1. Introduction
Autonomous cars are a well-known example of a safety-critical Cyber-Physical System (CPS), meaning that a failure could result in loss of life or in catastrophic consequences for the environment. One of the main challenges for autonomous driving in a real environment consists in ensuring such safety [
1]. When many autonomous and human drivers interact in the same environment, achieving safety is even more challenging, due to several factors such as the unpredictability of agents’ behavior and scalability.
The explosion of Artificial Intelligence (AI) and Machine Learning permitted the design of very powerful and efficient CPSs. However, it also increased the complexity and opacity of such systems. In real-world systems, where safety plays a crucial role, such opacity and the consequent loss of explainability can be serious issues. Indeed, explainability in AI is itself a prominent goal [
2].
In recent years, the formal methods community helped to tackle this problem [
3]. Formal methods allow us to describe safe requirements in a formal and rigorous way and to check in an automatic way when such requirements are satisfied. When dealing with data describing how values vary over time, a possibility is to use temporal logic languages. Temporal logic is a logic that comes with specific temporal operators to describe the temporal evolution of a system. In particular, we consider the Signal Temporal Logic (STL), a logic very suitable to specify properties over real-world trajectories. For example, given two trajectories that describe the velocity of a car and its distance to the closest car over time, with STL, we can formally specify simple properties such as “travel no faster than 30
”, as well as more complex properties such as “do not exceed 30
if, in the last minute, the closest other car has been closer than 30
”. Provided that an STL specification is available, the monitoring of a CPS can be done efficiently using suitable algorithms that can check when the trajectory satisfies the property [
4], possibly exploiting distributed processing paradigms [
5].
In principle, STL specifications can be designed by the human operator, who should both know the domain, i.e., the involved properties and the expected behavior, and master STL syntax and semantics. In practice, however, designing the right specification that fits the observable system is very hard, because many attributes (and hence many trajectories) should be considered at the same time. A possible solution is to learn the formal specification in an automatic way: given a sufficiently representative set of system trajectories describing the system behavior, some inference technique can be used to synthesize the specification that fits the data. While some approaches for specification inference from data exist (see
Section 2 for an overview), the vast majority of them require the user to either (1) specify the structure of the STL specification, while actually inferring only its numerical parameters, or (2) provide both positive and negative example trajectories that are representative of expected and unexpected behaviors. In practical settings, these requirements often become limitations and hamper the applicability of inference techniques.
In this paper, we present a methodology to learn STL specifications from real-world datasets of unlabeled trajectories, i.e., from trajectories for which no human-assigned labels are required that tell if the observations are related to an expected or undesired behavior of the system. Our methodology is based on grammar-based evolutionary optimization, namely Context-Free Grammar Genetic Programming (CFGGP) [
6]. We chose this kind of optimization because it is perfectly suited for searching in the space of strings of a language specified by means of grammar: in fact, the STL language can be specified with a grammar (see
Section 3). While designing our methodology, we were driven by two goals: generating STL specifications that (1) fit the data and (2) are human-readable. For achieving the first goal, we designed a fitness function, i.e., a measure of the quality of the candidate specification, that measures the degree of (dis)satisfaction of the trajectories with respect to the specification, to be minimized: intuitively, all the trajectories (which, we remark, are unlabeled) should
barely satisfy or dissatisfy the specification. For achieving the second goal, we structurally limited the complexity of the learned specification, by imposing special constraints within the grammar.
We assess experimentally our methodology on a real-world traffic dataset of 5678 unique vehicles tracked over 19,679 frames with information about velocity and position. After extracting the informative attributes from the dataset, we show how the method can learn STL specifications in an automatic and efficient way. The learned specifications provide relevant information concerning the dataset and are indeed human-interpretable.
The rest of this paper is structured as follows. In the next section, we survey the most significant previous research that is relevant to our study. In
Section 3, we briefly introduce the background about STL. In
Section 4, we formally define the problem that we aim to solve. In
Section 5, we describe our proposed solution, which we experimentally evaluate in
Section 6. Finally, we draw the conclusion and we sketch possible future lines of research in
Section 7.
2. Related Work
There exist several approaches devoted to learning temporal logic specifications, particularly for STL. We partition here them into two categories: template-based and template-free. While those in the former category rely on a user-provided template formula and focus on estimating parameters for it, the latter also try to learn the formula structure. We fall in the template-free domain.
Template-based methods cast the STL specification mining problem as an optimization problem in terms of the satisfaction degree
of an STL formula (see
Section 3). Succinctly, we define
as a (real-valued) degree of satisfaction of an STL formula with respect to a trajectory. Bartocci et al. [
7] adopted an active learning approach, dependent on a probability distribution over
, to query the next point in the parameters space to be evaluated. Bortolussi and Silvetti [
8] extended the work cited previously with a statistical approach that emulates the expected value of this probability distribution using Gaussian Process Regression [
9]; optimization of the emulation was then performed via the GP-UCB algorithm [
10]. In general, these approaches are labeled as Parametric Signal Temporal Logic (PSTL) [
11,
12].
Although interesting on its own, the applicability of PSTL is sometimes limited, since specifying templates can be hard to start with. As such, template-free methods also attempt to build an optimal structure for the formula. The vast majority of the works in this regard start from a dataset of labeled trajectories, partitioned into positive and negative examples, and try to learn an STL classifier for the data. As an example, Nenzi et al. [
13] proposed ROGE (RObustness GEnetic algorithm), a bi-level optimization procedure, which optimized the structure by a genetic algorithm and the parameters using Bayesian Optimization. To the best of our knowledge, it is the only attempt at using an evolutionary algorithm for solving the template-free problem. Others mined STL structure by exploring a directed acyclic graph [
14], using a decision-tree oriented approach [
15], or employing enumerative solvers [
16].
The achievements of the aforementioned approaches have been remarkable, but none of them addressed the problem of mining STL specifications from unlabeled data. Considering real-world scenarios, it is often the case that we labeled data that are not available, because labeling is costly. Still, those data do bring some information that could be, in principle, condensed in the form of an STL specification. Some special cases of the unlabeled data case have been considered: M. Vazquez-Chanlatte et al. [
17] and Mohammadinejad et al. [
16] addressed unsupervised clustering of time-series data using PSTL, i.e., they learned just the parameters of template formulas.
To the best of our knowledge, the only work learning both structure and parameters of a formula from unlabeled data is [
18], where the authors proposed a heuristic for sequentially building more complex formulas. This seems a very interesting approach, but its applicability to large datasets is unclear: the experimental evaluation of the cited paper is based on a single trajectory and the results concerning the learning of the structure of the formula are not clear. Unfortunately, the code is not available and this hampers reproducibility and comparisons.
A different approach for designing automatic rules for road traffic has been proposed by Medvet et al. [
19]. Similar to this study, the authors relied on grammar-based genetic programming and did not use labeled data. Differently from here, they did not use STL as the syntax for the rules and they optimized rules with the goal of maximizing the efficiency and safety of (simulated) road traffic rather than for describing real data of road traffic.
3. Background: Signal Temporal Logic
Signal Temporal Logic (STL) is a formal language to specify behaviors of dynamical systems through logic formulas. Let be a set of trajectories for every , with a time domain. We say that each trajectory is a p-dimensional signal of real-valued variables, and we denote by the projection on the i-th coordinate of at time . We now introduce the syntax of STL, the set of rules used for constructing specifications in this language.
Definition 1 (STL syntax).
We define the syntax of an STL formula using the following grammar:
where ⊤ is the Boolean constant true; , with , is a time interval such that ; is an atomic proposition of the form , with projecting the p-dimensional signal onto a single variable, and being a threshold (practically inequality over the variable of the signal); ¬ and ∧ are the usual Boolean connectives; is the Since temporal modality; is the Once temporal modality; and is the Historically temporal modality.
The
semantics of an STL formula
allows us to tell if and to which degree a trajectory
satisfies the formula
at time
t. We now define two kinds of semantics: with the Boolean semantics, the satisfaction assumes Boolean values (does satisfies, does not satisfy); with the quantitative semantics, the satisfaction assumes real-valued values [
20,
21].
Definition 2 (STL Boolean Semantics).
For the Boolean semantics, we write if holds for trajectory at time t. If is an atomic proposition , then if and only if is true. The semantics of and is trivial and the semantics of Since is defined as follows:with . In other words, we say that is satisfied at time t if occurs at some point in and holds continuously since then. The other temporal operators are defined based on Since: Once as and Historically as .
Definition 3 (STL Quantitative Semantics).
The quantitative satisfaction function returns a value quantifying the robustness degree of the formula by the trajectory at time t. It is defined recursively as follows:Similar to the Boolean semantics, the Once and Historically temporal operators are defined based on Since.
The sign of provides the link with the standard Boolean semantics. It holds that if and only if , while if and only if . The case , instead, is a borderline case, and the truth of cannot be assessed from the robustness degree alone.
In practical settings, systems are monitored for a given, finite amount of time, and, as a result, trajectories have a limited time span. We define as the length of a trajectory, i.e., its number of samples. For the sake of this study, monitoring an STL formula over a trajectory is constrained to , a subset of the time domain.
When talking about temporal formulas, the
necessary length concept is of importance [
20]. The necessary length of a formula
(let it be
) is defined recursively as:
Intuitively, the necessary length is the shortest trajectory length such that is well-defined. For example, the formula cannot be evaluated on trajectories shorter than 10 (assuming that and ), since this would imply looking at a future that is not part of the trajectory.
4. Problem Statement
We consider systems described by real-valued attributes and a set of trajectories that describe the way these attributes vary over time. We aim to mine specifications that (1) describe such trajectories (2) in a way that the specifications are readable and interpretable for a human.
Formally, let be a set of trajectories gathered from a system described by attributes . Let be the space of all possible STL formulas defined over A. We aim at finding a that is both human-readable and describes X. More specifically, should be
tight
with respect to X, i.e., the robustness value should be as much as possible close to zero for all and t. From another point of view, small perturbations on tight formulas should result in an overall increase in robustness for some trajectories of X; i.e., some trajectories could be described by a tighter formula .
Tightness is of fundamental importance when no labels are provided; in fact, the satisfaction of a robustness metric can be trivially maximized by “pushing” the parameters towards the boundaries of the parameter space, resulting in rules that are of no relevance. For example, if is satisfied by all trajectories, then will be satisfied as well and have a much greater degree of robustness.
Concerning human-interpretability, a formal, widely accepted definition for STL formulas does not exist. Indeed, the lack of such a definition holds for many other kinds of Machine Learning modules. Moreover, it is acknowledged that human-interpretability is not, itself, universal: different subjects might perceive the same model as differently interpretable [
22]. In this work, we circumvent the problem of defining interpretability with a practical approach: we force our method to search in a subset of
containing structurally simple formulas, where both the overall size of the formula and the maximum degree of nesting of temporal operators are limited. The rationale of the latter constraint is in the fact that the interpretability of symbolic models is affected differently by different kinds of components [
23].
We remark that our problem is more complex than the mere specification mining of a template formula where the structure of the formula is already fixed (see
Section 2), which searches only in the parameter space of the formula. In the easier case, the user has to provide a template formula
, and the problem is a numerical optimization problem; i.e., the solution has to be found in
, where
m is the number of numerical parameters in
. In our case, no burden is on the user, but the system is required to search in
rather than
. In
Section 5, we detail the methodology we employed to address this problem statement.
5. Methodology
Since the STL syntax can be defined by means of context-free grammar (CFG), we rely on CFGGP [
6], a grammar-based version of GP [
24]. In CFGGP, candidate solutions are represented as derivation trees of a grammar
, where
N is the set of non-terminal symbols,
T is the set of terminal symbols (with
),
is the starting symbol, and
R is the set of derivation rules. Each derivation rule describes how a non-terminal symbol may be replaced by a sequence of symbols, either terminal or non-terminal. A
derivation tree
is a tree where nodes are symbols of the grammar: leaf nodes are terminal symbols, and non-leaf nodes are non-terminal symbols. The children of each node match one of the derivation rules for the corresponding non-terminal symbol. The string of the language defined by the grammar corresponding to a given derivation tree is the sequence of the leaves of the tree. Note that a derivation tree is not an abstract syntax tree: the former is in general deeper than the latter, for the same formula.
Figure 1 shows an example of a derivation tree for the CFG of
Figure 2.
We use an improved version of CFGGP that promotes diversity in the population. The lack of diversity in the population may result in premature convergence towards a local optimum [
25], in particular when the search space is discrete, as in CFGGP [
26]. In this work, we promote diversity by simply enforcing the re-application of the genetic operator whenever a generated individual is already part of the population.
5.1. Evolutionary Algorithm
Given a CFG and a fitness function , CFGGP works as shown in Algorithm 1. After the initialization of the population P, CFGGP repeats times the following three steps.
- (1)
It builds the offspring population , with , by iteratively selecting one (mutation, with probability) or two (crossover, with probability) parents chosen with tournament selection of size and then applying the genetic operator. If the resulting solution is already part of the offspring or parent population P, a new solution is generated, and the process is repeated for a maximum number of attempts; otherwise is added to and its fitness is computed.
- (2)
It merges the parent and offspring populations and P.
- (3)
It shrinks the resulting new population P, until its size is , by iteratively removing the worst solution.
The initial population is built with the ramped half-and-half method [
27]. Let a range
for the depth of the derivation trees be given and let
be the number of trees to be generated. For each
d in the range, we build
k random approximately full derivation trees (i.e., where each leaf node is at depth
d) and
k random trees with the deepest leaf at depth
d, with
. We write “approximately” because it is not possible, in general, to build a derivation tree of a grammar
where each leaf is exactly at depth
d. This procedure ensures that the size, and hence, the complexity of the generated formulas is evenly distributed in a predefined range.
The genetic operators are defined over the space of derivation trees of the grammar . We used the standard CFGGP mutation and crossover. The former “replaces” a random subtree of the derivation tree with a randomly generated subtree that is appropriate according to . The crossover “replaces” a random subtree of one parent with an appropriate random subtree of the other parent. In both cases, it is ensured that the resulting derivation tree is at most deep.
| Algorithm 1: The EA for the optimization. |
![Applsci 11 10573 i001]() |
5.2. Fitness Function
To achieve the goals of
Section 4, we use as fitness function:
which computes the average absolute quantitative robustness of an individual
over the dataset
. Minimizing this quantity is consistent with the notion of achieving a tight evaluation with respect to the trajectories in
. Tightness is of importance when no labels are provided; in fact, the satisfaction of a robustness metric can be trivially maximized by “pushing” the parameters towards the boundaries of the parameter space, resulting in rules that are of no relevance. As a matter of example, if
is satisfied by all trajectories, then
will be satisfied as well and have a much greater degree of robustness. By minimizing the sum of the absolute values,
f achieves a tight evaluation as it rewards individuals
having robustness values as close as possible to zero. Finally, we divide by the total number of trajectories so that, for normalized data,
, with 0 corresponding to a formula that perfectly fits all of trajectories, and 1 corresponding to a formula that does not satisfy all of the trajectories in the worst possible way.
5.3. Grammar for STL Formula Structures
We need to define a grammar for the language of STL formulas. must be customizable for the considered problem, i.e., for its attributes A, and must allow generating formulas along with appropriate values as numerical parameters.
In order to favor the building of human-readable formulas, we build the grammar to explicitly limit the depth of nesting of temporal operators. We remark that the overall size of STL formulas is limited by the value of
used by CFGGP (in the operators and in the initialization of the population). However, we believe that posing a further limit on the composition of the temporal operators may make the STL formulas more readable, and not only just smaller. Our belief is corroborated by the findings of [
23] for mathematical expressions: some operators, such as log and sin, make the expressions less interpretable than others, e.g., + and ÷.
Figure 2 shows the grammar for STL formula structures with limited nesting of the temporal operators. The figure adopts the common Backus–Naur form: the non-terminal symbols are enclosed in angle brackets, whereas the terminal symbols are shown as literals (¬, ∧, …,
r,
,
, …, <, >, 0, …, 9); for each non-terminal, derivation rules are separated by |; the starting symbol is the topmost non-terminal, i.e.,
. The terminals
,
, …, derived from the non-terminal
, represent the attributes of the problem at hand: in this way, the grammar is tailored to a specific problem. For brevity, we express some of the non-terminals using a parameter
i that represents the maximum nesting. The only derivation rule that increases
i is the one for
, which represents (partial) formulas with temporal operators. The limit to nesting is enforced by the parametric definition of the derivation rule of
, that does not expand to
if
. In this study, we set the maximum nesting to
. This means that CFGGP operates on a grammar
that is the realization of the grammar of
Figure 2 with
and a given set of attributes
A.
When mapping a derivation tree into the corresponding STL formula, we apply the following adjustments concerning numerical parameters. To map a non-terminal interval symbol into the corresponding time interval, we map the first into the corresponding integer in and set it to be the start of the interval. We then map the second into the corresponding integer in and add it to the start to obtain the end of the interval. As such, we avoid any issue arising from intervals having a start greater or equal to the end. Moreover, we remark that, since there can be at most two nested temporal operators, the maximum necessary length of the formula will be 198, corresponding to the necessary length of a formula with two nested temporal operators with intervals . When mapping a non-terminal , we divide the product of its (the numeric constant in the atomic proposition) by 100. As a result, numeric constants lie in , and, for normalized data, we can express all possible thresholds.
6. Experimental Evaluation
Considering the goals described in
Section 4, we aim at answering the following research questions:
- RQ1
Can we mine specifications that describe the input unlabeled trajectories?
- RQ2
Are the mined specifications readable and interpretable for a human?
We consider to formula describe the dataset well if it tightly fits the pool of trajectories. To this end, we verify whether the fitness f of the learned formula is as close as possible to . We say that a formula is readable and interpretable for a human if it is parsimonious; to this end, we verify whether the size of a formula (number of nodes of the derivation tree), , is reasonable. Moreover, we also verify whether a formula is easily understandable by a human by manually inspecting and reporting it.
To answer the research questions according to these definitions, we ran an experimental campaign on real-world data of road traffic. We performed 10 evolutionary runs with different random seeds. We used the same parameter values for all the runs and set , , , , , , and .
6.1. Data
The dataset used in this study [
29] consists of the trajectories of all the vehicles crossing the eastbound I-80 Freeway in Emeryville, California (USA). Measurements date back to 13 April 2005 and were taken on a tract of approximately 1640
, comprising six lanes and an on-ramp. The full dataset is partitioned into three
sequences: 4:00 p.m. to 4:15 p.m., 5:00 p.m. to 5:15 p.m., and 5:15 pm to 5:30 p.m. Intuitively, they correspond to different traffic patterns, from the build-up of congestion to the peak period.
The dataset contains a total of 5678 unique vehicles tracked over 19,679 frames. For each vehicle and each frame, it contains the position of the vehicle (lateral and longitudinal offsets with respect to a reference position), its velocity, its size (width and length), and a lane identifier. All these attributes have been extracted by the creators of the dataset by means of image processing and computer vision techniques: we refer the reader to [
29] for more details.
Figure 3 provides a graphical representation of the information contained in a frame of the dataset.
6.2. Data Processing
The aim of the data processing step is to extract useful attributes. Chiefly, we want attributes that (1) are more meaningful to the other road settings than the one considered in this study and (2) effectively describe the phenomenon at hand, i.e., capture measurements that are relevant for monitoring road traffic. The first point discards attributes such lane identifier and position with respect to the reference point since they would be of no interest for roads with a different topology and number of lanes. At the same time, we want attributes that are relative to the vehicle and not to the setting. For example, positions and coordinates should be relative, not absolute. As a result, formulas are more readable as they employ attributes that are immediately comprehensible. In the following, we detail how we extracted additional attributes from the ones reported in the original dataset.
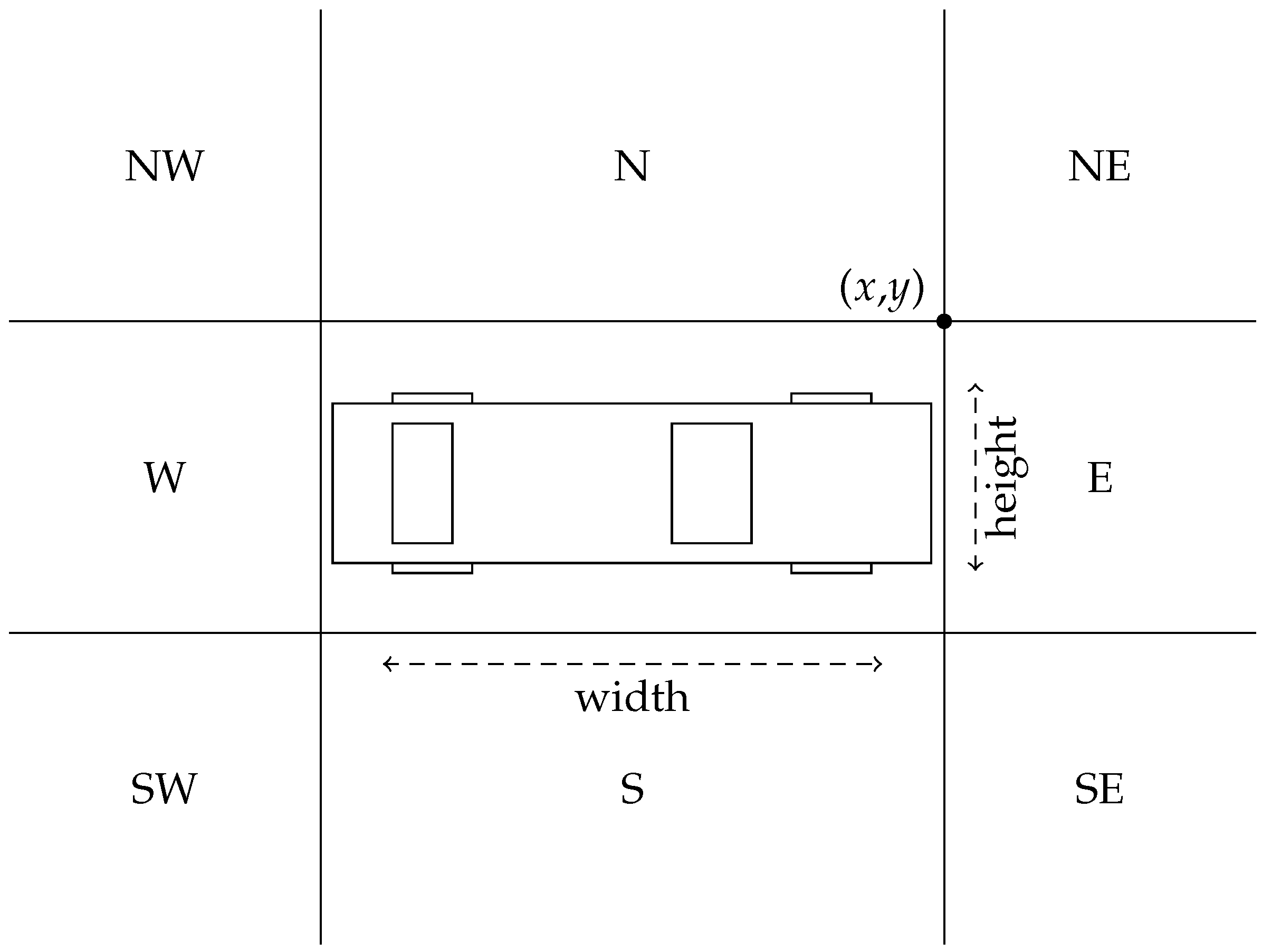
A set of very relevant attributes is the set of distances from the nearest neighbors of each vehicle. Intuitively, such a set of attributes is relevant for drivers and allows formulas to clearly and synthetically be expressed such as “ keep a safety distance of at least 10
from the closest front vehicle”. To formalize this, we partition the space surrounding each vehicle as shown in
Figure 4, and we find the closest vehicle in each of the eight regions. We thus consider eight new attributes, namely
,
,
,
,
,
,
, and
.
To efficiently compute them, we used a kd-tree [
30], a spatial data structure. Given a query point and a set of
k-dimensional points, it allows for logarithmic-time (in the number of points) look-up of nearest neighbors, improving over the quadratic time (in the number of points) of a brute-force search. For us, points are cars and are bi-dimensional (lateral and longitudinal offsets with respect to the reference position). Given that construction and update take both linear time (in the number of points) for a kd tree, we built a separate tree for every frame instead of updating all cars’ positions.
Finally, after having found the nearest neighbors for every car and for every frame, we trimmed neighbors that might not be sensed in a real-world setting. In particular, we set to the distances above . Moreover, we limit the neighbor search to the current and adjacent lanes of a vehicle, as we assume that drivers do not care about vehicles in far lanes.
To summarize, we built a dataset with velocity (
) and eight distances (
,
,
,
,
,
,
,
) as attributes, which together form the set of attributes
A mentioned in
Section 4. On the other hand, width and height were discarded.
We do not consider trajectories being longer than
, since that could result in specifications requiring agents (both human and automated) to consider an unpractically long behavior history. To accomplish this, we partitioned the trajectories as follows. Let
be the number of samples for trajectory
. For each trajectory
, we split it into a new set of trajectories by sliding a window of size
n over it, with
overlapping, obtaining approximately
new trajectories. The resulting pool of trajectories shares the same length
n, which must be chosen to reflect a sensible interval of monitoring for an autonomous agent. Thus, we set
, corresponding to 20
for this dataset. We remark that, by fixing
, all the new trajectories will have a maximum size (number of samples) of 200; given that, with our grammar, the maximum necessary length of the formula is 198 (see
Section 5.3), no issue regarding the necessary length of formulas arises.
Finally, as a consequence of our grammar shown in
Figure 2, and to avoid favoring attributes with shorter ranges, we normalize attributes to
by subtracting the minimum and dividing by the range.
6.3. Results
6.3.1. RQ1: Solutions That Are Effective
We ran an experimental campaign with the aforementioned parameters. To evaluate whether our approach is effective, we (1) verify whether it evolved tight formulas, and (2) compare the fitness
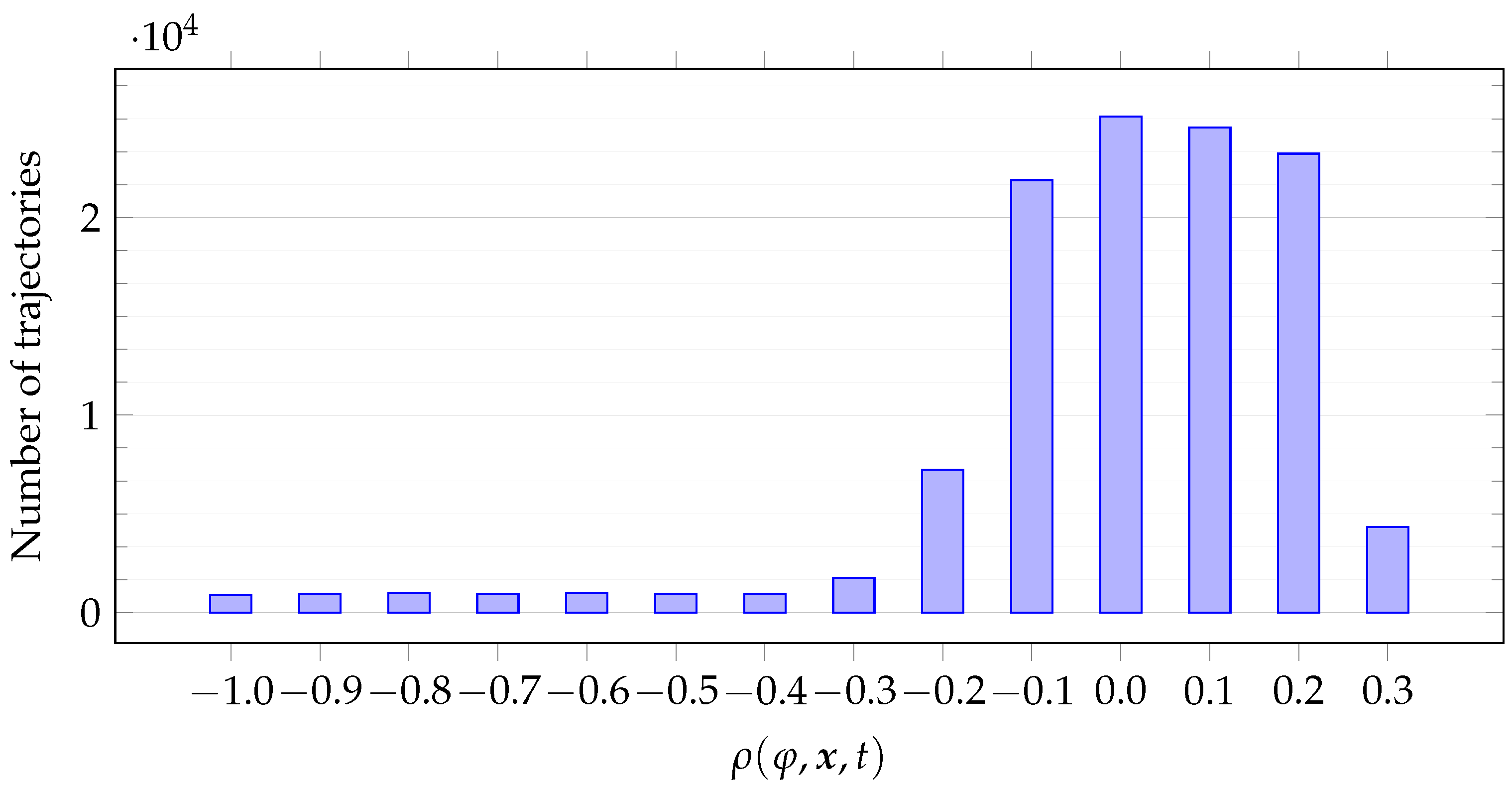
f of the best individuals with that of randomly initialized formulas. For the former,
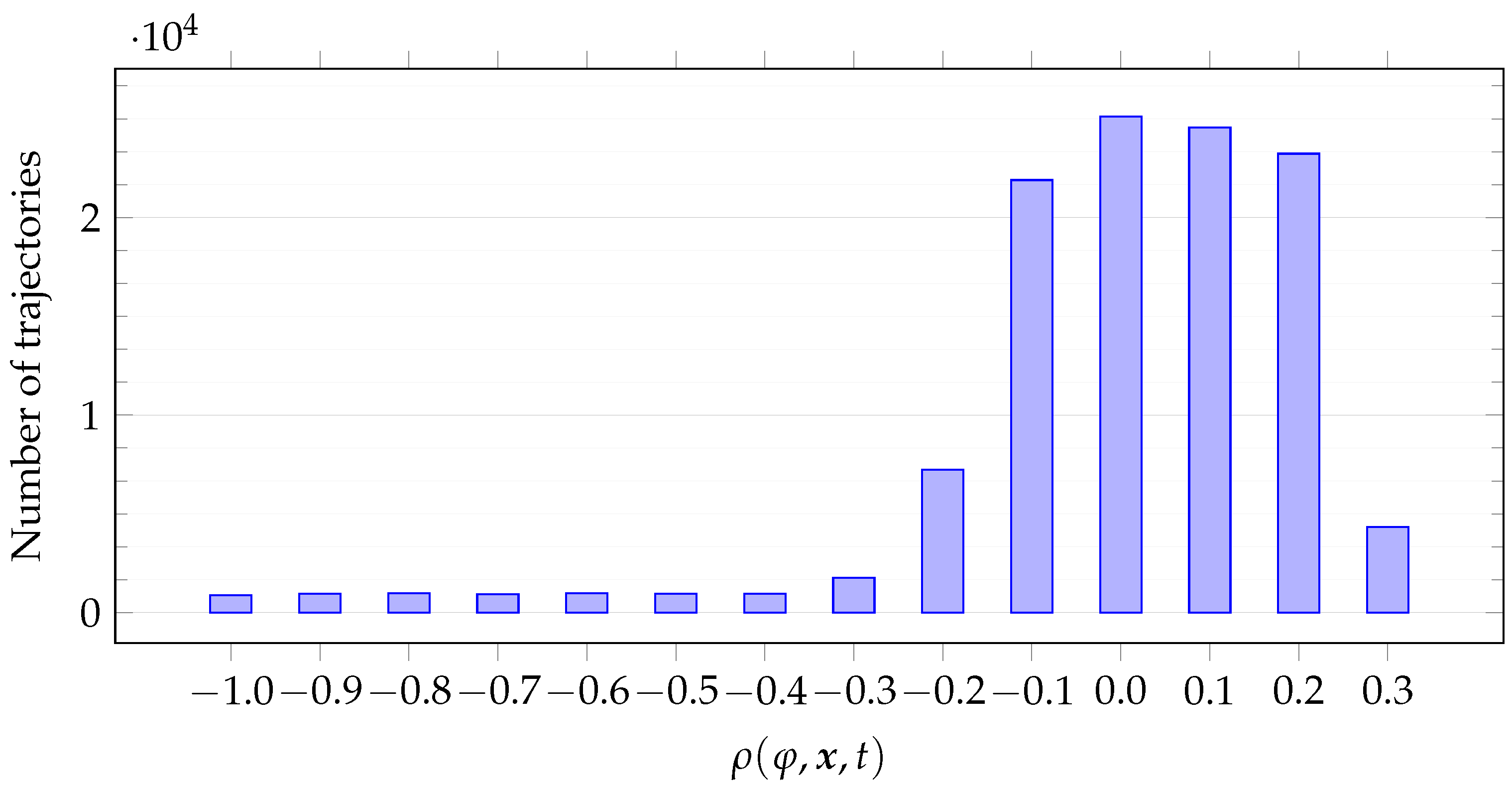
Figure 5 plots the histogram for the distribution of
for the best individuals
found in each run (i.e., the individual having the lowest fitness
f at the last generation) and for all the car trajectories
. For the latter,
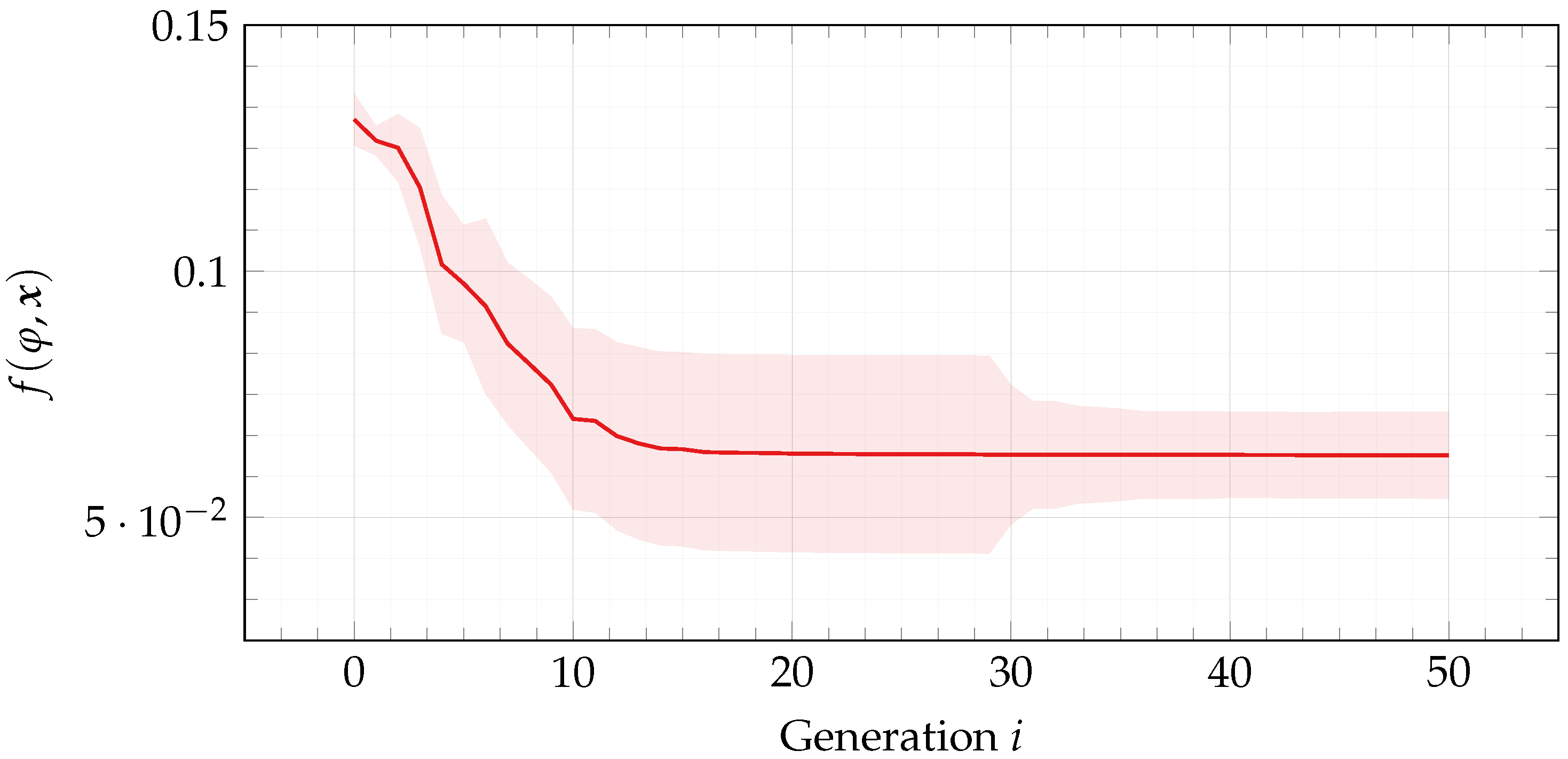
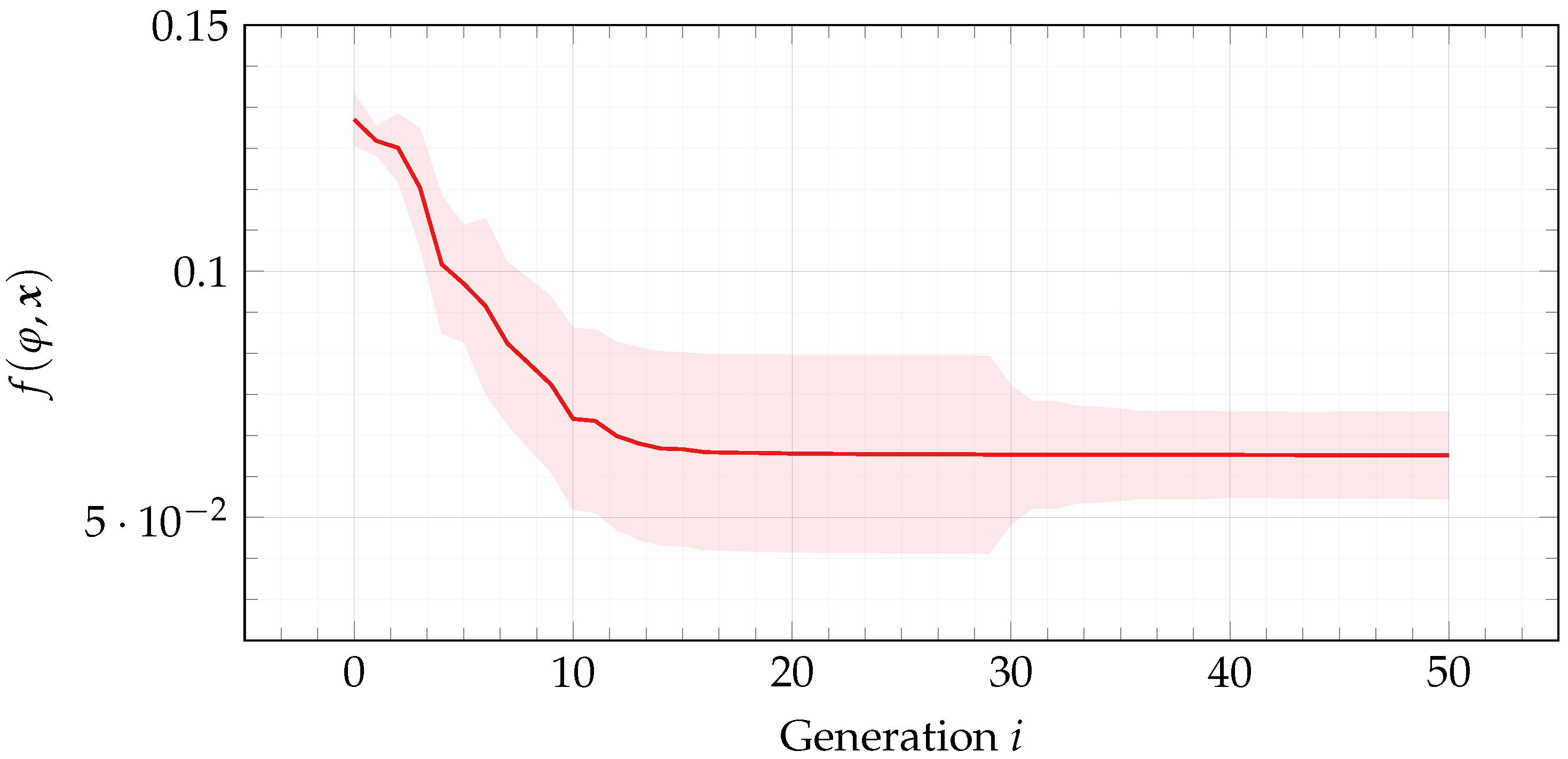
Figure 6 reports median ± standard deviation fitness
f over the course of evolution for the best individuals found in each run.
Table 1 summarizes (with median ± standard deviation) the results in terms of fitness
f and
for the best individual found in each run, as well as evolution time (in seconds).
From
Figure 5, two observations can be made. First, robustness values cluster around
. Second, robustness values cluster symmetrically.
Table 1 corroborates these observations. Recall from
Section 4 that our goal is to mine formulas that are tight since tightness is of fundamental importance when no labels are provided. Formulas are tight when robustness values are as close to zero as possible, in particular
, with
a small quantity, which depends on the system at hand. In other words, formulas must fit the pool of trajectories at hand and in such a way that small perturbations make the robustness value greater than
on some trajectory. By looking at
Figure 5, we remark that the mined formulas are indeed tight. Let a value
be fixed. The best individuals produce robustness values that fit into a segment centered in
and of length
; that is, they lie in
. Choose an adequate value for
, e.g.,
. From
Figure 5, we notice that the vast majority of values lie in
. Recalling our definition of tightness of a formula from
Section 4, these results confirm that the best individuals indeed are tight formulas.
As a further confirmation that our methodology actually learns tight formulas, we also show that learned formulas are significantly better than random formulas. As can be seen from
Figure 6, fitness
f progresses over the course of evolution and settles into a (local) optimum. Considering that the initial population is composed entirely of randomly initialized formulas (see
Section 5.1), this observation points to the fact that, in terms of fitness
f (and, thus, of tightness), the best individuals are clearly better than random formulas.
To comment, our methodology succeeds in mining specifications that are effective and tight with respect to the pool of trajectories.
6.3.2. RQ2: Specifications That Are Readable and Interpretable for a Human
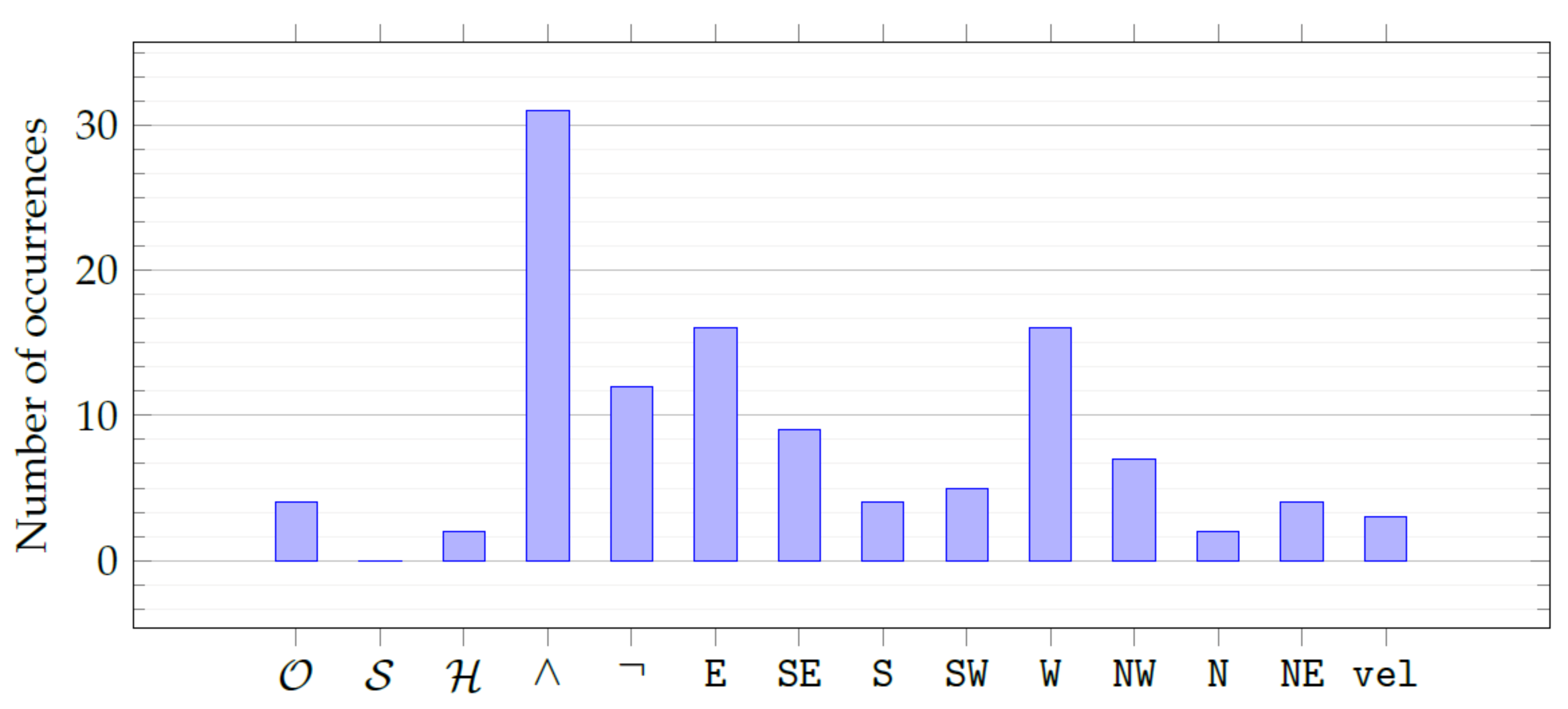
As far as readability is concerned, we found the mined specifications to be readable and interpretable by a human. To provide deeper insights,
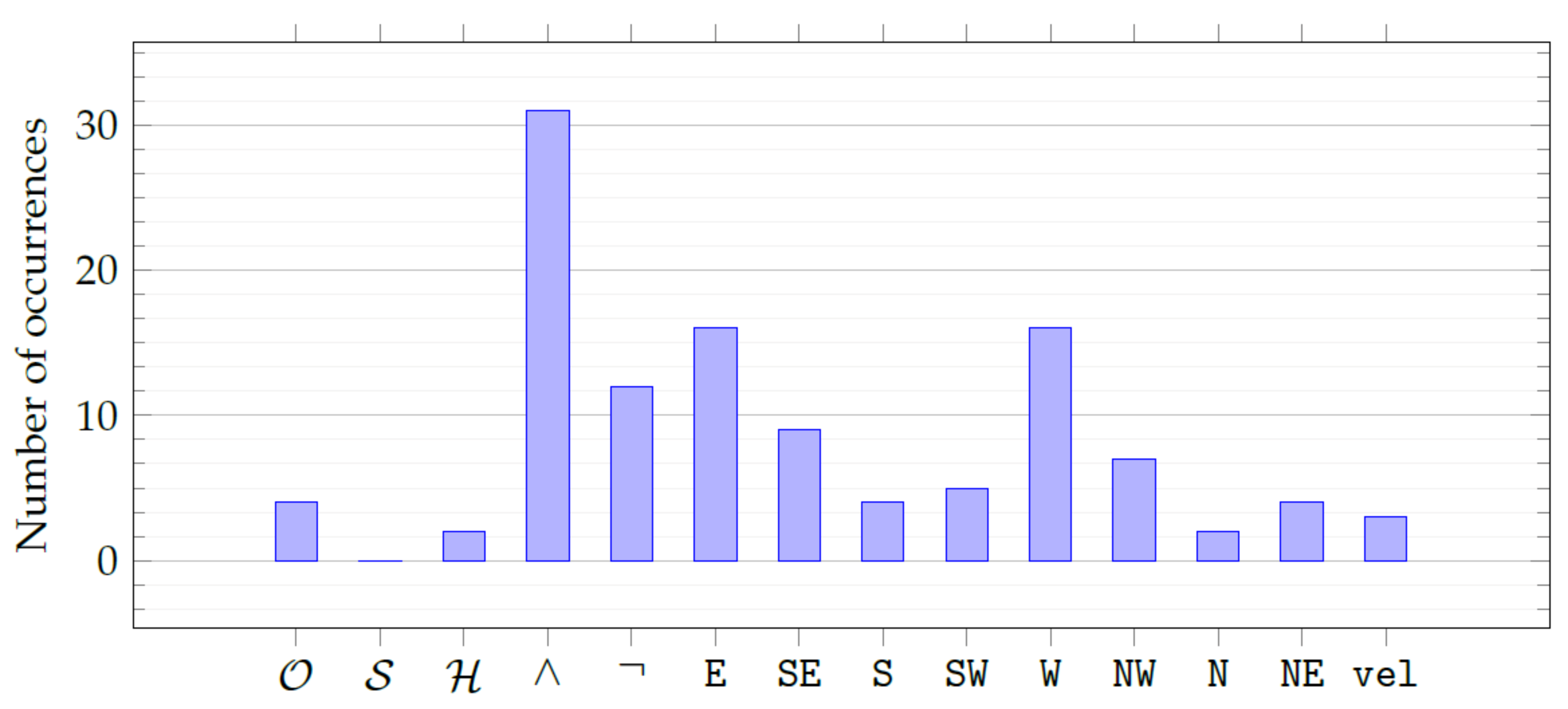
Figure 7 plots the histogram for the frequency distribution of the operators (see
Section 5.3) and the attributes (see
Section 6.2) in our grammar.
By manually inspecting the best individuals and visualizing the aggregate frequencies with
Figure 7, we found that all the attributes are present, with a slight overabundance of
and
that are, respectively, the distance from the front neighbor and the distance from the rear neighbor. Moreover, evolution prefers the ∧ and ¬ operators over the temporal operators (of which there is approximately one per formula). This finding is in line with our expectations since temporal operators are likely to be the least interpretable for a human (as confirmed for mathematical expressions in [
23]).
In the following, we transcribe some instances of best individuals. For ease of understanding, the numeric constants that appear in the formulas below have been denormalized by multiplying by the attribute range and summing the attribute minimum value. For example,
dictates a reasonable distance from the southeast neighbor (i.e., between
and
) at least once in the
past temporal window; at the same time, such a distance must not be lower than
and the distance from the southwest neighbor higher than
at the same time, showing that distances from neighbors must be, in general, balanced. Similarly, this other example:
dictates to stay farther than
from the southeast neighbor, while staying not closer than
to the north one and not farther than
from the east one. An example with Historically is:
which tells it to stay farther than
from the west neighbor, while keeping closer than
from the southeast neighbor and continuously over
closer than
from the northern neighbor. An example without temporal operators is:
which tells it to drive slower than
while keeping not too far away from the southern neighbor and reasonably far from the east and northwest neighbors. Finally,
compactly dictates to stay at a distance that is neither too far away nor too close to the northwest, southeast, and southwest neighbors.
From the examples above, we draw one very important conclusion. Recalling
Section 6.1 and
Figure 3, the dataset used here was collected on a very trafficked highway. The mined specifications follow a common pattern of the ruling:
- (i)
to poise the distances from the neighbors, and
- (ii)
to drive neither too fast nor too slow.
The former point is crucial, as keeping too far from one neighbor implies coming very close to the neighbors on the opposite side.
To summarize, the mined specifications closely mimic what a car stuck in dense traffic would do and point to the effectiveness of our approach. We believe the reason for such readability to be the parsimony of the mined STL formulas. Intuitively, parsimony is directly linked to interpretability. In fact, as reported in
Table 1, median solution size
is
, which is a reasonable size for an STL formula.
7. Conclusions and Future Work
We have considered the case of monitoring and describing the behavior of traffic systems by means of Signal Temporal Logic (STL) formulas. Authoring these formulas is a hard task due to the necessity of knowing the system at hand and mastering language syntax. Automatically learning STL formulas would allow for the real-time monitoring of traffic systems with the result of improving safety and providing an explanation for the behaviors of autonomous agents. We endeavor to do so with the goal of learning formulas that describe the system at hand and are interpretable for a human.
We proposed a methodology to learn STL formulas for real-world traffic trajectories; the trajectories are unlabeled, in the sense that there are no human-assigned labels discriminating between positive and negative behaviors. Since the STL language can be specified by means of grammar, we use a grammar-based evolutionary optimization algorithm to evolve STL formulas. We evaluate formulas against a fitness function that rewards those that tightly fit the pool of trajectories at hand.
With an experimental campaign, we showed that our approach (1) learns formulas that tightly fit the pool of trajectories and (2) appears interpretable to a human due to its parsimony. We believe that, by applying our approach for inferring formulas describing road traffic in different conditions (e.g., different countries), one could systematically compare alternatives using formulas instead of raw data.
In the future, we will extend our approach to supervised binary classification scenarios, i.e., scenarios in which trajectories come accompanied by human-assigned labels discriminating between positive and negative behaviors. We will also consider anomaly detection, in which only a subset of the positive trajectories is labeled and we want an STL classifier to correctly detect negative trajectories.





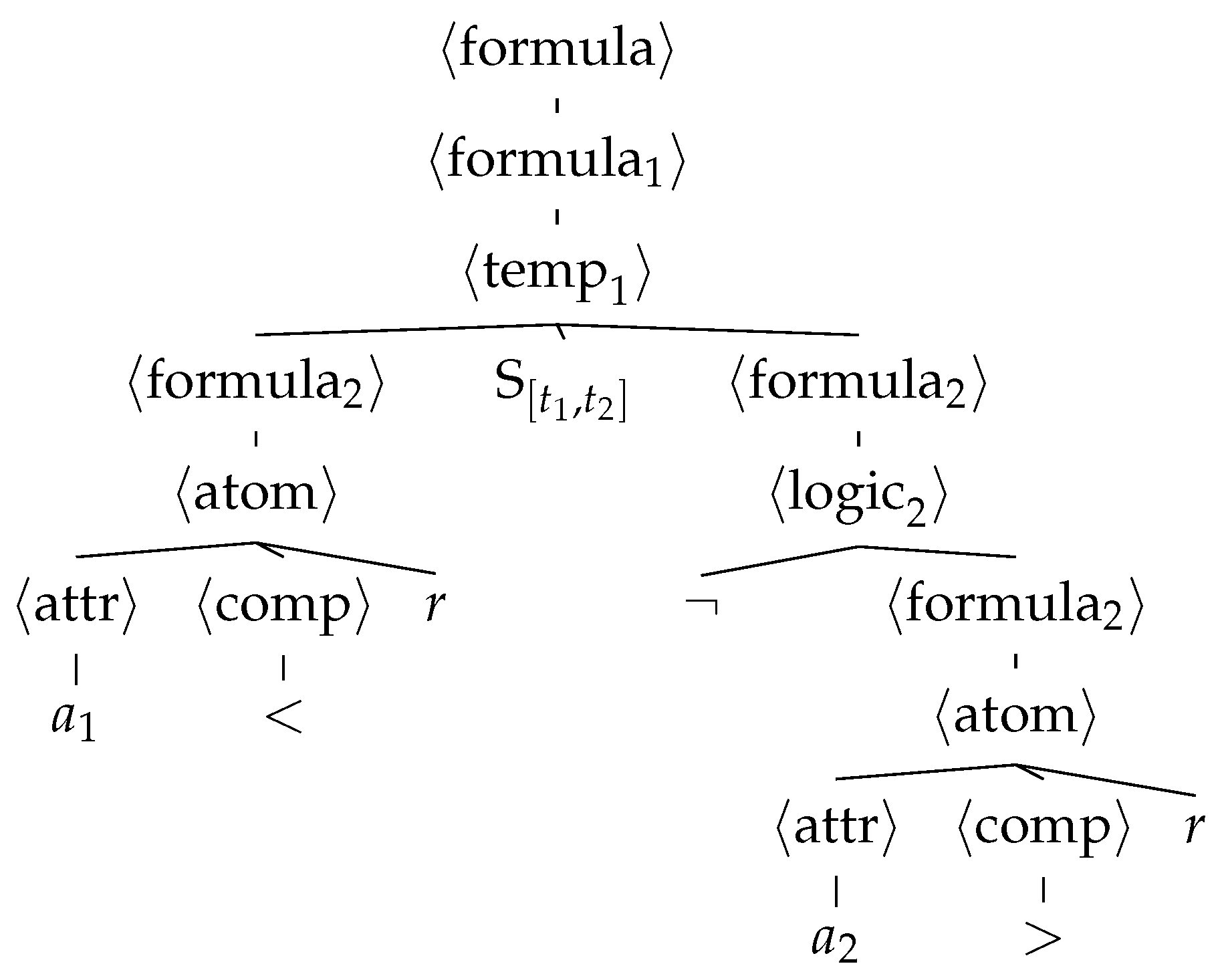




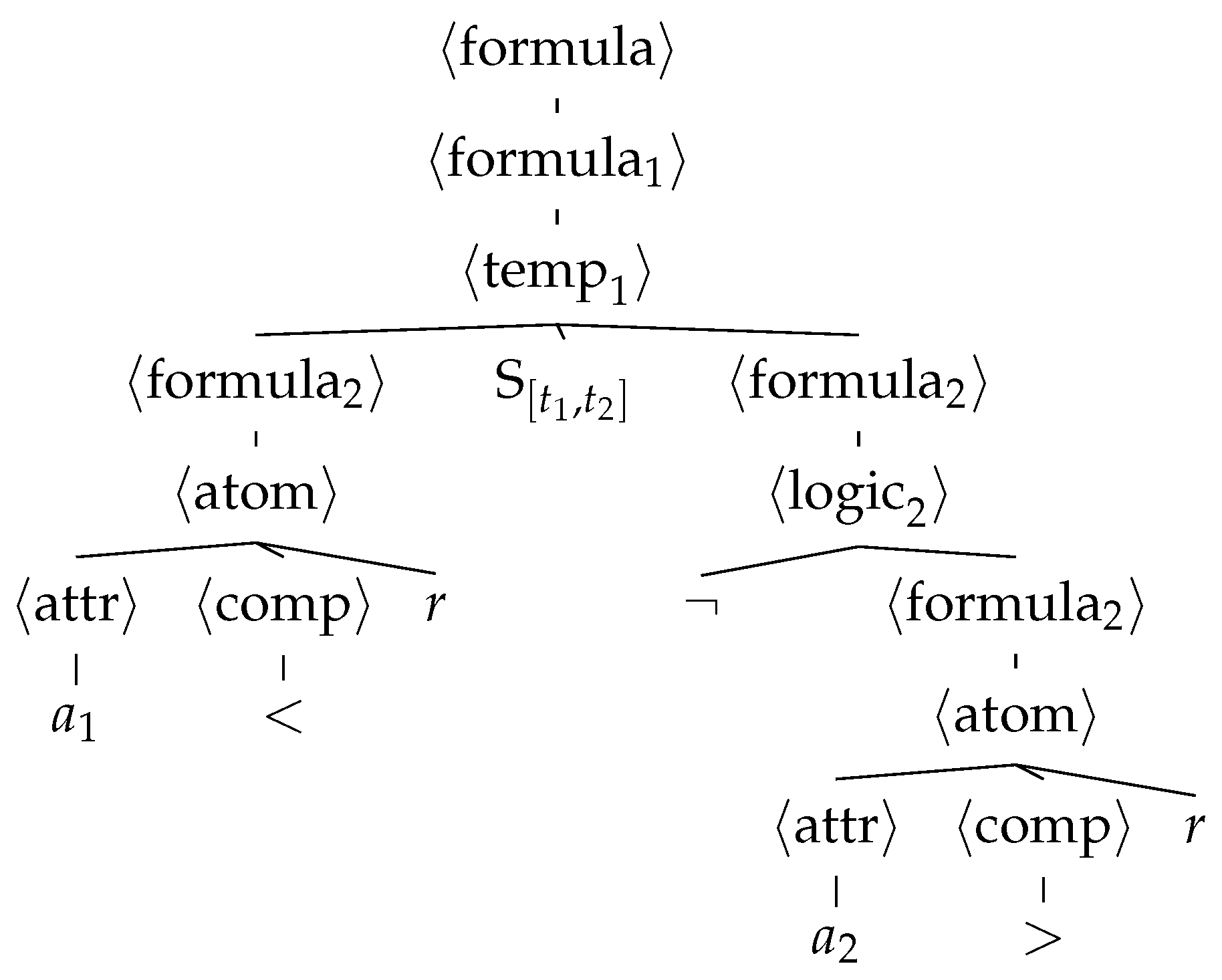{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}