
Modeling the Trip Distributions of Tourists Based on Trip Chain and Entropy-Maximizing Theory


Abstract
1. Introduction
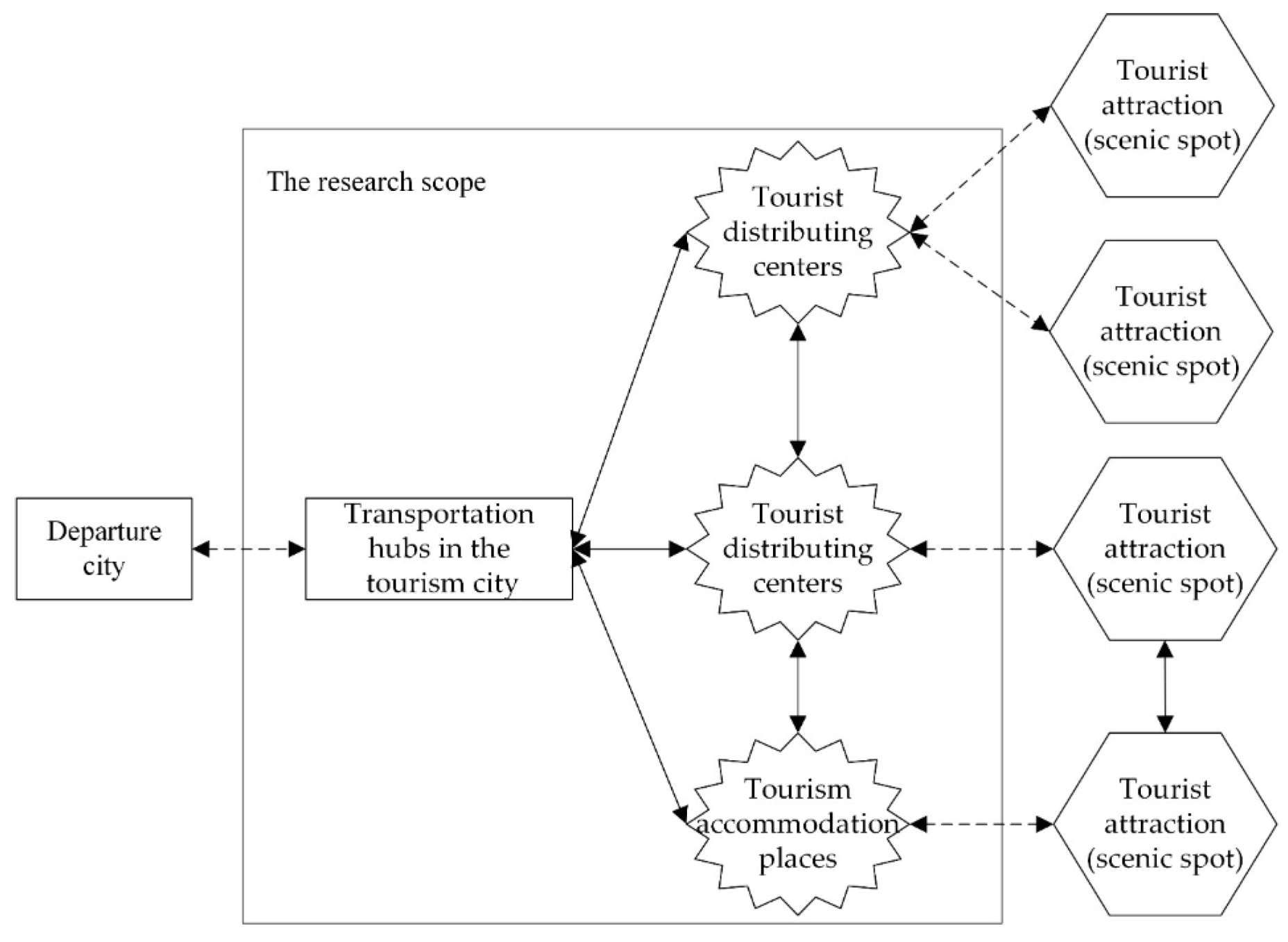
2. Trip Distribution Characteristics of Suburban Tourism Activities
- The multiple trips characteristic. Tourists usually like to visit multiple scenic spots when they travel in a tourism city. Each visit to a scenic spot is recorded as a trip. Thus, tourism activity could involve multiple trips. Note that the number of trips is generally limited due to the factors such as travel time and tourists’ willingness.
- The sequential characteristic. The travel paths of tourism activities are not randomly distributed but follow certain rules. For example, when tourists visit different scenic spots of a tourism city, they generally travel in a certain order. Specifically, they always travel starting from a departure point (e.g., a hotel or transportation hub), then arrive at various scenic spots, and finally end at an accommodation place or transportation hub. This indicates that the trips involved in tourism activity are sequential trips that can be linked as a trip chain.
- The trip distance characteristic. Activities between transportation hubs and scenic spots reflect the trip distance of tourists [23]. Trip distance between departure points and scenic spots, or between scenic spots, is a very important factor that can affect the time, costs, and experiences of tourism activities. It can be regarded as a traveling obstacle since long-distance travel is time-consuming, costly, and tiring. Thus, the scenic spots near the urban areas generally could attract more tourists.
- The clustering characteristic. Activity places of tourists in tourism cities mainly include transportation hubs, scenic spots (especially scenic spots close to each other), and accommodation places. Transportation hubs are distributing centers of tourists, scenic spots (tourist attractions) are the destinations of tourism activities, and accommodation places are the locations where tourists have rest, respectively. What they have in common is that they are the nodal areas that can attract and cluster a large number of tourists.
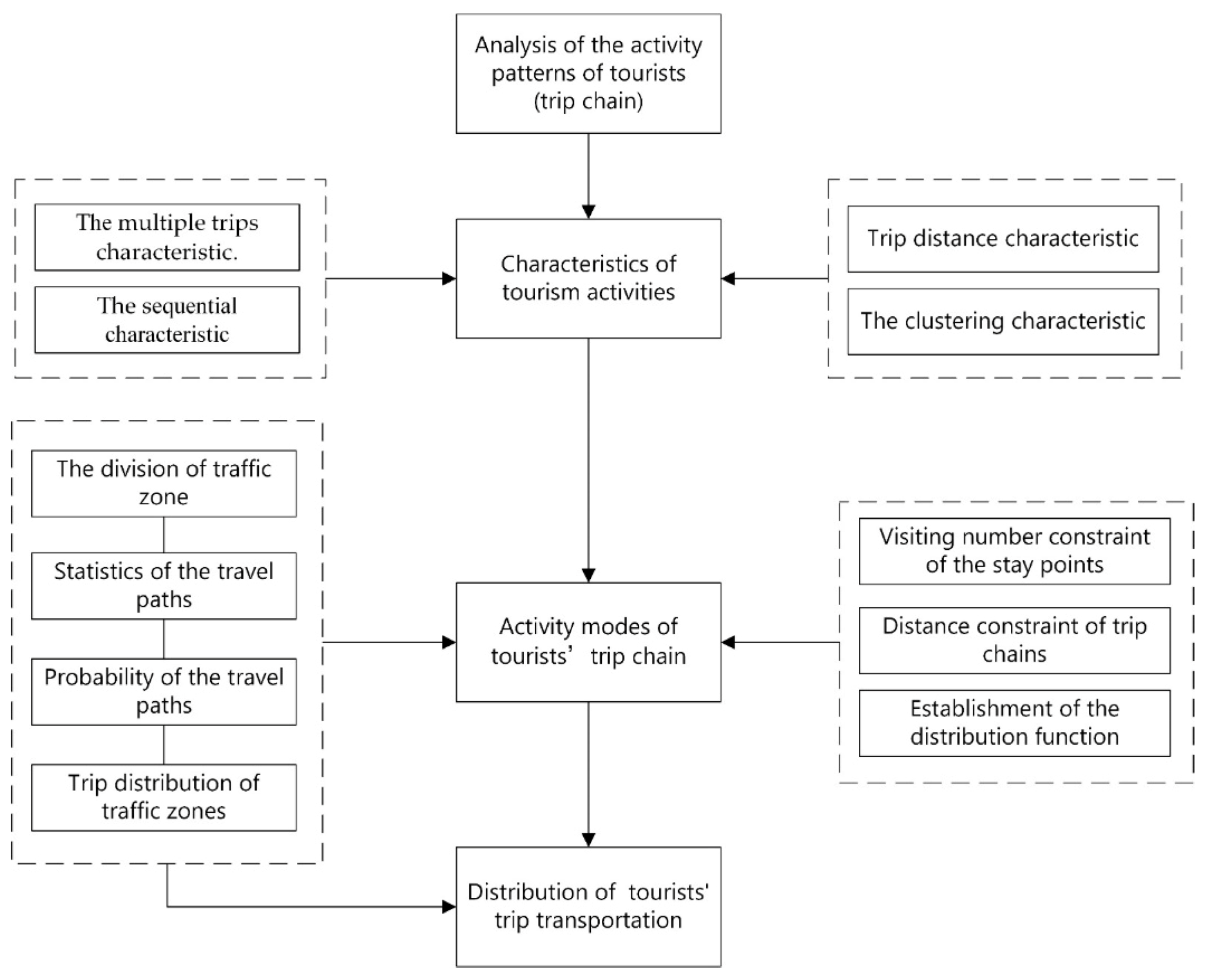
3. Tourist Trip Chain Modeling
3.1. Basic Idea for Trip Distribution Modeling
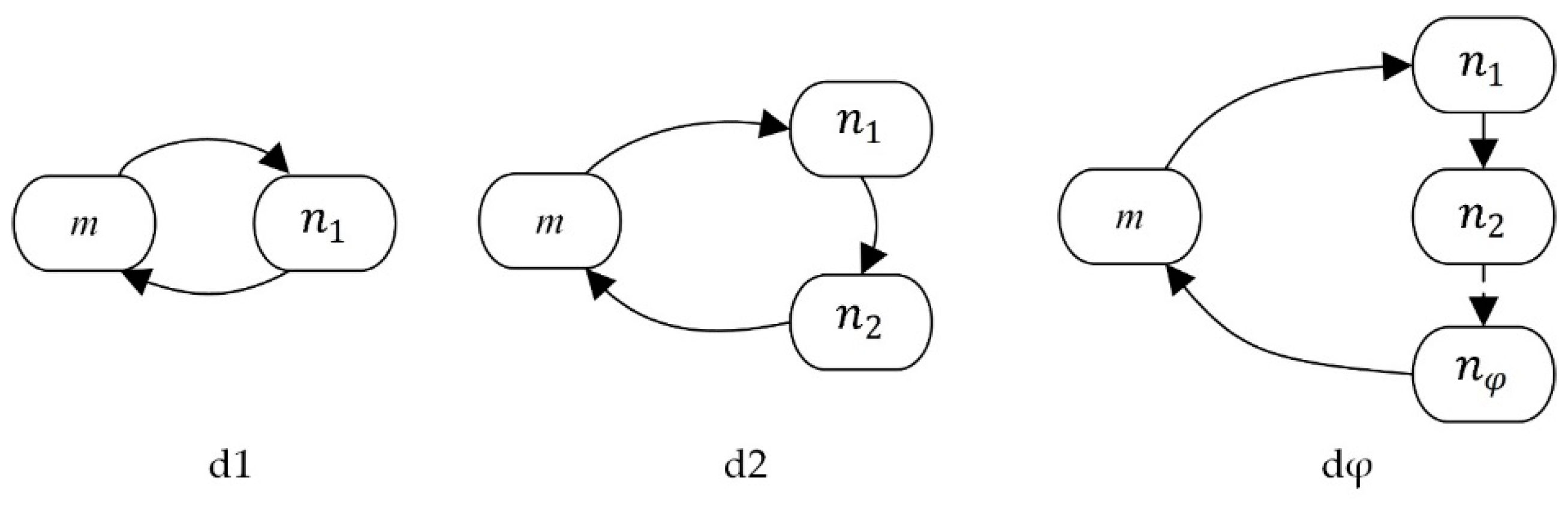
3.2. Basic Definitions of Tourist Trip Chain
3.3. The Number of Tourist Trip Chains
4. The Trip Distribution Forecasting Model Based on Trip Chains
4.1. Trip Chain Constraints
4.1.1. Visiting Volume Constraint of Stay Points
4.1.2. Trip Distance Constraint
4.2. Trip Distribution Forecasting Model
4.2.1. Objective Function
4.2.2. Model Building
4.2.3. Model Solving
- step 1: initialize parameter values, let γ = 1, λ = 1, , and the value of random residual ε = 0.05;
- step 2: calculate and according to Equation (14):where , .
- step 3: judge the two conditions and iteratively, if they satisfy, then go to step 4, otherwise let and back to step 2;
- step 4: let and calculate iteratively using Newton’s method, as shown in Equation (15):if the iterative calculation satisfies the condition , then end the iteration, otherwise let .
- step 5: let , then go back to step 2.
4.2.4. Model Inputs, Outputs, and Application
- Model inputs.
- 2.
- Model outputs.
- 3.
- Model application.
5. Case Study
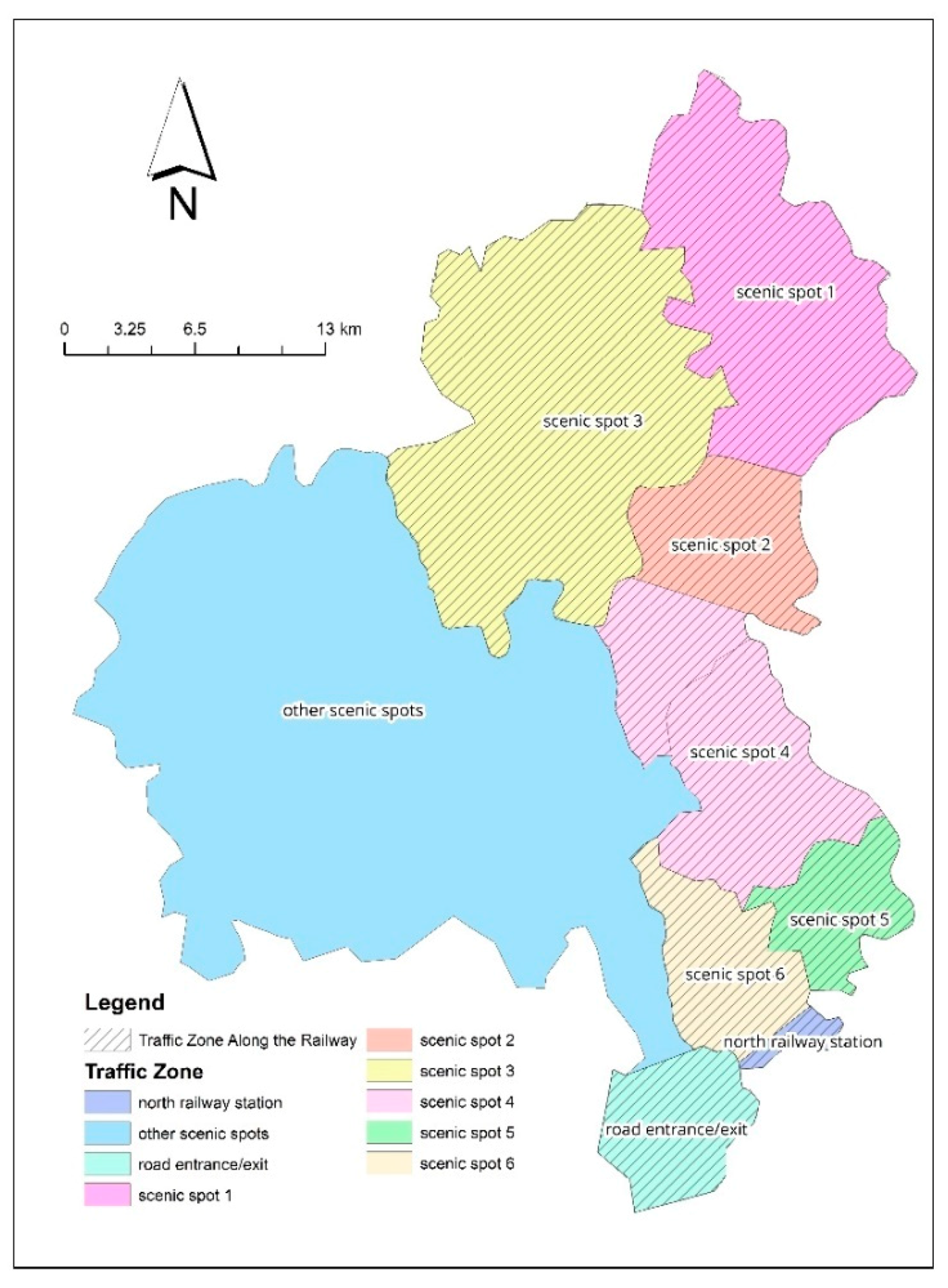
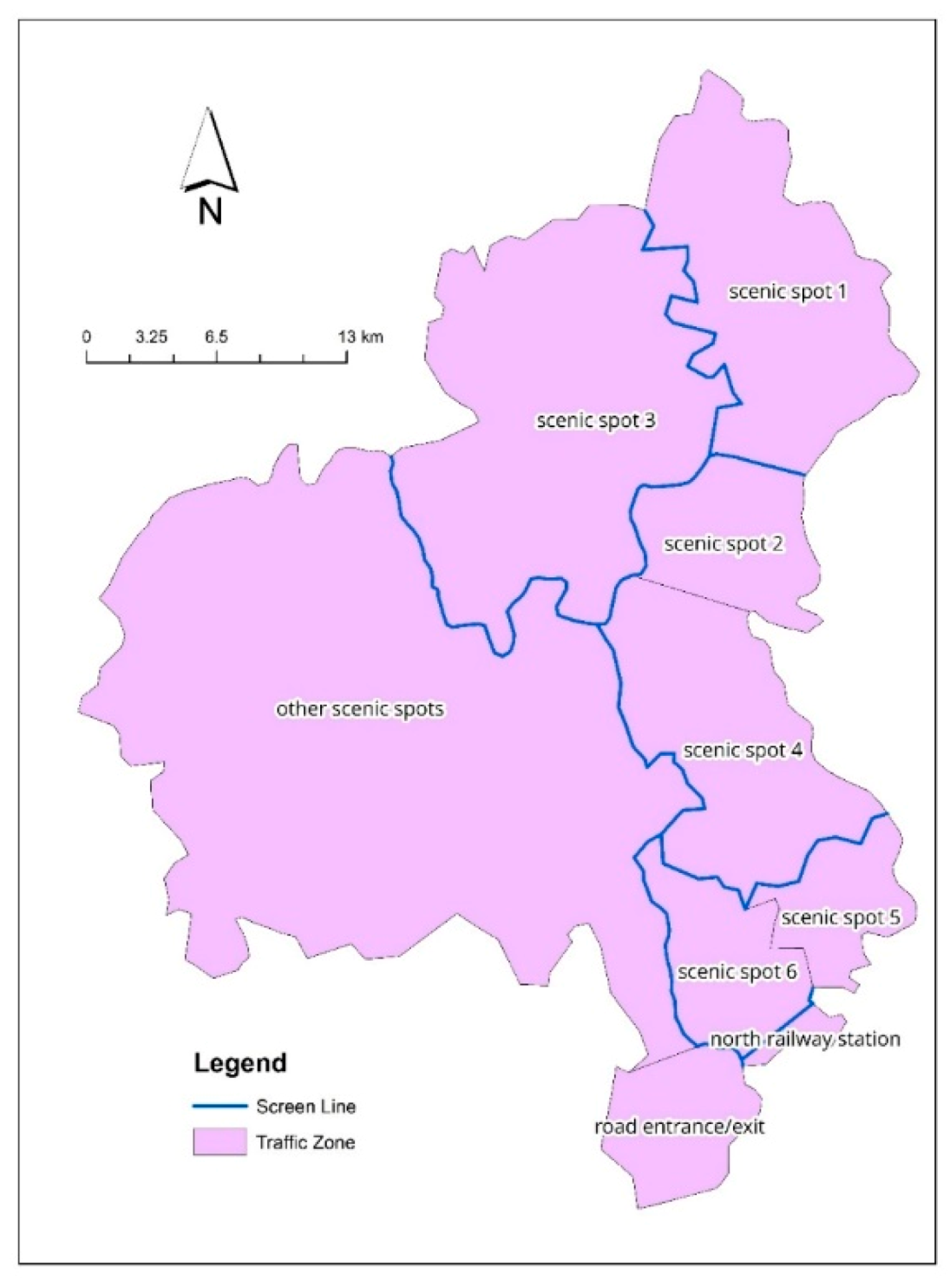
5.1. Problem Statement
5.2. Study Data
- 1.
- Distributing volume of traffic zone
- 2.
- Trip distance
5.3. Calculation of Model Parameters
5.4. Results and Analysis
- 1.
- Trip chain probability distribution
- 2.
- Analysis of the trip chain types
- 3.
- Analysis of trip distance
- 4.
- Analysis of trip distribution
- 5.
- Screenline Test
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Caffyn, A. Advocating and implementing slow tourism. Tour. Recreat. Res. 2012, 37, 77–80. [Google Scholar] [CrossRef]
- Sun, Y.-Y.; Lin, Z.-W. Move fast, travel slow: The influence of high-speed rail on tourism in Taiwan. J. Sustain. Tour. 2017, 26, 433–450. [Google Scholar] [CrossRef]
- Zhao, G.; Zhou, S. Today and future of suburban railway in China. China Railw. 2018, 8, 1–10. [Google Scholar]
- Li, X.; Yang, T.; Shi, Q. Applicative suburban line pattern of urban rail transit in China. Procedia-Soc. Behav. Sci. 2013, 96, 2260–2266. [Google Scholar] [CrossRef][Green Version]
- Xu, D.; Wang, Q.; Zhang, J.; Zhao, N.; Yan, B. Research on characteristics of urban tourism flow in multi-time scale based on big data: A case study of Nanjing. Mod. Urban Res. 2020, 1, 113–121. [Google Scholar]
- Li, W.; Lin, H. Research on spatiotemporal dynamic of the passenger flow distribution in in-bound tourism destination in Inner Mongolia. J. Arid. Land Resour. Environ. 2016, 30, 195–201. [Google Scholar]
- Song, T.; Guo, S. Construction and verification of big data statistical model for tourist flow. Stat. Decis. 2020, 24, 38–41. [Google Scholar]
- Cascetta, E.; Pagliara, F.; Papola, A. Alternative approaches to trip distribution modelling: A retrospective review and suggestions for combining different approaches. Pap. Reg. Sci. 2007, 86, 597–620. [Google Scholar] [CrossRef]
- Zipf, G.K. The P1 P2D Hypothesis: On the Intercity Movement of Persons. Am. Sociol. Rev. 1946, 11, 677. [Google Scholar] [CrossRef]
- Wilson, A. Entropy in Urban and Regional Modelling: Retrospect and Prospect. Geogr. Anal. 2010, 42, 364–394. [Google Scholar] [CrossRef]
- Erlander, S.; Stewart, N.F. The Gravity Model in Transportation Analysis: Theory and Extensions; VSP: Utrecht, The Netherlands, 1990; Volume 3. [Google Scholar]
- Stouffer, S.A. Intervening Opportunities: A Theory Relating Mobility and Distance. Am. Sociol. Rev. 1940, 5, 845–867. [Google Scholar] [CrossRef]
- Sheffi, Y. Urban Transportation Networks: Equilibrium Analysis with Mathematical Programming Methods; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1984. [Google Scholar]
- Pinjari, A.R.; Bhat, C.R. Activity-based travel demand analysis. In A Handbook of Transport Economics; Edward Elgar Publishing: Cheltenham, UK, 2011. [Google Scholar]
- Ding, W.; Yang, X.; Wu, S. A Review of activity-based travel behavior research. Hum. Geogr. 2008, 23, 85–91. [Google Scholar]
- Tian, G.; Zhang, Y.; Li, B. Tourism traffic demand forecast based on markov chain. In Proceedings of the 2013 China Urban Transportation Planning Annual Conference and the 27th Seminar, Beijing, China, 11 April 2014; pp. 1–8. [Google Scholar]
- Golob, T.F. A simultaneous model of household activity participation and trip chain generation. Transp. Res. Part B Methodol. 2000, 34, 355–376. [Google Scholar] [CrossRef]
- Primerano, F.; Taylor, M.A.P.; Pitaksringkarn, L.; Tisato, P. Defining and understanding trip chaining behaviour. Transportation 2007, 35, 55–72. [Google Scholar] [CrossRef]
- Wilson, A. A statistical theory of spatial distribution models. Transp. Res. 1967, 1, 253–269. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, S.; Chen, X.; Liu, F.; Zou, Y. Taxi trips distribution modeling based on Entropy-Maximizing theory: A case study in Harbin city—China. Phys. A Stat. Mech. Appl. 2018, 493, 430–443. [Google Scholar] [CrossRef]
- Pourebrahim, N.; Sultana, S.; Niakanlahiji, A.; Thill, J.-C. Trip distribution modeling with Twitter data. Comput. Environ. Urban Syst. 2019, 77, 101354. [Google Scholar] [CrossRef]
- Anda, C.; Erath, A.; Fourie, P. Transport modelling in the age of big data. Int. J. Urban Sci. 2015, 21, 19–42. [Google Scholar] [CrossRef]
- Lv, J.; Dong, Z.; Wu, B. Research on trip characteristics of intercity travel based on trip chain theory. Transp. Sci. Technol. 2014, 1, 102–105. [Google Scholar]
- Li, Z. Traffic Engineering, 3rd ed.; China Communications Press: Beijing, China, 2017. [Google Scholar]
- Chu, H.; Zheng, M.; Yang, X.; Han, X. A Study on trip-chain indices and their application. Urban Transp. China 2006, 4, 64–67. [Google Scholar]
- Zhao, X.; Guan, H. Activity-based model for tourist’s trip-chain choice behavior. J. Chongqing Jiaotong Univ. (Nat. Sci.) 2012, 31, 1207–1210. [Google Scholar]
- Grant-Muller, S.M.; Gal-Tzur, A.; Minkov, E.; Nocera, S.; Kuflik, T.; Shoor, I. Enhancing transport data collection through social media sources: Methods, challenges and opportunities for textual data. IET Intell. Transp. Syst. 2015, 9, 407–417. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic Zone Code | Traffic Zone | Trips Volume (10,000 Person/Year) |
|---|---|---|
| 1 | scenic spot 1 | 56 |
| 2 | scenic spot 2 | 125 |
| 3 | scenic spot 3 | 338 |
| 4 | scenic spot 4 | 86 |
| 5 | scenic spot 5 | 107 |
| 6 | scenic spot 6 | 42 |
| 7 | other scenic spots | 400 |
| 8 | north railway station | 379 |
| 9 | traffic zones based on the entrance/exit of roads | 595 |
| Traffic Zone Code | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 6586 | 14,709 | 24,801 | 32,110 | 37,291 | 29,416 | 40,013 | 44,567 |
| 2 | 6586 | 0 | 8221 | 18,547 | 26,144 | 31,285 | 23,114 | 34,172 | 38,304 |
| 3 | 14,709 | 8221 | 0 | 10,468 | 18,312 | 23,362 | 16,758 | 26,405 | 30,145 |
| 4 | 24,801 | 18,547 | 10,468 | 0 | 8025 | 12,936 | 14,990 | 16,090 | 19,774 |
| 5 | 32,110 | 26,144 | 18,312 | 8025 | 0 | 5186 | 19,863 | 8097 | 13,027 |
| 6 | 37,291 | 31,285 | 23,362 | 12,936 | 5186 | 0 | 22,423 | 3475 | 8224 |
| 7 | 29,416 | 23,114 | 16,758 | 14,990 | 19,863 | 22,423 | 0 | 25,832 | 24,850 |
| 8 | 40,013 | 34,172 | 26,405 | 16,090 | 8097 | 3475 | 25,832 | 0 | 7797 |
| 9 | 44,567 | 38,304 | 30,145 | 19,774 | 13,027 | 8224 | 24,850 | 7797 | 0 |
| Trip Chain Code | Actual Trip Chain | Trip Chain Code | Actual Trip Chain |
|---|---|---|---|
| 93 | RE1→SS2 3→RE | 95 | RE→SS 5→RE |
| 87 | NRS3→OSS4→NRS | 875 | NRS→OSS→SS 5→NRS |
| 97 | RE→OSS→RE | 925 | RE→SS 2→SS 5→RE |
| 83 | NRS→SS 3→ NRS | 935 | RE→SS 3→SS 5→RE |
| 92 | RE→SS 2→RE | 91 | RE→SS 1→RE |
| 94 | RE→SS 4→RE | 975 | RE→OSS→SS 5→RE |
| 82 | NRS→SS 2→NRS | 937 | RE→SS 3→OSS→RE |
| 84 | NRS→SS 4→NRS | …… | …… |
| Trip Chain Type | Trip Probability | Trip Chain Volume | Trip Volume (Including Trip Times) |
|---|---|---|---|
| simple trip chain | 0.78 | 7,580,051 | 15,120,493 |
| complex trip chain | 0.22 | 2,159,949 | 4,319,897 |
| total | 1 | 9,740,000 | 19,440,390 |
| Trip Distance (km) | Trip Probability |
|---|---|
| 0–5 | 0.00 |
| 5–10 | 0.01 |
| 10–15 | 0.02 |
| 15–20 | 0.06 |
| 20–25 | 0.15 |
| 25–30 | 0.25 |
| 30–35 | 0.22 |
| 35–40 | 0.06 |
| 40–45 | 0.07 |
| 45–50 | 0.06 |
| 50–55 | 0.03 |
| 55–60 | 0.02 |
| 60–65 | 0.01 |
| 65–70 | 0.01 |
| 70–75 | 0.01 |
| 75–80 | 0.01 |
| 80–85 | 0.01 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 86 | 5035 | 34,829 | 142,783 | 77,663 | 115,083 | 59,784 | 139,798 |
| 2 | 30 | 0 | 6489 | 46,715 | 201,113 | 108,646 | 153,099 | 243,055 | 531,318 |
| 3 | 453 | 1655 | 0 | 44,640 | 200,411 | 106,623 | 196,085 | 973,308 | 1,981,777 |
| 4 | 539 | 2050 | 7680 | 0 | 7465 | 3878 | 31,080 | 287,882 | 545,574 |
| 5 | 658 | 2630 | 10,273 | 2224 | 0 | 366 | 25,087 | 373,347 | 668,736 |
| 6 | 160 | 633 | 2437 | 515 | 163 | 0 | 3896 | 147,907 | 267,426 |
| 7 | 5875 | 22,181 | 111,360 | 102,591 | 277,942 | 96,829 | 0 | 1,705,019 | 1,815,069 |
| 8 | 166,177 | 388,441 | 1,083,681 | 212,398 | 70,919 | 8334 | 1,860,353 | 0 | 0 |
| 9 | 401,168 | 872,790 | 2,277,997 | 442,236 | 182,525 | 20,797 | 1,752,184 | 0 | 0 |
| Screenline Number | One Side of the Screenline | Another Side of the Screenline | Road Name | Line Segment |
|---|---|---|---|---|
| 1 | scenic spot 1 | non-scenic spot 1 | G3 | scenic spot 3 and 1 |
| G205 | scenic spot 3 and 1 | |||
| 2 | scenic spot 3 | non-scenic spot 3 | Gangcun Road | scenic spot 3 and other scenic spots |
| S103 | scenic spot 3 and other scenic spots | |||
| G3 | scenic spot 3 and 2 | |||
| 3 | scenic spot 2 and 4 | non-scenic spot 3 and 4 | G3 | scenic spot 3 and 2 |
| S103 | other scenic spots and scenic spot 4 | |||
| G205 | scenic spot 4 and 5 | |||
| 4 | scenic spot 5 and 6 | non-scenic spot 5 and 6 | G3 | scenic spot 6 and road entrance/exit |
| Yingbin Boulevard | other scenic spots and scenic spot 4 | |||
| G205 | scenic spot 4 to scenic spot 5 |
| Screenline | Actual Survey Data of Tourists | Screenline Allocated Data of Tourists | Error |
|---|---|---|---|
| 1 | 500,202 | 575,060 | 13.02% |
| 2 | 3,925,237 | 3,504,952 | −11.99% |
| 3 | 2,009,114 | 2,176,614 | 7.70% |
| 4 | 1,336,327 | 1,506,457 | 11.29% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Z.-W.; Yu, S.; Ji, T. Modeling the Trip Distributions of Tourists Based on Trip Chain and Entropy-Maximizing Theory. Appl. Sci. 2021, 11, 10058. https://doi.org/10.3390/app112110058
Hou Z-W, Yu S, Ji T. Modeling the Trip Distributions of Tourists Based on Trip Chain and Entropy-Maximizing Theory. Applied Sciences. 2021; 11(21):10058. https://doi.org/10.3390/app112110058
Chicago/Turabian StyleHou, Zhi-Wei, Shijun Yu, and Tao Ji. 2021. "Modeling the Trip Distributions of Tourists Based on Trip Chain and Entropy-Maximizing Theory" Applied Sciences 11, no. 21: 10058. https://doi.org/10.3390/app112110058
APA StyleHou, Z.-W., Yu, S., & Ji, T. (2021). Modeling the Trip Distributions of Tourists Based on Trip Chain and Entropy-Maximizing Theory. Applied Sciences, 11(21), 10058. https://doi.org/10.3390/app112110058