
Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis



Abstract
:1. Introduction
- 1.
- What are the most discussed topics posted by users in a customer service platform regarding a transport company from Twitter?
- 2.
- How do different topic modeling and clustering technologies compare in terms of performance?
- 3.
- What are the areas from transport and customer services where user satisfaction needs to be improved?
2. Related Work
3. Materials and Methods
3.1. Data Collection
- They must be written in English since our goal is to address the English- speaking community.
- Tweets posted by the customer service @Uber_Support were eliminated since our achievement is to analyze customers’ demands and issues with the brand.
- Duplicated tweets were eliminated.
- Concerning spam detection, some of the most popular methods for generating fundamental truth are physical examination and filtering of blacklists [18]. The use of machine learning methods for detecting spammers [19] is out of the scope of this work and left as an interesting research line. In our case, we have used a physical examination of the dataset by selecting the first 20 user accounts that posted the highest volume of tweets in the dataset. Then, if one of those users was a spammer, the whole account was eliminated from the dataset. In our particular case, we filtered 4 of these 20 accounts since we detected them as spammers. This analysis was fundamentally performed to reduce the creation of false topics in the topic modeling approach (Section 3.3).
3.2. Data Pre-Processing
3.3. LDA for Topic Modeling
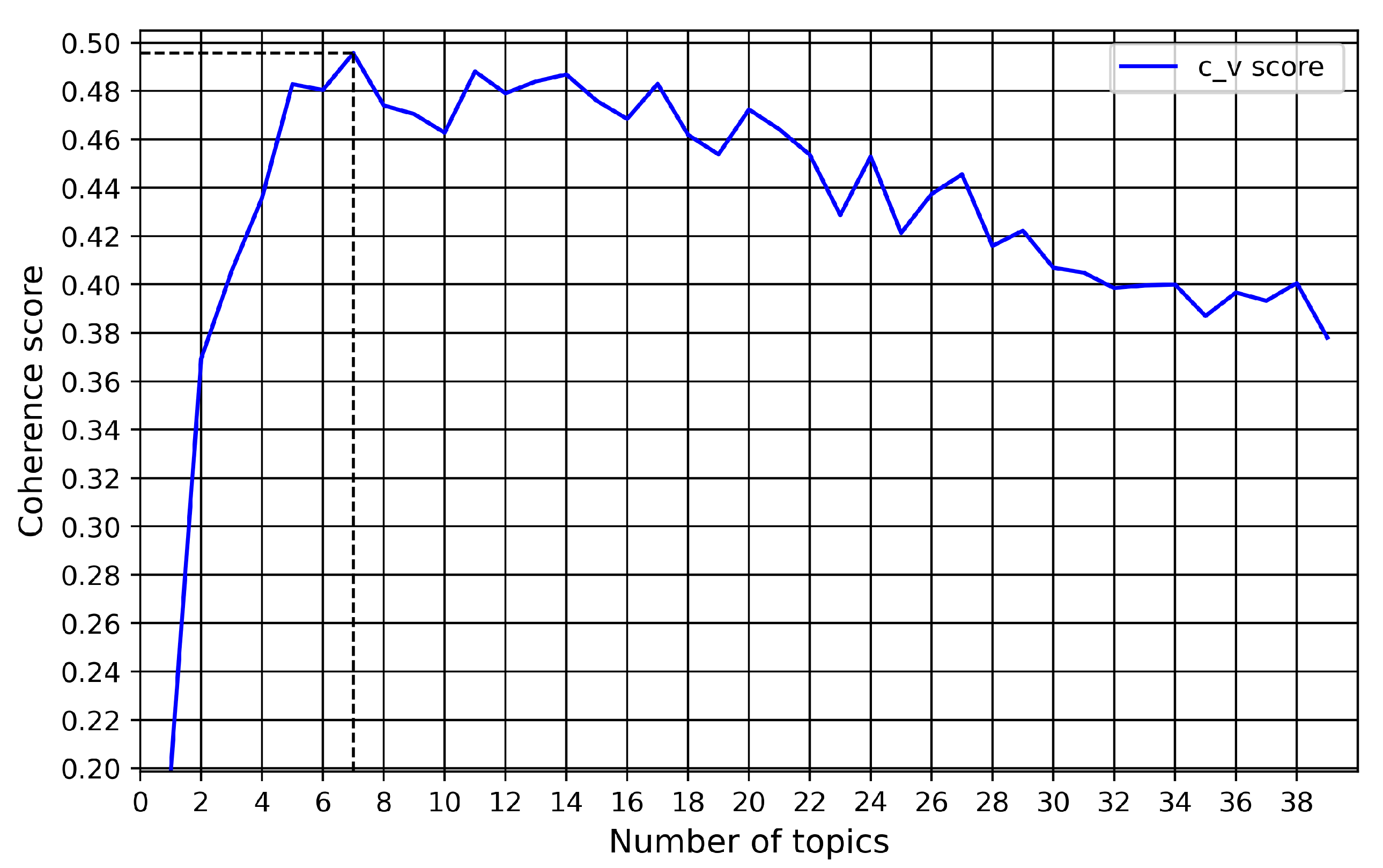
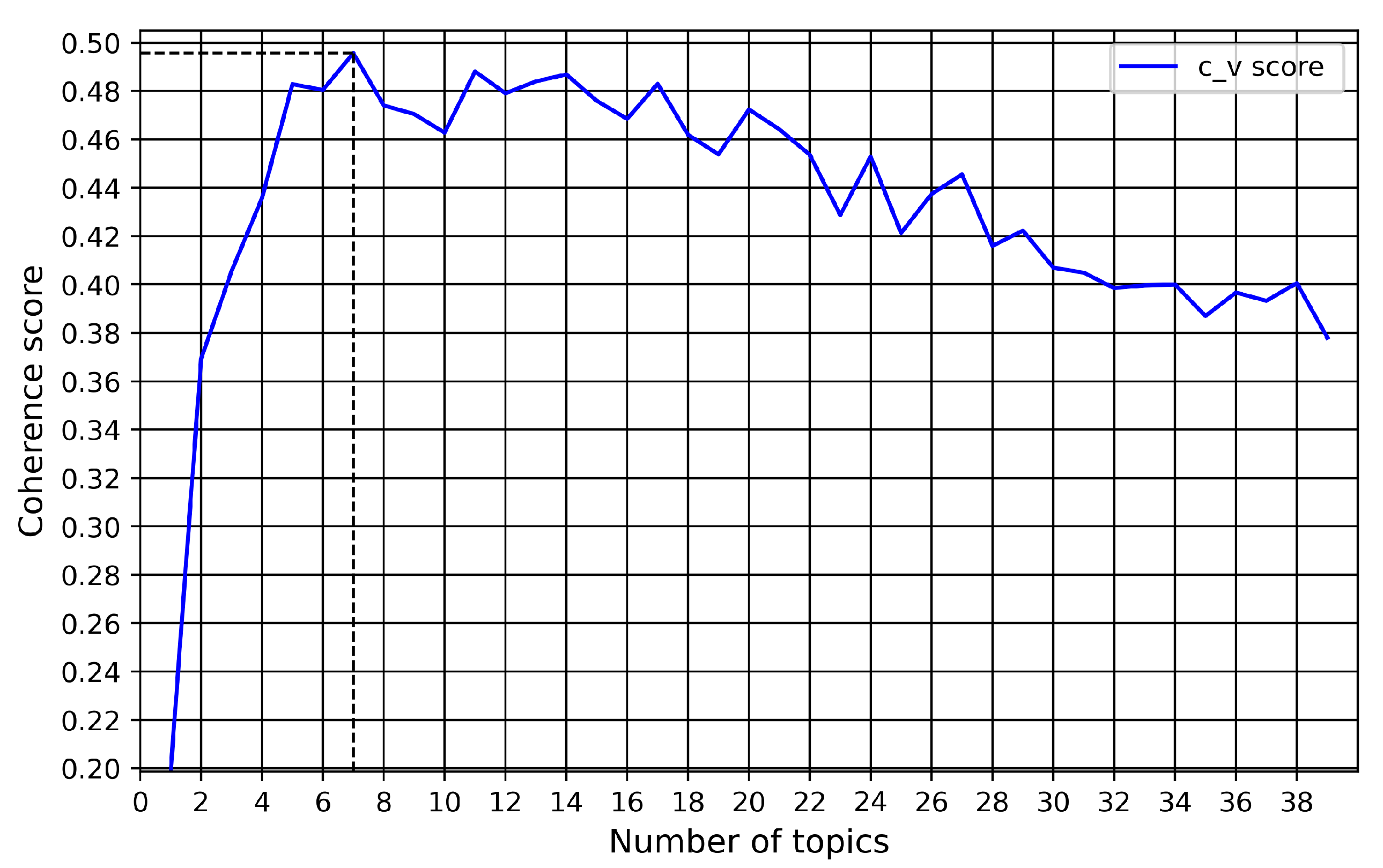
3.4. Determining T Optimal Number of Topics
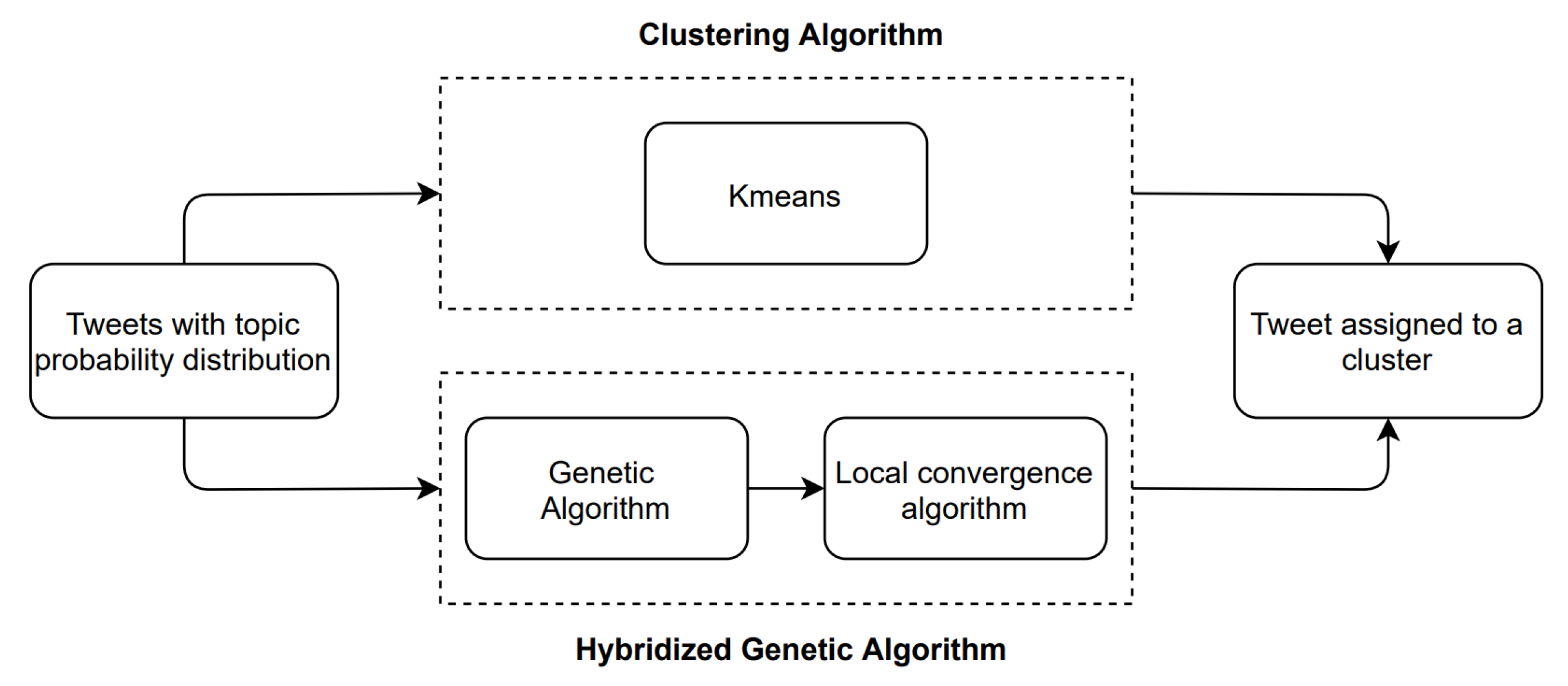
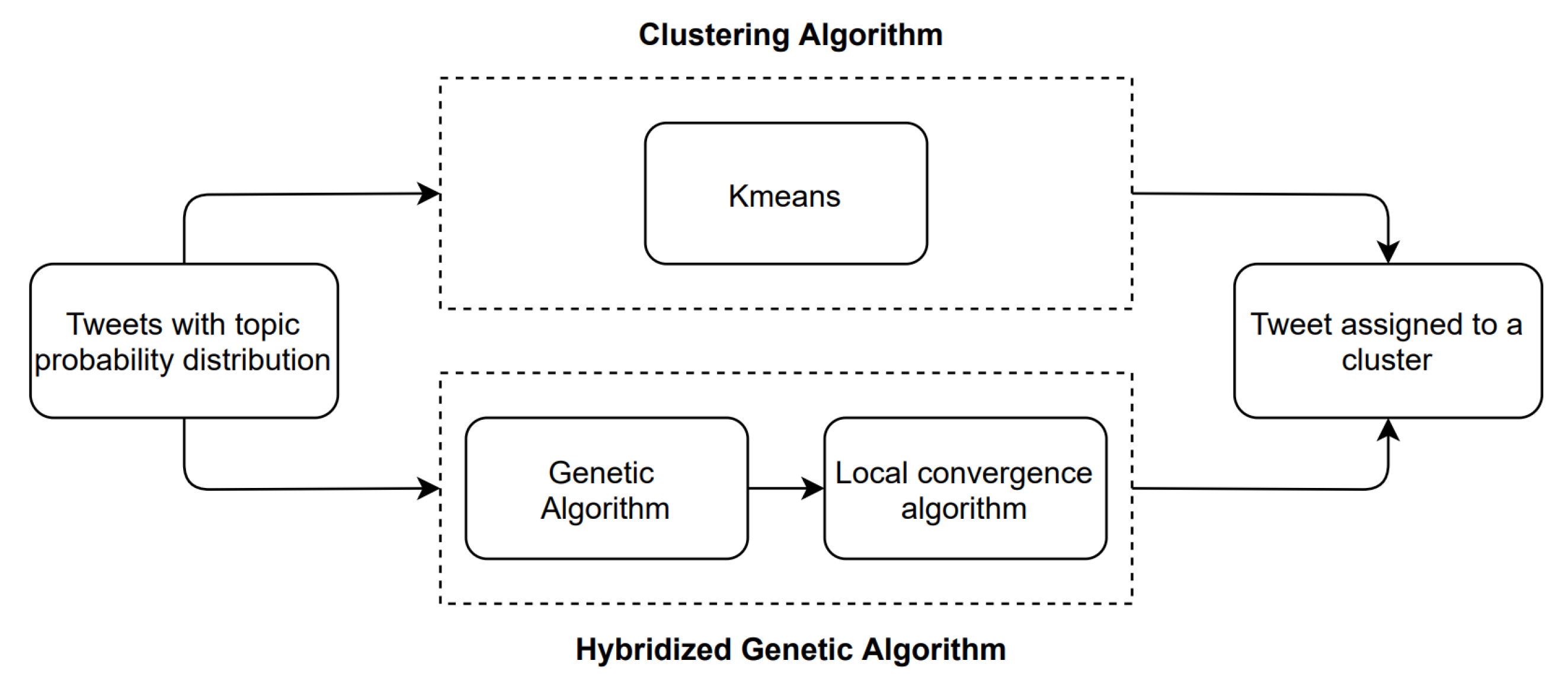
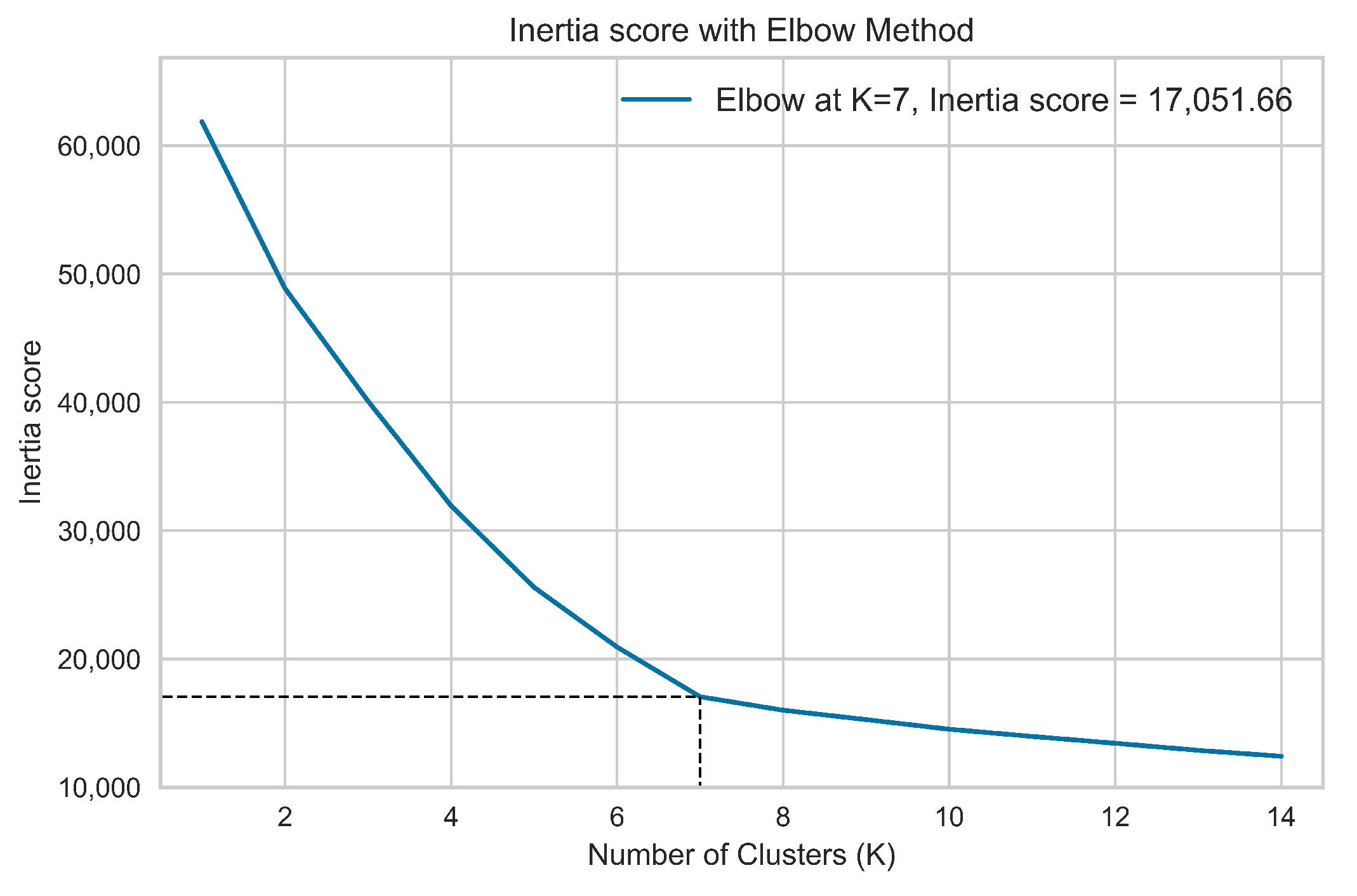
3.5. Document Clustering
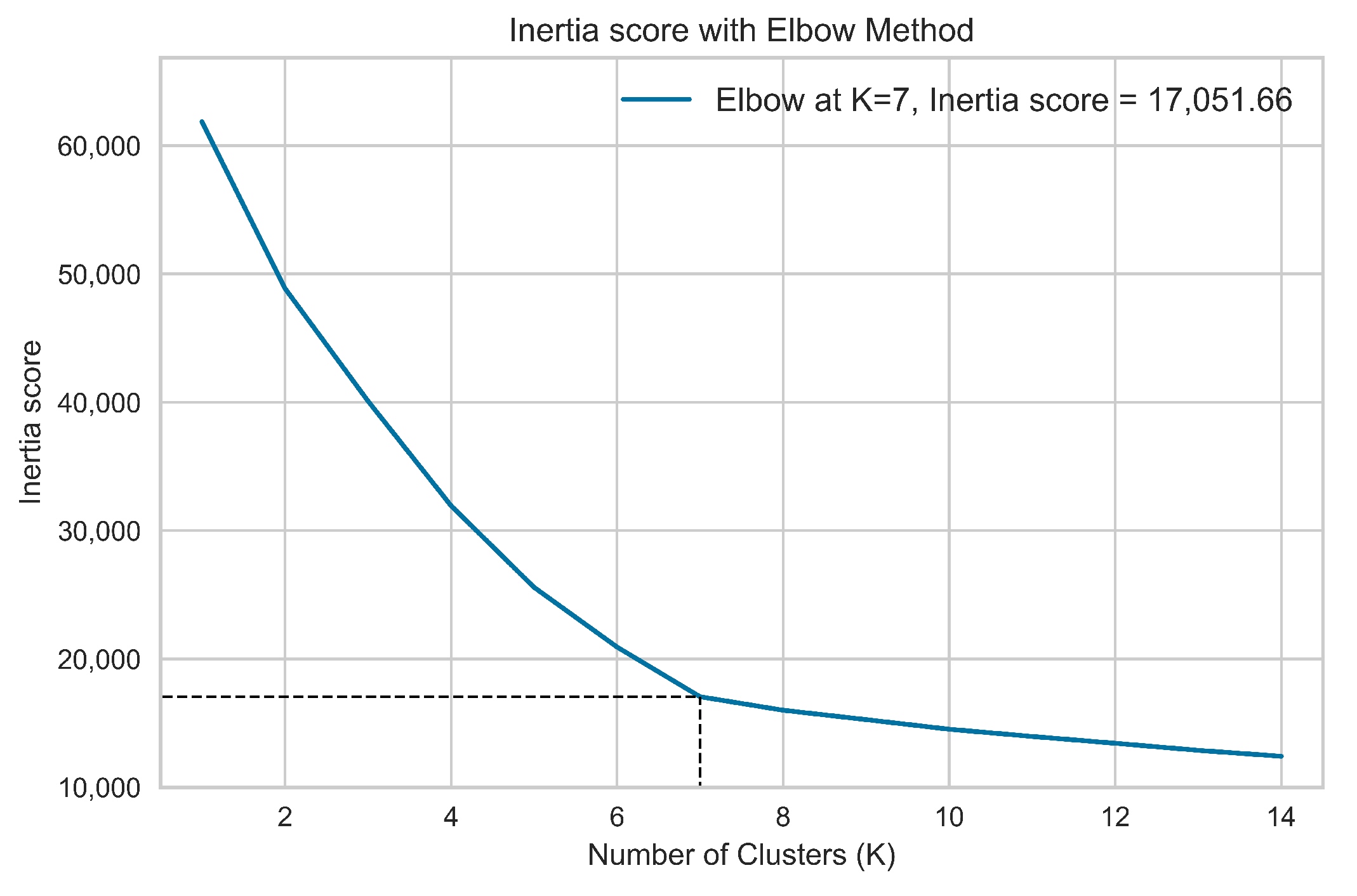
3.5.1. Clustering Algorithm: K-Means Description
3.5.2. Genetic Algorithm
3.5.3. Local Convergence Algorithm
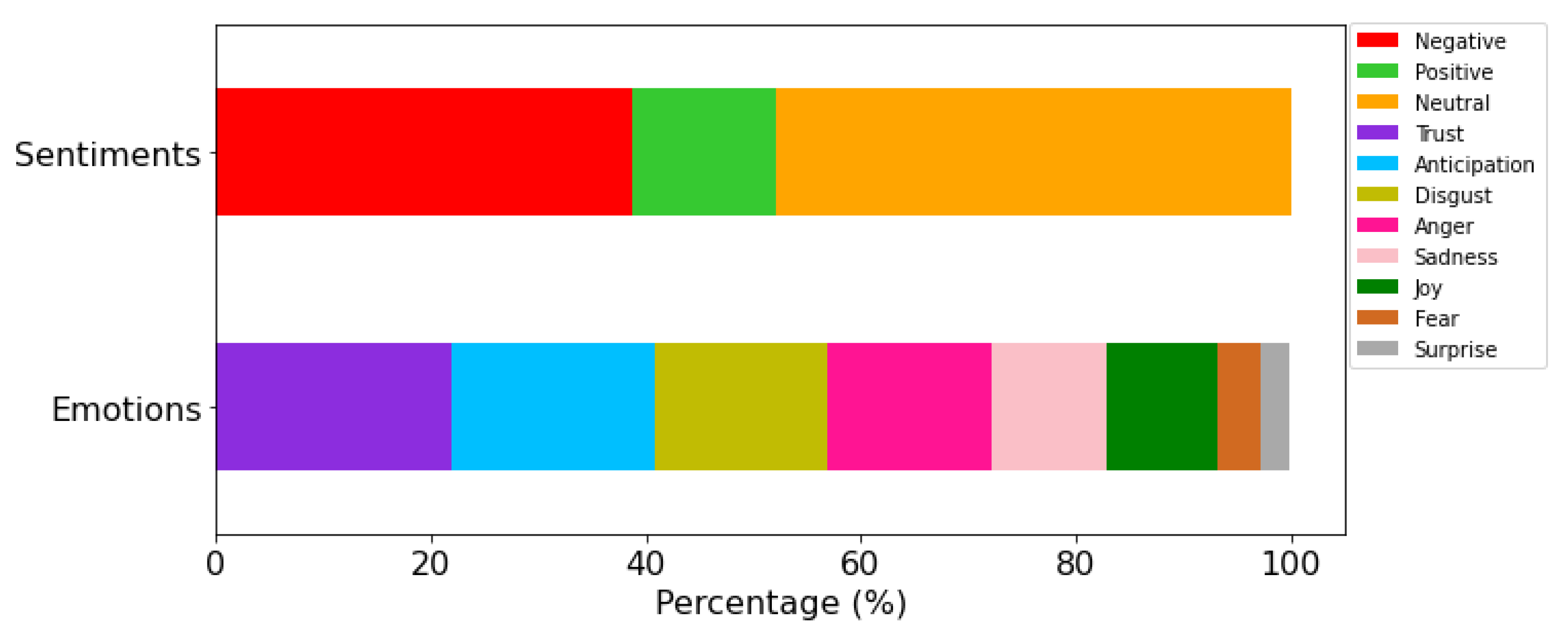
3.6. Sentiment and Emotion Analysis
- For the task of sentiment extraction, we have used the Senpy [38] framework that provides a simple interface to a wide number of Sentiment analysis services. In particular, we have used the plugin Sentiment 140 since it can be executed locally on our server.
- With respect to the methodology used for the emotion extraction, the framework Rapidminer [39] combined with the MeaningCloud [40] commercial platform was implemented through the Deep Categorization API. Specifically, the Emotion Recognition categorization model was used. Besides, this analysis resulted in the individual evaluation of each tweet which was classified as a mixture of trust, joy, sadness, anger, disgust, anticipation, fear, and surprise emotions.
4. Results
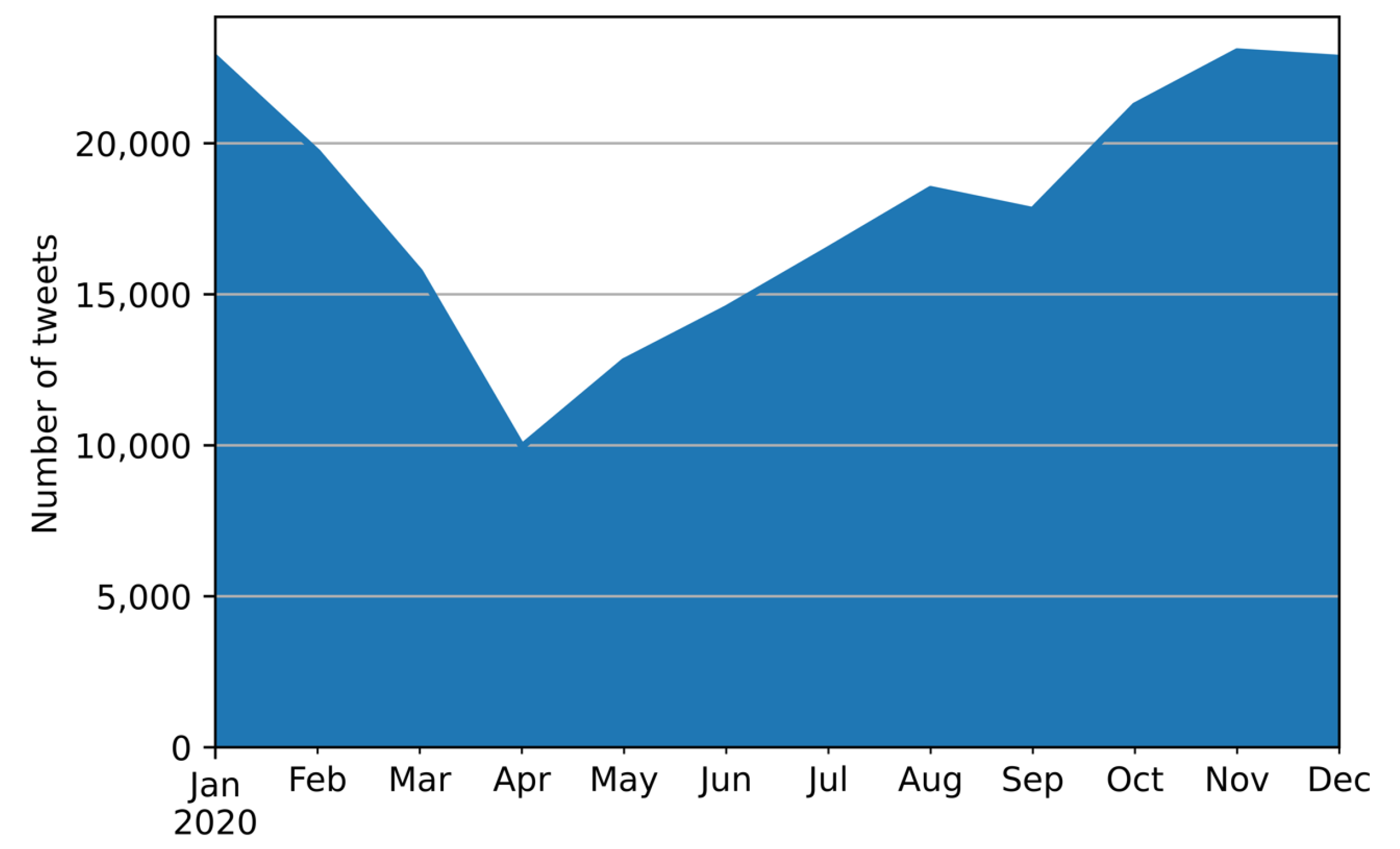
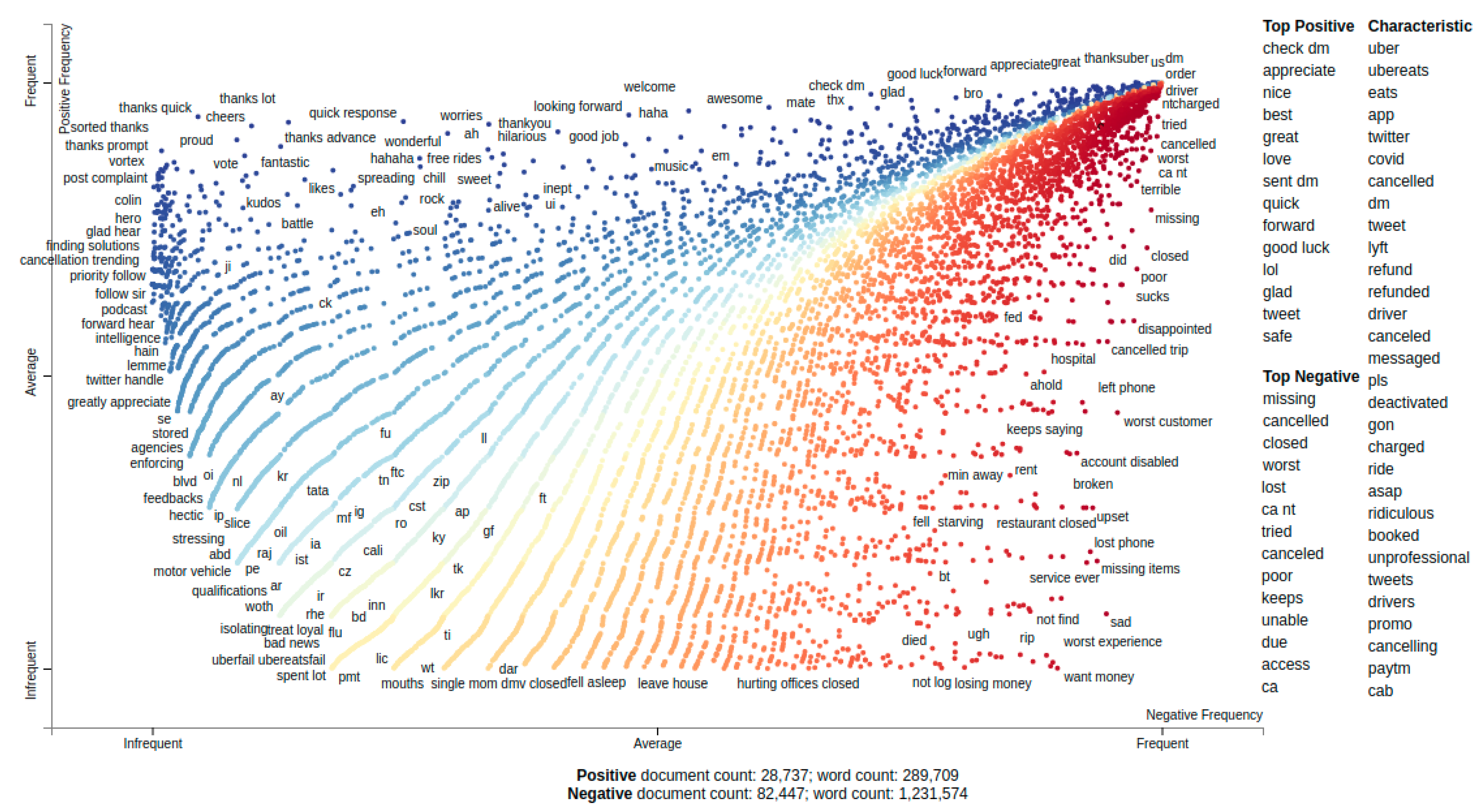
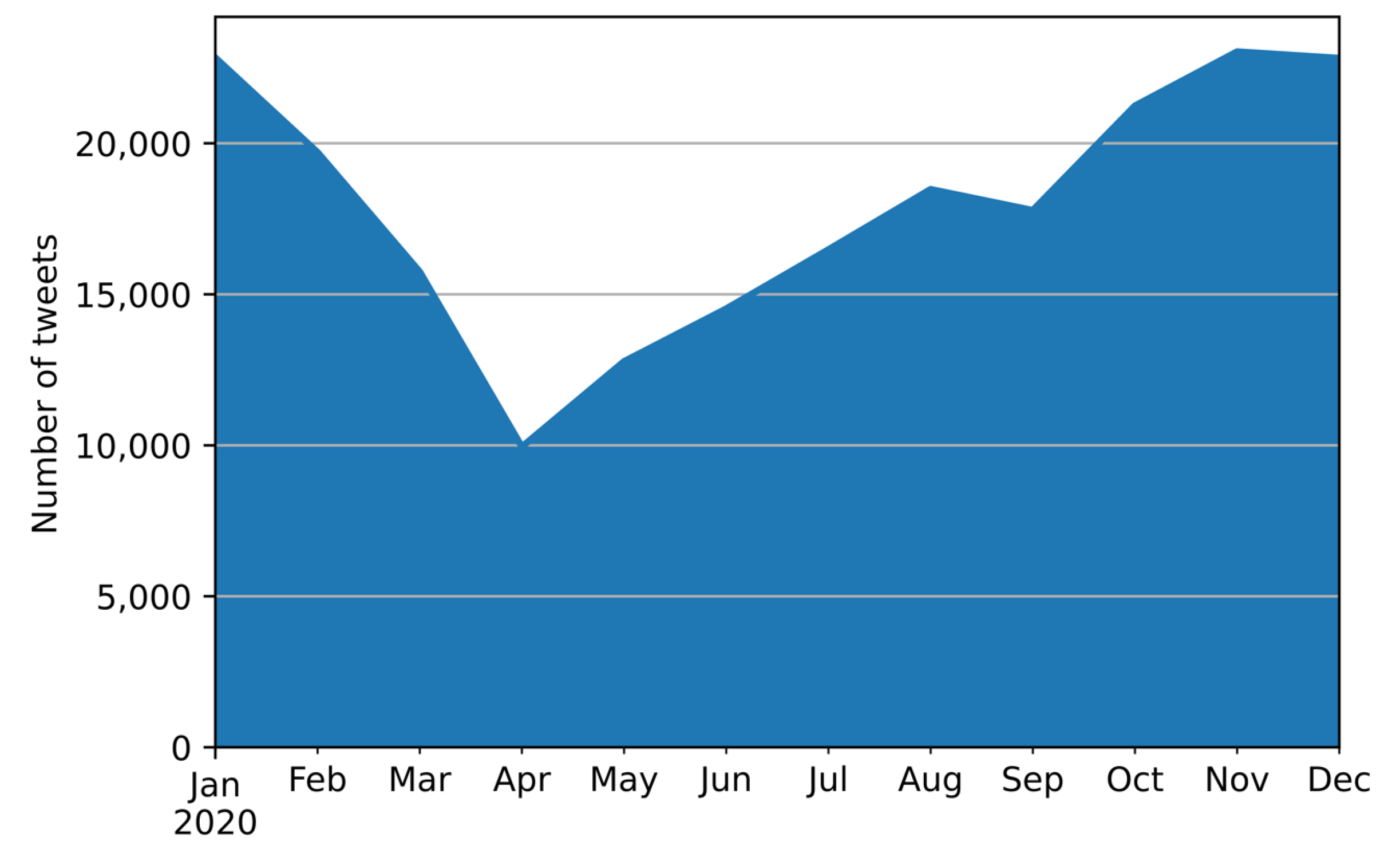
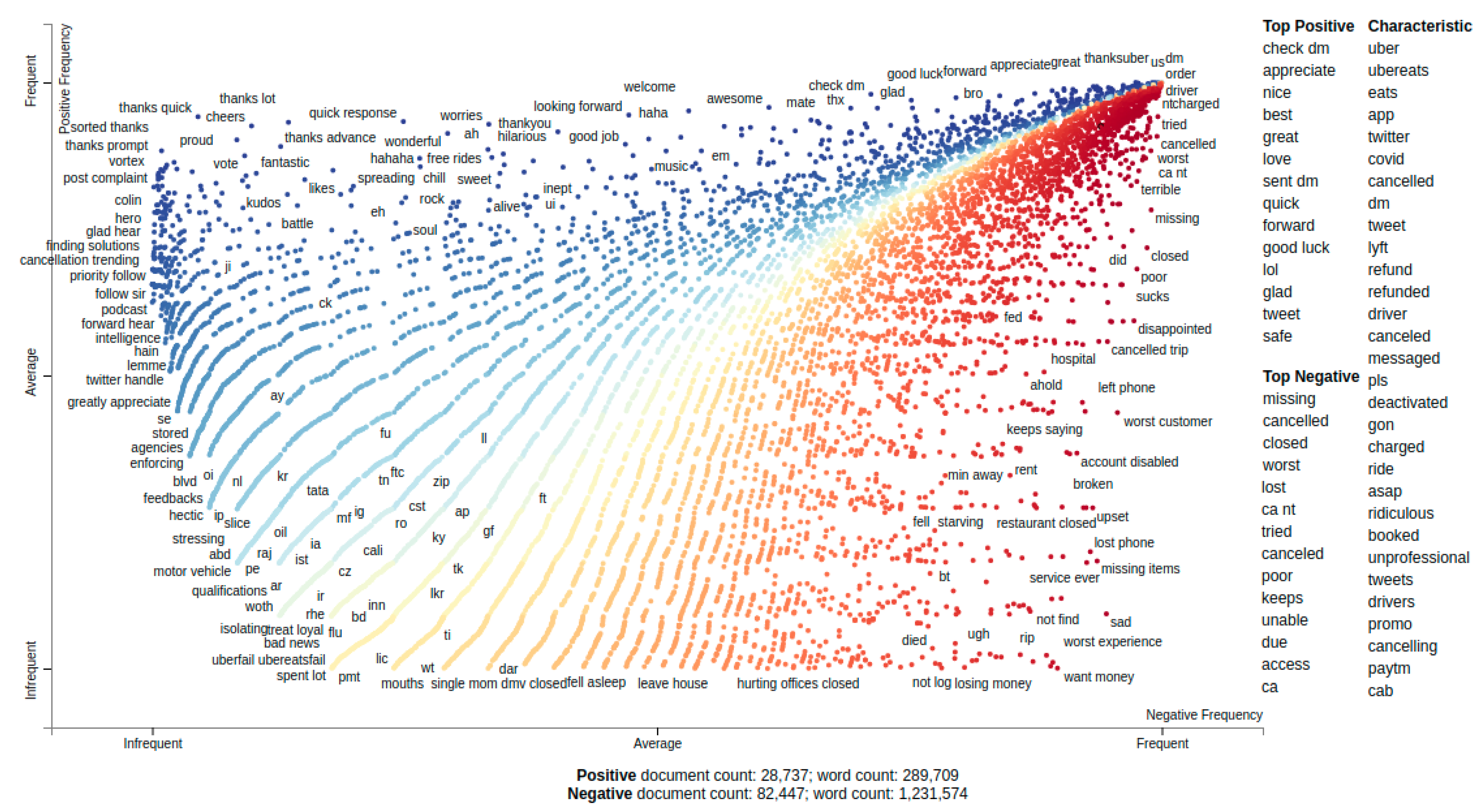
4.1. Data Collection and Global Analysis
4.2. Topic Modeling Performances and Results
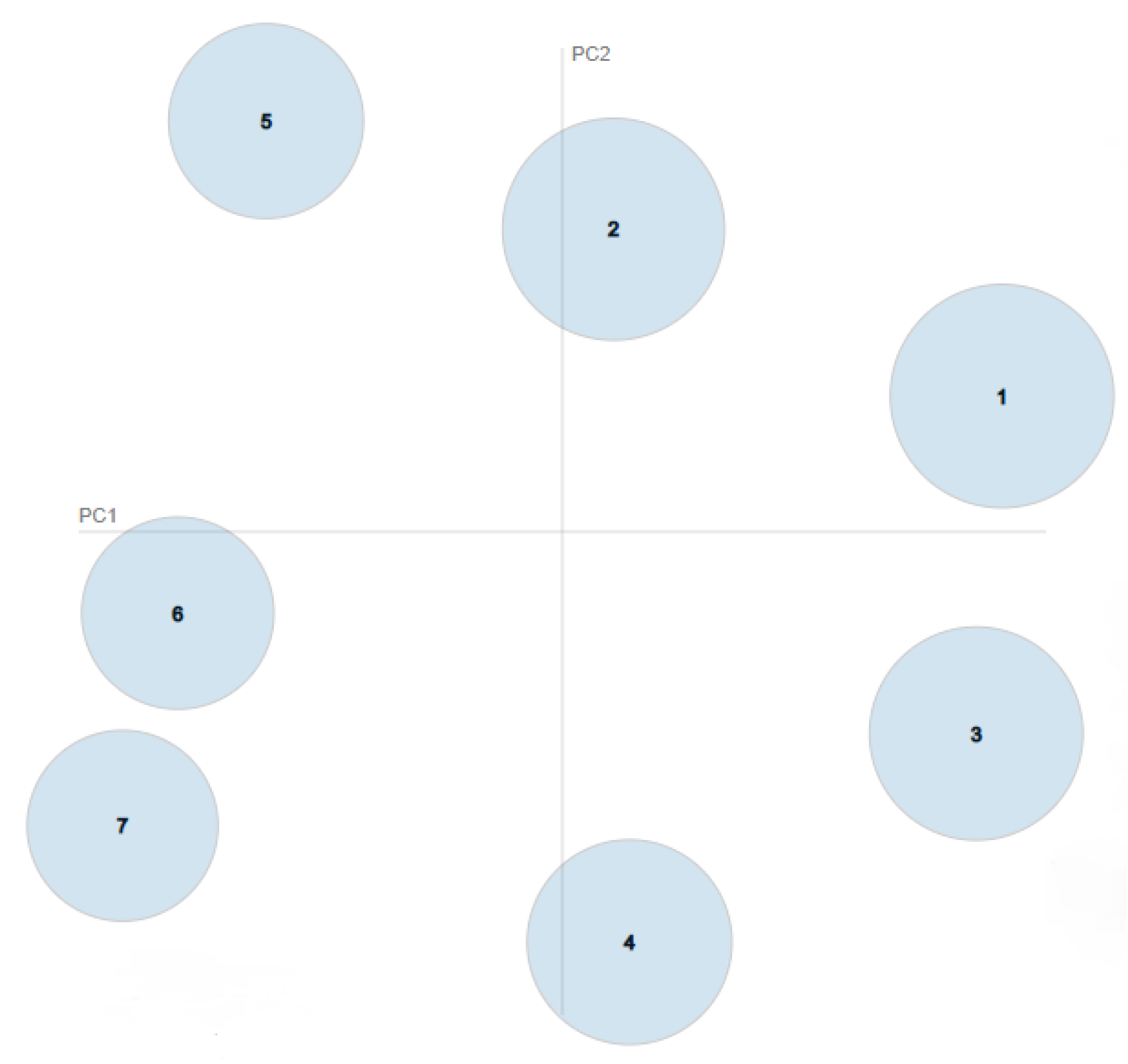
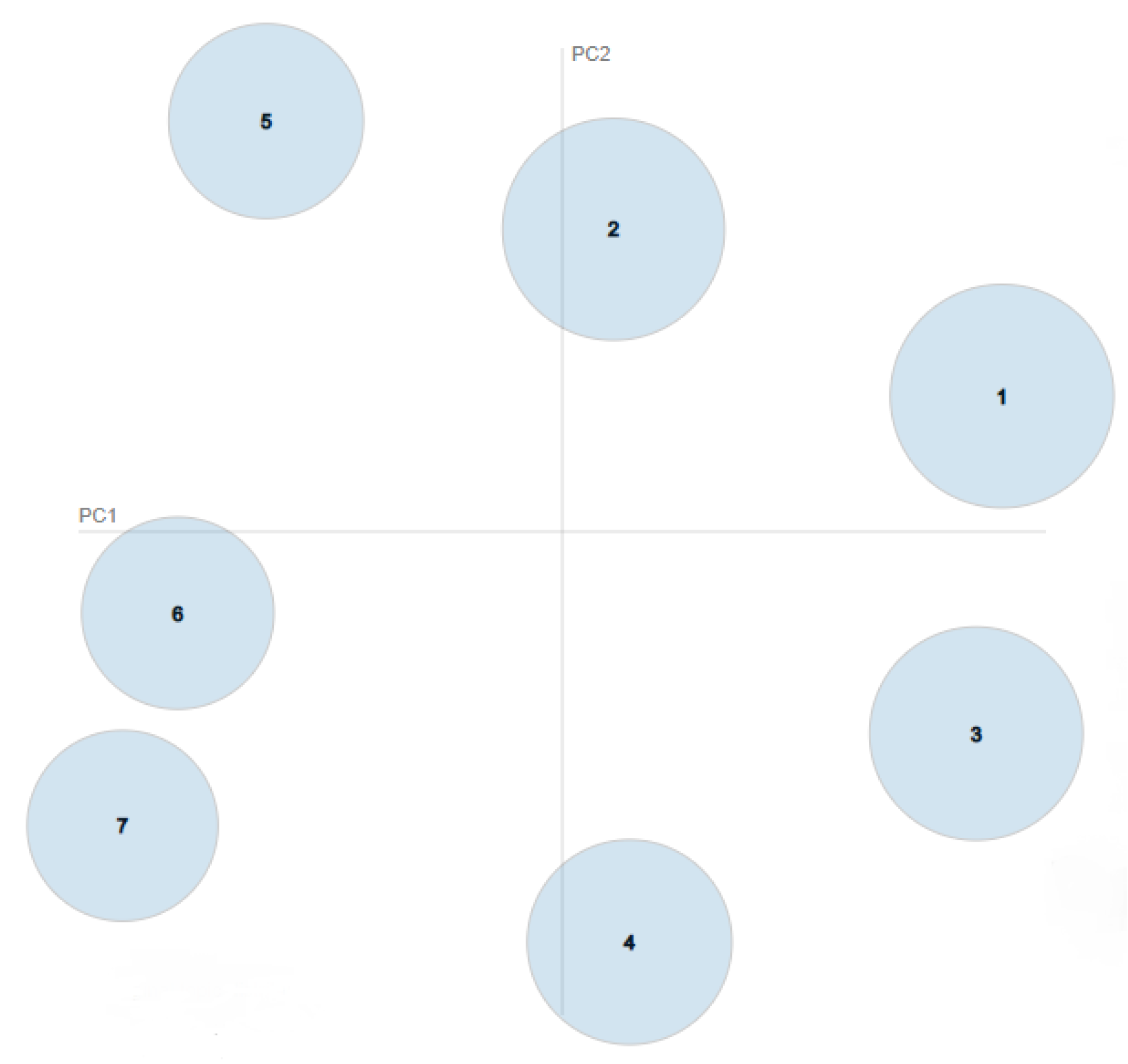
4.3. Clustering Performances and Results
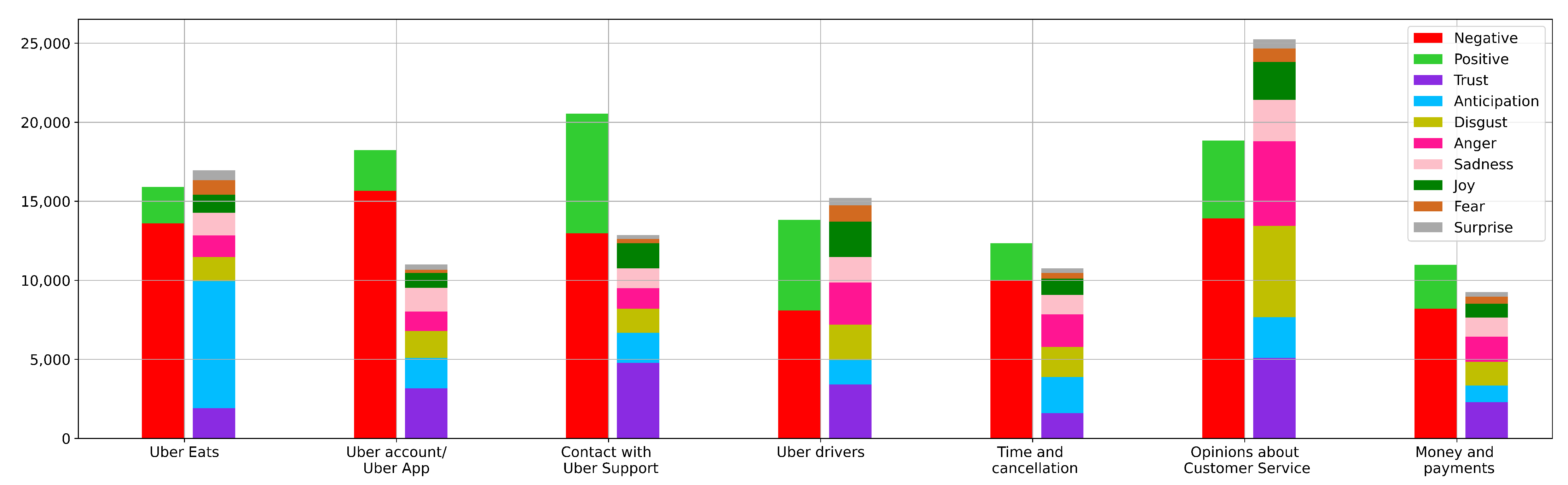
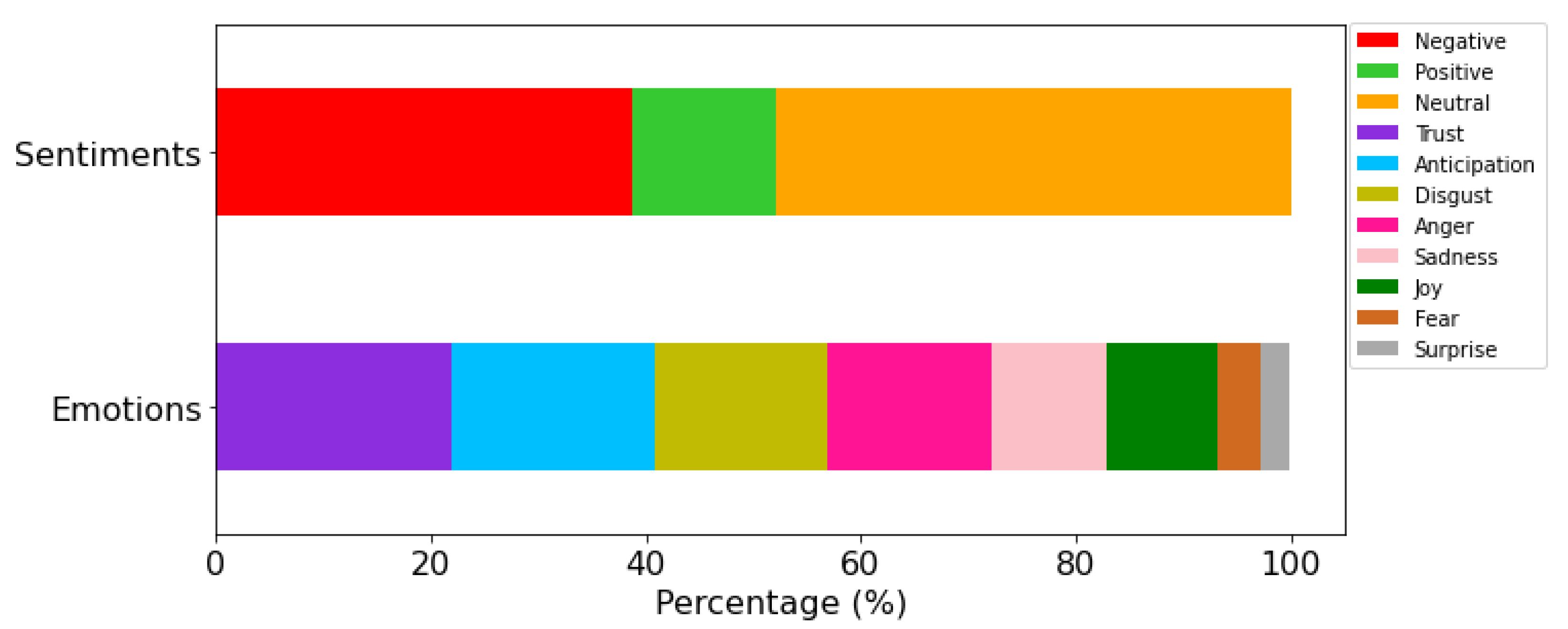
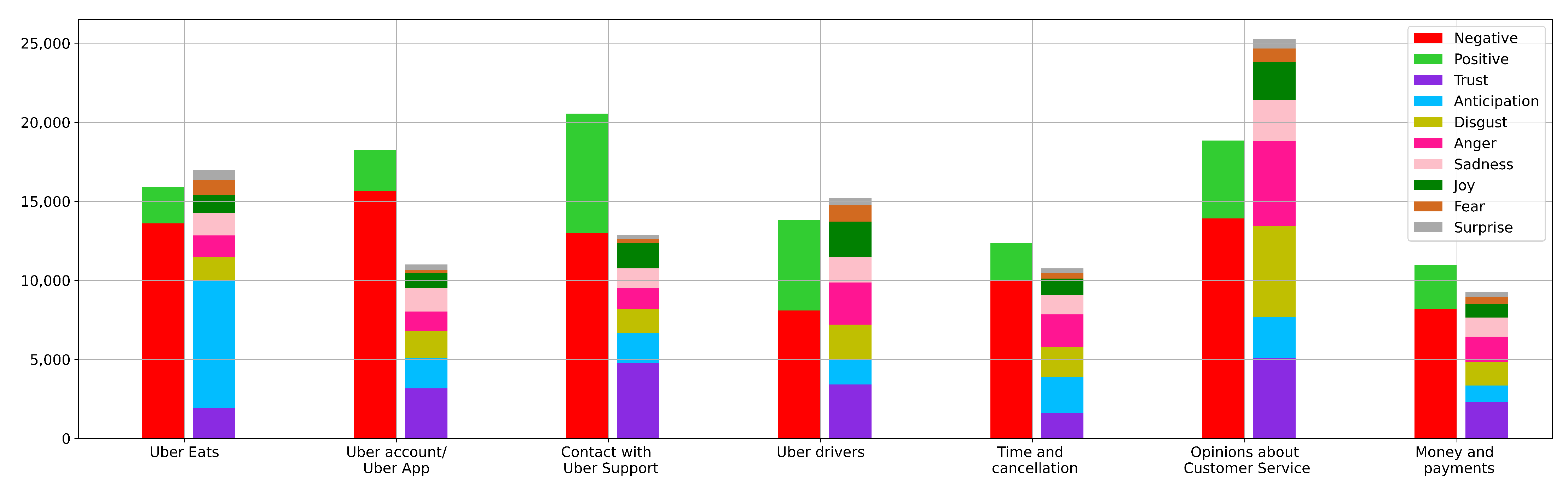
4.4. Sentiment and Emotion Analysis of Each Topic
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DEAP | Distributed Evolutionary Algorithms in Python |
| GA | Genetic Algorithm |
| LDA | Latent Dirichlet Allocation |
| LSI | Latent Semantic Analysis |
| MCMC | Markov Chain Monte Carlo |
| NLP | Natural Language Processing |
| NLTK | Natural Language Toolkit |
| NMF | Non-negative Matrix Factorization |
| POS | Part-Of-Speech |
| SLSQP | Sequential Least-Squares Programming |
| TWINT | Twitter Intelligence Tool |
References
- Subramanian, K. Influence of Social Media in Interpersonal Communication. Int. J. Sci. Prog. Res. (IJSPR) 2017, 109, 70–75. [Google Scholar]
- He, W.; Tian, X.; Chen, Y.; Chong, D. Actionable Social Media Competitive Analytics For Understanding Customer Experiences. J. Comput. Inf. Syst. 2016, 56, 145–155. [Google Scholar] [CrossRef]
- Baj-Rogowska, A. Sentiment analysis of Facebook posts: The Uber case. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 391–395. [Google Scholar]
- Morshed, S.A.; Khan, S.S.; Tanvir, R.B.; Nur, S. Impact of COVID-19 pandemic on ride-hailing services based on large-scale Twitter data analysis. J. Urban Manag. 2021, 10, 155–165. [Google Scholar] [CrossRef]
- Zulkarnain, Z.; Surjandari, I.; Wayasti, R. Sentiment Analysis for Mining Customer Opinion on Twitter: A Case Study of Ride-Hailing Service Provider. In Proceedings of the 5th International Conference on Information Science and Control Engineering (ICISCE), Zhengzhou, China, 20–22 July 2018; pp. 512–516. [Google Scholar] [CrossRef]
- Uber Customer Service Twitter Platform. Available online: https://twitter.com/Uber_Support (accessed on 21 June 2021).
- Wallsten, S. The Competitive Effects of the Sharing Economy: How is Uber Changing Taxis? Technol. Policy Inst. 2015, 22, 1–21. [Google Scholar]
- Statista. Number of Social Network Users Worldwide from 2017 to 2025. Available online: https://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/ (accessed on 21 June 2021).
- Malik, A.; Kapoor, D.; Singh, A. Sentiment Analysis on Political Tweets. In Proceedings of the Vth International Symposium on Fusion of Science and Technology, Prague, Czech Republic, 5–9 September 2016. [Google Scholar]
- Yu, Y.; Wang, X. World Cup 2014 in the Twitter World: A big data analysis of sentiments in U.S. sports fans’ tweets. Comput. Hum. Behav. 2015, 48, 392–400. [Google Scholar] [CrossRef]
- Gong, X.; Wang, Y. Exploring dynamics of sports fan behavior using social media big data—A case study of the 2019 National Basketball Association Finals. Appl. Geogr. 2021, 129, 102438. [Google Scholar] [CrossRef]
- Praveen, S.; Ittamalla, R.; Deepak, G. Analyzing Indian general public’s perspective on anxiety, stress and trauma during COVID-19—A machine learning study of 840,000 tweets. Diabetes Metab. Syndr. Clin. Res. Rev. 2021, 15, 667–671. [Google Scholar] [CrossRef] [PubMed]
- Ruan, Y.; Durresi, A.; Alfantoukh, L. Using Twitter trust network for stock market analysis. Knowl.-Based Syst. 2018, 145, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, N.F.; Wang, X. A text analytics approach for online retailing service improvement: Evidence from Twitter. Decis. Support Syst. 2019, 121, 37–50. [Google Scholar] [CrossRef] [Green Version]
- Pournarakis, D.E.; Sotiropoulos, D.N.; Giaglis, G.M. A computational model for mining consumer perceptions in social media. Decis. Support Syst. 2017, 93, 98–110. [Google Scholar] [CrossRef]
- Alamsyah, A.; Rizkika, W.; Nugroho, D.D.A.; Renaldi, F.; Saadah, S. Dynamic Large Scale Data on Twitter Using Sentiment Analysis and Topic Modeling. In Proceedings of the 2018 6th International Conference on Information and Communication Technology (ICoICT), Bandung, Indonesia, 3–4 May 2018; pp. 254–258. [Google Scholar] [CrossRef]
- Twitter Intelligence Tool (TWINT). Available online: https://github.com/twintproject/twint (accessed on 21 June 2021).
- Murugan, N.S.; Devi, G.U. Detecting streaming of Twitter spam using hybrid method. Wirel. Pers. Commun. 2018, 103, 1353–1374. [Google Scholar] [CrossRef]
- Gheewala, S.; Patel, R. Machine learning based Twitter Spam account detection: A review. In Proceedings of the 2018 Second International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 15–16 February 2018; pp. 79–84. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- NLTK: The Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 19 September 2021).
- Spacy: Industrial-Strength Natural Language Processing. Available online: https://spacy.io/ (accessed on 21 June 2021).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Li, X.; Fan, M.; Zhou, Y.; Fu, J.; Yuan, F.; Huang, L. Monitoring and forecasting the development trends of nanogenerator technology using citation analysis and text mining. Nano Energy 2020, 71, 104636. [Google Scholar] [CrossRef]
- Das, R.; Zaheer, M.; Dyer, C. Gaussian LDA for Topic Models with Word Embeddings. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 795–804. [Google Scholar] [CrossRef] [Green Version]
- Mimno, D.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011;–31; Volume 27–31, pp. 262–272. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stevens, K.; Kegelmeyer, P.; Andrzejewski, D.; Buttler, D. Exploring Topic Coherence over Many Models and Many Topics. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 952–961. [Google Scholar]
- Mifrah, S.; Benlahmar, E.H. Topic Modeling Coherence: A Comparative Study between LDA and NMF Models using COVID’19 Corpus. Int. J. Adv. Trends Comput. Sci. Eng. 2020. [Google Scholar] [CrossRef]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; pp. 63–70. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of MultiVariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Davis, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Fortin, F.A.; De Rainville, F.M.; Gardner, M.A.; Parizeau, M.; Gagné, C. DEAP: Evolutionary Algorithms Made Easy. J. Mach. Learn. Res. 2012, 13, 2171–2175. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sánchez-Rada, J.F.; Iglesias, C.A.; Corcuera-Platas, I.; Araque, O. Senpy: A Pragmatic Linked Sentiment Analysis Framework. In Proceedings of the DSAA 2016 Special Track on Emotion and Sentiment in Intelligent Systems and Big Social Data Analysis (SentISData), Montreal, QC, Canada, 17–19 October 2016; pp. 735–742. [Google Scholar]
- Ritthoff, O.; Klinkenberg, R.; Fischer, S.; Mierswa, I.; Felske, S. Yale: Yet Another Learning Environment; Technical Report; University of Dortmund: Dortmund, Germany, 2001. [Google Scholar] [CrossRef]
- MeaningCloud’s Deep Categorization API. Available online: https://www.meaningcloud.com/developer/deep-categorization (accessed on 21 June 2021).
- Kessler, J.S. Scattertext: A Browser-Based Tool for Visualizing how Corpora Differ. In Proceedings of the ACL 2017, System Demonstrations, Valencia, Spain, 3–7 April 2017; pp. 85–90. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Advances in Neural Information Processing Systems; Leen, T., Dietterich, T., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2001; Volume 13. [Google Scholar]
- Landauer, T.; Foltz, P.; Laham, D. An Introduction to Latent Semantic Analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Terragni, S.; Fersini, E.; Galuzzi, B.G.; Tropeano, P.; Candelieri, A. OCTIS: Comparing and Optimizing Topic Models is Simple! In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Online, 19–23 April 2021; pp. 263–270. [Google Scholar]
- Banerjee, A.; Basu, S. Topic Models over Text Streams: A Study of Batch and Online Unsupervised Learning; SDM: Philadelphia, PA, USA, 2007. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hashtags | Frecuency | Sentiment (%) | ||
|---|---|---|---|---|
| Positive | Negative | Neutral | ||
| #uber | 2207 | 18.12% | 38.92% | 42.95% |
| #ubereats | 1114 | 16.78% | 42.72% | 40.48% |
| #customerservice | 238 | 19.74% | 37.81% | 42.36% |
| #ubersucks | 224 | 9.82% | 37.5% | 52.67% |
| #boycottuber | 213 | 18.30% | 37.08% | 44.60% |
| #covid19 | 190 | 32.10% | 27.89% | 40% |
| #uberdriver | 174 | 14.36% | 46.55% | 39.08% |
| #fraud | 167 | 22.15% | 33.53% | 44.31% |
| #badcustomerservice | 157 | 26.75% | 31.84% | 41.40% |
| #customerexperience | 148 | 14.86% | 33.78% | 51.35% |
| Topic Modeling Evaluation | |||
|---|---|---|---|
| Evaluation Metrics | NMF | LDA | LSI |
| C_V | 0.4884 | 0.4902 | 0.3820 |
| UMass | −2.5915 | −2.727 | −2.2890 |
| UCI | 0.1641 | 0.1417 | 0.0039 |
| NPMI | 0.03629 | 0.03175 | 0.00496 |
| Topic Diversity | 0.6857 | 0.8142 | 0.3714 |
| Topic Name | Wordcloud | Topic Description |
|---|---|---|
| Uber account/Uber app |  | Customers reporting issues when logging into Uber app or validating their accounts. |
| Uber drivers |  | Customers reporting issues or giving their opinion about Uber drivers. This topic also includes Uber drivers asking for support about their licences and regulation. |
| Money and payments |  | Users contacting with Uber Support platform due to money issues and wrong payments on their accounts. |
| Uber Eats |  | Clients contacting with Uber Support to resolve issues related with Uber Eats platform. |
| Opinions about Customer Service |  | Tweets sharing the experience about contacting Customer Service or asking for additional support or refunds. |
| Time and cancellation | 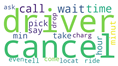 | Time related issues, including cancellation of the trip by the driver at the last minute and longer than expected waiting time to the driver to arrive. |
| Contact with Uber Support |  | Clients or drivers contacting directly with Uber Support to provide alternative ways of contact (email, telephone, direct message...) or answering previous conversations. |
| Topic Name | Predominant Component | No. Tweets (%) | ||
|---|---|---|---|---|
| Kmeans | Hybridized GA | Kmeans | Hybridized GA | |
| Uber account /Uber app | 0.5922 | 0.5931 | 15.21% | 15.22% |
| Contact with Uber Support | 0.6341 | 0.6348 | 20.93% | 20.94% |
| Time and cancellation | 0.5210 | 0.5226 | 10.23% | 10.23% |
| Opinions about customer service | 0.5777 | 0.5787 | 17.19% | 17.20% |
| Uber Eats | 0.5717 | 0.5738 | 12.35% | 12.33% |
| Money and payments | 0.5285 | 0.5317 | 10.50% | 10.47% |
| Uber drivers | 0.5040 | 0.5045 | 13.59% | 13.61% |
| Algorithms | K-Means | GA | Hybridized GA |
|---|---|---|---|
| Fitness | 0.08262 | 0.08576 | 0.08262 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno, A.; Iglesias, C.A. Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis. Appl. Sci. 2021, 11, 10169. https://doi.org/10.3390/app112110169
Moreno A, Iglesias CA. Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis. Applied Sciences. 2021; 11(21):10169. https://doi.org/10.3390/app112110169
Chicago/Turabian StyleMoreno, Alejandro, and Carlos A. Iglesias. 2021. "Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis" Applied Sciences 11, no. 21: 10169. https://doi.org/10.3390/app112110169
APA StyleMoreno, A., & Iglesias, C. A. (2021). Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis. Applied Sciences, 11(21), 10169. https://doi.org/10.3390/app112110169