
Design and Verification of Multi-Agent Systems with the Use of Bigraphs



Abstract
Featured Application
Abstract
1. Introduction
- Is the project correctly designed? We want to assure the syntactic correctness, i.e., the correct use of formal tools such as mathematical logic, differential equations, or pi-calculus. We also care about semantic correctness, i.e., the ability to transform a formal model into a real solution (implementable on robots).
- How does one perform a simulation illustrating MAS operation?
- Have non-functional requirements been met? Those regarding safety and speed of task execution in particular.
2. Methods and Materials
2.1. Basic Concepts
- Task—A collection of objects from the real world along with the actions they can perform, the initial state, and the target-desired (final) state(s). An example of a task might be:“In an area that is a 3 × 3 grid, there are two robots in opposite (diagonally) cells. Each robot can move to vertically and horizontally adjacent cells and connect to a second robot if both are in the same cell. The goal of the task is for both robots to connect with each other.”
- Mission—a realization of a task.
- Task element—a real-world entity that is relevant to the subject matter being modeled. Elements can be people, robots, areas, data sources, and receivers, etc.
- Passive object—a task element that can participate in activities without initializing them. It may contain other passive objects. We are not interested in their behavior, but we take into account the passage of time for them. The number of passive objects is constant during a mission.
- Active object (agent)—a task element that can participate in activities by initializing them. It can contain other active and passive objects. We are interested in their behavior, and we take into account the passage of time for them. We can control them. It is assumed that the number of agents during a mission is constant.
- Environment—a task element that can participate in activities without initializing them. It can contain passive and active objects and be owned by at most one other object. We are not interested in its behavior, and do not consider the passage of time for it.
- Behavior Policy—A set of planned actions for all agents that meets the following requirements:
- –
- Implementing a behavioral policy solves a given task;
- –
- All agents start the mission at the same time;
- –
- Agents can complete a mission at different points in time;
- –
- All agent activities must be performed continuously (without time gaps);
- –
- All agents that participate in a cooperative activity must start performing it at the same moment.
- Scenario—Mission using a specific behavioral policy.
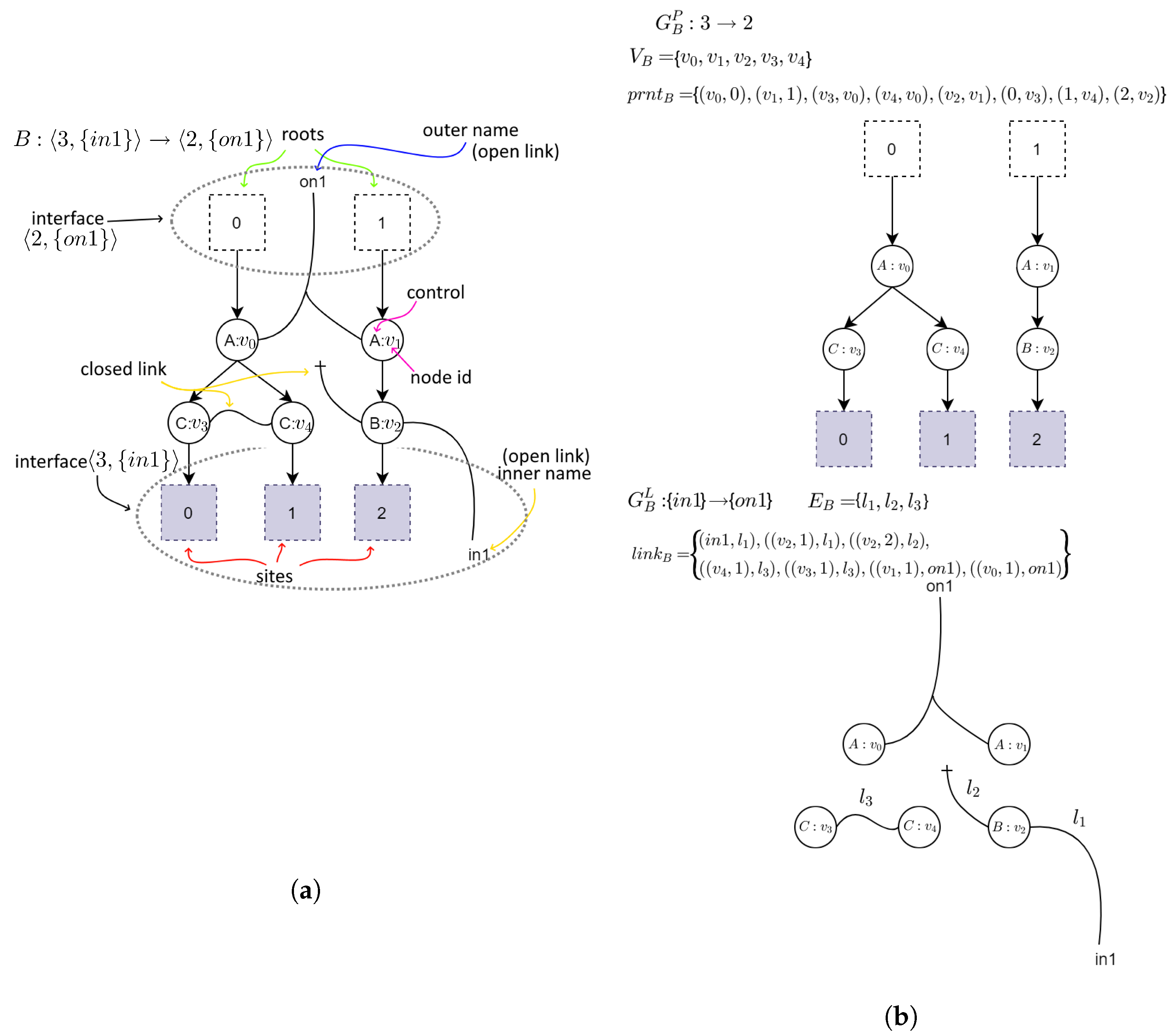
2.2. Bigraphs
- —a set of vertices identifiers;
- —a set of hyperedges identifiers. A union of both of these sets makes the bigraph support;
- —a function assigning a control type to vertices. K denotes a set of control types and is called a signature of the bigraph;
- and denote a place and a link graph respectively. A function defines hierarchical relations between vertices, roots, and sites. A function defines linking between vertices and hyperedges in the link graph;
- and denotes the inner face and outer face of the bigraph B. By we will denote sets of preceding ordinals of the form: . Sets X and Y represent inner and outer names respectively. When any of the elements of an interface is omitted it means it is either equal to 0 (when interface lacks an ordinal) or it is empty (when there is no set of names). For example, interface means it has no inner names.
- —a bigraph called redex;
- —a bigraph called reactum;
- —a map between sites from reactum to sites in redex;
- —a map of reactum’s node identifiers onto redex’s node identifiers. It allows one to indicate which elements of an input bigraph are “residues” in an output bigraph.
- —a set of bigraphs;
- —a set of redexes used to construct the TTS;
- —a set of labels;
- —an applicability relation;
- —a participation function. It indicates which vertices in an input bigraph correspond to elements in the redex of a transition;
- —a residue function. It maps vertices in an output bigraph that are residue of an input bigraph to the vertices in the input bigraph;
- —a transition relation.
2.3. State Space
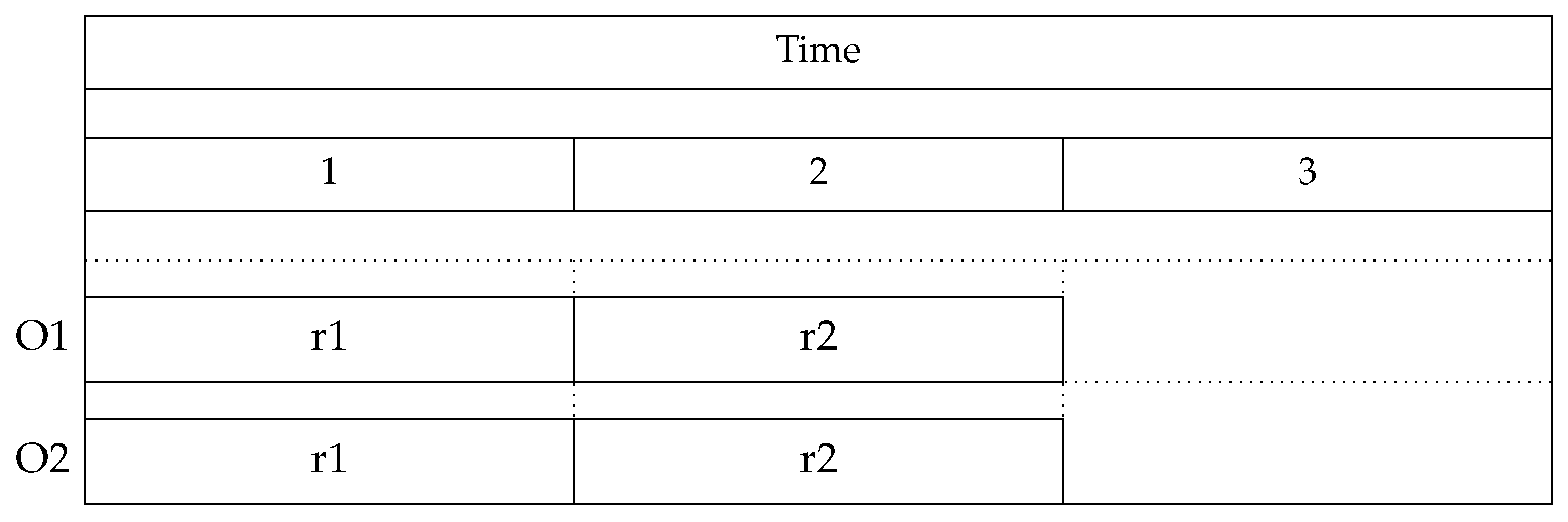
- A number of passive and active objects is constant during whole mission;
- A system cannot change its state without an explicit action of an agent (alone or in cooperation with other agents);
- No actions performed by agents are subject to uncertainty;
- A mission can end for each agent separately in different moments. In other words, agents do not have to finish their part of the mission all at the same time;
- In case of actions involving multiple objects (whether these are active or passive), it is required of all participants to start cooperation at the same moment.
- —a set of states in the state space. It corresponds to bigraphs in the Tracking Transition System;
- —a multiset of ordered pairs of states. Elements in this set are directed edges representing transition relations between states;
- L—a set of labels of changes in the system. It will usually consist of reaction rule names from the Tracking Transition System the state space originated from. To determine what changes, in what order, have led to a specific state we will additionally introduce set . Elements of the H set indicate what action (label) took place in what order (index value).
- —a set of possible state-at-time (SAT) configurations. The interpretation of elements in such a set is as follows. The first element in each of inner tuples denotes id of an object (either passive or active) in the system. The second element in each inner tuple is meant to represent time at which the object specified by the id is at. For example, for the element denotes a situation where the object with id 1 is at the moment 777 while the object with id 2 is at the moment 123.
- —a set of possible mission courses. 0 denotes the neutral element, i.e., . For the rest of the elements of C set the + symbol serves only as an associative conjunction operator and does not denote any meaningful operation. In other words for the rest of the elements the following formula is true: .
- —a set of functions defining progress of a mission. The function returns 0 regardless of input. Additionally, we will denote by a set of all mission progress functions from the i state to the j state.
- —a bijective mapping of edges to mission progress functions.
2.4. Behavior Policy
- —a series, where summands are mission courses leading to the state s;
- —a function returning a number of elements in a given series. According to the earlier definition, for any series this function returns a value of m (the greatest index of );
- —a series, whose summands are mission progress functions from the i to the j state;
- —a matrix whose elements are series indicating possible walks leading to each state. Index t denotes a number of steps made in a state space. By a step we understand a transition between vertices (including the situation where traversal does not change the vertex);
- —a matrix of transitions between states.
- —a convolution of the series defined above;
- —a multiplication of the matrices defined above. Elements of the new matrix are defined by the formula:
2.5. Verification and Visualization of Behavior Policies
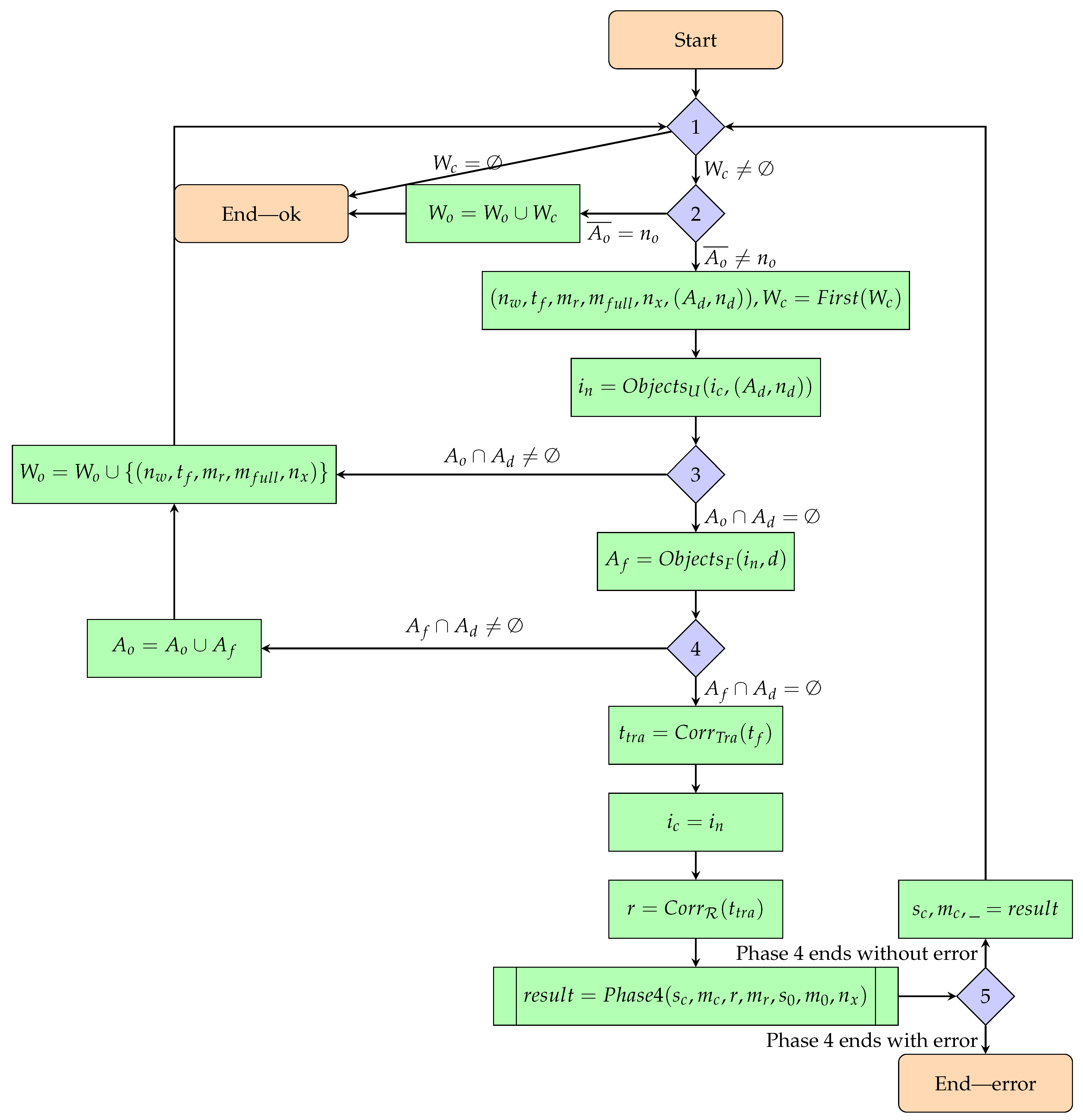
2.5.1. Phase 4—Applying a Single Transformation to Constructed State and Checking Correctness Beforehand
- Input:
- A currently constructed state—a bigraph;
- A map of unique identifiers to vertices of the currently constructed state (a bijection);
- The reaction rule to be applied to the constructed state;
- A map of unique identifiers to rule’s redex vertices (bijection);
- State at the previous moment in time—a bigraph;
- A mapping of unique identifiers to state vertices at a previous point in time;
- First new unique identifier—used when a new task element appears after a transformation.
- Output:
- Option 1—the model is correct:
- Newly constructed state—bigraph;
- Mapping of unique identifiers to vertices of the newly constructed state;
- First new unique identifier.
- Option 2—the model is incorrect:
- Information about the failed transformation. Whether the given reaction rule could not be applied to the state at the previous point in time or to the currently constructed state (given the mappings of unique identifiers to vertices).
- Formal definitions:
- —a set of unique identifiers (UIs) of task elements; It is used to track the environment and objects involved between system transformations. The idea behind this set is to assign to each task element a unique identifier, which makes it possible to check whether the task elements marked as taking part in a reaction rule are present in a given scenario state. The reaction rules themselves allow only to check whether alike (rather than the same) elements exist in both a reaction rule and a bigraph.
- —a function that assigns reaction rules to their corresponding redexes;
- —a set of functions assigning unique identifiers to elements of the support of a bigraph, which is either a scenario state or a redex of a reaction rule;
- —a function that determines whether it is possible to apply a reaction rule to a given state, taking into account the mapping of the UIs to the state’s vertices and the mapping of the UIs to the redex vertices of that rule;
- —a function that transforms the current state.
2.5.2. Phase 3—Constructing Scenario State at a Given Moment of Time
- Input:
- State at the previous moment in time—bigraph;
- A map of unique identifiers to state elements at the previous moment in time;
- A set of walk elements combined with a UIs mapping to the vertices of the redex of the reaction rule associated with this walk element, a UIs mapping to the vertices of the input state and the smallest new UI from which new task elements will be numbered.
- A linear order relation defined on the above set;
- State-At-Time configuration of the system at the previous moment in time;
- A moment of time for which the system state is constructed;
- Number of objects.
- Output:
- Option 1—the model is correct:
- A subset of the walk elements (given as input) that have not been used to construct the state at the given point in time;
- State at the given moment in time;
- Mapping of unique identifiers to state elements at the given point in time;
- State-at-time configuration at the set point in time.
- Option 2—the model is incorrect:
- A currently constructed state with its UIs mapping that could not be transformed (if it is the cause of the Phase 4 error);
- The state from the previous moment in time with its UIs mapping that could not be transformed (if it is the cause of the Phase 4 error);
- Reaction rule with UIs mapping to its redex vertices, which was not successfully applied.
- Formal definitions:
- —A collection of sets of mission object identifiers. The same identifiers are used in SAT configurations
- —an extended walk consisting of:
- A positional number;
- A transition function;
- A map of UIs to redex vertices. The redex is associated with the reaction rule corresponding to the above transition function;
- A map of UIs to vertices of the output state of the extended walk element;
- First new UI assigned to a new task element created by applying the reaction rule (useful only if the reaction rule corresponding to the transition function creates new environment elements);
- A set of object identifiers involved in the walk element along with the duration of that transformation. In other words, it is information about which objects are involved in the transformation represented by the walk element and how long it will take.
- —linear order relation on the elements of the extended walk.We will assume the following rule for ordering the elements of a walk:
- —a function that returns the “smallest” element of the walk and the “truncated” walk;
- —a function that assigns transition functions to transitions from TTS;
- —SAT configuration update function. Takes a current configuration and a set of objects for which the time will be changed along with the value by how much. The result is the new SAT configuration;
- —a function that determines for which objects activities are scheduled later than the moment of time for which the scenario state is constructed. Takes a SAT configuration and the moment of time for which the state is generated;
- —a function assigning reaction rules to transitions from TTS.
- The first condition checked is if we have reached the end of a walk. If so, then surely the state currently constructed is the state for the given moment of time.
- Do we omit actions of all mission objects? If so, the state constructed so far is the state for the given moment of time.
- Do any objects involved in the current action belong to the set of skipped objects? If so, we omit this walk element.
- Will all objects involved in the current action have finished before the moment d? If not, we disregard that activity in the currently constructed state and add those objects to the set of skipped objects.
- If Phase 4 is not completed correctly, it means that the model is incorrect.
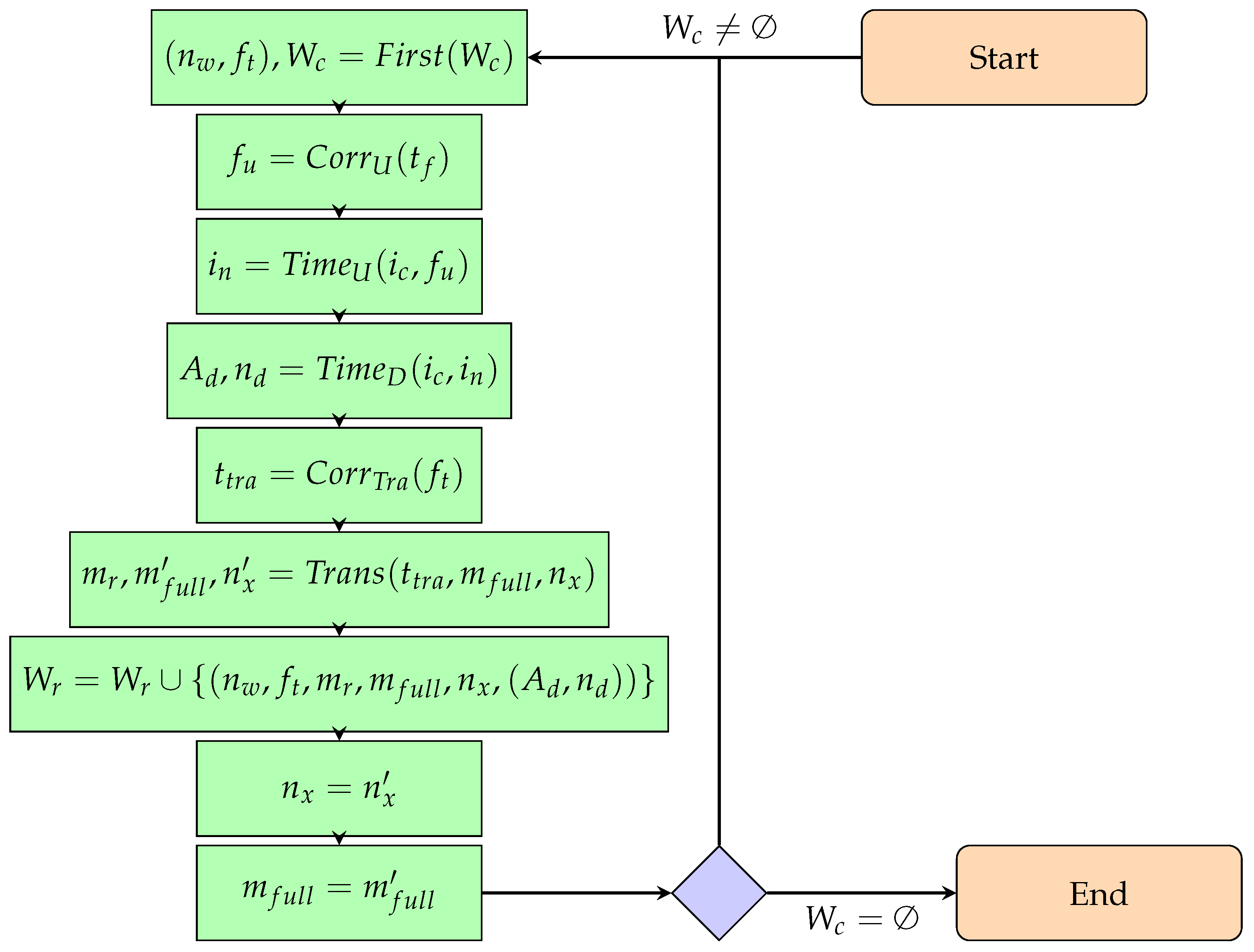
2.5.3. Phase 2—Extending a Previously Constructed Walk
- Input:
- A walk resulting from the algorithm presented in Section 2.4;
- Number of objects.
- Output:
- Extended walk.
- Formal definitions:
- —a walk. The first element denotes the positional number of the transition function that is the second element of the tuple;
- —linear order relation on the elements of the set W.As in the case of the set , we define the order relation by the following rule:
- —a function that returns the “smallest” walk element and a truncated walk;
- —a function that transforms a mapping of unique identifiers based on the given transition and the first new identifier (in case new environment elements appear in the output state of the transition and need to be tagged). The results are: a new UIs map to the redex of the reaction rule corresponding to the provided transition, a UIs mapping to the output state of the transition, and a new smallest UI;
- —a set of functions that update SAT configurations;
- —a function that assigns transition functions to their corresponding SAT configuration update functions;
- —a SAT configuration update function;
- —a time difference function for individual objects between SAT configurations. Returns information about which objects are involved in the transformation and how long it takes.
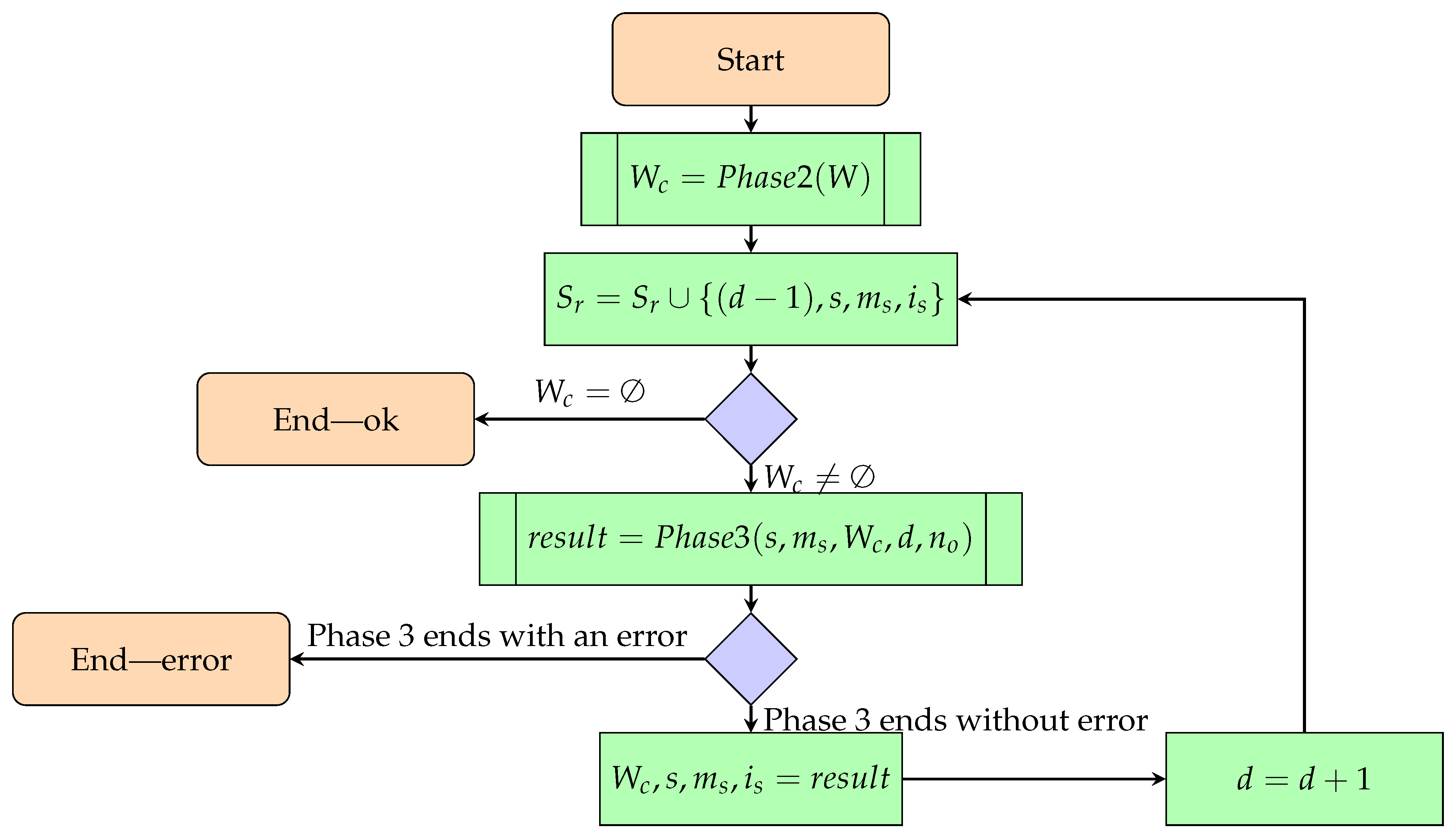
2.5.4. Phase 1—Constructing All Scenario States and Checking the Correctness of a Given Walk
- Input:
- Number of objects;
- A walk with a linear order relation on its elements.
- Output:
- The model is correct:
- A set of scenario states at consecutive moments in time with corresponding mappings of unique identifiers to the vertices of these states and SAT configurations;
- The model is incorrect:
- The moment of time for which the scenario state could not be generated;
- The element that could not be transformed (constructed state or state at some point in time);
- The reaction rule corresponding to the unsuccessful transformation;
- The UIs mapping of the element that could not be transformed and the redex of the above reaction rule.
3. Results
3.1. Model Verification Example
3.1.1. Introduction
3.1.2. Using the Algorithm for Model Verification
3.2. Example of Scenario States Visualization
3.2.1. Introduction
3.2.2. Using the Algorithm to Construct Scenario States
3.3. Example of Verifying the Fulfillment of Non-Functional Requirements
3.3.1. Non-Functional Requirement—Length of a Mission
3.3.2. Non-Functional Requirement—Collision Avoidance
3.4. Memory Complexity
- First N—a result of the convolution operation performed during a matrix multiplication is limited to the first N results. This way of searching for behavior policies is suitable when the first results found satisfy non-functional requirements;
- Best N—a result of the convolution operation is constrained to the N best results evaluated using an evaluation function (discussed below). This method of searching for walks is useful when a desired walk should have a certain length;
- All—the result of a convolution operation is not constrained in any way. Useful only for small systems to verify model correctness.
- All first found—Returns all walks leading to the goal state with the shortest length;
- First N found—returns all walks leading to the target state. The matrix multiplication operation is constrained by first N method;
- First N best found—returns all walks leading to the target state. The matrix multiplication operation is constrained by best N method;
- All up to a certain length—returns all walks leading to the target state of a length no greater than a given value;
- First N up to a certain length—returns all walks leading to the target state with a length no greater than a given value. The matrix multiplication operation to find walks in a state space is constrained by first N method which results in each set of walks of the same length being allowed to have a count of at most N elements;
- Best N up to a certain length—returns all walks leading to the target state with a length no greater than a given value. The matrix multiplication operation to find walks in a state space is constrained by best N method which results in each set of walks of the same length being allowed to have a count of at most N elements.
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dorri, A.; Kanhere, S.S.; Jurdak, R. Multi-Agent Systems: A Survey. IEEE Access 2018, 6, 28573–28593. [Google Scholar] [CrossRef]
- Falco, M.; Robiolo, G. A Systematic Literature Review in Multi-Agent Systems: Patterns and Trends. In Proceedings of the 2019 XLV Latin American Computing Conference (CLEI), Panama City, Panama, 30 September–4 October 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Canese, L.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Spanò, S. Multi-Agent Reinforcement Learning: A Review of Challenges and Applications. Appl. Sci. 2021, 11, 4948. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; De Schutter, B. A Comprehensive Survey of Multiagent Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2008, 38, 156–172. [Google Scholar] [CrossRef]
- Macal, C.M.; North, M.J. Tutorial on Agent-Based Modeling and Simulation. In Proceedings of the 37th Conference on Winter Simulation. Winter Simulation Conference, Orlando, FL, USA, 4–7 December 2005; pp. 2–15. [Google Scholar]
- Weyns, D.; Holvoet, T. A Formal Model for Situated Multi-Agent Systems. Fundam. Inf. 2004, 63, 125–158. [Google Scholar]
- Herrera, M.; Pérez-Hernández, M.; Kumar Parlikad, A.; Izquierdo, J. Multi-Agent Systems and Complex Networks: Review and Applications in Systems Engineering. Processes 2020, 8, 312. [Google Scholar] [CrossRef]
- Ota, J. Multi-agent robot systems as distributed autonomous systems. Adv. Eng. Inform. 2006, 20, 59–70. [Google Scholar] [CrossRef]
- Yan, Z.; Jouandeau, N.; Cherif, A.A. A Survey and Analysis of Multi-Robot Coordination. Int. J. Adv. Robot. Syst. 2013, 10, 399. [Google Scholar] [CrossRef]
- Iñigo-Blasco, P.; del Rio, F.D.; Romero-Ternero, M.C.; Cagigas-Muñiz, D.; Vicente-Diaz, S. Robotics software frameworks for multi-agent robotic systems development. Robot. Auton. Syst. 2012, 60, 803–821. [Google Scholar] [CrossRef]
- Geihs, K. Engineering Challenges Ahead for Robot Teamwork in Dynamic Environments. Appl. Sci. 2020, 10, 1368. [Google Scholar] [CrossRef]
- Bullo, F.; Cortés, J.; Martínez, S. Distributed Control of Robotic Networks: A Mathematical Approach to Motion Coordination Algorithms; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Yang, Z.; Zhang, Q.; Chen, Z. A novel adaptive flocking algorithm for multi-agents system with time delay and nonlinear dynamics. In Proceedings of the 32nd Chinese Control Conference, Xi’an, China, 26–28 July 2013; pp. 998–1001. [Google Scholar]
- Sadik, A.R.; Urban, B. An Ontology-Based Approach to Enable Knowledge Representation and Reasoning in Worker–Cobot Agile Manufacturing. Future Internet 2017, 9, 90. [Google Scholar] [CrossRef]
- Viseras, A.; Xu, Z.; Merino, L. Distributed Multi-Robot Information Gathering under Spatio-Temporal Inter-Robot Constraints. Sensors 2020, 20, 484. [Google Scholar] [CrossRef]
- Siefke, L.; Sommer, V.; Wudka, B.; Thomas, C. Robotic Systems of Systems Based on a Decentralized Service-Oriented Architecture. Robotics 2020, 9, 78. [Google Scholar] [CrossRef]
- Pal, C.V.; Leon, F.; Paprzycki, M.; Ganzha, M. A Review of Platforms for the Development of Agent Systems. arXiv 2020, arXiv:2007.08961. [Google Scholar]
- Jamroga, W.; Penczek, W. Specification and Verification of Multi-Agent Systems. In Lectures on Logic and Computation: ESSLLI 2010 Copenhagen, Denmark, August 2010, ESSLLI 2011, Ljubljana, Slovenia, August 2011, Selected Lecture Notes; Springer: Berlin/Heidelberg, Germany, 2012; pp. 210–263. [Google Scholar] [CrossRef]
- Blanes, D.; Insfran, E.; Abrahão, S. RE4Gaia: A Requirements Modeling Approach for the Development of Multi-Agent Systems. In Advances in Software Engineering; Ślęzak, D., Kim, T., Kiumi, A., Jiang, T., Verner, J., Abrahão, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 245–252. [Google Scholar]
- Bresciani, P.; Giorgini, P.; Giunchiglia, F.; Mylopoulos, J.; Perini, A. Tropos: An Agent-Oriented Software Development Methodology. Auton. Agents-Multi-Agent Syst. 2004, 8, 203–236. [Google Scholar] [CrossRef]
- Jamont, J.P.; Raievsky, C.; Occello, M. Handling Safety-Related Non-Functional Requirements in Embedded Multi-Agent System Design. In Advances in Practical Applications of Heterogeneous Multi-Agent Systems. The PAAMS Collection; Demazeau, Y., Zambonelli, F., Corchado, J.M., Bajo, J., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 159–170. [Google Scholar]
- Picard, G.; Gleizes, M.P. The ADELFE Methodology Designing Adaptive Cooperative Multi-Agent Systems. In Methodologies and Software Engineering for Agent Systems; Kluwer Publishing: Alphen aan den Rijn, The Netherlands, 2004; Chapter 8; pp. 157–176. [Google Scholar]
- Milner, R. The Space and Motion of Communicating Agents; Cambridge University Press: Cambridge, UK, 2009; Volume 20. [Google Scholar] [CrossRef]
- Sevegnani, M.; Calder, M. Bigraphs with sharing. Theor. Comput. Sci. 2015, 577, 43–73. [Google Scholar] [CrossRef]
- Krivine, J.; Milner, R.; Troina, A. Stochastic Bigraphs. Electron. Notes Theor. Comput. Sci. 2008, 218, 73–96. [Google Scholar] [CrossRef]
- Gassara, A.; Bouassida, I.; Jmaiel, M. A Tool for Modeling SoS Architectures Using Bigraphs. In Proceedings of the Symposium on Applied Computing; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1787–1792. [Google Scholar] [CrossRef]
- Archibald, B.; Shieh, M.Z.; Hu, Y.H.; Sevegnani, M.; Lin, Y.B. BigraphTalk: Verified Design of IoT Applications. IEEE Internet Things J. 2020, 7, 2955–2967. [Google Scholar] [CrossRef]
- Calder, M.; Koliousis, A.; Sevegnani, M.; Sventek, J. Real-time verification of wireless home networks using bigraphs with sharing. Sci. Comput. Program. 2014, 80, 288–310. [Google Scholar] [CrossRef][Green Version]
- Perrone, G.; Debois, S.; Hildebrandt, T. A model checker for Bigraphs. In Proceedings of the ACM Symposium on Applied Computing, New York, NY, USA, 26–30 March 2012. [Google Scholar] [CrossRef]
- Grzelak, D. Bigraph Framework for Java. 2021. Available online: https://bigraphs.org/products/bigraph-framework/ (accessed on 16 August 2021).
- Sevegnani, M.; Calder, M. BigraphER: Rewriting and Analysis Engine for Bigraphs. In Proceedings of the International Conference on Computer Aided Verification, Los Angeles, CA, USA, 21–24 July 2020; Springer: Cham, Switzerland, 2016; Volume 9780, pp. 494–501. [Google Scholar] [CrossRef]
- Mansutti, A.; Miculan, M.; Peressotti, M. Multi-agent Systems Design and Prototyping with Bigraphical Reactive Systems. Distributed Applications and Interoperable Systems; Magoutis, K., Pietzuch, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 201–208. [Google Scholar]
- Taki, A.; Dib, E.; Sahnoun, Z. Formal Specification of Multi-Agent System Architecture. In Proceedings of the ICAASE 2014 International Conference on Advanced Aspects of Software Engineering, Constantine, Algeria, 2–4 November 2014. [Google Scholar]
- Pereira, E.; Potiron, C.; Kirsch, C.M.; Sengupta, R. Modeling and controlling the structure of heterogeneous mobile robotic systems: A bigactor approach. In Proceedings of the 2013 IEEE International Systems Conference (SysCon), Orlando, FL, USA, 15–18 April 2013; pp. 442–447. [Google Scholar] [CrossRef]
- Agha, G. Actors: A Model of Concurrent Computation in Distributed Systems; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Cybulski, P.; Zieliński, Z. UAV Swarms Behavior Modeling Using Tracking Bigraphical Reactive Systems. Sensors 2021, 21, 622. [Google Scholar] [CrossRef] [PubMed]
- Mermoud, G.; Upadhyay, U.; Evans, W.C.; Martinoli, A. Top-Down vs. Bottom-Up Model-Based Methodologies for Distributed Control: A Comparative Experimental Study. In Experimental Robotics: The 12th International Symposium on Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 615–629. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, F.; Moscato, V.; Pascale, F.; Picariello, A. An agent-based approach for recommending cultural tours. Pattern Recognit. Lett. 2020, 131, 341–347. [Google Scholar] [CrossRef]
- Cybulski, P. Verification Tool for TRS-SSP Toolchain. (trs-ssp-verif). Available online: https://github.com/zajer/trs-ssp-verif (accessed on 16 August 2021).
- Cybulski, P. A Tool for Generating Walks in State Space of a TRS-Based Systems. 2021. Available online: https://github.com/zajer/trs-ssp (accessed on 16 August 2021).
- Cybulski, P. Visualization Tool for TRS-SSP Toolchain. (trs-ssp-frontend). Available online: https://github.com/zajer/trs-ssp-frontend (accessed on 16 August 2021).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graphical Representation | Name | Description |
|---|---|---|
 | s0 | The initial state of the system. |
 | s1 | The state where only one of the agents has moved to the B area. |
 | s2 | The state where both agents has moved to the B area. |
| Graphical Representation | Name |
|---|---|
 | |
 |
| Apl | Agt | Par | Res |
|---|---|---|---|
| s1 | |||
| s1 | |||
| s2 | |||
| s2 |
| Function | Function Definition |
|---|---|
| Variable | Description |
|---|---|
| Currently constructed scenario state | |
| Mapping of UIs to vertices of currently constructed state s | |
| Reaction rule | |
| Mapping of UIs to redex r vertices | |
| State at the previous moment in time | |
| Mapping of UIs to vertices of | |
| The first new UI |
| Variable | Description |
|---|---|
| Constructed state extended by application of the provided reaction rule | |
| Mapping of UIs to the vertices of | |
| The first new UI |
| Variable | Description |
|---|---|
| State at the previous point in time. | |
| Mapping of UIs to vertices of . | |
| A walk and the linear order relation on its elements. | |
| The SAT configuration at the previous moment of time. | |
| The moment of time for which the scenario state is constructed. | |
| Number of objects. |
| Variable | Description |
|---|---|
| Current constructed state. The initial value is . | |
| Mapping of UIs to vertices of . | |
| SAT configuration of the currently constructed state.The initial value is . | |
| A set of object identifiers, skipped in the constructed state. The initial value is the empty set. | |
| A collection of usable walk elements.The initial value is W. | |
| A collection of unused walk elements.The initial value is the empty set. |
| Variable | Description |
|---|---|
| Unused walk elements that will be used to construct subsequent scenario states. | |
| System state. | |
| Mapping of UIs to vertices of . | |
| SAT configuration at time d. |
| Variable | Description |
|---|---|
| A walk with a linear order relation on its elements. | |
| Number of objects. |
| Variable | Description |
|---|---|
| The value of a first new UI. The initial value is the number of vertices of the input state of the first walk element. | |
| The current UIs mapping to the vertices of the last processed output state. The initial value is a function that assigns consecutive natural numbers to the vertices of the input state of the first element of the walk. | |
| Elements of the extended walk. The initial value is the empty set. This is the result of this phase. | |
| A subset of walk elements that have not been processed yet. The initial value is W. | |
| Current SAT configuration. The initial value is . |
| Variable | Description |
|---|---|
| A walk with a linear order relation on its elements. | |
| Number of objects. |
| Variable | Description |
|---|---|
| A set of extended walk elements that have not been used yet. The initial value is the empty set but it is properly initialized with the result of Phase 2. | |
| d | The current moment of time for which a scenario state is constructed. The initial value is 1. |
| The scenario state at the time . The initial value is the input state of the first walk element W. | |
| Mapping of UIs to vertices of the state s. The initial value is a bijection of consecutive natural numbers on the vertices of s. | |
| SAT configuration for the scenario state at the time . The initial value is . | |
| A collection of states at successive moments in time with their corresponding UIs mapping and SAT configurations. The initial value is the empty set. This is the result of this phase. |
| Input State | Label | Output State | Par & Res |
|---|---|---|---|
 |  | ||
 |  |
| Category of Task Elements | Elements Belonging to the Category |
|---|---|
| Environment | |
| Passive objects | ∅ |
| Active objects (agents) |
| Phase | Step | Result/Comment |
|---|---|---|
| 1 |  | |
| 1 | ...) | |
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ttra = first row of Table 14 | |
| 3 | ||
| 3 | r = reaction rule mov1 | |
| 3 | Phase 4 completed without error | |
| 3 | sc =  | |
| ( is calculated in the same way as in Phase 2) | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | Table 14 | |
| 3 | ||
| 3 | mov2 | |
| 4 | rl =  | |
| 4 | ||
The pattern  does not occur in the bigraph does not occur in the bigraph  . .
| ||
| 1 | End—error |
| Input State | Label | Output State | Par & Res |
|---|---|---|---|
 |  | ||
 |  | ||
 |  | ||
 |  | ||
 |  | ||
 |  | ||
 |  | ||
 |  |
| Phase | Step | Result/Comment |
|---|---|---|
| 1 |  | |
| 1 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | Table 17 | |
| 3 | ||
| 3 | r1 | |
| 3 | Phase 4 completed without error | |
| 3 |
sc =  | |
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | Table 17 | |
| 3 | ||
| 3 | r1 | |
| 3 | Phase 4 completed without error | |
| 3 |  | |
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | End—ok | |
| 1 | s =  | |
| 1 | ||
| 1 |  | |
| 1 | ||
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | Table 17 | |
| 3 | ||
| 3 | r2 | |
| 3 | Phase 4 completed without error | |
| 3 | sc =  | |
| 3 | ||
| 3 | ||
| 3 | ||
| 3 | Table 17 | |
| 3 | ||
| 3 | r2 | |
| 3 | Phase 4 completed without error | |
| 3 | sc =  | |
| 3 | End—ok | |
| 1 | s =  | |
| 1 | ||
| 1 |  | |
| 1 | End—ok |
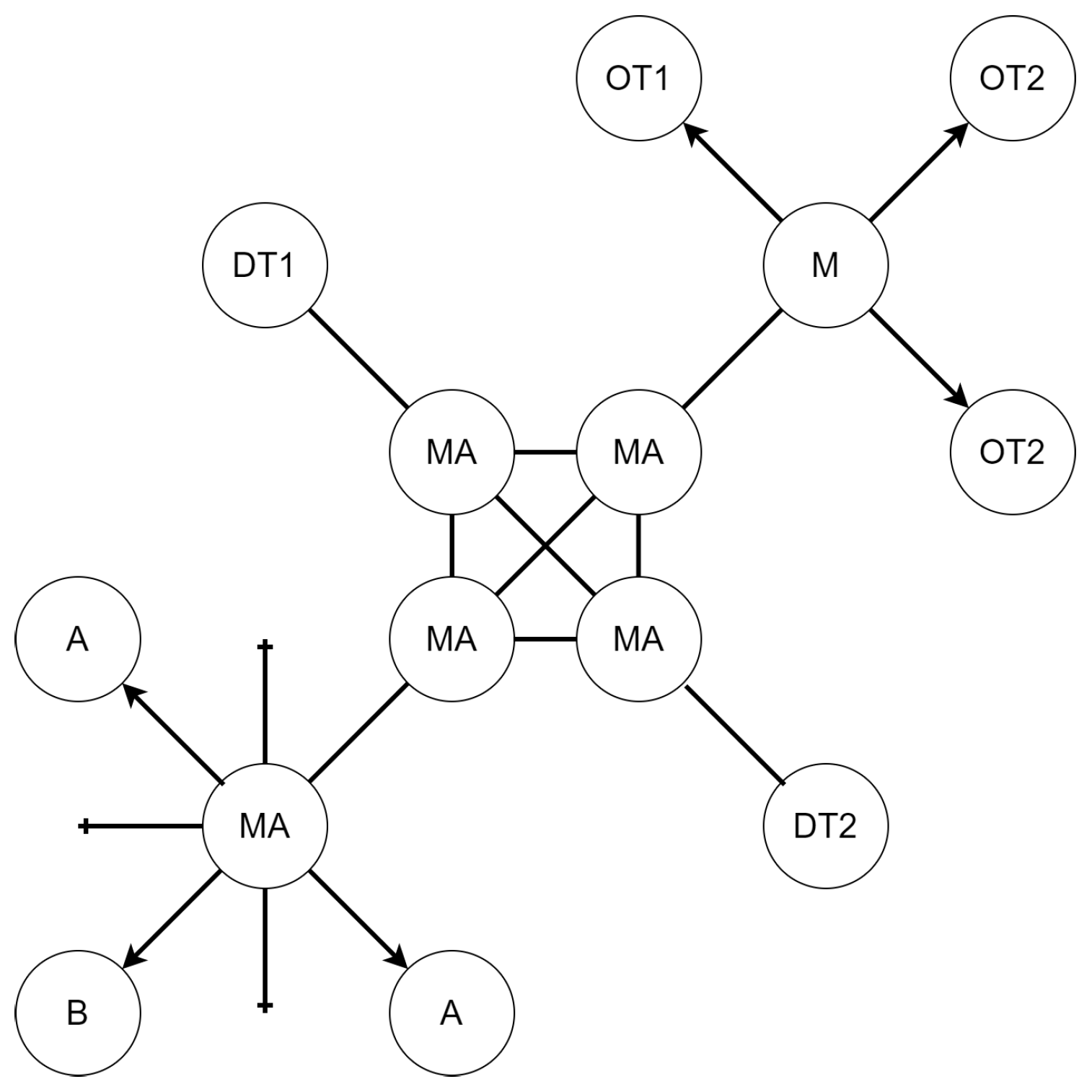
| Control | Real World Object |
|---|---|
| A | Robot |
| MA | Warehouse area—robots can move between them. |
| B | Beacon—indicates the warehouse area where robots should return after relocating objects. |
| M | Warehouse—it stores objects to be moved. |
| OT1 | Object of type 1 |
| OT2 | Object of type 2 |
| DT1 | Type 1 unloading area—the location where objects of type 1 are to be relocated. |
| DT2 | Type 2 unloading area—the location where objects of type 2 are to be relocated. |
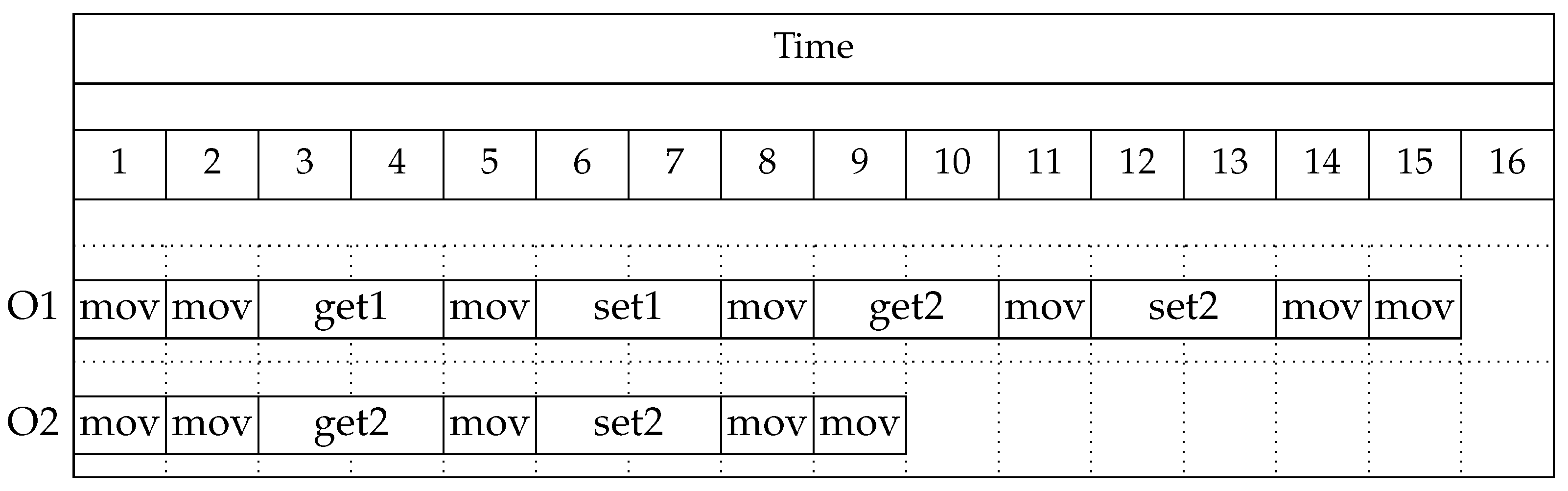
| Label | Description | |
|---|---|---|
| mov | Moving a robot between warehouse areas. | 1 |
| stay | A robot remains in the warehouse area where it is located. | 1 |
| get1 | A robot retrieves a type 1 object from the warehouse. | 2 |
| get2 | A robot retrieves a type 2 object from the warehouse. | 2 |
| set1 | A robot deposits a type 1 object into an unloading area. | 2 |
| set2 | A robot deposits a type 2 object into an unloading area. | 2 |
| i | ||
|---|---|---|
| 2 | 3 | |
| 6 | 1 | |
| 4 | ||
| 4 | ||
| 3 | 2 | |
| 1 | 2 |
| Strategy | MNoR | Pros | Cons |
|---|---|---|---|
| All first found | Unlimited | Perfect for assuring correctness of the model as this strategy gives all existing walks to the desired destination state. | Unfeasible for anything but small systems due to large memory consumption. |
| First N found | N | The fastest of all strategies since it does not sort results and can shrink an output of convolution operation. Perfect when the quality of a result is not important or when all results are expected to have similar quality. | Does not care about quality of returned results at all. |
| First N best found | N | With a good evaluation function this strategy can return the best results. Perfect when model has already been validated and the developer is looking for a behavior policy of a certain quality. | Slower than first N found since results are sorted with an evaluation function. |
| All up to a certain length | Unlimited | Gives a glimpse of how the length of a walk impacts the way a mission is executed. Since it is an extension of all first found it allows for throughout correctness testing. | Only for tiny systems. This is the most memory consuming strategy because it not only returns all found results but the search is continued until results have specified length. |
| First N up to a certain length | Allow for insight into how the length of a result impacts the way a mission is executed. Very fast as it is an extension of first N found. | Does not care about the quality of returned results at all. | |
| Best N up to a certain length | It gives good insight how the quality of results varies with the length of a walk. Perfect when the developer is looking for a behavior policy that he or she has no expectations about. | It is slower than first N found up to a certain length strategy due to sorting of results. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cybulski, P.; Zieliński, Z. Design and Verification of Multi-Agent Systems with the Use of Bigraphs. Appl. Sci. 2021, 11, 8291. https://doi.org/10.3390/app11188291
Cybulski P, Zieliński Z. Design and Verification of Multi-Agent Systems with the Use of Bigraphs. Applied Sciences. 2021; 11(18):8291. https://doi.org/10.3390/app11188291
Chicago/Turabian StyleCybulski, Piotr, and Zbigniew Zieliński. 2021. "Design and Verification of Multi-Agent Systems with the Use of Bigraphs" Applied Sciences 11, no. 18: 8291. https://doi.org/10.3390/app11188291
APA StyleCybulski, P., & Zieliński, Z. (2021). Design and Verification of Multi-Agent Systems with the Use of Bigraphs. Applied Sciences, 11(18), 8291. https://doi.org/10.3390/app11188291