2.1. Dataset Description
Outpatient case histories of 164 patients who received HLA-compatible renal allografts between 1992 and 2020 were retrospectively analyzed: 152 patients underwent transplantation for the first time—64 (42.1%) women and 88 (57.9%) male patients with a mean age of 32.6 ± 8.7 years (range = 18–60 years) at the time of transplantation, and 12 patients (5 (41.7%) women and 7 (58.3%) men), who received a second transplant kidney, who were on an outpatient basis in the Department Hospital Nephrology and Dialysis of the Lviv Regional Clinical Hospital (LRCH).
The study used a group of patients in whom transplantation was performed for the first time. Transplantation in Ukraine (Lviv, Kyiv, Zaporizhia, Kharkiv, Odessa) was performed in 79.6% of patients and other countries (Belarus, Poland, Italy, Turkey, Austria, China, Pakistan) 20.4% of patients. 86.2% of patients from Ukraine received a kidney from a family donor, 13.8% of patients, all from abroad, received a tube kidney. Acute rejection crisis occurred in 13.1% of patients, with cessation of graft function during the perioperative period.
Dataset consists of 80 features and one target attribute (feature characteristics are given in
Appendix A). 38 columns consist of more than 60% of missing data. Often, common methods such as mean, median, mode, frequent data, and constant do not provide correct data for missing values. That is why Multiple Imputation by Chained Equations (MICE) [
11] was used to impute missing data for these attributes. However, the standard deviation is changed more than 15%. That is why 38 columns were eliminated. Forty-two features were left. The preprocessed dataset is available
https://doi.org/10.6084/m9.figshare.14906241.v1, accessed on 4 July 2021.
2.3. Data Preprocessing
To perform statistical analysis of the obtained data, we developed analytical tables in the program Statistica 6.1 and Excel (Microsoft Office 2016), in which the collected primary data were entered. RStudio v.1.1.442 software (Slashdot Media, La Jolla, CA, USA) was used for statistical analysis of the obtained data.
First of all, the normality of the distribution in the obtained sample populations was determined using the Shapiro-Francia criterion. The results were presented as:
mean values and their standard deviations (M ± SD)—in the case of Gaussian distribution,
medians, 25th, and 75th percentiles: Me [25%; 75%]—in the case of non-Gaussian distribution,
shares (%).
When assessing the probability of the difference between the results obtained in the compared groups used:
odd t—criterion—for two groups with Gaussian distribution;
Mann Whitney U-test—for two groups with non-Gaussian distribution;
criterion 2 (xi-square)—when comparing particles.
The difference between the groups was considered significant at p < 0.05.
Next, the feature selection is provided. This procedure is organized as follows:
Imputation:
- ○
Missing data imputation using Multiple imputations by chained equations algorithm;
Feature selection:
- ○
Correlation;
- ○
Boruta feature selection;
- ○
Recursive Feature Elimination;
- ○
Hard voting of the mentioned algorithms.
Multiple imputations by chained equations (MICE) is a method for multiple imputations, accounts for the statistical uncertainty in the imputations. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g., continuous or binary) as well as complexities such as bounds [
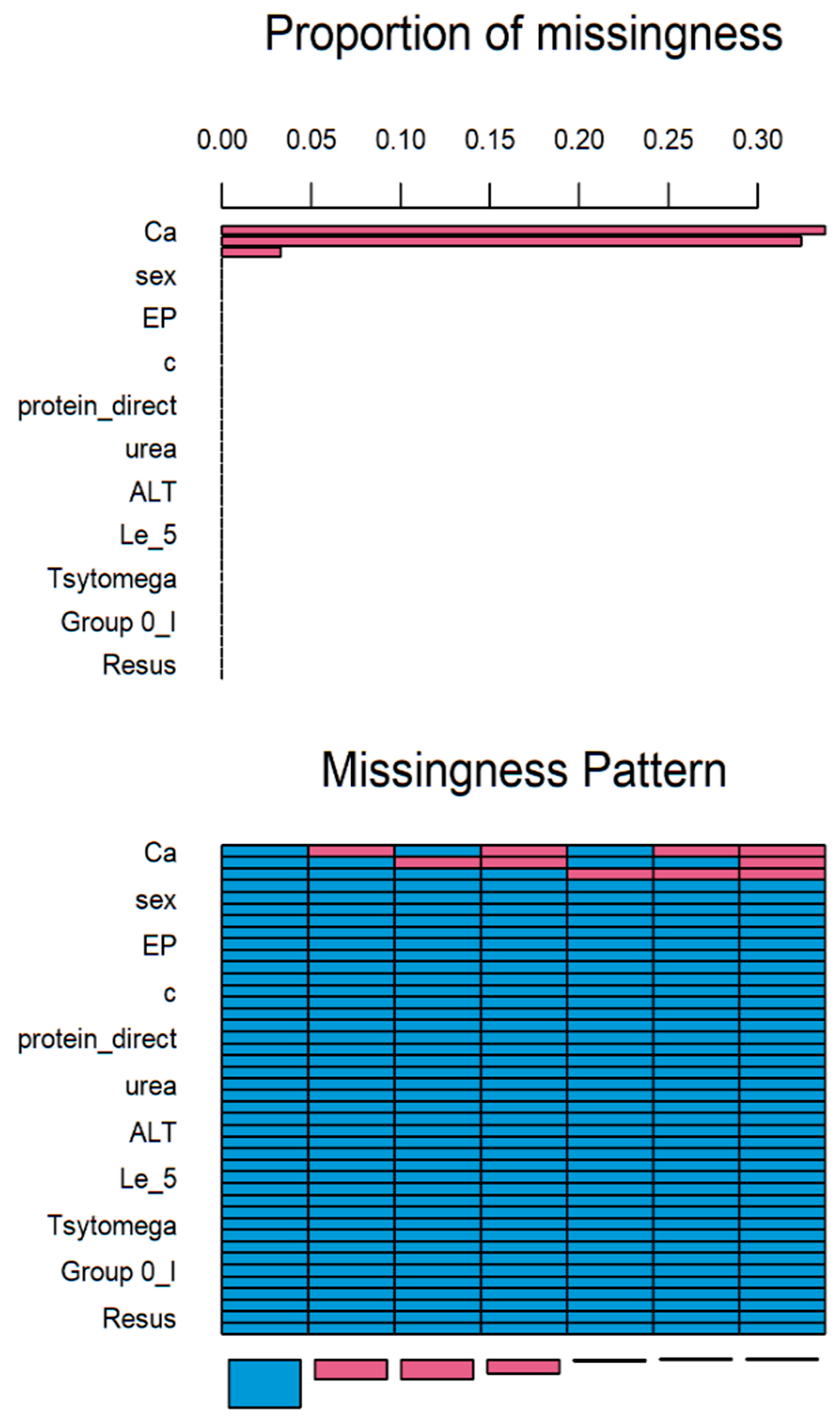
14]. Based on statistical analysis, more than 30% of values in Ca attribute is missed (
Figure 1). Axis x presents the attributes and axis y presents the proportion of missed values. Therefore, this attribute should be eliminated. The rest of the attributes were supplemented.
The imputation summary is given below.
| | age | sex | donor_type | duration | HB | EP | Le_norm_4 | e | n | c | l | m | ESR |
| 69 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 29 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 28 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | protein_direct | protein_total | glucose | creatynin | urea | K | Na |
| 69 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 29 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 28 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | ACT | ALT | ZAS_PV | proteint | Epit | Le_5 | Er | Tsyl | bacter | Tsytomega |
| 69 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 29 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 28 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | hepatitis | hepatitisB | hepatitisC | Group | 0_I | Gropu_A_2 | Group_B_3 |
| 69 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 29 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 28 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 20 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| | 0 | 0 | 0 | 0 | 0 | 0 | |
| | Group_AB_4 | Resus | Class | Hemodializ | Cross-match Ca |
| 69 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 29 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 28 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 20 | 1 | 1 | 1 | 1 | 0 | 0 | 2 |
| 3 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 | 1 | 0 | 2 |
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 3 |
| | 0 | 0 | 0 | 5 | 49 | 51 | 105 |
In given above matrix each row corresponds to a missing data pattern (1 = observed, 0 = missing). Rows and columns are sorted in increasing amounts of missing information. The last column and row contain row and column counts, respectively.
Feature selection is built of the ensemble consists of information gain, Boruta and Recursive Feature Elimination. Hard voting is used for obtained results. Only those features which survived the majority of selection algorithms are used.
The correlation more than 0.9 between HB and donor type as well as between EP and HB is founded.
The next, Boruta algorithm was used for features selection. Boruta is a ranking and selection algorithm based on a random forest algorithm [
15]. The advantage of Boruta is that it clearly decides whether a variable is important or not, and helps to select statistically significant variables.
Boruta extends the information system by adding copies of all variables and runs a random forest classifier on the extended information system and gather the Z scores computed. This procedure is repeated until the importance is assigned for all the attributes, or the algorithm has reached the previously set limit of the random forest runs. Obviously the larger the feature space and the more variables is redundant to, the larger the number of trees that must be in the forest for a tree where given attribute is not redundant to occur. However, cross-validated is optimal, if forest with a parametrization is used. This effect is why Boruta needs to run dozens of iterations to be effective. One hundred of iterations was provided in our case for depth = 5.
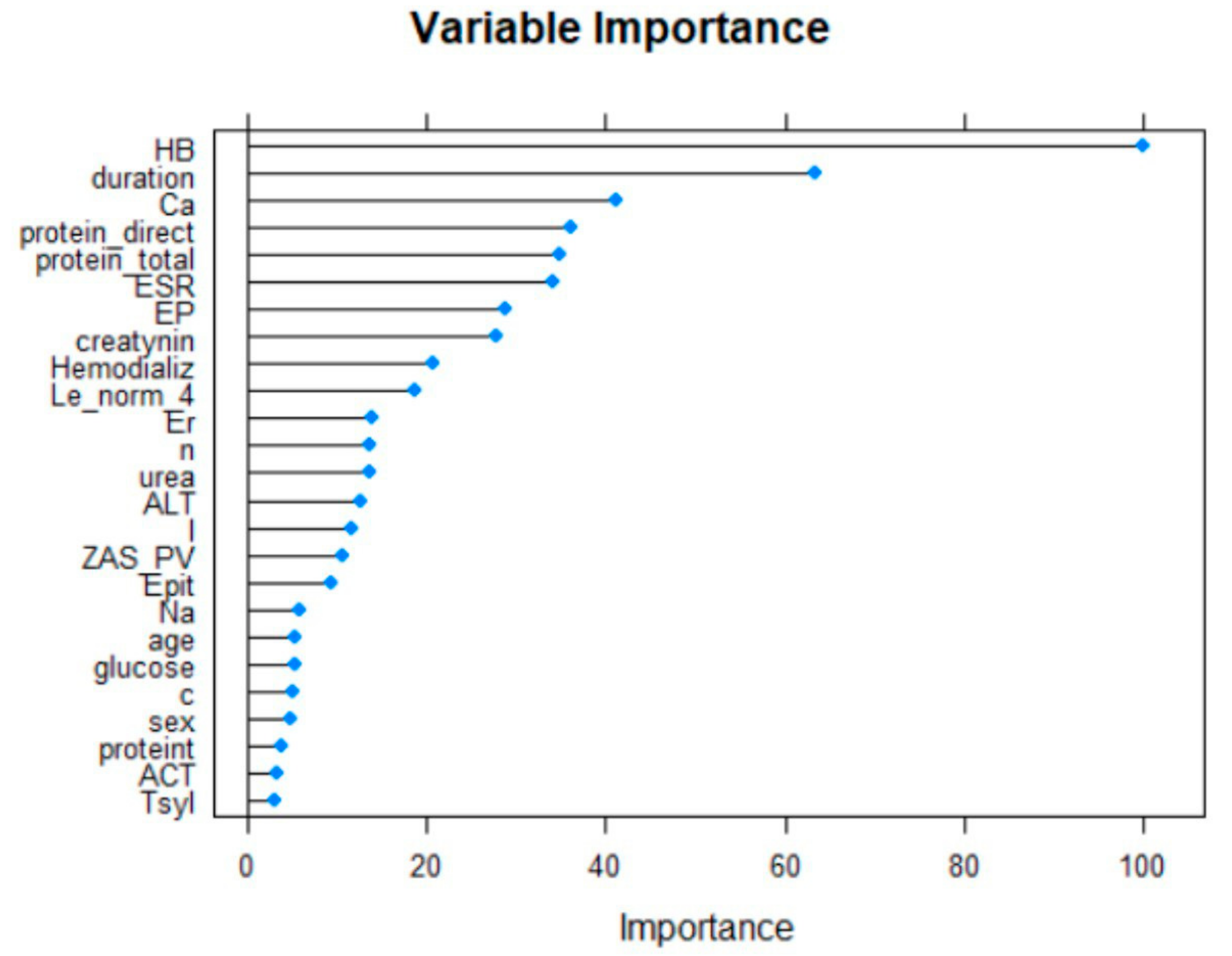
List of most influential variables is given in
Table 1.
The next feature selection using Recursive Feature Elimination [
16] is provided.
Recursive Feature Elimination (RFE) is a feature selection approach. It works by recursively removing attributes and building a model based on the attributes that remain. It uses the model’s fidelity to determine which attributes (and combinations of attributes) contribute most to predicting the target attribute.
The twenty-five most important variables are shown below (
Figure 2).
The next feature selector is built on information gain. The attributes that contribute more information will have a higher information gain value and can be selected (
Table 2).
Hard voting [
17] is the simplest case of a majority vote. In this case, the important features are selected by the majority of the information gain, Boruta and RFE results.
The final dataset consists of 20 selected features given in
Table 3.
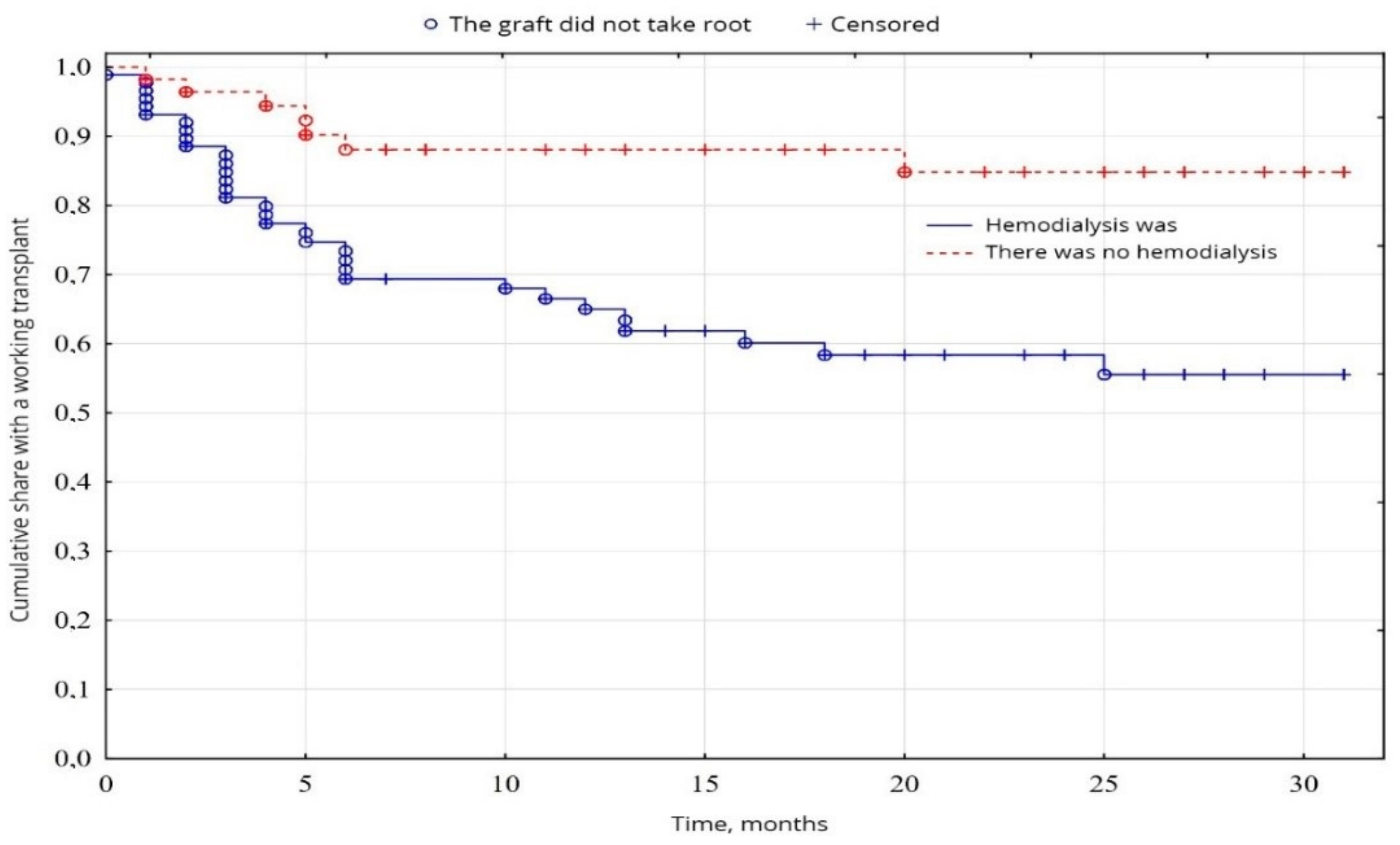
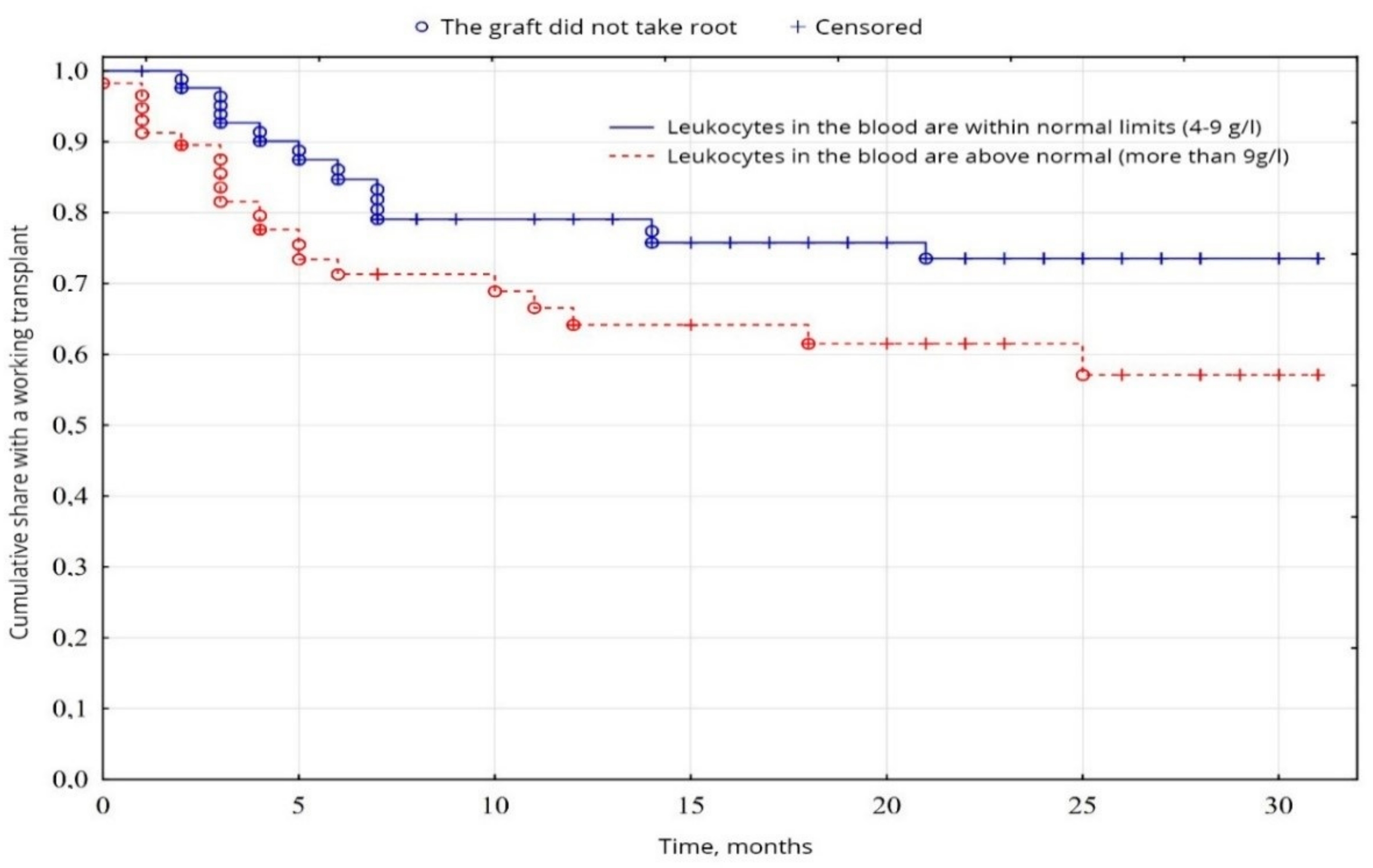
2.4. The Modeling of the Key Risk Factors Associated with Early Graft Rejection
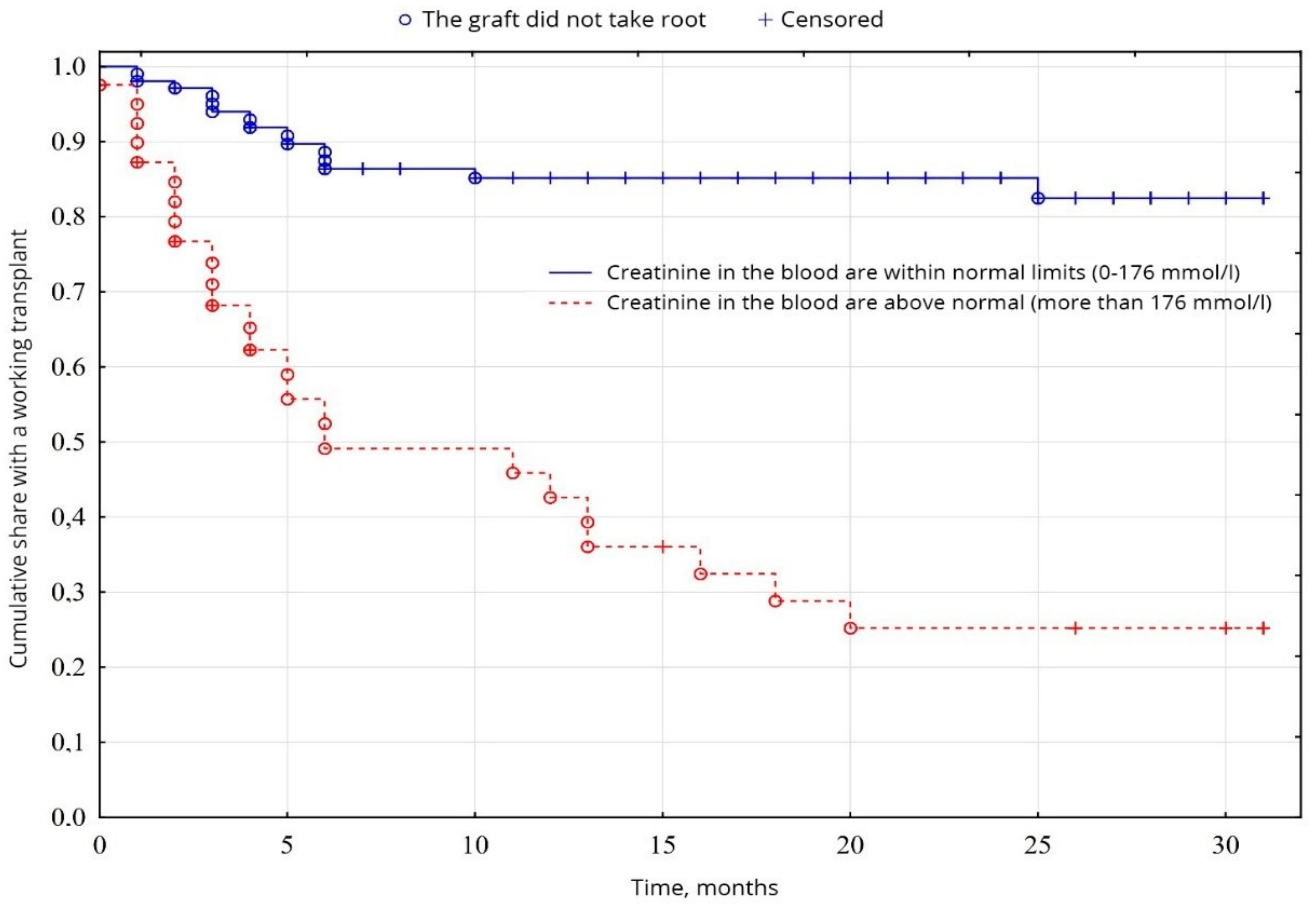
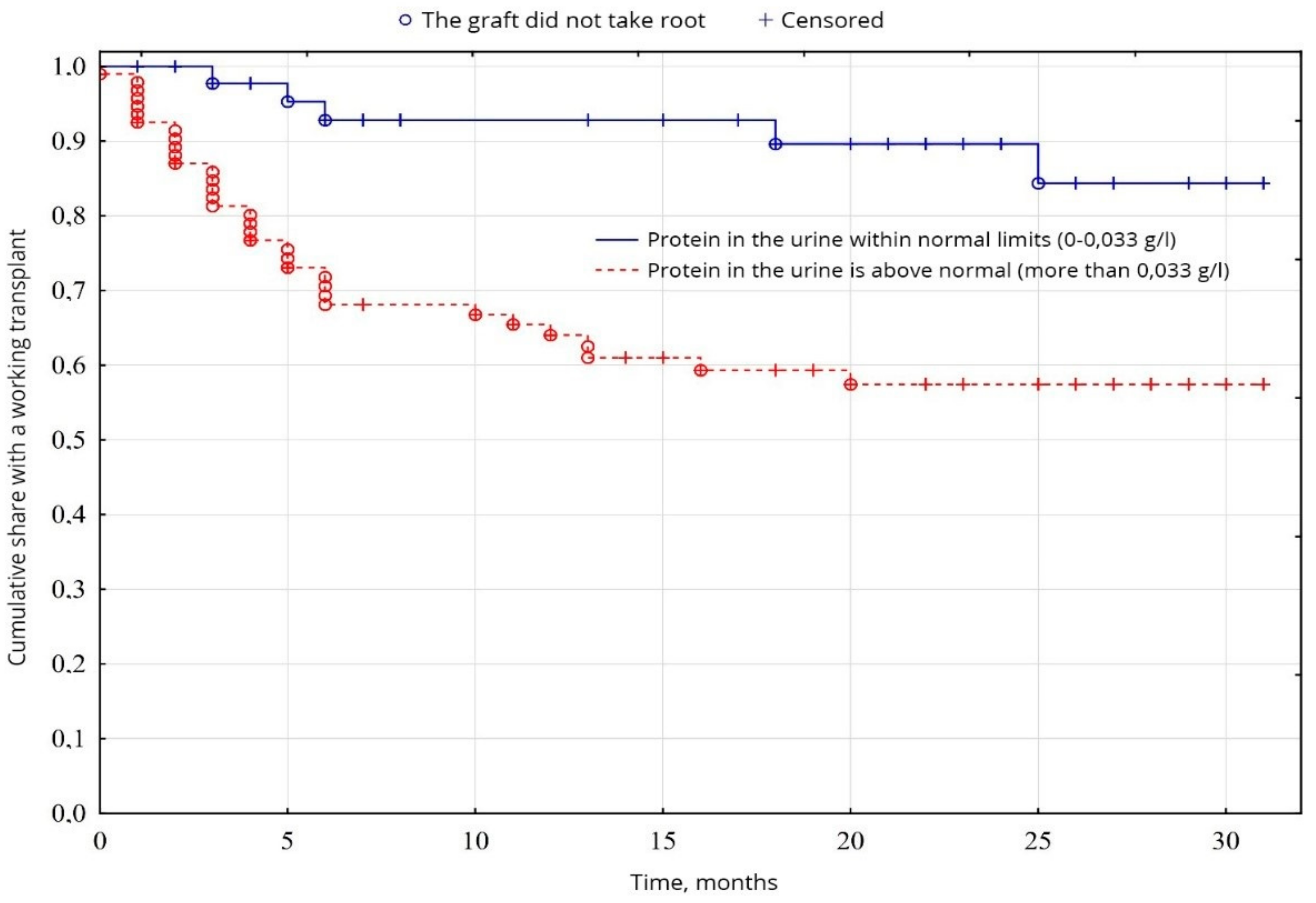
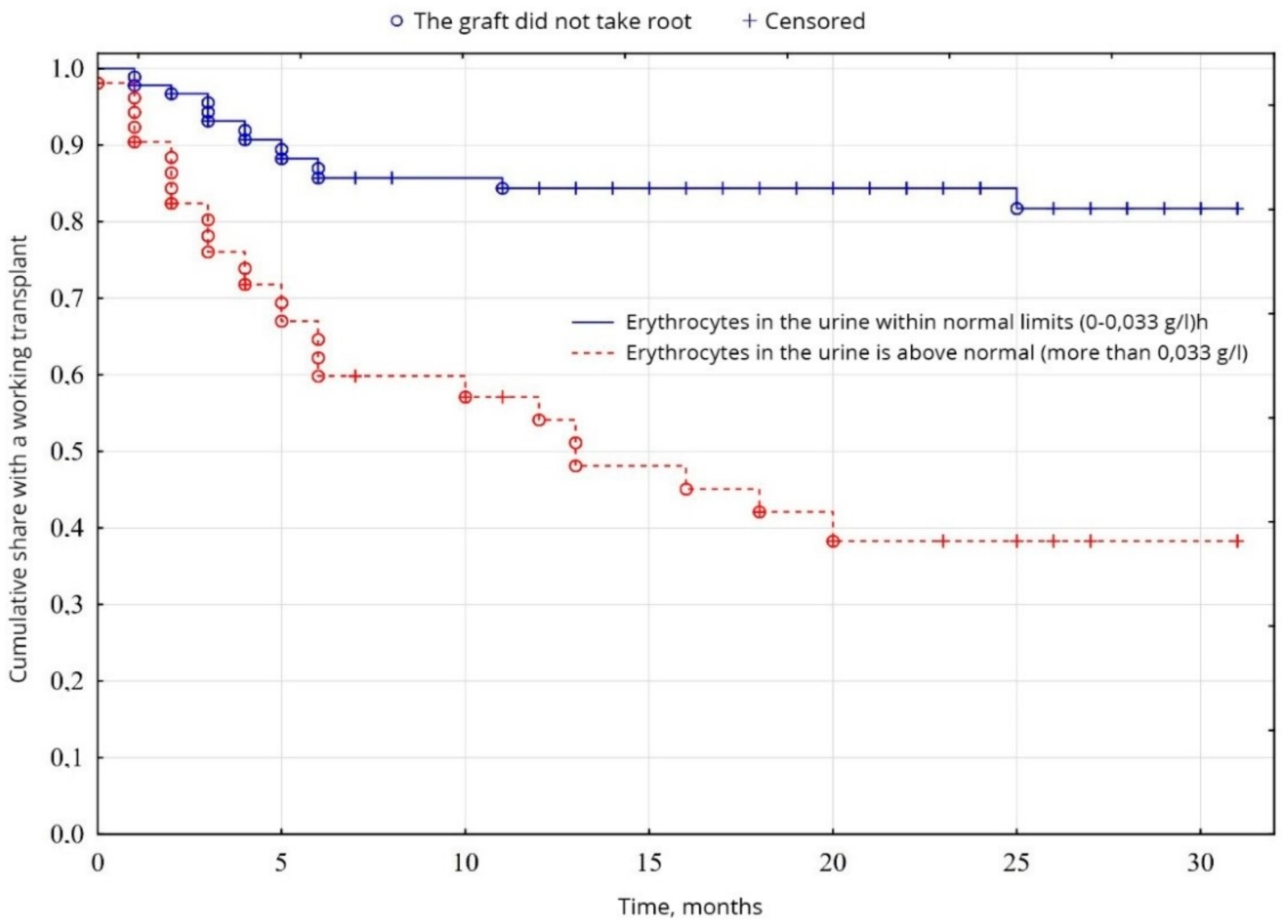
In the study of cumulative graft survival among patients, the censored Kaplan-Meier method [
18] was used. The significance of the difference in the difference in survival levels in individual groups was determined using a logarithmic rank coefficient.
In clinical practice today, the most common survival analysis method for describing censored observations is a Kaplan-Meier method. This method allows you to estimate the proportion of patients who did not have a terminal event and estimate the probability of the absence of an event (to stay alive) by a specific point in time from the beginning of the observation. This probability is called survival, the function of the dependence of survival on time—The function survival rate.
The Kaplan-Meier method is often called the multiplier by the Kaplan-Meier estimate since the value of the survival function at some point in time is the product of the probabilities of survival for all previous points in time. When the analyzed event occurs, the proportion of observed patients is calculated for whom this event has not yet been occurred. In this calculated proportion of patients, there is a probability of surviving the moment of the onset of event
i for observed patients. According to the rule of multiplication of probabilities, we obtain the cumulative probability of surviving until the event
i occurs for the entire study group of patients [
19].
A typical application might involve grouping patients into categories in medical statistics, for instance, those with Gene A profile and those with Gene B profile. In the graph, patients with Gene B die much quicker than those with Gene A. After two years, about 80% of the Gene A patients survive, but less than half of the patients with Gene B.
To generate a Kaplan–Meier estimator, at least two pieces of data are required for each patient (or each subject): the status at last observation (event occurrence or right-censored), and the time to event (or time to censoring). If the survival functions between two or more groups are to be compared, then the third piece of data is required: the group assignment of each subject [
20].
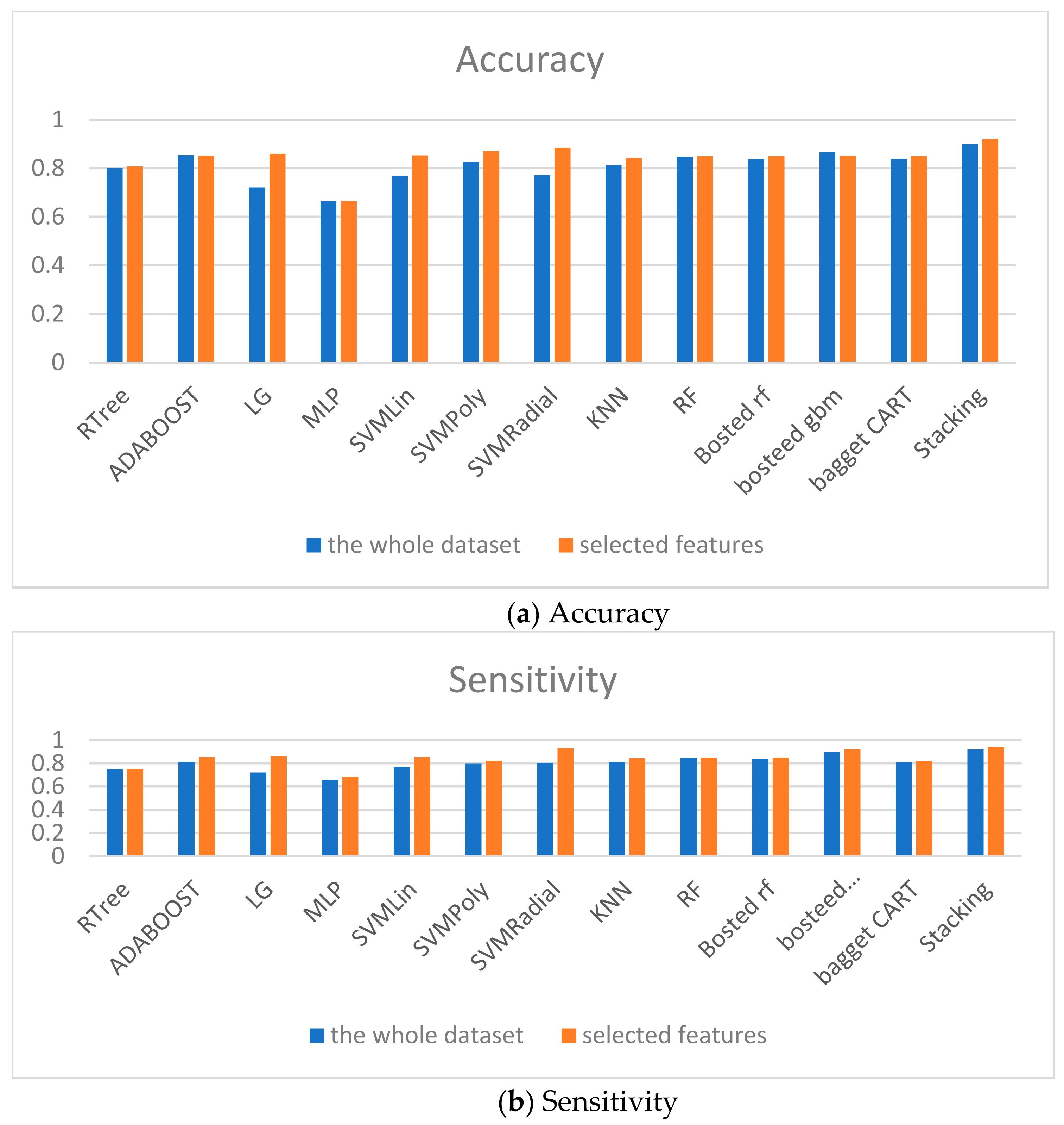
2.5. The Modeling of the Key Risk Factors Using Machine Learning Algorithms
The weak classifiers given below are used for classification. After that, the ensembles will be built.
The
k Nearest Neighbor (
k-NN) method is a metric algorithm for automatically organizing objects. This classifier is used for organ transplantation tasks in [
21]. The main principle of the nearest neighbor method is that the object is assigned to the class that is most common among the neighbors of a given element. Mathematically, the classification using
k-NN is reduced to the calculation:
where
CSV is categorization status value of object
,
Trk(dj) is the set
k of objects
, for which we achieve the maximum of
,
—(retrieval status value) similarity measure between training dataset
dj and object
,
—Value of the target attribute,
k—Threshold (number of objects) indicated how many similar objects we have to be considered to calculate
. Any similarity function, either a probabilistic or a vector measure, can be used for these purposes.
Logistic regression is used for classification [
22]. Input values (
x) are combined linearly, using weights or coefficient values (Beta) to predict the output value (
y). The key difference from linear regression is that the initial simulated value is binary (0 or 1), not a numeric value.
The following is an example of a logistic regression equation:
where
y is the predicted output,
b0 is the offset or interception,
b1 is the coefficient for a single input value (
x). In each input data column, there is a related
b coefficient (constant real value), which is obtained from the training sample.
The next method of data classification is the method of Support Vector Machine, SVM [
23]. The mathematical formulation of the classification problem is as follows: let X be the space of objects (for example,
Rn), Y be our classes (for example, Y = {−1,1}). Specified training sample: You need to construct a function F:X→Y (classifier) that maps the class
y of the object x.
The classification function F takes the form . Positive certainty is necessary in order for the corresponding Lagrange function in the optimization problem to be limited from below, i.e., the optimization problem would be correctly defined. The accuracy of the classifier depends, in particular, on the choice of the kernel.
A classifier based on a decision tree is a tree whose inner vertices are denoted by terms, and the edges are marked with test scales [
24]. The weight of the term in the vector representation of the test example is compared with these test scales. The leaves of such a tree are marked with category values. The classifier sequentially passes along the vertices of the tree, comparing the weight of the term of the current vertex in the presentation of the test example and determining the further direction of the bypass until it reaches the sheet. The value of the category of a given sheet is assigned to the test example.
The advantage of the decision tree is the ability to visualize the results and interpret the data obtained when obtaining a forecast.
A random forest is a classifier consists of a set of trees
, where
is independent equally distributed random vectors; each tree contributes one vote in determining class X [
24]. According to this definition, a random forest is a classifier consisting of an ensemble of decision trees, each of which is built using bagging. In this case,
is an independent equally distributed l-dimensional random vector, the coordinates of which are independent discrete random variables that take values from the subset {1,2,3,… l} with equal probabilities. The implementation of a random vector
determines the precedent numbers of the training sample, which form the bootstrap (i.e., the return sample, more details in the following sections) of the sample used in constructing the k-th decision tree.
The averaging of observational results can give a more stable and reliable estimate, as the effect of random fluctuations in a single dimension is weakened. The development of algorithms for combining models was based on a similar idea. The construction of their ensembles turned out to be one of the most powerful machine learning methods, which often surpasses other methods in the quality of forecasts.
One solution that provides the necessary variety of models is their re-learning on samples randomly selected from the general population or other subsets of data constructed from existing ones. To obtain a stable forecast, the predictions of these models are combined in one way or another, for example, by simple averaging or voting (possibly weighted).
Statistical bootstrap (bootstrapping) is a practical computer method for determining statistics of probability distributions based on multiple generations of samples by the Monte Carlo method based on the available sample. Allows you to easily and quickly evaluate various statistics (confidence intervals, variance, correlation, and so on) [
25].
Just as the averaging of several observations reduces the estimate of data variance, a reasonable way to reduce the forecast variance is to obtain a large number of data from the general population, build a predictive model for each training sample and average the forecasts obtained. If instead of separate training samples (which we, as a rule, always do not have enough) to execute a bootstrap and based on the generated pseudo-samples to construct n trees of regression, the average collective forecast will have a lower variance. This procedure is called bootstrap. Bagging can be performed with respect to regression trees and other models: reference vectors, linear discriminants, Bayesian probabilities, and others.
Another method of improving forecasts is boosting, which is an iterative process of sequential construction of private models [
26]. Each new model is learned using the information about the mistakes made in the previous step. The resulting function is a linear combination of the whole ensemble of models while minimizing the penalty function. Like bagging, boosting is a general approach that can be applied to many statistical methods of regression and classification. Here we will limit ourselves to discussing gradient boosting in the context of regression trees.
The AdaBoost is model where for any subsequent model the check and elimination of observations-emissions, erroneous conclusions of the previous model are carried out [
27].
Stacking (Stacked Generalization) is a combination of heterogeneous classifiers [
26]. To do this, models of any type are combined to create a composite model. It is similar to bagging, but is not limited to the decision tree. The initial data for basic training create features that can recombine with the data. A majority vote or weighing can combine basic training inputs. Additional data for retention is required if meta-learning parameters are used. It also increases the complexity of the model.



 ,
, 

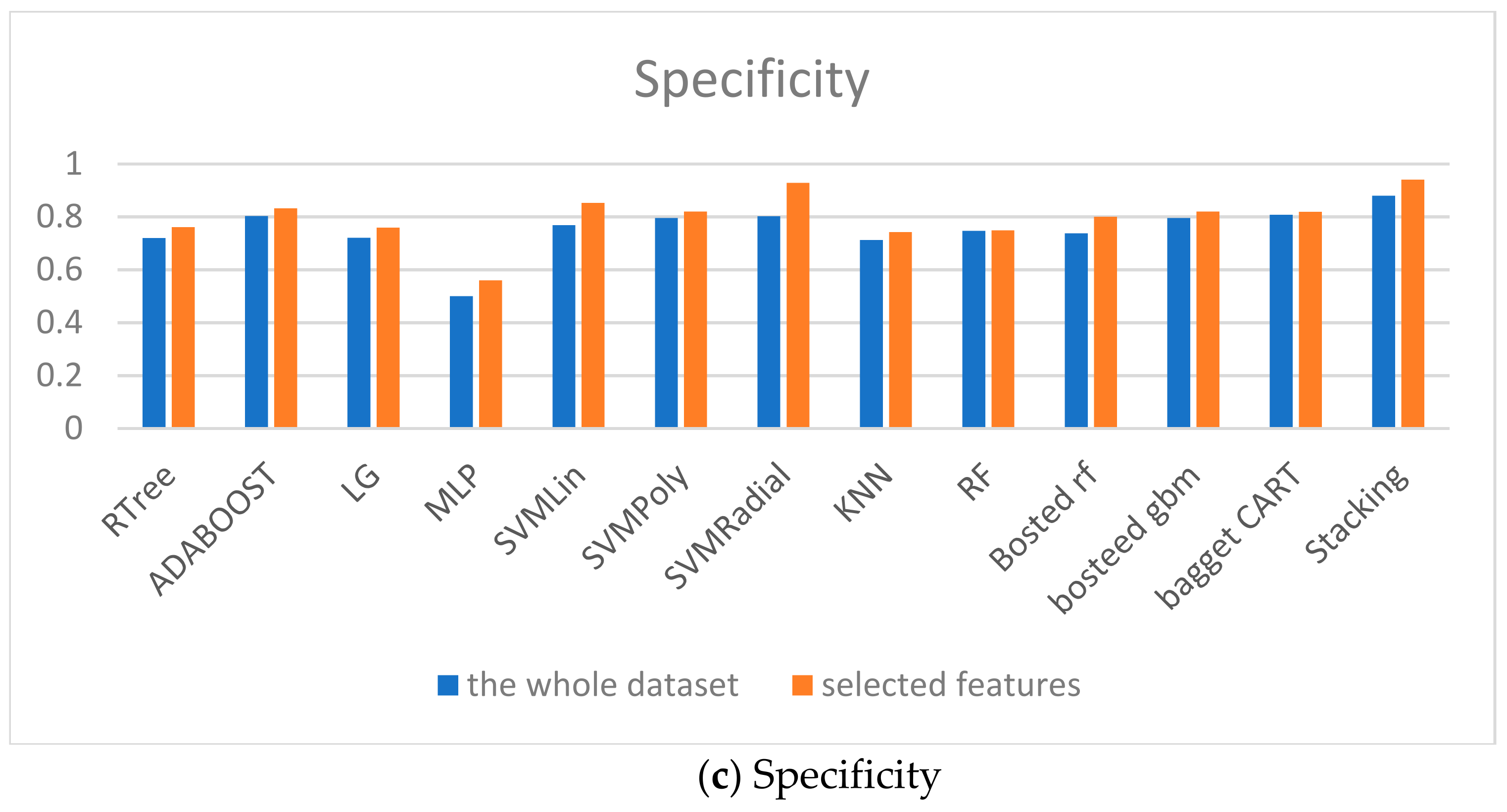

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}