
Explaining Bad Forecasts in Global Time Series Models

 ,
,  ,
,  , and
, and
Abstract
Featured Application
Abstract
1. Introduction
2. Review of Related Scientific Works
2.1. Forecasting Time Series: Local vs. Global Approach
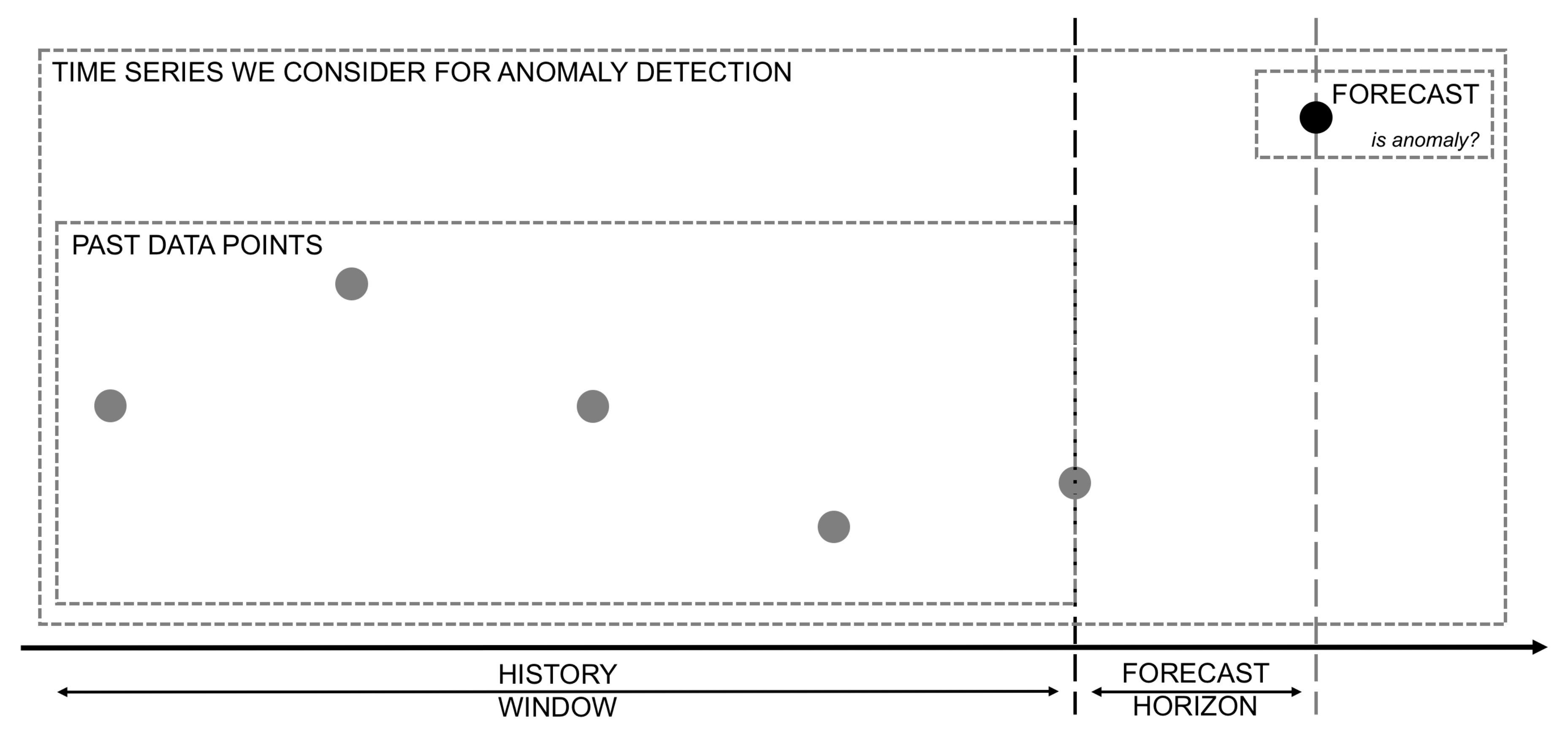
2.2. Time Series Anomaly Detection
2.3. Explainable Artificial Intelligence
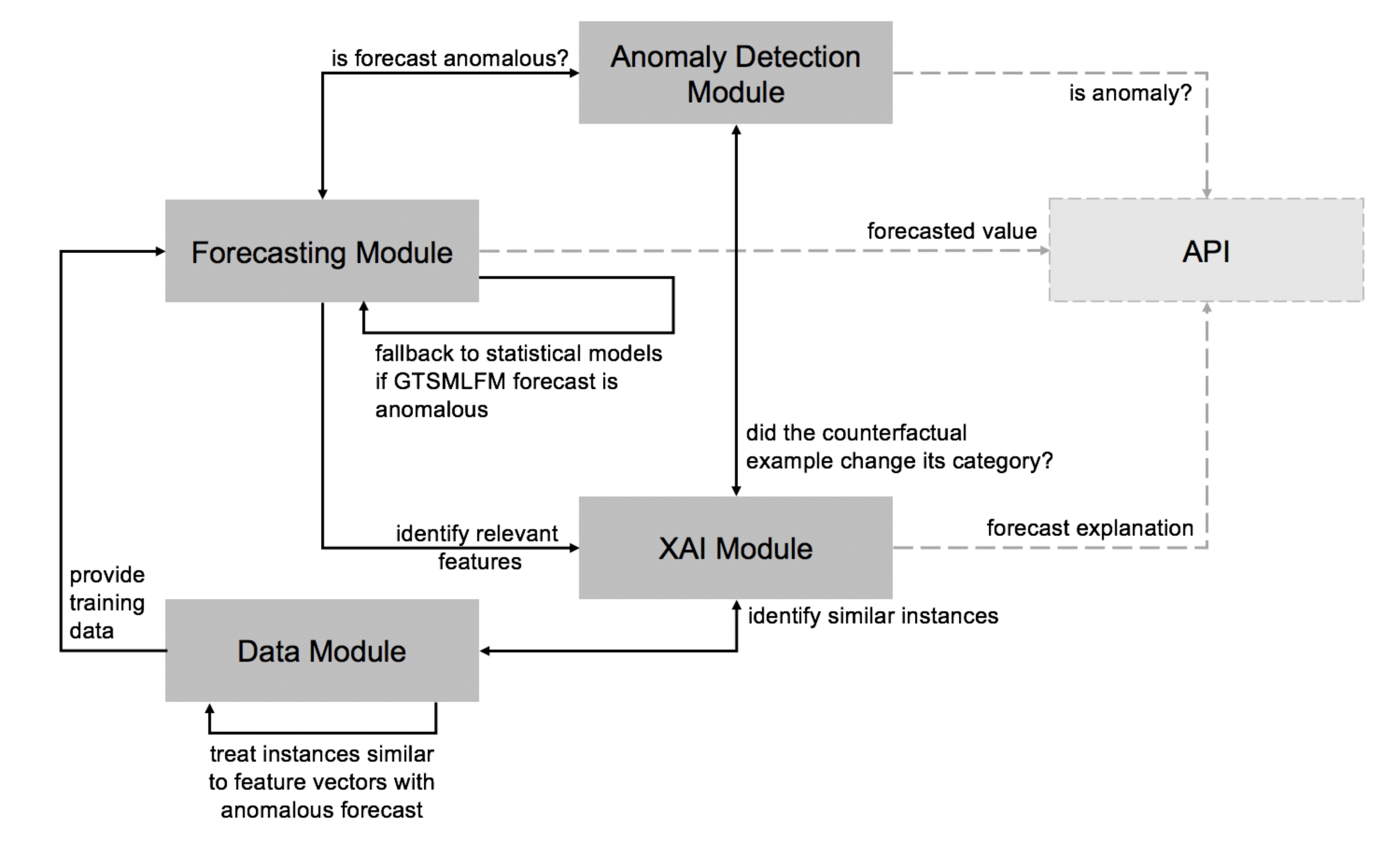
3. The Proposed Architecture
- Data Module: provides a dataset to train machine learning GTSMLFMs. The dataset comprises time series data, either considering their raw values and derivative features or a refined version where specific instances that could cause outlier forecasts were treated. The module wraps a set of strategies to find and treat data instances that are similar to the ones producing outlier forecasts, identified by the anomaly detection module.
- Forecasting Module: comprises a machine learning GTSMLFM, and a set of local statistical models to forecast the time series. The machine learning GTSMLFM is created based on a dataset obtained from the Data Module. The Forecasting Module makes use of the input provided by the Anomaly Detection Module to decide whether the outcome should be the forecast obtained from a GTSMLFM, or a local statistical model.
- Anomaly Detection Module: leverages algorithms and models to analyze the forecast in the context of a time series and classify it as an anomaly or not. It interacts with the Forecasting Module and the XAI Module, providing feedback on whether a forecast can be considered anomalous or not.
- XAI Module: uses various XAI algorithms and models to craft forecast explanations for the user. In particular, we envision that this module (i) indicates if the forecast is anomalous, (ii) crafts a text explanation highlighting most relevant features influencing a specific forecast, (iii) shows a sample of n data instances found in the train set that most likely influenced the GTSMLFM towards the given forecast, and (iv) shows a set of counterfactual examples created considering (a) the relevant features to that specific forecast, and (b) past values observed for that particular time series. We consider that this information provides the user a good insight into whether the forecast can be trusted and understand the behavior of the underlying model.
- API: a standard Application Programming Interface (API) endpoint can be used to serve the user as a front-facing interface, masking the structure, complexity, and deployment configuration of each of the modules mentioned above.
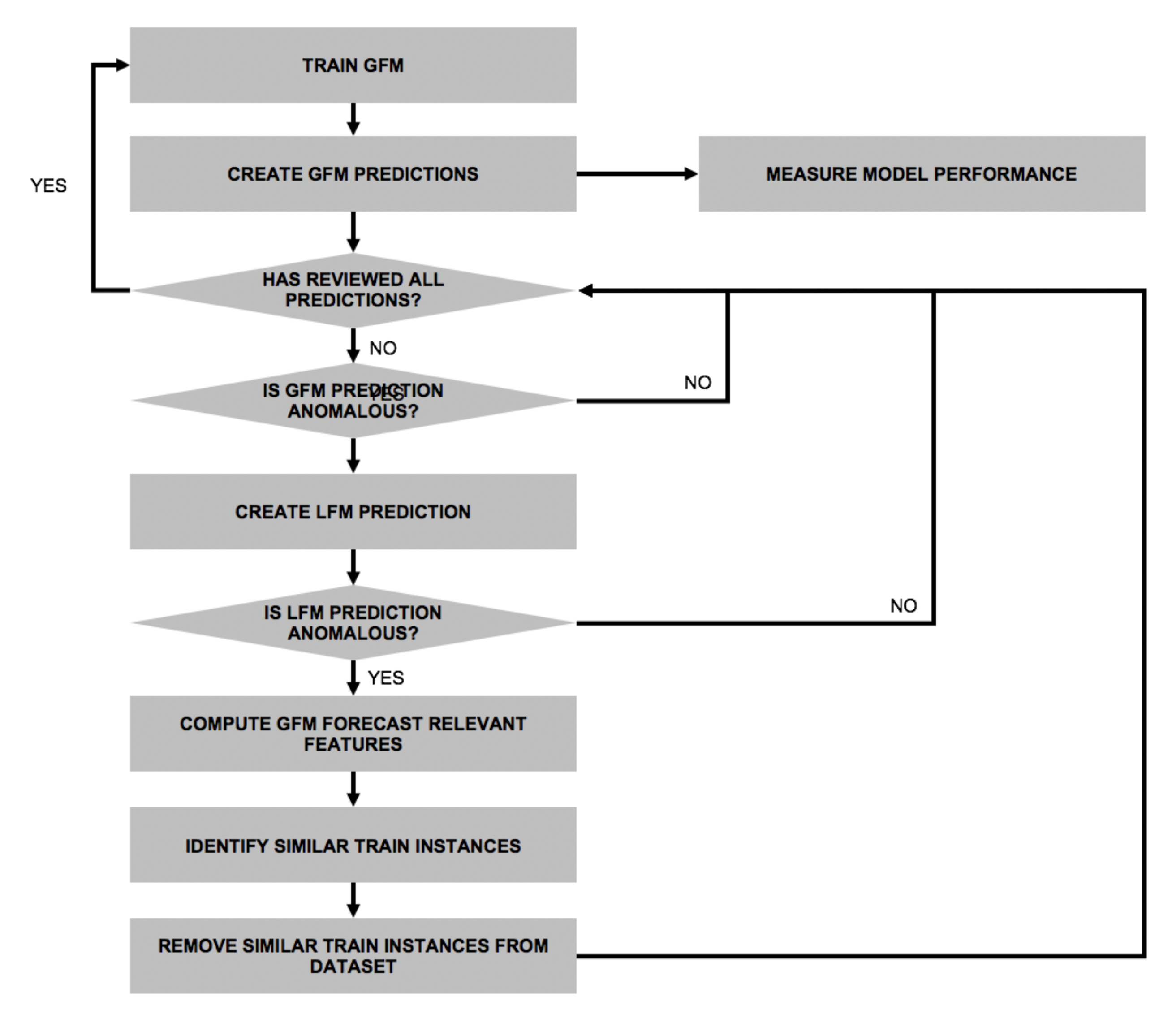
4. Methodology
5. Case Study
6. Experiments, Results, and Analysis
6.1. Premise Validation (Experiment 1)
6.2. Dealing with Anomalous GTSMLFM Forecasts (Experiment 2 and Experiment 4)
6.3. Dealing with Anomalous Fallback Forecasts (Experiment 3 and Experiment 5)
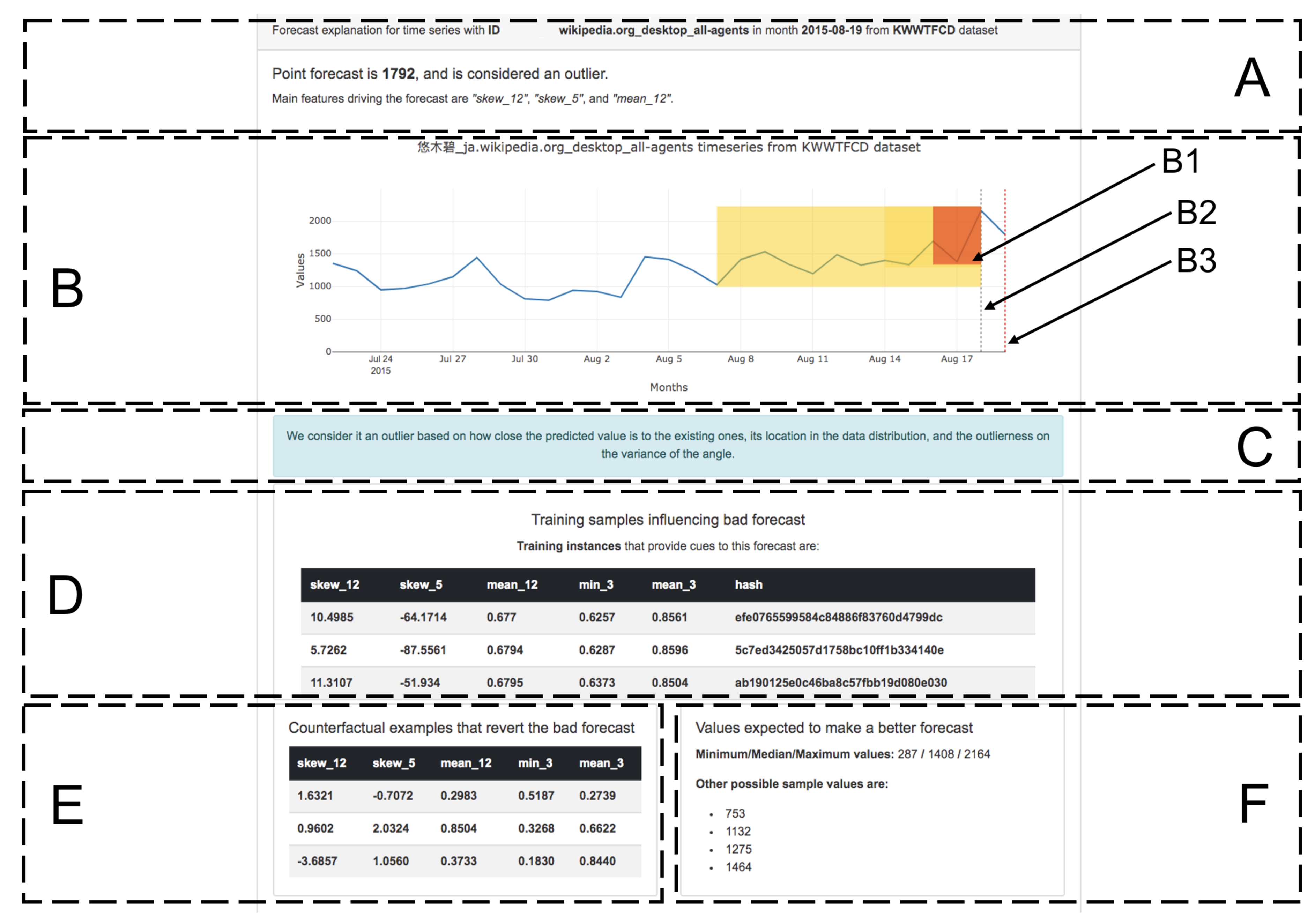
6.4. Dashboard
- # X_train: dataset train instances
- # feature_vector: feature vector used to issue the forecast
- # relevant_features: list of relevant features to the given forecast
- # model: forecasting model
- # anomaly_detector: some anomaly detector
- # n_samples: number of samples to draw from the Normal distribution
- given X_train, feature_vector, relevant_features, model, anomaly_detector
- synthetic_samples = new dictionary()
- for each feature in relevant_features:
- feature_mean = mean(X_train[feature])
- feature_std = standard_deviation(X_train[feature])
- feature_perturbed_values = normal(feature_mean, 3*feature_std, n_samples)
- synthetic_samples[feature]=feature_perturbed_values
- # create new dataset, merging data from non relevant features, and perturbed ones
- new_dataset = create_dataset(X_train, synthetic_samples)
- counterfactual_examples = new list()
- for each feature_vector in new_dataset:
- y_pred = model.predict(feature_vector)
- if not anomaly_detector.is_anomaly(y_pred):
- counterfactual_examples.append(feature_vector)
- return counterfactual_examples
7. Limitations and Improvement Opportunities
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AF | Anomalous Forecast |
| COF | Connectivity based Outlier Factor |
| ETI | Erased Train Instances |
| GBMR | Gradient Boosted Machine Regressor |
| GFM | Global Forecasting Model |
| GTSMLFM | Global Time Series Machine Learning Forecasting Model |
| INFLO | Influenced Outlierness |
| kNN | n-Nearest Neighbor |
| KWWTFCD | Kaggle Wikipedia Web Traffic Forecasting Competition Dataset |
| LFM | Local Forecasting Model |
| LOF | Local Outlier Factor |
| M4CD | M4 Competition Dataset |
| MASE | Mean Absolute Scaled Error |
| ODIN | Outlier Detection using Indegree Number |
| ROAR | RemOve And Retrain |
| TD | Target Discrepancy |
| TS | Time Series |
| TSDM | Time Series with Different Magnitude values |
| XAI | Explainable Artificial Intelligence |
References
- Sen, R.; Yu, H.F.; Dhillon, I. Think globally, act locally: A deep neural network approach to high-dimensional time series forecasting. arXiv 2019, arXiv:1905.03806. [Google Scholar]
- Bontempi, G.; Taieb, S.B.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In European Business Intelligence Summer School; Springer: Berlin/Heidelberg, Germany, 2012; pp. 62–77. [Google Scholar]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Global models for time series forecasting: A simulation study. arXiv 2020, arXiv:2012.12485. [Google Scholar]
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Bergmeir, C.; Bessa, R.J.; Boylan, J.E.; Browell, J.; Carnevale, C.; et al. Forecasting: Theory and practice. arXiv 2020, arXiv:2012.03854. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 accuracy competition: Results, findings and conclusions. Int. J. Forecast. 2020, in press. [Google Scholar] [CrossRef]
- Rojat, T.; Puget, R.; Filliat, D.; Del Ser, J.; Gelin, R.; Díaz-Rodríguez, N. Explainable Artificial Intelligence (XAI) on TimeSeries Data: A Survey. arXiv 2021, arXiv:2104.00950. [Google Scholar]
- Montero-Manso, P.; Hyndman, R.J. Principles and algorithms for forecasting groups of time series: Locality and globality. Int. J. Forecast. 2021, 37, 1632–1653. [Google Scholar] [CrossRef]
- Henin, C.; Le Métayer, D. A multi-layered approach for tailored black-box explanations. In Proceedings of the ICPR 2020—Workshop Explainable Deep Learning, Virtual, 10–15 January 2021. [Google Scholar]
- Hyndman, R.J. Another look at forecast-accuracy metrics for intermittent demand. Foresight 2006, 4, 43–46. [Google Scholar]
- Januschowski, T.; Gasthaus, J.; Wang, Y.; Salinas, D.; Flunkert, V.; Bohlke-Schneider, M.; Callot, L. Criteria for classifying forecasting methods. Int. J. Forecast. 2020, 36, 167–177. [Google Scholar] [CrossRef]
- Zellner, A. An efficient method of estimating seemingly unrelated regressions and tests for aggregation bias. J. Am. Stat. Assoc. 1962, 57, 348–368. [Google Scholar] [CrossRef]
- Duncan, G.T.; Gorr, W.L.; Szczypula, J. Forecasting analogous time series. In Principles of Forecasting; Springer: Boston, MA, USA, 2001; pp. 195–213. [Google Scholar]
- Bandara, K.; Bergmeir, C.; Smyl, S. Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach. Expert Syst. Appl. 2020, 140, 112896. [Google Scholar] [CrossRef]
- Godahewa, R.; Bandara, K.; Webb, G.I.; Smyl, S.; Bergmeir, C. Ensembles of localised models for time series forecasting. arXiv 2020, arXiv:2012.15059. [Google Scholar]
- Mori, H.; Yuihara, A. Deterministic annealing clustering for ANN-based short-term load forecasting. IEEE Trans. Power Syst. 2001, 16, 545–551. [Google Scholar] [CrossRef]
- Manojlović, I.; Švenda, G.; Erdeljan, A.; Gavrić, M. Time series grouping algorithm for load pattern recognition. Comput. Ind. 2019, 111, 140–147. [Google Scholar] [CrossRef]
- Marinazzo, D.; Liao, W.; Pellicoro, M.; Stramaglia, S. Grouping time series by pairwise measures of redundancy. Phys. Lett. A 2010, 374, 4040–4044. [Google Scholar] [CrossRef][Green Version]
- Romanov, A.; Perfilieva, I.; Yarushkina, N. Time series grouping on the basis of F 1-transform. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 6–11 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 517–521. [Google Scholar]
- Li, Y.; Liu, R.W.; Liu, Z.; Liu, J. Similarity grouping-guided neural network modeling for maritime time series prediction. IEEE Access 2019, 7, 72647–72659. [Google Scholar] [CrossRef]
- Fildes, R.; Beard, C. Forecasting systems for production and inventory control. Int. J. Oper. Prod. Manag. 1992. [Google Scholar] [CrossRef]
- Verdes, P.; Granitto, P.; Navone, H.; Ceccatto, H. Forecasting chaotic time series: Global vs. local methods. Novel Intell. Autom. Control. Syst. 1998, 1, 129–145. [Google Scholar]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef]
- Wen, R.; Torkkola, K.; Narayanaswamy, B.; Madeka, D. A multi-horizon quantile recurrent forecaster. arXiv 2017, arXiv:1711.11053. [Google Scholar]
- Laptev, N.; Yosinski, J.; Li, L.E.; Smyl, S. Time-series extreme event forecasting with neural networks at uber. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 34, pp. 1–5. [Google Scholar]
- Rangapuram, S.S.; Seeger, M.W.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep state space models for time series forecasting. Adv. Neural Inf. Process. Syst. 2018, 31, 7785–7794. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Burkart, N.; Huber, M.F. A survey on the explainability of supervised machine learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. (CSUR) 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Chapman and Hall: London, UK, 1980; Volume 11. [Google Scholar]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A deep learning approach for unsupervised anomaly detection in time series. IEEE Access 2018, 7, 1991–2005. [Google Scholar] [CrossRef]
- Fox, A.J. Outliers in time series. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 350–363. [Google Scholar] [CrossRef]
- Cook, A.A.; Mısırlı, G.; Fan, Z. Anomaly detection for IoT time-series data: A survey. IEEE Internet Things J. 2019, 7, 6481–6494. [Google Scholar] [CrossRef]
- Latecki, L.J.; Lazarevic, A.; Pokrajac, D. Outlier detection with kernel density functions. In Proceedings of the International Workshop on Machine Learning and Data Mining in Pattern Recognition, Leipzig, Germany, 18–20 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 61–75. [Google Scholar]
- Sheng, B.; Li, Q.; Mao, W.; Jin, W. Outlier detection in sensor networks. In Proceedings of the 8th ACM International Symposium on Mobile ad Hoc Networking and Computing, Montréal, QC, Canada, 9–14 September 2007; pp. 219–228. [Google Scholar]
- Goldstein, M.; Dengel, A. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In KI-2012: Poster and Demo Track; Citeseer: Princeton, NJ, USA, 2012; pp. 59–63. [Google Scholar]
- Sathe, S.; Aggarwal, C.C. Subspace histograms for outlier detection in linear time. Knowl. Inf. Syst. 2018, 56, 691–715. [Google Scholar] [CrossRef]
- Smiti, A. A critical overview of outlier detection methods. Comput. Sci. Rev. 2020, 38, 100306. [Google Scholar] [CrossRef]
- Wei, L.; Kumar, N.; Lolla, V.N.; Keogh, E.J.; Lonardi, S.; Ratanamahatana, C.A. Assumption-Free Anomaly Detection in Time Series. In Proceedings of the 17th International Conference on Scientific and Statistical Database Management, SSDBM 2005, Santa Barbara, CA, USA, 27–29 June 2005; Volume 5, pp. 237–242. [Google Scholar]
- Kumar, N.; Lolla, V.N.; Keogh, E.; Lonardi, S.; Ratanamahatana, C.A.; Wei, L. Time-series bitmaps: A practical visualization tool for working with large time series databases. In Proceedings of the 2005 SIAM International Conference on Data Mining, SIAM, Newport Beach, CA, USA, 21–23 April 2005; pp. 531–535. [Google Scholar]
- Ahmed, T. Online anomaly detection using KDE. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–8. [Google Scholar]
- Kim, J.; Scott, C.D. Robust kernel density estimation. J. Mach. Learn. Res. 2012, 13, 2529–2565. [Google Scholar]
- Zhang, L.; Lin, J.; Karim, R. Adaptive kernel density-based anomaly detection for nonlinear systems. Knowl.-Based Syst. 2018, 139, 50–63. [Google Scholar] [CrossRef]
- Laurikkala, J.; Juhola, M.; Kentala, E.; Lavrac, N.; Miksch, S.; Kavsek, B. Informal identification of outliers in medical data. In Proceedings of the Fifth International Workshop on Intelligent Data Analysis in Medicine and Pharmacology, Berlin, Germany, 22 August 2000; Citeseer: Princeton, NJ, USA, 2000; Volume 1, pp. 20–24. [Google Scholar]
- Pang, J.; Liu, D.; Liao, H.; Peng, Y.; Peng, X. Anomaly detection based on data stream monitoring and prediction with improved Gaussian process regression algorithm. In Proceedings of the 2014 International Conference on Prognostics and Health Management, Fort Worth, TX, USA, 29 September–2 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–7. [Google Scholar]
- Pandit, R.K.; Infield, D. SCADA-based wind turbine anomaly detection using Gaussian process models for wind turbine condition monitoring purposes. IET Renew. Power Gener. 2018, 12, 1249–1255. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Least median of squares regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Van Driessen, K. Computing LTS regression for large data sets. Data Min. Knowl. Discov. 2006, 12, 29–45. [Google Scholar] [CrossRef]
- Salibian-Barrera, M.; Yohai, V.J. A fast algorithm for S-regression estimates. J. Comput. Graph. Stat. 2006, 15, 414–427. [Google Scholar] [CrossRef]
- Ning, J.; Chen, L.; Zhou, C.; Wen, Y. Parameter k search strategy in outlier detection. Pattern Recognit. Lett. 2018, 112, 56–62. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier detection using k-nearest neighbour graph. In Proceedings of the 17th International Conference on Pattern Recognition—ICPR 2004, Cambridge, UK, 26 August 2004; Volume 3, pp. 430–433. [Google Scholar]
- Papadimitriou, S.; Kitagawa, H.; Gibbons, P.B.; Faloutsos, C. Loci: Fast outlier detection using the local correlation integral. In Proceedings 19th International Conference on Data Engineering (Cat. No. 03CH37405), Bangalore, India, 5–8 March 2003; IEEE: Bangalore, India, 2003; pp. 315–326. [Google Scholar]
- Tang, J.; Chen, Z.; Fu, A.W.C.; Cheung, D.W. Enhancing effectiveness of outlier detections for low density patterns. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Taipei, Taiwan, 6–8 May 2002; Springer-Verlag: Berlin/Heidelberg, Germany, 2002; pp. 535–548. [Google Scholar]
- Jin, W.; Tung, A.K.; Han, J.; Wang, W. Ranking outliers using symmetric neighborhood relationship. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 9–12 April 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 577–593. [Google Scholar]
- Ma, Y.; Zhao, X. POD: A Parallel Outlier Detection Algorithm Using Weighted kNN. IEEE Access 2021, 9, 81765–81777. [Google Scholar] [CrossRef]
- Trittenbach, H.; Englhardt, A.; Böhm, K. An overview and a benchmark of active learning for outlier detection with one-class classifiers. Expert Syst. Appl. 2020, 168, 114372. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Li, K.L.; Huang, H.K.; Tian, S.F.; Xu, W. Improving one-class SVM for anomaly detection. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), Xi’an, China, 5 November 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 5, pp. 3077–3081. [Google Scholar]
- Ji, M.; Xing, H.J. Adaptive-weighted one-class support vector machine for outlier detection. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1766–1771. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Z.; Weng, S.; Zhang, C. Solving one-class problem with outlier examples by SVM. Neurocomputing 2015, 149, 100–105. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Primartha, R.; Tama, B.A. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 Novermber; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Tama, B.A.; Rhee, K.H. An in-depth experimental study of anomaly detection using gradient boosted machine. Neural Comput. Appl. 2019, 31, 955–965. [Google Scholar] [CrossRef]
- Kieu, T.; Yang, B.; Jensen, C.S. Outlier detection for multidimensional time series using deep neural networks. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 125–134. [Google Scholar]
- Thomas, R.; Judith, J. Voting-Based Ensemble of Unsupervised Outlier Detectors. In Advances in Communication Systems and Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 501–511. [Google Scholar]
- Yu, Q.; Jibin, L.; Jiang, L. An improved ARIMA-based traffic anomaly detection algorithm for wireless sensor networks. Int. J. Distrib. Sens. Netw. 2016, 12, 9653230. [Google Scholar] [CrossRef]
- Zhou, Y.; Qin, R.; Xu, H.; Sadiq, S.; Yu, Y. A data quality control method for seafloor observatories: The application of observed time series data in the East China Sea. Sensors 2018, 18, 2628. [Google Scholar] [CrossRef]
- Munir, M.; Siddiqui, S.A.; Chattha, M.A.; Dengel, A.; Ahmed, S. FuseAD: Unsupervised anomaly detection in streaming sensors data by fusing statistical and deep learning models. Sensors 2019, 19, 2451. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, B.I.; Nicolae, D.C.; Khan, A.; Ali, S.I.; Khattak, A. VAE-GAN based zero-shot outlier detection. In Proceedings of the 2020 4th International Symposium on Computer Science and Intelligent Control, Newcastle upon Tyne, UK, 17–19 November 2020; pp. 1–5. [Google Scholar]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 563–574. [Google Scholar]
- Chan, L. Explainable AI as Epistemic Representation. In Proceedings of the AISB 2021 Symposium Overcoming Opacity in Machine Learning, London, UK, 7–9 April 2021; p. 7. [Google Scholar]
- Müller, V.C. Deep Opacity Undermines Data Protection and Explainable Artificial Intelligence. In Proceedings of the AISB 2021 Symposium Overcoming Opacity in Machine Learning, London, UK, 7–9 April 2021; p. 18. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar]
- Hall, P.; Gill, N.; Kurka, M.; Phan, W. Machine Learning Interpretability with H2O Driverless AI. H2O. AI. 2017. Available online: http://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdf (accessed on 5 August 2021).
- Zafar, M.R.; Khan, N.M. DLIME: A deterministic local interpretable model-agnostic explanations approach for computer-aided diagnosis systems. arXiv 2019, arXiv:1906.10263. [Google Scholar]
- Sokol, K.; Flach, P. LIMEtree: Interactively Customisable Explanations Based on Local Surrogate Multi-output Regression Trees. arXiv 2020, arXiv:2005.01427. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 18, pp. 1527–1535. [Google Scholar]
- van der Waa, J.; Robeer, M.; van Diggelen, J.; Brinkhuis, M.; Neerincx, M. Contrastive explanations with local foil trees. arXiv 2018, arXiv:1806.07470. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local rule-based explanations of black box decision systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Bento, J.; Saleiro, P.; Cruz, A.F.; Figueiredo, M.A.; Bizarro, P. TimeSHAP: Explaining recurrent models through sequence perturbations. arXiv 2020, arXiv:2012.00073. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not just a black box: Learning important features through propagating activation differences. arXiv 2016, arXiv:1605.01713. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Vinayavekhin, P.; Chaudhury, S.; Munawar, A.; Agravante, D.J.; De Magistris, G.; Kimura, D.; Tachibana, R. Focusing on what is relevant: Time-series learning and understanding using attention. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2624–2629. [Google Scholar]
- Viton, F.; Elbattah, M.; Guérin, J.L.; Dequen, G. Heatmaps for Visual Explainability of CNN-Based Predictions for Multivariate Time Series with Application to Healthcare. In Proceedings of the 2020 IEEE International Conference on Healthcare Informatics (ICHI), Virtual Conference, 30 November–3 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Schlegel, U.; Arnout, H.; El-Assady, M.; Oelke, D.; Keim, D.A. Towards a rigorous evaluation of xai methods on time series. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4197–4201. [Google Scholar]
- Pan, Q.; Hu, W.; Zhu, J. Series Saliency: Temporal Interpretation for Multivariate Time Series Forecasting. arXiv 2020, arXiv:2012.09324. [Google Scholar]
- Hsieh, T.Y.; Wang, S.; Sun, Y.; Honavar, V. Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns to Attend to Important Variables as Well as Time Intervals. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, 8–12 March 2021; pp. 607–615. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Explaining classifications for individual instances. IEEE Trans. Knowl. Data Eng. 2008, 20, 589–600. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Petsiuk, V.; Das, A.; Saenko, K. Rise: Randomized input sampling for explanation of black-box models. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Antwarg, L.; Miller, R.M.; Shapira, B.; Rokach, L. Explaining anomalies detected by autoencoders using SHAP. arXiv 2019, arXiv:1903.02407. [Google Scholar]
- Park, C.H.; Kim, J. An explainable outlier detection method using region-partition trees. J. Supercomput. 2021, 77, 3062–3076. [Google Scholar] [CrossRef]
- Jacob, V.; Song, F.; Stiegler, A.; Diao, Y.; Tatbul, N. AnomalyBench: An Open Benchmark for Explainable Anomaly Detection. arXiv 2020, arXiv:2010.05073. [Google Scholar]
- Song, F.; Diao, Y.; Read, J.; Stiegler, A.; Bifet, A. EXAD: A system for explainable anomaly detection on big data traces. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1435–1440. [Google Scholar]
- Amarasinghe, K.; Kenney, K.; Manic, M. Toward explainable deep neural network based anomaly detection. In Proceedings of the 2018 11th International Conference on Human System Interaction (HSI), Gdañsk, Poland, 4–6 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 311–317. [Google Scholar]
- Singh, R.; Dourish, P.; Howe, P.; Miller, T.; Sonenberg, L.; Velloso, E.; Vetere, F. Directive explanations for actionable explainability in machine learning applications. arXiv 2021, arXiv:2102.02671. [Google Scholar]
- Artelt, A.; Hammer, B. On the computation of counterfactual explanations–A survey. arXiv 2019, arXiv:1911.07749. [Google Scholar]
- Spooner, T.; Dervovic, D.; Long, J.; Shepard, J.; Chen, J.; Magazzeni, D. Counterfactual Explanations for Arbitrary Regression Models. arXiv 2021, arXiv:2106.15212. [Google Scholar]
- Karimi, A.H.; Barthe, G.; Balle, B.; Valera, I. Model-agnostic counterfactual explanations for consequential decisions. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 895–905. [Google Scholar]
- Rüping, S. Learning Interpretable Models 2006. H2O. AI. 2017. Available online: https://eldorado.tu-dortmund.de/bitstream/2003/23008/1/dissertation_rueping.pdf (accessed on 1 August 2021).
- Pedreschi, D.; Giannotti, F.; Guidotti, R.; Monreale, A.; Pappalardo, L.; Ruggieri, S.; Turini, F. Open the black box data-driven explanation of black box decision systems. arXiv 2018, arXiv:1806.09936. [Google Scholar]
- Samek, W.; Müller, K.R. Towards explainable artificial intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 5–22. [Google Scholar]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual Explanations for Machine Learning: A Review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Grinberg, M. Flask Web Development: Developing Web Applications with Python; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Plotly. Collaborative Data Science; P.T. Inc.: Montreal, QC, Canada, 2015. [Google Scholar]
- jQuery: A Fast, Small, and Feature-Rich JavaScript Library. Available online: https://jquery.com/ (accessed on 11 September 2021).
- Hooker, S.; Erhan, D.; Kindermans, P.J.; Kim, B. A benchmark for interpretability methods in deep neural networks. arXiv 2018, arXiv:1806.10758. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1885–1894. [Google Scholar]
- Petluri, N.; Al-Masri, E. Web traffic prediction of wikipedia pages. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5427–5429. [Google Scholar]
- Spiliotis, E.; Kouloumos, A.; Assimakopoulos, V.; Makridakis, S. Are forecasting competitions data representative of the reality? Int. J. Forecast. 2020, 36, 37–53. [Google Scholar] [CrossRef]
- Hua, J.; Xiong, Z.; Lowey, J.; Suh, E.; Dougherty, E.R. Optimal number of features as a function of sample size for various classification rules. Bioinformatics 2005, 21, 1509–1515. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Erratum: Estimating mutual information [Phys. Rev. E 69, 066138 (2004)]. Phys. Rev. E 2011, 83, 019903. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Rabanser, S.; Januschowski, T.; Flunkert, V.; Salinas, D.; Gasthaus, J. The effectiveness of discretization in forecasting: An empirical study on neural time series models. arXiv 2020, arXiv:2005.10111. [Google Scholar]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-based outlier detection. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1118–1123. [Google Scholar]
- Kriegel, H.P.; Schubert, M.; Zimek, A. Angle-based outlier detection in high-dimensional data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 444–452. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
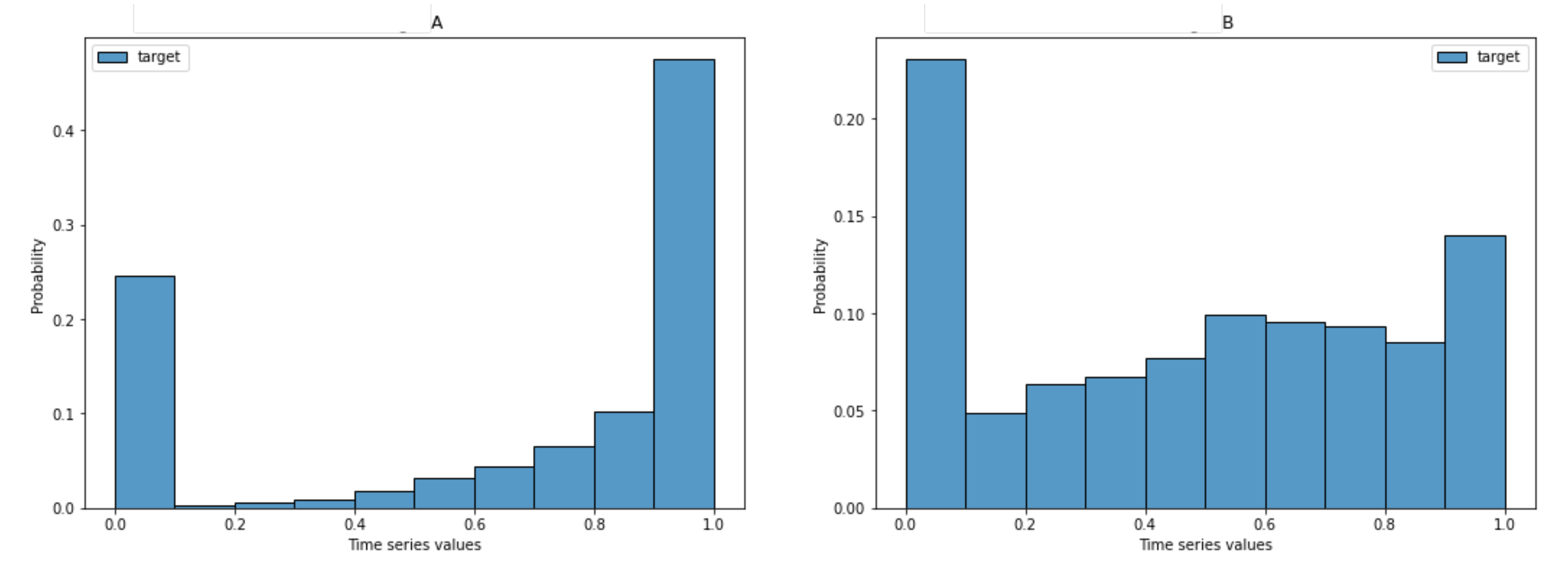
| Dataset | Original | Reduced Dataset | Test Window | ||||||
|---|---|---|---|---|---|---|---|---|---|
| # TS | % TSDM | # TS | # TSDM | TS Datapoints | # Instances | Mean (Target) | Std (Target) | ||
| M4CD | 47,983 | 55 | 2000 | 1097 | 45 | 90,000 | 0.6598 | 0.4036 | 12 |
| KWWTFCD | 145,063 | 74 | 2000 | 1488 | 56 | 112,000 | 0.4782 | 0.3442 | 14 |
| Feature | Data Type | Description |
|---|---|---|
| min_n | Double | Minimum value in rolling window of last n observations. |
| mean_n | Double | Mean of values in rolling window of last n observations. |
| std_n | Double | Standard deviation for values in rolling window of last n observations. |
| median_n | Double | Median value in rolling window of last n observations. |
| skew_n | Double | Skew value in rolling window of last n observations. |
| kurt_n | Double | Kurtosis value in rolling window of last n observations. |
| peaks_n | Integer | Count the number of peaks for a rolling window of last n observations. |
| above_mean_n | Double | Count the number of datapoints above the mean, for a rolling window of last n observations. The value is normalized by windows length. |
| n−1 | Double | Last observed target value, normalized by maximum value observed in time window n = 12. |
| Experiment | Description |
|---|---|
| Experiment 1 | Compare the performance of GFM and LFM. |
| Experiment 2 | Remove instances similar to the cases where the forecast was considered anomalous. The similarity of the train instances is measured on relevant features of the forecast feature vector. |
| Experiment 3 | Remove only instances similar to the cases where the fallback was considered anomalous. The similarity of the train instances is measured on relevant features of the forecast feature vector. |
| Experiment 4 | Remove instances similar to the cases where the forecast was considered anomalous. The similarity of the train instances is measured on relevant features of the forecast feature vector and target value. |
| Experiment 5 | Remove only instances similar to the cases where the fallback was considered anomalous. The similarity of the train instances is measured on relevant features of the forecast feature vector and target value. |
| Model Name | Description |
|---|---|
| MA(3) | Moving average over last three time steps. |
| näive | Last time step actual is used as the forecast value. |
| GM(GBMR) | Global model built with GBMR. |
| LM(GBMR) | Local model built with GBMR. |
| GM(GBMR)+näive | Forecasts are issued from GM(GBMR), except when the forecasted value is considered anomalous. In such cases, it falls back to a näive forecast. |
| Experiment | Dataset | MASE | Anomalies in Test | ETI | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MA(3) | GM(GBMR) | GM(GBMR)+näive | LM(GBMR) | GM(GBMR) vs. TD | Target | GM(GBMR) | GM(GBMR)+näive | # ETI | Ratio ETI | ||
| Experiment 1 | M4CD | 1.8473 | 0.7387 | 0.7644 | 4.3261 | 304 | 4337 | 1553/1857 (0.84) | 1555/2249 (0.69) | NA | NA |
| KWWTFCD | 1.4871 | 0.6828 | 0.7216 | 1.0360 | 407 | 2750 | 991/1398 (0.71) | 924/1916 (0.48) | NA | NA | |
| Experiment 2 | M4CD | 1.8473 | 0.7392 | 3.0213 | 4.3261 | 290 | 4337 | 1567/1857 (0.84) | 1555/2249 (0.69) | 1857 | 0.0281 |
| KWWTFCD | 1.4871 | 0.6832 | 1.5915 | 1.0360 | 374 | 2714 | 919/1293 (0.71) | 869/1808 (0.48) | 1293 | 0.0154 | |
| Experiment 3 | M4CD | 1.8473 | 0.7361 | 3.0228 | 4.3261 | 283 | 4337 | 1588/1871 (0.85) | 1555/2249 (0.69) | 1365 | 0.0207 |
| KWWTFCD | 1.4871 | 0.6829 | 1.5912 | 1.0360 | 375 | 2714 | 925/1300 (0.71) | 869/1808 (0.48) | 813 | 0.0097 | |
| Experiment 4 | M4CD | 1.8473 | 0.7392 | 3.0213 | 4.3261 | 290 | 4337 | 1567/1857 (0.84) | 1555/2249 (0.69) | 1857 | 0.0281 |
| KWWTFCD | 1.4871 | 0.6832 | 1.5915 | 1.0360 | 374 | 2714 | 919/1293 (0.71) | 869/1808 (0.48) | 1293 | 0.0154 | |
| Experiment 5 | M4CD | 1.8473 | 0.7361 | 3.0229 | 4.3261 | 283 | 4337 | 1588/1871 (0.85) | 1555/2249 (0.69) | 1365 | 0.0207 |
| KWWTFCD | 1.4871 | 0.6828 | 1.5911 | 1.0360 | 374 | 2714 | 925/1299 (0.71) | 869/1808 (0.48) | 813 | 0.0097 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rožanec, J.; Trajkova, E.; Kenda, K.; Fortuna, B.; Mladenić, D. Explaining Bad Forecasts in Global Time Series Models. Appl. Sci. 2021, 11, 9243. https://doi.org/10.3390/app11199243
Rožanec J, Trajkova E, Kenda K, Fortuna B, Mladenić D. Explaining Bad Forecasts in Global Time Series Models. Applied Sciences. 2021; 11(19):9243. https://doi.org/10.3390/app11199243
Chicago/Turabian StyleRožanec, Jože, Elena Trajkova, Klemen Kenda, Blaž Fortuna, and Dunja Mladenić. 2021. "Explaining Bad Forecasts in Global Time Series Models" Applied Sciences 11, no. 19: 9243. https://doi.org/10.3390/app11199243
APA StyleRožanec, J., Trajkova, E., Kenda, K., Fortuna, B., & Mladenić, D. (2021). Explaining Bad Forecasts in Global Time Series Models. Applied Sciences, 11(19), 9243. https://doi.org/10.3390/app11199243