Reversible and Plausibly Deniable Covert Channels in One-Time Passwords Based on Hash Chains †



Abstract
1. Introduction
2. Fundamentals and Related Work
2.1. Fundamentals
2.2. Related Work
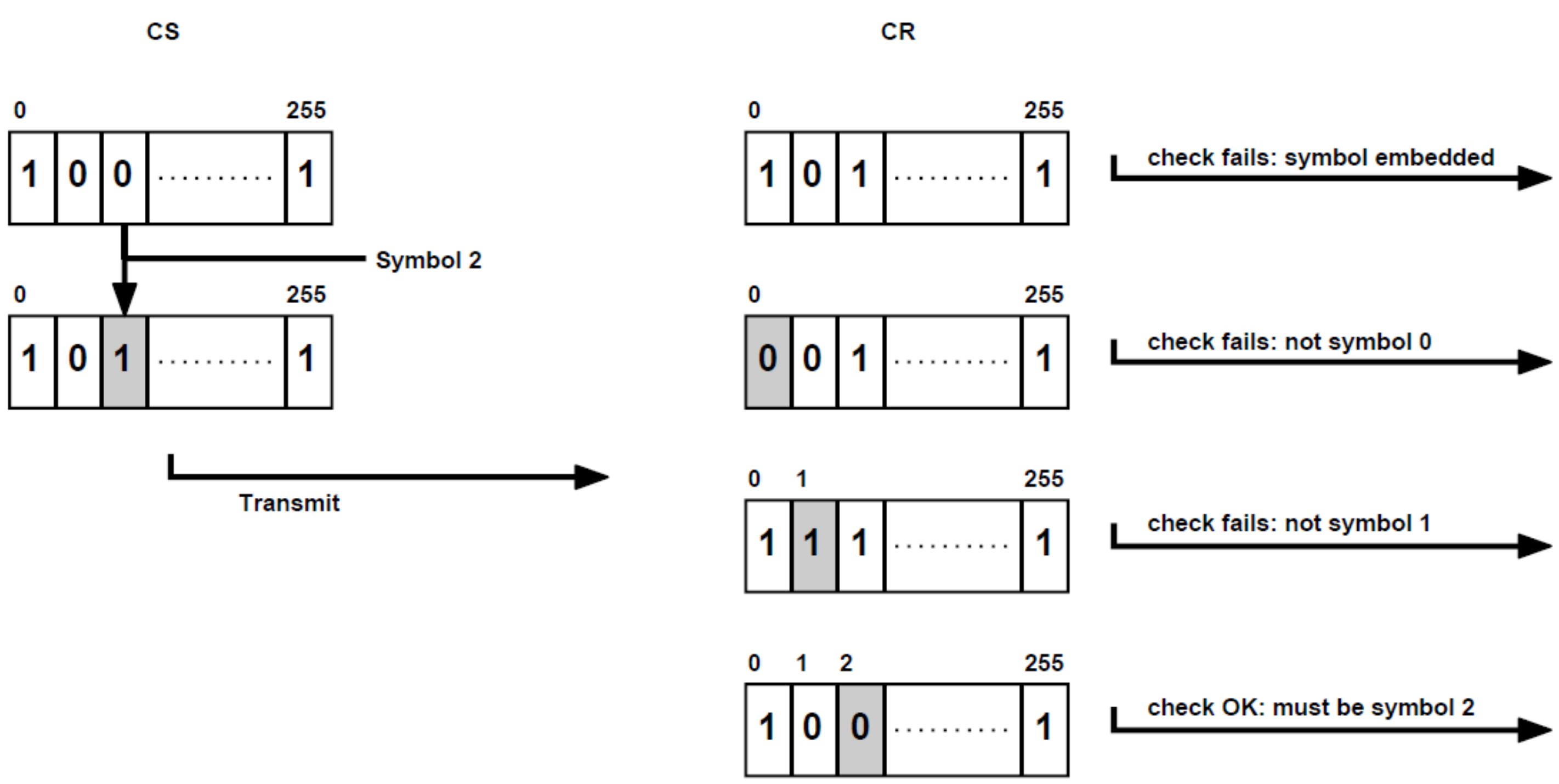
3. Covert Channels in Hash Chains
3.1. Channel Characteristics
- (1)
- Our channel variants allow plausible deniability as they replace selected bits of hash values in a pseudo-random manner so that the probability distribution of original and modified hash values are similar.
- (2)
- If CR is not just a passive observer but a hop on the path to B, CR is able to reconstruct the original hash value and can thus forward the illicit original message to B, rendering our approach reversible. This is feasible if, for example, B is a routing hop on a program in an IPC-chain between A and B. Due to the fact that we achieve full reversibility and do not exploit implicit or explicit reversibility methods, our technique is an intrinsic reversibility method.
- (3)
- Finally, our channel does not rely on indirect signaling methods, which makes it a direct covert channel. However, if CS applied a method to indirectly influence the transferred hash value, our channel would be a semi-passive one, while it would also be passive (indirect) if CR indirectly obtained the sent hash value (e.g., using a side channel) [38].
- (4)
- It does not matter for our covert channel whether the hash value is transmitted over a network or between local processes. The hash value can also be stored in a file at some point in time and then read later by another process, i.e., sender and receiver processes must not necessarily be active at the same time. However, in practice, most authentication scenarios would require A and B to be active simultaneously.
3.2. Covert Channel Variants
3.3. Hiding Pattern-Based Categorization
4. Countermeasures
5. Experiments
5.1. Performance
5.2. Randomness
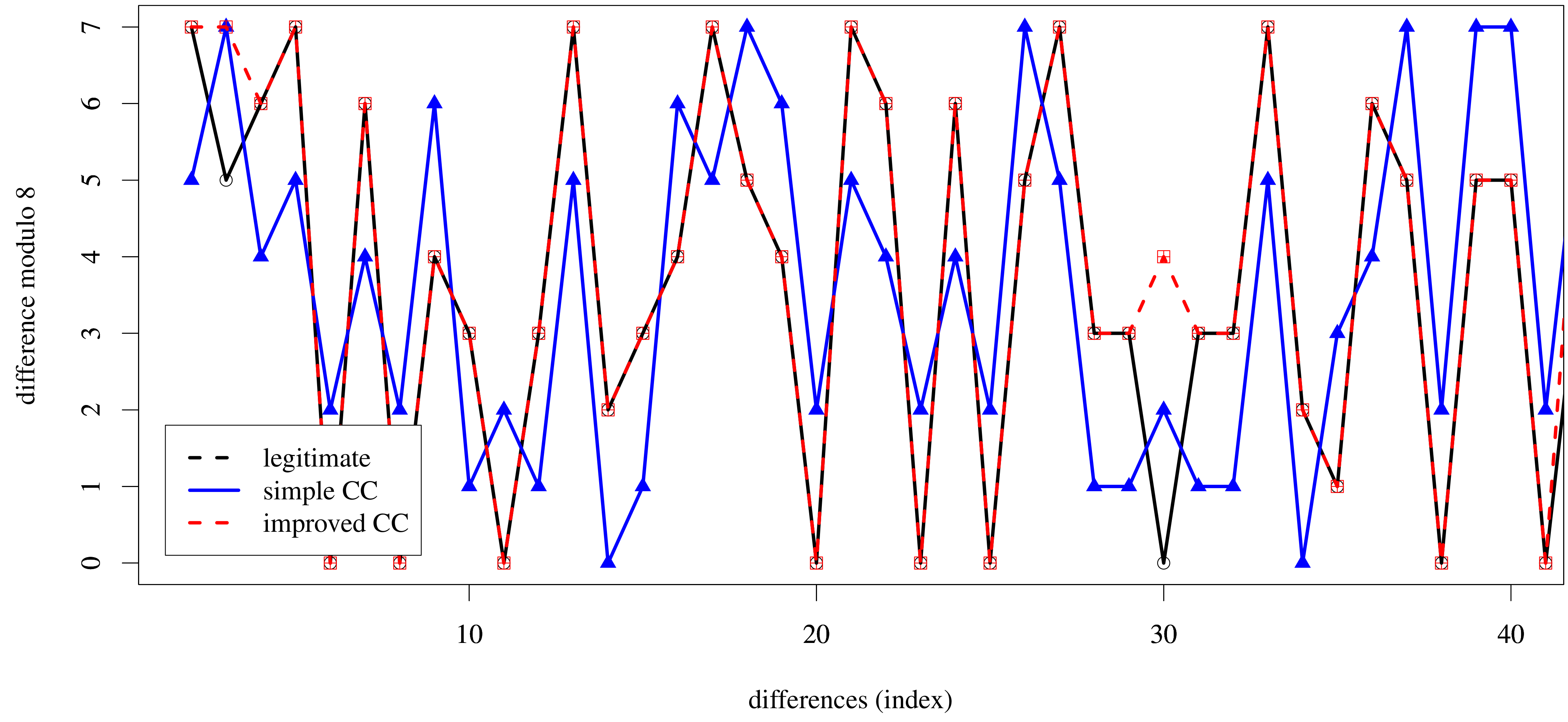
5.3. Detectability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lampson, B.W. A Note on the Confinement Problem. Commun. ACM 1973, 16, 613–615. [Google Scholar] [CrossRef]
- Lamport, L. Password authentication with insecure communication. Commun. ACM 1981, 24, 770–772. [Google Scholar] [CrossRef]
- Menezes, A.J.; van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Rivest, R. The MD5 Message-Digest Algorithm. In Request for Comments (RFC) 1321; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1992. [Google Scholar]
- National Institute of Standards and Technology (NIST). SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions. In Federal Information Processing Standards Publication (FIPS PUB) 202; NIST: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Bertoni, G.; Daemen, J.; Peeters, M.; Assche, G.V. The KECCAK reference, Version 3.0. In NIST SHA3 Submiss. Doc.; NIST: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Haller, N.; The S/KEY One-Time Password System. RFC 1760; RFC, Ed.; 1995. Available online: https://tools.ietf.org/html/rfc1760 (accessed on 13 January 2021).
- Perrig, A.; Canetti, R.; Tygar, J.D.; Song, D. The TESLA Broadcast Authentication Protocol. CryptoBytes 2002, 5, 2–13. [Google Scholar]
- Wendzel, S.; Zander, S.; Fechner, B.; Herdin, C. Pattern-Based Survey and Categorization of Network Covert Channel Techniques. Comput. Surv. 2015, 47. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-Y. Reversible steganographic method using SMVQ approach based on declustering. Inf. Sci. 2007, 177, 1796–1805. [Google Scholar]
- Mazurczyk, W.; Szary, P.; Wendzel, S.; Caviglione, L. Towards reversible storage network covert channels. In Proceedings of the 14th International Conference on Availability, Reliability and Security, Canterbury, UK, 26 August 2019; pp. 1–8. [Google Scholar]
- Bindschaedler, V.; Shokri, R.; Gunter, C.A. Plausible deniability for privacy-preserving data synthesis. arXiv 2017, arXiv:1708.07975. [Google Scholar] [CrossRef]
- Carrara, B.; Adams, C. Out-of-band covert channels—A survey. ACM Comput. Surv. (CSUR) 2016, 49, 1–36. [Google Scholar] [CrossRef]
- Hanspach, M.; Goetz, M. On covert acoustical mesh networks in air. arXiv 2014, arXiv:1406.1213. [Google Scholar] [CrossRef]
- Cronin, P.; Gouert, C.; Mouris, D.; Tsoutsos, N.G.; Yang, C. Covert Data Exfiltration Using Light and Power Channels. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, UAE, 17–20 November 2019; pp. 301–304. [Google Scholar]
- Matyunin, N.; Szefer, J.; Biedermann, S.; Katzenbeisser, S. Covert channels using mobile device’s magnetic field sensors. In Proceedings of the 2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macau, China, 25–28 January 2016; pp. 525–532. [Google Scholar]
- Mazurczyk, W.; Wendzel, S.; Zander, S.; Houmansadr, A.; Szczypiorski, K. Information Hiding in Communication Networks; IEEE Series on Information and Communication Networks Security; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Zander, S.; Armitage, G.; Branch, P. A survey of covert channels and countermeasures in computer network protocols. Comm. Surv. Tut. 2007, 9, 44–57. [Google Scholar] [CrossRef]
- Cabuk, S. Network Covert Channels: Design, Analysis, Detection, and Elimination. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2006. [Google Scholar]
- Xing, J.; Morrison, A.; Chen, A. NetWarden: Mitigating network covert channels without performance loss. In Proceedings of the 11th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 19), Renton, WA, USA, July 2019. [Google Scholar]
- Saenger, J.; Mazurczyk, W.; Keller, J.; Caviglione, L. VoIP network covert channels to enhance privacy and information sharing. Future Gener. Comput. Syst. 2020, 111, 96–106. [Google Scholar] [CrossRef]
- Zander, S.; Armitage, G.; Branch, P. Covert channels in the IP time to live field. In Proceedings of the Australian Telecommunication Networks and Application Conference (ATNAC), Melbourne, Australia, 4–6 December 2006. [Google Scholar]
- Zhang, X.; Guo, L.; Xue, Y.; Zhang, Q. A two-way VoLTE covert channel with feedback adaptive to mobile network environment. IEEE Access 2019, 7, 122214–122223. [Google Scholar] [CrossRef]
- Mazurczyk, W.; Caviglione, L. Steganography in modern smartphones and mitigation techniques. IEEE Commun. Surv. Tutor. 2014, 17, 334–357. [Google Scholar] [CrossRef]
- Urbanski, M.; Mazurczyk, W.; Lalande, J.F.; Caviglione, L. Detecting local covert channels using process activity correlation on android smartphones. Int. J. Comput. Syst. Sci. Eng. 2017, 32, 71–80. [Google Scholar]
- Wang, Z.; Lee, R.B. Covert and side channels due to processor architecture. In Proceedings of the 2006 22nd Annual Computer Security Applications Conference (ACSAC’06), Miami Beach, FL, USA, 11–15 December 2006; pp. 473–482. [Google Scholar]
- Chen, C.Y.; Mohan, S.; Pellizzoni, R.; Bobba, R.B.; Kiyavash, N. A Novel Side-Channel in Real-Time Schedulers. In Proceedings of the 2019 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Montreal, QC, Canada, 16–18 April 2019; pp. 90–102. [Google Scholar]
- Mileva, A.; Velinov, A.; Stojanov, D. New Covert Channels in Internet of Things. In Proceedings of the Twelfth International Conference on Emerging Security Information, Systems and Technologies (SECURWARE), Venice, Italy, 16–20 September 2018; pp. 30–36. [Google Scholar]
- Wendzel, S.; Mazurczyk, W.; Haas, G. Steganography for cyber-physical systems. J. Cyber Secur. Mobil. 2017, 6, 105–126. [Google Scholar] [CrossRef]
- Hildebrandt, M.; Lamshöft, K.; Dittmann, J.; Neubert, T.; Vielhauer, C. Information Hiding in Industrial Control Systems: An OPC UA based Supply Chain Attack and its Detection. In Proceedings of the 2020 ACM Workshop on Information Hiding and Multimedia Security, Denver, CO, USA, 22 June 2020; pp. 115–120. [Google Scholar]
- Calhoun, T.E., Jr.; Cao, X.; Li, Y.; Beyah, R. An 802.11 MAC layer covert channel. Wirel. Commun. Mob. Comput. 2012, 12, 393–405. [Google Scholar] [CrossRef]
- Anderson, R.; Needham, R.; Shamir, A. The steganographic file system. In International Workshop on Information Hiding; Springer: Berlin/Heidelberg, Germany, 1998; pp. 73–82. [Google Scholar]
- Craver, S.; Li, E.; Yu, J. Protocols for data hiding in pseudo-random state. In Media Forensics and Security; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; Volume 7254. [Google Scholar]
- Rutkowska, J. Passive Covert Channels Implementation in Linux Kernel. In Proceedings of the 21st Chaos Communications Congress, Berlin, Germany, 27–29 December 2004. [Google Scholar]
- Murdoch, S.J.; Lewis, S. Embedding covert channels into TCP/IP. In International Workshop on Information Hiding; Springer: Berlin/Heidelberg, Germany, 2005; pp. 247–261. [Google Scholar]
- Abad, C. IP Checksum Covert Channels and Selected Hash Collision; Technical Report; University of California: Los Angeles, CA, USA, 2001. [Google Scholar]
- Chang, C.C.; Lin, C.Y. Reversible steganography for VQ-compressed images using side matching and relocation. IEEE Trans. Inf. Forensics Secur. 2006, 1, 493–501. [Google Scholar] [CrossRef]
- Dittmann, J.; Hesse, D.; Hillert, R. Steganography and steganalysis in voice-over IP scenarios: Operational aspects and first experiences with a new steganalysis tool set. In Security, Steganography, and Watermarking of Multimedia Contents VII; International Society for Optics and Photonics: Bellingham, WA, USA, 2005; Volume 5681, pp. 607–618. [Google Scholar]
- Graham, R.L.; Knuth, D.E.; Patashnik, O. Concrete Mathematics, 2nd ed.; Addison-Wesley: Reading, MA, USA, 1994. [Google Scholar]
- Ugus, O.; Westhoff, D.; Bohli, J. A ROM-friendly secure code update mechanism for WSNs using a stateful-verifier tau-time signature scheme. In Proceedings of the Second ACM Conference on Wireless Network Security, WISEC 2009, Zurich, Switzerland, 16–19 March 2009; Basin, D.A., Capkun, S., Lee, W., Eds.; pp. 29–40. [Google Scholar] [CrossRef]
- Lewand, R. Cryptological Mathematics; Mathematical Association of America: Washington, DC, USA, 2000. [Google Scholar]
- Caviglione, L.; Gaggero, M.; Lalande, J.F.; Mazurczyk, W.; Urbański, M. Seeing the unseen: Revealing mobile malware hidden communications via energy consumption and artificial intelligence. IEEE Trans. Inf. Forensics Secur. (TIFS) 2015, 11, 799–810. [Google Scholar] [CrossRef]
- Marsaglia, G. The Marsaglia Random Number CDROM including the Diehard Battery of Tests of Randomness; Technical Report; Florida State University: Tallahassee, FL, USA, 1995. [Google Scholar]
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E.; Leigh, S.; Levenson, M.; Vangel, M.; Banks, D.; Heckert, A.; et al. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; National Institute of Standards and Technology; Special Publication 800-22 Revision 1a; Gaithersburg, MD, USA, 2010. [Google Scholar]



{kind=link}
{kind=link}
| OTP Hash Function | Without CC | With CC | With CC and Encrypt. |
|---|---|---|---|
| MD5 | 0.019 s | 0.350 s | 0.349 s |
| SHA-3 | 0.386 s | 6.737 s | 6.803 s |
| OTP Hash Function | Without CC | With CC | With CC and Encrypt. |
|---|---|---|---|
| MD5 | 0.968052 | 0.973558 | 0.986777 |
| SHA-3 | 0.864040 | 0.905754 | 0.864040 |
| OTP Hash Function | Without CC | With CC | With CC and Encrypt. |
|---|---|---|---|
| MD5 | 0.8212000 | 0.7555420 | 0.8038680 |
| SHA-3 | 0.6928455 | 0.6198775 | 0.6928455 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keller, J.; Wendzel, S. Reversible and Plausibly Deniable Covert Channels in One-Time Passwords Based on Hash Chains. Appl. Sci. 2021, 11, 731. https://doi.org/10.3390/app11020731
Keller J, Wendzel S. Reversible and Plausibly Deniable Covert Channels in One-Time Passwords Based on Hash Chains. Applied Sciences. 2021; 11(2):731. https://doi.org/10.3390/app11020731
Chicago/Turabian StyleKeller, Jörg, and Steffen Wendzel. 2021. "Reversible and Plausibly Deniable Covert Channels in One-Time Passwords Based on Hash Chains" Applied Sciences 11, no. 2: 731. https://doi.org/10.3390/app11020731
APA StyleKeller, J., & Wendzel, S. (2021). Reversible and Plausibly Deniable Covert Channels in One-Time Passwords Based on Hash Chains. Applied Sciences, 11(2), 731. https://doi.org/10.3390/app11020731