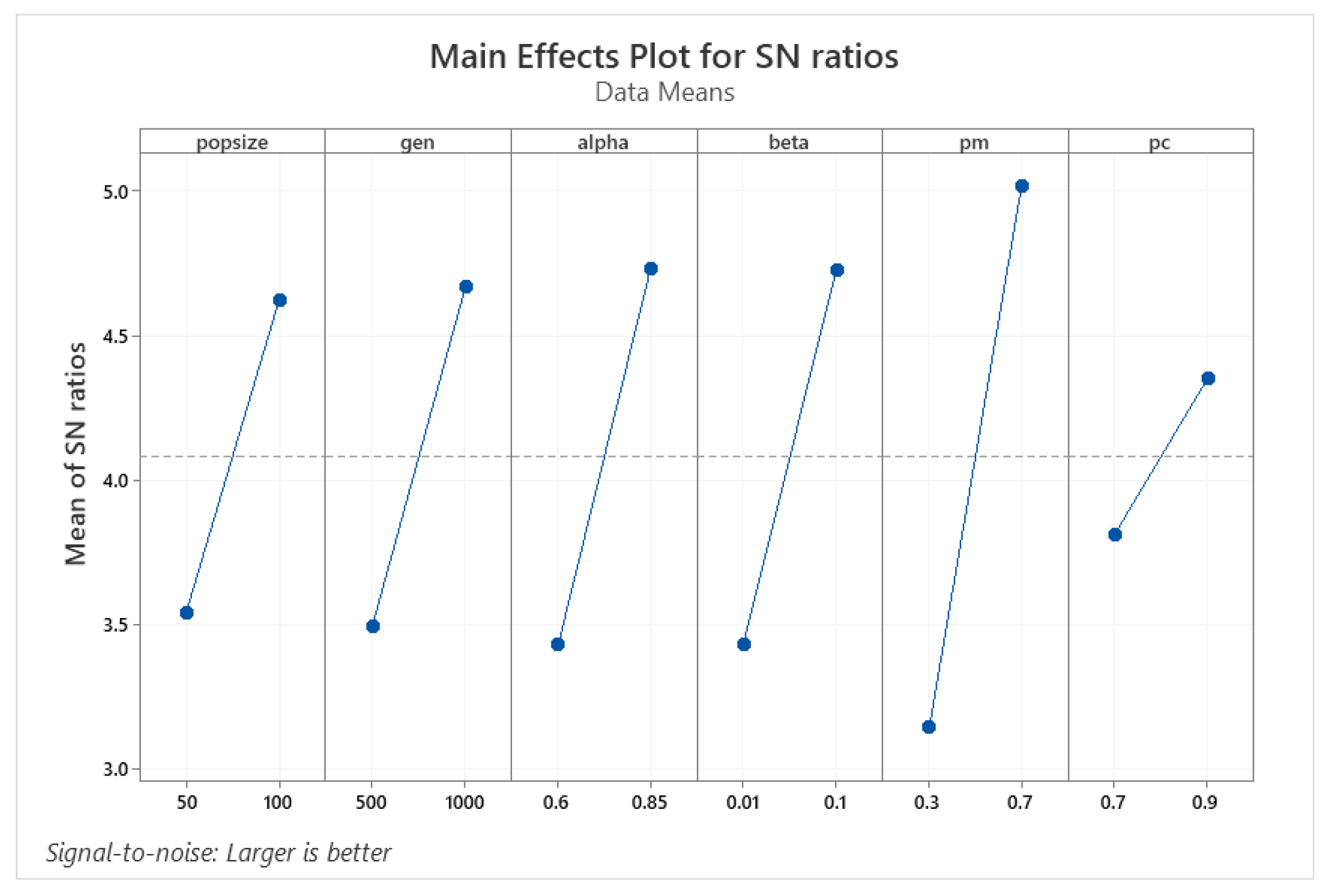
1. Introduction
In this period of economic recession stemming from the COVID-19 pandemic [
1] and coupled with the climate emergency, the implementation of effective policies and tools remains crucial to tackle current challenges. According to the International Energy Agency, the industrial sector accounted for almost 28% of the energy use in 2018, whereas the current crisis is likely to shift the industrial output to more energy-intensive manufacturers [
2]. Consequently, the International Panel on Climate Change urges governments and economic actors to engage rational and coordinated responses to the climate change through a sustainable development. The latter sets on economic, social and environmental pillars guarantying prosperity, social justice and nature conservation. In addition to scientific concerns, civil society is increasingly calling for sustainable development, pressuring governments and companies to adhere to ethical standards and green framework.
To curb GHG (greenhouse gas) emissions, for instance, the implementation of European Union Emission Trading System (EU ETS) for energy-intensive industry has been a keystone of EU energy policy. EU ETS forms a ‘cap and trade’ scheme allowing the companies to emit and exchange GHG allowances, decreasing on yearly basis. Heavy fines are applied if the allowance is not complied. Since its introduction, it has achieved a 8.7% cut on European GHG emissions [
3]. To complement EU ETS, members states introduce taxes on carbon whenever emissions exceeds a given threshold. In this context, this paper especially focuses on taxes on CO
2 emissions. Along with these regulations, monitoring energy consumption and carrying out an energy audit is now mandatory for companies that meet specific criteria. In our economy based on supply and demand, the industrial sector has been establishing itself as a major actor. For a manufacturing company, the production of goods to satisfy customers demand generates profit, investment and employment. Altogether, this participates in the real economy as the manufacturing sector contributes to nearly 20% of global gross domestic product [
4]. Therefore, the sector must adapt as effectively as possible to the newest regulations while maintaining competitiveness. This past decade, the environmental impact of the supply chain has been widely studied, suggesting that the operational level is more prone to profound changes. Indeed, integrating energy aspects into planning and scheduling, besides replacing obsolete equipment, is one of the most cost-effective ways to attain sustainability objectives [
5] such as reducing GHG emissions and energy consumption. However, a trade-off between reducing energy consumption and productivity is always noticeable [
6]. Nevertheless, energy sobriety is beneficial for both economic and environmental reasons. First, energy cost is a shortfall for heavy energy-using industry as the energy supplies are becoming expensive. For this purpose, smart grid technologies have already been deployed. In this context, energy providers have designed preferential tariffs rate such as time-of-use (TOU), real-time or critical peak pricing. TOU rates incite manufacturers to shift their production to cheaper off-peak hours instead of on-peak hours. Second, depending on the energy mix used (e.g., coal or gas based), reducing energy consumption or costs is a direct way to reduce GHG emissions [
7].
Early industry focused on mass production with high volumes of few products. Yet, this past decade, major changes in industry have been occurring [
8]. Product variety and demand for tailor-made products force manufacturers to make a compromise between their available production capacity, their production organization and their sales volume. This global trend appears in a plethora of manufacturing sectors from textiles to the food industry. Indeed, this can be observed in real manufacturing settings, such as printing processes in packaging companies [
9], service delivery including food or critical equipment maintenance companies facing time windows, high demands with limited resources deployment [
10,
11]. Order acceptance scheduling (OAS) is an abstraction to model this particular trend. In this vein, this paper investigates a single machine OAS problem with release date and sequence-dependent setup times under TOU tariffs and taxed carbon emissions. In this problem, the company has to decide which order to produce, among
n, and establish a schedule accordingly. Each order is available within a specific time window. Moreover, a setup operation is performed between orders, and its duration depends on the previous order sequenced. The objective is to maximize the total revenue of orders minus tardiness penalties while meeting clients deadlines and green manufacturing considerations. The latter has an impact on the orders selection and their schedule. Chen et al. [
12] are the first to introduce this problem while proposing a disjunctive Mixed Integer Linear Program (MILP). Bouzid et al. [
13] consider an arc-time-indexed (ATI) MILP to cope with the high complexity of this NP-hard problem and successfully solve some large instances. However, these approaches are limited by design and thus require the use of heuristics.
For this purpose, this paper analyses two time-indexed (TI) formulations and two Fix-and-Relax (FR) heuristics applied to the provided formulations. Moreover, an island-based genetic algorithm (GA) first proposed by Candan et al. [
14] is developed. The contributions of this paper are threefold. First, we refine mathematical models on this problem. Second, we give an overview of the formulations behavior with respect to the FR heuristic, and finally we propose a competitive and robust metaheuristic to fill the gap in the literature and improve existing results.
Section 2 presents a literature review on OAS under energy aspects and more globally on scheduling considering energy.
Section 3 presents in details the considered problem.
Section 4 is dedicated to the mathematical formulations, and
Section 5 presents the solving methods. Benchmark and experimental design are introduced in
Section 6 along with the results and their interpretation. Conclusion are drawn and perspectives are given in
Section 7.
2. Related Literature
This section presents existing literature on scheduling and OAS problems under energy aspects with their developed solution approaches. First, an overview on scheduling problems incorporating environmental aspects is given. Next, related works on OAS problems are introduced. Before concluding, a focus is made on the resolution techniques.
Gao et al.’s [
15] review on scheduling problems under energy aspects reveals that this topic has been growing in interest in recent years. Complex shop systems, including job shop and flow shop, represent the majority of the studies, whereas single machine features less than 4% of their corpus. One of the most important points highlighted in this study is that energy efficiency is conceptualized by two approaches. First and foremost, it is done by introducing it as a criterion. Indeed, targeted criteria such as Total Energy Consumption or Costs (TEC) or total carbon emissions have been successfully incorporated into scheduling problems in numerous work [
16,
17,
18,
19]. Second, energy efficiency is modeled by dedicated constraints coupled with a classical scheduling objective [
20,
21]. For example, in the work of Liao et al. [
20], weighted tardiness and completion times are minimized while satisfying a periodic threshold on energy consumption for a single machine.
In the literature, different assumptions relative to the energy aspects may be encountered. These assumptions are related to the quantity considered (carbon emissions, energy consumption, power etc.), the machine characteristics (energy states, speed), the variation of the energy costs during the day or the system involved (single machine or shop systems). Depending on these assumptions, the problem entails particular properties and thus is solved with specific approaches.
For single machines, Mouzon and Yildirim [
5] present an adaptive search metaheuristic to minimize TEC and total tardiness. In their study, they examine the idle, setup and processing energy of the machine in order to efficiently adjust the production and avoid tardy jobs. The neighborhood move developed by the authors inserts setup or idle times between jobs, which can reduce energy costs but can lead to tardiness. Che et al. [
22] consider a TI MILP to minimize TEC under TOU electricity tariffs and develop a greedy insertion heuristic which moves jobs to the off-peak periods. Aghelinejad et al. [
23] propose a dynamic program for the single machine problem under TOU tariffs considering machine states and investigate the complexity of various energy costs strategies that can induce the problem to be polynomial.
As for shop scheduling or parallel machines, other energy aspects are studied. Zhang et al. [
24] address a speed scaling job shop problem with the objective to minimize both tardiness and TEC. In their work, they monitor machines speed to efficiently modulate the production process. Dedicated local search procedures are designed to cope with the complexity of the problem. In the same vein, Jiang et al. [
25] consider energy consumption per time unit and idle energy consumption minimizing TEC and makespan. They employ an Evolutionary Algorithm (EA) in their solving approach. In [
26], the authors optimize the TEC and the makespan of unrelated parallel machines under time-and-machine-dependent electricity costs. Their solving approach involves an hybrid GA that incorporate an idle-time insertion procedure to cut costs on electricity expenses. Considering CO
2 emissions, Foumani and Smith-Miles [
27] assess common carbon reduction policies on a flow shop. One of their conclusion confirms that optimizing the schedule plays a key role in the reduction of CO
2 emissions rather than changing equipment. In the meantime, they show that the ’cap and trade’ approach is a cost-effective policy. In [
7], a flowshop under time-dependent electricity tariffs and CO
2 emissions is tackled. The authors propose a TI MILP to minimize simultaneously carbon footprint and TEC with machines having different consumption levels. Their study suggests that a trade-off between electricity costs and CO
2 emissions appears when the energy providers are coal-based. As in [
7,
12], the assumption on time-dependent CO
2 emissions and electricity costs holds for this paper.
OAS is a particular scheduling problem where the decision covers the selection of a subset of orders, among
n, and their sequencing in a capacity-constrained production system. Typically, this entails a fixed time frame to complete orders and an associated cost-driven event where the company fails to produce within the time-window. The solution space of OAS problem extends classical scheduling one, as jobs can be accepted or not. Indeed, at worst the number of possible solutions in OAS problem is
, where all the
k-permutations of
n without repetition are considered, whereas only
solutions form the solution space in classical scheduling problems. In the literature, for both single- or multi-machine systems, a variety of configurations of problems are considered such as sequence-dependent setup times [
9,
28,
29], preemption [
11] or resource constraints [
10,
30]. As for our research, the immediate related works are those presented in [
9,
28,
29]. A comprehensive survey [
31] presents an overview on OAS problems, while in [
32], a focus is made on scheduling problem with rejection.
OAS involves mainly economic-related criteria, primarily embodied by the maximization of the total profit generated by the orders. Service level [
33], percentage of accepted orders or utilization can also be maximized in OAS problems. In addition, cost penalties can be integrated in the objective function when tardiness or order rejection occur. For instance, Oguz et al. [
9] maximize the total profit of accepted orders minus their possible tardiness penalties. As in scheduling problem, OAS solving methods involve exact and heuristic approaches. MILP [
9,
28,
29], dynamic programming [
34] and branching methods [
35] have been employed for various OAS problems. In the meantime, as these problems are mostly NP-hard, a wide range of metaheuristics from local search to EA have been utilized and have shown very robust performances [
36,
37,
38]. Besides, reports in the literature describe an order-based and a time-based FR heuristics applied to an OAS problem under resource constraints [
30] that both achieve a tighter gap for large instances. A recent work of Tarhan et Oğuz [
39] proposes a two-phase matheuristic that exploit a time-indexed model. First, they assign orders to time segments using the relaxed version of their model and generate a schedule subsequently; the solution is then improved by a VNS. This process is repeated until the termination criterion is met. However, energy aspects are not considered in their work.
Literature on OAS considering resource constraints and/or energy aspects is very sparse. Garcia [
10] tackles an resource-constrained OAS problem with the objective to maximize profit with rejection penalties using an EA and a priority rule heuristic. Kong et al. [
40] maximize the net revenue of a parallel machines system with order acceptance and a global constraint on the energy consumed by machines and their launch budget. In their work, a comparative analysis between diverse variable neighbor search algorithms and a dynamic programming approach is conducted. Considering electricity tariffs, to the best of our knowledge, three papers have been reported [
12,
13,
41]. These papers follow up the works in [
12,
13] that both investigate the OAS problem under TOU and CO
2 emissions periods and sequence-dependent setup times with a disjunctive formulation in [
12] and an ATI model in [
13]. Moreover, this paper contributes to the comprehension of the OAS under energy aspects by introducing approached solving methods that improve the existing results.
A vast majority of the investigated problems on scheduling are NP-hard or pseudo-polynomial, justifying the significant use of heuristics that can outperform exact methods. Likewise, matheuristics are developed to tackle the aforementioned problems.
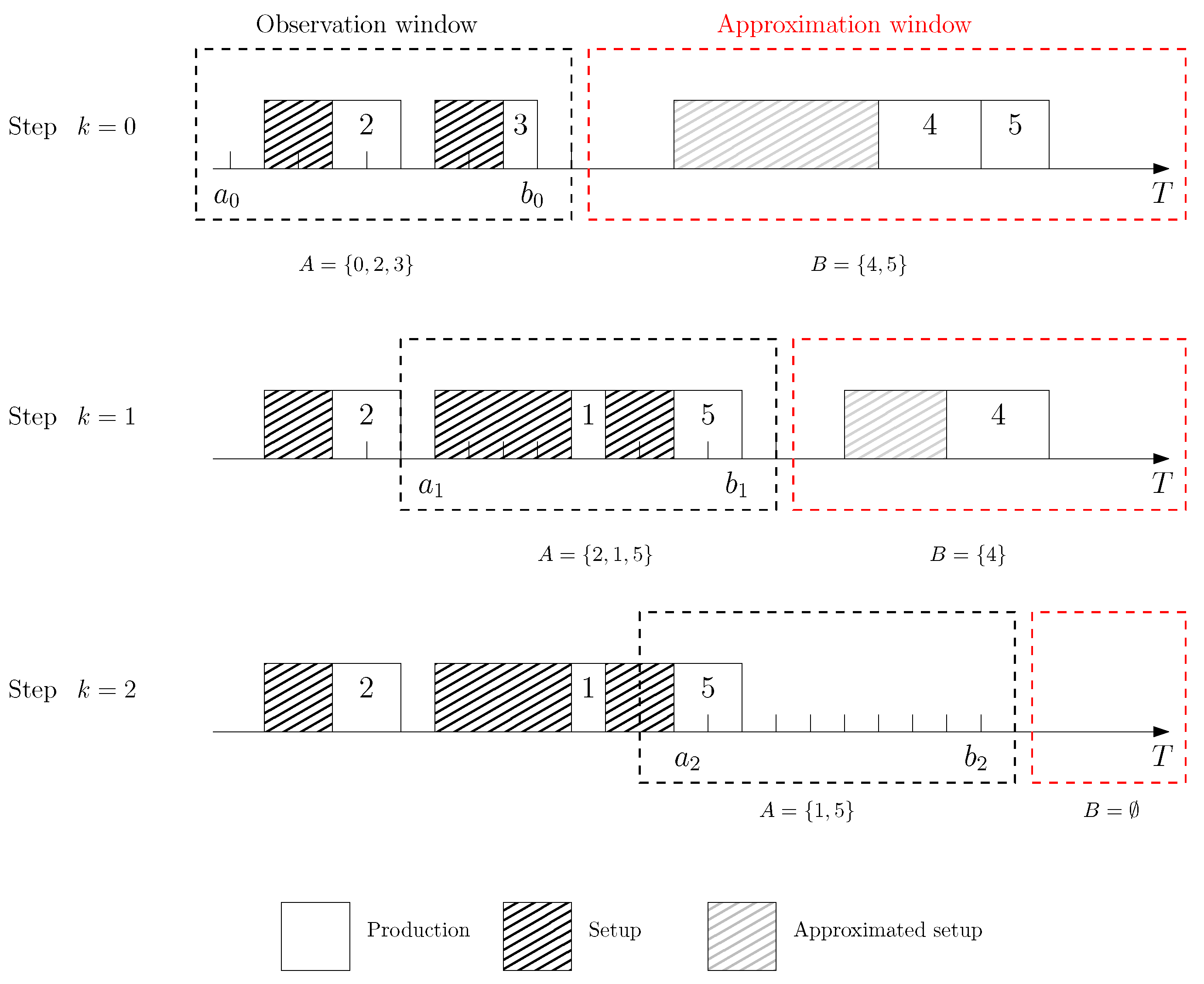
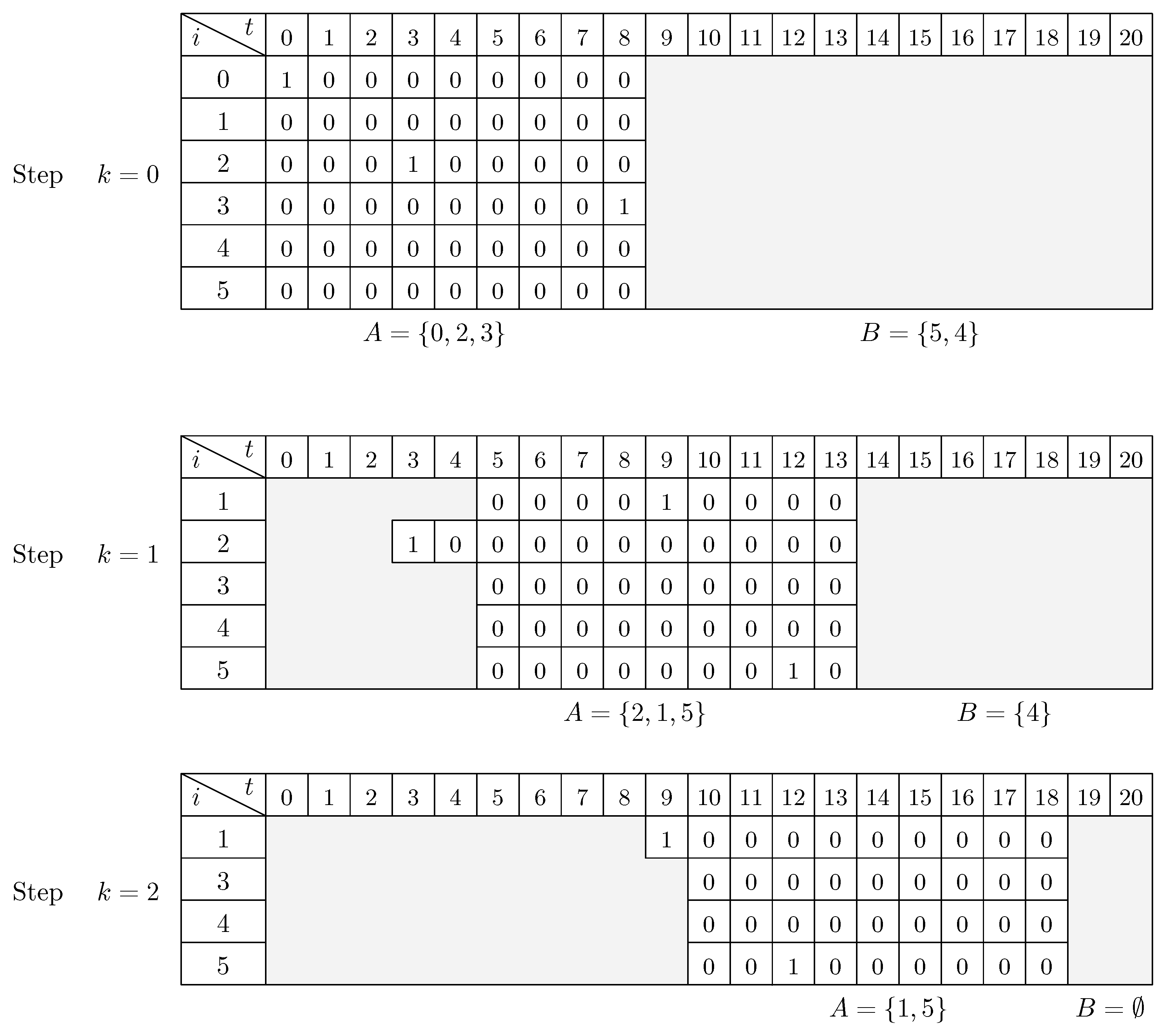
FR heuristic is a model-based heuristic which is applied in planning and scheduling problems. Promoted by Absi et al. [
42], this heuristic has been employed in production planning researches considering energy aspects [
43,
44]. For instance, Masmoudi et al. [
43] minimize TEC for a single-item capacitated lot sizing problem in a flow shop with TOU tariffs and power constraints. Their FR strategy relies on the relaxation of the binary decision variables involved in the time-dependent constraints. Besides, the FR heuristic is also used for scheduling problems such as operating rooms scheduling [
45,
46] and harvest scheduling [
47]. In [
45], Silva et al. maximize the use of operating rooms with constraints on the staff schedule and skills. Following the advances of Industry 4.0, a recent study of Li et al. [
48] features a GA combined with machine learning approaches that minimize makespan for a job shop rescheduling production system. The machine learning techniques aim at evaluating rescheduling patterns. Their framework is able to outperform classical approaches with less configuration changes made at the right time. The survey of Dolgui et al. [
49] summarizes the contours of scheduling problems from the point of view of optimal control. In the context of complex systems, this approach appears to answer to the new challenges raised by the Industry 4.0. Finally, Q-learning techniques have also been employed in [
50] for an online single machine scheduling with the objective to minimize tardiness in the context of a smart factory [
51]. This research compares the performances of classical scheduling methods against reinforcement learning techniques and concludes that the latter can improve the resolution quality and time [
25,
52,
53,
54]. In this vein, the island-based framework introduced in [
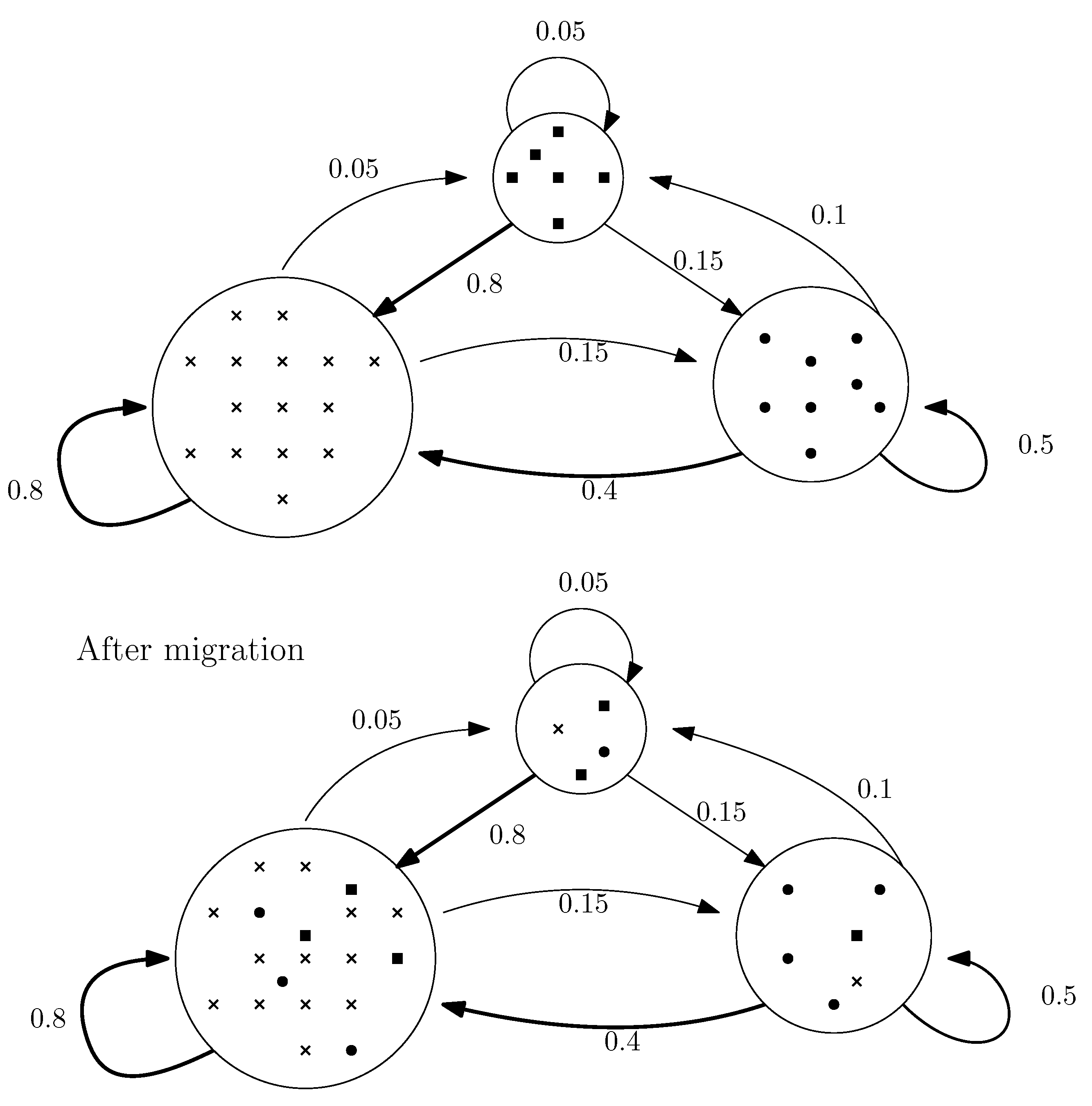
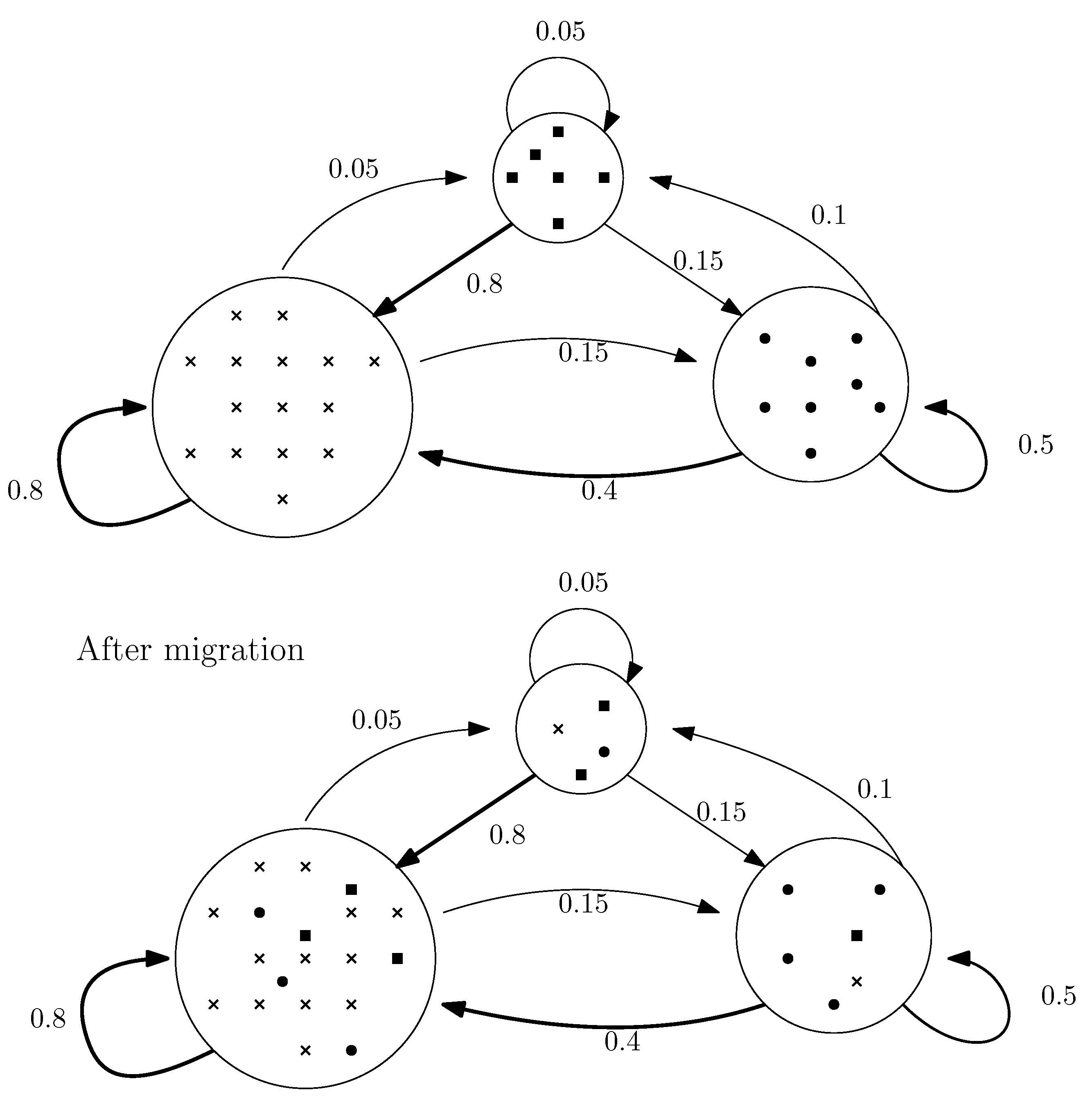
14] is a good candidate for solving combinatorial optimization problems such as scheduling. This framework proposes a self-adaptive migration policy between islands of individuals to efficiently explore and intensify the search. As in reinforcement learning techniques, the utility of the mutation operators, which control the number of individuals in each island, are re-evaluated at each iteration depending on the past performances. Good results have been presented for the 0/1 knapsack problem and the MAX-SAT problem in [
55]. Therefore, this paper proposes an island-based metaheuristic as well as two FR heuristics based on two distinct exact models in order to efficiently solve the OAS problem with released dates and sequence-dependent setup times under TOU and taxed CO
2 emissions.
To finish this section some conclusions can be drawn. First, with the growing interest on environmental issues, both industrial and academics are paying more attention to incorporate them in their production and their models. Second, in the current economic climate, OAS problems find numerous applications; this is due to their capacity to introduce constraints on resources that usually are assumed unlimited. Last, metaheuristics, or more globally, artificial intelligence approaches, are privileged over exact methods. Moreover, the current trend is to use novel machine learning techniques as standalone solving approaches or to boost heuristics.
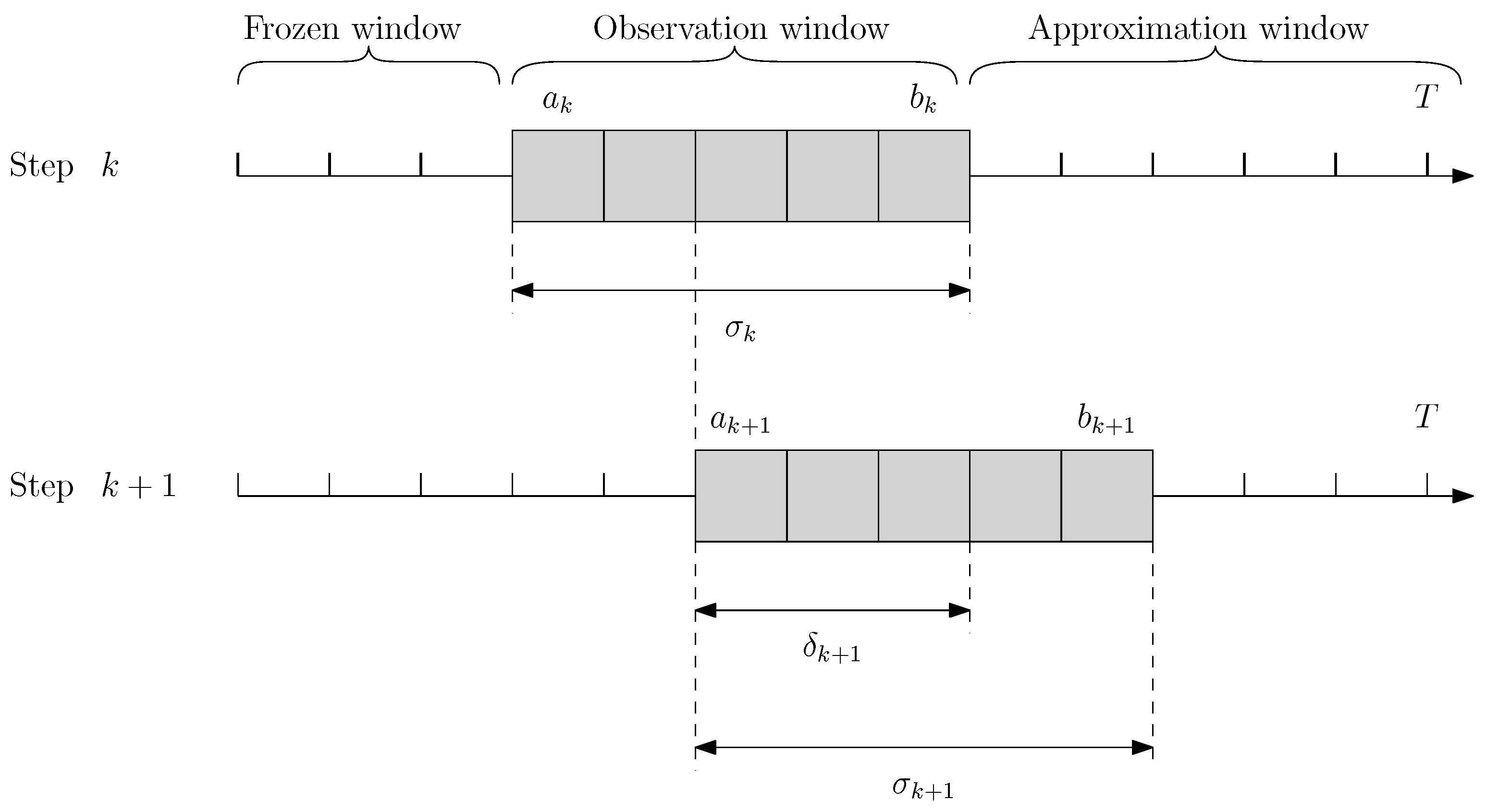
3. Problem Description
The OAS with sequence-dependent setup times, release date under TOU costs and taxed carbon periods is investigated in this paper. Parameters and notations are detailed in this section (
Table 1).
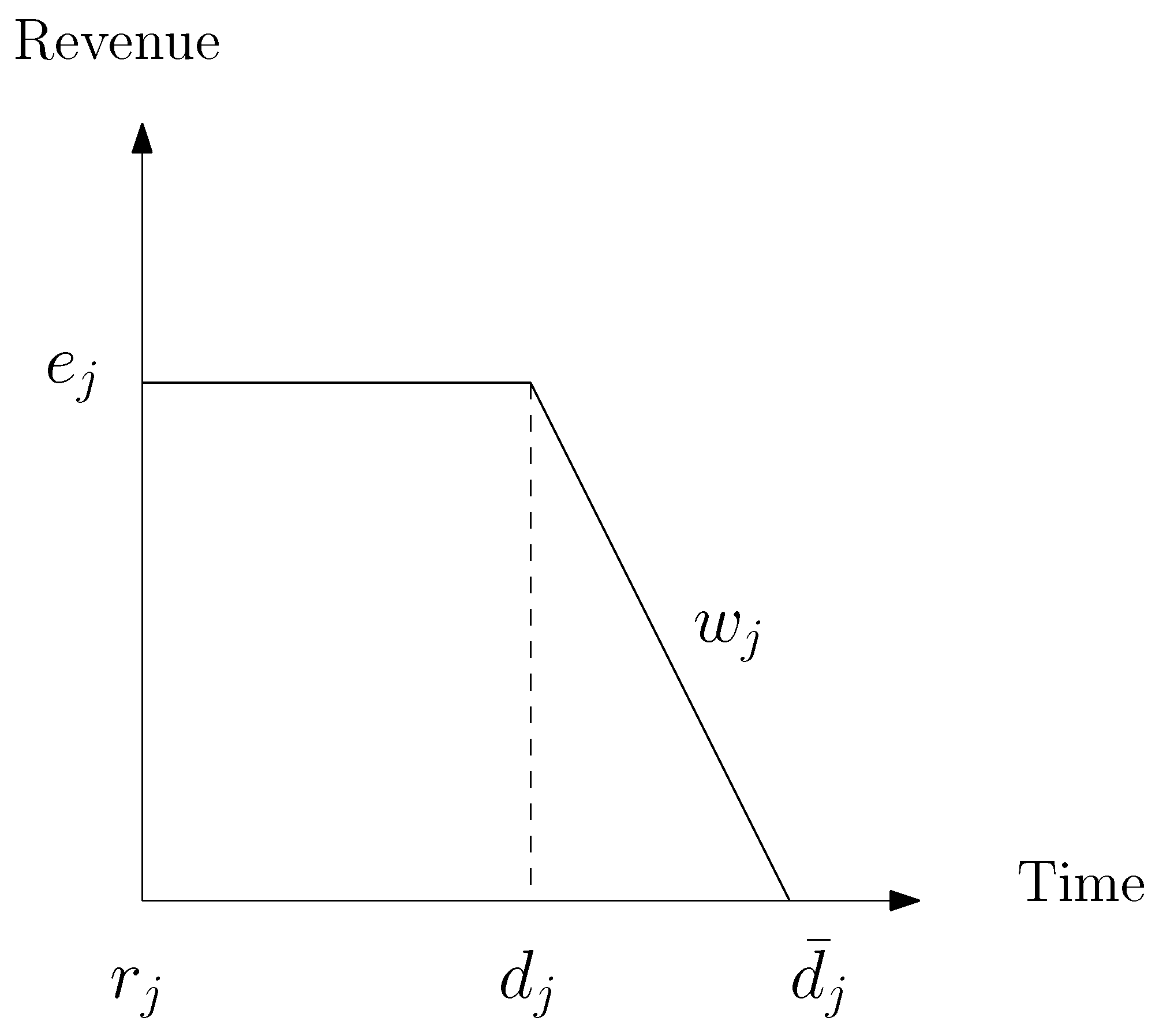
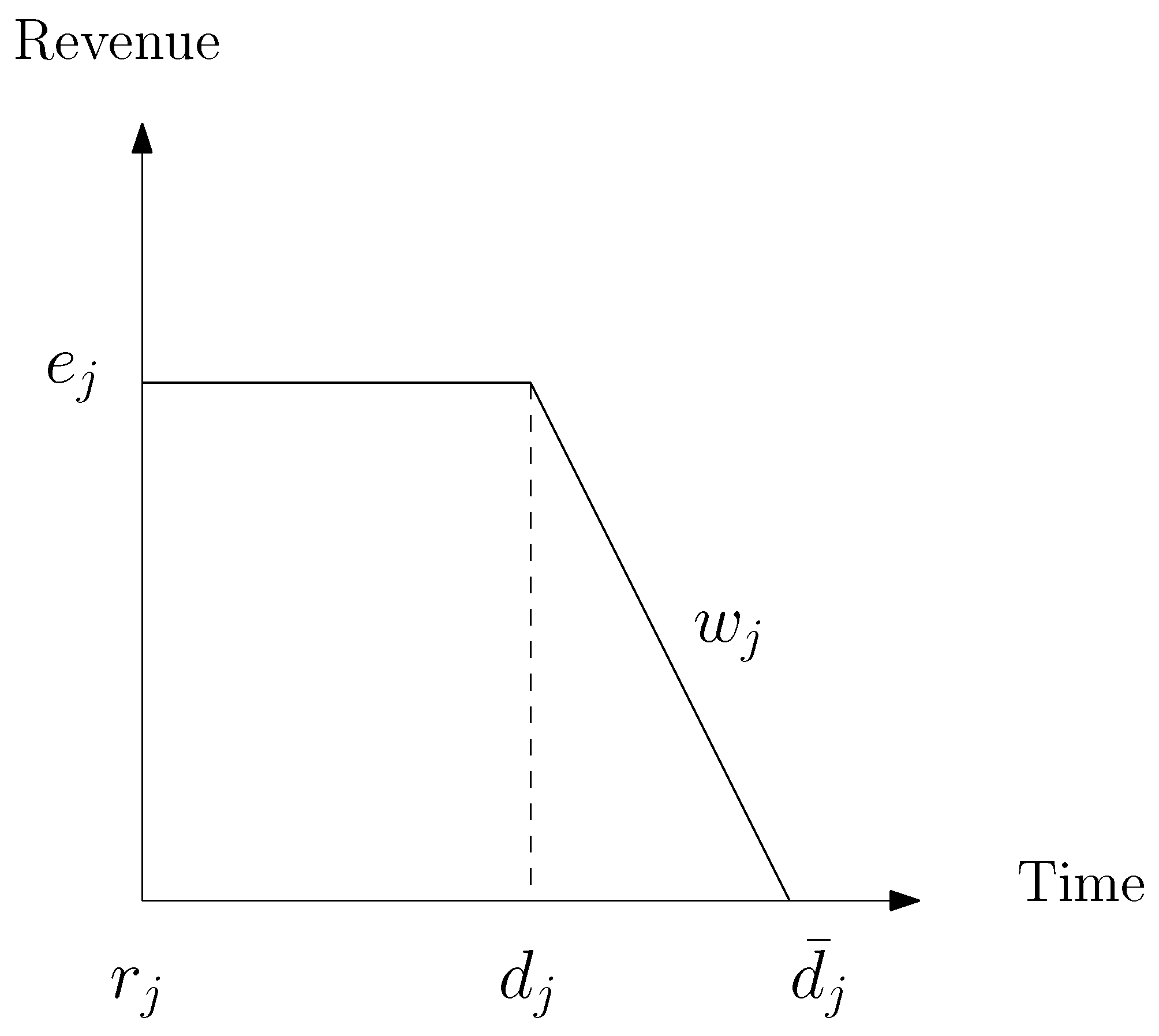
Each order is completely defined by its processing time , release date , due date , deadline , revenue , power consumption and tardiness penalties . In addition, a sequence-dependent setup time is defined between any pair of orders i and j. A dummy order 0 is introduced in order to start the sequence. Each of its properties are set to zero except its setup time between any order j.
An order
j is accepted when it is sequenced in the span ranging from its release date
to its deadline
and rejected otherwise. A tardiness penalty
is subtracted to an order revenue
for each time unit beyond its due date
. In
Figure 1,
represents the slope of the revenue decay between
and
. Moreover, in the original work, the planning horizon is divided into intervals with fluctuating TOU tariffs and CO
2 emissions. Each TOU interval
is characterized by a starting time
and an electricity cost
. Each CO
2 emissions interval
is determined by a starting time
and an amount of CO
2 per kg and a
per emitted kg of carbon. As in [
7,
12], by assumption, CO
2 emissions are time-dependent, i.e., the emitted amount fluctuates over the day as the employed power sources are coal-based during off-peak hours and gas-based during mid-peak and on-peak hours.
In this problem, the objective is to maximize the revenue minus tardiness penalties and energy costs. For simplification reasons, the energy costs can be calculated at each time-slots rather than at each intervals, especially as TOU and CO
2 emissions intervals partition differently the horizon. The energy cost
for any order
at any period
is thus computed with the formula given in Equation (
1).
The energy cost of each time period t and for each order j corresponds to the sum of the respective TOU and CO2 taxed emissions costs of the examined period t multiplied by the order’s energy consumption expressed into minutes. In this expression, the indicator function takes value 1 if condition x holds, and 0 otherwise. In addition, some assumptions are stated in this problem. Preemption is not allowed, idle time energy is negligible. Setup and production use the same amount of energy. The planning horizon ends at the maximum of deadlines, that is, .
7. Conclusions and Perspectives
This paper proposes two new mathematical formulations for a rather recent research, that is, the OAS problem with release dates, sequence-dependent setup times, TOU costs and CO2 emissions periods. The provided MILPs are time-indexed; however, these new exact models are limited to solve medium and large instances in presence of sequence-dependent setup times. Without setup, the TI On/Off formulation is the most competitive.
In this context, original FR heuristics that approximate setup are developed, taking advantage of time indexation. Better solutions have been found by these heuristics. According to the results obtained on the state-of-the-art benchmark, the best version of FR heuristic is the one with the TI Pulse formulation. Moreover, in this paper, a population-based metaheuristic is also developed. The latter is based on Dynamic Island Model framework. This procedure can solve small to large instances within half a minute on a personal computer with average performance features.
Future work can be dedicated to the extension of the problem to other systems such as parallel machines or floor shop. Determining mathematical properties of the studied problem can be undertaken. In addition, further analysis can be devoted to the instance settings and R and TOU tariffs policy. Moreover, an extensive analysis on other CO2 emissions reduction policies is an interesting prospect, as this work only focuses on the taxes on carbon emissions. For instance, a limitation on carbon emissions could be incorporated in the formulation.
Extended tests on larger instances shall be performed in order to assess the performance of FR heuristics. For instance, Benders decomposition approaches can be developed on the presented time-indexed formulations and compare the performances with the provided FR heuristics. As for the DIM, more specific mutation operators shall be developed in order to tackle instances that are difficult to solve. Other solution representation can also be explored in order to compare it with the sequence-based representation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}