
Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data


Abstract
1. Introduction
2. Related Works
2.1. GAN for Colorization
2.2. Pix2pix
2.3. Sketch Parsing
3. Webtoon Dataset for Seg2pix
4. Workflow Overview and Details
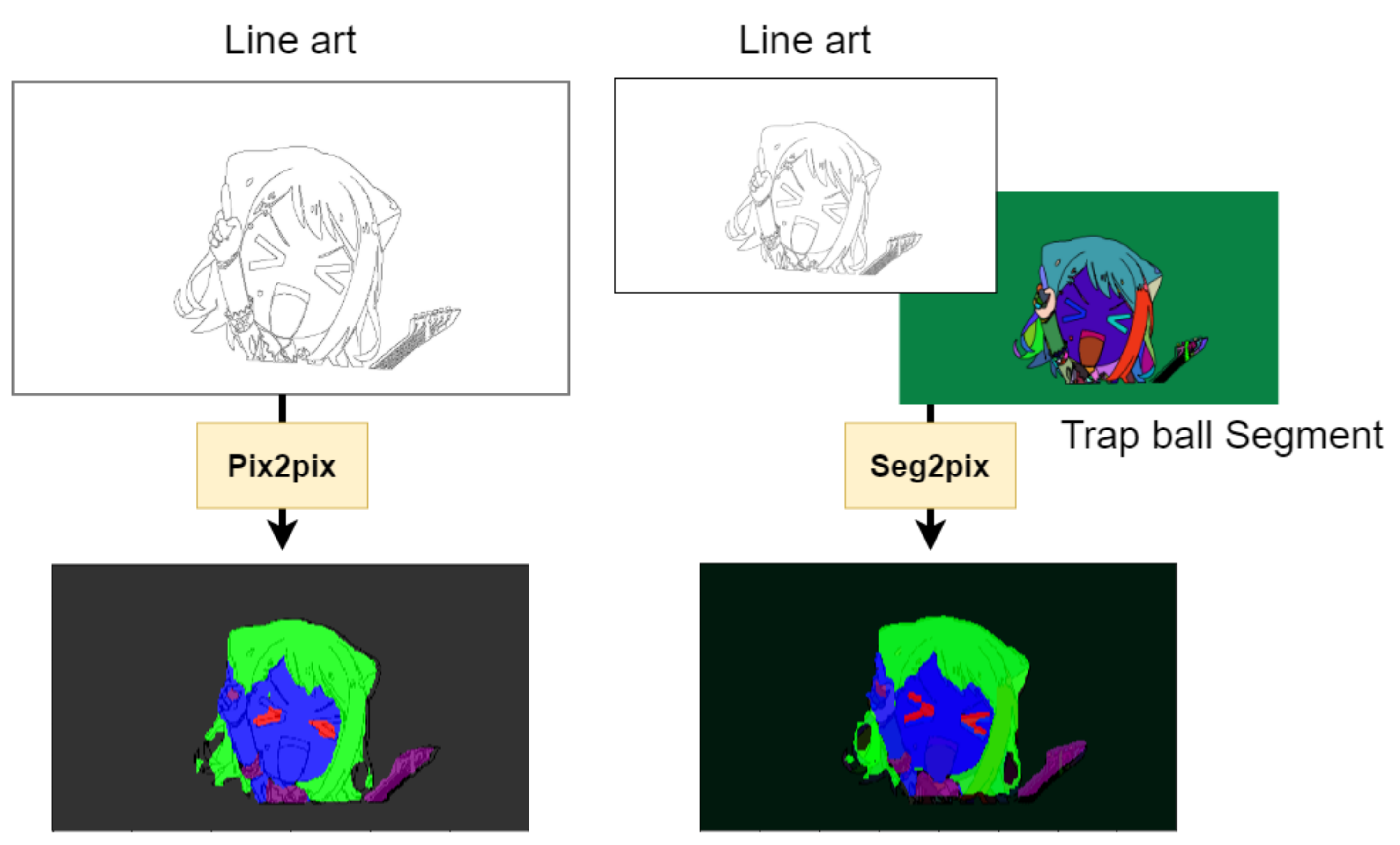
4.1. Trap Ball Segmentation
4.2. Segmentation
| Algorithm 1: Flood filling algorithm for trap ball segmentation. |
|
4.3. Colorize
4.4. Attention Layer
4.5. Loss
5. Experiments
5.1. Experimental Settings (Parameters)
| Algorithm 2: Optimizer learning rate algorithm. |
|
5.2. Comparisons
5.3. Analysis of the Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Dutchess County, NY, USA, 2014; Volume 27, pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Ci, Y.; Ma, X.; Wang, Z.; Li, H.; Luo, Z. User-guided deep anime line art colorization with conditional adversarial networks. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1536–1544. [Google Scholar]
- Hati, Y.; Jouet, G.; Rousseaux, F.; Duhart, C. PaintsTorch: A User-Guided Anime Line Art Colorization Tool with Double Generator Conditional Adversarial Network. In Proceedings of the European Conference on Visual Media Production, London, UK, 13–14 December 2019; pp. 1–10. [Google Scholar]
- Furusawa, C.; Hiroshiba, K.; Ogaki, K.; Odagiri, Y. Comicolorization: Semi-automatic manga colorization. In Proceedings of the SIGGRAPH Asia 2017 Technical Briefs (SA ’17), Association for Computing Machinery, New York, NY, USA, 27–30 November 2017; Article 12. pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, L.; Ji, Y.; Lin, X.; Liu, C. Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier gan. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 506–511. [Google Scholar] [CrossRef]
- Zhang, L.; Li, C.; Wong, T.T.; Ji, Y.; Liu, C. Two-stage sketch colorization. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Naoto Hosoda, Wasure Rareta Mirai Wo Motomete. 2014. Available online: http://ushinawareta-mirai.com/ (accessed on 22 April 2020).
- BanG Dream! Girls Band Party! PICO 2018. ©Bushiroad Co., Ltd. Available online: https://www.youtube.com/c/BanGDreamGirlsBandParty/featured (accessed on 13 March 2020).
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- lllyasviel, sketchKeras. Available online: https://github.com/lllyasviel/sketchKeras (accessed on 22 February 2020).
- Huang, Y.C.; Tung, Y.S.; Chen, J.C.; Wang, S.W.; Wu, J.L. An adaptive edge detection based colorization algorithm and its applications. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 2–10 November 2005; pp. 351–354. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization using optimization. In Proceedings of the ACM SIGGRAPH 2004 Papers (SIGGRAPH ’04), Association for Computing Machinery, New York, NY, USA, 8–12 August 2004; pp. 689–694. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Kim, H.; Jhoo, H.Y.; Park, E.; Yoo, S. Tag2pix: Line art colorization using text tag with secat and changing loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9056–9065. [Google Scholar]
- Ren, H.; Li, J.; Gao, N. Two-stage sketch colorization with color parsing. IEEE Access 2019, 8, 44599–44610. [Google Scholar] [CrossRef]
- Zheng, Y.; Yao, H.; Sun, X. Deep semantic parsing of freehand sketches with homogeneous transformation, soft-weighted loss, and staged learning. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Sarvadevabhatla, R.K.; Dwivedi, I.; Biswas, A.; Manocha, S. SketchParse: Towards rich descriptions for poorly drawn sketches using multi-task hierarchical deep networks. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 10–18. [Google Scholar]
- Wang, S.; Zhang, J.; Han, T.X.; Miao, Z. Sketch-based image retrieval through hypothesis-driven object boundary selection with HLR descriptor. IEEE Trans. Multimed. 2015, 17, 1045–1057. [Google Scholar] [CrossRef]
- Tolias, G.; Chum, O. Asymmetric feature maps with application to sketch based retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2377–2385. [Google Scholar]
- Zhang, Y.; Qian, X.; Tan, X.; Han, J.; Tang, Y. Sketch-based image retrieval by salient contour reinforcement. IEEE Trans. Multimed. 2016, 18, 1604–1615. [Google Scholar] [CrossRef]
- Xu, K.; Chen, K.; Fu, H.; Sun, W.L.; Hu, S.M. Sketch2Scene: Sketch-based co-retrieval and co-placement of 3D models. ACM Trans. Graph. (TOG) 2013, 32, 1–15. [Google Scholar] [CrossRef]
- Shao, T.; Xu, W.; Yin, K.; Wang, J.; Zhou, K.; Guo, B. Discriminative sketch-based 3d model retrieval via robust shape matching. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2011; Volume 30, pp. 2011–2020. [Google Scholar]
- Wang, F.; Kang, L.; Li, Y. Sketch-based 3d shape retrieval using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1875–1883. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Dong, J.; Cong, Y.; Sun, G.; Hou, D. Semantic-transferable weakly-supervised endoscopic lesions segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 10712–10721. [Google Scholar]
- Dong, J.; Cong, Y.; Sun, G.; Zhong, B.; Xu, X. What can be transferred: Unsupervised domain adaptation for endoscopic lesions segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4023–4032. [Google Scholar]
- Yumi’s Cell 2015. Yumi’s Cell Webtoon Series from Naver Webtoon. Available online: https://comic.naver.com/webtoon/list.nhn?titleId=651673 (accessed on 2 March 2020).
- Fantasy Sister 2019. Fantasy Sister Webtoon Series from Naver Webtoon. Available online: https://comic.naver.com/webtoon/list.nhn?titleId=730425 (accessed on 2 March 2020).
- Zhang, S.H.; Chen, T.; Zhang, Y.F.; Hu, S.M.; Martin, R.R. Vectorizing cartoon animations. IEEE Trans. Vis. Comput. Graph. 2009, 15, 618–629. [Google Scholar] [CrossRef] [PubMed]
- Hebesu, Trap-Ball Segmentaion Linefille. Available online: https://github.com/hepesu/LineFiller (accessed on 15 March 2020).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with Markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Munich, German, 8–16 October 2016; pp. 702–716. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 May 2019; pp. 7354–7363. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Workshop Autodiff Submission, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv arXiv:1412.6980.
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Parameter | Value |
|---|---|
| Learning rate discriminator Learning rate generator Learning rate policy Optimizer Loaded image size Epochs Epochs’ decay Generator encoder layer conv Generator decoder layer conv Discriminator layer conv | 0.0002 0.0002 linear Adam 512 × 288 200 100 64-128-256-256 (attention)-512-512-512-512-512 512-512-512-512-256-128-64 64-128-256-512-512-512 |
| Training Configuration | LPIPS (Average) |
|---|---|
| Style2paints PaintsChainer Tag2pix Seg2pix (without trap ball and attention) Seg2pix (without trap ball) pix2pix Seg2pix (without attention layer) Seg2pix (ours) | 0.3372 0.1772 0.0723 0.0488 0.0478 0.0477 0.0411 0.0375 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, C.W.; Seo, Y. Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data. Appl. Sci. 2021, 11, 1464. https://doi.org/10.3390/app11041464
Seo CW, Seo Y. Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data. Applied Sciences. 2021; 11(4):1464. https://doi.org/10.3390/app11041464
Chicago/Turabian StyleSeo, Chang Wook, and Yongduek Seo. 2021. "Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data" Applied Sciences 11, no. 4: 1464. https://doi.org/10.3390/app11041464
APA StyleSeo, C. W., & Seo, Y. (2021). Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data. Applied Sciences, 11(4), 1464. https://doi.org/10.3390/app11041464