
Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions


Abstract
:1. Introduction
2. Materials and Methods
2.1. Patient Population
2.2. Definitions
- The degree of calcification was visually estimated on fluoroscopy, defined as moderate when one-half of the total CTO segment exhibited visible residues, and as severe when the extension of calcification was >50% of the segment.
- Arterial tortuosity arises from abnormal elongation of the arteries and is characterized by blood vessel abnormalities, particularly abnormal twists and turns. The CTO was defined as straight if the pre-occlusive segment contained a bend of <70; moderate when a segment contained either two bends >70, or one bend >90; and as severe when it contained either two or more pre-occlusive bends of >90, or at least one bend of >120.
- The length of coronary occlusions was visually estimated from angiographic projections with single- or dual-contrast injections.
- Chronic obstructive pulmonary disease (COPD) is a chronic inflammatory lung disease that causes obstructed airflow from the lungs. It is characterized by long-term respiratory symptoms and airflow limitation.
- The morphology of the vessel stump was characterized as tapered, blunt, or unseen, depending on its appearance on fluoroscopy. The angiographic assessment of collateral connections was made according to the Werner classification.
- Dyslipidemia is present when an abnormally high amount of lipids is present.
- Renal failure is a long-term condition of kidney malfunction.
- Family history of coronary disease is present when one or more close relatives had early coronary artery disease (men <55 years, women <65 years).
- Peripheral disease was defined when abnormal narrowing of arteries was present.
- Segmental regional abnormalities were defined as regional abnormalities in contractile function.
- Previous MI was defined as documented history of previous myocardial infarction.
- In-stent CTO was defined when CTO inside a previous PCI existed.
- CTO location represented the vessel in which the CTO is located.
- Previous CABG corresponded to history of coronary artery bypass surgery.
- Technical success was defined as a residual stenosis of <10% at the end of the procedure with TIMI flow grade three antegrade flow.
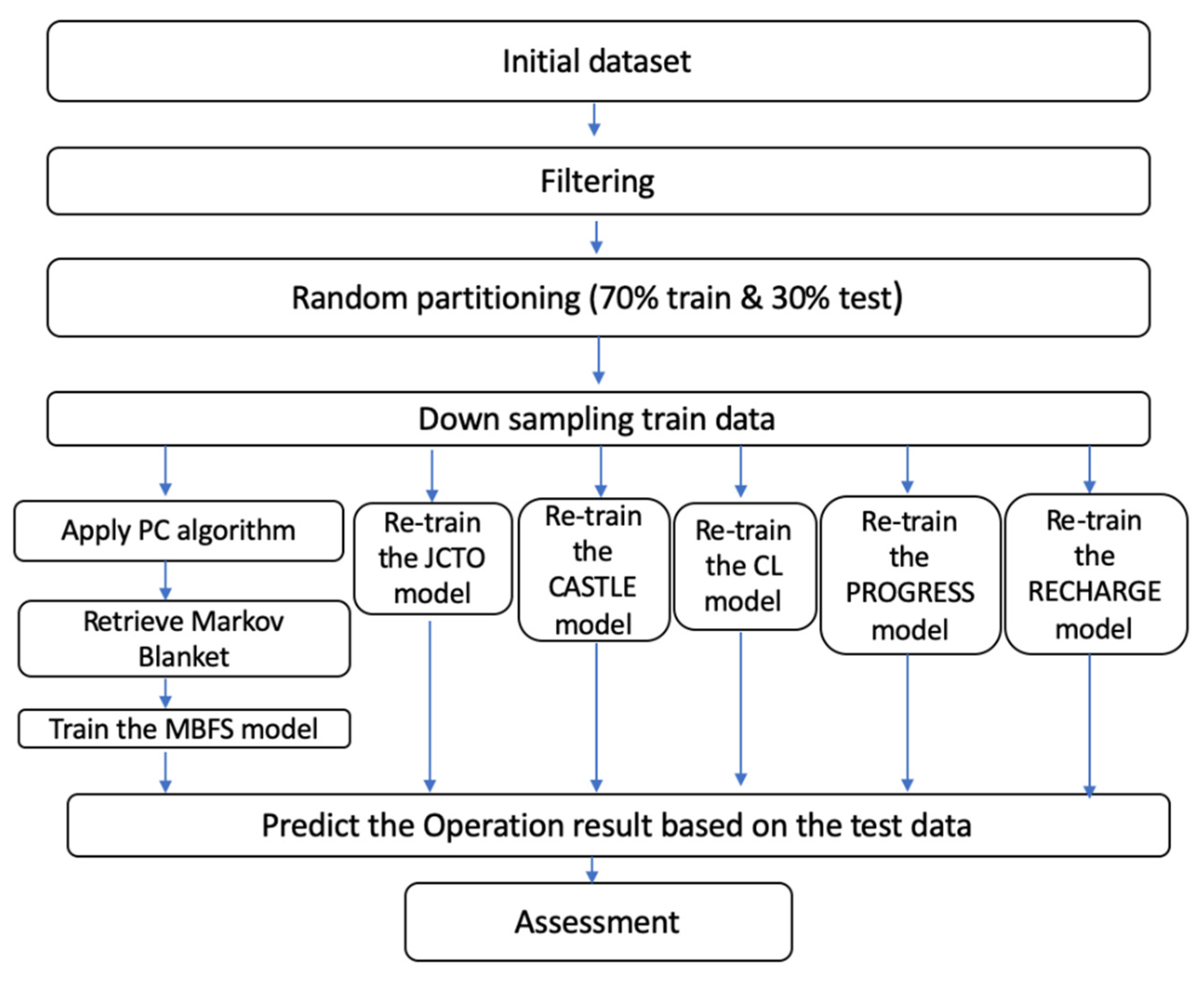
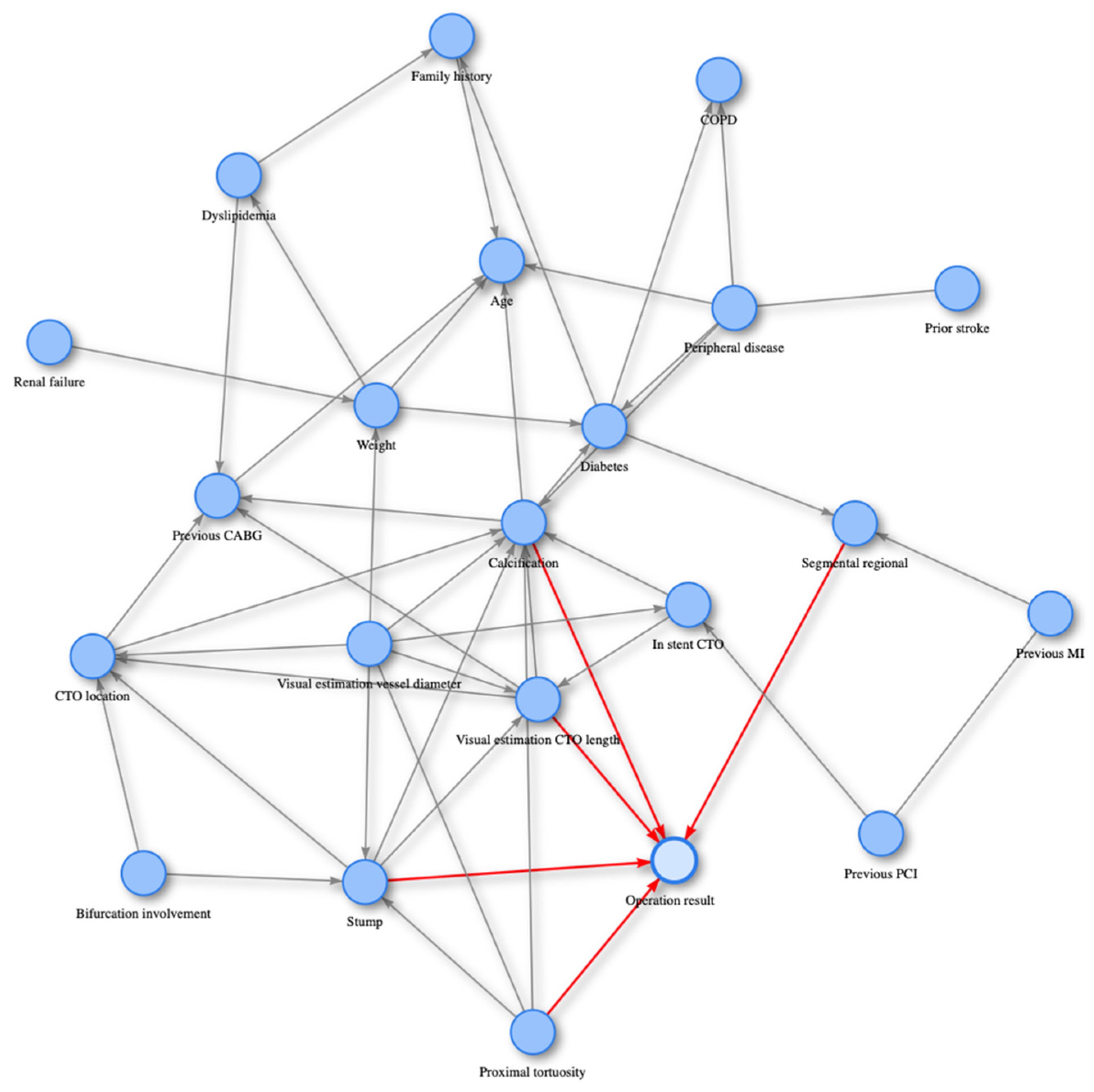
2.3. PC Algorithm
2.4. Statistical Analysis
2.4.1. Preprocessing
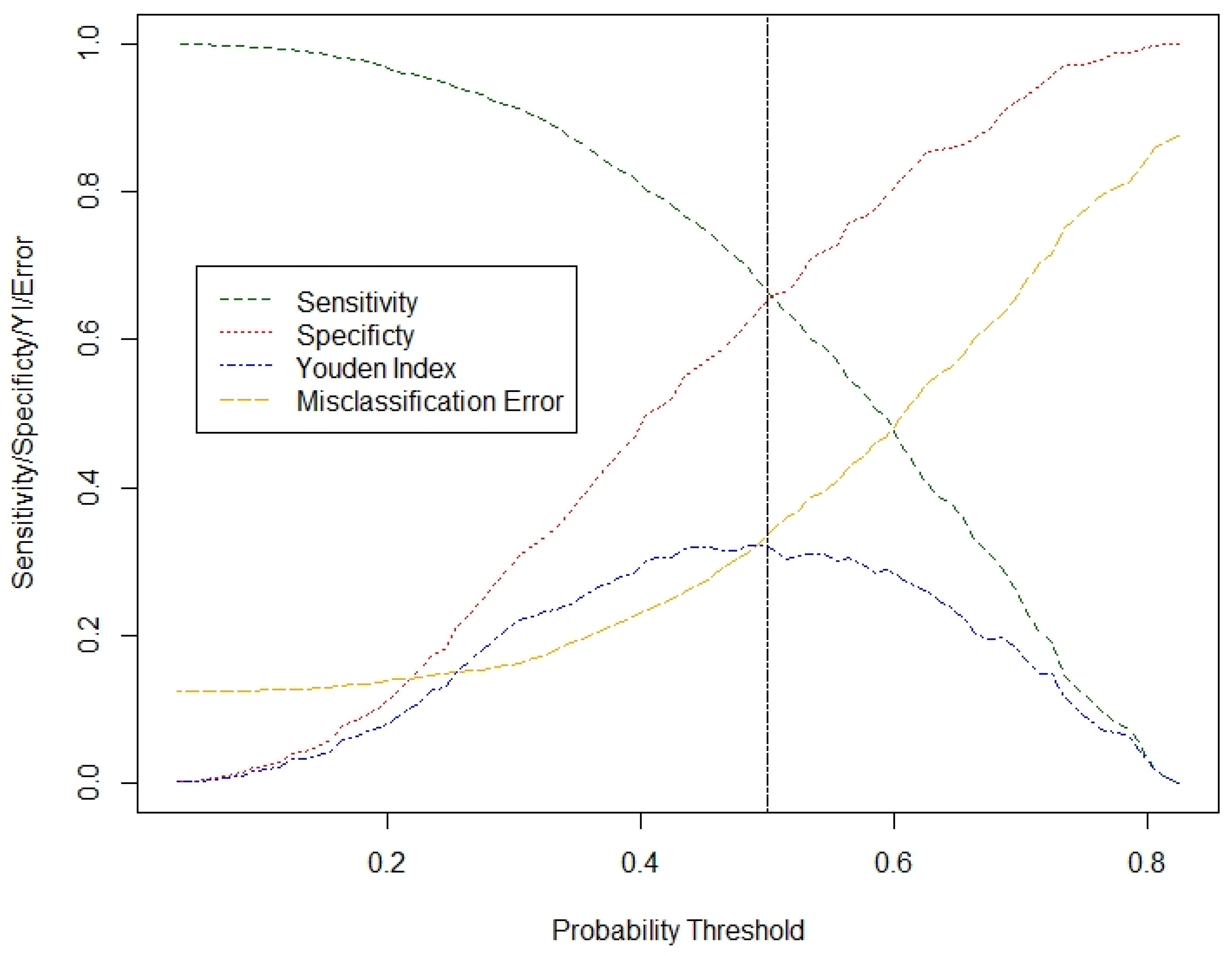
2.4.2. Analysis
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Operation Success n = 1513 | Operation Failure n = 1513 |
|---|---|---|
| Calcification (%) None/Mild (spots) Moderate(<=50% RLD) Severe (>50% RLD) | 902 (59.6) 407 (26.9) 204 (13.5) | 583 (38.5) 464 (30.7) 466 (30.8) |
| Segmental regional (%) Normal H/A/D | 835 (55.2) 678 (44.8) | 678 (44.8) 835 (55.2) |
| Age, mean (SD) | 64.12 (10.6) | 65.21 (10.1) |
| Weight, mean (SD) | 84.31 (16.5) | 84.47 (16.4) |
| Family history (%) No Yes | 1059 (70.0) 454 (30.0) | 1065 (70) 448 (29.6) |
| Dyslipidemia (%) No Yes | 338 (22.3) 1175 (77.7) | 303 (20.0) 1210 (80.0) |
| Diabetes (%) No Yes | 1045 (69.1) 468 (30.9) | 1025 (67.8) 488 (32.3) |
| Peripheral disease (%) No Yes | 1369 (90.5) 144 (9.5) | 1314 (88.8) 199 (13.2) |
| COPD (%) No Yes | 1429 (94.4) 84 (5.5) | 1411 (93.3) 102 (6.7) |
| Prior stroke (%) No Yes | 1472 (97.3) 41 (2.7) | 1456 (96.2) 57 (3.8) |
| Renal failure (%) No Yes | 1495 (98.8) 18 (1.2) | 1498 (99.0) 15 (1.0) |
| Previous MI (%) No Yes | 940 (62.1) 573 (37.9) | 901 (59.6) 612 (40.5) |
| Previous CABG (%) No Yes | 1325 (87.6) 188 (12.4) | 1239 (81.9) 274 (18.1) |
| Previous PCI (%) No Yes | 795 (52.5) 718 (47.5) | 730 (48.3) 783 (51.8) |
| CTO location (%) Ostial Proximal Mid Distal | 156 (10.3) 649 (42.9) 607 (40.1) 101 (6.7) | 219 (14.5) 638 (42.2) 571 (37.7) 85 (5.6) |
| In stent CTO (%) No Yes | 1401 (92.6) 112 (7.4) | 1409 (93.1) 104 (6.9) |
| Bifurcation involvement (%) No Yes | 1217 (80.4) 296 (19.6) | 1262 (83.4) 251 (16.6) |
| CTO length, mean (SD) | 28.28 (18.6) | 36.23 (22.1) |
| Vessel diameter, mean (SD) | 2.93 (0.4) | 2.90 (0.5) |
| Proximal tortuosity (%) Straight Moderate Severe | 1098 (72.6) 336 (22.2) 79 (5.2) | 822 (54.3) 463 (30.6) 228 (15.1) |
| Stump (%) No stump Tapered stump Blunt stump | 171 (11.3) 745 (49.2) 597 (39.5) | 358 (23.7) 413 (27.3) 742 (49.0) |
| Variable | Operation Success n = 10,647 | Operation Failure m = 1513 |
|---|---|---|
| Calcification (%) None/Mild (spots) Moderate (<=50% RLD) Severe (>50% RLD) | 6270 (58.9) 2877 (27.0) 1500 (14.1) | 583 (38.5) 464 (30.7) 466 (30.8) |
| Segmental regional (%) Normal H/A/D | 5658 (53.1) 4989 (46.9) | 678 (44.8) 835 (55.2) |
| Age, mean (SD) | 64.06 (10.7) | 65.21 (10.1) |
| Weight, mean (SD) | 84.32 (16.3) | 84.47 (16.4) |
| Family history (%) No Yes | 7379 (69.3) 3268 (30.7) | 1065 (70.4) 448 (29.6) |
| Dyslipidemia (%) No Yes | 2356 (22.1) 8291 (77.9) | 303 (20.0) 1210 (80.0) |
| Diabetes (%) No Yes | 7382 (69.3) 3265 (30.7) | 1025 (67.8) 488 (32.3) |
| Peripheral disease (%) No Yes | 9611 (90.3) 1036 (9.7) | 1314 (88.8) 199 (13.2) |
| COPD (%) No Yes | 10108 (94.9) 539 (5.1) | 1411 (93.3) 102 (6.7) |
| Prior stroke (%) No Yes | 10363 (97.3) 284 (2.7) | 1456 (96.2) 57 (3.8) |
| Renal failure (%) No Yes | 10536 (99.0) 111 (1.0) | 1498 (99.0) 15 (1.0) |
| Previous MI (%) No Yes | 6601 (62.0) 4046 (38.0) | 901 (59.6) 612 (40.5) |
| Previous CABG (%) No Yes | 9324 (87.6) 1323 (12.4) | 1239 (81.9) 274 (18.1) |
| Previous PCI (%) No Yes | 5591 (52.5) 5056 (47.5) | 730 (48.3) 783 (51.8) |
| CTO location (%) Ostial Proximal Mid Distal | 1018 (9.6) 4581 (43.0) 4311 (40.5) 737 (6.9) | 219 (14.5) 638 (42.2) 571 (37.7) 85 (5.6) |
| In stent CTO (%) No Yes | 9793 (92.0) 854 (8.0) | 1409 (93.1) 104 (6.9) |
| Bifurcation involvement (%) No Yes | 8526 (80.1) 2121 (19.9) | 1262 (83.4) 251 (16.6) |
| CTO length, mean (SD) | 28.72 (18.8) | 36.23 (22.1) |
| Vessel diameter, mean (SD) | 2.94 (0.4) | 2.90 (0.5) |
| Proximal tortuosity (%) Straight Moderate Severe | 7535(70.8) 2567(24.1) 545(5.1) | 822 (54.3) 463 (30.6) 228 (15.1) |
| Stump (%) No stump Tapered stump Blunt stump | 1219 (11.5) 5088 (47.8) 4340 (40.8) | 358 (23.7) 413 (27.3) 742 (49.0) |
| Variable | Operation Success n = 4562 | Operation Failure n = 648 |
|---|---|---|
| Calcification (%) None/Mild (spots) Moderate (<=50% RLD) Severe (>50% RLD) | 2714 (59.5) 1167 (25.6) 681 (14.9) | 246 (38.0) 178 (27.5) 224 (34.6) |
| Segmental regional (%) Normal H/A/D | 2430 (53.3) 2132 (46.7) | 277 (42.8) 371 (57.3) |
| Age, mean (SD) | 63.98 (10.6) | 65.53 (10.5) |
| Weight, mean (SD) | 84.34 (16.1) | 85.89 (16.8) |
| Family history (%) No Yes | 3132 (68.7) 1430 (31.4) | 444 (68.5) 204 (31.5) |
| Dyslipidemia (%) No Yes | 1027 (22.5) 3535 (77.5) | 143 (22.1) 505 (77.9) |
| Diabetes (%) No Yes | 3096 (67.9) 1466 (32.1) | 411 (63.4) 237 (36.6) |
| Peripheral disease (%) No Yes | 4106 (90.0) 456 (10.0) | 543 (83.8) 105 (16.2) |
| COPD (%) No Yes | 4339 (95.1) 223 (4.9) | 594 (91.7) 54 (8.3) |
| Prior stroke (%) No Yes | 4440 (97.3) 122 (2.7) | 625 (96.5) 23 (3.6) |
| Renal failure (%) No Yes | 4508 (98.8) 54 (1.2) | 638 (98.5) 10 (1.5) |
| Previous MI (%) No Yes | 2831 (62.1) 1731 (37.9) | 365 (56.3) 283 (43.7) |
| Previous CABG (%) No Yes | 3985 (87.4) 577 (12.7) | 516 (79.6) 132 (20.4) |
| Previous PCI (%) No Yes | 2357 (51.7) 2205 (48.3) | 300 (46.3) 348 (53.7) |
| CTO location (%) Ostial Proximal Mid Distal | 451 (9.9) 1985 (43.5) 1822 (39.9) 304 (6.7) | 84 (13.0) 272 (42.0) 250 (38.6) 42 (6.5) |
| In stent CTO (%) No Yes | 4144 (90.9) 418 (9.2) | 614 (94.8) 34 (5.3) |
| Bifurcation involvement (%) No Yes | 3653 (80.1) 909 (19.9) | 516 (79.6) 132 (20.4) |
| CTO length, mean (SD) | 29.07 (19.7) | 37.27 (22.9) |
| Vessel diameter, mean (SD) | 2.94 (0.4) | 2.91 (0.4) |
| Proximal tortuosity (%) Straight Moderate Severe | 3173 (69.6) 1161 (25.5) 228 (5.0) | 369 (57.0) 200 (30.9) 79 (12.2) |
| Stump (%) No stump Tapered stump Blunt stump | 538 (11.8) 2190 (48.0) 1834 (40.2) | 151 (23.3) 171 (26.4) 326 (50.3) |
References
- Konstantinidis, N.; Werner, G.; Deftereos, S.; Di Mario, C.; Galassi, A.; Buettner, J.; Avran, A.; Reifart, N.; Garbo, O.R.; Bufe, A.; et al. Temporal trends in chronic Total occlusion interventions in Europe: 17 626 procedures from the European registry of chronic Total occlusion. Circ. Cardiovasc. Interv. 2018, 11, e006229. [Google Scholar] [CrossRef] [PubMed]
- Morino, Y.; Abe, M.; Morimoto, T.; Kimura, T.; Hayashi, Y.; Muramatsu, T.; Ochiai, M.; Noguchi, Y.; Kato, K.; Shibata, Y.; et al. Predicting Successful Guidewire Crossing Through Chronic Total Occlusion of Native Coronary Lesions Within 30 Minutes: The J-CTO (Multicenter CTO Registry in Japan) Score as a Difficulty Grading and Time Assessment Tool. JACC Cardiovasc. Interv. 2011, 4, 213–221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szijgyarto, Z.; Rampat, R.; Werner, G.; Ho, C.; Reifart, N.; Lefevre, T.; Louvard, Y.; Avran, A.; Kambis, M.; Buettner, H.; et al. Derivation and validation of a chronic total coronary occlusion intervention procedural success score from the 20,000-patient EuroCTO registry: The EuroCTO (CASTLE) score. JACC Cardiovasc. Interv. 2019, 12, 335–342. [Google Scholar] [CrossRef] [PubMed]
- Alessandrino, G.; Chevalier, B.; Lefèvre, T.; Sanguineti, F.; Garot, P.; Unterseeh, T.; Hovasse, T.; Morice, M.-C.; Louvard, Y. A Clinical and Angiographic Scoring System to Predict the Probability of Successful First-Attempt Percutaneous Coronary Intervention in Patients with Total Chronic Coronary Occlusion. JACC Cardiovasc. Interv. 2015, 8, 1540–1548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christopoulos, G.; Kandzari, D.; Yeh, R.; Jaffer, F.; Karmpaliotis, D.; Wyman, M.; Alaswad, K.; Lombardi, W.; Grantham, J.; Moses, J.; et al. Development and validation of a novel scoring system for predicting technical success of chronic total occlusion percutaneous coronary interventions the PROGRESS CTO (Prospective Global Registry for the Study of Chronic Total Occlusion Intervention) score. JACC Cardiovasc. Interv. 2016, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maeremans, J.; Spratt, J.; Knaapen, P.; Walsh, S.; Agostoni, P.; Wilson, W.; Avran, A.; Faurie, B.; Bressollette, E.; Kayaert, P.; et al. Towards a contemporary, comprehensive scoring system for determining technical outcomes of hybrid percutaneous chronic total occlusion treatment: The RECHARGE score. Catheter. Cardiovasc. Interv. 2018, 91, 192–202. [Google Scholar] [CrossRef] [PubMed]
- Galassi, A.; Boukhris, M.; Azzarelli, S.; Castaing, M.; Marzà, F.; Tomasello, S. Percutaneous coronary revascularization for chronic total occlusions: A novel predictive score of technical failure using advanced technologies. JACC Cardiovasc. Interv. 2016, 9, 911–922. [Google Scholar] [CrossRef] [PubMed]
- Aliferis, C.F.; Statnikov, A.; Tsamardinos, I.; Mani, S.; Koutsoukos, X.D. Local causal and Markov blanket induction for causal discovery and feature selection for classification part I: Algorithms and empirical evaluation. J. Mach. Learn. Res. 2010, 11, 171–234. [Google Scholar]
- Raghu, V.K.; Zhao, W.; Pu, J.; Leader, J.K.; Wang, R.; Herman, J.; Yuan, J.-M.; Benos, P.V.; O Wilson, D. Feasibility of lung cancer prediction from low-dose CT scan and smoking factors using causal models. Thorax 2019, 74, 643–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piccininni, M.; Konigorski, S.; Rohmann, J.L.; Kurth, T. Directed acyclic graphs and causal thinking in clinical risk prediction modeling. BMC Med. Res. Methodol. 2020, 20, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Neopolitan, R.E. Learning Bayesian Networks; Prentice Hall: Hoboken, NJ, USA, 2003. [Google Scholar]
- Spirtes, P.; Glymour, C.C.; Scheines, R. Causation, Prediction, and Search, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Li, J.; Liu, L.; Le, T.D. Practical Approaches to Causal Relationship Exploration; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Fernández, A.; García, S.; Galar, M.; Prati, R.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10, pp. 978–983. [Google Scholar]
- Tsagris, M.; Bordoudakis, G.; Lagani, V.; Tsamardinos, I. Constraint-based causal discovery with mixed data. Int. J. Data Sci. Anal. 2018, 6, 19–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hajian-Tilaki, K. Receiver Operating Characteristic (ROC) Curve Analysis for Medical Diagnostic Test Evaluation. Casp. J. Intern. Med. 2013, 4, 627–635. [Google Scholar]
- Karatasakis, A.; Danek, B.A.; Karmpaliotis, D.; Alaswad, K.; Jaffer, F.A.; Yeh, R.W.; Patel, M.; Bahadorani, J.N.; Lombardi, W.L.; Wyman, R.M.; et al. Comparison of various scores for predicting success of chronic total occlusion percutaneous coronary intervention. Int. J. Cardiol. 2016, 224, 50–56. [Google Scholar] [CrossRef] [PubMed]
| 95% Confidence Interval for Exp (B) | ||||
|---|---|---|---|---|
| Variables | Exp (B) | Lower | Upper | p-Value |
| (Intercept) | 1.501 | 1.17 | 1.93 | 0.001 |
| Calcification_None/Mild (spots) | 1.000 | |||
| Calcification_Moderate (<=50% RLD) | 0.697 | 0.58 | 0.84 | <0.001 |
| Calcification_Severe (>50% RLD) | 0.395 | 0.32 | 0.49 | <0.001 |
| Segmental regional_Normal | 1.000 | |||
| Segmental regional_H/A/D | 0.674 | 0.58 | 0.79 | <0.001 |
| CTO length | 0.986 | 0.98 | 0.99 | <0.001 |
| Proximal tortuosity_Straight | 1.000 | |||
| Proximal tortuosity_Moderate | 0.671 | 0.56 | 0.80 | <0.001 |
| Proximal tortuosity_Severe | 0.355 | 0.27 | 0.47 | <0.001 |
| Stump_No | 1.000 | |||
| Stump_Tapered | 3.237 | 2.58 | 4.07 | <0.001 |
| Stump_Blunt | 1.946 | 1.56 | 2.43 | <0.001 |
| Accuracy Measures MBFS | |
|---|---|
| Overall Accuracy | 0.6647 |
| Sensitivity | 0.6662 |
| Specificity | 0.6543 |
| AUROC | 0.7145 |
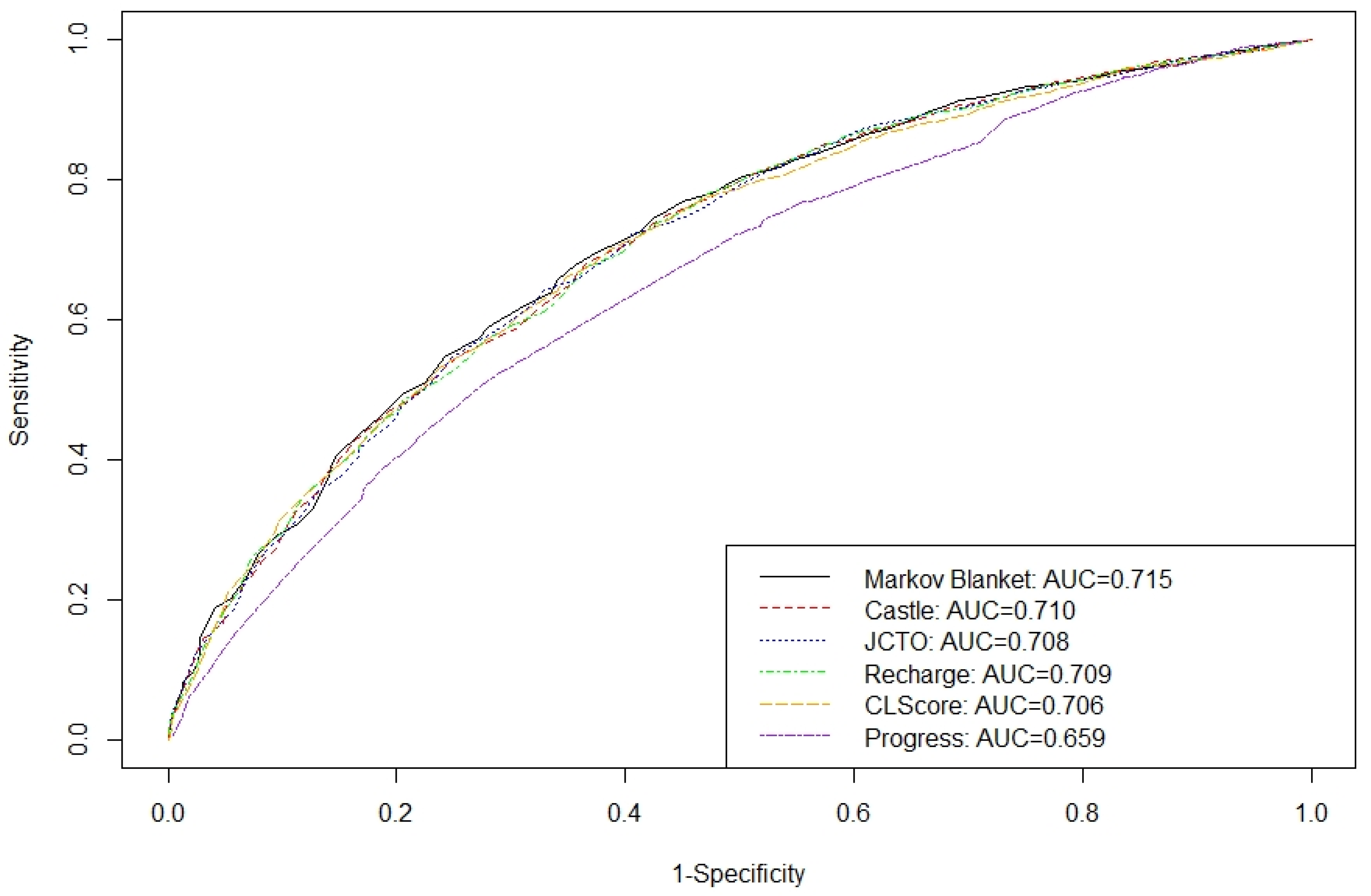
| Model Name | # of Features | FEATURES USED | AIC | AUROC |
|---|---|---|---|---|
| MBFS | 5 | Segmental, Proximal tortuosity, Calcification, Stump, CTO length | 3751.7 | 0.715 |
| CASTLE | 6 | Previous CABG, Age, Proximal tortuosity, Calcification, Stump, CTO length | 3774 | 0.710 |
| JCTO | 5 | Proximal tortuosity, Calcification, Stump, CTO length, Previously failed lesion | 3760.6 | 0.708 |
| RECHARGE | 5 | Previous CABG, Proximal tortuosity, Calcification, Stump, CTO length | 3774.1 | 0.709 |
| CL | 6 | Previous CABG, Previous MI, Calcification, Stump, CTO length, n-LAD | 3841.7 | 0.706 |
| PROGRESS | 4 | Previous PCI, Proximal tortuosity, Stump, CTO artery | 3915.1 | 0.659 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ganopoulou, M.; Kangelidis, I.; Sianos, G.; Angelis, L. Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions. Appl. Sci. 2021, 11, 9258. https://doi.org/10.3390/app11199258
Ganopoulou M, Kangelidis I, Sianos G, Angelis L. Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions. Applied Sciences. 2021; 11(19):9258. https://doi.org/10.3390/app11199258
Chicago/Turabian StyleGanopoulou, Maria, Ioannis Kangelidis, Georgios Sianos, and Lefteris Angelis. 2021. "Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions" Applied Sciences 11, no. 19: 9258. https://doi.org/10.3390/app11199258
APA StyleGanopoulou, M., Kangelidis, I., Sianos, G., & Angelis, L. (2021). Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions. Applied Sciences, 11(19), 9258. https://doi.org/10.3390/app11199258