
A Variable Ranking Method for Machine Learning Models with Correlated Features: In-Silico Validation and Application for Diabetes Prediction



Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. The Proposed Variable Ranking Algorithm
- Identify the groups of highly correlated numerical features. This can be achieved by computing the correlation coefficient (e.g., Spearman) between each pair of numerical features and then grouping the features with pairwise correlation higher than a threshold th (e.g., th = 0.70). Let us define as Cj, j = 1, ..., Ncorr the resulting groups of highly correlated features. Then, we will call Nuncorr the total number of uncorrelated features, i.e., all the features not included in any group Cj.
- Resampling the training set Xtrain to generate B different versions of the training data. This can be achieved, for example, by bootstrap resampling, i.e., randomly sampling with replacement ntrain elements from the training set, or by subset selection, i.e., by randomly sampling without replacement a fraction of elements of the training set (e.g., 80%).
- Perform RFE on each of the B training set variants. In this step, each group of correlated features is considered as a single variable; any time a variable from the group Cj is removed from the model, all the other variables in the same group Cj are also removed from the model and given the same rank. The obtained ranking has a number of positions equal to the number of uncorrelated features, Nuncorr, plus the number of groups of highly correlated features, Ncorr. Indeed, the highly correlated features in group Cj count in the ranking as a single variable. The ranks are assigned as follows: the variable (or group of variables) that is (are) removed first is assigned a rank equal to Nuncorr + Ncorr; the variable (or group of variables) that is (are) removed at the second RFE’s step is assigned a rank equal to Nuncorr + Ncorr − 1; and so on, until the last variable (or group of variables) remaining in the model is assigned rank 1. The ordered feature list obtained from each of the B training set variants is called Lb, b = 1, …, B.
- Aggregate the B ordered variable lists, Lb, b = 1, …, B, by the Borda method. This can be achieved by: (i) computing for each variable (or group of variables) the average rank across the B lists; and (ii) defining a new global rank by ordering the variables (or group of variables) according to the average rank. In this final global ranking, the most important feature (or group of features) will have the lowest rank, while the less important feature (or group of features) will have the highest rank.
2.2. Generation of In-Silico Data for Algorithm Validation
2.2.1. Method for Generating Simulated Datasets
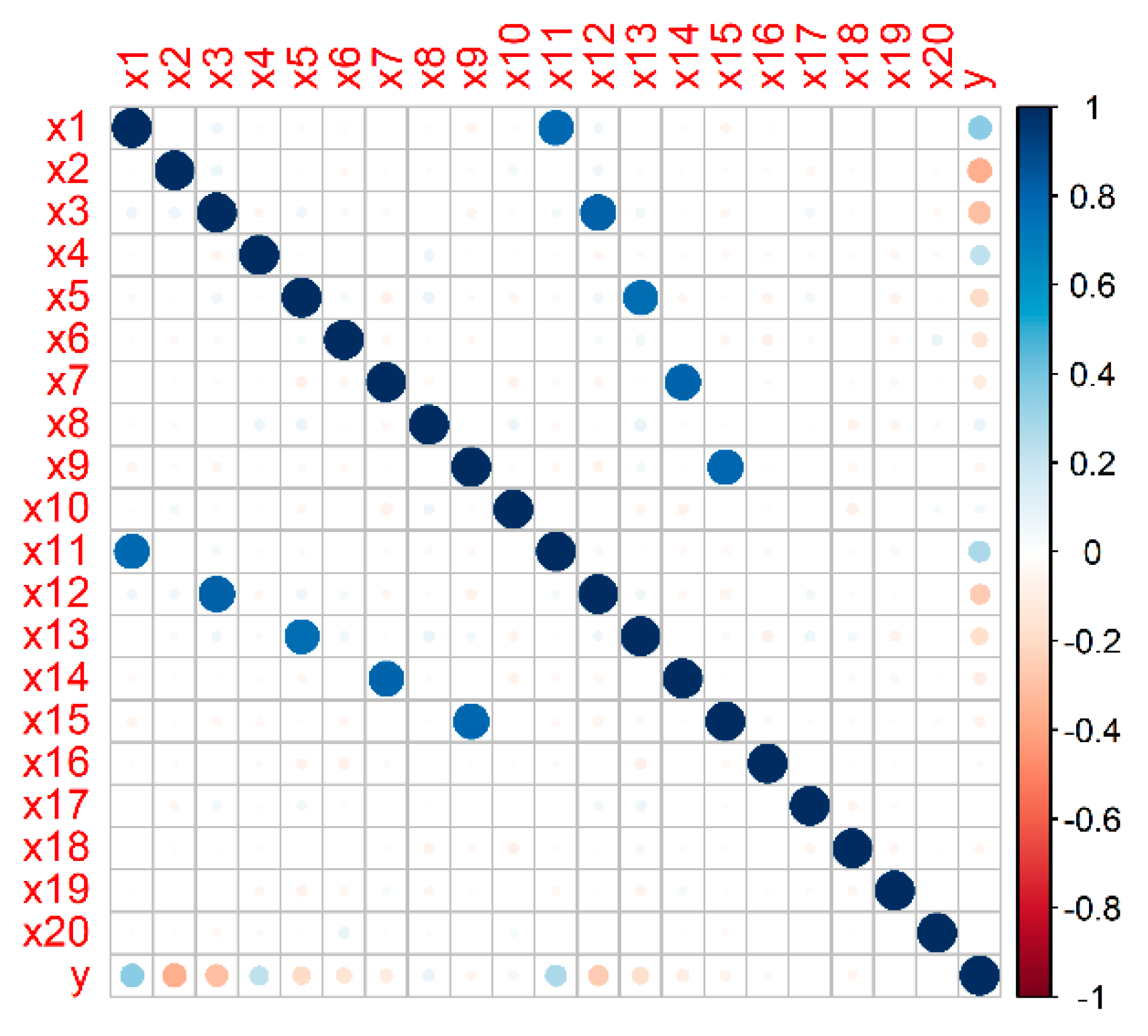
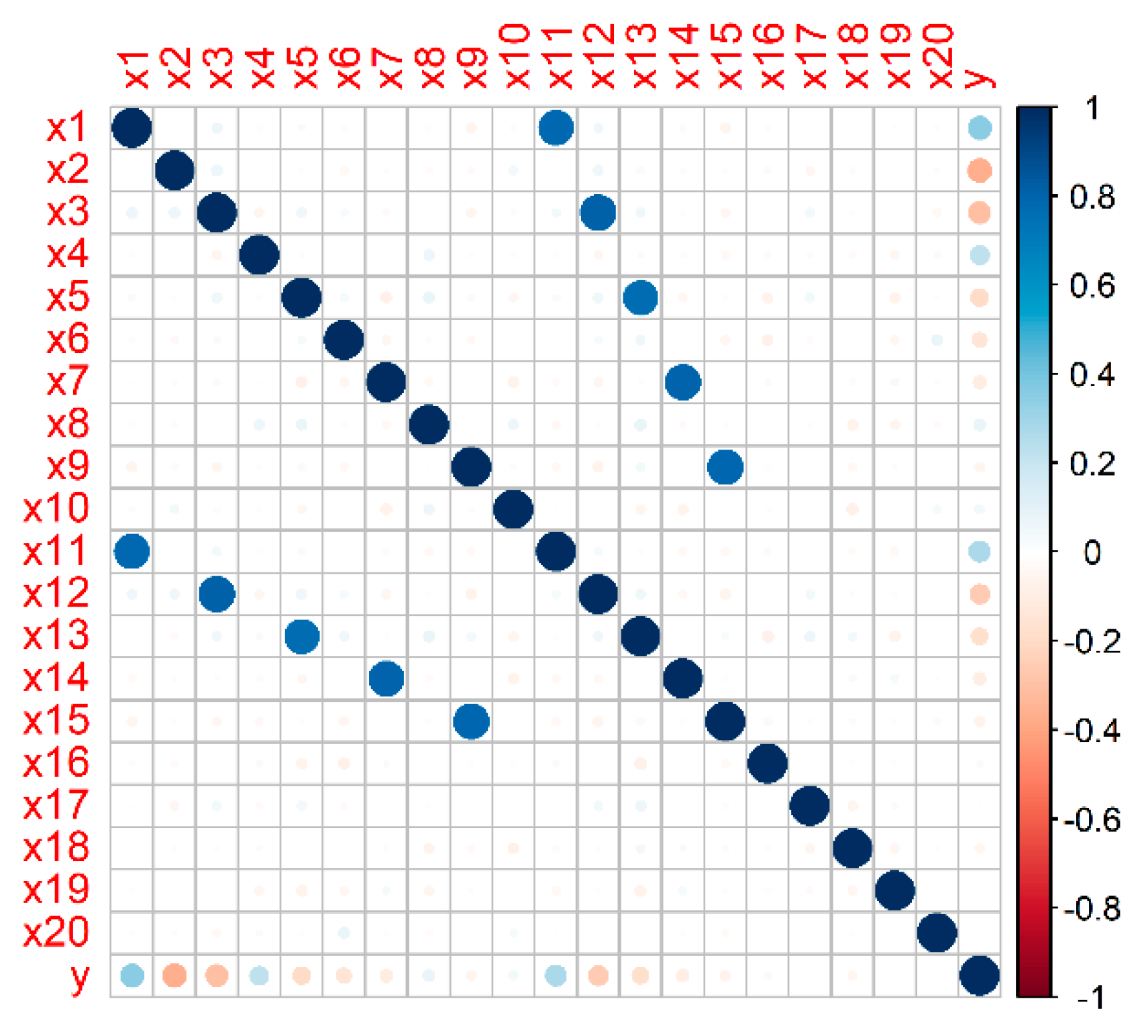
2.2.2. Generation of a Representative Simulated Dataset
2.2.3. Generation of Different Simulated Scenarios
2.3. A Case Study with Real Data: Prediction of Type 2 Diabetes Onset
2.3.1. Dataset: The English Longitudinal Study of Ageing
2.3.2. Data Pre-Processing
2.4. Application of the Ranking Algorithms on In-Silico and Real Data
2.4.1. Assessment of the Ranking Algorithms on In-Silico Data
- Approach 1: standard RFE-Borda count method without considering the correlation between features;
- Approach 2: the proposed algorithm that considers the correlation between features.
2.4.2. Application of the Ranking Algorithms to Real Data
- Approach 1: The correlation between BMI and waist circumference is ignored and the standard RFE-Borda count method is applied;
- Approach 2: The ranking is performed with the proposed algorithm that takes into account the correlation between BMI and waist circumference.
- Approach 3: Waist circumference is dropped from the analysis and the ranking is performed with the standard RFE-Borda count method, considering only BMI in the set of candidate predictors.
- Approach 4: BMI is dropped from the analysis and the ranking is performed with the standard RFE-Borda count method, considering only waist circumference in the set of candidate predictors.
- a table with the mean and the standard deviation (SD) of the rank obtained for each feature across the B iterations;
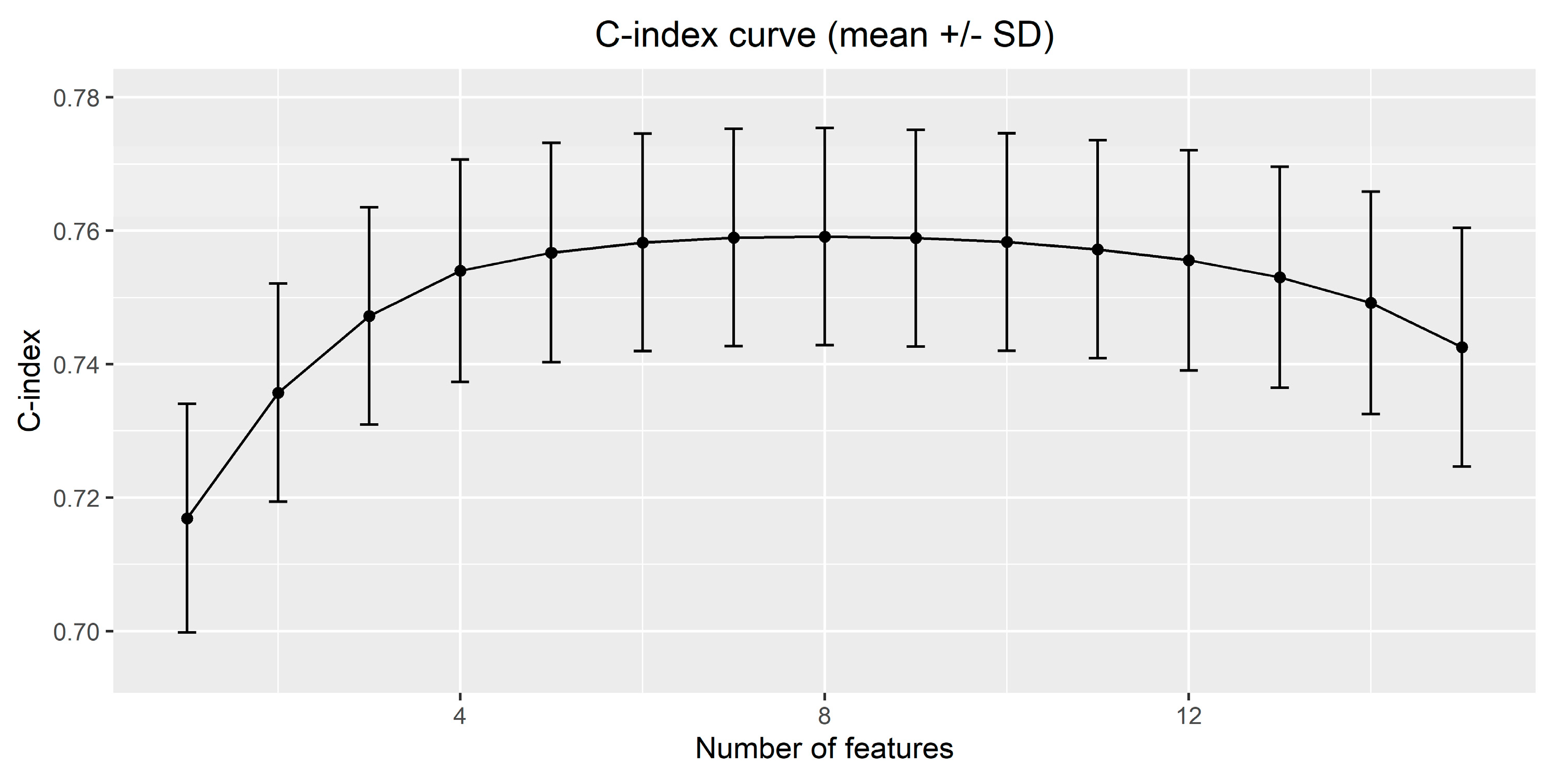
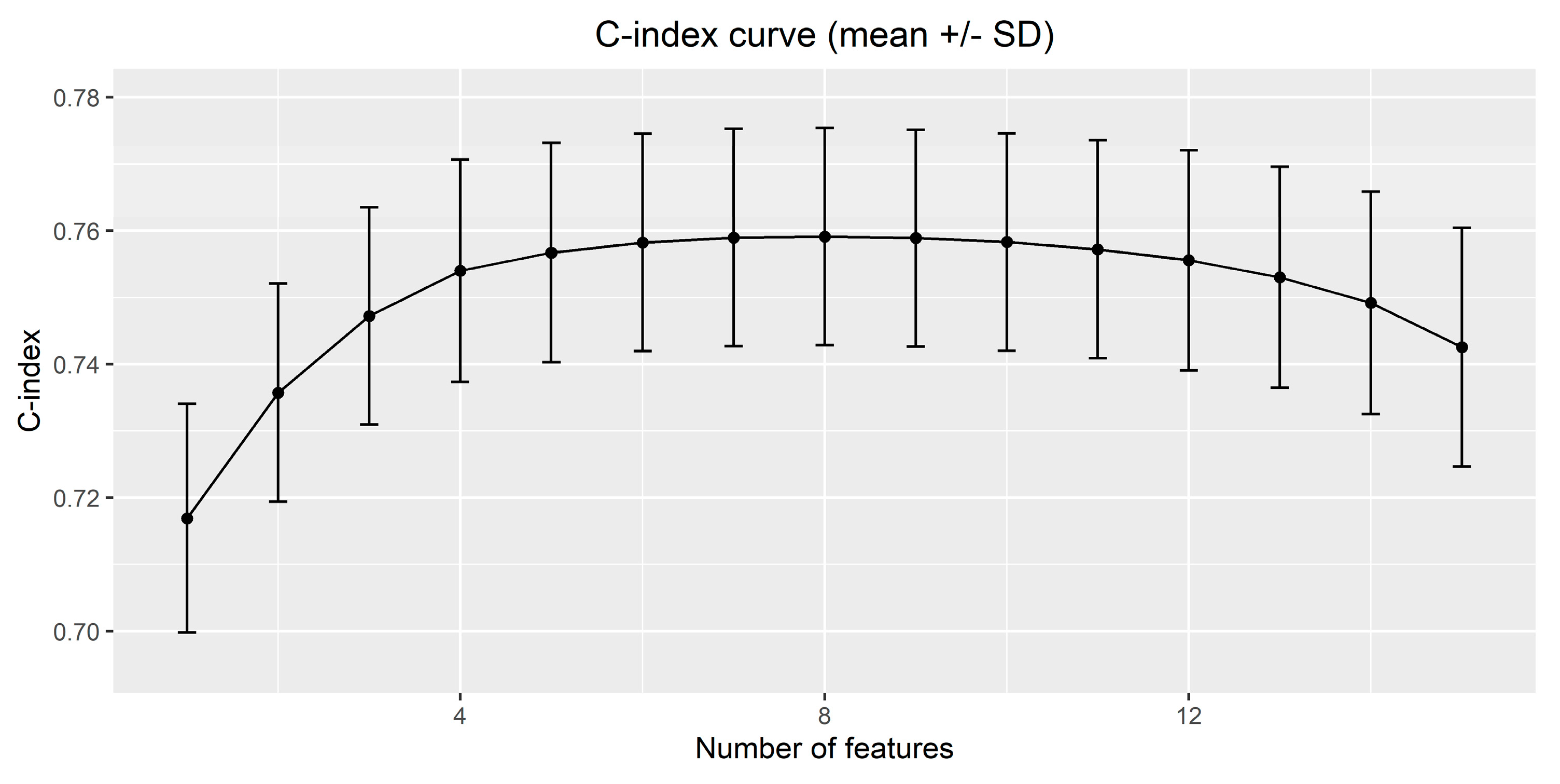
- a table with the value of the C-index (mean and SD) for models with different number of features.
3. Results
3.1. In-Silico Assessment of the Proposed Variable Ranking Algorithm
3.1.1. Results on a Representative Simulated Dataset
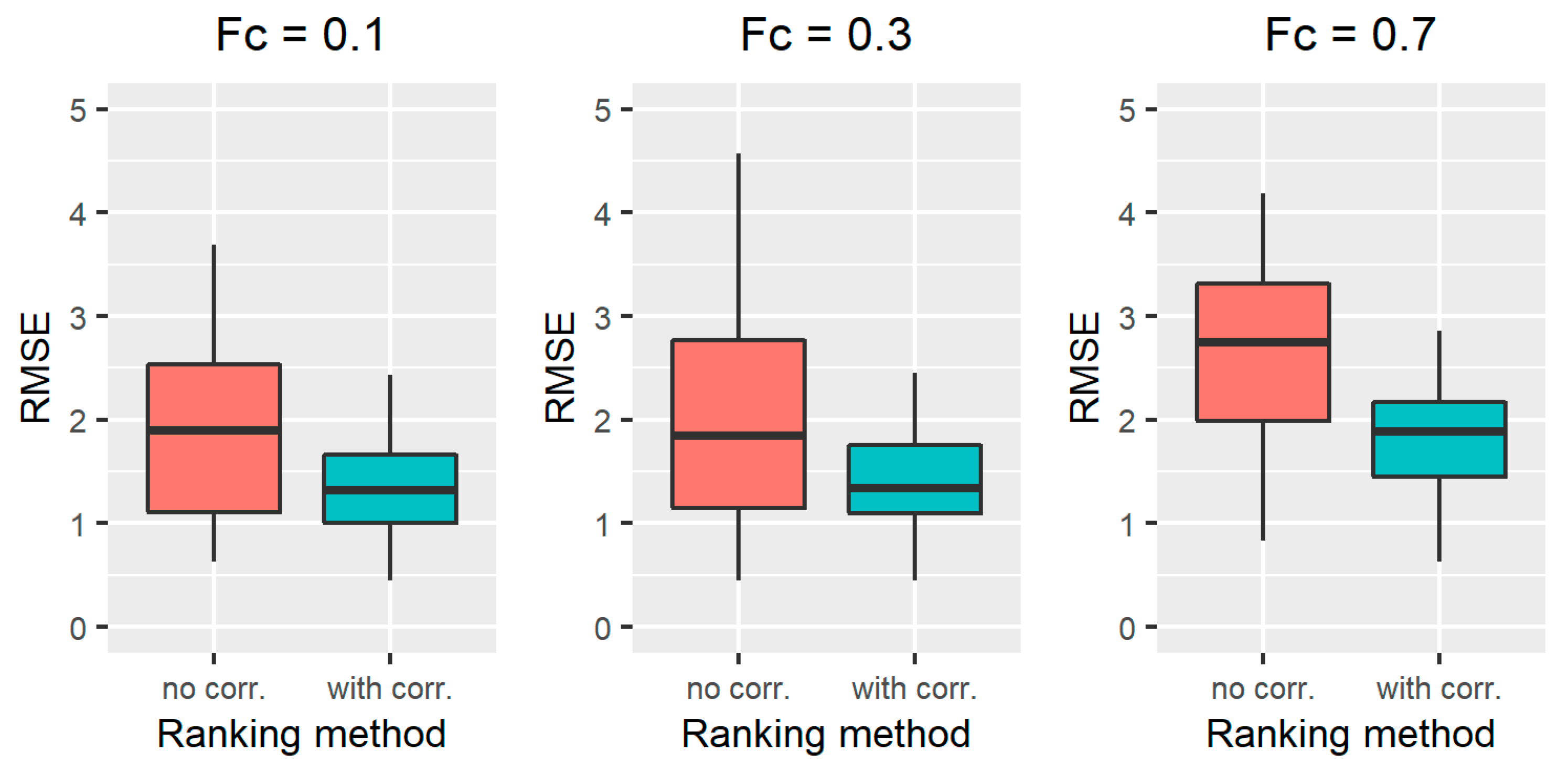
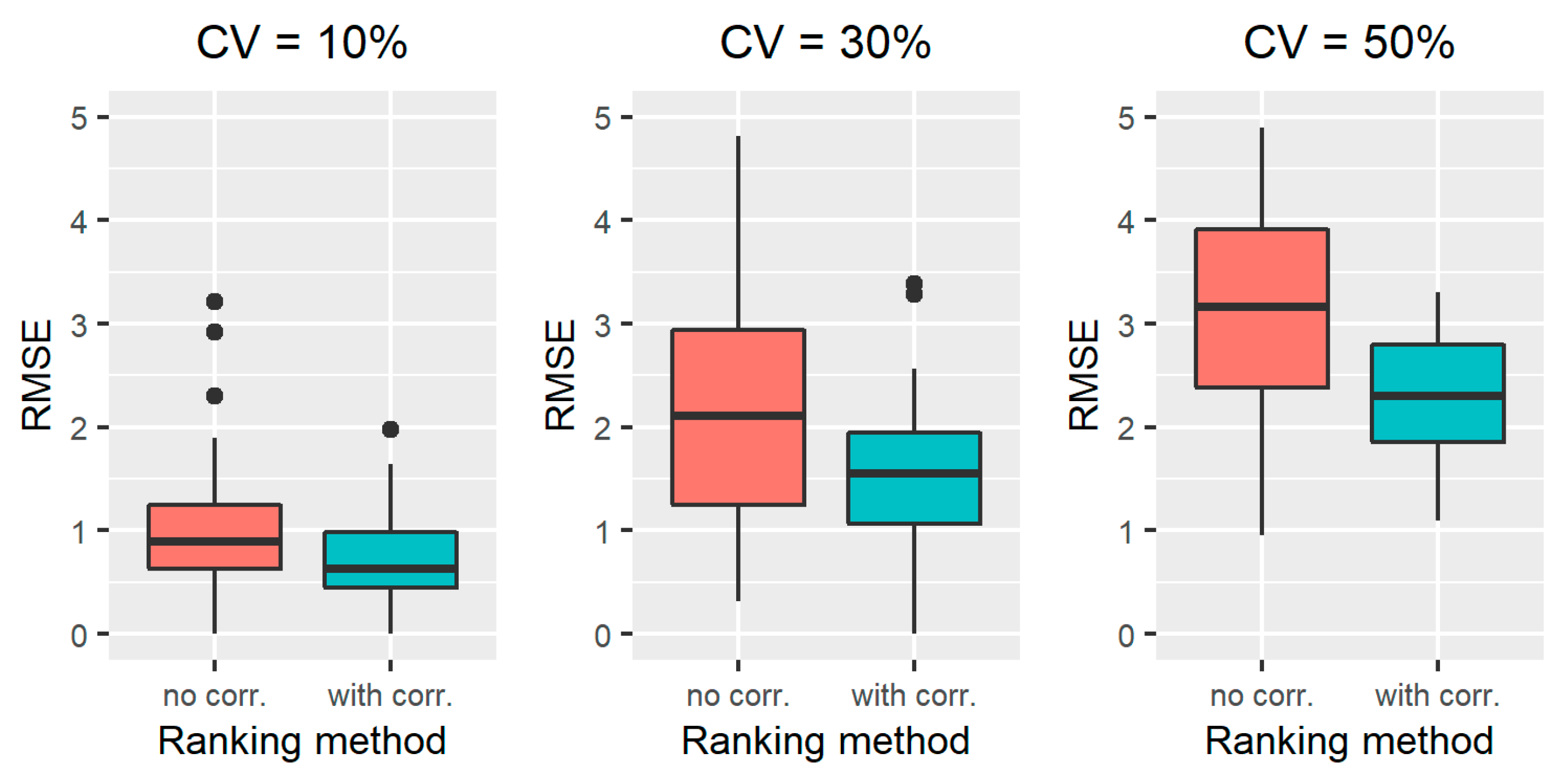
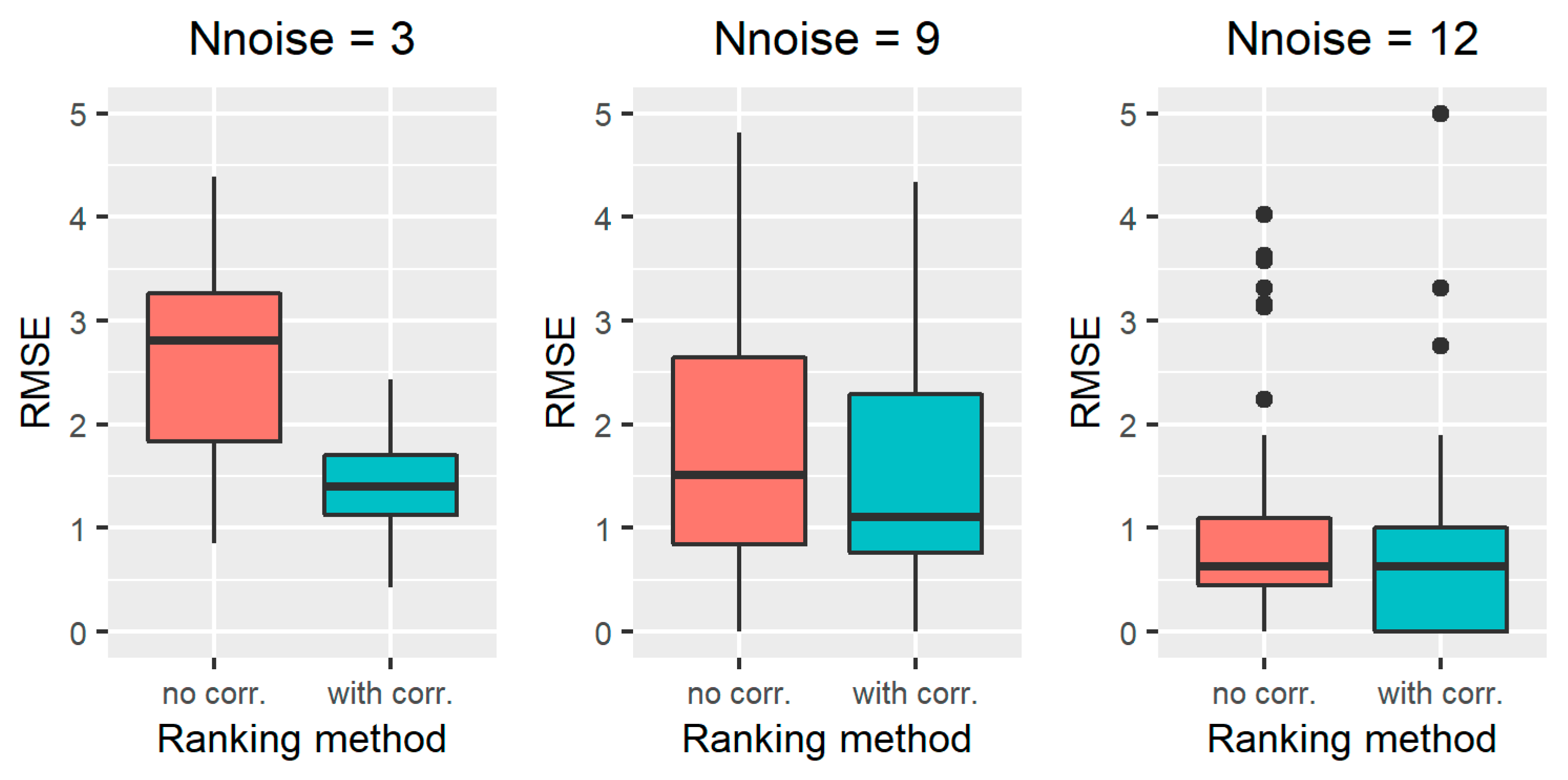
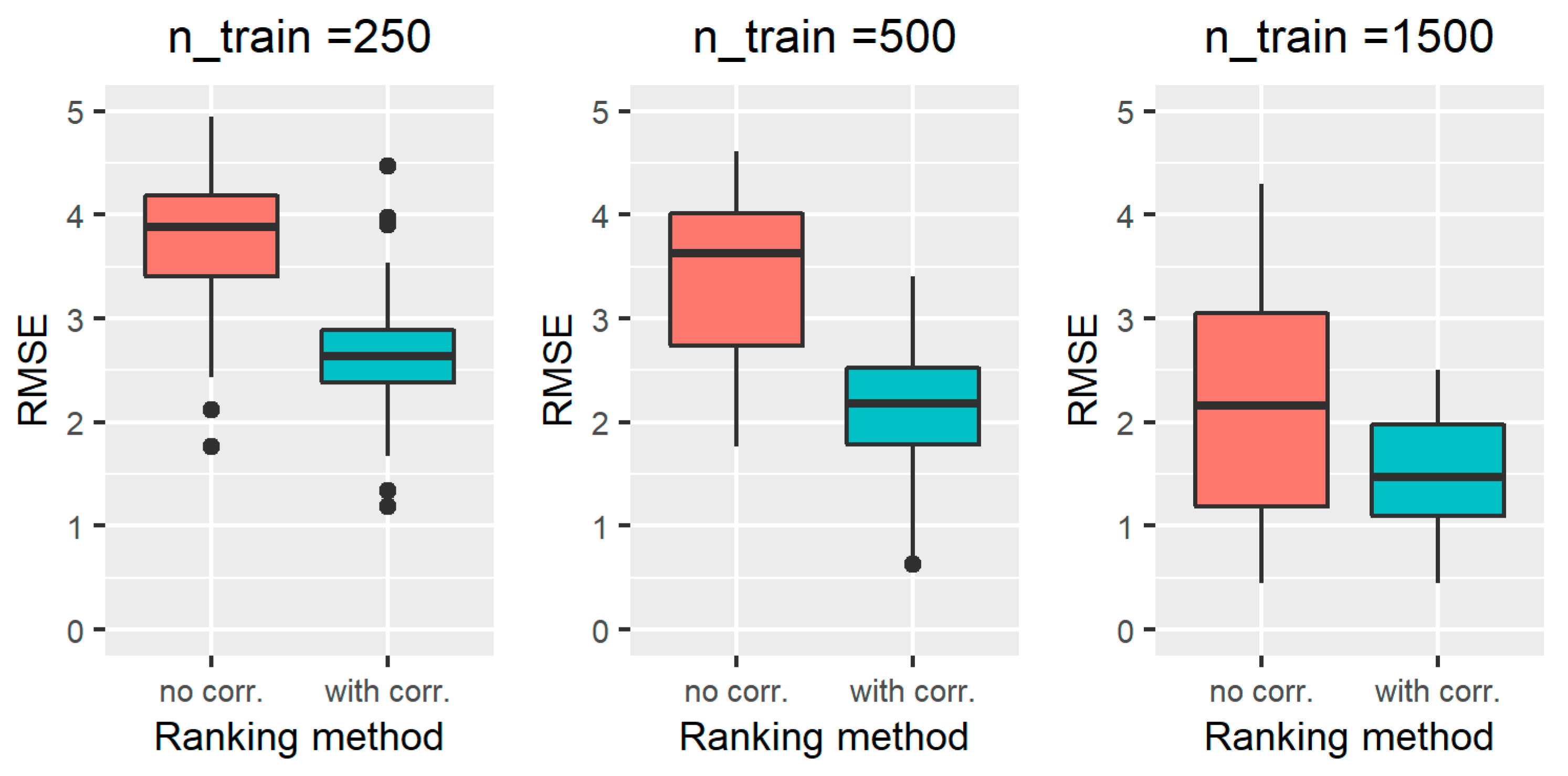
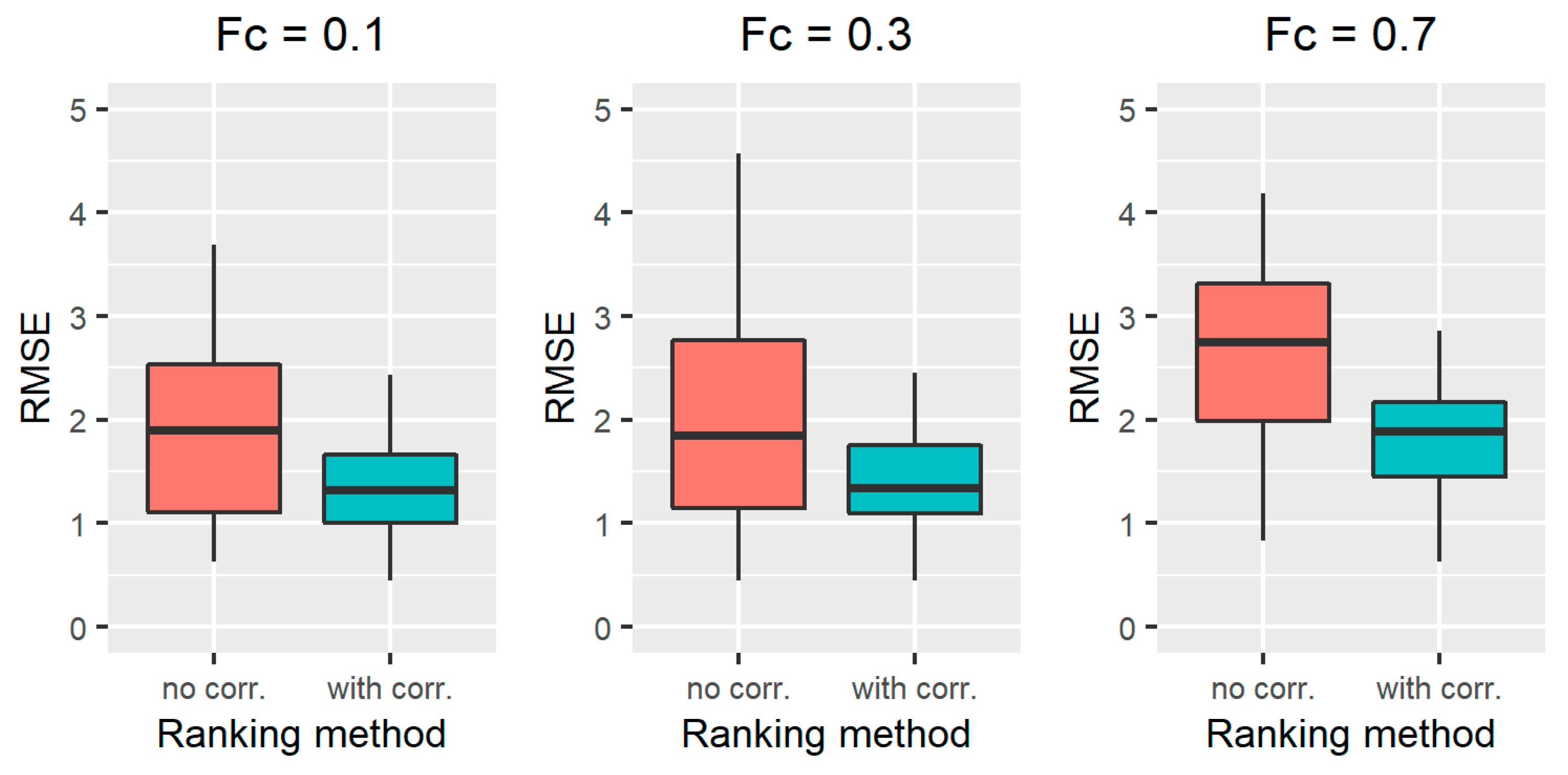
3.1.2. Results on All the Simulated Scenarios
3.2. Results on the Case Study with Real Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Software Availability
Abbreviations
References
- Grömping, U. Variable Importance Assessment in Regression: Linear Regression versus Random Forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Steyerberg, E.W. Selection of Main Effects. In Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating; Springer: New York, NY, USA, 2009; pp. 191–210. [Google Scholar]
- Vettoretti, M.; Longato, E.; Zandonà, A.; Li, Y.; Pagán, J.A.; Siscovick, D.; Carnethon, M.R.; Bertoni, A.G.; Facchinetti, A.; Di Camillo, B. Addressing Practical Issues of Predictive Models Translation into Everyday Practice and Public Health Management: A Combined Model to Predict the Risk of Type 2 Diabetes Improves Incidence Prediction and Reduces the Prevalence of Missing Risk Predictions. BMJ Open Diabetes Res. Care 2020, 8, e001223. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Qureshi, M.N.I.; Min, B.; Jo, H.J.; Lee, B. Multiclass Classification for the Differential Diagnosis on the ADHD Subtypes Using Recursive Feature Elimination and Hierarchical Extreme Learning Machine: Structural MRI Study. PLoS ONE 2016, 11, e0160697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wottschel, V.; Chard, D.T.; Enzinger, C.; Filippi, M.; Frederiksen, J.L.; Gasperini, C.; Giorgio, A.; Rocca, M.A.; Rovira, A.; De Stefano, N.; et al. SVM Recursive Feature Elimination Analyses of Structural Brain MRI Predicts Near-Term Relapses in Patients with Clinically Isolated Syndromes Suggestive of Multiple Sclerosis. NeuroImage Clin. 2019, 24, 102011. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Sun, L.; Xu, S.; Xiang, Q.; Zhao, J.; Xiong, W.; Xu, Y.; Chu, S. A Model Using Support Vector Machines Recursive Feature Elimination (SVM-RFE) Algorithm to Classify Whether COPD Patients Have Been Continuously Managed According to GOLD Guidelines. Int. J. Chron. Obstruct. Pulmon. Dis. 2020, 15, 2779–2786. [Google Scholar] [CrossRef]
- Park, D.; Lee, M.; Park, S.E.; Seong, J.-K.; Youn, I. Determination of Optimal Heart Rate Variability Features Based on SVM-Recursive Feature Elimination for Cumulative Stress Monitoring Using ECG Sensor. Sensors 2018, 18, 2387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sheng, J.; Shao, M.; Zhang, Q.; Zhou, R.; Wang, L.; Xin, Y. Alzheimer’s Disease, Mild Cognitive Impairment, and Normal Aging Distinguished by Multi-Modal Parcellation and Machine Learning. Sci. Rep. 2020, 10, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Sutton, E.J.; Onishi, N.; Fehr, D.A.; Dashevsky, B.Z.; Sadinski, M.; Pinker, K.; Martinez, D.; Brogi, E.; Braunstein, L.; Razavi, P.; et al. A Machine Learning Model that Classifies Breast Cancer Pathologic Complete Response on MRI Post-Neoadjuvant Chemotherapy. Breast Cancer Res. 2020, 22, 1–11. [Google Scholar] [CrossRef]
- Wu, X.; Yuan, X.; Wang, W.; Liu, K.; Qin, Y.; Sun, X.; Ma, W.; Zou, Y.; Zhang, H.; Zhou, X.; et al. Value of a Machine Learning Approach for Predicting Clinical Outcomes in Young Patients With Hypertension. Hypertension 2020, 75, 1271–1278. [Google Scholar] [CrossRef]
- Guo, C.-Y.; Chou, Y.-C. A Novel Machine Learning Strategy for Model Selections-Stepwise Support Vector Machine (StepSVM). PLoS ONE 2020, 15, e0238384. [Google Scholar] [CrossRef]
- Jurman, G.; Merler, S.; Barla, A.; Paoli, S.; Galea, A.; Furlanello, C. Algebraic Stability Indicators for Ranked Lists in Molecular Profiling. Bioinformatics 2007, 24, 258–264. [Google Scholar] [CrossRef] [PubMed]
- Camerlingo, N.; Vettoretti, M.; Del Favero, S.; Facchinetti, A.; Sparacino, G. Mathematical Models of Meal Amount and Timing Variability With Implementation in the Type-1 Diabetes Patient Decision Simulator. J. Diabetes Sci. Technol. 2020, 15, 346–359. [Google Scholar] [CrossRef]
- Francescatto, M.; Chierici, M.; Dezfooli, S.R.; Zandonà, A.; Jurman, G.; Furlanello, C. Multi-Omics Integration for Neuroblastoma Clinical Endpoint Prediction. Biol. Direct 2018, 13, 5. [Google Scholar] [CrossRef] [PubMed]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using Recursive Feature Elimination in Random Forest to Account for Correlated Variables in High Dimensional Data. BMC Genet. 2018, 19, 1–6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Linear Regression—Potential Problems. In An Introduction to Statistical Learning: With Applications in R.; Springer: New York, NY, USA, 2013; pp. 99–102. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Linear Model Selection and Regularization-Dimension Reduction Methods. In An introduction to statistical learning: With applications in R.; Springer: New York, NY, USA, 2013; pp. 99–102. [Google Scholar]
- Yousef, M.; Jung, S.; Showe, L.C.; Showe, M.K. Recursive Cluster Elimination (RCE) for Classification and Feature Selection from Gene Expression Data. BMC Bioinform. 2007, 8, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Knowler, W.C.; Barrett-Connor, E.; Fowler, S.E.; Hamman, R.F.; Lachin, J.; Walker, E.A.; Nathan, D.M.; Diabetes Prevention Program Research Group. Reduction in the Incidence of Type 2 Diabetes with Lifestyle Intervention or Metformin. N. Engl. J. Med. 2002, 346, 393–403. [Google Scholar] [CrossRef]
- Lindström, J.; Ilanne-Parikka, P.; Peltonen, M.; Aunola, S.; Eriksson, J.G.; Hemiö, K.; Hämäläinen, H.; Härkönen, P.; Keinänen-Kiukaanniemi, S.; et al.; Finnish Diabetes Prevention Study Group Sustained Reduction in the Incidence of Type 2 Diabetes by Lifestyle Intervention: Follow-Up of the Finnish Diabetes Prevention Study. Lancet 2006, 368, 1673–1679. [Google Scholar] [CrossRef]
- Noble, D.; Mathur, R.; Dent, T.; Meads, C.; Greenhalgh, T. Risk Models and Scores for Type 2 Diabetes: Systematic Review. BMJ 2011, 343, d7163. [Google Scholar] [CrossRef] [Green Version]
- De Silva, K.; Lee, W.K.; Forbes, A.; Demmer, R.T.; Barton, C.; Enticott, J. Use and Performance of Machine Learning Models for Type 2 Diabetes Prediction in Community Settings: A Systematic Review and Meta-Analysis. Int. J. Med. Inform. 2020, 143, 104268. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Shang, X.; Sreedharan, S.; Yan, X.; Liu, J.; Keel, S.; Wu, J.; Peng, W.; He, M. Predicting the Development of Type 2 Diabetes in a Large Australian Cohort Using Machine-Learning Techniques: Longitudinal Survey Study. JMIR Med. Inform. 2020, 8, e16850. [Google Scholar] [CrossRef]
- Fazakis, N.; Kocsis, O.; Dritsas, E.; Alexiou, S.; Fakotakis, N.; Moustakas, K. Machine Learning Tools for Long-Term Type 2 Diabetes Risk Prediction. IEEE Access 2021, 9, 103737–103757. [Google Scholar] [CrossRef]
- Lindström, J.; Tuomilehto, J. The Diabetes Risk Score: A Practical Tool to Predict Type 2 Diabetes Risk. Diabetes Care 2003, 26, 725–731. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.R. Regression Models and Life Tables (with Discussion). J. R. Stat. Soc. Series B 1972, 34, 187–220. [Google Scholar]
- Collett, D. The Cox Regression Model. In Modeling Survival Data in Medical Research, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2015; pp. 57–130. [Google Scholar]
- Maggio, C.A.; Pi-Sunyer, F.X. Obesity and Type 2 Diabetes. Endocrinol. Metab. Clin. North Am. 2003, 32, 805–822. [Google Scholar] [CrossRef]
- Di Camillo, B.; Hakaste, L.; Sambo, F.; Gabriel, R.; Kravic, J.; Isomaa, B.; Tuomilehto, J.; Alonso, M.; Longato, E.; Facchinetti, A.; et al. HAPT2D: High Accuracy of Prediction of T2D with a Model Combining Basic and Advanced Data Depending on Availability. Eur. J. Endocrinol. 2018, 178, 331–341. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hippisley-Cox, J.; Coupland, C.; Robson, J.; Sheikh, A.; Brindle, P. Predicting Risk of Type 2 Diabetes in England and Wales: Prospective Derivation and Validation of QDScore. BMJ 2009, 338, b880. [Google Scholar] [CrossRef] [Green Version]
- D’Agostino, R.B.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General Cardiovascular Risk Profile for Use in Primary Care: The Framingham Heart Study. Circulation 2008, 117, 743–753. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steptoe, A.; Breeze, E.; Banks, J.; Nazroo, J. Cohort Profile: The English Longitudinal Study of Ageing. Int. J. Epidemiol. 2012, 42, 1640–1648. [Google Scholar] [CrossRef] [Green Version]
- Longato, E.; Vettoretti, M.; Di Camillo, B. A Practical Perspective on the Concordance Index for the Evaluation and Selection of Prognostic Time-to-Event Models. J. Biomed. Inform. 2020, 108, 103496. [Google Scholar] [CrossRef]
- Anderson, J.P.; Parikh, J.R.; Shenfeld, D.K.; Ivanov, V.; Marks, C.; Church, B.W.; Laramie, J.M.; Mardekian, J.; Piper, B.A.; Willke, R.J.; et al. Reverse Engineering and Evaluation of Prediction Models for Progression to Type 2 Diabetes: An Application of Machine Learning Using Electronic Health Records. J. Diabetes Sci. Technol. 2015, 10, 6–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rotella, F.; Mannucci, E. Depression as a Risk Factor for Diabetes: A Meta-Analysis of Longitudinal Studies. J. Clin. Psychiatry 2013, 74, 31–37. [Google Scholar] [CrossRef]
- Kahn, H.S.; Cheng, Y.J.; Thompson, T.J.; Imperatore, G.; Gregg, E.W. Two Risk-Scoring Systems for Predicting Incident Diabetes Mellitus in U.S. Adults Age 45 to 64 Years. Ann. Intern. Med. 2009, 150, 741–751. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidt, M.I.; Duncan, B.B.; Bang, H.; Pankow, J.; Ballantyne, C.M.; Golden, S.H.; Folsom, A.R.; Chambless, L.E. For the Atherosclerosis Risk in Communities Investigators Identifying Individuals at High Risk for Diabetes: The Atherosclerosis Risk in Communities Study. Diabetes Care 2005, 28, 2013–2018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature Selection Using Joint Mutual Information Maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Model Coefficient |
|---|---|
| x1 | 4.77 |
| x2 | −4.69 |
| x3 | −3.74 |
| x4 | 2.93 |
| x5 | −2.74 |
| x6 | −2.29 |
| x7 | −1.52 |
| x8 | 1.02 |
| x9 | −0.88 |
| x10 | 0.70 |
| Scenario | CV | Nnoise | ntrain | Fc | Npred | Ncorr | Nfeat |
|---|---|---|---|---|---|---|---|
| 1 | 10% | 5 | 1000 | 0.5 | 10 | 5 | 20 |
| 2 | 30% | 5 | 1000 | 0.5 | 10 | 5 | 20 |
| 3 | 50% | 5 | 1000 | 0.5 | 10 | 5 | 20 |
| 4 | 30% | 3 | 1000 | 0.5 | 11 | 6 | 20 |
| 5 | 30% | 9 | 1000 | 0.5 | 7 | 4 | 20 |
| 6 | 30% | 12 | 1000 | 0.5 | 5 | 3 | 20 |
| 7 | 30% | 5 | 250 | 0.5 | 10 | 5 | 20 |
| 8 | 30% | 5 | 500 | 0.5 | 10 | 5 | 20 |
| 9 | 30% | 5 | 1500 | 0.5 | 10 | 5 | 20 |
| 10 | 30% | 5 | 1000 | 0.1 | 10 | 5 | 20 |
| 11 | 30% | 5 | 1000 | 0.3 | 10 | 5 | 20 |
| 12 | 30% | 5 | 1000 | 0.7 | 10 | 5 | 20 |
| Variable Name | Description | Values |
|---|---|---|
| sex | Sex | 0 = females 1 = males |
| age | Age | Continuous [years] |
| mar_stat | Marital status | 0 = married, living as married 1 = separated, widowed 2 = never married |
| depriv | Level of economic deprivation | Integers, range 1–5 |
| smoke | Smoking status | 0 = never smoked 1 = past smoker 2 = current smoker |
| phys_act | Frequency of moderate or vigorous physical activity | 0 = hardly ever or never 1 = 1–3 times per month 2 = once/week 3 = >once/week |
| bmi | Body mass index | Continuous [kg/m2] |
| waist | Waist circumference | Continuous [cm] |
| sys_bp | Systolic blood pressure | Continuous [mmHg] |
| depress | CESD-8 depression score | Integers, range 1–8 |
| life_exp | Life expectation | Integers, range 1–100 |
| phealth | Self-reported poor health | Integers, range 1–5 |
| htn | Ever had hypertension | 0 = no, 1 = yes |
| hchol | Ever had high cholesterol | 0 = no, 1 = yes |
| hdl | HDL cholesterol | Continuous [mg/dL] |
| tot_chol | Total cholesterol | Continuous [mg/dL] |
| Global Rank | Standard RFE-Borda Count Method (without Correlation) | Proposed Algorithm (with Correlation) | ||
|---|---|---|---|---|
| Variable | Mean Rank | Variable | Mean Rank | |
| 1 | x1 | 1.29 | x1–x11 | 1.22 |
| 2 | x3 | 2.37 | x2 | 2.47 |
| 3 | x2 | 2.76 | x3–x12 | 2.47 |
| 4 | x4 | 4.55 | x4 | 4.69 |
| 5 | x6 | 6.10 | x5–x13 | 5.68 |
| 6 | x5 | 6.16 | x6 | 5.94 |
| 7 | x7 | 9.53 | x7–x14 | 8.59 |
| 8 | x15 | 11.25 | x9–x15 | 10.04 |
| 9 | x8 | 11.76 | x8 | 10.15 |
| 10 | x19 | 12.73 | x10 | 10.87 |
| 11 | x18 | 13.44 | x18 | 11.21 |
| 12 | x14 | 13.48 | x19 | 11.28 |
| 13 | x12 | 13.61 | x20 | 11.34 |
| 14 | x9 | 13.88 | x16 | 11.82 |
| 15 | x13 | 13.89 | x17 | 12.23 |
| 16 | x11 | 14.08 | ||
| 17 | x20 | 14.38 | ||
| 18 | x10 | 14.47 | ||
| 19 | x16 | 15.01 | ||
| 20 | x17 | 15.26 | ||
| RMSE = 3.07 | RMSE = 0.50 | |||
| Approach 1 | Approach 2 | Approach 3 | Approach 4 | ||||
|---|---|---|---|---|---|---|---|
| Variable | Mean (SD) of Rank | Variable | Mean (SD) of Rank | Variable | Mean (SD) of Rank | Variable | Mean (SD) of Rank |
| hdl | 2.91 (3.04) | bmi-waist | 1.01 (0.10) | bmi | 1.02 (0.14) | waist | 1.04 (0.24) |
| sys_bp | 3.12 (3.42) | hdl | 2.83 (2.78) | hdl | 2.74 (3.06) | sys_bp | 2.76 (2.79) |
| bmi | 4.47 (4.66) | sys_bp | 2.96 (2.98) | sys_bp | 2.86 (3.01) | hdl | 2.82 (2.48) |
| waist | 4.51 (4.39) | phealth | 5.71 (5.00) | phealth | 5.44 (4.69) | phealth | 5.32 (5.11) |
| phealth | 6.16 (5.42) | depress | 6.21 (3.29) | age | 6.53 (3.03) | sex | 5.48 (3.08) |
| depress | 6.72 (3.41) | age | 6.70 (3.19) | depress | 6.64 (3.14) | depress | 6.65 (3.05) |
| age | 7.23 (3.31) | depriv | 7.08 (3.82) | depriv | 7.08 (3.72) | htn | 7.40 (4.21) |
| depriv | 7.23 (3.31) | htn | 7.32 (4.23) | htn | 7.59 (4.10) | depriv | 7.59 (3.50) |
| htn | 7.95 (4.52) | hchol | 8.96 (3.29) | sex | 8.32 (3.55) | age | 7.98 (2.91) |
| sex | 8.78 (3.74) | tot_chol | 8.99 (2.71) | hchol | 8.95 (3.10) | hchol | 9.22 (2.93) |
| hchol | 9.63 (3.43) | phys_act | 9.10 (2.63) | tot_chol | 9.13 (2.71) | tot_chol | 9.37 (2.62) |
| tot_chol | 9.74 (2.90) | sex | 9.27 (2.85) | phys_act | 9.42 (2.61) | phys_act | 9.52 (2.52) |
| phys_act | 9.85 (2.73) | life_exp | 9.52 (2.63) | life_exp | 9.58 (2.72) | life_exp | 9.82 (2.63) |
| life_exp | 10.17 (2.77) | smoke | 10.10 (2.77) | smoke | 10.33 (2.69) | mar_stat | 10.39 (3.10) |
| smoke | 10.97 (2.79) | mar_stat | 10.24 (3.10) | mar_stat | 10.37 (2.85) | smoke | 10.64 (2.32) |
| mar_stat | 11.06 (3.18) | ||||||
| Variable | Estimated Coefficient (Standard Error) | |||
|---|---|---|---|---|
| Approach 1 | Approach 2 | Approach 3 | Approach 4 | |
| bmi | 2.00 (0.62) | - | 3.34 (0.38) | - |
| waist | 2.17 (0.75) | 4.03 (0.48) | - | 4.14 (0.48) |
| hdl | −1.75 (0.35) | −1.59 (0.34) | −2.11 (0.33) | −1.81 (0.39) |
| sys_bp | 1.69 (0.40) | 1.74 (0.40) | 1.77 (0.39) | 1.81 (0.39) |
| phealth | 0.77 (0.23) | 0.82 (0.23) | 0.81 (0.23) | 0.81 (0.23) |
| depress | 0.22 (1.25) | 0.26 (0.23) | 0.17 (0.23) | 0.20 (0.23) |
| age | 0.40 (0.36) | 0.23 (0.35) | 0.43 (0.36) | - |
| depriv | 0.38 (0.20) | 0.40 (0.20) | 0.40 (0.20) | 0.36 (0.20) |
| htn | 0.26 (1.30) | 0.29 (0.11) | 0.26 (0.11) | 0.28 (0.11) |
| sex | - | - | - | −0.21 (0.12) |
| C-index 5-fold CV | 0.75 (0.02) | 0.75 (0.03) | 0.75 (0.02) | 0.75 (0.02) |
| C-index test | 0.74 | 0.74 | 0.74 | 0.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vettoretti, M.; Di Camillo, B. A Variable Ranking Method for Machine Learning Models with Correlated Features: In-Silico Validation and Application for Diabetes Prediction. Appl. Sci. 2021, 11, 7740. https://doi.org/10.3390/app11167740
Vettoretti M, Di Camillo B. A Variable Ranking Method for Machine Learning Models with Correlated Features: In-Silico Validation and Application for Diabetes Prediction. Applied Sciences. 2021; 11(16):7740. https://doi.org/10.3390/app11167740
Chicago/Turabian StyleVettoretti, Martina, and Barbara Di Camillo. 2021. "A Variable Ranking Method for Machine Learning Models with Correlated Features: In-Silico Validation and Application for Diabetes Prediction" Applied Sciences 11, no. 16: 7740. https://doi.org/10.3390/app11167740
APA StyleVettoretti, M., & Di Camillo, B. (2021). A Variable Ranking Method for Machine Learning Models with Correlated Features: In-Silico Validation and Application for Diabetes Prediction. Applied Sciences, 11(16), 7740. https://doi.org/10.3390/app11167740