
Analyzing the Performance of the S3 Object Storage API for HPC Workloads



Abstract
:1. Introduction
1.1. Background and Related Work
2. Materials and Methods
2.1. Benchmarks
- IOEasy simulating applications with well-optimized I/O patterns.
- IOHard simulating applications that utilize segmented input to a shared file.
- MDEasy simulating metadata access patterns on small objects.
- MDHard accessing small files (3901 bytes) in a shared bucket.
2.2. Modifications of Benchmarks
- Single bucket mode: created files and directories result in one empty dummy object (indicating that a file exists), every read/write access happens with exactly one object (file name contains the object name + size/offset tuple); deletion traverses the prefix and removes all the objects with the same prefix recursively.
- One bucket per file mode: for each file, a bucket is created. Every read/write access happens with exactly one object (object name contains the filename + size/offset tuple); deletion removes the bucket with all contained objects.
- One bucket, the D datasets are prefixed by the process rank.
- One bucket per dataset.
2.3. Utilizing S3 APIs in Data Centers
2.4. Measurement Protocol
2.5. Test System
2.6. MinIO Benchmarks in HPC
MinIO Deployment
- Standalone (sa): runs one MinIO server on one node with a single storage device. We test configurations from tmpfs (in-memory fs/shm) and the local ext4 file system.
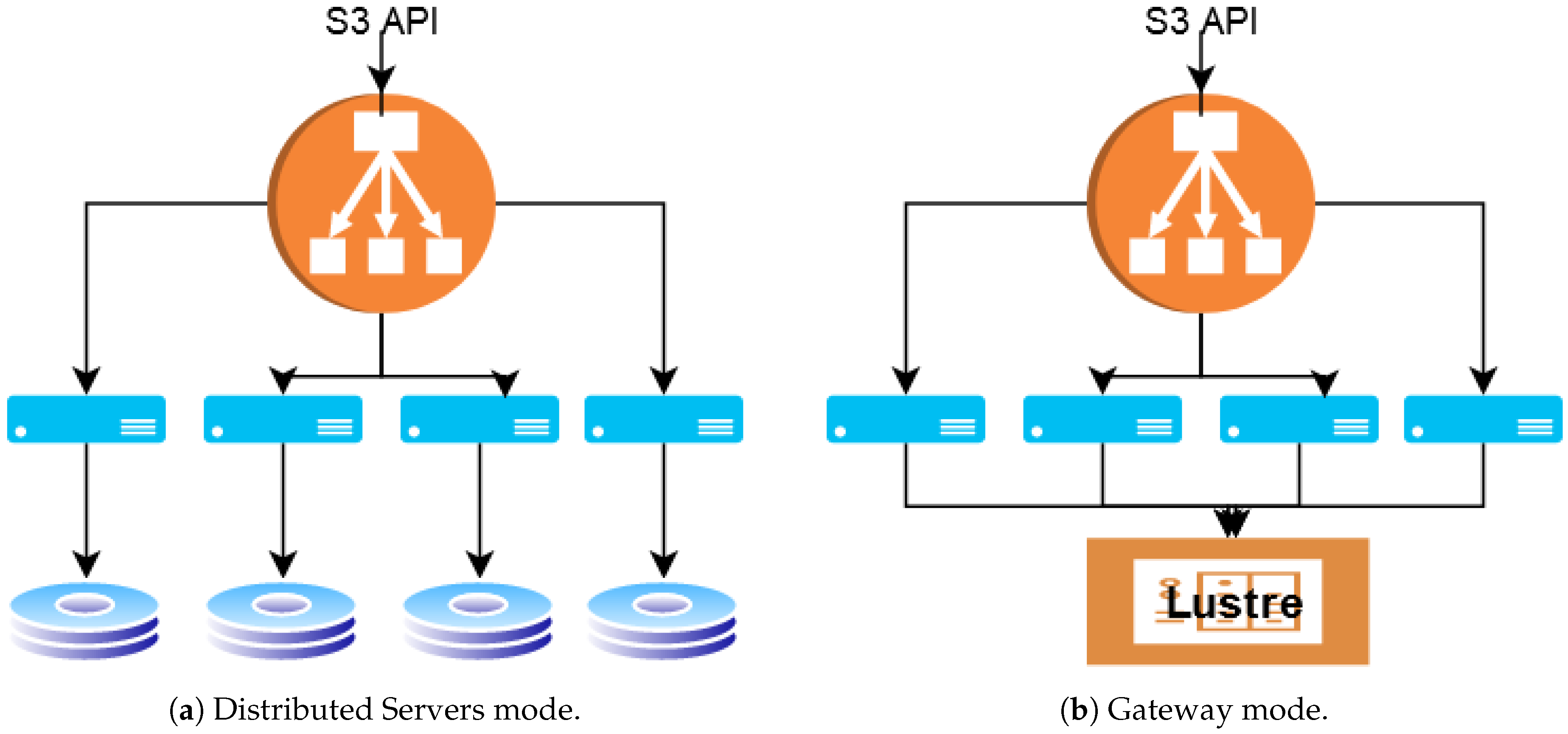
- Distributed servers (srv): runs on multiple nodes, object data and parity are striped across all disks in all nodes. The data are protected using object-level erasure coding and bitrot. Objects are accessible from any MinIO server node. In our setup, each server uses the local ext4 file system. Figure 1a illustrates the deployment.
- Gateway (gw): adds S3 compatibility to an existing shared storage. On Mistral, we use the Lustre distributed file system as the backend file system as seen in Figure 1b.
3. Results
3.1. MinIO Benchmarks in HPC Environment
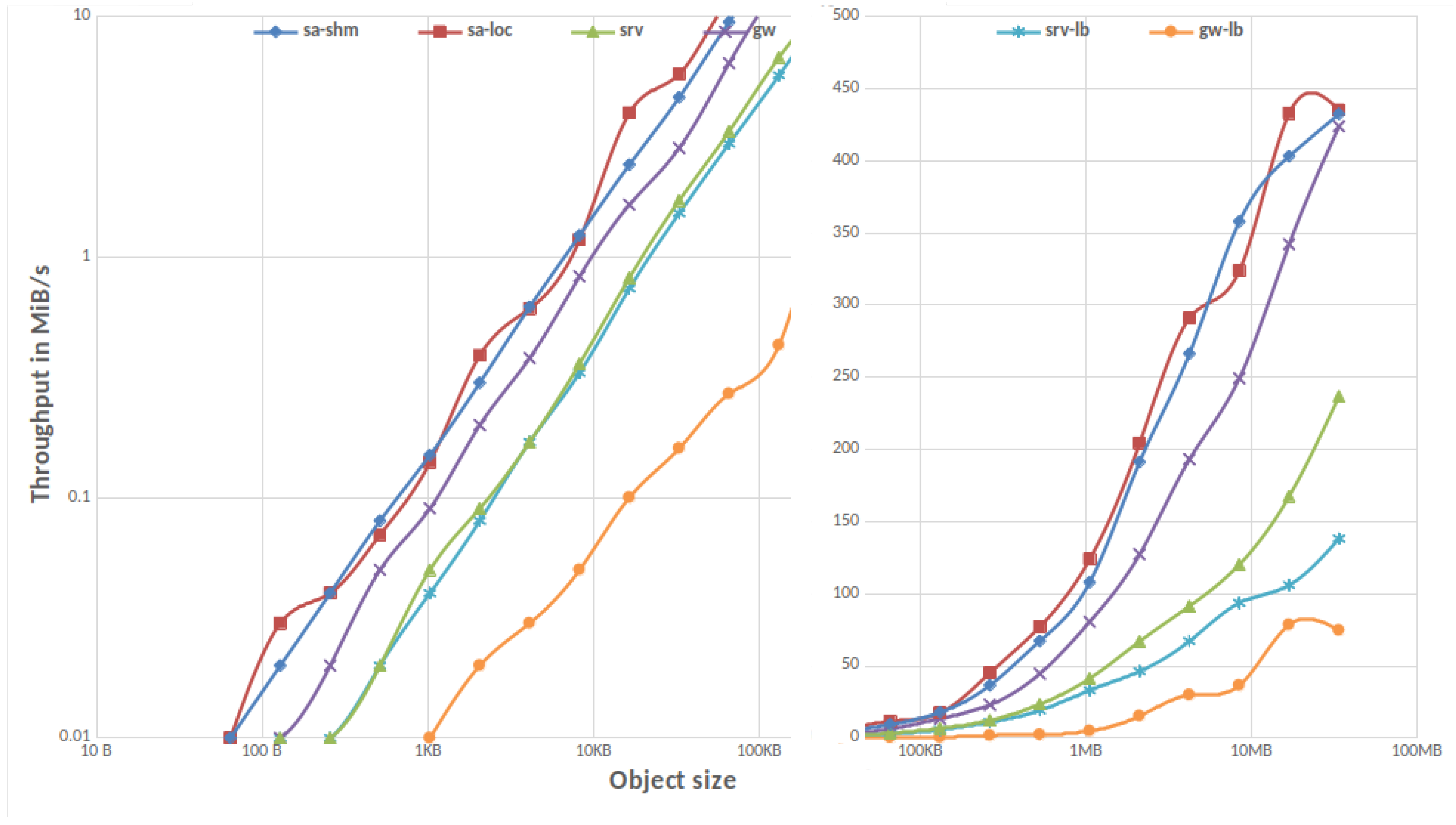
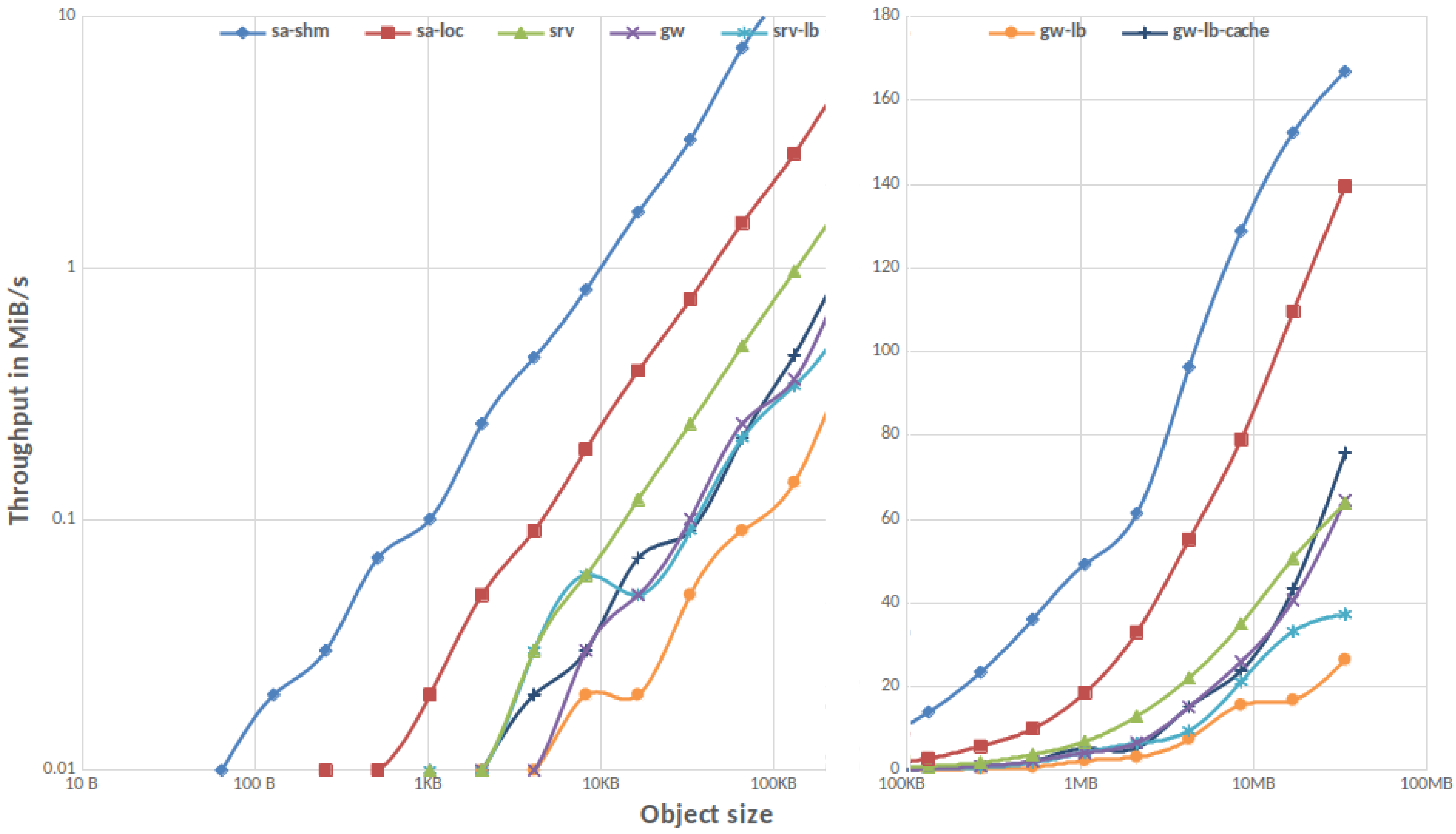
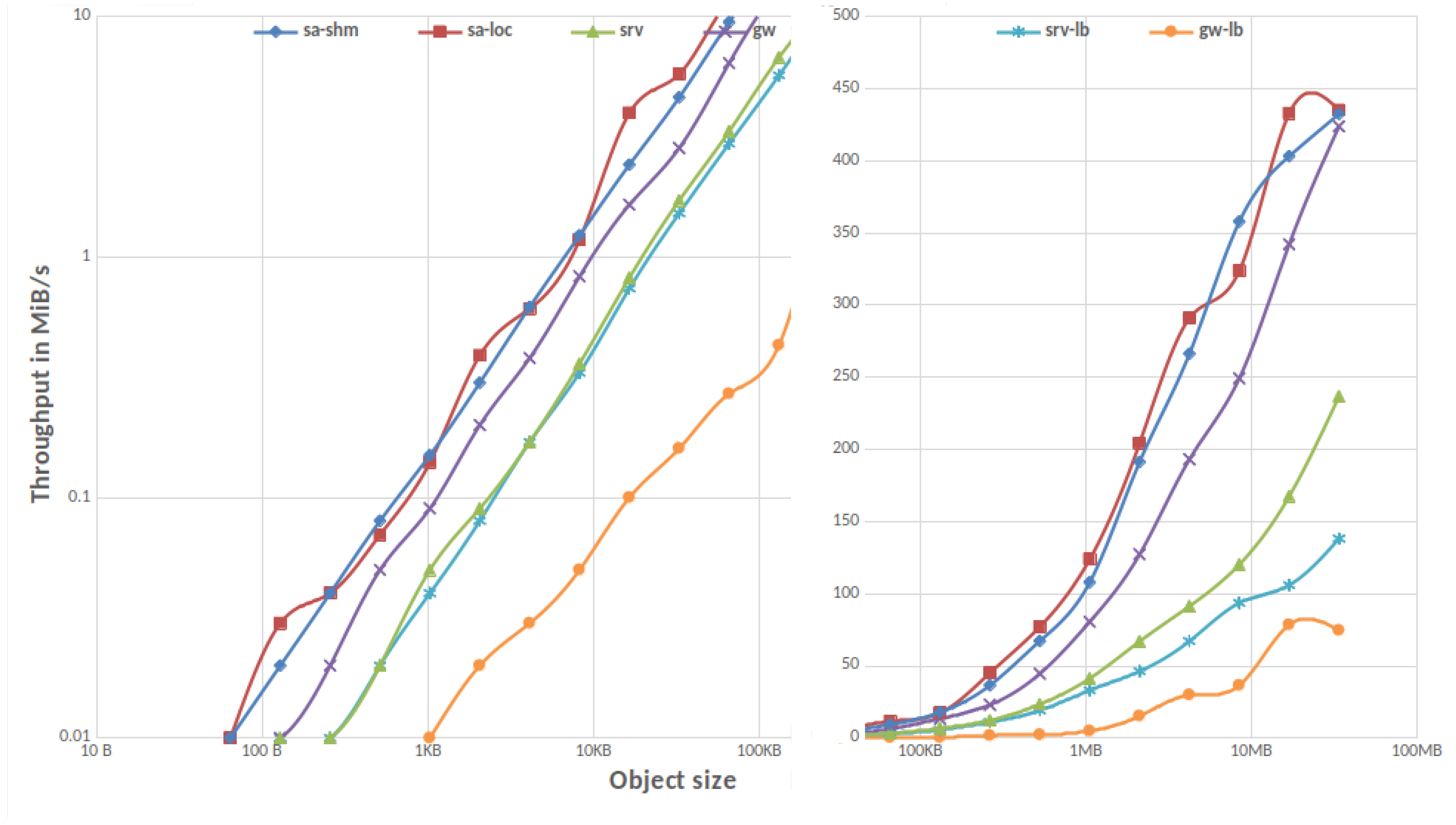
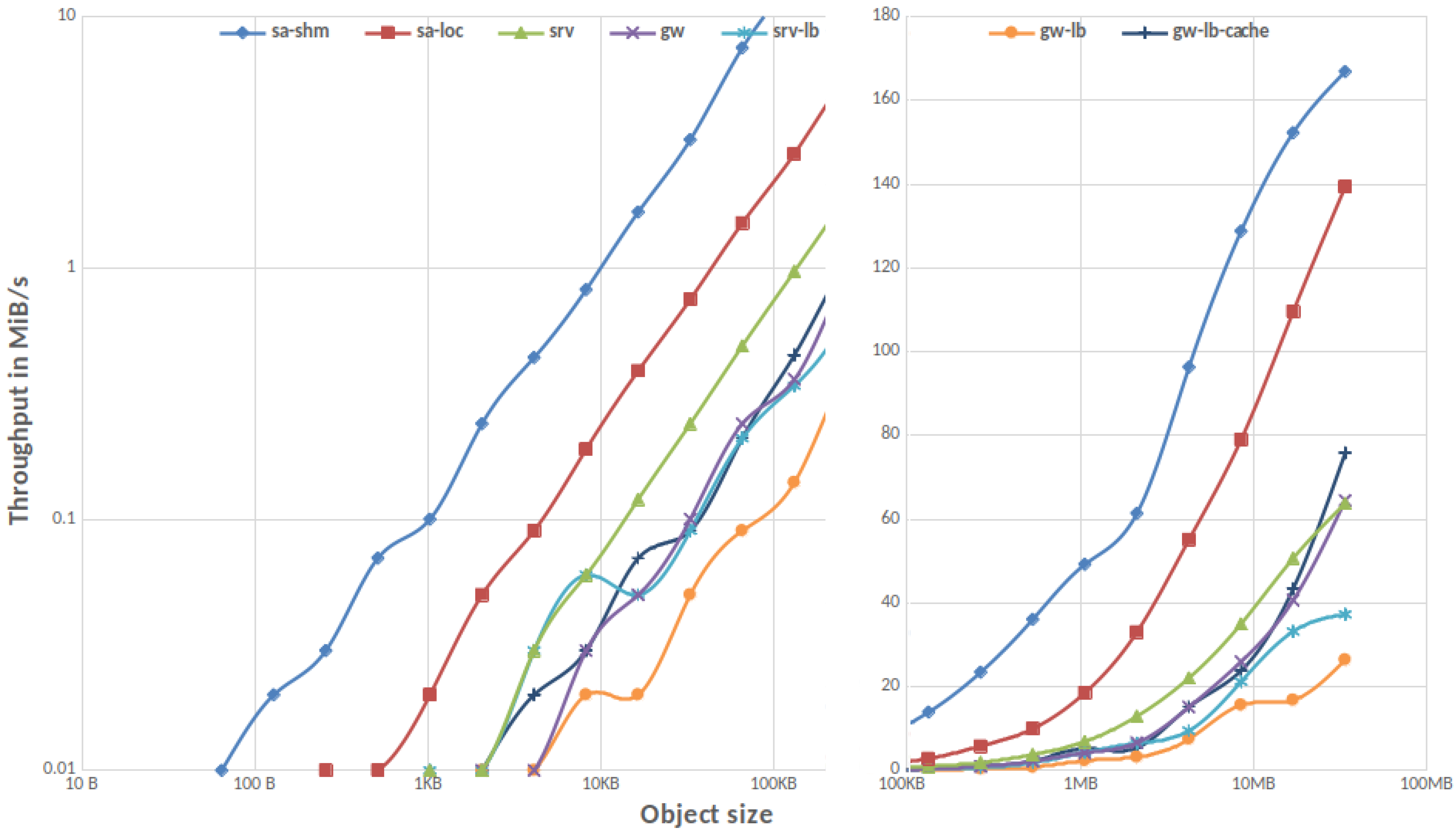
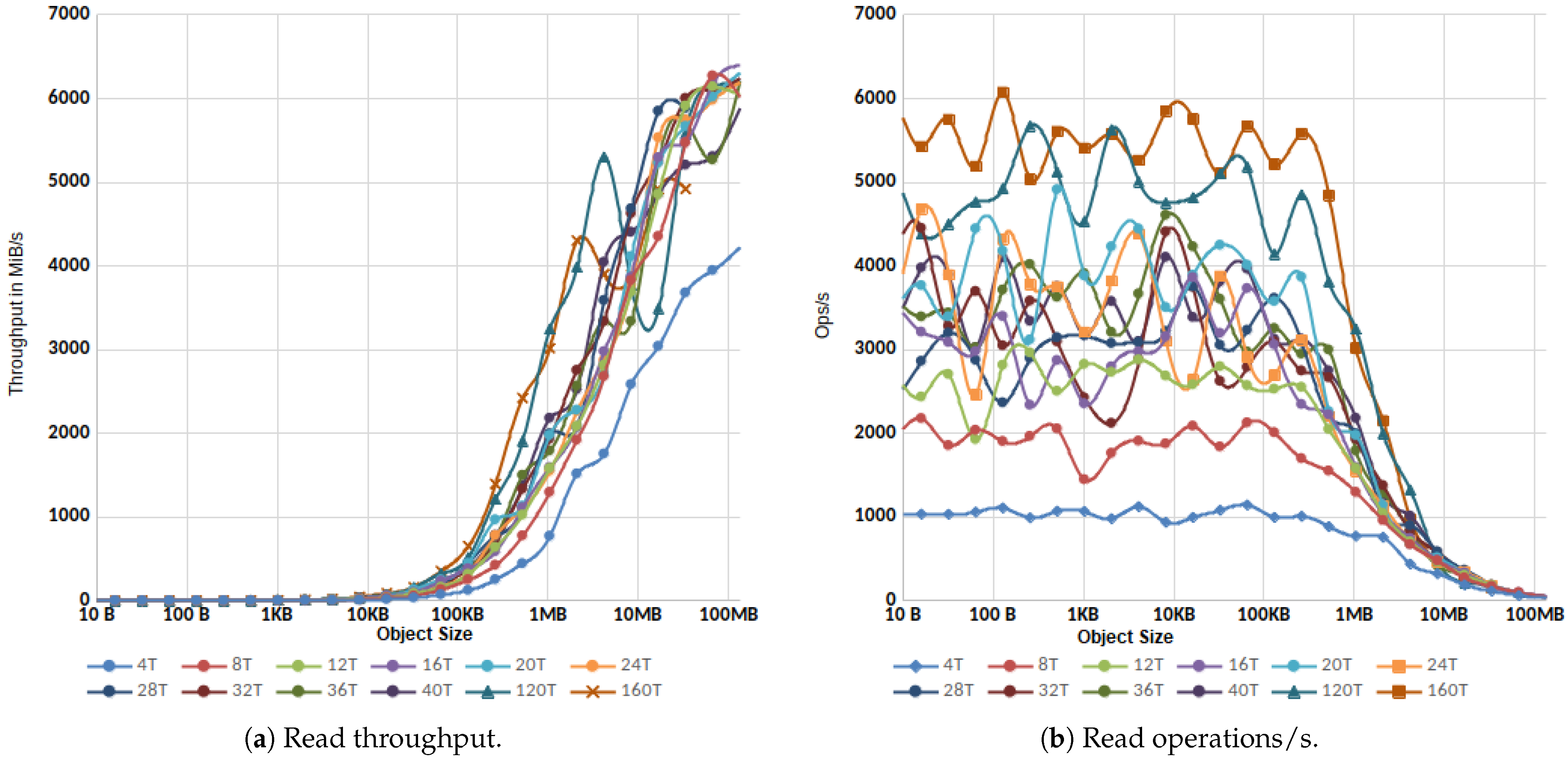
3.1.1. Single Client
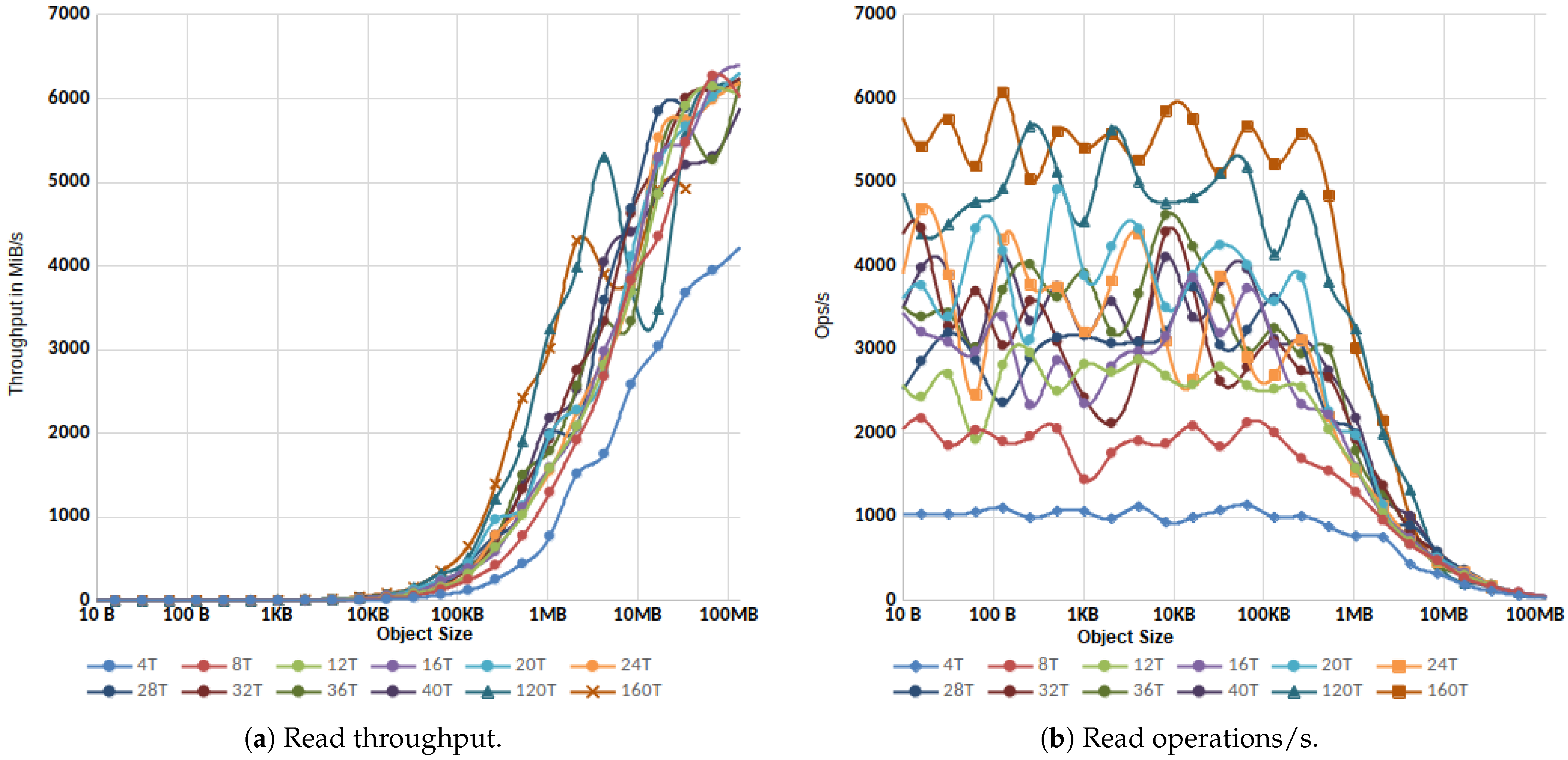
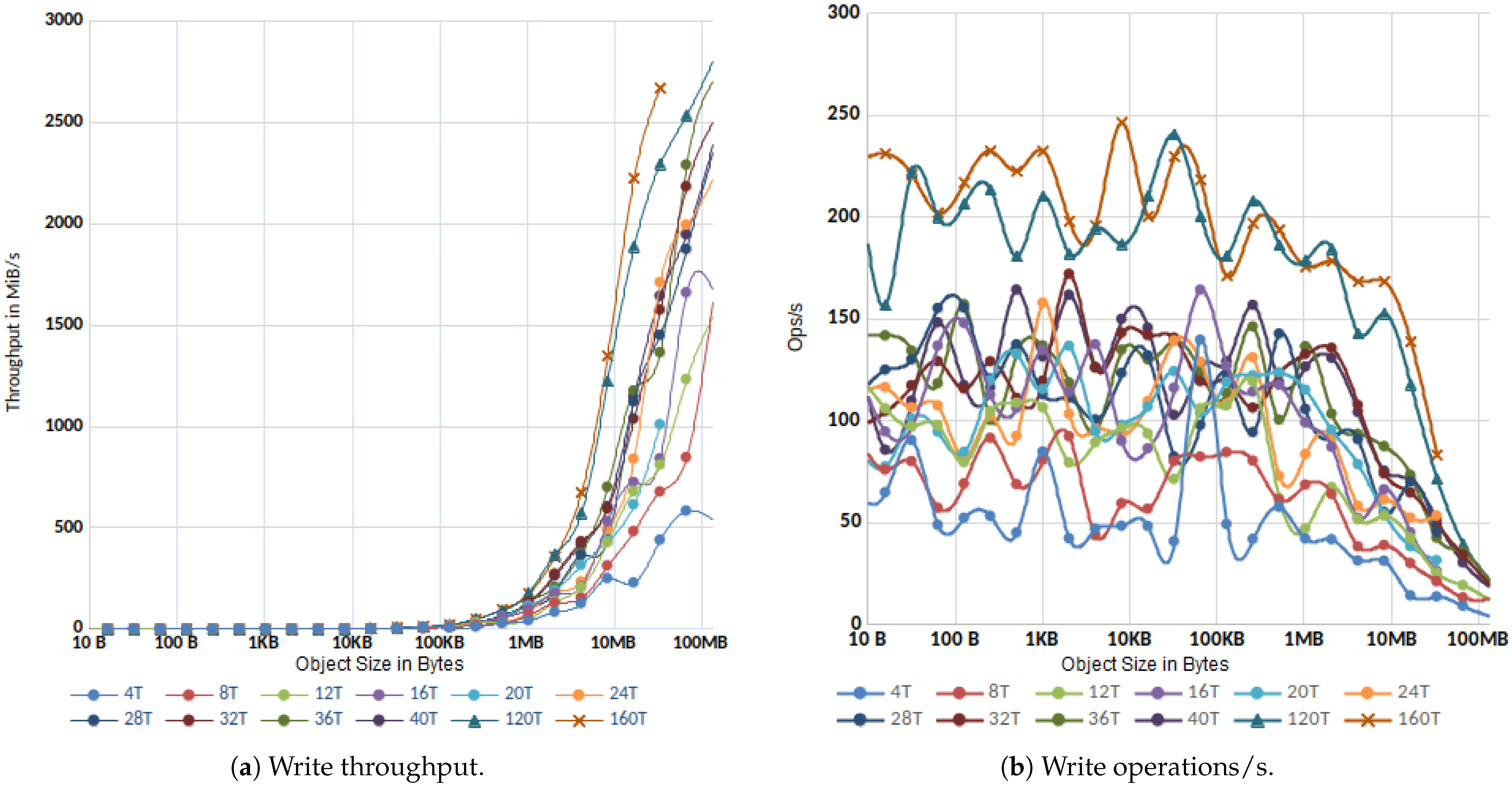
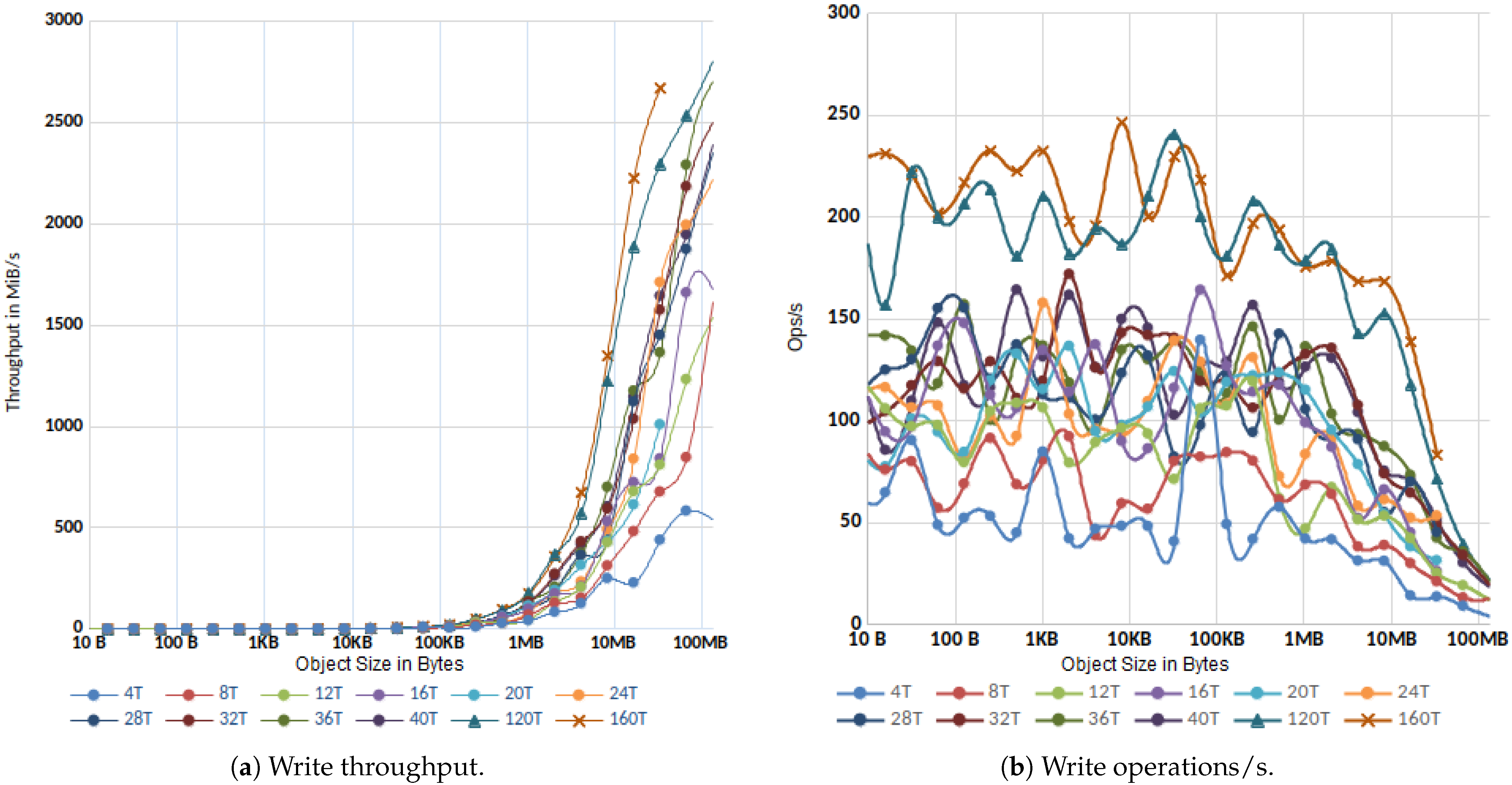
3.1.2. Parallel IO
3.1.3. MinIO Overhead in Gateway Mode
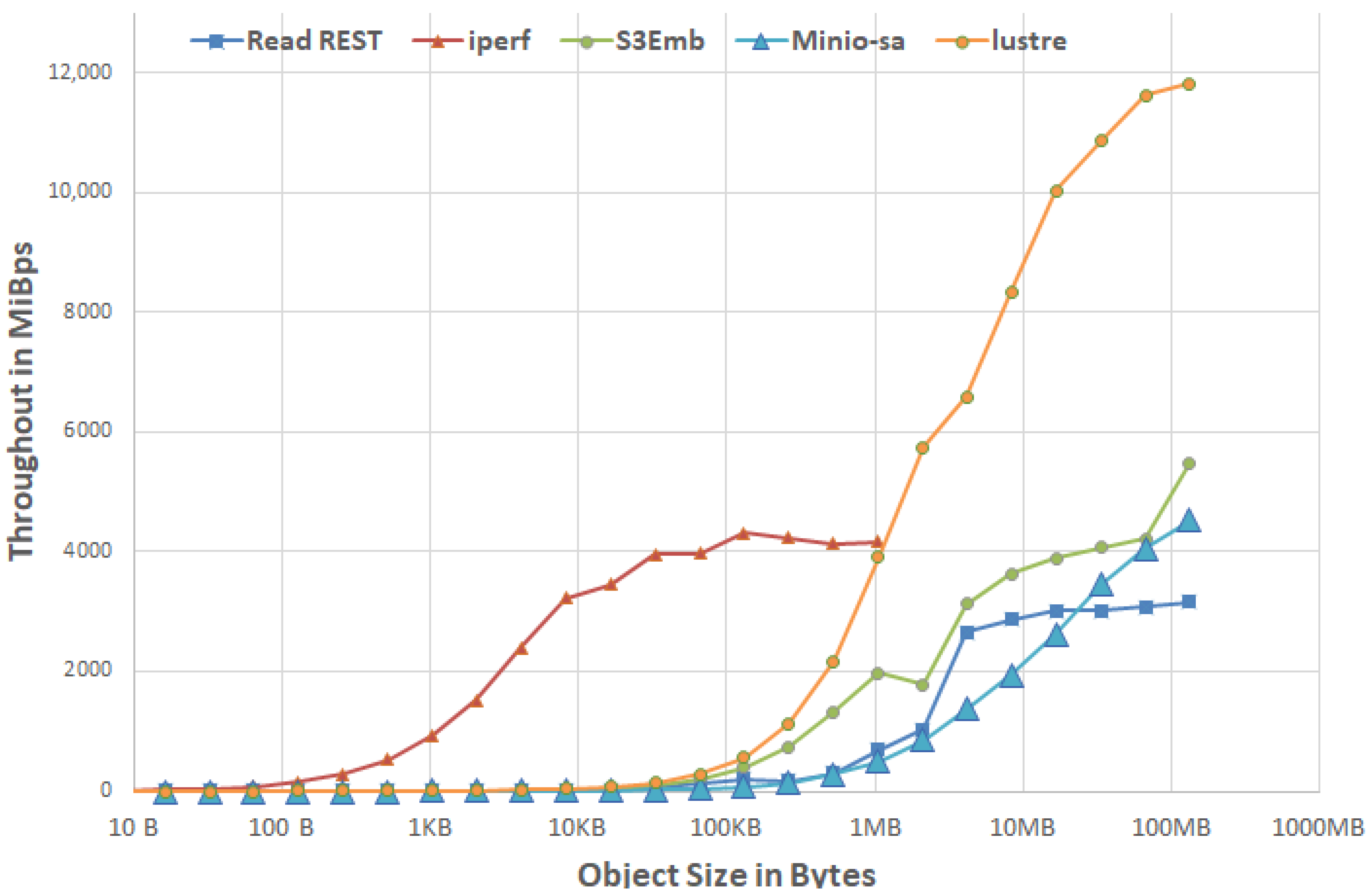
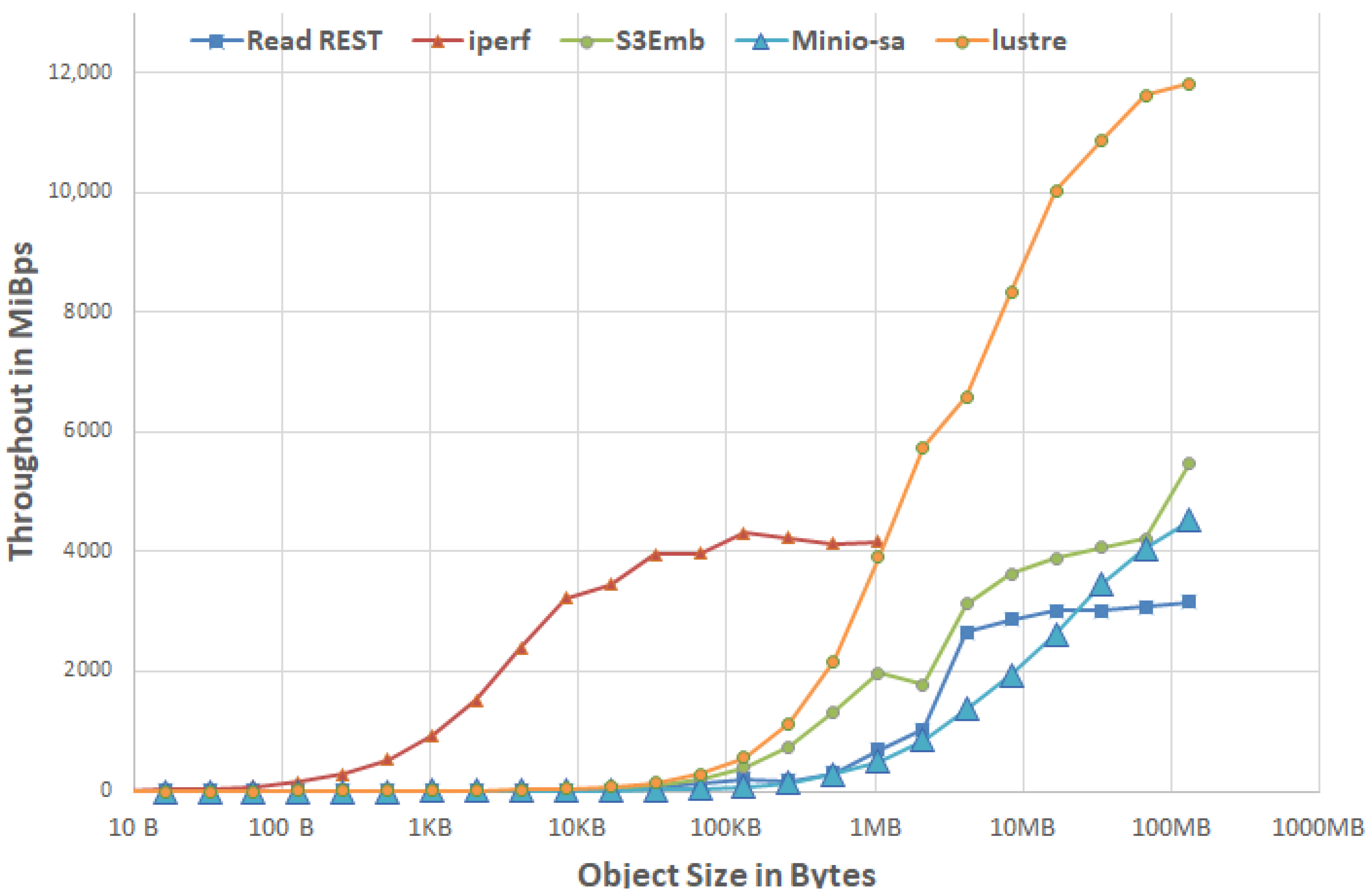
3.1.4. MinIO vs. REST vs. TCP/IP
- The IOR results of the direct lustre access using 1N-4PPN.
- The TCP/IP throughput measured using iperf.
- For reference, the S3Embedded results for a similar setup (1N-4PPN), which we will describe in more detail later in Section 4.
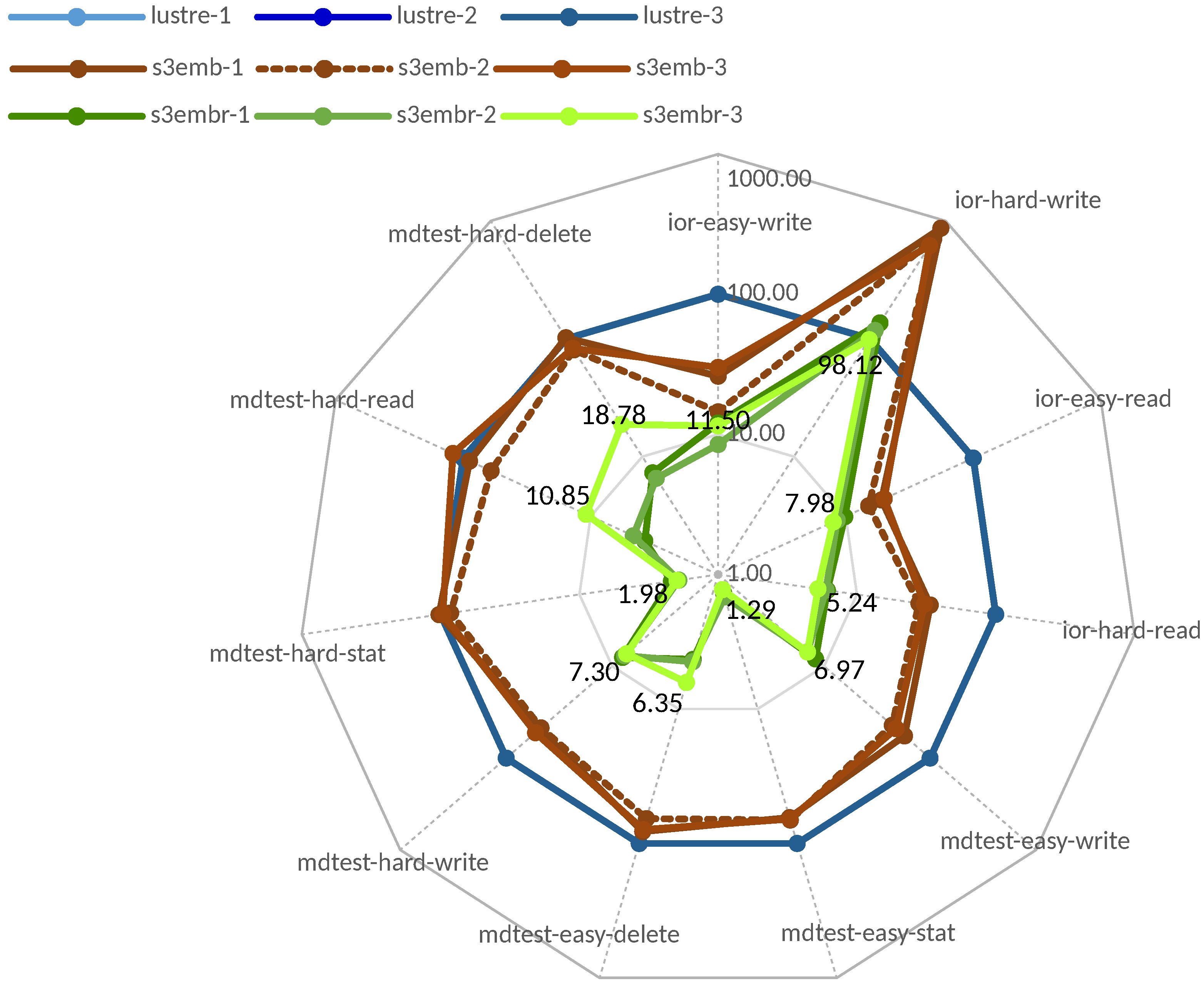
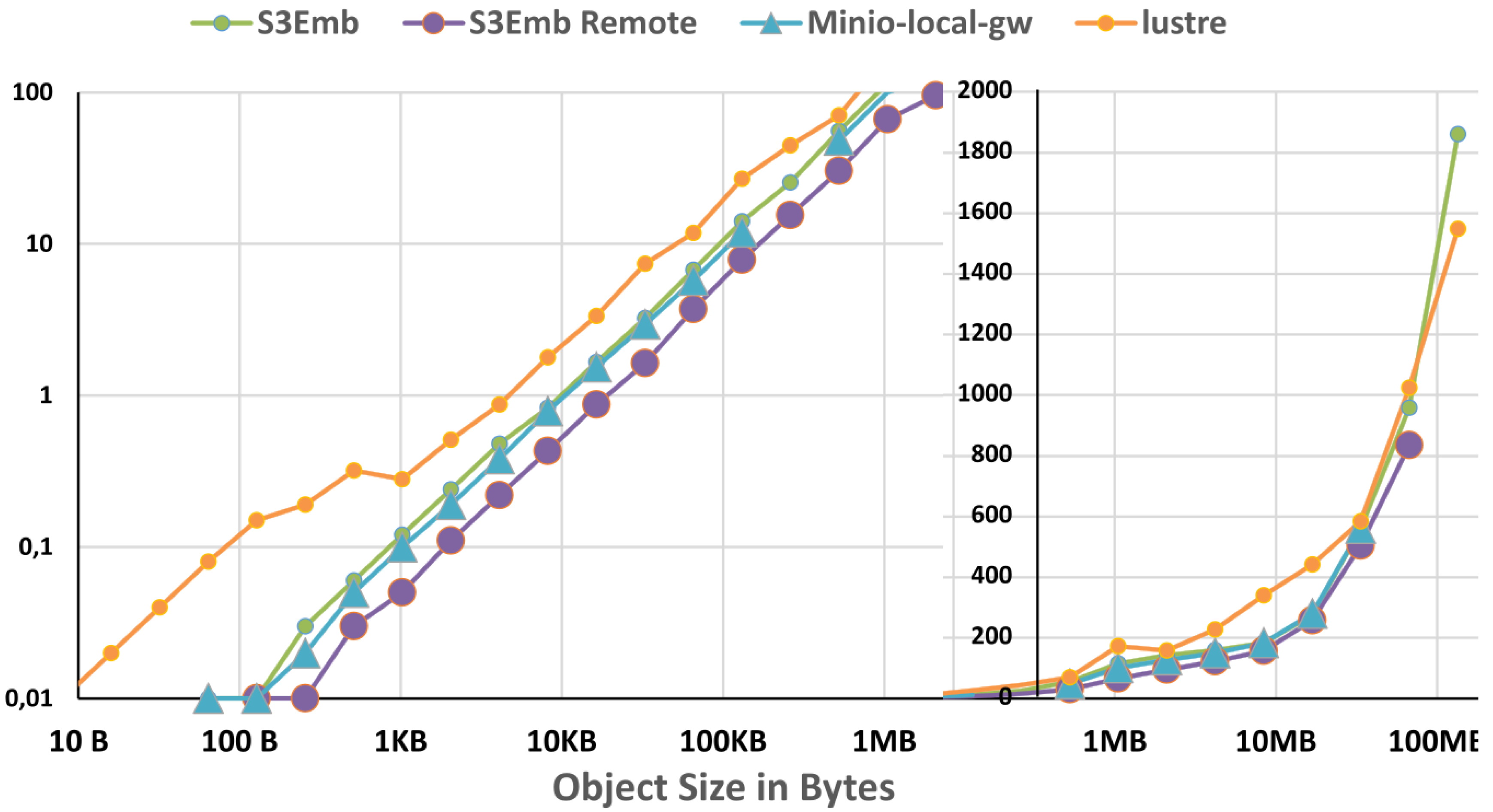
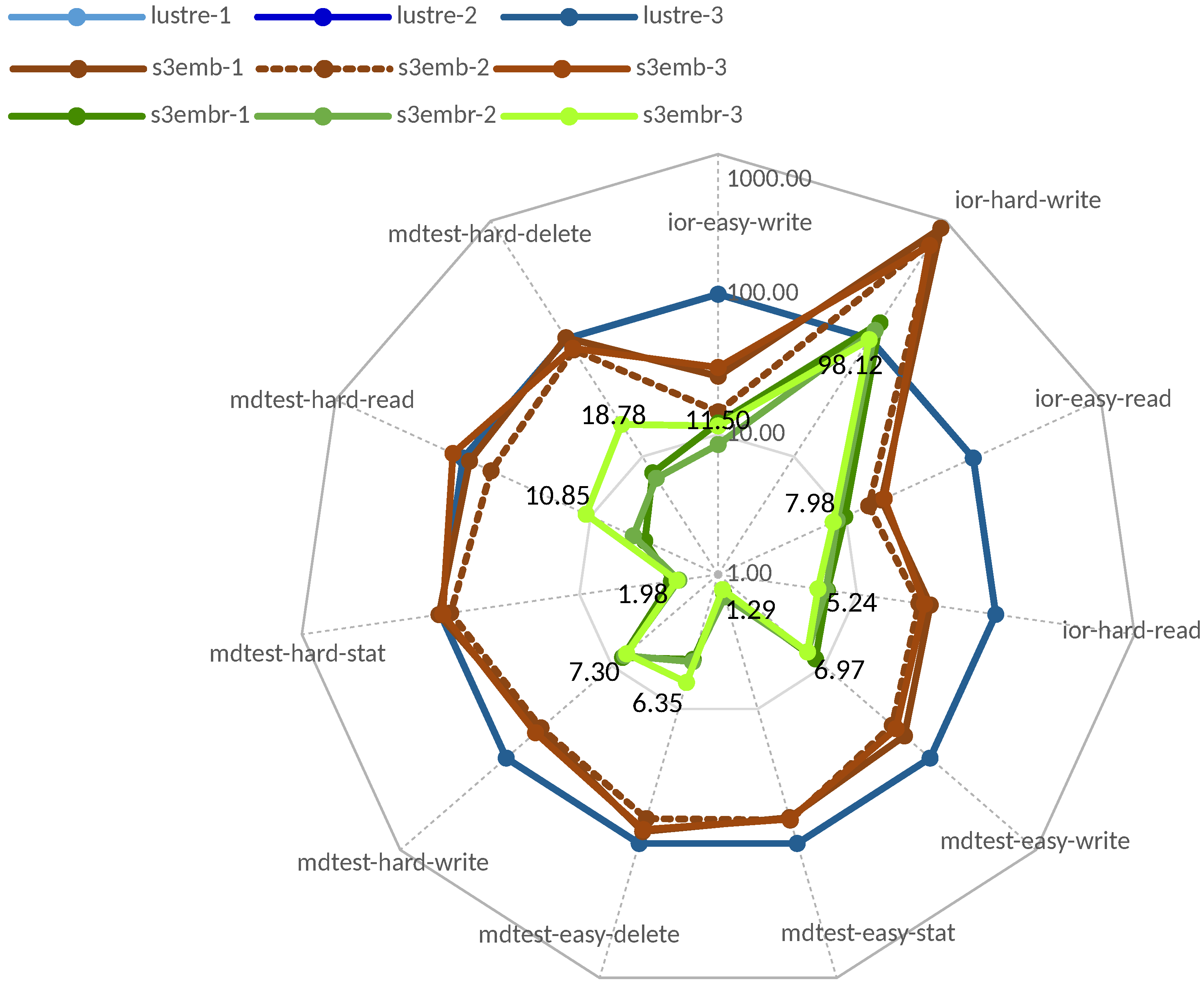
3.2. Tests against S3 Compatible Systems
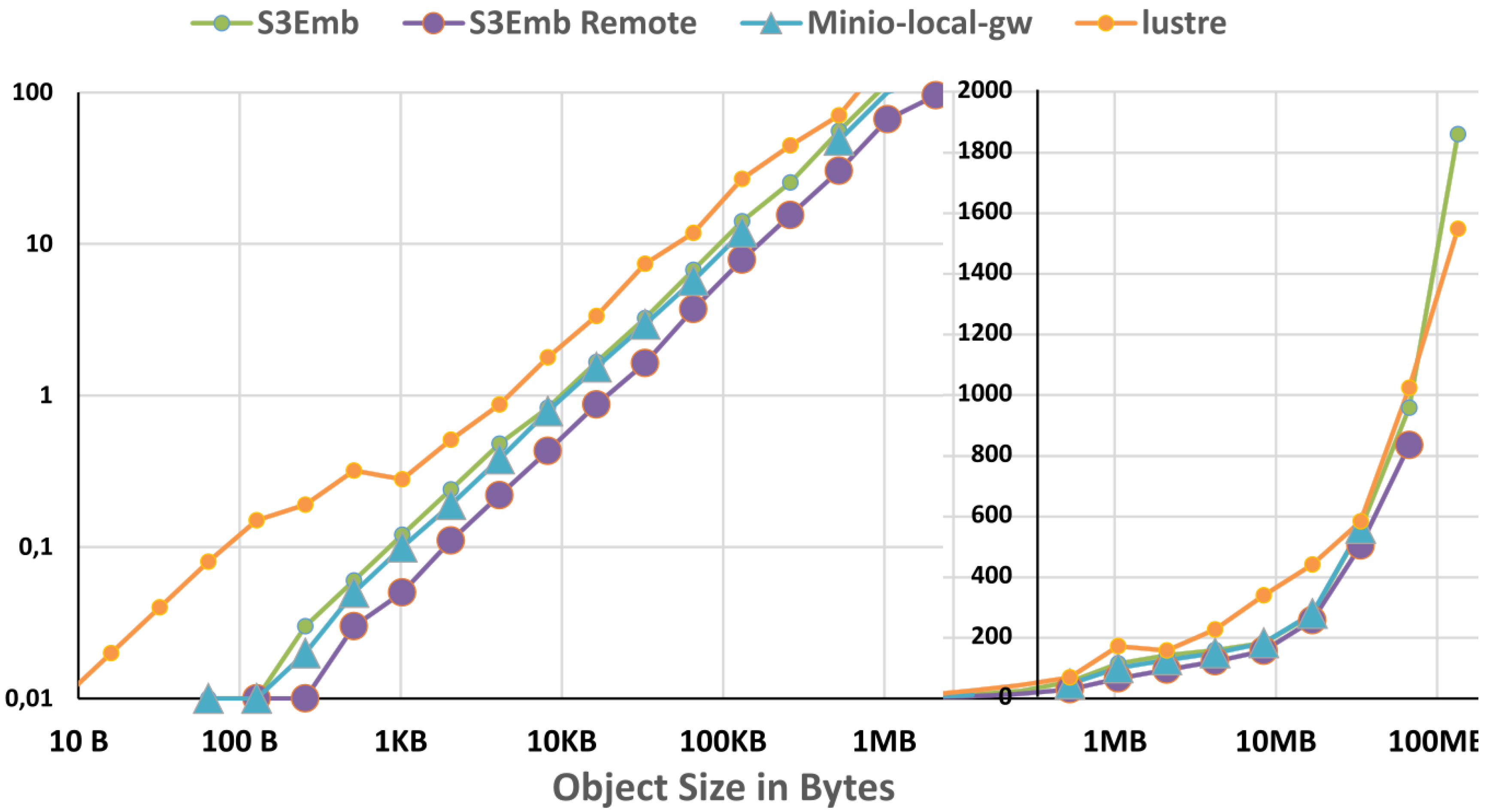
3.2.1. In-House Tests
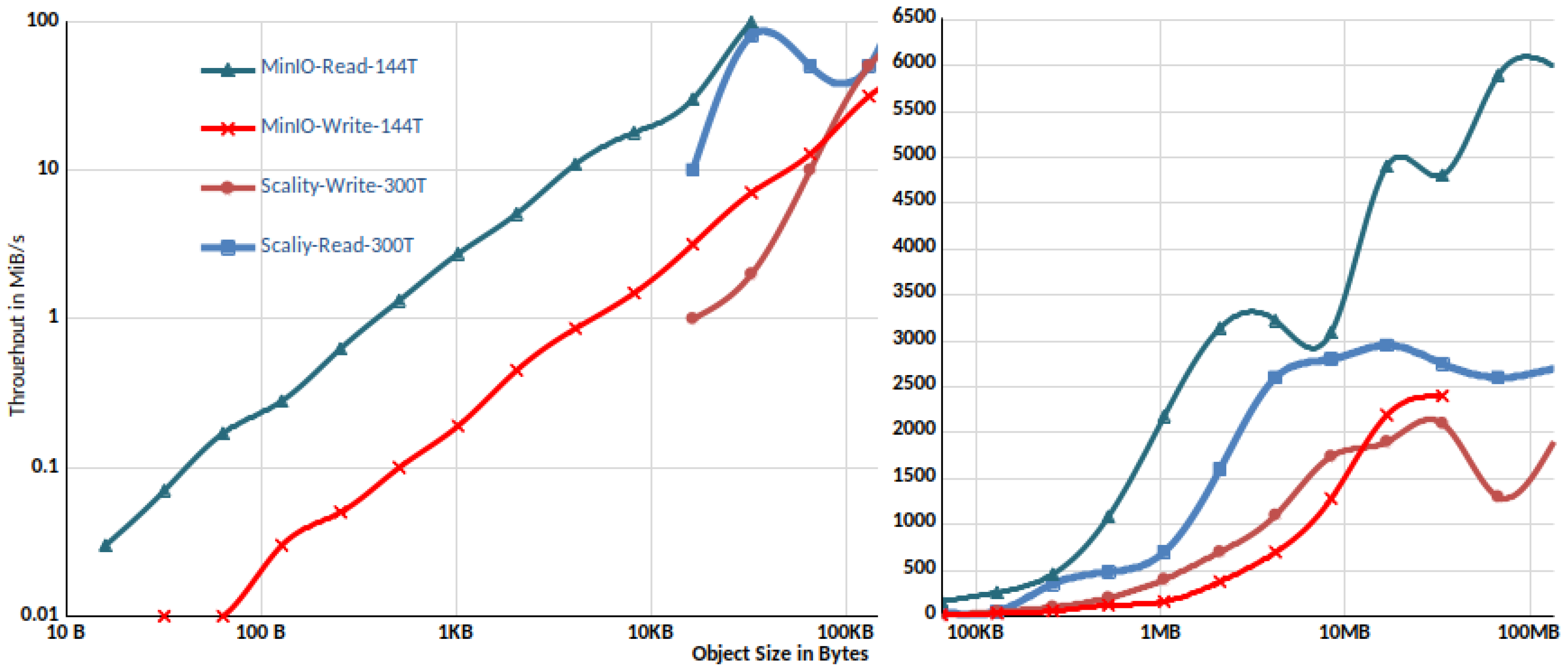
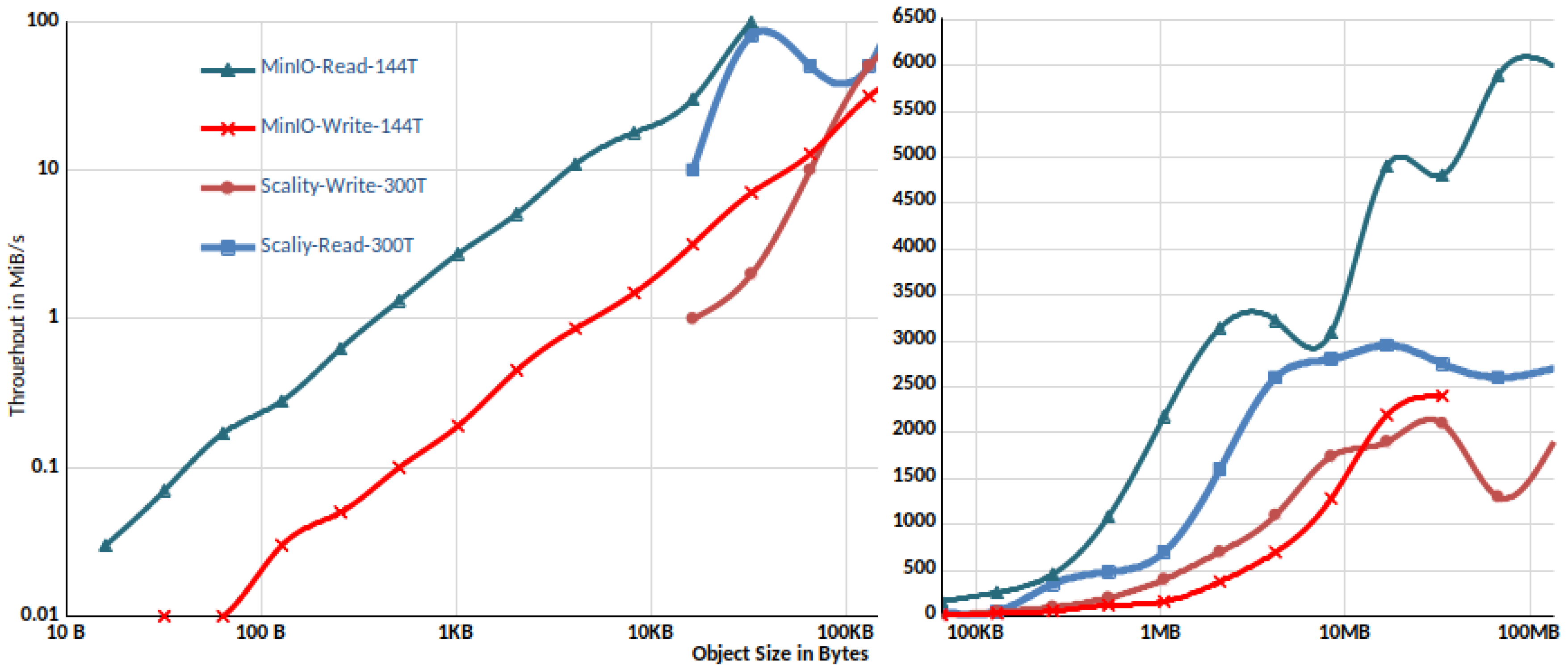
3.2.2. Comparison with Scality Ring
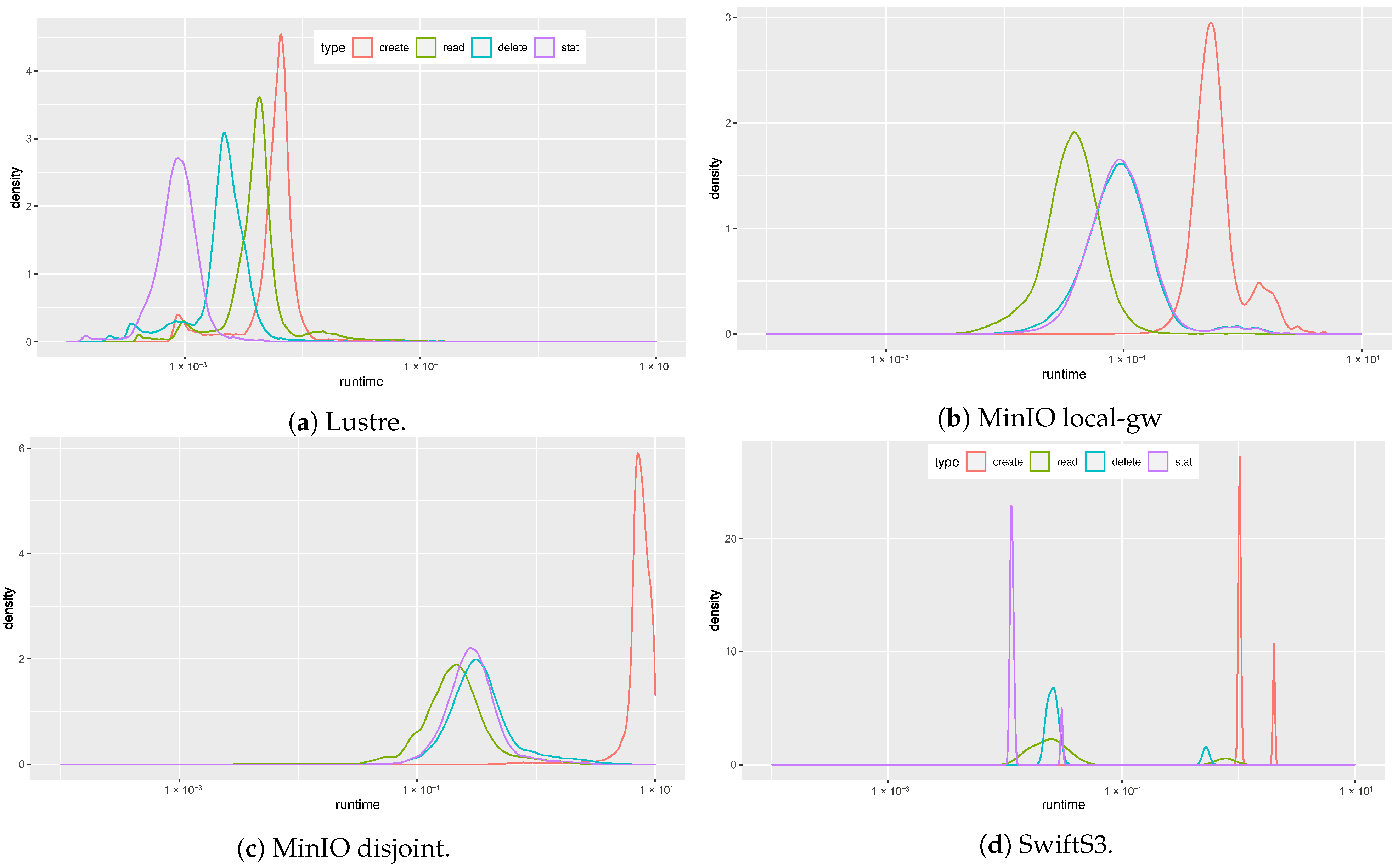
3.2.3. Latency Analysis
3.2.4. Tests against Cloud Systems
4. S3Embedded
- libS3e.so: This is an embedded library wrapper that converts libs3 calls to POSIX calls inside the application address space.
- libS3r.so: This library converts the libs3 calls via a binary conversion to TCP calls to a local libS3-gw application that then executes these POSIX calls, bypassing the HTTP protocol.
5. Conclusions
Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- AWS. AWS S3. Available online: https://aws.amazon.com/de/s3/ (accessed on 19 July 2019).
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.; Maltzahn, C. Ceph: A scalable, high-performance distributed file system. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation, Seattle, WA, USA, 6–8 November 2006; pp. 307–320. [Google Scholar]
- Foundation, O. OpenStack Swift. Available online: https://github.com/openstack/swift (accessed on 19 September 2020).
- MinIO, I. Kubernetes Native, High Performance Object Storage. Available online: https://min.io (accessed on 19 September 2020).
- Rew, R.; Davis, G. NetCDF: An interface for scientific data access. IEEE Comput. Graph. Appl. 1990, 10, 76–82. [Google Scholar] [CrossRef]
- Lofstead, J.F.; Klasky, S.; Schwan, K.; Podhorszki, N.; Jin, C. Flexible IO and integration for scientific codes through the adaptable IO system (ADIOS). In Proceedings of the 6th International Workshop on Challenges of Large Applications in Distributed Environments, Boston, MA, USA, 23 June 2008; pp. 15–24. [Google Scholar]
- Lofstead, J.; Jimenez, I.; Maltzahn, C.; Koziol, Q.; Bent, J.; Barton, E. DAOS and friends: A proposal for an exascale storage system. In Proceedings of the SC’16 International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 13–18 November 2016; pp. 585–596. [Google Scholar]
- Jamal, A.; Fleiner, R.; Kail, E. Performance Comparison between S3, HDFS and RDS storage technologies for real-time big-data applications. In Proceedings of the 2021 IEEE 15th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 19–21 May 2021; pp. 000491–000496. [Google Scholar]
- Milojicic, D.; Faraboschi, P.; Dube, N.; Roweth, D. Future of HPC: Diversifying Heterogeneity. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 276–281. [Google Scholar]
- S3EmbeddedLib. Available online: https://github.com/JulianKunkel/S3EmbeddedLib (accessed on 9 December 2020).
- bji. libs3. Available online: https://github.com/bji/libs3 (accessed on 19 August 2020).
- Kunkel, J.; Lofstead, G.F.; Bent, J. The Virtual Institute for I/O and the IO-500; Technical Report; Sandia National Lab. (SNL-NM): Albuquerque, NM, USA, 2017.
- Kunkel, J.M.; Markomanolis, G.S. Understanding metadata latency with MDWorkbench. In Proceedings of the International Conference on High Performance Computing, Frankfurt, Germany, 24–28 June 2018; pp. 75–88. [Google Scholar]
- DKRZ. Mistral. Available online: https://www.dkrz.de/up/systems/mistral/configuration (accessed on 19 July 2020).
- Garfinkel, S. An Evaluation of Amazon’s Grid Computing Services: EC2, S3, and SQS; Technical Report TR-08-07; Harvard Computer Science Group: Cambridge, MA, USA, 2007; Available online: http://nrs.harvard.edu/urn-3:HUL.InstRepos:24829568 (accessed on 19 July 2021).
- Palankar, M.R.; Iamnitchi, A.; Ripeanu, M.; Garfinkel, S. Amazon S3 for science grids: A viable solution? In Proceedings of the 2008 International Workshop on Data-Aware Distributed Computing, Boston, MA, USA, 24 June 2008; pp. 55–64. [Google Scholar]
- Bessani, A.; Correia, M.; Quaresma, B.; André, F.; Sousa, P. DepSky: Dependable and secure storage in a cloud-of-clouds. ACM Trans. Storage (Tos) 2013, 9, 1–33. [Google Scholar] [CrossRef]
- Arsuaga-Ríos, M.; Heikkilä, S.S.; Duellmann, D.; Meusel, R.; Blomer, J.; Couturier, B. Using S3 cloud storage with ROOT and CvmFS. J. Phys. Conf. Ser. Iop Publ. 2015, 664, 022001. [Google Scholar] [CrossRef] [Green Version]
- Sadooghi, I.; Martin, J.H.; Li, T.; Brandstatter, K.; Maheshwari, K.; de Lacerda Ruivo, T.P.P.; Garzoglio, G.; Timm, S.; Zhao, Y.; Raicu, I. Understanding the performance and potential of cloud computing for scientific applications. IEEE Trans. Cloud Comput. 2015, 5, 358–371. [Google Scholar] [CrossRef]
- Google. PerfKit Benchmarker. Available online: https://github.com/GoogleCloudPlatform/PerfKitBenchmarker (accessed on 19 July 2020).
- Bjornson, Z. Cloud Storage Performance. Available online: https://blog.zachbjornson.com/2015/12/29/cloud-storage-performance.html (accessed on 19 July 2020).
- Liu, Z.; Kettimuthu, R.; Chung, J.; Ananthakrishnan, R.; Link, M.; Foster, I. Design and Evaluation of a Simple Data Interface for Efficient Data Transfer across Diverse Storage. ACM Trans. Model. Perform. Eval. Comput. Syst. (TOMPECS) 2021, 6, 1–25. [Google Scholar] [CrossRef]
- Gadban, F.; Kunkel, J.; Ludwig, T. Investigating the Overhead of the REST Protocol When Using Cloud Services for HPC Storage. In Proceedings of the International Conference on High Performance Computing, Frankfurt am Main, Germany, 22–25 June 2020; pp. 161–176. [Google Scholar]
- Korolev, V. AWS4C—A C Lbrary to Interface with Amazon Web Services. Available online: https://github.com/vladistan/aws4c (accessed on 19 August 2020).
- Welch, B.; Noer, G. Optimizing a hybrid SSD/HDD HPC storage system based on file size distributions. In Proceedings of the 2013 IEEE 29th Symposium on Mass Storage Systems and Technologies (MSST), Long Beach, CA, USA, 6–10 May 2013; pp. 1–12. [Google Scholar]
- bji. libs3 Removes Support for Signature V2. Available online: https://github.com/bji/libs3/pull/50 (accessed on 19 August 2020).
- Braam, P. The Lustre storage architecture. arXiv 2019, arXiv:1903.01955. [Google Scholar]
- Sysoev, I. Nginx. Available online: https://nginx.org (accessed on 19 July 2020).
- LLNL. IOR Parallel I/O Benchmarks. Available online: https://github.com/hpc/ior (accessed on 19 September 2020).
- AWS. Multipart Upload Overview. Available online: https://docs.aws.amazon.com/AmazonS3/latest/dev/mpuoverview.html (accessed on 19 July 2020).
- Walsdorf, O. Cisco UCS C240 M5 with Scality Ring. Available online: https://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/UCS_CVDs/ucs_c240_m5_scalityring.html#_Toc15279751 (accessed on 19 September 2020).
- Zheng, Q.; Chen, H.; Wang, Y.; Duan, J.; Huang, Z. Cosbench: A benchmark tool for cloud object storage services. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 998–999. [Google Scholar]
- AWS. Performance Design Patterns for Amazon S3. Available online: https://docs.aws.amazon.com/AmazonS3/latest/dev/optimizing-performance-design-patterns.html (accessed on 19 September 2020).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lustre | MinIO | Local-Gw | ||||
|---|---|---|---|---|---|---|
| Benchmark | Metric | Unit | Disjoint-Gw | Local-Gw | % of Lustre | |
| md-workbench | rate | IOPS | 18337 | 37 | 425 | 2.3% |
| throughput | MiBps | 34.100 | 0.100 | 0.800 | 2.3% | |
| IO500 | ior-easy-write | GiB/s | 18.671 | 0.153 | 0.286 | 1.5% |
| mdtest-easy-write | kIOPS | 5.892 | 0.088 | 0.132 | 2.2% | |
| ior-hard-write | GiB/s | 0.014 | 0.003 | 0.006 | 45.7% | |
| mdtest-hard-write | kIOPS | 5.071 | 0.036 | 0.076 | 1.5% | |
| ior-easy-read | GiB/s | 11.475 | 0.693 | 2.071 | 18.1% | |
| mdtest-easy-stat | kIOPS | 24.954 | 1.198 | 4.092 | 16.4% | |
| ior-hard-read | GiB/s | 0.452 | 0.029 | 0.094 | 20.7% | |
| mdtest-hard-stat | kIOPS | 18.296 | 1.281 | 3.968 | 21.7% | |
| mdtest-easy-delete | kIOPS | 9.316 | 0.025 | 0.023 | 0.3% | |
| mdtest-hard-read | kIOPS | 6.950 | 0.449 | 1.636 | 23.5% | |
| mdtest-hard-delete | kIOPS | 4.863 | 0.029 | 0.025 | 0.5% | |
| Benchmark/System | Unit | Wasabi | IBM | MinIO-Local-Gw | |
|---|---|---|---|---|---|
| Score Bandwidth | MiB/s | 0.007 | 1.642 | 0.46 | 12.62 |
| ior-easy-write | MiB/s | 2.35 | 35.00 | 13.35 | 46.39 |
| mdtest-easy-write | IOPS | 13.04 | 81.72 | 21.79 | 27.96 |
| ior-rnd-write | MiB/s | 0.01 | 0.23 | 0.07 | 1.231 |
| mdworkbench-bench | IOPS | 5.75 | 47.23 | 12.83 | 15.25 |
| ior-easy-read | MiB/s | 1.20 | 45.37 | 7.81 | 73.86 |
| mdtest-easy-stat | IOPS | 20.92 | 145.09 | 51.10 | 260.97 |
| ior-hard-read | MiB/s | 0.05 | 5.59 | 1.38 | 6.01 |
| mdtest-hard-stat | IOPS | 20.74 | 149.64 | 49.48 | 297.62 |
| mdtest-easy-delete | IOPS | 10.35 | 35.02 | 9.37 | 81.06 |
| mdtest-hard-read | IOPS | 8.54 | 70.06 | 18.90 | 130.36 |
| mdtest-hard-delete | IOPS | 10.28 | 35.25 | 9.48 | 94.32 |
| System | Unit | MinIO-Local-Gw | Lustre | S3Embedded | S3Remote |
|---|---|---|---|---|---|
| ior-easy-write | GiB/s | 0.14 | 5.47 | 0.61 | 0.69 |
| mdtest-easy-write | kIOPS | 0.09 | 7.97 | 2.42 | 3.13 |
| ior-easy-read | GiB/s | 0.32 | 2.78 | 0.48 | 0.42 |
| mdtest-easy-stat | kIOPS | 0.85 | 13.82 | 8.02 | 6.94 |
| ior-hard-read | GiB/s | 0.019 | 0.139 | 0.046 | 0.042 |
| mdtest-hard-stat | kIOPS | 0.86 | 5.10 | 7.25 | 6.65 |
| Benchmark/System | Unit | MinIO-Local-Gw | Lustre | S3Embedded | S3Remote |
|---|---|---|---|---|---|
| ior-easy-write | GiB/s | 0.75 | 23.49 | 3.40 | 1.99 |
| mdtest-easy-write | kIOPS | 0.39 | 17.11 | 7.52 | 1.19 |
| ior-hard-write | GiB/s | 0.01 | 0.04 | 0.30 | 0.05 |
| mdtest-hard-write | kIOPS | 0.10 | 7.25 | 3.41 | 0.55 |
| ior-easy-read | GiB/s | 2.46 | 15.87 | 2.40 | 1.36 |
| mdtest-easy-stat | kIOPS | 5.09 | 42.59 | 28.53 | 0.62 |
| ior-hard-read | GiB/s | 0.11 | 0.38 | 0.11 | 0.02 |
| mdtest-hard-stat | kIOPS | 4.37 | 31.49 | 26.66 | 0.60 |
| mdtest-easy-delete | kIOPS | - | 9.15 | 5.98 | 0.41 |
| mdtest-hard-read | kIOPS | - | 6.34 | 3.82 | 0.29 |
| mdtest-hard-delete | kIOPS | - | 6.27 | 5.04 | 0.41 |
| Benchmark/System | Unit | Lustre | S3Embedded | S3Remote |
|---|---|---|---|---|
| ior-easy-write | GiB/s | 3.202073 | 0.990504 | 0.827451 |
| mdtest-easy-write | kIOPS | 13.548102 | 11.819631 | 0.240857 |
| ior-hard-write | GiB/s | 0.015462 | 0.215551 | 0.010041 |
| mdtest-hard-write | kIOPS | 5.615789 | 2.226332 | 0.111696 |
| ior-easy-read | GiB/s | 7.483045 | 0.375538 | 0.311502 |
| mdtest-easy-stat | kIOPS | 21.884679 | 20.489986 | 0.123976 |
| ior-hard-read | GiB/s | 0.095884 | 0.022462 | 0.005101 |
| mdtest-hard-stat | kIOPS | 17.428926 | 6.90457 | 0.125178 |
| mdtest-easy-delete | kIOPS | 8.995095 | 7.77739 | 0.10289 |
| mdtest-hard-read | kIOPS | 0.184843 | 1.287055 | 0.249273 |
| mdtest-hard-delete | kIOPS | 8.108844 | 6.711771 | 0.249282 |
| Benchmark/System | Unit | Lustre | S3Embedded | S3Remote |
|---|---|---|---|---|
| ior-easy-write | GiB/s | 16.262279 | 5.363676 | 1.516302 |
| mdtest-easy-write | kIOPS | 18.104786 | 15.952838 | 1.111315 |
| ior-hard-write | GiB/s | 0.030967 | 0.375326 | 0.032984 |
| mdtest-hard-write | kIOPS | 13.705966 | 4.337179 | 0.361589 |
| ior-easy-read | GiB/s | 43.390676 | 2.817122 | 1.309052 |
| mdtest-easy-stat | kIOPS | 46.662299 | 45.878814 | 0.620202 |
| ior-hard-read | GiB/s | 0.218977 | 0.128423 | 0.025549 |
| mdtest-hard-stat | kIOPS | 43.834921 | 44.443974 | 0.62586 |
| mdtest-easy-delete | kIOPS | 9.322632 | 9.262801 | 0.585572 |
| mdtest-hard-read | kIOPS | 4.079555 | 6.673985 | 1.246393 |
| mdtest-hard-delete | kIOPS | 8.457431 | 6.377992 | 1.246105 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gadban, F.; Kunkel, J. Analyzing the Performance of the S3 Object Storage API for HPC Workloads. Appl. Sci. 2021, 11, 8540. https://doi.org/10.3390/app11188540
Gadban F, Kunkel J. Analyzing the Performance of the S3 Object Storage API for HPC Workloads. Applied Sciences. 2021; 11(18):8540. https://doi.org/10.3390/app11188540
Chicago/Turabian StyleGadban, Frank, and Julian Kunkel. 2021. "Analyzing the Performance of the S3 Object Storage API for HPC Workloads" Applied Sciences 11, no. 18: 8540. https://doi.org/10.3390/app11188540
APA StyleGadban, F., & Kunkel, J. (2021). Analyzing the Performance of the S3 Object Storage API for HPC Workloads. Applied Sciences, 11(18), 8540. https://doi.org/10.3390/app11188540