
Fast Performance Modeling across Different Database Versions Using Partitioned Co-Kriging

Abstract
1. Introduction
- We perform a proof of concept that transferring the knowledge across different database versions using PCK can facilitate the fast performance modeling for a newer database version.
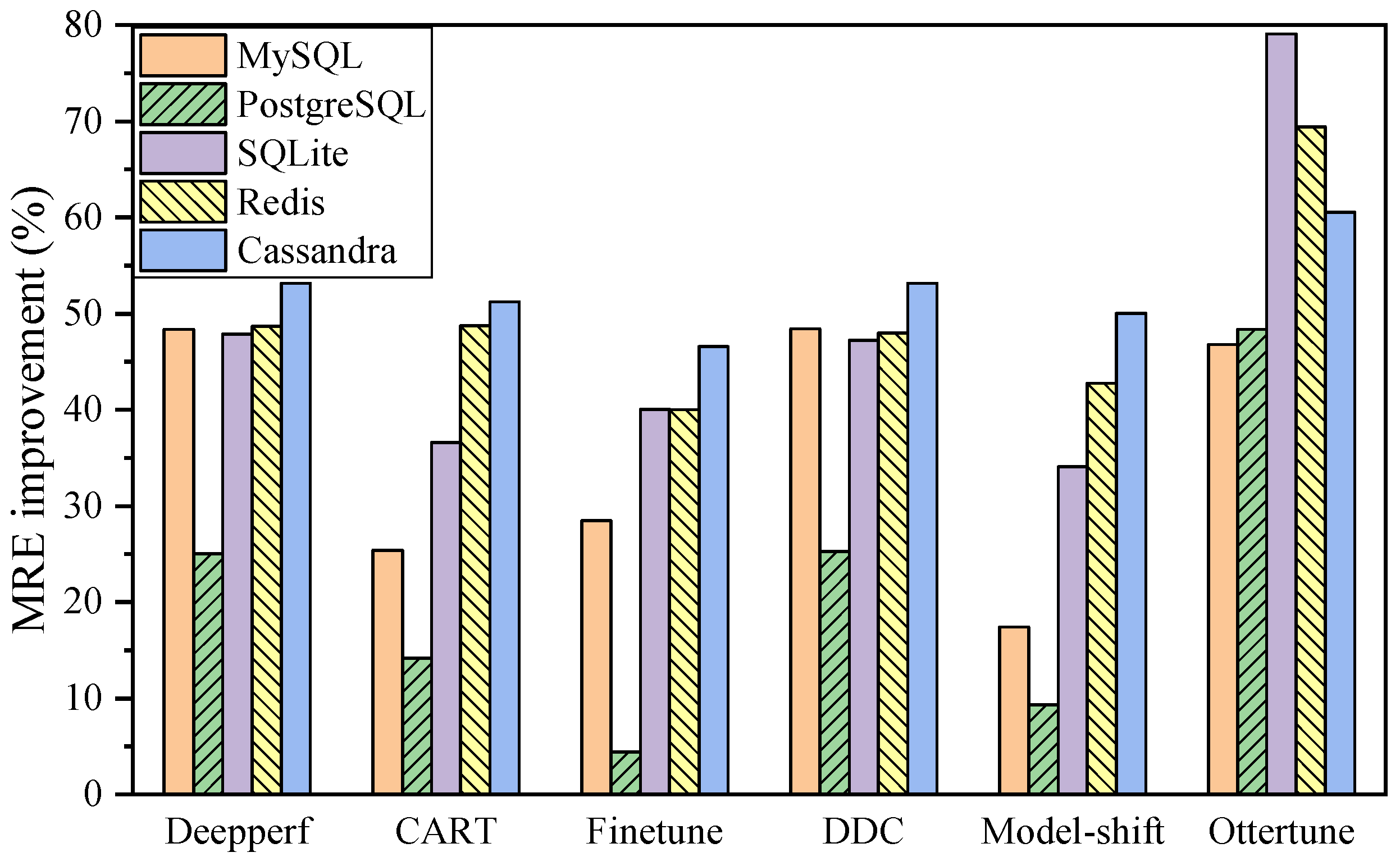
- We verify the feasibility and validity of PCK through extensive experiments under different categories of database systems with different versions. Experimental results show that our proposal outperforms six state-of-the-art baseline algorithms by 30.73–60.83% on average.
2. Related Work
3. Problem Overview
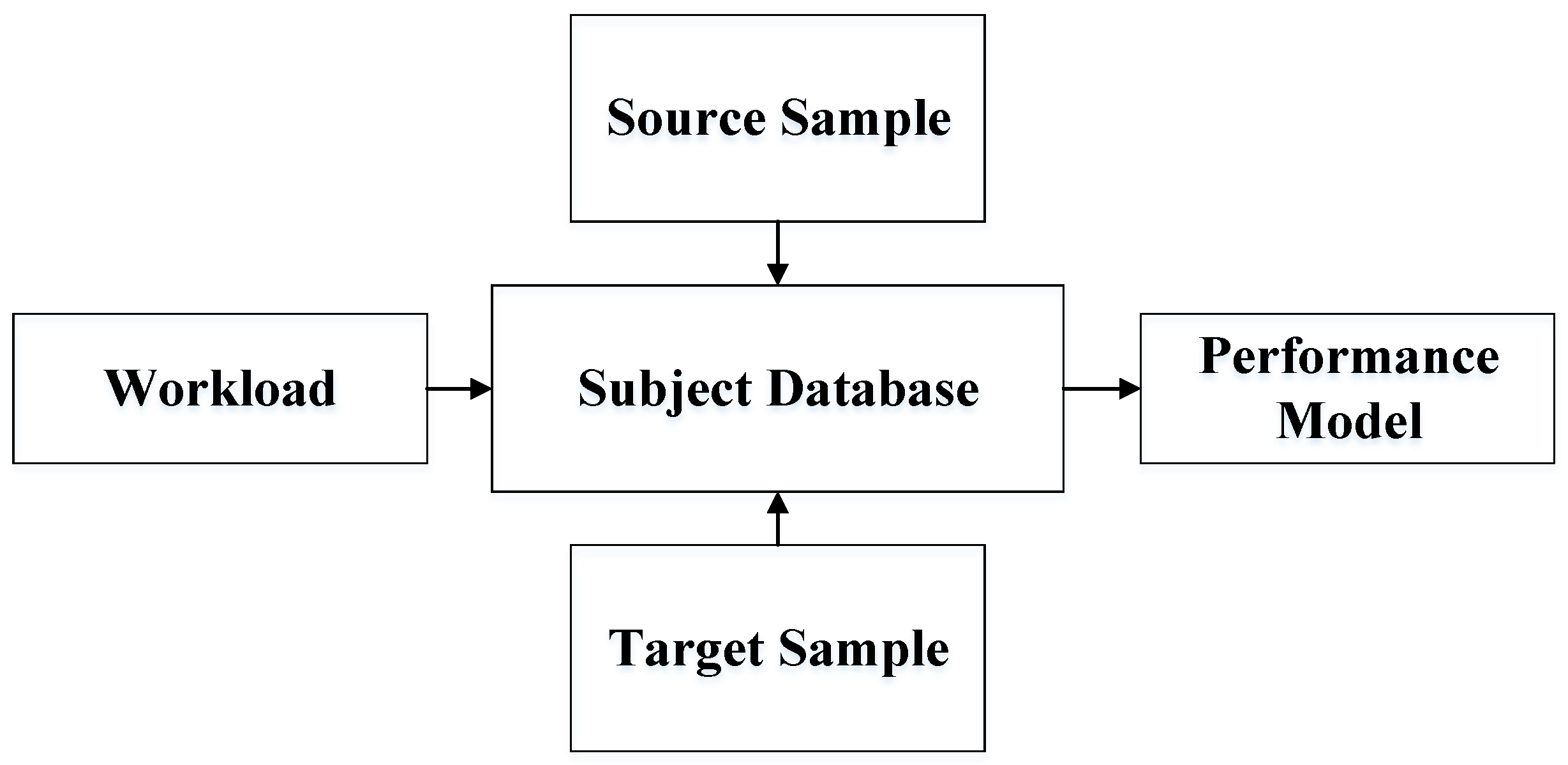
3.1. Problem Statement
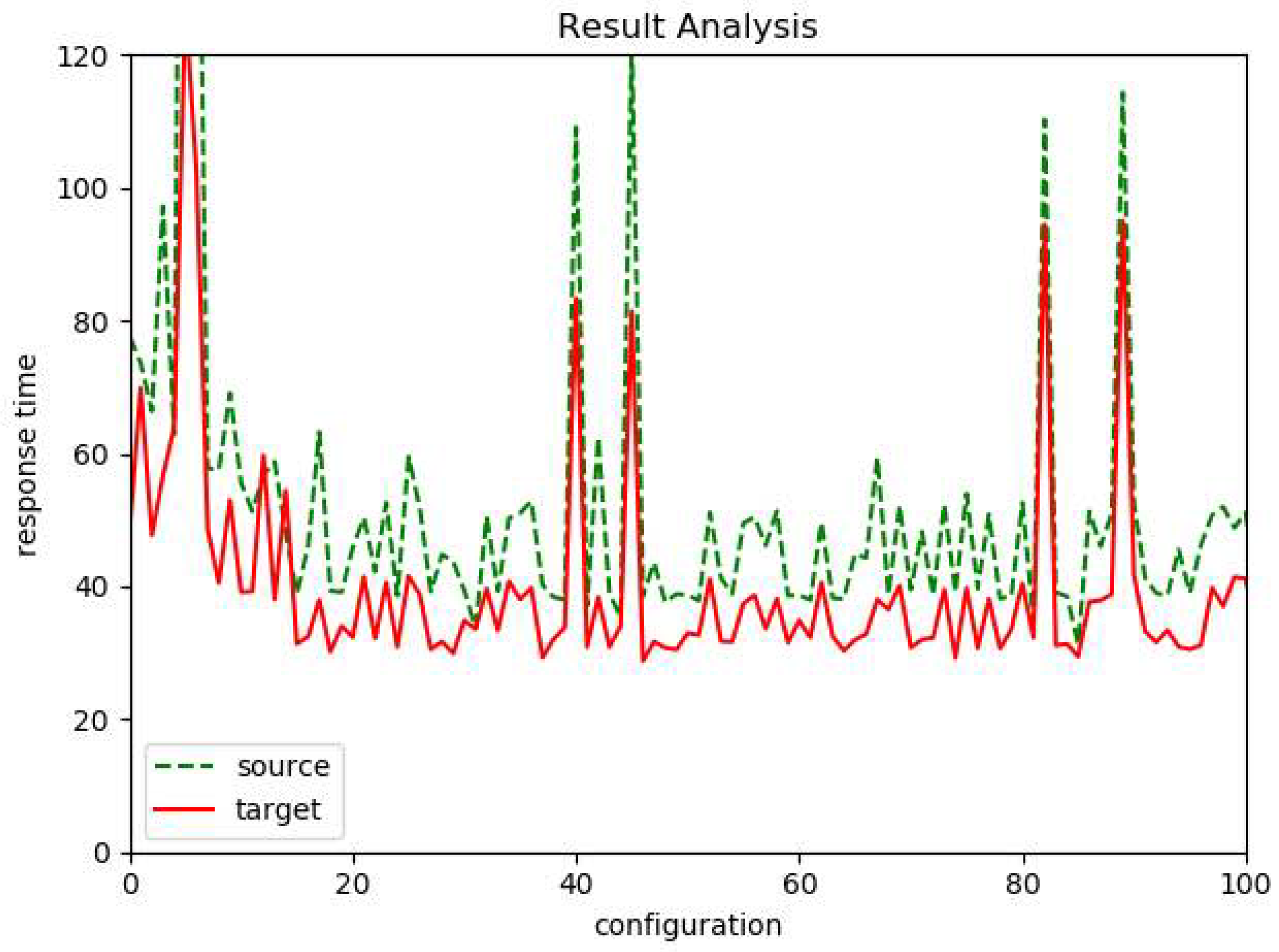
3.2. Key Observations
3.3. Assumptions and Limitations
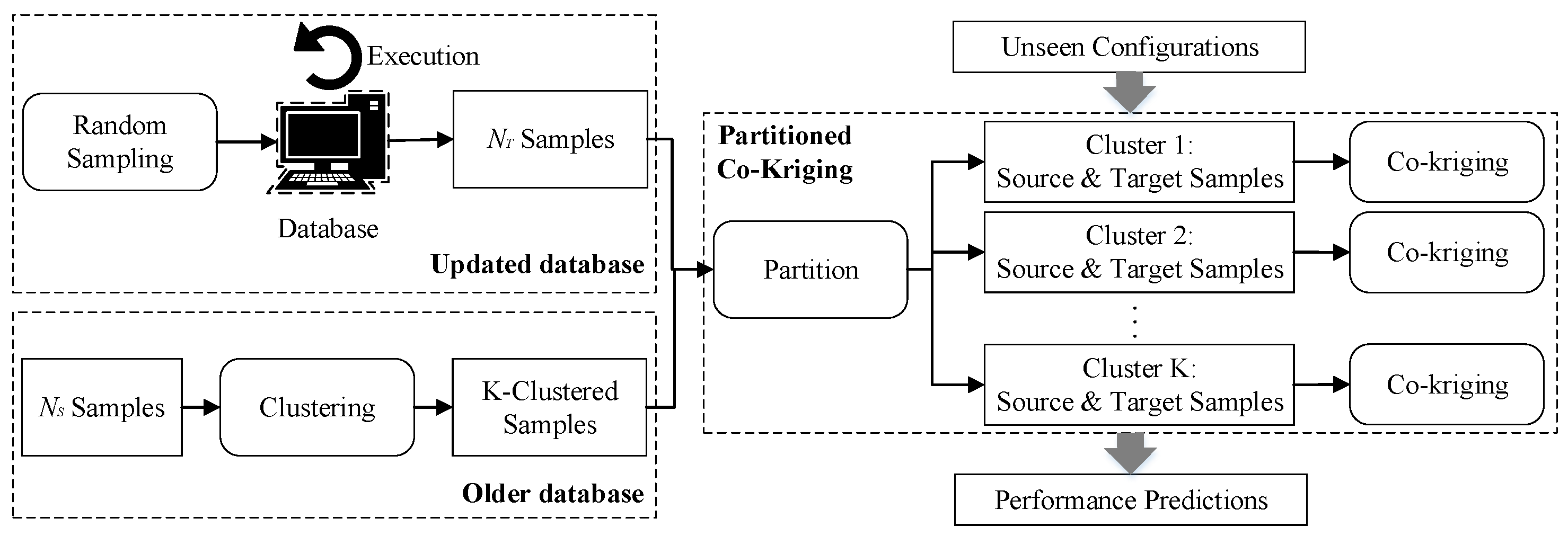
4. Partitioned Co-Kriging Based Performance Prediction
4.1. Overview
4.2. Performance Prediction with Partitioned Co-Kriging
| Algorithm 1 . |
| Input: A: the subject database; W: workload; P: configuration parameters; : configuration bounds; : the available samples in source domain; K: the number of clusters; : variogram model; : the unseen configurations in target domain. |
| Output: : performance predictions of the unseen configurations in target domain. |
| 1: ; |
| 2: K-clustered ←; |
| 3: K-clustered ←(, K-clustered ); |
| 4: K-clustered ←(, K-clustered ); |
| 5: for each do |
| 6: ← in corresponding cluster; |
| 7: end for |
| 8: return ; |
5. Experimental Evaluation
5.1. Experimental Settings
5.2. Evaluation of Prediction Accuracy
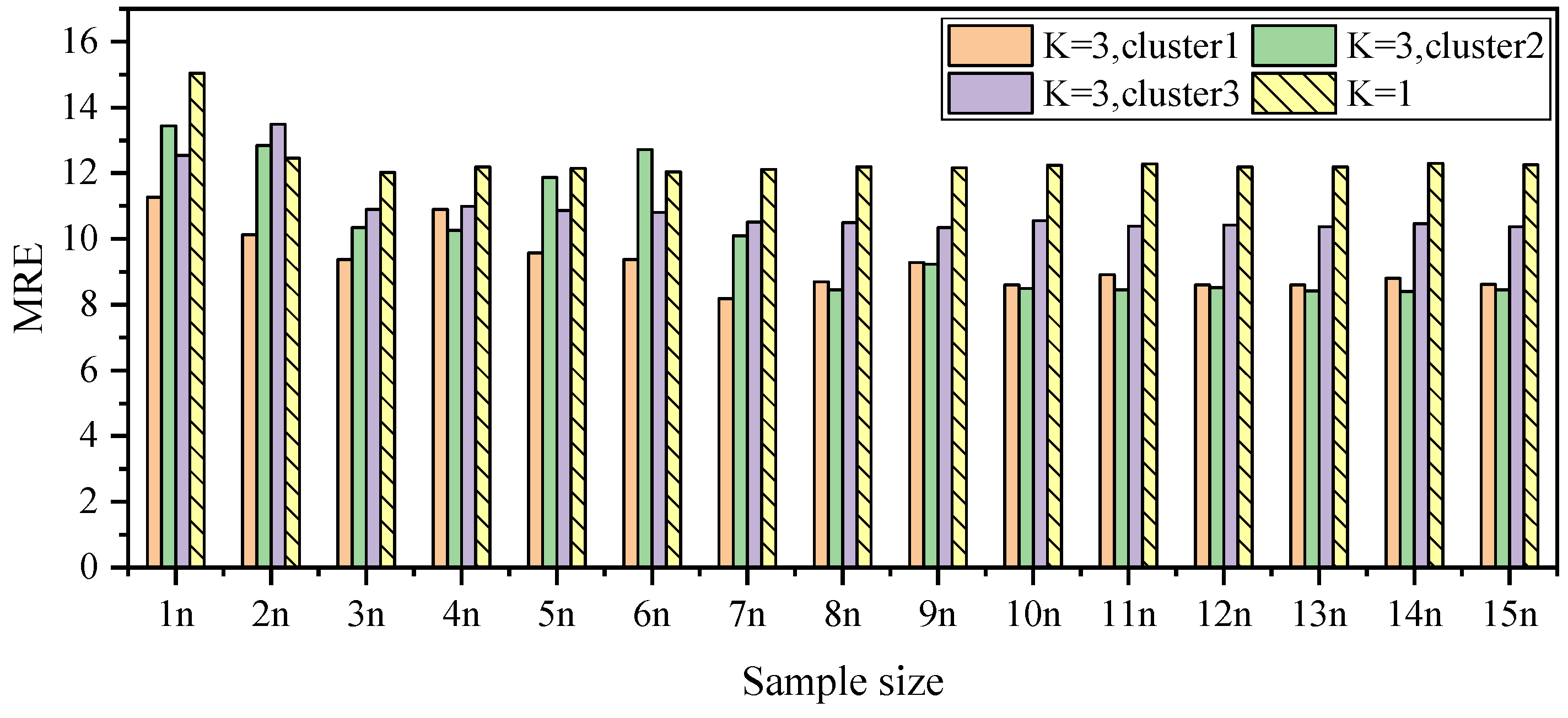
5.3. Trade-Off on Choosing K
6. Discussion
6.1. Prediction Accuracy
6.2. Measurement Effort
6.3. Effectiveness of Transfer Learning
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, T.; Jin, L.; Fan, X.; Zhou, Y.; Pasupathy, S.; Talwadker, R. Hey, You Have given Me Too Many Knobs!: Understanding and Dealing with over-Designed Configuration in System Software. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August 2015–4 September 2015; pp. 307–319. [Google Scholar]
- Van Aken, D.; Pavlo, A.; Gordon, G.J.; Zhang, B. Automatic database management system tuning through large-scale machine learning. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1009–1024. [Google Scholar]
- Guo, J.; Czarnecki, K.; Apel, S.; Siegmund, N.; Wąsowski, A. Variability-aware performance prediction: A statistical learning approach. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 301–311. [Google Scholar]
- Lu, J.; Chen, Y.; Herodotou, H.; Babu, S. Speedup your analytics: Automatic parameter tuning for databases and big data systems. Proc. VLDB Endow. 2019, 12, 1970–1973. [Google Scholar] [CrossRef]
- Guo, J.; Yang, D.; Siegmund, N.; Apel, S.; Sarkar, A.; Valov, P.; Czarnecki, K.; Wasowski, A.; Yu, H. Data-efficient performance learning for configurable systems. Empir. Softw. Eng. 2018, 23, 1826–1867. [Google Scholar] [CrossRef]
- Duan, S.; Thummala, V.; Babu, S. Tuning database configuration parameters with iTuned. Proc. VLDB Endow. 2009, 2, 1246–1257. [Google Scholar] [CrossRef]
- Mahgoub, A.; Wood, P.; Ganesh, S.; Mitra, S.; Gerlach, W.; Harrison, T.; Meyer, F.; Grama, A.; Bagchi, S.; Chaterji, S. Rafiki: A middleware for parameter tuning of nosql datastores for dynamic metagenomics workloads. In Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference, Las Vegas, NV, USA, 11–15 December 2017; pp. 28–40. [Google Scholar]
- Bao, L.; Liu, X.; Wang, F.; Fang, B. ACTGAN: Automatic Configuration Tuning for Software Systems with Generative Adversarial Networks. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 465–476. [Google Scholar]
- Zhu, Y.; Liu, J.; Guo, M.; Bao, Y.; Ma, W.; Liu, Z.; Song, K.; Yang, Y. Bestconfig: Tapping the performance potential of systems via automatic configuration tuning. In Proceedings of the 2017 Symposium on Cloud Computing, Santa Clara, CA, USA, 24–27 September 2017; pp. 338–350. [Google Scholar]
- Ha, H.; Zhang, H. Deepperf: Performance prediction for configurable software with deep sparse neural network. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 1095–1106. [Google Scholar]
- Nair, V.; Menzies, T.; Siegmund, N.; Apel, S. Faster discovery of faster system configurations with spectral learning. Autom. Softw. Eng. 2018, 25, 247–277. [Google Scholar] [CrossRef]
- Sarkar, A.; Guo, J.; Siegmund, N.; Apel, S.; Czarnecki, K. Cost-efficient sampling for performance prediction of configurable systems (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 342–352. [Google Scholar]
- Valov, P.; Guo, J.; Czarnecki, K. Empirical comparison of regression methods for variability-aware performance prediction. In Proceedings of the 19th International Conference on Software Product Line, Nashville, TN, USA, 20–24 July 2015; pp. 186–190. [Google Scholar]
- Nair, V.; Menzies, T.; Siegmund, N.; Apel, S. Using bad learners to find good configurations. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; pp. 257–267. [Google Scholar]
- Jamshidi, P.; Velez, M.; Kästner, C.; Siegmund, N. Learning to sample: Exploiting similarities across environments to learn performance models for configurable systems. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 71–82. [Google Scholar]
- Zhang, J.; Liu, Y.; Zhou, K.; Li, G.; Xiao, Z.; Cheng, B.; Xing, J.; Wang, Y.; Cheng, T.; Liu, L.; et al. An end-to-end automatic cloud database tuning system using deep reinforcement learning. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June 2019–5 July 2019; pp. 415–432. [Google Scholar]
- Jamshidi, P.; Siegmund, N.; Velez, M.; Kästner, C.; Patel, A.; Agarwal, Y. Transfer learning for performance modeling of configurable systems: An exploratory analysis. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October–3 November 2017; pp. 497–508. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. Kriging: A method of interpolation for geographical information systems. Int. J. Geogr. Inf. Syst. 1990, 4, 313–332. [Google Scholar] [CrossRef]
- Myers, D.E. CO-KRIGING: Methods and alternatives. In The Role of Data in Scientific Progress; Glaeser, P.S., Ed.; Elsevier Science Publisher: North-Holland, The Netherlands, 1985; pp. 425–428. [Google Scholar]
- Zhang, Y.; Guo, J.; Blais, E.; Czarnecki, K. Performance prediction of configurable software systems by fourier learning (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 365–373. [Google Scholar]
- Zhang, Y.; Guo, J.; Blais, E.; Czarnecki, K.; Yu, H. A mathematical model of performance-relevant feature interactions. In Proceedings of the 20th International Systems and Software Product Line Conference, Beijing, China, 16–23 September 2016; pp. 25–34. [Google Scholar]
- Kolesnikov, S.; Siegmund, N.; Kästner, C.; Grebhahn, A.; Apel, S. Tradeoffs in modeling performance of highly configurable software systems. Softw. Syst. Model. 2019, 18, 2265–2283. [Google Scholar] [CrossRef]
- Narayanan, D.; Thereska, E.; Ailamaki, A. Continuous resource monitoring for self-predicting DBMS. In Proceedings of the 13th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, Atlanta, GA, USA, 27–29 September 2005; pp. 239–248. [Google Scholar]
- Tran, D.N.; Huynh, P.C.; Tay, Y.C.; Tung, A.K. A new approach to dynamic self-tuning of database buffers. ACM Trans. Storage (TOS) 2008, 4, 1–25. [Google Scholar] [CrossRef]
- Tian, W.; Martin, P.; Powley, W. Techniques for automatically sizing multiple buffer pools in DB2. In Proceedings of the 2003 Conference of the Centre for Advanced Studies on Collaborative Research, Toronto, ON, Canada, 6–9 October 2003; pp. 294–302. [Google Scholar]
- Thummala, V.; Babu, S. iTuned: A tool for configuring and visualizing database parameters. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 1231–1234. [Google Scholar]
- Tan, J.; Zhang, T.; Li, F.; Chen, J.; Zheng, Q.; Zhang, P.; Qiao, H.; Shi, Y.; Cao, W.; Zhang, R. ibtune: Individualized buffer tuning for large-scale cloud databases. Proc. VLDB Endow. 2019, 12, 1221–1234. [Google Scholar] [CrossRef]
- Li, G.; Zhou, X.; Li, S.; Gao, B. Qtune: A query-aware database tuning system with deep reinforcement learning. Proc. VLDB Endow. 2019, 12, 2118–2130. [Google Scholar] [CrossRef]
- Tan, Z.; Babu, S. Tempo: Robust and self-tuning resource management in multi-tenant parallel databases. Proc. VLDB Endow. 2016, 9, 720–731. [Google Scholar] [CrossRef][Green Version]
- Mahgoub, A.; Wood, P.; Medoff, A.; Mitra, S.; Meyer, F.; Chaterji, S.; Bagchi, S. SOPHIA: Online reconfiguration of clustered nosql databases for time-varying workloads. In Proceedings of the 2019 USENIX Annual Technical Conference, Renton, WA, USA, 10–12 July 2019; pp. 223–240. [Google Scholar]
- Zhang, B.; Van Aken, D.; Wang, J.; Dai, T.; Jiang, S.; Lao, J.; Sheng, S.; Pavlo, A.; Gordon, G.J. A demonstration of the ottertune automatic database management system tuning service. Proc. VLDB Endow. 2018, 11, 1910–1913. [Google Scholar] [CrossRef]
- Valov, P.; Petkovich, J.C.; Guo, J.; Fischmeister, S.; Czarnecki, K. Transferring performance prediction models across different hardware platforms. In Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering, L’Aquila, Italy, 22–26 April 2017; pp. 39–50. [Google Scholar]
- Jamshidi, P.; Velez, M.; Kästner, C.; Siegmund, N.; Kawthekar, P. Transfer learning for improving model predictions in highly configurable software. In Proceedings of the 2017 IEEE/ACM 12th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), Buenos Aires, Argentina, 22–23 May 2017; pp. 31–41. [Google Scholar]
- Javidian, M.A.; Jamshidi, P.; Valtorta, M. Transfer learning for performance modeling of configurable systems: A causal analysis. arXiv 2019, arXiv:1902.10119. [Google Scholar]
- Krishna, R.; Nair, V.; Jamshidi, P.; Menzies, T. Whence to Learn? Transferring Knowledge in Configurable Systems using BEETLE. IEEE Trans. Softw. Eng. 2020. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Wong, J.A.H.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. 1979, 28, 100–108. [Google Scholar]
- Siegmund, N.; Grebhahn, A.; Apel, S.; Kästner, C. Performance-influence models for highly configurable systems. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September2015; pp. 284–294. [Google Scholar]
- Ishihara, Y.; Shiba, M. Dynamic Configuration Tuning of Working Database Management Systems. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 393–397. [Google Scholar]
- Zheng, C.; Ding, Z.; Hu, J. Self-tuning performance of database systems with neural network. In International Conference on Intelligent Computing, Proceedings of the Intelligent Computing Theory, ICIC 2014, Taiyuan, China, 3–6 August 2014; Springer: Cham, Switzerland, 2014; pp. 1–12. [Google Scholar]
- Debnath, B.K.; Lilja, D.J.; Mokbel, M.F. SARD: A statistical approach for ranking database tuning parameters. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering Workshop, Cancun, Mexico, 7–12 April 2008; pp. 11–18. [Google Scholar]
- Kanellis, K.; Alagappan, R.; Venkataraman, S. Too many knobs to tune? towards faster database tuning by pre-selecting important knobs. In Proceedings of the 12th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 20), Virtual, 13–14 July 2020. [Google Scholar]
- Mahgoub, A.; Medoff, A.M.; Kumar, R.; Mitra, S.; Klimovic, A.; Chaterji, S.; Bagchi, S. OPTIMUSCLOUD: Heterogeneous Configuration Optimization for Distributed Databases in the Cloud. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), Virtual, 15–17 July 2020; pp. 189–203. [Google Scholar]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 3320–3328. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject Database | Category | Subject Versions | Benchmark | # of Selected Parameters | Performance |
|---|---|---|---|---|---|
| MySQL | RDBMS | 5.5, 5.7, 8.0 | sysbench | 10 | Latency (ms) |
| PostgreSQL | ORDBMS | 9.3, 11.0 | pgbench | 9 | Transactions per second |
| SQLite | Embedded DB | 3.31.1, 3.36.0 | Customized | 8 | Transactions per second |
| Redis | In-memory DB | 4.0.1, 5.0.0, 6.0.5 | Redis-Bench | 9 | Requests per second |
| Cassandra | NoSQL DB | 2.1.0, 3.11.6 | YCSB | 28 | Throughput (MB/s) |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 21.829 | 24.653 | 21.446 | 22.757 | 23.050 | 23.234 | 21.508 | 21.313 | 20.849 | 21.033 | 15.444 | 19.558 | 16.970 | 16.493 | 17.168 |
| CART | 23.281 | 22.511 | 16.529 | 19.268 | 18.071 | 13.550 | 13.899 | 12.642 | 12.086 | 13.035 | 12.651 | 11.144 | 9.665 | 12.937 | 10.359 |
| Finetune | 14.532 | 13.854 | 13.320 | 12.640 | 12.649 | 13.376 | 13.610 | 14.906 | 14.467 | 12.527 | 14.550 | 13.703 | 14.050 | 14.037 | 13.087 |
| DDC | 19.255 | 25.563 | 26.350 | 21.325 | 21.912 | 22.096 | 24.017 | 18.917 | 19.936 | 19.174 | 19.285 | 19.935 | 17.632 | 15.661 | 16.233 |
| Model-shift | 15.848 | 16.171 | 11.314 | 11.248 | 12.902 | 10.128 | 11.342 | 10.224 | 10.697 | 11.064 | 11.419 | 10.822 | 10.217 | 11.198 | 11.246 |
| Ottertune | 16.846 | 19.041 | 18.605 | 21.737 | 19.475 | 19.258 | 19.293 | 18.322 | 19.081 | 18.945 | 17.393 | 19.100 | 17.991 | 17.379 | 16.504 |
| PCK | 12.399 | 12.177 | 10.222 | 10.734 | 10.747 | 10.922 | 9.618 | 9.268 | 9.645 | 9.273 | 9.303 | 9.230 | 9.183 | 9.280 | 9.197 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 9.637 | 6.384 | 4.997 | 3.835 | 3.577 | 3.525 | 3.209 | 3.219 | 3.276 | 3.12 | 3.031 | 2.828 | 2.816 | 2.828 | 2.819 |
| CART | 3.19 | 3.023 | 3.232 | 3.128 | 3.039 | 3.065 | 2.839 | 2.932 | 2.99 | 2.905 | 2.961 | 2.886 | 2.868 | 2.831 | 2.807 |
| Finetune | 2.778 | 2.767 | 2.838 | 2.677 | 2.725 | 2.591 | 2.729 | 2.763 | 2.783 | 2.522 | 2.595 | 2.552 | 2.621 | 2.61 | 2.593 |
| DDC | 7.415 | 5.619 | 4.507 | 3.749 | 3.385 | 3.382 | 2.968 | 2.928 | 3.095 | 2.943 | 2.767 | 2.756 | 2.714 | 2.809 | 2.757 |
| Model-shift | 2.718 | 2.603 | 2.645 | 2.991 | 2.858 | 2.932 | 2.75 | 2.676 | 2.902 | 2.831 | 2.799 | 2.674 | 2.798 | 2.886 | 2.745 |
| Ottertune | 11.934 | 9.289 | 9.373 | 7.792 | 6.812 | 6.431 | 5.127 | 4.76 | 4.486 | 4.173 | 3.824 | 3.574 | 3.312 | 3.274 | 3.217 |
| PCK | 2.634 | 2.616 | 2.593 | 2.590 | 2.606 | 2.585 | 2.568 | 2.576 | 2.572 | 2.570 | 2.573 | 2.568 | 2.558 | 2.564 | 2.167 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 9.109 | 2.846 | 2.249 | 1.945 | 2.007 | 2.007 | 1.857 | 1.917 | 1.841 | 1.799 | 1.736 | 1.711 | 1.606 | 1.544 | 1.56 |
| CART | 1.692 | 1.793 | 1.932 | 1.686 | 1.795 | 1.575 | 1.623 | 1.593 | 1.516 | 1.632 | 1.573 | 1.578 | 1.535 | 1.541 | 1.522 |
| Finetune | 2.39 | 2.271 | 1.876 | 1.722 | 1.801 | 1.692 | 1.754 | 1.66 | 1.64 | 1.67 | 1.539 | 1.584 | 1.547 | 1.517 | 1.567 |
| DDC | 5.452 | 2.873 | 2.286 | 2.058 | 1.819 | 1.926 | 1.91 | 1.806 | 1.673 | 1.713 | 1.861 | 1.633 | 1.692 | 1.628 | 1.705 |
| Model-shift | 1.593 | 1.352 | 1.724 | 1.471 | 1.708 | 1.519 | 1.61 | 1.57 | 1.596 | 1.565 | 1.655 | 1.572 | 1.598 | 1.55 | 1.577 |
| Ottertune | 8.804 | 8.768 | 8.621 | 7.754 | 7.501 | 6.283 | 6.271 | 5.755 | 5.509 | 5.161 | 4.445 | 3.944 | 3.664 | 2.718 | 2.09 |
| PCK | 1.208 | 1.101 | 1.058 | 1.052 | 1.028 | 1.033 | 1.012 | 1.024 | 1.010 | 1.016 | 1.000 | 0.997 | 1.002 | 1.001 | 0.999 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 10.405 | 7.598 | 6.304 | 5.608 | 5.873 | 6.060 | 5.947 | 5.482 | 5.727 | 5.552 | 5.341 | 5.135 | 5.355 | 5.187 | 5.294 |
| CART | 6.270 | 5.499 | 5.560 | 5.964 | 5.763 | 5.408 | 5.198 | 5.384 | 6.024 | 5.832 | 5.876 | 5.443 | 5.878 | 5.776 | 5.700 |
| Finetune | 4.790 | 5.721 | 5.227 | 4.779 | 5.331 | 5.007 | 5.451 | 4.931 | 5.150 | 4.664 | 4.638 | 4.780 | 4.796 | 4.667 | 4.666 |
| DDC | 9.688 | 7.430 | 6.805 | 5.377 | 5.847 | 5.292 | 5.562 | 5.711 | 5.229 | 5.417 | 5.549 | 5.442 | 5.415 | 5.248 | 5.084 |
| Model-shift | 4.682 | 4.643 | 4.927 | 5.460 | 5.314 | 5.024 | 5.342 | 5.061 | 5.279 | 5.280 | 5.217 | 5.127 | 5.013 | 5.110 | 4.960 |
| Ottertune | 31.177 | 16.059 | 11.747 | 11.413 | 10.210 | 9.895 | 10.033 | 9.929 | 10.089 | 9.111 | 9.168 | 8.769 | 8.299 | 8.222 | 7.718 |
| PCK | 3.278 | 3.083 | 2.931 | 2.877 | 3.036 | 2.889 | 2.886 | 2.879 | 2.889 | 2.868 | 2.873 | 2.877 | 2.867 | 2.870 | 2.867 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 25.608 | 24.309 | 24.907 | 25.054 | 24.571 | 25.485 | 25.249 | 24.674 | 24.507 | 24.125 | 24.274 | 24.451 | 24.114 | 24.105 | 24.219 |
| CART | 23.452 | 23.868 | 23.432 | 23.187 | 23.509 | 23.197 | 23.718 | 23.410 | 23.277 | 23.236 | 23.325 | 23.207 | 23.668 | 23.547 | 23.800 |
| Finetune | 22.369 | 21.408 | 21.742 | 22.306 | 21.454 | 21.770 | 20.984 | 21.282 | 21.503 | 21.465 | 21.113 | 21.622 | 21.340 | 21.554 | 21.443 |
| DDC | 26.090 | 24.983 | 24.865 | 24.938 | 24.103 | 24.390 | 24.333 | 24.385 | 24.702 | 24.362 | 24.157 | 24.356 | 23.959 | 24.671 | 24.206 |
| Model-shift | 23.307 | 22.721 | 22.923 | 22.66 | 23.196 | 23.039 | 22.883 | 23.086 | 22.971 | 22.860 | 22.914 | 22.868 | 22.912 | 22.900 | 22.987 |
| Ottertune | 36.852 | 32.771 | 30.581 | 30.592 | 29.660 | 29.379 | 29.003 | 28.677 | 28.792 | 28.450 | 28.333 | 28.266 | 27.925 | 28.056 | 27.732 |
| PCK | 11.832 | 11.222 | 11.555 | 11.381 | 11.406 | 11.306 | 11.512 | 11.464 | 11.511 | 11.477 | 11.463 | 11.397 | 11.482 | 11.437 | 11.474 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 23.382 | 9.871 | 12.726 | 11.228 | 7.129 | 9.979 | 8.657 | 11.102 | 6.753 | 9.426 | 8.412 | 9.59 | 10.216 | 10.35 | 10.188 |
| CART | 5.894 | 7.346 | 10.773 | 8.867 | 9.343 | 6.282 | 9.692 | 7.313 | 7.324 | 6.977 | 6.874 | 6.681 | 6.202 | 5.336 | 5.266 |
| Finetune | 7.018 | 6.408 | 5.473 | 5.665 | 5.822 | 5.011 | 4.897 | 5.149 | 4.644 | 5.357 | 3.908 | 4.81 | 4.726 | 4.048 | 3.823 |
| DDC | 13.168 | 9.108 | 8.034 | 14.538 | 9.597 | 13.554 | 11.181 | 9.321 | 10.081 | 10.472 | 10.152 | 10.928 | 9.201 | 10.797 | 8.821 |
| Model-shift | 5.587 | 5.627 | 12.67 | 5.461 | 6.82 | 8.996 | 6.34 | 4.789 | 7.892 | 9.289 | 5.382 | 9.685 | 5.586 | 5.871 | 10.351 |
| Ottertune | 18.722 | 17.439 | 15.247 | 18.019 | 16.598 | 15.49 | 15.321 | 14.539 | 19.944 | 21.559 | 15.15 | 19.487 | 19.186 | 13.52 | 18.009 |
| PCK | 2.658 | 2.368 | 2.646 | 2.573 | 2.639 | 2.594 | 2.616 | 2.659 | 2.552 | 2.544 | 2.594 | 2.556 | 2.504 | 2.547 | 2.523 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 16.05 | 14.429 | 14.079 | 15.59 | 16.058 | 14.952 | 15.827 | 15.063 | 15.694 | 16.011 | 15.847 | 15.171 | 15.283 | 16.054 | 16.123 |
| CART | 14.216 | 15.69 | 15.623 | 15.188 | 14.899 | 14.761 | 14.673 | 15.138 | 14.829 | 15.332 | 14.804 | 15.179 | 15.111 | 14.978 | 15.068 |
| Finetune | 11.484 | 11.893 | 11.596 | 12.333 | 12.052 | 11.973 | 12.393 | 11.949 | 12.068 | 12.029 | 12.23 | 12.277 | 12.291 | 12.262 | 12.21 |
| DDC | 12.338 | 14.678 | 15.911 | 15.801 | 15.371 | 15.87 | 15.262 | 15.743 | 15.239 | 15.53 | 15.51 | 16.239 | 15.431 | 15.362 | 15.826 |
| Model-shift | 15.19 | 14.767 | 14.529 | 14.161 | 14.14 | 14.306 | 13.889 | 14.123 | 14.087 | 14.105 | 13.985 | 13.948 | 14.121 | 14.079 | 14.219 |
| Ottertune | 26.182 | 20.683 | 18.483 | 16.688 | 17.756 | 13.857 | 14.196 | 14.553 | 11.754 | 12.433 | 11.537 | 11.065 | 10.648 | 10.298 | 9.311 |
| PCK | 10.522 | 10.392 | 10.355 | 10.487 | 10.256 | 10.332 | 10.326 | 10.301 | 10.272 | 10.295 | 10.331 | 10.359 | 10.319 | 10.303 | 9.997 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 9.058 | 5.308 | 4.421 | 3.654 | 2.879 | 2.442 | 2.014 | 2.118 | 2.143 | 2.037 | 1.854 | 1.737 | 1.81 | 1.761 | 1.821 |
| CART | 1.533 | 1.553 | 1.556 | 1.543 | 1.451 | 1.538 | 1.624 | 1.534 | 1.455 | 1.483 | 1.524 | 1.533 | 1.496 | 1.465 | 1.519 |
| Finetune | 1.561 | 1.756 | 1.653 | 1.577 | 1.555 | 1.558 | 1.516 | 1.521 | 1.513 | 1.52 | 1.491 | 1.485 | 1.539 | 1.458 | 1.446 |
| DDC | 8.308 | 6.838 | 4.144 | 3.133 | 2.28 | 2.291 | 2.063 | 2.068 | 2.004 | 1.728 | 1.748 | 1.88 | 1.834 | 1.824 | 1.704 |
| Model-shift | 1.561 | 1.66 | 1.531 | 1.558 | 1.602 | 1.529 | 1.547 | 1.55 | 1.554 | 1.562 | 1.528 | 1.555 | 1.502 | 1.534 | 1.549 |
| Ottertune | 36.173 | 15.021 | 9.428 | 7.813 | 8.428 | 7.331 | 7.361 | 6.491 | 6.146 | 5.836 | 5.603 | 5.279 | 5.18 | 4.906 | 4.496 |
| PCK | 1.322 | 1.32 | 1.314 | 1.313 | 1.284 | 1.261 | 1.275 | 1.202 | 1.161 | 1.113 | 1.088 | 0.999 | 0.904 | 0.911 | 1.01 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepPerf | 10.168 | 4.634 | 4.533 | 3.752 | 2.413 | 2.436 | 2.092 | 1.805 | 1.87 | 1.879 | 1.718 | 1.732 | 1.601 | 1.641 | 1.612 |
| CART | 1.266 | 1.391 | 1.259 | 1.416 | 1.349 | 1.311 | 1.298 | 1.32 | 1.308 | 1.31 | 1.334 | 1.257 | 1.271 | 1.323 | 1.362 |
| Finetune | 1.781 | 1.588 | 1.495 | 1.457 | 1.534 | 1.528 | 1.451 | 1.339 | 1.407 | 1.303 | 1.347 | 1.306 | 1.335 | 1.317 | 1.272 |
| DDC | 8.53 | 6.708 | 3.56 | 2.529 | 2.61 | 1.861 | 2.113 | 1.907 | 1.973 | 1.838 | 1.654 | 1.717 | 1.61 | 1.646 | 1.601 |
| Model-shift | 1.196 | 1.425 | 1.41 | 1.406 | 1.372 | 1.163 | 1.243 | 1.271 | 1.378 | 1.302 | 1.346 | 1.264 | 1.337 | 1.283 | 1.33 |
| Ottertune | 27.598 | 12.593 | 9.313 | 9.703 | 8.023 | 7.651 | 7.166 | 6.636 | 6.768 | 6.597 | 5.941 | 5.592 | 5.433 | 5.01 | 4.565 |
| PCK | 0.711 | 0.648 | 0.641 | 0.64 | 0.636 | 0.636 | 0.635 | 0.634 | 0.634 | 0.635 | 0.634 | 0.633 | 0.633 | 0.632 | 0.631 |
| Sample Size | 1n | 2n | 3n | 4n | 5n | 6n | 7n | 8n | 9n | 10n | 11n | 12n | 13n | 14n | 15n | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster Size | ||||||||||||||||
| 1 | 15.044 | 12.459 | 12.017 | 12.191 | 12.138 | 12.042 | 12.119 | 12.192 | 12.166 | 12.237 | 12.285 | 12.187 | 12.199 | 12.303 | 12.246 | |
| 2 | 14.272 | 14.492 | 12.353 | 10.992 | 11.229 | 10.969 | 10.314 | 10.285 | 10.454 | 10.515 | 10.429 | 10.445 | 10.364 | 10.357 | 10.337 | |
| 3 | 12.399 | 12.177 | 10.222 | 10.734 | 10.747 | 10.922 | 9.618 | 9.268 | 9.645 | 9.273 | 9.303 | 9.2304 | 9.183 | 9.280 | 9.197 | |
| 4 | 14.247 | 14.326 | 11.447 | 11.927 | 11.372 | 10.819 | 10.606 | 10.524 | 10.207 | 10.735 | 10.251 | 10.239 | 10.019 | 10.100 | 9.981 | |
| 5 | 16.045 | 13.674 | 12.458 | 11.943 | 12.435 | 11.119 | 10.381 | 10.569 | 11.027 | 10.347 | 10.097 | 10.010 | 10.084 | 10.027 | 9.931 | |
| 6 | 16.070 | 13.497 | 12.611 | 11.596 | 11.941 | 11.295 | 11.491 | 11.129 | 11.732 | 10.668 | 10.818 | 10.776 | 10.166 | 10.695 | 10.298 | |
| 7 | 15.287 | 15.504 | 13.382 | 13.005 | 12.271 | 11.748 | 11.547 | 12.520 | 11.918 | 11.731 | 11.631 | 11.924 | 11.408 | 11.821 | 11.858 | |
| 8 | 15.300 | 14.245 | 13.270 | 11.910 | 12.629 | 11.490 | 11.636 | 11.928 | 11.258 | 11.040 | 11.284 | 10.901 | 10.944 | 10.785 | 10.732 | |
| 9 | 15.464 | 14.066 | 12.943 | 12.756 | 12.254 | 12.332 | 11.842 | 11.601 | 11.929 | 10.984 | 10.949 | 10.999 | 11.042 | 10.920 | 10.892 | |
| 10 | 17.349 | 14.897 | 13.553 | 13.476 | 12.945 | 12.484 | 11.818 | 11.894 | 11.514 | 12.064 | 10.908 | 11.383 | 11.270 | 10.762 | 10.811 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, R.; Bao, L.; Wei, S.; Duan, J.; Wu, X.; Du, Y.; Sun, R. Fast Performance Modeling across Different Database Versions Using Partitioned Co-Kriging. Appl. Sci. 2021, 11, 9669. https://doi.org/10.3390/app11209669
Cao R, Bao L, Wei S, Duan J, Wu X, Du Y, Sun R. Fast Performance Modeling across Different Database Versions Using Partitioned Co-Kriging. Applied Sciences. 2021; 11(20):9669. https://doi.org/10.3390/app11209669
Chicago/Turabian StyleCao, Rong, Liang Bao, Shouxin Wei, Jiarui Duan, Xi Wu, Yeye Du, and Ren Sun. 2021. "Fast Performance Modeling across Different Database Versions Using Partitioned Co-Kriging" Applied Sciences 11, no. 20: 9669. https://doi.org/10.3390/app11209669
APA StyleCao, R., Bao, L., Wei, S., Duan, J., Wu, X., Du, Y., & Sun, R. (2021). Fast Performance Modeling across Different Database Versions Using Partitioned Co-Kriging. Applied Sciences, 11(20), 9669. https://doi.org/10.3390/app11209669