Semantic Scene Graph Generation Using RDF Model and Deep Learning



Abstract
:1. Introduction
2. Related Work
3. Proposed System
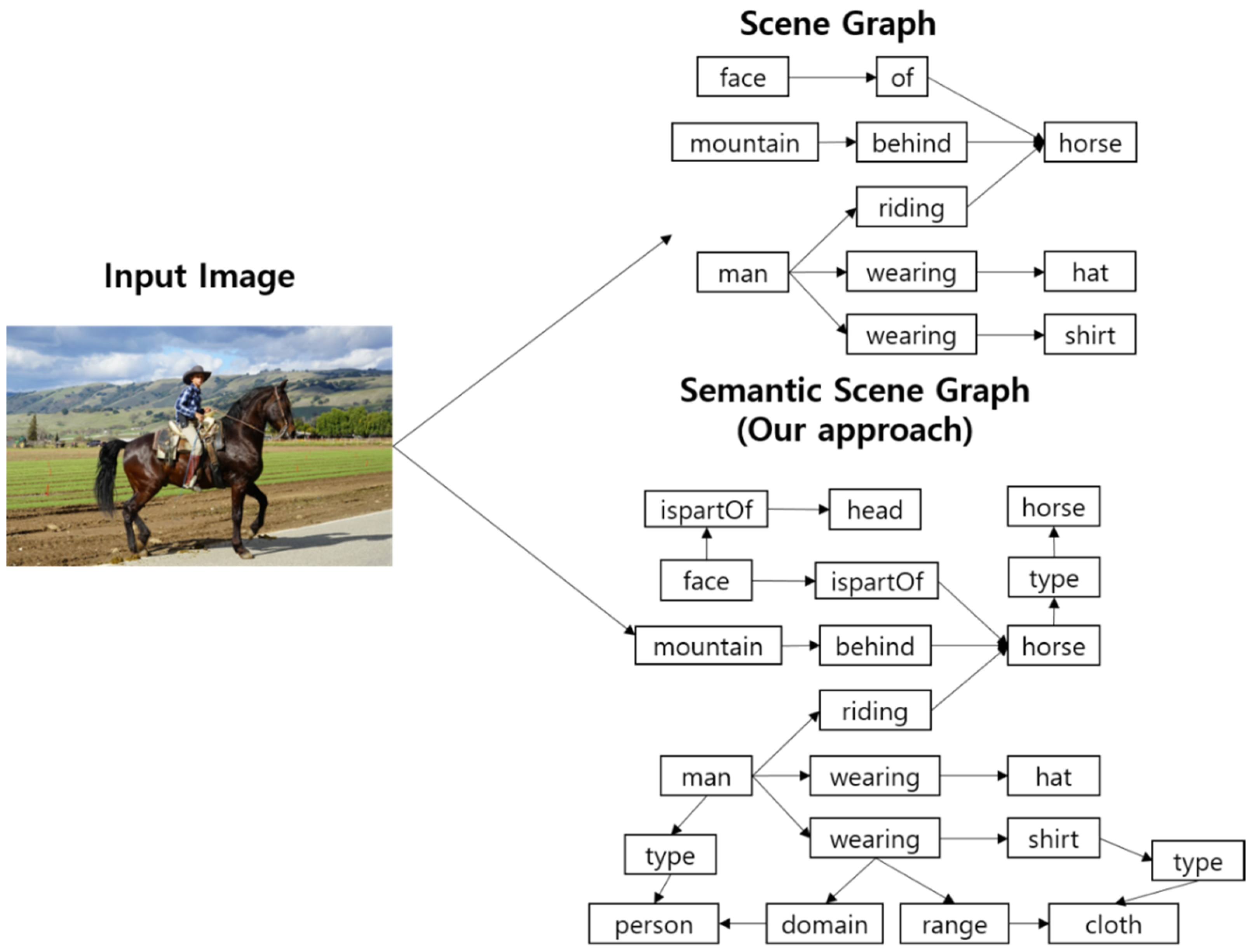
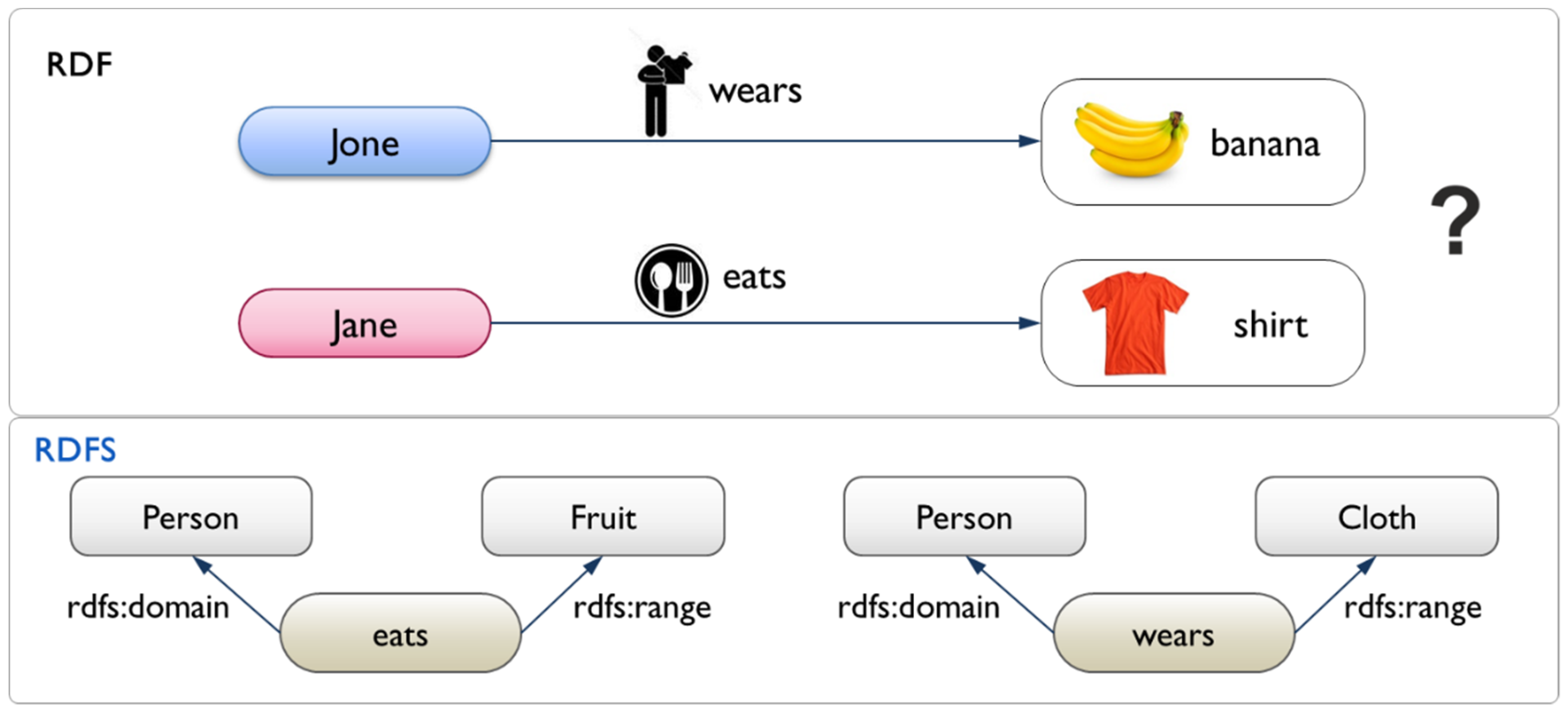
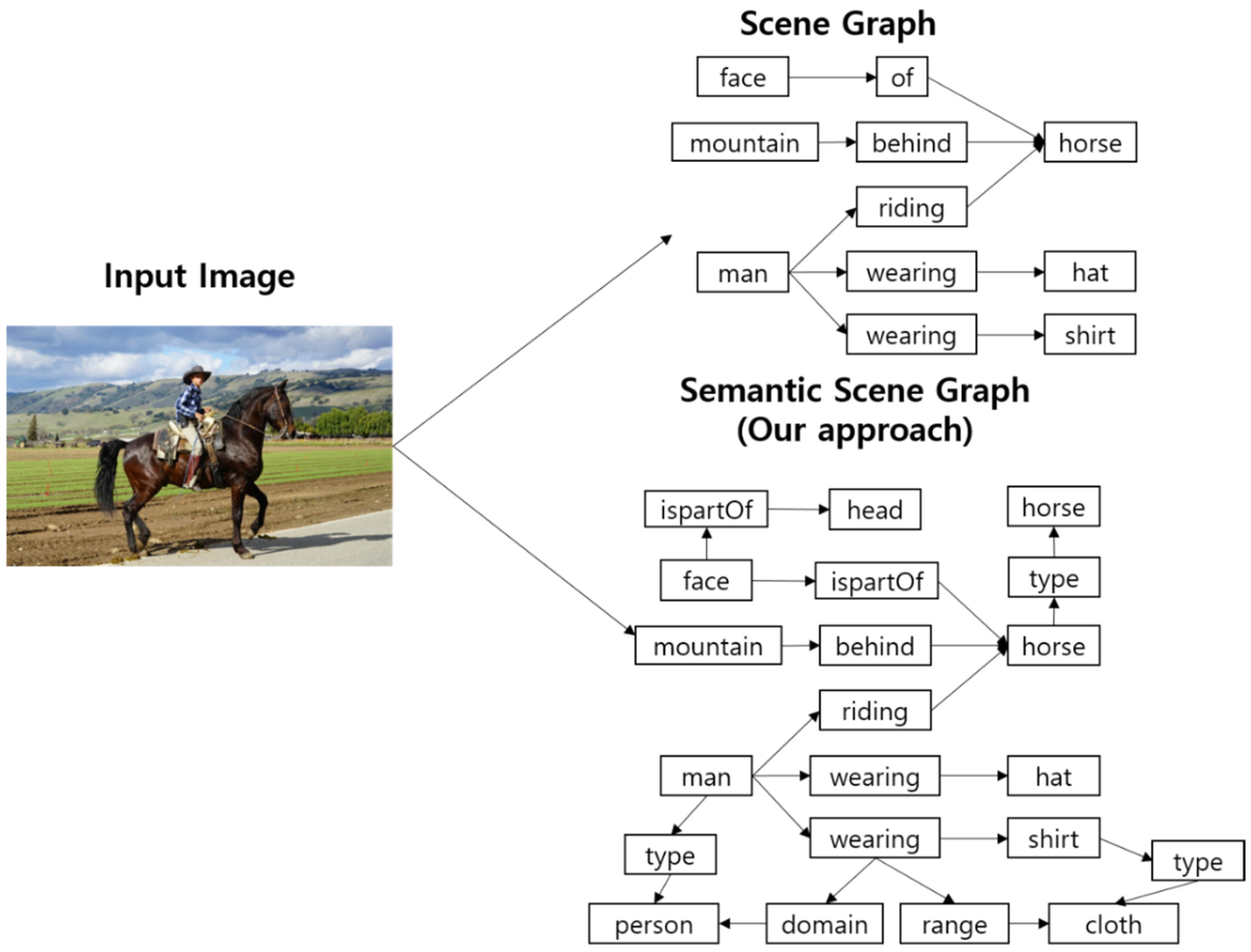
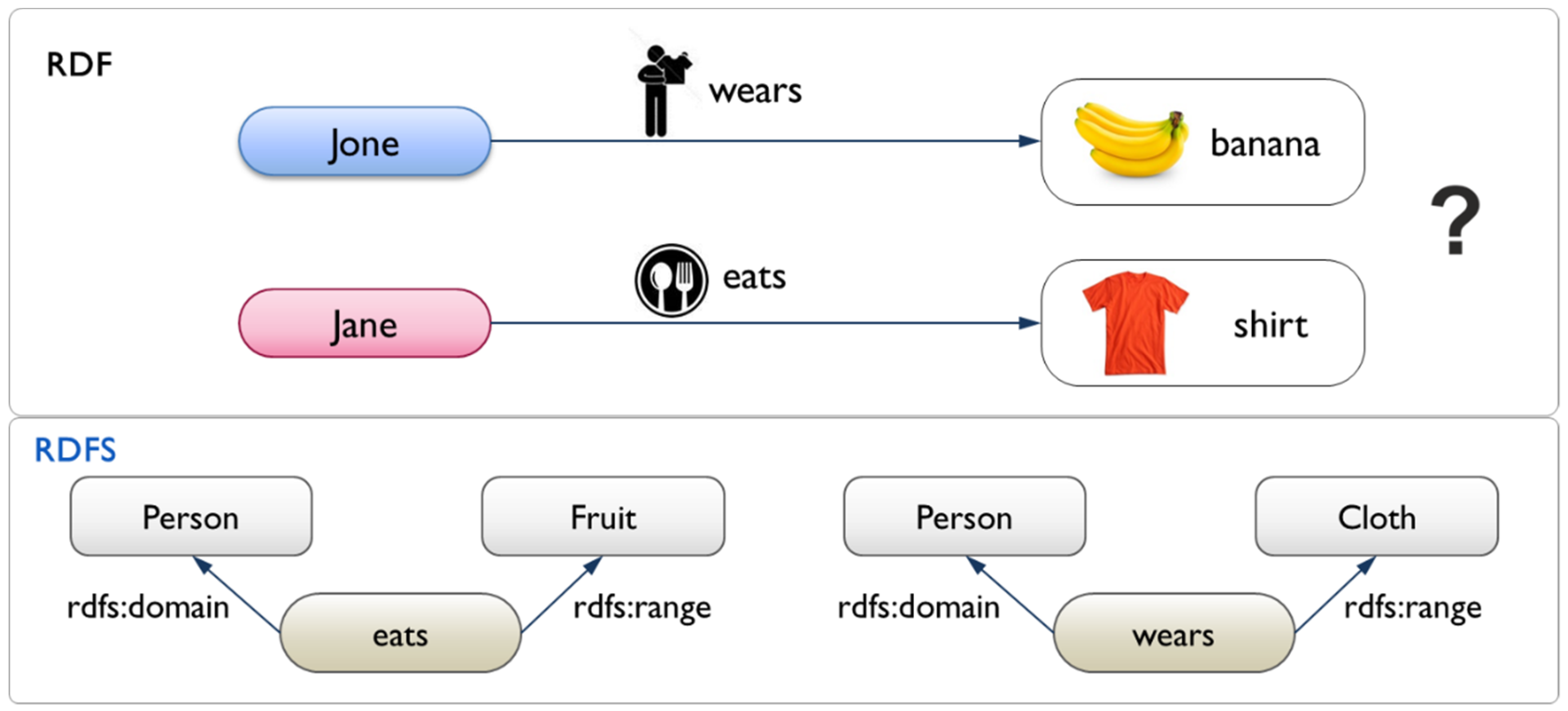
3.1. Semantic Scene Graph
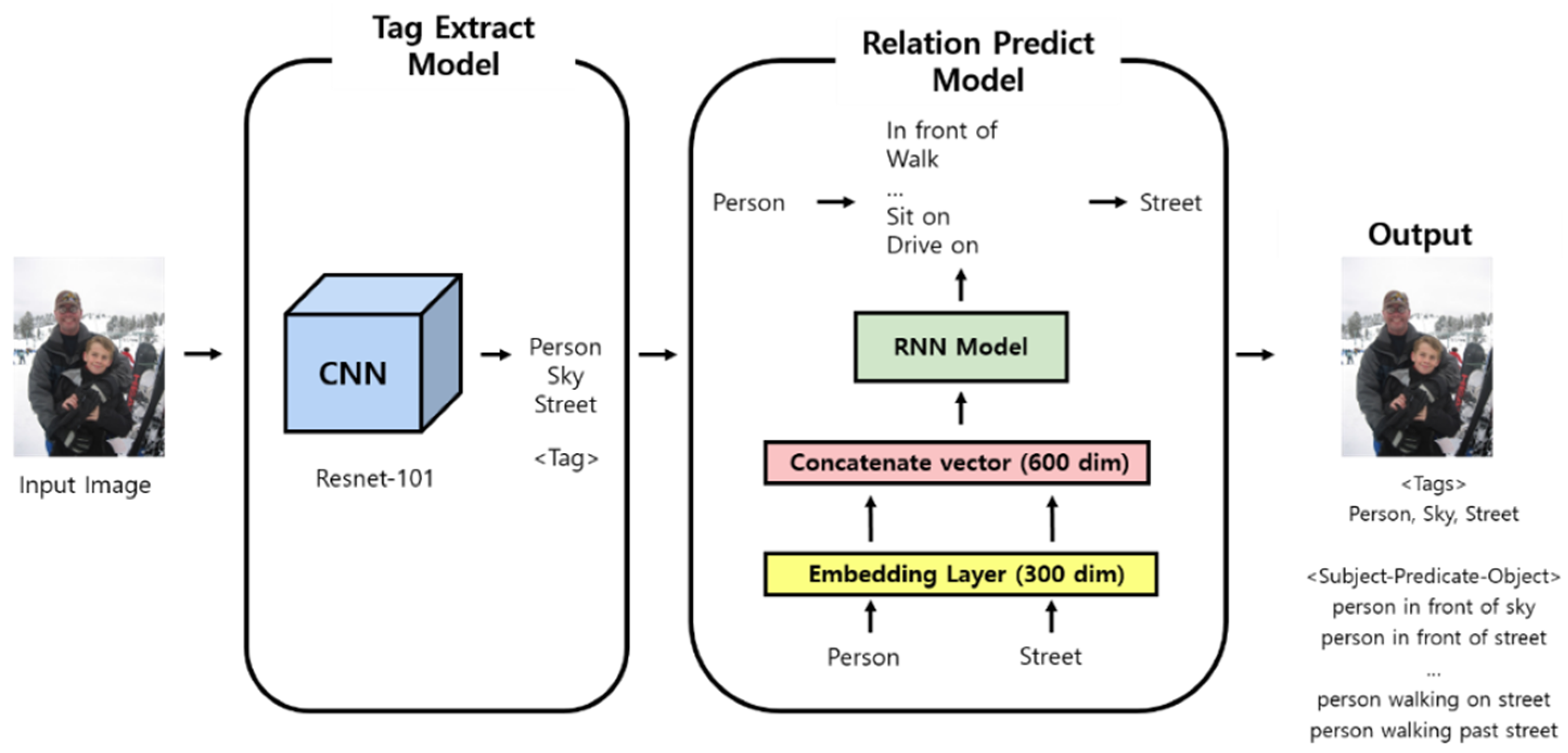
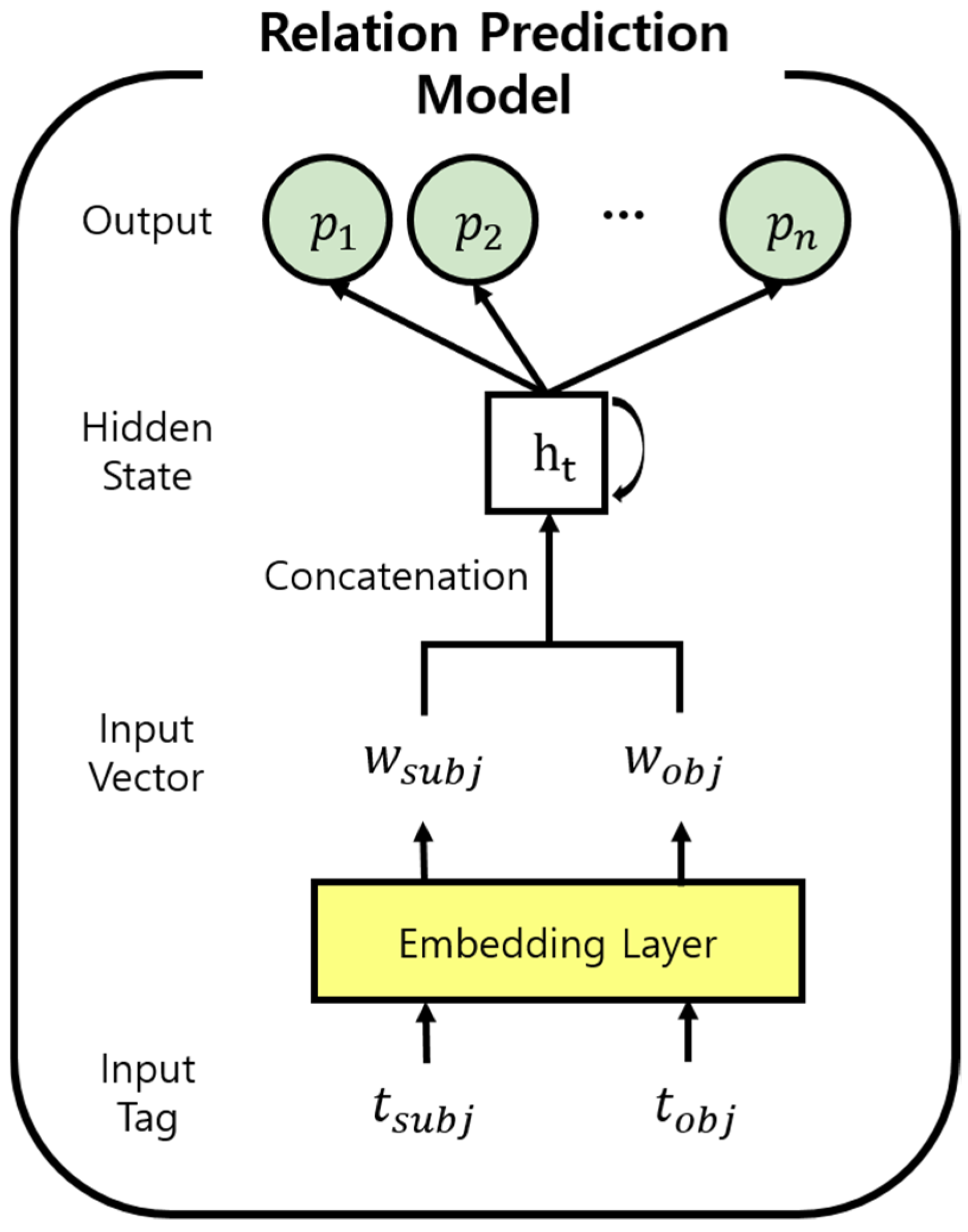
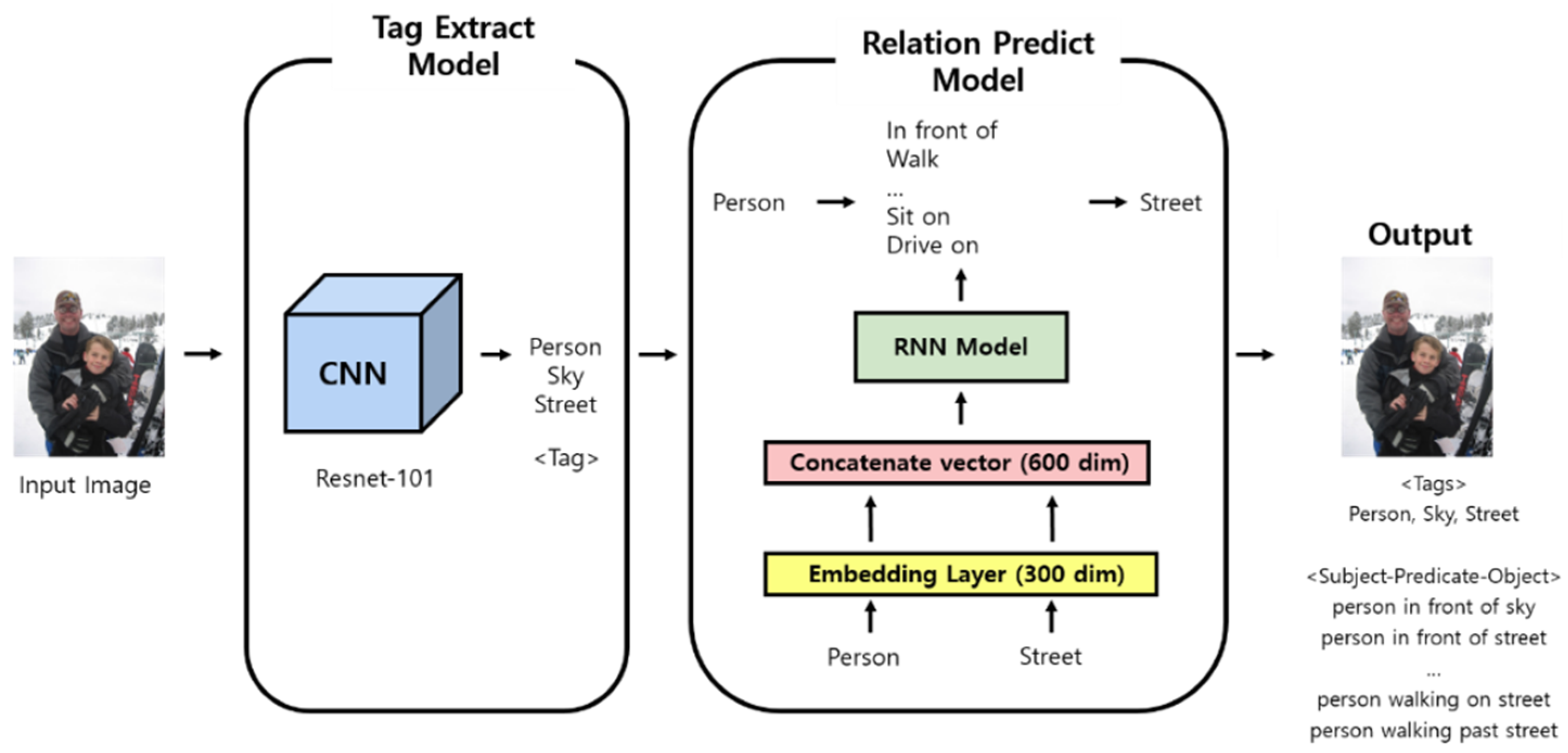
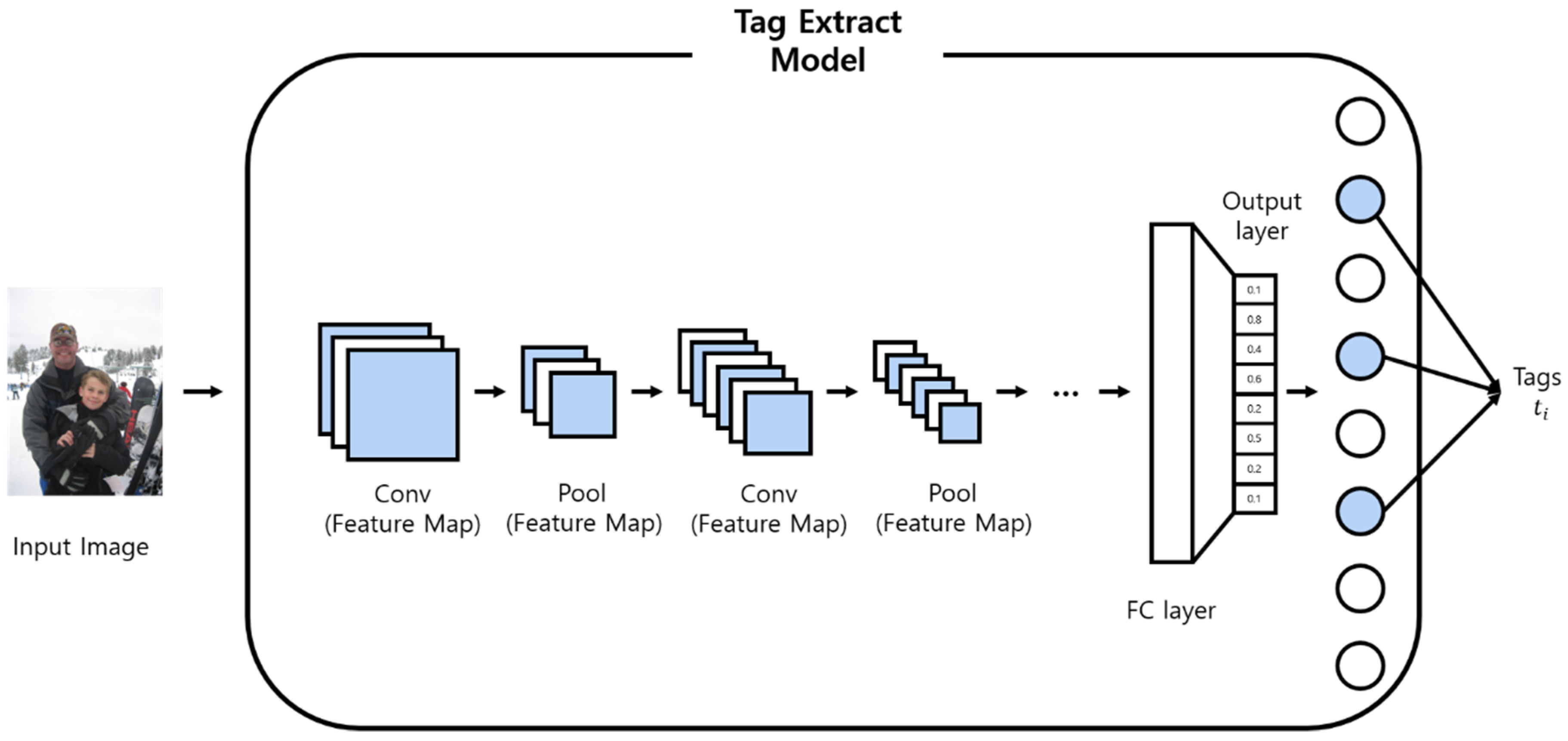
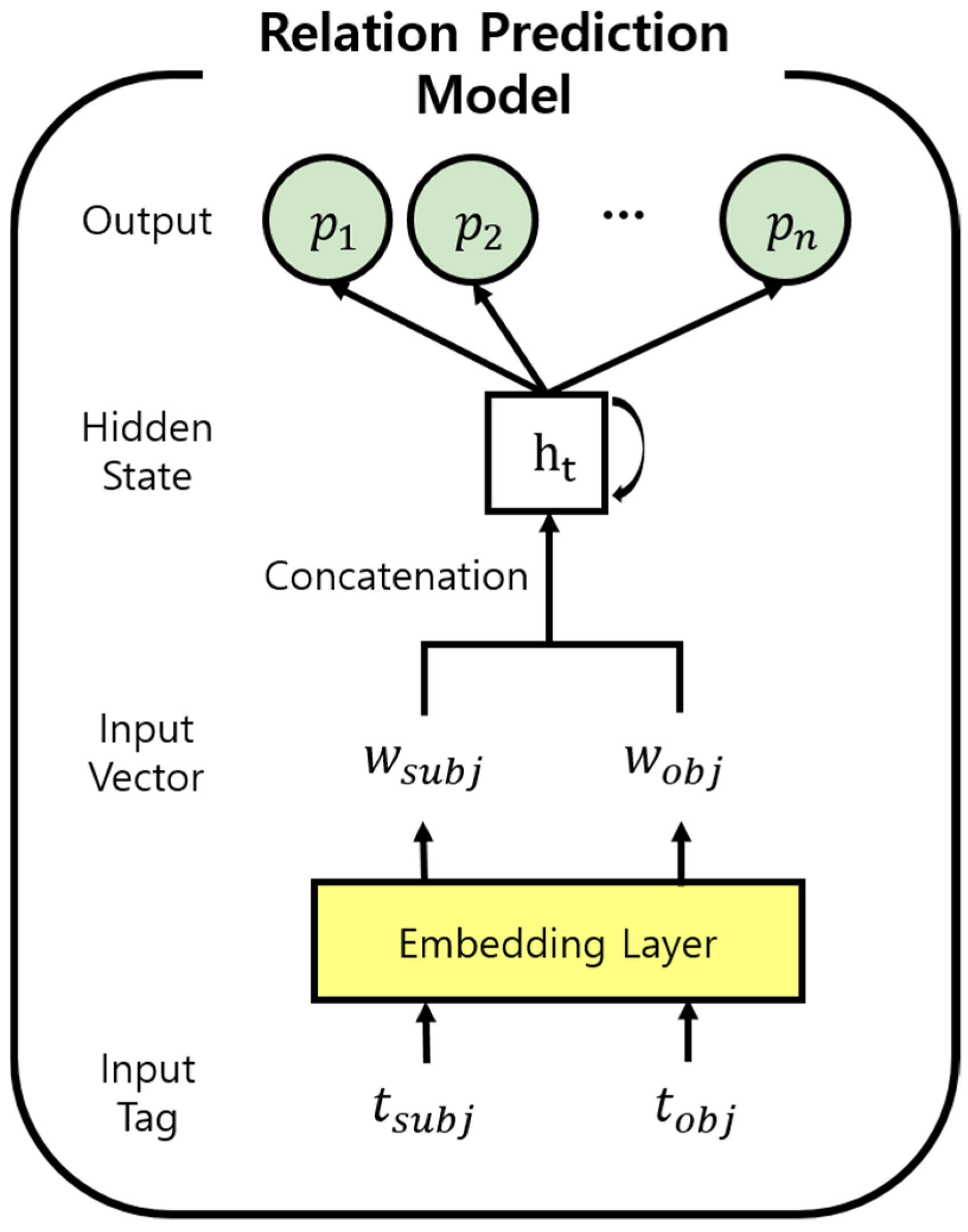
3.2. Creating a Deep Learning-Based Scene Graph
| Algorithm 1 Training Algorithm. |
|
Require: image tags ∈ T Procedure 1: Fine tune image tagging model on images using ResNet (Equations (1)–(3)) 2: for i = 1, 2, ⋯ epoch do 3: for in T 4: for in T 5: tags , convert to (Equations (4) and (5)). 6: Predict using (Equation (6)) 7: Use stochastic gradient descent to find optimal and backward LSTM using loss function (Equation (7)) End procedure |
3.3. Scene Graph Expansion Using Inference
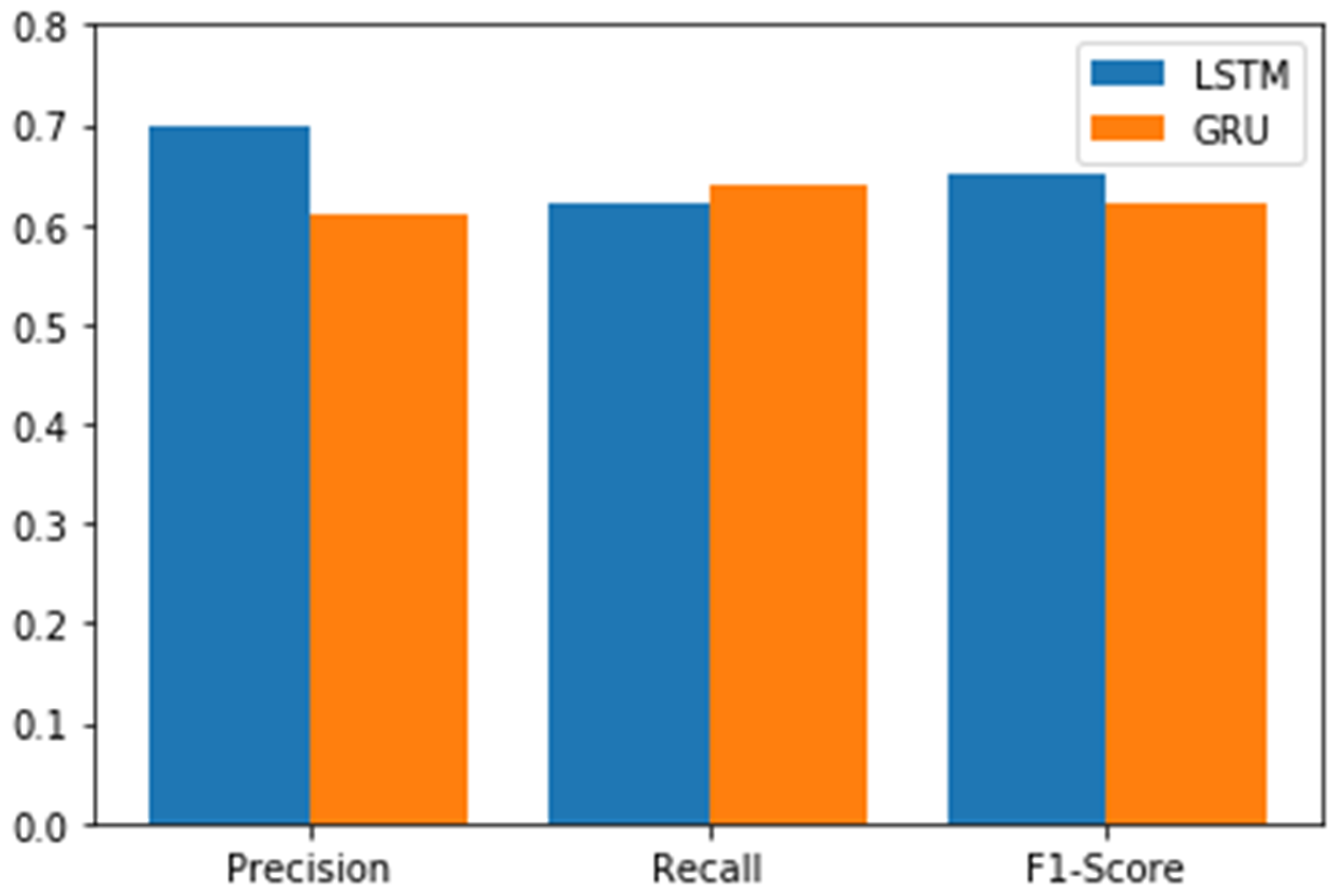
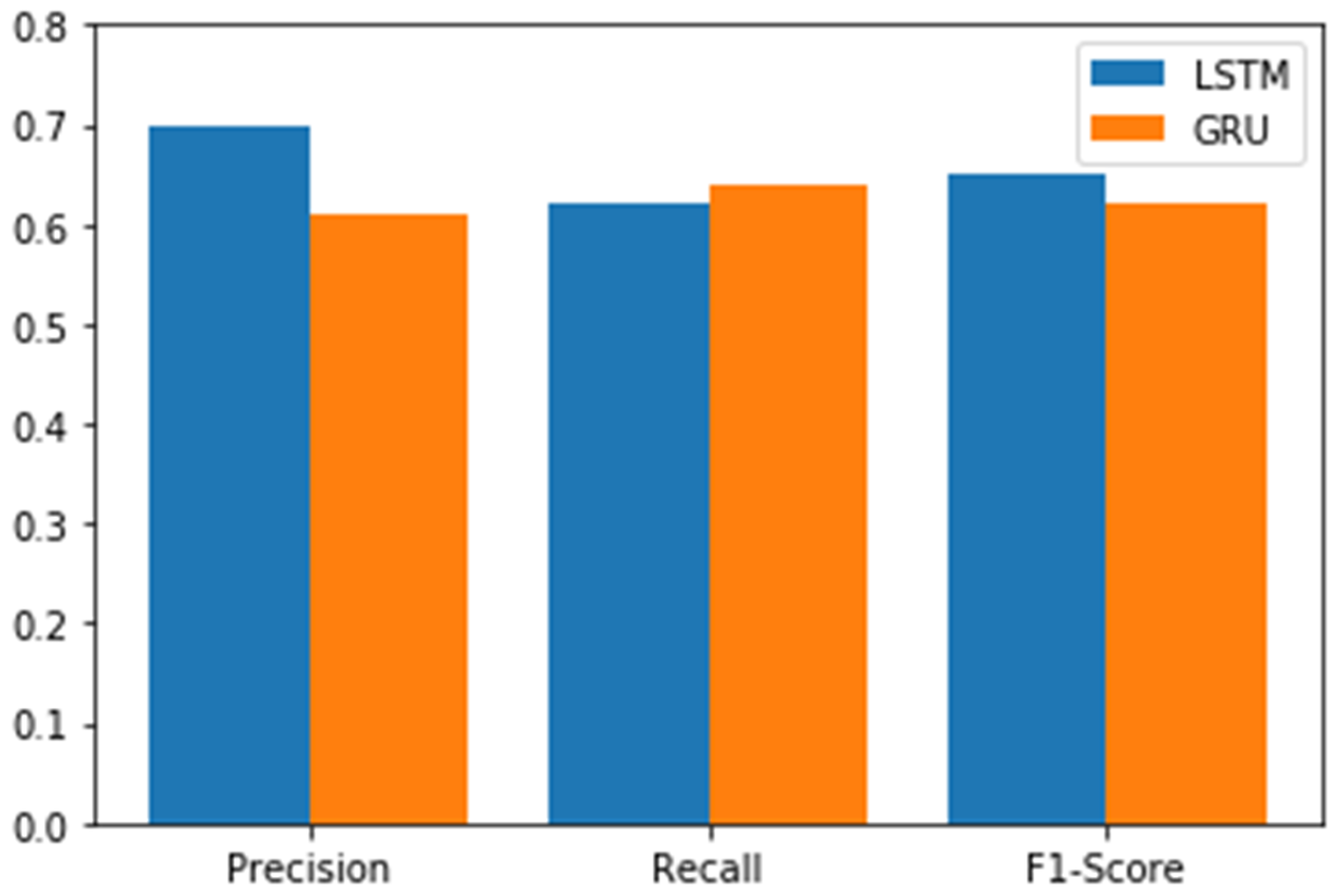
4. System Implementation and Testing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Margues, O.; Barman, N. Semi-automatic Semantic Annotation of Images using Machine Learning Techniques. In Proceedings of the ISWC: International Semantic Web Conference, Sanibel Island, FL, USA, 20–23 October 2003. [Google Scholar]
- Gayo, J.E.L.; De Pablos, P.O.; Lovelle, J.M.C. WESONet: Applying semantic web technologies and collaborative tagging to multimedia web information systems. Comput. Hum. Behav. 2010, 26, 205–209. [Google Scholar] [CrossRef]
- Im, D.-H.; Park, G.-D. Linked tag: Image annotation using semantic relationships between image tags. Multimed. Tools Appl. 2014, 74, 2273–2287. [Google Scholar] [CrossRef]
- Im, D.-H.; Park, G.-D. STAG: Semantic Image Annotation Using Relationships between Tags. In Proceedings of the 2013 International Conference on Information Science and Applications (ICISA), Pattaya, Thailand, 24–26 June 2013; pp. 1–2. [Google Scholar]
- Jeong, J.; Hong, H.; Lee, D. i-TagRanker: An Efficient Tag Ranking System for Image Sharing and Retrieval Using the se-mantic Relationships between Tags. Multimed. Tools Appl. 2013, 62, 451–478. [Google Scholar] [CrossRef]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual Relationship Detection with Language Priors. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene Graph Generation from Objects, Phrases and Region Captions. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1270–1279. [Google Scholar]
- Resource Description Framework(RDF): Concepts and Abstract Syntax. Available online: http://w3.org/TR/2014/REC-rdf11-concepts-20140225 (accessed on 17 November 2020).
- Chen, H.; Guo, A.; Ni, W.; Cheng, Y. Improving the representation of image descriptions for semantic image retrieval with RDF. J. Vis. Commun. Image Represent. 2020, 73, 102934. [Google Scholar] [CrossRef]
- Shin, Y.; Seo, K.; Ahn, J.; Im, D.H. Deep-learning-based image tagging for semantic image annotation. In Advanced in Computer Science and Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- SPARQL Query Language for RDF. Available online: http://w3c.org/TR/rdf-sparql-query/ (accessed on 17 November 2020).
- Elliott, B.; Ozsoyoglu, M. A comparison of methods for semantic photo annotation suggestion. In Proceedings of the 22nd International Symposium on Computer and Information Sciences, Ankara, Turkey, 7–9 November 2007. [Google Scholar]
- Chen, N.; Zhou, Q.; Prasnna, V. Understanding Web Image by Object Relation Network. In Proceedings of the International Conference on World Wide Web, Raleigh, SC, USA, 26–30 April 2010. [Google Scholar]
- Xia, S.; Gong, X.; Wang, W.; Tian, Y.; Yang, X.; Ma, J. Context-Aware Image Annotation and Retrieval on Mobile Device. In Proceedings of the 2010 Second International Conference on Multimedia and Information Technology, Kaifeng, China, 24–25 April 2010. [Google Scholar]
- Cui, P.; Liu, S.; Zhu, W. General Knowledge Embedded Image Representation Learning. IEEE Trans. Multimed. 2017, 20, 198–207. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the ICLR, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet5.5: An Open Multilingual Graph of General Knowledge; AAAI: Menlo Park, CA, USA, 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. In Proceedings of the NIPS, Montréal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Hayes, P. RDF Model Theory. W3C Working Draft. Available online: http://www.w3.org/TR/2001/WD-rdf-mt-20010925/ (accessed on 17 November 2020).
- Hollink, L.; Little, S.; Hunter, J. Evaluating the application of semantic inferencing rules to image annotation. In Proceedings of the 3rd International Conference on High Confidence Networked Systems, Berlin, Germany, 15–17 April 2004; Association for Computing Machinery (ACM): New York, NY, USA, 2005; p. 91. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rule | If E Contains | Then Add: |
|---|---|---|
| 1. | X A Y | A rdf:type rdf:Property |
| 2. | A rdfs:domain X U A Y | U rdf:type X |
| 3. | A rdfs:range X Y A V | V rdf:type X |
| 4. | U A B B A U | U rdf:type rdfs:Resource U rdf:type rdfs:Resource |
| 5. | U rdfs:subPropertyOf V V rdfs:subPropertyOf X | U rdfs:subPropertyOf X |
| 6. | U rdf:type rdf:PropertyOf | U rdfs:subPropertyOf U |
| 7. | A rdf:subPropertyOf B U A Y | U B Y |
| 8. | U rdf:type rdfs:Class | U rdfs:subClassOf rdfs:Resource |
| 9 | U rdf:subClassOf X V rdf:type U | V rdf:type X |
| 10. | U rdf:type rdfs:Class | U rdfs:subClassOf U |
| 11. | U rdfs:subClassOf V V rdfs:subClassOf X | U rdfs:subClassOf X |
| 12. | U rdf:type rdfs:ContainermembershipProperty | U rdfs:subProperty rdfs:member |
| 13. | U rdf:type rdfs:Datatype | U rdfs:subClassOf rdfs:Literal |
| Rule Type | Example |
|---|---|
| Season Inference | Between March and May it is spring, while from June to August it is summer, and from September to November it is autumn, and from December to February it is winter |
| Location Inference | If the location is part of Seoul, the location is also part of South Korea |
| Time Inference | If the time is eight to twelve o’clock, it is morning |
| Architecture | TOP-1 Error | TOP-5 Error |
|---|---|---|
| Ours | 22.73 | 6.44 |
| ResNet-101 [16] | 21.75 | 6.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Jeon, T.H.; Rhiu, I.; Ahn, J.; Im, D.-H. Semantic Scene Graph Generation Using RDF Model and Deep Learning. Appl. Sci. 2021, 11, 826. https://doi.org/10.3390/app11020826
Kim S, Jeon TH, Rhiu I, Ahn J, Im D-H. Semantic Scene Graph Generation Using RDF Model and Deep Learning. Applied Sciences. 2021; 11(2):826. https://doi.org/10.3390/app11020826
Chicago/Turabian StyleKim, Seongyong, Tae Hyeon Jeon, Ilsun Rhiu, Jinhyun Ahn, and Dong-Hyuk Im. 2021. "Semantic Scene Graph Generation Using RDF Model and Deep Learning" Applied Sciences 11, no. 2: 826. https://doi.org/10.3390/app11020826
APA StyleKim, S., Jeon, T. H., Rhiu, I., Ahn, J., & Im, D.-H. (2021). Semantic Scene Graph Generation Using RDF Model and Deep Learning. Applied Sciences, 11(2), 826. https://doi.org/10.3390/app11020826