
Lossless Compression of Sensor Signals Using an Untrained Multi-Channel Recurrent Neural Predictor


Abstract
:1. Introduction
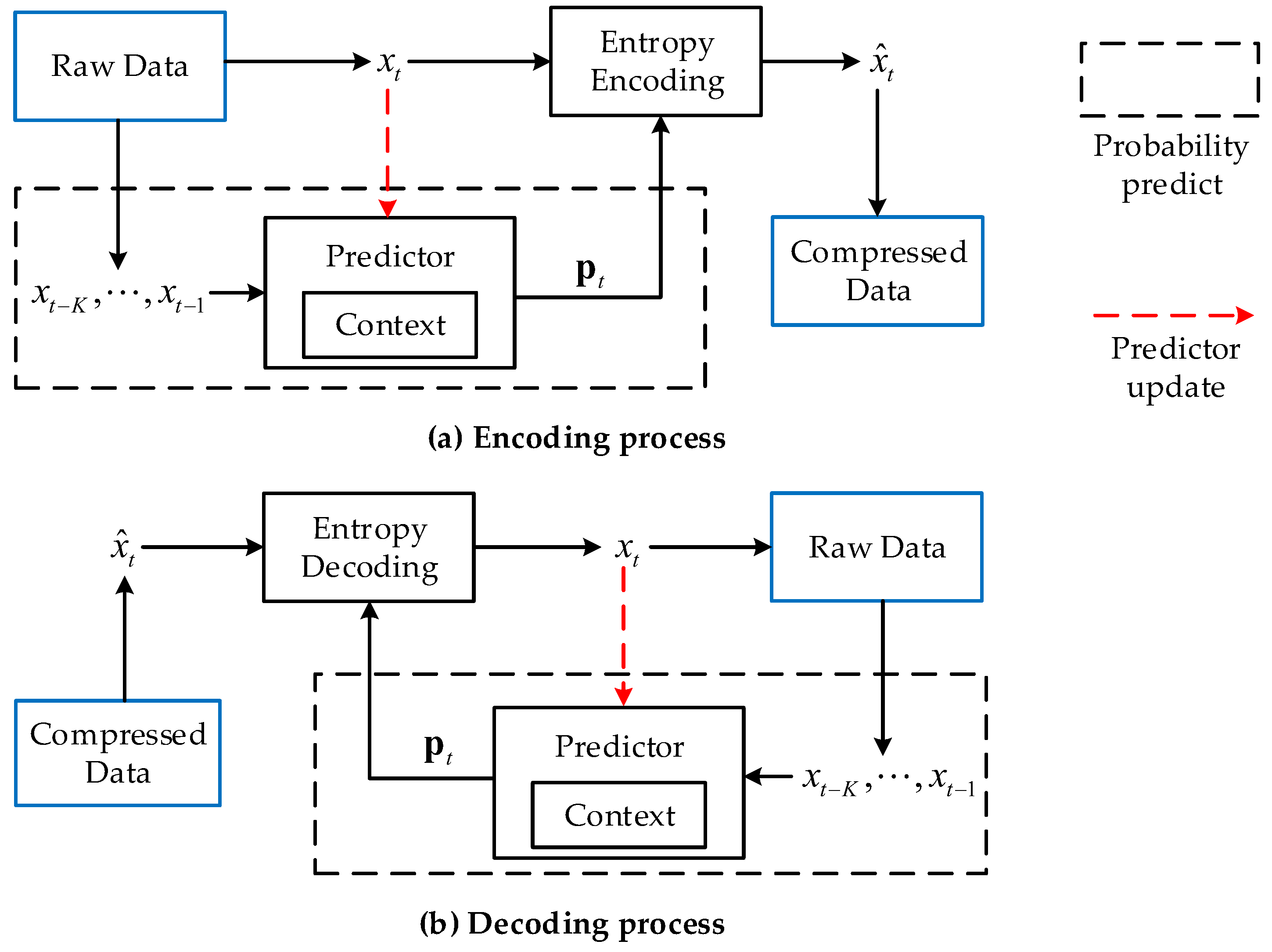
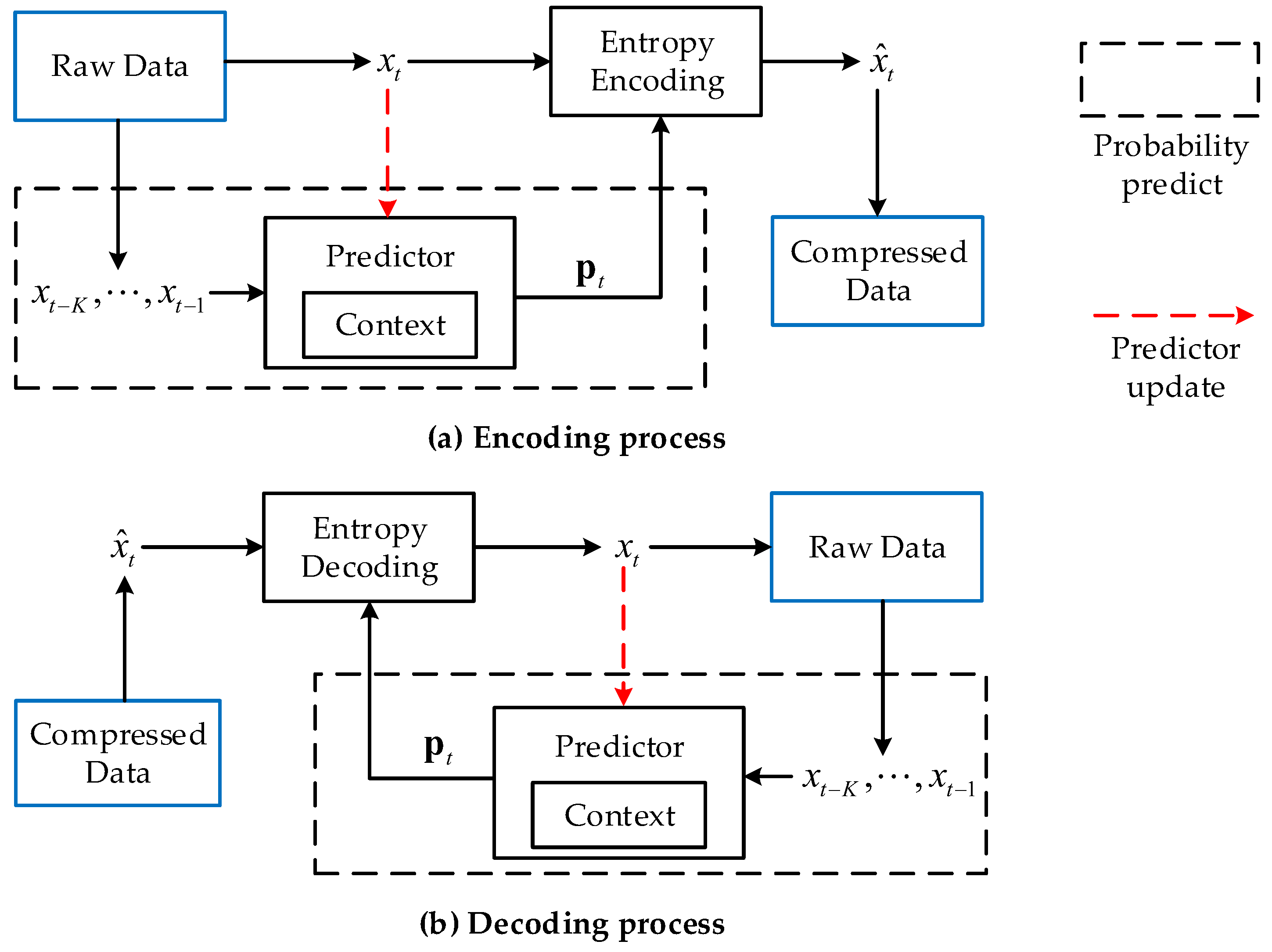
2. Context-Based Lossless Compression for Sensor Signals
2.1. Digital Signals and Sequence Predictor
2.2. Context-Based Encoding and Decoding
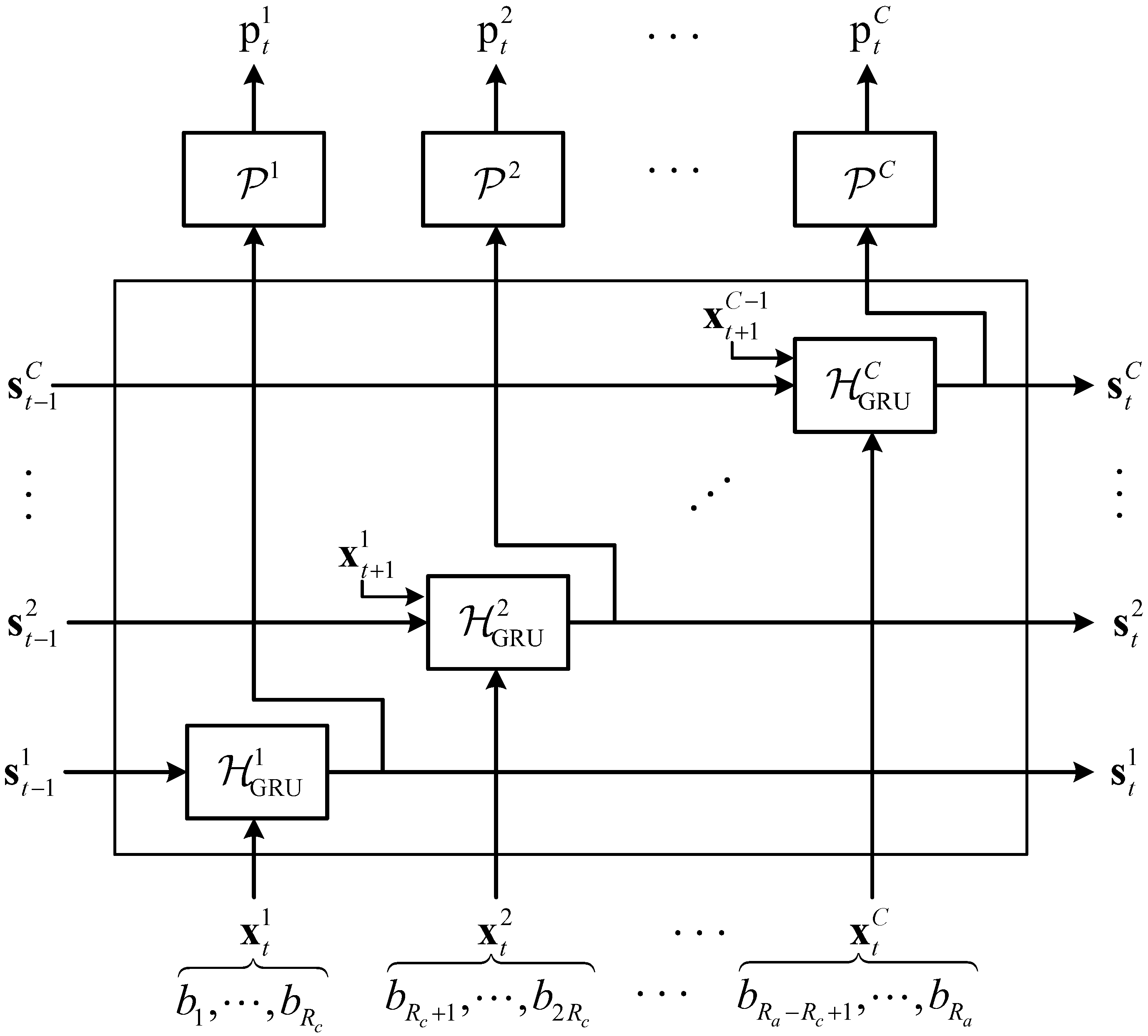
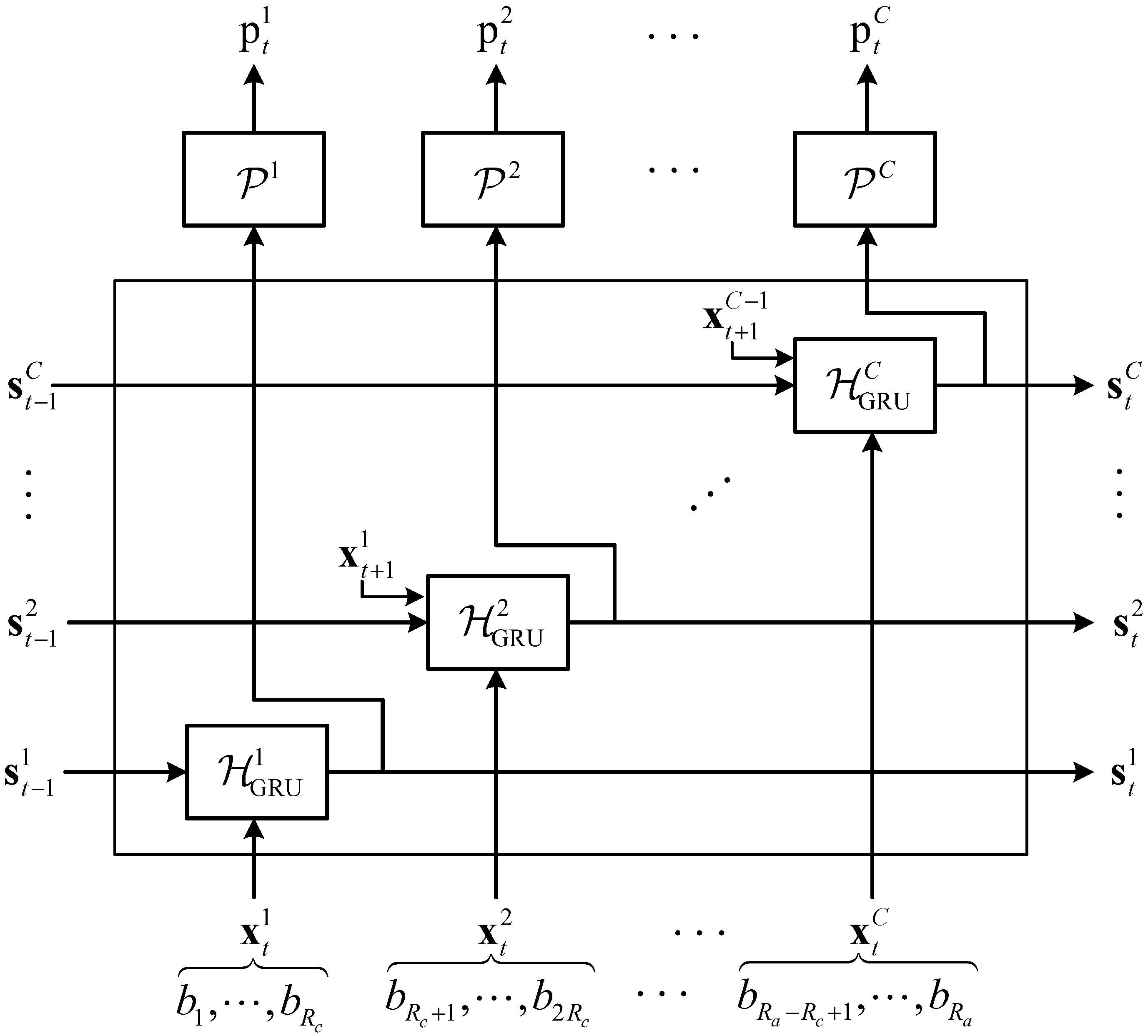
3. Multi-Channel Recurrent Predictor
3.1. Recurrent Neural Networks
3.2. Multi-Channel Recurrent Unit
4. Experiments
4.1. Datasets
4.2. Experiment Setup
4.3. Results of Different Recurrent Units
4.4. Results of Different Compressors
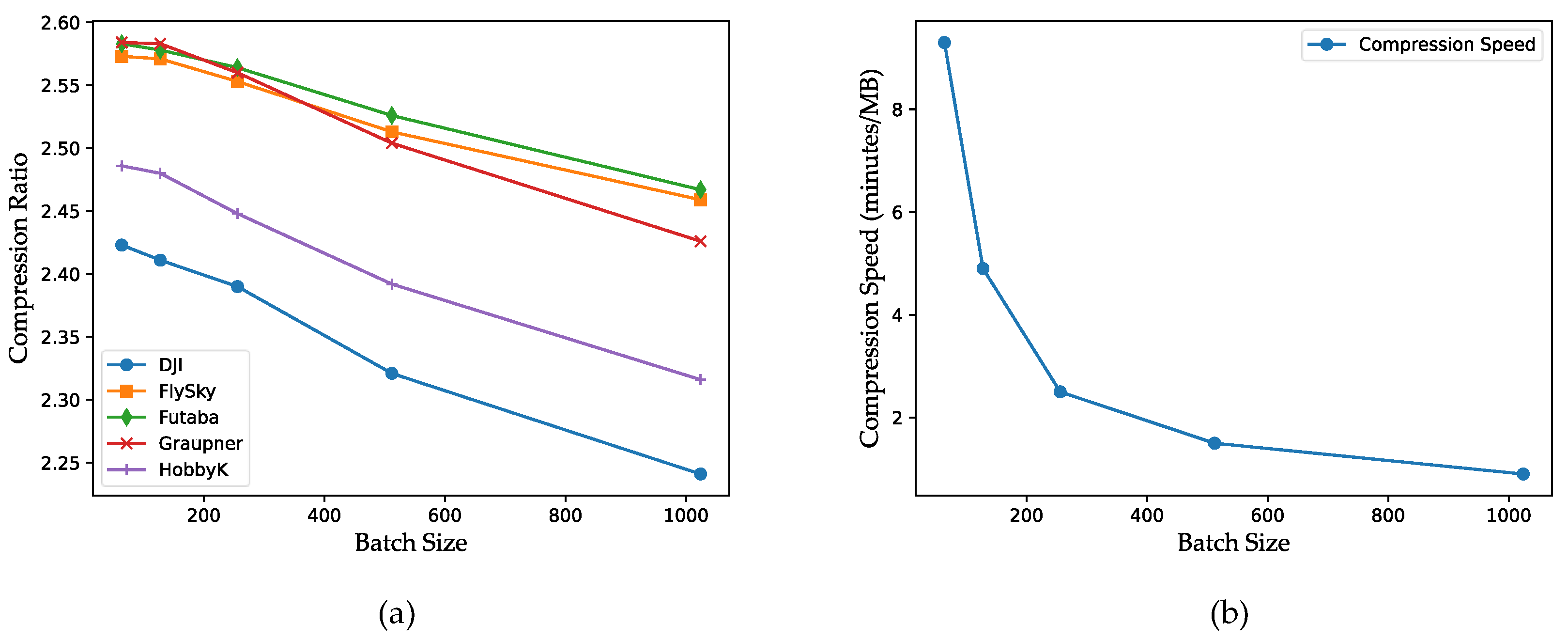
4.5. Compression Speed
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tan, L.; Yu, K.; Bashir, A.K.; Cheng, X.; Ming, F.; Zhao, L.; Zhou, X. Toward real-time and efficient cardiovascular monitoring for COVID-19 patients by 5G-enabled wearable medical devices: A deep learning approach. Neural Comput. Appl. 2021, 1–14. [Google Scholar] [CrossRef]
- Manogaran, G.; Lopez, D. Disease surveillance system for big climate data processing and dengue transmission. In Climate Change and Environmental Concerns: Breakthroughs in Research and Practice; IGI Global: Hershey, PA, USA, 2018; pp. 427–446. [Google Scholar]
- Lv, Z.; Hu, B.; Lv, H. Infrastructure monitoring and operation for smart cities based on IoT system. IEEE Trans. Ind. Inform. 2019, 16, 1957–1962. [Google Scholar] [CrossRef]
- Qing, A.; Hongtao, Z.; Zhikun, H.; Zhiwen, C. A compression approach of power quality monitoring data based on two-dimension dct. In Proceedings of the 2011 Third International Conference on Measuring Technology and Mechatronics Automation, Shanghai, China, 6–7 January 2011; Volume 1, pp. 20–24. [Google Scholar]
- Rui, Z.; Hong-jiao, Y.; Chuan-guang, Z. Compression method of power quality data based on wavelet transform. In Proceedings of the 2013 2nd International Conference on Measurement, Information and Control, Harbin, China, 16–18 August 2013; Volume 2, pp. 987–990. [Google Scholar]
- Bruni, G.; Johansson, H.T. DPTC—An FPGA-Based Trace Compression. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 67, 189–197. [Google Scholar] [CrossRef] [Green Version]
- Biagetti, G.; Crippa, P.; Falaschetti, L.; Mansour, A.; Turchetti, C. Energy and Performance Analysis of Lossless Compression Algorithms for Wireless EMG Sensors. Sensors 2021, 21, 5160. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Pasco, R.C. Source Coding Algorithms for Fast Data Compression. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1976. [Google Scholar]
- Duda, J.; Tahboub, K.; Gadgil, N.J.; Delp, E.J. The use of asymmetric numeral systems as an accurate replacement for Huffman coding. In Proceedings of the 2015 Picture Coding Symposium (PCS), Cairns, QLD, Australia, 31 May–3 June 2015; pp. 65–69. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef] [Green Version]
- Mahoney, M.V. Adaptive Weighing of Context Models for Lossless Data Compression; Technical Report; Florida Institute of Technology: Melbourne, FL, USA, 2005. [Google Scholar]
- Knoll, B.; de Freitas, N. A machine learning perspective on predictive coding with PAQ8. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 377–386. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Goyal, M.; Tatwawadi, K.; Chandak, S.; Ochoa, I. DZip: Improved general-purpose loss less compression based on novel neural network modeling. In Proceedings of the 2021 Data Compression Conference (DCC), Snowbird, UT, USA, 23–26 March 2021; pp. 153–162. [Google Scholar]
- Byron, K. Tensorflow-Compress. 2020. Available online: https://github.com/byronknoll/tensorflow-compress (accessed on June 2021).
- Dai, S.; Liu, W.; Wang, Z.; Li, K.; Zhu, P.; Wang, P. An Efficient Lossless Compression Method for Periodic Signals Based on Adaptive Dictionary Predictive Coding. Appl. Sci. 2020, 10, 4918. [Google Scholar] [CrossRef]
- Huang, F.; Qin, T.; Wang, L.; Wan, H.; Ren, J. An ECG signal prediction method based on ARIMA model and DWT. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; Volume 1, pp. 1298–1304. [Google Scholar]
- Graves, A. Generating Sequences with Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Hutter Prize. 2020. Available online: http://prize.hutter1.net/ (accessed on September 2021).
- Silesia Open Source Compression Benchmark. 2021. Available online: http://mattmahoney.net/dc/silesia.html (accessed on September 2021).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Luo, W.; Yu, F. Recurrent Highway Networks With Grouped Auxiliary Memory. IEEE Access 2019, 7, 182037–182049. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Kriechbaumer, T.; Jacobsen, H.A. BLOND, a building-level office environment dataset of typical electrical appliances. Sci. Data 2018, 5, 180048. [Google Scholar] [CrossRef] [PubMed]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Ezuma, M.; Erden, F.; Anjinappa, C.K.; Ozdemir, O.; Guvenc, I. Drone Remote Controller RF Signal Dataset; IEEE Dataport; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Ilya, G. BSC. 2015. Available online: http://libbsc.com/ (accessed on June 2021).
- NVIDIA. Framework-Determinism. 2019. Available online: https://github.com/NVIDIA/framework-determinism (accessed on June 2021).


{kind=link}
{kind=link}
{kind=link}
| Name | Gzip | BSC | PAQ | CMIX | Ours |
|---|---|---|---|---|---|
| BLOND-1 | 1.644 | 4.348 | 4.658 | 4.869 | 4.684 |
| BLOND-2 | 1.627 | 4.215 | 4.508 | 4.753 | 4.577 |
| BLOND-3 | 1.594 | 4.012 | 4.295 | 4.655 | 4.896 |
| BLOND-4 | 1.600 | 4.107 | 4.418 | 4.651 | 4.487 |
| BLOND-5 | 1.491 | 3.196 | 3.474 | 3.662 | 3.584 |
| ESC-0 | 1.631 | 2.309 | 2.812 | 3.177 | 3.344 |
| ESC-1 | 2.070 | 2.491 | 3.108 | 3.431 | 3.651 |
| ESC-2 | 1.437 | 1.734 | 2.039 | 2.206 | 2.297 |
| ESC-3 | 1.388 | 1.743 | 2.166 | 2.382 | 2.501 |
| ESC-4 | 1.299 | 1.519 | 1.854 | 2.083 | 2.164 |
| MPACT-DJI | 1.357 | 1.564 | 2.117 | 2.342 | 2.390 |
| MPACT-FlySky | 1.367 | 1.863 | 2.142 | 2.457 | 2.553 |
| MPACT-Futaba | 1.399 | 1.904 | 2.162 | 2.472 | 2.564 |
| MPACT-Graupner | 1.382 | 1.892 | 2.204 | 2.477 | 2.560 |
| MPACT-HobbyK | 1.300 | 1.766 | 2.102 | 2.380 | 2.446 |
| DJI-14bits | 1.109 | 1.272 | 1.670 | 1.916 | 2.090 |
| FlySky-14bits | 1.103 | 1.420 | 1.777 | 2.004 | 2.219 |
| Futaba-14bits | 1.117 | 1.474 | 1.806 | 2.026 | 2.234 |
| Graupner-14bits | 1.144 | 1.407 | 1.792 | 2.037 | 2.230 |
| HobbyK-14bits | 1.083 | 1.303 | 1.659 | 1.924 | 2.156 |
| Dataset | Sampling Rate | Resolution | Sampling Time |
|---|---|---|---|
| BLOND | 50 KSa/s | 16 bits | 120 s |
| ESC | 44.1 KSa/s | 16 bits | 105 s–190 s |
| MPACT | 20 GSa/s | 16 bits | 0.25 ms |
| MPACT-14bits | 20 GSa/s | 14 bits | 0.25 ms |
| Name | Version | Method |
|---|---|---|
| Gzip | v1.5 | Dictionary coding + Huffman coding |
| BSC | v3.1 | Block-sorting compression |
| PAQ | 8L | Context mixing algorithm |
| CMIX | v18 | Context mixing algorithm + LSTM |
| tensorflow-compress (TC) | v3 | RNN based predictor + arithmetic coding |
| Hyper-Parameter | LSTM | GRU | MCRU |
|---|---|---|---|
| State size | 1024 | 1024 | 1024 × 2 |
| Recurrent layers | 2 | 2 | 1 |
| Step length | 16 | 16 | 8 |
| Batch size | 256 | 256 | 256 |
| Channels C | - | - | 2 |
| Resolution | 8 | 8 | |
| Optimizer | Adam | Adam | Adam |
| Start learning rate | 0.0005 | 0.0005 | 0.0005 |
| End learning rate | 0.0001 | 0.0001 | 0.0001 |
| Gradient clipping value | 5.0 | 5.0 | 5.0 |
| Learnable parameters (≈) | 15.2 M | 11.5 M | 10.0 M/8.1 M |
| Signal | LSTM | GRU | MCRU |
|---|---|---|---|
| BLOND-1 | 1.714 | 1.717 | 1.708 |
| BLOND-2 | 1.754 | 1.755 | 1.748 |
| BLOND-3 | 1.802 | 1.796 | 1.634 |
| BLOND-4 | 1.787 | 1.791 | 1.783 |
| BLOND-5 | 2.230 | 2.232 | 2.232 |
| ESC-0 | 2.689 | 2.644 | 2.392 |
| ESC-1 | 2.490 | 2.471 | 2.191 |
| ESC-2 | 3.804 | 3.764 | 3.483 |
| ESC-3 | 3.572 | 3.575 | 3.198 |
| ESC-4 | 4.036 | 4.041 | 3.696 |
| MPACT-DJI | 3.554 | 3.546 | 3.347 |
| MPACT-FlySky | 3.261 | 3.273 | 3.134 |
| MPACT-Futaba | 3.275 | 3.271 | 3.120 |
| MPACT-Graupner | 3.241 | 3.272 | 3.125 |
| MPACT-HobbyK | 3.450 | 3.432 | 3.271 |
| DJI-14bits | 4.381 | 4.387 | 3.827 |
| FlySky-14bits | 4.131 | 4.139 | 3.606 |
| Futaba-14bits | 4.073 | 4.097 | 3.581 |
| Graupner-14bits | 4.105 | 4.080 | 3.587 |
| HobbyK-14bits | 4.391 | 4.370 | 3.710 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Wu, W.; Luo, W. Lossless Compression of Sensor Signals Using an Untrained Multi-Channel Recurrent Neural Predictor. Appl. Sci. 2021, 11, 10240. https://doi.org/10.3390/app112110240
Chen Q, Wu W, Luo W. Lossless Compression of Sensor Signals Using an Untrained Multi-Channel Recurrent Neural Predictor. Applied Sciences. 2021; 11(21):10240. https://doi.org/10.3390/app112110240
Chicago/Turabian StyleChen, Qianhao, Wenqi Wu, and Wei Luo. 2021. "Lossless Compression of Sensor Signals Using an Untrained Multi-Channel Recurrent Neural Predictor" Applied Sciences 11, no. 21: 10240. https://doi.org/10.3390/app112110240
APA StyleChen, Q., Wu, W., & Luo, W. (2021). Lossless Compression of Sensor Signals Using an Untrained Multi-Channel Recurrent Neural Predictor. Applied Sciences, 11(21), 10240. https://doi.org/10.3390/app112110240