1. Introduction
The advanced persistent threat (APT) attack is receiving attention from security professionals, as attackers have shifted their targets from institutions with military backgrounds to businesses that focus on education, energy, computers, finance, and diplomacy. APT can be defined as an entity that engages in malicious, organized, and highly sophisticated long-term intrusion or exploitation operation to obtain information from a target organization [
1]. There are two purposes of APT attacks, one is to steal critical data and the other is to destroy system infrastructure. By analyzing some very well-known APT attacks, such as TitanRain, Hydraq, Stuxnet, and the RSA SecureID Attack, the most typical common characteristics can be summarized as long term and multi stage [
2], which means that an APT attack has strong concealment. Only when attackers are exposed or complete their missions may the intrusion be discovered [
2,
3]. On the other hand, it is also an unavoidable problem that APT attackers will use the latest vulnerabilities and tools. They are very difficult to detect [
4]. Therefore, APT attack detection and defense research are very important for key institutions and network systems [
5].
Currently, there are many methods attempting to solve the problem of APT detection.
- (1)
Qualitative analysis-based methods, which utilize expert knowledge for analyzing attack, study the relationship between network feature and attacks. For example, a hybrid strategy game-based model is proposed by [
6] to compute the Nash equilibrium of network and possibility of APT attacks. It also proposed a data-fusion method to improve accuracy of the model. The literature [
7] uses cumulative prospect theory to model APT attacks and proposes a policy hill-climbing-based detection scheme, which improves the APT detection performance in dynamic games. The literature [
8] utilizes four parallel classifiers to generate the events, then utilizes the correlation rules developed by experts to process the events, and finally, obtains the result by voting. Four classifiers are genetic programming, classification, and regression trees, support vector machine (SVM), and dynamic Bayesian game model. The literature [
9] proposes a semantic-based correlation approach for detecting hybrid and low-level APT. They claim that this method is a big step towards the automatic detection of APT, while they mention that they did not take slow APT into account and could definitely not detect them. The literature [
10] presents an APT detection system based on audit log data, which uses correlation information and kill-chain to process information and eventually output a high-level attack scenario graph for security experts to analyze. Qualitative analysis-based methods rely heavily on expert knowledge and intelligence, which are both strengths and weaknesses. Expert knowledge and intelligence can be utilized to detect unknown APT attack and reduce detection time. However, qualitative analysis-based methods are not accurate enough, which cannot detect APT accurately.
- (2)
Data-driven methods, which utilize data for training nonlinear model. The literature [
11] proposes an intrusion detection system based on the decision tree by using analysis of behavior information to detect APT attacks. The literature [
12] uses the continuous association rule mining algorithm to process intrusion detection events as attack scenarios and, then, predicts APT attacks by rules. The literature [
13] proposes an innovative APT attack detection model based on a semi-supervised learning approach and complex networks characteristics, which is based on the shared nearest neighbor clustering algorithm. The literature [
14] uses principal component analysis to reduce the dimension of data, then compares the performance of four methods, including SVM, naive Bayes, decision tree, and multi-layer perceptron (MLP). The literature [
15] proposes a Bayesian network based weighted attack paths modeling technique to model APT attack paths. The literature [
16] proposes a novel machine learning-based system to detect and predict APT attacks in a holistic approach, which uses a filter, cluster, and index (FCI) correlation framework to find the alerts that relate APT attack scenario, and finally, uses decision tree, SVM, k-nearest neighbors, and ensemble learning to detect APT. The literature [
17,
18] propose an APT detection frameworks by using unsupervised clustering and deep learning method with DNS logs, which develops a new feature that can represent the relationship between DNS request and response message. The literature [
19] proposes a spatio-temporal association analysis to detect the APT attack in industrial network, which utilizes a frequent pattern (FP) growth algorithm to mine association rules and, finally, uses SVM for classification detection. The literature [
20] uses feature extraction and normalization to process network traffic and, then, scores the hosts to obtain the final list of hosts receiving APT attack threats. The literature [
21] presents an APT detection method based on the gradient boosting decision tree that uses temporal correlation features, traffic-based features, and combined features. Data-driven methods require a large number of samples to train the parameters of the detection model, which need sufficient data to obtain the optimal parameters to detect APT attack accurately. However, APT samples are hard to obtain due to their special characteristics mentioned above.
- (3)
Semi-quantitative analysis-based methods, which can both utilize expert knowledge and quantitative data. The literature [
22] reconstructs APT attack scenarios using the alert correlation framework and, then, utilizes the hidden Markov model (HMM) to find the most consistent APT attack sequences and to predict the next phase of attacks. Traditional semi-quantitative analysis-based methods can combine expert knowledge and quantitative information to obtain more interpretable and accurate results with fewer samples, but it cannot exploit multiple uncertain information simultaneously. In addition, how to better embed expert knowledge into the model is also an urgent problem.
Therefore, to solve the above problems, a novel detection method based on belief rule base (BRB) is proposed in this paper, where a set of decision rules is firstly defined by mechanism analysis and expert knowledge, and then, a small number of quantitative data samples are used to optimize the model. Through a combination of expert knowledge and quantitative data, the proposed method can effectively solve the concealment problem caused by long-time and multi-stage characteristics of APT attack. Moreover, the proposed method also has the advantages of dealing with many kinds of uncertain information and the transparent reasoning process, which makes it possible to obtain more objective and accurate detection results with interpretability.
The remainder of this paper is organized as follows. In
Section 2, basic problems about APT attack are described. In
Section 3, the BRB model is introduced, and the BRB-based APT detection model is proposed. A simulation-based case study is designed to test the effectiveness of the proposed method in
Section 4. Finally,
Section 5 presents conclusions and directions for further research.
4. Case Study
In this section, a dataset is used to prove the advantage of the proposed method. The raw dataset has 90 raw samples generated by Network Simulator 3. The processed sample set can be obtained after processing the original samples. The dataset has three kinds of samples, as shown in
Table 2.
Network structure of the case is shown in
Figure 4. The network includes two web servers, one SQL server, and five host groups. Web server stores resources for public network access. SQL server is used to store important internal information and update web server resources. The five host groups are management, technology, finance, human resources, and public relations, and their relationships are shown in
Figure 5. They are divided into different areas depending on their importance. Management, finance, technology, and SQLserver belong to the important area. Human resources and public relations are in the secondary areas. Web server and public network are divided into a separate area.
Both the server and the host are considered as nodes in the simulation software. The network connection between them is determined by deterministic codes. When the simulation software runs, the code generates network connections and sends data packets. One raw sample is the network traffic in the network in a fixed period of time, which includes many flows. The no-attack raw sample has three traffic counts, 42, 84, and 126. The other two samples are the same. Network connections are divided into normal connections and attack connections. Network connections contain three settable attributes: address, bandwidth, and duration. The address and bandwidth of a normal connection are deterministic. The address of an attack connection is artificially randomly selected. Some possible APT paths are shown as red lines in
Figure 6. The bandwidth of an attack connection is deterministic. The duration of a network connection is the base time plus an offset time. The base time of a normal connection is deterministic. The base time of an attack connection is artificially randomly chosen. The offset time is a pseudo-random number selection within an artificially specified random range. The settings of all the above parameters are subject to expert knowledge.
Normal attacks and APT attacks are designed according to their respective characteristics. APT attackers are more patient and careful than normal attackers. APT has a higher focus on important resources. APT has a longer attack cycle and less traffic than normal attacks. In this case, the path of the APT attack tends to be more towards the most important areas, with a larger time interval, lower rate, and less traffic. Normal traffic has the most comprehensive path, with smaller time intervals, higher rate, and larger traffic. Normal attacks fall somewhere in between. The attack traffic generation code is inserted into the normal code according to the above knowledge.
The 90 raw data samples are then generated via NS3. This is acceptable, although there are many deterministic elements. First, there are deterministic standards for bandwidth and addresses in real networks. In this example, just a few values are chosen as criteria. Second, the network and normal business processes are designed by experts. Therefore, it is reasonable to design the normal network connection based on expert knowledge in this example. Third, APT attacks are launched by humans and are influenced by the attacker’s expert knowledge. Therefore, it is acceptable to determine the attack connection based on expert knowledge. Finally, the random offset time complements the network fluctuations that exist in practice. Additionally, it increases the randomness of launching APT attacks in this example.
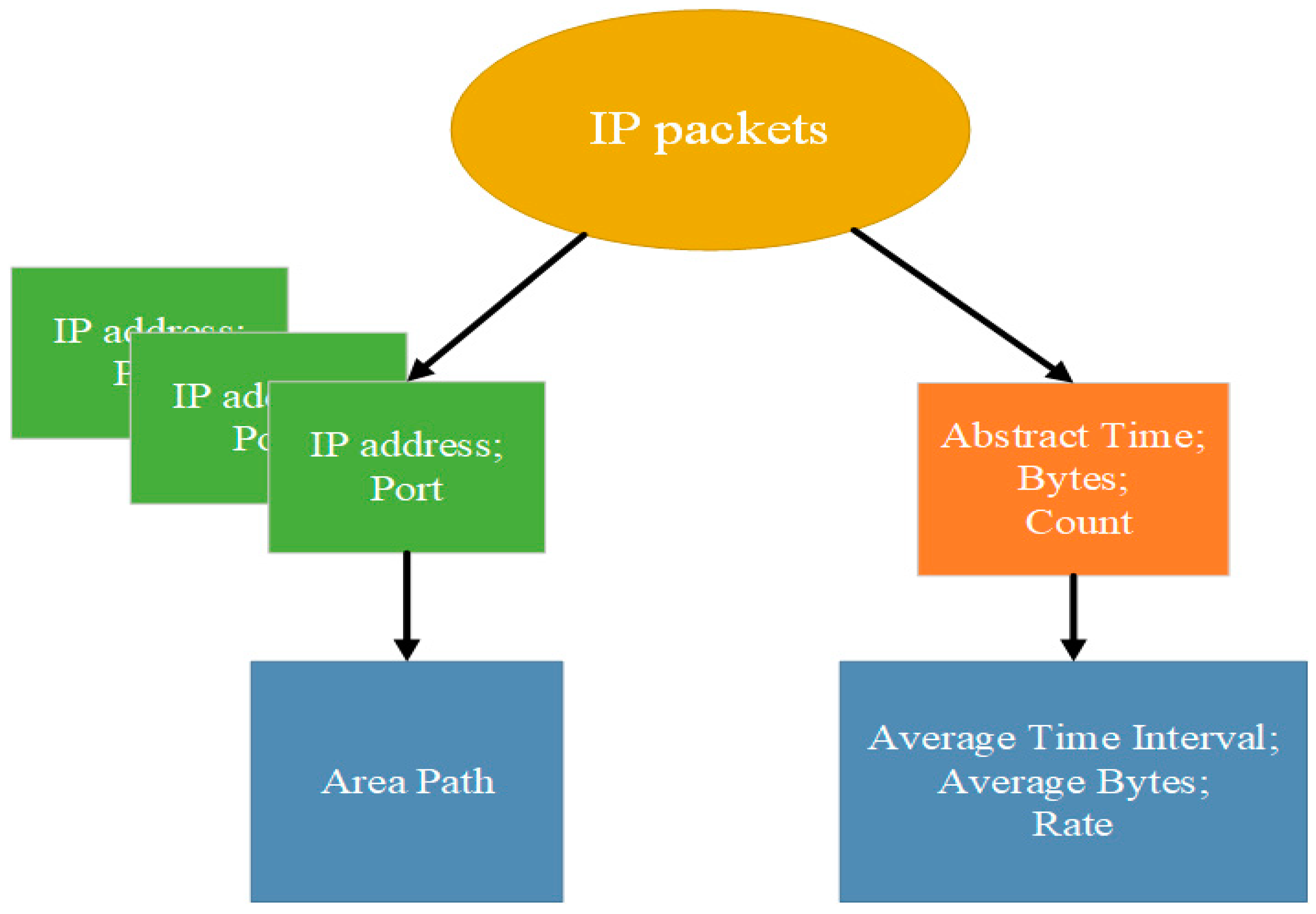
The raw data need to be processed, as discussed in
Section 3.2. Combining information of two IP packets to obtain the path, time interval, and total number of bytes within each raw sample. For examples, packet_1 is from A to B and packet_2 is from B to C. Then, the path is from A to B to C. The time interval calculates by
(which
is the time of packets start sending). The byte totals are directly summed. The IP address is, then, replaced by the area. The same area paths are fused to calculate the average time interval, average total number of bytes, and rate of a path, then selecting the data corresponding to one area path as a processed sample. The dataset used below consists of processed samples. The dataset includes area difference, rate difference, average time interval difference, and average total transferred bytes difference, as shown in
Figure 7,
Figure 8,
Figure 9 and
Figure 10.
According to
Figure 7, it can be seen that the regional path does not include all possibilities, but this is reasonable because there is expert knowledge as a supplement. The paths of APT and normal attacks are partially overlapped. It is known from expert knowledge that the normal path should have an overlapping part with the attack path, but
Figure 7 does not contain it.
Figure 8 shows that No Attack has the highest rate and APT is the lowest. The rate of normal attacks is centered. As shown in
Figure 9, the time interval of APT is random, while the time interval of normal data is regular. The time interval of Normal Attack is somewhere in between. In
Figure 10, the transferred bytes of APT is very small and the transferred bytes of No Attack is large. The transferred bytes of Normal Attack are slightly higher than those of an APT.
According to the expert knowledge derived from above analysis to establish the BRB detection model, the reference values are derived according to
Figure 7,
Figure 8,
Figure 9 and
Figure 10 and are shown in
Table 3,
Table 4,
Table 5 and
Table 6. Area-1, area-2, and area-3 have the same reference values in
Table 3. The values of all samples fall within the reference value interval in
Table 4,
Table 5 and
Table 6. The reference value of “Low” in
Table 6 is lower than the lowest value of transferred bytes in all samples, which is set to 1024 bytes. The reference value of “High” is set to 2.5 × 1024 × 1024 bytes over the maximum value of transferred bytes in all samples. Additionally, the reference value of “Medium” is set to 200 × 1024 according to the value of Normal Attack in
Figure 10 and expert knowledge. Semantic results are replaced with numbers to facilitate program processing as shown in
Table 7. The reference values in
Table 7 are used only as a distinction of the results and have no other meaning.
So, the rules can be described as follows:
The BRB detection model has 1728 rules combined by the above six attributes. Expert knowledge is used to set initial weights and belief degrees for each rule. Some of rules are shown in
Table 8. Expert knowledge only gives approximate values, which are imprecise. For rule 1 in
Table 8, when the area-1, area-2, area-3, etc., are determined, the expert is uncertain about whether an apt attack actually occurred. However, it is certain that it is not an normal attack. So, the belief degree is set to 0.5, 0, and 0.5.
The data are randomly sorted as the input data. The top 25 of the input data are taken as the testing set and the remaining part as the training set. The P-CMA-ES algorithm is utilized to optimize the parameters to get the better results. The model is optimized for 80 rounds. Then, the 2nd to 26th samples of the input data are used as the testing set and the rest as the training set. It continues until, finally, the last 25 samples of the input data are used as the test set and the rest as the training set. A total of 65 rounds of training and testing are completed, and the average of the results is shown in
Table 9. According to
Table 9, the No Attack samples are all detected, but some other attacks are incorrectly detected as No Attack. The Normal Attack samples are detected in 77.88% of the total number of Normal Attack samples, but with 95.2% precision. The APT samples are detected in 93.84% of the total number of APT samples, with 87.25% precision.
Compare experiment is necessary. Two models are selected to compare with the BRB which are SVM and MLP. They are typical machine learning algorithms. The parameters of these models are shown in
Table 10 and
Table 11. “kernel” in
Table 10 has better results when set to “rbf”, which is the result of comparison with other functions. “C” and “gama” are used to prevent over-fitting. “decision_function_shape” is set to “ovr”, indicating the division of a class from other classes at multiple classification. In
Table 11, when the sample is not large, “solver” is set to “Lbfgs” with better effect. The values of “activation”, “alpha”, and “hidden_layer” are the better parameters under multiple tests. The training and testing sets are standardization and, then, fed to SVM and MLP for training and testing. Then, the comparisons of evaluations are shown in
Table 12,
Table 13,
Table 14 and
Table 15.
From the numerical value of the results, BRB does not dominate. In
Table 12, the prediction precision of BRB for No Attack is only 93.06%, which is smaller than the 100% of SVM and MLP. In
Table 13, the recall of No Attack is 100%. This indicates that BRB detected all correct No Attack samples, but also detected some other samples incorrectly as No Attack. In
Table 12, BRB has a precision of 95.2% between SVM and MLP for Normal Attack and 87.25% for APT. In
Table 13, BRB has a recall rate of only 77.88% for Normal Attack, and a detection accuracy of 93.84% for APT between SVM and MLP. F1-score is defined as the harmonic mean between precision and recall as shown in
Table 14. BRB has an F1-score of 96.03% for No Attack, an F1-score of 84.66% for Normal Attack, and an F1-score of 89.87% for APT between SVM and MLP. Accuracy is the ratio of the number of correctly classified samples to the total number of samples as shown in
Table 15. The accuracy of BRB is 91.14%, which is lower than the 93.23% of SVM and 95.32% of MLP. Although the accuracy of BRB is not the best, it is acceptable and the results are interpretable. The high accuracy obtained by SVM and MLP with very few samples is difficult to explain.
Multi-layer perceptron is initialized using random numbers. This approach implies that the starting point of the search results with suitable weights is random. The MLP model does not receive sufficient training with a limited sample size, so the final weights differ from the most suitable ones. However, in this case, the MLP achieved the highest accuracy with a small sample. This is difficult to interpret and does not provide valid suggestions for improving the defense plan. The SVM model with the “rbf” kernel has the same problem. In the case of small samples, there are no more samples to verify whether MLP and SVM really learn the appropriate parameters. MLP and SVM have high accuracy, but the reliability of the results is doubtful.
BRB is different from SVM and MLP and is built from expert knowledge. Therefore, the initial values of the BRB model have received a large amount of expert knowledge constraints. This approach already allows BRB to fit functions close to the appropriate weights when BRB is not yet trained. BRB can achieve high accuracy after training with a small number of samples. The accuracy of the BRB model is very dependent on expert knowledge. If the expert knowledge is biased, the results of the model are not good. In this example, the BRB model has 91.14% accuracy, which is lower than SVM and MLP. However, the BRB model is interpretable. Based on the training process, we believe that it is caused by the bias of the expert knowledge. The biased expert knowledge makes the scope of the constraints shifted. This bias still exists after optimization and has an impact on the final results. The results can help experts to validate and adjust their own knowledge, which is beneficial for updating BRB rules and correcting the defense plan.
The results illustrate that BRB obtained a reliable acceptable accuracy of 91% in the small sample case. MLP and SVM have high accuracy but cannot be interpreted and are unreliable. BRB uses expert knowledge to set the initial values of the parameters so that only a small number of samples are needed to complete the training, solving the small sample problem. BRB utilizes the membership function to deal with the randomness of the APT attack time. The SVM and MLP models are fit-based, while the BRB model is rule-based, and its interpretation is better than the fitted model. The BRB model is white box and has good interpretability, which facilitates the analysis and traceability of BRB results.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}