
Machine-Learning-Based Android Malware Family Classification Using Built-In and Custom Permissions


Abstract
:1. Introduction
- We extracted built-in and custom permissions from malicious apps statically and used them as the feature for classifiers. The permissions were simply obtained from the Manifest.xml in each APK. Therefore, there was no need to reverse engineer, decrypt, or execute the Dalvik executable (DEX) file. In addition, our approach is resilient to code obfuscation and requires little domain knowledge;
- We applied seven machine learning classifiers for Android malware familial classification and compared their performance. The classifiers were ANN, DNN, random forest, Extra Trees, AdaBoost, XGBoost, and LightGBM;
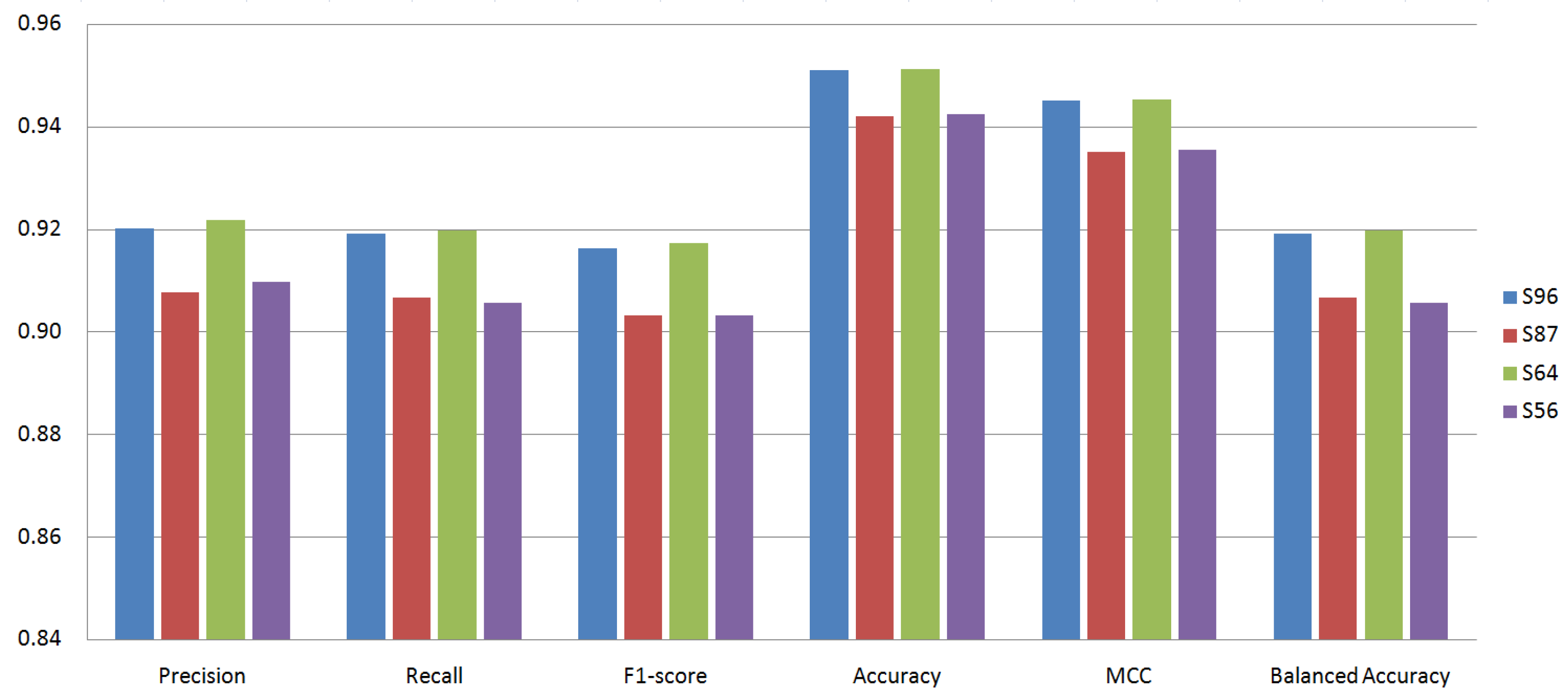
- We evaluated the classification models with the following four metrics: ACC, macrolevel F1-score, BAC, and the MCC. The latter two metrics, BAC and the MCC, are suitable metrics for the malware familial classification model whose datasets are imbalanced. When experimenting with 64 permissions (56 built-in + 8 custom permissions), the LightGBM classifier achieved 0.9173 (F1-score), 0.9512 (ACC), 0.9198 (BAC), and 0.9453 (MCC) on average;
- We inspected which Android permissions were primarily requested by a particular family or used only by a specific family. This can identify the permissions with which we can efficiently cluster malware instances into their families. For example, the three permissions ACCESS_SURFACE_FLINGER, BACKUP, and BIND_APPWIDGET are requested only by the Plankton malware family, and the two permissions BROADCAST_PACKAGE_REMOVED and WRITE_CALENDAR are requested only by the Adrd family;
- We considered all ninety-six permissions including nine custom ones and, then, considered eighty=seven built-in permissions alone, excluding custom ones. We then analyzed the impact of custom permissions on malware family classification.
2. Background
2.1. Android Permission Model
2.2. Evaluation Metrics for Imbalanced Data Classification
3. Malware Family Classification
4. Experiment Setup
4.1. Dataset
4.2. Parameter Tuning
4.3. Performance Metrics
- True positive: The actual class is k, and the predicted class is also k. The number of true positive instances is ;
- False positive: The actual class is not k, but the predicted class is k. The number of false positive instances is ;
- False negative: The actual class is k, but the predicted class is not k. The number of false negative instances is ;
- True negative: The actual class is not k, and the predicted class is also not k. The number of true negative instances is .
- : the number of samples belonging to class k;
- : the number of samples predicted as class k;
- : the total number of samples correctly predicted;
- : the total number of samples.
5. Evaluation
5.1. Feature Sets
5.2. Effect of Classifiers and Custom Permissions
- S96: 96 permissions;
- S87: 87 permissions (excluding custom permissions);
- S64: 64 permissions (excluding 0-importance permissions);
- S56: 56 permissions (excluding custom permissions and 0-importance ones).
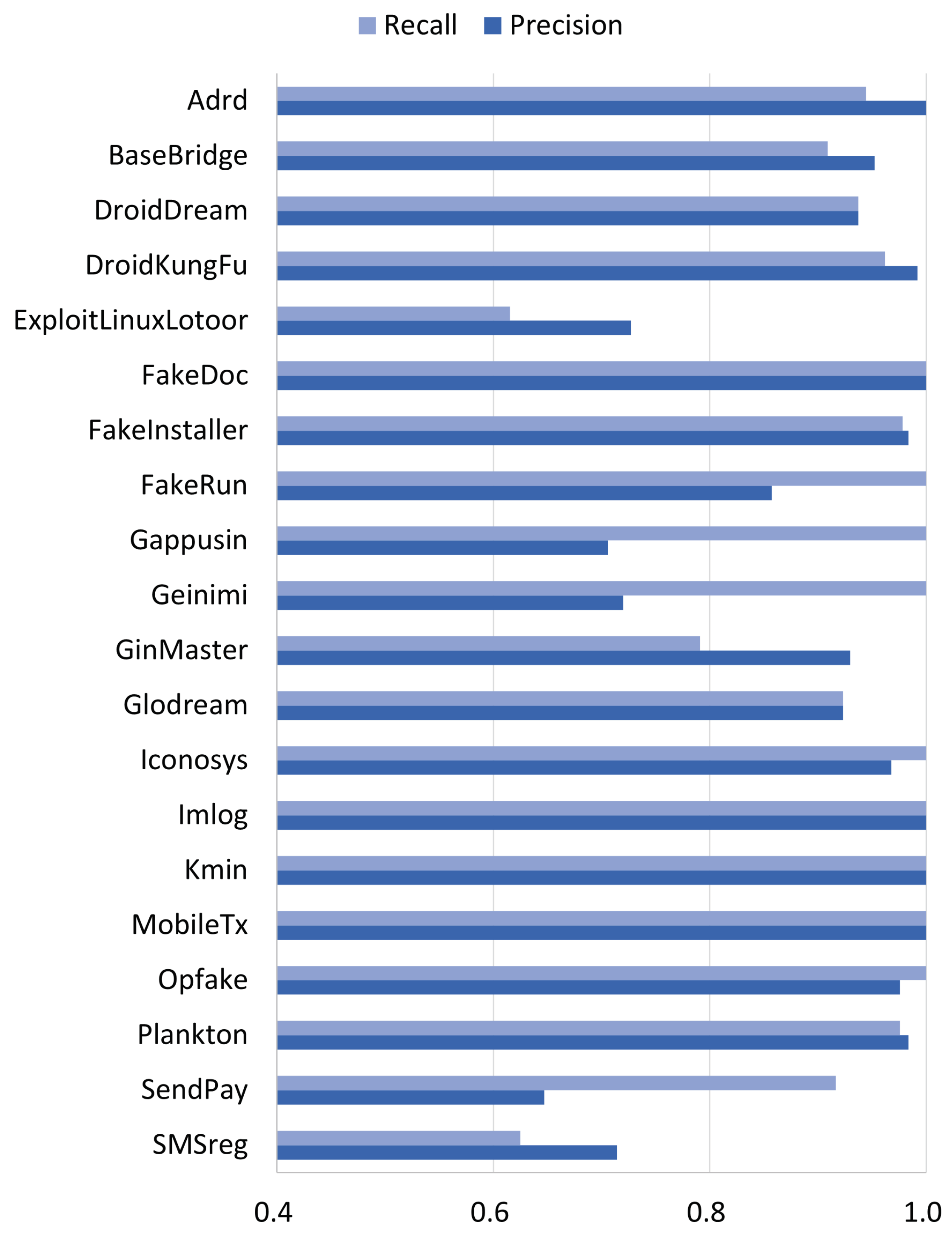
5.3. Family-Level Performance
6. Related Work
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F1-Score | ACC | MCC | BAC | |||
|---|---|---|---|---|---|---|
| ANN | 0.9246 | 0.9003 | 0.9065 | 0.9458 | 0.9392 | 0.9003 |
| DNN | 0.8956 | 0.8832 | 0.8834 | 0.9361 | 0.9284 | 0.8832 |
| RF | 0.9168 | 0.9058 | 0.9001 | 0.9404 | 0.9337 | 0.9058 |
| ET | 0.9184 | 0.9125 | 0.9055 | 0.9445 | 0.9382 | 0.9125 |
| AdaBoost | 0.9326 | 0.9174 | 0.9212 | 0.9541 | 0.9484 | 0.9174 |
| XGBoost | 0.9202 | 0.9178 | 0.9155 | 0.9515 | 0.9455 | 0.9178 |
| LightGBM | 0.9201 | 0.9192 | 0.9162 | 0.9510 | 0.9451 | 0.9192 |
| F1-Score | ACC | MCC | BAC | |||
|---|---|---|---|---|---|---|
| ANN | 0.9078 | 0.8900 | 0.8942 | 0.9309 | 0.9224 | 0.8900 |
| DNN | 0.8838 | 0.8753 | 0.8744 | 0.9268 | 0.9178 | 0.8753 |
| RF | 0.9086 | 0.8922 | 0.8880 | 0.9291 | 0.9212 | 0.8922 |
| ET | 0.9070 | 0.8908 | 0.8865 | 0.9281 | 0.9201 | 0.8908 |
| AdaBoost | 0.9190 | 0.8973 | 0.9029 | 0.9398 | 0.9324 | 0.8973 |
| XGBoost | 0.9111 | 0.9028 | 0.9029 | 0.9400 | 0.9326 | 0.9028 |
| LightGBM | 0.9077 | 0.9066 | 0.9033 | 0.9421 | 0.9351 | 0.9066 |
| F1-Score | ACC | MCC | BAC | |||
|---|---|---|---|---|---|---|
| ANN | 0.9217 | 0.8906 | 0.8988 | 0.9406 | 0.9333 | 0.8906 |
| DNN | 0.8953 | 0.8904 | 0.8899 | 0.9385 | 0.9309 | 0.8904 |
| RF | 0.9160 | 0.9034 | 0.8981 | 0.9424 | 0.9358 | 0.9034 |
| ET | 0.9149 | 0.9113 | 0.9030 | 0.9434 | 0.9370 | 0.9113 |
| AdaBoost | 0.9351 | 0.9040 | 0.9146 | 0.9430 | 0.9364 | 0.9040 |
| XGBoost | 0.9165 | 0.9167 | 0.9125 | 0.9495 | 0.9434 | 0.9167 |
| LightGBM | 0.9219 | 0.9198 | 0.9173 | 0.9512 | 0.9453 | 0.9198 |
| F1-Score | ACC | MCC | BAC | |||
|---|---|---|---|---|---|---|
| ANN | 0.8989 | 0.8632 | 0.8731 | 0.9174 | 0.9073 | 0.8632 |
| DNN | 0.8784 | 0.8658 | 0.8674 | 0.9222 | 0.9127 | 0.8658 |
| RF | 0.9089 | 0.8909 | 0.8871 | 0.9285 | 0.9205 | 0.8909 |
| ET | 0.9073 | 0.8928 | 0.8874 | 0.9276 | 0.9196 | 0.8928 |
| AdaBoost | 0.9189 | 0.8925 | 0.8997 | 0.9395 | 0.9322 | 0.8925 |
| XGBoost | 0.9117 | 0.9035 | 0.9033 | 0.9400 | 0.9326 | 0.9035 |
| LightGBM | 0.9097 | 0.9056 | 0.9033 | 0.9424 | 0.9354 | 0.9056 |
| Adrd | Base-Bridge | Droid-Dream | Droid-KungFu | Expl | Fake-Doc | Fake-Inst 2 | Fake-Run | Gapp-Usin | Gei-Nimi | Gin-Master | Glod-Ream | Icon-Osys | Imlog | Kmin | Mobi-LeTx | Op-Fake | Plan-Kton | SMS-Reg | Send-Pay | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adrd | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| BaseBridge | 0 | 60 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| DroidDream | 0 | 0 | 15 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| DroidKungFu | 0 | 0 | 1 | 127 | 0 | 0 | 0 | 0 | 1 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Expl | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 2 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FakeDoc | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FakeInst | 0 | 0 | 0 | 0 | 0 | 0 | 180 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 1 | 0 |
| FakeRun | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Gappusin | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Geinimi | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| GinMaster | 0 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 53 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 6 |
| Glodream | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Iconosys | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Imlog | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 |
| Kmin | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 29 | 0 | 0 | 0 | 0 | 0 |
| MobileTx | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 14 | 0 | 0 | 0 | 0 |
| Opfake | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 120 | 0 | 0 | 0 |
| Plankton | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 121 | 0 | 0 |
| SMSreg | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 0 |
| SendPay | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 11 |
References
- Development of New Android Malware Worldwide from June 2016 to March 2020. Available online: https://www.statista.com/statistics/680705/global-android-malware-volume/ (accessed on 16 January 2021).
- Mobile Malware Report—No Let-Up with Android Malware. Available online: https://www.gdatasoftware.com/news/2019/07/35228-mobile-malware-report-no-let-up-with-android-malware (accessed on 16 January 2021).
- Alswaina, F.; Elleithy, K. Android Malware Family Classification and Analysis: Current Status and Future Directions. Electronics 2020, 9, 942. [Google Scholar] [CrossRef]
- Fan, M.; Liu, J.; Luo, X.; Chen, K.; Tian, Z.; Zheng, Q.; Liu, T. Android malware familial classification and representative sample selection via frequent subgraph analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1890–1905. [Google Scholar] [CrossRef]
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Wang, Y.; Xiang, Y. A3CM: Automatic Capability Annotation for Android Malware. IEEE Access 2019, 7, 147156–147168. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, M.; Gao, Z.; Xu, G.; Xian, H.; Li, Y.; Zhang, X. Constructing features for detecting android malicious applications: Issues, taxonomy and directions. IEEE Access 2019, 7, 67602–67631. [Google Scholar] [CrossRef]
- Altaher, A. An improved Android malware detection scheme based on an evolving hybrid neuro-fuzzy classifier (EHNFC) and permission-based features. Neural Comput. Appl. 2017, 28, 4147–4157. [Google Scholar] [CrossRef]
- Alswaina, F.; Elleithy, K. Android malware permission-based multi-class classification using extremely randomized trees. IEEE Access 2018, 6, 76217–76227. [Google Scholar] [CrossRef]
- Chen, S.; Xue, M.; Tang, Z.; Xu, L.; Zhu, H. Stormdroid: A streaminglized machine-learning-based system for detecting android malware. In Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016; pp. 377–388. [Google Scholar]
- Suarez-Tangil, G.; Dash, S.K.; Ahmadi, M.; Kinder, J.; Giacinto, G.; Cavallaro, L. Droidsieve: Fast and accurate classification of obfuscated android malware. In Proceedings of the Seventh ACM on Conference on Data and Application Security and Privacy (CODASPY 2017), Scottsdale, AZ, USA, 22–24 March 2017; pp. 309–320. [Google Scholar]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-An, W.; Ye, H. Significant Permission Identification for Machine-Learning-Based Android Malware Detection. IEEE Trans. Ind. Inform. 2018, 14, 3216–3225. [Google Scholar] [CrossRef]
- Park, J.; Kang, M.; Cho, S.J.; Han, H.; Suh, K. Analysis of Permission Selection Techniques in Machine Learning-based Malicious App Detection. In Proceedings of the 3rd IEEE International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 9–13 December 2020; pp. 13–22. [Google Scholar]
- Mathur, A.; Podila, L.M.; Kulkarni, K.; Niyaz, Q.; Javaid, A.Y. NATICUSdroid: A malware detection framework for Android using native and custom permissions. J. Inf. Secur. Appl. 2021, 58, 102696. [Google Scholar]
- Rossow, C.; Dietrich, C.J.; Grier, C.; Kreibich, C.; Paxson, V.; Pohlmann, N.; Steen, M. Prudent practices for designing malware experiments: Status quo and outlook. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 23–27 May 2012; pp. 65–79. [Google Scholar] [CrossRef] [Green Version]
- Raff, E.; Nicholas, C. Malware classification and class imbalance via stochastic hashed LZJD. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security (AISec), Dallas, TX, USA, 3 November 2017; pp. 111–120. [Google Scholar]
- Bai, Y.; Xing, Z.; Ma, D.; Li, X.; Feng, Z. Comparative analysis of feature representations and machine learning methods in Android family classification. Comput. Netw. 2020, 184, 107639. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roy, S.; DeLoach, J.; Li, Y.; Herndon, N.; Caragea, D.; Ou, X.; Ranganath, V.P.; Li, H.; Guevara, N. Experimental study with real-world data for android app security analysis using machine learning. In Proceedings of the 31st Annual Computer Security Applications Conference, Los Angeles, CA, USA, 7–11 December 2015; pp. 81–90. [Google Scholar]
- Carrillo, H.; Brodersen, K.H.; Castellanos, J.A. Probabilistic performance evaluation for multiclass classification using the posterior balanced accuracy. In Proceedings of the ROBOT2013: First Iberian Robotics Conference, Madrid, Spain, 28–29 November 2013; pp. 347–361. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Jurman, G.; Riccadonna, S.; Furlanello, C. A comparison of MCC and CEN error measures in multi-class prediction. PLoS ONE 2012, 7, e41882. [Google Scholar] [CrossRef] [Green Version]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K. DREBIN: Effective and explainable detection of android malware in your pocket. In Proceedings of the 2014 Network and Distributed System Security (NDSS) Symposium, San Diego, CA, USA, 23–26 February 2014; pp. 23–26. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Russell, I. Neural Networks Module. 2012. Available online: https://scholar.google.co.jp/citations?view_op=view_citation&hl=zh-TW&user=Oy46FHsAAAAJ&sortby=pubdate&citation_for_view=Oy46FHsAAAAJ:_FxGoFyzp5QC (accessed on 29 July 2021).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E.; Abe, N. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Xiao, J.; Chen, S.; He, Q.; Feng, Z.; Xue, X. An Android application risk evaluation framework based on minimum permission set identification. J. Syst. Softw. 2020, 163, 110533. [Google Scholar] [CrossRef] [Green Version]
- Backes, M.; Bugiel, S.; Derr, E.; McDaniel, P.; Octeau, D.; Weisgerber, S. On demystifying the android application framework: Re-visiting android permission specification analysis. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 1101–1118. [Google Scholar]
- Tuncay, G.S.; Demetriou, S.; Ganju, K.; Gunter, C. Resolving the Predicament of Android Custom Permissions. In Proceedings of the Network and Distributed System Security Symposium (NDSS 2018), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Bagheri, H.; Kang, E.; Malek, S.; Jackson, D. Detection of design flaws in the android permission protocol through bounded verification. In Proceedings of the International Symposium on Formal Methods, Oslo, Norway, 24–26 June 2015; pp. 73–89. [Google Scholar]
- Bagheri, H.; Kang, E.; Malek, S.; Jackson, D. A formal approach for detection of security flaws in the android permission system. Form. Asp. Comput. 2018, 30, 525–544. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, A.; Jabbarvand, R.; Ghorbani, N.; Bagheri, H.; Malek, S. A temporal permission analysis and enforcement framework for android. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 846–857. [Google Scholar]
- Garcia, J.; Hammad, M.; Malek, S. Lightweight, obfuscation-resilient detection and family identification of android malware. ACM Trans. Softw. Eng. Methodol. 2018, 26, 1–29. [Google Scholar] [CrossRef]
- Dilhara, M.; Cai, H.; Jenkins, J. Automated detection and repair of incompatible uses of runtime permissions in android apps. In Proceedings of the 5th International Conference on Mobile Software Engineering and Systems, Gothenburg, Sweden, 27–28 May 2018; pp. 67–71. [Google Scholar]
- Wang, Y.; Wang, Y.; Wang, S.; Liu, Y.; Xu, C.; Cheung, S.C.; Yu, H.; Zhu, Z. Runtime Permission Issues in Android Apps: Taxonomy, Practices, and Ways Forward. arXiv 2021, arXiv:2106.13012. [Google Scholar]
- Aafer, Y.; Du, W.; Yin, H. Droidapiminer: Mining api-level features for robust malware detection in android. In Proceedings of the International Conference on Security and Privacy in Communication Systems (SecureComm 2013), Sydney, Australia, 25–27 September 2013; pp. 86–103. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marsland, S. Machine Learning: An Algorithmic Perspective, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanz, B.; Santos, I.; Laorden, C.; Ugarte-Pedrero, X.; Bringas, P.G.; Álvarez, G. Puma: Permission usage to detect malware in android. In Proceedings of the International Joint Conference CISIS’12-ICEUTE 12-SOCO 12 Special Sessions, Ostrava, Czech Republic, 5–7 September 2012; pp. 289–298. [Google Scholar]
- Scikit-Learn: Machine Learning in Python. Available online: https://scikit-learn.org (accessed on 20 October 2020).
- Idrees, F.; Rajarajan, M.; Conti, M.; Chen, T.M.; Rahulamathavan, Y. PIndroid: A novel Android malware detection system using ensemble learning methods. Comput. Secur. 2017, 68, 36–46. [Google Scholar] [CrossRef] [Green Version]
- Feng, P.; Ma, J.; Sun, C.; Xu, X.; Ma, Y. A novel dynamic Android malware detection system with ensemble learning. IEEE Access 2018, 6, 30996–31011. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Q.; Ma, X.; Yang, Z.; Jiang, J. Using multi-features and ensemble learning method for imbalanced malware classification. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 965–973. [Google Scholar]
- Performance Measures for Multi-Class Problems. Available online: https://www.datascienceblog.net/post/machine-learning/performance-measures-multi-class-problems/ (accessed on 24 February 2021).
- Xie, N.; Wang, X.; Wang, W.; Liu, J. Fingerprinting Android malware families. Front. Comput. Sci. 2019, 13, 637–646. [Google Scholar] [CrossRef]
- Türker, S.; Can, A.B. Andmfc: Android malware family classification framework. In Proceedings of the 30th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC Workshops), Istanbul, Turkey, 8 September 2019; pp. 1–6. [Google Scholar]
- Sedano, J.; Chira, C.; González, S.; Herrero, Á.; Corchado, E.; Villar, J.R. Characterization of android malware families by a reduced set of static features. In Proceedings of the International Joint Conference SOCO’16-CISIS’16-ICEUTE’16, San Sebastián, Spain, 19–21 October 2016; pp. 607–617. [Google Scholar]
- Chakraborty, T.; Pierazzi, F.; Subrahmanian, V.S. EC2: Ensemble Clustering and Classification for Predicting Android Malware Families. IEEE Trans. Dependable Secur. Comput. 2017, 17, 262–277. [Google Scholar] [CrossRef] [Green Version]
- Atzeni, A.; Díaz, F.; Marcelli, A.; Sánchez, A.; Squillero, G.; Tonda, A. Countering android malware: A scalable semi-supervised approach for family-signature generation. IEEE Access 2018, 6, 59540–59556. [Google Scholar] [CrossRef]
- Kim, H.M.; Song, H.M.; Seo, J.W.; Kim, H.K. Andro-simnet: Android malware family classification using social network analysis. In Proceedings of the 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, UK, 28–30 August 2018; pp. 1–8. [Google Scholar]
- Gao, H.; Cheng, S.; Zhang, W. GDroid: Android malware detection and classification with graph convolutional network. Comput. Secur. 2021, 106, 102264. [Google Scholar] [CrossRef]
- Nisa, M.; Shah, J.H.; Kanwal, S.; Raza, M.; Khan, M.A.; Damaševičius, R.; Blažauskas, T. Hybrid malware classification method using segmentation-based fractal texture analysis and deep convolution neural network features. Appl. Sci. 2020, 10, 4966. [Google Scholar] [CrossRef]
- Cai, H.; Meng, N.; Ryder, B.; Yao, D. DroidCat: Effective Android Malware Detection and Categorization via App-Level Profiling. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1455–1470. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J. A two-layered permission-based Android malware detection scheme. In Proceedings of the 2014 2nd IEEE International Conference on Mobile Cloud Computing, Services, and Engineering, Oxford, UK, 8–11 April 2014; pp. 142–148. [Google Scholar]
- Cai, H. Embracing mobile app evolution via continuous ecosystem mining and characterization. In Proceedings of the IEEE/ACM 7th International Conference on Mobile Software Engineering and Systems, Seoul, Korea, 13–15 July 2020; pp. 31–35. [Google Scholar]
- Fu, X.; Cai, H. On the deterioration of learning-based malware detectors for Android. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering, Montreal, QC, Canada, 25–31 May 2019; pp. 272–273. [Google Scholar]
- Zhang, X.; Zhang, Y.; Zhong, M.; Ding, D.; Cao, Y.; Zhang, Y.; Zhang, M.; Yang, M. Enhancing state-of-the-art classifiers with API semantics to detect evolved android malware. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, USA, 30 October–3 November 2020; pp. 757–770. [Google Scholar]
- Xu, K.; Li, Y.; Deng, R.; Chen, K.; Xu, J. DroidEvolver: Self-evolving Android malware detection system. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 17–19 June 2019; pp. 47–62. [Google Scholar]
- Cai, H. Assessing and improving malware detection sustainability through app evolution studies. ACM Trans. Softw. Eng. Methodol. 2020, 29, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Jenkins, J. Towards sustainable android malware detection. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 350–351. [Google Scholar]
- Yang, W.; Zhang, Y.; Li, J.; Shu, J.; Li, B.; Hu, W.; Gu, D. Appspear: Bytecode decrypting and dex reassembling for packed android malware. In Proceedings of the 18th International Symposium on Recent Advances in Intrusion Detection (RAID 2015), Kyoto, Japan, 2–4 November 2015; pp. 359–381. [Google Scholar]
- Aonzo, S.; Georgiu, G.C.; Verderame, L.; Merlo, A. Obfuscapk: An open-source black-box obfuscation tool for Android apps. SoftwareX 2020, 11, 100403. [Google Scholar] [CrossRef]


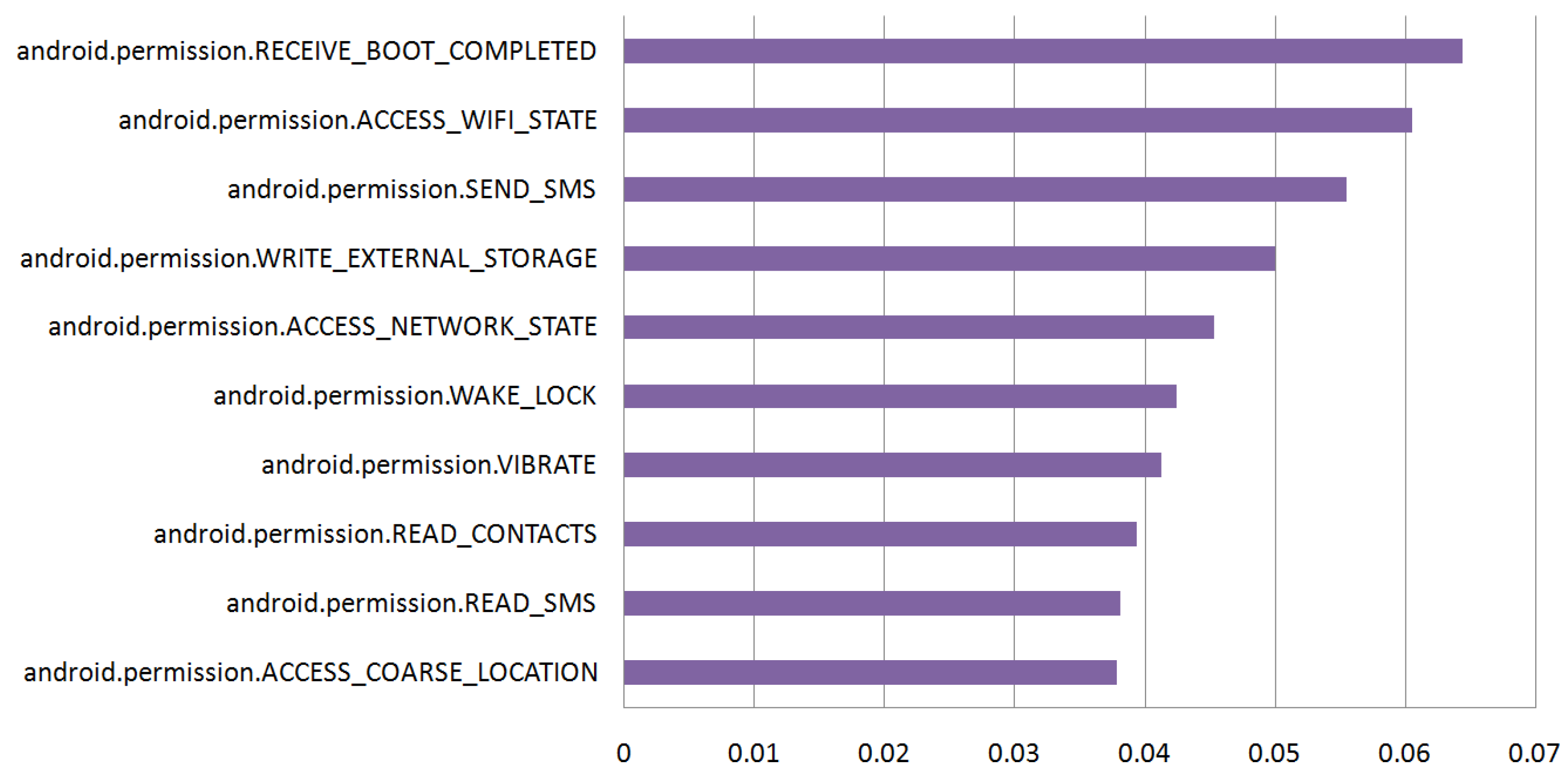
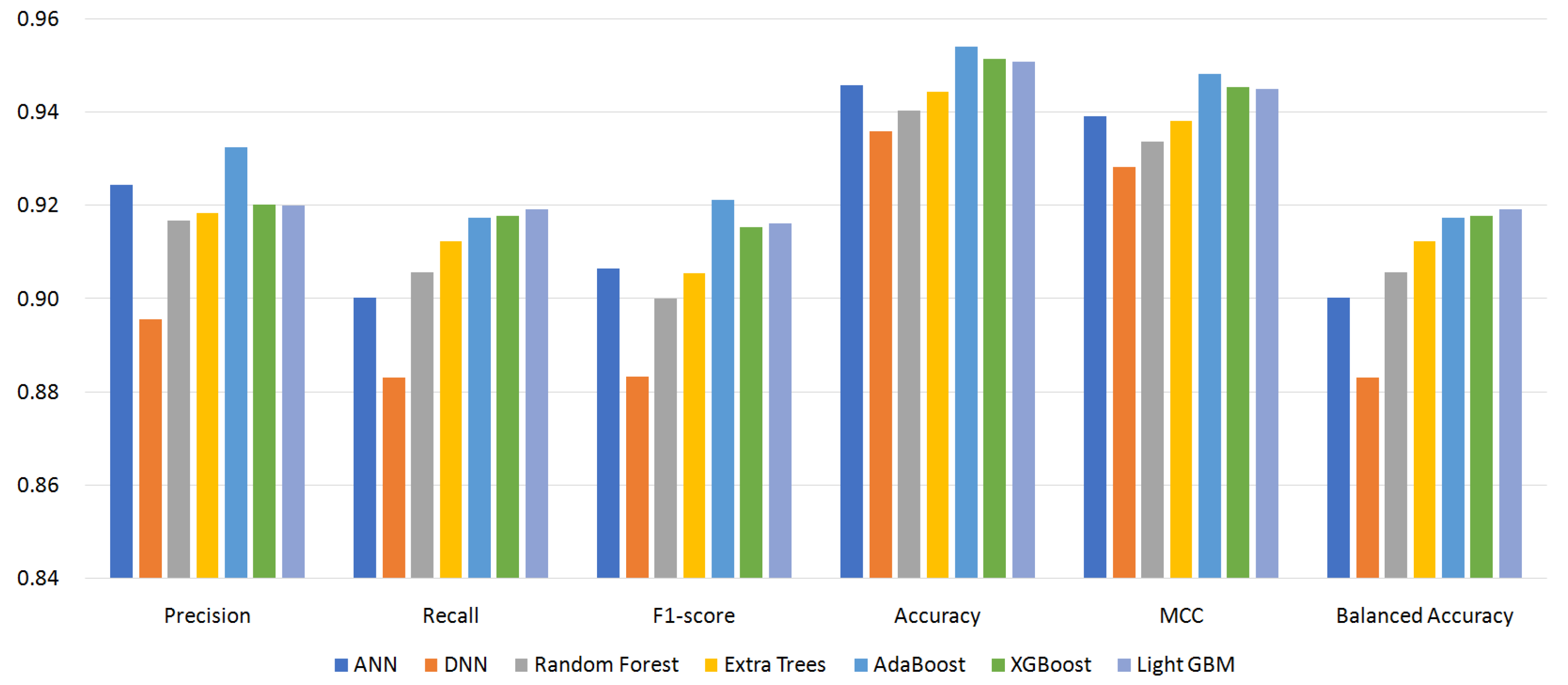
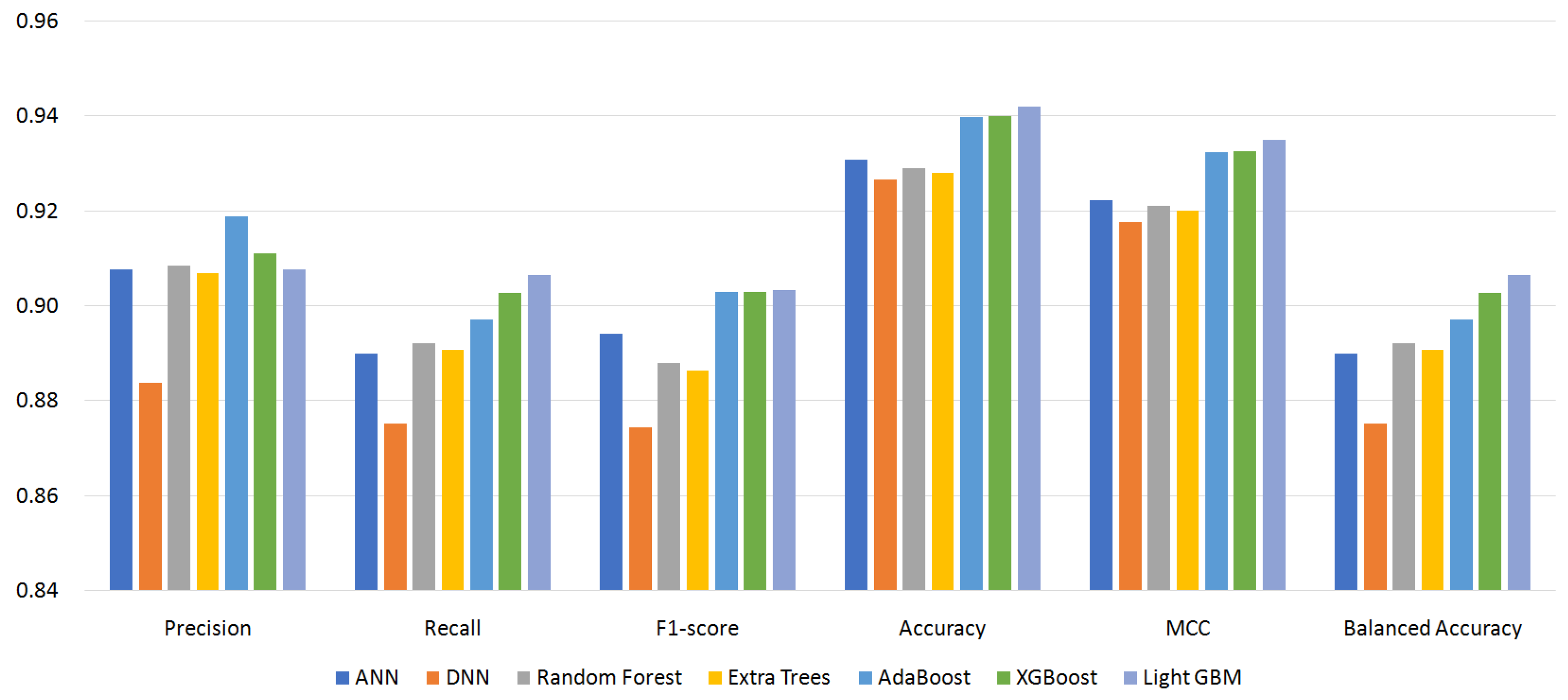

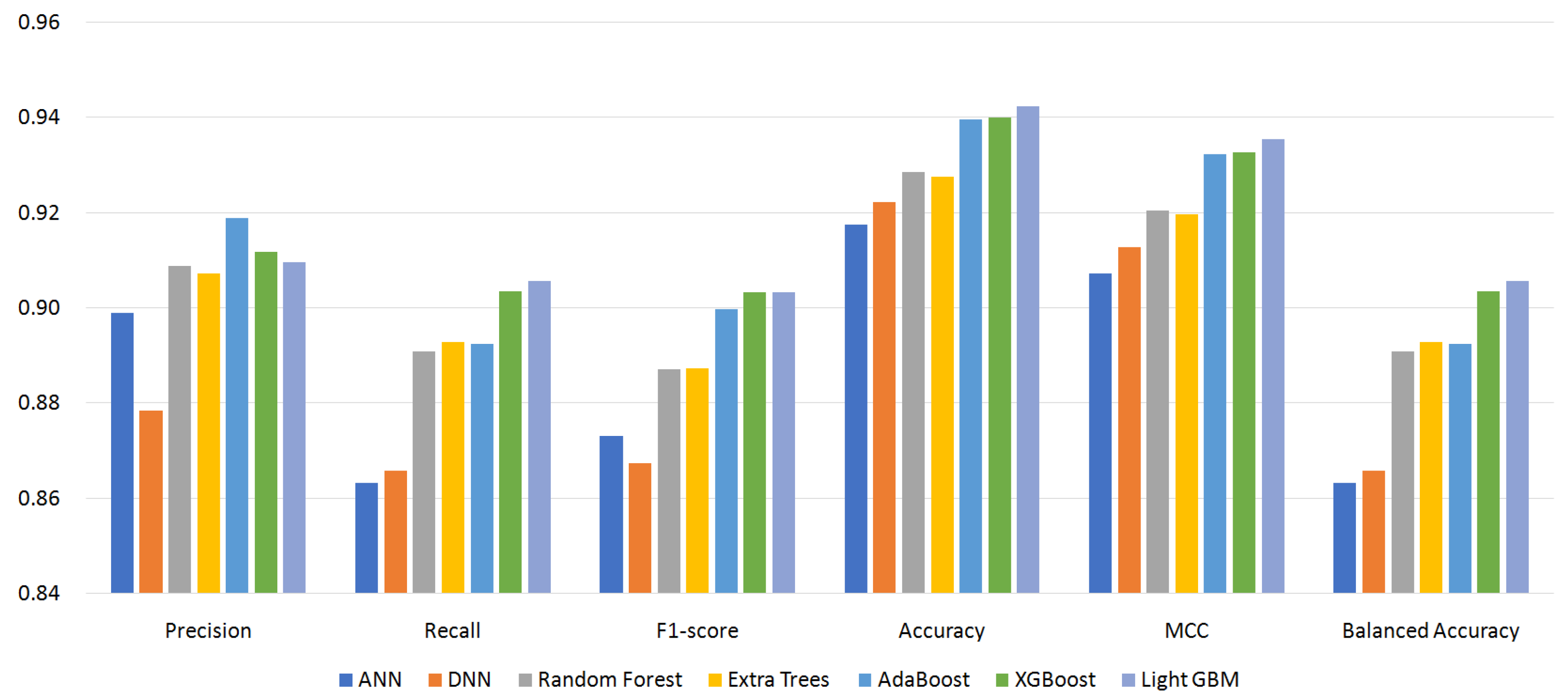
| Family | Rank | # of Apps | # of Permissions | |
|---|---|---|---|---|
| Built-In | Custom | |||
| Fakeinstaller | 1 | 920 | 42 | 1 |
| DroidKungFu | 2 | 660 | 59 | 5 |
| Plankton | 3 | 621 | 64 | 6 |
| Opfake | 4 | 601 | 35 | 2 |
| GinMaster | 5 | 336 | 43 | 5 |
| BaseBRIDGE | 6 | 327 | 36 | 1 |
| Iconosys | 7 | 152 | 21 | 0 |
| Kmin | 8 | 145 | 24 | 2 |
| FakeDoc | 9 | 132 | 36 | 4 |
| Adrd | 10 | 91 | 50 | 5 |
| Geinimi | 11 | 89 | 29 | 5 |
| DroidDream | 12 | 81 | 50 | 2 |
| MobileTx | 13 | 69 | 8 | 0 |
| ExplitLinuxLotoor | 14 | 66 | 48 | 4 |
| Glodream | 14 | 66 | 29 | 6 |
| FakeRun | 16 | 61 | 17 | 4 |
| Gappusin | 17 | 58 | 31 | 1 |
| Sendpay | 17 | 58 | 14 | 0 |
| Imlog | 19 | 43 | 8 | 0 |
| SMSreg | 20 | 39 | 25 | 5 |
| 4615 | 669 | 58 | ||
| ANN | DNN | Random Forest | Extra Trees | Ada Boost | XGBoost | Light GBM | ||
|---|---|---|---|---|---|---|---|---|
| Hidden layers | 0 | 10 | N estimators | 100 | 90 | 90 | 100 | 100 |
| Epochs | 100 | 100 | Depth | 100 | ||||
| Batch size | 128 | 128 | Max depth | 90 | 40 |
| S96 | S87 | S64 | S56 | |
|---|---|---|---|---|
| Precision | 0.9326 | 0.9190 | 0.9351 | 0.9198 |
| (AdaBoost) | (AdaBoost) | (AdaBoost) | (AdaBoost) | |
| Recall | 0.9192 | 0.9066 | 0.9198 | 0.9056 |
| (LightGBM) | (LightGBM) | (LightGBM) | (LightGBM) | |
| F1-score | 0.9212 | 0.9033 | 0.9173 | 0.9033 |
| (AdaBoost) | (LightGBM) | (LightGBM) | (LightGBM) | |
| ACC | 0.9541 | 0.9421 | 0.9512 | 0.9424 |
| (AdaBoost) | (LightGBM) | (LightGBM) | (LightGBM) | |
| MCC | 0.9484 | 0.9351 | 0.9453 | 0.9354 |
| (AdaBoost) | (LightGBM) | (LightGBM) | (LightGBM) | |
| BAC | 0.9192 | 0.9066 | 0.9198 | 0.9056 |
| (LightGBM) | (LightGBM) | (LightGBM) | (LightGBM) |
| Study | Features | Classifiers | Metrics | Dataset |
|---|---|---|---|---|
| A3CM [5] | Requested permissions, | SVM, DT, DNN | Precision, recall, F1-score | DREBIN, AMD/ |
| used permissions, | Hamming loss, accuracy | 4 capability types | ||
| API calls, network address | ||||
| Atzeni et al. [54] | Permissions, components, | Clustering algorithms | Adjusted Rand index, | 1.5 million apps |
| dynamic app interaction, | homogeneity, completeness, | |||
| etc. | V-measure | |||
| Alswaina et al. [8] | Requested permissions | SVM, DT(ID3), RF, | Accuracy | StormDroid [9]/ |
| NN, k-NN, bagging | 28 families | |||
| EC2 [53] | Permissions, dynamic | SVM, RF, DT, | Precision, recall, | DREBIN, Koodous/ |
| features (network, system | k-NN, LR, NB | F1-score, AUC at macrolevel and | 44 families | |
| information, etc.) | microlevels | |||
| DREBIN [23] | Requested permissions, | SVM | Accuracy, | DREBIN/ |
| used permissions, | detection rate | 20 families | ||
| API calls, network address, | ||||
| HW components, etc. | ||||
| Bai et al. [16] | Permissions, API calls, | SVM, DT, RF, | Precision, recall, | Genome, DREBIN, AMD/ |
| ICC attributes | k-NN, MLP | F1-score, accuracy | 32, 131, 71 families | |
| DroidSieve [10] | Permissions, API calls, | Extra Trees | Accuracy, F1-score | DREBIN / 108 families, |
| code structure, | detection rate | PRAGuard/not specified | ||
| invoked components | ||||
| Xie et al. [50] | Built-in permissions, | SVM | Accuracy | 11,643 apps from Anzhi/ |
| API calls, HW components | 10 families | |||
| AndMFC [51] | Requested permissions, | SVM, DT, LR, k-NN, | Macrolevel precision, | AMD, DREBIN, UpDroid/ |
| API calls | RF, AdaBoost, MLP, | recall, and F1-score, | 71, 132, 20 families | |
| Majority voting | accuracy | |||
| Sedano et al. [52] | Permissions, API calls, | Genetic algorithm | Not specified | DREBIN/ |
| HW components, intents, | for feature selection | 179 families | ||
| network address, etc. | ||||
| Our study | Requested permissions | ANN, DNN, RF, | Precision, recall, and F1-score | DREBIN/ |
| (built-in permissions + | Extra Trees, AdaBoost, | at macrolevel, accuracy | 20 families | |
| custom permissions) | XGBoost, LightGBM | balanced accuracy, MCC |
| Family Name | Permission List |
|---|---|
| Adrd | android.permission.WRITE_CALENDAR |
| android.permission.BROADCAST_PACKAGE_REMOVED | |
| DroidKunFu | android.permission.BROADCAST_WAP_PUSH |
| android.permission.CALL_PRIVILEGED | |
| ExploitLinuxLotoor | android.permission.REORDER_TASKS |
| FakeInstall | android.permission.ACCOUNT_MANAGER |
| android.permission.BRICK | |
| android.permission.BROADCAST_SMS | |
| android.permission.CLEAR_APP_USER_DATA | |
| android.permission.READ_CALENDAR | |
| Geinimi | com.google.android.googleapps.permission.GOOGLE_AUTH |
| Opfake | android.permission.GLOBAL_SEARCH |
| android.permission.UPDATE_DEVICE_STATS | |
| com.android.alarm.permission.SET_ALARM | |
| Plankton | android.permission.ACCESS_SURFACE_FLINGER |
| android.permission.BACKUP | |
| android.permission.BIND_APPWIDGET | |
| android.permission.CHANGE_WIFI_MULTICAST_STATE |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Kim, D.; Hwang, C.; Cho, S.; Han, S.; Park, M. Machine-Learning-Based Android Malware Family Classification Using Built-In and Custom Permissions. Appl. Sci. 2021, 11, 10244. https://doi.org/10.3390/app112110244
Kim M, Kim D, Hwang C, Cho S, Han S, Park M. Machine-Learning-Based Android Malware Family Classification Using Built-In and Custom Permissions. Applied Sciences. 2021; 11(21):10244. https://doi.org/10.3390/app112110244
Chicago/Turabian StyleKim, Minki, Daehan Kim, Changha Hwang, Seongje Cho, Sangchul Han, and Minkyu Park. 2021. "Machine-Learning-Based Android Malware Family Classification Using Built-In and Custom Permissions" Applied Sciences 11, no. 21: 10244. https://doi.org/10.3390/app112110244
APA StyleKim, M., Kim, D., Hwang, C., Cho, S., Han, S., & Park, M. (2021). Machine-Learning-Based Android Malware Family Classification Using Built-In and Custom Permissions. Applied Sciences, 11(21), 10244. https://doi.org/10.3390/app112110244