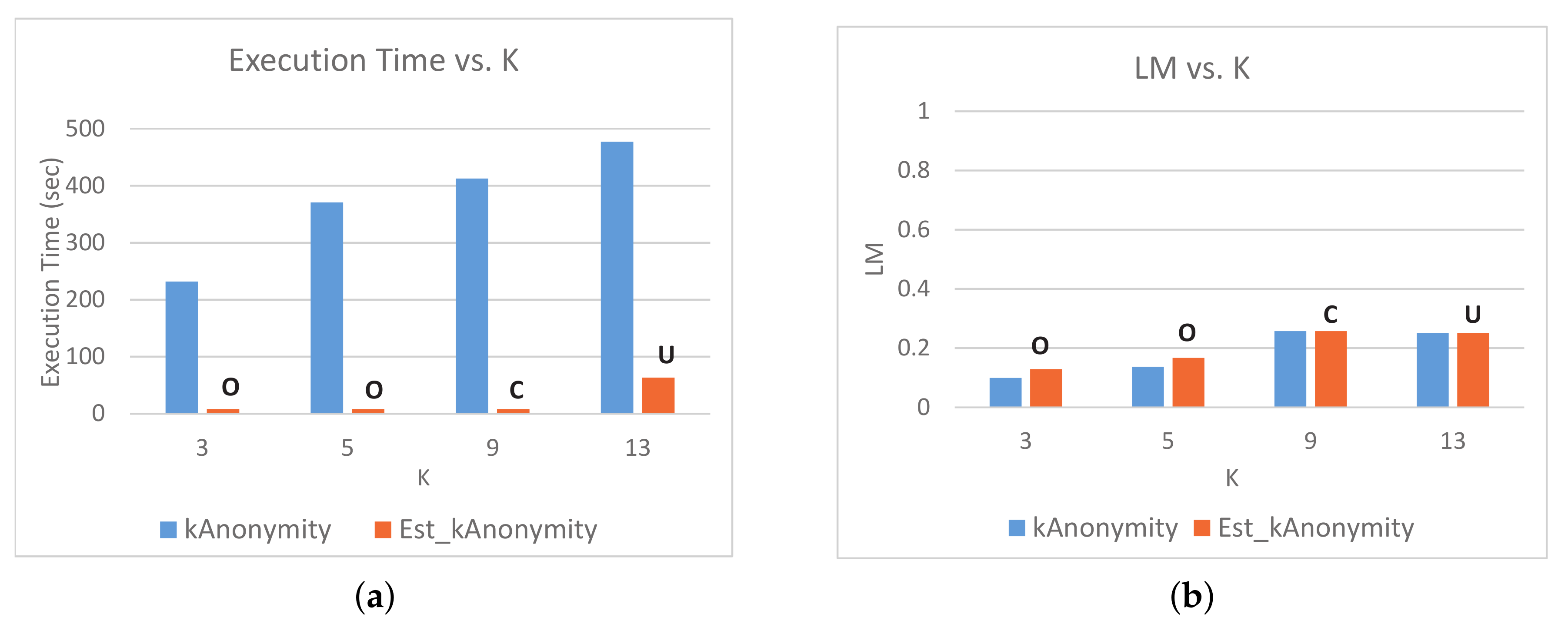
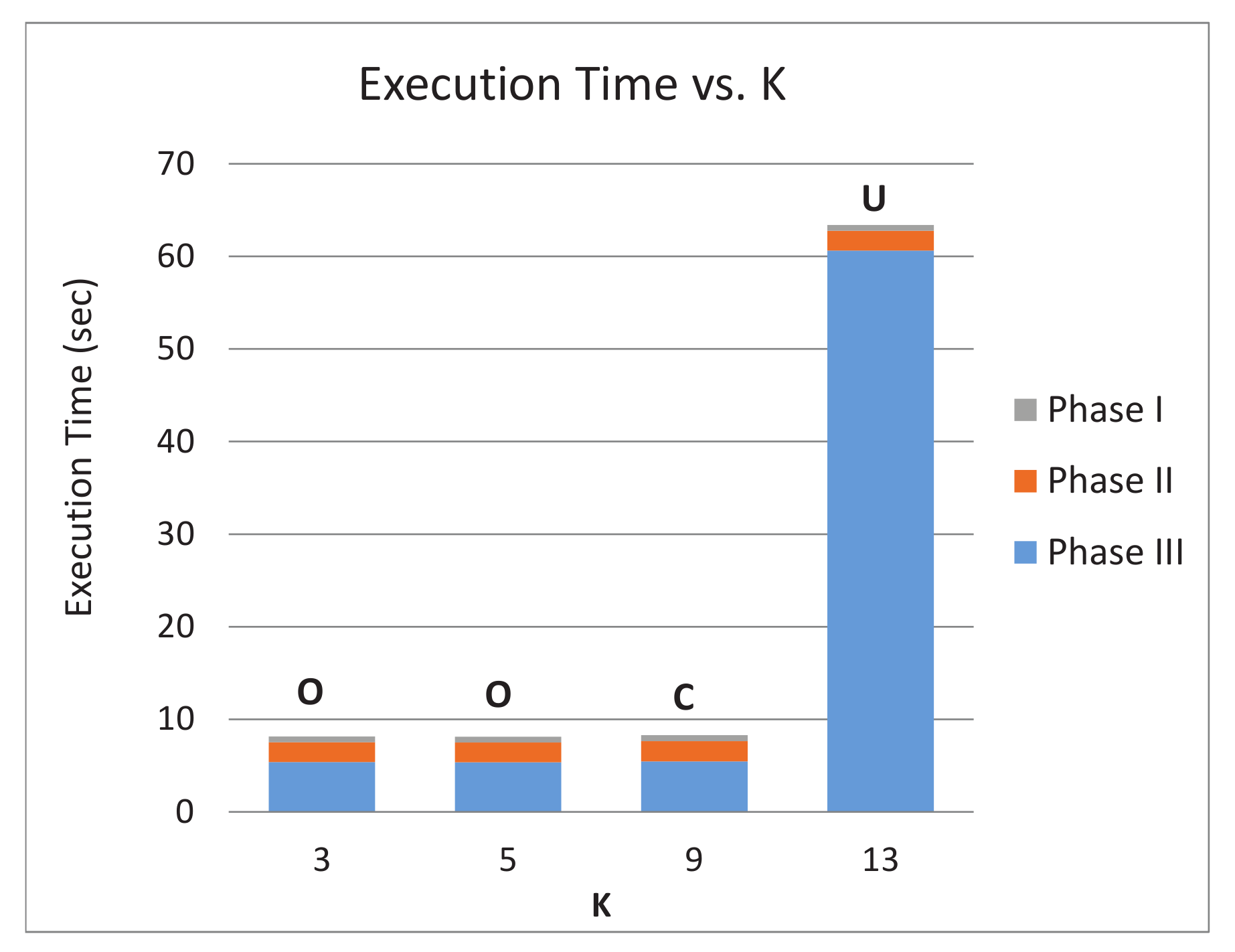
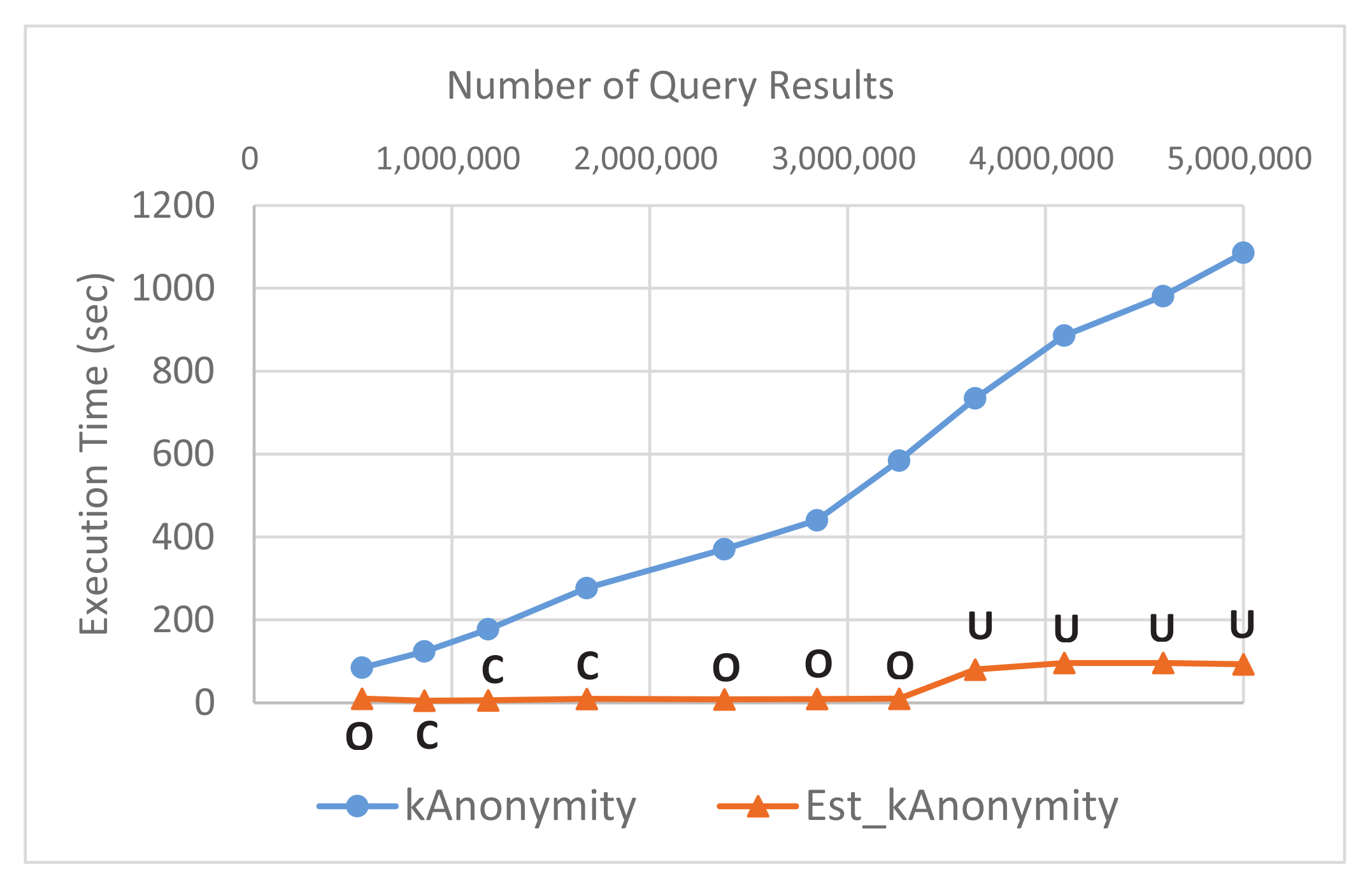
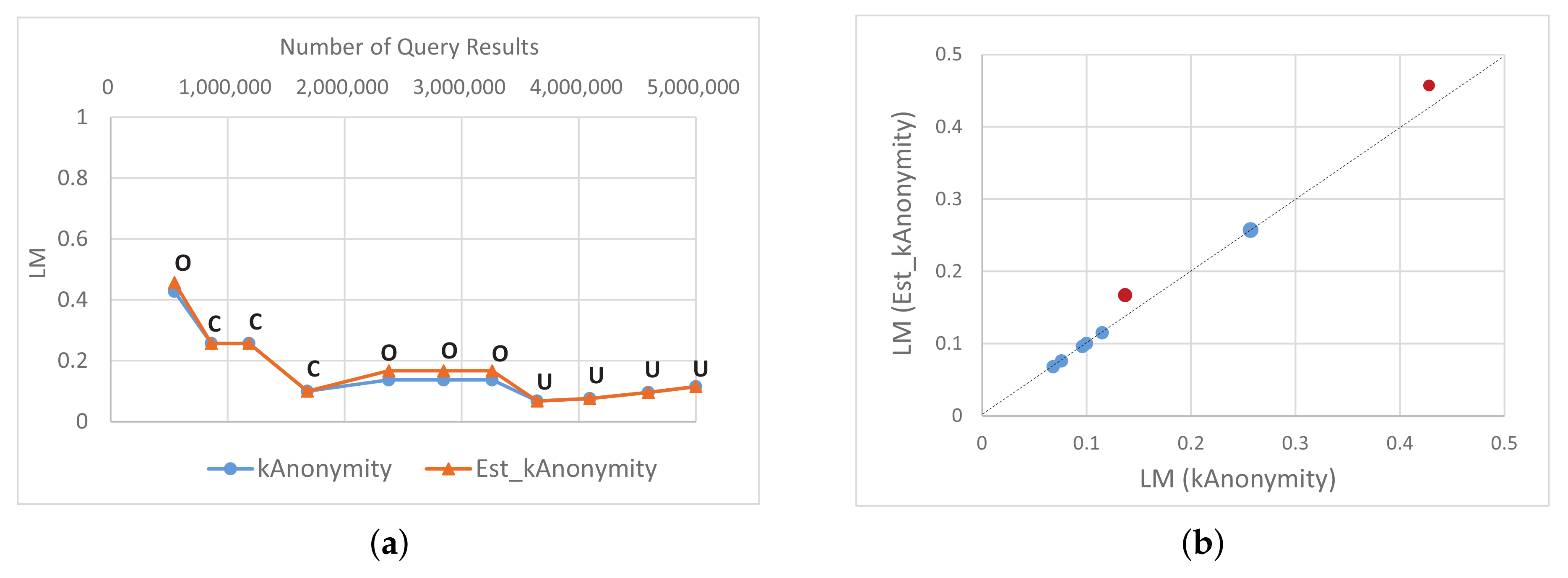
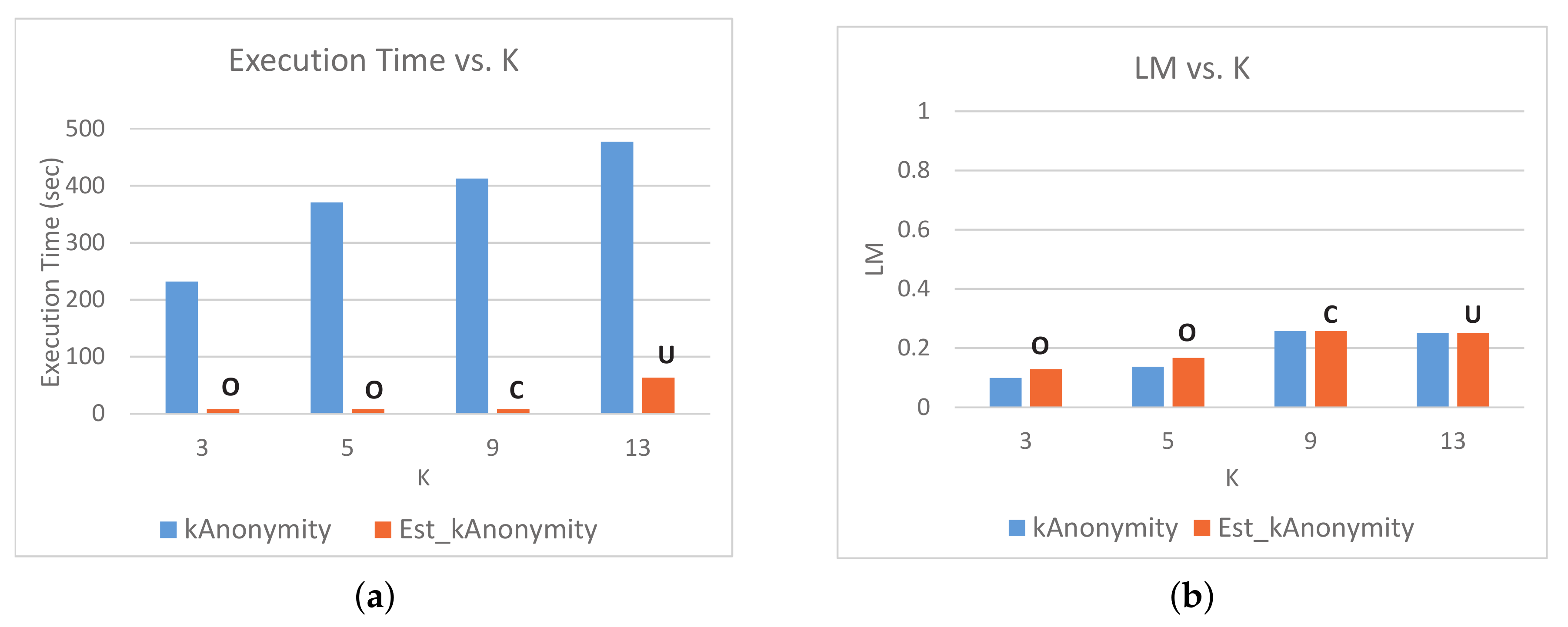
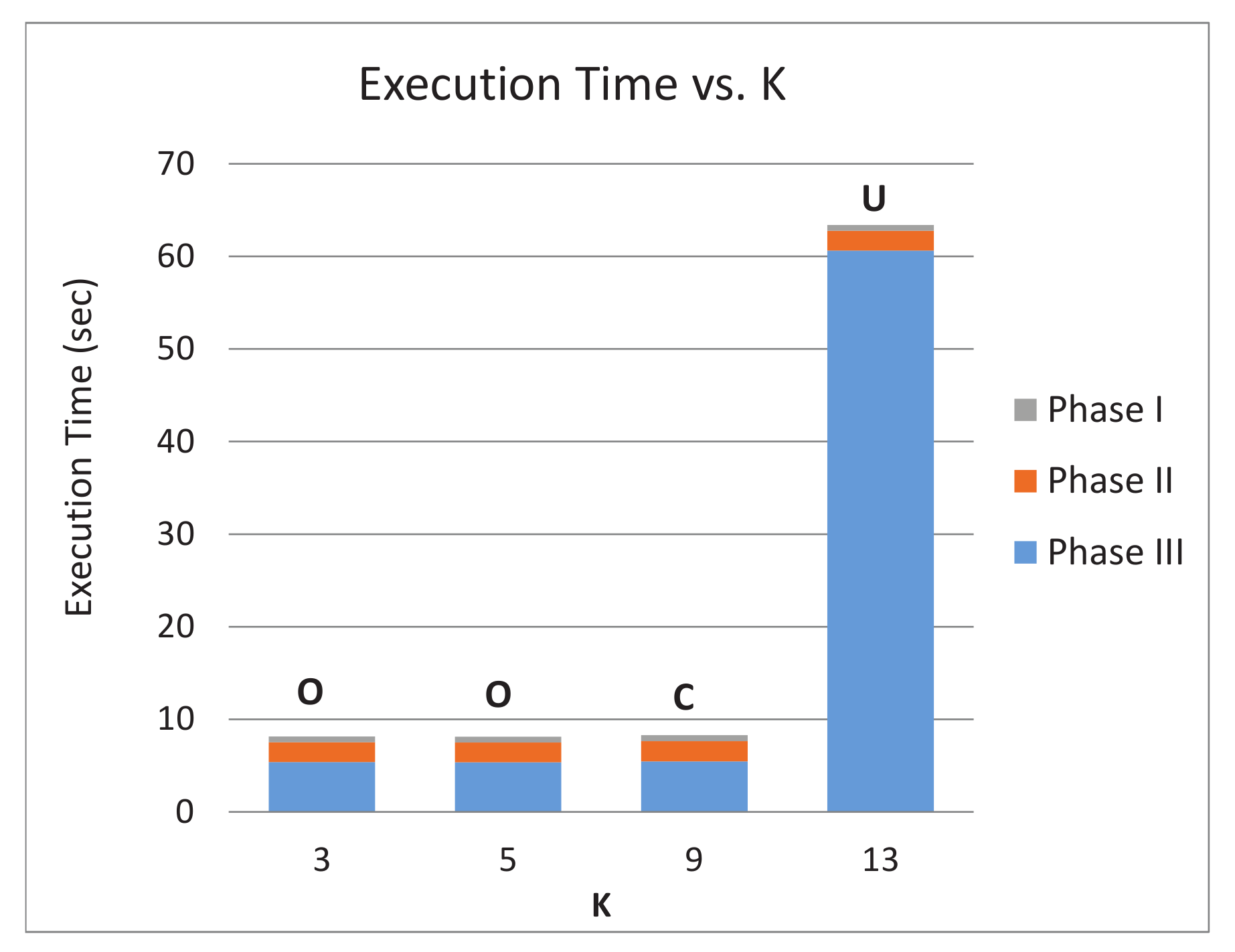
5.2. Results and Discussion
6. Conclusions
Funding
Conflicts of Interest
References
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Incognito: Efficient full domain k-anonymity. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005. [Google Scholar]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3-es. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond kanonymity and l-diversity. In Proceedings of the International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007. [Google Scholar]
- Biskup, J.; Bonatti, P.A. Controlled query evaluation for known policies by combining lying and refusal. In Proceedings of the International Symposium on Foundations of Information and Knowledge Systems, Salzau Castle, Germany, 20–23 February 2002. [Google Scholar]
- Kenthapadi, K.; Mishra, N.; Nissim, K. Simulatable auditing. In Proceedings of the ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Baltimore, MD, USA, 14–16 June 2005. [Google Scholar]
- Nabar, S.U.; Marthi, B.; Kenthapadi, K.; Mishra, N.; Motwani, R. Towards robustness in query auditing. In Proceedings of the International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006. [Google Scholar]
- Katsomallos, M.; Tzompanaki, K.; Kotzinos, D. Privacy, space and time: A survey on privacy-preserving continuous data publishing. J. Spat. Inf. Sci. 2019, 19, 57–103. [Google Scholar] [CrossRef]
- Wang, K.; Fung, B.C.M. Anonymizing sequential releases. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Fung, B.C.M.; Wang, K.; Fu, A.; Pei, J. Anonymity for continuous data publishing. In Proceedings of the International Conference on Extending Database Technology, Nantes, France, 25–29 March 2008. [Google Scholar]
- Xiao, X.; Tao, Y. M-invariance: Towards privacy preserving re-publication of dynamic data sets. In Proceedings of the ACM SIGMOD international conference on Management of Data, Beijing, China, 12–14 June 2007. [Google Scholar]
- He, Y.; Barman, S.; Naughtoni, J.F. Preventing equivalence attacks in updated, anonymized data. In Proceedings of the IEEE International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011. [Google Scholar]
- Wang, K.; Yu, P.S.; Chakraborty, S. Bottom-up generalization: A data mining solution to privacy protection. In Proceedings of the IEEE International Conference on Data Mining, Brighton, UK, 1–4 November 2004. [Google Scholar]
- Fung, B.C.M.; Wang, K.; Yu, P.S. Top-down specialization for information and privacy preservation. In Proceedings of the IEEE International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the IEEE International Conference on Data Engineering, Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Byun, J.W.; Kamra, A.; Bertino, E.; Li, N. Efficient k-anonymization using clustering technique. In Advances in Databases: Concepts, Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 188–200. [Google Scholar]
- Aggarwal, G.; Panigrahy, R.; Feder, T.; Thomas, D.; Kenthapadi, K.; Khuller, S.; Zhu, A. Achieving anonymity via clustering. ACM Trans. Algorithms 2010, 6, 1–19. [Google Scholar] [CrossRef]
- Sun, X.; Sun, L.; Wang, H. Extended k-anonymity models against sensitive attribute disclosure. Comput. Commun. 2011, 34, 526–535. [Google Scholar] [CrossRef]
- Anjum, A.; Malik, S.U.R.; Choo, K.-K.R.; Khan, A.; Haroon, A.; Khan, S.; Khan, S.U.; Ahmad, N.; Raza, B. An efficient privacy mechanism for electronic health records. Comput. Secur. 2018, 72, 196–211. [Google Scholar] [CrossRef]
- Kanwal, T.; Anjum, A.; Malik, S.U.R.; Sajjad, H.; Khan, A.; Manzoor, U.; Asheralieva, A. A robust privacy preserving approach for electronic health records using multiple dataset with multiple sensitive attributes. Comput. Secur. 2021, 105, 102224. [Google Scholar] [CrossRef]
- Kim, S.; Sung, M.K.; Chung, Y.D. A framework to preserve the privacy of electronic health data streams. J. Biomed. Inform. 2014, 50, 95–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, H.; Kim, S.; Kim, J.W.; Chung, Y.D. Utility-preserving anonymization for health data publishing. BMC Med. Inform. Decis. Mak. 2017, 17, 104. [Google Scholar] [CrossRef]
- Khan, R.; Tao, X.; Anjum, A.; Kanwal, T.; Malik, S.R.; Khan, A.; Rehman, W.; Maple, C. θ-Sensitive k-Anonymity: An anonymization model for IoT based electronic health records. Electronics 2020, 9, 716. [Google Scholar] [CrossRef]
- Fung, B.C.M.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. 2010, 42, 1–53. [Google Scholar] [CrossRef]
- Mohammed, N.; Fung, B.C.M.; Hung, P.C.K.; Lee, C.K. Centralized and distributed anonymization for high-dimensional healthcare data. ACM Trans. Knowl. Discov. Data 2010, 4, 1–33. [Google Scholar] [CrossRef]
- Gkoulalas-Divanis, A.; Loukides, G.; Sun, J. Publishing data from electronic health records while preserving privacy: A survey of algorithms. J. Biomed. Inform. 2014, 50, 4–19. [Google Scholar] [CrossRef] [Green Version]
- Abdelhameed, S.A.; Moussa, S.M.; Khalifa, M.E. Privacy-preserving tabular data publishing: A comprehensive evaluation from web to cloud. Comput. Secur. 2018, 72, 74–95. [Google Scholar] [CrossRef]
- Majeed, A.; Lee, S. Anonymization techniques for privacy preserving data publishing: A comprehensive survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Zigomitros, A.; Casino, F.; Solanas, A.; Patsakis, C. A survey on privacy properties for data publishing of relational data. IEEE Access 2020, 9, 51071–51099. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy. In Proceedings of the International Conference on Automata, Languages and Programming, Venice, Italy, 10–14 July 2006. [Google Scholar]
- Li, H.; Xiong, L.; Zhang, L.; Jiang, X. DPSynthesizer: Differentially private data synthesizer for privacy preserving data sharing. In Proceedings of the VLDB Endowment, Hangzhou, China, 1–5 September 2014. [Google Scholar]
- Xiao, X.; Bender, G.; Hay, M.; Gehrke, J. iReduct: Differential privacy with reduced relative errors. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2014. [Google Scholar]
- Erlingsson, U.; Pihur, V.; Korolova, A. RAPPOR: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
- Bassily, R.; Smith, A. Local, private, efficient protocols for succinct histograms. In Proceedings of the ACM Symposium on Theory of Computing, Portland, OR, USA, 13–15 June 2015; pp. 127–135. [Google Scholar]
- Wang, N.; Xiao, X.; Yang, Y.; Hoang, T.D.; Shin, H.; Shin, J.; Yu, G. Privtrie: Effective frequent term discovery under local differential privacy. In Proceedings of the IEEE International Conference on Data Engineering, Paris, France, 16–19 April 2018; pp. 821–832. [Google Scholar]
- Wang, T.; Li, N.; Jha, S. Locally differentially private heavy hitter identification. IEEE Trans. Dependable Secur. Comput. 2021, 18, 982–993. [Google Scholar] [CrossRef] [Green Version]
- Andres, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Berlin, Germany, 4–8 November 2013; pp. 901–914. [Google Scholar]
- Ahuja, R.; Ghinita, G.; Shahabi, C. A utility-preserving and scalable technique for protecting location data with geo-indistinguishability. In Proceedings of the International Conference on Extending Database Technology, Lisbon, Portuga, 26–29 March 2019; pp. 210–231. [Google Scholar]
- Zhang, J.; Xiao, X.; Xie, X. Privtree: A differentially private algorithm for hierarchical decompositions. In Proceedings of the International Conference on Management of Data, San Francisco, CA, USA, 14–19 June 2016; pp. 155–170. [Google Scholar]
- Kim, J.S.; Chung, Y.D.; Kim, J.W. Differentially private and skew-aware spatial decompositions for mobile crowdsensing. Sensors 2018, 18, 3696. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, H.; Chung, Y.D. Differentially private release of medical microdata: An efficient and practical approach for preserving informative attribute values. BMC Med. Inform. Decis. Mak. 2020, 20, 155. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Yang, M.; Wan, B. A practical privacy-preserving publishing mechanism based on personalized k-anonymity and temporal differential privacy for wearable IoT applications. Symmetry 2021, 13, 1043. [Google Scholar] [CrossRef]
- Meyerson, A.; Williams, R. On the complexity of optimal k-anonymity. In Proceedings of the ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Paris, France, 14–16 June 2004. [Google Scholar]
- Park, H.; Shim, K. Approximate algorithms for k-anonymity. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 12–14 June 2007. [Google Scholar]
- Sun, X.; Li, M.; Wang, H.; Plank, A. An efficient hash-based algorithm for minimal k-anonymity. In Proceedings of the Australasian Conference on Computer Science, Wollongong, Australia, 22–25 January 2008. [Google Scholar]
- Babu, K.S.; Reddy, N.; Kumar, N.; Elliot, M.; Jena, S.K. Achieving k-anonymity using improved greedy heuristics for very large relational databases. Trans. Data Priv. 2013, 6, 1–17. [Google Scholar]
- Hernandez-Baigorri, D.R.C.; Forne, J.; Soriano, M. Incremental k-anonymous microaggregation in large-scale electronic surveys with optimized scheduling. IEEE Access 2018, 6, 60016–60044. [Google Scholar]
- Chaudhuri, S.; Motwani, R.; Narasayya, V. On Random Sampling over Joins. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 31 May–3 June 1999. [Google Scholar]
- Chakrabarti, K.; Garofalakis, M.; Rastogi, R.; Shim, K. Approximate query processing using wavelets. In Proceedings of the International Conference on Very Large Data Bases, Cairo, Egypt, 10–14 September 2000. [Google Scholar]
- Babcock, B.; Chaudhuri, S. Towards a robust query optimizer: A principled and practical approach. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005. [Google Scholar]
- Spiegel, J.; Polyzotis, N. Graph-based synopses for relational selectivity estimation. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006. [Google Scholar]
- Kim, J.W.; Candan, K.S. PICC counting: Who needs joins when you can propagate efficiently? In Proceedings of the SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009. [Google Scholar]
- Han, Y.; Wu, Z.; Wu, P.; Zhu, R.; Yang, J.; Tan, L.W.; Zeng, K.; Cong, G.; Qin, Y.; Pfadler, A.; et al. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation. arXiv 2021, arXiv:2109.05877. [Google Scholar]
- PostgreSQL: The World’s Most Advanced Open Source Relational Database. 2021. Available online: https://www.postgresql.org/ (accessed on 5 November 2021).
- Health Insurance Review and Assessment Service in Korea. 2012. Available online: http://opendata.hira.or.kr (accessed on 5 November 2021).
- MySQL. 2017. Available online: https://www.mysql.com/ (accessed on 5 November 2021).
- Iyengar, V.S. Transforming data to satisfy privacy constraints. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.W. Efficiently Supporting Online Privacy-Preserving Data Publishing in a Distributed Computing Environment. Appl. Sci. 2021, 11, 10740. https://doi.org/10.3390/app112210740
Kim JW. Efficiently Supporting Online Privacy-Preserving Data Publishing in a Distributed Computing Environment. Applied Sciences. 2021; 11(22):10740. https://doi.org/10.3390/app112210740
Chicago/Turabian StyleKim, Jong Wook. 2021. "Efficiently Supporting Online Privacy-Preserving Data Publishing in a Distributed Computing Environment" Applied Sciences 11, no. 22: 10740. https://doi.org/10.3390/app112210740
APA StyleKim, J. W. (2021). Efficiently Supporting Online Privacy-Preserving Data Publishing in a Distributed Computing Environment. Applied Sciences, 11(22), 10740. https://doi.org/10.3390/app112210740