
A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings

 ,
,  ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
- •
- An alternative strategy that uses all the data and makes a forecast for the next 24 h at any hour of the day.
- •
- A comparative analysis from a statistical point of view of various machine learning and deep learning models.
- •
- A methodology for building energy consumption forecasting that incorporates as input variables: historical data, calendar data, climatic data, and past series values.
2. Data and Preliminary Process
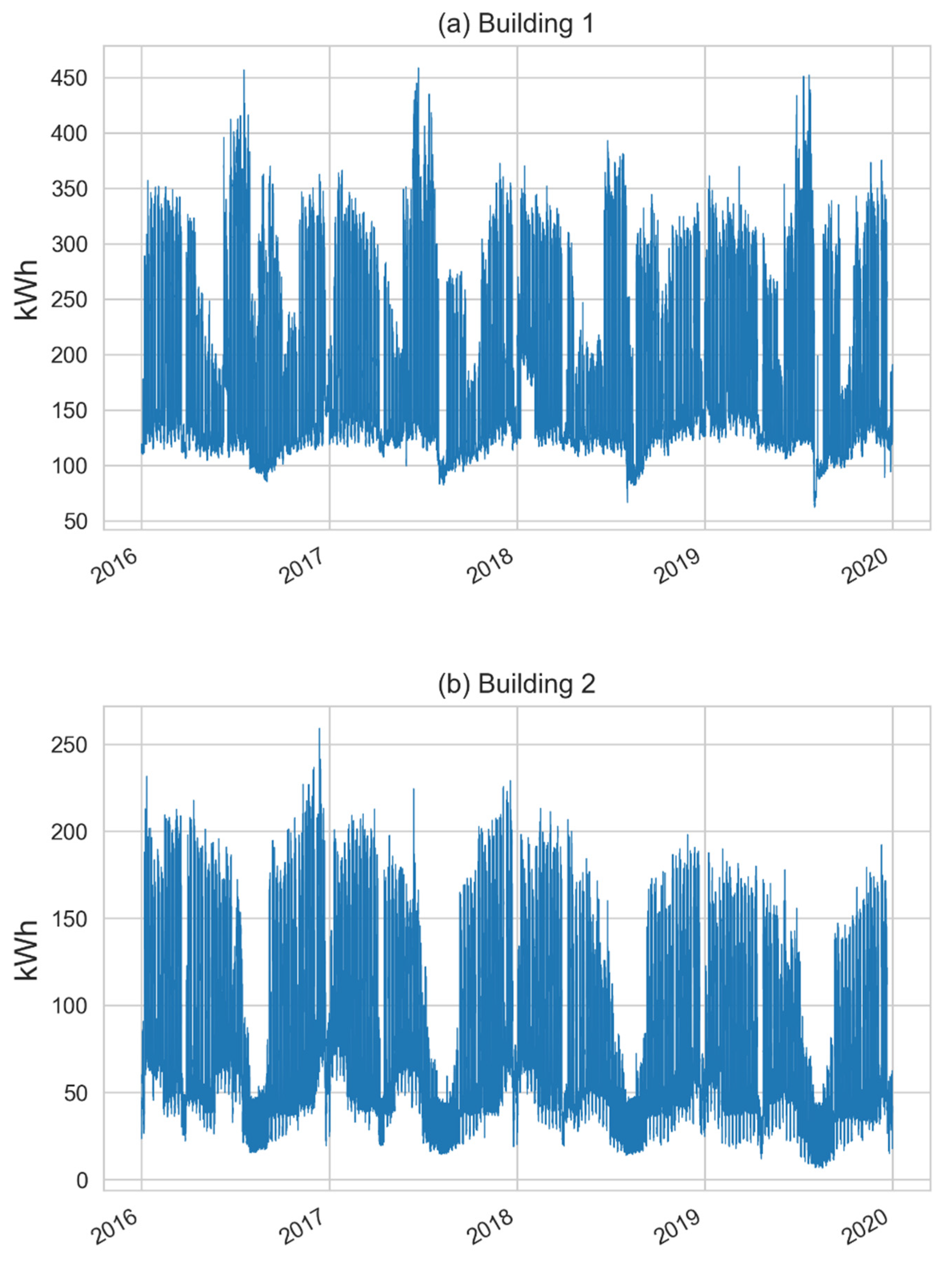
2.1. Data Collection
2.2. Data Preparation
- Data imputation. The raw data gathered for each building presented missing values. To solve this issue, the raw data were preprocessed. As the missing data were less than 0.3% of the total data, the linear interpolation method was used to solve the issue.
- Calendar data creation. To obtain a better result in the forecast, the following calendar variables were created: hour, weekday, month, and holiday.
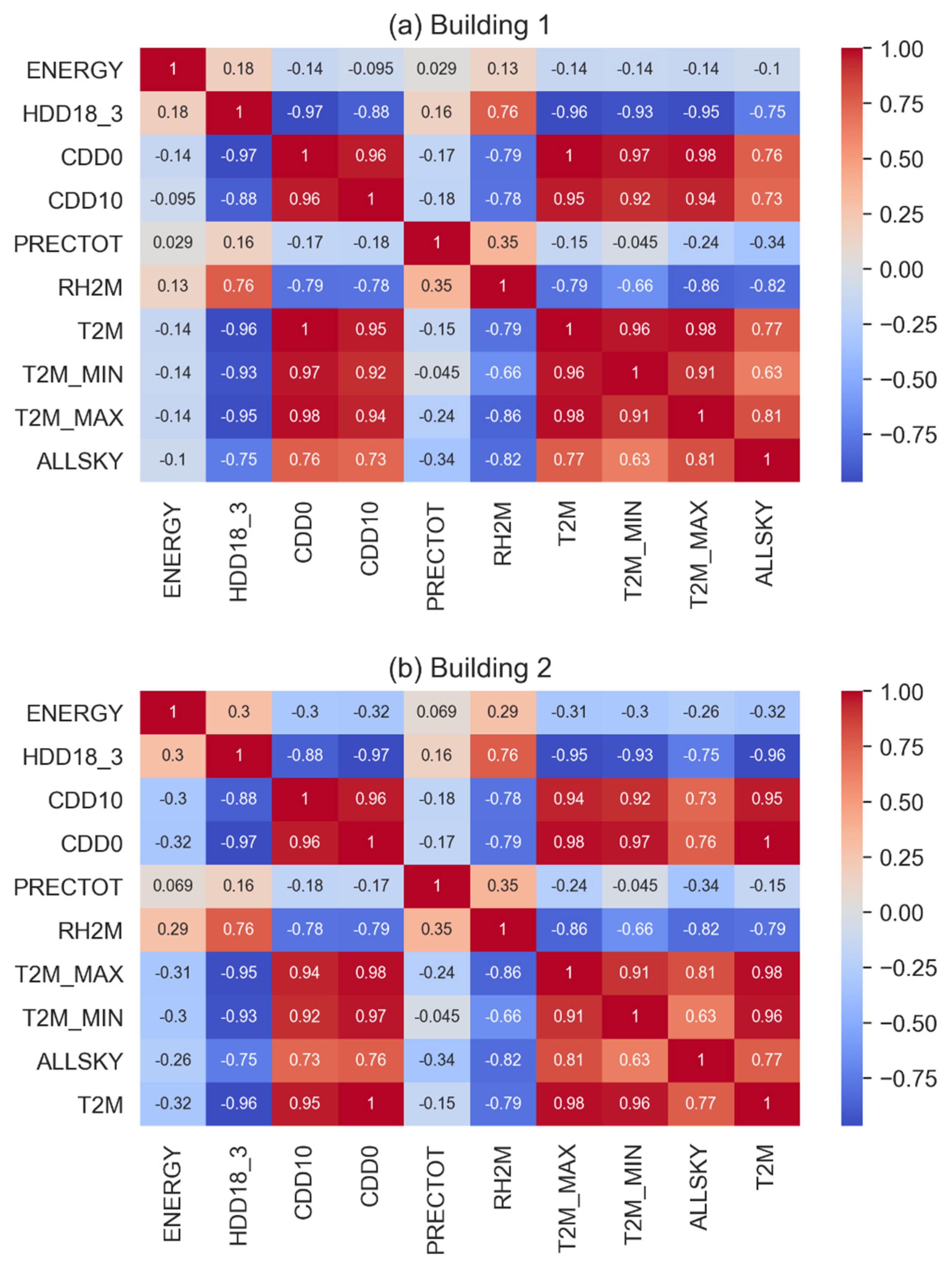
- Weather data preparation. To avoid adding error to the forecasting models by not knowing exactly the future values of the climatic variables, the values of the previous day were used.
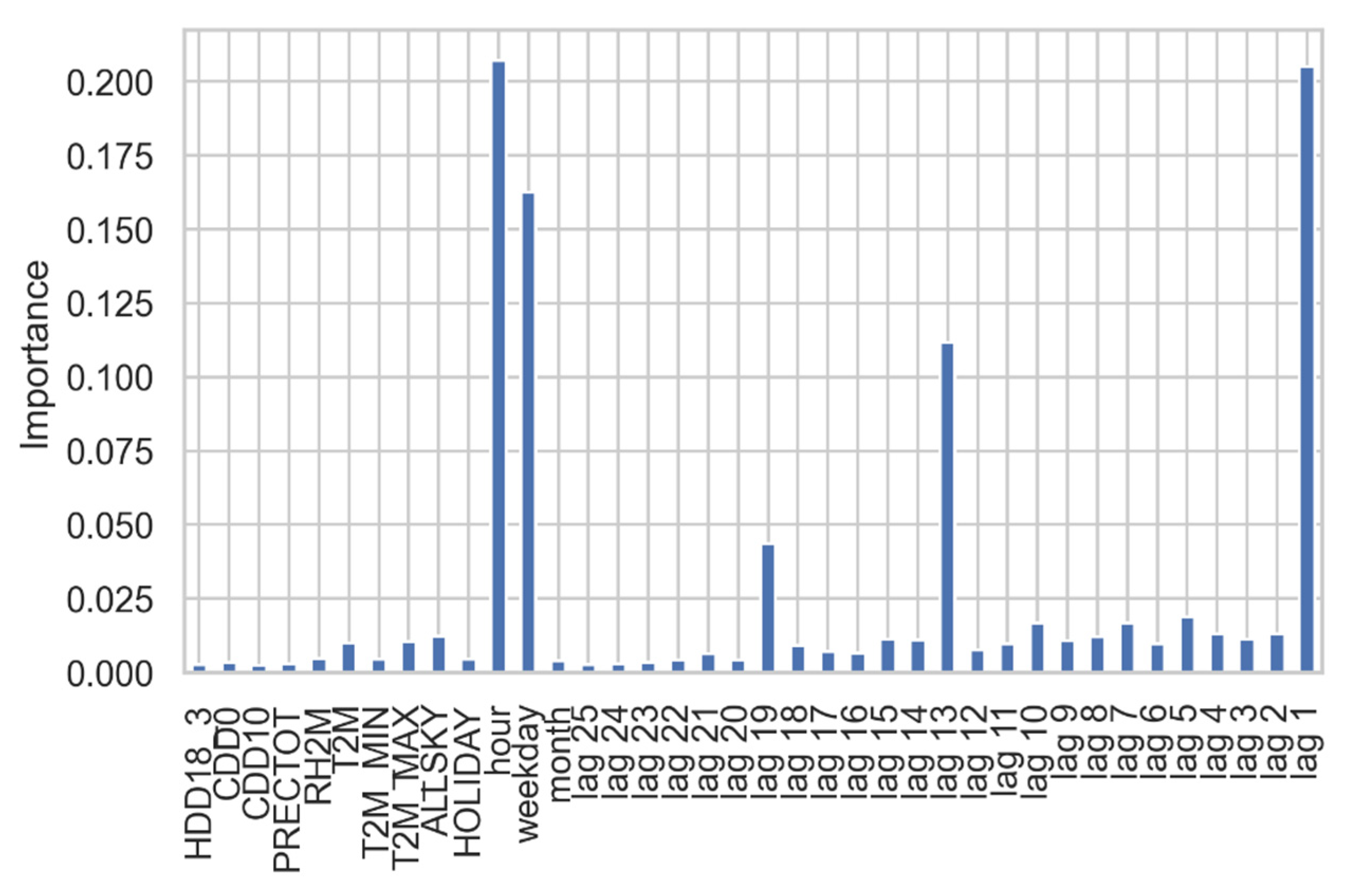
- Past series values creation. From the analysis of the ACF and PACF, the decision to use 25 time gaps was reached because after 25 lags the partial correlation decreases significantly.
- Dataset formation. After creating all the variables that would be used, the final dataset was built with the aforementioned steps.
3. Methodology and Approach
3.1. Selected Forecasting Models
- •
- Multiple Linear Regression (MLR) is a statistical method generally utilized for time-series forecasting. The fundamental thought behind simple linear regression is to attempt to discover the connection between two variables. For the situation where various independent variables are utilized to decide the value of a dependent variable, the process is called multiple linear regression [26].
- •
- Artificial Neural Network (ANN) is planned to copy the fundamental architecture of the human brain, whose essential component is called a processing unit modeling a biological neuron. The network comprises a large number of these process units exhibited in layers, and process units in various layers are associated with each other via connections [27].
- •
- Random Forest (RF) is a model where a bunch of decision trees are utilized to create the last output, utilizing a democratic plan. Each tree is initiated from an arbitrarily chosen preparing subset and additionally utilizing a randomly chosen subset of highlights. This suggests that the trees rely upon the upsides of an autonomously tested information dataset, utilizing similar dispersion for all trees [28].
- •
- Extreme Gradient Boost (XGBoost): the fundamental thought behind this method is to adapt successively in which the current regression tree is fitted to the residuals from the past trees. This new regression tree is then added to the fitted model to refresh the residuals. The principle of gradient boosting further improves the adaptability of the boosting algorithm by developing the new regression trees to be maximally related to the negative of the gradient of the loss function [29].
- •
- Long-Term Short Memory (LTSM) comprises a memory block that is answerable for deciding the expansion and erasure of data through three entryways, namely input gate, forget gate, and output gate. The memory cell in the memory block recollects worldly state data about current and past timesteps [30].
- •
- Convolutional Neural Network(CNN) comprises of four fundamental parts: convolutional layer, which includes maps of the information; pooling layers, which are applied to lessen the dimensionality of the convoluted element; flattening, which changes the information into a column vector; and a connected hidden layer, which computes the loss function [31].
- •
- Temporal Convolutional Network (TCN) is a sort of convolutional neural network with a particular design that makes them appropriate for time series forecasting. TCN fulfills two primary standards: the network’s output has a similar length as the input arrangement, and they avoid leakage of data from the future to the past by utilizing causal convolutions [32].
- •
- Temporal Fusion Transformer(TFT) utilizes specific elements such as sequence-to-sequence and consideration-based temporal processing elements that catch time-fluctuating connections at various timescales; static covariate encoders that permit to condition temporal forecasts on static metadata; gating segments that empower skipping over unnecessary elements of the network; variable determination to pick important information at each time step, and quantile expectations to obtain output spans across all forecast horizons [33].
3.2. Forecasting Models Training, Tunning, and Execution
3.3. Accuracy Metrics
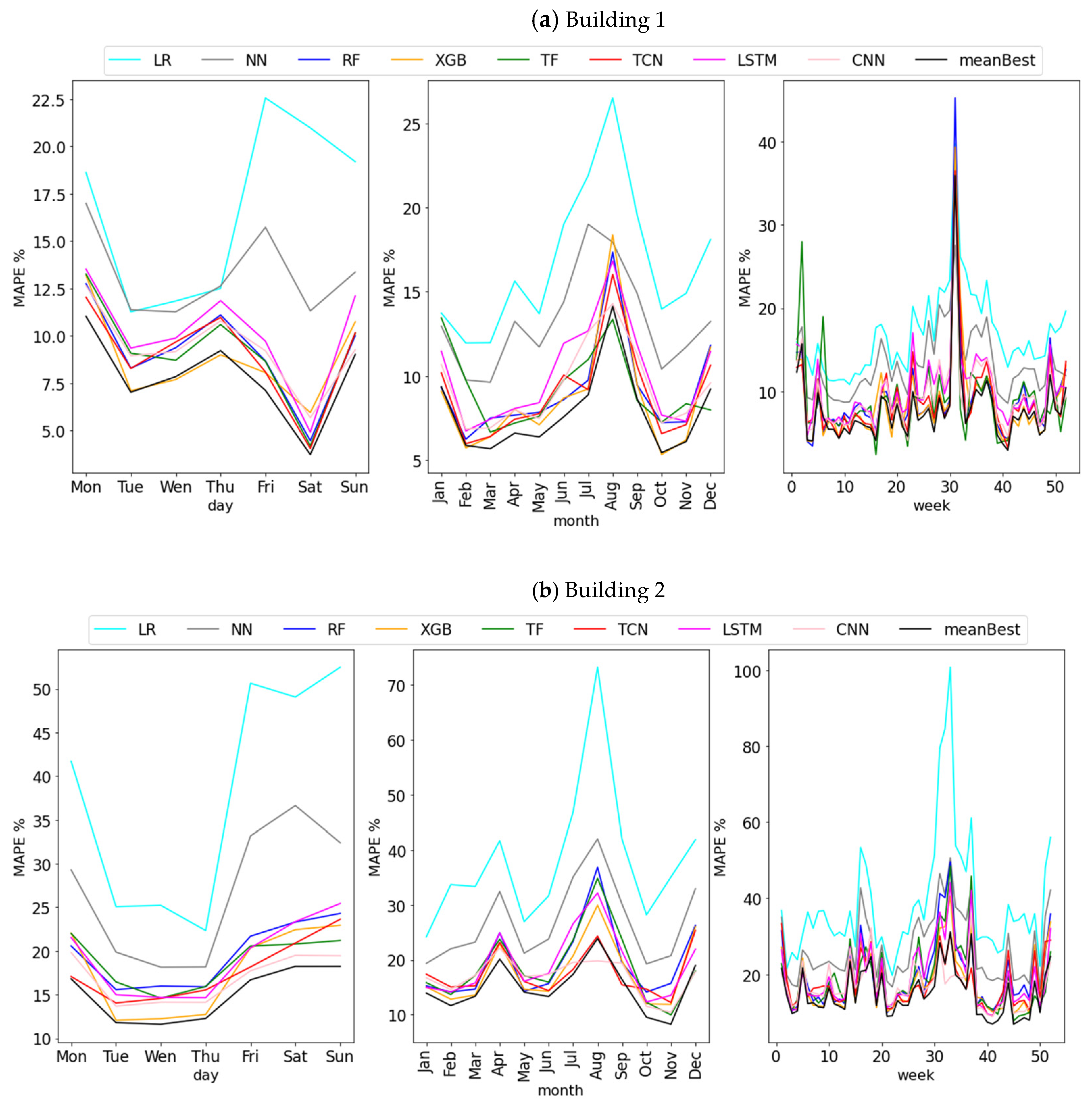
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A Review on Time Series Forecasting Techniques for Building Energy Consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Somu, N.; MR, G.R.; Ramamritham, K. A Deep Learning Framework for Building Energy Consumption Forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Zhang, C.; Li, J.; Zhao, Y.; Li, T.; Chen, Q.; Zhang, X. A Hybrid Deep Learning-Based Method for Short-Term Building Energy Load Prediction Combined with an Interpretation Process. Energy Build. 2020, 225, 110301. [Google Scholar] [CrossRef]
- Son, N.; Yang, S.; Na, J. Deep Neural Network and Long Short-Term Memory for Electric Power Load Forecasting. Appl. Sci. 2020, 10, 6489. [Google Scholar] [CrossRef]
- Runge, J.; Zmeureanu, R. A Review of Deep Learning Techniques for Forecasting Energy Use in Buildings. Energies 2021, 14, 608. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wen, J.; Li, Y.; Chen, J.; Ye, Y.; Fu, Y.; Livingood, W. A Review of Machine Learning in Building Load Prediction. Appl. Energy 2021, 285, 116452. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Xiao, F.; Ma, J.; Lee, D.; Wang, J.; Tseng, Y.C. Statistical Investigations of Transfer Learning-Based Methodology for Short-Term Building Energy Predictions. Appl. Energy 2020, 262, 114499. [Google Scholar] [CrossRef]
- Fang, X.; Gong, G.; Li, G.; Chun, L.; Li, W.; Peng, P. A Hybrid Deep Transfer Learning Strategy for Short Term Cross-Building Energy Prediction. Energy 2021, 215, 119208. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Q.; Yuan, T. Research on Short-Term and Ultra-Short-Term Cooling Load Prediction Models for Office Buildings. Energy Build. 2017, 154, 254–267. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Sanchez-Esguevillas, A.; Hernandez-Callejo, L.; Arribas, J.I.; Carro, B. Novel Data-Driven Models Applied to Short-Term Electric Load Forecasting. Appl. Sci. 2021, 11, 5708. [Google Scholar] [CrossRef]
- Moon, J.; Jung, S.; Rew, J.; Rho, S.; Hwang, E. Combination of Short-Term Load Forecasting Models Based on a Stacking Ensemble Approach. Energy Build. 2020, 216, 109921. [Google Scholar] [CrossRef]
- Somu, N.; MR, G.R.; Ramamritham, K. A Hybrid Model for Building Energy Consumption Forecasting Using Long Short Term Memory Networks. Appl. Energy 2020, 261, 114131. [Google Scholar] [CrossRef]
- Yang; Tan; Santamouris; Lee Building Energy Consumption Raw Data Forecasting Using Data Cleaning and Deep Recurrent Neural Networks. Buildings 2019, 9, 204. [CrossRef] [Green Version]
- Ishaq, M.; Kwon, S. Short-Term Energy Forecasting Framework Using an Ensemble Deep Learning Approach. IEEE Access 2021, 9, 94262–94271. [Google Scholar] [CrossRef]
- Xue, P.; Jiang, Y.; Zhou, Z.; Chen, X.; Fang, X.; Liu, J. Multi-Step Ahead Forecasting of Heat Load in District Heating Systems Using Machine Learning Algorithms. Energy 2019, 188, 116085. [Google Scholar] [CrossRef]
- Kolokas, N.; Ioannidis, D.; Tzovaras, D. Multi-Step Energy Demand and Generation Forecasting with Confidence Used for Specification-Free Aggregate Demand Optimization. Energies 2021, 14, 3162. [Google Scholar] [CrossRef]
- Shao, X.; Kim, C.S. Multi-Step Short-Term Power Consumption Forecasting Using Multi-Channel LSTM with Time Location Considering Customer Behavior. IEEE Access 2020, 8, 125263–125273. [Google Scholar] [CrossRef]
- NASA POWER NASA Prediction of Worldwide Energy Resources. Available online: https://power.larc.nasa.gov/ (accessed on 1 February 2021).
- Mariano-Hernández, D.; Hernández-Callejo, L.; García, F.S.; Duque-Perez, O.; Zorita-Lamadrid, A.L. A Review of Energy Consumption Forecasting in Smart Buildings: Methods, Input Variables, Forecasting Horizon and Metrics. Appl. Sci. 2020, 10, 8323. [Google Scholar] [CrossRef]
- Peng, L.; Wang, L.; Xia, D.; Gao, Q. Effective Energy Consumption Forecasting Using Empirical Wavelet Transform and Long Short-Term Memory. Energy 2021, 121756. [Google Scholar] [CrossRef]
- Bourhnane, S.; Abid, M.R.; Lghoul, R.; Zine-Dine, K.; Elkamoun, N.; Benhaddou, D. Machine Learning for Energy Consumption Prediction and Scheduling in Smart Buildings. SN Appl. Sci. 2020, 2, 297. [Google Scholar] [CrossRef] [Green Version]
- Kathirgamanathan, A.; De Rosa, M.; Mangina, E.; Finn, D.P. Data-Driven Predictive Control for Unlocking Building Energy Flexibility: A Review. Renew. Sustain. Energy Rev. 2021, 135, 110120. [Google Scholar] [CrossRef]
- Bendaoud, N.M.M.; Farah, N. Using Deep Learning for Short-Term Load Forecasting. Neural Comput. Appl. 2020, 32, 15029–15041. [Google Scholar] [CrossRef]
- Lu, H.; Cheng, F.; Ma, X.; Hu, G. Short-Term Prediction of Building Energy Consumption Employing an Improved Extreme Gradient Boosting Model: A Case Study of an Intake Tower. Energy 2020, 203, 117756. [Google Scholar] [CrossRef]
- Divina, F.; García Torres, M.; Goméz Vela, F.A.; Vázquez Noguera, J.L. A Comparative Study of Time Series Forecasting Methods for Short Term Electric Energy Consumption Prediction in Smart Buildings. Energies 2019, 12, 1934. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A Review of Data-Driven Approaches for Prediction and Classification of Building Energy Consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, D.; Elzarka, H. Early Detection of Faults in HVAC Systems Using an XGBoost Model with a Dynamic Threshold. Energy Build. 2019, 185, 326–344. [Google Scholar] [CrossRef]
- Luo, X.J.; Oyedele, L.O.; Ajayi, A.O.; Akinade, O.O.; Owolabi, H.A.; Ahmed, A. Feature Extraction and Genetic Algorithm Enhanced Adaptive Deep Neural Network for Energy Consumption Prediction in Buildings. Renew. Sustain. Energy Rev. 2020, 131, 109980. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 0262035618. [Google Scholar]
- Lara-Benítez, P.; Carranza-García, M.; Luna-Romera, J.M.; Riquelme, J.C. Temporal Convolutional Networks Applied to Energy-Related Time Series Forecasting. Appl. Sci. 2020, 10, 2322. [Google Scholar] [CrossRef] [Green Version]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-Horizon Time Series Forecasting. Int. J. Forecast. 2021, in press. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Amasyali, K.; El-Gohary, N.M. A Review of Data-Driven Building Energy Consumption Prediction Studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Ali, U.; Shamsi, M.H.; Bohacek, M.; Hoare, C.; Purcell, K.; Mangina, E.; O’Donnell, J. A Data-Driven Approach to Optimize Urban Scale Energy Retrofit Decisions for Residential Buildings. Appl. Energy 2020, 267, 114861. [Google Scholar] [CrossRef]
- Khosravani, H.; Castilla, M.; Berenguel, M.; Ruano, A.; Ferreira, P. A Comparison of Energy Consumption Prediction Models Based on Neural Networks of a Bioclimatic Building. Energies 2016, 9, 57. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Meng, Z. A Hybrid Transfer Learning Model for Short-Term Electric Load Forecasting. Electr. Eng. 2020, 102, 1371–1381. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Lv, S.-X. Forecasting Energy Consumption and Wind Power Generation Using Deep Echo State Network. Renew. Energy 2020, 154, 598–613. [Google Scholar] [CrossRef]
- Chan, F.; Pauwels, L.L. Some Theoretical Results on Forecast Combinations. Int. J. Forecast. 2018, 34, 64–74. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 Time Series and 61 Forecasting Methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]



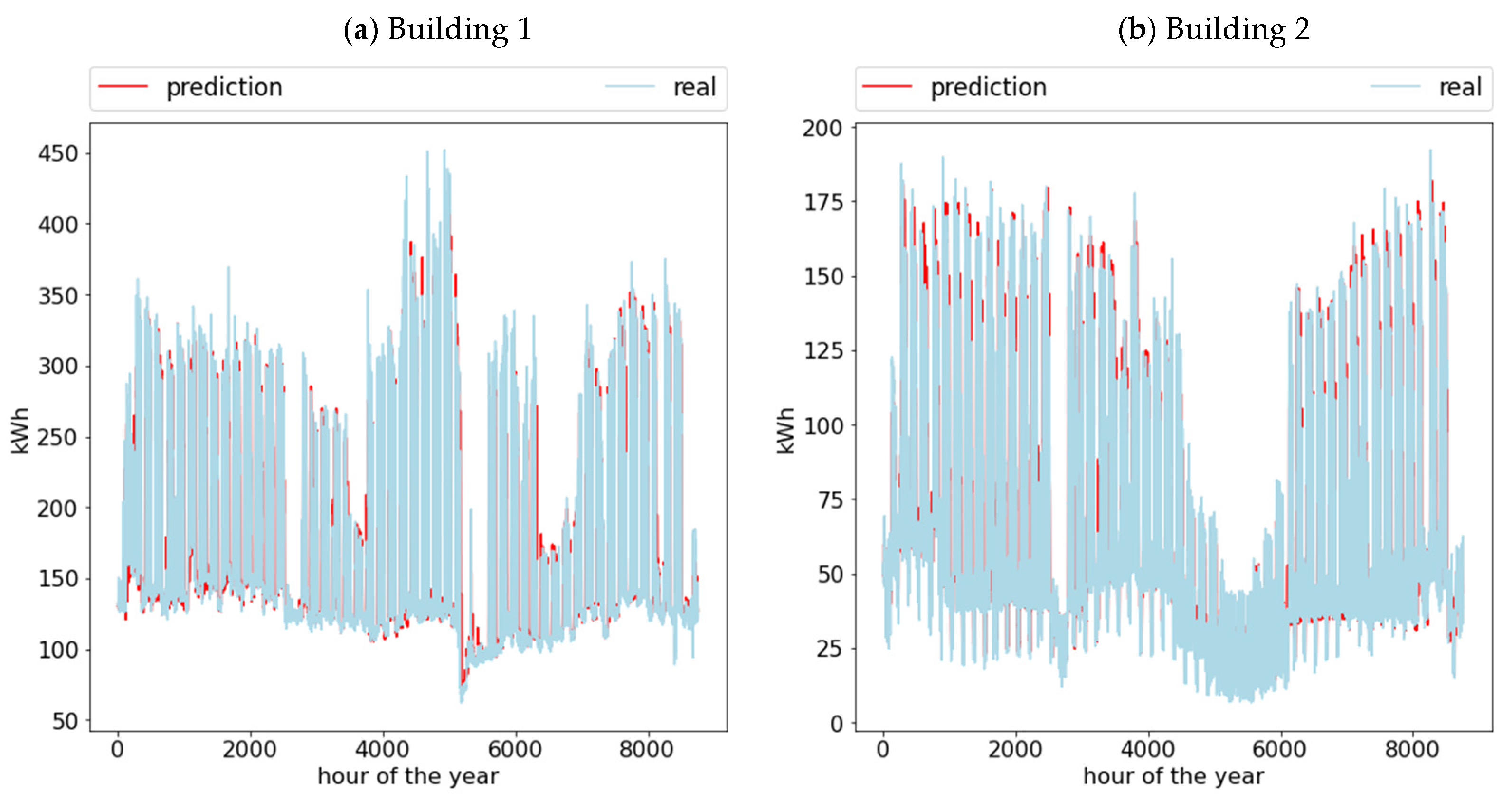

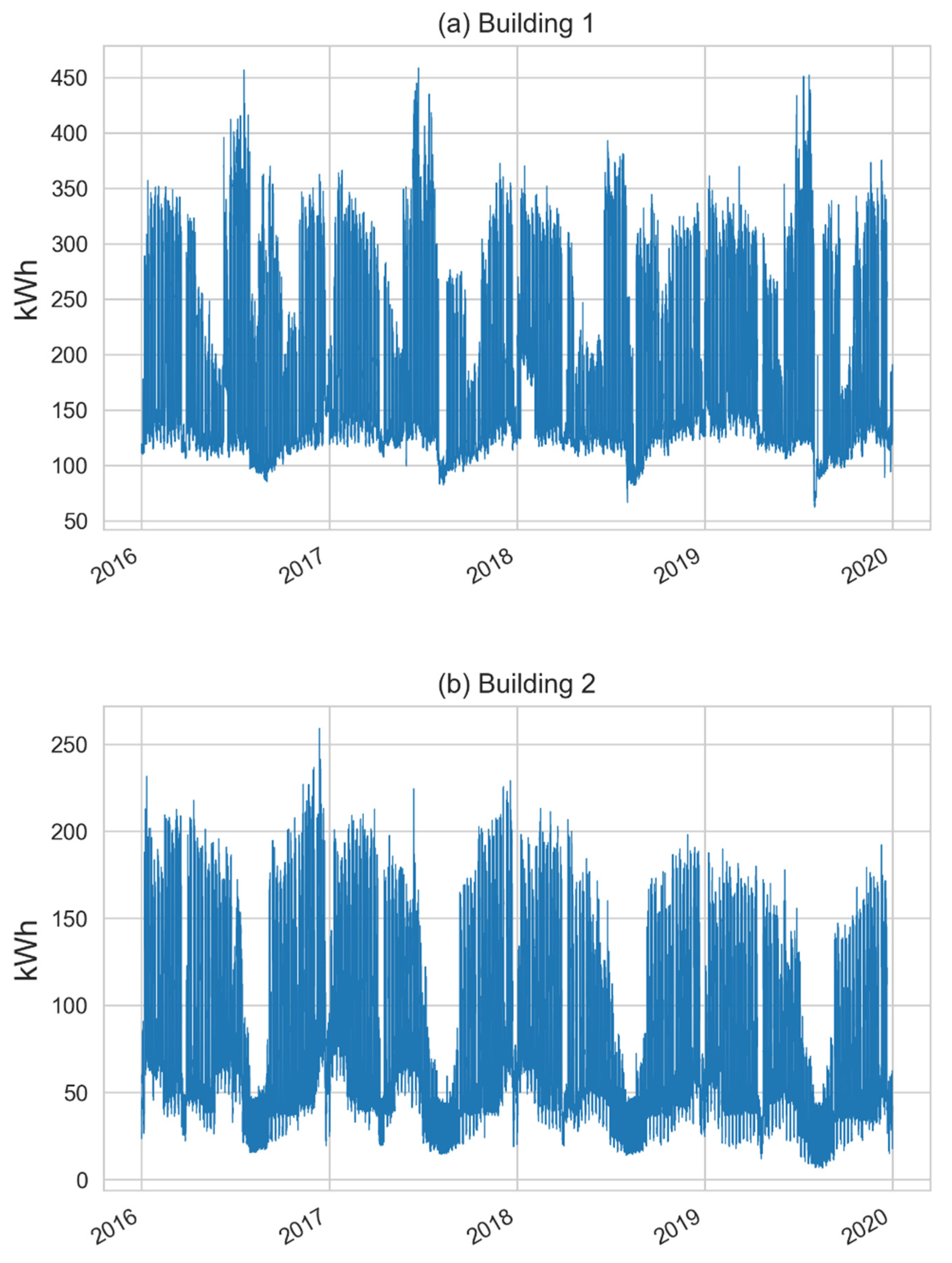{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
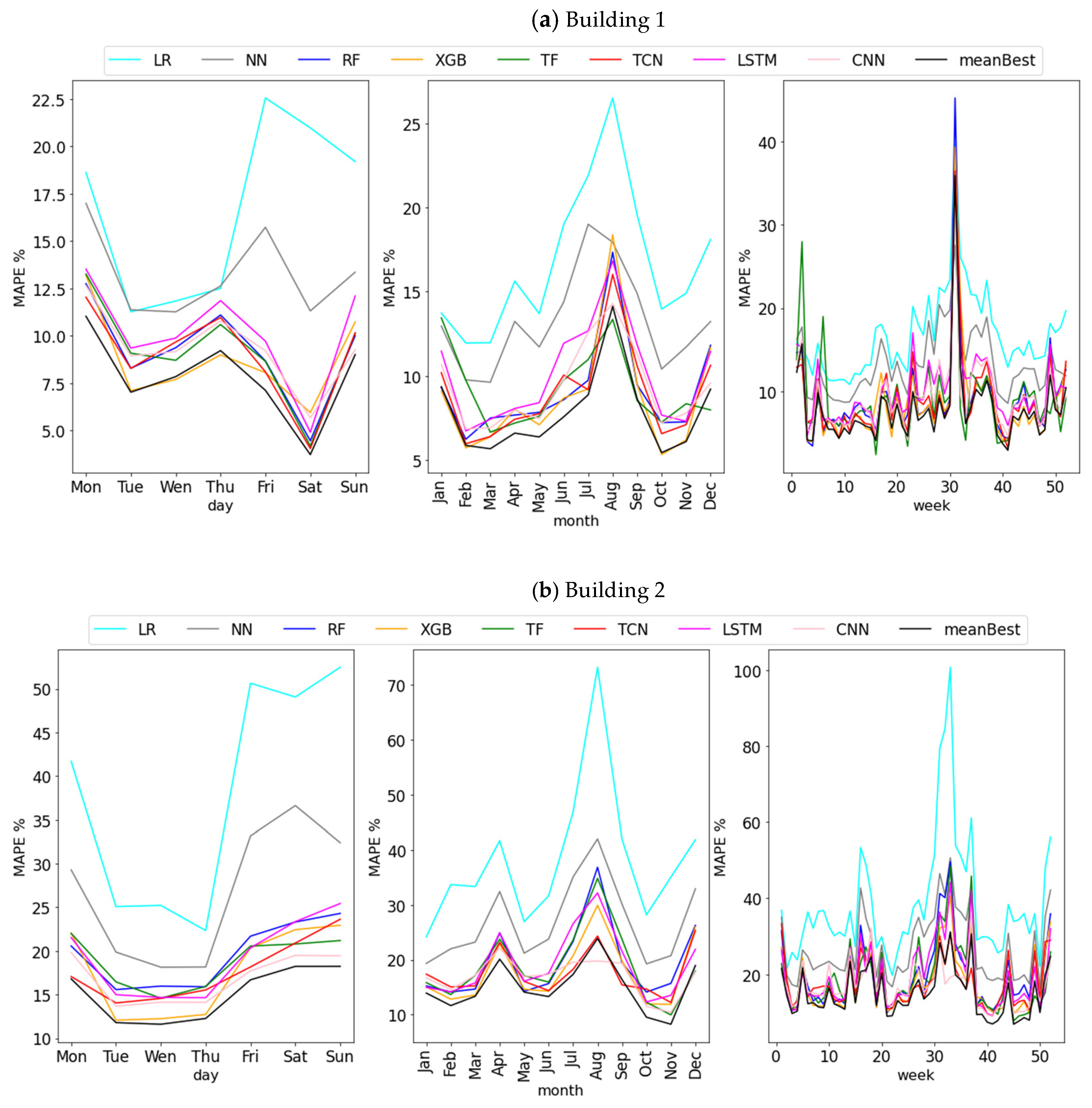{kind=link}
{kind=link}
{kind=link}
| Model | Python Library | Architectures and Hyper-Parameters |
|---|---|---|
| MLR | Scikit-learn |
|
| ANN | Scikit-learn |
|
| RF | Scikit-learn |
|
| XGBoost | Scikit-learnXGBoost |
|
| LSTM | TensorFlow |
|
| CNN | TensorFlow |
|
| TCN | TensorFlow |
|
| TFT | PyTorch |
|
| Building 1 | Building 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | R2 | RMSE (kWh) | MAE (kWh) | MAPE (%) | R2 | RMSE kWh) | MAE (kWh) | MAPE (%) |
| MLR | 0.72 | 37.34 | 26.19 | 16.79 | 0.72 | 21.01 | 15.27 | 38.31 |
| ANN | 0.75 | 35.48 | 22.56 | 13.26 | 0.79 | 18.19 | 12.22 | 26.84 |
| RF | 0.83 | 29.45 | 16.2 | 9.22 | 0.86 | 15.16 | 9.15 | 19.68 |
| XGBoost | 0.85 | 27.23 | 15 | 8.83 | 0.87 | 14.12 | 8.22 | 17.92 |
| LSTM | 0.79 | 32.26 | 17.74 | 10.18 | 0.83 | 16.38 | 9.33 | 19.36 |
| CNN | 0.81 | 30.71 | 17.07 | 9.38 | 0.81 | 17.35 | 9.59 | 16.96 |
| TCN | 0.83 | 29.43 | 15.84 | 9.02 | 0.84 | 16.04 | 9.01 | 17.74 |
| TFT | 0.69 | 39.57 | 17.7 | 9.22 | 0.84 | 16.08 | 9.53 | 18.84 |
| Building 1 | Building 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Assembled Model | R2 | RMSE (kWh) | MAE (kWh) | MAPE (%) | R2 | RMSE (kWh) | MAE (kWh) | MAPE (%) |
| C2 | 0.86 | 26.70 | 14.40 | 8.31 | 0.86 | 14.78 | 8.25 | 15.66 |
| C3 | 0.86 | 26.73 | 14.43 | 8.27 | 0.88 | 13.81 | 7.69 | 15.44 |
| C4 | 0.86 | 26.76 | 14.34 | 7.97 | 0.89 | 13.27 | 7.50 | 15.14 |
| C5 | 0.86 | 26.42 | 14.20 | 7.85 | 0.89 | 13.31 | 7.48 | 15.31 |
| C6 | 0.86 | 26.41 | 14.29 | 7.95 | 0.89 | 13.20 | 7.48 | 15.60 |
| C7 | 0.86 | 26.43 | 14.62 | 8.17 | 0.89 | 13.28 | 7.69 | 16.40 |
| C8 | 0.86 | 26.55 | 15.20 | 8.61 | 0.89 | 13.44 | 8.01 | 17.72 |
| Model 1 | Model 2 | p-adj | Decision |
|---|---|---|---|
| meanBest | RF | 1.97 × 10−171 | True |
| meanBest | TCN | 9.15 × 10−127 | True |
| meanBest | TF | 1.89 × 10−56 | True |
| meanBest | XGB | 5.09 × 10−102 | True |
| RF | TCN | 1.5 × 10−2 | True |
| RF | TF | 1 | False |
| RF | XGB | 5.03 × 10−14 | True |
| TCN | TF | 8.09 × 10−1 | False |
| TCN | XGB | 2.2 × 10−2 | True |
| TF | XGB | 7 × 10−3 | True |
| Model 1 | Model 2 | p-adj | Decision |
|---|---|---|---|
| CNN | meanBest | 6.32 × 10−56 | True |
| CNN | TCN | 7.56 × 10−6 | True |
| CNN | TF | 8.53 × 10−51 | True |
| CNN | XGB | 3.89 × 10−11 | True |
| meanBest | TCN | 4.67 × 10−109 | True |
| meanBest | TF | 2.33 × 10−195 | True |
| meanBest | XGB | 5.99 × 10−254 | True |
| TCN | TF | 2.18 × 10−8 | True |
| TCN | XGB | 1 | False |
| TF | XGB | 1.89 × 10−9 | True |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariano-Hernández, D.; Hernández-Callejo, L.; Solís, M.; Zorita-Lamadrid, A.; Duque-Perez, O.; Gonzalez-Morales, L.; Santos-García, F. A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings. Appl. Sci. 2021, 11, 7886. https://doi.org/10.3390/app11177886
Mariano-Hernández D, Hernández-Callejo L, Solís M, Zorita-Lamadrid A, Duque-Perez O, Gonzalez-Morales L, Santos-García F. A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings. Applied Sciences. 2021; 11(17):7886. https://doi.org/10.3390/app11177886
Chicago/Turabian StyleMariano-Hernández, Deyslen, Luis Hernández-Callejo, Martín Solís, Angel Zorita-Lamadrid, Oscar Duque-Perez, Luis Gonzalez-Morales, and Felix Santos-García. 2021. "A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings" Applied Sciences 11, no. 17: 7886. https://doi.org/10.3390/app11177886
APA StyleMariano-Hernández, D., Hernández-Callejo, L., Solís, M., Zorita-Lamadrid, A., Duque-Perez, O., Gonzalez-Morales, L., & Santos-García, F. (2021). A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings. Applied Sciences, 11(17), 7886. https://doi.org/10.3390/app11177886