
Multi-Class Strategies for Joint Building Footprint and Road Detection in Remote Sensing



Abstract
:1. Introduction
2. Methods
2.1. Problem Statement
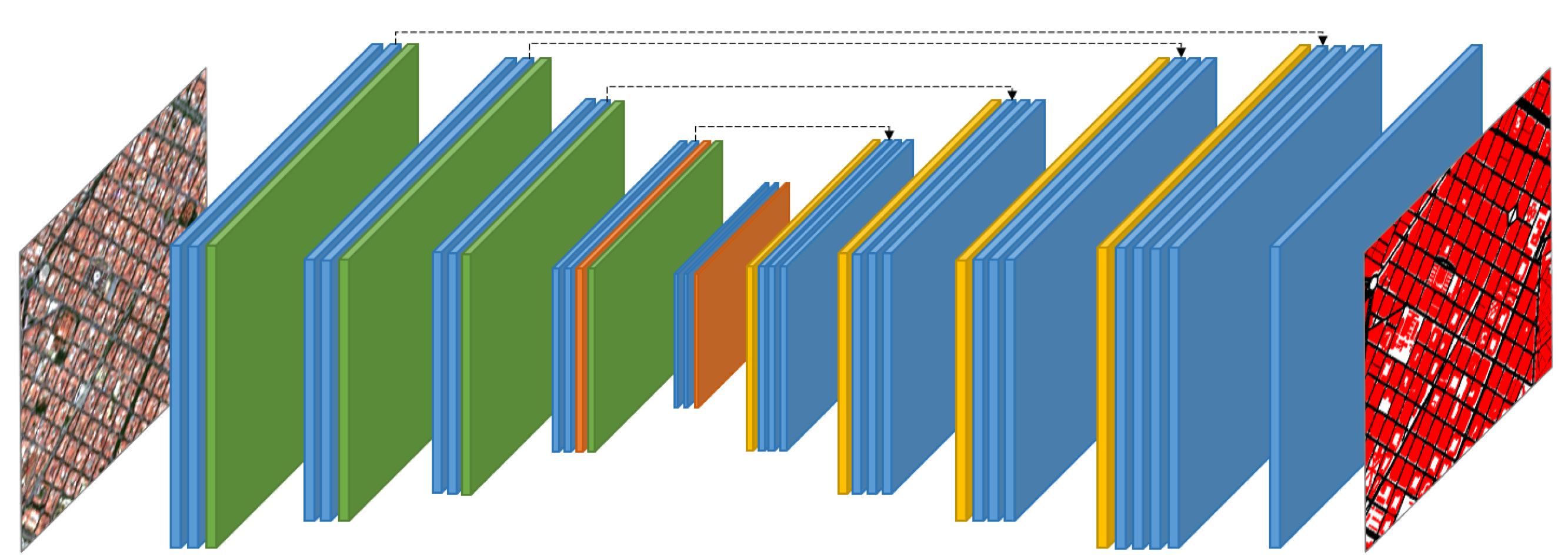
2.2. Direct Multi-Class Approach
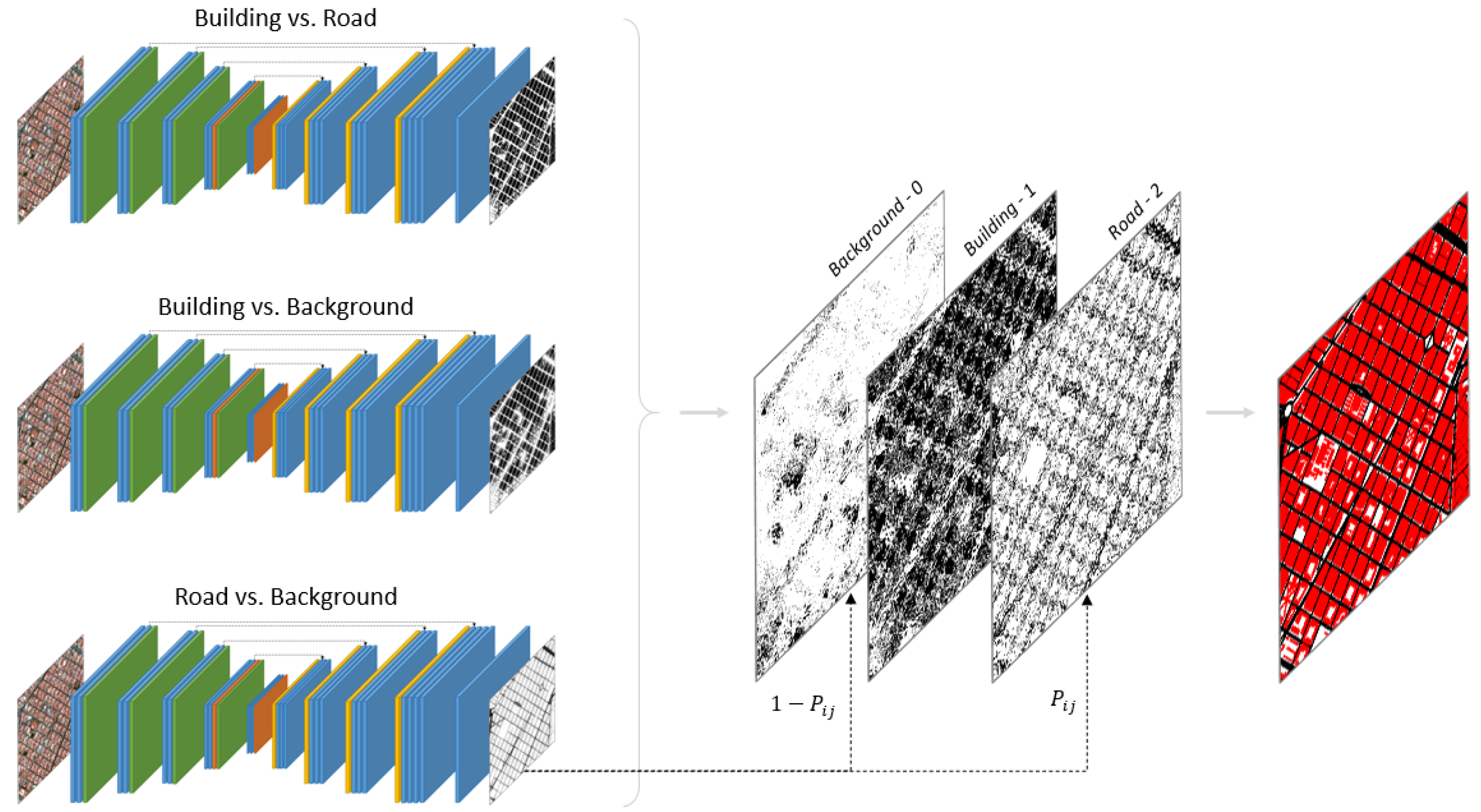
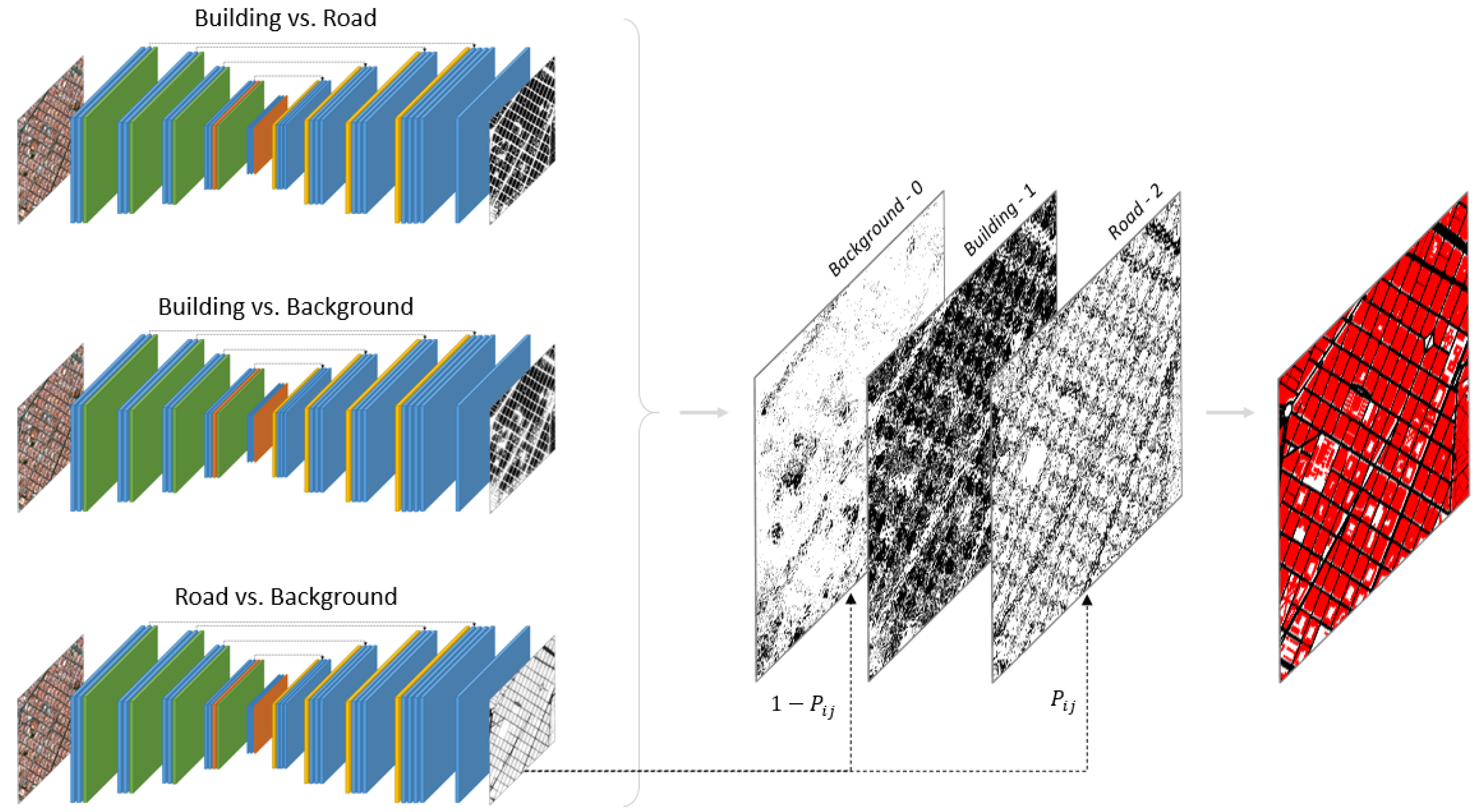
2.3. One-vs.-One Strategy
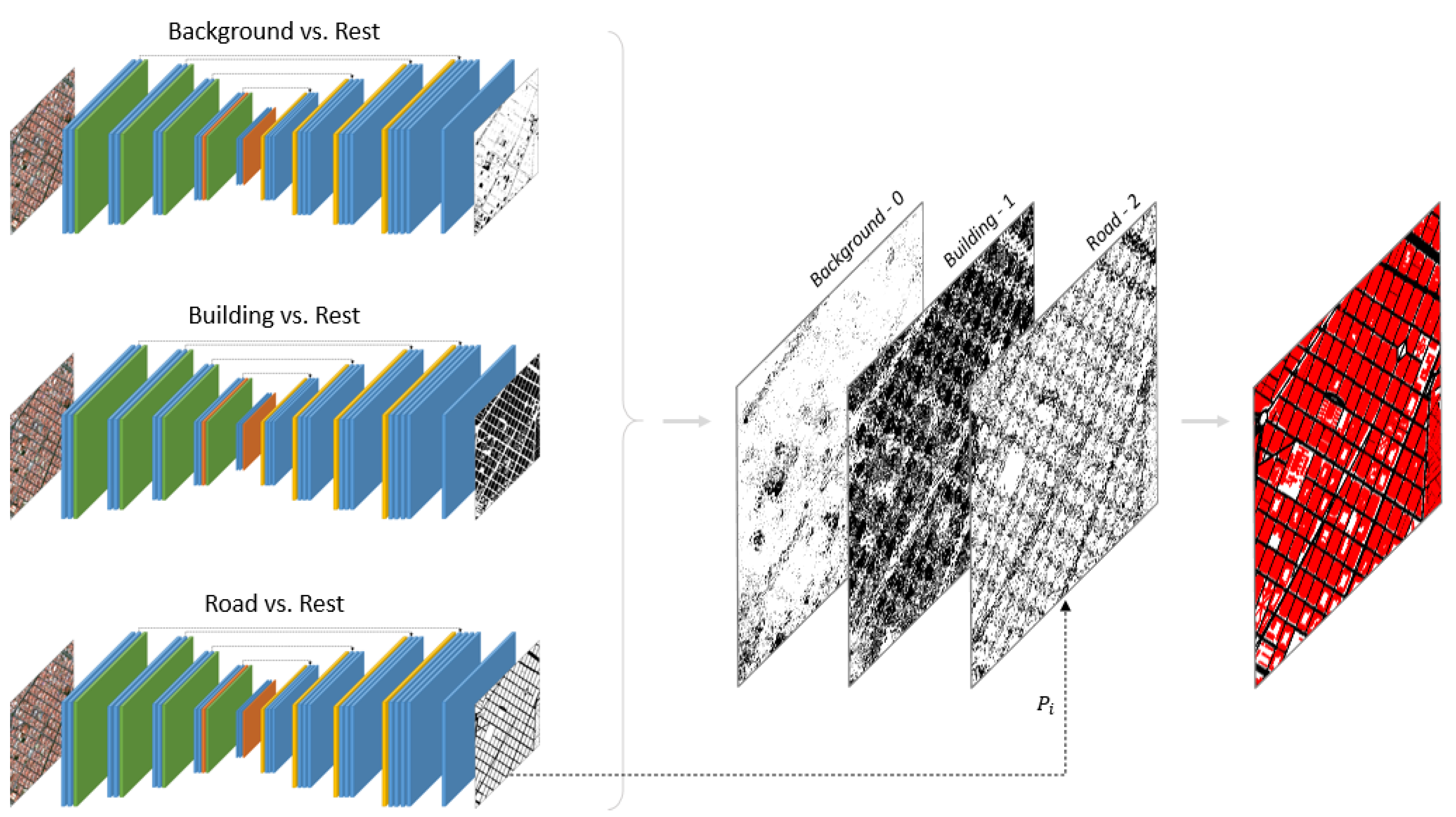
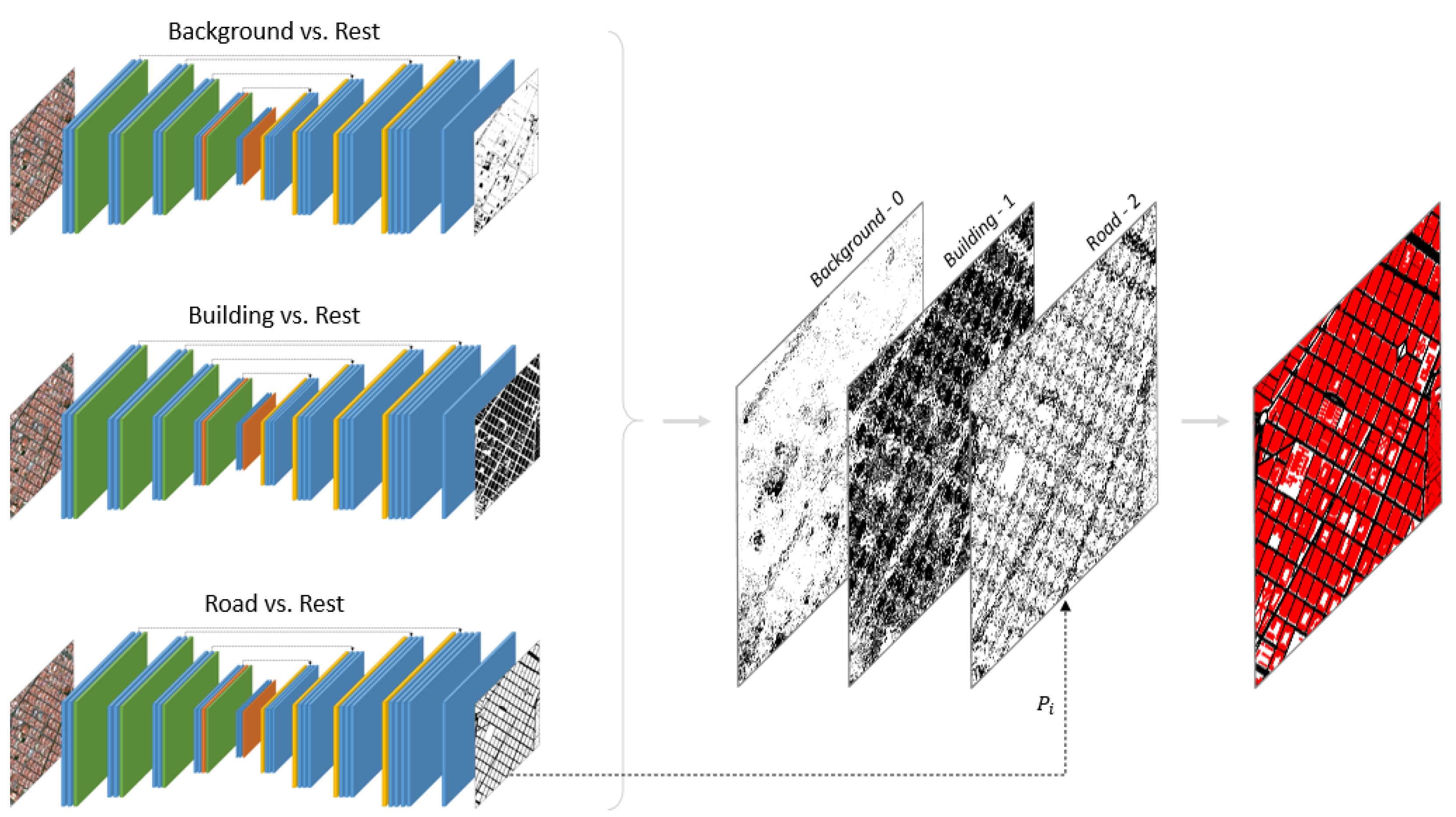
2.4. One-vs.-All Strategy
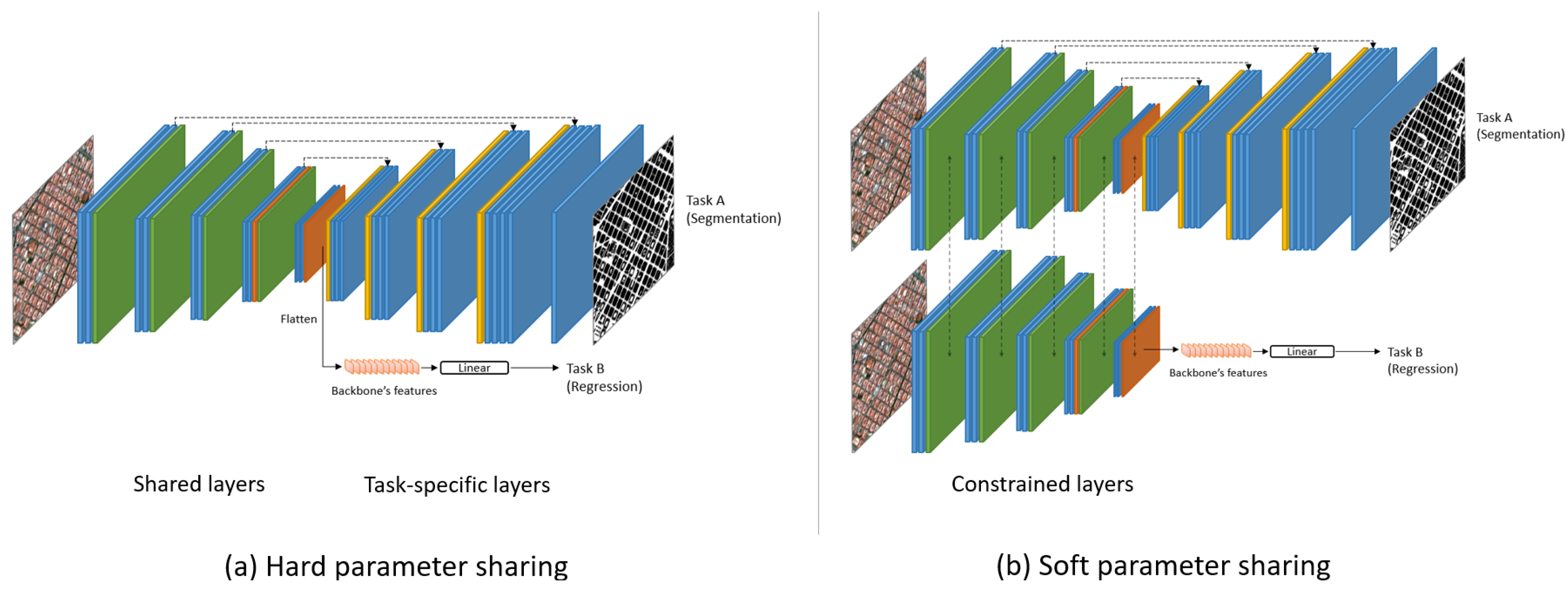
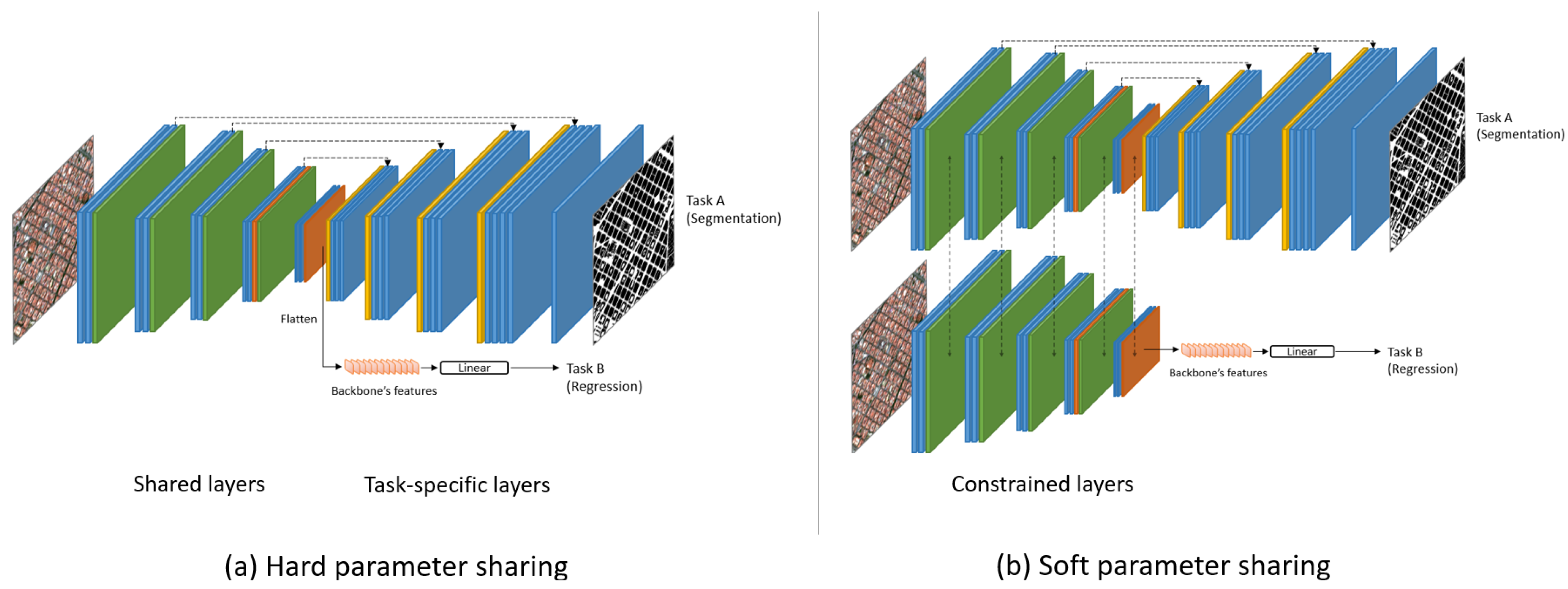
2.5. Multi-Task Strategy
3. Experimental Framework
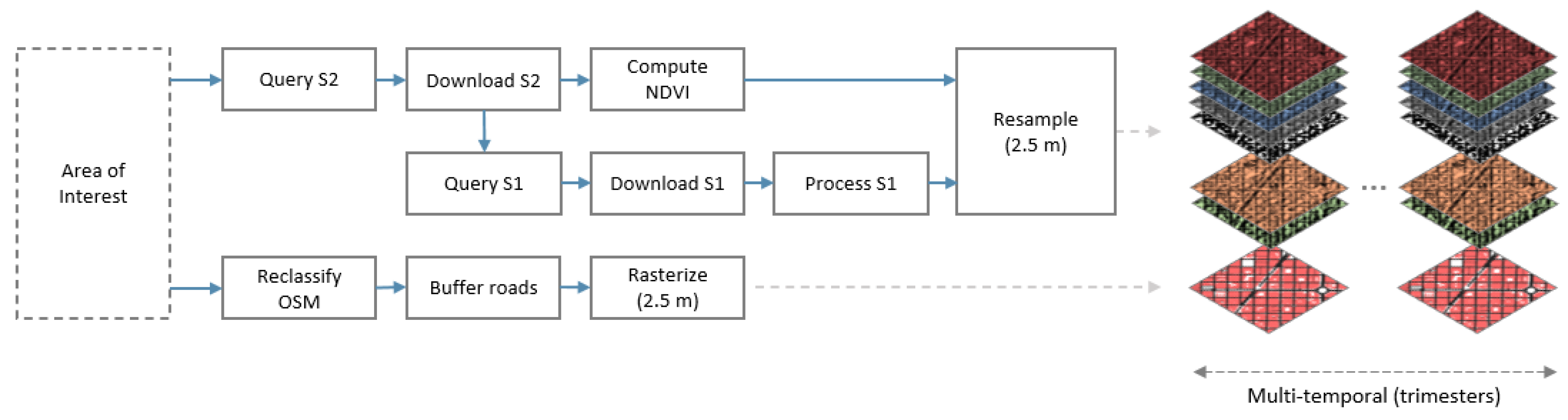
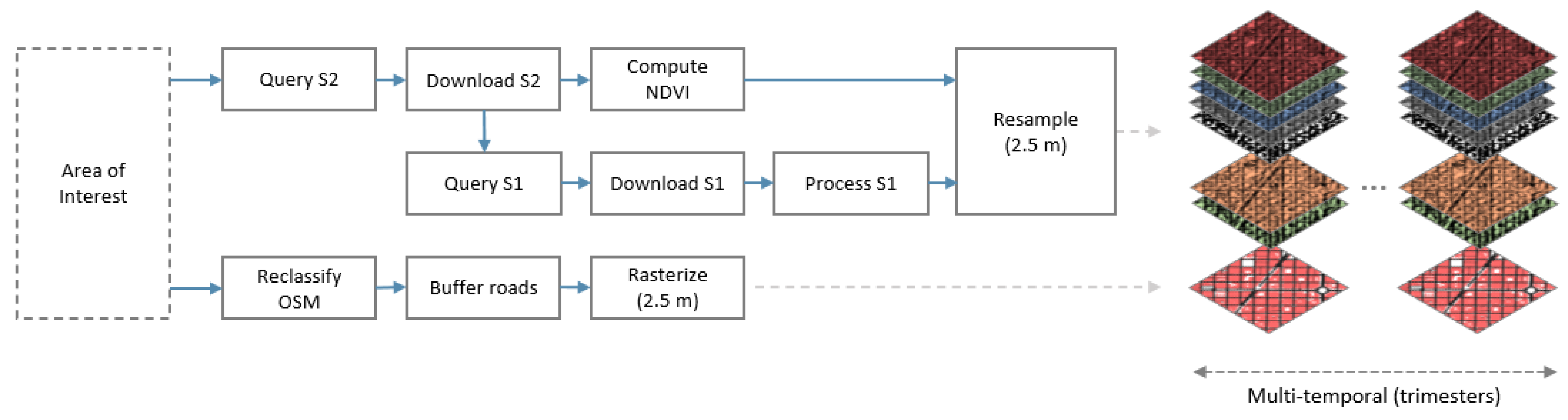
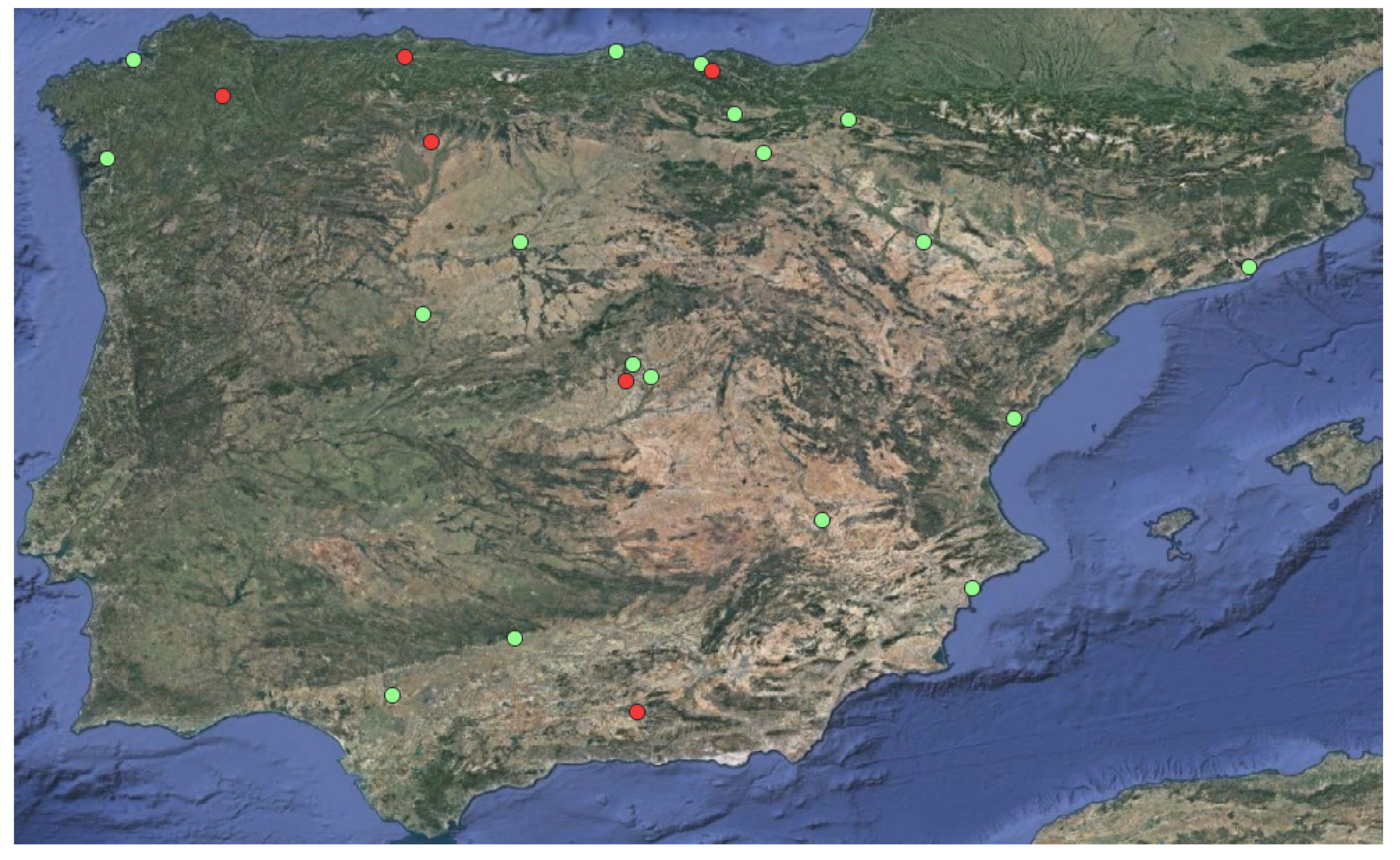
3.1. Dataset
3.2. Training Details
3.3. Performance Measures and Evaluation
4. Experimental Study
- Can binary decomposition strategies be beneficial to address remote sensing multi-class semantic segmentation problems?
- Can a multi-task learning scheme be used to further improve the performance in remote sensing semantic segmentation problems?
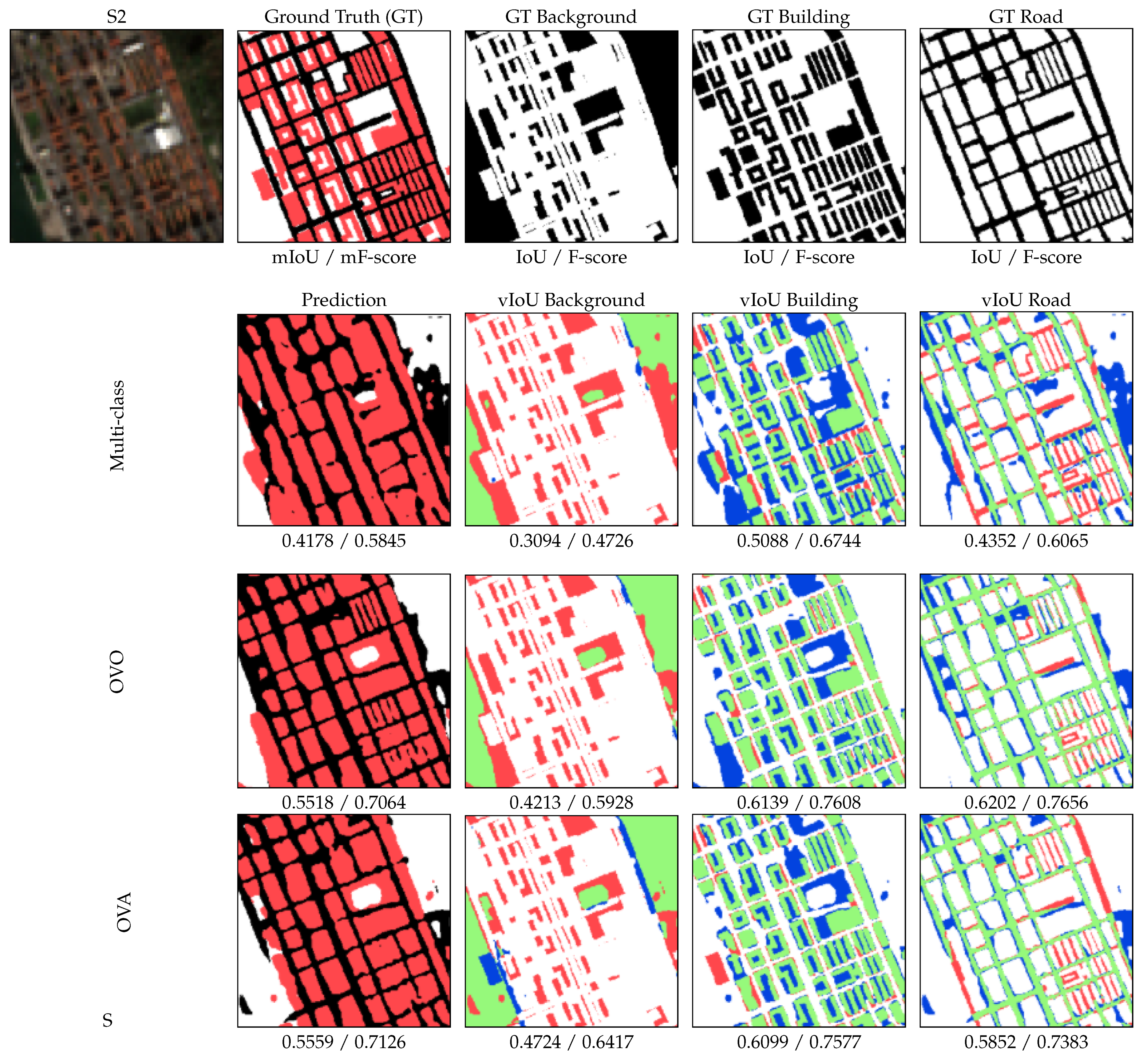
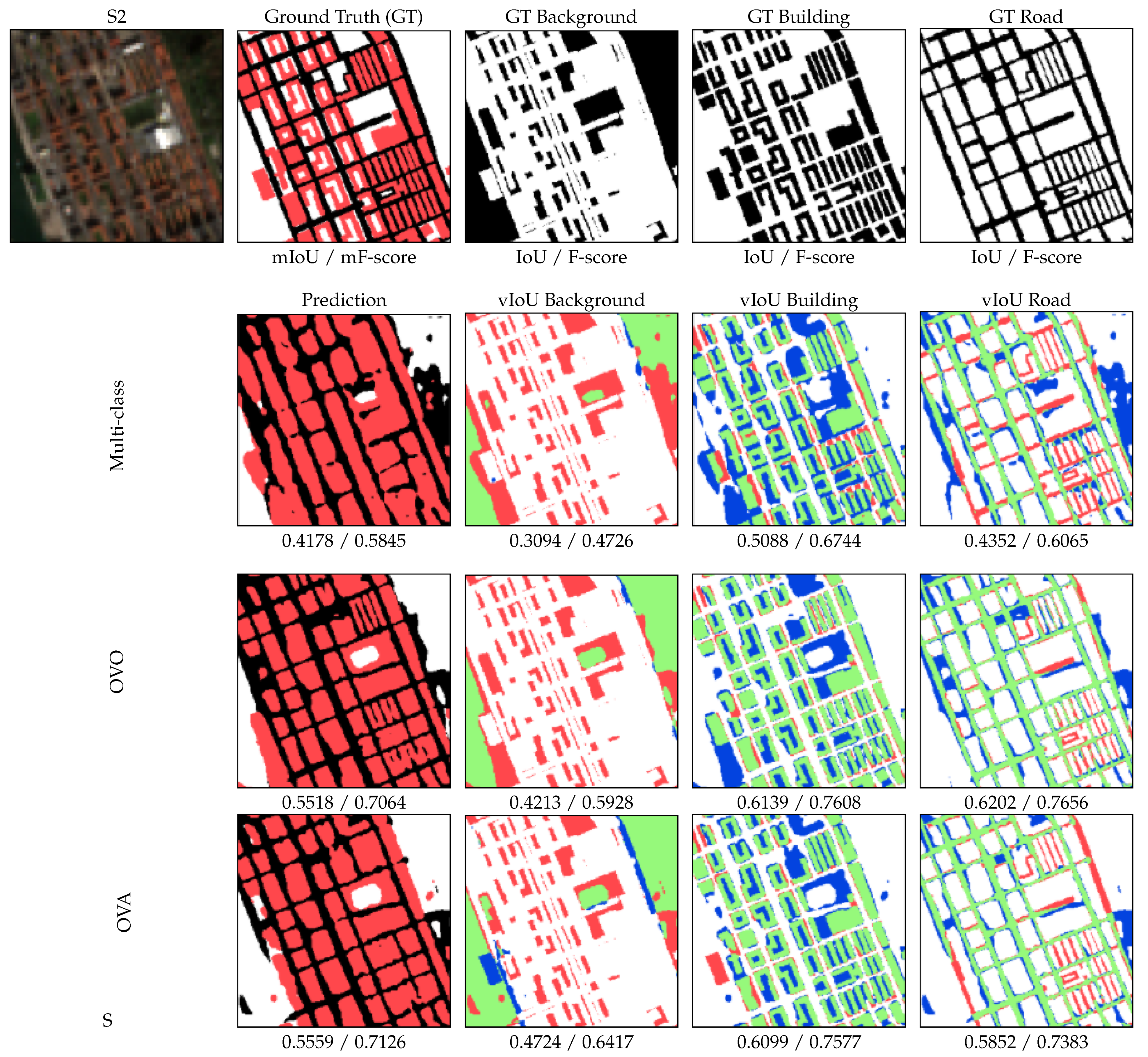
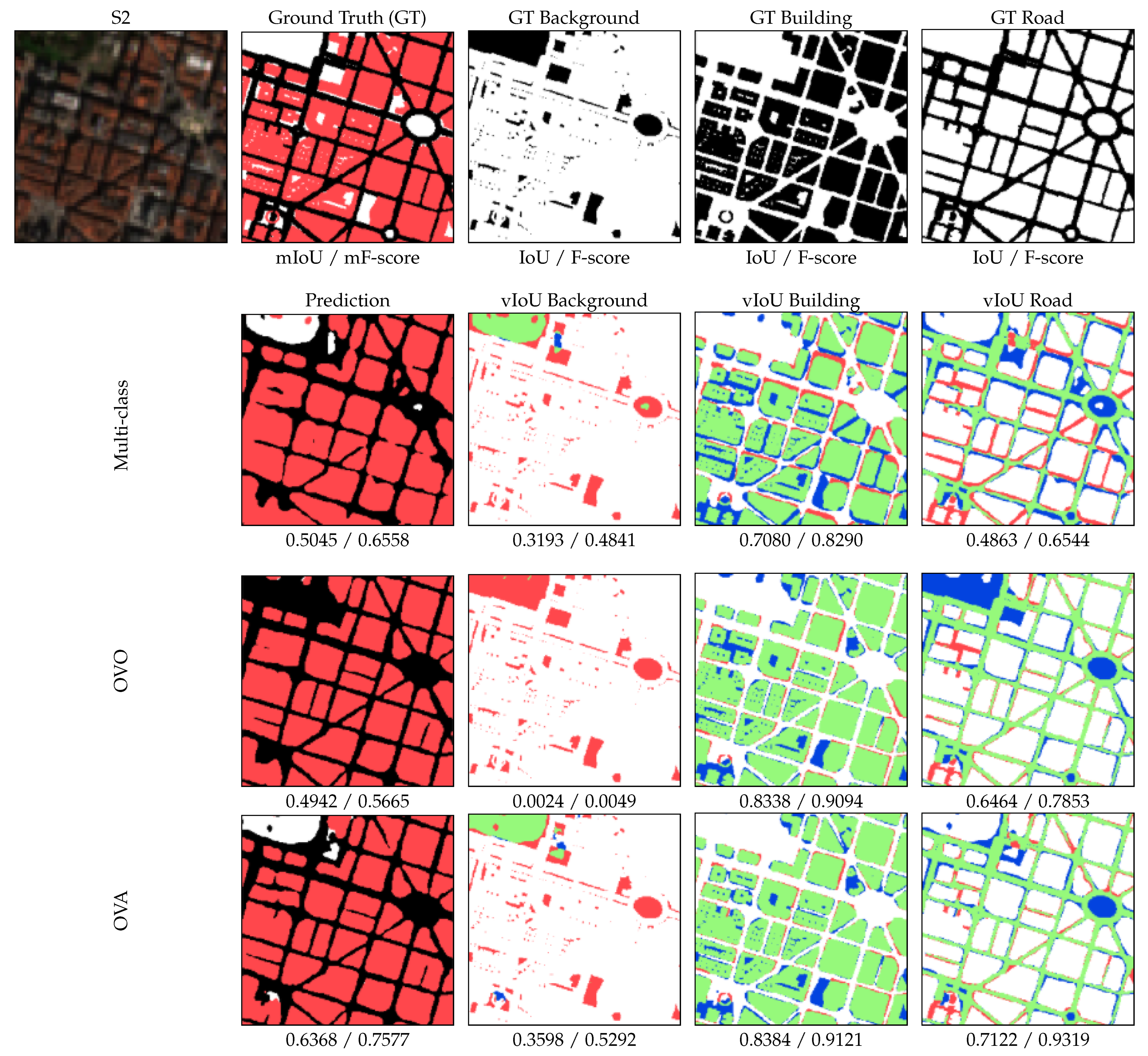
4.1. Experiment 1: Decomposing a Multi-Class Problem
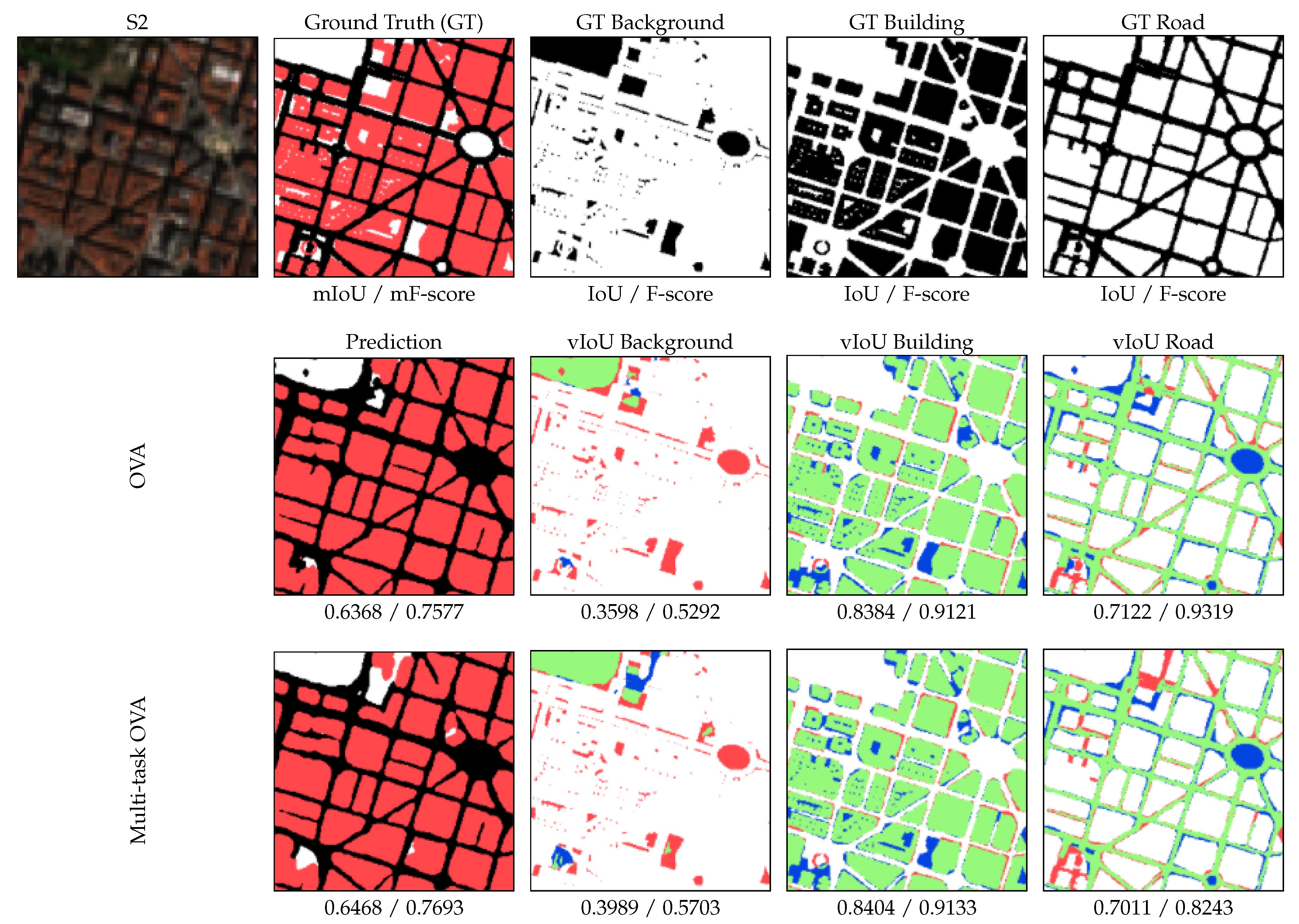
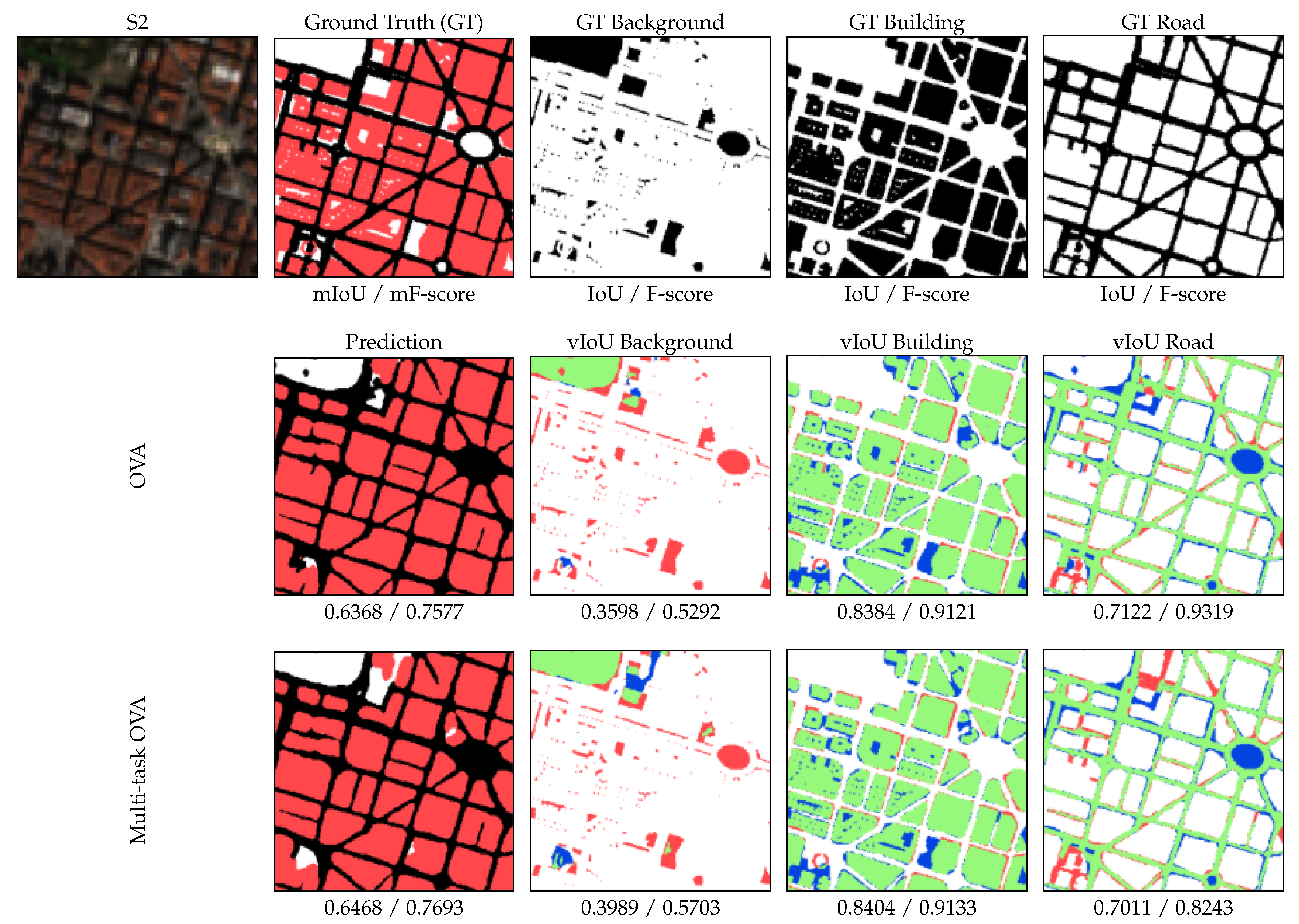
4.2. Experiment 2: Improving the Binary Performance Using a Multi-Task Scheme
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Bengio, Y. Deep learning of Representations: Looking Forward. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 2013. Available online: https://link.springer.com/chapter/10.1007/978-3-642-39593-2_1 (accessed on 6 September 2021).
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2016), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Team, T.T.D. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016, arXiv:1605.02688. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Available online: https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 6 September 2021).
- Yang, R.; Yu, Y. Artificial Convolutional Neural Network in Object Detection and Semantic Segmentation for Medical Imaging Analysis. Front. Oncol. 2021, 11, 573. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Feng, Y.; Yang, C.; Sester, M. Multi-Scale Building Maps from Aerial Imagery. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 41–47. [Google Scholar] [CrossRef]
- Corbane, C.; Syrris, V.; Sabo, F.; Politis, P.; Melchiorri, M.; Pesaresi, M.; Soille, P.; Kemper, T. Convolutional neural networks for global human settlements mapping from Sentinel-2 satellite imagery. Neural Comput. Appl. 2021, 33, 6697–6720. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Ayala, C.; Aranda, C.; Galar, M. Towards Fine-Grained Road Maps Extraction Using Sentinel-2 Imagery. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 2021, 9–14. [Google Scholar] [CrossRef]
- European Spatial Agency. Copernicus Programme. Available online: https://www.copernicus.eu (accessed on 6 September 2021).
- El Mendili, L.; Puissant, A.; Chougrad, M.; Sebari, I. Towards a Multi-Temporal Deep Learning Approach for Mapping Urban Fabric Using Sentinel 2 Images. Remote Sens. 2020, 12, 423. [Google Scholar] [CrossRef] [Green Version]
- Oehmcke, S.; Thrysøe, C.; Borgstad, A.; Salles, M.A.V.; Brandt, M.; Gieseke, F. Detecting Hardly Visible Roads in Low-Resolution Satellite Time Series Data. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2403–2412. [Google Scholar]
- Alem, A.; Kumar, S. Deep Learning Methods for Land Cover and Land Use Classification in Remote Sensing: A Review. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 903–908. [Google Scholar]
- Ayala, C.; Sesma, R.; Aranda, C.; Galar, M. A Deep Learning Approach to an Enhanced Building Footprint and Road Detection in High-Resolution Satellite Imagery. Remote Sens. 2021, 13, 3135. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, Y.; Aoki, Y. Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks. J. Imaging Sci. Technol. 2016, 60, 10402. [Google Scholar] [CrossRef]
- Lorena, A.; Carvalho, A.; Gama, J. A review on the combination of binary classifiers in multiclass problems. Artif. Intell. Rev. 2008, 30, 19–37. [Google Scholar] [CrossRef]
- Zhou, J.T.; Tsang, I.W.; Ho, S.S.; Müller, K.R. N-ary decomposition for multi-class classification. Mach. Learn. 2019, 108, 809–830. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl.-Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs.-one and one-vs.-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Knerr, S.; Personnaz, L.; Dreyfus, G. Single-layer learning revisited: A stepwise procedure for building and training a neural network. In Neurocomputing; Springer: Berlin/Heidelberg, Germany, 1990; pp. 41–50. [Google Scholar]
- Anand, R.; Mehrotra, K.; Mohan, C.; Ranka, S. Efficient classification for multiclass problems using modular neural networks. IEEE Trans. Neural Netw. 1995, 6, 117–124. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 2015. Available online: https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28 (accessed on 6 September 2021).
- Hüllermeier, E.; Vanderlooy, S. Combining predictions in pairwise classification: An optimal adaptive voting strategy and its relation to weighted voting. Pattern Recognit. 2010, 43, 128–142. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Another Approach to Polychotomous Classification; Technical Report; Department of Statistics, Stanford University: Stanford, CA, USA, 1996. [Google Scholar]
- Caruana, R. Multitask Learning: A Knowledge-Based Source of Inductive Bias. In Proceedings of the Tenth International Conference on Machine Learning, Morgan Kaufmann, Amherst, MA, USA, 27–29 July 1993; pp. 41–48. [Google Scholar]
- Duong, L.; Cohn, T.; Bird, S.; Cook, P. Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 845–850. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Haklay, M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation from Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- European Spatial Agency. Copernicus Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 6 September 2021).
- Filipponi, F. Sentinel-1 GRD Preprocessing Workflow. Proceedings 2019, 18, 11. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Taghanaki, S.A.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo Loss: Handling Input and Output Imbalance in Multi-Organ Segmentation. Comput. Med. Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | |||
|---|---|---|---|
| City | Dimensions | ||
| A coruña | 704 × 576 | ||
| Albacete | 1280 × 1152 | ||
| Alicante | 1216 × 1472 | ||
| Barakaldo | 1088 × 896 | ||
| Barcelona N. | 1152 × 1728 | ||
| Castellón | 1024 × 1024 | ||
| Córdoba | 1088 × 1792 | ||
| Logroño | 768 × 960 | ||
| Madrid N. | 1920 × 2688 | ||
| Pamplona | 1600 × 1536 | ||
| Pontevedra | 384 × 512 | ||
| Rivas-vacía | 1088 × 1088 | ||
| Salamanca | 832 × 960 | ||
| Santander | 1152 × 1216 | ||
| Sevilla | 2176 × 2368 | ||
| Valladolid | 1408 × 1408 | ||
| Vitoria | 576 × 896 | ||
| Zaragoza | 2304 × 2752 | ||
| Test | |||
| City | Dimensions | Valid Extension (km2) | |
| Building | Road | ||
| Bilbao | 576 × 832 | 3172 | 4956 |
| Granada | 1664 × 1600 | 16,879 | 74,333 |
| León | 1216 × 768 | 1151 | 18,934 |
| Lugo | 768 × 576 | 80 | 983 |
| Madrid S. | 1280 × 2624 | 84,797 | 246,651 |
| Oviedo | 960 × 896 | 9588 | 17,892 |
| IoU | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| City | Multi-Class | OVO | OVA | ||||||
| Background | Building | Road | Background | Building | Road | Background | Building | Road | |
| Bilbao | 0.6835 | 0.5080 | 0.3728 | 0.8047 | 0.6108 | 0.4976 | 0.8381 | 0.6367 | 0.5118 |
| Granada | 0.6361 | 0.3222 | 0.3472 | 0.8550 | 0.5745 | 0.5012 | 0.8841 | 0.5660 | 0.5554 |
| Leon | 0.6087 | 0.2508 | 0.3217 | 0.8485 | 0.6944 | 0.5355 | 0.8756 | 0.7020 | 0.5826 |
| Lugo | 0.6105 | 0.1333 | 0.3472 | 0.7859 | 0.5494 | 0.4605 | 0.8501 | 0.5932 | 0.4798 |
| Madrid S. | 0.6175 | 0.4189 | 0.3773 | 0.8195 | 0.5492 | 0.5970 | 0.8676 | 0.5705 | 0.6392 |
| Oviedo | 0.6565 | 0.4574 | 0.3272 | 0.8239 | 0.5160 | 0.4750 | 0.8604 | 0.5430 | 0.4894 |
| Average | 0.6320 | 0.3994 | 0.3565 | 0.8279 | 0.5629 | 0.5427 | 0.8670 | 0.5789 | 0.5828 |
| F-Score | |||||||||
| City | Multi-Class | OVO | OVA | ||||||
| Background | Building | Road | Background | Building | Road | Background | Building | Road | |
| Bilbao | 0.8119 | 0.6736 | 0.5431 | 0.8918 | 0.7574 | 0.6641 | 0.9119 | 0.7771 | 0.6764 |
| Granada | 0.7775 | 0.4874 | 0.5154 | 0.9218 | 0.7297 | 0.6677 | 0.9385 | 0.7228 | 0.7141 |
| Leon | 0.7568 | 0.4009 | 0.4866 | 0.9180 | 0.8196 | 0.6974 | 0.9337 | 0.8248 | 0.7362 |
| Lugo | 0.7578 | 0.2350 | 0.5143 | 0.8801 | 0.7083 | 0.6305 | 0.9189 | 0.7444 | 0.6484 |
| Madrid S. | 0.7635 | 0.5904 | 0.5479 | 0.9008 | 0.7088 | 0.7476 | 0.9291 | 0.7265 | 0.7799 |
| Oviedo | 0.7926 | 0.6276 | 0.4930 | 0.9034 | 0.6807 | 0.6439 | 0.9249 | 0.7037 | 0.6569 |
| Average | 0.7742 | 0.5666 | 0.5252 | 0.9057 | 0.7193 | 0.7021 | 0.9287 | 0.7325 | 0.7347 |
| IoU | ||||||
|---|---|---|---|---|---|---|
| City | OVA | Multi-Task OVA | ||||
| Background | Building | Road | Background | Building | Road | |
| Bilbao | 0.8381 | 0.6367 | 0.5118 | 0.8465 | 0.6319 | 0.5290 |
| Granada | 0.8841 | 0.5660 | 0.5554 | 0.8760 | 0.6554 | 0.5450 |
| Leon | 0.8756 | 0.7020 | 0.5826 | 0.8880 | 0.7070 | 0.5849 |
| Lugo | 0.8501 | 0.5932 | 0.4798 | 0.8428 | 0.6213 | 0.4865 |
| Madrid S. | 0.8676 | 0.5705 | 0.6392 | 0.8452 | 0.5548 | 0.5989 |
| Oviedo | 0.8604 | 0.5430 | 0.4894 | 0.8781 | 0.5732 | 0.5371 |
| Average | 0.8670 | 0.5789 | 0.5828 | 0.8631 | 0.5954 | 0.5698 |
| F-Score | ||||||
| City | OVA | Multi-Task OVA | ||||
| Background | Building | Road | Background | Building | Road | |
| Bilbao | 0.9119 | 0.7771 | 0.6764 | 0.9169 | 0.7736 | 0.6917 |
| Granada | 0.9385 | 0.7228 | 0.7141 | 0.9339 | 0.7918 | 0.7054 |
| Leon | 0.9337 | 0.8248 | 0.7362 | 0.9407 | 0.8282 | 0.7381 |
| Lugo | 0.9189 | 0.7444 | 0.6484 | 0.9147 | 0.7659 | 0.6545 |
| Madrid S. | 0.9291 | 0.7265 | 0.7799 | 0.9161 | 0.7136 | 0.7488 |
| Oviedo | 0.9249 | 0.7037 | 0.6569 | 0.9351 | 0.7284 | 0.6985 |
| Average | 0.9287 | 0.7325 | 0.7347 | 0.9264 | 0.7450 | 0.7252 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayala, C.; Aranda, C.; Galar, M. Multi-Class Strategies for Joint Building Footprint and Road Detection in Remote Sensing. Appl. Sci. 2021, 11, 8340. https://doi.org/10.3390/app11188340
Ayala C, Aranda C, Galar M. Multi-Class Strategies for Joint Building Footprint and Road Detection in Remote Sensing. Applied Sciences. 2021; 11(18):8340. https://doi.org/10.3390/app11188340
Chicago/Turabian StyleAyala, Christian, Carlos Aranda, and Mikel Galar. 2021. "Multi-Class Strategies for Joint Building Footprint and Road Detection in Remote Sensing" Applied Sciences 11, no. 18: 8340. https://doi.org/10.3390/app11188340
APA StyleAyala, C., Aranda, C., & Galar, M. (2021). Multi-Class Strategies for Joint Building Footprint and Road Detection in Remote Sensing. Applied Sciences, 11(18), 8340. https://doi.org/10.3390/app11188340