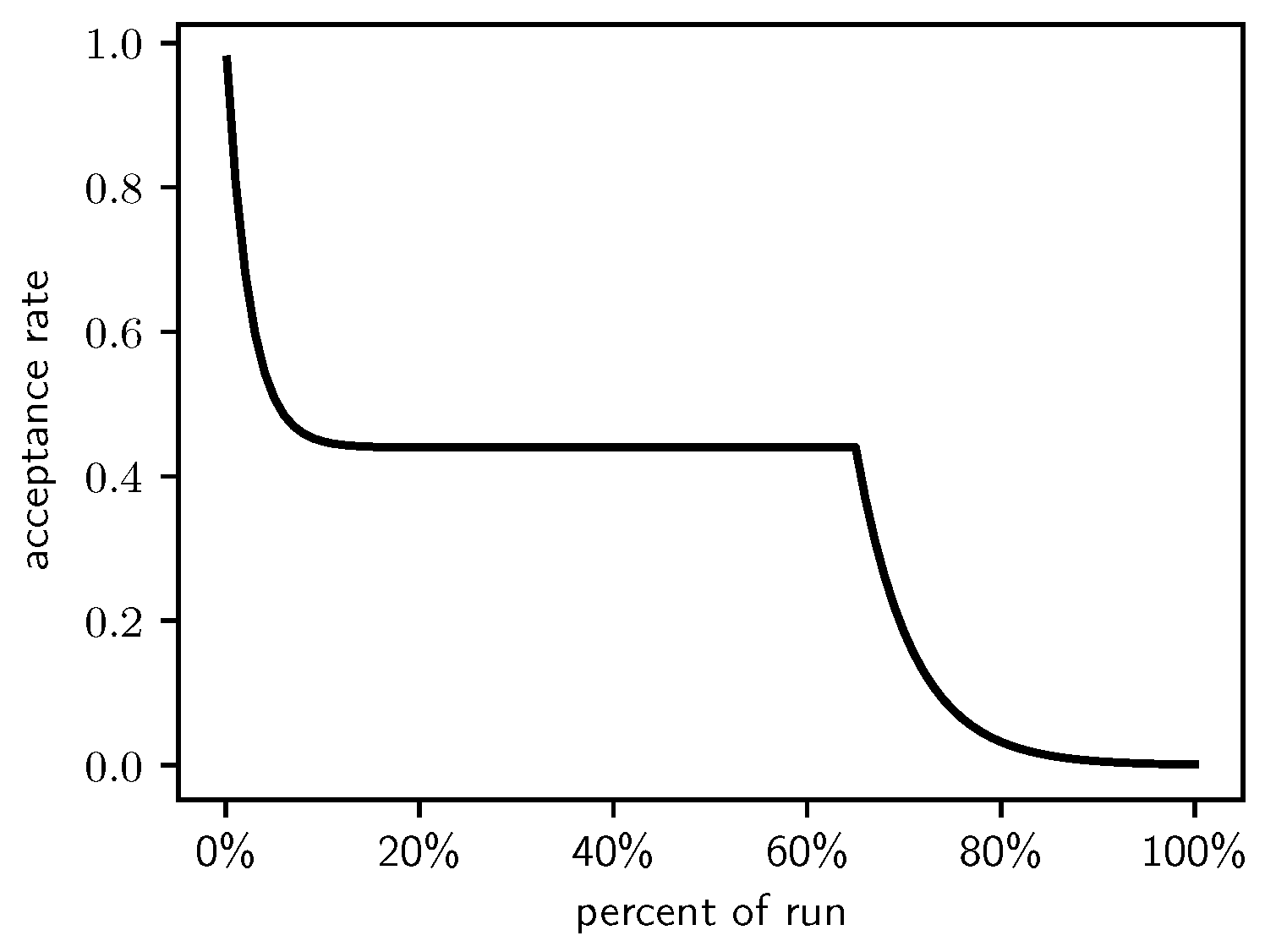
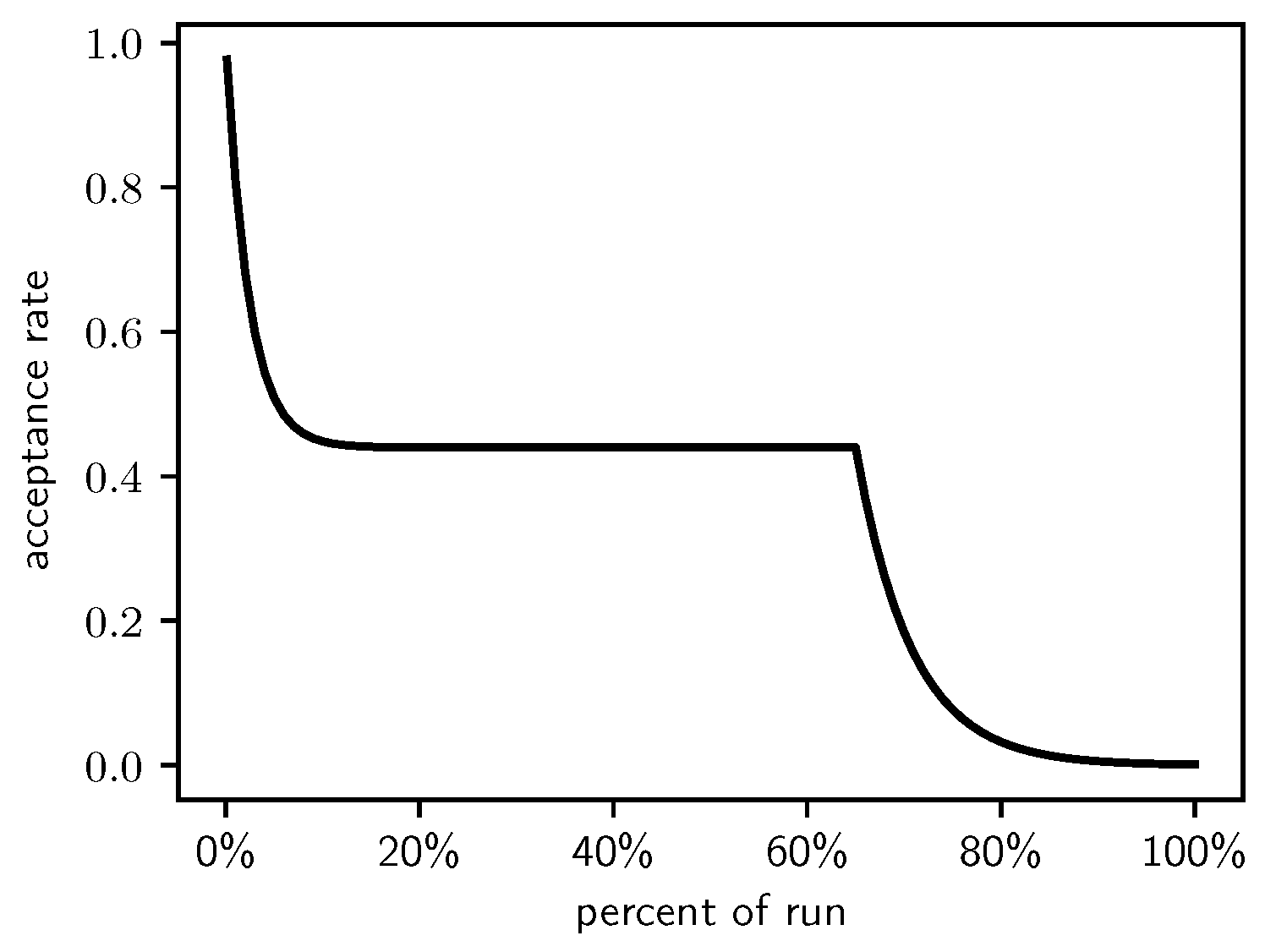
Figure 1.
The Lam target acceptance rate.
Figure 1.
The Lam target acceptance rate.
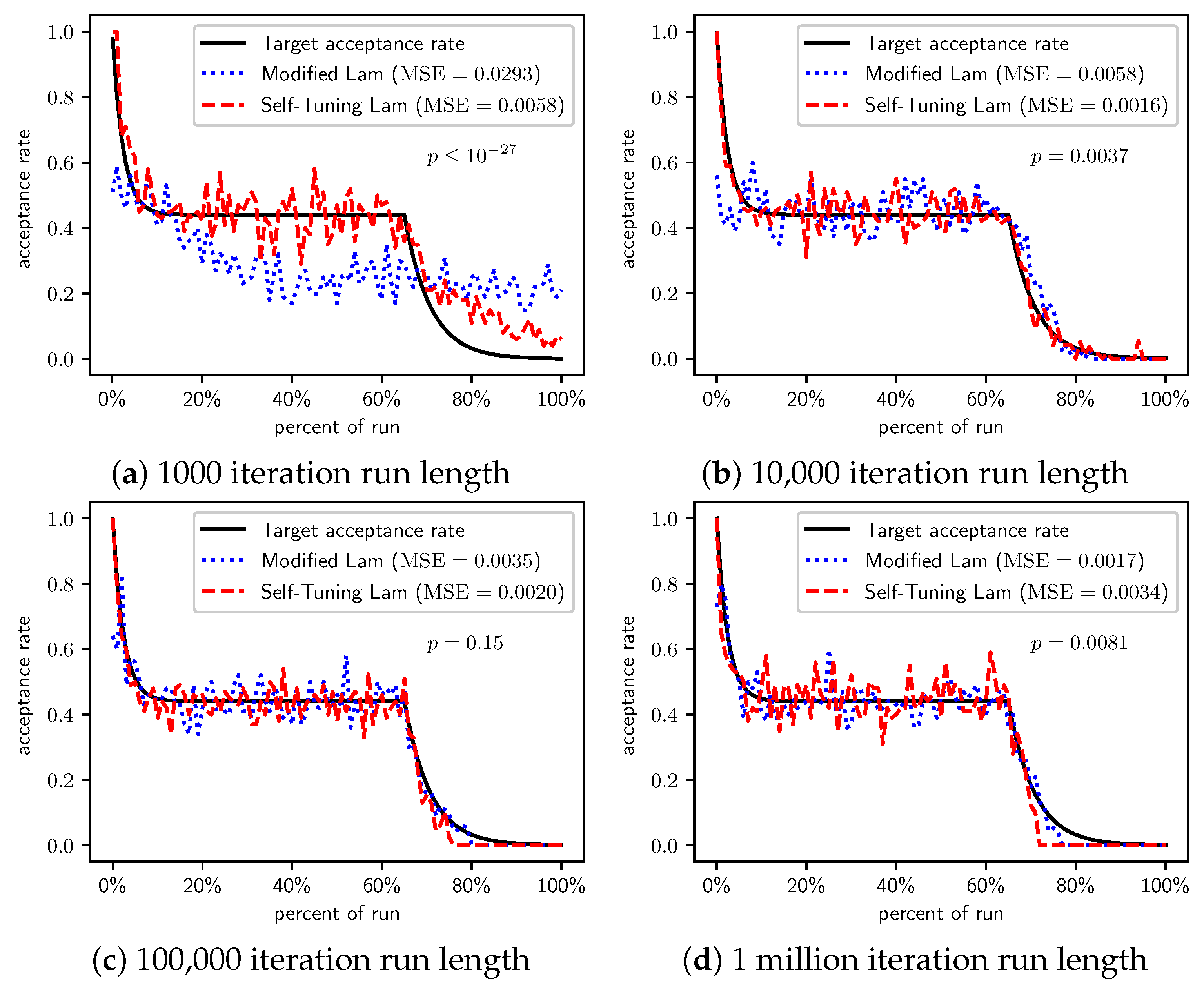
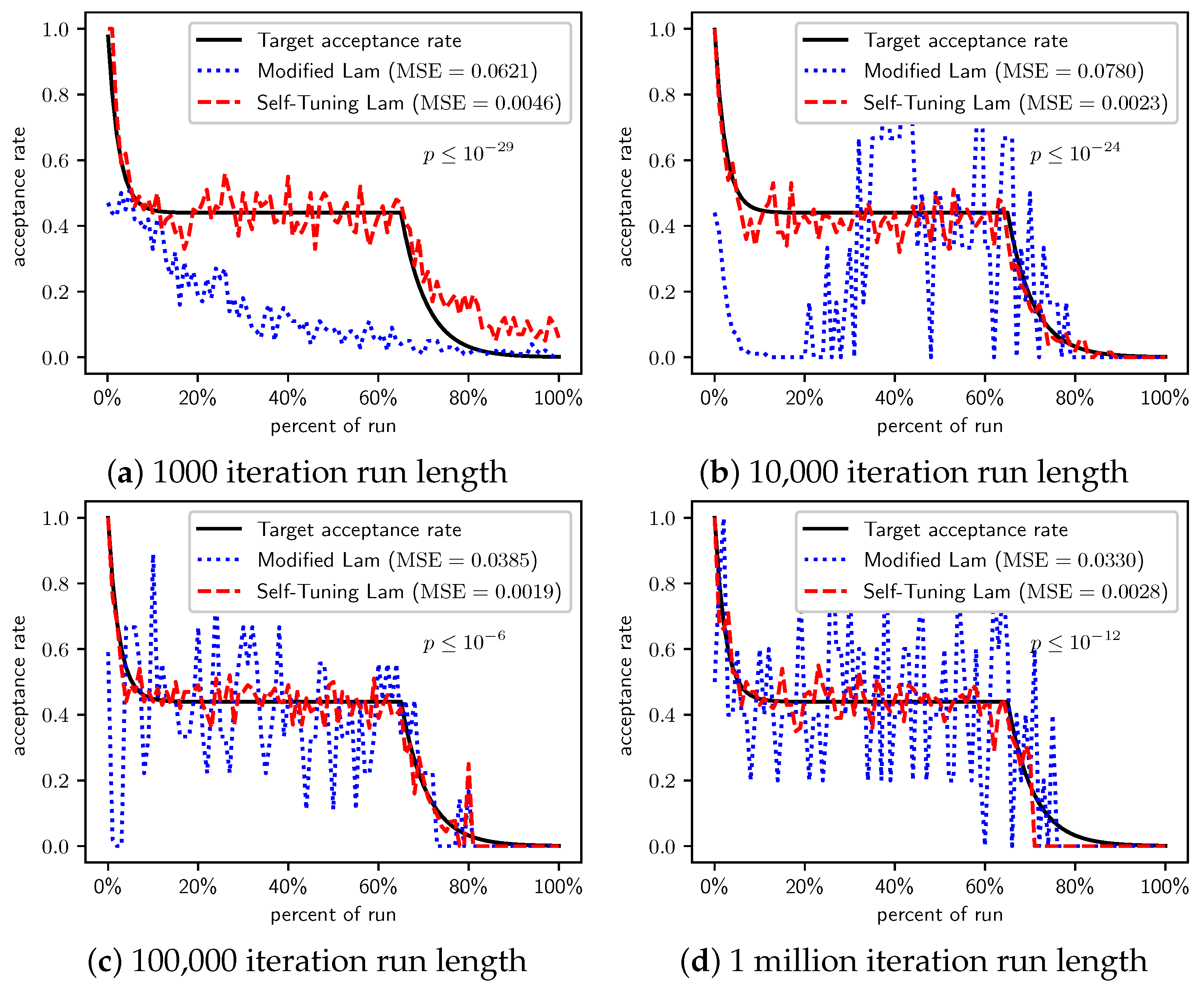
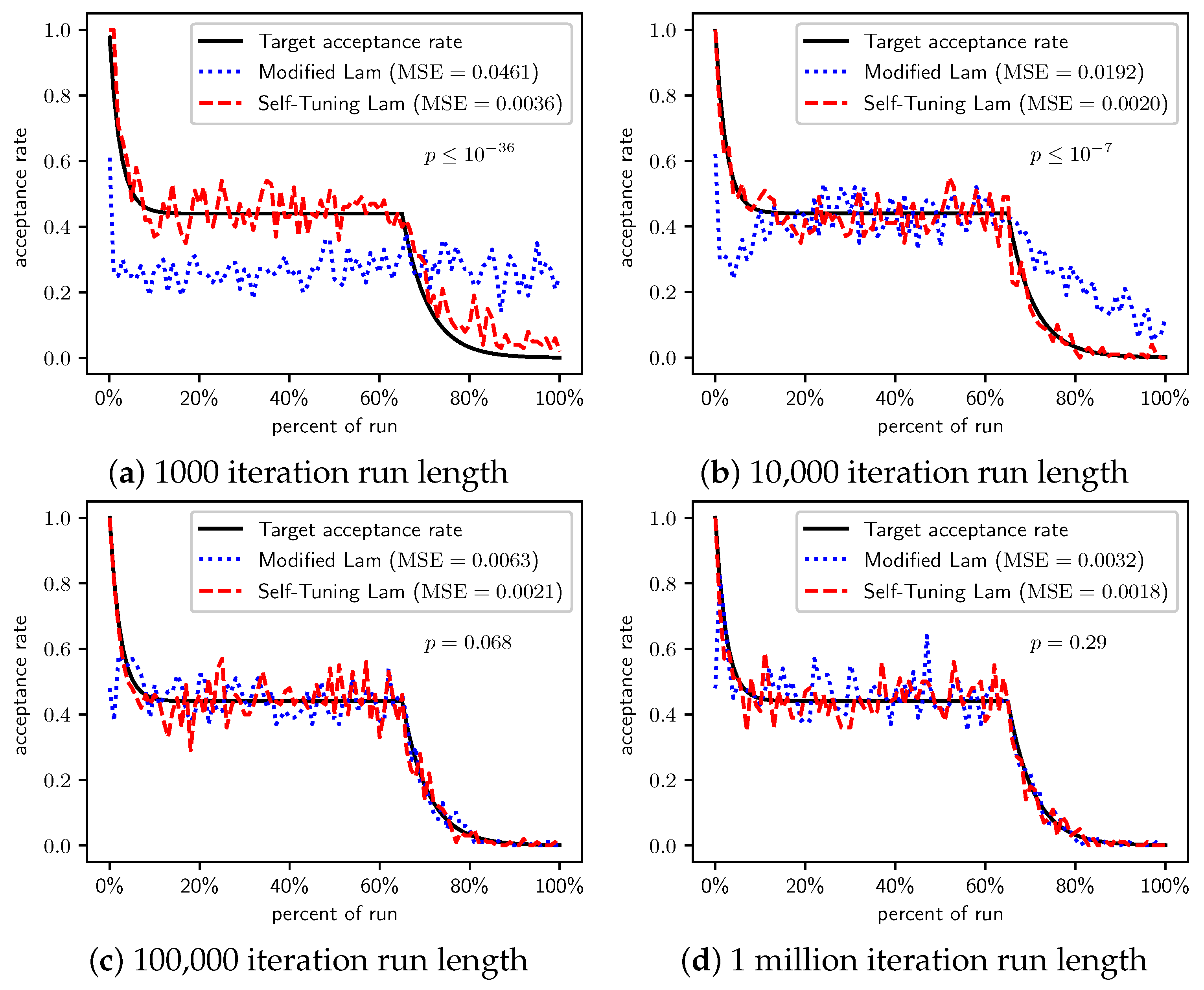
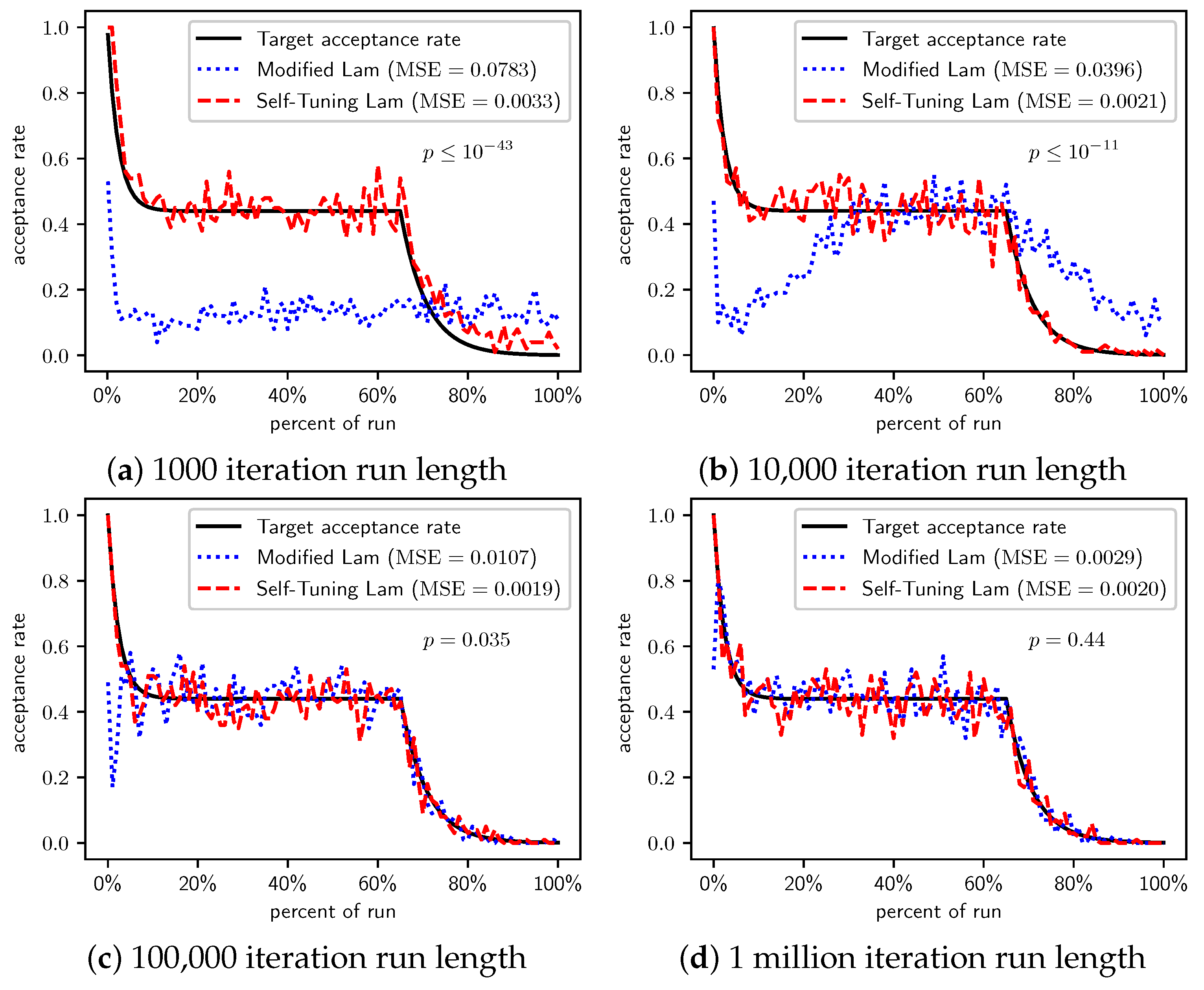
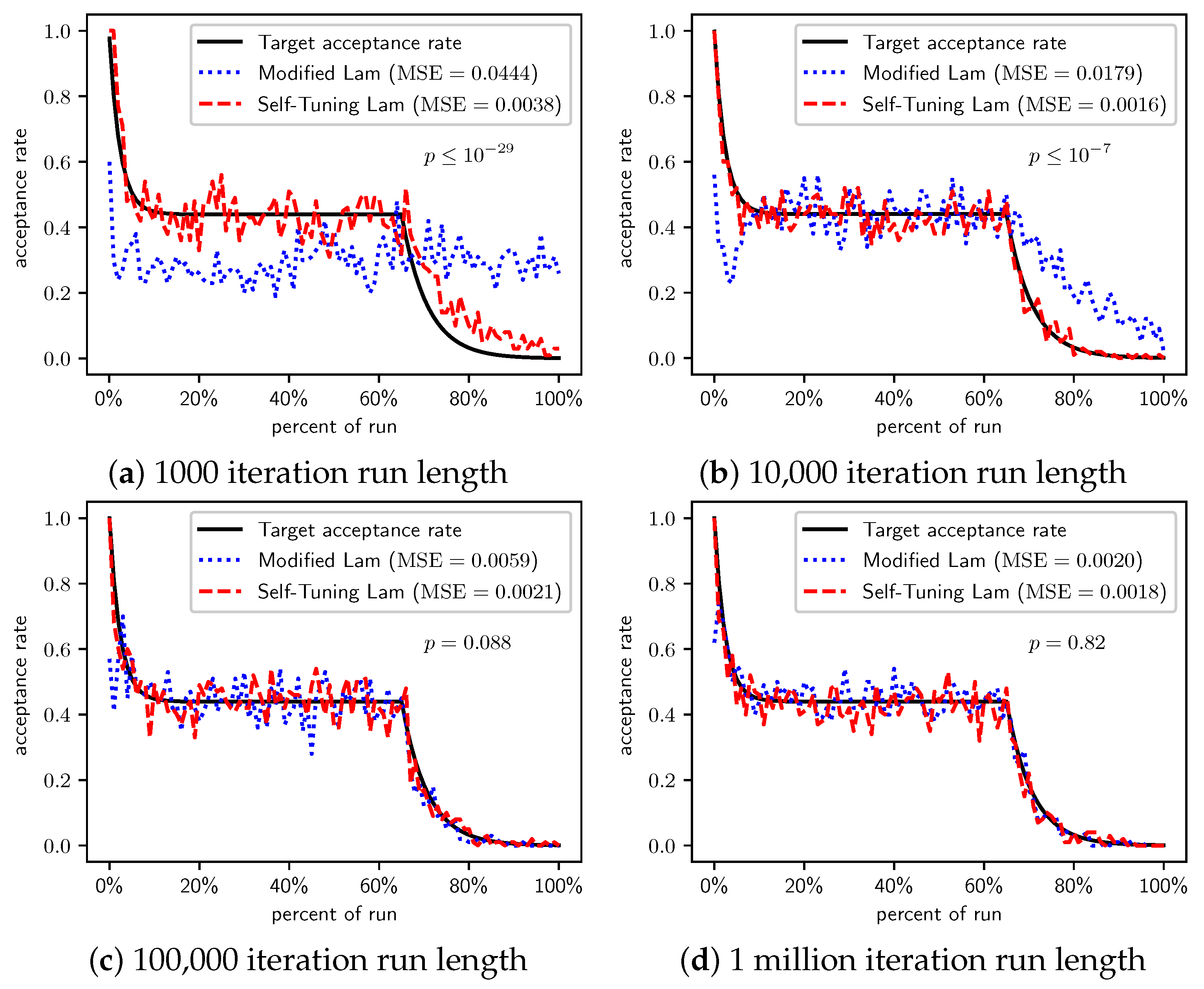
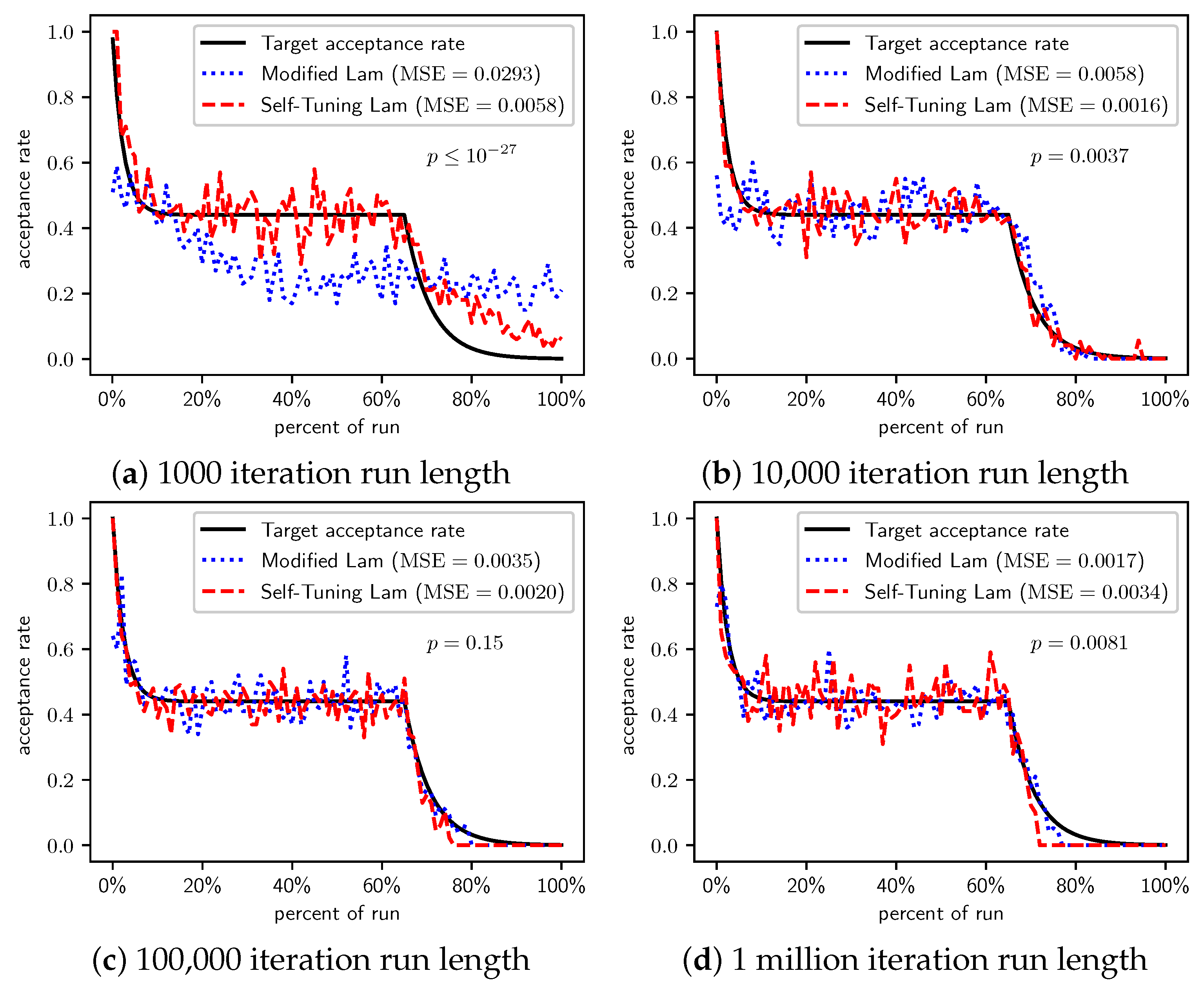
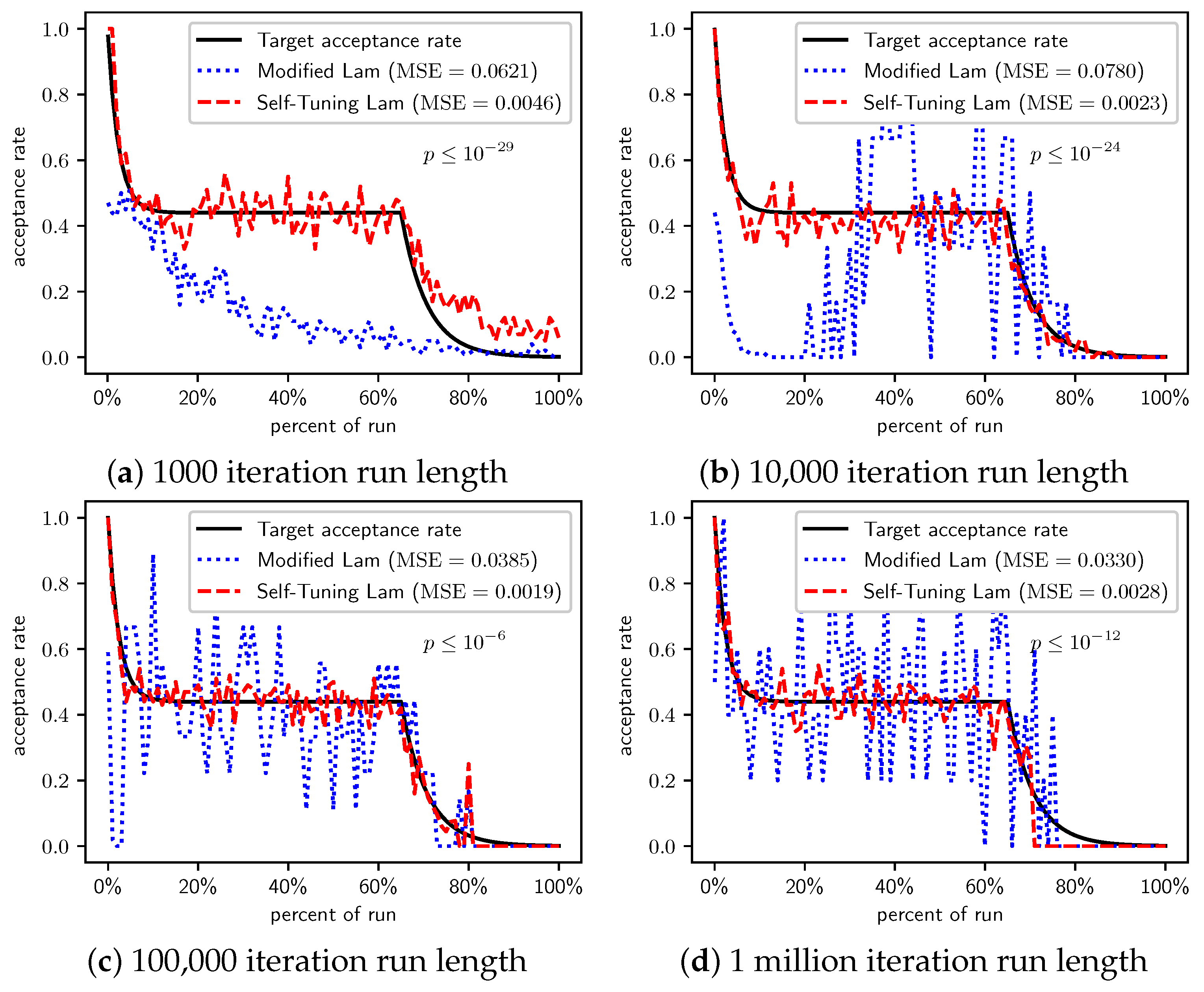
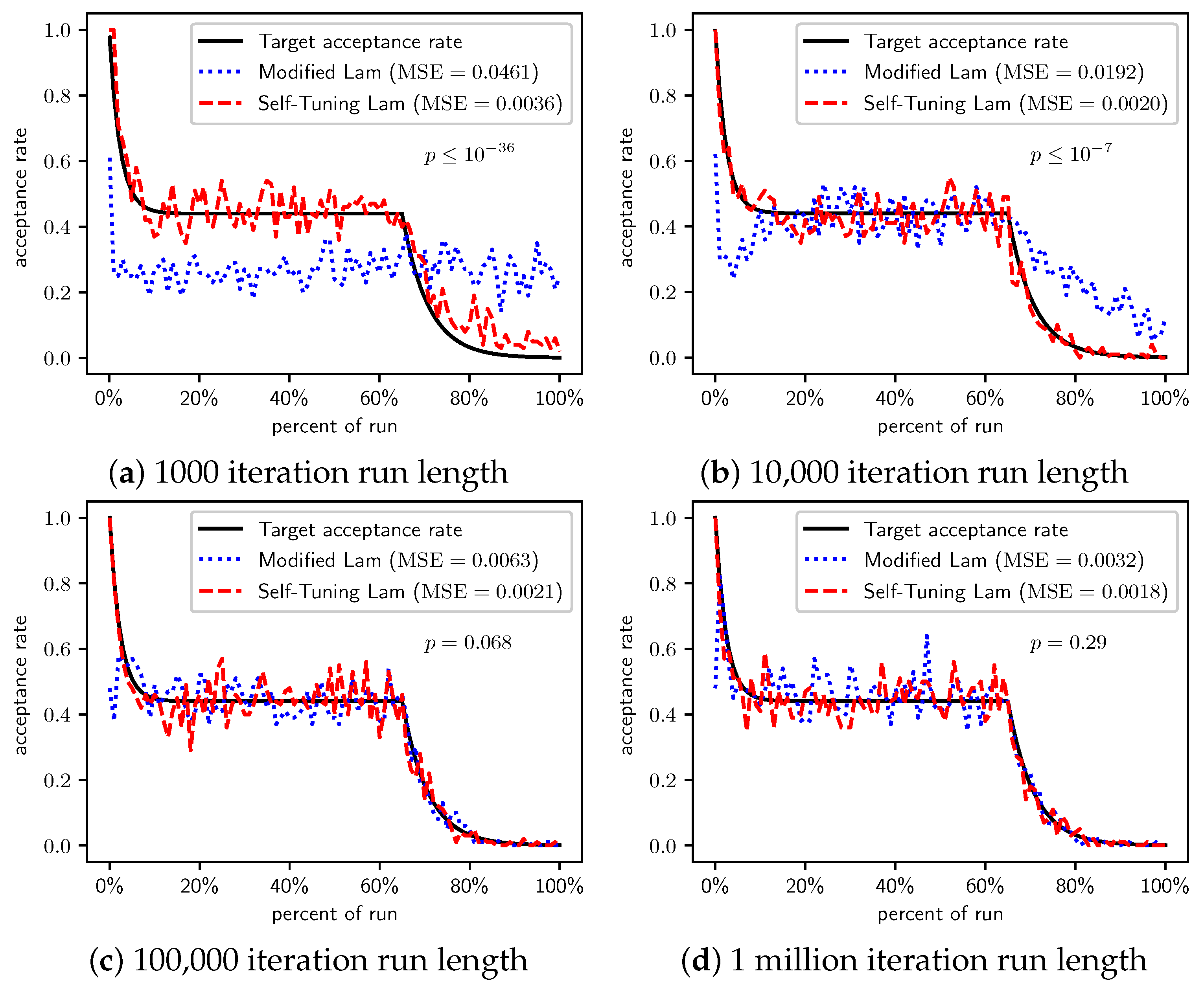
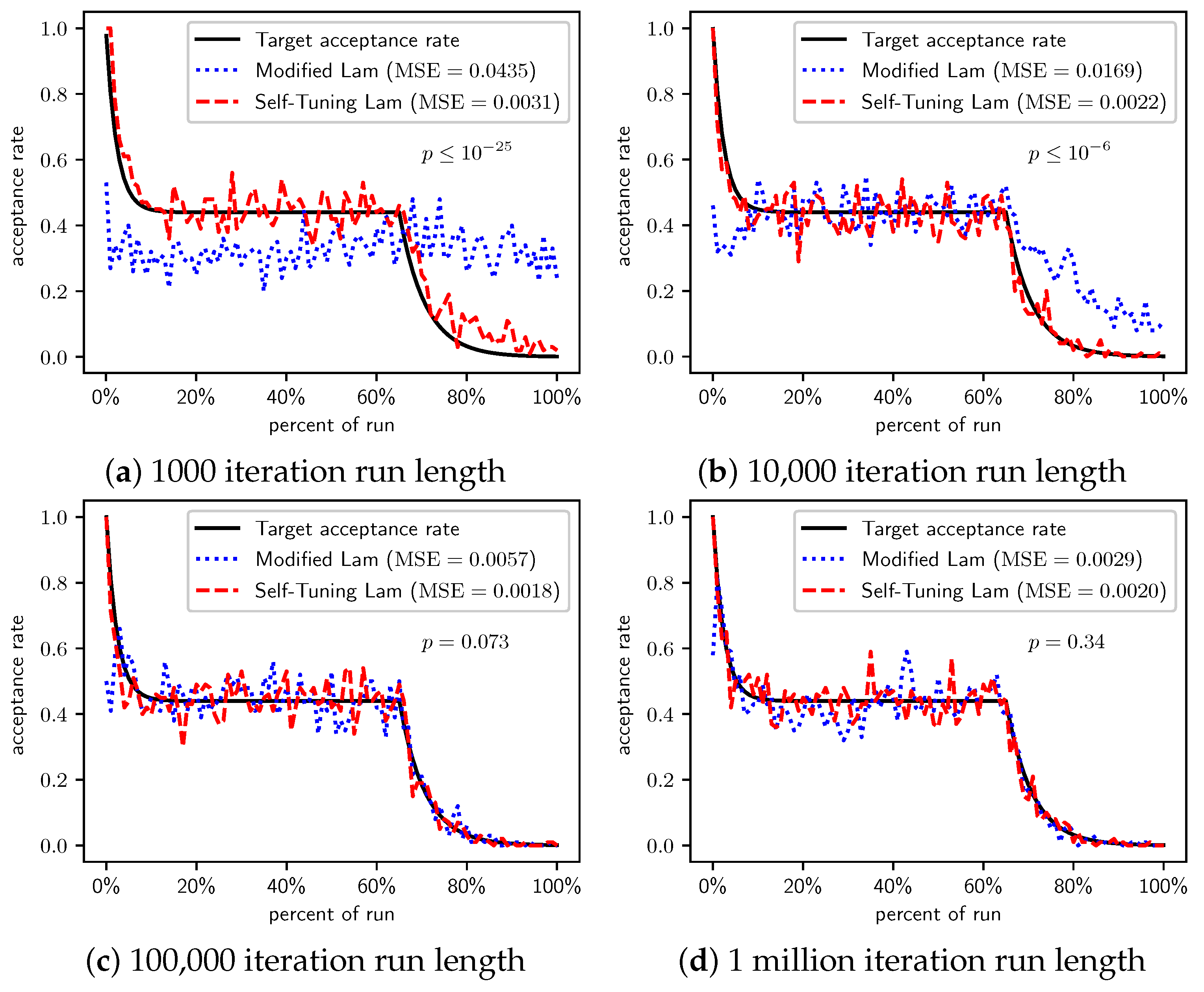
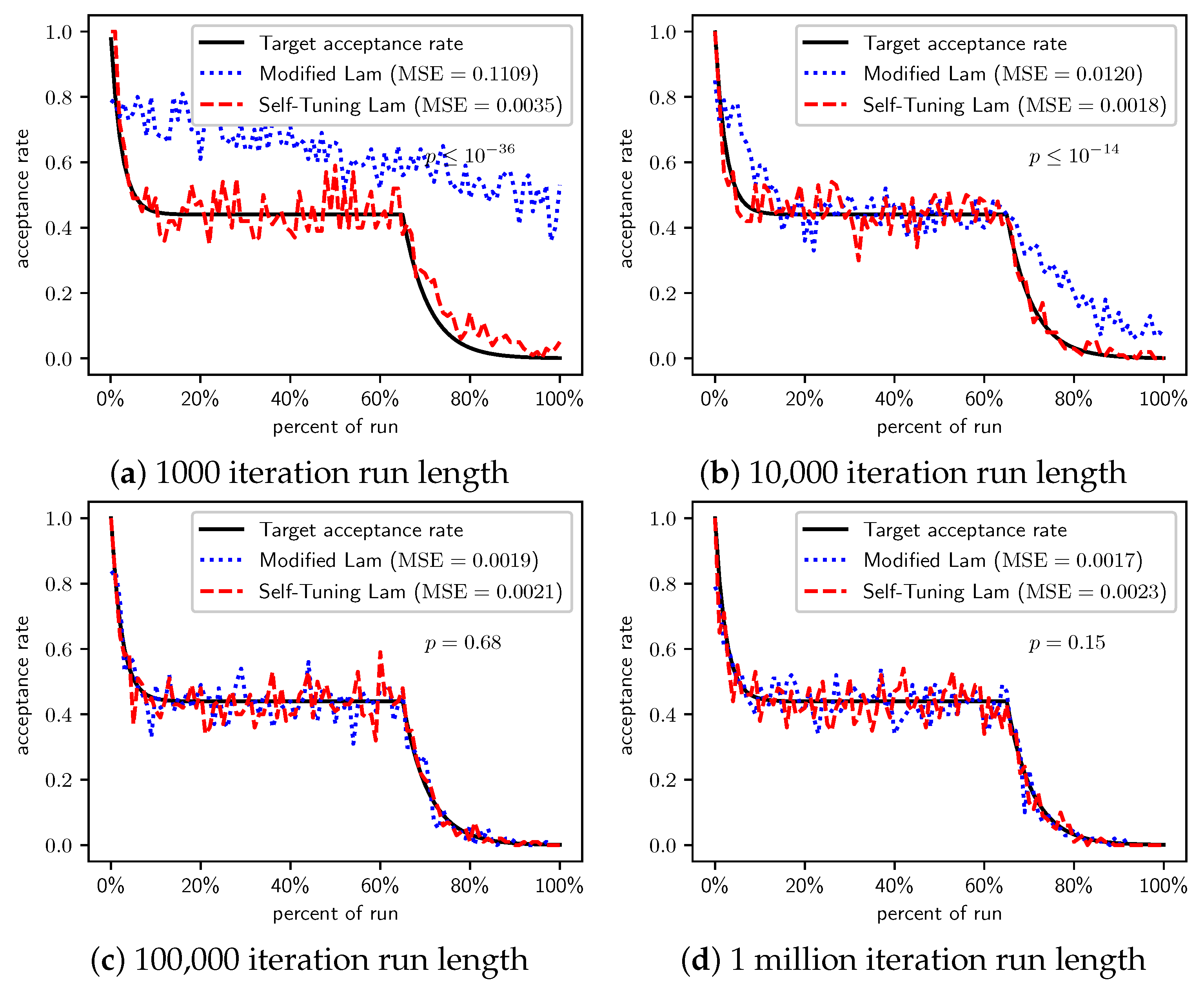
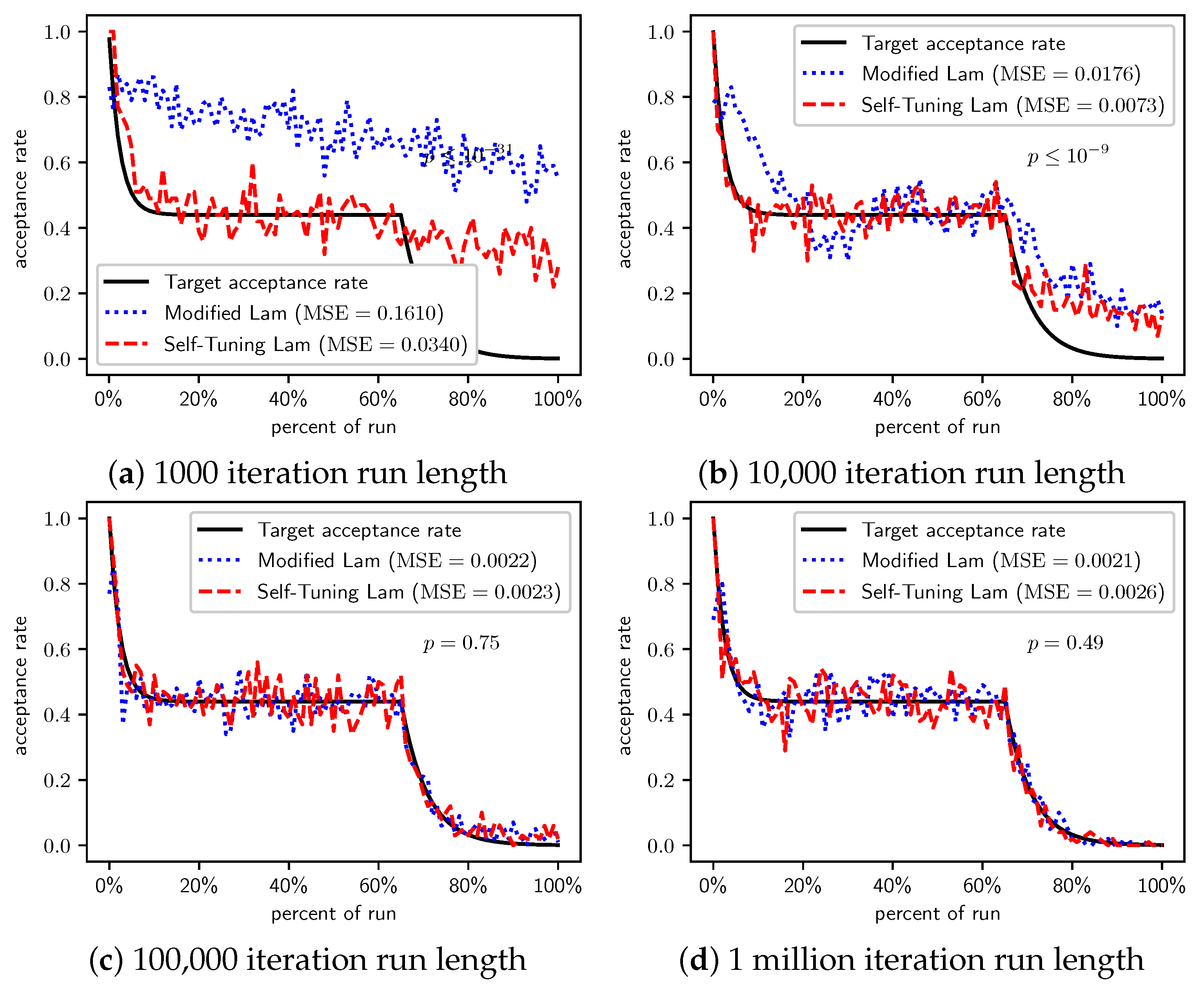
Figure 2.
OneMax (each 0-bit costs 1): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 2.
OneMax (each 0-bit costs 1): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
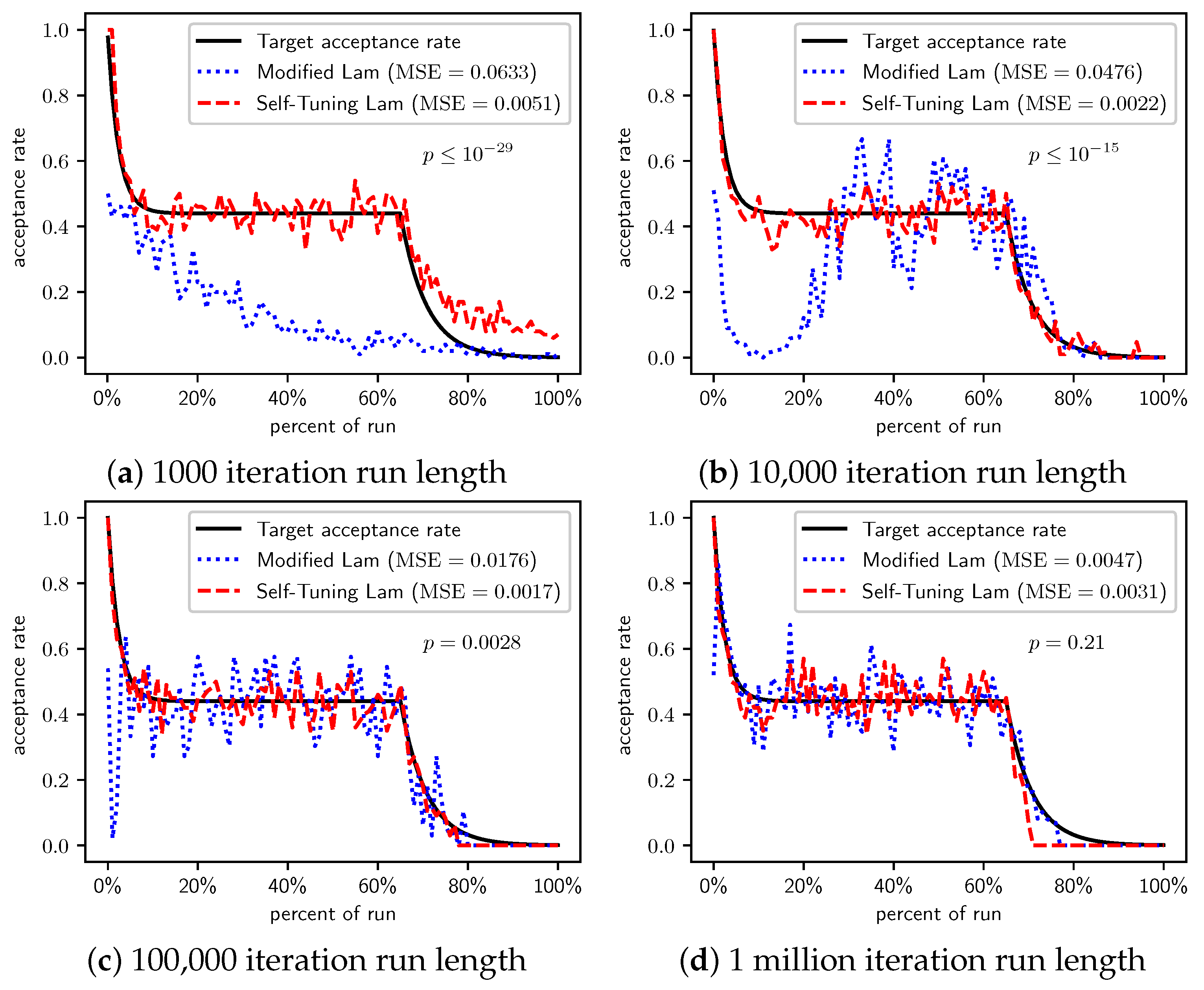
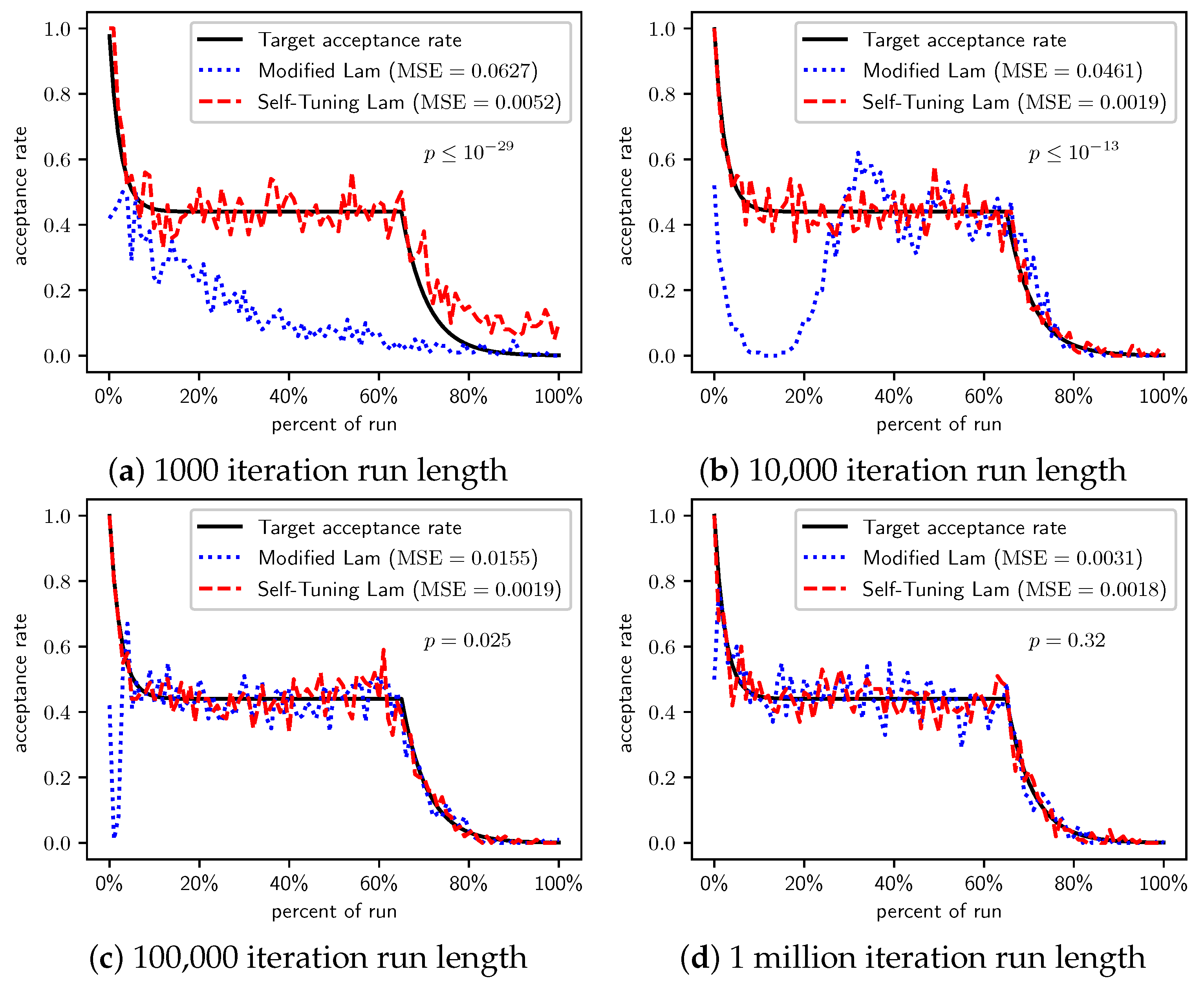
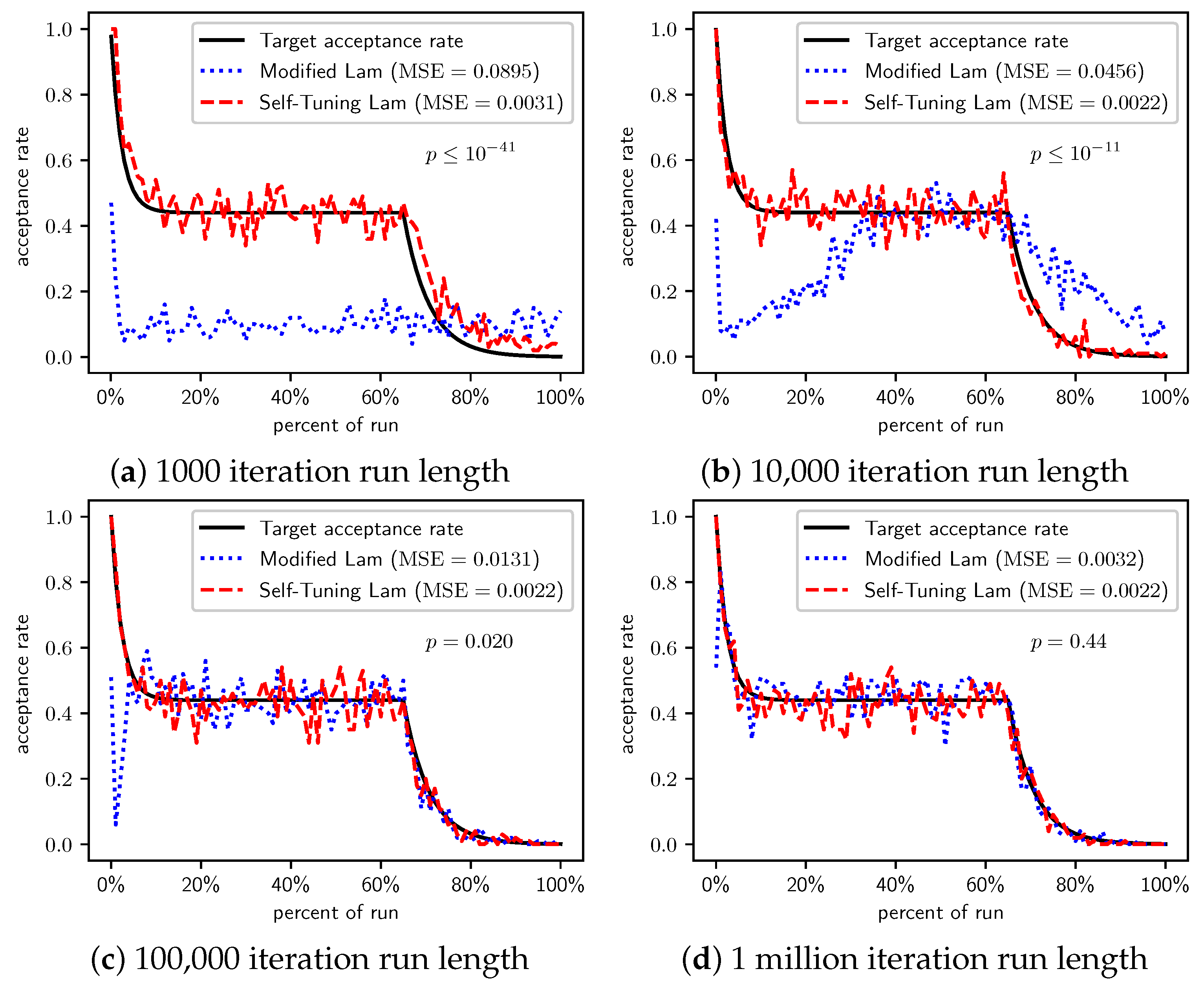
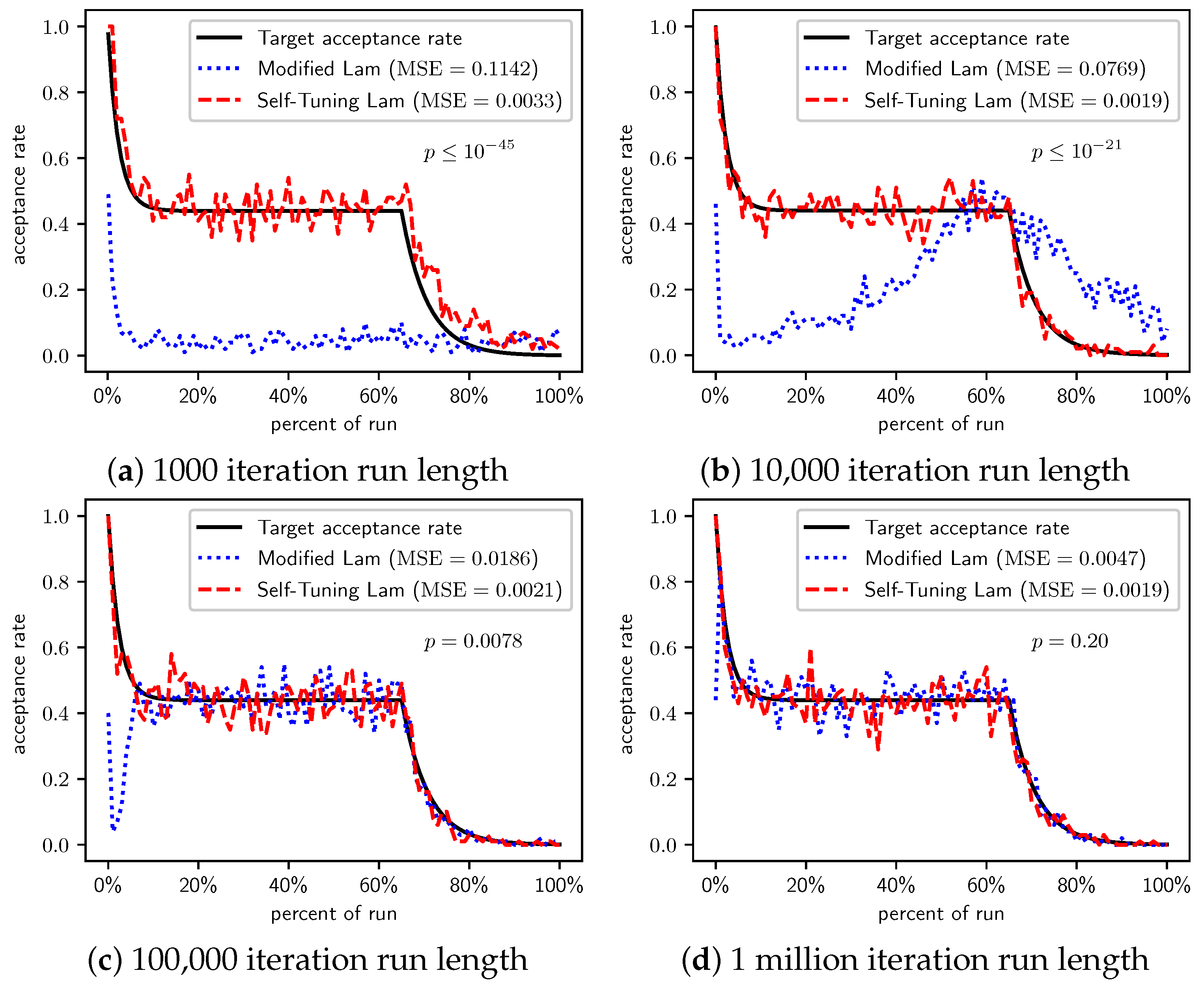
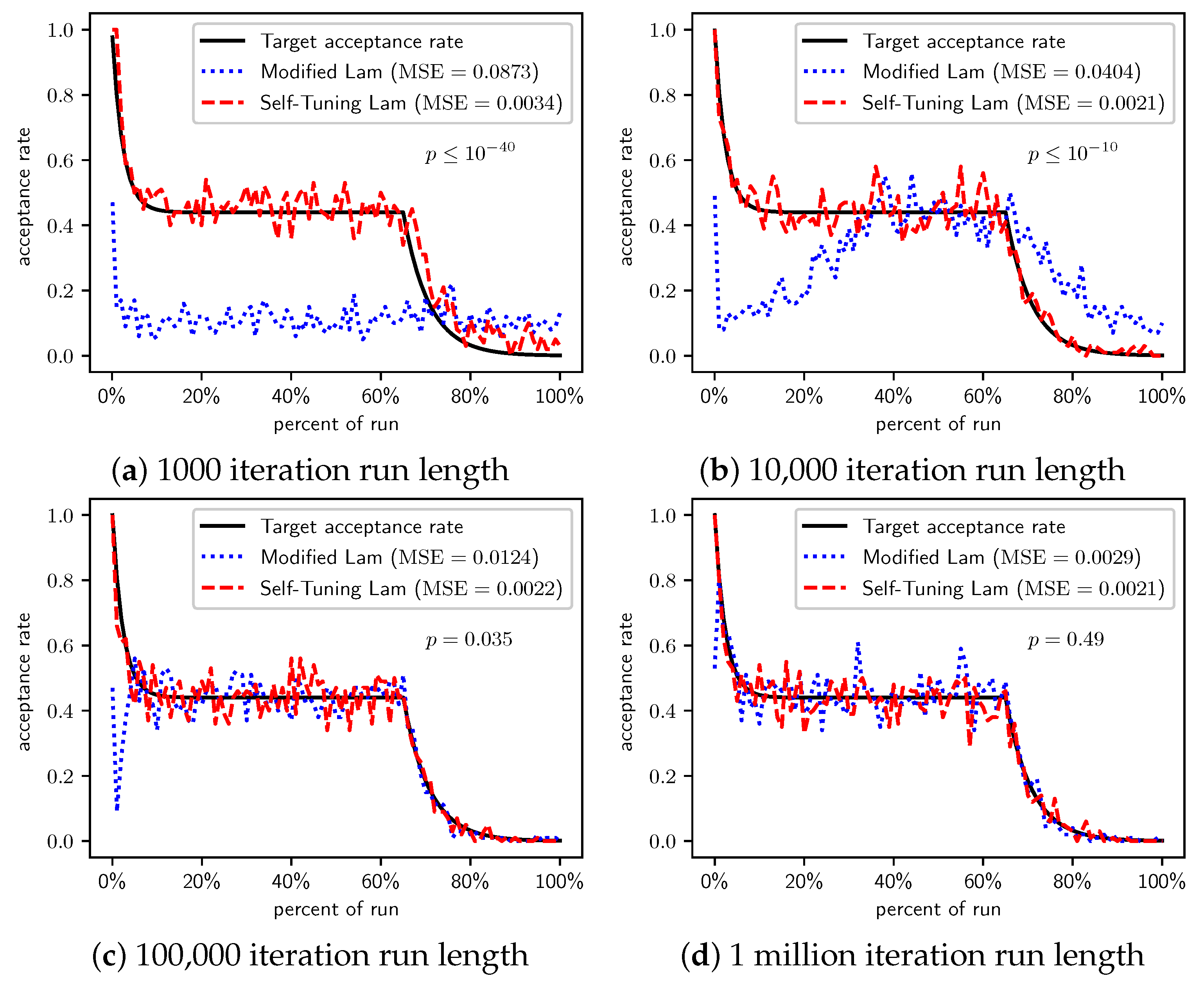
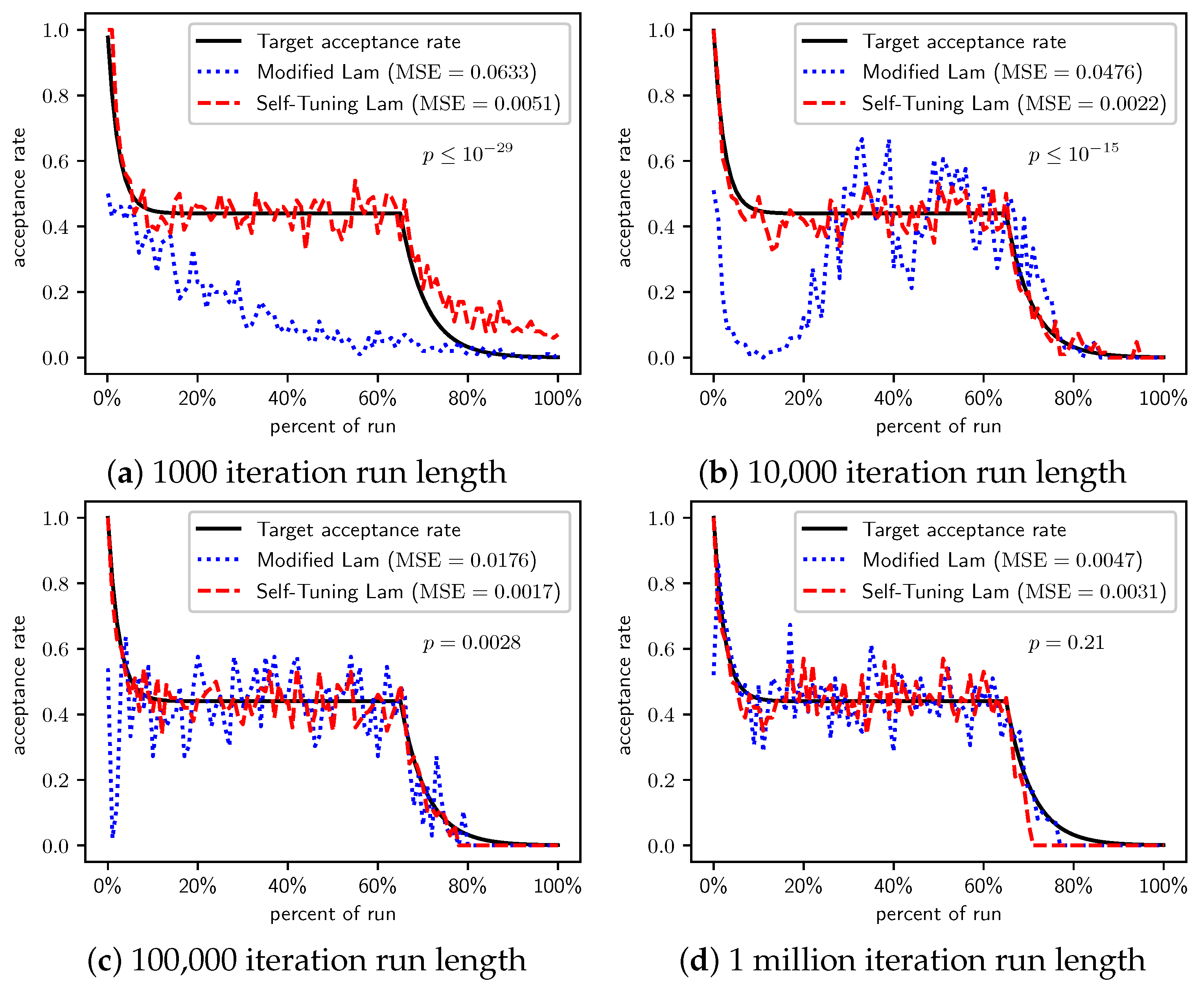
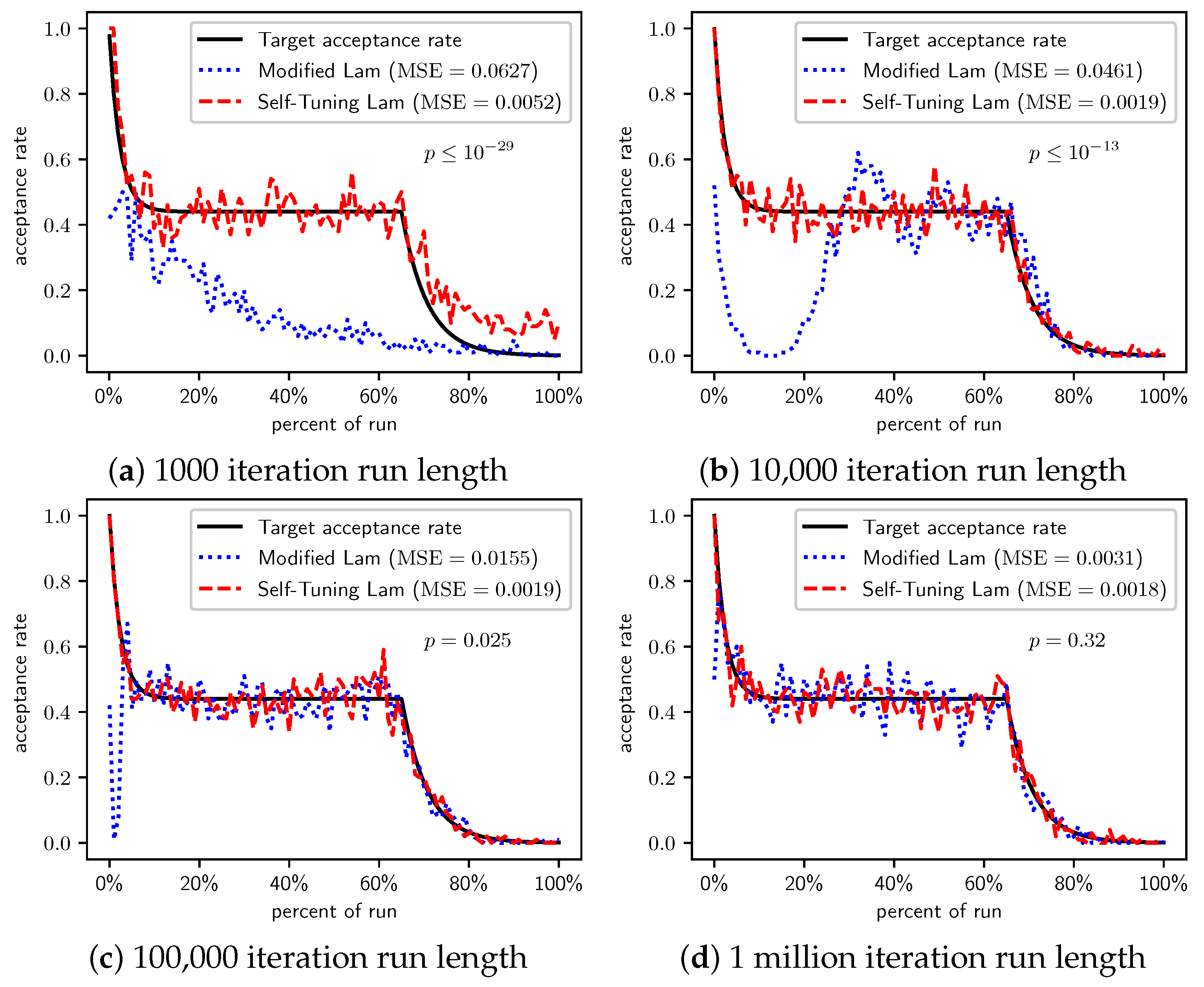
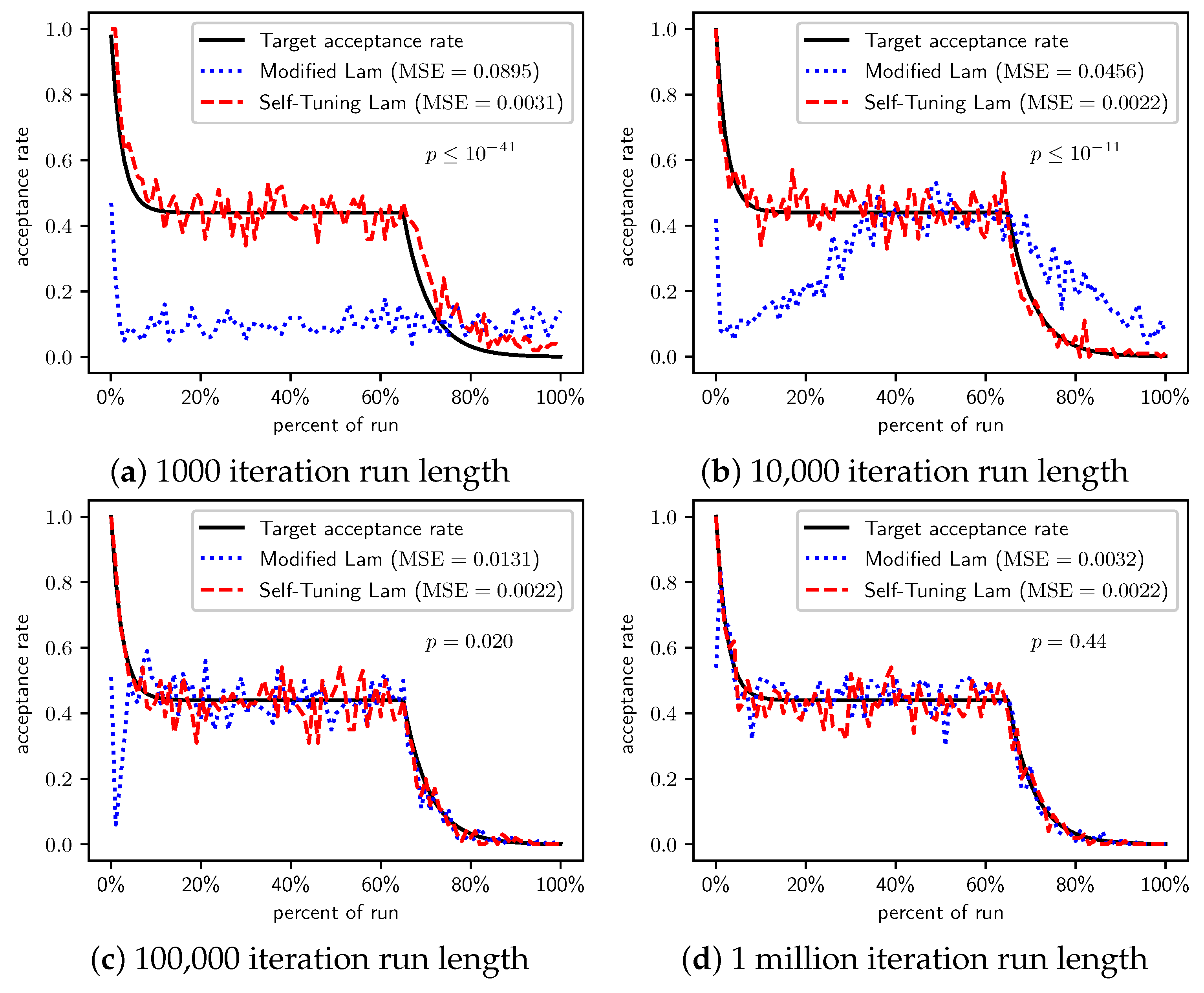
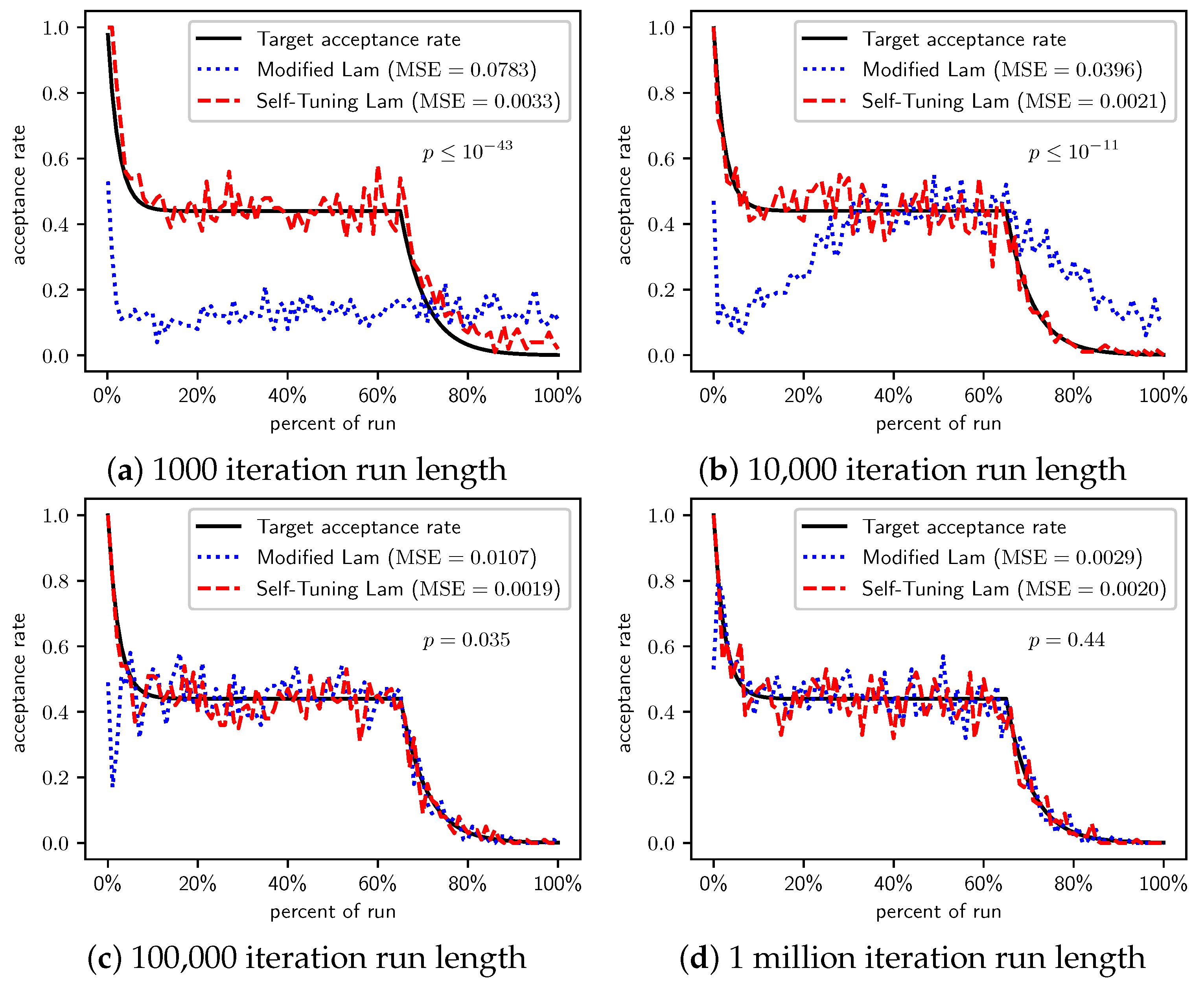
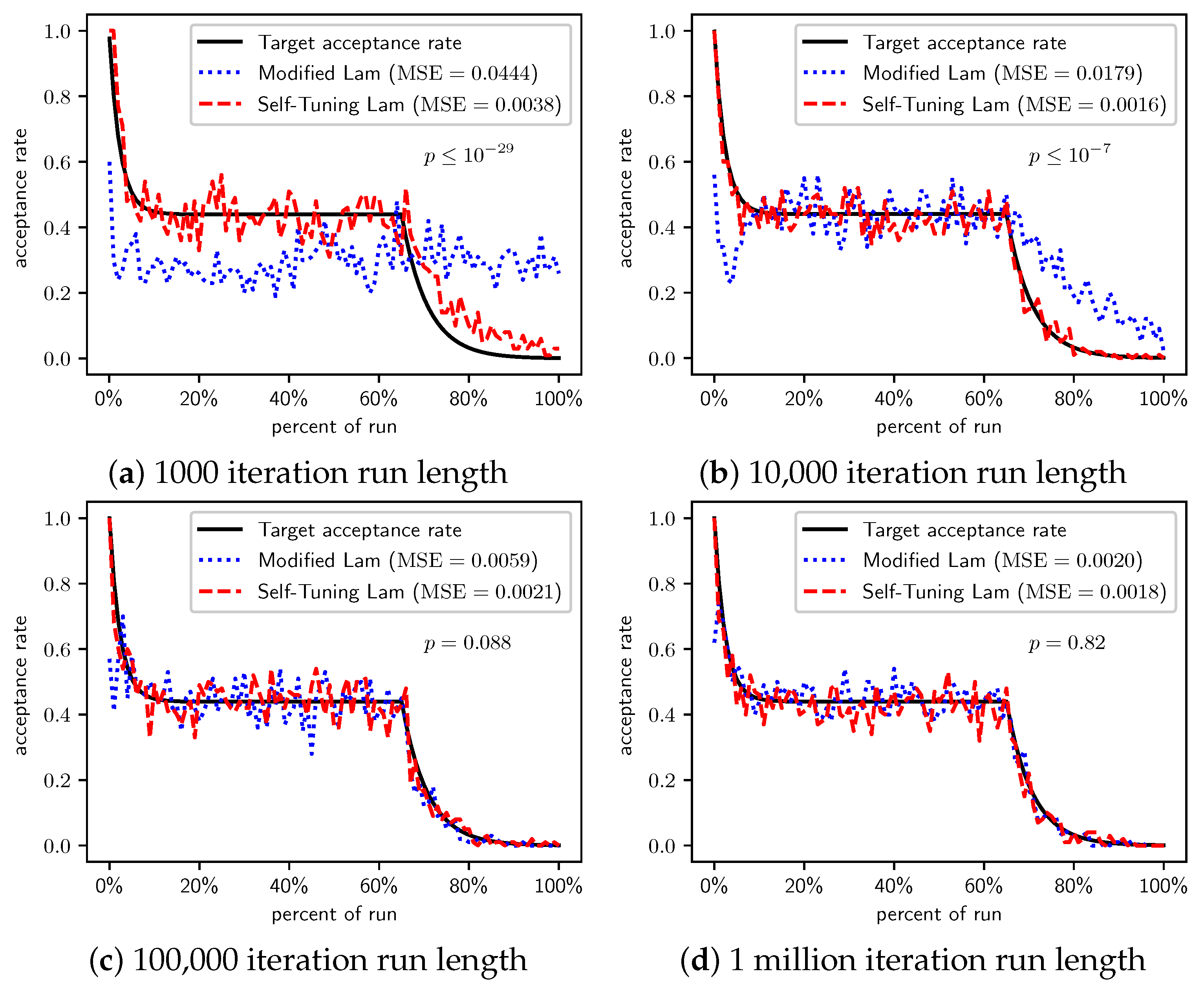
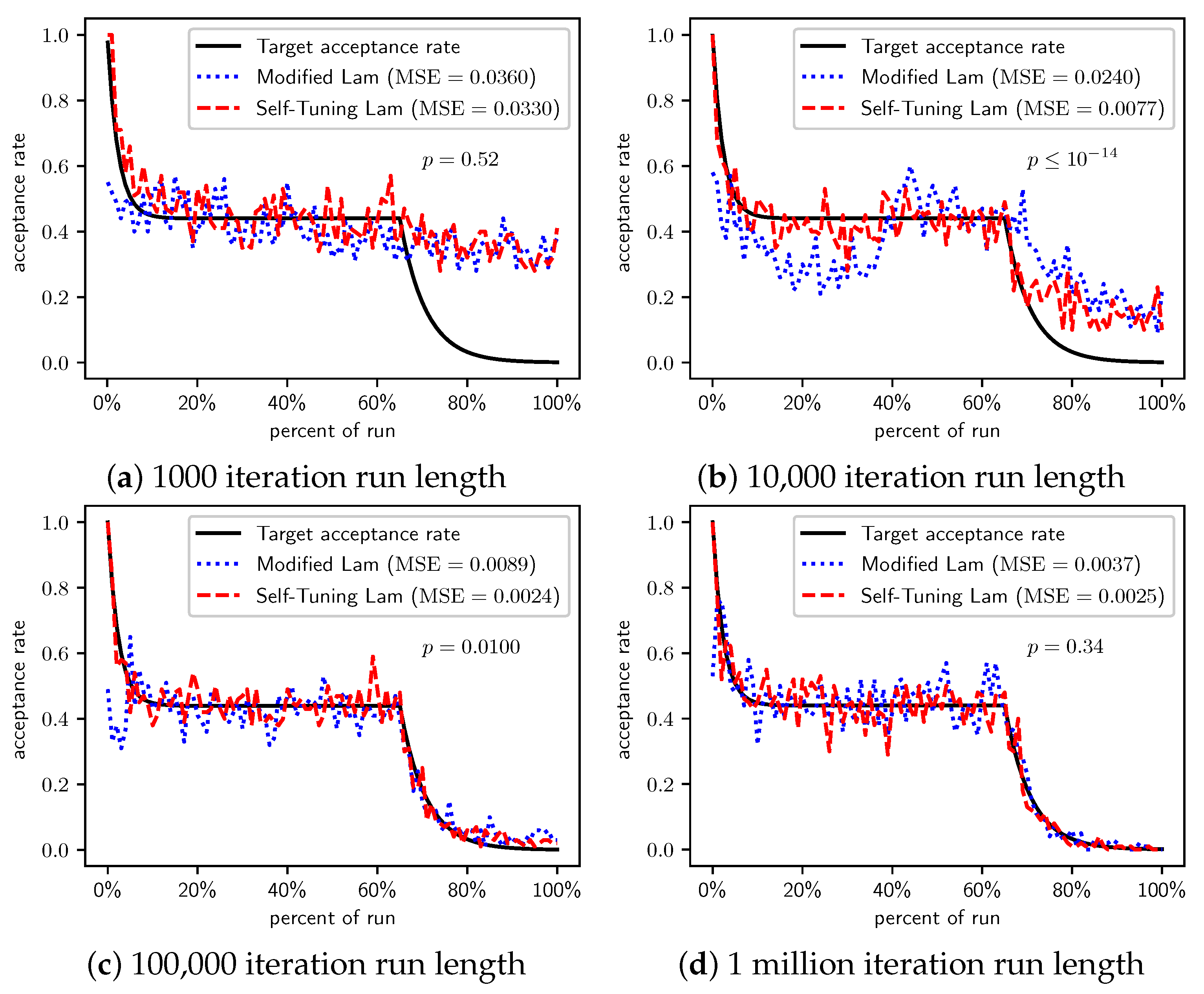
Figure 3.
OneMax (each 0-bit costs 10): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 3.
OneMax (each 0-bit costs 10): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
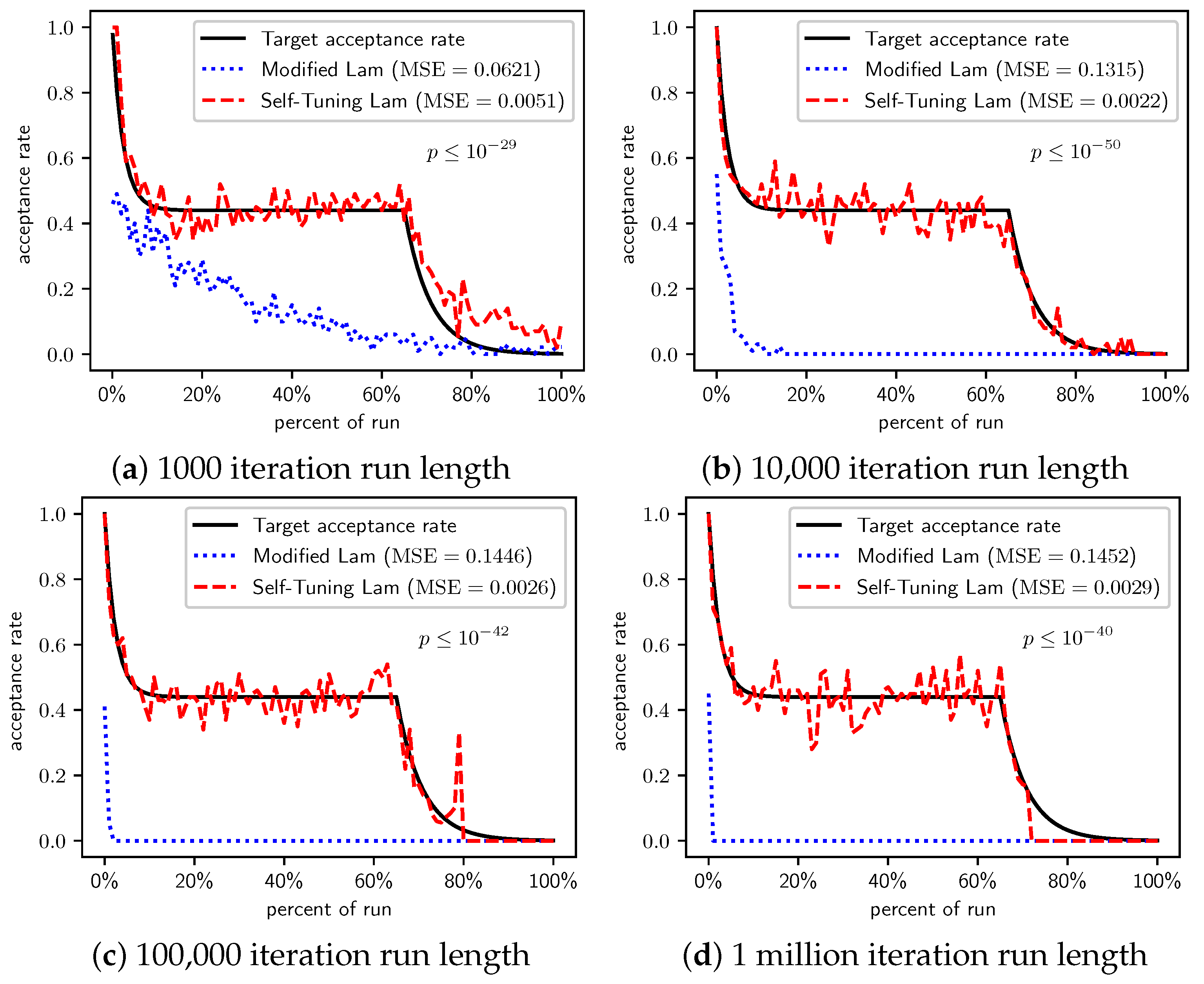
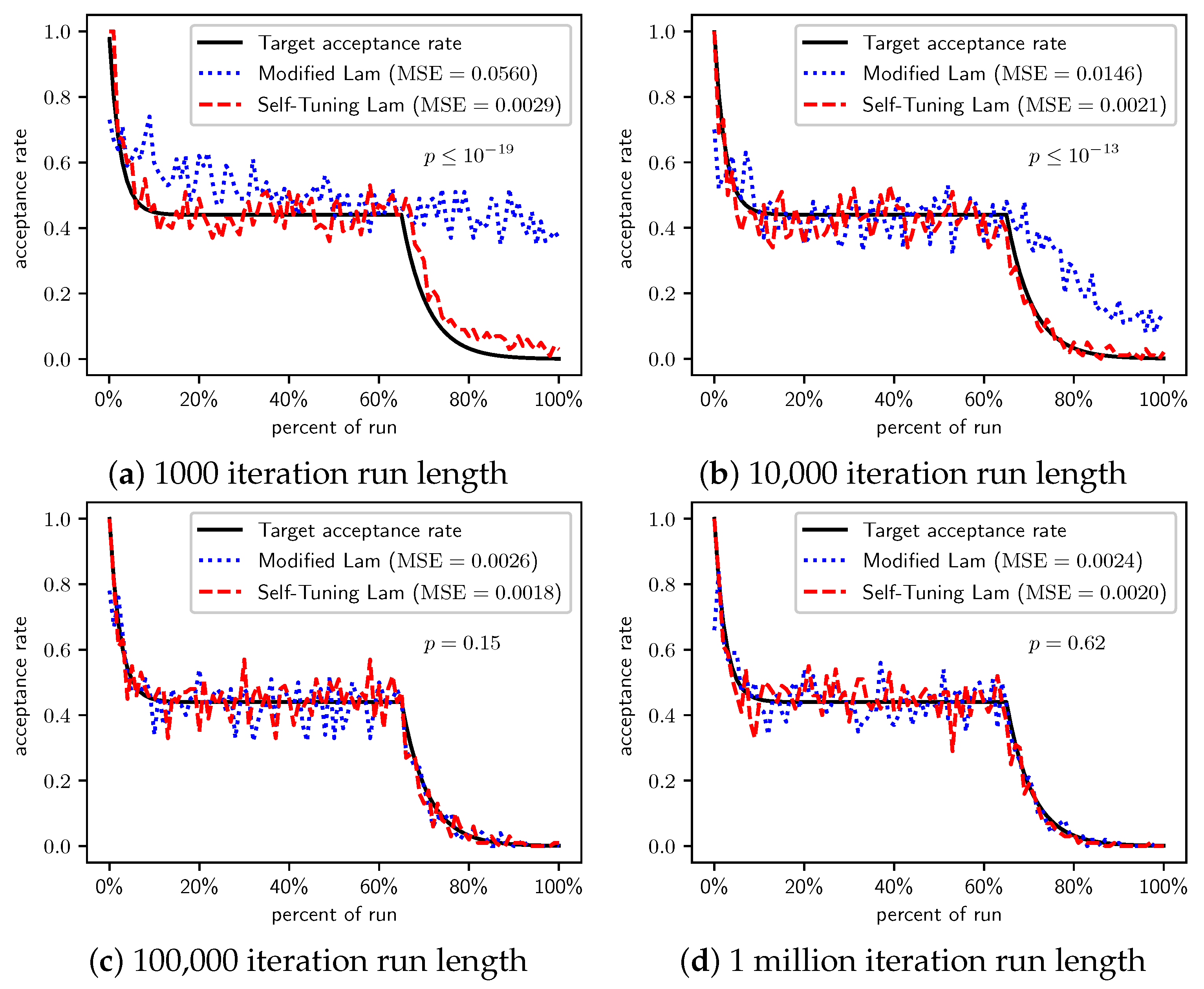
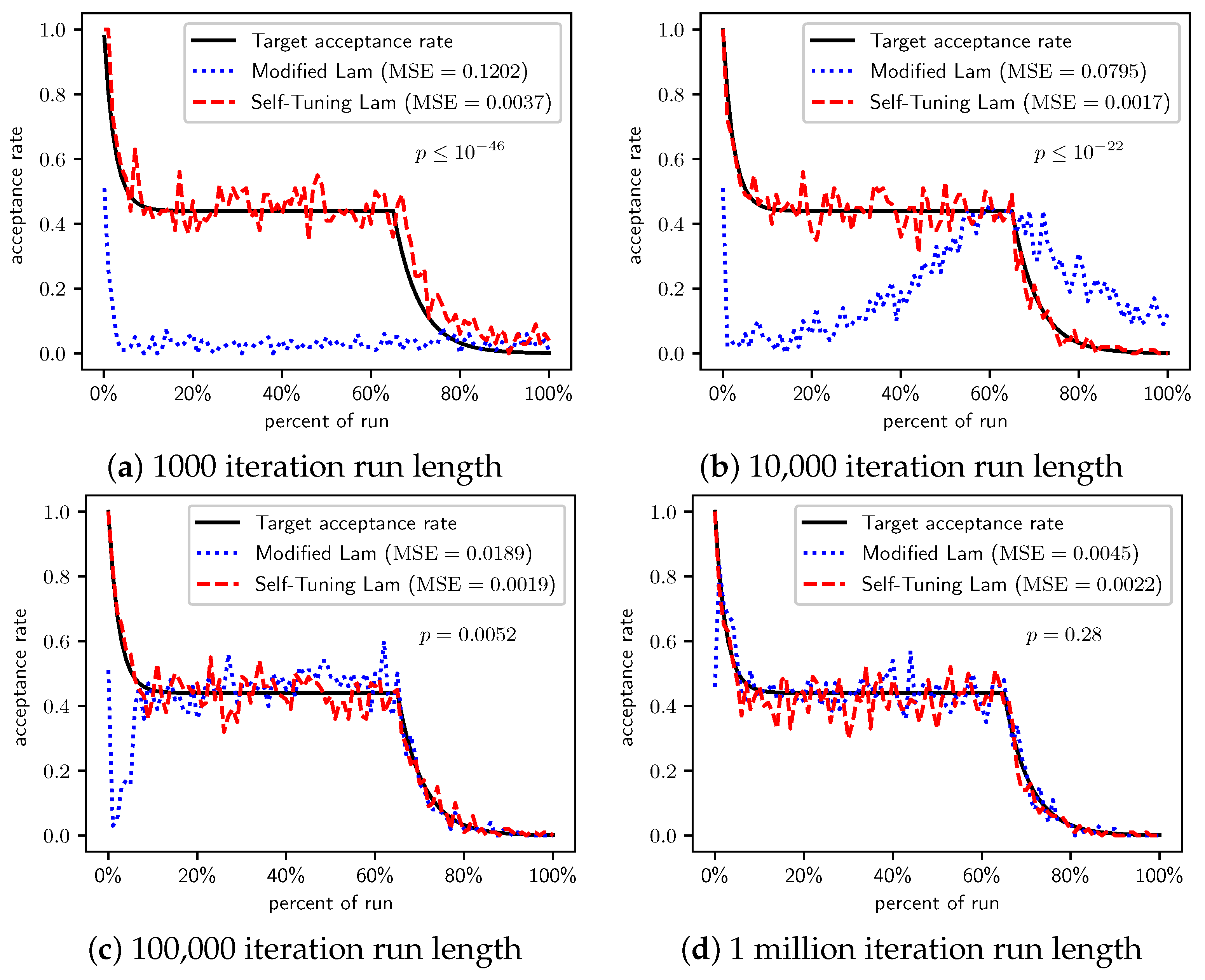
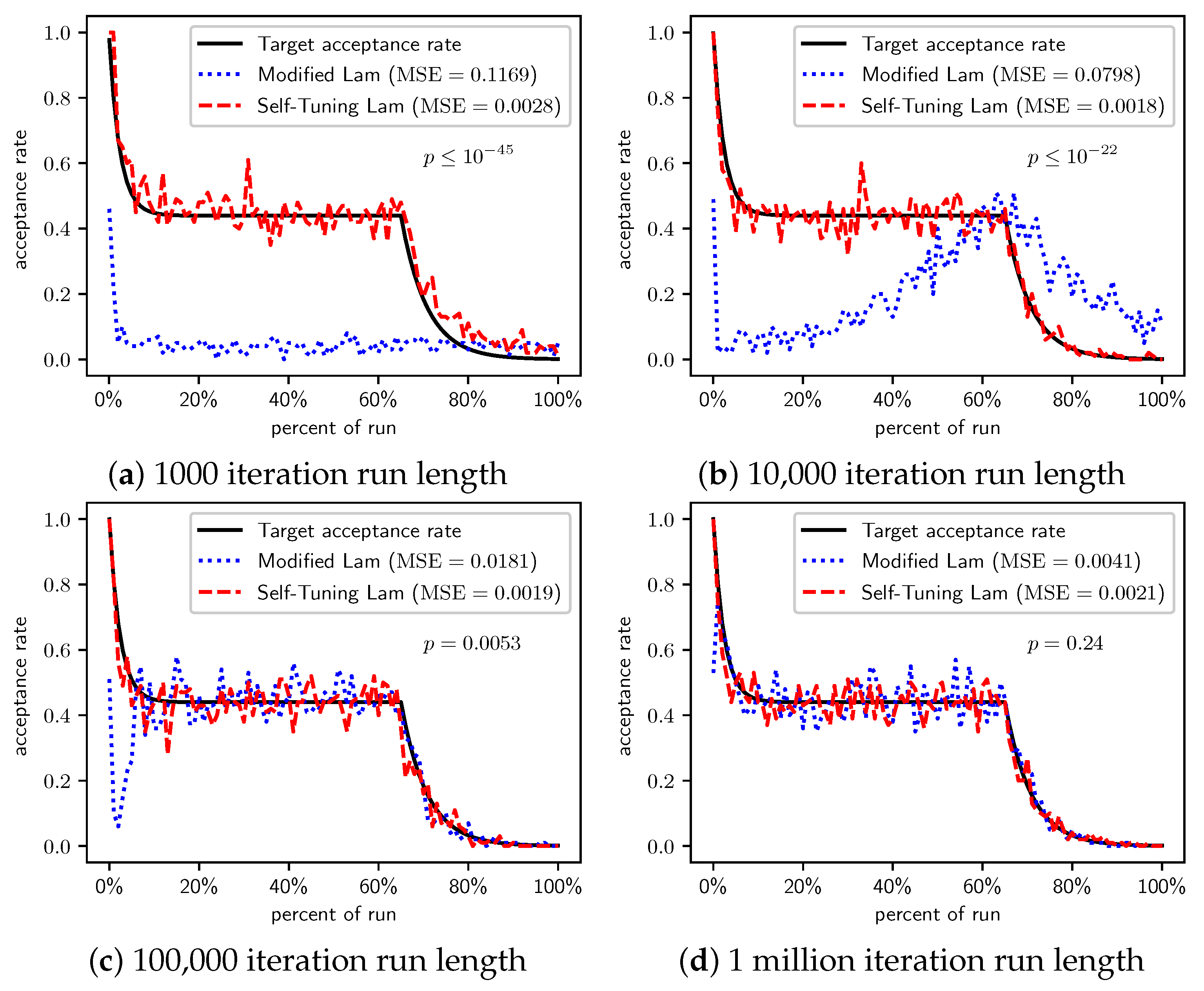
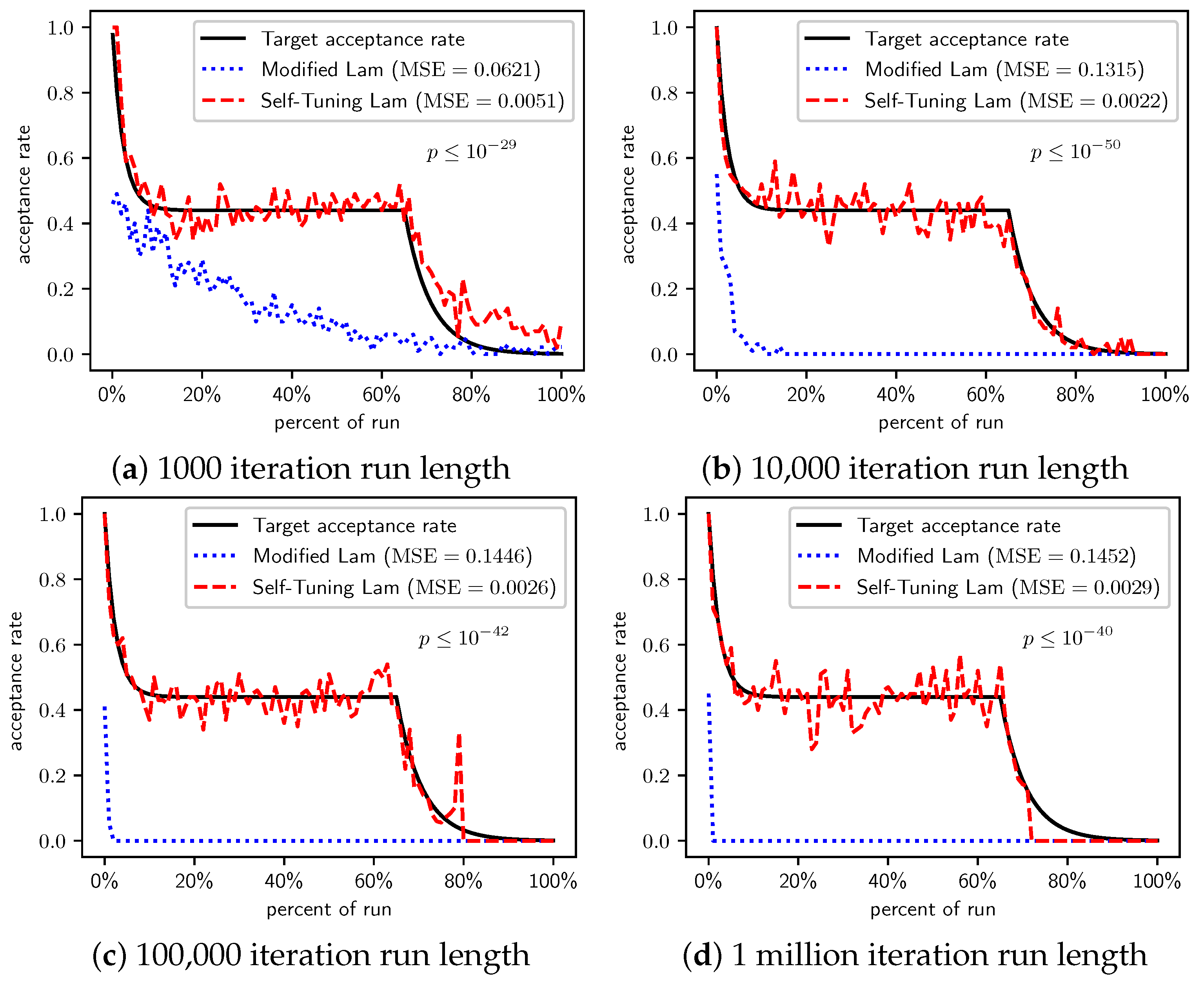
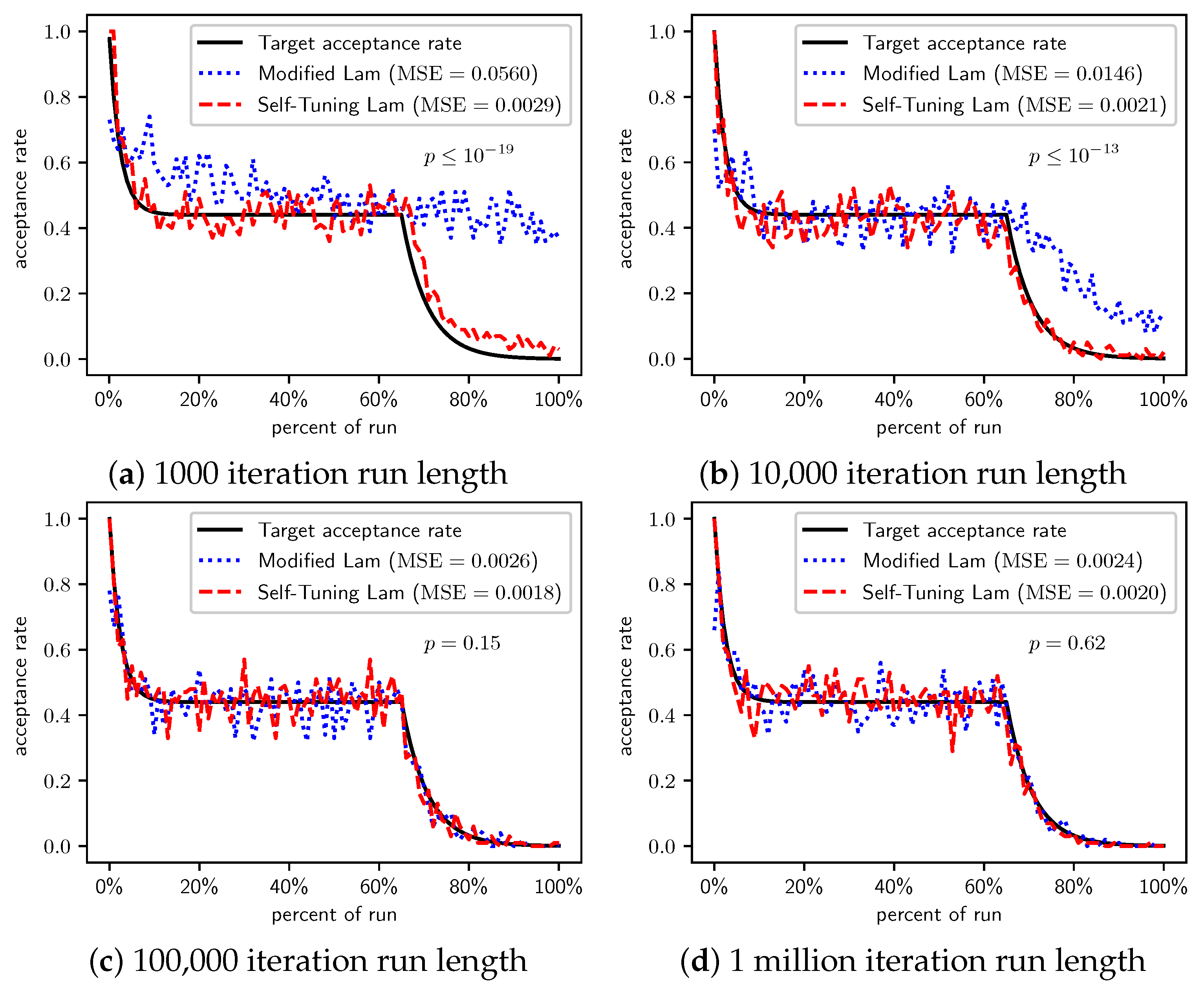
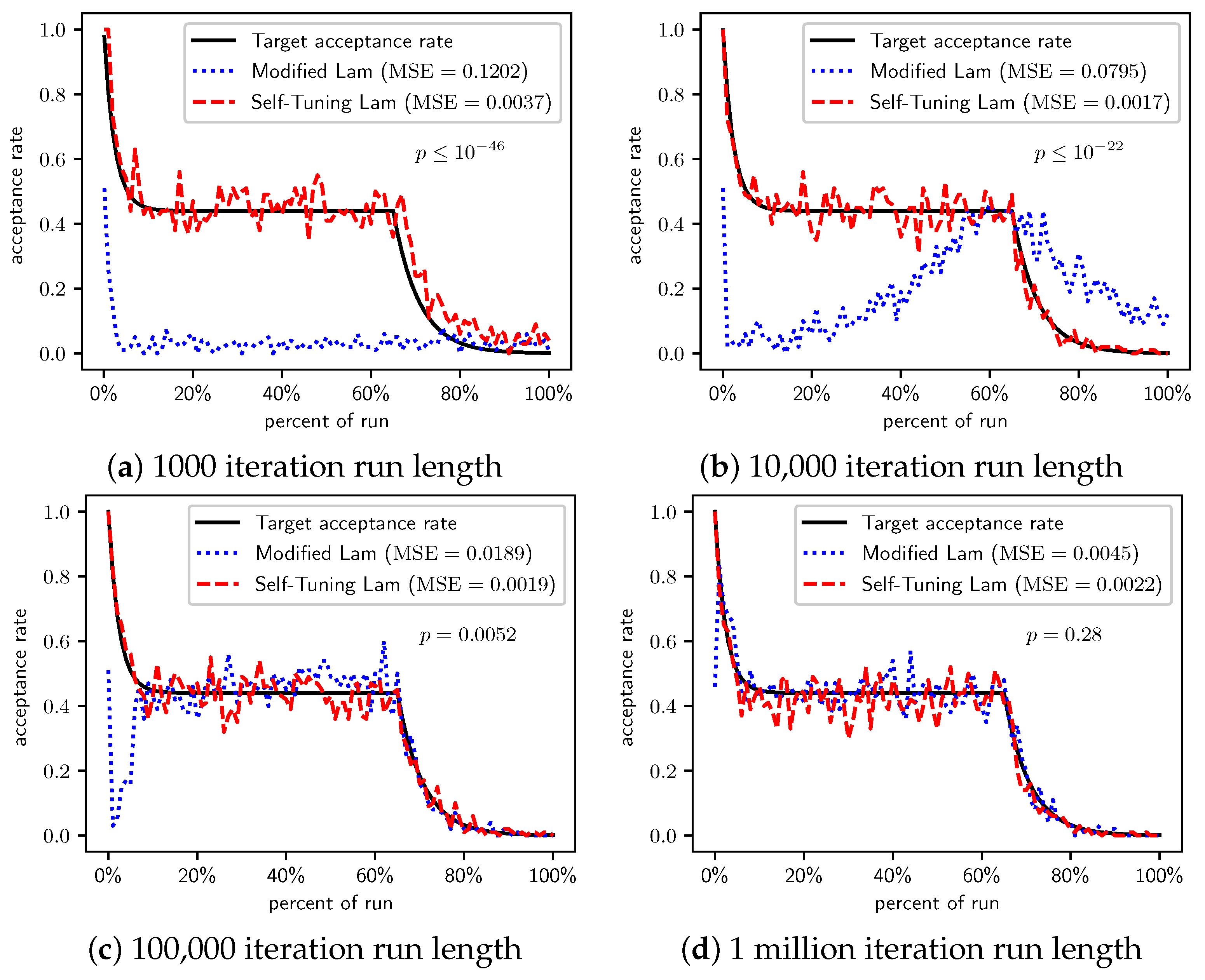
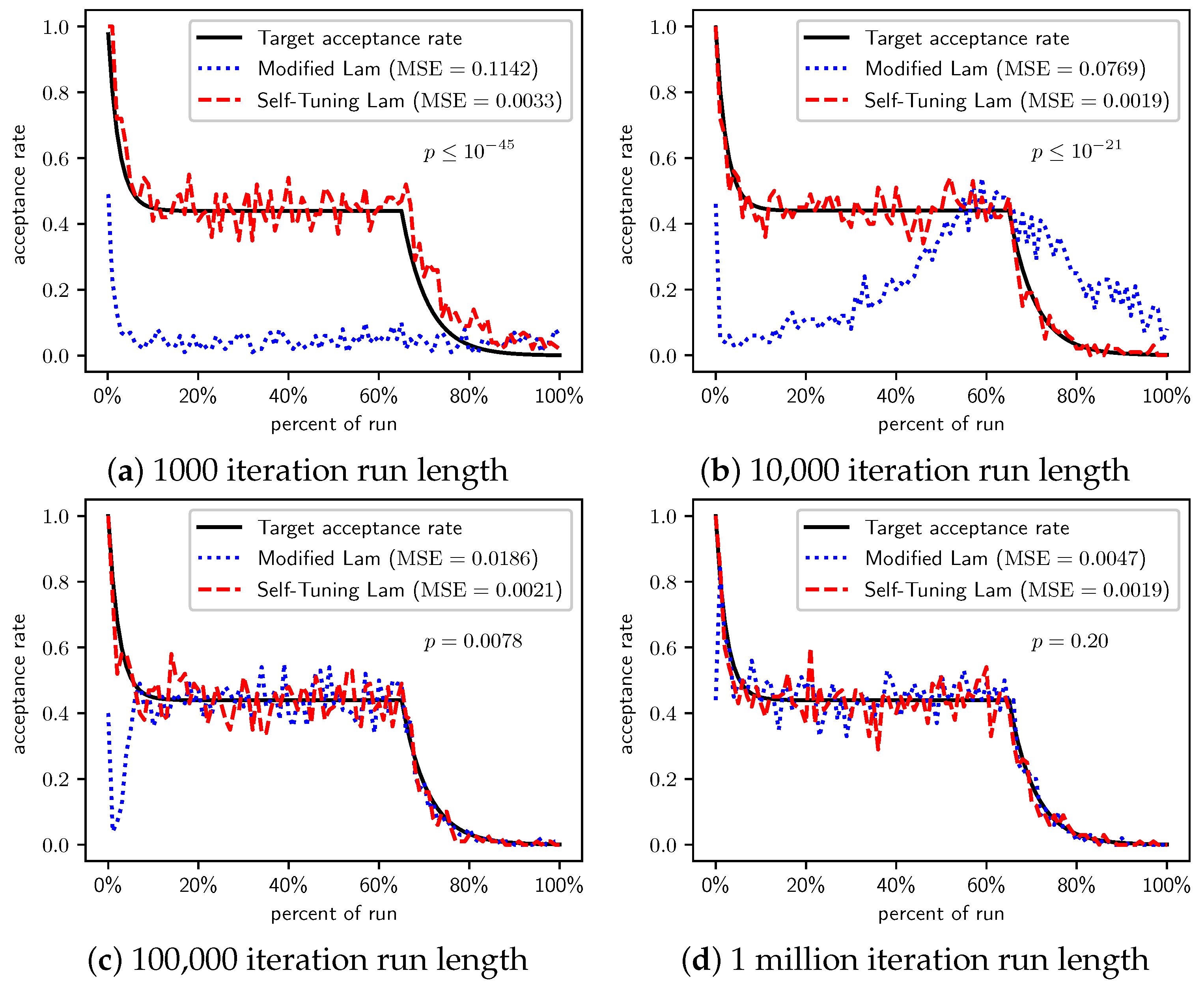
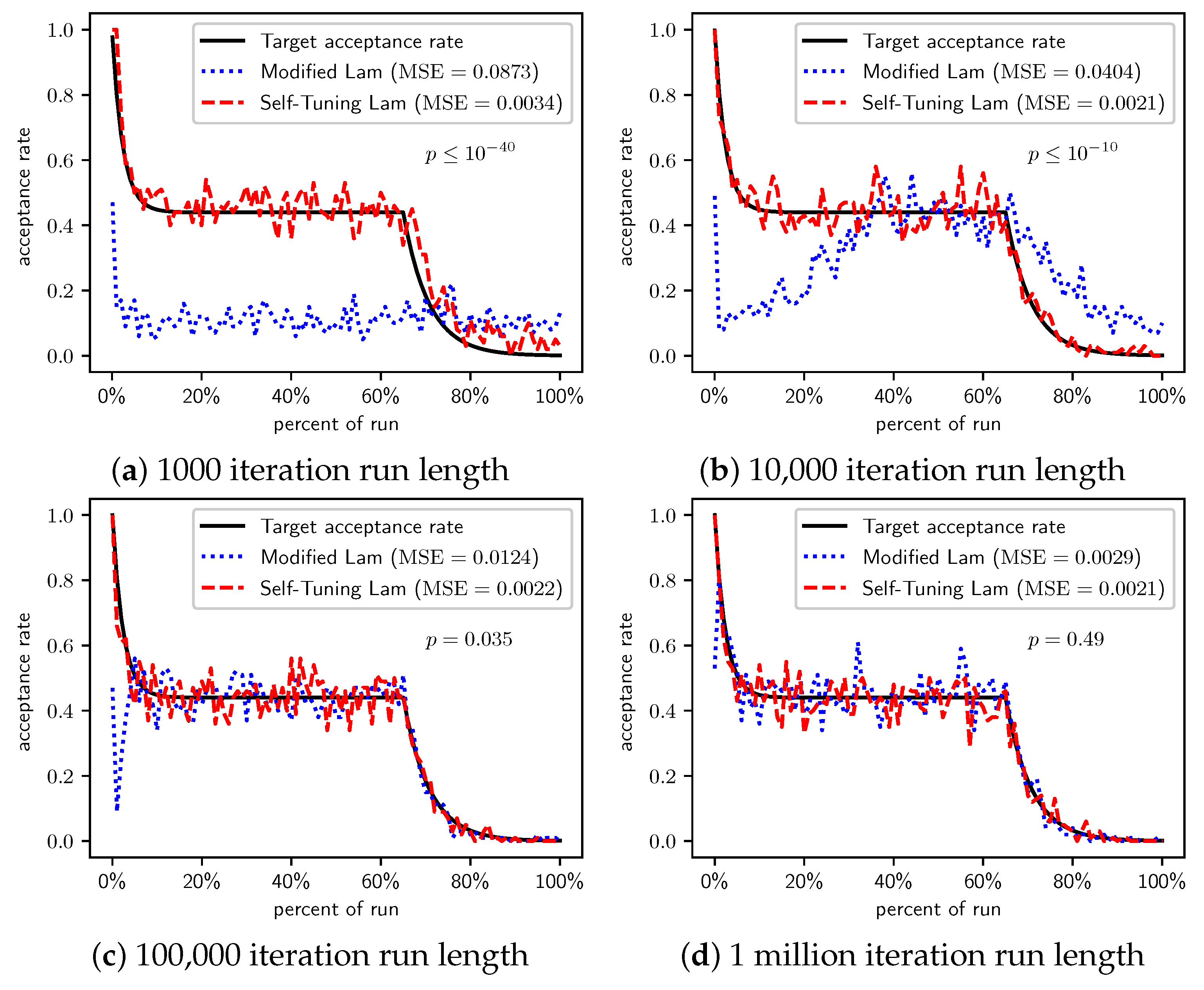
Figure 4.
OneMax (each 0-bit costs 100): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 4.
OneMax (each 0-bit costs 100): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
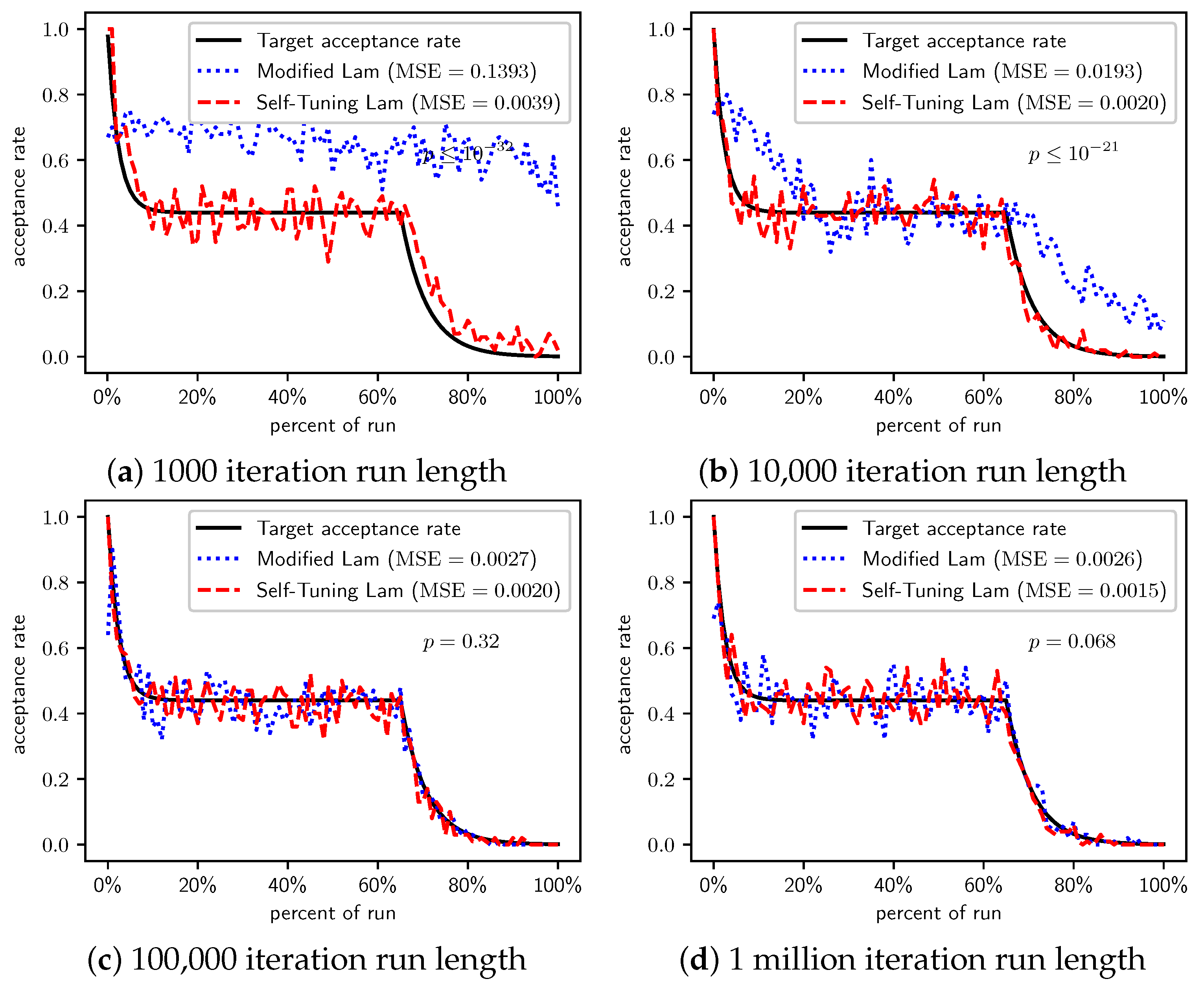
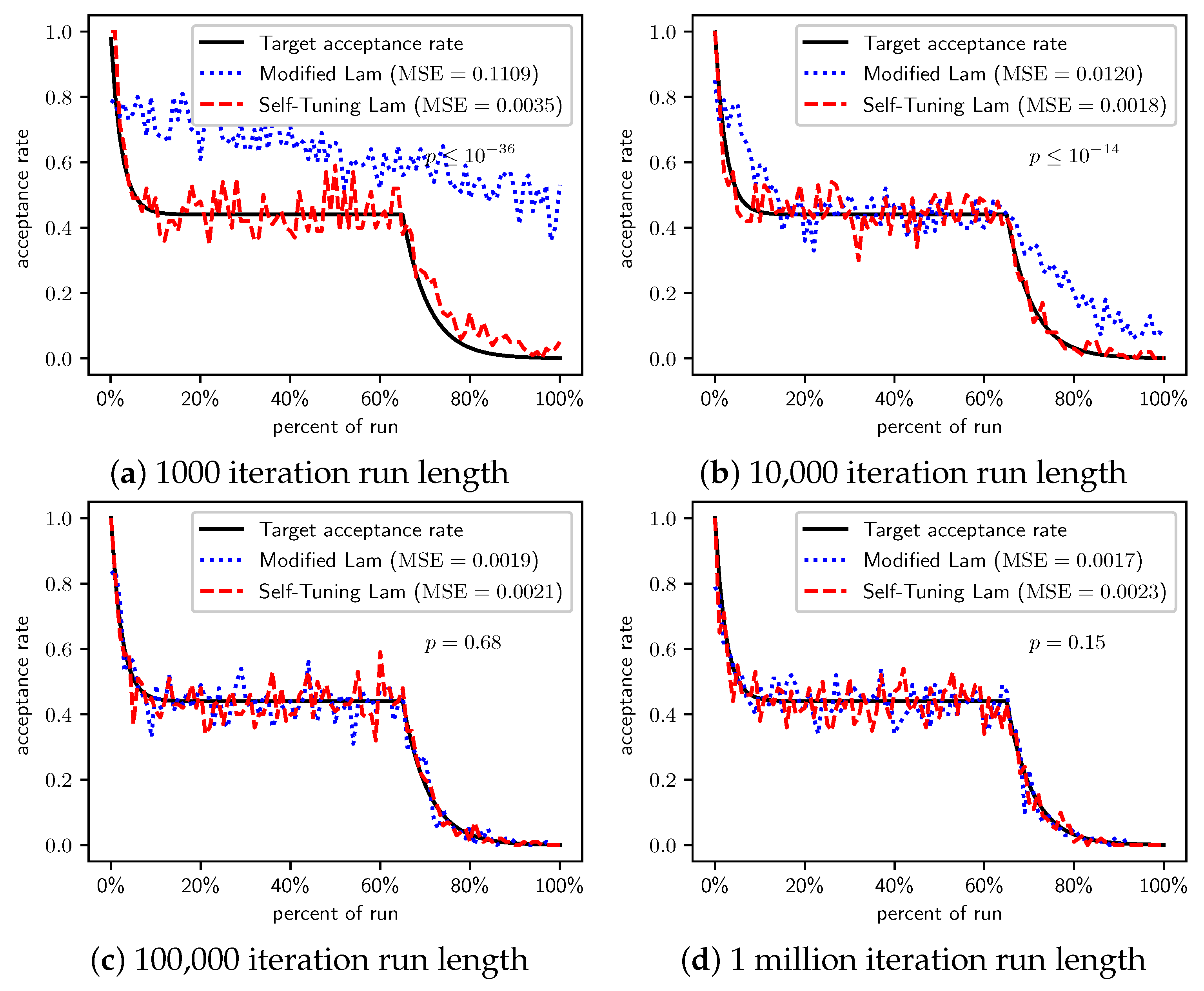
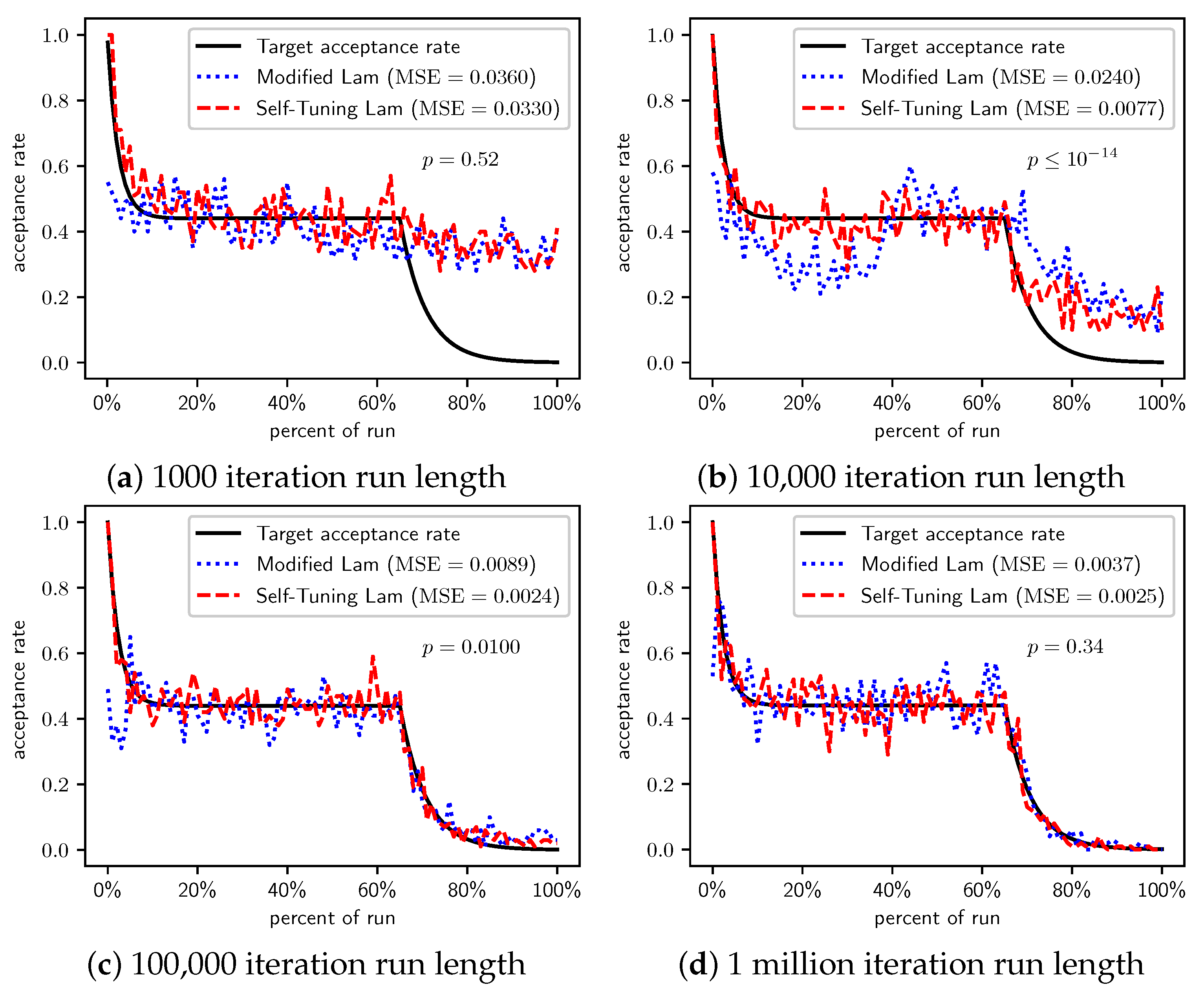
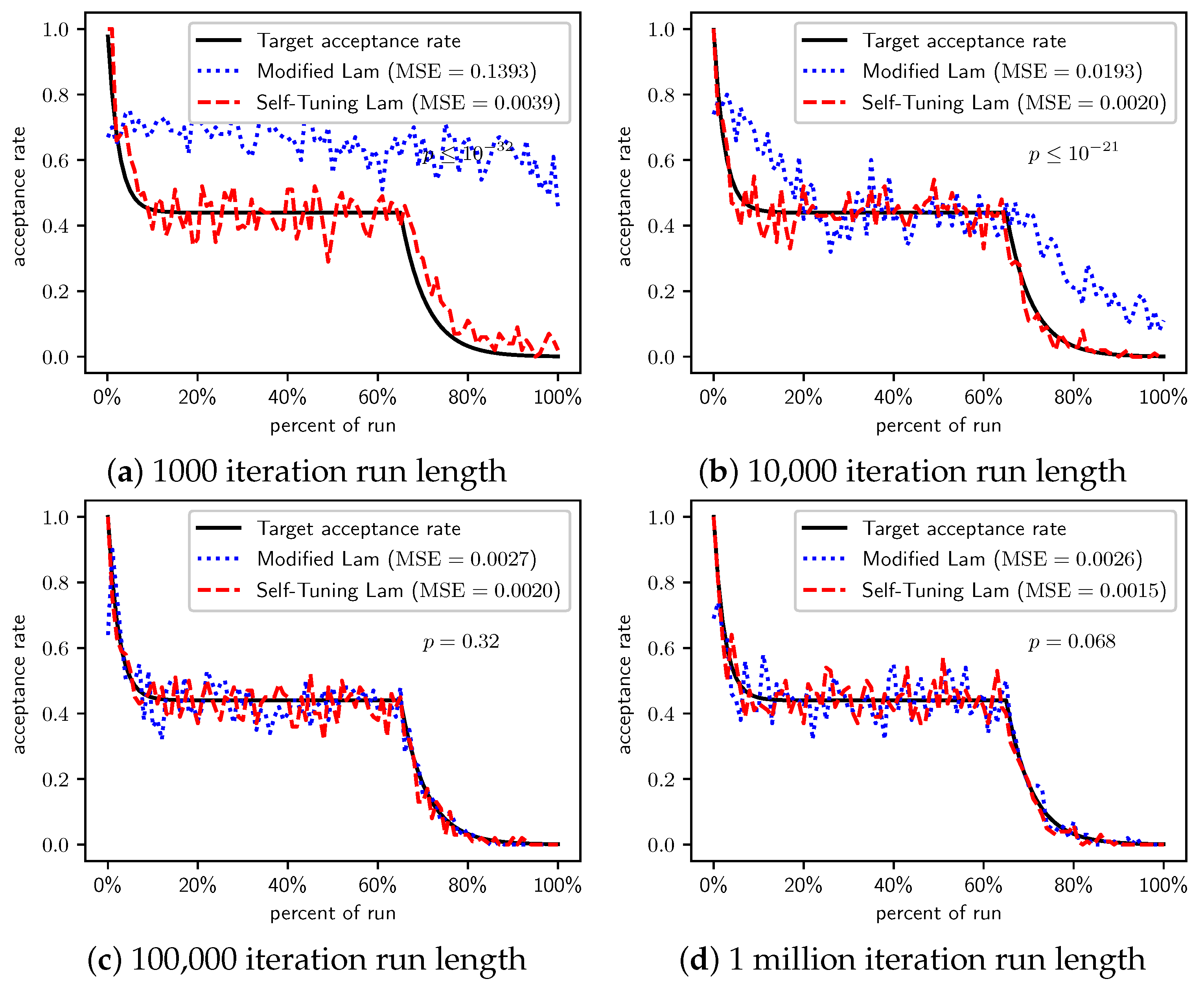
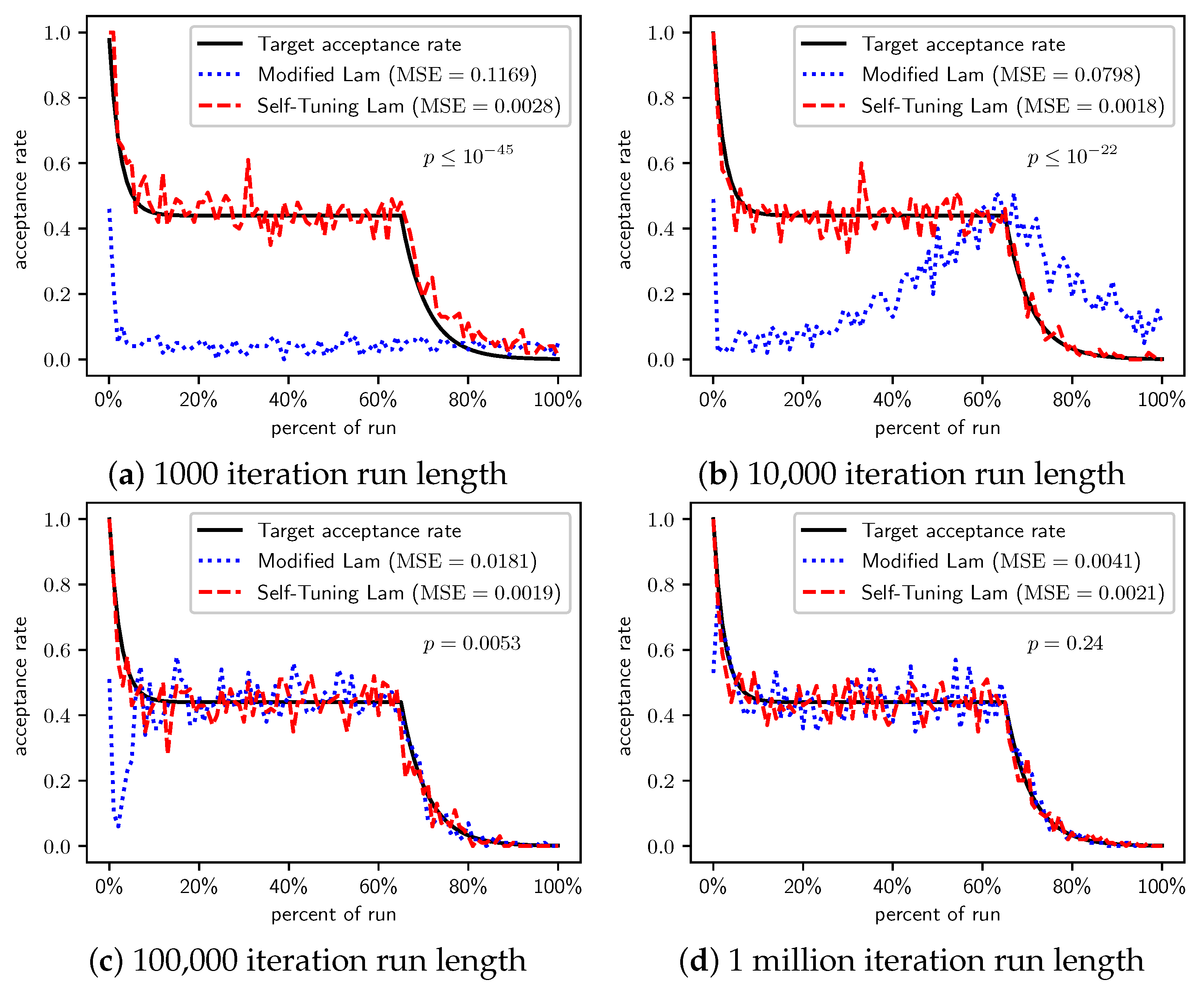
Figure 5.
TwoMax problem: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 5.
TwoMax problem: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 6.
Trap problem: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 6.
Trap problem: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
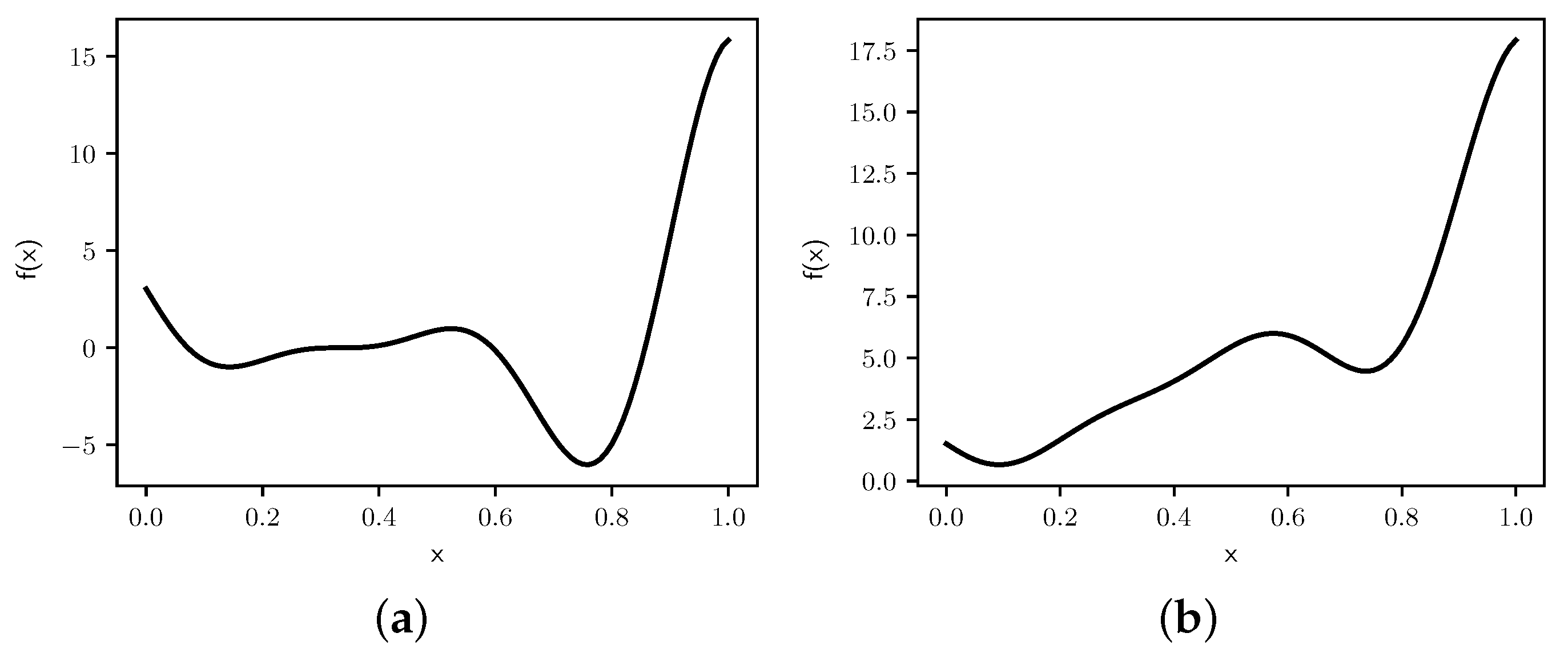
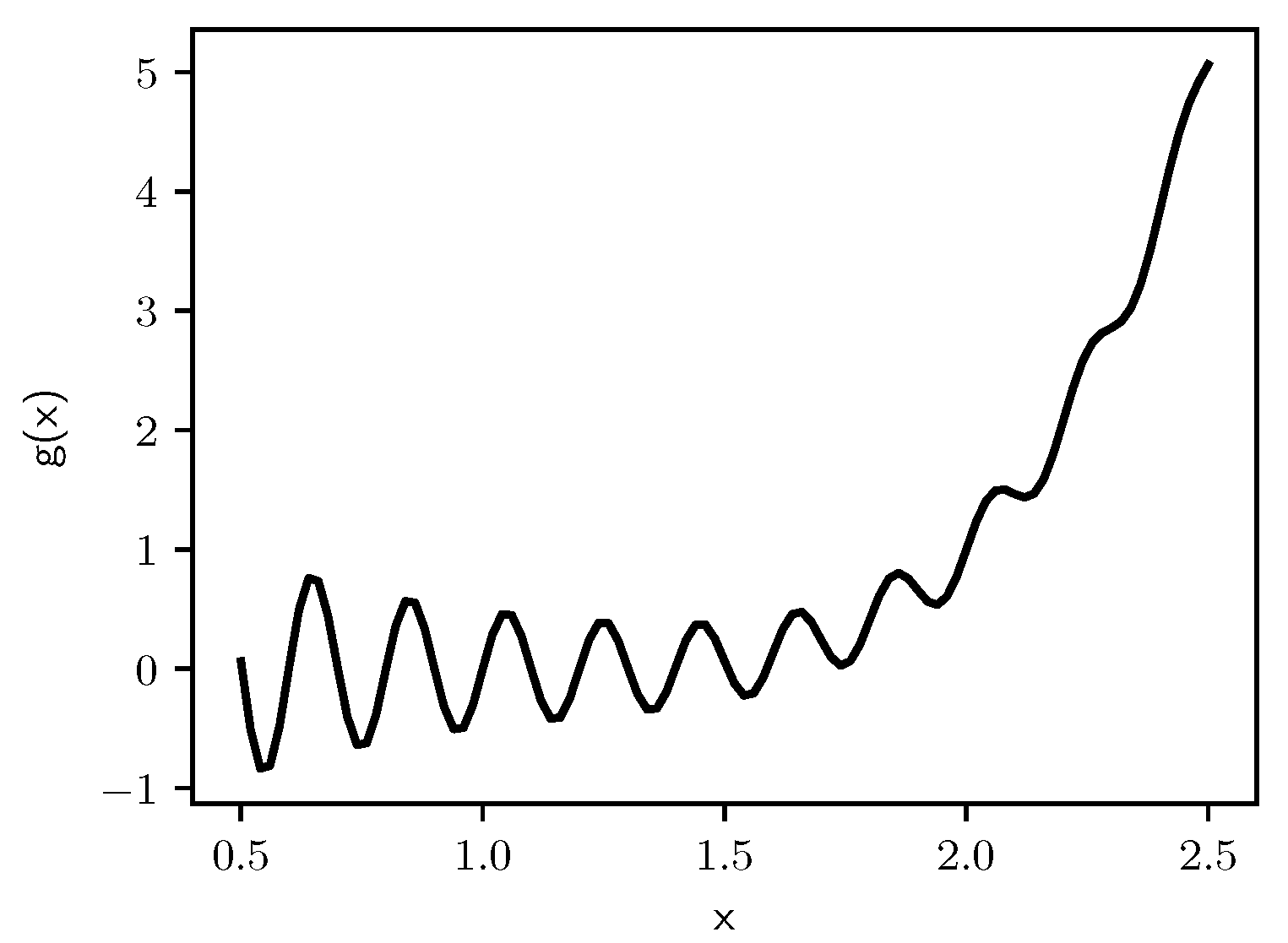
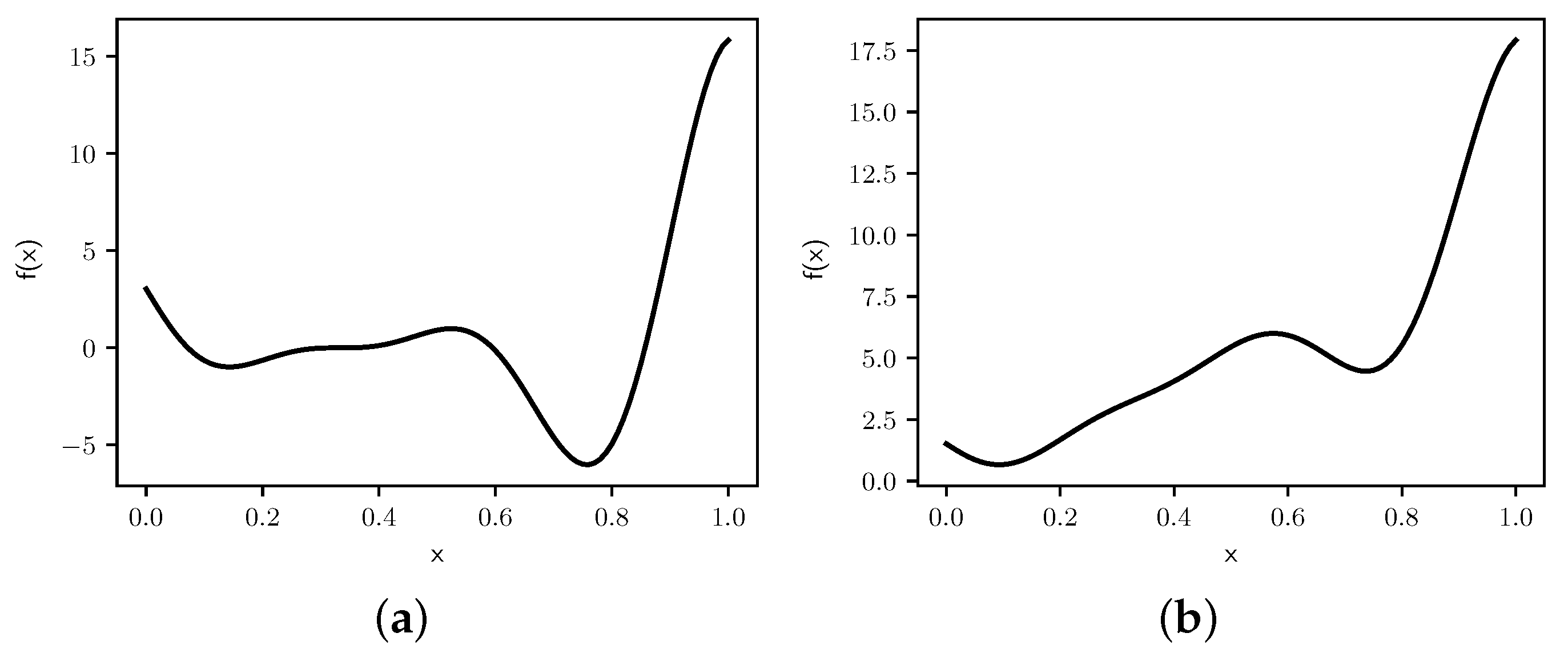
Figure 7.
Graphs of (a) and (b) .
Figure 7.
Graphs of (a) and (b) .
Figure 8.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 8.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 9.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 9.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 10.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 10.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 11.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 11.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 12.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 12.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 13.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 13.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 14.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 14.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 15.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 15.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
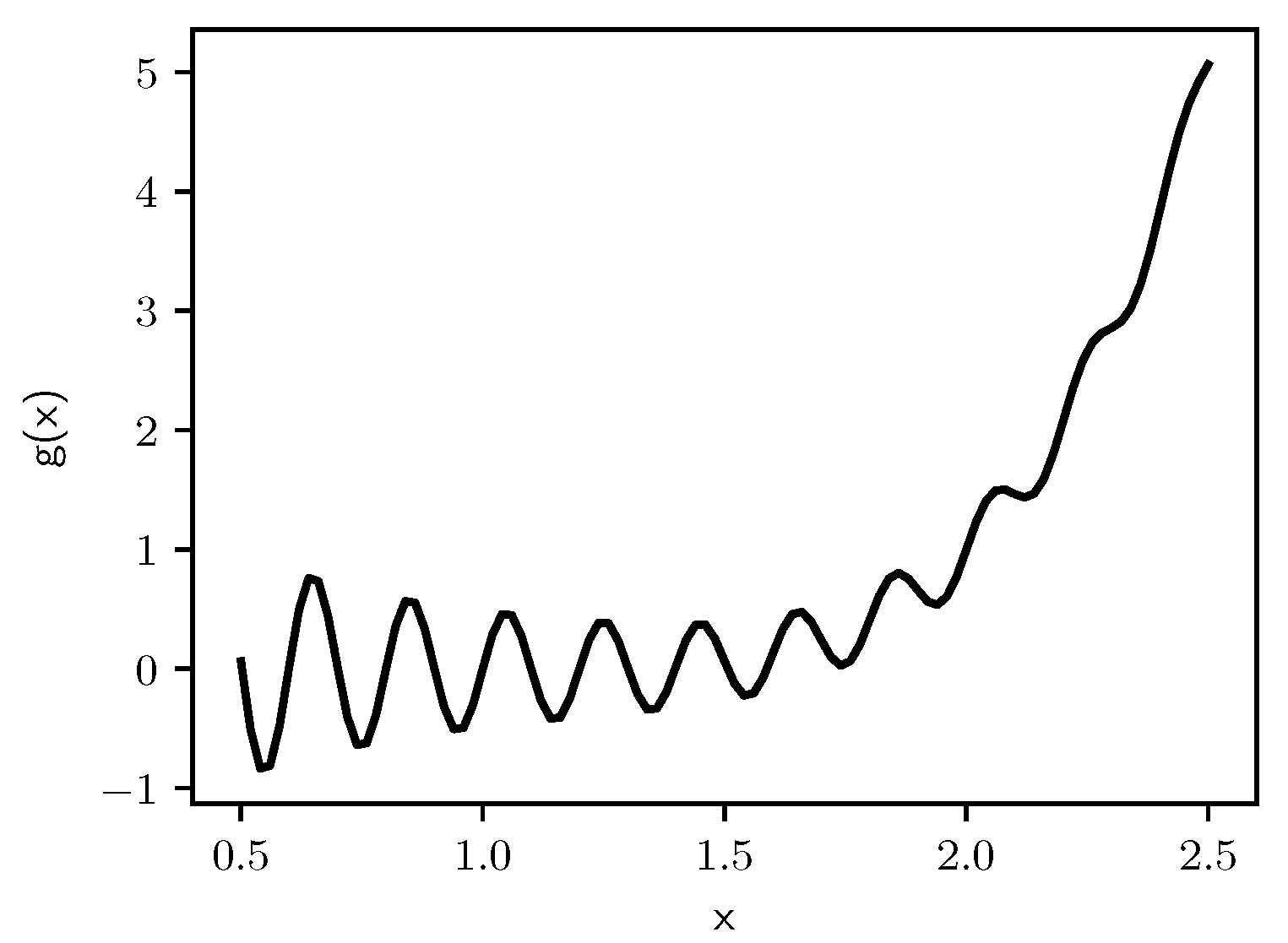
Figure 16.
Graph of .
Figure 16.
Graph of .
Figure 17.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 17.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 18.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 18.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 19.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 19.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 20.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 20.
Minimize : Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 21.
TSP with cities in unit square: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 21.
TSP with cities in unit square: Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 22.
TSP (cities in 100 by 100 square): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Figure 22.
TSP (cities in 100 by 100 square): Self-Tuning Lam, Modified Lam, and target acceptance rates for (a) 1000 iterations, (b) 10,000 iterations, (c) 100,000 iterations, and (d) 1 million iterations.
Table 1.
Constants used in the specification of the Self-Tuning Lam, including the constant, its mathematical definition, and its double-precision floating point value.
Table 1.
Constants used in the specification of the Self-Tuning Lam, including the constant, its mathematical definition, and its double-precision floating point value.
| Constant | Definition | Value |
|---|
| | 0.9768670788789564 |
| | 0.9546897506857566 |
| | 0.8072615745900611 |
| | 0.6808590431613767 |
| | 0.3141120890121576 |
| | 0.260731492877931 |
| | 0.18987910472222955 |
| | 0.17334743675123146 |
Table 2.
Average solution cost for the OneMax problem, case when each 0-bit costs 1.
Table 2.
Average solution cost for the OneMax problem, case when each 0-bit costs 1.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | n/a |
| | | n/a |
Table 3.
Average solution cost for the OneMax problem, case when each 0-bit costs 10.
Table 3.
Average solution cost for the OneMax problem, case when each 0-bit costs 10.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | n/a |
| | | n/a |
Table 4.
Average solution cost for the OneMax problem, case when each 0-bit costs 100.
Table 4.
Average solution cost for the OneMax problem, case when each 0-bit costs 100.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | n/a |
| | | n/a |
Table 5.
Average solution cost for the TwoMax problem.
Table 5.
Average solution cost for the TwoMax problem.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | |
| | | n/a |
Table 6.
Average solution cost for the Trap problem.
Table 6.
Average solution cost for the Trap problem.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | n/a |
| | | n/a |
Table 7.
Average solution for minimizing . The minimum is .
Table 7.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | |
| | | |
| | | n/a |
Table 8.
Average solution for minimizing . The minimum is .
Table 8.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | < |
| | | |
Table 9.
Average solution for minimizing . The minimum is .
Table 9.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | < |
| | | |
Table 10.
Average solution for minimizing . The minimum is .
Table 10.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | < |
| | | |
Table 11.
Average solution for minimizing . The minimum is .
Table 11.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | |
| | | |
| | | |
Table 12.
Average solution for minimizing . The minimum is .
Table 12.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | < |
| | | |
| | | |
Table 13.
Average solution for minimizing . The minimum is .
Table 13.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | |
| | | |
Table 14.
Average solution for minimizing . The minimum is .
Table 14.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | |
| | | |
Table 15.
Average solution for minimizing . The minimum is .
Table 15.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | |
| | | |
| | | |
Table 16.
Average solution for minimizing . The minimum is .
Table 16.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | |
| | | |
| | | |
Table 17.
Average solution for minimizing . The minimum is .
Table 17.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | < |
| | | |
| | | |
Table 18.
Average solution for minimizing . The minimum is .
Table 18.
Average solution for minimizing . The minimum is .
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | < |
| | | |
| | | |
Table 19.
Average cost of solution to TSP with 1000 cities distributed within a unit square.
Table 19.
Average cost of solution to TSP with 1000 cities distributed within a unit square.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | < |
| | | < |
| | | |
| | | |
Table 20.
Average cost of solution to TSP with 1000 cities distributed within a 100 by 100 square.
Table 20.
Average cost of solution to TSP with 1000 cities distributed within a 100 by 100 square.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| 1000 | | | |
| | | < |
| | | |
| | | |
Table 21.
Runtime comparison, measured in seconds of CPU time, of the Modified Lam and Self-Tuning Lam annealing schedules. Averages of 100 runs of each run length.
Table 21.
Runtime comparison, measured in seconds of CPU time, of the Modified Lam and Self-Tuning Lam annealing schedules. Averages of 100 runs of each run length.
| N | Modified Lam | Self-Tuning Lam | T-Test p-Value |
|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}